#pipelines Azure pipelines
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Azure Data Factory Components

Azure Data Factory Components are as below:
Pipelines: The Workflow Container
A Pipeline in Azure Data Factory is a container that holds a set of activities meant to perform a specific task. Think of it as the blueprint for your data movement or transformation logic. Pipelines allow you to define the order of execution, configure dependencies, and reuse logic with parameters. Whether you’re ingesting raw files from a data lake, transforming them using Mapping Data Flows, or loading them into an Azure SQL Database or Synapse, the pipeline coordinates all the steps. As one of the key Azure Data Factory components, the pipeline provides centralized management and monitoring of the entire workflow.
Activities: The Operational Units
Activities are the actual tasks executed within a pipeline. Each activity performs a discrete function like copying data, transforming it, running stored procedures, or triggering notebooks in Databricks. Among the Azure Data Factory components, activities provide the processing logic. They come in multiple types:
Data Movement Activities – Copy Activity
Data Transformation Activities – Mapping Data Flow
Control Activities – If Condition, ForEach
External Activities – HDInsight, Azure ML, Databricks
This modular design allows engineers to handle everything from batch jobs to event-driven ETL pipelines efficiently.
Triggers: Automating Pipeline Execution
Triggers are another core part of the Azure Data Factory components. They define when a pipeline should execute. Triggers enable automation by launching pipelines based on time schedules, events, or manual inputs.
Types of triggers include:
Schedule Trigger – Executes at fixed times
Event-based Trigger – Responds to changes in data, such as a file drop
Manual Trigger – Initiated on-demand through the portal or API
Triggers remove the need for external schedulers and make ADF workflows truly serverless and dynamic.
How These Components Work Together
The synergy between pipelines, activities, and triggers defines the power of ADF. Triggers initiate pipelines, which in turn execute a sequence of activities. This trio of Azure Data Factory components provides a flexible, reusable, and fully managed framework to build complex data workflows across multiple data sources, destinations, and formats.
Conclusion
To summarize, Pipelines, Activities & Triggers are foundational Azure Data Factory components. Together, they form a powerful data orchestration engine that supports modern cloud-based data engineering. Mastering these elements enables engineers to build scalable, fault-tolerant, and automated data solutions. Whether you’re managing daily ingestion processes or building real-time data platforms, a solid understanding of these components is key to unlocking the full potential of Azure Data Factory.
At Learnomate Technologies, we don’t just teach tools, we train you with real-world, hands-on knowledge that sticks. Our Azure Data Engineering training program is designed to help you crack job interviews, build solid projects, and grow confidently in your cloud career.
Want to see how we teach? Hop over to our YouTube channel for bite-sized tutorials, student success stories, and technical deep-dives explained in simple English.
Ready to get certified and hired? Check out our Azure Data Engineering course page for full curriculum details, placement assistance, and batch schedules.
Curious about who’s behind the scenes? I’m Ankush Thavali, founder of Learnomate and your trainer for all things cloud and data. Let’s connect on LinkedIn—I regularly share practical insights, job alerts, and learning tips to keep you ahead of the curve.
And hey, if this article got your curiosity going…
Thanks for reading. Now it’s time to turn this knowledge into action. Happy learning and see you in class or in the next blog!
Happy Vibes!
ANKUSH
#education#it course#it training#technology#training#azure data factory components#azure data factory key components#key components of azure data factory#what are the key components of azure data factory?#data factory components#azure data factory concepts#azure data factory#data factory components tutorial.#azure data factory course#azure data factory course online#azure data factory v2#data factory azure#azure data factory pipeline#data factory azure ml#learn azure data factory#azure data factory pipelines#what is azure data factory
2 notes
·
View notes
Text
Azure DevOps & CI/CD Demystified: Deliver Software Faster with Automation | OpsNexa
Learn what Azure DevOps and CI/CD (Continuous Integration/Continuous Delivery) are and how they work together to streamline software development. This comprehensive guide explains how Azure DevOps automates the build, test, and deployment processes, What Azure DevOps and CI/CD, helping teams deliver high-quality software faster. Whether you're new to DevOps or looking to optimize your processes, this article provides key insights into using Azure DevOps for modern software delivery and continuous integration.
