
priyaaank
19 posts
I am Priyank. A polyglot programmer @Sahaj with love for technology
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by priyaaank and here's what we found interesting.
Average Info
Notes Per Post
34
Likes Per Post
30
Reblog Per Post
4
Reply Per Post
0
Time Between Posts
5 months
Number of Posts By Type
Text
15
Photo
1
Quote
1
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Strangulating bare-metal infrastructure to Containers
Change is inevitable. Change for the better is a full-time job ~ Adlai Stevenson I
We run a successful digital platform for one of our clients. It manages huge amounts of data aggregation and analysis in Out of Home advertising domain.
The platform had been running successfully for a while. Our original implementation was focused on time to market. As it expanded across geographies and impact, we decided to shift our infrastructure to containers for reasons outlined later in the post. Our day to day operations and release cadence needed to remain unaffected during this migration. To ensure those goals, we chose an approach of incremental strangulation to make the shift.
Strangler pattern is an established pattern that has been used in the software industry at various levels of abstraction. Documented by Microsoft and talked about by Martin Fowler are just two examples. The basic premise is to build an incremental replacement for an existing system or sub-system. The approach often involves creating a Strangler Facade that abstracts both existing and new implementations consistently. As features are re-implemented with improvements behind the facade, the traffic or calls are incrementally routed via new implementation. This approach is taken until all the traffic/calls go only via new implementation and old implementation can be deprecated. We applied the same approach to gradually rebuild the infrastructure in a fundamentally different way. Because of the approach taken our production disruption was under a few minutes.
This writeup will explore some of the scaffolding we did to enable the transition and the approach leading to a quick switch over with confidence. We will also talk about tech stack from an infrastructure point of view and the shift that we brought in. We believe the approach is generic enough to be applied across a wide array of deployments.
The as-is
###Infrastructure
We rely on Amazon Web Service to do the heavy lifting for infrastructure. At the same time, we try to stay away from cloud-provider lock-in by using components that are open source or can be hosted independently if needed. Our infrastructure consisted of services in double digits, at least 3 different data stores, messaging queues, an elaborate centralized logging setup (Elastic-search, Logstash and Kibana) as well as monitoring cluster with (Grafana and Prometheus). The provisioning and deployments were automated with Ansible. A combination of queues and load balancers provided us with the capability to scale services. Databases were configured with replica sets with automated failovers. The service deployment topology across servers was pre-determined and configured manually in Ansible config. Auto-scaling was not built into the design because our traffic and user-base are pretty stable and we have reasonable forewarning for a capacity change. All machines were bare-metal machines and multiple services co-existed on each machine. All servers were organized across various VPCs and subnets for security fencing and were accessible only via bastion instance.
###Release cadence
Delivering code to production early and frequently is core to the way we work. All the code added within a sprint is released to production at the end. Some features can span across sprints. The feature toggle service allows features to be enabled/disable in various environments. We are a fairly large team divided into small cohesive streams. To manage release cadence across all streams, we trigger an auto-release to our UAT environment at a fixed schedule at the end of the sprint. The point-in-time snapshot of the git master is released. We do a subsequent automated deploy to production that is triggered manually.
CI and release pipelines
Code and release pipelines are managed in Gitlab. Each service has GitLab pipelines to test, build, package and deploy. Before the infrastructure migration, the deployment folder was co-located with source code to tag/version deployment and code together. The deploy pipelines in GitLab triggered Ansible deployment that deployed binary to various environments.

Figure 1 — The as-is release process with Ansible + BareMetal combination
The gaps
While we had a very stable infrastructure and matured deployment process, we had aspirations which required some changes to the existing infrastructure. This section will outline some of the gaps and aspirations.
Cost of adding a new service
Adding a new service meant that we needed to replicate and setup deployment scripts for the service. We also needed to plan deployment topology. This planning required taking into account the existing machine loads, resource requirements as well as the resource needs of the new service. When required new hardware was provisioned. Even with that, we couldn’t dynamically optimize infrastructure use. All of this required precious time to be spent planning the deployment structure and changes to the configuration.
Lack of service isolation
Multiple services ran on each box without any isolation or sandboxing. A bug in service could fill up the disk with logs and have a cascading effect on other services. We addressed these issues with automated checks both at package time and runtime however our services were always susceptible to noisy neighbour issue without service sandboxing.
Multi-AZ deployments
High availability setup required meticulous planning. While we had a multi-node deployment for each component, we did not have a safeguard against an availability zone failure. Planning for an availability zone required leveraging Amazon Web Service’s constructs which would have locked us in deeper into the AWS infrastructure. We wanted to address this without a significant lock-in.
Lack of artefact promotion
Our release process was centred around branches, not artefacts. Every auto-release created a branch called RELEASE that was promoted across environments. Artefacts were rebuilt on the branch. This isn’t ideal as a change in an external dependency within the same version can cause a failure in a rare scenario. Artefact versioning and promotion are more ideal in our opinion. There is higher confidence attached to releasing a tested binary.
Need for a low-cost spin-up of environment
As we expanded into more geographical regions rapidly, spinning up full-fledged environments quickly became crucial. In addition to that without infrastructure optimization, the cost continued to mount up, leaving a lot of room for optimization. If we could re-use the underlying hardware across environments, we could reduce operational costs.
Provisioning cost at deployment time
Any significant changes to the underlying machine were made during deployment time. This effectively meant that we paid the cost of provisioning during deployments. This led to longer deployment downtime in some cases.
Considering containers & Kubernetes
It was possible to address most of the existing gaps in the infrastructure with additional changes. For instance, Route53 would have allowed us to set up services for high availability across AZs, extending Ansible would have enabled multi-AZ support and changing build pipelines and scripts could have brought in artefact promotion.
However, containers, specifically Kubernetes solved a lot of those issues either out of the box or with small effort. Using KOps also allowed us to remained cloud-agnostic for a large part. We decided that moving to containers will provide the much-needed service isolation as well as other benefits including lower cost of operation with higher availability.
Since containers differ significantly in how they are packaged and deployed. We needed an approach that had a minimum or zero impact to the day to day operations and ongoing production releases. This required some thinking and planning. Rest of the post covers an overview of our thinking, approach and the results.
The infrastructure strangulation
A big change like this warrants experimentation and confidence that it will meet all our needs with reasonable trade-offs. So we decided to adopt the process incrementally. The strangulation approach was a great fit for an incremental rollout. It helped in assessing all the aspects early on. It also gave us enough time to get everyone on the team up to speed. Having a good operating knowledge of deployment and infrastructure concerns across the team is crucial for us. The whole team collectively owns the production, deployments and infrastructure setup. We rotate on responsibilities and production support.
Our plan was a multi-step process. Each step was designed to give us more confidence and incremental improvement without disrupting the existing deployment and release process. We also prioritized the most uncertain areas first to ensure that we address the biggest issues at the start itself.
We chose Helm as the Kubernetes package manager to help us with the deployments and image management. The images were stored and scanned in AWS ECR.
The first service
We picked the most complicated service as the first candidate for migration. A change was required to augment the packaging step. In addition to the existing binary file, we added a step to generate a docker image as well. Once the service was packaged and ready to be deployed, we provisioned the underlying Kubernetes infrastructure to deploy our containers. We could deploy only one service at this point but that was ok to prove the correctness of the approach. We updated GitLab pipelines to enable dual deploy. Upon code check-in, the binary would get deployed to existing test environments as well as to new Kubernetes setup.
Some of the things we gained out of these steps were the confidence of reliably converting our services into Docker images and the fact that dual deploy could work automatically without any disruption to existing work.
Migrating logging & monitoring
The second step was to prove that our logging and monitoring stack could continue to work with containers. To address this, we provisioned new servers for both logging and monitoring. We also evaluated Loki to see if we could converge tooling for logging and monitoring. However, due to various gaps in Loki given our need, we stayed with ElasticSearch stack. We did replace logstash and filebeat with Fluentd. This helped us address some of the issues that we had seen with filebeat our old infrastructure. Monitoring had new dashboards for the Kubernetes setup as we now cared about both pods as well in addition to host machine health.
At the end of the step, we had a functioning logging and monitoring stack which could show data for a single Kubernetes service container as well across logical service/component. It made us confident about the observability of our infrastructure. We kept new and old logging & monitoring infrastructure separate to keep the migration overhead out of the picture. Our approach was to keep both of them alive in parallel until the end of the data retention period.
Addressing stateful components
One of the key ingredients for strangulation was to make any changes to stateful components post initial migration. This way, both the new and old infrastructure can point to the same data stores and reflect/update data state uniformly.
So as part of this step, we configured newly deployed service to point to existing data stores and ensure that all read/writes worked seamlessly and reflected on both infrastructures.
Deployment repository and pipeline replication
With one service and support system ready, we extracted out a generic way to build images with docker files and deployment to new infrastructure. These steps could be used to add dual-deployment to all services. We also changed our deployment approach. In a new setup, the deployment code lived in a separate repository where each environment and region was represented by a branch example uk-qa,uk-prod or in-qa etc. These branches carried the variables for the region + environment. In addition to that, we provisioned a Hashicorp Vault to manage secrets and introduced structure to retrieve them by region + environment combination. We introduced namespaces to accommodate multiple environments over the same underlying hardware.
Crowd-sourced migration of services
Once we had basic building blocks ready, the next big step was to convert all our remaining services to have a dual deployment step for new infrastructure. This was an opportunity to familiarize the team with new infrastructure. So we organized a session where people paired up to migrate one service per pair. This introduced everyone to docker files, new deployment pipelines and infrastructure setup.
Because the process was jointly driven by the whole team, we migrated all the services to have dual deployment path in a couple of days. At the end of the process, we had all services ready to be deployed across two environments concurrently.
Test environment migration
At this point, we did a shift and updated the Nameservers with updated DNS for our QA and UAT environments. The existing domain started pointing to Kubernetes setup. Once the setup was stable, we decommissioned the old infrastructure. We also removed old GitLab pipelines. Forcing only Kubernetes setup for all test environments forced us to address the issues promptly.
In a couple of days, we were running all our test environments across Kubernetes. Each team member stepped up to address the fault lines that surfaced. Running this only on test environments for a couple of sprints gave us enough feedback and confidence in our ability to understand and handle issues.
Establishing dual deployment cadence
While we were running Kubernetes on the test environment, the production was still on old infrastructure and dual deployments were working as expected. We continued to release to production in the old style.
We would generate images that could be deployed to production but they were not deployed and merely archived.
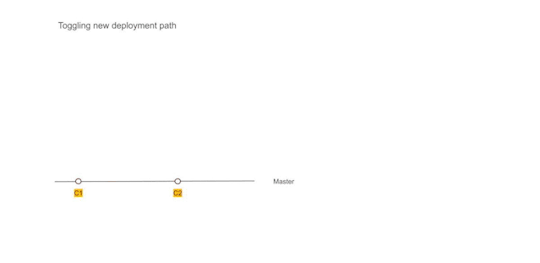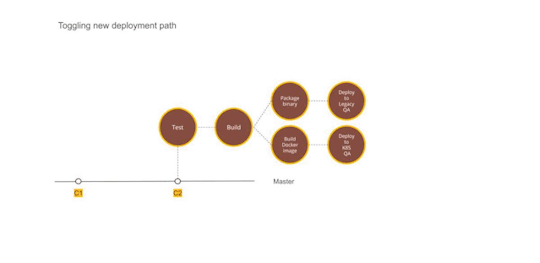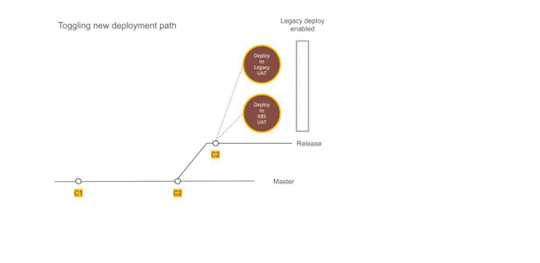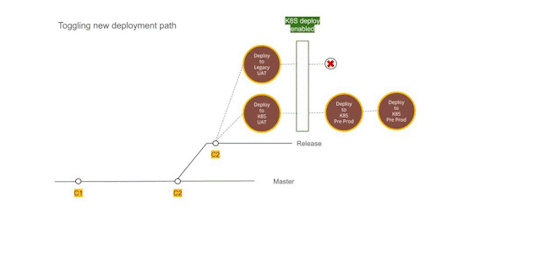
Figure 2 — Using Dual deployment to toggle deployment path to new infrastructure
As the test environment ran on Kubernetes and got stabilized, we used the time to establish dual deployment cadence across all non-prod environments.
Troubleshooting and strengthening
Before migrating to the production we spent time addressing and assessing a few things.
We updated the liveness and readiness probes for various services with the right values to ensure that long-running DB migrations don’t cause container shutdown/respawn. We eventually pulled out migrations into separate containers which could run as a job in Kubernetes rather than as a service.
We spent time establishing the right container sizing. This was driven by data from our old monitoring dashboards and the resource peaks from the past gave us a good idea of the ceiling in terms of the baseline of resources needed. We planned enough headroom considering the roll out updates for services.
We setup ECR scanning to ensure that we get notified about any vulnerabilities in our images in time so that we can address them promptly.
We ran security scans to ensure that the new infrastructure is not vulnerable to attacks that we might have overlooked.
We addressed a few performance and application issues. Particularly for batch processes, which were split across servers running the same component. This wasn’t possible in Kubernetes setup, as each instance of a service container feeds off the same central config. So we generated multiple images that were responsible for part of batch jobs and they were identified and deployed as separate containers.
Upgrading production passively
Finally, with all the testing we were confident about rolling out Kubernetes setup to the production environment. We provisioned all the underlying infrastructure across multiple availability zones and deployed services to them. The infrastructure ran in parallel and connected to all the production data stores but it did not have a public domain configured to access it. Days before going live the TTL for our DNS records was reduced to a few minutes. Next 72 hours gave us enough time to refresh this across all DNS servers.
Meanwhile, we tested and ensured that things worked as expected using an alternate hostname. Once everything was ready, we were ready for DNS switchover without any user disruption or impact.
DNS record update
The go-live switch-over involved updating the nameservers’ DNS record to point to the API gateway fronting Kubernetes infrastructure. An alternate domain name continued to point to the old infrastructure to preserve access. It remained on standby for two weeks to provide a fallback option. However, with all the testing and setup, the switch over went smooth. Eventually, the old infrastructure was decommissioned and old GitLab pipelines deleted.

