#dataops
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
What sets Konnect Insights apart from other data orchestration and analysis tools available in the market for improving customer experiences in the aviation industry?
I can highlight some general factors that may set Konnect Insights apart from other data orchestration and analysis tools available in the market for improving customer experiences in the aviation industry. Keep in mind that the competitive landscape and product offerings may have evolved since my last knowledge update. Here are some potential differentiators:

Aviation Industry Expertise: Konnect Insights may offer specialized features and expertise tailored to the unique needs and challenges of the aviation industry, including airports, airlines, and related businesses.
Multi-Channel Data Integration: Konnect Insights may excel in its ability to integrate data from a wide range of sources, including social media, online platforms, offline locations within airports, and more. This comprehensive data collection can provide a holistic view of the customer journey.
Real-Time Monitoring: The platform may provide real-time monitoring and alerting capabilities, allowing airports to respond swiftly to emerging issues or trends and enhance customer satisfaction.
Customization: Konnect Insights may offer extensive customization options, allowing airports to tailor the solution to their specific needs, adapt to unique workflows, and focus on the most relevant KPIs.
Actionable Insights: The platform may be designed to provide actionable insights and recommendations, guiding airports on concrete steps to improve the customer experience and operational efficiency.
Competitor Benchmarking: Konnect Insights may offer benchmarking capabilities that allow airports to compare their performance to industry peers or competitors, helping them identify areas for differentiation.
Security and Compliance: Given the sensitive nature of data in the aviation industry, Konnect Insights may include robust security features and compliance measures to ensure data protection and adherence to industry regulations.
Scalability: The platform may be designed to scale effectively to accommodate the data needs of large and busy airports, ensuring it can handle high volumes of data and interactions.
Customer Support and Training: Konnect Insights may offer strong customer support, training, and consulting services to help airports maximize the value of the platform and implement best practices for customer experience improvement.
Integration Capabilities: It may provide seamless integration with existing airport systems, such as CRM, ERP, and database systems, to ensure data interoperability and process efficiency.
Historical Analysis: The platform may enable airports to conduct historical analysis to track the impact of improvements and initiatives over time, helping measure progress and refine strategies.
User-Friendly Interface: Konnect Insights may prioritize a user-friendly and intuitive interface, making it accessible to a wide range of airport staff without requiring extensive technical expertise.

It's important for airports and organizations in the aviation industry to thoroughly evaluate their specific needs and conduct a comparative analysis of available solutions to determine which one aligns best with their goals and requirements. Additionally, staying updated with the latest developments and customer feedback regarding Konnect Insights and other similar tools can provide valuable insights when making a decision.
#DataOrchestration#DataManagement#DataOps#DataIntegration#DataEngineering#DataPipeline#DataAutomation#DataWorkflow#ETL (Extract#Transform#Load)#DataIntegrationPlatform#BigData#CloudComputing#Analytics#DataScience#AI (Artificial Intelligence)#MachineLearning#IoT (Internet of Things)#DataGovernance#DataQuality#DataSecurity
2 notes
·
View notes
Text
Beyond the Pipeline: Choosing the Right Data Engineering Service Providers for Long-Term Scalability
Introduction: Why Choosing the Right Data Engineering Service Provider is More Critical Than Ever
In an age where data is more valuable than oil, simply having pipelines isn’t enough. You need refineries, infrastructure, governance, and agility. Choosing the right data engineering service providers can make or break your enterprise’s ability to extract meaningful insights from data at scale. In fact, Gartner predicts that by 2025, 80% of data initiatives will fail due to poor data engineering practices or provider mismatches.
If you're already familiar with the basics of data engineering, this article dives deeper into why selecting the right partner isn't just a technical decision—it’s a strategic one. With rising data volumes, regulatory changes like GDPR and CCPA, and cloud-native transformations, companies can no longer afford to treat data engineering service providers as simple vendors. They are strategic enablers of business agility and innovation.
In this post, we’ll explore how to identify the most capable data engineering service providers, what advanced value propositions you should expect from them, and how to build a long-term partnership that adapts with your business.
