#google web scraping tool
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
Top Custom Web App Development Company Near You
Zyneto Technologies is a trusted web app development company, providing best and custom web development services that specifically fulfill your business goals. Whichever website developers near me means to you or global partners you’ll gain access to a team of scalable, responsive, and feature rich web development solutions. We design intuitive user interfaces, build powerful web applications that perform seamlessly, providing awesome user experiences. Our expertise in modern technologies and framework enables us to design, develop and customize websites /apps that best fit your brand persona and objectives. The bespoke solution lines up to whether it is a startup or enterprise level project, the Zyneto Technologies delivers robust and innovative solution that will enable your business grow and succeed.
Zyneto Technologies: A Leading Custom Web Development and Web App Development Company
In the digital age, having a well-designed, high-performing website or web application is crucial to a business’s success. Zyneto Technologies stands out as a trusted web app development company, providing top-tier custom web development services tailored to meet the specific goals of your business. Whether you’re searching for “website developers near me” or partnering with global experts, Zyneto offers scalable, responsive, and feature-rich solutions that are designed to help your business grow.
Why Zyneto Technologies is the Top Custom Web Development Company Near You
Zyneto Technologies is a highly regarded name in the world of web development, with a reputation for delivering custom web solutions that perfectly align with your business objectives. Whether you're a startup looking for a personalized web solution or an established enterprise aiming for a digital overhaul, Zyneto offers custom web development services that deliver lasting value. With a focus on modern web technologies and frameworks, their development team crafts innovative and robust web applications and websites that drive business growth.
Expert Web App Development Services to Match Your Business Needs
As one of the leading web app development companies, Zyneto specializes in creating web applications that perform seamlessly across platforms. Their expert team of developers is proficient in designing intuitive user interfaces and building powerful web applications that provide a smooth and engaging user experience. Whether you require a custom website or a sophisticated web app, Zyneto’s expertise ensures that your digital solutions are scalable, responsive, and optimized for the best performance.
Tailored Custom Web Development Solutions for Your Brand
Zyneto Technologies understands that every business is unique, which is why they offer custom web development solutions that align with your brand’s persona and objectives. Their team works closely with clients to understand their vision and create bespoke solutions that fit perfectly within their business model. Whether you're developing a new website or upgrading an existing one, Zyneto delivers web applications and websites that are designed to reflect your brand’s identity while driving engagement and conversions.
Comprehensive Web Development Services for Startups and Enterprises
Zyneto Technologies offers web development solutions that cater to both startups and large enterprises. Their custom approach ensures that every project, regardless of scale, receives the attention it deserves. By leveraging modern technologies, frameworks, and best practices in web development, Zyneto delivers solutions that are not only technically advanced but also tailored to meet the specific needs of your business. Whether you’re building a simple website or a complex web app, their team ensures your project is executed efficiently and effectively.
Why Zyneto Technologies is Your Ideal Web Development Partner
When searching for "website developers near me" or a top custom web app development company, Zyneto Technologies is the ideal choice. Their combination of global expertise, cutting-edge technology, and focus on user experience ensures that every solution they deliver is designed to meet your business goals. Whether you need a custom website, web application, or enterprise-level solution, Zyneto offers the expertise and dedication to bring your digital vision to life.
Elevate Your Business with Zyneto’s Custom Web Development Services
Partnering with Zyneto Technologies means choosing a web development company that is committed to providing high-quality, customized solutions. From start to finish, Zyneto focuses on delivering robust and innovative web applications and websites that support your business objectives. Their team ensures seamless project execution, from initial design to final deployment, making them a trusted partner for businesses of all sizes.
Get Started with Zyneto Technologies Today
Ready to take your business to the next level with custom web development? Zyneto Technologies is here to help. Whether you are in need of website developers near you or a comprehensive web app development company, their team offers scalable, responsive, and user-friendly solutions that are built to last. Connect with Zyneto Technologies today and discover how their web development expertise can help your business grow and succeed.