Figure 3 — DNS record update to toggle from legacy infrastructure to containerized setup
We kept old logs and monitoring data stores until the end of the retention period to be able to query them in case of a need. Post-go-live the new monitoring and logging stack continued to provide needed support capabilities and visibility.
Observations and results
Post-migration, time to create environments has reduced drastically and we can reuse the underlying hardware more optimally. Our production runs all services in HA mode without an increase in the cost. We are set up across multiple availability zones. Our data stores are replicated across AZs as well although they are managed outside the Kubernetes setup. Kubernetes had a learning curve and it required a few significant architectural changes, however, because we planned for an incremental rollout with coexistence in mind, we could take our time to change, test and build confidence across the team. While it may be a bit early to conclude, the transition has been seamless and benefits are evident.
2 notes
·
View notes
Text
Patterns for microservices - Sync vs Async
Microservices is an architecture paradigm. In this architectural style, small and independent components work together as a system. Despite its higher operational complexity, the paradigm has seen a rapid adoption. It is because it helps break down a complex system into manageable services. The services embrace micro-level concerns like single responsibility, separation of concerns, modularity, etc.
Patterns for microservices is a series of blogs. Each blog will focus on an architectural pattern of microservices. It will reason about the possibilities and outline situations where they are applicable. All that while keeping in mind various system design constraints that tug at each other.
Inter-service communication and execution flow is a foundational decision for a distributed system. It can be synchronous or asynchronous in nature. Both the approaches have their trade-offs and strengths. This blog attempts to dissect various choices in detail and understand their implications.
Dimensions
Each implementation style has trade-offs. At the same time, there can be various dimensions to a system under consideration. Evaluating trade-offs against these constraints can help us reason about approaches and applicability. There are various dimensions of a system that impact the execution flow and the communication style of a system. Let’s look at some of them.
Consumers
Consumers of a system can be external programs, web/mobile interfaces, IoT devices etc. Consumer applications often deal with the server synchronously and expect the interface to support that. It is also desirable to mask the complexity of a distributed system with a unified interface for consumers. So it is imperative that our communication style allows us to facilitate it.
Workflow management
With many participating services, the management of a business-workflow is crucial. It can be implicit and can happen at each service and therefore remain distributed across services. Alternatively, it can be explicit. An orchestrator service can own up the responsibility for orchestrating the business-flows. The orchestration is a combination of two things. A workflow specification, that lays out the sequence of execution and the actual calls to the services. The latter is tightly bound to the communication paradigm that the participating services follow. Communication style and execution flow drive the implementation of an orchestrator.
A third option is an event-choreography based design. This substitutes an orchestrator via an event bus that each service binds to.
All these are mechanisms to manage a workflow in a system. We will cover workflow management in detail, later in this series. However, we will consider constraints associated with them in the current context as we evaluate and select a communication paradigm.
Read/Write frequency bias
Read/Write frequency of the system can be a crucial factor in its architecture. A read-heavy system expects a majority of operations to complete synchronously. A good example would be a public API for a weather forecast service that operates at scale. Alternatively, a write-heavy system benefits from asynchronous execution. An example would be a platform where numerous IoT devices are constantly reporting data. And of course, there are systems in between. Sometimes it is useful to favor a style because of the read-write skew. At other times, it may make sense to split reads and writes into separate components.
As we look through various approaches we need to keep these constraints in perspective. These dimensions will help us distill the applicability of each style of implementation.
Synchronous
Synchronous communication is a style of communication where the caller waits until a response is available. It is a prominent and widely used approach. Its conceptual simplicity allows for a straightforward implementation making it a good fit for most of the situations.
Synchronous communication is closely associated with HTTP protocol. However, other protocols remain an equally reasonable way to implement synchronous communication. A good example of an alternative is RPC calls. Each component exposes a synchronous interface that other services call.
An interceptor near the entry point intercepts the business flow request. It then pushes the request to downstream services. All the subsequent calls are synchronous in nature. These calls can be parallel or sequential until processing is complete. Handling of the calls within the system can vary in style. An orchestrator can explicitly orchestrate all the calls. Or calls can percolate organically across components. Let’s look at few possible mechanisms.
Variations
Within synchronous systems, there are several approaches that an architecture can take. Here is a quick rundown of the possibilities.
De-centralized and synchronous
A de-centralized and synchronous communication style intercepts a flow at the entry point. The interceptor forwards the request to the next step and awaits a response. This cycle continues downstream until all services have completed their execution. Each service can execute one or more downstream service sequentially or in parallel. While the implementation is straightforward, the flow details remain distributed in the system. This results in coupling between components to execute a flow.
The calls remain synchronous throughout the system. Thus, the communication style can fulfill the expectations of a synchronous consumer. Because of distributed workflow nature, the approach doesn’t allow room for flexibility. It is not well suited for a complex workflow that is susceptible to change. Since each request to the system can block services simultaneously, it is not ideal for a system with high read/write frequency.

Orchestrated, synchronous and sequential
A variation of a synchronous communication is with a central orchestrator. The orchestrator remains the intercepting service. It processes the incoming request with workflow definition and forwards it to downstream services. Each service, in turn, responds back to the orchestrator. Until the processing of a request, orchestrator keeps making calls to services.
Among the constraints listed at the beginning, the workflow management is more flexible in this approach. The workflow changes remain local to orchestrator and allow for flexibility. Since the communication is synchronous, synchronous consumers can communicate without a mediating component. However, orchestrator continues to hold all active requests. This burdens orchestrator more than other services. It is also susceptible to being a single point of failure. This style of architecture is still suitable for a read-heavy system.

Orchestrated, synchronous and parallel
A small improvement on the previous approach is to make independent requests parallel. This leads to higher efficiency and performance. Since this responsibility falls within the realms of orchestration, it is easy to do. Workflow management is already centralized. It only requires changes in the declaration to distinguish between parallel and sequential calls.
This can allow for faster execution of a flow. With shorter response times, orchestrator can have a higher throughput.
Workflow management is more complex than the previous approach. It still might be a reasonable trade off since it improves both throughput and performance. All that, while keeping the communication synchronous for consumers. Due to its synchronous nature, the system is still better for a read-heavy architecture.

Trade offs
Although, synchronous calls are simpler to grasp, debug and implement, there are certain trade-offs which are worth acknowledging in a distributed setup.
Balanced capacity
It requires a deliberate balancing of the capacity for all the services. A temporary burst at one component can flood other services with requests. In asynchronous style, queues can mitigate temporary bursts. Synchronous communication lacks this mediation and requires service capacity to match up during bursts. Failing this, a cascading failure is possible. Alternatively, resilience paradigms like circuit breakers can help mitigate a traffic burst in a synchronous system.
Risk of cascading failures
Synchronous communication leaves upstream services susceptible to cascading failure in a microservices architecture. If downstream service fail or worst yet, take too long to respond back, the resources can deplete quickly. This can cause a domino effect for the system. A possible mitigation strategy can involve consistent error handling, sensible timeouts for connections and enforcing SLAs. In a synchronous environment, the impact of a deteriorating service ripple through other services immediately. As mentioned previously, prevention of cascading errors can happen by implementing a bulkhead architecture or with circuit breakers.
Increased load balancing & service discovery overhead
The redundancy and availability needs for a participating service can be addressed by setting them up behind a load balancer. This adds a level of indirection per service. Additionally, each service needs to participate in a central service discovery setup. This allows it to push its own address and resolve the address of the downstream services.
Coupling
A synchronous system can exhibit much tighter coupling over a period of time. Without abstractions in between, services bind directly to the contracts of the other services. This develops a strong coupling over a period of time. For simple changes in the contract, the owning service is forced to adopt versioning early on. Thereby increasing the system complexity. Or it trickles down a change to all consumer services which are coupled to the contract.
With emerging architectural paradigms like service mesh, it is possible to address some of the stated issues. Tools like Istio, Linkerd, Envoy etc. allow for a service mesh creation. This space is maturing and remains promising. It can help build systems that are synchronous, more decoupled and fault tolerant.
Asynchronous
Asynchronous communication is well suited for a distributed architecture. It removes the need to wait for a response thereby decoupling the execution of two or more services. Implementation of asynchronous communication is possible with several variations. Direct calls to a remote service over RPC (for instance grpc) or via a mediating message bus are few examples. Both orchestrated message passing and event choreography use message bus as a channel.
One of the advantages of a central message bus is consistent communication and message delivery semantics. This can be a huge benefit over direct asynchronous communication between services. It is common to use a medium like a message bus that facilitates communication consistently across services. The variations of asynchronous communications discussed below will assume a central message pipeline.
Variations
The asynchronous communication deals better with sporadic bursts of traffic. Each service in the architecture either produces messages, consumes messages or does both. Let’s look at different structural styles of this paradigm.
Choreographed asynchronous events
In this approach, each component listens to a central message bus and awaits an event. The arrival of an event is a signal for execution. Any context needed by execution is part of the event payload. Triggering of downstream events is a responsibility that each service owns. One of the goals in event-based architecture is to decouple the components. Unfortunately, the design needs to be responsible to cater to this need.