#Azure Devops#Microsoft-azure-devops#Azure-pipelines#Azure-devops-services#Azure-devops-consulting#Azure-devops-integration
0 notes
Text
Steps on how to create a working pipeline to release #SSIS packages using #Azure #DevOps from the creation of the artifact to the #deployment.
0 notes
Text
Sentra Secures $50M Series B to Safeguard AI-Driven Enterprises in the Age of Shadow Data
New Post has been published on https://thedigitalinsider.com/sentra-secures-50m-series-b-to-safeguard-ai-driven-enterprises-in-the-age-of-shadow-data/
Sentra Secures $50M Series B to Safeguard AI-Driven Enterprises in the Age of Shadow Data

In a landmark moment for data security, Sentra, a trailblazer in cloud-native data protection, has raised $50 million in Series B funding, bringing its total funding to over $100 million. The round was led by Key1 Capital with continued support from top-tier investors like Bessemer Venture Partners, Zeev Ventures, Standard Investments, and Munich Re Ventures.
This new investment arrives at a pivotal time, with AI adoption exploding across enterprises and bringing with it a tidal wave of sensitive data—and new security risks. Sentra, already experiencing 300% year-over-year growth and seeing fast adoption among Fortune 500 companies, is now doubling down on its mission: empowering organizations to innovate with AI without compromising on data security.
The AI Boom’s Dark Side: Unseen Risks in “Shadow Data”
While AI opens doors to unprecedented innovation, it also introduces a hidden threat—shadow data. As companies rush to harness the power of GenAI, data scientists and engineers frequently duplicate, move, and manipulate data across environments. Much of this activity flies under the radar of traditional security tools, leading to invisible data sprawl and growing compliance risks.
Gartner predicts that by 2025, GenAI will drive a 15% spike in data and application security spending, as organizations scramble to plug these emerging gaps. That’s where Sentra comes in.
What Makes Sentra Different?
Sentra’s Cloud-Native Data Security Platform (DSP) doesn’t just bolt security onto existing infrastructure. Instead, it’s designed from the ground up to autonomously discover, classify, and secure sensitive data—whether it lives in AWS, Azure, Google Cloud, SaaS apps, on-prem servers, or inside your AI pipeline.
At the heart of Sentra’s platform is an AI-powered classification engine that leverages large language models (LLMs). Unlike traditional data scanning tools that rely on fixed rules or predefined regex, Sentra’s LLMs understand the business context of data. That means they can identify sensitive information even in unstructured formats like documents, images, audio, or code repositories—with over 95% accuracy.
Importantly, no data ever leaves your environment. Sentra runs natively in your cloud or hybrid environment, maintaining full compliance with data residency requirements and avoiding any risk of exposure during the scanning process.
Beyond Classification: A Full Security Lifecycle
Sentra’s platform combines multiple layers of data security into one unified system:
DSPM (Data Security Posture Management) continuously assesses risks like misconfigured access controls, duplicated sensitive data, and misplaced files.
DDR (Data Detection & Response) flags suspicious activity in real-time—such as exfiltration attempts or ransomware encryption—empowering security teams to act before damage occurs.
DAG (Data Access Governance) maps user and application identities to data permissions and enforces least privilege access, a key principle in modern cybersecurity.
This approach transforms the once-static notion of data protection into a living, breathing security layer that scales with your business.
Led by a World-Class Cybersecurity Team
Sentra’s leadership team reads like a who’s who of Israeli cyber intelligence:
Asaf Kochan, President, is the former Commander of Unit 8200, Israel’s elite cyber intelligence unit.
Yoav Regev, CEO, led the Cyber Department within Unit 8200.
Ron Reiter, CTO, is a serial entrepreneur with deep technical expertise.
Yair Cohen, VP of Product, brings years of experience from Microsoft and Datadog.
Their shared vision: to reimagine data security for the cloud- and AI-first world.
And the market agrees. Sentra was recently named both a Leader and Fast Mover in the GigaOm Radar for Data Security Posture Management (DSPM), underscoring its growing influence in the security space.
Building a Safer Future for AI
The $50 million boost will allow Sentra to scale its operations, grow its expert team, and enhance its platform with new capabilities to secure GenAI workloads, AI assistants, and emerging data pipelines. These advancements will provide security teams with even greater visibility and control over sensitive data—across petabyte-scale estates and AI ecosystems.
