
Last Seen Blogs

riveluart
Ally James Lyons

phandompicnic
Phandom Picnic 2024

microcreation-blog
Untitled

samplummerlivepiano-blog
Sam Plummer

corludayasam1
İsimsiz
Text
Wie führe ich eine große Anzahl von Testfällen mit begrenzter Zeit und Ressourcen aus?

Wahrlich, eine hervorragende Frage. Hier werde ich einige Schritte aus meiner persönlichen Erfahrung erklären.
- Wir brauchen dafür eine gute Teamarbeit.
- Hier möchte ich nur den Begriff "Alle Testfälle/Suite ausführen" klären. Wir müssen die Testfälle in vier Quadranten wie unten beschrieben priorisieren.

- Führt am besten viele explorative Tests anstelle eines vollständig skriptbasierten Ansatzes durch.
- Versucht, alle geschäftskritischen Abläufe zuerst abzudecken.
- Versucht, alle früheren Produktionsfehler zu testen und im aktuellen Regressionszyklus abzudecken.
- Gebt euch etwas Zeit für die richtige Planung, bevor ihr mit einem sequenziellen Ansatz beginnen. Welche Art von Modulen und Testfällen könnt ihr zuerst eliminieren, und entfernt diese zuerst, sodass ihr nun eine Liste aller wichtigen Aufgaben habt. Verwendet Serneut den Prioritätsquadranten .
- Und zu guter Letzt. Wieder brauchen wir Schritt-1
Im Grunde haben ihr nie angemessen Zeit und Ressourcen, um alles zu testen. Eure Testfälle sind bereits eine Teilmenge dieses unendlichen "Alles".
Was könnt also tun? Prioritäten setzen. Eine gängige Heuristik ist RCRCRC:
- Neu: neue Funktionen
- Kern: wesentliche Funktionen Ihres Produkts
- Risiko: Risiko ist definiert als die Wahrscheinlichkeit des Auftretens (wie wahrscheinlich ist es, dass es passiert) multipliziert mit der Auswirkung (wie hoch ist der Schaden, in verlorenen Geldstunden oder irgendetwas Relevantem).
- Konfigurationsempfindlich: dies repräsentiert sowohl die interne Konfiguration als auch die Umgebungseinstellungen, insbesondere den Gerätetyp oder das Betriebssystem.
- Repariert: Kürzlich reparierte Fehler stehen für nicht getestete Bereiche
- Chronisch: einige Bereiche sind als anfällig bekannt. Dies kann auf die Komplexität, das Niveau der Entwickler oder auf einen Bereich zurückzuführen sein, der zwischen den Verantwortlichkeiten liegt.
Nehmt eure Liste der Testfälle und stuft sie für jeden Punkt ein, sagen wir 1 - 5 (verwendet keine Null, da dies den nächsten Schritt beeinträchtigen würde), multipliziert dann die sechsstellige Zahl und sortiert nach dem Ergebnis. So erhaltet ihr eine erste Einschätzung, was zuerst getestet werden sollte und warum.
Weitere Punkte:
Priorisiert die Testfälle
In meinen früheren Projekten haben wir die Testfälle nach Prioritäten geordnet. Wir haben HP ALM verwendet und dort hatten wir auch einige Testfälle und es war unmöglich, sie alle auszuführen. Also haben wir die Testfälle einfach priorisiert, z.B. Kritisch, Sehr Hoch, Hoch, Mittel, Niedrig - so wie man es auch bei Fehlern machen würde. Alle erstellten Testfälle basierten auf der ebenfalls von uns erstellten Veröffentlichungsrichtlinie. Dies half uns, uns auf die wichtigsten Testfälle zu konzentrieren.
Bezieht andere in den Testumfang ein, z. B. Product Owner, und übertragen ihnen einige Testfälle.
Bezieht andere in das Testteam ein. Testen bedeutet nicht, dass ihr nur allein mit euren Testkollegen testet. Es bedeutet, dass ihr auch andere Teammitglieder einbeziehen könnt. In unserem Projekt haben wir daher auch den Product Owner in die Tests einbezogen. Und zwar nicht erst am Ende (z. B. wenn die Bereitstellung erfolgt ist und das UAT über die Fachabteilung und den Product Owner durchgeführt werden sollte). In Janet Gregorys Buch habe ich den Hinweis gefunden, dass UAT meist erst nach dem Deployment durchgeführt wird und dies nicht bedeutet, dass man es dem Endspiel überlassen sollte (Janet Gregory "More Agile Testing" Seite 202). Wenn man ein Produkt testet, kann man natürlich auch andere Stakeholder einbeziehen, um ein Produkt zu testen. In unserem Fall haben unsere Product Owner geholfen, einige Testfälle zu testen! Übrigens könnt ihr auch die UX-Abteilung bitten, euch zu unterstützen. Wir haben auch unsere UX-Abteilung gebeten, uns bei der Durchführung einiger Testfälle zu unterstützen, und wir haben auch von ihnen wertvolles Feedback erhalten.
Organisiert eine Art Mob-Testing und agiert als Testkoordinator, der euch Testfälle zuwirft!
Ihr könnt auch versuchen, eine Mob-Testing-Sitzung durchzuführen. Gebt ihnen einfach einige Testfälle (die leicht verständlich sind) und einige Anweisungen (und bereitet z.B. Testdaten vor) und lasst sie die Testfälle einfach ausführen! Wir haben dies getan, als wir einige Beteiligte aus anderen Abteilungen eingeladen haben, um uns zu unterstützen! Das hat funktioniert und der Input war sehr hilfreich für uns (weil wir auch Feedback für neue Änderungswünsche bekamen). Das Gute daran war, dass wir nur einen unserer Testanalysten dorthin schickten, der für vier bis fünf Zweiergruppen verantwortlich war. Irgendwie ist das wie ein Beschleuniger, um mit den Testfällen voranzukommen.
Bittet die Fachabteilung um Unterstützung
Wir haben auch die Fachabteilung um Unterstützung gebeten. Normalerweise wird die Fachabteilung nur tätig, wenn das UAT durchgeführt werden soll. Wir baten sie jedoch um Unterstützung und begründeten dies damit, dass die Hilfe wertvoll wäre, um ein (test-)stabiles Produkt zu liefern.
Verwendung eines Protokollierungstools für Sondierungstests
Wir haben auch den Zeitaufwand für die Erstellung von Testfällen reduziert, als wir uns für den Einsatz eines Capture-Replay-Tools entschieden haben. In unserem Fall war es tricentis/quasymphony. Während der Testdurchführung erstellt dieses Tool Testfälle und während dieser Zeit haben wir eine Art exploratives Testen durchgeführt. Das heißt, Ausführung und Erstellung von Testfällen. Dadurch wurde die Zeit für die Erstellung konkreter Testfälle etwas verkürzt.
Ihr seht, es gibt eine Menge Ideen. Aber die wichtigste ist, dass Testen ein Ansatz für das ganze Team ist! Ihr könnt also alle relevanten Beteiligten zur Unterstützung einladen - und unserer Erfahrung nach waren die meisten bereit, uns zu unterstützen.
Read the full article
0 notes
Text
Was ist der Unterschied zwischen "automatisierten Tests" und "automatisierten Regressionstests"?

Ein Regressionstest ist etwas, das eure Testergebnisse mit bestimmten Anforderungen abgleicht. Gute Beispiele hierfür sind Unit-Tests und funktionale Tests. Diese geben Aufschluss darüber, ob sich die Funktionalität eurer Anwendung verschlechtert hat oder nicht (daher Regression).
Es gibt noch andere Arten von automatisierten Tests: Fuzzy-Inputs und automatisierte Erkundungstests kommen mir in den Sinn. Diese haben nicht immer vorhersehbare, wiederholbare Ergebnisse, wie eure Regressionstests. Für einen Tester wäre es ziemlich mühsam und zeitaufwendig, sie manuell durchzuführen, daher ist es nicht verkehrt, sie zu automatisieren und das Ergebnis zu betrachten. Die Grenze des Testens liegt darin, wie schnell man denken und dann automatisieren kann, und nicht darin, wie schnell man klicken kann.
Einige Beispiele für automatisierte Nicht-Regressionstests sind:
- Jeder automatisierte Test, der weggeworfen und nicht für Regressionstests verwendet wird, ist kein Regressionstest, einschließlich Unit-Tests, die später nicht für Regressionstests verwendet werden. Technisch gesehen ist jeder automatisierte Test, der für eine neue Funktionalität geschrieben wurde, kein Regressionstest, solange er nicht mindestens einmal die korrekte Funktionalität überprüft hat. Erst dann kann er nachweisen, dass sich die Funktionalität nicht geändert hat.
- Zuverlässigkeitstests, bei denen ihr das zu testende System so lange wie möglich in einer produktionsnahen Umgebung laufen lasst, um zu sehen, wie lange es ohne Fehler oder Abstürze läuft
Stresstests, bei denen es darum geht, zu sehen, wie sich das zu testende System bei starker Beanspruchung oder eingeschränkten Ressourcen verhält; Ihr könnt z. B. CPUs entfernen oder die Bandbreite verringern oder eine große Anzahl von Benutzern simulieren.
- Bei einigen Leistungstests gibt es möglicherweise keine spezifischen Prüfungen, die zu verifizieren sind, und es wird eine Person benötigt, um die Ergebnisse zu interpretieren, obwohl einige Leistungstests als Regressionstests durchgeführt werden können (z. B. "Führe 100 Iterationen dieser Funktion aus. Wenn es weniger als 5 Sekunden gedauert hat, ist der Test bestanden, ansonsten ist er fehlgeschlagen").
Glowcoder erwähnte Fuzz-Tests, bei denen die Eingaben in eine Funktion nach dem Zufallsprinzip erfolgen, aber das Thema verdient es, etwas erweitert zu werden. Beim Fuzz-Testing sucht der Tester nach unerwartetem Verhalten, das Probleme verursachen könnte, wie Sicherheitslücken, Abstürze und Hänger.
Beispiele für Regressionstests sind:
- Wiederholung früherer Tests: Tests, die zuvor durchgeführt wurden, um sicherzustellen, dass sie auch nach einer Änderung weiterhin erfolgreich durchgeführt werden können.
- Funktionalitätstests: Tests, die sicherstellen, dass die bestehenden Funktionen der Software nach einer Änderung weiterhin korrekt funktionieren. Dies kann z.B. die Überprüfung von Benutzereingaben, die Ausgabe von Daten oder die Interaktion mit anderen Systemen umfassen.
- Edge-Case-Tests: Tests, die sicherstellen, dass die Software auch in Randfällen oder ungewöhnlichen Szenarien korrekt funktioniert. Dies könnte z.B. die Behandlung von ungültigen Eingaben oder unerwarteten Zuständen sein.
- Integrationstests: Tests, die sicherstellen, dass die Software nach einer Änderung weiterhin korrekt mit anderen Komponenten oder Systemen interagiert.
- Leistungstests als Regressionstests: Bestimmte Leistungstests können auch als Regressionstests dienen, wenn sie sicherstellen, dass Änderungen keine negativen Auswirkungen auf die Leistung der Software haben.
Aber wie definiert man das nun genauer?
"Automatisierte Tests" bezieht sich im Allgemeinen auf Tests, die automatisiert durchgeführt werden, um die Funktionalität einer Software zu überprüfen. Diese Tests können verschiedene Arten von Tests umfassen, wie z.B. Unit-Tests, Integrationstests oder Systemtests. Das Hauptziel automatisierter Tests ist es, Fehler frühzeitig im Entwicklungsprozess zu finden und die Qualität der Software sicherzustellen.
"Automatisierte Regressionstests" sind eine spezifische Art von automatisierten Tests, die darauf abzielen, sicherzustellen, dass neue Änderungen oder Updates an einer Software keine bereits behobenen Fehler reintroduzieren (Regressionen). Sie überprüfen, ob die bestehende Funktionalität nach einer Änderung immer noch wie erwartet funktioniert. Regressionstests werden typischerweise nach jeder Änderung am Code oder an der Konfiguration durchgeführt, um sicherzustellen, dass keine unerwünschten Nebeneffekte auftreten.
Read the full article
0 notes
Text
Wie testet man das Datenmigrationsverfahren?
Datenmigration ist ein entscheidender Schritt bei der Aktualisierung von Systemen, dem Wechsel von Plattformen oder der Konsolidierung von Datenquellen. Es handelt sich dabei um den Prozess des Übertragens von Daten von einem Speicherort auf einen anderen, während sicherzustellen ist, dass die Integrität, Sicherheit und Qualität der Daten erhalten bleiben. Da Daten das Rückgrat vieler Unternehmen bilden, ist es unerlässlich, das Datenmigrationsverfahren sorgfältig zu testen, um unerwünschte Auswirkungen zu vermeiden. Und ja es wird nicht einfach, versuchen wir heute mal eine sinnvolle Anleitung zu diesem Thema hier zu erarbeiten.
Aus meiner persönlichen Erfahrung würde ich auf einige zusätzliche Dinge achten:
- Stellt sicher, dass ihr euch die aktuellen Randfälle anseht und diese bei der Migration berücksichtigt werden. Für einen Entwickler ist es einfach, alle Daten zu verarbeiten, die normalerweise erwartet werden. Es gibt jedoch immer Grenzfälle, in denen Daten für bestimmte Kunden oder bestimmte Konfigurationen anders gespeichert werden, und ihr müsst sicherstellen, dass auch diese Sonderfälle ordnungsgemäß behandelt werden.
- Wenn das System während der Migration online sein wird (ich denke an eine Migration, die Stunden oder sogar Tage oder Wochen dauern kann), stellt sicher, dass der Bereinigungsprozess nach dem ersten Durchlauf, um alle Daten seit dem Beginn der Migration zu erhalten, genauso robust ist wie der ursprüngliche Prozess. Für Entwickler ist es einfach, weniger Zeit auf diesen Teil zu verwenden, aber er ist genauso wichtig. Es ist auch schwieriger zu testen, wenn ihr nur mit einer kleinen Teilmenge der Daten testet.
https://www.youtube.com/watch?v=cmiJm-_GdVA
Hier sind einige bewährte Methoden, wie man das Datenmigrationsverfahren erfolgreich testet:
- Erstellung eines Testplans: Bevor ihr mit dem Testen beginnt, ist es wichtig, einen detaillierten Testplan zu erstellen. Dieser sollte die Ziele der Migration, die zu testenden Szenarien, die verwendeten Werkzeuge und die zugewiesenen Ressourcen umfassen. Hier Beispiele: 01,02,03
- Testumgebung einrichten: Eine dedizierte Testumgebung sollte eingerichtet werden, die die Produktionsumgebung so genau wie möglich nachbildet. Dies ermöglicht es, Tests durchzuführen, ohne die Live-Daten zu gefährden. Eigentlich natürlich der entscheidende Punkt, den man immer umsetzen muss. Fummelt bitte nicht irgendwie und irgendwo am Live-System herum. Selbst wenn euer Vorgesetzter das verlangt!
- Datenprofilierung: Vor der Migration sollten die Daten gründlich analysiert und profiliert werden, um ein besseres Verständnis für ihre Struktur, Qualität und Beziehungen zu erhalten. Dies hilft, potenzielle Probleme im Voraus zu erkennen.
- Durchführung von Stresstests: Simuliert eine hohe Last oder große Datenmengen, um sicherzustellen, dass das Migrationsverfahren unter extremen Bedingungen stabil bleibt. Dies kann die Leistungsfähigkeit der Zielsysteme bewerten und Engpässe identifizieren.
- Vollständigkeitstests: Überprüft, ob alle erforderlichen Daten erfolgreich migriert wurden und ob keine Daten verloren gegangen sind. Vergleicht die Quell- und Ziel-Datensätze, um sicherzustellen, dass die Migration vollständig war.
- Validierung der Datenintegrität: Überprüft die Integrität der Daten nach der Migration, indem ihr sicherstellt, dass sie konsistent, korrekt und vollständig sind. Dies kann durch Vergleich mit Quelldaten, Validierung von Referenzintegrität und Durchführung von Datenintegritätstests erfolgen.
- Wiederherstellungstests: Simuliert mögliche Fehler- oder Unterbrechungsszenarien und überprüft die Fähigkeit des Systems, sich zu erholen und den Migrationsprozess fortzusetzen.
- Sicherheitstests: Stellt sicher, dass sensible Daten während des Migrationsprozesses angemessen geschützt sind und Sicherheitsrichtlinien eingehalten werden. Überprüft die Zugriffskontrollen und Verschlüsselungsmechanismen, um potenzielle Sicherheitslücken zu identifizieren.
- Benutzertests: Führt Tests durch, um sicherzustellen, dass die Benutzererfahrung nach der Migration nicht beeinträchtigt wird. Überprüfen Sie die Funktionalität von Anwendungen und Benutzeroberflächen, um sicherzustellen, dass sie wie erwartet funktionieren.
- Dokumentation: Dokumentiert sorgfältig alle Tests, Ergebnisse und beobachteten Probleme während des gesamten Migrationsprozesses. Dies dient als Referenz für zukünftige Migrationen und ermöglicht es, bewährte Praktiken zu etablieren.
Read the full article
0 notes
Text
Die Kunst der Eingabevalidierung: So schützt ihr eure Website vor schädlichen Benutzereingaben

Die Sicherheit eurer Website steht an erster Stelle, und eine der grundlegenden Maßnahmen zur Gewährleistung der Sicherheit besteht darin, die von Benutzern eingegebenen Daten sorgfältig zu validieren und zu säubern. In diesem Artikel werden wir uns eingehend mit der Eingabevalidierung befassen und wie ihr diese automatisieren könnt, um eure Website vor potenziell schädlichen Benutzereingaben zu schützen.
Was ist die Eingabevalidierung?
Eingabevalidierung, auch als Säubern von Eingaben bezeichnet, beinhaltet die Überprüfung von Daten, die von Benutzern bereitgestellt werden, auf Einhaltung vordefinierter Regeln. Dieser Prozess ist entscheidend, um sicherzustellen, dass nur Daten akzeptiert und gespeichert werden, die den festgelegten Kriterien entsprechen. Ein klassisches Beispiel hierfür sind E-Mail- und Passworteingaben, bei denen spezifische Regeln gelten, wie das Vorhandensein des "@"-Symbols in einer E-Mail-Adresse oder die Mindestanzahl von Zeichen für ein Passwort.
Automatisierung der Eingabevalidierung
Die Automatisierung der Eingabevalidierung ist ein wichtiger Schritt, um sicherzustellen, dass eure Website immer geschützt ist. Hier sind die Schritte zur Automatisierung:
- Definiert Validierungsregeln: Beginnt damit, klare Regeln für die Validierung eurer Benutzereingaben festzulegen. Überlegt euch, welche Bedingungen erfüllt sein müssen, damit eine Eingabe als gültig betrachtet wird.
- Erstellt Testfälle: Entwickelt Testfälle, die die Validierung Ihrer Eingaben überprüfen. Denkt dabei an verschiedene Szenarien, wie das Testen von ungültigen Zeichen, SQL-Injektionen oder überlangen Eingaben.
- Verwendet ein Test-Framework: Wählt ein geeignetes Test-Framework für eure Anwendung aus. Beliebte Optionen sind Selenium für Webanwendungen oder Appium für mobile Anwendungen.
- Integriert Tests in euren Workflow: Automatisierte Tests zur Validierung von Benutzereingaben sollten integraler Bestandteil eures Entwicklungs- und Bereitstellungsworkflows sein. Diese sollten bei jeder Code-Änderung automatisch ausgeführt werden.
- Überwacht die Ergebnisse: Stellt sicher, dass eure Tests die erwarteten Ergebnisse liefern. Wenn eine Validierung fehlschlägt, sollte die Benutzeroberfläche den Benutzer darüber informieren und ihn daran hindern, fortzufahren, bis die Eingabe korrigiert ist.
Beispiele für Testfälle
Beispiel 1: Registrierungsformular für eine Website
Annahmen:
- Die Website erfordert eine Registrierung mit Benutzername, E-Mail-Adresse und Passwort.
- Der Benutzername darf nur aus Buchstaben und Zahlen bestehen.
- Die E-Mail-Adresse muss ein "@"-Zeichen enthalten.
- Das Passwort muss mindestens 8 Zeichen lang sein.
Testfälle:
- Ein gültiger Benutzername, eine gültige E-Mail-Adresse und ein gültiges Passwort werden eingegeben. Der Benutzer sollte erfolgreich registriert werden.
- Ein Benutzername mit Sonderzeichen wird eingegeben. Das System sollte eine Fehlermeldung anzeigen.
- Eine ungültige E-Mail-Adresse (ohne "@"-Zeichen) wird eingegeben. Das System sollte eine Fehlermeldung anzeigen.
- Ein zu kurzes Passwort (weniger als 8 Zeichen) wird eingegeben. Das System sollte eine Fehlermeldung anzeigen.
Automatisierung
Dieses Beispiel zeigt, wie ihr mit Selenium Testfälle für die Registrierung auf einer Website durchführen könnt. Beachtet, dass ihr die Elemente (z.B., "username", "email", "password") und IDs entsprechend eurer Website anpassen müssen. Sie können auch weitere Testfälle hinzufügen, um die Abdeckung der Validierungsfunktionen zu erhöhen.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Starten des Webdrivers (z.B., Chrome)
driver = webdriver.Chrome()
# Testfall 1: Gültige Registrierung
driver.get("http://example.com/register")
username = driver.find_element_by_id("username")
email = driver.find_element_by_id("email")
password = driver.find_element_by_id("password")
username.send_keys("gültigerBenutzer123")
email.send_keys("gü[email protected]")
password.send_keys("sicheresPasswort123")
password.send_keys(Keys.RETURN) # Drückt die Enter-Taste
# Testfall 2: Ungültiger Benutzername mit Sonderzeichen
driver.get("http://example.com/register")
username = driver.find_element_by_id("username")
username.send_keys("ungültiger!Benutzer")
# Klicken auf die Registrieren-Schaltfläche
register_button = driver.find_element_by_id("register-button")
register_button.click()
# Überprüfen, ob eine Fehlermeldung angezeigt wird
error_message = driver.find_element_by_id("error-message")
assert "Ungültiger Benutzername" in error_message.text
# Testfall 3: Ungültige E-Mail-Adresse ohne "@"-Zeichen
driver.get("http://example.com/register")
email = driver.find_element_by_id("email")
email.send_keys("ungültigeemail.com")
# Klicken auf die Registrieren-Schaltfläche
register_button = driver.find_element_by_id("register-button")
register_button.click()
# Überprüfen, ob eine Fehlermeldung angezeigt wird
error_message = driver.find_element_by_id("error-message")
assert "Ungültige E-Mail-Adresse" in error_message.text
# Testfall 4: Zu kurzes Passwort
driver.get("http://example.com/register")
password = driver.find_element_by_id("password")
password.send_keys("kurz")
# Klicken auf die Registrieren-Schaltfläche
register_button = driver.find_element_by_id("register-button")
register_button.click()
# Überprüfen, ob eine Fehlermeldung angezeigt wird
error_message = driver.find_element_by_id("error-message")
assert "Passwort zu kurz" in error_message.text
# Schließen des Browsers
driver.quit()
Beispiel 2: Kommentarfunktion in einem Blog
Annahmen:
- Die Blog-Plattform ermöglicht es Benutzern, Kommentare zu Beiträgen zu hinterlassen.
- Kommentare sollten keine HTML- oder JavaScript-Tags enthalten, um Cross-Site Scripting (XSS) zu verhindern.
Testfälle:
- Ein gültiger Kommentar ohne HTML- oder JavaScript-Tags wird hinterlassen. Der Kommentar sollte veröffentlicht werden.
- Ein Kommentar mit HTML-Tags (z.B., Besuch diese Seite!) wird hinterlassen. Das System sollte die Tags entfernen und den Kommentar veröffentlichen.
- Ein Kommentar mit JavaScript-Code (z.B., ) wird hinterlassen. Das System sollte den Code entfernen und den Kommentar veröffentlichen.
- Ein Kommentar mit einer Kombination von HTML-Tags und JavaScript-Code wird hinterlassen. Das System sollte alle unerwünschten Elemente entfernen und den Kommentar veröffentlichen.
Automatisierung
Dieses Beispiel zeigt, wie ihr die Testfälle für die Kommentarfunktion eines Blogs in Python mit Selenium umsetzen könnt. Stellt sicher, dass Sie die Elemente (z.B., "comment-box", "submit-comment") und IDs entsprechend eurer Website anpassen. Dieses Beispiel demonstriert die Validierung und Säuberung von Benutzereingaben in einem realen Anwendungsszenario.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# Starten des Webdrivers (z.B., Chrome)
driver = webdriver.Chrome()
# Testfall 1: Gültiger Kommentar ohne HTML- oder JavaScript-Tags
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = "Dies ist ein gültiger Kommentar ohne Tags."
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob der Kommentar erfolgreich veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert comment_text in last_comment.text
# Testfall 2: Kommentar mit HTML-Tags
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = "Besuch diese Seite!"
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob HTML-Tags entfernt wurden und der Kommentar veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert "Besuch diese Seite!" in last_comment.text
assert "" not in last_comment.text
# Testfall 3: Kommentar mit JavaScript-Code
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = ""
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob JavaScript-Code entfernt wurde und der Kommentar veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert "Böser Code" not in last_comment.text
assert "" not in last_comment.text
# Testfall 4: Kommentar mit Kombination von HTML-Tags und JavaScript-Code
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = "Besuch diese Seite!"
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob alle unerwünschten Elemente entfernt wurden und der Kommentar veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert "Besuch diese Seite!" in last_comment.text
assert "" not in last_comment.text
assert "Böser Code" not in last_comment.text
assert "" not in last_comment.text
# Schließen des Browsers
driver.quit()
Read the full article
0 notes
Text
Die Kunst der Eingabevalidierung: So schützt ihr eure Website vor schädlichen Benutzereingaben