visit - https://zyneto.com/
#devops automation tools#devops services and solutions#devops solutions and services#devops solution providers#devops solutions company#devops solutions and service provider company#devops services#devops development services#devops consulting service#devops services company#web scraping solutions#web scraping chrome extension free#web scraping using google colab#selenium web scraping#best web scraping tools#node js web scraping#artificial intelligence web scraping#beautiful soup web scraping#best web scraping software#node js for web scraping#web scraping software#web scraping ai#free web scraping tools#web scraping python beautifulsoup#selenium web scraping python#web scraping with selenium and python#web site development#website design company near me#website design companies near me#website developers near me
0 notes
Text

#google maps#google marketing agency#google map scraping#google map scraping tool#google map scraping free#google map scraping python#google map scraping make.com#google map scraping using python#google map scraping in urdu#how to do google map scraping#google map data scraping#cara scraping data google map#google map scraping fiverr#google map scraping github#google map scraping extension#google map scraping meaning#google map web scraping
0 notes
Text
Quick way to get data from Google Search
Google is a multinational technology company headquartered in Mountain View, California, United States. Founded by Larry Page and Sergey Brin in 1998, it has become one of the world's leading technology giants. Google is primarily known for its search engine, which quickly became the most widely used search tool on the internet.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
Export to Excel:
1. Create a task
(1) Copy the URL

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
How to import and export scraping task
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
How to set the fields

3. Set up and start the scraping task
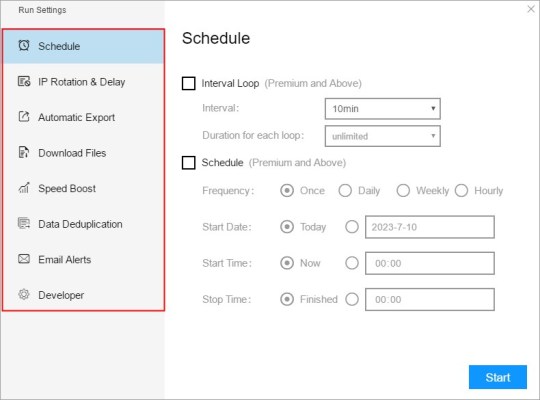
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
How to configure the scraping task
(2)Wait a moment, you will see the data being scraped.

4. Export and view data
(1) Click "Export" to download your data.

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
How to export data

0 notes
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
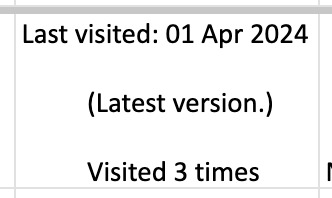
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Text
NO AI
TL;DR: almost all social platforms are stealing your art and use it to train generative AI (or sell your content to AI developers); please beware and do something. Or don’t, if you’re okay with this.
Which platforms are NOT safe to use for sharing you art:
Facebook, Instagram and all Meta products and platforms (although if you live in the EU, you can forbid Meta to use your content for AI training)
Reddit (sold out all its content to OpenAI)
Twitter
Bluesky (it has no protection from AI scraping and you can’t opt out from 3rd party data / content collection yet)
DeviantArt, Flikr and literally every stock image platform (some didn’t bother to protect their content from scraping, some sold it out to AI developers)
Here’s WHAT YOU CAN DO:
1. Just say no:
Block all 3rd party data collection: you can do this here on Tumblr (here’s how); all other platforms are merely taking suggestions, tbh
Use Cara (they can’t stop illegal scraping yet, but they are currently working with Glaze to built in ‘AI poisoning’, so… fingers crossed)
2. Use art style masking tools:
Glaze: you can a) download the app and run it locally or b) use Glaze’s free web service, all you need to do is register. This one is a fav of mine, ‘cause, unlike all the other tools, it doesn’t require any coding skills (also it is 100% non-commercial and was developed by a bunch of enthusiasts at the University of Chicago)
Anti-DreamBooth: free code; it was originally developed to protect personal photos from being used for forging deepfakes, but it works for art to
Mist: free code for Windows; if you use MacOS or don’t have powerful enough GPU, you can run Mist on Google’s Colab Notebook
(art style masking tools change some pixels in digital images so that AI models can’t process them properly; the changes are almost invisible, so it doesn’t affect your audiences perception)
3. Use ‘AI poisoning’ tools
Nightshade: free code for Windows 10/11 and MacOS; you’ll need GPU/CPU and a bunch of machine learning libraries to use it though.