A notification component may expect an event to trigger an email or SMS. It may seem pretty decoupled since all that the other services need to do is produce the event. However, someone does need to own the responsibility of deciding type of notification and content. Either notification can make that decision based on an incoming event info. If that happens then we have established a coupling between notifications and upstream services. If upstream services include this as part of the payload, then they remain aware of flows downstream.
Even so, event choreography is a good fit for implicit actions that need to happen. Error handling, notifications, search-indexing etc. It follows a decentralized workflow management. The architecture scales well for a write-heavy system. The downside is that synchronous reads need mediation and workflow is spread through the system.
Orchestrated, asynchronous and sequential
We can borrow a little from our approach in orchestrated synchronous communication. We can build an asynchronous communication with orchestrator at the center.
Each service is a producer and consumer to the central message bus. Responsibilities of orchestrator involve routing messages to their corresponding services. Each component consumes an incoming event or message and produces the response back on the message queue. Orchestrator consumes this response and does transformation before routing ahead to next step. This cycle continues until the specified workflow has reached its last state in the system.
In this style, the workflow management is local to the orchestrator. The system fares well with write-heavy traffic. And mediation is necessary for synchronous consumers. This is something that is prevalent in all asynchronous variations.
The solution to choreography coupling problem is more elegant in the orchestrated system. The workflow is with orchestrator in this case. A rich workflow specification can capture information like notification type and content template. Any changes to workflow remain with orchestrator service.

Hybrid with orchestration and event choreography
Another successful variation is hybrid systems with orchestration and event choreography both. The orchestration is excellent for explicit flow execution, while choreography can handle implicit execution. Execution of leaf nodes in a workflow can be implicit. Workflow specification can facilitate emanation of events at specific steps. This can result in the execution of tasks like notifications, indexing, et-cetera. The orchestration can continue to drive explicit execution.
This amalgamation of two approaches provides best of both worlds. Although, there is a need for precaution to ensure they don’t overlap responsibilities and clear boundaries dictate their functioning.
Overview
Asynchronous style of architecture addresses some of the pitfalls that synchronous systems have. An asynchronous set-up fares better with temporary bursts of requests. Central queues allow services to catch up with a reasonable backlog of requests. This is useful both when a lot of requests come in a short span of time or when a service goes down momentarily.
Each service connects to a message queue as a consumer or producer. Only the message queue requires service discovery. So the need for a central service discovery solution is less pressing. Additionally, since multiple instances of a service are connected to a queue, external load balancing is not required. This prevents another level of indirection that otherwise, load balancer introduces. It also allows services to linear scale seamlessly.
Trade Offs
Service flows that are asynchronous in nature can be hard to follow through the system. There are some trade-offs that a system adopting asynchronous communication will make. Let’s look at some of them.
Higher system complexity
Asynchronous systems tend to be significantly more complex than synchronous ones. However, the complexity of system and demands of performance and scale are justified for the overhead. Once adopted both orchestrator and individual components need to embrace the asynchronous execution.
Reads/Queries require mediation
Unless handled specifically synchronous consumers are most affected by an asynchronous architecture. Either the consumers need to adapt to work with an asynchronous system, or the system should present a synchronous interface for the consumers. Asynchronous architecture is a natural fit for the write-heavy system. However, it needs mediation for synchronous reads/queries. There are several ways to manage this need. Each one has certain complexity associated with it.
Sync wrapper
Simplest of all approaches is building a sync wrapper over an async system. This is an entry point that can invoke asynchronous flows downstream. At the same time, it holds the request awaiting until the response returns or a timeout occurs. A synchronous wrapper is a stateful component. An incoming request ties itself to the server it lands on. The response from downstream services needs to arrive at the server where original request is waiting. This isn’t ideal for a distributed system, especially one that operates at scale. However, it is simple to write and easy to manage. For a system with reasonable scaling and performance needs it can fit the bill. A sync wrapper should be a consideration before a more drastic restructuring.

CQRS
CQRS is an architectural style that separates reads from writes. CQRS brings a significant amount of risk and complexity to a system. It is a good fit for systems that operate at scale and requite heavy reads and writes. In CQRS architecture, data from write database streams to a read database. Queries run on a read-optimized database. Read/Write layers are separate and the system remains eventually consistent. Optimization of both the layers is independent. A system like this is far more complex in structure but it scales better. Moreover, the components can remain stateless (unlike sync wrappers).

Dual support
There is a middle ground here between a sync wrapper and a CQRS implementation. Each service/component can support synchronous queries and asynchronous writes. This works well for a system which is operating at a medium scale. So read queries can hop between components to finish reads synchronously. Writes to the system, on the other hand, will flow down asynchronous channels. There is a trade-off here though. The optimization of a system for both reads and writes independently is not possible. Something, that is beneficial for a system operating at high traffic.
Message bus is a central point of failure
This is not a trade-off, but a precaution. In the asynchronous communication style, message bus is the backbone of the system. All services constantly produce-to and consume-from the message bus. This makes the message bus the Achilles heel of the system as it remains a central point of failure. It is important for a message bus to support horizontal scaling otherwise it can work against the goals of a distributed system.
Eventual consistency
An asynchronous system can be eventually consistent. It means that results in queries may not be latest, even though the system has issued the writes. While this trade-off allows the system to scale better, it is something to factor-in into system’s design and user experience both.
Hybrid
It is possible to use both asynchronous and synchronous communication together. When done the trade-offs of both approaches overpower their advantages. The system has to deal with two communication styles interchangeably. The synchronous calls can cascade degradation and failures. On the other hand, the asynchronous communication will add complexity to the design. In my experience, choosing one approach in isolation is more fruitful for a system design.
Verdict
Martin Fowler has a great blog on approaching the decision to build microservices. Once decided, a microservice architecture requires careful deliberation around its execution flow style. For a write, heavy system asynchronous is the best bet with a sync-over-async wrapper. Whereas, for a read-heavy system, synchronous communication works well.
For a system that is both read and write heavy, but has moderate scale requirements, a synchronous design will go a long way in keeping the design simple. If a system has significant scale and performance needs, asynchronous design with CQRS pattern might be the way to go.
9 notes
·
View notes
Text
How I learned to love personal development
Our daily grind has a tendency to push personal development in shadows of delivery and deadlines. Personal development, something that needs constant fostering often attracts muted attention and gets precipitous intervention when "people-team" reminds us about the half yearly review cycle. Even after spending a decade in my profession, I find myself often disoriented and confused about how I am tracking my progress against the goals that I have; and that is, if I have charted out my goals at all. In recent past, I have made a renewed effort to find structure in my personal development and reorganize it in ways to make it easier to tackle and track both. While I am still on a journey to realize its effectiveness, I hope to share my thought process and the technique both in a hope that you find it relevant and useful too.

The road ahead
For me introspection is crucial part of personal development. It is important for me to know and have an opinion about how my career is going. However at the same time I find the thought process overwhelming. I typically attack it by building a list of role models and find a persona that resonates with me most. Using that persona coupled with my interests, I try to chart a long term goal that leads me in that direction. It is worth noting that personas merely act as a guide to chart my long term career path and high level skill categorization. I would eschew from imitating the exact skills since the individual strengths can vary significantly. To elaborate on this, I have few fictional personas listed below; let me pick one and walk through the process.



I would say that I resonate with Sara most and I have a strong belief that mobile and internet of things will converge eventually. I also think there is a huge potential to simplify the bridging between both. Coupling them together, a reasonable goal for me for next 18-24 months could be “I want to establish and associate myself to mobile and Internet of things domain. I intend to contribute by building an ecosystem & community that simplifies and makes cross platform development for mobile & other devices effective.”
A high level goal is great however it needs to be broken down into short term actionable items. This step requires me to build structure in which I would collect feedback, collate data and measure. At this point I would have given enough thought to my goal and would have a sense about the most crucial skills that I need to acquire? I tend to classify similar skills together and pull them in a category. Although I know people who approach this other way round. They look at generic categories and identifying things they would like to focus on under each of them. An example output of this categorization for me would involve categorizing activities like blogging, conferences, FOSS etc together in "community contribution"; while each of those would become axes I measure myself on. Lets look at this in bit more of detail.
Pivoting on spider charts
Once I have taken a look at my long term goal, it is probably wise to take a stock of where I am currently. This will help me identify areas that need most work and actionable items that will help me reach there. There are two ways I gather this data. Feedback is a great way to start, but I usually find it more useful if I distill down my thoughts first into spider chart visualizations asking myself “How did last 6 months go for me”. It helps me build a sense of things and rate myself on different axes. Once I have that data ready, I reach out for feedback and compare the perception of people around me, on those axes to the data I have from my intuition. It helps me spot outliers and identify false notions both.
Coming back to spider charts, I define them with identified categorizations, axes and levels. I would typically identify root categorization like Technology, Community contribution, Soft skills and Consulting. Each of these categories have a spider chart of their own with sub categories as axes and each axis has typically three rating levels. These levels are very personalized and the lowest bar is in context of my experience with that categorization and an assumption that I have room to improve.
Take a cursory look at the charts, categorization, sub categorization and ratings below to get a sense of data I have at this point. The charts on left are based on "how I feel" about capabilities and skills and the ones on right are based on "feedback from team". Each axis represent a single subcategorization listed in "axes" column and three levels of ratings are defined by "rating levels" column.

Axes
Mobile platforms - How many of them do I understand?
Mobile development as a skill - How well do I understand mobile?
Code Hygiene - How well can I write code?
Rating Levels
Drive individually
Bootstrapping a team and running with it
Impacting community

Axes
Blogging
Speaking
Open source contribution to existing frameworks
Open source frameworks used by at least 5 people/teams
Rating Levels
Amateur contributor
Internal impact
External impact
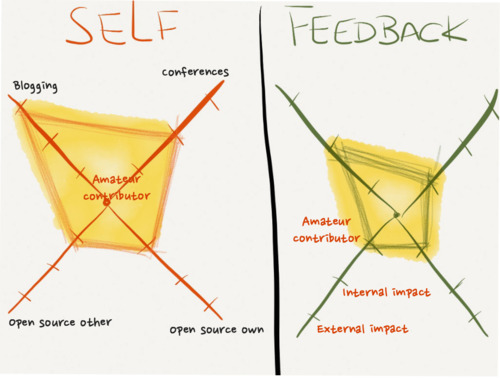
Axes
Mentoring & Leading
Assertiveness - Based on feedback in past. (Am I assertive when needed?)
Planning - Based on suggestion in past (Do I proactively plan on behalf of team?)
Rating Levels
Comfortable
Excited
Addicted
As you can see, these charts are often a great reality check tool apart from presenting relevant data visually. In soft skills section, rating levels are more generic and rational for different sub categorization is bit more pragmatic. Some I want to proactively track, for others past feedback/suggestions is a motivation. This is to highlight, that intuition and feedback both should help build up axes of a categorization. I have covered only few categorizations here, however in reality, I would keep a few more. Some of those would include additional bits, like what have I done to improve efficiency, quality and innovation of our team as collective.
Introspection to action
Once I have looked at visualizations and identified feedback and data against each category/axis I tend to define broad action items as stories on a wall. After all we are agile and feedback driven in daily delivery why should it be any different when it comes to our own development? However discipline to strike through the items is also the hardest part for the next six months. (Six months is a period I feel comfortable with to revisit my progress and up-skilling). The obvious mistake that I have done in past is bog myself down with tons of action items or make action items too beefy resulting in constant procrastination. So this time around I am experimenting with two key differences.
I have limited the number of goals for next 6 months between 6-8. These can be further broken down into small tasks though.
I track my progress using a combination of virtual wall and labeled classification to keep a check on balance I strike between different categorization.
You can see the goals, task list and labels in the images below. Feel free to check out the wall here on Trello. The wall is public but it may not show you label classification in read only mode.


Periodic checkpoint and follow through
I find a periodic catch up with select few to be a good motivator to stay on track, so I have set a 5 minute recurring google calendar invite with few people to review my Trello boardevery 30 days for next 6 months. That reminds everyone periodically about taking out a minute to review progress and also helps me stay focused on tasks to prepare for next catch up.

Aspirations and support
Individuals often need to invest time on team to build better software, it is equally important that teams take time to allow individuals to focus on personal development. Therefore, accommodating a personal development story card for an individual in iteration planning is an excellent way to allocate time for individual development and reap benefits as a team. This approach can be powerful as it often help tackle tasks that require either experimentation, a chunk of continuous time or resources/complexity that only project can offer.
Beyond that I typically identify any aspiration or support that I need from organization. Letting those know up front helps tap opportunities better and allow for a better planning for individual development as well. This is very organization specific, however in my current organization, this support in terms of resources and time both, is easy to find. So there isn’t a lot I need to do about this as long as I know what I want and how it helps.
The final word
All of that being said it is probably prudent to accept that, no matter how many failsafe mechanism I put to refrain myself from being distracted or straying away into an ad-hoc approach; nothing trumps focus and discipline. I do not see this approach as a substitute for that, it is merely a structure that forces me to give personal development enough thought and augments to it by helping me define tasks that are easier to follow through, range across skill sets and require smaller/gradual time commitment.
I hope, you find at least few things that are interesting to you. I would love to hear about, how you attack your personal development and things that work for you or don't.
Note: All artwork in this blog was drawn with love using Paper by 53 on iPad
1 note
·
View note
Text
Reinforced design with TDD
This is my fifth blog in the series of “Decoding ThoughtWorks’ coding problems”. If you haven’t checked out the first four blogs, please read my blogs on “Decoding ThoughtWorks coding problems”, “Objects that talk domain", "Objects that are loose & discrete” and "Design Patterns for Win".
Let me begin this post with a simple explanation of TDD a.k.a Test Driven Development. Test driven development or test first approach is as its name suggest, an approach to development where tests are written as the first step. And then code is subsequently added to pass those tests. The process can be summarized in three simple steps:
Write a failing test for a business scenario. The code for this scenario doesn’t exist.
Add code that exclusively addresses the scenario that test covers. Nothing more, nothing less.
Make test run and validate that it passes now.
Continue to add a series of tests and code until all business scenarios are covered and you are confident that every line that you coded is sufficiently tested. Note the usage of phrase “sufficiently tested”. The emphasis is not on 100% test coverage but instead on what's practical and useful in business context.
This approach is dominant in unit tests that are written. In Java this would be done using JUnit and moq or a similar framework. C# NUnit. Ruby rspec or Test::Unit etc.
Once you get the hang of it apart from being tons of fun, this approach of development helps in several ways:
It forces you to break down current problem into small units of functionality.
It forces you to think about “behavior” of an object while testing it and helps in solidifying the encapsulation.
It documents code as you go and it is a means of documenting code which doesn’t get outdated. As soon as code evolves, the existing tests fail, forcing a developer to update the specs.
It builds a safety net around codebase for a team. This helps in ensuring that quality is shipped from day one and collaboration on same codebase is faster. As a developer I would feel confident in making code changes, since I know that any changes that breaks a related/unrelated functionality will be caught by existing test suite.
Every project that I have worked on in ThoughtWorks follows a discipline of building this safety from day one. Our pre-commit hooks and continuous integration servers run these tests and provide immediate feedback for each commit, in an event, a piece of functionality is broken.
As part of the coding problem solution sent in by candidates, we rarely get to see unit tests, let alone tests that have evidence of Test Driven Development in them. This is primarily due to lack of awareness and practice. While I personally do not penalize codebases for not having tests or TDD approach, presence of those definitely earns brownie points from me. We love to see like minded people who believe in quality and development approach that we are big proponent of.
I hope to substantiate the above concepts with some code that is part of Mars Rover problem. Take a look at the internal details of the Rover class in solution. Once you understand the rover, pretend it doesn’t exist. And lets write simple test structure to drive the creation of this behavior through tests.
Here is a gist of skeleton methods that tests the key behavior of the rover. If you would look closely, you will see that beyond the behavior that is tested, we do not want to know anything about the rover. So the internal workings of a rover can be encapsulated and hidden from the outer world.
https://gist.github.com/priyaaank/e57389b1c256a6ac0299
It is worth noting that for reference purpose while I have created a full class listing all methods to test behavior, in reality, we would approach each method’s red (failing test) test and green (passing test) test cycle one by one. A more complete implementation of the rover test is here.
It is worth mentioning that while a huge community of developers favors unit testing, there are camps where TDD is looked down upon (not unit testing though). You can find an invigorating debate on this subject here between several luminaries.
There are additional resources and books to enrich your understanding about TDD. I hope you find them useful.
http://martinfowler.com/bliki/TestDrivenDevelopment.html
An excellent chapter on TDD from book The Art of Agile Development
Test Driven Development by Kent Beck
3 notes
·
View notes
Text
Design Patterns for Win
This is my fourth blog in the series of “Decoding ThoughtWorks’ coding problems”. If you haven’t checked out the first three blogs, please read my blogs on “Decoding ThoughtWorks coding problems”, "Objects that talk domain" and "Objects that are loose & discrete".
If you are not familiar with design pattern, then I would explain design pattern as “a tried and tested pattern or template to organize your object design, given a set of constraints and requirements around object interaction. In other words, they are dictionary of formalized best object design practices to handle common issues of object interactions”.
Design patterns do several things for me.
They are tried and tested way of organizing object interactions. Most of the design patterns emphasize on basic code hygiene that we have talked about in previous blog post of “discrete objects and loose coupling”. This means, that using a design pattern means not having to reinvent the wheel and have a tried and tested way to solve a design problem. It makes me more efficient and code cleaner.
They embody a design approach in a succinct definition. When I am pairing with someone (ThoughtWorks adopts Extreme Programming practices on day to day basis, which involves pairing) to solve a business problem in context of domain, the name of design patterns tells me what my pair is thinking and intends to do, without an elaborate discussion. An example would be “Hey, lets convert this switch case branching of rules for tax calculation at Airport or City with a strategy pattern”. I would presume, that anyone who is familiar with strategy pattern, this statement would indicate to you instantly where the refactoring will go to.
They leave code more predictable and readable. Purely from readability point of view; when I am looking at a code that I haven’t written I am left to my own means to build the mental models required to understand the cobweb of object interactions. However, for instance, if I see “visitor” keywords somewhere indicating a “Visitor pattern”, I instantly grasp what the intention and structure of object interactions. Thereby simplifying the code for me. The structure becomes more readable and predictable.
That being said, it must be noted that lot of design patterns seem like a “simple and obvious” choice only if you have read and experienced them once. Without the knowledge the design can come off as obtuse and complex. Benefit of better collaboration is only evident when all involved people understand design patterns. And therefore to be a better programmer and a collaborative pair, it is recommended you understand at least some of the commonly used design patterns.
In this post, I will explore few design patterns to relay the benefits they bring in. Also I’ll talk about the mars rover problem and show how Command Pattern simplifies the design extremely without any conditional branching in logic.
Command Pattern to parse rover commands
A typical rover command’s implementation can often look like:
https://gist.github.com/priyaaank/bfae96a306afd3bc88fd
If you look closely above, the logic is concise to start with but it is using branching to distinguish flows. While in this specific instance refactoring further in order to simplify the logic is somewhat debatable, in large and complex systems code fragments like this tend to bind several flows and evolve into labyrinth of incomprehensible and unreadable code.
A simple choice of Command Pattern can alleviate the issue here. In contrast the code can be refactored to as follows.
https://gist.github.com/priyaaank/1afc714ccde8a05b5230
As I mentioned already if you are not familiar with design patterns, at first glance the code above can seem like a refactoring that has created more components and files. However once you have experienced the benefits of design patterns in context of flexibility and extensibility first hand you will see the rationale of this refactoring.
Additionally, another most popular pattern to handle conditional branching and switch cases is using polymorphism or “Strategy Pattern”. Here is an example code before refactoring.
https://gist.github.com/priyaaank/6e4c37b238d5d64c875a
Lets create a strategy to create a beverage which has concrete classes that implement that strategy to prepare a beverage based on the type of strategy. When a beverage needs to be created, a concrete type of beverage strategy must be instantiated and injected into the prepare method. Resulting code creates a clear separation of concerns and isolates case specific steps that need to be executed to prepare a beverage. Look at the resulting structure below. You will notice that it also hints at using builder pattern apart from strategy to prepare a beverage.
https://gist.github.com/priyaaank/d4a84b98879b68d67556
Beyond singleton, factory and abstract factory patterns; some of the other popular design patterns that I have found immensely helpful more often than others, to solve common design problems while coding or brainstorming are as follows:
Observer pattern
Strategy pattern
Command pattern
Builder pattern
Decorator pattern
Bridge pattern
Visitor pattern
Based on my personal experience I would recommend reading, understanding and applying these patterns in suitable conditions. A number of available good books can tell you how to identify the situation which presents a motivation to use a specific pattern. Adding knowledge of these to your toolbelt will equip you well to handle design problems with ease and proven patterns.
As an additional read, Martin Folwer maintains a comprehensive list of refactoring situations and examples on refactoring.com. Please do check these out. In addition to design patterns I find these helpful to guide me refactor code to a more readable state. A more detailed rationale for each each refactoring can be found in his book.
You might want to check out the next blog post in the series, "Reinforced design with TDD".
2 notes
·
View notes
Text
Objects that are loose & discrete
This is my third blog in the series of “Decoding ThoughtWorks’ coding problems”. If you haven’t checked out the first two blogs, please read my blog on “Decoding ThoughtWorks coding problems” and “Objects that talk domain” here.
We looked at how models need to represent the language of a domain. Now lets explore a bit around the concepts that help us build the solution that has loosely coupled models. It is worth talking about why loose coupling between objects is desirable. First, as Martin Fowler defines in his article on coupling, “If changing a module in program requires a change in another module, then coupling exists”. Coupling itself isn’t bad, as long as objects are not too tightly coupled. I will try to present some guidelines to help quantity what would qualify as “tightly coupled” design. On the other hand, these could also be used as design principles to build a loosely coupled program.
State vs. Behavior
State of an object is a snapshot in time of it’s attributes and their values. This snapshot is one of the possible and a legitimate combination of attribute values for a given domain. A simple example is that of a light switch. If an object represents a flip switch with a boolean, then possible states of an object are “ON” and “OFF”. A similar example with in context of mars rover solution would be, Mars rover pointing North, with coordinates marked as 2,3. The combination is valid both from program’s and domain perspective. Behavior, on the other hand, is a set of rules that often change the state of current or other objects else based on current state of the participating objects.
Poor encapsulation of state inadvertently leads to tight coupling between objects. A discrete object is one, which is mindful about exposing its internal state. Drawing clear distinction between state and behavior is the first step to loose coupling. In our example code, if we look at the method of moving a rover, we see that a “move” command generates a new set of coordinates for rover internally, and hence changes state. However oblivious to this, rest of the world just relies on the understanding that “rover has moved”. Here coordinate is the internal state that represents movement, “move” is the behavior that can be called on a rover.
In case of a flip switch for a light, to preserve the state, the switch object will not allow anyone to set the boolean “ON/OFF” value directly, instead it would expose methods “switchOn” and “switchOff” to world, which are responsible for modifying the state.
Tell, don’t ask
Among all the objects that participate in building our solution, we should aspire for interactions where objects “Tell” another object about what needs to be done and “not ask”. This promotes the encapsulation of state, since only behavior is exposed and not state. A simple example from mars rover would be, checking if a coordinate is within the bounds of a plateau. If I asked the plateau its boundary coordinates and compared that myself, then I have accessed the internal state and plateau by itself has no value to contribute in the program. It poignant existence would be that of a value holder object. However by exposing the behavior, we centralize the logic in one place and irrespective of dependent objects, needed change in logic would be required only once, should it change.
Unidirectional associations
Keep your object model simple. If two objects share bidirectional association, then chances are that a change or modification in either will affect the other. Also, their reusability with other objects becomes questionable as their existence is closely coupled with each other. Bi-directional associations ties two objects together and reduces reusability. Unidirectional objects, when used with abstractions of interfaces, promotes reusability and loose coupling both.
In Mars rover, Coordinates exhibit unidirectional relationship with rover. Since coordinates do not know about rover in specific, it also means that any object can use coordinates to represent its position.
Here is a dependency graph for the Mars Rover application. It is worth noting that Rover and commands share a bidirectional relationships. It is definitely something worth improving however, given the context and problem statement, it seems a bit pre-mature to sort that out. In any case, the association has been abstracted by creating a command interface so that coupling isn't concrete.

Law of Demeter or principle of least knowledge
Law of demeter is a design philosophy which has following three guidelines.
Each object should have limited knowledge about other objects. It should know about objects, which are closest to it in domain.
Each object should talk to only objects it knows about and not an unknown object. Here the objects that a model may know about are the objects that it contains and the objects those objects contain subsequently. Synonymous to “Friend of a friend” on facebook.
Only talk to the objects that you know directly and not their friends. So in facebook analogy, you should not interact with friend of a friend. A friend should do that on your behalf if need be.
To elaborate the guidelines with mars rover solution there three instances, each representing a guideline.
A rover knows about most of the other objects, however the relationship is unidirectional. Domain does not demand that a direction, coordinate or plateau knows about a rover, and so they don’t. Bringing in that knowledge will couple all of them together tightly.
In accordance with second guideline, the objects identified as part of mars rover solution interact with only objects they are closely associated with and not to an object they don’t know about.
A command object like “MoveCommand” knows about the Rover and it needs to change the rover’s state. One possible way for move command, is to ask rover it’s coordinate or direction and modify it directly. But that would be breaking the last guideline. Instead that action is delegated to rover, which in turns extracts information from friend and updates the state.
A simple way to put this principle across is, that if you see a long method chaining in an object, that runs deep across objects, then it is most probably breaking the law of demeter. e.g.
rocket.engine.blastOff();
In statement above, someone is accessing an action on rockets’ friend engine, even though it only knows about rocket directly. Changing following to
rocket.liftOff();
and have “liftOff” internally call “blastOff” on engine is a more decoupled way of doing the same thing.
Dependency injection
Finally, to manage dependency between objects it is advisable to program to interfaces and use constructor injection to plant an object instance. Elaborating it in context of mars rover, once again, passing in plateau, direction and coordinates to a rover allows a program to inject a specialized version of an object. For example if instead of Mars, same rover was deployed on Pluto, I can inject a pluto plateau with different boundary values. This would automatically change the program output, when a mars rover crosses a boundary (which would be much smaller in pluto’s case, since the size of the planet is relatively smaller).
This is especially effective when done in combination with generic interfaces that define contract. The reason I have not done it here is because I personally think, creating interfaces up front without variation in subclasses’ behavior sort of comes off as an over engineering. I tend to add interfaces when I have more than one concrete type and when situation demands for it. It is always relatively easier to extract them out. More about it in section that talks about YAGNI and KISS.
In mars rover, only place where an interface made sense was for command objects. ICommand represents a generic contract for all the move or rotate commands. And that helps in executing a command on a rover in a uniform way.
Tight coupling between objects is pervasive and if it becomes entrenched in a program, it directly affects readability and maintainability. Bi-directional relationships require a bloated thought bubble to contextualize all interactions between models making it hard to understand and navigate through code.
Hopefully, this gave you some sense about how to decouple your objects using some basic guidelines. Please head over to the next blog post to read more about “Design patterns for win”.
2 notes
·
View notes
Text
Objects that talk domain
This is my second blog in the series of “Decoding ThoughtWorks’ coding problems”. If you haven’t checked out the first blog, please read my blog on “Decoding ThoughtWorks coding problems”.
A significant number of candidates who apply at ThoughtWorks as a developers, often come from a rich enterprise app development background. A big part of their career has been spent in developing applications in J2EE platform or similar frameworks in other languages like C#. Years of acquired learning of layered development with plethora of services, factories and data transfer objects is hard to shrug off. And it shows.
The most common problem that plagues the coding solution is that it is ripe with prolific use of data transfer objects. They hold state and have no behavior. Everything they own is public.
Before I talk about what is putting off about that, let me ask you a question. If you were to ask your friend her age, would you just expect the friend to let you know the year, month and date separately or just tell you the age? The difference between both responses is “who owns the information” and “who responsibility is it to do the work to get the answer”. I would claim, it is your friend’s responsibility, since she has all the data she need to give you an answer. Divulging her year, month and date is needless when all you need is age.
I hope you catch my drift.
The core and essential part of any coding problem is it’s domain. And unless that domain is succinctly represented in a set of models which own the behavior that pertains to them, a solution always seems a bit kludgy and off putting.
I would love to pick some points around utility of domain objects from Domain driven design by Eric Evans to elaborate on what a object design consideration would be.
When I say “model”, I intend to talk about an object that represents an implementation which can act as a backbone of the language used by the team in context of domain. A model would represent a distilled version of domain, agreed upon as a team, to represent terms, concepts and behavior to collaborate seamlessly with domain experts without translation.
It is understandable that candidate won’t have the understanding of the terminologies for an abstract coding problem like the one we ask you to solve as part of coding round. Instead we would love for candidates to define a domain terminology based on the problem statement and elaborate it for readers using the models they compose. It would be a asking too much if I did not substantiate this with an example. So to illustrate my point I would like to use a code that is a solution for one of the initial ThoughtWorks’ coding problem and my favorite; “Mars Rover”.
Problem statement here and solution coded in Java here.
Before we look at some code, let me outline how I think about the problem in terms of models. I feel, we would have a “Rover” that should have a sense of its “Coordinates” and “Direction”. Coordinate and direction together would make for a “Location” if there is enough behavior that we derive out of location itself. However currently based on problem statement it doesn’t seem like, we do. There are “Commands” that rover can understand. And finally rover must have been deployed on a “Plateau” as problem states. So that summary highlights a sequence of models that represent my domain. How are they connected is driven by their interaction and that translates into the behavior each of these model encompass.
The objects I have identified in problem are as follows:
https://gist.github.com/priyaaank/fcabe6575313774ac1d8
Having had that look at the identified objects, here are few things I find comforting about this instance of object design.
Models reflect the domain that was outlined by the problem statement. It builds concepts and interactions as behavior and actors in problem statement as models.
Once you understand model, you can use the model names to talk about domain without having to translate. An example statement could be, for instance “Should rover process move command when it is pointing to a north direction and on the boundary coordinates of the plateau?”.
Each model is rich with behavior. It has rules to process state internally and subsequently change either its own state or other objects’. And this has been exposed as model’s behavior to external world.
The models distill the knowledge of domain to those few needed concepts and discard everything that isn’t relevant to solution at hand. For example, a Plateau could do so much more if we wanted to, but in scope of this problem all we need is, to check if something within the bounds of plateau and that is it. So that is the behavior we distill and incorporate as part of Plateau model.
Of course, design is an iterative process and for me to design it even in its current form took several iterations and discussions. And I encourage you to do the same as you build your own solution.
Having identified objects pertaining to domain, we need to follow to the discipline of organizing them in such a way that they don’t become too tightly coupled. This is where the design aspects take over a bit. Lets look at some of the considerations in my next blog, to find out how interactions of objects should be structured to keep them loosely coupled. Head over to "Objects that are loose and discrete"
#thoughtworks#coding#coding problems#object oriented programming#recruiting#domain driven design#mars rover
2 notes
·
View notes
Text
Decoding ThoughtWorks' coding problems
I think it is only apt that I introduce myself before I kick start an in-depth post about Object Oriented design of coding problems that we send out in Thoughtworks’ interview process.
I have been developer for 10 years and more than half of that time has been spent at ThoughtWorks. I have actively worked across languages and frameworks like Java, Ruby, C#, Rails and now mobile technologies. In recent years my involvement in developing mobile applications and frameworks for hybrid apps has been prolific. And as part of my day job, I am often presented with an opportunity, every now and then, to evaluate the codes that have been sent in for review as part of interview process.
It is those learnings of my own and expectations of several other ThoughtWorkers that I am trying to distill into a series of blogs. My end goal is to talk about things that some of us, as code reviewers, would look for in a solution. And hopefully I can rationalize the reasoning for those expectations.
Use of Object Oriented paradigm to develop programs is not a new one. It has been around for years and as a developer myself I am on a journey to refine my understanding of it as I continue to practice it everyday. My suggestions, rationale and illustrations here are merely a single way to present what is “one of the better” (or at least I think so) approaches to development. But it is by no means, “the only way”. I hope you are open to look at things from a different point of view, because I am. A closed mind and a dogmatic approach is probably the biggest injustice one can do to a subjective topic like “good code and good design”.
As part of my involvement in code reviews, I have often seen individual potential eclipsed by misplaced understanding of “good code”. While the definition is subjective and quite broad; my hope here is to decode; what does “good code” means in context of ThoughtWorks’ code reviews? What do we look for? Along the way, I will also try to answer, what do some of us hope to gain out of this?
This series has following blog posts which focus on individual aspects of code design. Look at the list below and feel free to look at them in order you desire; I would try to keep them as independent as possible.
Objects that talk domain
Objects that are loose and discrete
Design patterns for win
Reinforced design with TDD
All the blog posts above use our one time favorite but now decommssioned coding problem called mars rover written in Java to illustrate the concepts. The code is completely open source and public. Feel free to deploy it on mars (or not!) and tear it apart if that makes you happy.
Needless to say, I would love to hear feedback and suggestion about what you disagree with and what could be improved both in code example and blogs. I am always reachable with comments on this blog or more discreetly on priyaaank at gmail.com.
Lets start our deep dive into the meat of the blog series with "Objects that talk domain".
2 notes
·
View notes
Text
I love ThoughtWorks too
*The views presented in this article are purely individual and do not represent ThoughtWorks' stand on the issue in anyway.
This post of mine has been motivated by a feedback that one of our recent candidate shared after a sour experience in interview. Often candidates are generous enough to leave this kind of feedback with our recruiters while other times they blog about it. This is not the first although I hope this can be our last. But every time a review like this comes anywhere on internet it spawns countless debates within ThoughtWorks. Having endured with numerous things said about ThoughtWorks, that I don't agree with, today I feel compelled enough to present my view, so as to try and balance the information and perspectives about ThoughtWorks that we find in a beautiful place called internet.
I have been a developer for 10 years now and more than half of my career has been spent at ThoughtWorks. So when I say that "I love ThoughtWorks", I hope that I can add some credibility to it. And I hope to do so without the cloak of anonymity. I believe that to truly criticize or appreciate something or someone, if you need to duck under a cloak of invisibility, then you are refusing to stand your ground and eschewing away from the consequences. Only if, all the battles to set the world right were fought that way.
Anyway, over the years that I have spent at ThoughtWorks, I have seen fair share of criticism for both; things that Thoughtworks do as a company, and things that ThoughtWorkers do as an individual. In both the cases I have seen ourselves introspect both as an organization and as individuals. When our project teams do retrospection every few weeks, introspection is hardly a radical concept.
And that is the first and foremost thing I love about ThoughtWorks.
Introspection
Ability to introspect its actions as an organization and as individuals who are weaved into it's culture, is the biggest strength. Internet is a breeding ground for half baked and biased judgements. Ignoring it is the simplest and easiest path forward. However that is not how ThoughtWorkers work. A simple anonymous criticism have spawned threads and internal debates with massive participation across offices. Different perspectives are represented and debated. Sometimes it causes ripples of changes within, sometimes tweaks are done to improve processes and structure. But one thing that happens every time is "learning". In my limited experience of different organizations, I have never seen such level of acceptance to a feedback that thousands of other organizations would discard due to "lack of credibility". That fact that ThoughtWorkers talk seriously about it, points to the fact that we are accepting to the fact that most (if not all) of us are human.
Criticism can often be ugly, pointed, biased and brutally truthful. Debates that follow within ThoughtWorks are often harsher, question our existing processes/structure and judgement and yet they enriching and invigorating. I remember an ex-ThoughtWorker left a public review on glassdoor which critiqued ThoughtWorks on various subjects. The internal discussion that spawned had the primary theme, that "isn't our environment safe enough internally" to be able to provide that feedback directly? It saw unprecedented participation from all offices across India.
The key point to note here is, how all our introspection, retrospection and criticism was open to all ThoughtWorkers irrespective of the experience they had and role they played. Everyone vocally presented their arguments, debated about existing problems and denial of issues. And reached a consensus. In a gist, the whole process was Transparent. Thats the second bit I love about ThoughtWorks.
Transparency