Die Sicherheit eurer Website steht an erster Stelle, und eine der grundlegenden Maßnahmen zur Gewährleistung der Sicherheit besteht darin, die von Benutzern eingegebenen Daten sorgfältig zu validieren und zu säubern. In diesem Artikel werden wir uns eingehend mit der Eingabevalidierung befassen und wie ihr diese automatisieren könnt, um eure Website vor potenziell schädlichen Benutzereingaben zu schützen.
Was ist die Eingabevalidierung?
Eingabevalidierung, auch als Säubern von Eingaben bezeichnet, beinhaltet die Überprüfung von Daten, die von Benutzern bereitgestellt werden, auf Einhaltung vordefinierter Regeln. Dieser Prozess ist entscheidend, um sicherzustellen, dass nur Daten akzeptiert und gespeichert werden, die den festgelegten Kriterien entsprechen. Ein klassisches Beispiel hierfür sind E-Mail- und Passworteingaben, bei denen spezifische Regeln gelten, wie das Vorhandensein des "@"-Symbols in einer E-Mail-Adresse oder die Mindestanzahl von Zeichen für ein Passwort.
Automatisierung der Eingabevalidierung
Die Automatisierung der Eingabevalidierung ist ein wichtiger Schritt, um sicherzustellen, dass eure Website immer geschützt ist. Hier sind die Schritte zur Automatisierung:
- Definiert Validierungsregeln: Beginnt damit, klare Regeln für die Validierung eurer Benutzereingaben festzulegen. Überlegt euch, welche Bedingungen erfüllt sein müssen, damit eine Eingabe als gültig betrachtet wird.
- Erstellt Testfälle: Entwickelt Testfälle, die die Validierung Ihrer Eingaben überprüfen. Denkt dabei an verschiedene Szenarien, wie das Testen von ungültigen Zeichen, SQL-Injektionen oder überlangen Eingaben.
- Verwendet ein Test-Framework: Wählt ein geeignetes Test-Framework für eure Anwendung aus. Beliebte Optionen sind Selenium für Webanwendungen oder Appium für mobile Anwendungen.
- Integriert Tests in euren Workflow: Automatisierte Tests zur Validierung von Benutzereingaben sollten integraler Bestandteil eures Entwicklungs- und Bereitstellungsworkflows sein. Diese sollten bei jeder Code-Änderung automatisch ausgeführt werden.
- Überwacht die Ergebnisse: Stellt sicher, dass eure Tests die erwarteten Ergebnisse liefern. Wenn eine Validierung fehlschlägt, sollte die Benutzeroberfläche den Benutzer darüber informieren und ihn daran hindern, fortzufahren, bis die Eingabe korrigiert ist.
Beispiele für Testfälle
Beispiel 1: Registrierungsformular für eine Website
Annahmen:
- Die Website erfordert eine Registrierung mit Benutzername, E-Mail-Adresse und Passwort.
- Der Benutzername darf nur aus Buchstaben und Zahlen bestehen.
- Die E-Mail-Adresse muss ein "@"-Zeichen enthalten.
- Das Passwort muss mindestens 8 Zeichen lang sein.
Testfälle:
- Ein gültiger Benutzername, eine gültige E-Mail-Adresse und ein gültiges Passwort werden eingegeben. Der Benutzer sollte erfolgreich registriert werden.
- Ein Benutzername mit Sonderzeichen wird eingegeben. Das System sollte eine Fehlermeldung anzeigen.
- Eine ungültige E-Mail-Adresse (ohne "@"-Zeichen) wird eingegeben. Das System sollte eine Fehlermeldung anzeigen.
- Ein zu kurzes Passwort (weniger als 8 Zeichen) wird eingegeben. Das System sollte eine Fehlermeldung anzeigen.
Automatisierung
Dieses Beispiel zeigt, wie ihr mit Selenium Testfälle für die Registrierung auf einer Website durchführen könnt. Beachtet, dass ihr die Elemente (z.B., "username", "email", "password") und IDs entsprechend eurer Website anpassen müssen. Sie können auch weitere Testfälle hinzufügen, um die Abdeckung der Validierungsfunktionen zu erhöhen.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Starten des Webdrivers (z.B., Chrome)
driver = webdriver.Chrome()
# Testfall 1: Gültige Registrierung
driver.get("http://example.com/register")
username = driver.find_element_by_id("username")
email = driver.find_element_by_id("email")
password = driver.find_element_by_id("password")
username.send_keys("gültigerBenutzer123")
email.send_keys("gü[email protected]")
password.send_keys("sicheresPasswort123")
password.send_keys(Keys.RETURN) # Drückt die Enter-Taste
# Testfall 2: Ungültiger Benutzername mit Sonderzeichen
driver.get("http://example.com/register")
username = driver.find_element_by_id("username")
username.send_keys("ungültiger!Benutzer")
# Klicken auf die Registrieren-Schaltfläche
register_button = driver.find_element_by_id("register-button")
register_button.click()
# Überprüfen, ob eine Fehlermeldung angezeigt wird
error_message = driver.find_element_by_id("error-message")
assert "Ungültiger Benutzername" in error_message.text
# Testfall 3: Ungültige E-Mail-Adresse ohne "@"-Zeichen
driver.get("http://example.com/register")
email = driver.find_element_by_id("email")
email.send_keys("ungültigeemail.com")
# Klicken auf die Registrieren-Schaltfläche
register_button = driver.find_element_by_id("register-button")
register_button.click()
# Überprüfen, ob eine Fehlermeldung angezeigt wird
error_message = driver.find_element_by_id("error-message")
assert "Ungültige E-Mail-Adresse" in error_message.text
# Testfall 4: Zu kurzes Passwort
driver.get("http://example.com/register")
password = driver.find_element_by_id("password")
password.send_keys("kurz")
# Klicken auf die Registrieren-Schaltfläche
register_button = driver.find_element_by_id("register-button")
register_button.click()
# Überprüfen, ob eine Fehlermeldung angezeigt wird
error_message = driver.find_element_by_id("error-message")
assert "Passwort zu kurz" in error_message.text
# Schließen des Browsers
driver.quit()
Beispiel 2: Kommentarfunktion in einem Blog
Annahmen:
- Die Blog-Plattform ermöglicht es Benutzern, Kommentare zu Beiträgen zu hinterlassen.
- Kommentare sollten keine HTML- oder JavaScript-Tags enthalten, um Cross-Site Scripting (XSS) zu verhindern.
Testfälle:
- Ein gültiger Kommentar ohne HTML- oder JavaScript-Tags wird hinterlassen. Der Kommentar sollte veröffentlicht werden.
- Ein Kommentar mit HTML-Tags (z.B., Besuch diese Seite!) wird hinterlassen. Das System sollte die Tags entfernen und den Kommentar veröffentlichen.
- Ein Kommentar mit JavaScript-Code (z.B., ) wird hinterlassen. Das System sollte den Code entfernen und den Kommentar veröffentlichen.
- Ein Kommentar mit einer Kombination von HTML-Tags und JavaScript-Code wird hinterlassen. Das System sollte alle unerwünschten Elemente entfernen und den Kommentar veröffentlichen.
Automatisierung
Dieses Beispiel zeigt, wie ihr die Testfälle für die Kommentarfunktion eines Blogs in Python mit Selenium umsetzen könnt. Stellt sicher, dass Sie die Elemente (z.B., "comment-box", "submit-comment") und IDs entsprechend eurer Website anpassen. Dieses Beispiel demonstriert die Validierung und Säuberung von Benutzereingaben in einem realen Anwendungsszenario.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# Starten des Webdrivers (z.B., Chrome)
driver = webdriver.Chrome()
# Testfall 1: Gültiger Kommentar ohne HTML- oder JavaScript-Tags
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = "Dies ist ein gültiger Kommentar ohne Tags."
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob der Kommentar erfolgreich veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert comment_text in last_comment.text
# Testfall 2: Kommentar mit HTML-Tags
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = "Besuch diese Seite!"
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob HTML-Tags entfernt wurden und der Kommentar veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert "Besuch diese Seite!" in last_comment.text
assert "" not in last_comment.text
# Testfall 3: Kommentar mit JavaScript-Code
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = ""
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob JavaScript-Code entfernt wurde und der Kommentar veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert "Böser Code" not in last_comment.text
assert "" not in last_comment.text
# Testfall 4: Kommentar mit Kombination von HTML-Tags und JavaScript-Code
driver.get("http://example-blog.com/post/123")
comment_box = driver.find_element_by_id("comment-box")
comment_text = "Besuch diese Seite!"
comment_box.send_keys(comment_text)
# Klicken auf die "Kommentar abschicken"-Schaltfläche
submit_button = driver.find_element_by_id("submit-comment")
submit_button.click()
# Überprüfen, ob alle unerwünschten Elemente entfernt wurden und der Kommentar veröffentlicht wurde
time.sleep(2) # Warten auf die Verarbeitung
comments = driver.find_elements_by_class_name("comment")
last_comment = comments
assert "Besuch diese Seite!" in last_comment.text
assert "" not in last_comment.text
assert "Böser Code" not in last_comment.text
assert "" not in last_comment.text
# Schließen des Browsers
driver.quit()
Read the full article
0 notes
Text
Wie kann man Testfälle für ein Spezifikationsdokument erstellen?

Das Testen einer funktionalen Design-Layout-Spezifikationsdatei kann recht überwältigend erscheinen, ist jedoch eine wesentliche Methode, um sicherzustellen, dass das weiterentwickelte Softwareprodukt die gewünschten Anforderungen erfüllt. Hier sind die Schritte, die ihr befolgen könnt, um Testinstanzen für eine Spezifikationsdatei zu erstellen:
- Stimmige Informationen: Vergewissert euch, dass ihr über ausgezeichnete Informationen über die Datei und ihre zahlreichen Abschnitte verfügt, einschließlich des Zwecks, der Funktionen und der Erfordernisse.
- Alle Anforderungen: Sucht nach den genauen Anforderungen in der Datei und erstellt eine Liste aller Funktionen und Merkmale, die geprüft werden sollen.
- Grundlage für Anforderungen: Legt auf der Grundlage der Anforderungen die Ziele der einzelnen Prüfungen fest und bestimmt die voraussichtlichen Endergebnisse.
- Aufteilung der Anforderungen: Teilt die Anforderungen in kleinere, realisierbare Teile auf, die einzeln geprüft werden können. Dies wird euch helfen, extra zentrierte und vollständige Prüffälle zu erstellen.
- Saubere Prüffälle: Schreibt die sogenannten Prüffälle sauber und prägnant auf, einschließlich der Prüfschritte, der voraussichtlichen Ergebnisse und aller Vorbedingungen, die erfüllt sein müssen.
- Prüfinstanzen überprüfen: Überprüft die Prüfinstanzen, um sicherzugehen, dass sie vollständig und genau sind und alle in der Datei enthaltenen Anforderungen erfüllen.
- Priorisierung: Basierend auf der Kritikalität der Anforderungen, priorisiert die Prüfinstanzen so, dass die wichtigsten zuerst geprüft werden.
- Ergebnisse archivieren: Führt die Prüfinstanzen durch und archiviert die Ergebnisse. Wenn irgendwelche Fehler oder Defekte gefunden werden, dokumentiert diese und arbeitet mit der Verbesserungsgruppe zusammen, um sie zu beheben.
- Überprüfen: Überprüft die Prüfinstanzen regelmäßig und ersetzet sie, wenn Anpassungen an der Spezifikationsdatei vorgenommen werden.
Beispiel eines Testfalls für ein Feature aus einem Spezifikationsdokument
Feature: Passwort-Zurücksetzung über E-Mail
Spezifikationsdetails:
- Der Benutzer sollten in der Lage sein, ihr Passwort über einen "Passwort vergessen?"-Link auf der Login-Seite zurückzusetzen.
- Nach Eingabe ihrer E-Mail sollte ein Link zum Zurücksetzen des Passworts versendet werden.
Test Case ID: TC_PW_RESET_001
Titel: Überprüfung der Passwort-Zurücksetzungsfunktion
Beschreibung: Dieser Testfall prüft, ob das Zurücksetzen des Passworts über die Funktion "Passwort vergessen?" mit einer gültigen E-Mail-Adresse funktioniert.
Voraussetzungen:
- Der Benutzer hat bereits ein Konto mit einer verifizierten E-Mail-Adresse.
- Der Mailserver ist betriebsbereit.
Testdaten:
- E-Mail-Adresse: [email protected]
- Neues Passwort: NeuesSicheresPasswort123!
Test Schritte:
- Gehe zur Login-Seite der Anwendung.
- Klicke auf den Link "Passwort vergessen?".
- Gib die E-Mail-Adresse [email protected] in das dafür vorgesehene Feld ein.
- Bestätige die Eingabe und sende die Anfrage ab.
- Überprüfe den Eingang der E-Mail zur Passwortrücksetzung.
- Klicke auf den Link im E-Mail zur Passwortrücksetzung.
- Gib das neue Passwort NeuesSicheresPasswort123! ein und bestätige es.
Erwartetes Ergebnis:
- Der Benutzer erhält innerhalb von 5 Minuten eine E-Mail zur Passwortrücksetzung.
- Der Link in der E-Mail führt zu einer Seite, auf der ein neues Passwort festgelegt werden kann.
- Nach Festlegung eines neuen Passworts wird der Benutzer auf die Login-Seite umgeleitet und kann sich mit dem neuen Passwort anmelden.
Post-Bedingungen:
- Das alte Passwort ist ungültig.
- Der Benutzer kann sich mit dem neuen Passwort einloggen.
Priorität: Hoch
Automatisierbar: Ja
Tester: Maria Musterfrau
Geplantes Testdatum: 21.11.2023
Tatsächliches Ergebnis: (wird nach der Testausführung ausgefüllt)
Status: (Offen/Geschlossen/In Bearbeitung - wird nach der Testausführung ausgefüllt)
Bemerkungen: (Hinzufügen von Anmerkungen oder Besonderheiten, die während des Tests aufgefallen sind)
Angehängte Dokumente: (Screenshots, Log-Dateien etc.)
Diese strukturierte Vorgehensweise sorgt dafür, dass die Testfälle gründlich geplant, durchgeführt und dokumentiert werden, was die Qualität der Software erheblich verbessern kann.
Wie man das automatisieren könnte?
Die Automatisierung von Testfällen kann mit Hilfe verschiedener Werkzeuge und Frameworks erfolgen, die sich auf automatisiertes Testen spezialisieren. Hier ist ein Überblick darüber, wie man den oben genannten Testfall für die Passwort-Zurücksetzung automatisieren könnte, unter Verwendung eines automatisierten Test-Frameworks wie Selenium für Webanwendungen:
Schritt 1: Wähle ein Testautomatisierungs-Framework
Selenium WebDriver ist eine beliebte Wahl für Webanwendungen. Es ermöglicht euch, in verschiedenen Programmiersprachen wie Java, C#, Python etc. zu programmieren.
Schritt 2: Einrichten der Testumgebung
- Selenium installieren: Installiert Selenium-Bibliotheken für die gewählte Programmiersprache.
- Browser-Treiber installieren: Ladet die entsprechenden Browser-Treiber herunter (z.B. ChromeDriver für Google Chrome).
- Test Runner wählen: Wählt ein Unit-Testing-Framework wie JUnit oder TestNG für Java oder pytest für Python.
Schritt 3: Erstelt ein Test-Skript
Unten ist ein einfaches Beispiel, wie ein Testskript in Python mit Selenium aussehen könnte:
from selenium import webdriver
import unittest
import time
class PasswordResetTest(unittest.TestCase):
def setUp(self):
# Initialisieren des WebDrivers
self.driver = webdriver.Chrome('/path/to/chromedriver')
self.driver.get("http://www.example.com/login")
def test_password_reset(self):
driver = self.driver
# Klicken auf "Passwort vergessen?"
driver.find_element_by_link_text("Passwort vergessen?").click()
# E-Mail-Adresse eingeben und Formular absenden
driver.find_element_by_id("email").send_keys("[email protected]")
driver.find_element_by_id("submit").click()
# Warten, um E-Mail-Überprüfung zu simulieren
time.sleep(5)
# Normalerweise würde hier der E-Mail-Zugang simuliert,
# um den Link zur Passwortrücksetzung zu überprüfen.
# Das neue Passwort setzen - diese URL würde von der echten E-Mail kommen
driver.get("http://www.example.com/reset-password/XYZ123")
driver.find_element_by_id("new_password").send_keys("NeuesSicheresPasswort123!")
driver.find_element_by_id("confirm_password").send_keys("NeuesSicheresPasswort123!")
driver.find_element_by_id("submit").click()
# Überprüfen, ob nach dem Zurücksetzen das Login möglich ist
assert "Login" in driver.title
def tearDown(self):
# Schließen des Browsers am Ende des Tests
self.driver.close()
if __name__ == "__main__":
unittest.main()
Schritt 4: Konfiguriert eure Testumgebung
Stellt sicher, dass alle benötigten Dienste laufen (z.B. E-Mail-Server, Anwendungsserver) und dass ihr Zugriff auf erforderliche Ressourcen wie Test-E-Mail-Konten habt.
Schritt 5: Testausführung und -überwachung
Führt die Tests aus und überwacht die Ergebnisse. Tools wie Jenkins oder GitLab CI/CD können verwendet werden, um Testskripte in einer CI/CD-Pipeline automatisch auszuführen.
Schritt 6: Fehlerbehebung und Wartung
Wenn Fehler auftreten, überprüft die Testskripte und passt sie an Änderungen der Webanwendung an.
Anmerkungen zur E-Mail-Verifikation
Das Automatisieren des Schritts zur E-Mail-Verifikation kann kompliziert sein, da es den Zugriff auf ein E-Mail-System erfordert. Hier könnt ihr:
- E-Mail-APIs verwenden, wie z.B. Gmail API, um das E-Mail-Konto zu überprüfen und den Link zur Passwortrücksetzung abzurufen.
- Dummy-E-Mail-Dienste verwenden, die für Testzwecke erstellt wurden, z.B. Mailinator, um eine öffentliche E-Mail-Inbox zu verwenden.
- Stubbing/Mocking verwenden, um die E-Mail-Sendefunktion zu simulieren, wenn ihr Zugriff auf den Code habt.
Die genauen Schritte hängen von den Spezifikationen der zu testenden Anwendung, den verwendeten Technologien und der Infrastruktur ab. Testautomatisierung ist ein fortlaufender Prozess und erfordert regelmäßige Pflege, um mit den Änderungen an der Anwendung Schritt zu halten.
Read the full article
#Automation#Manuell#Sandboxtesting.Sandbox.Testautomation#Spezifikationsdokument#Testautomation#Testfall
0 notes
Text
Kosten senken durch Abhärtung von automatisierten Testfällen ?