“AI is only as secure as the data behind it,” said CEO Yoav Regev. “Every enterprise wants to harness AI—but without confidence in their data security, they’re stuck in a holding pattern. Sentra breaks that barrier, enabling fast, safe innovation.”
As AI adoption accelerates and regulatory scrutiny tightens, Sentra’s approach may very well become the blueprint for modern enterprise data protection. For businesses looking to embrace AI with confidence, Sentra offers something powerful: security that moves at the speed of innovation.
#2025#adoption#ai#AI adoption#AI-powered#amp#Application Security#approach#apps#assistants#audio#AWS#azure#barrier#blueprint#Building#Business#CEO#Cloud#Cloud-Native#code#Companies#compliance#CTO#cyber#cybersecurity#Dark#data#data pipelines#data protection
1 note
·
View note
Text
How to improve software development with Azure DevOps consulting services?
With the advancement of the technological sphere, Azure DevOps consulting services have created a storm to the internet. As the service provides end-to-end automation while enhancing development efficiency by utilizing tools like Azure Pipelines, Repos, and Artifacts, businesses can achieve smooth CI CD workflows. Consultants like us help to implement cloud-based infrastructure, automate deployments, and improve security, while ensuring rapid software releases with minimal downtime, optimizing cloud and on-premises environments.

0 notes
Text
Data Engineering Guide to Build Strong Azure Data Pipeline

This data engineering guide is useful for understanding the concept of building a strong data pipeline in Azure. Information nowadays is considered the main indicator in decision-making, business practice, and analysis, still, the main issue is having this data collected, processed, and maintained effectively and properly. Azure Data Engineering, Microsoft’s cloud services, offers solutions that help businesses design massive amounts of information transport pipelines in a structured, secure way. In this guide, we will shed light on how building an effective information pipeline can be achieved using Azure Data Engineering services even if it was your first time in this area.
Explain the concept of a data pipeline.
A data pipeline refers to an automated system. It transmits unstructured information from a source to a designated endpoint where it can be eventually stored and analyzed. Data is collected from different sources, such as applications, files, archives, databases, and services, and may be converted into a generic format, processed, and then transferred to the endpoint. Pipelines facilitate the smooth flow of information and the automation of such a process helps to keep the system under control by avoiding any human intervention and lets it process information in real-time or in batches at established intervals. Finally, the pipeline can handle an extremely high volume of data while tracking workflow actions comprehensively and reliably. This is essential for data-driven business processes that rely on huge amounts of information.
Why Use Azure Data Engineering Services for Building Data Pipelines?
There are many services and tools provided by Azure to strengthen the pipelines. Azure services are cloud-based services which means ‘anytime anywhere’ and scale. Handling a small one-line task (DevOps) to a complex task (workflow) can easily be implemented without thinking about the hardware resources. Another benefit of having services on the cloud is the scalability for the future. It also provides security for all the information. Now, let’s break down the steps involved in creating a strong pipeline in Azure.
Steps to Building a Pipeline in Azure
Step 1: Understand Your Information Requirements
The first step towards building your pipeline is to figure out what your needs are. What are the origins of the information that needs to be liquidated? Does it come from a database, an API, files, or a different system? Second, what will be done to the information as soon as it is extracted? Will it need to be cleaned? Transformed or aggregated? Finally, what will be the destination of the liquid information? Once, you identify the needs, you are good to implement the second step.
Step 2: Choose the Right Azure Services
Azure offers many services that you can use to compose pipelines. The most important are:
Azure Data Factory (ADF): This service allows you to construct and monitor pipelines. It orchestrates operations both on-premises and in the cloud and runs workflows on demand.
Azure Blob Storage: For business data primarily collected in raw form from many sources, for instance, Azure Blob Storage provides storage of unstructured data.
Azure SQL Database: Eventually, when the information is sufficiently processed, it could be written to a relational database, such as Azure SQL Database, for the ultimate in structured storage and ease of querying.
Azure Synapse Analytics: This service is suited to big-data analytics.
Azure Logic Apps: It allows the automation of workflows, integrating various services and triggers.
Each of these services offers different functionalities depending on your pipeline requirements.
Step 3: Setting Up Azure Data Factory
Having picked the services, the next activity is to set up an Azure Data Factory (ADF). ADF serves as the central management engine to control your pipeline and directs the flow of information from source to destination.
Create an ADF instance: In the Azure portal, the first step is to create an Azure Data Factory instance. You may use any name of your choice.