4. Stay safe and fuck all this corporate shit.
75 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
246 notes
·
View notes
Text
Are there generative AI tools I can use that are perhaps slightly more ethical than others? —Better Choices
No, I don't think any one generative AI tool from the major players is more ethical than any other. Here’s why.
For me, the ethics of generative AI use can be broken down to issues with how the models are developed—specifically, how the data used to train them was accessed—as well as ongoing concerns about their environmental impact. In order to power a chatbot or image generator, an obscene amount of data is required, and the decisions developers have made in the past—and continue to make—to obtain this repository of data are questionable and shrouded in secrecy. Even what people in Silicon Valley call “open source” models hide the training datasets inside.
Despite complaints from authors, artists, filmmakers, YouTube creators, and even just social media users who don’t want their posts scraped and turned into chatbot sludge, AI companies have typically behaved as if consent from those creators isn’t necessary for their output to be used as training data. One familiar claim from AI proponents is that to obtain this vast amount of data with the consent of the humans who crafted it would be too unwieldy and would impede innovation. Even for companies that have struck licensing deals with major publishers, that “clean” data is an infinitesimal part of the colossal machine.
Although some devs are working on approaches to fairly compensate people when their work is used to train AI models, these projects remain fairly niche alternatives to the mainstream behemoths.
And then there are the ecological consequences. The current environmental impact of generative AI usage is similarly outsized across the major options. While generative AI still represents a small slice of humanity's aggregate stress on the environment, gen-AI software tools require vastly more energy to create and run than their non-generative counterparts. Using a chatbot for research assistance is contributing much more to the climate crisis than just searching the web in Google.
It’s possible the amount of energy required to run the tools could be lowered—new approaches like DeepSeek’s latest model sip precious energy resources rather than chug them—but the big AI companies appear more interested in accelerating development than pausing to consider approaches less harmful to the planet.
How do we make AI wiser and more ethical rather than smarter and more powerful? —Galaxy Brain
Thank you for your wise question, fellow human. This predicament may be more of a common topic of discussion among those building generative AI tools than you might expect. For example, Anthropic’s “constitutional” approach to its Claude chatbot attempts to instill a sense of core values into the machine.
The confusion at the heart of your question traces back to how we talk about the software. Recently, multiple companies have released models focused on “reasoning” and “chain-of-thought” approaches to perform research. Describing what the AI tools do with humanlike terms and phrases makes the line between human and machine unnecessarily hazy. I mean, if the model can truly reason and have chains of thoughts, why wouldn’t we be able to send the software down some path of self-enlightenment?
Because it doesn’t think. Words like reasoning, deep thought, understanding—those are all just ways to describe how the algorithm processes information. When I take pause at the ethics of how these models are trained and the environmental impact, my stance isn’t based on an amalgamation of predictive patterns or text, but rather the sum of my individual experiences and closely held beliefs.
The ethical aspects of AI outputs will always circle back to our human inputs. What are the intentions of the user’s prompts when interacting with a chatbot? What were the biases in the training data? How did the devs teach the bot to respond to controversial queries? Rather than focusing on making the AI itself wiser, the real task at hand is cultivating more ethical development practices and user interactions.
13 notes
·
View notes
Text
Social Media and Privacy Concerns!!! What You Need to Know???