Bekanntlich ein sehr großes Problem, die Wartung von Testfällen gerade in der Testautomatisierung kostet Zeit, obwohl meistens die Änderung relativ klein ist. Vielfach liegt es daran das in den Testfällen harte Codierungen von Werten vorliegen, das verursacht dann zeitnah einen Ausfall solch eines Testfalls.
Und in den meisten Fällen müssen dann immer diese Testfälle bearbeitet werden, obwohl sich eventuell nur ein Pixel geändert hat. Das ist aber ein vollkommen falscher Ansatz, Ziel muss immer die Abhärtung eines Testfalls sein, nicht die elend lange Bearbeitung von Testfällen, was nachhaltig mehr Kosten verursacht als euch und euren Vorgesetzten, bzw. eurem Team lieb ist.
https://www.dev-crowd.com/2022/08/09/wie-mache-ich-automatisierte-testfaelle-effizienter/
Schon 2022 hatte (siehe oberhalb) ich mir dazu Gedanken gemacht, wie man automatisierte Testfälle effektiver machen könnte. Betrachtet man das zusätzlich mit der Möglichkeit eines Einsatzes einer KI (wäre effektiv darüber nachzudenken) so ergibt sich ein neuer Ansatz, über den ich hier mal berichten möchte.
Warum spare ich Kosten?
- Weniger False-Positive Ergebnisse: Stabilisierte Tests führen zu weniger Fehlalarmen. Falsch-positive Ergebnisse können Teams dazu veranlassen, unnötig Zeit in die Untersuchung von Problemen zu investieren, die tatsächlich nicht existieren.
- Zeitersparnis: Wenn Testfälle stabil sind und weniger oft fehlschlagen, verbringen Entwickler und QA-Teams weniger Zeit damit, die Ursachen von Testfehlern zu untersuchen.
- Höhere Zuverlässigkeit: Stabile Tests erhöhen das Vertrauen in die Testergebnisse. Dies kann dazu führen, dass Software schneller freigegeben wird, da weniger Zeit für manuelle Überprüfungen aufgewendet wird.
- Weniger Wartungsaufwand: Stabile automatisierte Testfälle benötigen weniger häufige Überarbeitungen. Das reduziert die Gesamtkosten für die Wartung des Testframeworks.
- Bessere Nutzung von Ressourcen: Durch die Reduzierung von Fehlalarmen und den damit verbundenen manuellen Überprüfungen können Ressourcen (z. B. Testumgebungen, Hardware) effizienter genutzt werden.
- Frühe Fehlererkennung: Gut abgegrenzte automatisierte Tests können Fehler früh im Entwicklungszyklus aufdecken, was oft kostengünstiger ist als das Beheben von Fehlern in späteren Phasen oder nach der Produktfreigabe.
- Konsistente Testausführung: Automatisierte Tests werden jedes Mal in der gleichen Weise ausgeführt, was eine größere Konsistenz im Vergleich zu manuellen Tests gewährleistet.
- Skalierbarkeit: Ihr könnt mehr Tests in kürzerer Zeit ausführen, insbesondere wenn ihr in der Lage seid, Tests parallel oder in verteilten Umgebungen auszuführen.
- Dokumentation: Automatisierte Testfälle können als eine Art von Dokumentation für das Verhalten des Systems dienen. Sie zeigen klar, was von der Software erwartet wird.
- Rückmeldung in Echtzeit: Bei der Integration von Testautomatisierung in eine CI/CD-Pipeline können Entwickler sofortiges Feedback über den Status ihres Codes erhalten.
- Höhere Testabdeckung: Automatisierte Tests können eine höhere Codeabdeckung erreichen, besonders wenn sie regelmäßig und umfassend eingesetzt werden.
- Häufigere Releases: Mit stabilen Tests können Organisationen sicherer und häufiger Software-Releases durchführen.
- Verbesserung der Teammoral: Wenn QA-Teams weniger Zeit mit wiederholtem manuellen Testen und der Untersuchung von Fehlalarmen verbringen, könnt ihr euch auf komplexere und wertvollere Aufgaben konzentrieren.
- Reduzierung menschlicher Fehler: Während des manuellen Testens können menschliche Fehler auftreten, etwa durch Übersehen oder inkonsistente Testausführung. Automatisierte Tests reduzieren dieses Risiko.
- Erhöhte Marktreife: Die Fähigkeit, Software schneller und mit höherer Qualität zu testen und zu releasen, kann den Markteintritt beschleunigen.
- Regressionsüberprüfung: Automatisierte Tests erleichtern die Durchführung von Regressionstests, um sicherzustellen, dass neue Änderungen keine vorhandenen Funktionen beeinträchtigen.
Wie setze ich das um?
- Gute Testdesign-Praktiken: Dies beinhaltet die Verwendung von Page-Object-Modellen, geeignete Testdatenverwaltung und das Isolieren von Tests voneinander.
- Wartezeiten und Synchronisierung: Bei UI-Tests sollten dynamische Wartezeiten verwendet werden, um sicherzustellen, dass Elemente geladen sind, bevor Aktionen ausgeführt werden.
- Umgang mit flüchtigen Tests: Tests, die intermittierend fehlschlagen, sollten identifiziert und behoben oder vorübergehend deaktiviert werden.
- Regelmäßige Überprüfung und Aktualisierung: Tests sollten regelmäßig überprüft werden, um sicherzustellen, dass sie noch relevant sind und korrekt funktionieren.
- Granularität der Tests: Schreibt kleine, zielgerichtete Tests, die nur eine bestimmte Funktionalität oder ein bestimmtes Feature testen. Dadurch wird die Fehlersuche erleichtert, da fehlschlagende Tests schnell auf eine spezifische Ursache hindeuten.
- Idempotenz: Stellt sicher, dass Tests idempotent sind, d.h., sie können mehrmals unter denselben Bedingungen ausgeführt werden und liefern jedes Mal dasselbe Ergebnis.
- Testumgebungen: Verwendet dedizierte Testumgebungen, die dem Produktionsumfeld so ähnlich wie möglich sind, um sicherzustellen, dass Tests in einer konsistenten und kontrollierten Umgebung laufen.
- Logging und Berichterstattung: Ein gutes Logging und Berichtssystem kann dabei helfen, Probleme schneller zu diagnostizieren. Insbesondere bei Fehlschlägen sollte detaillierte Information verfügbar sein.
- Code-Review für Tests: Genau wie Produktionscode sollten auch Testcodes regelmäßig überprüft werden. Dies stellt sicher, dass die Tests den Best Practices folgen und effektiv sind.
- Priorisierung von Tests: Nicht alle Tests sind gleich wichtig. Bestimmt, welche Tests kritisch sind und welche weniger kritisch sind. Dies hilft bei der Entscheidungsfindung, wenn ihr beispielsweise eine schnelle Regressionstest-Suite ausführen müsst.
- Cross-Browser- und Cross-Plattform-Tests: Wenn ihr Webanwendungen testet, stellt sicher, dass Ihre Tests in verschiedenen Browsern und Plattformen funktionieren. Tools wie Selenium Grid oder Dienste wie BrowserStack und Sauce Labs können dabei helfen.
- Datengetriebene Tests: Anstatt für jede Datenkombination einen separaten Test zu schreiben, könnt ihr einen Test schreiben, der durch eine Reihe von Datenpunkten geführt wird. Frameworks wie pytest bieten Unterstützung für datengetriebene Tests.
- Fehlerbehandlung: Berücksichtigt wie euer Testframework mit unerwarteten Fehlern, wie z.B. Timeouts, Abstürzen oder externen Abhängigkeiten, umgeht. Implementiert geeignete Fehlerbehandlungen, um solche Situationen zu adressieren.
- Integration mit CI/CD: Integriert eure Tests in Ihre Continuous Integration/Continuous Deployment-Pipeline, um sicherzustellen, dass Tests automatisch bei jedem Code-Check-in oder -Release ausgeführt werden.
- Monitoring und Alarmierung: Stellt sicher, dass ihr benachrichtigt werdet, wenn Tests fehlschlagen, insbesondere in CI/CD-Pipelines oder bei nächtlichen Testläufen.
- Testabdeckung: VerwendetTools zur Messung der Codeabdeckung, um sicherzustellen, dass Ihr Code angemessen durch Tests abgedeckt ist.
- Isolation von externen Diensten: Wenn euer Code externe Dienste oder APIs verwendet, sollten ihr diese Dienste während des Tests durch Mocks oder Stubs ersetzen, um sicherzustellen, dass eure Tests nicht von externen Faktoren beeinflusst werden.
- Modularisierung von Testcodes: Vermeidet redundante Codes, indem ihr gemeinsame Vorgehensweisen und Funktionen in wiederverwendbare Module oder Hilfsfunktionen auslagert.
- State Management: Stellt sicher, dass ihr den Zustand vor und nach Tests zurücksetzt, um Seiteneffekte zu vermeiden und die Unabhängigkeit der Tests zu gewährleisten.
- Testen von Rand- und Ausnahmefällen: Neben den Standard-Testfällen sollten ihr auch Rand- und Ausnahmefälle in Betracht ziehen, um die Robustheit eures Codes zu überprüfen.
- Performance- und Lasttests: Neben funktionalen Tests solltet ihr auch die Leistung und Skalierbarkeit eurer Anwendung unter verschiedenen Lastbedingungen testen.
- Testen von Sicherheitsaspekten: Führt Sicherheitstests durch, um potenzielle Schwachstellen oder Sicherheitslücken in eurer Anwendung zu identifizieren.
- Visual Testing: Für UI-basierte Anwendungen kann das visuelle Testen sicherstellen, dass die Benutzeroberfläche wie erwartet erscheint, insbesondere nach Änderungen oder Updates.
- Verwaltung von Testkonfigurationen: Stellt sicher, dass ihr leicht zwischen verschiedenen Testkonfigurationen (z.B. verschiedene Umgebungen, Datenbanken oder Endpunkte) wechseln könnt.
- Feedback-Schleifen: Nutzt das Feedback aus den Tests, um den Entwicklungsprozess kontinuierlich zu verbessern.
- Schulung und Wissenstransfer: Stellt sicher, dass das Team regelmäßig geschult wird und Best Practices in Bezug auf Testautomatisierung und zugehörige Werkzeuge kennt.
- Testtreiber und Teststubs: In einem TDD (Test Driven Development) Ansatz können Testtreiber (um fehlende Teile zu simulieren) und Teststubs (um komplexe Teile zu vereinfachen) verwendet werden, um den Testprozess zu erleichtern.
- Code- und Testmetriken: Verwendet Metriken, um den Zustand euer Tests und eures Codes im Laufe der Zeit zu überwachen.
Wie härte ich Selenium und Python basierte Testfälle ab?
Wartet auf Elemente:
- Verwendet explizite Wartezeiten, um auf das Erscheinen von Elementen zu warten, anstatt feste Zeitverzögerungen zu verwenden.
- Nutzt Wartebedingungen wie WebDriverWait in Kombination mit erwarteten Bedingungen (ExpectedConditions), um auf das gewünschte Element zu warten, bevor ihr damit interagieren.
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Beispiel für das Warten auf ein Element mit WebDriverWait
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "element_id"))
)
Fehlerbehandlung:
- Implementiert robuste Fehlerbehandlungen, um auf unerwartete Ausnahmen vorbereitet zu sein.
- Verwendet try-except-Blöcke, um Ausnahmen abzufangen und entsprechend zu reagieren.
try:
# Führen Sie hier Ihre Aktionen aus
except NoSuchElementException:
# Handle den Fall, wenn das Element nicht gefunden wird
except TimeoutException:
# Handle den Fall, wenn ein Timeout auftritt
Loggt eure Informationen:
- Fügt Protokollausgaben hinzu, um den Testverlauf und Fehlermeldungen besser nachverfolgen zu können.
- Verwendet Python-Logging oder andere geeignete Protokollierungsmechanismen.
import logging
# Konfigurieren Sie das Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Protokollieren von Informationen
logger.info("Aktion erfolgreich ausgeführt")
logger.error("Ein Fehler ist aufgetreten")
Verwendet den Headless-Modus:
- Führt Tests im Headless-Modus aus, um die Leistung zu verbessern und die Stabilität zu erhöhen, insbesondere auf Servern ohne grafische Benutzeroberfläche.
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
driver = webdriver.Chrome(options=options)
Testdatenmanagement:
- Trennt die Testdaten von Testfällen, um die Wartbarkeit zu verbessern.
- Verwendet externe Dateien oder Datenbanken, um Testdaten zu speichern und auf sie zuzugreifen
Parallelisierung:
- Nutzt Tools wie Selenium Grid oder Cloud-basierte Testplattformen, um Tests parallel auf verschiedenen Browsern und Plattformen auszuführen, was die Ausführung beschleunigen und die Ausfallsicherheit erhöhen kann.
Überwachung und Berichterstattung:
- Überwacht eure Testausführungen und erstellt detaillierte Berichte über den Status und die Ergebnisse Ieurer Tests.
- Verwendet Test-Frameworks und Berichterstattungswerkzeuge wie PyTest und Allure Report.
Read the full article
0 notes
Text
Last- & Performance-Testing für einen Chatbot

Grundsätzlich verhält sich ein Last- und Performancetest eines Chatbots nicht anders als eben andere Last- und Performancetest auch. Für einen einfachen weg habe ich ein Python Skript geschrieben, welches auf einfacher weise einen gezielten Test auf ein Chatbot System durcführt. Aktuell wird hier nur eine GET-Anfrage ausgeführt, aber weiter unterhalb findet ihr auch eine geupdatete Version, das neben dem GET-Befehl auch den POST-Befehl ausführt. Anpassungen sind in Arbeit und ich würde mich freuen, wenn ihr dazu Vorschläge habt.
Wie nutzte ich das Skript?
Konfiguration:
- Ändert die url Variable, um die URL eures Chatbots anzugeben.
- Passt die num_users Variable an, um die Anzahl der simulierten Benutzer festzulegen.
- Passt die num_threads Variable an, um die Anzahl der Threads festzulegen (obwohl diese Variable im aktuellen Skript nicht verwendet wird).
- Passt die http_method Variable an, um die HTTP-Methode festzulegen (obwohl das Skript derzeit nur GET-Anfragen unterstützt).
- Passt die think_time Variable an, um die Denkzeit zwischen den Anfragen festzulegen.
Ausführung:
- Führt das Skript aus. Es wird die angegebene Anzahl von Benutzern simulieren, die Anfragen an den Chatbot senden.
- Die Fortschrittsleiste zeigt den Fortschritt des Tests an.
- Nach Abschluss des Tests werden statistische Daten wie Durchschnitt, Median, Varianz, Standardabweichung und die 95. und 99. Perzentile der Antwortzeiten angezeigt.
- Ein Histogramm der Antwortzeiten wird ebenfalls angezeigt.
Analyse:
- Überprüft die statistischen Daten, um zu verstehen, wie euer Chatbot unter Last reagiert.
- Das Histogramm gibt euch eine visuelle Vorstellung von der Verteilung der Antwortzeiten.
Fehlerbehandlung:
- Das Skript protokolliert Fehler in einer Datei namens logfile.log im Verzeichnis Load_and_Performance_Tooling/Logging/. Überprüft diese Datei, wenn während des Tests Fehler auftreten.
import aiohttp
import asyncio
import time
import statistics
import logging
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
from tqdm import tqdm
# Author: Frank Rentmeister
# URL: https:meinchatbot.com
# Date: 2023-08-23
# Version: 2.0
# Description: Load and Performance Tooling (Asynchronous with Progressbar)
# Set the log level to DEBUG to log all messages
LOG_FORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s - %(threadName)s - %(thread)d - %(lineno)d - %(funcName)s'
logging.basicConfig(level=logging.DEBUG, format=LOG_FORMAT, filename='Load_and_Performance_Tooling/Logging/logfile.log', filemode='w')
logger = logging.getLogger()
# Configuration Parameters
url = "https://meinchatbot.com"
num_users = 200
num_threads = 10
http_method = "GET"
think_time = 2
# Define a function to calculate statistical data
def calculate_statistics(response_times):
mean_response_time = statistics.mean(response_times)
median_response_time = statistics.median(response_times)
variance_response_time = statistics.variance(response_times)
stddev_response_time = statistics.stdev(response_times)
percentile_95 = np.percentile(response_times, 95)
percentile_99 = np.percentile(response_times, 99)
return {
'mean': mean_response_time,
'median': median_response_time,
'variance': variance_response_time,
'stddev': stddev_response_time,
'95_percentile': percentile_95,
'99_percentile': percentile_99
}
# Define a function to simulate a user making a request
async def simulate_user_request(session, response_times, pbar):
try:
start_timestamp = datetime.now()
async with session.get(url) as response: # Assume only GET requests for simplicity
response_time = datetime.now() - start_timestamp
response.raise_for_status()
response_times.append(response_time.total_seconds())
pbar.update(1) # Update the progress bar
await asyncio.sleep(think_time) # Implementing the think time
except Exception as e:
logger.error(f"An unexpected error occurred: {e}")
pbar.update(1) # Update the progress bar even if there's an error
# Define a function to run the load test asynchronously
async def run_load_test():
start_timestamp = datetime.now()
response_times =
with tqdm(total=num_users, desc="Progress", position=0, bar_format="{l_bar}{bar:20}{r_bar}{bar:-10b}", colour="green") as pbar:
async with aiohttp.ClientSession() as session:
tasks =
await asyncio.gather(*tasks)
num_successful_requests = len(response_times)
num_failed_requests = num_users - num_successful_requests
print(f"Number of successful requests: {num_successful_requests}")
print(f"Number of failed requests: {num_failed_requests}")
stats = calculate_statistics(response_times)
print(f"Mean Response Time: {stats:.3f} seconds")
print(f"Median Response Time: {stats:.3f} seconds")
print(f"Variance of Response Times: {stats:.3f}")
print(f"Standard Deviation of Response Times: {stats:.3f}")
print(f"95th Percentile of Response Times: {stats:.3f} seconds")
print(f"99th Percentile of Response Times: {stats:.3f} seconds")
# Create a histogram of response times
plt.figure(figsize=(8, 6))
plt.hist(response_times, bins=20, color='skyblue', edgecolor='black')
plt.title('Response Time Distribution')
plt.xlabel('Response Time (seconds)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
# Run the load test asynchronously
asyncio.run(run_load_test())
Read the full article
0 notes
Text
Chatbots auf Schwachstellen Testen mit Owasp Zap

