#sql server ide
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Best Methods to Rename a Table in SQL Server

Renaming tables in SQL Server seems simple, but there are quite a few things to keep in mind.
Yes, the basic method is using sp_rename:
EXEC sp_rename 'Schema.OldName', 'Schema.NewName';
But this doesn’t update references in views, stored procedures, or other dependent objects. That’s where it gets tricky.
For complex databases, it’s worth checking object dependencies beforehand and considering how renaming might affect other parts of the system. Sometimes it’s easier to use scripts when working with many tables or to handle renaming inside a transaction to avoid issues in high-concurrency environments.
Some tools (like dbForge Studio for SQL Server) can help by showing dependencies and letting you refactor names without breaking things.
Read this guide to learn more about the SQL Server rename table methods.
#sql gui#sql ide#sqlserver#sql#sql server#sql server ide#sql server gui#sql server rename table#sql tutorial
0 notes
Text
I'm not promising anything, and you know how my feelings towards something being hopeless change very frequently but this something I've been meaning to ask for a while
Again no promises this will happen I'm literally just trying gauge numbers, languages could potentially change I'm aware that I'm technically misusing the word backend but visuals are all in place and id love to recycle as much as possible of the game we have rn, don't bank on playtester being a big thing
10 notes
·
View notes
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
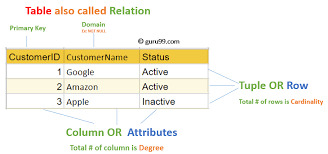
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
The SQL Server REPLACE function is a valuable tool for replacing every instance of a given substring in a string with a different substring. Let's Explore:
https://madesimplemssql.com/sql-server-replace/
Please follow us on FB: https://www.facebook.com/profile.php?id=100091338502392
OR
Join our Group: https://www.facebook.com/groups/652527240081844

5 notes
·
View notes
Text
How-To IT
Topic: Core areas of IT
1. Hardware
• Computers (Desktops, Laptops, Workstations)
• Servers and Data Centers
• Networking Devices (Routers, Switches, Modems)
• Storage Devices (HDDs, SSDs, NAS)
• Peripheral Devices (Printers, Scanners, Monitors)
2. Software
• Operating Systems (Windows, Linux, macOS)
• Application Software (Office Suites, ERP, CRM)
• Development Software (IDEs, Code Libraries, APIs)
• Middleware (Integration Tools)
• Security Software (Antivirus, Firewalls, SIEM)
3. Networking and Telecommunications
• LAN/WAN Infrastructure
• Wireless Networking (Wi-Fi, 5G)
• VPNs (Virtual Private Networks)
• Communication Systems (VoIP, Email Servers)
• Internet Services
4. Data Management
• Databases (SQL, NoSQL)
• Data Warehousing
• Big Data Technologies (Hadoop, Spark)
• Backup and Recovery Systems
• Data Integration Tools
5. Cybersecurity
• Network Security
• Endpoint Protection
• Identity and Access Management (IAM)
• Threat Detection and Incident Response
• Encryption and Data Privacy
6. Software Development
• Front-End Development (UI/UX Design)
• Back-End Development
• DevOps and CI/CD Pipelines
• Mobile App Development
• Cloud-Native Development
7. Cloud Computing
• Infrastructure as a Service (IaaS)
• Platform as a Service (PaaS)
• Software as a Service (SaaS)
• Serverless Computing
• Cloud Storage and Management
8. IT Support and Services
• Help Desk Support
• IT Service Management (ITSM)
• System Administration
• Hardware and Software Troubleshooting
• End-User Training
9. Artificial Intelligence and Machine Learning
• AI Algorithms and Frameworks
• Natural Language Processing (NLP)
• Computer Vision
• Robotics
• Predictive Analytics
10. Business Intelligence and Analytics
• Reporting Tools (Tableau, Power BI)
• Data Visualization
• Business Analytics Platforms
• Predictive Modeling
11. Internet of Things (IoT)
• IoT Devices and Sensors
• IoT Platforms
• Edge Computing
• Smart Systems (Homes, Cities, Vehicles)
12. Enterprise Systems
• Enterprise Resource Planning (ERP)
• Customer Relationship Management (CRM)
• Human Resource Management Systems (HRMS)
• Supply Chain Management Systems
13. IT Governance and Compliance
• ITIL (Information Technology Infrastructure Library)
• COBIT (Control Objectives for Information Technologies)
• ISO/IEC Standards
• Regulatory Compliance (GDPR, HIPAA, SOX)
14. Emerging Technologies
• Blockchain
• Quantum Computing
• Augmented Reality (AR) and Virtual Reality (VR)
• 3D Printing
• Digital Twins
15. IT Project Management
• Agile, Scrum, and Kanban
• Waterfall Methodology
• Resource Allocation
• Risk Management
16. IT Infrastructure
• Data Centers
• Virtualization (VMware, Hyper-V)
• Disaster Recovery Planning
• Load Balancing
17. IT Education and Certifications
• Vendor Certifications (Microsoft, Cisco, AWS)
• Training and Development Programs
• Online Learning Platforms
18. IT Operations and Monitoring
• Performance Monitoring (APM, Network Monitoring)
• IT Asset Management
• Event and Incident Management
19. Software Testing
• Manual Testing: Human testers evaluate software by executing test cases without using automation tools.
• Automated Testing: Use of testing tools (e.g., Selenium, JUnit) to run automated scripts and check software behavior.
• Functional Testing: Validating that the software performs its intended functions.
• Non-Functional Testing: Assessing non-functional aspects such as performance, usability, and security.
• Unit Testing: Testing individual components or units of code for correctness.
• Integration Testing: Ensuring that different modules or systems work together as expected.
• System Testing: Verifying the complete software system’s behavior against requirements.
• Acceptance Testing: Conducting tests to confirm that the software meets business requirements (including UAT - User Acceptance Testing).
• Regression Testing: Ensuring that new changes or features do not negatively affect existing functionalities.
• Performance Testing: Testing software performance under various conditions (load, stress, scalability).
• Security Testing: Identifying vulnerabilities and assessing the software’s ability to protect data.
• Compatibility Testing: Ensuring the software works on different operating systems, browsers, or devices.
• Continuous Testing: Integrating testing into the development lifecycle to provide quick feedback and minimize bugs.
• Test Automation Frameworks: Tools and structures used to automate testing processes (e.g., TestNG, Appium).
19. VoIP (Voice over IP)
VoIP Protocols & Standards
• SIP (Session Initiation Protocol)
• H.323
• RTP (Real-Time Transport Protocol)
• MGCP (Media Gateway Control Protocol)
VoIP Hardware
• IP Phones (Desk Phones, Mobile Clients)
• VoIP Gateways
• Analog Telephone Adapters (ATAs)
• VoIP Servers
• Network Switches/ Routers for VoIP
VoIP Software
• Softphones (e.g., Zoiper, X-Lite)
• PBX (Private Branch Exchange) Systems
• VoIP Management Software
• Call Center Solutions (e.g., Asterisk, 3CX)
VoIP Network Infrastructure
• Quality of Service (QoS) Configuration
• VPNs (Virtual Private Networks) for VoIP
• VoIP Traffic Shaping & Bandwidth Management
• Firewall and Security Configurations for VoIP
• Network Monitoring & Optimization Tools
VoIP Security
• Encryption (SRTP, TLS)
• Authentication and Authorization
• Firewall & Intrusion Detection Systems
• VoIP Fraud DetectionVoIP Providers
• Hosted VoIP Services (e.g., RingCentral, Vonage)
• SIP Trunking Providers
• PBX Hosting & Managed Services
VoIP Quality and Testing
• Call Quality Monitoring
• Latency, Jitter, and Packet Loss Testing
• VoIP Performance Metrics and Reporting Tools
• User Acceptance Testing (UAT) for VoIP Systems
Integration with Other Systems
• CRM Integration (e.g., Salesforce with VoIP)
• Unified Communications (UC) Solutions
• Contact Center Integration
• Email, Chat, and Video Communication Integration
2 notes
·
View notes
Text
SQLi Potential Mitigation Measures
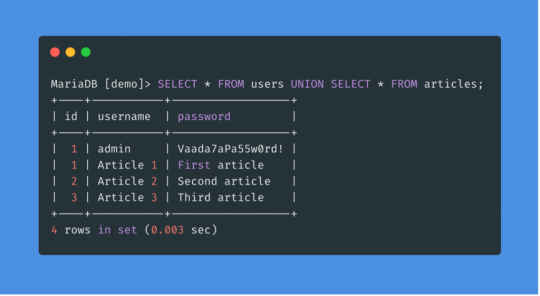
Phase: Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that prevents this weakness or makes it easier to avoid. For example, persistence layers like Hibernate or Enterprise Java Beans can offer protection against SQL injection when used correctly.