Set up linked services: Connections to sources such as databases, APIs, and destinations such as storage services to interact with them through ADF.
Data sets: All about what’s coming into or going out – the data. They’re about what you dictate the shape/type/nature of the information is at
Pipeline acts: A pipeline is a type of activity – things that do something. Pipelines are composed of acts that define how information flows through the system. You can add multiple steps with copy, transform, and validate types of operations on the incoming information.
Step 4: Data Ingestion
Collecting the information you need is called ingestion. In Azure Data Factory, you can ingest information collected from different sources, from databases to flat files, to APIs, and more. After you’ve ingested the information, it’s important to validate that the information still holds up. You can do this by using triggers and monitors to automate your ingestion process. For near real-time ingestion, options include Azure Event Hubs and Azure Stream Analytics, which are best employed in a continuous flow.
Step 5: Transformation and Processing
After it’s consumed, the data might need to be cleansed or transformed before processing. In Azure, this can be done through Mapping Data Flows built into ADF, or through the more advanced capabilities of Azure Databricks. For instance, if you have information that has to be cleaned (to weed out duplicates, say, or align different datasets that belong together), you’ll design transformation tasks to be part of the pipeline. Finally, the processed information will be ready for an analysis or reporting task, so it can have the maximum possible impact.
Step 6: Loading the Information
The final step is to load the processed data into a storage system that you can query and retrieve data from later. For structured data, common destinations are Azure SQL Database or Azure Synapse Analytics. If you’ll be storing files or unstructured information, the location of choice is Azure Blob Storage or Azure Data Lake. It’s possible to set up schedules within ADF to automate the pipeline, ingesting new data and storing it regularly without requiring human input.
Step 7: Monitoring and Maintenance
Once your pipeline is built and processing data, the scaled engineering decisions are all in the past, and all you have to do is make sure everything is working. You can use Azure Monitor and the Azure Data Factory (ADF) monitoring dashboard to track the channeled information – which routes it’s taking, in what order, and when it failed. Of course, you’ll tweak the flow as data changes, queries come in, and all sorts of black swans rear their ugly heads. You also need regular maintenance to keep things humming along nicely. As your corpus grows, you will need to tweak things here and there to handle larger information loads.
Conclusion
Designing an Azure pipeline can be daunting but, if you follow these steps, you will have a system capable of efficiently processing large amounts of information. Knowing your domain, using the right Azure data engineering services, and monitoring the system regularly will help build a strong and reliable pipeline.
Spiral Mantra’s Data Engineering Services
Spiral Mantra specializes in building production-grade pipelines and managing complex workflows. Our work includes collecting, processing, and storing vast amounts of information with cloud services such as Azure to create purpose-built pipelines that meet your business needs. If you want to build pipelines or workflows, whether it is real-time processing or a batch workflow, Spiral Mantra delivers reliable and scalable services to meet your information needs.
0 notes
Text
Optimizing Azure Container App Deployments: Best Practices for Pipelines & Security
🚀 Just shared a new blog on boosting Azure Container App deployments! Dive into best practices for Continuous Deployment, choosing the right agents, and securely managing variables. Perfect for making updates smoother and safer!