Section 1: The Evolving Role of Data Engineering Service Providers in 2025 and Beyond
What you needed from a provider in 2020 is outdated today. The landscape has changed:
📌 Real-time data pipelines are replacing batch processes
📌 Cloud-native architectures like Snowflake, Databricks, and Redshift are dominating
📌 Machine learning and AI integration are table stakes
📌 Regulatory compliance and data governance have become core priorities
Modern data engineering service providers are not just builders—they are data architects, compliance consultants, and even AI strategists. You should look for:
📌 End-to-end capabilities: From ingestion to analytics
📌 Expertise in multi-cloud and hybrid data ecosystems
📌 Proficiency with data mesh, lakehouse, and decentralized architectures
📌 Support for DataOps, MLOps, and automation pipelines
Real-world example: A Fortune 500 retailer moved from Hadoop-based systems to a cloud-native lakehouse model with the help of a modern provider, reducing their ETL costs by 40% and speeding up analytics delivery by 60%.
Section 2: What to Look for When Vetting Data Engineering Service Providers
Before you even begin consultations, define your objectives. Are you aiming for cost efficiency, performance, real-time analytics, compliance, or all of the above?
Here’s a checklist when evaluating providers:
📌 Do they offer strategic consulting or just hands-on coding?
📌 Can they support data scaling as your organization grows?
📌 Do they have domain expertise (e.g., healthcare, finance, retail)?
📌 How do they approach data governance and privacy?
📌 What automation tools and accelerators do they provide?
📌 Can they deliver under tight deadlines without compromising quality?
Quote to consider: "We don't just need engineers. We need architects who think two years ahead." – Head of Data, FinTech company
Avoid the mistake of over-indexing on cost or credentials alone. A cheaper provider might lack scalability planning, leading to massive rework costs later.
Section 3: Red Flags That Signal Poor Fit with Data Engineering Service Providers
Not all providers are created equal. Some red flags include:
📌 One-size-fits-all data pipeline solutions
📌 Poor documentation and handover practices
📌 Lack of DevOps/DataOps maturity
📌 No visibility into data lineage or quality monitoring
📌 Heavy reliance on legacy tools
A real scenario: A manufacturing firm spent over $500k on a provider that delivered rigid ETL scripts. When the data source changed, the whole system collapsed.
Avoid this by asking your provider to walk you through previous projects, particularly how they handled pivots, scaling, and changing data regulations.
Section 4: Building a Long-Term Partnership with Data Engineering Service Providers
Think beyond the first project. Great data engineering service providers work iteratively and evolve with your business.
Steps to build strong relationships:
📌 Start with a proof-of-concept that solves a real pain point
📌 Use agile methodologies for faster, collaborative execution
📌 Schedule quarterly strategic reviews—not just performance updates
📌 Establish shared KPIs tied to business outcomes, not just delivery milestones
📌 Encourage co-innovation and sandbox testing for new data products
Real-world story: A healthcare analytics company co-developed an internal patient insights platform with their provider, eventually spinning it into a commercial SaaS product.
Section 5: Trends and Technologies the Best Data Engineering Service Providers Are Already Embracing
Stay ahead by partnering with forward-looking providers who are ahead of the curve:
📌 Data contracts and schema enforcement in streaming pipelines
📌 Use of low-code/no-code orchestration (e.g., Apache Airflow, Prefect)
📌 Serverless data engineering with tools like AWS Glue, Azure Data Factory
📌 Graph analytics and complex entity resolution
📌 Synthetic data generation for model training under privacy laws
Case in point: A financial institution cut model training costs by 30% by using synthetic data generated by its engineering provider, enabling robust yet compliant ML workflows.
Conclusion: Making the Right Choice for Long-Term Data Success
The right data engineering service providers are not just technical executioners—they’re transformation partners. They enable scalable analytics, data democratization, and even new business models.
To recap:
📌 Define goals and pain points clearly
📌 Vet for strategy, scalability, and domain expertise
📌 Watch out for rigidity, legacy tools, and shallow implementations
📌 Build agile, iterative relationships
📌 Choose providers embracing the future
Your next provider shouldn’t just deliver pipelines—they should future-proof your data ecosystem. Take a step back, ask the right questions, and choose wisely. The next few quarters of your business could depend on it.