Phase: Architecture and Design
Strategy: Parameterization
Use structured mechanisms that enforce separation between data and code, such as prepared statements, parameterized queries, or stored procedures. Avoid constructing and executing query strings with "exec" to prevent SQL injection [REF-867].
Phases: Architecture and Design; Operation
Strategy: Environment Hardening
Run your code with the minimum privileges necessary for the task [REF-76]. Limit user privileges to prevent unauthorized access if an attack occurs, such as by ensuring database applications don’t run as an administrator.
Phase: Architecture and Design
Duplicate client-side security checks on the server to avoid CWE-602. Attackers can bypass client checks by altering values or removing checks entirely, making server-side validation essential.
Phase: Implementation
Strategy: Output Encoding
Avoid dynamically generating query strings, code, or commands that mix control and data. If unavoidable, use strict allowlists, escape/filter characters, and quote arguments to mitigate risks like SQL injection (CWE-88).
Phase: Implementation
Strategy: Input Validation
Assume all input is malicious. Use strict input validation with allowlists for specifications and reject non-conforming inputs. For SQL queries, limit characters based on parameter expectations for attack prevention.
Phase: Architecture and Design
Strategy: Enforcement by Conversion
For limited sets of acceptable inputs, map fixed values like numeric IDs to filenames or URLs, rejecting anything outside the known set.
Phase: Implementation
Ensure error messages reveal only necessary details, avoiding cryptic language or excessive information. Store sensitive error details in logs but be cautious with content visible to users to prevent revealing internal states.
Phase: Operation
Strategy: Firewall
Use an application firewall to detect attacks against weaknesses in cases where the code can’t be fixed. Firewalls offer defense in depth, though they may require customization and won’t cover all input vectors.
Phases: Operation; Implementation
Strategy: Environment Hardening
In PHP, avoid using register_globals to prevent weaknesses like CWE-95 and CWE-621. Avoid emulating this feature to reduce risks. source
3 notes
·
View notes
Text
Unveiling the Ultimate Handbook for Aspiring Full Stack Developers

In the ever-evolving realm of technology, the role of a full-stack developer has undeniably gained prominence. Full-stack developers epitomize versatility and are an indispensable asset to any enterprise or endeavor. They wield a comprehensive array of competencies that empower them to navigate the intricate landscape of both front-end and back-end web development. In this exhaustive compendium, we shall delve into the intricacies of transforming into a proficient full-stack developer, dissecting the requisite skills, indispensable tools, and strategies for excellence in this domain.
Deciphering the Full Stack Developer Persona
A full-stack developer stands as a connoisseur of both front-end and back-end web development. Their mastery extends across the entire spectrum of web development, rendering them highly coveted entities within the tech sector. The front end of a website is the facet accessible to users, while the back end operates stealthily behind the scenes, handling the intricacies of databases and server management. You can learn it from Uncodemy which is the Best Full stack Developer Institute in Delhi.
The Requisite Competencies
To embark on a successful journey as a full-stack developer, one must amass a diverse skill set. These proficiencies can be broadly categorized into front-end and back-end development, coupled with other quintessential talents:
Front-End Development
Markup Linguistics and Style Sheets: Cultivating an in-depth grasp of markup linguistics and style sheets like HTML and CSS is fundamental to crafting visually captivating and responsive user interfaces.
JavaScript Mastery: JavaScript constitutes the linchpin of front-end development. Proficiency in this language is the linchpin for crafting dynamic web applications.
Frameworks and Libraries: Familiarization with popular front-end frameworks and libraries such as React, Angular, and Vue.js is indispensable as they streamline the development process and elevate the user experience.
Back-End Development
Server-Side Linguistics: Proficiency in server-side languages like Node.js, Python, Ruby, or Java is imperative as these languages fuel the back-end functionalities of websites.
Database Dexterity: Acquiring proficiency in the manipulation of databases, including SQL and NoSQL variants like MySQL, PostgreSQL, and MongoDB, is paramount.
API Expertise: Comprehending the creation and consumption of APIs is essential, serving as the conduit for data interchange between the front-end and back-end facets.
Supplementary Competencies
Version Control Proficiency: Mastery in version control systems such as Git assumes monumental significance for collaborative code management.
Embracing DevOps: Familiarity with DevOps practices is instrumental in automating and streamlining the development and deployment processes.
Problem-Solving Prowess: Full-stack developers necessitate robust problem-solving acumen to diagnose issues and optimize code for enhanced efficiency.
The Instruments of the Craft
Full-stack developers wield an arsenal of tools and technologies to conceive, validate, and deploy web applications. The following are indispensable tools that merit assimilation:
Integrated Development Environments (IDEs)
Visual Studio Code: This open-source code editor, hailed for its customizability, enjoys widespread adoption within the development fraternity.
Sublime Text: A lightweight and efficient code editor replete with an extensive repository of extensions.
Version Control
Git: As the preeminent version control system, Git is indispensable for tracking code modifications and facilitating collaborative efforts.
GitHub: A web-based platform dedicated to hosting Git repositories and fostering collaboration among developers.
Front-End Frameworks
React A potent JavaScript library for crafting user interfaces with finesse.
Angular: A comprehensive front-end framework catering to the construction of dynamic web applications.
Back-End Technologies
Node.js: A favored server-side runtime that facilitates the development of scalable, high-performance applications.
Express.js: A web application framework tailor-made for Node.js, simplifying back-end development endeavors.
Databases
MongoDB: A NoSQL database perfectly suited for managing copious amounts of unstructured data.
PostgreSQL: A potent open-source relational database management system.
Elevating Your Proficiency as a Full-Stack Developer
True excellence as a full-stack developer transcends mere technical acumen. Here are some strategies to help you distinguish yourself in this competitive sphere:
Continual Learning: Given the rapid evolution of technology, it's imperative to remain abreast of the latest trends and tools.
Embark on Personal Projects: Forge your path by creating bespoke web applications to showcase your skills and amass a portfolio.
Collaboration and Networking: Participation in developer communities, attendance at conferences, and collaborative ventures with fellow professionals are key to growth.
A Problem-Solving Mindset: Cultivate a robust ability to navigate complex challenges and optimize code for enhanced efficiency.
Embracing Soft Skills: Effective communication, collaborative teamwork, and adaptability are indispensable in a professional milieu.
In Closing
Becoming a full-stack developer is a gratifying odyssey that demands unwavering dedication and a resolute commitment to perpetual learning. Armed with the right skill set, tools, and mindset, one can truly shine in this dynamic domain. Full-stack developers are in high demand, and as you embark on this voyage, you'll discover a plethora of opportunities beckoning you.
So, if you aspire to join the echelons of full-stack developers and etch your name in the annals of the tech world, commence your journey by honing your skills and laying a robust foundation in both front-end and back-end development. Your odyssey to becoming an adept full-stack developer commences now.