In the fifth part of our series, we explored how Continuous Deployment (CD) pipelines and revisions bring efficiency to Azure Container Apps. From quicker feature rollouts to minimal downtime, CD ensures that you’re not just deploying updates but doing it confidently. Now, let’s take it a step further by optimizing deployments using Azure Pipelines. In this part, we’ll dive into the nuts and…
#Agent Configuration#app deployment#Azure Container Apps#Azure Pipelines#CI/CD#Cloud Applications#Cloud Security#continuous deployment#Deployment Best Practices#DevOps#microsoft azure#Pipeline Automation#Secure Variables
0 notes
Text
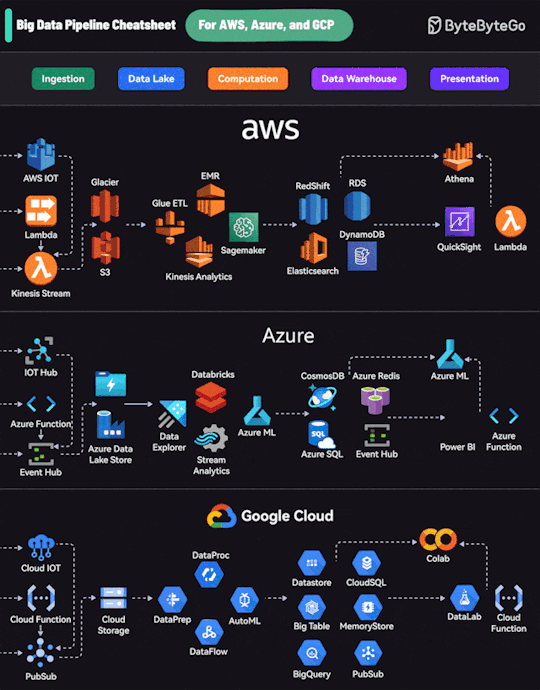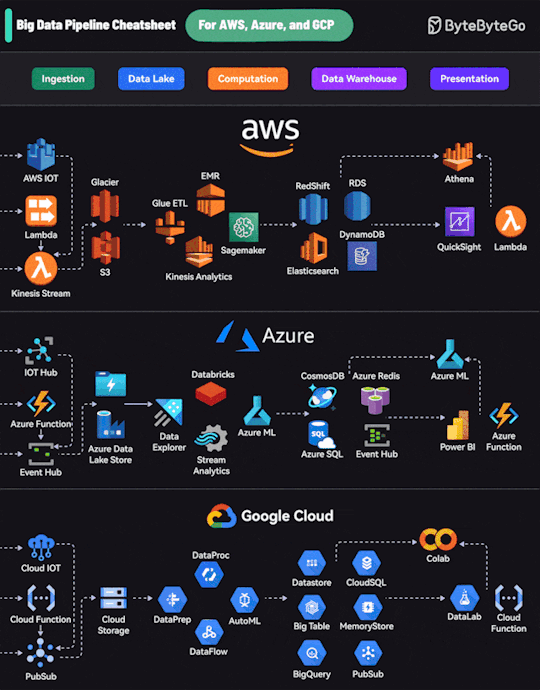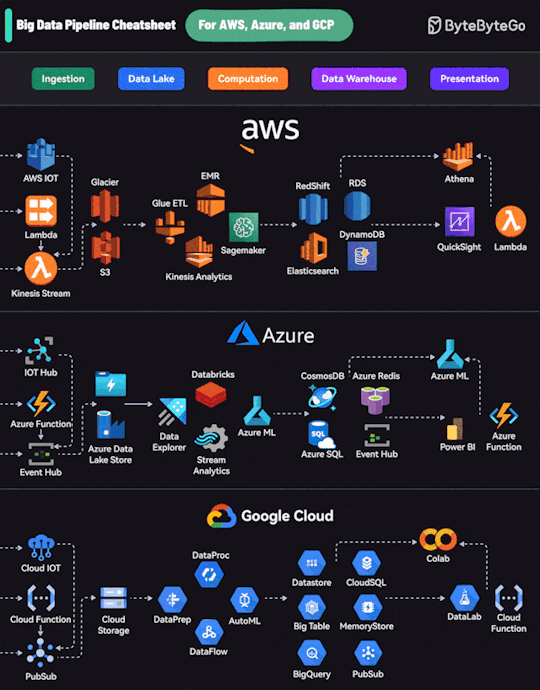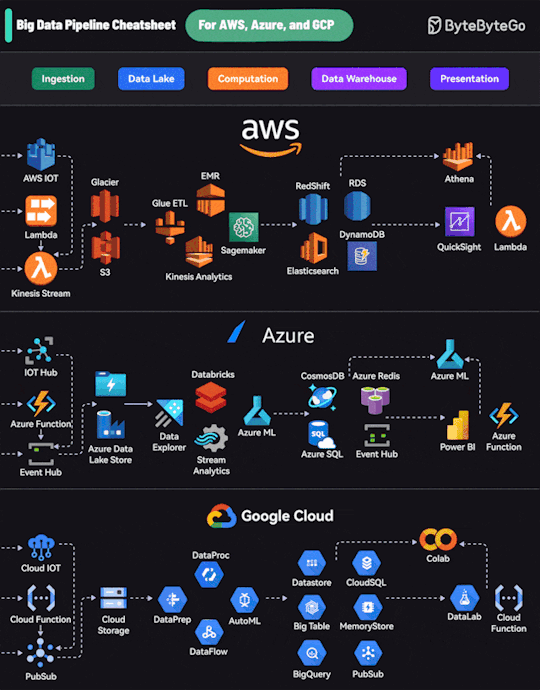
1 note
·
View note
Text
Data Engineering project : ETL data pipeline using azure ( Intermediate )
After a break I’m back again with another video, The concept of this video is to orchestrate a simple data pipeline using azure data … source
0 notes
Text
How to Create Shared Steps in Azure DevOps- OpsNexa!