#DataEngineering#DataEngineeringServices#DataStrategy#BigDataSolutions#ModernDataStack#CloudDataEngineering#DataPipeline#MLOps#DataOps#DataGovernance#DigitalTransformation#TechConsulting#EnterpriseData#AIandAnalytics#InnovationStrategy#FutureOfData#SmartDataDecisions#ScaleWithData#AnalyticsLeadership#DataDrivenInnovation
0 notes
Text
The Data Value Chain: Integrating DataOps, MLOps, and AI for Enterprise Growth
Unlocking Enterprise Value: Maximizing Data Potential with DataOps, MLOps, and AI
In today’s digital-first economy, data has emerged as the most valuable asset for enterprises striving to gain competitive advantage, improve operational efficiency, and foster innovation. However, the sheer volume, velocity, and variety of data generated by modern organizations create complex challenges around management, integration, and actionable insights. To truly harness the potential of enterprise data, businesses are increasingly turning to integrated frameworks such as DataOps, MLOps, and Artificial Intelligence (AI). These methodologies enable streamlined data workflows, robust machine learning lifecycle management, and intelligent automation — together transforming raw data into powerful business outcomes.

The Data Challenge in Modern Enterprises
The explosion of data from sources like IoT devices, customer interactions, social media, and internal systems has overwhelmed traditional data management practices. Enterprises struggle with:
Data silos causing fragmented information and poor collaboration.
Inconsistent data quality leading to unreliable insights.
Slow, manual data pipeline processes delaying analytics.
Difficulty deploying, monitoring, and scaling machine learning models.
Limited ability to automate decision-making in real-time.
To overcome these barriers and unlock data-driven innovation, enterprises must adopt holistic frameworks that combine process automation, governance, and advanced analytics at scale. This is where DataOps, MLOps, and AI converge as complementary approaches to maximize data potential.
DataOps: Accelerating Reliable Data Delivery
DataOps, short for Data Operations, is an emerging discipline inspired by DevOps principles in software engineering. It emphasizes collaboration, automation, and continuous improvement to manage data pipelines efficiently and reliably.
Key aspects of DataOps include:
Automation: Automating data ingestion, cleansing, transformation, and delivery pipelines to reduce manual effort and errors.
Collaboration: Bridging gaps between data engineers, analysts, scientists, and business teams for seamless workflows.
Monitoring & Quality: Implementing real-time monitoring and testing of data pipelines to ensure quality and detect anomalies early.
Agility: Enabling rapid iterations and continuous deployment of data workflows to adapt to evolving business needs.
By adopting DataOps, enterprises can shorten the time-to-insight and create trust in the data that powers analytics and machine learning. This foundation is critical for building advanced AI capabilities that depend on high-quality, timely data.
MLOps: Operationalizing Machine Learning at Scale
Machine learning (ML) has become a vital tool for enterprises to extract predictive insights and automate decision-making. However, managing the entire ML lifecycle — from model development and training to deployment, monitoring, and retraining — is highly complex.
MLOps (Machine Learning Operations) extends DevOps principles to ML systems, offering a standardized approach to operationalize ML models effectively.
Core components of MLOps include:
Model Versioning and Reproducibility: Tracking different model versions, datasets, and training parameters to ensure reproducibility.
Continuous Integration and Delivery (CI/CD): Automating model testing and deployment pipelines for faster, reliable updates.
Monitoring and Governance: Continuously monitoring model performance and detecting data drift or bias for compliance and accuracy.
Collaboration: Facilitating cooperation between data scientists, engineers, and IT teams to streamline model lifecycle management.
Enterprises employing MLOps frameworks can accelerate model deployment from weeks to days or hours, improving responsiveness to market changes. MLOps also helps maintain trust in AI-powered decisions by ensuring models perform reliably in production environments.
AI: The Catalyst for Intelligent Enterprise Transformation
Artificial Intelligence acts as the strategic layer that extracts actionable insights and automates complex tasks using data and ML models. AI capabilities range from natural language processing and computer vision to predictive analytics and recommendation systems.