5 notes
·
View notes
Text
Hack the Future: Top Ethical Hacking Tools & Techniques You Need in 2025 Cybersecurity threats are evolving, and ethical hacking has become a crucial practice for protecting digital assets. Ethical hackers, also known as white-hat hackers, use their skills to identify vulnerabilities and strengthen security. This guide explores the top tools and techniques every ethical hacker should know in 2025. Understanding Ethical Hacking Ethical hacking involves simulating cyberattacks to uncover weaknesses before malicious hackers can exploit them. It follows a structured approach: Reconnaissance – Gathering information about the target. Scanning – Identifying vulnerabilities using specialized tools. Exploitation – Attempting to breach security to test defenses. Post-Exploitation – Assessing the impact and documenting findings. Reporting & Mitigation – Providing recommendations to fix vulnerabilities. Top Ethical Hacking Tools in 2025 1. Metasploit A powerful penetration testing framework that automates the exploitation process. It includes thousands of exploits and payloads for testing vulnerabilities. msfconsole use exploit/windows/smb/ms17_010_eternalblue set RHOSTS target_ip exploit 2. Nmap A network scanning tool that helps discover hosts, open ports, and services running on a target system. nmap -A -T4 target_ip 3. Burp Suite A web security testing tool used for detecting vulnerabilities like SQL injection and cross-site scripting (XSS). 4. Wireshark A network protocol analyzer that captures and inspects network traffic to detect potential security threats. 5. John the Ripper A password-cracking tool that helps ethical hackers test password strength. john --wordlist=rockyou.txt hash_file 6. Aircrack-ng A toolset for assessing Wi-Fi network security, helping ethical hackers test for weak encryption. airmon-ng start wlan0 airodump-ng wlan0mon aircrack-ng -b target_bssid -w wordlist.txt capture_file.cap 7. SQLmap An automated tool for detecting and exploiting SQL injection vulnerabilities. sqlmap -u "http://example.com/index.php?id=1" --dbs 8. Hydra A fast and flexible brute-force password-cracking tool used for testing login security. hydra -l admin -P passwords.txt target_ip ssh 9. OSINT Framework A collection of open-source intelligence (OSINT) tools used for gathering information about a target from publicly available sources. 10. Cobalt Strike A professional red-teaming platform used for advanced penetration testing and adversary simulation. Key Ethical Hacking Techniques 1. Social Engineering Manipulating individuals into divulging confidential information through phishing, pretexting, or baiting. 2. Wireless Network Attacks Exploiting weak Wi-Fi security protocols using tools like Aircrack-ng to gain unauthorized access. 3. Man-in-the-Middle (MitM) Attacks Intercepting and altering communications between two parties to extract sensitive data. 4. Privilege Escalation Exploiting system vulnerabilities to gain higher access privileges. 5. Reverse Engineering Analyzing software or hardware to find vulnerabilities and potential exploits. 6. Zero-Day Exploits Identifying and exploiting undiscovered security flaws before patches are released. 7. Web Application Penetration Testing Assessing web applications for vulnerabilities like cross-site scripting (XSS), SQL injection, and security misconfigurations. 8. Endpoint Security Testing Evaluating workstation and server defenses against malware, ransomware, and unauthorized access. The Future of Ethical Hacking in 2025 The rise of AI, machine learning, and quantum computing is reshaping cybersecurity. Ethical hackers must continuously update their skills and leverage AI-driven security tools to stay ahead of cyber threats. Conclusion Ethical hacking is an essential practice in modern cybersecurity. By mastering these tools
and techniques, ethical hackers can help organizations strengthen their defenses against cyber threats. Continuous learning and adaptation to emerging technologies will be crucial in 2025 and beyond.
0 notes
Text
SQL Interview Questions for Database Developers and Administrators

Structured Query Language, or SQL, is the foundation of database management. Whether you're a database developer crafting robust schemas and queries or a database administrator ensuring performance, security, and data integrity, proficiency in SQL is essential. This blog will walk you through some of the most commonly asked SQL interview questions tailored for both developers and DBAs (Database Administrators), with clear examples and explanations.
Why SQL Interview Questions Matter
SQL is not just about writing SELECT queries. It's about understanding how to model data, query efficiently, prevent anomalies, and secure sensitive information. Interviewers test both practical SQL skills and conceptual understanding. Whether you're a fresher or experienced professional, preparing well for SQL questions is crucial for landing a job in roles like:
Database Developer
Data Analyst
Data Engineer
DBA (Database Administrator)
Backend Developer
Basic SQL Interview Questions
1. What is SQL?
SQL stands for Structured Query Language. It is used to store, retrieve, manipulate, and manage data in relational databases such as MySQL, SQL Server, PostgreSQL, and Oracle.
2. What is the difference between DELETE, TRUNCATE, and DROP?
Command Description Can Rollback DELETE Deletes specific rows using a WHERE clause Yes TRUNCATE Removes all rows from a table without logging No DROP Deletes the entire table (structure + data) No
3. What is a Primary Key?
A Primary Key is a column (or combination of columns) that uniquely identifies each record in a table. It cannot contain NULL values and must be unique.CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100) );
4. What are the different types of joins in SQL?
INNER JOIN: Returns records with matching values in both tables
LEFT JOIN: Returns all records from the left table, and matched ones from the right
RIGHT JOIN: Returns all records from the right table, and matched ones from the left
FULL OUTER JOIN: Returns all records when there is a match in one of the tables
Intermediate SQL Interview Questions
5. What is normalization? Explain its types.
Normalization is the process of organizing data to reduce redundancy and improve integrity. Common normal forms:
1NF: Atomic columns
2NF: Remove partial dependencies
3NF: Remove transitive dependencies
6. What is an index in SQL?
An index improves the speed of data retrieval. It is similar to the index in a book.CREATE INDEX idx_lastname ON employees(last_name);
Tip: Overusing indexes can slow down write operations.
7. What is a subquery?
A subquery is a query nested inside another query.SELECT name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
8. What are aggregate functions in SQL?
Functions that operate on sets of values and return a single value:
SUM()
AVG()
COUNT()
MAX()
MIN()
Advanced SQL Interview Questions (For Developers & DBAs)
9. What is a stored procedure?
A stored procedure is a precompiled set of SQL statements stored in the database. CREATE PROCEDURE GetEmployeeCount AS BEGIN SELECT COUNT(*) FROM employees; END;
Used for code reusability and performance optimization.
10. How do transactions work in SQL?
A transaction is a unit of work performed against a database. It follows ACID properties:
Atomicity
Consistency
Isolation
Durability
BEGIN TRANSACTION; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; COMMIT;
11. What is deadlock and how do you resolve it?
A deadlock occurs when two or more transactions block each other by holding locks on resources the other transactions need. To resolve:
Set proper lock timeouts
Use consistent locking order
Implement deadlock detection
12. What are triggers in SQL?
A trigger is a special stored procedure that runs automatically in response to certain events (INSERT, UPDATE, DELETE).CREATE TRIGGER before_insert_trigger BEFORE INSERT ON employees FOR EACH ROW BEGIN SET NEW.created_at = NOW(); END;
13. How do you optimize a slow-running query?
Use EXPLAIN to analyze the query plan
Create indexes on frequently searched columns
Avoid SELECT *
Use joins instead of subqueries where appropriate
Limit results using LIMIT or TOP clauses
SQL Questions for DBA-Specific Roles
14. What are the responsibilities of a DBA related to SQL?
Creating and managing databases and users
Backup and recovery
Performance tuning
Monitoring database health
Ensuring data security and access control
15. How do you implement backup and recovery in SQL Server?
Backup BACKUP DATABASE myDB TO DISK = 'D:\Backup\myDB.bak'; -- Restore RESTORE DATABASE myDB FROM DISK = 'D:\Backup\myDB.bak';
Conclusion
SQL remains the backbone of modern data management and application development. These SQL interview questions for database developers and administrators are just a sample of what you may encounter during a technical interview. To excel, practice queries, understand the theory behind relational database design, and stay updated with the latest SQL standards and features.
#SQLInterviewQuestions#DatabaseDeveloper#DBA#SQLQueries#StoredProcedures#SQLJoins#SQLOptimization#DatabaseAdmin#TechInterviews
0 notes
Text
What do we have to study in SAP HANA training?
