#learn apache spark
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
SQL Course Training: Advancing Your Database Skills

In the realm of data analysis and management, SQL (Structured Query Language) stands as a foundational skill indispensable for professionals seeking to navigate and manipulate databases effectively. As the demand for data-driven insights continues to soar, honing your SQL proficiency through targeted training can significantly enhance your capabilities in data analysis and open doors to diverse career opportunities. Let's explore the significance of SQL course training and how it can advance your database skills.
Understanding the Importance of SQL in Data Analysis:
SQL serves as the universal language for communicating with relational databases, enabling users to retrieve, manipulate, and manage data efficiently. Whether you're a data analyst, data scientist, or database administrator, mastering SQL empowers you to extract valuable insights, perform complex queries, and optimize database performance. With its widespread adoption across industries, SQL proficiency has become a prerequisite for roles involving data analysis and database management.
Key Components of SQL Course Training:
SQL course training encompasses a range of topics tailored to equip learners with comprehensive database management skills. From basic SQL syntax to advanced query optimization techniques, these courses cover essential concepts and best practices for leveraging SQL effectively. Key components of SQL course training include:
- SQL Fundamentals: Understanding basic SQL commands, data types, and database objects.
- Querying Databases: Crafting SELECT statements to retrieve data from tables and apply filtering, sorting, and aggregation.
- Data Manipulation: Performing INSERT, UPDATE, DELETE operations to modify data within tables.
- Database Design: Understanding principles of database normalization, table relationships, and entity-relationship modeling.
- Advanced SQL Topics: Exploring advanced SQL features such as joins, subqueries, stored procedures, and triggers.
- Optimization and Performance Tuning: Techniques for optimizing SQL queries, indexing strategies, and enhancing database performance.
Choosing the Best SQL Course:
When selecting a SQL course online, it's essential to consider factors such as:
- Curriculum: Ensure the course covers a comprehensive range of SQL topics, from fundamentals to advanced concepts.
- Hands-On Practice: Look for courses that offer hands-on exercises and projects to reinforce learning and practical application.
- Instructor Expertise: Choose courses led by experienced SQL professionals with a track record of delivering high-quality instruction.
- Student Reviews: Assess feedback from past learners to gauge the course's effectiveness and relevance to your learning goals.
- Certification: Some SQL courses offer certification upon completion, which can validate your skills and enhance your credentials in the job market.
Integrating SQL with Data Analysis:
SQL proficiency synergizes seamlessly with data analysis tasks, enabling analysts to extract, transform, and analyze data stored in relational databases. Whether you're performing ad-hoc analysis, generating reports, or building data pipelines, SQL serves as a powerful tool for accessing and manipulating data effectively. By mastering SQL alongside data analysis skills and tools such as Python and Apache Spark, you can enhance your capabilities as a data professional and tackle complex analytical challenges with confidence.
Conclusion:
Investing in SQL course training is a strategic step towards mastering database management skills and advancing your career in data analysis. Whether you're a novice seeking to build a solid foundation in SQL or an experienced professional aiming to sharpen your expertise, there are ample opportunities to enhance your database skills through online SQL courses. By selecting the best SQL course that aligns with your learning objectives and investing time and effort into mastering SQL concepts, you can unlock new possibilities in data analysis and become a proficient database practitioner poised for success in today's data-driven world.
#apache spark course#data analysis#data analysis skill#python course#best python course#data analysis course#data analysis course online#master data analysis#python course online#sql course#sql course online#best sql course#data analysis online#python course training#sql course training#apache spark course online#best apache spark course#learn python#learn apache spark#learn data analysis#learn sql
1 note
·
View note
Text

In 2013, Databricks was born out of UC Berkeley with one mission: simplify big data and unleash AI through Apache Spark. Founders like Ali Ghodsi believed the future of computing lay in seamless data platforms. With $𝟑𝟑 𝐦𝐢𝐥𝐥𝐢𝐨𝐧 in early backing from Andreessen Horowitz and NEA, Databricks introduced a cloud-based environment where teams could collaborate on data science and machine learning. By 2020, it had over 𝟓,𝟎𝟎𝟎 𝐜𝐮𝐬𝐭𝐨𝐦𝐞𝐫𝐬, including Shell and HP. Its 2023 funding round pushed its valuation to $𝟒𝟑 𝐛𝐢𝐥𝐥𝐢𝐨𝐧, cementing it as a leader in the AI infrastructure space. Databricks now powers analytics for over 𝐨𝐯𝐞𝐫 𝟓𝟎% of Fortune 500 companies.
