
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by pleasantinternetfest and here's what we found interesting.
Average Info
Notes Per Post
3
Likes Per Post
3
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
5 days
Number of Posts By Type
Text
8
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Analysing large data sets using AWS Athena
Handling large datasets can feel overwhelming, especially when you're faced with endless rows of data and complex information. At our company, we faced these challenges head-on until we discovered AWS Athena. Athena transformed the way we handle massive datasets by simplifying the querying process without the hassle of managing servers or dealing with complex infrastructure. In this article, I’ll Walk you through how AWS Athena has revolutionized our approach to data analysis. We’ll explore how it leverages SQL to make working with big data straightforward and efficient. If you’ve ever struggled with managing large datasets and are looking for a practical solution, you’re in the right place.
Efficient Data Storage and Querying
Through our experiences, we found that two key strategies significantly enhanced our performance with Athena: partitioning data and using columnar storage formats like Parquet. These methods have dramatically reduced our query times and improved our data analysis efficiency. Here’s a closer look at how we’ve implemented these strategies:
Data Organization for Partitioning and Parquet
Organize your data in S3 for efficient querying:
s3://your-bucket/your-data/
├── year=2023/
│ ├── month=01/
│ │ ├── day=01/
│ │ │ └── data-file
│ │ └── day=02/
│ └── month=02/
└── year=2024/
└── month=01/
└── day=01/
Preprocessing Data for Optimal Performance
Before importing datasets into AWS Glue and Athena, preprocessing is essential to ensure consistency and efficiency. This involves handling mixed data types, adding date columns for partitioning, and converting files to a format suitable for Athena.
Note: The following steps are optional based on the data and requirements. Use them according to your requirements.
1. Handling Mixed Data Types
To address columns with mixed data types, standardize them to the most common type using the following code snippet:def determine_majority_type(series): # get the types of all non-null values types = series.dropna().apply(type) # count the occurrences of each type type_counts = types.value_counts()
preprocess.py
2. Adding Date Columns for Partitioning
To facilitate partitioning, add additional columns for year, month, and day:def add_date_columns_to_csv(file_path): try: # read the CSV file df = pd.read_csv(file_path)
partitioning.py
3. Converting CSV to Parquet Format
For optimized storage and querying, convert CSV files to Parquet format:def detect_and_convert_mixed_types(df): for col in df.columns: # detect mixed types in the column if df[col].apply(type).nunique() > 1:
paraquet.py
4. Concatenating Multiple CSV Files
To consolidate multiple CSV files into one for Parquet conversion:def read_and_concatenate_csv_files(directory): all_dfs = [] # recursively search for CSV files in the directory
concatenate.py
Step-by-Step Guide to Managing Datasets with AWS Glue and Athena
1. Place Your Source Dataset in S3
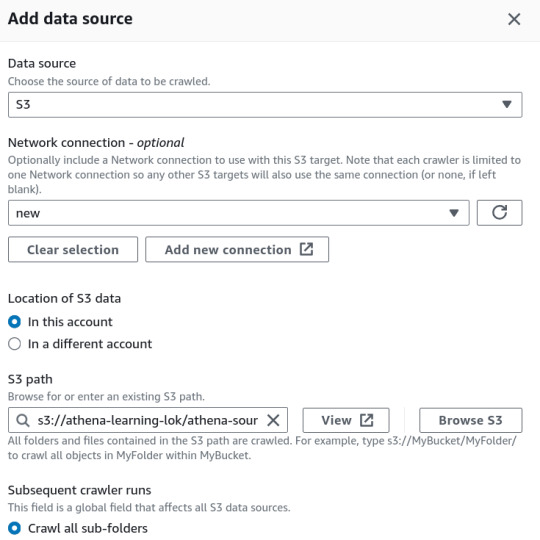
2. Create a Crawler in AWS Glue
In the AWS Glue console, create a new crawler to catalog your data and make it queryable with Athena.
Specify Your S3 Bucket: Set the S3 bucket path as the data source in the crawler configuration.
IAM Role: Assign an IAM role with the necessary permissions to access your S3 bucket and Glue Data Catalog.
3. Set Up the Glue Database
Create a new database in the AWS Glue Data Catalog where your CSV data will be stored. This database acts as a container for your tables.
Database Creation: Go to the AWS Glue Data Catalog section and create a new database.
Crawler Output Configuration: Specify this database for storing the table metadata and optionally provide a prefix for your table names.
4. Configure Crawler Schedule
Set the crawler schedule to keep your data catalog up to date:
Hourly
Daily
Weekly
Monthly
On-Demand
Scheduling the crawler ensures data will be updated to our table, if any updates to existing data or adding of new files etc.
5. Run the Crawler
Initiate the crawler by clicking the "Run Crawler" button in the Glue console. The crawler will analyze your data, determine optimal data types for each column, and create a table in the Glue Data Catalog.
6. Review and Edit the Table Schema
Post-crawler, review and modify the table schema:
Change Data Types: Adjust data types for any column as needed.
Create Partitions: Set up partitions to improve query performance and data organization.