Few organizations can even dare to aspire the level of transparency I have seen within. Everything that is an employee prerogative to know is talked about in open internally. Salaries, work opportunities abroad, client relationships, project health, financial health & profits. All these things are transparent to a healthy level. Everyone is free to make observation, request scientific proof in form of statistics and critique them if need be.
Operating at such a level of transparency promotes trust and inclusivity of perspectives. A small but fundamental thing like selection of an "architect" and "ideas" for new office are done in open, on the floor. It can be a significant overhead, but inclusivity and an engaged workforce is a result worth all that trouble.
It is worth noting that such transparency highlights rigidness in our process of travel, interviews, client relationships. And the only ingredient that makes it all tick is "Common sense and flexibility".
Common Sense & Flexibility
Like any other organizations there are policies that drive different aspects of our employee lives day to day. Be it travel, benefits or need for ergonomic equipment for development. The only policy that I have seen in ThoughtWorks remain same across the time I have spent is "common sense". Every other organization moulds your need into a structure that is defined by a policy, except ThoughtWorks. People across all functions are pragmatic, thoughtful and supportive of your needs.
A brilliant example, that I simply loved from a discussion that is not even a month old was around our international fly back policies. Usually you would get 2 fly backs with all your family if you are on an international assignment. If you are married, then this would mean your spouse and children. A question was raised, what about people who are living with partners instead? What about people with different sexual orientations who do not parent children naturally? The ThoughtWorks' investment of limited resources on that individual is far less, since s/he doesn't fit in the constrained & skewed definition of a "family". Isn't it a bit unfair to them? They might be living away from their partners? Should the whole concept of "Family" be revised from merely talking about a hetrosexual couple and their kids? The ThoughtWorks answer to that puzzle, was "absolutely". Policies are merely guidelines and are flexible enough to recognize individual constraints. Strike a dialogue and figure something out that works for you. Fly your partner in, or fly yourself out as per need. All driven by common sense and pragmatic thinking.
Nowhere else, I have seen an effort to bring in inclusivity and diversity to such an extent. And these are not policies, this is "common sense and flexibility". The pragmatic nature of the organization that I work with is absolute pleasure.
For such a great foundation set up, it should be obvious by now, that it must take a set of incredibly talented and smart people to create a conducive environment like this. And to hire these people we rely relentlessly on our interview process. People that get hired are often opinionated and so do the people who hire them, as all ThoughtWorks are. Sometimes to a fault of being stubborn.
Talking about interview processes; based on the experience for interviews that I have had an opportunity to do so far in my life; all I can say is that I wish it was just like "threading a needle". Tricky but consistent in how you do it.
Unfortunately it is not. Interviewing is an art and you acquire it over time. It is highly subjective and inadequate to gauge individual skills in an hour of time.
When I interviewed with ThoughtWorks more than 5 years back; I had been a hard core Java fanatic, who was in denial of the language ecosystem spawning all around. My perspective was skewed and my thinking was constrained by what I had seen.
I spent a whole day over weekend interviewing. From code pairing round to last round, my interviewers talked about radically different subjects such as inter process communications, crawling web, 8086 assembly language, design problems for code, database scalability options and finally value of information or data?
It is worth mentioning, except databases and Java, I had no real experiences in any of the other subjects. I presume now, it was all to assess my ability to comprehend problem and come to a reasonable solution based on what I knew.
For me, it was a satisfying learning experience. My interviewer talked to me about advantages of Ruby, applications of OCaml, design patterns and other languages. They paired with me to improved design of a coded problem I had submitted. Showed a snippet in Ruby to show how concise the construct can get and then had a heated debate over benefits of perceived performance in Java over concise constructs of Ruby. And it was an enlightening one.
I learned new things and gained a perspective. I also realized how horribly outdated I had become. I could do so, because I came with an open mind to learn while I talk about things I knew. And I learned better because my interviewers showed me examples of what they meant in addition to the theoretical knowledge.
I have ever since tried to create same experience in interviews for all the candidates that come in. Sometimes I am successful, sometimes I am not. Some of us are much better at doing this than others.
Since I joined ThoughtWorks, I worked on Java, Ruby, C#, Objective-C and several other technologies and frameworks. The biggest learning for me was the need to constantly learn.
All of that being said, I can understand that sometimes, due to strong opinions and conflicts, interviews can flare up. After all we wouldn't be anywhere if people did not feel passionately about what they do and what they believe in. But shaming in public anonymously is a resort I personally do not approve of. I personally would like to believe, that irrespective of how things went, I would have courage to tell someone, what I did not agree with. It is ok to agree to disagree.
A good interview is where questions revolve around learnability, aptitude and attitude. More succinctly "cognitive abilities". Measuring those in a short span of time, along with cultural fit is a tricky thing.
Personally I do not feel bad that someone found the interview or the interviewer short of their expectations. It can happen and there is no reason to hold a grudge. It is the poor structuring of feedback I take offence to. Feedback is something I look at, that can help an individual or a group to improve. I see a good feedback a mix of three things. Unbiased, focused outline of the issue minus the mocking. A recommendation of an aspiration and a list of small suggestions, as to how to get there. A feedback like that shows you care. If a feedback starts like a rant, than I find it hard to gain anything out of it and barrier to receptiveness becomes significant.
To substantiate my point, here is an example ludicrous critique of the blog by Logan:
Egocentricity is a funny thing. Egocentric people tend to berate anything that they don't agree with, on par with Justin Bieber’s & Yo Yo Honey Singh’s singing and appearances. Because thats the closest arrow available in their quiver of internet garnered cliches. Of course this blog starts from proving me right and ends at a place, where my comments will seem like golden stupendous wisdom.
Just because your abilities to lookup incomprehensible synonyms from urban dictionary surpasses your technical skills, does not mean that you are the alpha species that represents the whole blogosphere. A blog as moot as this one is as laughable as Miley cyrus’s dressing sense.
Five minutes into reading it and you know it is going to be those rabbit holes which are richly abundant in the “I am just venting out” poop because I didn't get hired. They make for a fun reading, but doesn’t mean that you will be awarded the booker prize for this year. The bit that crack me up while reading the blog was that, the author goes on to call himself the “good people” that companies lose. I was gonna go with egocentricity as the golden trait, but now I can't decide if it is the humility or the modesty instead that I should really commend.
This excerpt is everything that is wrong with an "opinion". It doesn't rationalize a viewpoint, it doesn't tone constructive criticism appropriately and is useless in its current form both to a reader and author; since it doesn't help in addressing any real concerns in the inadequacy. The only way to make it worse would be to make it anonymous. Because then it also lose any credibility too.
Please note, the short counter-write up above is merely for substantiating my argument and does not represent my view point in anyway. If anything I am keen to learn from our mistakes; but I wish that there were more anchor points I could hold on to in that blog.
My love for Thoughtworks stem from the technical frameworks and products I have used for all my life to do things better. I wish the world's opinion of a company as great as this isn't formed from an interview that lasted about an hour and a blog post that presents one side of the story. Both of them are a poor resources to form an opinion from.
Having written about ThoughtWork's niceties to my hearts content, let me accept that there are numerous flaws that plague ThoughtWorkers and ThoughtWorks both. However they are not the ones listed in Logan's blog.
I would say one thing that I said on our internal discussions as well; "If we want to hire people smarter than us, then we need to treat them like they are". Keeping that in mind, there are things I can be mindful about in future interviews that I participate in, but as prospective candidates please do understand, that ThoughtWorks would value a candid & constructive feedback more than anything else. Please reach out to anyone in recruiting team or interview panels to share your concerns, disappointments and suggestions. We would ring of hypocrisy if we aren't flexible, transparent and introspective in our interviews too. A lot of splendid candidates not only provide great feedback in person, they seek feedback too. Continuous improvement is something that I think would resonate with ThoughtWorkers.
When it comes to trying to drive a change through feedback, write ups or dialog, here is a quote from Mahatma Gandhi that rings apt.
In a gentle way, you can shake the world - Mahatma Gandhi
3 notes
·
View notes
Text
Validating SSL certificates in mobile apps
Music is blaring, everyone around seems to be grooving to beats and you are having a good time. But is this the actual party you intended to attend? Similar question should be asked, when your mobile app is talking to a server api; even on HTTPS.
I was recently introduced to following talk by Moxie Marlinspike at Defcon. It was fascinating, enlightening and depressing all at the same time.
DEFCON 17: More Tricks For Defeating SSL
Everyone relies on HTTPS over SSL (TLS to be technically correct) to communicate securely to a web server. Traditionally the validation to of SSL certificates served by websites have been done by browsers. A green or a yellow padlock in address bar is good enough to indicate to a user, that s/he is secure and this website is who it claims to be.
While browsers have played a role of being a ubiquitous window to the world of internet, hand held devices and internet connected eye-glasses are defying that tradition.
When you open up your mobile app, how do you know, that you are indeed talking to the right server? How are you certain that someone isn't snooping on everything that you send over wire to server. (Anyone in addition to NSA that is)
I guess, it is the blatant trust that you have in the app, to do the right thing. And that is the assumption that we need to challenge there. Merely using an SSL/TLS api isn't good enough. Apps need to be responsible to ensure that are absolutely hundred percent sure of the identity of the server they are talking to.
Lets take a small proof of concept of what someone could do to deceive your apps into thinking they are secure when they are not.
If you familiar with Pocket or formerly known as Read it later; then I hope you have used their apps. I am using their Android app to demonstrate the concept and the flaw I intend to talk about.
What I Intend to do?
I want to run my phone traffic through a proxy and see if I can fool Pocket app into thinking that it is safely talking to the server over https and traffic can't be intercepted. And subsequently read everything that gets transferred over ssl/tls, including my credentials, in plain text.
What does that prove?
Lets assume that you are in a coffee-shop, and you have a wifi that says "Free Wifi". Just to humour me, lets say, that wifi is run by a nefarious hacker, who would like you steal your credentials, information and money. Now, if you connect through that wifi endpoint, s/he has the ability to run your traffic through a proxy and conduct, what is called as "Man in the middle attack". And thats what we are trying to do, proving that app isn't well safe guarded against that.
What is this "Man in the middle attack"?
Every time you app wants to talk to a server, it agrees with server on a simple "crypto code". This code is used to garble the text that is being sent. Only server know the "crypto code" and can convert this text back into plain text. So this way, if someone happens to look at the garbled text, then s/he won't understand it.
Now how does your app agree on this crypto code with server? They do what is called a SSL handshake. Where a server, will show the app a "certificate" that has a name on it. And the app can see the name of the server because server has it's name on the badge it's wearing. If they both match then app knows it is indeed "The server".
If someone comes between you and the server, then when you initiate a SSL handshake, it would give you a fake certificate, that has a name on it, that matches the server name. Lets assume, your app falls for it and agree on a "crypto code". Then the person will go to server and initiate an SSL handshake with it. So it has a "crypto code with server". Now the attacker has two "crypto code", one for you and one for the actual server.
Everything you say, is garbled with the crypto code. However attacker take that, converts it into plain text and then garbles it again and sends it to server. It does the same thing with the things that server says. So now, essentially s/he can read everything and anything that your app and server are talking about; without both of you knowing that he is sitting in between.
This is Man in the middle attack. You ability to know if a certificate that is presented to you is fake or real is deciding factor whether you will fall for the man in the middle or not.
This is an age old problem why are we talking about this again?
Until now, since most of the server interactions happened via browsers, the responsibility to show error if certificate is invalid, stayed with the browser. Since these were built by teams developing against RFC standards, they knew what they were doing. Also, over period of time these implementations became mature and more robust.
Now, mobile applications are individually doing varying level of certificate validations. A lot of them assume that communicating over SSL/TLS is good enough to preserve the data integrity.
Ok Got it! So, how do we test this?
If you would like to reproduce it locally, here is what you can do.
Install MITMPROXY or man in the middle proxy.
Installation instructions are here. You may have to install pip package manager to successfully complete the installation.
Once the proxy is installed, run following command
mitmproxy -p 8888
This will run the proxy on port 8888.
Configure your android phone to use the proxy. Do following steps. These steps are for Android 4.2.1(Jelly Bean), for your version setting a proxy may include a different set of steps. I would recommend googling it up:
Go to Settings > Wifi
Long tap on wifi endpoint you are connected to.
Select "Modify Network"
Check "Show advanced options"
Specific IP address of the computer in hostname
Specify 8888 as the port number
Now validate that browsing to a website in your mobile browser results in an entry in mitmproxy interface. If so, you are all set.
Open pocket app and log out if you were logged in. Now log back in. For sure you will see a POST request in mitmproxy for authentication. This is how it should look:

However, as you can see, everything is available in plain text. And so is the response below for the fetch call.


But we didn't specify a certificate to spoof
Fortunately, mitmproxy implements several clever tricks to spoof certificates. In this case, it would go and get the actual certificate from getPocket's site. Extract values from that certificate like fqdn name etc. Create a new certificate and sign it with it's own fake certificate. But since, mitmproxy's certificate is neither a recognised Root CA's signing certificate not a certificate that you intend to trust, the SSL handshake should have failed here.
Sometimes, you may need to generate a certificate of your own to serve a specific site and you can do so by following steps:
openssl genrsa -out myown.cert.key 8192
openssl req -new -x509 -key myown.cert.key -out pocketsfake.cert
Specify all values like Company, BU, Country etc, as they appear in real certificate.
cat myown.cert.key pocketsfake.cert > pocketsfake.pem
Once the fake certificate for pocket has been generated, run mitmproxy with following command.
mitmproxy -p 8888 --cert=pocketsfake.pem
Thats it, now you would be serving this certificate to anyone who establishes a connection. In this case, the pocket app.
So why does SSL Handshake proceed when the certificate is not valid?
As part of certificate validation Pocketapp is ensuring that certificate is signed. However the authority that signed the certificate is not a valid one and that's where the check has been ignored. Here either it should be checked that signing authority is a one I trust even if it is not a widely trusted or known authority (in cases where organisations use self signed certificates). Or ensure that the signing authority is one, that is widely recognised.
However, even in latter case above, some CA (Certificate Authorities) have been compromised when their root certificate was leaked. example DigiNotar. This resulted in valid, however malicious certificates that browsers and such checks couldn't guard you against it.
In such cases, it has been advised that a technique called "certificate pinning" is used. This is to ascertain that even a valid looking certificate is one that you expect. There are of course several overheads to maintain a certificate pinning, however it does make the apps more secure. A lot more can be read about different techniques of certificate pinning at links below:
Certificate Pinning
Kenny root from android development team talks about similar concepts as certificate pinning.
Android developer write up on SSL/TLS security
Additional Reading:
Rouge access point
Man in the middle attack
5 notes
·
View notes
Text
Snapshotting Vagrant
On my current project I have been setting up a vagrant box to setup specific environment. This contains a bunch of recipes that download around 200MB of data. Large amount of data download can be slow depending on your internet bandwidth. But when that is coupled with compiling and installation of packages locally, it's absolutely unbearable.
In my case, I had something going wrong on the last step of setup, which would mean that my environment wouldn't work as expected. The issue was a tricky one and required vagrant provision rerun as manual steps worked just fine.
So I was left with no choice but to tear down vagrant box repeatedly and build the whole box back from scratch. While thats the purpose of vagrant boxes and Chef, the feedback time of the whole process was driving me nuts.
I am guessing, it must be a common problem for people who frequently work with vagrant to provision large and complicated setups.
If like me you are using Vagrant > version 1.0, then Vagrant-vbox-snapshot is the way to go. All you need to do is
vagrant plugin install vagrant-vbox-snapshot
That installed the vagrant plugin. It's uses internal virtual box's capability to take vm snapshots and restore them. Very quick and effective.
With that I ran provisioning script to a point where I was fairly comfortable with the setup. Took a snapshot and restoring it back to that for repeated runs. No data download and no setup time wasted. Here is the command line options that plugin provides you.
vagrant snapshot
the options are:
back : Roll back to the last snapshot
delete: Delete the snapshot
go: Go to a specific snapshot
list: List all the existing snapshots
take: Take a new snapshot with a name
More details on the github repo.
1 note
·
View note
Photo