The moral? When you streamline complexity, you don’t just sell software—you unlock transformation.
#Databricks#Big Data#ai infrastructure#apache spark#data science#machine learning#tech innovation#uc berkley#vengo ai
0 notes
Text
Are you looking to build a career in Big Data Analytics? Gain in-depth knowledge of Hadoop and its ecosystem with expert-led training at Sunbeam Institute, Pune – a trusted name in IT education.
Why Choose Our Big Data Hadoop Classes?
🔹 Comprehensive Curriculum: Covering Hadoop, HDFS, MapReduce, Apache Spark, Hive, Pig, HBase, Sqoop, Flume, and more. 🔹 Hands-on Training: Work on real-world projects and industry use cases to gain practical experience. 🔹 Expert Faculty: Learn from experienced professionals with real-time industry exposure. 🔹 Placement Assistance: Get career guidance, resume building support, and interview preparation. 🔹 Flexible Learning Modes: Classroom and online training options available. 🔹 Industry-Recognized Certification: Boost your resume with a professional certification.
Who Should Join?
✔️ Freshers and IT professionals looking to enter the field of Big Data & Analytics ✔️ Software developers, system administrators, and data engineers ✔️ Business intelligence professionals and database administrators ✔️ Anyone passionate about Big Data and Machine Learning

#Big Data Hadoop training in Pune#Hadoop classes Pune#Big Data course Pune#Hadoop certification Pune#learn Hadoop in Pune#Apache Spark training Pune#best Big Data course Pune#Hadoop coaching in Pune#Big Data Analytics training Pune#Hadoop and Spark training Pune
0 notes
Text
Unveiling the Power of Delta Lake in Microsoft Fabric
Discover how Microsoft Fabric and Delta Lake can revolutionize your data management and analytics. Learn to optimize data ingestion with Spark and unlock the full potential of your data for smarter decision-making.
In today’s digital era, data is the new gold. Companies are constantly searching for ways to efficiently manage and analyze vast amounts of information to drive decision-making and innovation. However, with the growing volume and variety of data, traditional data processing methods often fall short. This is where Microsoft Fabric, Apache Spark and Delta Lake come into play. These powerful…
#ACID Transactions#Apache Spark#Big Data#Data Analytics#data engineering#Data Governance#Data Ingestion#Data Integration#Data Lakehouse#Data management#Data Pipelines#Data Processing#Data Science#Data Warehousing#Delta Lake#machine learning#Microsoft Fabric#Real-Time Analytics#Unified Data Platform
0 notes
Link
Learn how to perform full and incremental loads in Fabric with a little SparkSQL. The post Full vs. Incremental Loads – Data Engineering with Fabric appeared first on SQLServerCentral.
#Microsoft Fabric (Azure Synapse#Data Engineering#etc.)#Apache Spark#Bronze#data engineering#Erase Hive Tables#Full Load Code#Incremental Load Code#John F. Miner III#Learn#Microsoft Fabric#Quality Zones#Raw#Silver
0 notes
Text
Ngôn ngữ lập trình Scala là gì? Có nên học không?
🚀 Scala là gì mà được gọi là "con lai giữa Java và Functional"?
Bạn đã từng nghe tới Scala chưa? 👀 Nếu bạn là dân lập trình hoặc đang lấn sân vào lĩnh vực dữ liệu lớn, thì Scala chính là một “vũ khí” cực mạnh mà bạn không nên bỏ qua!
👉 Scala kết hợp sự ổn định của Java với sự “thần sầu” của lập trình hàm (Functional Programming). Điều đó có nghĩa là gì? 🔸 Code ít hơn – hiệu quả hơn 🔸 Chạy cực nhanh trên JVM (giống Java) 🔸 Được "ông lớn" như Twitter, LinkedIn, Netflix tin dùng!
😎 Đặc biệt, Scala cực kỳ phù hợp với Big Data và là trái tim của nhiều công cụ như Apache Spark. Nếu bạn muốn làm về Data Engineering hay Machine Learning – đừng bỏ qua!