Aktuell werden sehr fleißig in vielen Projekten Chatbots implementiert oder gleich eine API-Anbindung an ChatAI genutzt. Aber wie so oft in den letzten 30 Jahren kommt meistens der Test viel zu kurz, und eben auch der Test auf Schwachstellen. Versuchen wir heute mal eine Möglichkeit mit OWASP Zap aufzuzeigen.
Es gibt gerade beim Test von Chatbots muss man einiges beachten:
-
Interaktionstyp: Bei Chatbots handelt es sich um interaktive Systeme, die auf Benutzereingaben reagieren. Im Gegensatz zu herkömmlicher Software, bei der Tests häufig auf festen Eingabe-Ausgabe-Mustern basieren, müssen Chatbot-Tests eine Vielzahl von Benutzereingaben und -interaktionen berücksichtigen.
-
Unvorhersehbarkeit der Eingabe: Benutzer können Fragen auf viele verschiedene Arten stellen. Daher muss ein Chatbot-Test verschiedene Formulierungen, Synonyme und Dialekte berücksichtigen.
-
Kontextabhängigkeit: Chatbots müssen den Kontext einer Konversation verstehen und darauf reagieren können. Das Testen dieser Fähigkeit erfordert spezielle Szenarien und Testfälle.
-
NLP (Natural Language Processing): Chatbots verwenden oft NLP-Techniken, um Benutzereingaben zu verstehen. Das Testen der Effizienz und Genauigkeit dieser Techniken ist entscheidend.
-
Intent-Erkennung: Es ist wichtig zu testen, wie gut der Chatbot die Absicht des Benutzers erkennt und darauf reagiert.
-
Konversationsfluss: Im Gegensatz zu herkömmlicher Software, bei der der Datenfluss oft linear ist, können Chatbot-Konversationen in viele Richtungen gehen. Das Testen des Konversationsflusses und der Übergänge zwischen verschiedenen Themen ist daher wichtig.
-
Emotionale Intelligenz: Einige fortschrittliche Chatbots können die Emotionen des Benutzers erkennen und darauf reagieren. Das Testen dieser Fähigkeit kann für solche Bots relevant sein.
-
Integrationstests: Chatbots können in verschiedene Plattformen und Systeme integriert werden (z.B. Websites, Messaging-Apps, CRM-Systeme). Das Testen dieser Integrationen ist entscheidend.
-
Performance-Tests: Wie bei jeder Software ist es wichtig zu testen, wie der Chatbot unter Last reagiert, insbesondere wenn viele Benutzer gleichzeitig interagieren.
-
Sicherheitstests: Da Benutzer oft persönliche Informationen in Chatbots eingeben, ist es wichtig, die Sicherheit und den Datenschutz des Bots zu testen.
https://www.youtube.com/watch?v=mXh6hVKK84s&pp=ygUPdGVzdGluZyBjaGF0Ym90
Wichtig anzumerken ihr benötigt eine Installation von OWASP ZAP eine IDE wie Visual Studio Code und Python!
Injection-Angriffe
Bei Injection-Angriffen wird versucht, schädlichen Code oder Befehle in eine Anfrage einzufügen, die dann vom System interpretiert und ausgeführt wird. SQL-Injection ist eine der bekanntesten Formen von Injection-Angriffen, bei denen ein Angreifer SQL-Befehle in eine Anfrage einfügt, die dann von der Datenbank ausgeführt werden.
In dem gegebenen Beispiel für Injection-Angriffe wird ein Payload verwendet, der versucht, eine SQL-Injection durchzuführen, indem er einen Befehl einschließt, der eine Tabelle löscht (DROP TABLE users). Die Idee ist, zu testen, ob der Chatbot die Benutzereingabe richtig bereinigt und solche Angriffe verhindert.
Die folgende Python-Codeblock startet einen Scan mit OWASP ZAP, um einen Injection-Angriff auf einen spezifischen Endpunkt zu testen, und zeigt eine Fortschrittsleiste, um den Fortschritt des Scans anzuzeigen.
from zapv2 import ZAPv2
from tqdm import tqdm
import time
zap = ZAPv2(proxies={'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'})
# Ziel-URL
target_url = 'https://example.com/chatbot/api'
# Spider starten
zap.spider.scan(target_url)
# Angriffsanfrage
injection_payload = {"userInput": "'; DROP TABLE users; --"}
# Aktiven Scan mit Injection-Angriff starten
scan_id = zap.ascan.scan(target_url, postdata=str(injection_payload))
# Fortschrittsanzeige
for progress in tqdm(range(0, 100), desc="Scanning for Injection vulnerabilities"):
while int(zap.ascan.status(scan_id)) < progress:
time.sleep(1)
Bitte beachtet , dass das obige Beispiel auf der Annahme basiert, dass die Benutzereingabe als JSON im Request-Body gesendet wird. Die genaue Implementierung kann je nach den spezifischen Details eures Chatbots variieren.
Unsichere API-Endpunkte
Unsichere API-Endpunkte sind solche, die nicht ordnungsgemäß gesichert sind und möglicherweise für unautorisierte Zugriffe anfällig sind. Ein Angreifer könnte versuchen, solche Endpunkte zu nutzen, um auf sensible Informationen zuzugreifen oder unautorisierte Aktionen durchzuführen.
Hier ist ein Beispiel für ein Skript, das OWASP ZAP und die tqdm-Bibliothek verwendet, um einen Sicherheitsscan auf einem spezifischen API-Endpunkt durchzuführen, und eine Fortschrittsleiste anzeigt, um den Fortschritt des Scans zu verfolgen:
from zapv2 import ZAPv2
from tqdm import tqdm
import time
zap = ZAPv2(proxies={'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'})
# Ziel-URL, das den unsicheren API-Endpunkt repräsentiert
target_url = 'https://example.com/chatbot/api/secureEndpoint'
# Spider starten, um die Anwendung zu erforschen
zap.spider.scan(target_url)
# Aktiven Scan starten, um den Endpunkt auf bekannte Schwachstellen zu prüfen
scan_id = zap.ascan.scan(target_url)
# Fortschrittsanzeige
for progress in tqdm(range(0, 100), desc="Scanning for insecure API endpoints"):
while int(zap.ascan.status(scan_id)) < progress:
time.sleep(1)
Dieser Code startet einen aktiven Scan auf den angegebenen Endpunkt und verfolgt den Fortschritt mit einer Fortschrittsleiste. Der Scan könnte Schwachstellen wie fehlende oder schwache Authentifizierung, unsachgemäße Berechtigungsprüfungen und andere Sicherheitslücken in der API offenlegen.
Die Ergebnisse des Scans könnten dann analysiert werden, um spezifische Schwachstellen zu identifizieren und Empfehlungen für deren Behebung zu geben.
Cross-Site-Scripting (XSS)
Cross-Site-Scripting (XSS) ist eine Art von Sicherheitslücke, bei der ein Angreifer in der Lage ist, schädlichen Code in eine Webanwendung einzuschleusen, der dann im Browser eines Opfers ausgeführt wird. Wenn ein Chatbot in einer Webanwendung eingebettet ist und die Benutzereingabe nicht ordnungsgemäß bereinigt, könnte er anfällig für XSS-Angriffe sein.
Hier ist ein Beispiel für ein Skript, das OWASP ZAP verwendet, um einen XSS-Angriff auf einen bestimmten Endpunkt zu testen, und eine Fortschrittsleiste anzeigt, um den Fortschritt des Scans zu verfolgen:
from zapv2 import ZAPv2
from tqdm import tqdm
import time
zap = ZAPv2(proxies={'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'})
# Ziel-URL
target_url = 'https://example.com/chatbot/api'
# Spider starten
zap.spider.scan(target_url)
# XSS-Angriffsanfrage
xss_payload = {"userInput": ""}
# Aktiven Scan mit XSS-Angriff starten
scan_id = zap.ascan.scan(target_url, postdata=str(xss_payload))
# Fortschrittsanzeige
for progress in tqdm(range(0, 100), desc="Scanning for Cross-Site Scripting vulnerabilities"):
while int(zap.ascan.status(scan_id)) < progress:
time.sleep(1)
Dieser Code testet, ob der angegebene Endpunkt anfällig für XSS ist, indem er versucht, schädlichen JavaScript-Code in die Benutzereingabe einzufügen. Der Fortschritt des Scans wird in einer Fortschrittsleiste angezeigt.
Wenn der Scan eine XSS-Schwachstelle findet, sollten Sie die Ergebnisse analysieren und die notwendigen Korrekturen vornehmen, um die Benutzereingabe ordnungsgemäß zu bereinigen und zu validieren, damit solche Angriffe verhindert werden.
Data Leakage
Data Leakage bezieht sich auf das ungewollte Austreten von sensiblen Informationen aus einer Anwendung, was ein ernsthaftes Sicherheitsproblem darstellen kann. Ein Data-Leakage-Test versucht, Schwachstellen in der Anwendung zu identifizieren, die es ermöglichen könnten, auf vertrauliche Informationen zuzugreifen.
Im Kontext eines Chatbots könnte dies bedeuten, dass der Bot versehentlich vertrauliche Informationen wie Benutzerdaten, Kreditkarteninformationen oder interne Systemdetails preisgibt.
Das folgende Python-Skript verwendet OWASP ZAP, um einen spezifischen API-Endpunkt auf mögliche Data Leakage zu überprüfen, und zeigt eine Fortschrittsleiste, um den Fortschritt des Scans zu verfolgen:
from zapv2 import ZAPv2
from tqdm import tqdm
import time
zap = ZAPv2(proxies={'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'})
# Ziel-URL, die den Endpunkt repräsentiert
target_url = 'https://example.com/chatbot/api'
# Spider starten, um die Anwendung zu erkunden
zap.spider.scan(target_url)
# Aktiven Scan starten, um den Endpunkt auf bekannte Schwachstellen zu prüfen
scan_id = zap.ascan.scan(target_url)
# Fortschrittsanzeige
for progress in tqdm(range(0, 100), desc="Scanning for Data Leakage vulnerabilities"):
while int(zap.ascan.status(scan_id)) < progress:
time.sleep(1)
Wenn der Scan abgeschlossen ist, solltet ihr die Ergebnisse überprüfen, um festzustellen, ob es Anzeichen für das Austreten von sensiblen Daten gibt. Es kann nützlich sein, die Anfragen und Antworten genau zu überprüfen und zu verstehen, wie die Daten innerhalb der Anwendung behandelt werden. Eventuell notwendige Sicherheitsverbesserungen könnten Dinge wie die Verstärkung der Authentifizierung, die Anwendung von Verschlüsselung und die ordnungsgemäße Maskierung von sensiblen Daten umfassen.
Authentifizierungs- und Autorisierungstests
Authentifizierungs- und Autorisierungstests sind entscheidend, um sicherzustellen, dass nur berechtigte Benutzer Zugang zu bestimmten Ressourcen oder Funktionen haben. Authentifizierung bezieht sich auf den Prozess, die Identität eines Benutzers zu verifizieren, während Autorisierung sicherstellt, dass ein authentifizierter Benutzer nur auf die Ressourcen zugreifen kann, die ihm zugewiesen sind.
Mit OWASP ZAP könnt diese Tests durchführen. Hier ist ein Beispiel:
from zapv2 import ZAPv2
from tqdm import tqdm
import time
# ZAP-Proxy-Verbindung
zap = ZAPv2(proxies={'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080'})
# Ziel-URL
target_url = 'https://example.com/'
# Spider starten, um die Anwendung zu erkunden
zap.spider.scan(target_url)
# Authentifizierungskonfiguration (abhängig von der Authentifizierungsmethode)
# Zum Beispiel für Formularbasierte Authentifizierung
zap.authentication.set_authentication_method(
contextid='1',
authmethodname='formBasedAuthentication',
authmethodconfigparams='loginUrl=https://example.com/login&loginRequestData=usernameusernamepasswordpassword')
# Benutzer hinzufügen
zap.users.new_user(contextid='1', name='testuser')
zap.users.set_authentication_credentials(contextid='1', userid='0', authcredentialsconfigparams='username=testuser&password=secret')
# Aktiven Scan starten
scan_id = zap.ascan.scan(target_url)
# Fortschrittsanzeige
for progress in tqdm(range(0, 100), desc="Authentication and Authorization Testing"):
while int(zap.ascan.status(scan_id)) < progress:
time.sleep(1)
Security Misconfigurations
Sicherheitskonfigurationsfehler entstehen durch unsachgemäße Konfiguration von Servern, Datenbanken oder Anwendungen. Diese könnten dazu führen, dass sensible Informationen öffentlich zugänglich sind oder unerwünschte Aktionen ermöglichen.
Sicherheitskonfigurationsfehler sind eine häufige Schwachstelle in vielen Webanwendungen. Hier sind einige Beispiele und Erklärungen für verschiedene Arten von Sicherheitskonfigurationsfehlern:
- Öffentlicher Zugriff auf Verzeichnisse und Dateien: Ein häufiger Fehler besteht darin, dass sensible Dateien oder Verzeichnisse (z. B. Konfigurationsdateien, Log-Dateien, Backup-Dateien) für jeden im Internet zugänglich sind. Das kann es Angreifern ermöglichen, wertvolle Informationen über die Anwendung oder den Server zu sammeln.
- Standard-Passwörter und Standard-Anmeldedaten: Wenn Standard-Passwörter oder Anmeldedaten nicht geändert werden, könnten Angreifer leicht auf Konten zugreifen oder die Anwendung übernehmen. Administratorkonten mit Standard-Anmeldedaten sind ein besonders kritisches Problem.
- Unzureichende Berechtigungen: Fehlerhafte Berechtigungseinstellungen können dazu führen, dass Benutzer auf Funktionen oder Ressourcen zugreifen können, auf die sie keinen Zugriff haben sollten. Das kann zu Datenlecks oder unerwünschten Aktionen führen.
- Serverkonfiguration: Fehlkonfigurationen von Webservern, Datenbanken oder Anwendungsservern könnten Sicherheitslücken verursachen. Dies könnte Angreifern erlauben, Informationen zu sammeln, Schadcode einzuführen oder den Server zu beeinträchtigen.
- Fehlende oder unsichere Transportverschlüsselung: Wenn eine Anwendung keine ausreichende Transportverschlüsselung (z. B. HTTPS) verwendet oder unsichere Verschlüsselungsprotokolle einsetzt, könnten Angreifer den Datenverkehr abhören oder manipulieren.
- Offene Debugging- oder Entwicklungs-Endpunkte: Wenn Entwicklungs- oder Debugging-Endpunkte in der Produktionsumgebung verbleiben, könnten Angreifer möglicherweise sensible Informationen erhalten oder Angriffe durchführen.
Um Sicherheitskonfigurationsfehler zu vermeiden, solltet ihr folgende Maßnahmen ergreifen:
- Verwende sichere Standardeinstellungen für Server und Anwendungen.
- Entferne oder sichere Dateien und Verzeichnisse, die nicht öffentlich zugänglich sein sollten.
- Ändere Standard-Anmeldedaten und verwende starke Passwörter.
- Vergebe Berechtigungen basierend auf dem Prinzip des geringsten Privilegs.
- Aktualisiere regelmäßig Software und Patches, um bekannte Schwachstellen zu beheben.
- Implementiere Transportverschlüsselung für die Kommunikation zwischen Client und Server.
- Schalte Debugging- und Entwicklungs-Endpunkte in der Produktionsumgebung ab.
Ihr könnt dieses Skript nutzen:
from zapv2 import ZAPv2
# Setze die ZAP-Adresse (standardmäßig läuft ZAP auf localhost:8080)
zap_proxy = 'http://localhost:8080'
# Erstelle eine ZAP-Instanz
zap = ZAPv2(proxies={'http': zap_proxy, 'https': zap_proxy})
# Warte, bis ZAP einsatzbereit ist
while not zap.core.is_daemon_running():
time.sleep(2)
# Gib die ZAP-Version aus
print("ZAP Version: {}".format(zap.core.version))
# Setze die Ziel-URL, die du testen möchtest
target_url = 'http://your-chatbot-url-here'
# Starte den Spider, um alle erreichbaren Seiten zu finden
print("Starte Spider...")
scan_id = zap.spider.scan(target_url)
while int(zap.spider.status(scan_id)) < 100:
print("Spider Fortschritt: {}%".format(zap.spider.status(scan_id)))
time.sleep(2)
print("Spider abgeschlossen!")
# Starte den aktiven Scan
print("Starte aktiven Scan...")
scan_id = zap.ascan.scan(target_url)
while int(zap.ascan.status(scan_id)) < 100:
print("Aktiver Scan Fortschritt: {}%".format(zap.ascan.status(scan_id)))
time.sleep(2)
print("Aktiver Scan abgeschlossen!")
# Erhalte und gib die gefundenen Schwachstellen aus
alerts = zap.core.alerts(baseurl=target_url)
print("Gefundene Schwachstellen:")
for alert in alerts:
print("Name: {}, Risiko: {}, Beschreibung: {}".format(alert.get('name'), alert.get('risk'), alert.get('description')))
Broken Authentication and Session Management
Schwachstellen in der Authentifizierung und Sitzungsverwaltung könnten es einem Angreifer ermöglichen, sich als anderer Benutzer auszugeben, sich ohne gültige Anmeldeinformationen anzumelden oder Sitzungen von anderen Benutzern zu übernehmen.
"Broken Authentication and Session Management" ist eine der häufigsten und kritischsten Sicherheitslücken in Webanwendungen. Es bezieht sich auf Mängel in den Authentifizierungs- und Sitzungsverwaltungsprozessen einer Anwendung, die es Angreifern ermöglichen können, die Identität eines Benutzers zu übernehmen.
from zapv2 import ZAPv2
# Setze die ZAP-Adresse (standardmäßig läuft ZAP auf localhost:8080)
zap_proxy = 'http://localhost:8080'
# Erstelle eine ZAP-Instanz
zap = ZAPv2(proxies={'http': zap_proxy, 'https': zap_proxy})
# Warte, bis ZAP einsatzbereit ist
while not zap.core.is_daemon_running():
time.sleep(2)
# Gib die ZAP-Version aus
print("ZAP Version: {}".format(zap.core.version))
# Setze die Ziel-URL, die du testen möchtest
target_url = 'http://your-chatbot-url-here'
# Starte den aktiven Scan auf Schwachstellen
print("Starte aktiven Scan auf Authentifizierung und Sitzungsverwaltung...")
scan_id = zap.ascan.scan(target_url, scanpolicyname='autobaseline')
while int(zap.ascan.status(scan_id)) < 100:
print("Aktiver Scan Fortschritt: {}%".format(zap.ascan.status(scan_id)))
time.sleep(2)
print("Aktiver Scan auf Authentifizierung und Sitzungsverwaltung abgeschlossen!")
# Erhalte und gib die gefundenen Schwachstellen aus
alerts = zap.core.alerts(baseurl=target_url)
print("Gefundene Schwachstellen in Authentifizierung und Sitzungsverwaltung:")
for alert in alerts:
print("Name: {}, Risiko: {}, Beschreibung: {}".format(alert.get('name'), alert.get('risk'), alert.get('description')))
Das bereitgestellte Skript verwendet die OWASP ZAP API, um eine Sicherheitsüberprüfung auf einer bestimmten Website durchzuführen, wobei der Schwerpunkt auf Schwachstellen in der Authentifizierung und Sitzungsverwaltung liegt. Hier ist eine Erklärung des Skripts in fließendem Text:
Das Skript beginnt mit dem Importieren der ZAPv2-Bibliothek, die die notwendigen Funktionen und Methoden zur Interaktion mit der ZAP API bereitstellt. Anschließend wird die Proxy-Adresse von ZAP festgelegt, die standardmäßig auf localhost:8080 läuft.
Mit dieser Proxy-Adresse wird eine neue ZAP-Instanz erstellt. Das Skript überprüft dann, ob ZAP ordnungsgemäß läuft und wartet, falls notwendig, bis ZAP vollständig gestartet ist.
Nachdem sichergestellt wurde, dass ZAP läuft, gibt das Skript die aktuelle Version von ZAP aus.
Read the full article
0 notes
Text
Wie man Sicherheitstests für AngularJS mit Hilfe von OWASP ZAP durchführt