SAP HANA (High-Performance Analytic Appliance) training covers both the theoretical concepts and practical skills needed to work with SAP's in-memory database platform. Key areas of study include an overview of HANA architecture, in-memory computing, and columnar data storage. Learners gain hands-on experience in data modeling using tools like HANA Studio or Web IDE, developing calculation views, and building real-time analytics. Training also covers SQL scripting with HANA SQLScript, creating procedures, functions, and managing data provisioning using Smart Data Integration (SDI), Smart Data Access (SDA), or SLT replication.
Additional topics include user and role management, data security, performance tuning, and HANA application development for both native and XS advanced models. For functional consultants, the focus may be on using HANA as the backend for S/4HANA, embedded analytics, and integrating with other SAP modules.

Anubhav Trainings offers industry-recognized SAP HANA training led by seasoned experts, including live project exposure and real-time examples. Their training blends deep conceptual knowledge with practical implementation, making it ideal for both freshers and experienced consultants aiming to upskill in SAP HANA. With flexible timing and dedicated server access, Anubhav Trainings ensures learners are job-ready from day one.
0 notes
Text
SocialMedia Front-End design Copycat
Just interested in which problems persisted that started the framework bloat we see today [looking at you React Devs].
So I'm going to type out a pseudo-code design paper, that's closer to twitterX for the site with hooks to add-in stuff Facebook later added.
So a basic design for the HTML looks kinda like this:
Http Index
- header stuff
- Visual Body
- Body Header
-Sidebar stuff
- Body Body
- footer nobody ever sees or reads or care that it exists that provides contact info that is relatively unused or non-existent.
There's only a few moving parts in the front end, a Login/sign up widget (which could be its own page, doesn't matter)
The Comments&Posts, which are mostly sorted and distributed from the backend
The Post Bar itself which is just a textbox
The big parts we care about initially are the posts and comments.
In the HTML this is a single template like this:
<div id="post template" class="post/comment">
<img class="Avatar" src="whatever the backend.jpeg" />
<p class="text">The Text</p>
</div>
And then all you need to do is copy and paste that for every "actively visible" comment, and as you scroll, more comments appear as they are downloaded to the page.
Which is something like
Onload(){ global template= document.get("div#post_template")
Function DisplayPosts(array) {foreach (item in array; that is visibile) { post = template.copy; post.populate(item). }
In React this turns into something else;
ReactWidget PostTemplate = theAboveTemplate
New post = new PostTemplate(array item);
With which to simplify the code needed to process, and to help separate all the pieces from the original HTML page.
Which does help clarify stuff... But how would it have been brittle originally? I can only think that it was perhaps the devices that Facebook originally had use of, and modified in order to be able to be on cheapo devices that don't really exist anymore.
Or maybe due to the original way JS worked in browsers. And I. mobile specifically.
As I'm writing this, I still see most of the processing being done on the back ends... So the only way I can think it would be particularly buggy is if a lot of all that backend stuff was integrated into the frontend somehow.
Extensive ajax calls maybe? Unsequenced calls?
It's a handler that determines if the page should request more comments from the server or not, and maybe need to unload non-visible comments for performance reasons.
How many posts on a single scrolling page would it take for it to affect the performance these days?
100? 1000? Uncertain. In this day and age, even the cheapest devices can load an encyclopedia (or several) worths of information on the background and work fine.
Youd also need to handle for pages to view a post with comments... Twitter handles this by making ALL comments just posts with @tags and #tags.
So they all are at the same level in the database, probably.
Non-SQL Backends append a sub-stack to the original post as well. I wonder how that affects backend performance.
There's also pointers and stuff that get shuffled around that need to be built together to fully form the data for front lend use. UniqueIds for every post entry, directing to user accounts with their own personalization and not having immediate access at the comment level.
Old bugs in Social Media would have artifacts like [User#######] while the page is loading extra stuff, so you'd be able to read the comment before knowing who posted it. And [User Deleted] on Reddit when that ID is no longer pollable.
Browsers really need to allow for html_templates (and not HTML written in the JavaScript portion) to encourage ease of access...
The purpose of react, it seems, was to create a single widget used to populate comments and posts, and make it a little bit easier to read.
And now... Components are out of hand.
Too much developing in JavaScript and not enough talking with the w3c and browser devs to make the coding conventions easier on everyone maybe. A product of the times.
Or maybe the templates each had their own JavaScript and ajax handlers and that's why it became brittle...
Calling the backend whenever a *blank comment* becomes visible which requests a new comment for each newly visible comment and then some?
I think it's that one. That one's the most likely mistake I would have made during a prototype.
I believe that it's highly probably that a refined social media page could be reduced in size and complexity. But what isn't inherently visible is about how many *wasted processes* are prevalent because we no longer need to deal with because the Technology of the average device improved.
And, because of that, how much waste gets added on top of it to error-correct for things that would have been fixed correcting those oversights..?
Well, if I were a billionaire who recently lost a lot of money purchasing a thing that may be needs to be worked on... That's where I'd look first. Which processes actually need to be handled by the front end, and a reduction in the amount of calls to the backend per user.
As the said billionaires are working on other ways to make money instead, I doubt these are things that will get fixed...
I kinda want to write a social media thing to throw on GitHub or something, just to prove the thing. But I'm also... Not about that life right now for some reason...
I'm just curious as to why apps that are primarily just Fetch(More Text) water so much battery and data on their lonesome.
Since May 21 (it is currently July 4th+1) TwitterX has used 16gigs! And I rarely click the video media... Because everything is viens and tiktoks now I guess.
In comparison, Tumblr used 3... Though, I don't scroll as much on Tumblr due to my feed here not updating as much as Twitter. Probably?
Staying connected, always on like that, might be good for ads... But... It doesn't mean the user is actively engaging with the content. Or even caring about everything in there feed.
I would assume that the price of scrolling outweighs the adverts being fed to the users, and hence the blue check marks, which likely are also not helping catch up.
So while the cost reduction from the URL when Twitter switched to X is a stop gap.
Possibly meaning that there's a catch-22 on twitterX, where you need more scrolls to make money, but they also cost more money from data serving costs.
Those backend calls add up.
How would you make an analysis team to discover and develop a path that won't interrupt service? Honestly...
It'd be cheaper to hire a [small experienced team] to develop the front end as if they were starting from scratch and developing as minimalistically as possible with a very solid design and game plan.
And then creating a deployment test bed to see whether or not all the calls made right now are value added.
I say that, because it's quite likely that most (if not all of social media) today is still built on the original code bases, which were extended to add features, and not really dedicated to ironing out the interfaces. (Because needed to make money somehow).
But now, you're worried about retaining customers and satisfying advertisers instead, which affords the opportunity to work on it. Or to find a small coder that already put a concept on GitHub already.
(Probably the real reason I don't just make another one.)
Actually. Let's see where this AI-Generated-Full-Stack development goes....I wanna see exactly how much the ancient newbie coder bugs can destroy.
0 notes
Text
dbForge Edge Overview | All-in-One Database Development and Design Solution

Learn how dbForge Edge enhances database development and design with powerful features such as context-aware code completion, visual query building, and version control integration. Whether you work with SQL Server, MySQL, Oracle or PostgreSQL, dbForge Edge will help you easily reinvent and streamline your daily workflow.
Watch the full video on Youtube: dbForge Edge Overview | All-in-One Database Development and Design Solution
Get more information about how dbForge Edge can help you to enhance database development and design.
Check the full overview of the comprehensive database IDE - dbForge Edge.
You can download dbForge Edge for a free 30-day trial.
#database development#database design#database#database tool#database ide#database gui#mysql#mariadb#sql server#oracle#postgresql
0 notes
Text
API Security Testing 101: Protecting Your Data from Vulnerabilities

Data is vital to everything we do in the modern world. When it comes to data, we cannot ignore APIs. They act as the internet's functional backbone, helping in the smooth transfer of data between servers, apps, and devices. APIs must be protected from risks and vulnerabilities because they are used at every step. This is where security testing for APIs comes in. Ignoring this could be costly because it could compromise the privacy of sensitive user data, disrupt business operations, and harm your company's reputation with customers.