📍Tò mò không biết học Scala có khó không? Dễ hay khó hơn Java? 📥 Xem ngay bài viết chi tiết tại đây nhé: https://interdata.vn/blog/scala-la-gi/
🌐Website: https://interdata.vn/ 📌VPĐD: 240 Nguyễn Đình Chính, Phường Phú Nhuận, Thành phố Hồ Chí Minh 📌VPGD: 211 Đường số 5, Khu Đô Thị Lakeview City, Phường Bình Trưng, Thành phố Hồ Chí Minh 📞Phone: 1900636822 📧Email: [email protected] 🌐Group Zalo: https://zalo.me/g/ingoza480

2 notes
·
View notes
Text
SQL for Hadoop: Mastering Hive and SparkSQL
In the ever-evolving world of big data, having the ability to efficiently query and analyze data is crucial. SQL, or Structured Query Language, has been the backbone of data manipulation for decades. But how does SQL adapt to the massive datasets found in Hadoop environments? Enter Hive and SparkSQL—two powerful tools that bring SQL capabilities to Hadoop. In this blog, we'll explore how you can master these query languages to unlock the full potential of your data.
Hive Architecture and Data Warehouse Concept
Apache Hive is a data warehouse software built on top of Hadoop. It provides an SQL-like interface to query and manage large datasets residing in distributed storage. Hive's architecture is designed to facilitate the reading, writing, and managing of large datasets with ease. It consists of three main components: the Hive Metastore, which stores metadata about tables and schemas; the Hive Driver, which compiles, optimizes, and executes queries; and the Hive Query Engine, which processes the execution of queries.
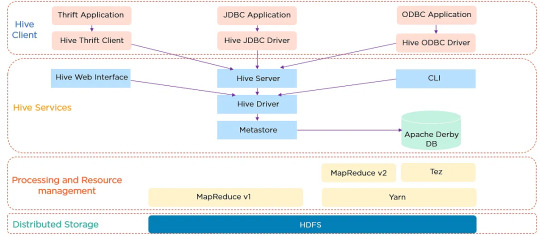
Hive Architecture
Hive's data warehouse concept revolves around the idea of abstracting the complexity of distributed storage and processing, allowing users to focus on the data itself. This abstraction makes it easier for users to write queries without needing to know the intricacies of Hadoop.
Writing HiveQL Queries
HiveQL, or Hive Query Language, is a SQL-like query language that allows users to query data stored in Hadoop. While similar to SQL, HiveQL is specifically designed to handle the complexities of big data. Here are some basic HiveQL queries to get you started:
Creating a Table:
CREATE TABLE employees ( id INT, name STRING, salary FLOAT );
Loading Data:
LOAD DATA INPATH '/user/hive/data/employees.csv' INTO TABLE employees;
Querying Data:
SELECT name, salary FROM employees WHERE salary > 50000;
HiveQL supports a wide range of functions and features, including joins, group by, and aggregations, making it a versatile tool for data analysis.
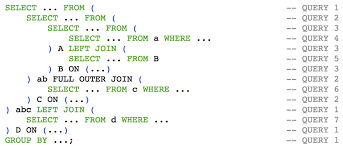
HiveQL Queries
SparkSQL vs HiveQL: Similarities & Differences
Both SparkSQL and HiveQL offer SQL-like querying capabilities, but they have distinct differences:
Execution Engine: HiveQL relies on Hadoop's MapReduce engine, which can be slower due to its batch processing nature. SparkSQL, on the other hand, leverages Apache Spark's in-memory computing, resulting in faster query execution.
Ease of Use: HiveQL is easier for those familiar with traditional SQL syntax, while SparkSQL requires understanding Spark's APIs and dataframes.
Integration: SparkSQL integrates well with Spark's ecosystem, allowing for seamless data processing and machine learning tasks. HiveQL is more focused on data warehousing and batch processing.
Despite these differences, both languages provide powerful tools for interacting with big data, and knowing when to use each is key to mastering them.

SparkSQL vs HiveQL
Running SQL Queries on Massive Distributed Data
Running SQL queries on massive datasets requires careful consideration of performance and efficiency. Hive and SparkSQL both offer powerful mechanisms to optimize query execution, such as partitioning and bucketing.