When powered by DataOps and MLOps, AI solutions become more scalable, trustworthy, and business-aligned.
Examples of AI-driven enterprise benefits include:
Enhanced Customer Experiences: AI chatbots, personalized marketing, and sentiment analysis deliver tailored, responsive interactions.
Operational Efficiency: Predictive maintenance, process automation, and intelligent workflows reduce costs and downtime.
Innovation Enablement: AI uncovers new business opportunities, optimizes supply chains, and supports data-driven product development.
By integrating AI into enterprise processes with the support of disciplined DataOps and MLOps practices, businesses unlock transformative potential from their data assets.
Synergizing DataOps, MLOps, and AI for Maximum Impact
While each discipline delivers unique value, the real power lies in combining DataOps, MLOps, and AI into a cohesive strategy.
Reliable Data Pipelines with DataOps: Provide high-quality, timely data needed for model training and real-time inference.
Scalable ML Model Management via MLOps: Ensure AI models are robust, continuously improved, and safely deployed.
Intelligent Automation with AI: Drive business outcomes by embedding AI insights into workflows, products, and customer experiences.
Together, these frameworks enable enterprises to build a continuous intelligence loop — where data fuels AI models that automate decisions, generating new data and insights in turn. This virtuous cycle accelerates innovation, operational agility, and competitive differentiation.
Practical Steps for Enterprises to Maximize Data Potential
To implement an effective strategy around DataOps, MLOps, and AI, enterprises should consider the following:
Assess Current Data Maturity: Understand existing data infrastructure, pipeline bottlenecks, and analytics capabilities.
Define Business Objectives: Align data and AI initiatives with measurable goals like reducing churn, increasing revenue, or improving operational metrics.
Invest in Automation Tools: Adopt data pipeline orchestration platforms, ML lifecycle management tools, and AI frameworks that support automation and collaboration.
Build Cross-functional Teams: Foster collaboration between data engineers, scientists, IT, and business stakeholders.
Implement Governance and Compliance: Establish data quality standards, security controls, and model audit trails to maintain trust.
Focus on Continuous Improvement: Use metrics and feedback loops to iterate on data pipelines, model performance, and AI outcomes.
The Future Outlook
As enterprises continue their digital transformation journeys, the convergence of DataOps, MLOps, and AI will be essential for unlocking the full value of data. Organizations that successfully adopt these integrated frameworks will benefit from faster insights, higher quality models, and more impactful AI applications. This foundation will enable them to adapt rapidly in a dynamic market landscape and pioneer new data-driven innovations.
Read Full Article : https://businessinfopro.com/maximize-enterprise-data-potential-with-dataops-mlops-and-ai/
Visit Now: https://businessinfopro.com/
0 notes
Text
Latest Trends in DevOps Services for Cloud Migration (2025)

Cloud migration in 2025 is being shaped by a convergence of advanced DevOps practices and emerging technologies. Here are the most significant trends:
Hybrid and Multi-Cloud Strategies
Organizations are increasingly adopting hybrid and multi-cloud environments to avoid vendor lock-in, optimize workloads, and enhance redundancy. Modern DevOps consulting services are focusing on seamless transitions between on-premises, private, and multiple public clouds, leveraging advanced orchestration tools to automate deployments and ensure compatibility across diverse platforms.
AI-Driven Optimization
Artificial Intelligence is revolutionizing cloud migration. AI-powered tools analyze workloads for optimal placement, predict migration issues, and provide real-time insights for dynamic resource allocation. Post-migration, AI continues to monitor and optimize cloud environments, ensuring ongoing performance and cost efficiency.
Serverless and Cloud-Native DevOps
The adoption of serverless computing and cloud-native architectures is accelerating. Serverless CI/CD pipelines and tools like Kubernetes and Docker are enabling microservices-based deployments, allowing teams to focus on application logic while infrastructure management is automated and scalable.
GitOps and Infrastructure as Code (IaC)
GitOps is becoming a core practice, allowing infrastructure and application code to be managed in version-controlled repositories. This approach ensures consistency, auditability, and rapid recovery, and integrates smoothly with CI/CD and DevSecOps workflows.