7. Query Your Data with AWS Athena
In the Athena console:
Connect to Glue Database: Use the database created by the Glue Crawler.
Write SQL Queries: Leverage SQL for querying your data directly in Athena.
8. Performance Comparison
After the performance optimizations, we got the following results:
To illustrate it, I ran following queries on 1.6 GB data:
For Parquet data format without partitioning
SELECT * FROM "athena-learn"."parquet" WHERE transdate='2024-07-05';
For Partitioning with CSV

Query Runtime for Parquet Files: 8.748 seconds. Parquet’s columnar storage format and compression contribute to this efficiency.
Query Runtime for Partitioned CSV Files: 2.901 seconds. Partitioning helps reduce the data scanned, improving query speed.
Data Scanned for Paraquet Files: 60.44MB
Data Scanned for Partitioned CSV Files: 40.04MB
Key Insight: Partitioning CSV files improves query performance, but using Parquet files offers superior results due to their optimized storage and compression features.
9. AWS Athena Pricing and Optimization
AWS Athena pricing is straightforward: you pay $5.00 per terabyte (TB) of data scanned by your SQL queries. However, you can significantly reduce costs and enhance query performance by implementing several optimization strategies.
Conclusion
AWS Athena offers a powerful, serverless SQL interface for querying large datasets. By adopting best practices in data preprocessing, organization, and Athena usage, you can manage and analyze your data efficiently without the overhead of complex infrastructure.
0 notes
Text

Unified Lending Interface is set to be launched by RBI
0 notes

Text
Unified Lending Interface (ULI)
The Unified Lending Interface (ULI) is an innovative digital platform by Reserve Bank of India (RBI), designed to streamline the credit appraisal process by enabling the seamless and consent-based flow of digital information between various data service providers and lenders. RBI launched it as pilot project - Public Tech Platform in 2023, now set to launch as Unified Lending Interface.
How It Works?
A significant challenge in digital credit delivery is the fragmentation of essential data across various entities, including Central and State governments, Account aggregators, banks, and credit information companies, each operating within separate systems. This fragmentation complicates lenders' ability to efficiently access the comprehensive data required for credit appraisal. As a result, the lending process is often delayed, impeding the timely and seamless execution of rule-based lending, especially in situations where prompt decisions are crucial.
The Unified Lending Interface (ULI) addresses the challenge of fragmented data by creating a centralized platform that integrates disparate data sources. Through ULI, lenders gain unified access to both financial and non-financial customer data, including critical information such as land records, all through a consent-based system. This streamlined access facilitates a smoother and faster credit appraisal process, accelerating decision-making and ensuring timely credit delivery.
At the core of ULI's architecture are common and standardized APIs (Application Programming Interface). These APIs are designed with a 'plug and play' approach, making it incredibly easy for lenders to tap into diverse information sources without the usual hassle.