Partitioning, Bucketing, and Performance Tuning
Partitioning and bucketing are techniques used to optimize query performance in Hive and SparkSQL:
Partitioning: Divides data into distinct subsets, allowing queries to skip irrelevant partitions and reduce the amount of data scanned. For example, partitioning by date can significantly speed up queries that filter by specific time ranges.
Bucketing: Further subdivides data within partitions into buckets based on a hash function. This can improve join performance by aligning data in a way that allows for more efficient processing.
Performance tuning in Hive and SparkSQL involves understanding and leveraging these techniques, along with optimizing query logic and resource allocation.

Hive and SparkSQL Partitioning & Bucketing
FAQ
1. What is the primary use of Hive in a Hadoop environment? Hive is primarily used as a data warehousing solution, enabling users to query and manage large datasets with an SQL-like interface.
2. Can HiveQL and SparkSQL be used interchangeably? While both offer SQL-like querying capabilities, they have different execution engines and integration capabilities. HiveQL is suited for batch processing, while SparkSQL excels in in-memory data processing.
3. How do partitioning and bucketing improve query performance? Partitioning reduces the data scanned by dividing it into subsets, while bucketing organizes data within partitions, optimizing joins and aggregations.
4. Is it necessary to know Java or Scala to use SparkSQL? No, SparkSQL can be used with Python, R, and SQL, though understanding Spark's APIs in Java or Scala can provide additional flexibility.
5. How does SparkSQL achieve faster query execution compared to HiveQL? SparkSQL utilizes Apache Spark's in-memory computation, reducing the latency associated with disk I/O and providing faster query execution times.
Home
instagram
#Hive#SparkSQL#DistributedComputing#BigDataProcessing#SQLOnBigData#ApacheSpark#HadoopEcosystem#DataAnalytics#SunshineDigitalServices#TechForAnalysts#Instagram
2 notes
·
View notes
Text
#Apache Spark Databricks tutorial#Best data engineering tools 2025#Data engineering with Databricks#Databricks certification course#Databricks training#learn databricks in 2025#Learn Databricks online
0 notes
Text
Data Science vs Data Engineering: What’s the Difference?

The Short Answer: Builders vs Explorers
Think of data engineers as the people who build the roads, and data scientists as the people who drive on them looking for treasure. A data engineer creates the systems and pipelines that collect, clean, and organize raw data. A data scientist, on the other hand, takes that cleaned-up data and analyzes it to uncover insights, patterns, and predictions.
You can’t have one without the other. If data engineers didn’t build the infrastructure, data scientists would be stuck cleaning messy spreadsheets all day. And without data scientists, all that clean, beautiful data would just sit there doing nothing — like a shiny sports car in a garage.
So if you’re asking “Data Science vs Data Engineering: What’s the Difference?”, it really comes down to what part of the data journey excites you more.
What Does a Data Engineer Do?
Data engineers are the behind-the-scenes heroes who make sure data is usable, accessible, and fast. They design databases, write code to move data from one place to another, and make sure everything is running smoothly.
You’ll find them working with tools like Apache Spark, Kafka, SQL, and ETL pipelines. Their job is technical, logical, and kind of like building Lego structures — but instead of bricks, they’re stacking code and cloud platforms.
They may not always be the ones doing the fancy machine learning, but without them, machine learning wouldn’t even be possible. They’re like the stage crew in a big play — quietly making everything work behind the scenes so the stars can shine.
What Does a Data Scientist Do?
Data scientists are the curious minds asking big questions like “Why are sales dropping?” or “Can we predict what customers want next?” They take the data that engineers prepare and run experiments, visualizations, and models to uncover trends and make smart decisions.
Their toolbox includes Python, R, Pandas, Matplotlib, scikit-learn, and plenty of Jupyter notebooks. They often use machine learning algorithms to make predictions and identify patterns. If data engineering is about getting the data ready, data science is about making sense of it.
They’re creative, analytical, and a little bit detective. So if you love puzzles and want to tell stories with numbers, data science might be your jam.
How Do They Work Together?
In most modern data teams, data scientists and engineers are like teammates on the same mission. The engineer prepares the data pipeline and builds systems to handle huge amounts of information. The scientist uses those systems to run models and generate business insights.
The magic really happens when they collaborate well. The better the pipeline, the faster the insights. The better the insights, the more valuable the data becomes. It’s a team sport — and when done right, it leads to smarter decisions, better products, and happy stakeholders.