Schon 2018 hatte ich mich sehr umfassend mit dem Thema Voyager 1 und Voyager 2 beschäftigt. Dabei ging es um eine „fixe“ Idee, dass man das Board System welches Fortran beruht auf Python umswitcht. Ich habe in diesem Beitrag von 2018 dargelegt, wie die einzelnen Komponenten aufgebaut sind, wie man eventuell hier Python zum Einsatz bringen könnte. Aber nachhaltig auch festgestellt, dass ein Umstieg auf Python eventuell sogar schädlicher wäre.
https://www.dev-crowd.com/2018/12/22/retro-engineering-am-beispiel-voyager-1-und-voyager-2-mission/
Betrachtet man die Meldung bezüglich des „falschen Befehls“ der an Voyager 2 versendet wurde, so hätte man das in einer entsprechenden Emulation eigentlich feststellen müssen, dass eben dieser Befehl klar falsch ist. Bisher bin ich immer davon ausgegangen, dass so etwas in einer Emulation auf einem Environment stattfindet. Denn wie bei allen uns bekannten Sprachen, die man entsprechend einsetzt, gibt es entsprechende Testframeworks, die entsprechende Emulationen ausführen.
Die Antenne von »Voyager 2« zeigt nicht mehr exakt zur Erde, der Kontakt ist dadurch unterbrochen. Der Grund: ein falscher Befehl. Doch im Oktober könnte die Kommunikation wieder aufgenommen werden.
Quelle: https://www.spiegel.de/wissenschaft/nasa-verliert-kontakt-zu-sonde-voyager-2-wegen-eines-falschen-befehls-a-2c41883b-2e28-4413-a40b-075c59c10ce1
Hier eine weitere Meldung:
Der Kontakt zu der Sonde war am 21. Juli 2023 abgebrochen, nachdem "eine Serie geplanter Befehle" an sie gesendet worden war. Die hatten dazu geführt, dass sich die Antenne um 2 Grad von der Erde wegdrehte, weshalb kein Kontakt mehr möglich war.
Quelle: https://www.golem.de/news/raumfahrt-nasa-empfaengt-signal-von-voyager-2-2308-176370.html
Fortran spielte in den frühen Jahren der Raumfahrt und insbesondere bei der Entwicklung von Raumsonden eine wichtige Rolle. Das Voyager-Programm wurde in den 1970er Jahren gestartet, als Fortran immer noch eine der vorherrschenden Programmiersprachen für wissenschaftliche und technische Anwendungen war. Und Fortan wird bis heute gerade auch im wissenschaftlichen Umfeld immer noch genutzt!
Welche Fortran Versionen gibt es?
- Fortran I (1957): Die erste Version von Fortran wurde 1957 von IBM entwickelt. Sie wurde für den IBM 704 Computer entwickelt und war die erste höhere Programmiersprache überhaupt. Fortran I unterstützte die grundlegenden Konzepte der Programmierung, aber es gab noch keine Unterprogramme (keine Unterstützung für Unterprogramme wie Funktionen oder Subroutinen).
- Fortran II (1958): Fortran II wurde 1958 veröffentlicht und fügte einige neue Funktionen hinzu, darunter Unterprogramme und die Möglichkeit, Unterprogramme in anderen Unterprogrammen aufzurufen. Es war eine verbesserte Version von Fortran I.
- Fortran IV (1962): Fortran IV war eine weiter verbesserte Version von Fortran und wurde 1962 veröffentlicht. Es führte neue Funktionen wie logische Variablen, DO-Schleifen und FORMAT-Anweisungen ein, um die Ausgabe zu formatieren.
- Fortran 66: Fortran 66, auch bekannt als Fortran IV oder Fortran 66 Standard, wurde 1966 eingeführt. Es war die erste offizielle Version der Sprache mit einem standardisierten Sprachumfang. Fortran 66 führte neue Funktionen wie das IF-THEN-ELSE-Konstrukt ein und standardisierte einige vorhandene Sprachkonstrukte.
- Fortran 77: Fortran 77, auch bekannt als Fortran 1977 Standard, wurde 1977 veröffentlicht. Es war eine bedeutende Aktualisierung und erweiterte den Funktionsumfang von Fortran erheblich. Fortran 77 führte Zeichenkettenverarbeitung, dynamische Speicherzuweisung (mit der ALLOCATE-Anweisung) und verbesserte Array-Funktionen ein.
- Fortran 90: Fortran 90 wurde 1991 veröffentlicht und brachte wichtige Erweiterungen in die Sprache. Es führte den freien Formatierungsstil ein, verbesserte die Array-Unterstützung (einschließlich dynamischer Arrays und Array-Schnittoperationen), fügte neue Sprachkonstrukte wie MODULES, POINTERs und DO WHILE-Schleifen hinzu und ermöglichte rekursive Unterprogramme.
- Fortran 95: Fortran 95 wurde 1997 als geringfügige Aktualisierung von Fortran 90 veröffentlicht. Es behebt einige Unklarheiten und Fehler in Fortran 90 und fügt einige neue Funktionen hinzu, wie beispielsweise Verbesserungen bei der ALLOCATE-Anweisung und Unterstützung für den CHARACTER-Datentyp mit variabler Länge.
- Fortran 2003, Fortran 2008, Fortran 2018: Diese Versionen sind weitere Erweiterungen von Fortran, die neue Funktionen und Verbesserungen in die Sprache einbringen, wie z. B. Verbesserungen bei der Behandlung von Zeichenketten, Verbesserungen bei der parallelen Programmierung (Fortran 2008) und viele andere Funktionen.
Testframeworks für Fortran
In der Welt von Fortran gibt es mehrere Testframeworks, die verwendet werden können, um Unit-Tests für Fortran-Code durchzuführen. Wobei man sagen muss das Voyger 2 in Teilen noch auf Fortran 77 beruht aber auch Fortran 90.
Hier sind einige beliebte Testframeworks, es gibt aber weitaus mehr unter anderem entwickelt durch NASA Mitarbeiter:
Testframework
Details
Weiterführende Informationen
Alternative
FRUIT (Fortran Unit Tester):
FRUIT ist eines der ältesten Testframeworks für Fortran und wird häufig verwendet, um Unit-Tests für Fortran-77-Code zu schreiben. Es unterstützt die Erstellung von Testsuiten und Assertions, um die Funktionalität von Fortran-Routinen zu überprüfen.
https://github.com/mortele/FRUIT
FUnit
FUnit ist ein moderneres Testframework für Fortran, das speziell für die Erstellung von Unit-Tests in Fortran entwickelt wurde. Es unterstützt Fortran 90 und höher und bietet eine Vielzahl von Testfunktionen und Assertions.
https://fortranwiki.org/fortran/show/FUnit
Fortran Unit Test (FUT):
FUT ist ein weiteres Testframework für Fortran, das es ermöglicht, Unit-Tests für Fortran-Code zu schreiben. Es bietet Funktionen wie Assertions und die Möglichkeit, Testergebnisse zu protokollieren.
https://github.com/dongli/fortran-unit-test
PFUnit (Parallel Fortran Unit Test):
PFUnit ist ein Testframework, das speziell für den Test paralleler Fortran-Code entwickelt wurde. Es ermöglicht die Durchführung von Tests für parallele Funktionen und Routinen.
https://github.com/Goddard-Fortran-Ecosystem/pFUnit
Fortran Test Framework (FTF):
Das Fortran Test Framework ist ein einfaches und leichtgewichtiges Testframework für Fortran. Es unterstützt die Erstellung von Unit-Tests und Assertions.
https://github.com/agforero/FTFramework
Ein Flussdiagramm zur Beschreibung der Laufzeit:
ForFUnit:
ForFUnit ist ein weiteres Testframework für Fortran, das es ermöglicht, Unit-Tests für Fortran-Code zu schreiben. Es bietet Funktionen wie Assertions und die Möglichkeit, Testergebnisse zu protokollieren.
Fortuno
Benutzerfreundliches, flexibles und erweiterbares objektorientiertes Fortran-Unit-Testing-Framework zum Testen von seriellen, MPI-parallelisierten und Coarray-parallelisierten Anwendungen.
https://github.com/aradi/fortuno
Aufbau von Testszenarien in Fortran
In Fortran gibt es keine eingebauten Testframeworks oder Assertions wie in einigen modernen Programmiersprachen. Daher müssen Entwickler Testroutinen und Assertions oft manuell implementieren. Hier ist ein einfaches Beispiel, wie ihr eine Testroutine mit Assertions in Fortran erstellen könnt:
PROGRAM TestExample
IMPLICIT NONE
! Function to be tested
REAL FUNCTION Square(x)
REAL, INTENT(IN) :: x
Square = x * x
END FUNCTION Square
! Test routine
SUBROUTINE RunTests
INTEGER :: numTests, i
REAL :: input, result, expected
! Array of test cases: (input, expected result)
REAL, DIMENSION(3, 2) :: testCases
testCases = RESHAPE(, )
numTests = SIZE(testCases, 1)
DO i = 1, numTests
input = testCases(i, 1)
expected = testCases(i, 2)
result = Square(input)
! Assertion
IF (result == expected) THEN
WRITE(*, '(A, F6.2, A, F6.2)') 'Test ', input, ': Passed. Result = ', result
ELSE
WRITE(*, '(A, F6.2, A, F6.2, A, F6.2)') 'Test ', input, ': Failed. Expected = ', expected, ', Got = ', result
END IF
END DO
END SUBROUTINE RunTests
! Run the tests
CALL RunTests()
END PROGRAM TestExample
Aufbau einer Testsuite in Fortran
In Fortran gibt es keine eingebaute Testsuit-Struktur wie in einigen modernen Programmiersprachen. Daher müssen Entwickler Testsuiten manuell implementieren. Eine Testsuite in Fortran ist eine Sammlung von mehreren Testroutinen, die verschiedene Funktionen oder Teile des Fortran-Codes testen. Hier ist ein einfaches Beispiel, wie Sie eine Testsuite in Fortran erstellen können:
Angenommen, ihr habt eine Fortran-Datei my_functions.f90, die einige Funktionen enthält, die ihr testen möchtet. Ihr könnt eine separate Testdatei test_my_functions.f90 erstellen, die eure Testsuite enthält.
! Datei: my_functions.f90
MODULE MyFunctions
IMPLICIT NONE
CONTAINS
! Funktion 1: Berechne das Quadrat einer Zahl
REAL FUNCTION Square(x)
REAL, INTENT(IN) :: x
Square = x * x
END FUNCTION Square
! Funktion 2: Berechne die Fakultät einer ganzen Zahl
INTEGER FUNCTION Factorial(n)
INTEGER, INTENT(IN) :: n
INTEGER :: i, result
result = 1
DO i = 1, n
result = result * i
END DO
Factorial = result
END FUNCTION Factorial
END MODULE MyFunctions
! Datei: test_my_functions.f90
PROGRAM TestSuite
USE MyFunctions
IMPLICIT NONE
! Testroutine für Square
SUBROUTINE TestSquare
REAL :: input, result, expected
! Testfälle: (input, erwartetes Ergebnis)
REAL, DIMENSION(3, 2) :: testCases
testCases = RESHAPE(, )
WRITE(*, '(A)') 'Testing Square'
DO i = 1, SIZE(testCases, 1)
input = testCases(i, 1)
expected = testCases(i, 2)
result = Square(input)
! Assertion
IF (result == expected) THEN
WRITE(*, '(A, F6.2, A, F6.2)') 'Test ', input, ': Passed. Result = ', result
ELSE
WRITE(*, '(A, F6.2, A, F6.2, A, F6.2)') 'Test ', input, ': Failed. Expected = ', expected, ', Got = ', result
END IF
END DO
END SUBROUTINE TestSquare
! Testroutine für Factorial
SUBROUTINE TestFactorial
INTEGER :: input, result, expected
! Testfälle: (input, erwartetes Ergebnis)
INTEGER, DIMENSION(3, 2) :: testCases
testCases = RESHAPE(, )
WRITE(*, '(A)') 'Testing Factorial'
DO i = 1, SIZE(testCases, 1)
input = testCases(i, 1)
expected = testCases(i, 2)
result = Factorial(input)
! Assertion
IF (result == expected) THEN
WRITE(*, '(A, I3, A, I6)') 'Test ', input, ': Passed. Result = ', result
ELSE
WRITE(*, '(A, I3, A, I6, A, I6)') 'Test ', input, ': Failed. Expected = ', expected, ', Got = ', result
END IF
END DO
END SUBROUTINE TestFactorial
! Hauptprogramm der Testsuite
CALL TestSquare()
CALL TestFactorial()
END PROGRAM TestSuite
Wie man den Fehler hätte verhindern können?
Grundsätzlich gehe ich davom aus das die NASA solche Testmethoden einsetzt und auch entsprechende Emulationen laufen hat? Trotzdem wundert es das man hier eben doch falsche Befehle versendet hat. Entweder ist es menschliches Versagen, oder die Befehle wurden nicht ausreichend geprüft?
Das Testen von falschen oder fehlerhaften Befehlen in Fortran kann schwierig sein, da der Fortran-Compiler normalerweise während der Kompilierung Fehler in ungültigen Befehlen erkennt und den Kompilationsprozess beendet. Dennoch könnt ihr in einigen Fällen Testfälle erstellen, um zu überprüfen, wie Ihr Code mit fehlerhaften Befehlen umgeht.
Hier sind einige Möglichkeiten, wie ihr falsche Befehle in Fortran testen könntet:
- Ungültige Variablennamen: Erstellt Testfälle mit ungültigen oder nicht deklarierten Variablennamen, um zu überprüfen, wie euer Code auf solche Fehler reagiert.
- Syntaxfehler: Erstellt Testfälle mit fehlerhaften Syntaxkonstruktionen, wie beispielsweise fehlenden Klammern, falschen Zeichenketten oder fehlenden Semikolons.
- Falsche Datentypen: Überprüft, wie euer Code auf ungültige Datentypen reagiert, z. B. wenn ihr versucht, eine Zeichenkette in eine ganze Zahl umzuwandeln oder umgekehrt.
- Ungültige Compilerdirektiven: Testet, wie euer Code auf ungültige oder nicht unterstützte Compilerdirektiven reagiert.
- Fehlerhafte Ein-/Ausgabeoperationen: Testet, wie euer Code auf fehlerhafte Ein-/Ausgabeoperationen reagiert, z. B. wenn ihr versucht, in eine geschlossene Datei zu schreiben oder von einer nicht vorhandenen Datei zu lesen.
Die folgenden Beispiele zeigen, wie einige der oben genannten Szenarien in einer Testumgebung aussehen könnten:
FUNCTION Divide(a, b)
REAL, INTENT(IN) :: a, b
REAL :: Divide
IF (b == 0.0) THEN
WRITE(*, '(A)') 'Error: Division by zero.'
STOP
END IF
Divide = a / b
END FUNCTION Divide
SUBROUTINE TestNegativeDivision
REAL :: result
! Negative Test: Division durch Null
result = Divide(5.0, 0.0) ! Erwartung: Fehlermeldung "Error: Division by zero."
END SUBROUTINE TestNegativeDivision
FUNCTION GetStringLength(str)
CHARACTER(*), INTENT(IN) :: str
INTEGER :: GetStringLength
GetStringLength = LEN_TRIM(str)
END FUNCTION GetStringLength
SUBROUTINE TestInvalidStringLength
INTEGER :: length
CHARACTER(5) :: myString = "Hello"
! Negative Test: Zuweisen eines zu langen Strings zu einer begrenzten Zeichenkette
length = GetStringLength(myString) ! Erwartung: Compilerfehler oder Laufzeitfehler
END SUBROUTINE TestInvalidStringLength
Diese Beispiele zeigen, wie ihr Testfälle erstellen könnt, die fehlerhafte Befehle in eurem Fortran-Code auslösen, um sicherzustellen, dass euer Code angemessen auf solche Fehler reagiert.
Wie in jeder anderen Sprache sollte man auch die entsprecchenden Workflows einhalten. Es geht immer um den Test von Schwachstellen, daher ergeben sich auch immer die gleichen Szenarieren im Test.
Statische Code-Analyse: Statische Code-Analysetools durchsuchen euren Quellcode, um mögliche Schwachstellen und Fehler zu erkennen, ohne den Code tatsächlich auszuführen. Diese Tools können beispielsweise potenzielle Speicherzugriffsfehler, uninitialisierte Variablen oder unsichere Aufrufe von Funktionen erkennen. Einige gängige statische Analysetools für Fortran sind:
- Frama-C: Ein Framework für die statische Analyse von C- und Fortran-Code.
- FortranLint: Ein kommerzielles statisches Analysetool für Fortran.
Dynamische Code-Analyse: Dynamische Code-Analysetools führen Ihren Code aus und überwachen sein Verhalten zur Laufzeit. Diese Tools können Laufzeitfehler, Speicherlecks und andere potenzielle Probleme erkennen. Beim Testen von Fortran ist es wichtig, Ihre Tests mit verschiedenen Eingabewerten und Grenzfallbedingungen durchzuführen. Mit selbst ist nur ein Tool bekannt welches Entsprechend ab Fortran 77 eingesetzt werden kann:
Code-Reviews: Peer-Reviews und Sicherheitsüberprüfungen sind ebenfalls wichtige Schritte, um potenzielle Schwachstellen im Code zu entdecken. Lassen Sie andere Entwickler Ihren Code überprüfen und Feedback geben, um mögliche Sicherheitslücken zu identifizieren.
Kann man diesen Testcode automatisieren?
Ja, ihr könnt den Testcode in Jenkins oder GitHub in einer Pipeline automatisieren, um eine kontinuierliche Integration und automatisierte Testabläufe zu ermöglichen. Beide Plattformen bieten Möglichkeiten, Skripte und Tests in einer Pipeline zu definieren und auszuführen, um sicherzustellen, dass euer Code kontinuierlich getestet wird. Es wundert mich das dieser fehler gerade der NASA passiert ist, denn einige der oben genannten Testframeworks sind eigene Entwicklungen von NASA Mitarbeitern.
Beispiel Jenkins:
In Jenkins könnt ihr eine Pipeline erstellen, um eure Fortran-Tests zu automatisieren.
Ein einfacher Jenkins-Pipeline-Code könnte wie folgt aussehen:
pipeline {
agent any
stages {
stage('Build') {
steps {
// Hier den Code aus dem Repository klonen und den Fortran-Compiler ausführen, um den Code zu kompilieren
}
}
stage('Test') {
steps {
sh 'gfortran -o test_my_functions test_my_functions.f90 my_functions.f90' // Kompilieren des Testcodes
sh './test_my_functions' // Ausführen der Testsuite
}
}
}
}
Beispiel Github Actions;
In GitHub können Sie eine ähnliche Pipeline in Form von GitHub Actions erstellen. GitHub Actions ermöglicht es Ihnen, den Testcode in einer YAML-Datei zu definieren, die im Repository gespeichert wird.
Read the full article
0 notes
Text
Wie man Sicherheitstests für AngularJS mit Hilfe von OWASP ZAP durchführt

Voyager 1 erreichte im August 2012 den interstellaren Raum und ist das am weitesten entfernte von Menschen gemachte Objekt ((Hier findet ihr den aktuellen Missionsstatus von Voyager 1 - https://voyager.jpl.nasa.gov/mission/status/)). Voyager 1 wurde kurz nach seiner Schwestersonde Voyager 2 im Jahr 1977 gestartet und erforschte die jupianischen und saturnischen Systeme ((Hier verweise ich auf den ausführlichen Wikipediaartikel zum Thema Saturn und Jupiter - https://de.wikipedia.org/wiki/Saturn_(Planet) )), entdeckte neue Monde, aktive Vulkane und eine Fülle von Daten über das äußere Sonnensystem.
Die Voyager 1 und 2 wurden entwickelt, um die seltene Ausrichtung der Planeten zu nutzen, die nur einmal in 176 Jahren auftritt. Beide Raumsonden tragen eine Art Zeitkapsel namens Golden Record , ((Anbei eine Übersicht über die Golden Record - https://voyager.jpl.nasa.gov/golden-record/golden-record-cover/)) eine vergoldete 12-Zoll-Kupferscheibe mit Klängen und Bildern, die ausgewählt wurden, um die Geschichte unserer Welt für Außerirdische darzustellen.
Voyager Golden Record Cover Explanation https://commons.wikimedia.org/wiki/File:Voyager_Golden_Record_Cover_Explanation.svg
Ich gehe davon aus, dass die große Mehrheit der Menschen, die die Software für diese Missionen erstellt haben, jetzt im Ruhestand ist ((Die Raumfahrt-Rentner der Voyager-Mission. Sehr gute Zusammenfassung zum aktuellen Software Team der Voyager Missionen - https://www.swr.de/swr2/programm/sendungen/wissen/die-raumfahrt-rentner-der-voyager-mission/-/id=660374/did=15958530/nid=660374/10sk2n7/index.html)) ((Eine weitere kurze Erwähnung was genau für eine Programmiersprache genau genutzt wurde - https://www.popularmechanics.com/space/a17991/voyager-1-voyager-2-retiring-engineer/)), aber in den letzten 40 Jahren der fortschreitenden Entwicklung sind die Programiersprachen natürlich stark fortschrittlich. Einst hatte das Voyager Team über 200 Mitarbeiter, aktuell sind es noch 8 Mitarbeiter. ((Ein sehr guter Audio Beitrag zum Thema Voyager Team, hier als Zusammenfassung - https://www.swr.de/-/id=15958532/property=download/nid=660374/1s7qh3e/swr2-wissen-20150914.pdf))
Immerhin wurden die beiden Sonden noch mit Fortran, und Assembler programmiert. In den Raumsonden selber verrichten Uralt-Prozessoren von General Electric ihr Werk. Sie müssen dabei mit einem 64-Kilobyte-Speicher auskommen. ((Hier in diesem Interview auch nochmal erklärt warum es 64kb sind, und nicht weniger wie es einige behaupten - https://www.popularmechanics.com/space/a17991/voyager-1-voyager-2-retiring-engineer/))

Viking CCS memory.
https://history.nasa.gov/computers/p163b.jpg

The Flight Data System hardware
So startete sie 1977. Nach 35 Jahren erreichte Voyager den interstellaren Raum.
Aber warum stelle ich mir diese Fragen nun? Mich interessiert der Entwicklungsprozess hinter den Voyager Missionen. Und hier bin ich zwar selber noch mehr oder weniger in den Nasa Archiven am forschen, aber einiges konnte ich wenigstens schon beantworten.
Welche Prozessoren wurden genutzt?
Anscheinend verwendeten sie das von JPL speziell entwickelte und gebaute Computer Command System (CCS) des Viking-Landers. Sie haben geringfügige Modifikationen vorgenommen, um ein Flight Data System (FDS) und ein Attitude Articulation Control System (AACS) hinzuzufügen. Der CCS ist der Hauptcomputer und führt Befehle und Speicher aus, von denen er knapp 70 KB hat ((Hier in diesem Interview wird bestätigt das es 64 kilobyte sind - https://www.popularmechanics.com/space/a17991/voyager-1-voyager-2-retiring-engineer/)).
Der FDS übernimmt die Erfassung der wissenschaftlichen Daten und die Speicherung auf Magnetbändern (ich bin nicht sicher, ob das CCS auch Zugriff auf die Bänder hat, aber ich gehe davon aus!). Das AACS ist der Flugcomputer und steuert die Ausrichtung des Raumfahrzeugs (anscheinend erfüllt das CCS bei einigen dieser Dinge doppelte Aufgaben?).
Die AACS der Voyager-Sonden ((In diesem Artikel auführlich beschrieben - https://www.allaboutcircuits.com/news/voyager-mission-anniversary-computers-command-data-attitude-control/)) bestimmen die Ausrichtung und halten sie auf die Erde gerichtet. Die ursprüngliche Absicht der Designer war es, eine neue Technologie namens "HYSPACE" (Hybrid Programmable Attitude Control Electronics) für das AACS zu verwenden. HYSPACE kombinierte analoge und digitale Elemente, verwendete Indexregisteradressierung und eine serielle 4-Byte-Architektur. Dies erlaubte die Verwendung des gleichen Codes für alle drei Achsen des AACS.

Different types of packaging used in the Viking computer system. Note the discrete components in the leftmost device. (JPL photo 360-276-AC)
Voyager verwendete den gleichen Computer wie der Viking Orbiter nur in einem seiner 3 computergestützten Subsysteme (Command and Control Subsystem). Das Attitude- und Articulation Control Subsystem hat eine erweiterte Version des CCS-Computers verwendet, der eine Einheit (die Hybrid-Puffer-Interface-Schaltung (HYBIC)) zwischen CPU und RAM eingefügt hat, die die Befehle abgefangen hat, um die indizierte Adressierungsfunktion (auf Kosten anderer Anweisungen) hinzuzufügen. und beschleunigte Anweisungen, die Leerlaufzyklen verwendeten. Der dritte Computer, der im Flight Data Subsystem verwendet wurde, war ein neues benutzerdefiniertes Design im CMOS mit 128 Registern, serieller Nibble-CPU und 8096 Wörtern mit 16-Bit-RAM. Es lieferte ungefähr 80.000 Anweisungen pro Sekunde.
Dazu dieses Zitat mit weiteren Informationen:
NASA reeled from massive budget cuts during the 1970s. A changed political climate ended the Apollo era of near "carte blanche." Hampered by expensive Shuttle contracts as well as other factors, NASA management reduced its plans for unmanned exploration of the solar system. As Voyager developed under the new conditions, cost savings became a key ingredient in all engineering evaluations. JPL thus conducted a "CCS/CCS Memory Subsystem Design Inheritance Review" on January 17, 19749. Held a year after Greenberg's proposal for standardizing the Viking computer, the Review resulted in the adoption of the Viking CCS as the Voyager CCS. The eventual hardware functional requirements document reads like a copy of the Viking document10. I/O interfaces with the new Flight Data System and Attitude Articulation and Control System computers are the major differences. Software such as the command decoder, certain fault processing routines, and others are fundamentally identical to Viking11. Here again, differences are related to the new computers. All command changes and memory loads for the other computers are routed through the CCS12. This required the addition of the routine MEMLOAD13. Another routine, AACSIN, was added to evaluate power codes sent from the Attitude Control computer as a "heartbeat" to inform the CCS of its health14. The frequency of the heartbeat, roughly 30 times per minute, caused concern that the CCS would be worn out processing it. Mission Operations estimated that the CCS would have to be active 3% to 4% of the time, whereas the Viking Orbiter computer had trouble if it was more than 0.2% active15. As it turns out, this worry was unwarranted. Part of the reason why the more complex Voyager spacecraft could be controlled by a computer with the same size memory as Viking is the ability to change software loads. In-flight reprogramming, begun when the programmable sequencers flew on Mariners, and brought to a state of high quality on Mariner X, was a nearly routine task by the time of Voyager's launch in 1977. Both the CCS and Flight Data System computer have been reprogrammed extensively. No less than 18 loads were uplinked to Voyager l during its Jupiter encounter. During long-duration cruise, such as between Saturn and Uranus, new loads are spaced to every 3 months16. As pioneered on Mariner X, a disaster backup sequence was stored in the Voyager 2 CCS memory for the Uranus encounter, and later for the Neptune encounter. Required because of the loss of redundancy after the primary radio receiver developed an internal short, the backup sequence will execute minimum experiment sequences and transmit data to earth; it occupies 20% of the 4K memory17. CCS programmers are studying ways to use some bit positions in a failed Flight Data System memory to compensate for the shortened memory in their system. A readout register in the Flight Data System has a failed bit, giving the impression that the entire memory has a one stored in that position in each word. Remaining "good" areas may be assigned to the use of the CCS18.
Hier noch Informationen zu den einzelnen zur genutzen Hardware:

In dieser Übersicht gibt es nun ein Blockdiagramm der Hardware des Viking Orbiter Command Computer Subsystems. Diese grundlegende Konfiguration mit zwei Computern wurde sowohl für Viking-Computer als auch für alle drei Voyager-Computersysteme verwendet.
Blockdiagramm für Viking und Voyager CCS. ((Blockdiagramm für Viking und Voyager - https://history.nasa.gov/computers/p158.htm))
Wie viele Codezeilen gibt es und in welcher Sprache ist der Source geschrieben?
Geschrieben wurde der Source Code der Voyager Missionen in Fortran und Assembler, in Teilen auch umgestellt auf C ((Hier wird explizit auch auf die Umstellung auf C hingewiesen - also neben Fortran und Assembler hat man eben auch auf C umgestellt - https://www.wired.com/2013/09/vintage-voyager-probes/)). ((Spezielle Informationen zur Entwicklung des Fortran Source Codes im Rahmen der Voyager Missionen mit Hinweis das erst Fortran 5 nutzte und dann auf Fortran 77 ((Hier noch einige Informationen zu Fortran 77 - https://de.wikipedia.org/wiki/Fortran)) ((Hier sind noch allgemeine Informationen zu finden zum Thema ob der Source Code von Voyager öffentlich ist - https://www.muckrock.com/foi/united-states-of-america-10/voyager-command-analysis-software-source-code-28641/))
"The spacecrafts’ original control and analysis software was written in Fortran 5 (later ported to Fortran 77). Some of the software is still in Fortran, though other pieces have now been ported to the somewhat more modern C."
Hier anbei eine Übersicht der einzelnen Source Zeilen Pro Mission seit 1969.
- 1969 Mariner-6 (30)
- 1975 Viking (5K)
- 1977 Voyager (3K)
- 1989 Galileo (8K)
- 1990 Cassini (120K)
- 1997 Pathfinder (175K)
- 1999 DS1 (349K)
- 2003 SIRTF/Spitzer (554K)
- 2004 MER (555K)
- 2005 MRO (545K)
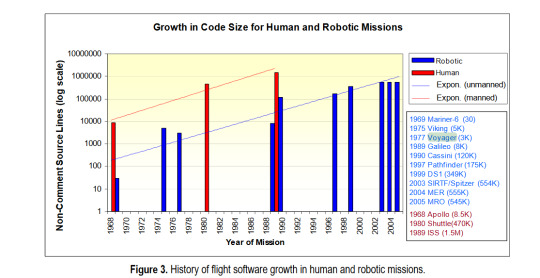
Laut dem folgenden Beitrag gibt es den Source Code für Apollo 11 und verschiedene andere NASA-Projekte, die offen (Open Source?) sind, aber der Source der Voyager Sonden scheint hier zu fehlen: https://voat.co/v/programming/comments/306663
Fortran zu Python
Interessant finde ich eben auch die Tatsache das es in Python eben einen Fortran Wrapper gibt ((Fortan to Python Wrapper - Hier in der Übersicht https://de.wikibooks.org/wiki/Fortran:_Fortran_und_Python)),((Hier noch weitere Informationen zum Fortran to Python Wrapper - https://sysbio.ioc.ee/projects/f2py2e/)), wird dieser oder ähnliche Lösungen im Voyager Team genutzt?
Wäre sicherlich eine Möglichkeit, auch den in die Jahre gekommen Source entsprechend noch anzupassen. Ob das Voyager Team aber immer nocht Fortran77 nutzt , oder C, oder eben Wrapper für beides, dass konnte ich bisher noch nicht ganz erkennen. Da sind die Informationen einfach noch zu schwammig. Aber ich bleibe an dem Thema dran.
Wie sahen die Entwicklungsprozesse hinter den Missionen aus? Sind diese noch aktiv?
https://www.youtube.com/watch?v=lh_y-vqNvuw
Read the full article
0 notes
Text
Sind Blackbox-Automatisierungstests in variablen Anwendungskonfigurationen sinnvoll?