Cryptography has always been a interest of mine. I have never had an opportunity to understand the fundamentals and historic background. But I have started exploring the lighter side of it with The Code Book by Simon Singh.
I have to say, it's been gripping so far. The storylike narration just keeps you hooked. Hopefully once I am done with this one; I'll be able to post a summary here.
But even with small bits that I have read; it's a must read for anyone with slightest of interest in Ciphers.
0 notes
Text
Speaking at Droidcon 2012 India
Confirmation for my Talk on Mobile cross platform development : Bridging the gap just came in. It has caught me a bit unprepared, as I wasn't sure of the confirmation, given my submission had been late. But I am very thrilled now and looking forward to speaking to all the Gentlemen and Gentlewomen at Droidcon 2012 India (Bangalore).
If you are attending too, please do plan to attend my talk; it would excite me to take you through the new found approach for cross platform development; that we leveraged at ThoughtWorks. (Recently released as an open source framework).
I'll be posting sneak peek video soon. Hope to see you there!
Here is the link to the video of the talk.
0 notes
Text
Excerpt from my diary from ages ago
Because someone didn't ask you, doesn't mean they don't care.
Some days are like ocean; thick and deep. the weight of water and fatigue of effort weighs you down. The taste of water is nasty and it evokes vomit. but what we need is not repulsion; rather imagination; because while world around you will never cease to deteriorate; the beauty of life will depend on your ability to perceive and percept the uncommon truth. For instance, a swim in cool ocean under a sunny blue soot free sky is a dream of many and while you may think life isn't stopping being a bitch; maybe all it is being is a lucky draw! sometimes you need and like what you get and sometime you don't.
But if you really want something; work for it. Nothing, including nothing, is served on a silver platter to anyone. Behind a momentous breakthrough of those few minutes there is diligent hard work of years.
May be you hate your life, maybe you don't but just don't run away from everything for wrong reasons. Don't be needy and treat people you love like sand; more clenched is you hold; faster they escape.
Don't melt away in pressure; cause no pressure, no diamonds.
0 notes
Quote
Any fool can know. The point is to understand.
Albert Einstein
0 notes
Text
Culinary art of provisioning with Chef and Vagrant
Continuous integration is a part of our daily life at ThoughtWorks. Every project that we do in ThoughtWorks, TDD and continuos integration is a must. Most of the projects that we start, are greenfield and a several of them are either inherited, rescue or re-write projects. In either case, projects start small with a few number of tests to run on CI. But with rapid speed of development and explosion of tests around new code; we run into thousands of unit and functional scenarios soon enough.
We optimize our test run in several ways. One of them being run them in parallel on same machine with multiple cores with a library like parallel tests or we use CI agents to schedule jobs/builds across agents.
Provisioning a CI and its agents is a tedious task; by the time you reach a point where additional agents are needed to speed up CI builds, it also becomes repetitive. Thats where we can leverage chef provisioning.
Before I take a deep dive into different aspects and components of provisioning; let me step back and spell out what each of them mean and why we need them.
In our context Provisioning refers to the art of preparing a machine with required application and environment setup. For the Jenkins example that we'll run through this post; we need to setup a machine with Java, Apache (If we want to front-end Jenkins with apache) and apt package manager (we are assuming a Debian/Ubuntu machine). All of this, in an automated, idempotent and repeatable way. The last automated bit is the crux of it, as it ensures that, this way your infrastructure lives in your source control as code and can be replicated as and when required. A setup of this kind also helps businesses achieve auto-scaling of infrastructure.
Chef/Chef-Solo
Chef and Chef-solo are tools written by Opscode to manage Ruby scripts that help you provision machines. Chef streamlines the concept of provisioning and related processes. It standardises the different components involved in provisioning infrastructure and tie them all together with things like cookbooks, recipes, attributes, resources, providers and bunch of other things. As we go through the exercise, you will get a better sense of what we are dealing with here.
Vagrant
I am sure the concept of provisioning sounds appealing and interesting both at this point. But one problem you would face in real life provisioning-script development is procuring a machine and repeatedly wiping it off clean, so that you can test your script runs. This again can be a tedious process if you do it manually and takes out all the fun from provisioning. Thats where, Vagrant steps in. Vagrant is a VirtualBox wrapper that lets you create virtual machines of your choice. It provides a minimalistic and clean command line interface to bootstrap new virtual machines or strip them down. Vagrant is meant to be used with provisioning tools providers like chef, chef-solo and puppet. Vagrant is really cool and if you have used VirtualBox or any similar application in past, the concept will come naturally; with additional benefit of built in support to run your provisioning scripts on virtual machine. Vagrant is what we are going to use to showcase the power of provisioning; as we bootstrap a new virtual machine and then destroy it almost few minutes later without a hiccup. A combination of vagrant VMs and Chef scripts can successfully emulate a setup of complicated multi-server production environment. And we will take the first step to see how it is done.
Jenkins
Jenkins is one of the popular CI (Continuous Integration) solutions, which is open source with strong community support. It's extensible with plethora of available plugins. We are going to use it as one of the examples to show how repeated provisioning of a CI environment can be handled effortlessly by a provisioning setup.
Now that we have got the basics out of the way; lets see a step by step process of how you can get started with provisioning from scratch.
Prerequisites
As a pre-requisite for this exercise I am assuming that you already have ruby, rvm and bundler setup on your machine. rvm and bundler are of course optional; but with them set up your life will be far easier.
Vagrant Setup
Lets start off by setting up vagrant first.
For Vagrant to work, first ensure that VirtualBox is installed on machine. Download here.
Once VirtualBox is setup, download and install Vagrant from here. After installation you will have the ability to bootstrap or destroy light weight virtual machines at a stroke of a command.
And we are ready with Vagrant. Lets take Vagrant for a spin. Create a new directory and on command line run
vagrant box add ci http://files.vagrantup.com/lucid32.box
vagrant init ci
vagrant up
In above commands, the first command tells the vagrant to fetch an image of ubuntu Lucid Lynx. Using the image we create a box called "ci". In next step we initialize the box; which in turn creates a Vagrantfile in the current directory. This file contains all the configurations for our VM. The last command, tell vagrant to get the virtual machine up and running. You are free to explore inside the machine. Just type
vagrant ssh
Once you have changed directories and investigated configurations to your hearts content, exit and say
vagrant halt
vagrant destroy (optional)
Halt will merely shutdown the machine while destroy with remove the box. But creating a new one should be easy as specified in initial steps above minus the image download.
Chef Setup
Installation for chef can vary for different Operating systems. Refer links below to see what fits your requirements.
Setup instructions here and here.
Librarian Setup
While chef and vagrant are enough to get started with provisioning; I would strongly recommend using Librarian to manage chef-packages (cookbooks). If you have used bundler before to manage gem sets for ruby; think of Librarian as the cookbook manager for chef. They work exactly the same way with same philosophy. Opscode cookbook repo serves as the central repository for cookbooks. A cookbook is a script which manages the setup or installation for a specific runtime environment, took, application etc. For example we would have cookbooks for installing java, apache etc. They are managed in a central repository hosted by Opscode. Librarian deals with the cookbook management aspect. We'll understand it bit more as we work our way through it.
Librarian is just a gem and you can create a Gemfile and use bundler to install it. Gemfile content can look as follows.
source :rubygems
gem 'librarian'
Getting Vagrant VM up and running with Apt and Apache
Now that we have walked through various component setups; we are finally ready to see some magic happen. In our Vagrant setup, when we did vagrant init ci, we observed that it generated a Vagrantfile. This file contains all the configurations for our virtual machine. This is how it should look like for our example. We'll talk through each attribute of this file below.
Note: In your case, generated Vagrantfile will contain lot more properties, but I am listing only stuff that matters to us.
https://gist.github.com/3954313
There are three properties in Vagrantfile above that we have specified.
config.vm.box - This configures the name of vm we are using.
config.vm.network - This helps us configure that guest vm is reachable from host machine only. Also I have assigned a specific ip address that I'd like it to have here. This would help me access the machine on this ip.
config.vm.provision :chef_solo - Finally a block that contains a list of all the cookbooks that we need to run on our newly provisioned vm. Since we know we need to install Apt package manager for ubuntu and Apache; I have added those cookbooks. Next step to show; how we get those. Along with that it also contains cookbooks path. Those are the paths where Vagrant will find cookbooks that have been specified below. "cookbooks" is auto generated by librarian, as we will see below. "site-cookbooks" is a path we create to add our custom cookbooks.
Managing cookbooks with Librarian.
We explicitly specified the cookbooks for Apache and Apt in our Vagrant file; but how did we get those cookbooks?
librarian-chef init
Once your librarian setup is done, all you need to do is to run that command and it'll create a Cheffile in the directory. This Cheffile is very close to how Gemfile looks for bundler. Our Cheffile will look like this.
https://gist.github.com/3954367
Once the entries have been made for Apt and Apache, run following command.
librarian-chef install
You should see a "cookbook" folder containing all the relevant cookbooks, pulled down from central repository. These cookbooks should not be modified, as the changes will be overwritten by librarian-chef in next run. Any custom cookbooks or changes must be overridden via configurations of custom cookbooks managed in site-cookbooks.
At this point we are ready to take our new VM for a spin. If your VM is running run command
vagrant halt
This is important, as cookbooks path were added while VM is running, and cookbook paths are shared with vm to access provisioning scripts while it bootstraps. if we run
vagrant provision
at this point, Vagrant will curse for not having access to those scripts. So we need to restart our VM so that cookbooks are accessible. Post the halt, all we need to do is
vagrant up
This action will run "provision" as part of it. Once the VM is up and running, you can do
vagrant ssh
and assert that Apt and Apache were installed. You'd be able to see the activity in the logs, as VM boots up. Pretty neat huh?
At this junction getting up and running with Jenkins requires us to just add a cookbook that does the jenkins provisioning for us. To do that, just add following line to your Cheffile
cookbook 'jenkins'
And run
librarian-chef install
Once, cookbook has been pulled, you can modify Vagrant file to look like as follows
https://gist.github.com/3954446
Run
vagrant provision
This should provision the Jenkins setup on the machine too. And voila, now your vm is running Jenkins fronted by apache. Once you have done this, this setup can be repeated on as many machines as possible and as many times as required; taking under 5 minutes.
You can make backup of Jenkins config files and add them to a custom cookbook and you would have a Jenkins CI, that can be provisioned; run your tests and be thrown away. Wouldn't that be cool!?
There are some quirks that you have have to sort out to make this work completely; especially with hostnames. But if you understand Apache configurations, they should be very easy to do. I have done those small changes with an additional custom cookbook here. Very simple and easy to understand. Find it as part of complete source code here.
Hopefully this will get you running with Jenkins in no time. I'll write more soon on how you can have Agents provisioned against this Jenkins instance and also how you can take these scripts from running against a VM in cloud like Amazon EC2 instance instead of Vagrant.
0 notes
Text
Building modular APIs with Grape and Rails
Recently I started working on a personal project. It involved creating RESTful APIs for consumption on various mobile devices as well as on web front end. I have used Sinatra in past to solve similar problems. Sinatra works really well, if you mount it on rack along side rails. Here is my post on how I went about doing that. While Sinatra served us really well, there were few learning we had from that style. A subset of them are listed here:
Unstructured Code: We used helpers and modules as much as we could; however we still felt that we could do better in terms of how code could be organised.
Unravelling Rabl: We wanted a flat representation of our models and their associations. This would often vary from their domain and would include some computed fields. Rabl worked well for simpler representations; however for complex and deeply nested association, there was a steep curve in understanding Rabl's nitty gritty and also it made our rabl view a bit intimidating.
Versioning: Right from day one we knew, we would need to version our APIs at some point of time. So we built that support from start. Since we used Sinatra to serve our APIs, we had to build that capability ourselves. The solution worked moderately well; however we couldn't maximize the code reuse between versions and that meant duplication (especially in cases where new versions had a different response structure).
While on the surface these problems seem minor and I would agree that they can be solved with some refactoring; I looked out if there existed a library that would support building APIs in a more structured way. And I landed onto Grape
I gave Grape a quick run on my new side project and I have to say that I was pleasantly surprised with Grape's ability and approach to solve the problems mentioned above.
Let me talk through an example of how you can implement Grape and make your API light weight, simpler and flexible. Yes, all at the same time.
Problem Statement: Lets assume we need to expose an api from a rails app for a user profile. User profile should contain following json structure:
https://gist.github.com/46ab750c2cb8d99704e1
Overview Of Solution: Lets assume, that you have an existing rails app or you would like to support this API outside the existing controller structure that you use for web; but on top of existing user model. Also for this example I would presume following components.
Rails 3.2.0
Mongodb with Mongoid (3.0.5) as ORM (because I <3 mongo)
Grape for API
Given our approach will use a active record or mongoid document user model; it would be straight forward to build the API either on an existing rails app or in a new one.
Step by Step Guide:
Generate a Rails app without active record
rails new GrapeAPI -O
Add following list of gems in the Gemfile
https://gist.github.com/3926315
Lets assume following models exists in our codebase
https://gist.github.com/3926360
Grape allows APIs to be defined in a single file or modularize them in individual modules and then mount those into the other definition files. This works great from the modular perspective; as for each API, different versions can be defined in their own modules and then mounted back on the one that acts as root api module.
Below we will see, how version 1 of the user api can be defined into a module and then be mounted back onto the primary API module. Whats great is, that based on the version passed in header/url (configurable) methods in the right modules are invoked.
Besides this modular structure, the views can be configured too; which feed off a model object. These modules for views can be further sub divided if they have nested objects or relations.
Here is a gist, that explains the implementation of the user api. Take a look.
Before that ensure that Grape api is mounted correctly in your routes.rb. Here is the line we will add. This will ensure that all the urls starting with "/api" are routed to Grape.
mount API => "/api"
https://gist.github.com/3926492
Things to note in above implementation:
We have specified default API format as :json and error_format as :json in api.rb. Also we indicate that version should be passed to server as header value for "Accept".
apiv1.rb is a specific version 1 implementation for users. It lives at "app/api/users/". It defines a api url for where id comes as a parameter. This format is very close to that of Sinatra, if you have used it in past.
present methods, presents the model object handed over using the GrapeEntity defined with "with" clause. As you can see in sample above, we have defined them as per the need of json respone.
Great part about the Grape::Entity is that, they can be further modularised by segregating the nested entities. We have done so for contact info and phone numbers. This makes the code organisation very simple and scalable.
Command below can be fired to see the response from server. Note the header that is being passed for version 1. "vnd.app-v1+json"; app is the vendor name we specified above in api.rb.
curl -H Accept=application/vnd.app-v1+json http://localhost:3000/api/user/5083ba93e2870b9420000001
Hope this rundown has given you a better insight into how Grape can be used to version and modularise an API; while keeping views very simple too. Of course the views in form of Grape::Entity that we have used here, showcase only limited options.
Check out well documented Grape github page to see more details and exciting options/features. Complete source for this example is available in my github repo here.
2 notes
·
View notes