Which One Is Right for You?
If you love solving technical problems and enjoy working with infrastructure and systems, data engineering could be a great fit. If you’re more into statistics, analytics, and asking “why” all the time, data science might be the path for you.
Both careers are in demand, both pay well, and both are at the heart of every data-driven company. You just need to decide which role gets you more excited.
And if you’re still unsure, try building a mini project! Play with a dataset, clean it, analyze it, and see which part you enjoyed more.
Final Thoughts
So now you know the answer to that confusing question: Data Science vs Data Engineering — what’s the difference? One builds the systems, the other finds the insights. Both are crucial. And hey, if you learn a little of both, you’ll be even more unstoppable in your data career.
At Coding Brushup, we make it easy to explore both paths with hands-on resources, real-world projects, and simplified learning tools. Whether you’re cleaning data or building pipelines, Coding Brushup helps you sharpen your skills and stay ahead in the ever-growing world of data.
3 notes
·
View notes
Text
Why Python Will Thrive: Future Trends and Applications
Python has already made a significant impact in the tech world, and its trajectory for the future is even more promising. From its simplicity and versatility to its widespread use in cutting-edge technologies, Python is expected to continue thriving in the coming years. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Let's explore why Python will remain at the forefront of software development and what trends and applications will contribute to its ongoing dominance.
1. Artificial Intelligence and Machine Learning
Python is already the go-to language for AI and machine learning, and its role in these fields is set to expand further. With powerful libraries such as TensorFlow, PyTorch, and Scikit-learn, Python simplifies the development of machine learning models and artificial intelligence applications. As more industries integrate AI for automation, personalization, and predictive analytics, Python will remain a core language for developing intelligent systems.
2. Data Science and Big Data
Data science is one of the most significant areas where Python has excelled. Libraries like Pandas, NumPy, and Matplotlib make data manipulation and visualization simple and efficient. As companies and organizations continue to generate and analyze vast amounts of data, Python’s ability to process, clean, and visualize big data will only become more critical. Additionally, Python’s compatibility with big data platforms like Hadoop and Apache Spark ensures that it will remain a major player in data-driven decision-making.
3. Web Development
Python’s role in web development is growing thanks to frameworks like Django and Flask, which provide robust, scalable, and secure solutions for building web applications. With the increasing demand for interactive websites and APIs, Python is well-positioned to continue serving as a top language for backend development. Its integration with cloud computing platforms will also fuel its growth in building modern web applications that scale efficiently.
4. Automation and Scripting
Automation is another area where Python excels. Developers use Python to automate tasks ranging from system administration to testing and deployment. With the rise of DevOps practices and the growing demand for workflow automation, Python’s role in streamlining repetitive processes will continue to grow. Businesses across industries will rely on Python to boost productivity, reduce errors, and optimize performance. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

5. Cybersecurity and Ethical Hacking
With cyber threats becoming increasingly sophisticated, cybersecurity is a critical concern for businesses worldwide. Python is widely used for penetration testing, vulnerability scanning, and threat detection due to its simplicity and effectiveness. Libraries like Scapy and PyCrypto make Python an excellent choice for ethical hacking and security professionals. As the need for robust cybersecurity measures increases, Python’s role in safeguarding digital assets will continue to thrive.
6. Internet of Things (IoT)
Python’s compatibility with microcontrollers and embedded systems makes it a strong contender in the growing field of IoT. Frameworks like MicroPython and CircuitPython enable developers to build IoT applications efficiently, whether for home automation, smart cities, or industrial systems. As the number of connected devices continues to rise, Python will remain a dominant language for creating scalable and reliable IoT solutions.
7. Cloud Computing and Serverless Architectures
The rise of cloud computing and serverless architectures has created new opportunities for Python. Cloud platforms like AWS, Google Cloud, and Microsoft Azure all support Python, allowing developers to build scalable and cost-efficient applications. With its flexibility and integration capabilities, Python is perfectly suited for developing cloud-based applications, serverless functions, and microservices.
8. Gaming and Virtual Reality
Python has long been used in game development, with libraries such as Pygame offering simple tools to create 2D games. However, as gaming and virtual reality (VR) technologies evolve, Python’s role in developing immersive experiences will grow. The language’s ease of use and integration with game engines will make it a popular choice for building gaming platforms, VR applications, and simulations.