Learn how to improve efficiency and maintain consistency in your Azure DevOps pipelines by creating and using shared steps. How to Create Shared Steps in Azure DevOps This comprehensive guide explains how to define and reuse YAML templates in modern pipelines, and how to leverage task groups in Classic Pipelines to simplify repetitive configurations. Whether you're managing complex CI/CD workflows or aiming to standardize DevOps practices across teams, this tutorial helps you streamline development, reduce errors, and accelerate deployment cycles.
#Azure DevOps#Shared Steps#DevOps Pipelines#CI/CD Automation#Task Groups#YAML Templates#Pipeline Reusability
0 notes
Text
Here I explain how #releasing #Windows #Services using pipelines in #Azure #DevOps. It helps you achieve a CD/CI for your Windows Service project
0 notes
Text
0 notes
Text
It’s important to note that even though Foulques lives in standard Ava canon hes still very much like. A sidequest ARR NPC who is absolutely not qualified for the shit going on in the MSQ and it shows. He’s Ava’s trophy husband. No one recognizes who he is he wasn’t even an official scion. He’s just kind of along for the ride, it’s not like he has anywhere else to be at this point.
His essential role in the story is to be a tsukkomi.
#He DOES also have the role of helping out with Ava’s azure dragoon duties when she’s stuck saving the world and shit#however. main role is tsukkomi. it’s hard being an ARR NPC in a expac world#Val roars#my posts#the ARR sidequest antag to tsukkomi trophy husband pipeline
0 notes
Text
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
New Post has been published on https://thedigitalinsider.com/datasets-matter-the-battle-between-open-and-closed-generative-ai-is-not-only-about-models-anymore/
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
Two major open source datasets were released this week.
Created Using DALL-E
Next Week in The Sequence:
Edge 403: Our series about autonomous agents continues covering memory-based planning methods. The research behind the TravelPlanner benchmark for planning in LLMs and the impressive MemGPT framework for autonomous agents.
The Sequence Chat: A super cool interview with one of the engineers behind Azure OpenAI Service and Microsoft CoPilot.
Edge 404: We dive into Meta AI’s amazing research for predicting multiple tokens at the same time in LLMs.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
The battle between open and closed generative AI has been at the center of industry developments. From the very beginning, the focus has been on open vs. closed models, such as Mistral and Llama vs. GPT-4 and Claude. Less attention has been paid to other foundational aspects of the model lifecycle, such as the datasets used for training and fine-tuning. In fact, one of the limitations of the so-called open weight models is that they don’t disclose the training datasets and pipeline. What if we had high-quality open source datasets that rival those used to pretrain massive foundation models?
Open source datasets are one of the key aspects to unlocking innovation in generative AI. The costs required to build multi-trillion token datasets are completely prohibitive to most organizations. Leading AI labs, such as the Allen AI Institute, have been at the forefront of this idea, regularly open sourcing high-quality datasets such as the ones used for the Olmo model. Now it seems that they are getting some help.
This week, we saw two major efforts related to open source generative AI datasets. Hugging Face open-sourced FineWeb, a 44TB dataset of 15 trillion tokens derived from 96 CommonCrawl snapshots. Hugging Face also released FineWeb-Edu, a subset of FineWeb focused on educational value. But Hugging Face was not the only company actively releasing open source datasets. Complementing the FineWeb release, AI startup Zyphra released Zyda, a 1.3 trillion token dataset for language modeling. The construction of Zyda seems to have focused on a very meticulous filtering and deduplication process and shows remarkable performance compared to other datasets such as Dolma or RedefinedWeb.
High-quality open source datasets are paramount to enabling innovation in open generative models. Researchers using these datasets can now focus on pretraining pipelines and optimizations, while teams using those models for fine-tuning or inference can have a clearer way to explain outputs based on the composition of the dataset. The battle between open and closed generative AI is not just about models anymore.