Enhanced Security and DevSecOps
Security is being integrated earlier in the migration process through DevSecOps. Advanced security protocols, including Zero Trust Architecture, end-to-end encryption, and AI-driven threat detection, are now standard to protect data and ensure compliance during and after migration.
Cost-Efficiency and FinOps
Migration services are adopting cost-optimization strategies, such as subscription-based pricing and containerization. FinOps practices are being integrated to provide visibility into cloud expenses and help organizations manage and optimize spending.
Sustainability Initiatives
Eco-friendly practices are gaining prominence. Providers are investing in green data centers, carbon footprint monitoring, and sustainable migration processes to address the environmental impact of cloud computing.
Collaboration and Communication Tools
Enhanced collaboration is being facilitated by ChatOps and integrated communication platforms, allowing real-time troubleshooting and deployment commands within familiar messaging interfaces, thus improving agility and response times.
Continuous Improvement and Post-Migration Optimization
DevOps emphasizes continuous monitoring, incident management, and iterative optimization after migration. This ensures that cloud environments are always aligned with business goals and performance expectations.
These trends reflect a holistic approach to cloud migration, where DevOps is not just about automation but also about intelligence, security, sustainability, and collaboration, ensuring organizations achieve agility, resilience, and cost-effectiveness in their cloud journeys.
0 notes
Text
Data observability empowers real‑time visibility into data quality, lineage & access—crucial for trustworthy AI, proactive governance & operational agility. Shift from reactive to intelligent data trust.
0 notes
Text
💻 Scraping the web sounds simple until it isn’t.
Behind every clean dataset is a messy reality: broken scripts, blocked IPs, legal landmines, and sleepless devs.
In our latest blog, we break down the 6 biggest mistakes enterprises make with web scraping, and how to fix them before they break you.
📖 Read it here → https://shorturl.at/qkNi6
0 notes
Text
youtube
Power Platform Bootcamp Buenos Aires
Evento de la comunidad Argentina con grandes sesiones.
El Poder de Python y R en Power BI por Mike Ramirez
Transforme datos con buenas prácticas de Power Query por Ignacio Barrau
Agentes en Power Platform: El Futuro de la IA por Andrés Arias Falcón
Power Virtual Agent - Charlando con tu base de datos por Matias Molina y Nicolas Muñoz
¿Por qué deberían los desarrolladores automatizar? por Mauro Gioberti
Microsoft Fabric + Power BI: Arquitecturas y Licenciamiento - Todo lo que necesitas saber por Gonzalo Bissio y Maximiliano Accotto
El auge de los copilotos: De la adopción del low-code a la maestría en análisis de datos por Gaston Cruz y Alex Rostan
Libérate de las Tareas Repetitivas: Potencia tu Talento con Power Apps y Power Automate por Anderson Estrada
Introducción a Microsoft Fabric - Data analytics para la era de al Inteligencia Artificial por Javier Villegas
Tu Primer despliegue con PBIP Power BI Control de versiones CI/CD GIT en GITHUB por Vicente Antonio Juan Magallanes
Espero que lo disfruten
#power bi#power platform#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tips#power bi tutorial#power bi training#fabric#microsoft fabric#dataops#power bi cicd#Youtube
0 notes
Text

Agile data systems enable businesses to innovate and scale with confidence. At #RoundTheClockTechnologies, data engineering services are designed to provide clean, integrated, and business-aligned datasets that fuel innovation across every department. From setting up reliable data lakes to configuring BI-friendly data marts, our solutions bridge the gap between raw inputs and strategic outcomes.
We automate complex transformations, eliminate data duplication, and ensure that every pipeline is optimized for speed and accuracy. Leveraging platforms like AWS, Snowflake, and Azure, we create secure and high-performing data environments tailored to business needs. Whether supporting real-time analytics or feeding predictive models, our goal is to help organizations unlock the full value of their data assets—efficiently, consistently, and securely.