9. Expanding Job Market
As Python’s applications continue to grow, so does the demand for Python developers. From startups to tech giants like Google, Facebook, and Amazon, companies across industries are seeking professionals who are proficient in Python. The increasing adoption of Python in various fields, including data science, AI, cybersecurity, and cloud computing, ensures a thriving job market for Python developers in the future.
10. Constant Evolution and Community Support
Python’s open-source nature means that it’s constantly evolving with new libraries, frameworks, and features. Its vibrant community of developers contributes to its growth and ensures that Python stays relevant to emerging trends and technologies. Whether it’s a new tool for AI or a breakthrough in web development, Python’s community is always working to improve the language and make it more efficient for developers.
Conclusion
Python’s future is bright, with its presence continuing to grow in AI, data science, automation, web development, and beyond. As industries become increasingly data-driven, automated, and connected, Python’s simplicity, versatility, and strong community support make it an ideal choice for developers. Whether you are a beginner looking to start your coding journey or a seasoned professional exploring new career opportunities, learning Python offers long-term benefits in a rapidly evolving tech landscape.
#python course#python training#python#technology#tech#python programming#python online training#python online course#python online classes#python certification
2 notes
·
View notes
Text

Are you looking to build a career in Big Data Analytics? Gain in-depth knowledge of Hadoop and its ecosystem with expert-led training at Sunbeam Institute, Pune – a trusted name in IT education.
Why Choose Our Big Data Hadoop Classes?
🔹 Comprehensive Curriculum: Covering Hadoop, HDFS, MapReduce, Apache Spark, Hive, Pig, HBase, Sqoop, Flume, and more. 🔹 Hands-on Training: Work on real-world projects and industry use cases to gain practical experience. 🔹 Expert Faculty: Learn from experienced professionals with real-time industry exposure. 🔹 Placement Assistance: Get career guidance, resume building support, and interview preparation. 🔹 Flexible Learning Modes: Classroom and online training options available. 🔹 Industry-Recognized Certification: Boost your resume with a professional certification.
Who Should Join?
✔️ Freshers and IT professionals looking to enter the field of Big Data & Analytics ✔️ Software developers, system administrators, and data engineers ✔️ Business intelligence professionals and database administrators ✔️ Anyone passionate about Big Data and Machine Learning
Course Highlights:
✅ Introduction to Big Data & Hadoop Framework ✅ HDFS (Hadoop Distributed File System) – Storage & Processing ✅ MapReduce Programming – Core of Hadoop Processing ✅ Apache Spark – Fast and Unified Analytics Engine ✅ Hive, Pig, HBase – Data Querying & Management ✅ Data Ingestion Tools – Sqoop & Flume ✅ Real-time Project Implementation
#Big Data Hadoop training in Pune#Hadoop classes Pune#Big Data course Pune#Hadoop certification Pune#learn Hadoop in Pune#Apache Spark training Pune#best Big Data course Pune#Hadoop coaching in Pune#Big Data Analytics training Pune#Hadoop and Spark training Pune
0 notes
Text
Master Big Data with a Comprehensive Databricks Course
A Databricks Course is the perfect way to master big data analytics and Apache Spark. Whether you are a beginner or an experienced professional, this course helps you build expertise in data engineering, AI-driven analytics, and cloud-based collaboration. You will learn how to work with Spark SQL, Delta Lake, and MLflow to process large datasets and create smart data solutions.
This Databricks Course provides hands-on training with real-world projects, allowing you to apply your knowledge effectively. Learn from industry experts who will guide you through data transformation, real-time streaming, and optimizing data workflows. The course also covers managing both structured and unstructured data, helping you make better data-driven decisions.
By enrolling in this Databricks Course, you will gain valuable skills that are highly sought after in the tech industry. Engage with specialists and improve your ability to handle big data analytics at scale. Whether you want to advance your career or stay ahead in the fast-growing data industry, this course equips you with the right tools.
🚀 Enroll now and start your journey toward mastering big data analytics with Databricks!
2 notes
·
View notes
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
NVIDIA AI Workflows Detect False Credit Card Transactions

A Novel AI Workflow from NVIDIA Identifies False Credit Card Transactions.
The process, which is powered by the NVIDIA AI platform on AWS, may reduce risk and save money for financial services companies.