In a world that is becoming more digital by the day, social media has also become part of our day-to-day lives. From the beginning of sharing personal updates to networking with professionals, social media sites like Facebook, Instagram, and Twitter have changed the way we communicate. However, concerns over privacy have also grown, where users are wondering what happens to their personal information. If you use social media often, it is important to be aware of these privacy risks. In this article, we will outline the main issues and the steps you need to take to protect your online data privacy. (Related: Top 10 Pros and Cons of Social media)

1. How Social Media Platforms Scrape Your Data The majority of social media platforms scrape plenty of user information, including your: ✅ Name, email address, and phone number ✅ Location and web browsing history ✅ Likes, comments, and search history-derived interests. Although this enhances the user experience as well as advertising, it has serious privacy issues. (Read more about social media pros and cons here) 2. Risks of Excessive Sharing Personal Information Many users unknowingly expose themselves to security risks through excessive sharing of personal information. Posting details of your daily routine, location, or personal life can lead to: ⚠️ Identity theft ⚠️Stalking and harassment ⚠️ Cyber fraud

This is why you need to alter your privacy settings and be careful about what you post on the internet. (Read this article to understand how social media affects users.) 3. The Role of Third-Party Apps in Data Breaches Did you register for a site with Google or Facebook? Handy, maybe, but in doing so, you're granting apps access to look at your data, normally more than is necessary. Some high profile privacy scandals, the Cambridge Analytica one being an example, have shown how social media information can be leveraged for in politics and advertising. To minimize danger: 👍Regularly check app permissions 👍Don't sign up multiple accounts where you don't need to 👍Strong passwords and two-factor authentication To get an in-depth overview of social media's impact on security, read this detailed guide. 4. How Social Media Algorithms Follow You You may not realize this, but social media algorithms are tracking you everywhere. From the likes you share to the amount of time you watch a video, sites monitor it all through AI-driven algorithms that learn from behavior and build personalized feeds. Though it can drive user engagement, it also: ⚠️ Forms filter bubbles that limit different perspectives ⚠️ Increases data exposure in case of hacks ⚠️ Increases ethical concerns around online surveillance Understanding the advantages and disadvantages of social media will help you make an informed decision. (Find out more about it here) 5. Maintaining Your Privacy: Real-Life Tips

To protect your personal data on social media: ✅ Update privacy settings to limit sharing of data ✅ Be cautious when accepting friend requests from unknown people ✅ Think before you post—consider anything shared online can be seen by others ✅ Use encrypted messaging apps for sensitive conversations These small habits can take you a long way in protecting your online existence. (For more detailed information, read this article) Final Thoughts Social media is a powerful tool that connects people, companies, and communities. There are privacy concerns, though, and you need to be clever about how your data is being utilized. Being careful about what you share, adjusting privacy settings, and using security best practices can enable you to enjoy the benefits of social media while being safe online. Interested in learning more about how social media influences us? Check out our detailed article on the advantages and disadvantages of social media and the measures to be taken to stay safe on social media.
#social media#online privacy#privacymatters#data privacy#digital privacy#hacking#identity theft#data breach#socialmediaprosandcons#social media safety#cyber security#social security
2 notes
·
View notes
Text
Battle of the Fear Bands!
B6R2: The Eye
Research Me Obsessively:
“Rebecca and Valencia spend 3 days internet stalking their mutual ex-boyfriend's new girlfriend. The song goes both into the creepy lengths one can go to in order to gain access to this sort of information while joking about how this search for information is unhealthy and detrimental to those embarking upon it.”
youtube
Knowledge:
“Narrator seeks knowledge without caring about the cost or consequences. As quintessentially Eye as you can get”
youtube
Lyrics below the line!
Research Me Obsessively:
Hey, what are you doing for the next thirteen hours?
Don't do anything healthy. Don't be productive. Give in to your desire.
Research me obsessively
Uh-huh!
Find out everything you can about me You know you want to dig for me relentlessly
Uh-huh!
Using every available search tool and all forms of social media
You know you want to look at my Instagram but it's private so Google me until you find out where I went to high school and then set up a fake Instagram account using the name and the photo of someone that went to my high school and hope that I remember that person a little bit
Then request access to my private Instagram from the fake account and in the meantime scour my work Instagram account cause that one's public.
Research me obsessively
Uh-huh!
Find an actual picture of my parents' house on Google Maps You know you want to hunt for me tirelessly
Uh-huh!
It's not stalking 'cause the information is all technically public
Check out every guy I used to date
And deduce who broke up with who based on the hesitation in our smiles
So many unanswered questions.
Did I go to the University of Texas?
Am I an EMT?
Is that my obituary in which I'm survived by my loving husband of 50 years; children Susan and Mathew and grandchild Stephanie?
Wait no. That's just all the people with my same name.
Or is it?
Pay only 9.99 on a background check web site to know for sure.
So don't stop, just research me obsessively
Uh-huh!
and in lieu of flowers donate to other me's favorite charity
Research me just research me and research me and research me
Oops.
It's three days later.