Introduction to API Security
API security testing simulates the behavior of cyber attackers. It involves sending incorrect inputs, requesting unauthorized access ,replicating injection or brute-force attacks, allowing you to identify and remediate vulnerabilities before a real hacker does it for you.
In this blog, you'll learn:
Learn why API security testing is important
A demo-ready example to help apply best practices
Tools like Keploy helps you to test your API in ease with Security
APIs present unique dangers because of the direct system-to-system access and automation-friendly interfaces APIs enable. If you understand these risks beforehand you can build an effective defense. So let’s dive into the different types of risks that APIs pose.
Broken Object-Level Authentication (BOLA)APIs can allow a malicious user to obtain user-specific information if there is no access control to every individual object by their ID (e.g., /users/123), allowing sensitive personal user information to be compromised.
Broken AuthenticationPoor token management, such as tokens that do not expire or weak credentials make it difficult to manage tokens securely. Brute force attacks are much easier in this environment.
Excessive Data Exposure / Mass AssignmentWhen an API provides responses with too much unfiltered data, it can reveal how the app works behind the scenes, allowing attackers to access sensitive data or take actions that shouldn't have been possible.
No Rate LimitsWhen an API does not limit the number of requests someone can send, it is easy to overload the API or perform brute force attacks by sending many repeated requests.
Security MisconfigurationThese common mistakes create easy routes for attackers, such as using outdated API versions, open CORS policies, and debugging endpoints.
Injection AttacksWith no input validation in place, malicious SQL, NoSQL, or script commands can be injected into the system, leading to data corruption or complete compromise of the system.
Insufficient Logging & MonitoringWithout logging requests to API endpoints or raising alerts. Threats can go unnoticed, making it hard to catch a security breach in time.
What Is API Security Testing?
API security testing is a proactive simulation of cyberattacks to your API, such as malformed inputs, brute-force attacks, and authentication bypasses, so that security weaknesses can be determined and remediated before attackers can exploit them.
This builds resilience by testing:
The codebase against known defects (via SAST)
The running API under attack (via DAST)
The API behavior under actual use (via IAST, etc.)
The resistance to logic attacks or chained exploits (via Pen Testing)
In conclusion, it is not just testing, it is a security first way of thinking that helps you ensure your API is robust, compliant, and consistent.
How API Security Testing Works

API security testing is a structured, multi-step approach designed to systematically identify and fix vulnerabilities.
1. Scope & Discovery
Identify all API endpoints internal, external, or third party and rank them based on exposure and sensitivity using OpenAPI specifications, documentation or logs.
2. Threat modeling
Identify and map attack vectors against the OWASP API Top 10, broken or lack of authentication, injection, data exposure, insufficient rate limit; etc.
3. Automated scanning
SAST: Identify injection flaws, secrets and configuration issues statically by scanning source code.
DAST: Identify runtime problems by hitting running API's with crafted requests.
4. Manual penetration testing
Testers who are professionals simulate as closely as possible real attacks, manual testing allows testers to target business logic and follow chains of vulnerabilities allowing for a much wider scope than the forms of testing discussed above.
5. Analyze & report
Go through the findings to understand severity (CVSS), reproduce findings, and list (unless stated otherwise) simple remediation steps for technical teams to work wih.
6. Fix & retest
Once patches are released:
Automated scanning
Manual Validations
How is API Security Different From General Application Security?
API security may be thought of as part of application security. However, there is a different mindset and testing methodology required for APIs. Here is a breakdown of the differences:
What They Are Protecting
Application security protects the user interface, session management, client-side attacks like XSS or CSRF.
API security protects backend services that communicate directly in between systems (without user interface interaction).
Attack Surface
Applications are limited to attacks through a UI, forms, inputs, and session-based attacks.
APIs are exposed to attacks via endpoints, payloads, headers, tokens, and sometimes even business logic directly.
Authentication and Access Control
Applications will rely on session authentication flows (cookies, login flows, etc.).
APIs rely on token-based authentication (JWT, OAuth, API keys, etc.) which introduces its risks (token leakage, absence of scope validation, absence of expiration).
Testing Methodology
Application security testing focuses on UI behavior and user flow.
API security testing focuses on sending raw HTTP requests, creating malformed payloads, bypassing authentication and abusing the business logic of the application.
Risk of Automation
Applications have a UI layer that a user has to interact with and exposes the steps of a flow.
APIs are machine friendly, provide direct access and are not limited by UI. This makes them less restrictive and increases the risk of bots and scripting abuse.
Types of API Security Tests
To ensure resilient APIs, it's important to layer different types of security testing. Each method reveals different weaknesses from vulnerability in code, runtime issues on environments etc.

What are API testing Tools and Frameworks
API testing tools and frameworks are software tools that developers use to test if their APIs are working. By sending HTTP requests to the API endpoints, it verifies the responses against the expected outcomes including status codes, response times, and data formats.
Types of API Testing Tools
CategoryWhat They DoPopular ToolsBest ForGUI-Based

API Security Testing Best Practices
API security vulnerabilities cost companies millions in breaches. Here are 5 essential practices with simple demos to secure your APIs effectively.
1. Implement Authentication & Authorization
Why it matters: 61% of data breaches involve compromised credentials.
Quick Demo - JWT Authentication:CopyCopy// Simple JWT middleware const jwt = require('jsonwebtoken'); const authenticateToken = (req, res, next) => { const token = req.headers['authorization']?.split(' ')[1]; if (!token) return res.status(401).json({ error: 'Token required' }); jwt.verify(token, process.env.JWT_SECRET, (err, user) => { if (err) return res.status(403).json({ error: 'Invalid token' }); req.user = user; next(); }); }; // Protected route app.get('/api/profile', authenticateToken, (req, res) => { res.json({ userId: req.user.id, role: req.user.role }); });
Test it:CopyCopy# Should fail without token curl http://localhost:3000/api/profile # Expected: 401 Unauthorized # Should work with valid token curl -H "Authorization: Bearer YOUR_JWT_TOKEN" http://localhost:3000/api/profile
2. Validate All Input
Why it matters: Input validation prevents 90% of injection attacks.
Quick Demo - Input Sanitization:CopyCopyconst validator = require('validator'); const validateUser = (req, res, next) => { const { email, username } = req.body; // Basic validation if (!email || !validator.isEmail(email)) { return res.status(400).json({ error: 'Valid email required' }); } if (!username || username.length < 3) { return res.status(400).json({ error: 'Username must be 3+ characters' }); } // Sanitize input req.body.email = validator.normalizeEmail(email); req.body.username = validator.escape(username); next(); }; app.post('/api/users', validateUser, (req, res) => { // Safe to process - input is validated createUser(req.body); res.json({ message: 'User created' }); });
Test it:CopyCopy# Test malicious input curl -X POST http://localhost:3000/api/users \ -H "Content-Type: application/json" \ -d '{"email":"test","username":"<script>alert(1)</script>"}' # Expected: 400 Validation error
3. Add Rate Limiting
Why it matters: Rate limiting prevents 99% of brute force attacks.
Quick Demo - Basic Rate Limiting:CopyCopyconst rateLimit = require('express-rate-limit'); // General API rate limit const apiLimiter = rateLimit({ windowMs: 15 * 60 * 1000, // 15 minutes max: 100, // 100 requests per window message: { error: 'Too many requests, try again later' } }); // Strict rate limit for sensitive endpoints const authLimiter = rateLimit({ windowMs: 15 * 60 * 1000, max: 5, // Only 5 login attempts per 15 minutes message: { error: 'Too many login attempts' } }); app.use('/api/', apiLimiter); app.use('/api/auth/', authLimiter);
Test it:CopyCopy# Test rate limiting (run multiple times quickly) for i in {1..10}; do curl http://localhost:3000/api/auth/login; done # Expected: First few succeed, then 429 Too Many Requests
4. Follow OWASP Guidelines
Why it matters: OWASP API Top 10 covers 95% of common vulnerabilities.
Quick Demo - Prevent Data Exposure:CopyCopy// BAD: Exposes sensitive data app.get('/api/users/:id', (req, res) => { const user = getUserById(req.params.id); res.json(user); // Returns password, tokens, etc. }); // GOOD: Return only necessary data app.get('/api/users/:id', authenticateToken, (req, res) => { const user = getUserById(req.params.id); // Only return safe fields const safeUser = { id: user.id, username: user.username, email: user.email, createdAt: user.createdAt }; res.json(safeUser); });
Common OWASP Issues to Test:
Broken authentication
Excessive data exposure
Lack of rate limiting
Broken access control
5. Automate Security Testing
Why it matters: Manual testing misses 70% of vulnerabilities.
Quick Demo - Basic Security Tests:CopyCopy// test/security.test.js const request = require('supertest'); const app = require('../app'); describe('API Security Tests', () => { test('should require authentication', async () => { const response = await request(app).get('/api/profile'); expect(response.status).toBe(401); }); test('should reject malicious input', async () => { const response = await request(app) .post('/api/users') .send({ username: '<script>alert(1)</script>' }); expect(response.status).toBe(400); }); test('should enforce rate limits', async () => { // Make multiple requests quickly const requests = Array(10).fill().map(() => request(app).post('/api/auth/login') ); const responses = await Promise.all(requests); const blocked = responses.some(r => r.status === 429); expect(blocked).toBe(true); }); });
Run Security Tests:CopyCopy# Add to package.json "scripts": { "test:security": "jest test/security.test.js", "security-audit": "npm audit --audit-level=high" } # Run tests npm run test:security npm run security-audit
How Keploy Makes Your API Testing More Secure
In this blog, we are discussing API security, right? What if the platform provided a way to make API testing more secure and implement all the best practices? Yes, you can now test your APIs without writing any tests and ensure 100% security. Sounds interesting?
Go to: app.keploy.io
The interesting part is, if your APIs have any authentication, you can integrate all of those through a simple, intuitive UI.

Once everything is set, Keploy API Testing agent starts creating APIs without you writing any test cases. Once the test suites are created, you can run and test them. Here’s the catch:
Concerned about privacy? No worries! You can use our local private agent for running your test suites, ensuring your data stays within your control. Whether you choose the local private agent or the hosted agent, Keploy offers flexible options to suit your needs.

To know more Keploy API Testing agent: https://keploy.io/docs/running-keploy/api-test-generator/
Related Resources
For developers looking to enhance their API security testing strategy, explore these useful guides:
Complete API Testing Guide - Fundamentals of API testing methodologies
REST Assured Alternatives - Compare 20 powerful testing tools including Keploy
No-Code API Testing - Simplify testing workflows with automation
Test Mock Data Best Practices - Create secure and realistic test data
API Performance Testing - Optimize API speed and security simultaneously
Conclusion
APIs are an important part of the digital systems we use today, but as more APIs are used, the number of attacks and security issues also increases. Securing APIs through regular testing is now a must and should be seen as a basic need. API security testing helps you find problems early, protect user data, and prevent costly attacks. Tools like Keploy make it easier by turning real traffic into useful test cases. Adding security testing to your software development process and following trusted standards like the OWASP API Top 10 lets you build safer APIs while keeping your team's speed and productivity. Good API security protects your business and builds trust with your users.
FAQs
Are all cyberattacks preventable via API security testing?API security testing helps reduce risk by identifying vulnerabilities before they can be exploited by attackers. However, it should be part of a comprehensive security plan that includes incident response and monitoring.
How often should I test my API security?Manual testing should be done every three months, while automated testing should be integrated into your CI/CD pipeline, and more extensive testing should be conducted for major API changes.
How do penetration testing and API security testing differ?API security testing automatically scans for known vulnerabilities. Penetration testing involves experts simulating real attacks to find complex vulnerabilities.
How Secure is Keploy API Testing agent?Keploy is built with security-first principles and is compliant with major industry standards:
✅ SOC 2
✅ ISO 27001
✅ GDPR
✅ HIPAA
Your data and test traffic are handled securely, with the option to run Keploy entirely within your network using our self-hosted agent or BYO LLM infrastructure.
What’s the difference between manual and automated API security testing?Automated testing (SAST, Keploy replay testing, DAST) should be done with every code change or CI build to catch issues early. Manual testing, like quarterly or post-release penetration testing, finds more complex exploits and logic errors.
0 notes
Text
With support for novice and seasoned developers, SQL Server Express Edition stands out in the dynamic world of database management systems. Let's Explore Deeply:
https://madesimplemssql.com/sql-server-express/
Follow us on FB: https://www.facebook.com/profile.php?id=100091338502392
&
Join our Group: https://www.facebook.com/groups/652527240081844
Please review this article & share your valuable feedback.
2 notes
·
View notes
Text
Базы данных. Как выбрать идеальное решение?
SQL и RDBMS
Когда каждый из нас начинает изучать программирование, он учит циклы, операторы ветвления, и когда дело доходит до баз данных, мы изучаем SQL и реляционные СУБД (RDBMS). PostgreSQL, MS SQL Server, MySQL — это всё они, наши старые добрые реляционные базы данных.
SQL-хранилища относятся к классу систем OLTP (Online Transactional Processing — обработка транзакций в реальном времени). Такие базы данных идеально подходят для операций, требующих строгой консистентности и транзакционности: банковские системы, платформы для бронирования билетов, интернет-магазины (учёт заказов, профили пользователей) и так далее. Они гарантируют нам ACID (Atomicity, Consistency, Isolation, Durability).
Если у вас небольшое приложение с невысокой нагрузкой, то просто используйте SQL-хранилище и не парьтесь. Это надёжное, проверенное временем решение.
Но как только возникает большая нагрузка — например, тысячи или десятки тысяч запросов в секунду, то ваша SQL-база может захлебнуться. Реляционная база данных плохо масштабируется горизонтально. Тогда-то и приходят на помощь другие классы хранилищ.
NoSQL
Для определённых задач запросы в SQL-хранилища могут требовать слишком много времени или ресурсов. Например, поиск всех друзей друзей в социальной сети превращается в дорогостоящий рекурсивный JOIN. Именно для таких специфичных кейсов и были придуманы NoSQL-решения.
NoSQL (Not Only SQL) — это широкий класс систем управления базами данных, которые не являются реляционными. Они не требуют жёсткой схемы данных, как правило, лучше масштабируются горизонтально и оптимизированы под конкретные типы нагрузки.
NoSQL-системы часто жертвуют строгой согласованностью (Strong Consistency) ради масштабируемости, предлагая Eventual Consistency, когда данные согласуются между узлами с некоторой задержкой.
Важно понимать: NoSQL — это не синоним OLAP (Online Analytical Processing — анализ данных в реальном времени). Некоторые NoSQL-базы отлично подходят для OLTP-нагрузок (например, Cassandra), другие — для аналитики (OLAP), а третьи вообще не вписываются в эту классификацию.
Давайте разберёмся в их многообразии.
Key-Value хранилища и кэши
Key-Value хранилища — тип нереляционной базы данных, которая хранит данные в виде пар «ключ — значение». Некоторые хранилища типа ключ-значние часто используются в качестве кэша.
Кэш — это высокоскоростное хранилище, которое держит данные в оперативной памяти (RAM) для максимально быстрого доступа к ним. Его основная задача — быстро возвращать значение по ключу, что активно применяется, когда нужно оптимизировать доступ к более м��дленной, основной базе данных.
Например, чтобы ускорить получение информации о популярном посте на Хабре, можно сохранить уже готовую HTML-страницу или JSON с данными этого поста в кэше по ключу (ID поста). При следующем запросе мы мгновенно достанем его из кэша по ключу, не нагружая основную базу данных. Самые распространённые кэши — это Redis и Memcached.