Die Frage, ob Black-Box-Automatisierungstests in variablen Anwendungskonfigurationen sinnvoll sind, ist komplex, und die Antwort hängt von einer Reihe von Faktoren ab.
Zunächst ist es wichtig, den Unterschied zwischen Black-Box- und White-Box-Tests zu verstehen. Black-Box-Tests sind eine Testmethode, bei der der Tester keine Kenntnisse über die interne Funktionsweise der getesteten Anwendung hat. Der Tester konzentriert sich ausschließlich auf die Eingaben und Ausgaben der Anwendung. Beim White-Box-Testing hingegen wird das Innenleben der Anwendung getestet, z. B. der Code und die Datenbank.
https://www.youtube.com/watch?v=nQQwBsK7YII
Bei einem variablen Anwendungsaufbau können Black-Box-Tests ein n��tzlicher Ansatz sein. Da jede Anwendung über einen anderen Technologie-Stack verfügt, ist es für QAs möglicherweise nicht machbar oder effizient, mehrere Technologien zu erlernen, um anwendungsnahe Unit-/Integrationstests zu schreiben. In diesem Fall kann die Verwendung von Tools wie Postman für API-Tests und UI-Frameworks wie Playwright oder Cypress für UI-Tests eine gute Option sein. Diese Tools sind eher für externe Tests konzipiert und können mit einer Vielzahl von Technologie-Stacks arbeiten.
https://www.youtube.com/watch?v=4BRHQ-yXFZ8
Es ist jedoch wichtig zu beachten, dass Blackbox-Tests ihre Grenzen haben. Da der Tester keine Kenntnisse über die interne Funktionsweise der Anwendung hat, kann es schwieriger sein, bestimmte Probleme oder Fehler zu erkennen. An dieser Stelle können White-Box-Tests nützlich sein. Durch das Testen der internen Funktionsweise der Anwendung können QAs Probleme auf einer detaillierteren Ebene identifizieren.
Letztendlich hängt der beste Ansatz von den spezifischen Bedürfnissen und Anforderungen Ihres Unternehmens und Ihrer Anwendungen ab. Je nach Situation kann es sinnvoll sein, eine Kombination aus Black-Box- und White-Box-Tests zu verwenden. Das Wichtigste ist, dass ihr einen Testansatz wählt, der effektiv und effizient ist und der es Ihnen ermöglicht, Probleme so schnell und effektiv wie möglich zu erkennen und zu beheben.
Black-Box-Computerisierungstests können in Abhängigkeit von der jeweiligen Einstellung und den Zielen des Testsystems bei der Gestaltung von Anwendungen hilfreich sein. Black-Box-Tests beziehen sich auf eine Strategie, bei der die inneren Funktionen der zu testenden Anwendung dem Analysator nicht bekannt sind. Alles in allem konzentriert sich der Analysator auf die Datenquellen und Ergebnisse des Frameworks, um dessen Verhalten zu bestätigen.
Bei faktoriellen Anwendungsarrangements, bei denen sich die Designs, Bedingungen oder Informationsdatenquellen ändern können, können Black-Box-Tests dabei helfen, zu garantieren, dass die Anwendung unter verschiedenen Umständen formgetreu arbeitet. Im Folgenden werden einige Überlegungen angestellt:
Funktionales Testen: Black-Box-Tests können bei der Überprüfung der praktischen Voraussetzungen der Anwendung unter verschiedenen Bedingungen sehr hilfreich sein. Durch die Angabe von Datenquellen und die Betrachtung der Ergebnisse können die Analysatoren bestätigen, dass die Anwendung unabhängig von der grundlegenden Anordnung korrekt funktioniert.
https://www.youtube.com/watch?v=d4gZ89r1_YU
Regressionstests: Wenn Änderungen an der Anwendung oder ihren aktuellen Gegebenheiten vorgenommen werden, sind Rückfalltests unerlässlich, um zu gewährleisten, dass die aktuelle Nützlichkeit nicht beeinträchtigt wird. Black-Box-Computerisierungstests können bei der schnellen Durchführung einer Reihe von Tests helfen, die bestätigen, dass die Anwendung tatsächlich formgetreu funktioniert.
https://www.youtube.com/watch?v=AWX6WvYktwk&t=2s
Kompatibilitätstests: Variable Anwendungsarrangements können verschiedene Arbeitsrahmen, Programme oder Gadgets umfassen. Black-Box-Tests können dabei helfen, die Ähnlichkeit der Anwendung mit diesen unterschiedlichen Bedingungen zu untersuchen, indem sie das Verhalten der Anwendung in zahlreichen Designs überprüfen.
https://www.youtube.com/watch?v=ST4qubEcqyI&t=1s
Testen der Benutzerfreundlichkeit: Blackbox-Tests können bei der Bewertung der Kundenerfahrung mit der Anwendung in verschiedenen Arrangements hilfreich sein. Analysatoren können sich auf Aspekte wie Bequemlichkeit, Reaktionsfähigkeit und Offenheit konzentrieren, ohne Punkt für Punkt Informationen über die innere Ausführung zu benötigen.
https://www.youtube.com/watch?v=q8IPHOlUbV0
Dennoch ist es wichtig zu beachten, dass Blackbox-Tests Einschränkungen haben. Sie sind möglicherweise nicht geeignet, um Defekte auf niedriger Ebene oder Ausführungsfehler aufzudecken, die Informationen über die inneren Abläufe erfordern. In solchen Fällen kann eine Mischung aus Black-Box- und White-Box-Tests (bei denen der innere Aufbau bekannt ist) besser geeignet sein.
Letztendlich hängt die Entscheidung über den Testansatz von den jeweiligen Zielen, Anforderungen und verfügbaren Ressourcen ab. Häufig ist es sinnvoll, ein ausgewogenes Testsystem zu haben, das eine Mischung aus verschiedenen Methoden enthält, um eine vollständige Einbeziehung zu gewährleisten.
Read the full article
0 notes
Text
Heuristiken zur Erkennung von "einmaligen" Tests?

Bei der Entscheidung, ob ich einer Regressionssuite etwas hinzufüge oder nicht, würde ich eine Reihe von Aspekten berücksichtigen. Vieles von dem, was ich in Betracht ziehen würde, wäre allerdings sehr produktspezifisch; zu verstehen, wie die Kunden das Produkt verwenden, wie das Upgrade-Verhalten aussieht und so weiter, wäre hier notwendig.
- Wie hoch ist das Risiko, dass der Fehler, den der Test aufdecken soll, übersehen wird?
Je nachdem, auf welcher Ebene der Test stattfindet (Einheitstest, Integrationstest, Validierungstest usw.), kann dies schwer abzuschätzen sein, aber je näher ihr an dem seid, was der Endbenutzer sehen wird, desto einfacher ist es wahrscheinlich, das Risiko einzuschätzen.
- Wo in der Programmhierarchie befindet sich die Codeänderung, die getestet werden soll? Bei miserablem Spaghetti-Code ist das vielleicht schwer zu erkennen, aber je mehr Dinge von einer Funktion abhängen, desto weniger Dinge müsst ihr (wahrscheinlich) im Zusammenhang mit dieser Funktion testen, da ihr Ausfall eine Reihe anderer Komponenten des Betriebssystems zerstören könnte.
- Wie viele Dinge müssen schiefgehen, damit der Fehler aufgedeckt wird? Hier würde ich dazu tendieren, Dinge, bei denen mehr Dinge schiefgehen können, in der Regressionssuite zu belassen, als Dinge, die sich leichter aufdecken lassen, weil es wahrscheinlicher ist, dass man die einfachen Fehler in unverbundenen Tests findet, als die komplizierteren Fehler. (Dies setzt voraus, dass ihr Tester habt, denen Fehler auffallen, die nicht in der Dokumentation des Testszenarios enthalten sind).
- Wie lange ist der fragliche Fehler schon im Code, und wodurch wurde er aufgedeckt? Dies ist schwer zu quantifizieren, ohne mehr darüber zu wissen, was getestet wird, aber wenn ihr etwas habt, das speziell durch einen Sonderfall aufgedeckt wurde, würde ich es nicht unbedingt zu einem Regressionssuit hinzufügen, aber ich würde es zu meiner Liste der "dummen Dinge, die Endbenutzer tun, die mir nie in den Sinn gekommen wären" hinzufügen, die ich in Zukunft beim Schreiben von Tests berücksichtigen sollte.
- Wie subtil wäre ein Problem in einem bestimmten Bereich? Je subtiler das Problem ist, desto mehr Tests solltet ihr darum herum durchführen.
- Wie oft wird eine Funktion in der Praxis vorkommen? In dem von Ihnen genannten Beispiel, der Datenbankaktualisierung, muss diese Funktion vielleicht nur einmal getestet werden, wenn ihr sicher sein könnt, dass jeder den neuen Code erhält, sobald er freigegeben wird, bevor ihr eine neue Version veröffentlichen. Wenn ihr jedoch jemanden habt, der in drei Jahren eine neue Version des Programms erhält und derzeit eine Version benutzt, die zwei Jahre veraltet ist, dann könnte es ein Problem sein, das Upgrade-Szenario nicht in Ihren Regressionssuit aufzunehmen. (Ich bin mir nicht sicher, wie ihr die Migrationstests jetzt durchführt, daher kann dies etwas sein, worüber ihr euch Gedanken machen müsst, oder auch nicht).
Ich verstehe die Bedeutung von guten "Regressionstests", um sicherzustellen, dass behobene Fehler nicht erneut auftreten. Aber ich denke, es ist möglich, zu weit zu gehen und am Ende mit einer massiven "Regressionstest-Suite" für jeden behobenen Fehler, jede geänderte Funktion, sogar jede entfernte Funktion zu landen... ihr versteht, worauf ich hinaus will. Gibt es Heuristiken oder Techniken, um zu identifizieren, wann ein Test in die langfristige Regressionssuite gehört, im Gegensatz dazu, wann es besser wäre, einen "Einmal"- oder "Wegwerf"-Test zu schreiben, der für die nächste Version ausgeführt und dann verworfen wird? Idealerweise möchten wir dies zum Zeitpunkt der Erstellung der Tests identifizieren, aber auch Tipps zur Identifizierung dessen, was im Laufe der Zeit aussortiert werden kann, sind hilfreich.
Die Hauptsorge besteht darin, den Zeitaufwand für jeden Release-Test zu minimieren. Wir haben eine große Legacy-Codebasis, die alte Technologien verwendet, die nicht sehr geeignet für automatisiertes Testen sind, was bedeutet, dass ein großer Teil unserer Regressionstests manuell durchgeführt wird. Wir möchten unsere manuelle Testbelastung für jeden Release nicht mit Tests erhöhen, die keinen langfristigen Wert bieten.
Wir befinden uns auch in einer regulierten Umgebung, daher benötigen wir eine Möglichkeit, zu dokumentieren, was wir getestet haben, und ich denke, es ist sinnvoll, einen guten Test zu entwerfen, wenn ihr etwas ändert, anstatt nur ad hoc zu testen. Aber einige Dinge werden realistischerweise nicht zwei Jahre später plötzlich fehlschlagen, wenn wir jetzt zeigen, dass sie behoben sind.
Einige Beispiele, bei denen mein "Bauchgefühl" sagt, dass sie nur für die erste Version nützlich sind:
- Änderung der Form einer grafischen Steuerungsanzeige und Sicherstellen, dass alle Stellen, an denen eine solche Anzeige angezeigt wird, die neue Form verwenden (d.h., wir haben uns nicht wiederholt und den Code für die Anzeige dupliziert - dies ist ein Beispiel aus unserer Legacy-Codebasis, in der wir häufig kopierten Code und andere Wiederholungen gefunden haben).
- Für ein Softwareprodukt, das Hardware steuert, haben wir die Unterstützung für einige Add-On-Geräte entfernt, die von der Hardware unterstützt wurden und in einer Datenbank gespeichert sind. Wir haben getestet, dass ein Upgrade der Datenbank von der Version, die die Geräte unterstützt hat, zur Version, die sie nicht mehr unterstützt, angemessen funktioniert und dass die Geräte in der neuen Version nicht mehr vorhanden sind.
- Behebung eines "offensichtlichen" Fehlers, bei dem ein Dialogfeld nicht ordnungsgemäß aufgeräumt wird, wenn abgebrochen wird, usw.
Um die manuelle Regressionssuite davor zu bewahren, übermäßig groß zu werden:
- Testwartung und -bereinigung: Überprüft regelmäßig die vorhandene Regressionssuite und identifiziert Tests, die nicht mehr relevant sind, redundant sind oder nur geringen Mehrwert bieten. Entfernen oder überarbeitet solche Tests, um Duplizierungen zu minimieren und den Fokus der Suite zu optimieren.
- Testpriorisierung: Priorisiert die Tests basierend auf ihrer Bedeutung, der Abdeckung von Risiken und den Nutzungsmustern. Konzentrieren Sie sich auf kritische Funktionen, Bereiche mit hohem Risiko und häufig verwendete Funktionen. Durch die Priorisierung von Tests können begrenzte manuelle Testressourcen effektiv eingesetzt werden.
- Risikobasiertes Testen: Wendet risikobasierte Testtechniken an, um Bereiche mit hohem Risiko zu identifizieren und die Testbemühungen entsprechend zu verteilen. Diese Vorgehensweise stellt sicher, dass die kritischsten und anfälligsten Teile des Systems angemessen berücksichtigt werden, während weniger kritische Bereiche einer leichteren Prüfung unterzogen werden.
- Automatisierungsmöglichkeiten: Untersucht die Möglichkeiten zur Automatisierung bestimmter Aspekte des Regressionstests. Automatisierte Tests können den manuellen Testaufwand erheblich reduzieren und eine umfassendere Abdeckung ermöglichen, ohne dass dabei erheblicher Zeitaufwand entsteht. Konzentriert euch auf die Automatisierung von wiederholten oder zeitaufwändigen Tests.
- Testgetriebene Entwicklung: Fördert einen testgetriebenen Entwicklungsansatz, bei dem Tests vor der Implementierung neuer Funktionen oder der Behebung von Fehlern geschrieben werden. Diese Praxis fördert die Erstellung gezielter, gut konzipierter Tests, die weniger dazu neigen, die Regressionssuite aufzublähen.
Beachtet, dass es ein iterativer Prozess ist, die richtige Balance zwischen gründlichem Regressionstesten und effizientem manuellem Testen zu finden. Überprüft und passt die Regressionssuite regelmäßig anhand von Feedback, Testergebnissen und sich ändernden Prioritäten an.
Read the full article
0 notes
Text
Automatisiertes Testen: Welche QA-Prozesse sollten auf die Validierung von Testcode ausgerichtet sein?

Idealerweise sollte die Testautomatisierung dem gleichen Grad an Validierung unterliegen, wie der Produktionscode - was natürlich zu dem Problem führt, dass der Testcode den Testcode testet, der den Testcode testet, der den Testcode testet... ad infinitum.
Was ich als brauchbare Alternative gefunden habe, ist eine Sammlung von Praktiken und Strategien, die im Allgemeinen funktionieren, um die Testautomatisierung in vernünftiger Ordnung zu halten. Es ist sicherlich keine umfangreiche Liste, aber eben das, was ich in 25 Jahren Quality Assurance erlernen konnte:
- Code-Reviews - entweder ein Entwickler oder ein anderer Testautomatisierer (letzteres ist besser, es sei denn, der Entwickler ist mit der Codebasis der Automatisierung vertraut) überprüft jeden neuen Code. Dies hilft, die "return true"-Probleme zu vermeiden, und ermöglicht auch Vorschläge zur Verbesserung der Codestruktur, Hinweise auf Hilfsbibliotheken, die bereits Funktionen enthalten, die ein Tester neu erstellen möchte (dies geschieht, wenn die Testcodebasis groß genug ist - ich habe es getan und musste dann die Funktionen bereinigen und vereinheitlichen), und so weiter.
- Ergebnisanalyse - jemand geht jeden Durchlauf durch und prüft, ob es sich bei allen nicht bestandenen Ergebnissen um tatsächliche Probleme handelt. Dies kann bei schlecht geschriebener Testautomatisierung sehr zeitaufwendig sein (ich habe es selbst erlebt...) und dient als Anreiz, den Automatisierungscode zu bereinigen, damit es einfacher ist, die erste Abweichung von den Erwartungen festzustellen. In meiner vorherigen Position habe ich 10 Jahre alten Automatisierungscode geerbt, der als Aufzeichnungs-Wiedergabe mit Tastendrucken begonnen hatte, um die Anwendung im Test zu manipulieren, und oft war der einzige Weg, um herauszufinden, was schiefgelaufen war, den Lauf (alle 4+ Stunden davon...) erneut abzuspielen und zu beobachten, bis etwas passierte. Ich hoffe aufrichtig, dass dieses spezielle Skript veraltet ist...
- Prüfungen: Führt eine Zusammenfassung der Ergebnisse im Laufe der Zeit durch - dies kann sehr hilfreich sein, wenn es darum geht, die Zuverlässigkeit eures Automatisierungscodes zu bewerten. Wenn ein Skript viele Fehlalarme verursacht, ist es ein guter Kandidat für ein Refactoring.
- Pflege: Plant Zeit für die Pflege der Automatisierungscodebasis ein - Dies ist ein entscheidender Punkt, der meiner Erfahrung nach oft vergessen wird. Wenn alle eurer Automatisierer Zeit für die Wartung der Automatisierungscodebasis aufwenden müssen, wird diese mit der Zeit immer anfälliger, selbst wenn die vom neuen Code betroffenen Bereiche durch Refactoring ergänzt werden. Ich würde empfehlen, jemanden dafür freizustellen, einfach ein paar Wochen lang zu überwachen, wie viel Zeit er für die Wartung des Automatisierungscodes aufwendet, um eine Vorstellung davon zu bekommen, wie viel Zeit eure Codebasis benötigt, und diese Zahl dann als Grundlage für eine nicht verhandelbare Zeitzuweisung von x Stunden pro Woche zu verwenden.
- Unit-Tests für Testcode: Es ist wichtig, dass der Testcode selbst durch Unit-Tests abgedeckt wird, um sicherzustellen, dass er korrekt funktioniert. Diese Tests sollten die erwarteten Ergebnisse überprüfen und sicherstellen, dass der Testcode die beabsichtigte Funktionalität abdeckt.
- Testabdeckungsmetriken: Verwendet Tools zur Messung der Testabdeckung, um sicherzustellen, dass der Testcode ausreichend viele Codezeilen oder Funktionalitäten abdeckt. Dies hilft dabei, Lücken in der Testabdeckung zu identifizieren und sicherzustellen, dass alle relevanten Bereiche des Codes getestet werden.
- Wartbarkeit und Lesbarkeit des Testcodes: Der Testcode sollte gut strukturiert, leicht verständlich und wartbar sein. Verwendet aussagekräftige Namen für Testfälle und -methoden, kommentiert komplexe Teile des Codes und haltt euch an gängige Konventionen und Stilrichtlinien.
- Automatisierte Testausführung und Berichterstattung: Automatisiert die Ausführung der Tests und die Erstellung von Testberichten. Dadurch wird sichergestellt, dass die Tests regelmäßig und konsistent ausgeführt werden, und ermöglicht es euch, schnell auf Fehler zu reagieren und den Testfortschritt zu überwachen.
- Regressionstests: Stellt sicher, dass der Testcode als Teil des Regressionstestprozesses regelmäßig ausgeführt wird, um sicherzustellen, dass vorhandene Funktionalität weiterhin wie erwartet funktioniert. Dies hilft, Regressionen zu erkennen und sicherzustellen, dass Codeänderungen keine unerwünschten Auswirkungen haben.
- Integration mit CI/CD-Pipelines: Integriert den Testcode in Ihre kontinuierlichen Integrations- und Bereitstellungspipelines, um sicherzustellen, dass die Tests bei jeder Codeänderung automatisch ausgeführt werden. Dadurch wird eine schnelle Rückmeldung ermöglicht und die Qualität des Codes überwacht.
- Dokumentation: Dokumentiert den Testcode, um anderen Teammitgliedern zu helfen, den Code zu verstehen und ihn gegebenenfalls zu erweitern oder anzupassen. Beschreibt die Testfälle und deren erwartetes Verhalten sowie etwaige Abhängigkeiten oder spezielle Konfigurationen.
Read the full article
0 notes
Text
Python: Einfacher und flexibler Portscanner zum Schwachstellentesten (Version 0.1)