Knowledge:
I can scrape off of my face All the soot from all the places I have been to And call it knowledge I can stitch and rip the gash That was a scar until I scratched and reinvoked it And call it knowledge And I won't complain about the blisters on my heel That we've surrendered to the real Or the feral dogs who feed on knowledge
I'm a statue of a man who looks nothing like a man But here I stand Grim and solid No scarlet secret's mine to hold Just a century of cold and thin and useless Sexless knowledge So I won't complain when my shattering is dreamt By the ninety-nine percent I'll surrender to their knowledge
'Cause I have read the terms and conditions I have read the terms and conditions Let the record show I agree to my position I accept the terms and conditions
Well I woke up this morning and saw the pitchforks at my door Said I woke up this morning—it was dark still—and there were pitchforks at my door And they were shining with a righteousness no knowledge ever shone before
I have read the terms and conditions I have read the terms and conditions I have read the terms and conditions I have read the terms and conditions
Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves
3 notes
·
View notes
Note
[RE: your post about a comment on copyright and AI-Art]
Hope this doesn’t come off as rude, but what do you mean when artists should be responsible to keep their art from being stored in publicly accessible digital spaces (especially if these public spaces opt-in to allowing AI to use their library without the artists’ knowledge)?
It is not an artists right to control which people view, learn from, or interpret their public work. If an artist does not want certain people or tools to view their images, and believes that the inability to control this is unacceptable, then they must make the decision to post their work on webpages that are either explicitly blocked from web-crawlers, or behind paywalls/membership subscriptions.
These public spaces have opted in to having their user data collected into massive databases for decades, and these petabyte sized scrapes done by organizations like google and the internet archive are well established as a core part of internet infrastructure since the turn of the millennia.
I hope this makes sense. I am neither a lawyer nor a machine learning engineer, I'm just a guy with a hate-on for the systems of copyright and intellectual property.
26 notes
·
View notes
Text
We were making an ai classifier toda which was pretty interesting, like you get a bunch of photos for multiple things (i did it on moths so, one class is rosy maple moth, second is atlas moth, third is herculese moth etc etc) and train it to recognize the patterns and if you show it a moth it will try to guess what moth it is (regarding the classes you made for it). We made a quizz off it after.
However because we scraped the web for images to train it on, most of us used google. And it just proved the point of how useless google's image search actually is. We used an image downloading extention called "imageye" which basically scrapes all the images from the website you have open and downloads them, this also means it downloads absolutely all favicons and random icons that nobody wants so you have to filter them.
And oh my god it was garbage. ~10% of your results depending on what moth you searched were AI sludge. Then it shows you shop listings (obviously), then it shows you a completely different moth. It was impossible to get photos for the rosy maple moth because 50% were plushie/etsy listings. Like I get it its a popular moth thats really cute but jesus christ. I had to go to flickr to get pictures of that thing because after sorting the images i was left with like. 15 files. Which is Not enough for a classifier.
I think the saddest part beside the fact of youre just downloading random images with no permission is that there was barely any art in the search results. Like there were a couple of moth drawings, and some "buff moths" (bc i was looking up buff tip moth lol) but the rest was just... online listings, ai sludge, or some other thing you didnt need.
I think the classifier itself is a more useful tool than an image generator since you can train it to recognize plants and animals, like those mushroom identifier books but automated. The professor showed us a classifier that sb had made for shooing away foxes and raccoons from their garden, so if it detected it it would make a noise and scare them away. Lol
7 notes
·
View notes
Text
Zyneto Technologies: Leading Mobile App Development Companies in the US & India
In today’s mobile-first world, having a robust and feature-rich mobile application is key to staying ahead of the competition. Whether you’re a startup or an established enterprise, the right mobile app development partner can help elevate your business. Zyneto Technologies is recognized as one of the top mobile app development companies in the USA and India, offering innovative and scalable solutions that meet the diverse needs of businesses across the globe.