Redis хранит данные в оперативн��й памяти, но при этом обеспечивает персистентность (сохранность данных после перезагрузки) за счёт двух механизмов: снэпшотов (RDB), когда он периодически сохраняет всё состояние на диск, или AOF (Append-Only File), когда он логгирует на диск каждую операцию записи. Эти механизмы работают независимо и могут использоваться по отдельности или вместе для обеспечения разной степени надёжности и удобства восстановления данных.
Примеры использования кэша:
Кэширование результатов часто выполняемых запросов к базе данных для ускорения доступа к данным.
Хранение сессий пользователей в веб-приложениях для уменьшения нагрузки на основную базу данных.
Wide-Columnlar
А что делать, если нам нужно очень-очень много писать? Например, сообщения в онлайн-мессенджере или данные с IoT-устройств? Тут обычная реляционная база данных не справится с нагрузкой на запись.
Здесь на помощь подходит вид хранилища под названием "широкие колонки" (Wide-Column). Самым популярным представителем является Cassandra, которую изначально разработали в Facebook для поиска по входящим сообщениям. Форк Cassandra также активно используется для реализации ленты новостей и сообщений в социальной сети Одноклассники.
Cassandra строится на основе LSM-дерева (Log-structured merge-tree). Если просто, все операции записи сначала попадают в быструю структуру в памяти (Memtable), а затем асинхронно сбрасываются на диск в виде неизменяемых файлов (SSTables). Это делает запись невероятно быстрой, так как нет необходимости искать нужную ячейку на диске и перезаписывать её. Чтение может быть медленнее, но для write-heavy (когда запись происходит чаще, чем чтение) нагрузок это идеальное решение.
Ключевой особенностью Cassandra является её линейная масштабируемость: чтобы увеличить мощность, просто добавьте новые узлы в кластер. Данные распределяются (шардируются) между узлами на основе Partition Key (ключа партиции). Все строки с одинаковым Partition Key гарантированно хранятся на одном узле, что обеспечивает быстрый доступ к связанным данным в рамках партиции.
Примеры использования Wide-Columnlar (широких колонок):
Хранение постов пользователей в социальных сетях, и их распространение для миллионов пользователей с преимущественно записью.
Обработка данных с IoT-устройств, генерирующих большие объёмы данных в реальном времени.
Columlar
Колоночные базы данных — это хранилища, которые физически хранят данные по колонкам, а не по строкам. Самый известный представитель — ClickHouse от Яндекса.
В отличие от традиционных БД, где все значения одной строки (например, ID, Имя, Фамилия, Возраст) лежат на диске рядом, в колоночных базах рядом лежат все значения одной колонки (все ID, затем все Имена, все Фамилии). Это даёт два преимущества:
Фантастическое сжатие данных, так как данные одного типа (например, числа) сжимаются гораздо лучше, чем разнородные.
Высокая скорость аналитических запросов. Если вам нужно посчитать средний возраст пользователей (SELECT AVG(age) FROM users), база прочитает с диска только одну колонку age, а не всю таблицу.
Колоночные базы данных — это идеальный представитель OLAP-систем, где скорость анализа огромных объемов данных критична. Использование ключа сортировки (ORDER BY) в ClickHouse — это не просто рекомендация, а фундамент производительности. Он определяет, в каком физическом порядке данные будут лежать на диске. Это важно, потому что:
На основе этого ключа автоматически строится первичный индекс — главный помощник при поиске.
Когда вы фильтруете данные по столбцам, входящим в ORDER BY (например, WHERE date = '2023-10-01' AND user_id = 123), ClickHouse может мгновенно найти нужные "куски" данных на диске, пропуская всё остальное. Без правильного ORDER BY ему пришлось бы перебирать всё — а это очень медленно на петабайтах.
Примеры использования колоночных баз данных:
Аналитика продаж в ритейле, где требуется агрегирование данных по большим объёмам транзакций.
Логирование и анализ системных событий в крупных распределённых системах.
Документные базы данных
Документные базы данных — это вид NoSQL-хранилищ, которые хранят данные в виде документов, обычно в формате JSON или его бинарном аналоге BSON. Самый популярный представитель — это MongoDB.
Внутренне это выглядит так: каждый документ — это самодостаточная структура со своими полями и значениями (обычно JSON-объект), которая может иметь вложенные документы и массивы. Это очень удобно для программистов, так как структура документа в базе часто напрямую соответствует объекту в коде. Данные хранятся в коллекциях (аналог таблиц в SQL). Для быстрого поиска MongoDB позволяет создавать индексы по любым полям документа, даже по вложенным. Это избавляет от необходимости делать JOIN и позволяет быстро получать всю связанную информацию одним запросом.
Примеры использования документоориентированных БД:
Хранение профилей пользователей в социальных сетях со сложной и изменяемой структурой данных.
Управление конфигурациями устройств, где каждый документ может представлять собой конфигурацию конкретного устройства.
Графовые базы данных
Графовая база данных — это система, созданная для хранения данных в виде графа, состоящего из вершин (узлов) и рёбер (связей).
Тут же возникает вопрос: а зачем? В каком случае она может понадобиться? А я вам скажу: она нужна в одном простом случае — когда нужно быстро и эффективно работать со связями между сущностями. Например, при проектировании социальной сети в графовой базе данных вы можете хранить информацию о друзьях или подписках на группы. Запрос вида «найти всех друзей моих друзей, которые живут в Москве» выполнится в графовой базе данных разы быстрее, чем в SQL.
Также графовые базы данных незаменимы в задачах построения рекомендательных систем, поиска мошеннических схем и анализа сложных сетей (например, логистических или телекоммуникационных).
Самый известный представитель — Neo4j .
Под капотом графовые базы данных хранят узлы и рёбра как основные сущности. Вместо того чтобы вычислять связи через JOIN-операции, они хранят прямые указатели от одной вершины к другой (через списки смежности). Благодаря этому обход графа — это просто переход по указателям в памяти или на диске, что невероятно быстро.
Примеры использования графовых БД:
Моделирование и анализ социальных графов для выявления сообществ и рекомендаций.
Обнаружение мошеннических схем в финансовых транзакциях путём анализа связей между участниками.
Поисковые движки
Инвертированный индекс — это структура данных, которая хранит отображение из контента (например, слов) в его расположение в документе или наборе документов. Соответственно, базы данных, которые строятся на этом принципе, — это поисковые движки.
Самый известный представитель — Elasticsearch. Без баз данных на основе инвертированных индексов просто невозможно построить ни один современный поиск (текстовый, по логам, по каталогу товаров).
Внутренне такие хранилища строятся следующим образом: для каждого слова (терма) в документе создаётся запись в индексе, которая указывает на все документы, где это слово встречается. Когда вы делаете поисковый запрос, движок мгновенно находит все документы по нужным словам, а затем ранжирует их по релевантности.
Примеры использования инвертированных индексов:
Реализация полнотекстового поиска по каталогу товаров в интернет-магазине.
Анализ логов серверов для выявления аномалий и ошибок.
Time Series Database
TSDB (Time Series Database) — это специализированное хранилище, заточенное под данные, где временная метка — главный ключ. Хотя они часто ассоциируются с метриками серверов, их применение гораздо шире: любые потоки событ��й или измерений, строго привязанных ко времени, от финансовых котировок до действий пользователей в приложении. Самый распространённый представитель TSDB — InfluxDB.
Внутреннее устройство TSDB оптимизировано для работы с временными рядами. Данные физически группируются и сжимаются по времени. Используются специальные алгоритмы сжатия, которые отлично работают на монотонно растущих временных метках и значениях. Это позволяет эффективно хранить огромные объёмы данных и очень быстро выполнять запросы по временным диапазонам.
Примеры использования БД временных рядов:
Хранение данных о финансовых тиках на бирже.
Хранение метрик мониторинга.
NewSQL
NewSQL — это класс современных распределённых реляционных баз данных, которые стремятся объединить лучшее из двух миров: горизонтальную масштабируемость NoSQL-систем с полными ACID-гарантиями традиционных SQL-баз. По сути, это попытка преодолеть главный недостаток классических реляционных СУБД: сложность масштабирования OLTP-нагрузок без потери транзакций и строгой консистентности.