Learn more about our data engineering services at https://rtctek.com/data-engineering-services/
#rtctek#roundtheclocktechnologies#dataengineering#dataanalytics#datadriven#etlprocesses#cloudataengineering#dataintegration#businessintelligence#dataops
0 notes
Text
In today’s world, data is considered one of the most valuable assets any business can have. However, to truly unlock the power of data, it’s not enough to simply collect it—organizations need to ensure that the data they are working with is accurate, consistent, and reliable. That’s where Data Quality Observability comes in.
Data Quality Observability is the ability to monitor, understand, and proactively manage the state of data across an entire ecosystem. With the growing complexity of data pipelines and the increasing reliance on data-driven decisions, organizations can no longer afford to ignore the health of their data. Data quality observability helps businesses identify issues before they impact operations, making it a critical part of any data strategy.
#datagaps#data quality#data#dataops#dataops suite#data quality observability#QA tester#Data Analysts#BI Experts
0 notes
Text
𝐓𝐡𝐞 𝐔𝐥𝐭𝐢𝐦𝐚𝐭𝐞 𝐃𝐚𝐭𝐚 𝐏𝐥𝐚𝐲𝐛𝐨𝐨𝐤 𝐢𝐧 2025 (𝐖𝐡𝐚𝐭'𝐬 𝐈𝐧, 𝐖𝐡𝐚𝐭'𝐬 𝐎𝐮𝐭)
The modern data stack is evolving—fast. In this video, we’ll break down the essential tools, trends, and architectures defining data in 2025. From Snowflake vs Databricks to ELT 2.0, metadata layers, and real-time infra—this is your executive cheat sheet.
Whether you're building a data platform, leading a team, or just staying ahead, this is the future-proof playbook.
Watch more https://youtu.be/EyTmxn4xHrU
#moderndatastack#datainfrastructure#dataengineering#dataanalytics#elt#datapipeline#dbt#snowflake#databricks#dagster#realdata#data2025#futureofdata#dataops#apacheiceberg#duckdb#vectordatabase#langchain#analyticsstack#dataarchitecture
0 notes
Text
Maven Essential Tutorial for Beginners with Demo 2021 | Part -1
AiOps & MLOps School empowers IT professionals through hands-on training, certifications, and expert mentorship, combining practical skills with industry insights. We offer training, certification, guidance, and consulting for DevOps, Big Data, Cloud, dataops, AiOps, MLOps, DevSecOps, GitOps, DataOps, ITOps, SysOps, SecOps, ModelOps, NoOps, FinOps, XOps, BizDevOps, CloudOps, SRE and PlatformOps. 🔔 Don't Miss Out! Hit Subscribe and Ring the Bell! 🔔 👉 Subscribe Now
0 notes
Text
0 notes
Text

Siloed data can hinder your journey to becoming a truly data-driven business. DataOps accelerates this process by bringing Data and Ops teams together on a unified platform. This collaboration streamlines workflows, enabling data to flow through the pipeline faster and continuously delivering actionable insights and measurable value to your business. Take a look at this infographic for a quick introduction to DataOps.
0 notes
Text
Creole Studios Launches Comprehensive Data Engineering Services with Azure Databricks Partnership
Creole Studios introduces its cutting-edge Data Engineering Services, aimed at empowering organizations to extract actionable insights from their data. Backed by certified experts and a strategic partnership with Azure Databricks, we offer comprehensive solutions spanning data strategy, advanced analytics, and secure data warehousing. Unlock the full potential of your data with Creole Studios' tailored data engineering services, designed to drive innovation and efficiency across industries.

#DataEngineering#BigDataAnalytics#DataStrategy#DataOps#DataQuality#AzureDatabricks#DataWarehousing#MachineLearning#DataAnalytics#BusinessIntelligence
0 notes
Text

Why Big Data needs DevOps
#BigDataDevOps#DataOps#TechIntegration#DataEngineering#DevOpsCulture#DataScience#ContinuousIntegration#DataManagement
0 notes
Text
Estrategia para licencias PowerBi - Fabric
La popularidad de Fabric no para de extenderse y eso hace que cada vez más aparezcan confusiones y dudas sobre licencias. Cada día llegan más dudas sobre el formato de licencias y como encaja lo nuevo en lo viejo. Dentro de esas dudas aparecen muchas alternativas para manejo de licencias.