Why Zyneto Technologies Stands Out Among Mobile App Development Companies in the USA and India
Zyneto Technologies is known for delivering high-quality mobile app development solutions that are tailored to your business needs. With a team of highly skilled developers, they specialize in building responsive, scalable, and feature
website- zyneto.com
#devops automation tools#devops services and solutions#devops solutions and services#devops solution providers#devops solutions company#devops solutions and service provider company#devops services#devops development services#devops consulting service#devops services company#web scraping solutions#web scraping chrome extension free#web scraping using google colab#selenium web scraping#best web scraping tools#node js web scraping#artificial intelligence web scraping#beautiful soup web scraping#best web scraping software#node js for web scraping#web scraping software#web scraping ai#free web scraping tools#web scraping python beautifulsoup#selenium web scraping python#web scraping with selenium and python#web site development#website design company near me#website design companies near me#website developers near me
0 notes
Text
Unsolicited Rec: My webhost of 20 years — I owe them my soul
Hey if anyone is looking for a webhost for their websites, blogs, a shop front, public or password-protected file storage, mailing lists, or would just like to have their email in reasonable privacy where Google can't scrape it, I just noticed my old webhost ICDSoft is having a 75% off sale so your first year is $2/mo, renewing at $80/year, + (last time I checked?) $5 for domain name registration.  I think they were $60 per year when I started 20 years ago, and they just keep adding more storage space and tools (eg social media backup & sync)
Their dashboard has oodles of tools for setting up various types of websites and things with acronyms somebody more techy than me would appreciate, Their online documentation and tips blog and 24/7 tech support are great and — no really, they are GOOD. I foisted my mom on them decades ago after she asked me about starting her business website, and they've been her tech support ever since.
Which is where the soul-iou comes in.
ANYWAY, ICDsoft has never let me down in 20+ years, they protect their servers from attacks so I've never been hacked or had downtime that I know of (knock wood), and they are literally the only company I trust.

[Above: screencap of the top of their order page listing some features of basic account.]
This is not a paid shill. I've just been thinking about renovating my old websites and dormant blogs because of recent Tumblr posts talking about the good old days when the web wasn't consolidated, owned, sandboxed and mined by social media companies and Google.
Think of it as a community garden, where you pay a fee for your plot and do the gardening yourself, but there's a couple on-duty gardeners to keep out pests, maintain the hoses and fences, and advise you on projects or even help you set up your beds.
2 notes
·
View notes
Text
Friends dont let friends use google docs, a wonderful writing tool that i exclusively use is ellipsus, a writing site that will never scrape your data for ai, and has wonderful tools for writing; it also allows for direct export to ao3, and on web collaboration and posting!
@ellipsus-writes You guys are fantastic!
people who write their fics directly onto archive of our own site do not fear death by the way
in all seriousness, please always keep backups of your works, write them somewhere else (google doc is a good choice) then copy and paste onto ao3 when you're done, because ao3 itself does not automatically save your works for you, meaning you can lose all of your progress
17K notes
·
View notes
Text
Integration of AI and Machine Learning into Web Scraping APIs

Introduction
Artificial Intelligence (AI) and Machine Learning (ML) have recently advanced rapidly and revolutionized several industries. One of the most dramatic changes with these advancements is the transformation of web scraping. Web scraping was considered the traditional coding suite for data extraction from websites. However, the latest developments in AI and ML have turned this into something much more efficient, accurate, and adaptable. This blog will venture into the integration of AI and ML into Web Scraping APIs, along with discussing its advantages, challenges, and prospects for the future.
Understanding the Web Scraping APIs
Web Scraping APIs are specialized tools that give access to developers for extracting data from a website in a programmatic manner. These APIs considerably simplify the web scraping process by allowing automated mechanisms to fetch, parse, and structure data. Conventional web scraping is dependent upon static scripts able to parse HTML structures to retrieve specific data. However, because of the dynamic nature of today's web, classical methods struggle in the face of dealing with contemporary JavaScript-powered web pages, CAPTCHAs, and anti-scraping mechanisms.
The Role of AI in Web Scraping APIs
Artificial Intelligence within Web Scraping APIs has been a game changer for data collection, data processing, and data use. AI-powered scraping tools are able to withstand complex challenges such as modification in website structure, dynamic content load, and anti-scraping mechanisms. How AI supports Web Scraping APIs are:
1. Pre-empt Data Extraction
AI-enabled web scrapers may analyze page structures and extract relevant data without any predefined rules.
ML models may recognize patterns that help them to make changes according to the changes in website layouts.
2. Counter Anti-Scraping Measures
To prevent automated access, websites implement various anti-scraping measures, including CAPTCHA, blocking specific IP addresses, and user-agent detection.
AI bots could use CAPTCHA solvers, IP rotation, and human-like patterns to bypass these barriers.