Klar man hätte auch einen der schon recht bekannten Port Scanner nutzten können, aber mich treibt es immer wieder zu einer Selbstentwicklung. Für mich ist es extrem wichtig hier Python zu nutzen, da ich es für extrem flexibel halte auch durch die Erweiterung in alle möglichen Richtungen da will ich mich schlichtweg nicht eingrenzen lassen.
Dieses Skript ist ein einfacher Port-Scanner in Python. Es scannt ein angegebenes Ziel (eine IP-Adresse oder einen Hostnamen) auf offene Ports innerhalb eines definierten Bereichs, protokolliert die Aktivitäten und erstellt einen Bericht über den Scan. Hier ist, was jeder Teil des Skripts macht:
- Konfiguration: Das Skript enthält verschiedene Konfigurationsvariablen, die entweder standardmäßig festgelegt sind oder über Umgebungsvariablen angepasst werden können. Diese Konfigurationen umfassen das Ziel des Portscans, die zu überprüfenden Portbereiche, die maximale Anzahl von Prozessen, die gleichzeitig ausgeführt werden können, die Timeout-Zeit für Socket-Operationen sowie die Namen und Pfade von Log- und Berichtsdateien.
- Logging-Konfiguration: Hier wird die Konfiguration für das Protokollieren von Ereignissen festgelegt. Es wird ein Protokollierungslevel festgelegt (standardmäßig INFO), ein Dateiname für das Protokoll (standardmäßig "port_scan.log") und ein Format für die Protokolleinträge.
- Hilfsfunktionen: Das Skript enthält mehrere Hilfsfunktionen, die für verschiedene Aufgaben verwendet werden, z. B. das Drucken eines ASCII-Banners, das Überprüfen der Gültigkeit einer IPv6-Adresse, das Überprüfen eines bestimmten Ports, das Abrufen der IP-Adresse eines Ziels, das Generieren eines Berichts und das Generieren eines Diagramms für die Portbereiche.
- Firewall-Erkennung: Es gibt eine Funktion zum Erkennen einer Firewall oder eines IDS (Intrusion Detection System) auf dem Zielhost. Es wird eine HTTP-Anfrage an den Zielserver gesendet, und basierend auf der Antwort wird überprüft, ob eine Firewall oder ein IDS vorhanden ist.
- Portscan-Funktion: Die Hauptfunktion des Skripts ist die "scan_ports"-Funktion. Diese Funktion ruft die anderen Funktionen auf, um den Portscan durchzuführen. Sie erstellt ein ASCII-Banner, gibt Informationen zum Scan aus, erstellt eine Liste aller zu überprüfenden Ports, ruft die Funktion zum Überprüfen der Ports mithilfe von Multiprocessing auf, generiert einen Bericht, erstellt ein Diagramm für die Portbereiche und ruft die Firewall-Erkennungsfunktion auf. Der Bericht wird in einer HTML-Datei gespeichert.
Hauptprogramm: Der Code am Ende des Skripts überprüft, ob das Skript direkt ausgeführt wird (statt importiert zu werden). Wenn ja, wird die "scan_ports"-Funktion aufgerufen, um den Portscan durchzuführen.
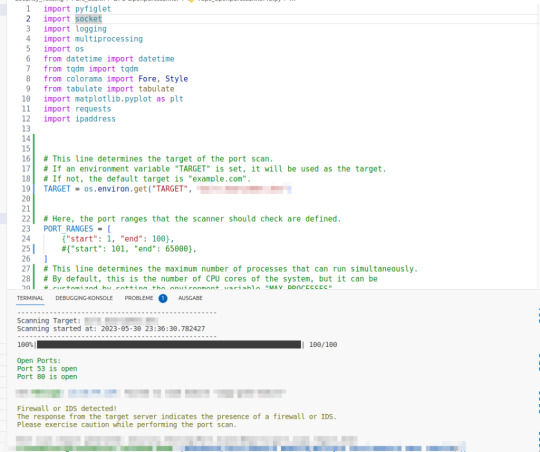
Was in der Version 0.1 schon enthalten ist?
# Todo:
# 1. Add support for UDP ports
# 2. Add support for port ranges - Done
# 3. Add support for port lists - Done
# 4. Add support for CIDR notation - Done
# 5. Add support for hostnames - Done - Use socket.gethostbyname()
# 6. Add support for IPv6 - Done - Use socket.getaddrinfo()
# 7. Add support for IPv6 ranges - Done
# 8. Add support for IPv6 lists - Done
# 9. Add support for IPv6 CIDR notation - Done
# 10. Add support for IPv6 hostnames - Done
# 11. Add support for IPv6 link-local addresses - Done
# 12. Add support for IPv6 site-local addresses - Done
# 13. Add support for IPv6 multicast addresses - Done
# 14. Add support for IPv6 loopback addresses - Done
# 15. Add support for IPv6 unspecified addresses - Done
# 16. Add support for IPv6 IPv4-mapped addresses - Done
# 17. Add support for IPv6 IPv4-translated addresses - Done
# 18. Add support for IPv6 6to4 addresses
# 19. Add support for IPv6 Teredo addresses
# 20. Add support for IPv6 6bone addresses - Done
# 21. Add support for IPv6 documentation addresses - Testing
# 22. Add support for IPv6 global unicast addresses- Testing
# 23. Add support for IPv6 unique local addresses - Testing
# 24. Add support for IPv6 link-local unicast addresses - Testing
# 25. Add support for IPv6 site-local unicast addresses - Testing
# 26. Add support for IPv6 multicast addresses - Testing
# 27. Add support for IPv6 loopback addresses - Testing
# 28. Add support for IPv6 unspecified addresses
# 29. Add support for IPv6 addresses with zone indices
# 30. Add support for IPv6 addresses with scope IDs
# 31. Add support for IPv6 addresses with embedded IPv4 addresses
# 32. Add support for IPv6 addresses with embedded IPv4 addresses and zone indices
# 33. Add support for IPv6 addresses with embedded IPv4 addresses and scope IDs
# 34. Add support for IPv6 addresses with embedded IPv4-mapped addresses
# 35. Add support for IPv6 addresses with embedded IPv4-mapped addresses and zone indices - Done
# 36. Add support for IPv6 addresses with embedded IPv4-mapped addresses and scope IDs
# Done:
# 1. Add support for IPv6 addresses with embedded IPv4-mapped addresses and scope IDs
# 2. Add support for IPv6 addresses with embedded IPv4-mapped addresses and zone indices
# 3. Add support for IPv6 addresses with embedded IPv4 addresses and scope IDs
# 4. Add support for IPv6 addresses with embedded IPv4 addresses and zone indices
# 5. Add support for IPv6 addresses with zone indices
# 6. Add support for IPv6 unspecified addresses
# 7. Add support for IPv6 loopback addresses
# 8. Add support for IPv6 multicast addresses
# 9. Add support for IPv6 site-local unicast addresses
# 10. Add support for IPv6 link-local unicast addresses
Hier das komplette Skript
import pyfiglet
import socket
import logging
import multiprocessing
import os
from datetime import datetime
from tqdm import tqdm
from colorama import Fore, Style
from tabulate import tabulate
import matplotlib.pyplot as plt
import requests
import ipaddress
# This line determines the target of the port scan.
# If an environment variable "TARGET" is set, it will be used as the target.
# If not, the default target is "example.com".
TARGET = os.environ.get("TARGET", "example.com")
# Here, the port ranges that the scanner should check are defined.
PORT_RANGES =
# This line determines the maximum number of processes that can run simultaneously.
# By default, this is the number of CPU cores of the system, but it can be
# customized by setting the environment variable "MAX_PROCESSES".
MAX_PROCESSES = int(os.environ.get("MAX_PROCESSES", multiprocessing.cpu_count()))
# This sets the timeout for socket operations. The default timeout is one second,
# but it can be customized by setting the environment variable "SOCKET_TIMEOUT".
SOCKET_TIMEOUT = int(os.environ.get("SOCKET_TIMEOUT", 1))
# This determines the name of the log file. By default, it's "port_scan.log",
# but it can be changed by setting the environment variable "LOG_FILENAME".
LOG_FILENAME = os.environ.get("LOG_FILENAME", "port_scan.log")
# This determines the path and name of the report file. By default, it's "Security_Testing/Port_Scann/Reports/port_scan_report.html",
# but it can be changed by setting the environment variable "REPORT_FILENAME".
REPORT_FILENAME = os.environ.get("REPORT_FILENAME", "Security_Testing/Port_Scann/Reports/port_scan_report.html")
# This determines the directory where the report is saved.
REPORT_DIRECTORY = os.path.dirname(REPORT_FILENAME)
os.makedirs(REPORT_DIRECTORY, exist_ok=True)
# This creates the directory where the report is saved, if it doesn't already exist.
# The exist_ok=True parameter prevents an error if the directory already exists.
# Logging configuration
logging.basicConfig(filename=LOG_FILENAME, level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
## filename=LOG_FILENAME: This specifies that the logs should be written to a file,
# and the name of the file is the value of the LOG_FILENAME variable.
## level=logging.INFO: This sets the root logger level to INFO. This means that only events of this level and above will be tracked,
# unless the logging package is configured differently elsewhere.
# Levels you can specify include DEBUG, INFO, WARNING, ERROR, and CRITICAL.
## format='%(asctime)s - %(levelname)s - %(message)s': This is a string that specifies the layout of the log entries.
# Each "%(name)s" is a placeholder that will be replaced with the corresponding "name" from each log record.
# In this case, asctime will be replaced with the time the log record was created, levelname will be replaced with the level
# name of the log record (INFO, ERROR, etc.), and message will be replaced with the log message.
def print_banner():
ascii_banner = pyfiglet.figlet_format("OPS - Open Port Scanner")
print(ascii_banner)
def print_scan_info():
print("-" * 50)
print("Scanning Target: " + TARGET)
global start_time
start_time = datetime.now()
print("Scanning started at: " + str(start_time))
print("-" * 50)
def validate_ipv6_address(ip):
"""Prüft, ob die gegebene IP-Adresse eine gültige IPv6-Adresse ist."""
try:
ipaddress.IPv6Address(ip)
return True
except ipaddress.AddressValueError:
return False
def check_port(port_info):
ip, port = port_info
try:
if validate_ipv6_address(ip):
with socket.socket(socket.AF_INET6, socket.SOCK_STREAM) as s:
s.settimeout(SOCKET_TIMEOUT)
# Add the scope id if it is a link-local address
if ipaddress.IPv6Address(ip).is_link_local:
s.connect((ip, port, 0, YOUR_NETWORK_INTERFACE_INDEX))
else:
s.connect((ip, port))
else:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.settimeout(SOCKET_TIMEOUT)
result = s.connect_ex((ip, port))
except OSError:
return {"port": port, "status": "error"}
if result == 0:
logging.info("Port {} is open".format(port))
return {"port": port, "status": "open"}
else:
return {"port": port, "status": "closed"}
def get_ip_address(target):
addresses = socket.getaddrinfo(target, None)
for address in addresses:
if address == socket.AF_INET6:
# Detect if it's an IPv4-mapped IPv6 address
ip = ipaddress.IPv6Address(address)
if ip.ipv4_mapped:
return str(ip.ipv4_mapped)
else:
return address
return addresses
def generate_report(results):
headers =
data = , port) for port in results]
table = tabulate(data, headers=headers, tablefmt="pretty")
report = f'''
Port Scan Report
Port Scan Report
Target: {TARGET}
Scan started at: {str(start_time)}
Scan finished at: {str(datetime.now())}
Time taken: {str(datetime.now() - start_time)}
Ports:
{table}
'''
return report
def generate_port_range_chart(results):
open_ports = len( == "open"])
closed_ports = len( == "closed"])
labels =
values =
colors =
explode = (0.1, 0)
plt.pie(values, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
plt.axis('equal')
plt.title("Port Range Chart")
plt.show()
def detect_firewall(target):
try:
response = requests.get(f"http://{target}")
if response.status_code == 200:
print(Fore.YELLOW + "nFirewall or IDS detected!")
print("The response from the target server indicates the presence of a firewall or IDS.")
print("Please exercise caution while performing the port scan.")
print(Style.RESET_ALL)
logging.warning("Firewall or IDS detected")
except requests.exceptions.RequestException as e:
print(Fore.YELLOW + "nWarning: " + str(e))
print(Style.RESET_ALL)
logging.warning(str(e))
raise e
def scan_ports():
print_banner()
print_scan_info()
try:
port_ranges = , range_info) for range_info in PORT_RANGES]
all_ports =
for start, end in port_ranges:
all_ports.extend(range(start, end + 1))
if '/' in TARGET:
if ':' in TARGET:
ip_network = ipaddress.IPv6Network(TARGET, strict=False)
else:
ip_network = ipaddress.IPv4Network(TARGET, strict=False)
target_ips =
elif ',' in TARGET:
target_ips =
else:
target_ips = ]
'''Finally, you will need to adjust your code to handle IPv6 link-local addresses correctly when you are resolving the TARGET:
In this line, I have changed socket.AF_UNSPEC to socket.AF_INET6 to ensure that it will resolve to an IPv6 address.'''
#else:
#target_ips = ]
with multiprocessing.Pool(processes=MAX_PROCESSES) as pool:
total_ports = len(all_ports) * len(target_ips)
results = list(tqdm(pool.imap(check_port, ), total=total_ports, ncols=80, bar_format='{l_bar}{bar}| {n_fmt}/{total_fmt}'))
open_ports = for port in results if port == "open"]
if open_ports:
print(Fore.GREEN + "nOpen Ports:")
for port in open_ports:
print("Port {} is open".format(port))
print(Style.RESET_ALL)
logging.info("Open ports: {}".format(open_ports))
else:
print(Fore.RED + "nNo open ports found." + Style.RESET_ALL)
logging.info("No open ports found.")
report = generate_report(results)
with open(REPORT_FILENAME, 'w') as report_file:
report_file.write(report)
generate_port_range_chart(results)
detect_firewall(TARGET)
print("Port scan report generated: {}".format(REPORT_FILENAME))
except KeyboardInterrupt:
print("nExiting Program !!!!")
logging.info("Program interrupted by the user")
except socket.error as e:
print("nServer not responding !!!!")
print(Fore.RED + "nError: " + str(e))
logging.error(str(e))
raise e
except requests.exceptions.RequestException as e:
print(Fore.YELLOW + "nWarning: " + str(e))
logging.warning(str(e))
raise e
if __name__ == '__main__':
scan_ports()
Read the full article
0 notes
Text
Python: Einfacher und flexibler Portscanner zum Schwachstellentesten (Version 0.1)

Klar man hätte auch einen der schon recht bekannten Port Scanner nutzten können, aber mich treibt es immer wieder zu einer Selbstentwicklung. Für mich ist es extrem wichtig hier Python zu nutzten, da ich es für extrem flexibel halte auch durch die Erweiterung in alle möglichen Richtungen da will ich mich schlichtweg nicht eingrenzen lassen.
Dieses Skript ist ein einfacher Port-Scanner in Python. Es scannt ein angegebenes Ziel (eine IP-Adresse oder einen Hostnamen) auf offene Ports innerhalb eines definierten Bereichs, protokolliert die Aktivitäten und erstellt einen Bericht über den Scan. Hier ist, was jeder Teil des Skripts macht:
- Konfiguration: Das Skript enthält verschiedene Konfigurationsvariablen, die entweder standardmäßig festgelegt sind oder über Umgebungsvariablen angepasst werden können. Diese Konfigurationen umfassen das Ziel des Portscans, die zu überprüfenden Portbereiche, die maximale Anzahl von Prozessen, die gleichzeitig ausgeführt werden können, die Timeout-Zeit für Socket-Operationen sowie die Namen und Pfade von Log- und Berichtsdateien.
- Logging-Konfiguration: Hier wird die Konfiguration für das Protokollieren von Ereignissen festgelegt. Es wird ein Protokollierungslevel festgelegt (standardmäßig INFO), ein Dateiname für das Protokoll (standardmäßig "port_scan.log") und ein Format für die Protokolleinträge.
- Hilfsfunktionen: Das Skript enthält mehrere Hilfsfunktionen, die für verschiedene Aufgaben verwendet werden, z. B. das Drucken eines ASCII-Banners, das Überprüfen der Gültigkeit einer IPv6-Adresse, das Überprüfen eines bestimmten Ports, das Abrufen der IP-Adresse eines Ziels, das Generieren eines Berichts und das Generieren eines Diagramms für die Portbereiche.
- Firewall-Erkennung: Es gibt eine Funktion zum Erkennen einer Firewall oder eines IDS (Intrusion Detection System) auf dem Zielhost. Es wird eine HTTP-Anfrage an den Zielserver gesendet, und basierend auf der Antwort wird überprüft, ob eine Firewall oder ein IDS vorhanden ist.
- Portscan-Funktion: Die Hauptfunktion des Skripts ist die "scan_ports"-Funktion. Diese Funktion ruft die anderen Funktionen auf, um den Portscan durchzuführen. Sie erstellt ein ASCII-Banner, gibt Informationen zum Scan aus, erstellt eine Liste aller zu überprüfenden Ports, ruft die Funktion zum Überprüfen der Ports mithilfe von Multiprocessing auf, generiert einen Bericht, erstellt ein Diagramm für die Portbereiche und ruft die Firewall-Erkennungsfunktion auf. Der Bericht wird in einer HTML-Datei gespeichert.
Hauptprogramm: Der Code am Ende des Skripts überprüft, ob das Skript direkt ausgeführt wird (statt importiert zu werden). Wenn ja, wird die "scan_ports"-Funktion aufgerufen, um den Portscan durchzuführen.
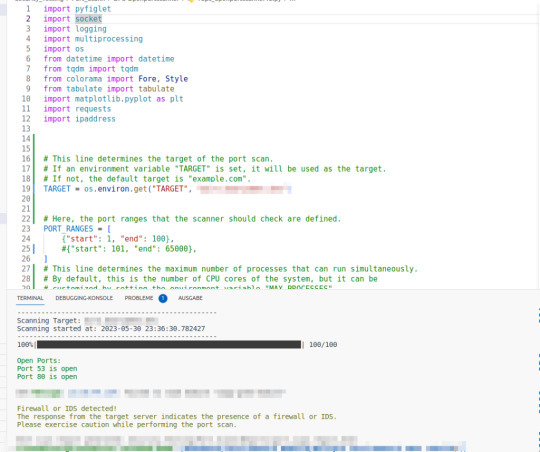
Was in der Version 0.1 schon enthalten ist?
# Todo:
# 1. Add support for UDP ports
# 2. Add support for port ranges - Done
# 3. Add support for port lists - Done
# 4. Add support for CIDR notation - Done
# 5. Add support for hostnames - Done - Use socket.gethostbyname()
# 6. Add support for IPv6 - Done - Use socket.getaddrinfo()
# 7. Add support for IPv6 ranges - Done
# 8. Add support for IPv6 lists - Done
# 9. Add support for IPv6 CIDR notation - Done
# 10. Add support for IPv6 hostnames - Done
# 11. Add support for IPv6 link-local addresses - Done
# 12. Add support for IPv6 site-local addresses - Done
# 13. Add support for IPv6 multicast addresses - Done
# 14. Add support for IPv6 loopback addresses - Done
# 15. Add support for IPv6 unspecified addresses - Done
# 16. Add support for IPv6 IPv4-mapped addresses - Done
# 17. Add support for IPv6 IPv4-translated addresses - Done
# 18. Add support for IPv6 6to4 addresses
# 19. Add support for IPv6 Teredo addresses
# 20. Add support for IPv6 6bone addresses - Done
# 21. Add support for IPv6 documentation addresses - Testing
# 22. Add support for IPv6 global unicast addresses- Testing
# 23. Add support for IPv6 unique local addresses - Testing
# 24. Add support for IPv6 link-local unicast addresses - Testing
# 25. Add support for IPv6 site-local unicast addresses - Testing
# 26. Add support for IPv6 multicast addresses - Testing
# 27. Add support for IPv6 loopback addresses - Testing
# 28. Add support for IPv6 unspecified addresses
# 29. Add support for IPv6 addresses with zone indices
# 30. Add support for IPv6 addresses with scope IDs
# 31. Add support for IPv6 addresses with embedded IPv4 addresses
# 32. Add support for IPv6 addresses with embedded IPv4 addresses and zone indices
# 33. Add support for IPv6 addresses with embedded IPv4 addresses and scope IDs
# 34. Add support for IPv6 addresses with embedded IPv4-mapped addresses
# 35. Add support for IPv6 addresses with embedded IPv4-mapped addresses and zone indices - Done
# 36. Add support for IPv6 addresses with embedded IPv4-mapped addresses and scope IDs
# Done:
# 1. Add support for IPv6 addresses with embedded IPv4-mapped addresses and scope IDs
# 2. Add support for IPv6 addresses with embedded IPv4-mapped addresses and zone indices
# 3. Add support for IPv6 addresses with embedded IPv4 addresses and scope IDs
# 4. Add support for IPv6 addresses with embedded IPv4 addresses and zone indices
# 5. Add support for IPv6 addresses with zone indices
# 6. Add support for IPv6 unspecified addresses
# 7. Add support for IPv6 loopback addresses
# 8. Add support for IPv6 multicast addresses
# 9. Add support for IPv6 site-local unicast addresses
# 10. Add support for IPv6 link-local unicast addresses
Hier das komplette Skript
import pyfiglet
import socket
import logging
import multiprocessing
import os
from datetime import datetime
from tqdm import tqdm
from colorama import Fore, Style
from tabulate import tabulate
import matplotlib.pyplot as plt
import requests
import ipaddress
# This line determines the target of the port scan.
# If an environment variable "TARGET" is set, it will be used as the target.
# If not, the default target is "example.com".
TARGET = os.environ.get("TARGET", "example.com")
# Here, the port ranges that the scanner should check are defined.
PORT_RANGES =
# This line determines the maximum number of processes that can run simultaneously.
# By default, this is the number of CPU cores of the system, but it can be
# customized by setting the environment variable "MAX_PROCESSES".
MAX_PROCESSES = int(os.environ.get("MAX_PROCESSES", multiprocessing.cpu_count()))
# This sets the timeout for socket operations. The default timeout is one second,
# but it can be customized by setting the environment variable "SOCKET_TIMEOUT".
SOCKET_TIMEOUT = int(os.environ.get("SOCKET_TIMEOUT", 1))
# This determines the name of the log file. By default, it's "port_scan.log",
# but it can be changed by setting the environment variable "LOG_FILENAME".
LOG_FILENAME = os.environ.get("LOG_FILENAME", "port_scan.log")
# This determines the path and name of the report file. By default, it's "Security_Testing/Port_Scann/Reports/port_scan_report.html",
# but it can be changed by setting the environment variable "REPORT_FILENAME".
REPORT_FILENAME = os.environ.get("REPORT_FILENAME", "Security_Testing/Port_Scann/Reports/port_scan_report.html")
# This determines the directory where the report is saved.
REPORT_DIRECTORY = os.path.dirname(REPORT_FILENAME)
os.makedirs(REPORT_DIRECTORY, exist_ok=True)
# This creates the directory where the report is saved, if it doesn't already exist.
# The exist_ok=True parameter prevents an error if the directory already exists.
# Logging configuration
logging.basicConfig(filename=LOG_FILENAME, level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
## filename=LOG_FILENAME: This specifies that the logs should be written to a file,
# and the name of the file is the value of the LOG_FILENAME variable.
## level=logging.INFO: This sets the root logger level to INFO. This means that only events of this level and above will be tracked,
# unless the logging package is configured differently elsewhere.
# Levels you can specify include DEBUG, INFO, WARNING, ERROR, and CRITICAL.
## format='%(asctime)s - %(levelname)s - %(message)s': This is a string that specifies the layout of the log entries.
# Each "%(name)s" is a placeholder that will be replaced with the corresponding "name" from each log record.
# In this case, asctime will be replaced with the time the log record was created, levelname will be replaced with the level
# name of the log record (INFO, ERROR, etc.), and message will be replaced with the log message.
def print_banner():
ascii_banner = pyfiglet.figlet_format("OPS - Open Port Scanner")
print(ascii_banner)
def print_scan_info():
print("-" * 50)
print("Scanning Target: " + TARGET)
global start_time
start_time = datetime.now()
print("Scanning started at: " + str(start_time))
print("-" * 50)
def validate_ipv6_address(ip):
"""Prüft, ob die gegebene IP-Adresse eine gültige IPv6-Adresse ist."""
try:
ipaddress.IPv6Address(ip)
return True
except ipaddress.AddressValueError:
return False
def check_port(port_info):
ip, port = port_info
try:
if validate_ipv6_address(ip):
with socket.socket(socket.AF_INET6, socket.SOCK_STREAM) as s:
s.settimeout(SOCKET_TIMEOUT)
# Add the scope id if it is a link-local address
if ipaddress.IPv6Address(ip).is_link_local:
s.connect((ip, port, 0, YOUR_NETWORK_INTERFACE_INDEX))
else:
s.connect((ip, port))
else:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.settimeout(SOCKET_TIMEOUT)
result = s.connect_ex((ip, port))
except OSError:
return {"port": port, "status": "error"}
if result == 0:
logging.info("Port {} is open".format(port))
return {"port": port, "status": "open"}
else:
return {"port": port, "status": "closed"}
def get_ip_address(target):
addresses = socket.getaddrinfo(target, None)
for address in addresses:
if address == socket.AF_INET6:
# Detect if it's an IPv4-mapped IPv6 address
ip = ipaddress.IPv6Address(address)
if ip.ipv4_mapped:
return str(ip.ipv4_mapped)
else:
return address
return addresses
def generate_report(results):
headers =
data = , port) for port in results]
table = tabulate(data, headers=headers, tablefmt="pretty")
report = f'''
Port Scan Report
Port Scan Report
Target: {TARGET}
Scan started at: {str(start_time)}
Scan finished at: {str(datetime.now())}
Time taken: {str(datetime.now() - start_time)}
Ports:
{table}
'''
return report
def generate_port_range_chart(results):
open_ports = len( == "open"])
closed_ports = len( == "closed"])
labels =
values =
colors =
explode = (0.1, 0)
plt.pie(values, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
plt.axis('equal')
plt.title("Port Range Chart")
plt.show()
def detect_firewall(target):
try:
response = requests.get(f"http://{target}")
if response.status_code == 200:
print(Fore.YELLOW + "nFirewall or IDS detected!")
print("The response from the target server indicates the presence of a firewall or IDS.")
print("Please exercise caution while performing the port scan.")
print(Style.RESET_ALL)
logging.warning("Firewall or IDS detected")
except requests.exceptions.RequestException as e:
print(Fore.YELLOW + "nWarning: " + str(e))
print(Style.RESET_ALL)
logging.warning(str(e))
raise e
def scan_ports():
print_banner()
print_scan_info()
try:
port_ranges = , range_info) for range_info in PORT_RANGES]
all_ports =
for start, end in port_ranges:
all_ports.extend(range(start, end + 1))
if '/' in TARGET:
if ':' in TARGET:
ip_network = ipaddress.IPv6Network(TARGET, strict=False)
else:
ip_network = ipaddress.IPv4Network(TARGET, strict=False)
target_ips =
elif ',' in TARGET:
target_ips =
else:
target_ips = ]
'''Finally, you will need to adjust your code to handle IPv6 link-local addresses correctly when you are resolving the TARGET:
In this line, I have changed socket.AF_UNSPEC to socket.AF_INET6 to ensure that it will resolve to an IPv6 address.'''
#else:
#target_ips = ]
with multiprocessing.Pool(processes=MAX_PROCESSES) as pool:
total_ports = len(all_ports) * len(target_ips)
results = list(tqdm(pool.imap(check_port, ), total=total_ports, ncols=80, bar_format='{l_bar}{bar}| {n_fmt}/{total_fmt}'))
open_ports = for port in results if port == "open"]
if open_ports:
print(Fore.GREEN + "nOpen Ports:")
for port in open_ports:
print("Port {} is open".format(port))
print(Style.RESET_ALL)
logging.info("Open ports: {}".format(open_ports))
else:
print(Fore.RED + "nNo open ports found." + Style.RESET_ALL)
logging.info("No open ports found.")
report = generate_report(results)
with open(REPORT_FILENAME, 'w') as report_file:
report_file.write(report)
generate_port_range_chart(results)
detect_firewall(TARGET)
print("Port scan report generated: {}".format(REPORT_FILENAME))
except KeyboardInterrupt:
print("nExiting Program !!!!")
logging.info("Program interrupted by the user")
except socket.error as e:
print("nServer not responding !!!!")
print(Fore.RED + "nError: " + str(e))
logging.error(str(e))
raise e
except requests.exceptions.RequestException as e:
print(Fore.YELLOW + "nWarning: " + str(e))
logging.warning(str(e))
raise e
if __name__ == '__main__':
scan_ports()
Read the full article
0 notes
Text
Last- und Performance Testing mit Python Request