ULI – What difference does it make in Digital Lending?
1. Friction-less credit:
The Unified Lending Interface (ULI) is expected to reduce paperwork and waiting times for loan applications. By minimizing the need for extensive documentation, ULI aims to streamline the process and expedite responses from lenders, ensuring a smoother and more effortless experience for borrowers.
2. Cutting Down Loan Turnaround Time (TAT):
By consolidating data from multiple sources, the Unified Lending Interface (ULI) significantly reduces the time needed for credit evaluation. This streamlined approach allows for quicker assessment of loan applications, speeding up the overall loan processing time. As a result, borrowers can expect faster decisions and reduced turnaround times for their credit requests.
3. Meeting unmet credit needs:
The Unified Lending Interface (ULI) is expected to address the significant unmet demand for credit in sectors like agriculture and Micro, Small, and Medium Enterprises (MSMEs). By streamlining access to loans and simplifying the application process, ULI will make it easier for these underserved sectors to obtain the financing they need, fostering growth and development.
4. Seamless and Consent-Driven Data Flow:
The Unified Lending Interface (ULI) enables a smooth, consent-based transfer of both financial and non-financial data, stored in various silos including state land records. This consolidated , digital data is easily accessible to lenders, allowing for more informed and efficient credit assessments while ensuring borrower consent and data privacy.
Conclusion:
The Unified Lending Interface (ULI) is set to revolutionize India's digital lending ecosystem with its upcoming launch by the Reserve Bank of India (RBI). By creating a centralized, consent-driven platform, ULI aims to overcome the challenges of fragmented data and reduce loan processing times. This initiative promises to enhance the borrower experience and ensure timely credit access for underserved sectors, driving greater financial inclusion and supporting the growth of industries like agriculture and MSMEs.
0 notes
Text

Key Features of Unified Data Analytics Platform
With the rapid progression of digital lending technologies, staying ahead requires leveraging the best tools and insights. Our Unified Data Analytics Platform integrates data from LMS, LOS, CRM, and other sources into a cohesive system, enabling accurate credit assessments and actionable insights. With real-time analytics, automated reporting, customizable dashboards, robust security features, and effortless scalability, our platform is designed to optimize your operations and support your long-term growth objectives.
For more information, contact us at https://www.aptuz.com/contact-us/
0 notes
Text