3. Understanding the Data with Natural Language Processing (NLP)
NLP models enable scrapers to comprehend unstructured text, extract relevant information, and even summarize content.
While sentiment analysis, keyword extraction, and named entity recognition can enhance the usability of data successfully scraped otherwise.
4. Adaptive Learning for Changing Web Structures
Machine learning algorithms can track and learn from ongoing changes in a concerned website so that data can be collected freely without constant script updating.
Deep learning models can also analyze DOM elements and infer patterns dynamically.
5. Intelligent Data Cleaning and Pre-Processing
AI techniques will delete duplicates, fix inconsistencies, and fill in missing values from scraped data.
Anomaly detection identifies and corrects erroneous data points.
Key Technologies Enabling AI and ML in Web Scraping APIs
Several technologies and frameworks empower AI and ML in Web Scraping APIs:
Python libraries: BeautifulSoup, Scrapy, or Selenium, combined with TensorFlow, PyTorch, or Scikit-learn.
AI-Based Browsers: Puppeteer and Playwright for headless browsing with ML enhancements.
Cloud Computing and APIs: Google Cloud AI, AWS AI services, and OpenAI APIs for intelligent scraping.
Data Annotation and Reinforcement Learning: Using human-labeled datasets to train ML models for better accuracy.
Benefits of AI and ML in Web Scraping APIs
Applications of AI and ML in Web Scraping APIs bring advantages, including:
Faster- AI-based scrapers can deliver results in an instant.
Scalability- ML algorithms enable web scraping tools to scale to various domains and handle huge datasets.
Reduced Maintenance- Reinforced learning will lead to reduced script-update requirements.
Better Accuracy- AI filtering can effectively sort noise and deliver upper-rend data.
Even exploitable security- AI approaches help avoid any anti-bot mechanisms and follow the principle of ethical scraping.
Challenges and Ethical Considerations
However, AI web scraping challenges are offset by apparent advantages:
1. Legal and Ethical Issues Unsurprisingly
Most web places deny scraping in their terms of service.
Any scraping carried out by AI needs to be mindful of data privacy issues such as GDPR and CCPA.
2. Complex Website Structures
AI scrapers need to cope with dynamic page rendering with JavaScript and AJAX-based content or rendering.
3. Computational Costs
Running ML models for web scraping entails high computational costs and therefore running costs.
4. Validation and Data Quality
The AI scrapers need to have a strong mechanism for validation to confirm the accuracy of the data being extracted.
Best Practices for Using AI in Web Scraping APIs
To get the best out of AI in Web Scraping APIs, developers are expected to follow these best practices:
Respect Website Terms and Policies- Always check the site's robots.txt file, and respect its rules.
Implement Conscious Scraping Approach- Avoid hammering the website with too many requests; set limits for the bot to follow.
Implement Smart Proxy Rotations and User Agents- Rotate IP addresses and user-agent strings that mirror real users.
Monitor Pageload Activities- Have some ML-powered monitoring to track alterations to websites' structures.
Ensure Data Privacy- Follow the existing legal regimes to protect user data and avoid unauthorized collection of data.
Future Possibilities of AI and ML in Web Scraping APIs
The integration of AI and ML into Web Scraping APIs would expand with improvements in:
Self-Learning Web Scrapers- Full autonomic scrapers learning & adapting without human help.
AI-Powered Semantic Understanding- In other words, using more advanced NLP paradigms like GPT-4 for extracting context insight.
Decentralized Scrapping Networks- A distributed AI-driven scraping that minimizes the risk of detection and scales up easily.
Frameworks for Ethical AI Scraping- Formulating common norms for responsible web scraping practices.
Conclusion
AI and ML in Web Scraping APIs have transformed data extraction, making it more intelligent, resilient, and efficient. Despite challenges such as legal concerns and computational demands, AI-powered web scraping is set to become an indispensable tool for businesses and researchers. By leveraging adaptive learning, NLP, and automation, the future of Web Scraping APIs will be more sophisticated, ensuring seamless data extraction while adhering to ethical standards.
Know More : https://www.crawlxpert.com/blog/ai-and-machine-learning-into-web-scraping-apis
0 notes
Text
AI Tactics to Drive More Traffic to Your Shopify Store

💥 You built your Shopify store. The design looks clean. The products are live. But traffic? Still trickling in like a leaky faucet. Here’s the reality: Shopify doesn’t bring traffic— strategy does. If you want real, sustainable growth, you need to master SEO.AIO.GEO.SXO.AI-driven traffic systems.