Ihr kennt das Problem sicherlich auch, der Kunde will "mal eben" einen Last und Performance Test durchführen, um an Ergebnisse zu kommen. Meistens wird dazu immer noch Jmeter genutzt, aber ich zeige euch wie man mit diesem Python Skript viel umfassender und flexibler arbeiten kann. Die Anpassungen sind für jedes mögliches Szenario auslegbar, selbst ich habe noch nicht alle Möglichkeiten dieses Skriptes hier entsprechend angepasst.
Einige Ziele, die ich noch nicht umgesetzt habe:
- Grafisches Reporting ähnlich Jmeter
- Besseres Reporting in HTML oder PDF
import requests
import threading
import time
import csv
from tqdm import tqdm
import statistics
import logging
# Todo:
## 1. Logging
## 2. CSV-Datei
## 3. Statistiken
## 4. Auswertung
## 5. Ausgabe
## 6. Dokumentation
## 7. Testen
#Author: Frank Rentmeister 2023
#URL: https://example.com
#Date: 2021-09-30
#Version: 1.0
#Description: Load and Performance Tooling
# Set the log level to DEBUG to log all messages
LOG_FORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s - %(threadName)s - %(thread)d - %(lineno)d - %(funcName)s - %(process)d - %(processName)s - %(levelname)s - %(message)s - %(pathname)s - %(filename)s - %(module)s - %(exc_info)s - %(exc_text)s - %(created)f - %(relativeCreated)d - %(msecs)d - %(thread)d - %(threadName)s - %(process)d - %(processName)s - %(levelname)s - %(message)s - %(pathname)s - %(filename)s - %(module)s - %(exc_info)s - %(exc_text)s - %(created)f - %(relativeCreated)d - %(msecs)d - %(thread)d - %(threadName)s - %(process)d - %(processName)s - %(levelname)s - %(message)s - %(pathname)s - %(filename)s - %(module)s - %(exc_info)s - %(exc_text)s - %(created)f - %(relativeCreated)d - %(msecs)d - %(thread)d - %(threadName)s - %(process)d - %(processName)s - %(levelname)s - %(message)s - %(pathname)s - %(filename)s - %(module)s - %(exc_info)s - %(exc_text)s - %(created)f - %(relativeCreated)d - %(msecs)d'
logging.basicConfig(level=logging.DEBUG, format=LOG_FORMAT, filename='Load_and_Performance_Tooling/Logging/logfile.log', filemode='w')
logger = logging.getLogger()
# Example usage of logging
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
logging.info('This is an info message with %s', 'some parameters')
logging.info('This is an info message with %s and %s', 'two', 'parameters')
logging.info('This is an info message with %s and %s and %s', 'three', 'parameters', 'here')
logging.info('This is an info message with %s and %s and %s and %s', 'four', 'parameters', 'here', 'now')
logging.info('This is an info message with %s and %s and %s and %s and %s', 'five', 'parameters', 'here', 'now', 'again')
logging.info('This is an info message with %s and %s and %s and %s and %s and %s', 'six', 'parameters', 'here', 'now', 'again', 'and again')
logging.info('This is an info message with %s and %s and %s and %s and %s and %s and %s', 'seven', 'parameters', 'here', 'now', 'again', 'and again', 'and again')
logging.info('This is an info message with %s and %s and %s and %s and %s and %s and %s and %s', 'eight', 'parameters', 'here', 'now', 'again', 'and again', 'and again', 'and again')
logging.info('This is an info message with %s and %s and %s and %s and %s and %s and %s and %s and %s', 'nine', 'parameters', 'here', 'now', 'again', 'and again', 'and again', 'and again', 'and again')
# URL to test
url = "https://example.com"
assert url.startswith("http"), "URL must start with http:// or https://" # Make sure the URL starts with http:// or https://
#assert url.count(".") >= 2, "URL must contain at least two periods" # Make sure the URL contains at least two periods
assert url.count(" ") == 0, "URL must not contain spaces" # Make sure the URL does not contain spaces
# Number of users to simulate
num_users = 2000
# Number of threads to use for testing
num_threads = 10
# NEW- Create a list to hold the response times
def simulate_user_request(url):
try:
response = requests.get(url)
response.raise_for_status() # Raise an exception for HTTP errors
return response.text
except requests.exceptions.RequestException as e:
print("An error occurred:", e)
# Define a function to simulate a user making a request
def simulate_user_request(thread_id, progress, response_times):
for i in tqdm(range(num_users//num_threads), desc=f"Thread {thread_id}", position=thread_id, bar_format="{l_bar}{bar:20}{r_bar}{bar:-10b}", colour="green"):
try:
# Make a GET request to the URL
start_time = time.time()
response = requests.get(url)
response_time = time.time() - start_time
response.raise_for_status() # Raise exception if response code is not 2xx
response.close() # Close the connection
# Append the response time to the response_times list
response_times.append(response_time)
# Increment the progress counter for the corresponding thread
progress += 1
except:
pass
# Define a function to split the load among multiple threads
def run_threads(progress, response_times):
# Create a list to hold the threads
threads =
# Start the threads
for i in range(num_threads):
thread = threading.Thread(target=simulate_user_request, args=(i, progress, response_times))
thread.start()
threads.append(thread)
# Wait for the threads to finish
for thread in threads:
thread.join()
# Define a function to run the load test
def run_load_test():
# Start the load test
start_time = time.time()
response_times =
progress = * num_threads # Define the progress list here
with tqdm(total=num_users, desc=f"Overall Progress ({url})", bar_format="{l_bar}{bar:20}{r_bar}{bar:-10b}", colour="green") as pbar:
while True:
run_threads(progress, response_times) # Pass progress list to run_threads
total_progress = sum(progress)
pbar.update(total_progress - pbar.n)
if total_progress == num_users: # Stop when all users have been simulated
break
time.sleep(0.1) # Wait for threads to catch up
pbar.refresh() # Refresh the progress bar display
# NEW - Calculate the access time statistics
mean_access_time = statistics.mean(response_times)
median_access_time = statistics.median(response_times)
max_access_time = max(response_times)
min_access_time = min(response_times)
# NEW -Print the access time statistics
print(f"Mean access time: {mean_access_time:.3f} seconds")
print(f"Median access time: {median_access_time:.3f} seconds")
print(f"Maximum access time: {max_access_time:.3f} seconds")
print(f"Minimum access time: {min_access_time:.3f} seconds")
#todo: Save the load test results to a CSV file (think about this one)
# hier werden die Zugriffszeiten gesammelt
#access_times = {
# 'https://example.com': ,
# 'https://example.org': ,
# 'https://example.net':
#}
# Calculate the duration of the load test
duration = time.time() - start_time
# Calculate access times and performance metrics
access_times = )/num_threads for i in range(num_users//num_threads)]
mean_access_time = sum(access_times)/len(access_times)
median_access_time = sorted(access_times)
max_access_time = max(access_times)
min_access_time = min(access_times)
throughput = num_users/duration
requests_per_second = throughput/num_threads
# Print the load test results
print(f"Mean access time: {mean_access_time*1000:.2f} milliseconds")
print(f"Load test duration: {duration:.2f} seconds")
print(f"Mean access time: {mean_access_time:.3f} seconds")
print(f"Median access time: {median_access_time:.3f} seconds")
print(f"Maximum access time: {max_access_time:.3f} seconds")
print(f"Minimum access time: {min_access_time:.3f} seconds")
print(f"Throughput: {throughput:.2f} requests/second")
print(f"Requests per second: {requests_per_second:.2f} requests/second")
print(f"Number of users: {num_users}")
print(f"Number of threads: {num_threads}")
print(f"Number of requests per user: {num_users/num_threads}")
print(f"Number of requests per thread: {num_users/num_threads/num_threads}")
print(f"Number of requests per second: {num_users/duration}")
print(f"Number of requests per second per thread: {num_users/duration/num_threads}")
print(f"Number of requests per second per user: {num_users/duration/num_users}")
print(f"Total duration: {duration:.2f} seconds")
print(f"Total progress: {sum(progress)}")
print(f"Total progress per second: {sum(progress)/duration:.2f}")
print(f"Total progress per second per thread: {sum(progress)/duration/num_threads:.2f}")
print(f"Total progress per second per user: {sum(progress)/duration/num_users:.2f}")
print(f"Total progress per thread: {sum(progress)/num_threads:.2f}")
print(f"Total progress per user: {sum(progress)/num_users:.2f}")
print(f"Total progress per request: {sum(progress)/num_users/num_threads:.2f}")
print(f"Total progress per request per second: {sum(progress)/num_users/num_threads/duration:.2f}")
print(f"Total progress per request per second per thread: {sum(progress)/num_users/num_threads/duration/num_threads:.2f}")
print(f"Total progress per request per second per user: {sum(progress)/num_users/num_threads/duration/num_users:.2f}")
print(f"Total progress per request per thread: {sum(progress)/num_users/num_threads:.2f}")
print(f"Total progress per request per user: {sum(progress)/num_users/num_threads:.2f}")
print(f"Total progress per second per request: {sum(progress)/duration/num_users/num_threads:.2f}")
print(f"Total progress per second per request per thread: {sum(progress)/duration/num_users/num_threads/num_threads:.2f}")
print(f"Total progress per second per request per user: {sum(progress)/duration/num_users/num_threads/num_users:.2f}")
# Save the load test results to a CSV file
with open("load_test_results.csv", "w", newline='') as csv_file:
fieldnames =
# Create a CSV writer
csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames, delimiter=",", quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writeheader()
# Write the load test results to the CSV file
csv_writer.writerow({"Metric": "Average Response Time (seconds)", "Value": mean_access_time, "Short Value": round(mean_access_time, 3)})
csv_writer.writerow({"Metric": "Load Test Duration (seconds)", "Value": duration, "Short Value": round(duration, 2)})
csv_writer.writerow({"Metric": "Mean Access Time (milliseconds)", "Value": mean_access_time * 1000, "Short Value": round(mean_access_time * 1000, 2)})
csv_writer.writerow({"Metric": "Median Access Time (seconds)", "Value": median_access_time, "Short Value": round(median_access_time, 3)})
csv_writer.writerow({"Metric": "Maximum Access Time (seconds)", "Value": max_access_time, "Short Value": round(max_access_time, 3)})
csv_writer.writerow({"Metric": "Minimum Access Time (seconds)", "Value": min_access_time, "Short Value": round(min_access_time, 3)})
csv_writer.writerow({"Metric": "Throughput (requests/second)", "Value": throughput, "Short Value": round(throughput, 2)})
csv_writer.writerow({"Metric": "Requests per Second (requests/second)", "Value": requests_per_second, "Short Value": round(requests_per_second, 2)})
csv_writer.writerow({"Metric": "Number of Users", "Value": num_users, "Short Value": num_users})
csv_writer.writerow({"Metric": "Number of Threads", "Value": num_threads, "Short Value": num_threads})
csv_writer.writerow({"Metric": "Number of Requests per User", "Value": num_users / num_threads, "Short Value": round(num_users / num_threads)})
csv_writer.writerow({"Metric": "Number of Requests per Thread", "Value": num_users / (num_threads * num_threads), "Short Value": round(num_users / (num_threads * num_threads))})
csv_writer.writerow({"Metric": "Number of Requests per Second", "Value": num_users / duration, "Short Value": round(num_users / duration)})
csv_writer.writerow({"Metric": "Number of Requests per Second per Thread", "Value": num_users / (duration * num_threads), "Short Value": round(num_users / (duration * num_threads))})
csv_writer.writerow({"Metric": "Number of Requests per Second per User", "Value": num_users / (duration * num_users), "Short Value": round(num_users / (duration * num_users))})
csv_writer.writerow({"Metric": "Number of Requests per Minute", "Value": num_users / duration * 60, "Short Value": round(num_users / duration * 60)})
csv_writer.writerow({"Metric": "Number of Requests per Minute per Thread", "Value": num_users / (duration * num_threads) * 60, "Short Value": round(num_users / (duration * num_threads) * 60)})
csv_writer.writerow({"Metric": "Number of Requests per Minute per User", "Value": num_users / (duration * num_users) * 60, "Short Value": round(num_users / (duration * num_users) * 60)})
csv_writer.writerow({"Metric": "Number of Requests per Hour", "Value": num_users / duration * 60 * 60, "Short Value": round(num_users / duration * 60 * 60)})
csv_writer.writerow({"Metric": "Number of Requests per Hour per Thread", "Value": num_users / (duration * num_threads) * 60 * 60, "Short Value": round(num_users / (duration * num_threads) * 60 * 60)})
csv_writer.writerow({"Metric": "Number of Requests per Hour per User", "Value": num_users / (duration * num_users) * 60 * 60, "Short Value": round(num_users / (duration * num_users) * 60 * 60)})
csv_writer.writerow({"Metric": "Number of Requests per Day", "Value": num_users / duration * 60 * 60 * 24, "Short Value": round(num_users / duration * 60 * 60 * 24)})
csv_writer.writerow({"Metric": "Number of Requests per Day per Thread", "Value": num_users / (duration * num_threads) * 60 * 60 * 24, "Short Value": round(num_users / (duration * num_threads) * 60 * 60 * 24)})
csv_writer.writerow({"Metric": "Number of Requests per Day per User", "Value": num_users / (duration * num_users) * 60 * 60 * 24, "Short Value": round(num_users / (duration * num_users) * 60 * 60 * 24)})
csv_writer.writerow({"Metric": "Number of Requests per Month", "Value": num_users / duration * 60 * 60 * 24 * 30, "Short Value": round(num_users / duration * 60 * 60 * 24 * 30)})
csv_writer.writerow({"Metric": "Number of Requests per Month per Thread", "Value": num_users / (duration * num_threads) * 60 * 60 * 24 * 30, "Short Value": round(num_users / (duration * num_threads) * 60 * 60 * 24 * 30)})
csv_writer.writerow({"Metric": "Number of Requests per Month per User", "Value": num_users / (duration * num_users) * 60 * 60 * 24 * 30, "Short Value": round(num_users / (duration * num_users) * 60 * 60 * 24 * 30)})
csv_writer.writerow({"Metric": "Number of Requests per Year", "Value": num_users / duration * 60 * 60 * 24 * 365, "Short Value": round(num_users / duration * 60 * 60 * 24 * 365)})
csv_writer.writerow({"Metric": "Number of Requests per Year per Thread", "Value": num_users / (duration * num_threads) * 60 * 60 * 24 * 365, "Short Value": round(num_users / (duration * num_threads) * 60 * 60 * 24 * 365)})
csv_writer.writerow({"Metric": "Number of Requests per Year per User", "Value": num_users / (duration * num_users) * 60 * 60 * 24 * 365, "Short Value": round(num_users / (duration * num_users) * 60 * 60 * 24 * 365)})
#csv_writer.writeheader() # Add an empty row to separate the access times from the metrics
#csv_writer.writerow({"Metric": "Access Time (seconds)", "Value": None})
# Write the access times to the CSV file
csv_writer.writerow({"Metric": "Access Time (seconds)", "Value": None})
for access_time in response_times:
csv_writer.writerow({"Metric": None, "Value": access_time})
# Sort the response times and write them to the CSV file
response_times.sort()
for response_time in response_times:
csv_writer.writerow({"Metric": None, "Value": response_time})
# Run the load test
run_load_test()
# Path: Load_and_Performance/test_100_user.py
##### Documentation #####
'''
- The script imports the necessary modules for load testing, such as requests for making HTTP requests, threading for running multiple threads simultaneously, time for measuring time, csv for reading and writing CSV files, tqdm for displaying a progress bar, statistics for calculating performance metrics, and logging for logging messages.
- The script defines the URL to test and checks that it starts with "http://" or "https://", that it contains at least two periods, and that it does not contain any spaces.
- The script sets the number of users to simulate and the number of threads to use for testing.
- The script defines a function called simulate_user_request() that simulates a user making a request to the URL. The function makes a GET request to the URL, measures the response time, and appends the response time to a list called response_times. The function also increments the progress counter for the corresponding thread. The function takes three arguments: thread_id, progress, and response_times.
- The script defines a function called run_threads() that splits the load among multiple threads. The function creates a list to hold the threads, starts each thread, and waits for all threads to finish. The function takes two arguments: progress and response_times.
- The script defines a function called run_load_test() that runs the load test. The function initializes the response_times list and a progress list that will keep track of the progress for each thread. The function then starts a progress bar using the tqdm module and enters a loop that runs until all users have been simulated. In each iteration of the loop, the function calls run_threads() to split the load among multiple threads, updates the progress bar, and waits for the threads to catch up.
Read the full article
0 notes