En este artículo vamos a hablar de puntos medios y grises para optimizar costos de nuestras licencias encontrando el mejor balance con los nuevos planes que nos ofrece Fabric.
Primero vamos con conocimientos básicos de licencias en este antiguo artículo que escribí. En el mismo vamos a conocer detalles de las licencias disponibles en julio 2024.
Si ya conocen las de PowerBi, lo nuevo es Fabric. Una licencia por capacidad que viene a expandir los artefactos o contenidos que podemos crear dentro de un área de trabajo. Sus planes inician con valores más económicos que las capacidades anteriores, lo que permiten que todo tipo de organización pueda acceder al uso de éstos artefactos. Sin embargo, el uso de los tradicionales contenidos de PowerBi siguen bajo el mismo esquema.
La estrategía de optimización se base específicamente en los usuarios. Si tenemos capacidades dedicadas... ¿Por qué pagamos licencias por usuarios? esta es la pregunta que trae el principal contexto y razón del artículo. A las organizaciones les cuesta este concepto, más aún viendo que los contenidos de Fabric no necesitan licencias de usuario. No necesitamos una licencia PRO para desarrollar un notebook, escribir en Onelake o consultar un warehouse con SQL. Para resolver esta paradoja vamos a dividir nuestro enfoque en los dos tipos de usuarios, desarrolladores y visores.
Enfoque de Visores
Algo que suele trae mucho dolor a organizaciones que usan PowerBi es que los visores en entornos de capacidad compartida (pro o ppu), tengan que pagar licencia. Uno puede pensar que pagando una "Capacidad Dedicada" como premium lo soluciona, sin embargo premium va a desaparecer y quedará Fabric. Muchos podrán pensar que esta es la solución definitiva, puesto que Fabric comienza con planes muy económicos, pero no es cierto. La característica de compartir con usuarios gratuitos comienza en un plan F64, cuyo costo ronda entre 5000 y 8000 dolares (dependiendo el tipo de pago). Lo que nos hace pensar que valdría la pena si nuestra operación interna cuenta con más de 500 usuarios visores de PowerBi (puesto que una licencia pro sale 10 dolares). Ciertamente, un número que solo grandes empresas pueden considerar.
Entonces, ¿Qué hacemos cuando no podemos pagar ese monto? Si podemos comprar capacidades dedicadas más chicas, ¿Cómo podríamos compartir a usuarios visores sin pagarles licencias Pro? La respuesta es una característica bastante olvidada en el entorno de analytics. Estoy hablando de la feature de "Embedded". PowerBi cuenta con una compleja pero poderosa posibilidad de embeber informes en aplicaciones web con grandes posibilidades. Una de esas posibilidades es delegar la seguridad y loguear a la aplicación que refleja los informes. De ese modo, podríamos compartir a todos los usuarios visores que querramos sin pagar licencias. Sin embargo, no es tan simple puesto que necesitaríamos un potente equipo de desarrollo que construya esta web app aprendiendo todos los enfoques de power bi con especial atención a la seguridad, dado que ahora es responsabilidad nuestra (nos la delega microsoft al usar embedded).
Si no tenemos equipo de desarrollo y queremos aprovechar esa capacidad. ¿Cómo lo resolvemos?. La opción más viable sería comprando un producto de un tercero. Varias instituciones proveen este tipo de software. Por ejemplo, una que conozco en español es PiBi. PiBi es una plataforma web como servicio (SaaS) que usa la característica de Power Bi Embedded. Una construcción que interactúa con tu entorno de Azure y te permite distribuir informes de PowerBi de manera segura, simple y eficiente.
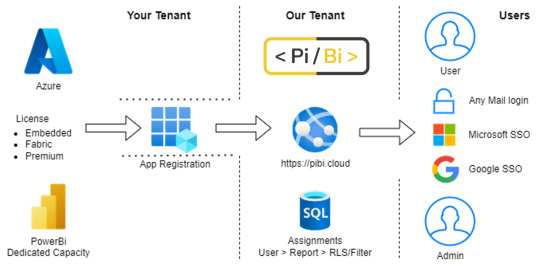
¿Qué ventajas encontramos si nos embarcamos en este camino?