Let’s break it down 👇
🧠 1. Intent-Based Keyword Targeting (SEO + SXO)
Most store owners use product names as keywords. That’s a mistake. Your pages need buyer-intent keywords that match what people actually search.
✅ Example: Don’t use “Eco Yoga Mat”
👉 Use: “Best Non-Slip Yoga Mat for Home Workouts”
🛠 Use tools like Google Search Console, SEO.AIO, or SXO.ai to map real queries.
🌍 2. Geo-Intent Optimization (GEO + Local SEO)
Shopify stores rarely optimize for hyperlocal intent.
📍 Add city, state, or regional modifiers to product/category pages.
✅ Example: “Organic Skincare Products in Austin, TX”
🔍 Use structured data (schema) and geo-tagged images for location signals.
📸 3. Visual Search Optimization (AIO + SXO)
In 2025, image SEO = traffic gold.
🔹 Rename image files with keyword-rich titles.
🔹 Use ALT text that describes product features and use case.
🔹 Optimize with AIO tools to adapt images for Google Lens, Pinterest, and Bing Visual.
🏷 4. Category Pages = High-Intent Traffic
Most Shopify owners sleep on category pages. Don’t.
💡 These are keyword goldmines for mid-funnel searches.
✅ Example: “Women’s Running Shoes” ➝ Target users browsing but not yet decided.
📈 Optimize with 300–500 words of copy, internal links, and embedded FAQs.
✍️ 5. AI-Enhanced Blogging with Buyer-Focused Topics
A blog without strategy is just noise. Use AIO/SEO.AI tools to generate low competition, high intent blog ideas.
✅ Example Posts:
“Best Shopify Apps to Boost Store Speed”
“Top 5 Sustainable Fashion Trends in 2025”
🎯 Publish weekly. Optimize around search clusters, not just keywords.
🧭 6. Smart Navigation = Better Crawlability (SEO + UX)
Your traffic is leaking through bad UX.
🛠 Implement faceted navigation for large inventories.
🧩 Use internal linking to connect product → category → blog → home. Result? Better crawl budget, higher indexation rate, improved rankings.
⚡ 7. Speed = Sales (Core Web Vitals + SXO)
Site slow? Your traffic (and conversions) are dying.
📉 53% of users bounce if your store takes longer than 3 seconds.
🔥 What to do:
Switch to a Shopify speed-optimized theme.
Compress images (use WebP).
Use lazy loading and minified code. Run tests with PageSpeed Insights and fix red flags.
🤖 8. Leverage Structured Data (SEO + AI)
Schema markup isn’t optional.
📦 Use product, review, FAQ, and breadcrumb schemas.
🧠 Add SXO-style markup for enhanced CTR on SERPs (like price, reviews, stock status). Tools like SEO.AIO and RankMath streamline this in Shopify.
🔗 9. AI-Powered Backlink Outreach
You can’t rank without links. Period. But you don’t need spammy directories—you need contextual relevance.
🎯 Use AI tools to scrape niche blogs, influencers, and media sites. Send smart pitches offering:
Product reviews
Guest content
Data-backed insights (infographics, mini-reports) Build 3-5 backlinks/month, and your domain authority climbs fast.
📲 10. SXO-Optimized Mobile Experience
70%+ of Shopify traffic = mobile. Is your store designed for conversion-first mobile UX?
✅ Checklist:
Sticky “Add to Cart” button
1-click checkout
Mobile-optimized product images
Real-time shipping calculators SXO = Search Experience Optimization. Google rewards pages with low bounce, high interaction.
✅ Final Thoughts
🚫 You don’t need more ads.
✅ You need more organic, intent-aligned, geo-aware traffic. 2025 belongs to store owners who merge SEO, GEO, SXO, and AI into one unstoppable engine.
🔁 Save this post. 💬 Drop a comment: Which tactic are you going to try first?
#shopifytips #ecommercemarketing #sxoai #seoaio #geoai #shopifyseo #organictraffic #digitalgrowth #shopifystores #contentstrategy #technicalseo
0 notes