Самые известные представители — YDB (Yandex Database) и CockroachDB.
Такой вид хранилищ используется для высоконагруженных OLTP-систем, которые требуют и строгой консистентности, и горизонтального масштабирования. Они часто совмещают в себе плюсы OLTP и OLAP, что называется HTAP (Hybrid Transactional/Analytical Processing — гибридная транзакционная/аналитическая обработка).
NewSQL является мощным инструментом для очень специфичных задач, когда нужны транзакции для больших данных и возможность горизонтального масштабирования. Но для большинства проектов проверенные PostgreSQL, MySQL остаются проще, дешевле и надежнее. Это не замена, а специализированное решение для тех, кто "перерос" классические БД.
Примеры использования NewSQL:
Высоконагруженные e-commerce платформы, требующие строгой консистентности и масштабируемости.
Финансовые системы, обрабатывающие большое количество транзакций в реальном времени.
Смежные технологии и системы хранения
Есть отдельные инструменты, которые не всегда являются базами данных в классическом понимании, но используются для хранения или обработки данных.
Системы обработки больших данных
Есть отдельные фреймворки, предназначенные для распределённой обработки огромных объёмов данных (петабайты данных). К таким системам относятся Hadoop (с его файловой системой HDFS), Spark и YTsaurus. Они не являются базами данных для вашего приложения, а скорее платформой для batch или stream-обработки данных в аналитических целях.
Примеры использования систем обработки больших данных:
Анализ данных о поведении пользователей в крупных онлайн-сервисах для улучшения пользовательского опыта.
Обработка спутниковых данных для мониторинга климатических изменений.
S3 (Object Storage)
Объектное хранилище (S3 — Simple Storage Service) — это сервис для хранения файлов (объектов) в виде неструктурированных данных. Ключевое отличие от файловой системы в том, что у него плоская структура. Вы обращаетесь к объекту по уникальному ключу. S3 обеспечивает высочайшую надёжность, масштабируемость и низкую стоимость хранения. Идеально подходит для бэкапов, медиаконтента (видео, фото), статических данных сайта.
Примеры использования S3:
Хранение бэкапов данных для обеспечения их надёжности и доступности.
Хранение медиафайлов (видео, фото) для использования в контент-менеджменте.
CDN (Content Delivery Network)
CDN — это географически распределённая сеть серверов, которая кэширует контент (картинки, видео, статику) как можно ближе к конечным пользователям. Это не хранилище в прямом смысле, а слой доставки, который кардинально снижает задержку при загрузке контента для пользователей из разных уголков мира.
Примеры использования CDN:
Распределение статического контента (изображения, стили CSS, JavaScript-файлы) для ускорения загрузки веб-сайтов.
Доставка видеопотоков пользователям по всему миру с минимальной задержкой.
Некоторые кейсы
Также я написал небольшую подборку кейсов, которая позволит разобрать ещё больше примеров, какой тип хранилища лучше использовать и их преимущества.
Решаемая задача
Требуемое хранилище
Объяснение, почему выбрано хранилище
Хранение профилей пользователей в социальной сети с сложной и изменяемой структурой данных
Документная БД (MongoDB)
Гибкость и возможность хранения сложных структур данных
Запись данных с IoT-устройств, генерирующих большие объёмы данных в реальном времени
Wide-Columnlar (Cassandra)
Высокая пропускная способность на запись и горизонтальное масштабирование
Аналитика продаж в ритейле, где требуется агрегирование данных по большим объёмам транзакций
Колоночная БД (ClickHouse)
Быстрая скорость аналитических запросов и эффективное сжатие данных
Реализация полнотекстового поиска по каталогу товаров в интернет-магазине
Поисковый движок (Elasticsearch)
Быстрый поиск по ключевым словам и релевантность результатов
Хранение метрик мониторинга серверов
TSDB (Prometheus)
Оптимизация для работы с временными рядами и эффективное хранение данных
Обработка большого количества транзакций в реальном времени в финансовой системе
NewSQL (YDB)
Строгая консистентность и горизонтальное масштабирование
Анализ данных о поведении пользователей в крупных онлайн-сервисах
Системы обработки больших данных (Apache Hadoop)
Распределённая обработка огромных объёмов данных
Хранение бэкапов данных для обеспечения их надёжности и доступности
S3 (Object Storage)
Высочайшая надёжность, масштабируемость и низкая стоимость хранения
Распределение статического контента (изображения, стили CSS, JavaScript-файлы) для ускорения загрузки веб-сайтов
CDN (Content Delivery Network)
Снижение задержки при загрузке контента для пользователей из разных уголков мира
Моделирование и анализ социальных графов для выявления сообществ и рекомендаций
Графовая БД (Neo4j)
Эффективная работа со связями между сущностями и быстрый обход графа
Саммари
В статье мы разобрали:
различные типы хранилищ данных, включая SQL, Key-Value, Wide-Column, Columnar, документные, графовые, поисковые движки, TSDB, NewSQL;
особенности и преимущества каждого типа хранилища;
примеры использования различных хранилищ в реальных сценариях;
смежные технологии и системы хранения, такие как системы обработки больших данных, S3 и CDN.
Помните главное: идеального хранилища "на все случаи жизни" не существует. Каждое решение — это компромисс. Выбирая базу, вы всегда будете жертвовать чем-то ради чего-то другого. Поэтому спросите себя: что для вашей задачи критичнее? Скорость чтения или записи? Данные чаще читают или пишут? А может, ключевой фактор — это возможность легко масштабироваться горизонтально? Eventual consistency в NoSQL может привести к временным аномалиям в согласованности данных. А транзакции в SQL — к низкой производительности из-за блокировок.
Важно правильно пределять приоритеты, и тогда выбор становится яснее.
уничтожение клопов сэс
в организации ТехТурбо в Санкт-Петербурге осуществляют квалифицированный ремонт и модернизацию турбин с гарантией.
ремонт турбин
заказывали в этой компании производство упаковок для бизнеса из гофрокартона, объемом 11 000 шт. с нанесением на них картинки своего товара
0 notes
Text
How to test app for the SQL injection

During code review
Check for any queries to the database are not done via prepared statements.
If dynamic statements are being made please check if the data is sanitized before used as part of the statement.
Auditors should always look for uses of sp_execute, execute or exec within SQL Server stored procedures. Similar audit guidelines are necessary for similar functions for other vendors.
Automated Exploitation
Most of the situation and techniques on testing an app for SQLi can be performed in a automated way using some tools (e.g. perform an automated auditing using SQLMap)
Equally Static Code Analysis Data flow rules can detect of unsanitised user controlled input can change the SQL query.
Stored Procedure Injection
When using dynamic SQL within a stored procedure, the application must properly sanitise the user input to eliminate the risk of code injection. If not sanitised, the user could enter malicious SQL that will be executed within the stored procedure.
Time delay Exploitation technique
The time delay exploitation technique is very useful when the tester find a Blind SQL Injection situation, in which nothing is known on the outcome of an operation. This technique consists in sending an injected query and in case the conditional is true, the tester can monitor the time taken to for the server to respond. If there is a delay, the tester can assume the result of the conditional query is true. This exploitation technique can be different from DBMS to DBMS.
http://www.example.com/product.php?id=10 AND IF(version() like '5%', sleep(10), 'false'))--
In this example the tester is checking whether the MySql version is 5.x or not, making the server delay the answer by 10 seconds. The tester can increase the delay time and monitor the responses. The tester also doesn't need to wait for the response. Sometimes they can set a very high value (e.g. 100) and cancel the request after some seconds.
Out-of-band Exploitation technique
This technique is very useful when the tester find a Blind SQL Injection situation, in which nothing is known on the outcome of an operation. The technique consists of the use of DBMS functions to perform an out of band connection and deliver the results of the injected query as part of the request to the tester's server. Like the error based techniques, each DBMS has its own functions. Check for specific DBMS section.
4 notes
·
View notes