As the financial landscape rapidly progresses, digital lending is revolutionizing the way we access credit. But to truly unlock its potential, lenders need specialized data analytics. By harnessing the power of advanced analytics, digital lenders can optimize costs, enhance operational efficiency, gain a competitive edge, and make real-time decisions that better serve their customers. Let’s explore how specialized data analytics is transforming digital lending and driving the industry forward.
To leverage the benefits of Unified Data Analytics platform: Contact us at https://www.aptuz.com/contact-us/
0 notes
Text
Big Data Analytics: A Game changer for lenders
As digital lending continues to grow and evolve, the strategic application of data analytics is becoming increasingly crucial for lenders seeking to stay ahead of the competition and deliver exceptional value to their customers. Data analytics can put the lender ahead of the following aspects:
1) Predicting Creditworthiness:
According to Moody, residential mortgage-backed security issuances for non-QM (non-qualified mortgage) loans climbed from $570 million in 2016 to more than $25 billion in 2021. Because many non-QM consumers lack a traditional credit history, mortgage lenders turn to new ways to determine trustworthiness. Big data and data analytics can assist in filling that void.
Through big data and predictive analytics, they can use these systems to access a wide range of internal and publicly available data, ranging from physical addresses to social media data to email accounts to phone numbers and more, to identify any hidden patterns within loan applications that may point to fraudulent information or activity.
Data Analytics can also be used to determine the probability of delinquency. Sometimes some customers might pose as perfect customers to get a loan. Here, data analytics help mortgage companies by estimating the probability of delinquency.
The prediction of delinquency is based on previous transactions and loans. It also includes how many times the borrower has not paid the full amount earlier.
2) Strategic Advantage:
Lenders equipped with advanced data analytics hold a significant competitive edge over those who do not.
According to Ellie Mae’s Data & Analytics survey, lenders are all over the map when it comes to their data and analytics journeys.
Descriptive Phase: 37% of lenders have just begun their journey. They can see simple facts about past business performance.
Analytical Phase: 36% of lenders have reached the stage where they not only understand what happened but why it happened, too.
Predictive Phase: 24% percent of lenders have taken it a step further and are using data to see patterns and meaningful trends that affect their business.
Prescriptive Phase: Only 3% of lenders are far enough along their data journey to conduct the type of prescriptive-level analyses that can inform how they should make future decisions, for example, recommending loan programs for specific applicants based on a set of predetermined factors.
Lenders that effectively leverage advanced data analytics can outperform their competitors by offering better risk management, personalized services, operational efficiencies, and strategic insights, thus establishing themselves as leaders in the industry
3) Be Tech-Smart in a Digital Age:
With rapid digitalization, the sheer amount of data that lenders need to manage can be overwhelming. But with the rights tools and technology, lenders can harness the power of their data to make data-driven decisions and optimize their operations. The biggest trend seen in the industry is using technology to underwrite better and give a seamless experience to customers.
Technology plays a vital role in combating mortgage fraud, which has become a growing concern in the industry. AI-powered fraud detection systems can analyze large datasets to identify potential red flags and suspicious activities
By offering digital self-service options, lenders can enhance the overall borrower experience and attract tech-savvy customers.
The mortgage industry is subject to numerous regulations and compliance requirements. By automating compliance processes, lenders can reduce the risk of errors, improve audit trails and maintain regulatory compliance more effectively.
According to Economic times BFSI report, the use of AI and ML streamline loan approvals, predict default risks and detect fraud making the process faster and more secure.
4) Early detection of fraud:
According to the Federal Trade Commission’s 2022 consumer Sentinel Network Data book, consumers lost $ 5.8 billion to fraud the year before. Meanwhile, mortgage lenders are often responsible for the unpaid loans that result from fraudulent schemes.
Data analytics are instrumental in detecting and preventing mortgage fraud — from schemes that involve false information on borrower applications to document fabrication to identify theft to wire fraud.
By analyzing borrower data, identifying anomalies, and cross-referencing information, lenders can flag suspicious activities early in the application process.
This proactive approach saves lenders from financial losses and protects borrowers from potentially harmful fraudulent schemes ultimately resulting in minimization of potential risks.
5) Data driven decision making:
Mortgage lenders gather extensive data from loan applications, enhancing processing efficiency while navigating regulatory and technical challenges. Data-driven decision-making (DDDM) fosters innovation and efficiency, creating a seamless home ownership journey for all stakeholders.
Every year, lenders invest trillions to modernize their businesses, focusing on digitalization and automation. Despite these efforts, a lack of data culture hampers metrics like cycle time and approval rates. Lenders handle vast amounts of data, with each mortgage application containing at least 250 data points. The challenges they face include:
Siloed Data: Millions of borrowers’ data stored in various systems and formats, making visualization difficult.
Multiple Formats: Data from different channels, requiring digitization through OCR (Optical Character Recognition) systems.
Continuous Ingestion: Lenders continuously receive data in real time and in batches from multiple sources and there is continuous data flow.
Lenders with data analytics can leverage a 360-degree view of customers to personalize offers and tailor-fit prices within regulatory constraints through data-driven decision-making (DDDM). This involves identifying business problems, sourcing quality data, and using visual analytics to develop actionable insights.
In conclusion, Advanced data analytics allows lenders to boost conversions and revenue with inclusive mortgage products, streamline operations by removing redundant processes, and accurately detect fraud. It also aids in proactive customer relationship management, retaining clients and preventing revenue loss, ultimately enhancing efficiency and competitive positioning in the lending industry.
0 notes
Text

Data Fragmentation
This is the list of challenges that the businesses face due to data distribution across multiple systems in the digital lending industry
3 notes
·
View notes