Operación de informes en un solo lugar
Más sencillo de usar que Fabric/PowerBi Service
Compartir con usuarios externos a la organización
Logins SSO Google/Microsoft
Mantener seguridad y privacidad
El requerimiento para usar Embedded es tener una licencia por capacidad. Herramientas como ésts pueden partir de valores como 450 dolares por mes, que junto a una licencia básica de Fabric con pago anual de 150 dolares son 600 dolares. Si nuestra operación de usuarios internos ronda entre 60 y 500 usuarios, encaja perfectamente para optimizar nuestra estrategia de Power Bi. Por supuesto, que habría detalles como si tenemos modelos y mucho volumen de datos, puede que necesitemos un Fabric un poco más elevado, pero deberíamos pensar a ese como costo de almacenamiento y no de distribución de contenido a los usuarios.
Enfoque de desarrolladores
En la mayoría de los casos, lo primero que normalmente tendería a evolucionar, son los visores. Una vez encontrado un punto de madurez en ellos, seguirá esta propuesta. Esto quiere decir que lo más probable es que YA contemos con capacidad dedicada (para usar la feature embedded). Pero no desesperen si no la tienen, esta estretegia es totalmente viable sin capacidad tal como lo explico en este otro artículo. Las estrategias no estan ligadas una a otra, aunque son poderosas juntas.
El eje para liberar a los usuarios desarrolladores de sus licencias es pensar en desarrollo de software convencional. Si pensamos en la industra de software, un desarrollador, sea backend o frontend, tiene como trabajo solamente desarrollar. Su eje y foco esta en construir. Hoy esos roles no hacen integración de soluciones, implementaciones o deploys, puestas en producción, etc. Existen roles como DevOps que ayudan a delegar la construcción final.
Tomando este enfoque como guía, si queremos que los desarrolladores de PowerBi no usen licencias, debemos concentrarnos en lo básico, un repositorio. Hoy Fabric nos da la posibilidad de integrar repositorios de GIT con Áreas de Trabajo. Esto no solo nos ayuda a que el desarrollador ni piense en Fabric o PowerBi Service, sino que también almacena los desarrollos en formato Power Bi Project que nos deja mergear código. Si queremos ver eso en más profundidad pueden abrir éste artículo.
Así los desarrolladores de Power Bi. Solo desarrollarán. Comienzan el día armando o con un pull a su branch de repositorio, comiteando cambios y al terminar un push. Ni piensa ni escucha quienes ven que informes y donde está. Luego podemos pensar en otro perfil que podemos decirle Admin del Area o DataOps que garantice que los reportes están en el lugar apropiado o sean automáticamente deployados. Veamos un poco más gráfico esto:
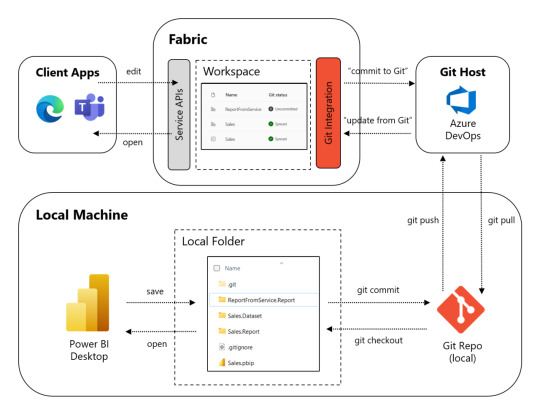
Vean como Local Machine nunca ve Fabric. El desarrollador no necesita ingresar al portal web. Solo necesitamos licencias para DataOps o Administradores de areas. Así es como reducimos licencias y ganamos robustez y soluciones tanto versionables como escalables.
Se que fue mucho texto pero espero que haya sido a meno y les traigan nuevas ideas para optimizar efectivamente la operación y licencias de sus entornos.
#fabric#microsoft fabric#powerbi#power bi#dataops#pibi#ladataweb#power bi embedded#power bi training#power bi tutorial#power bi tips#power bi argentina#power bi cordoba#power bi jujuy#power bi isv
0 notes