🔎 ML Research
Extracting Concepts from GPT-4
OpenAI published a paper proposing an interpretability technique to understanding neural activity within LLMs. Specifically, the method uses k-sparse autoencoders to control sparsity which leads to more interpretable models —> Read more.
Transformer are SSMs
Researchers from Princeton University and Carnegie Mellon University published a paper outlining theoretical connections between transformers and SSMs. The paper also proposes a framework called state space duality and a new architecture called Mamba-2 which improves the performance over its predecessors by 2-8x —> Read more.
Believe or Not Believe LLMs
Google DeepMind published a paper proposing a technique to quantify uncertainty in LLM responses. The paper explores different sources of uncertainty such as lack of knowledge and randomness in order to quantify the reliability of an LLM output —> Read more.
CodecLM
Google Research published a paper introducing CodecLM, a framework for using synthetic data for LLM alignment in downstream tasks. CodecLM leverages LLMs like Gemini to encode seed intrstructions into the metadata and then decodes it into synthetic intstructions —> Read more.
TinyAgent
Researchers from UC Berkeley published a detailed blog post about TinyAgent, a function calling tuning method for small language models. TinyAgent aims to enable function calling LLMs that can run on mobile or IoT devices —> Read more.
Parrot
Researchers from Shanghai Jiao Tong University and Microsoft Research published a paper introducing Parrot, a framework for correlating multiple LLM requests. Parrot uses the concept of a Semantic Variable to annotate input/output variables in LLMs to enable the creation of a data pipeline with LLMs —> Read more.
🤖 Cool AI Tech Releases
FineWeb
HuggingFace open sourced FineWeb, a 15 trillion token dataset for LLM training —> Read more.
Stable Audion Open
Stability AI open source Stable Audio Open, its new generative audio model —> Read more.
Mistral Fine-Tune
Mistral open sourced mistral-finetune SDK and services for fine-tuning models programmatically —> Read more.
Zyda
Zyphra Technologies open sourced Zyda, a 1.3 trillion token dataset that powers the version of its Zamba models —> Read more.
🛠 Real World AI
Salesforce discusses their use of Amazon SageMaker in their Einstein platform —> Read more.
📡AI Radar
Cisco announced a $1B AI investment fund with some major positions in companies like Cohere, Mistral and Scale AI.
Cloudera acquired AI startup Verta.
Databricks acquired data management company Tabular.
Tektonic, raised $10 million to build generative agents for business operations —> Read more.
AI task management startup Hoop raised $5 million.
Galileo announced Luna, a family of evaluation foundation models.
Browserbase raised $6.5 million for its LLM browser-based automation platform.
AI artwork platform Exactly.ai raised $4.3 million.
Sirion acquired AI document management platform Eigen Technologies.
Asana added AI teammates to complement task management capabilities.
Eyebot raised $6 million for its AI-powered vision exams.
AI code base platform Greptile raised a $4 million seed round.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#agents#ai#AI-powered#amazing#Amazon#architecture#Asana#attention#audio#automation#automation platform#autonomous agents#azure#azure openai#benchmark#Blog#browser#Business#Carnegie Mellon University#claude#code#Companies#Composition#construction#data#Data Management#data pipeline#databricks#datasets#DeepMind
0 notes
Text
Leveraging AI and Automation in Azure DevOps Consulting for Smarter Workflows
Azure DevOps consulting is evolving with the integration of Artificial Intelligence (AI) and automation, enabling organizations to optimize their CI CD pipelines to enhance predictive analytics. Spiral mantra , your strategic DevOps consultants in USA helps businesses harness AI-powered DevOps tools, ensuring seamless deployment and increased efficiency in software development lifecycles. Backed with certified experts, we help businesses to stay ahead by adopting AI-driven Azure DevOps consulting services for smarter, faster, and more reliable software delivery.

0 notes
Text
How to connect GitHub and Build a CI/CD Pipeline with Vercel
Gone are the days when it became difficult to deploy your code for real-time changes. The continuous integration and continuous deployment process has put a stop to the previous archaic way of deployment. We now have several platforms that you can use on the bounce to achieve this task easily. One of these platforms is Vercel which can be used to deploy several applications fast. You do not need…

View On WordPress
#AWS#Azure CI/CD build Pipeline#cicd#deployment#development#Github#Google#Pipeline#Pipelines#Repository#software#vercel#Windows
0 notes