By 2026, global credit card transaction fraud is predicted to cause $43 billion in damages.
Using rapid data processing and sophisticated algorithms, a new fraud detection NVIDIA AI workflows on Amazon Web Services (AWS) will assist fight this growing pandemic by enhancing AI’s capacity to identify and stop credit card transaction fraud.
In contrast to conventional techniques, the process, which was introduced this week at the Money20/20 fintech conference, helps financial institutions spot minute trends and irregularities in transaction data by analyzing user behavior. This increases accuracy and lowers false positives.
Users may use the NVIDIA AI Enterprise software platform and NVIDIA GPU instances to expedite the transition of their fraud detection operations from conventional computation to accelerated compute.
Companies that use complete machine learning tools and methods may see an estimated 40% increase in the accuracy of fraud detection, which will help them find and stop criminals more quickly and lessen damage.
As a result, top financial institutions like Capital One and American Express have started using AI to develop exclusive solutions that improve client safety and reduce fraud.
With the help of NVIDIA AI, the new NVIDIA workflow speeds up data processing, model training, and inference while showcasing how these elements can be combined into a single, user-friendly software package.
The procedure, which is now geared for credit card transaction fraud, might be modified for use cases including money laundering, account takeover, and new account fraud.
Enhanced Processing for Fraud Identification
It is more crucial than ever for businesses in all sectors, including financial services, to use computational capacity that is economical and energy-efficient as AI models grow in complexity, size, and variety.
Conventional data science pipelines don’t have the compute acceleration needed to process the enormous amounts of data needed to combat fraud in the face of the industry’s continually increasing losses. Payment organizations may be able to save money and time on data processing by using NVIDIA RAPIDS Accelerator for Apache Spark.
Financial institutions are using NVIDIA’s AI and accelerated computing solutions to effectively handle massive datasets and provide real-time AI performance with intricate AI models.
The industry standard for detecting fraud has long been the use of gradient-boosted decision trees, a kind of machine learning technique that uses libraries like XGBoost.
Utilizing the NVIDIA RAPIDS suite of AI libraries, the new NVIDIA AI workflows for fraud detection improves XGBoost by adding graph neural network (GNN) embeddings as extra features to assist lower false positives.
In order to generate and train a model that can be coordinated with the NVIDIA Triton Inference Server and the NVIDIA Morpheus Runtime Core library for real-time inferencing, the GNN embeddings are fed into XGBoost.
All incoming data is safely inspected and categorized by the NVIDIA Morpheus framework, which also flags potentially suspicious behavior and tags it with patterns. The NVIDIA Triton Inference Server optimizes throughput, latency, and utilization while making it easier to infer all kinds of AI model deployments in production.
NVIDIA AI Enterprise provides Morpheus, RAPIDS, and Triton Inference Server.
Leading Financial Services Companies Use AI
AI is assisting in the fight against the growing trend of online or mobile fraud losses, which are being reported by several major financial institutions in North America.
American Express started using artificial intelligence (AI) to combat fraud in 2010. The company uses fraud detection algorithms to track all client transactions worldwide in real time, producing fraud determinations in a matter of milliseconds. American Express improved model accuracy by using a variety of sophisticated algorithms, one of which used the NVIDIA AI platform, therefore strengthening the organization’s capacity to combat fraud.
Large language models and generative AI are used by the European digital bank Bunq to assist in the detection of fraud and money laundering. With NVIDIA accelerated processing, its AI-powered transaction-monitoring system was able to train models at over 100 times quicker rates.
In March, BNY said that it was the first big bank to implement an NVIDIA DGX SuperPOD with DGX H100 systems. This would aid in the development of solutions that enable use cases such as fraud detection.
In order to improve their financial services apps and help protect their clients’ funds, identities, and digital accounts, systems integrators, software suppliers, and cloud service providers may now include the new NVIDIA AI workflows for fraud detection. NVIDIA Technical Blog post on enhancing fraud detection with GNNs and investigate the NVIDIA AI workflows for fraud detection.
Read more on Govindhtech.com
#NVIDIAAI#AWS#FraudDetection#AI#GenerativeAI#LLM#AImodels#News#Technews#Technology#Technologytrends#govindhtech#Technologynews
2 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
The Quest for Knowledge: Exploring Various Data Science Disciplines
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes