
readevalprint
READ EVAL PRINT
Grue's programming blog. Mostly Common Lisp and Scheme related. Maybe Python too.
19 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

noirs1madame
·—Ɲꫀρhꫀᥣꫀ°࿐

jorgeborgesblog
Mercado livre/Shopee

yashfafabrics
Yashfa Enterprises

hyenawatch2
The Blogging of Risager 665

teenagecreationcrown
Sans titre
Text
Ichiran@home 2021: the ultimate guide
Recently I’ve been contacted by several people who wanted to use my Japanese text segmenter Ichiran in their own projects. This is not surprising since it’s vastly superior to Mecab and similar software, and is occassionally updated with new vocabulary unlike many other segmenters. Ichiran powers ichi.moe which is a very cool webapp that helped literally dozens of people learn Japanese.
A big obstacle towards the adoption of Ichiran is the fact that it’s written in Common Lisp and people who want to use it are often unfamiliar with this language. To fix this issue, I’m now providing a way to build Ichiran as a command line utility, which could then be called as a subprocess by scripts in other languages.
This is a master post how to get Ichiran installed and how to use it for people who don’t know any Common Lisp at all. I’m providing instructions for Linux (Ubuntu) and Windows, I haven’t tested whether it works on other operating systems but it probably should.
PostgreSQL
Ichiran uses a PostgreSQL database as a source for its vocabulary and other things. On Linux install postgresql using your preferred package manager. On Windows use the official installer. You should remember the password for the postgres user, or create a new user if you know how to do it.
Download the latest release of Ichiran database. On the release page there are commands needed to restore the dump. On Windows they don't really work, instead try to create database and restore the dump using pgAdmin (which is usually installed together with Postgres). Right-click on PostgreSQL/Databases/postgres and select "Query tool...". Paste the following into Query editor and hit the Execute button.
CREATE DATABASE [database_name] WITH TEMPLATE = template0 OWNER = postgres ENCODING = 'UTF8' LC_COLLATE = 'Japanese_Japan.932' LC_CTYPE = 'Japanese_Japan.932' TABLESPACE = pg_default CONNECTION LIMIT = -1;
Then refresh the Databases folder and you should see your new database. Right-click on it then select "Restore", then choose the file that you downloaded (it wants ".backup" extension by default so choose "Format: All files" if you can't find the file).
You might get a bunch of errors when restoring the dump saying that "user ichiran doesn't exist". Just ignore them.
SBCL
Ichiran uses SBCL to run its Common Lisp code. You can download Windows binaries for SBCL 2.0.0 from the official site, and on Linux you can use the package manager, or also use binaries from the official site although they might be incompatible with your operating system.
However you really want the latest version 2.1.0, especially on Windows for uh... reasons. There's a workaround for Windows 10 though, so if you don't mind turning on that option, you can stick with SBCL 2.0.0 really.
After installing some version of SBCL (SBCL requires SBCL to compile itself), download the source code of the latest version and let's get to business.
On Linux it should be easy, just run
sh make.sh --fancy sudo sh install.sh
in the source directory.
On Windows it's somewhat harder. Install MSYS2, then run "MSYS2 MinGW 64-bit".
pacman -S mingw-w64-x86_64-toolchain make # for paths in MSYS2 replace drive prefix C:/ by /c/ and so on cd [path_to_sbcl_source] export PATH="$PATH:[directory_where_sbcl.exe_is_currently]" # check that you can run sbcl from command line now # type (sb-ext:quit) to quit sbcl sh make.sh --fancy unset SBCL_HOME INSTALL_ROOT=/c/sbcl sh install.sh
Then edit Windows environment variables so that PATH contains c:\sbcl\bin and SBCL_HOME is c:\sbcl\lib\sbcl (replace c:\sbcl here and in INSTALL_ROOT with another directory if applicable). Check that you can run a normal Windows shell (cmd) and run sbcl from it.
Quicklisp
Quicklisp is a library manager for Common Lisp. You'll need it to install the dependencies of Ichiran. Download quicklisp.lisp from the official site and run the following command:
sbcl --load /path/to/quicklisp.lisp
In SBCL shell execute the following commands:
(quicklisp-quickstart:install) (ql:add-to-init-file) (sb-ext:quit)
This will ensure quicklisp is loaded every time SBCL starts.
Ichiran
Find the directory ~/quicklisp/local-projects (%USERPROFILE%\quicklisp\local-projects on Windows) and git clone Ichiran source code into it. It is possible to place it into an arbitrary directory, but that requires configuring ASDF, while ~/quicklisp/local-projects/ should work out of the box, as should ~/common-lisp/ but I'm not sure about Windows equivalent for this one.
Ichiran wouldn't load without settings.lisp file which you might notice is absent from the repository. Instead, there's a settings.lisp.template file. Copy settings.lisp.template to settings.lisp and edit the following values in settings.lisp:
*connection* this is the main database connection. It is a list of at least 4 elements: database name, database user (usually "postgres"), database password and database host ("localhost"). It can be followed by options like :port 5434 if the database is running on a non-standard port.
*connections* is an optional parameter, if you want to switch between several databases. You can probably ignore it.
*jmdict-data* this should be a path to these files from JMdict project. They contain descriptions of parts of speech etc.
ignore all the other parameters, they're only needed for creating the database from scratch
Run sbcl. You should now be able to load Ichiran with
(ql:quickload :ichiran)
On the first run, run the following command. It should also be run after downloading a new database dump and updating Ichiran code, as it fixes various issues with the original JMdict data.
(ichiran/mnt:add-errata)
Run the test suite with
(ichiran/test:run-all-tests)
If not all tests pass, you did something wrong! If none of the tests pass, check that you configured the database connection correctly. If all tests pass, you have a working installation of Ichiran. Congratulations!
Some commands that can be used in Ichiran:
(ichiran:romanize "一覧は最高だぞ" :with-info t) this is basically a text-only equivalent of ichi.moe, everyone's favorite webapp based on Ichiran.
(ichiran/dict:simple-segment "一覧は最高だぞ") returns a list of WORD-INFO objects which contain a lot of interesting data which is available through "accessor functions". For example (mapcar 'ichiran/dict:word-info-text (ichiran/dict:simple-segment "一覧は最高だぞ") will return a list of separate words in a sentence.
(ichiran/dict:dict-segment "一覧は最高だぞ" :limit 5) like simple-segment but returns top 5 segmentations.
(ichiran/dict:word-info-from-text "一覧") gets a WORD-INFO object for a specific word.
ichiran/dict:word-info-str converts a WORD-INFO object to a human-readable string.
ichiran/dict:word-info-gloss-json converts a WORD-INFO object into a "json" "object" containing dictionary information about a word, which is not really JSON but an equivalent Lisp representation of it. But, it can be converted into a real JSON string with jsown:to-json function. Putting it all together, the following code will convert the word 一覧 into a JSON string:
(jsown:to-json (ichiran/dict:word-info-json (ichiran/dict:word-info-from-text "一覧")))
Now, if you're not familiar with Common Lisp all this stuff might seem confusing. Which is where ichiran-cli comes in, a brand new Command Line Interface to Ichiran.
ichiran-cli
ichiran-cli is just a simple command-line application that can be called by scripts just like mecab and its ilk. The main difference is that it must be built by the user, who has already did the previous steps of the Ichiran installation process. It needs to access the postgres database and the connection settings from settings.lisp are currently "baked in" during the build. It also contains a cache of some database references, so modifying the database (i.e. updating to a newer database dump) without also rebuilding ichiran-cli is highly inadvisable.
The build process is very easy. Just run sbcl and execute the following commands:
(ql:quickload :ichiran/cli) (ichiran/cli:build)
sbcl should exit at this point, and you'll have a new ichiran-cli (ichiran-cli.exe on Windows) executable in ichiran source directory. If sbcl didn't exit, try deleting the old ichiran-cli and do it again, it seems that on Linux sbcl sometimes can't overwrite this file for some reason.
Use -h option to show how to use this tool. There will be more options in the future but at the time of this post, it prints out the following:
>ichiran-cli -h Command line interface for Ichiran Usage: ichiran-cli [-h|--help] [-e|--eval] [-i|--with-info] [-f|--full] [input] Available options: -h, --help print this help text -e, --eval evaluate arbitrary expression and print the result -i, --with-info print dictionary info -f, --full full split info (as JSON) By default calls ichiran:romanize, other options change this behavior
Here's the example usage of these switches
ichiran-cli "一覧は最高だぞ" just prints out the romanization
ichiran-cli -i "一覧は最高だぞ" - equivalent of ichiran:romanize :with-info t above
ichiran-cli -f "一覧は最高だぞ" - outputs the full result of segmentation as JSON. This is the one you'll probably want to use in scripts etc.
ichiran-cli -e "(+ 1 2 3)" - execute arbitrary Common Lisp code... yup that's right. Since this is a new feature, I don't know yet which commands people really want, so this option can be used to execute any command such as those listed in the previous section.
By the way, as I mentioned before, on Windows SBCL prior to 2.1.0 doesn't parse non-ascii command line arguments correctly. Which is why I had to include a section about building a newer version of SBCL. However if you use Windows 10, there's a workaround that avoids having to build SBCL 2.1.0. Open "Language Settings", find a link to "Administrative language settings", click on "Change system locale...", and turn on "Beta: Use Unicode UTF-8 for worldwide language support". Then reboot your computer. Voila, everything will work now. At least in regards to SBCL. I can't guarantee that other command line apps which use locales will work after that.
That's it for now, hope you enjoy playing around with Ichiran in this new year. よろしくおねがいします!
6 notes
·
View notes
Text
Previewing images in and out of SLIME REPL
As any Common Lisp coder knows, a REPL is an incredibly useful tool. It can be used not just for development, but for running all sorts of tasks. Personally, I don’t bother making my Lisp tools into executable scripts and just run them directly from SLIME. As such, any operation that requires leaving the REPL is quite inconvenient. For me, one such operation was viewing image files, for example in conjunction with my match-client:match tool. So lately I’ve been researching various methods to incorporate this functionality into the normal REPL workflow. Below, I present 3 methods that can be used to achieve this.
Open in external program
This one’s easy. When you want to view a file, launch an external process with your favorite image viewer. On Windows a shell command consisting of the image filename would launch the associated application, on Linux it’s necessary to provide the name of the image viewer.
(defvar *image-app* nil) ;; set it to '("eog") or something (defun view-file-native (file) (let ((ns (uiop:native-namestring file))) (uiop:launch-program (if *image-app* (append *image-app* (list ns)) (uiop:escape-shell-token ns)))))
Note that uiop:launch-program is used instead of uiop:run-program. The difference is that launch- is non-blocking - you can continue to work in your REPL while the image is displayed, whereas run- will not return until you close the image viewer.
Also note that when the first argument to run/launch-program is a string, it is not escaped, so I have to do it manually. And if the first argument is a list, it must be a program and a list of its arguments, so merely using (list ns) wouldn't work on Windows.
Inline image in REPL
The disadvantage of the previous method is that the external program might steal focus, appear on top of your REPL and disrupt your workflow. And it’s well known that Emacs can do everything, including viewing images, so why not use that?
In fact, SLIME has a plugin specifically for displaying images in REPL, slime-media. However it's difficult to find any information on how to use it. Eventually I figured out that SWANK (SLIME's CL backend) needs to send an event :write-image with appropriate arguments and slime-media’s handler will display it right in the REPL. The easiest way is to just send the file path. The second argument is the resulting image’s string value. If you copy-paste (sorry, “kill-yank”) it in the repl, it would act just like if you typed this string.
(swank::send-to-emacs '(:write-image "/path/to/test.png" "test"))
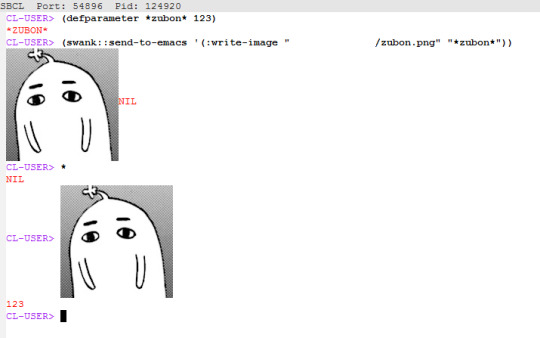
You can even send raw image data using this method. I don’t have anything on hand to generate raw image data so here’s some code that reads from a file, converts it to a base64 string and sends it over SWANK.
(with-open-file (in "/path/to/test.png" :direction :input :element-type '(unsigned-byte 8)) (let* ((arr (make-array (file-length in) :element-type '(unsigned-byte 8))) (b64 (progn (read-sequence arr in) (cl-base64:usb8-array-to-base64-string arr)))) (swank::send-to-emacs `(:write-image ((:data ,b64 :type swank-io-package::png)) "12345"))))
Note that the first argument to :write-image must be a list with a single element, which is itself a plist containing :data and :type keys. :data must be a base64-encoded raw image data. :type must be a symbol in swank-io-package. It's not exactly convenient, so if you're going to use this functionality a helper function/macro might be necessary.
Image in a SLIME popup buffer
Inline images are not always convenient. They can't be resized, and will take up as much space as is necessary to display them. Meanwhile EMACS itself has a built-in image viewer (image-mode) which can fit images to width or height of a buffer. And SLIME has a concept of a "popup buffer" which is for example used by macroexpander (C-c C-m) to display the result of a macro expansion in a separate window.
Interestingly, slime-media.el defines an event :popup-buffer but it seems impossible to trigger it from SWANK. It is however a useful code reference for how to create the popup buffer in ELisp. This time we won't bother with "events" and just straight up execute some ELisp code using swank::eval-in-emacs. However by default, this feature is disabled on Emacs-side, so you'll have to set Emacs variable slime-enable-evaluate-in-emacs to t in order for this method to work.
Also Emacs must be compiled with ImageMagick for the resizing functionality to work.
Anyway, the code to view file in the popup buffer looks like this:
(defun view-file-slime (file &key (bufname "*image-viewer*")) (let ((ns (namestring file))) (swank::eval-in-emacs `(progn (slime-with-popup-buffer (,bufname :connection t :package t) (insert-image (create-image ,ns)) (image-mode) (setf buffer-file-name ,ns) (not-modified) (image-toggle-display-image)) ;; try to resize the image after the buffer is displayed (with-current-buffer ,bufname (image-toggle-display-image)))))) ))
Arriving to this solution has required reading image-mode's source code to understand what exactly makes image-mode behave just like if the image file was opened in Emacs via C-x C-f. First off, image-mode can be a major and a minor mode - and the minor mode is not nearly as useful. slime-with-popup-buffer has a :mode keyword argument but it would cause image-mode to be set before the image is inserted, and it will be a minor mode in this case! Therefore (image-mode) must be called after insert-image.
Next, the buffer must satisfy several conditions in order to get image data from the filename and not from the buffer itself. Technically it shouldn't be necessary, but I couldn't get auto resizing to work when data-p is true. So I set buffer-file-name to image's filename and set not-modified flag on.
Next, image-toggle-display-image is called to possibly resize the image according to image-mode settings. It’s called outside of slime-with-popup-buffer for the following reason: the buffer might not yet be visible and have any specific dimensions assigned to it, and therefore resizing will do nothing.
Here's an example of how calling this function looks in Emacs.

The position of the popup buffer depends on whether the original Emacs window is wide enough or not. I think it looks better when it's divided vertically. Use M-x image-transform-fit-to-height or M-x image-transform-fit-to-width to set up the auto-resizing method (it gets remembered for future images). Unfortunately there's no way to fit both height and width, at least with vanilla Emacs. I prefer fit-to-width because in case the image is too tall, it is possible to scroll the image vertically with M-PgDn and M-PgUp from the other buffer. Unlike other image-mode buffers, this buffer supports a shortcut q to close itself, as well as various SLIME shortcuts, for example C-c C-z to return to the REPL.
That’s it for now, hope you enjoyed this overview and if you happen to know a better way to display images in Emacs, I would be interested to hear about it.
4 notes
·
View notes
Text
Multi-threaded testing with lisp-unit and lparallel
There’s no shortage of testing libraries in Common Lisp world. In fact the first library a Lisp developer writes is usually a unit testing library. Everyone has their favorite as well.
For my project, Ichiran I had to start testing early on, mainly to keep track of regressions of the segmentation algorithm. One of the main features of this project is the ability to split a sentence of Japanese text into separate words (there are no spaces), which it does better than other known algorithms.
For the testing framework, I chose lisp-unit. I think it's considered somewhat old-fashioned these days, and it certainly doesn't have a lot of fancy features, but its dead simplicity is also an advantage.
From the start, the testing procedure was simple. I had an assert-segment macro which basically compared two lists of strings, and a test segmentation-test which had a lot of assert-segments in it.
(defmacro assert-segment (str &rest segmentation) `(assert-equal ',segmentation (simple-segment ,str))) (define-test segmentation-test (assert-segment "ご注文はうさぎですか" "ご注文" "は" "うさぎ" "です" "か") ... )
At some point I had enough of these test segmentations that the test took a while to finish. After using lparallel in another project I got an idea that segmentation tests can be parallelized in a similar way, without changing the testing framework. Eventually I had an implementation that was "decent enough", however it had some flaws that I just kept ignoring. Recently I went about fixing these flaws, and so I present the proper way to have tests running in parallel in lisp-unit. A similar approach might also work in other test frameworks.
Let's start with the assert-segment macro above. It can be divided into two parts. The first part is (assert-equal expected-result actual-result) which is fast, and has to run in the main thread (because it modifies lisp-unit's special variables and can't be assumed to be thread-safe). The second part is (simple-segment str) which produces actual-result, is relatively slow, and we want to run it in the thread pool. Now we have the following criteria:
simple-segment must be computed before it can be decided whether the test passes.
assert-equal must be performed in the main thread.
assert-segment must be placed sequentially in the body of segmentation-test.
At first it might seem impossible to satisfy these criteria while also having simple-segment execute in parallel. After all, each assert-segment expands to assert-equal and that can't evaluate until simple-segment returns the result of segmentation.
To resolve this apparent contradiction, we will use lparallel's concept of "promises". A promise is an object that indicates a result of some computation, which might have not finished, or not even started. To actually get the result from promise, we must force it, which will wait for the computation to finish. It's an extremely powerful concept, though perhaps not very intuitive.
We will use two types of promises: future starts running some computation in lparallel's thread pool when it's created. delay starts running only when it is forced - it's basically identical to creating a closure and funcalling it later.
Here's how our test will work. Each assert-segment will create a simple-segment future which would start executing in the thread pool, and assert-equal delay which would force this future. The delays will only be forced at the end of the test, at which point all the segmentations are already scheduled to be executed. Here's the outline of the test:
(defvar *delays*) (defmacro define-parallel-test (name &body body) `(define-test ,name (let ((*delays* nil)) ,@body (map nil 'lparallel:force (reverse *delays*))))) (define-parallel-test segmentation-test (assert-segment ...) (assert-segment ...) (assert-segment ...) ... )
Each assert-segment will have to push its delay into a special variable *delays*, and then they will be waited for in the same order they were pushed (which requires reversing the list of delays).
Before I define assert-segment, I would like to abstract the concept of it. Let's create a generic macro test-job that would define one of the jobs that need to be executed during a test. Each test-job will have a tester (the part that executes in the main thread) and a worker (the part that executes in the thread pool).
(defun test-progress (result &optional err) (princ (cond (err "E") (result ".") (t "F")))) (defmacro test-job ((result-var) tester &body worker) (alexandria:with-gensyms (future error) `(push (let ((,future (lparallel:future (ignore-errors ,@worker)))) (lparallel:delay (multiple-value-bind (,result-var ,error) (lparallel:force ,future) (cond (,error (test-progress nil t) (error ,error)) (t (test-progress ,tester)))))) *delays*)))
The code is a bit nasty. First off, to keep track of completed tests I added a test-progress function. It will print a small dot for a successful test and a big letter if something went wrong.
The future is created with lparallel:future. You might notice that the worker code is wrapped with ignore-errors. However I'm not really ignoring them - the condition object is returned as the second value of ignore-errors, and lparallel:future thankfully does preserve multiple values. In fact, this error is immediately re-raised after printing test-progress. Remember that the code within lparallel:future is executed in a thread pool. Which means the error handlers set up by lisp-unit in the main thread are not handling any errors in that code! Which means if the test code is producing an error, you get a faceful of debugger windows in SLIME, one for each test case, which are quite hard to get rid of! ignore-errors solves this problem by transferring the error object into the main thread, where it is gracefully handled (and accounted for) by lisp-unit.
Note that it is critical that lparallel:future is created outside of lparallel:delay. Otherwise the computation won't start until the delay is forced, which will defeat the whole point.
Finally, assert-segment will look like this:
(defun assert-segment (str &rest segmentation) (test-job (result) (assert-equal segmentation result) (simple-segment str)))
Oh right, one last thing. Now that this test uses a lparallel thread pool, it cannot be run with a mere lisp-unit:run-tests! A test runner must create lparallel's kernel and also gracefully shut it down. Here's an example:
(defparameter *test-thread-count* 4) (defun run-parallel-tests (&optional (tests :all) (pkg :ichiran/test)) (let* ((lparallel:*kernel* (lparallel:make-kernel *test-thread-count*)) (res (unwind-protect (run-tests tests pkg) (lparallel:end-kernel)))) (print-failures res) (print-errors res) res))
I hope this post has shed some light on using lparallel's promises abstractions to execute parallel tasks. I think it's the most natural interface to do such a thing, and as you can see it allows to transform seemingly sequential code into what really is multithreaded code. In this case it allowed to trick a single-threaded library like lisp-unit into running several jobs in parallel. And that's it for today's post, see you next time!
1 note
·
View note
Text
How caches work in Ichiran
Welcome to another update of very frequently updating (not!) web blog READ EVAL PRINT.
Recently I had some free time to work on my Ichiran / ichi.moe project, which I had written about in previous posts here. A new feature has been developed to load various extra data in the dictionary, and as a proof of concept I added all city/town/village names in Japan to it.
Also I’ve taken a stab at optimizing some frequently running code. The single biggest (both in run-time and code size) function calc-score has been optimized to (speed 3) with all optimization suggestions taken care of.
The profiler has also identified a function named get-conj-data as another time-waster. This function is one of many called by the abovementioned calc-score to calculate the score of a word. The reason why it's so wasteful is that it is called for every single word (often twice), and it performs a database query on every single call.
After I fixed the being-called-twice thing, the other possible optimization was clearly to avoid querying the database so much. As the name implies, get-conj-data gets conjugation metadata of a word. For example, the word starts in English is a plural form of the noun start, while also being a third-person form of the verb to start. In Japanese, there's a lot more verb conjugations than in English, so most words in Ichiran database are actually verb conjugations.
Still, in a given sentence there will only be a few conjugatable words and yet get-conj-data is called on every word. If only we could know in advance that a given word doesn't have any conjugations... And this is where the so-called "caching" comes in.
Ichiran database is mostly read-only, so there are a lot of opportunities to reduce database queries, though these opportunities are often unused. I have created a simple caching interface located in the file conn.lisp which is full of esoteric Lisp goodness such as a macro involving PROGV. Let's look at the implementation:
(defclass cache () ((mapping :initform nil :allocation :class) (name :initarg :name :reader cache-name) (var :initarg :var :reader cache-var) (lock :reader cache-lock)))
Each cache will be an instance of this class. However the data is not held in a slot, but rather in a special variable referred to by var slot. There's also a lock slot because I don't want to have one cache loading the same data in two threads at once. The slot mapping is especially interesting: it has :allocation :class so all caches have the same "mapping". This mapping associates name of a cache (which is a keyword) to an actual instance of cache. This allows to refer to a cache instance from anywhere in the code, knowing only its name.
(defmethod initialize-instance :after ((cache cache) &key &allow-other-keys) (let* ((name (cache-name cache)) (old-cache (getf (slot-value cache 'mapping) name))) (setf (slot-value cache 'lock) (if old-cache (cache-lock old-cache) (sb-thread:make-mutex :name (symbol-name name)))) (setf (getf (slot-value cache 'mapping) name) cache)))
You can see there's some code dealing with "old cache". When a cache definition (using defcache below) is recompiled, make-instance will be used to create a new cache object. To avoid having to repopulate the cache, the data is not stored in the cache instance, but in a separate special variable. The cache lock is also transferred from the old cache to prevent any weirdness when the cache is initialized when the old cache is still ingesting data.
(defun all-caches () (slot-value (sb-mop:class-prototype (find-class 'cache)) 'mapping)) (defun get-cache (name) (getf (all-caches) name))
To get a cache instance by name, we need to access the mapping slot. But is it possible to access it without having any particular cache instance at hand? It turns out yes, but only by using the extra MOP functionality. You can use closer-mop:class-prototype for portable code.
(defmacro defcache (name var &body init-body) (alexandria:with-gensyms (cache-var) `(progn (def-conn-var ,var nil) (make-instance 'cache :name ',name :var ',var) (defmethod init-cache ((,cache-var (eql ,name))) (with-connection *connection* ,@init-body)))))
Here's what defcache looks like. def-conn-var is explained in the PROGV post. It's basically a special variable that gets swapped depending on the current connection. make-instance is called at top-level here, the only reason it's not garbage collected is because the class-allocated mapping slot refers to it. init-cache is a custom method to load all data into the cache. It's specialized on the name keyword which is somewhat unusual.
(defgeneric reset-cache (cache-name) (:method (cache-name) (let ((val (init-cache cache-name)) (cache (get-cache cache-name))) (sb-thread:with-mutex ((cache-lock cache)) (setf (symbol-value (cache-var cache)) val))))) (defgeneric ensure (cache-name) (:method (cache-name) (let ((cache (get-cache cache-name))) (or (symbol-value (cache-var cache)) (sb-thread:with-mutex ((cache-lock cache)) (or (symbol-value (cache-var cache)) (let ((val (init-cache cache-name))) (setf (symbol-value (cache-var cache)) val)))))))) (defun init-all-caches (&optional reset) (loop with fn = (if reset 'reset-cache 'ensure) for (name . rest) on (all-caches) by #'cddr do (funcall fn name)))
The rest of the implementation is fairly straightforward. ensure is the function that will be used as an accessor to cache, init-all-caches is called at startup, and reset-cache is mostly to be used interactively when I want to refresh a specific cache.
Note that ensure checks that cache is non-NIL again after receiving the lock: another thread could've filled the cache while it's still waiting for the lock.
Note also that init-all-caches uses single-quote to refer to functions 'reset-cache and 'ensure, but uses #'cddr in the loop. As a rule, I almost always use a symbol as a function designator. The problem with #' is that it reads the function definition at evaluation time, and not when it's actually called, so in a project like mine with a lot of global state, it might result in outdated function objects hanging around when I redefine some functions on the fly. However using single-quote function designator in the by clause of loop leads to the following warning in SBCL:
WARNING: Use of QUOTE around stepping function in LOOP will be left verbatim.
Why is this a warning, I have no idea. The code works, and my use of quote is totally intentional. So I'm using #' here just to avoid this warning. But since built-in functions like cddr can't be redefined anyway, it doesn't really matter.
EDIT: I have received response from one of SBCL developers, stassats, and apparently this warning is a relic from an old era and will be removed in the next version. Also apparently what I wrote about #' in the first version of this article was wrong, so now I rewrote my justification for not using it.
Now let's look at how a specific cache can be defined and used:
(defcache :no-conj-data *no-conj-data* (let ((no-conj-data (make-hash-table :size 200000))) (dolist (seq (query (:select (:distinct 'entry.seq) :from 'entry :left-join (:as 'conjugation 'c) :on (:= 'entry.seq 'c.seq) :where (:and (:is-null 'c.seq))) :column)) (setf (gethash seq no-conj-data) t)) no-conj-data)) (defun no-conj-data (seq) (nth-value 1 (gethash seq (ensure :no-conj-data)))) (defun get-conj-data (seq &optional from/conj-ids texts) (when (no-conj-data seq) (return-from get-conj-data nil)) ... )
defcache is used to define a custom loading procedure. In this case, the data is a set of sequence numbers, implemented as keys of a hash table. Because the majority of the words in the database are conjugations, it's more memory-efficient to only store the entries that aren't.
With the cache being present, get-conj-data can exit early if the sequence number is known to not be a conjugation of anything, avoiding an extra database query.
In the end, between calc-score optimization and get-conj-data optimization I achieved about 2x speedup of the test suite, and it will likely apply to real life performance as well.
Hopefully you enjoyed this writeup and hopefully I'll write more sometime in the future. Until next time!
0 notes
Text
Your personal DIY image search
Hi everyone, it’s been a while! I bet you forgot this blog even existed. I happen to be a big supporter of quality over quantity, so while my work on parsing Japanese counters earlier this year was pretty interesting, I already wrote way too many articles about Ichiran/ichi.moe so I decided to keep it to myself. Recently I’ve been working on a little side-project and now that it finally works, I think it deserves a full-fledged blog post.
For a bit of a nostalgia trip, let's go back to the early 00s. Remember when TinEye first appeared? It was amazing. For the first time you could easily find where that one image you once saved from some random phpBB forum is really from. It didn't matter if your image was resized, or slightly edited from the original, it still worked. That shit was magic, my friends. Of course these days nobody is impressed by this stuff. Google Image Search indexes pretty much anything that exists on the Internet and even uses neural networks to identify content of an image.
Back to the present day. I discovered I have an image hoarding problem. Over the years of using the Intertubes, I have accumulated a massive number of images on my hard drive. When I see an image I like my first thought is "do I have this one saved already?" because how could I possibly remember? At this point I need my own personal Google Image Search. And (spoiler alert) now I have one.
First of all, I needed an actual image matching technology. These days the cloud is all the rage, so I definitely wanted to have this thing running in the cloud (as opposed to my local PC) so that I could search my images from anywhere in the world. After a cursory search, my eyes fell on a thing called Pavlov Match which runs from a Docker container, so should be pretty easy to install. I installed docker and docker-compose on my VPS, and then git-cloned Match and ran make dev according to instructions. This will actually run an Elasticsearch instance on the same VPS, and apparently the damn thing eats memory for breakfast, at least with the default settings. I'm using a cheap 2GB RAM Linode, so the memory is actually a very finite resource here, as I will find out later. The default settings will also completely expose your match installation AND elasticsearch to the world. But don't worry, I figured this out so that you don't have to. Let's edit docker-compose.yml from match repository as follows:
version: '2' services: match: image: pavlov/match:latest ports: - 127.0.0.1:8888:8888 command: ["/wait-for-it.sh", "-t", "60", "elasticsearch:9200", "--", "gunicorn", "-b", "0.0.0.0:8888", "-w", "4", "--preload", "server:app"] links: - elasticsearch elasticsearch: image: elasticsearch environment: - "ES_JAVA_OPTS=-Xms256m -Xmx256m" - bootstrap.mlockall=true expose: - "9200"
This will make match server only available on local network within the VPS on port 8888, and elasticsearch only available to these two docker containers. It will also restrict elasticsearch RAM consumption to 512mb and --preload flag reduces the amount of memory gunicorn workers consume.
To make match server available from outside I recommend proxying it through nginx or some other proper web server. You can also add authentication/IP whitelist in nginx because the match server has no authentication features whatsoever, so anyone will be able to search/add/delete the data on it.
That was the backend part. No programming required here! But this is a Lisp blog, so the next step is writing a Lisp client that can communicate with this server. The first step is reading the match API documentation. You might notice it's a bit... idiosyncratic. I guess REST is out of fashion these days. Anyway, I started implementing a client using the trusty drakma, but I quickly hit a limitation: match expects all parameters to be sent encoded as form data, but drakma can only encode POST parameters as form data and not, say, DELETE parameters. Not to be foiled by a badly designed API, I tried dexador, and while dex:delete does not encode parameters as form data, dex:request is flexible enough to do so. Each response (a JSON string) is parsed using jsown.
(defun parse-request (&rest args) (when *auth* (setf args `(,@args :basic-auth ,*auth*))) (multiple-value-bind (content return-code) (handler-bind ((dex:http-request-failed #'dex:ignore-and-continue)) (apply 'dex:request args)) (cond ((<= 400 return-code 499) (jsown:new-js ("status" "fail") ("error" content) ("code" return-code))) (t (let ((obj (jsown:parse content))) (jsown:extend-js obj ("code" return-code))))))) (defun add-local (file &key path (metadata "{}")) "Add local image to Match server" (parse-request (api-url "/add") :method :post :content `(("image" . ,(pathname file)) ("filepath" . ,(or path file)) ("metadata" . ,metadata))))
With this basic client in place, I can add and delete individual images, but it would be incredibly cumbersome to manage thousands of images with it. I had to write some code that would scan specified directories for images, track any changes and then add/update/delete information from Match server as needed. I already wrote something like this before, so this was pretty easy. Of course SBCL's "sb-posix:stat doesn't work on Unicode filenames" bug has reared its head again, but I already knew the workaround. This time I completely relied on UIOP for recursively walking directories (uiop:subdirectories and uiop:directory-files are your friends). Each image file is represented as CLOS object and saved into a hash-table which is serialized to a file using CL-STORE. The object has a status attribute which can be :new, :update, :delete, :ok and so on. Based on status, an action needs to be performed, such as uploading an image to Match server (for :new and :update).
Now, I could just send a bunch of requests one after another, but that would be a waste. Remember, we have 4 gunicorn workers running on our server! This clearly calls for a thread pool. I thought PCALL would be perfect for this, but nope. It uses sb-thread:interrupt-thread which is incredibly unsafe and the result is that you basically can't safely make http requests from thread workers. Debugging this took way too much time. In the end, I implemented a thread pool based on lparallel promises which is kind of an overkill for such a simple use case, but at least it worked.
(setf *cache* (update-cache)) (let ((lparallel:*kernel* (lparallel:make-kernel threads))) (unwind-protect (loop for value in (alexandria:hash-table-values *cache*) collect (worker value) into futures finally (map nil 'lparallel:force futures)) (lparallel:end-kernel))) (save-cache *cache*))
Note that you must be very careful when doing things that affect global state inside the threads. For example :delete action removes a key from the hash table *cache*. This is not guaranteed to be an atomic operation, so it's necessary to grab a global lock when doing it.
(defvar *cache-lock* (bordeaux-threads:make-lock "match-cache-lock")) ... (bordeaux-threads:with-lock-held (*cache-lock*) (remhash key *cache*))
Printing messages to REPL from inside threads also requires a separate lock and (force-output), otherwise it will look like a complete mess!
(defun format-msg (str &rest args) (bordeaux-threads:with-lock-held (*msg-lock*) (terpri) (apply 'format t str args) (force-output)))
Now that the required functionality is implemented, it's time to test upload a bunch of stuff... and get back a bunch of errors. It took some sleuthing to discover that gunicorn workers of my Match server are routinely getting killed by "OOM killer". Basically, the server runs out of memory and the system in desperation kills a process that it doesn't like. Remember, I only have 2Gb of memory there!
I figured out that it's images with very large dimensions that are the most problematic in terms of memory usage. If I were to resize these images to some reasonable size, the matching should still work pretty well. In order to execute this plan, I thought I'd use some Lisp to ImageMagick interface. There's in fact a pure Lisp solution called OptiCL but would it really handle any image? Remind me to test that later! Anyway, back to ImageMagick. Neither lisp-magick nor lisp-magick-wand would work with the most recent ImageMagick version (seems its API has changed a bit). However the last one I tried cl-graphicsmagick, which uses a fork of ImageMagick called GraphicsMagick, has unexpectedly worked (at least on my Windows laptop. Note that you need to install Microsoft Visual C Redistributable 2008 otherwise the library wouldn't load with CFFI) so I went with that.
Using very useful temporary files functionality of UIOP (uiop:with-temporary-file), I resize each oversized image to reasonable dimensions and save into a temporary file, which is then uploaded to Match server. I also send the file's original and resized dimensions as metadata. Thankfully this completely eradicated the memory issue. There's a minor problem where GraphicsMagick cannot do Unicode pathnames on Windows, so I copy the original image into a temporary file with ASCII-only name in that case.
(defun resize-image (input-path output-path &key (max-width *max-dimension*) (max-height *max-dimension*) (filter :%QuadraticFilter) (blur 1)) (gm::with-magick-wand (wand) (handler-case (gm::%MagickReadImage wand input-path) ;; graphicsmagick cannot read Unicode filenames on Windows so attempt to load a copy (gm::magick-error () (uiop:with-temporary-file (:pathname tmp :prefix "gm" :type (pathname-type input-path)) (uiop:copy-file input-path tmp) (setf wand (gm::%NewMagickWand)) (gm::%MagickReadImage wand (namestring tmp))))) (let ((w (gm::%MagickGetImageWidth wand)) (h (gm::%MagickGetImageHeight wand)) (res nil)) (multiple-value-bind (fw fh) (gm::fit-width-height w h max-width max-height) (unless (and (= w fw) (= h fh)) (gm::%MagickResizeImage wand fw fh filter blur) (gm::%MagickWriteImage wand output-path) (setf res output-path)) (values res w h fw fh)))))
Later I tested this code on an Ubuntu machine with GraphicsMagick installed from Apt repository and SBCL crashed into ldb debugger mode straight away... Welp. The helpful folks of #lisp told me the problem is with signal handlers established by GraphicsMagick library, somehow they confuse SBCL. Based on that advice, eventually I succeeded making this work. Uninstall apt Graphicsmagick and grab the sources. Find the file called magick.c and replace the line
InitializeMagickSignalHandlers(); /* Signal handlers */
with
// InitializeMagickSignalHandlers(); /* Signal handlers */
(commenting it out). Then do configure --enable-shared (see readme for possible options), make and sudo make install. This will make it work when called from SBCL on Linux.
Anyways, the full code of MATCH-CLIENT can be found at my Github. It's not installable from quicklisp for obvious reasons, in fact it's a complete pain to install as you might've already guessed, but if you wanna try it, you're welcome. The main two commands are update and match. The first is called to upload all images in your *root-dirs* to the server and then to update them if anything changes. match is used to match any image on the Internet (passed as URL string) or a local pathname (passed as pathname object) compared to the server. It returns a list of jsown objects (basically alists) that contain score (up to 100 for exact match), path (with "local tag" which can be different per device) and metadata containing original and resized dimensions.
((:OBJ ("score" . 96.00956) ("filepath" . "[HOME] d:/foo/bar/baz.jpg") ("metadata" :OBJ ("rw" . 1218) ("rh" . 2048) ("w" . 3413) ("h" . 5736))))
Anyway, this was a fun (although often frustrating) thing to build and ended up being quite useful! Thanks for reading and see you next time.
4 notes
·
View notes
Note
Displaced arrays are, by the way, super useful, because they allow to have an efficient array slice operation (see RUTILS slice for an example implementation)
Well, I’ve been hearing conflicting information on whether they are actually efficient. Accessing an element of a displaced array introduces a new level of indirection as opposed to just passing :start and :end arguments along with the array. Because they aren’t used very often, the existing implementations might not be very efficient at handling them.
However in the case of Ichiran, there is a certain part where I have to iterate through every substring of a string. Creating a new string for every substring seemed wasteful to me, no matter how you slice it (pun intended). So I went with the following method: create one displaced array and adjust it to the new boundaries for every cycle. This seems, if not time, then at least memory efficient way to handle this task because only one new object is created instead of O(n²).
(relevant source code is here)
0 notes
Text
All you need is PROGV
I have never seen PROGV in use -- Erik Naggum
Common Lisp is very, very old. Tagbody and progv, anyone? -- Hacker News user pwnstigator
I haven’t written anything on this blog lately, mostly because of lack of time to work on side projects and consequently the lack of Lisp things to talk about. However recently I’ve been working on various improvements to my Ichiran project, and here’s the story of how I came to use the much maligned (or rather, extremely obscure) special operator PROGV for the first time.
Ichiran is basically a glorified Japanese dictionary (used as the backend for the web app ichi.moe) and it heavily depends on a Postgres database that contains all the words, definitions and so on. The database is based on a dump of an open JMdict dictionary, which is constantly updated based on the users’ submissions.
Well, the last time I generated the database from this dump was almost a year ago, and I wanted to update the definitions for a while. However this tends to break the accuracy of my word segmenting algorithm. For this reason I want to keep the old and the new database at the same time and be able to run the whatever code with either of the databases.
I’m using Postmodern to access the database, which has a useful macro named with-connection. If I have a special variable *connection* and consistently use (with-connection *connection* ...) in my database-accessing functions then I can later call
(let ((*connection* '("foo" "bar" "baz" "quux"))) (some-database-accessing-function))
and it will use connection ("foo" "bar" "baz" "quux") instead of the default one. I can even encapsulate it as a macro
(defmacro with-db (dbid &body body) `(let ((*connection* (get-spec ,dbid))) (with-connection *connection* ,@body)))
(dbid and get-spec are just more convenience features, so that I can refer to the connection by a single keyword instead of a list of 4 elements).
So far so good, but there's a flaw with this approach. For performance reasons, some of the data from the database is stored in certain global variables. For example I have a variable *suffix-cache* that contains a mapping between various word suffixes and objects in the database that represent these suffixes. Obviously if I run something with a different connection, I want to use *suffix-cache* that's actually suitable for this connection.
I created a simple wrapper macro around defvar that looks like this:
(defvar *conn-vars* nil) (defmacro def-conn-var (name initial-value &rest args) `(progn (defvar ,name ,initial-value ,@args) (pushnew (cons ',name ,initial-value) *conn-vars* :key 'car)))
Now with-db can potentially add new dynamic variable bindings together with *connection* based on the contents of *conn-vars*. It's pretty trivial to add the new bindings at the macro expansion time. However that poses another problem: now all the conn-vars need to be defined before with-db is expanded. Moreover, if I introduce a new conn-var, all instances of with-db macro must be recompiled. This might be not a problem for something like a desktop app, but my web app usually runs for months without being restarted, with new code being hot-swapped into the running image. I certainly don't need the extra hassle of having to recompile everything in a specific order.
Meanwhile I had the definition of let opened in the Hyperspec, and there was a link to progv at the bottom. I had no idea what it does, and thinking that my Lisp has gotten rusty, clicked through to refresh my memory. Imagine my surprise when I found that 1) I have never used this feature before and 2) it was exactly what I needed. Indeed, if I can bind dynamic variables at runtime, then I don't need to re-expand the macro every time the set of these variables changes.
The final code ended up being pretty messy, but it worked:
(defvar *conn-var-cache* (make-hash-table :test #'equal)) (defmacro with-db (dbid &body body) (alexandria:with-gensyms (pv-pairs var vars val vals iv key exists) `(let* ((*connection* (get-spec ,dbid)) (,pv-pairs (when ,dbid (loop for (,var . ,iv) in *conn-vars* for ,key = (cons ,var *connection*) for (,val ,exists) = (multiple-value-list (gethash ,key *conn-var-cache*)) collect ,var into ,vars if ,exists collect ,val into ,vals else collect ,iv into ,vals finally (return (cons ,vars ,vals)))))) (progv (car ,pv-pairs) (cdr ,pv-pairs) (unwind-protect (with-connection *connection* ,@body) (loop for ,var in (car ,pv-pairs) for ,key = (cons ,var *connection*) do (setf (gethash ,key *conn-var-cache*) (symbol-value ,var))))))))
Basically the loop creates a pair of list of variables and list of their values (no idea why progv couldn't have accepted an alist or something). The values are taken from *conn-var-cache* which takes the pairing of variable name and connection spec as the key. Then I also add an unwind-protect to save the values of the variables that might have changed within the body back into the cache. Note that this makes nested with-db's unreliable! The fix is possible, and left as an exercise to the reader. Another problem is that dynamic variables bindings don't get passed into new threads, so no threads should be spawned within the with-db macro.
And this is how I ended up using progv in production. This probably dethrones displaced array strings as the most obscure feature in my codebase. Hopefully I'll have more things to write about in the future. Until next time!
1 note
·
View note
Text
It's alive! The path from library to web-app.
In case you'd rather just play with the website instead of reading this boring post, the url is http://ichi.moe/
In my previous posts (part 1, part 2, part 3) I described the development process of a romanization algorithm for texts in Japanese language. However the ultimate goal was always to make a simple one-purpose web application that makes use of this algorithm. It took quite a while, but it's finally here. In this post I will describe the technical details behind the development of this website.
I decided to build it with bare Hunchentoot; while there are some nice Lisp web frameworks developed lately like Restas or Caveman, my app would be too simple to need them. There would be a single handler that takes a query and various options as GET parameters, and returns a nicely formatted result.
Now I needed something to produce HTML. I used CL-WHO before, but this time I wanted a templating library where I can just copy-paste plain HTML into. I settled on closure-templates, which is based on Google Closure Templates but the syntax is slightly different. Now, I don't know if I should recommend this library because its documentation in English is rather sparse and it has a dead link in its Github description. It has a detailed manual written in Russian, so I was able to read that. As to why I chose it, this library has a major advantage over its competitors. The same template can be compiled into a Common Lisp function and into Javascript! Why is this useful? Well, for example, I have these cute cards that explain the definition of a word:

These are mostly generated statically by the Common Lisp backend. But if I want to make such card on the fly client-side, I can call the corresponding Javascript function and it will produce the exact same HTML content. Makes dynamic HTML generation really easy.
For the front-end framework I chose Foundation. Bootstrap was my first choice, but it really doesn't look all that great and it's difficult to customize. So I decided to try something else. Foundation was pretty nice, it was easy to make my website responsive and look decent on mobile screen. The only problem, like I later discovered, was its sheer size. The 183kb javascript file (minified!) was refused to be cached by my browser for some reason, so each page load took quite a while. Fortunately that was solved by loading this file from cloudflare CDN.
One thing I didn't concern myself about when writing the backend Ichiran algorithm was thread safety. However, as Hunchentoot uses threads to process requests, this matter becomes very important. Fortunately writing thread-safe code in Lisp is not that hard. Mostly you should just avoid modifying global special variables (binding them with let is okay) and be careful with writing persistent data. Since my app is pretty much read-only, there was only one such issue. I am storing a cache of word suffixes in a special variable. Generating this cache takes several seconds, but is only done once per session. As you can guess, this creates problems with thread safety, so I put a lock around this procedure and called it when the server is launched. Each server launch would therefore take several seconds, which is suboptimal. Later I would make the lock non-blocking and display a warning if the init-suffixes procedure is in progress.
Like I said before, I wanted my data to be compatible between Common Lisp and Javascript, so I added some functions to Ichiran to produce JSON objects containing various data. There are many JSON libraries for Common Lisp. I was using jsown before, so I decided to stick with it. jsown objects are lists with :obj as the first element and alist of properties as its cdr. The problem was that closure-templates only supports plists and alists as its context parameter, and jsown object is neither. The solution was to extend the methods fetch-property and fetch-keys. Since they are already defined for lists, I added :around methods to check for jsown objects specifically and call-next-method on cdr in that case.
(defmethod closure-template:fetch-property :around ((map list) key) "Support for jsown dict objects" (if (and (not (integerp key)) (eql (car map) :obj) (every #'listp (cdr map))) (call-next-method (cdr map) key) (call-next-method))) (defmethod closure-template:fetch-keys :around ((map list)) (if (and (eql (car map) :obj) (every #'listp (cdr map))) (call-next-method (cdr map)) (call-next-method)))
Theoretically this would fail if passed a valid plist like '(:obj (1 2)), but this cannot possibly happen in my application.
Now, at some point I had to actually put my app online. I needed a server and a domain name and I needed them cheap (because I'm currently unemployed (pls hire me)). For the server I chose Linode VPS, and I bought ichi.moe domain from Name.com. I still think these new TLDs are a pretty stupid idea, but at least it gives us all an opportunity to buy a short and memorable domain name. I spent the rest of the day configuring my Linode server, which I never did before. Thankfully the documentation they provide is really good.
Because I wanted to get the most juice out of my cheap-ass server, the plan was to put hunchentoot server behind Nginx and to cache everything. There are existing guides on how to do this setup, which were very helpful. In my setup everything is served by Nginx except for URLs that start with /cl/, which are passed to Hunchentoot. The static pages (including error pages) are also generated by closure-template (so that the design is consistent), but they are just dumped into .html files served by Nginx. Nginx also caches dynamic content, which might help if some high-traffic site links to a certain query. This, and the fact that Linodes are hosted on SSD made the site run pretty smooth.
Now let's talk about my infrastructure. As described in the guides above, I have a special hunchentoot user in addition to the main user. The main user's quicklisp directory is symlinked to hunchentoot's so the server can load the code but cannot write there. The code is stored in 2 repositories. One is the open-source core of the project (ichiran) and the other one is a private bitbucket repository ichiran-web which holds web-related code. However a simple git pull doesn't update the code running on the server. If I'm lazy, I do "sudo service hunchentoot restart", which restarts everything and reloads the code. This might of course create service interruptions for the users. Another option is hot swapping all the changes. For this purpose my hunchentoot server also starts a swank server like this:
(defun start-app (&optional (port 8080)) (handler-case (swank:create-server :dont-close t) (error ())) (ichiran/dict:init-suffixes) (refresh-handlers) (let ((acceptor (make-instance 'easy-acceptor :port port :access-log-destination *access-log* :message-log-destination *message-log* ))) (setf *ichiran-web-server* (start acceptor))))
Swank is, of course, the server-side component of SLIME. It runs on a port that is not accessible remotely and can only be connected to locally or via SSH tunnel. I use the latter to connect SLIME on my PC to Swank running on my server, which allows me to apply various fixes without restarting, either from the REPL or by using C-c C-c to recompile some function.
Anyway, I'm pretty happy with the way things turned out, and I got some positive feedback already. The biggest thing left is tightening up the web design, which is my least favorite part of web development. The other thing is attracting enough traffic so that I can analyze the performance (I'm only getting a few people a day right now, which barely makes a blip on my server's CPU graph).
In retrospect, getting this website up and running was pretty easy. I spent much more time trying to tweak ichiran library to split the sentences in a correct way (and I'm still working on it). It's not much harder than, say, building a Django-based site. The tools are all there, the documentation is out there (kind of). VPSes are cheap. And it spreads awareness of Common Lisp. No reason not to try!
6 notes
·
View notes
Text
Words made out of words
Since my last post I've done a lot of work on my Japanese sentence-segmenting algorithm, so it's time for an update.
First of all, I added conjugations. Here's how JMdict does conjugations. That's for a single verb. There's a note saying "this table has been automatically generated"; indeed, in JMdict conjugations are generated on a basis of a rather large .csv file and are not stored in the database. Obviously for my purposes it is more efficient to have these in my database, so I ported a (rather simple) algorithm to Common Lisp and wrote a (really complex) procedure to load them. It takes quite a while to INSERT those one by one, which made me wish postmodern had some sort of bulk inserting mechanism. Some time later I discovered that some of these conjugations are themselves verbs that can be (and often are) conjugated. So I added "second level" conjugations that point both to first level conjugation and to the original verb. Hopefully "third level" conjugations are rarely used.
Meanwhile I've been trying to improve the segmentation algorithm. The first major change was calculating n best segmentations instead of just one. That would allow me to have a better picture of what the algorithm prefers. I came up with the structure that I call top-array, which is basically an array of n scores sorted from the biggest to smallest and when a new score is added, we go from the end and push everything smaller than the new score to the right. I thought it was pretty elegant and probably the fastest way to do this for small n (obviously some sort of tree would work better for large n).
(defstruct (top-array-item (:conc-name tai-)) score payload) (defclass top-array () ((array :reader top-array) (count :reader item-count :initform 0) )) (defmethod initialize-instance :after ((obj top-array) &key (limit 5)) (setf (slot-value obj 'array) (make-array limit :initial-element nil))) (defgeneric register-item (collection score payload) (:method ((obj top-array) score payload) (with-slots (array count) obj (let ((item (make-top-array-item :score score :payload payload)) (len (length array))) (loop for idx from (min count len) downto 0 for prev-item = (when (> idx 0) (aref array (1- idx))) for done = (or (not prev-item) (>= (tai-score prev-item) score)) when (< idx len) do (setf (aref array idx) (if done item prev-item)) until done) (incf count))))) (defgeneric get-array (collection) (:method ((obj top-array)) (with-slots (array count) obj (if (>= count (length array)) array (subseq array 0 count)))))
An instance of top-array is created for every segment (found word in a sentence), as well as one for the entire sentence, from which the best path (a sequence of words) is taken in the end. Then the basic algorithm is similar to the one described in my previous post, but gains an extra inner loop.
(loop for (seg1 . rest) on segments for score1 = (get-segment-score seg1) do (register-item (segment-top seg1) score1 (list seg1)) (register-item top score1 (list seg1)) (loop for seg2 in rest for score2 = (get-segment-score seg2) when (>= (segment-start seg2) (segment-end seg1)) do (loop for tai across (get-array (segment-top seg1)) for path = (cons seg2 (tai-payload tai)) for score = (+ score2 (tai-score tai)) do (register-item (segment-top seg2) score path) (register-item top score path))))
Then (get-array top) would return n best paths.
After this I started thinking on how to make my algorithm more context-sensitive. The way in which every segment is scored is completely independent of the other segments, which might cause best scored path to be a sequence of words that make no sense when put next to each other! The above algorithm is easy to modify to add some sort of bonus to two subsequent segments, so my first attempt was to encourage words that like to be next to each other in natural language with some extra score (I called that "synergy"). So, for example, there are "no-adjectives", which are basically nouns, but when followed by particle "no" they become adjectives. I added a synergy that adds 15 points if such word is followed by particle "no". In the end this way to do things has proven itself limited. Words can have wildly different scores and when things go wrong, extra 15 points might not be enough to make them right. On the other hand, if I increase this bonus too much, this might erroneously break up words that just so happen to have "no" in them.
Later I came up with the concept of compound words, which are "words" that don't exist in the database, but rather consist of several words that do exist in the database. Right now, it's mostly a primary word + one or several suffixes, but potentially there could be prefixes too. For the purposes of segmentation a compound word acts like one single word. One example of a common suffix would be "たい" (-tai) , which follows a verb ("to X") conjugated in a certain way and the resultant meaning is "to want to X". Most of these suffixes themselves have many conjugations. To check if a word can be understood as a compound word, I need to check if it ends with one of many suffixes, and then check if the part before the suffix has correct part of speech or conjugation. All possible suffixes and their meanings are put into a hashtable and then we can check if a word ends with some of them by checking all its endings versus the hashtable.
(defun get-suffixes (word) (init-suffixes) (loop for start from (1- (length word)) downto 1 for substr = (subseq word start) for val = (gethash substr *suffix-cache*) when val collect (cons substr val)))
The concept of suffixes has fared much better as now I am able to calculate scores of compound words in a more versatile way.
I would still sometimes encounter phrases that are split badly by my algorithm, but a human would segment easily. For example if the words "AB" and "ABC" both exist in database, but "AB" happens to score higher (e.g. because it's a really common word, while ABC is not so much), then "ABC" would never be segmented as one word "ABC", it would be "AB"+"C", even if "C" is a completely worthless word, or even not a word at all (a gap). An example of a "worthless" word is a hiragana spelling of one-syllable word that would normally be spelled with a kanji. I didn't care about those much, because they had really low scores and thus only appeared when something went awry. However getting rid of these low-scoring words would allow me to place a large penalty on gaps and thus "ABC" will be able to score higher than "AB"+gap. In the path-finding algorithm above the same score is put into top and segment-top top-arrays. But if we want to penalize gaps, the score put into top should also include a penalty for the gap to the right of the last segment, if it exists. Penalties for gaps to the left of the leftmost segment and in-between segments should be added to both.
Anyway, I'm pretty happy with how this thing is progressing, and I'm going to switch my efforts to building a web-interface. Here's how it currently works in REPL:
(click here for full-res image)
Kinda messy, isn't it? The challenge would be to display all this information in reasonable manner. I already have some ideas, but it would still probably take some effort to decipher. But then again, translating the sentence was never the goal, just romanizing it, which ichiran does pretty well right now.
0 notes
Text
Who needs graph theory anyway?
In my last post I discussed how to make a Japanese->English transliterator and outlined some problems that limited its usefulness. One problem is that there's no obvious way to segment a sentence into words. I looked up existing solutions, and a lightweight Javascript implementation caught my eye. I quickly ported it to Common Lisp and to the surprise of absolutely no one, the results were awful
It was clear that I needed an actual database of Japanese words to do segmentation properly. This would also solve the "kanji problem" since this database would also include how to pronounce the words. My first hunch was Wiktionary, but it's dump format turned out to be pretty inefficient for parsing.
Fortunately I quickly discovered a free JMDict database which was exactly what I needed. It even had open-source code in Python for parsing and loading its XML dumps. Naturally, I wrote my own code to parse it since its database schema looked too complex for my needs. But I'm not going to discuss that in this post, as it is quite boring.
Since now I had a comprehensive Postgres database of every word in Japanese language (not really, as it doesn't include conjugations) it was only a matter of identifying the words in the sentence. To do this, for every substring of a sentence look up the database for exact matches. There are n(n+1)/2 substrings in a string, so we aren't doing too badly in terms of performance (and the string wouldn't be too long anyway since prior to running this procedure I'll be splitting it by punctuation etc.)
(defstruct segment start end word)) (defun find-substring-words (str) (loop for start from 0 below (length str) nconcing (loop for end from (1+ start) upto (length str) for substr = (subseq str start end) nconcing (mapcar (lambda (word) (make-segment :start start :end end :word word)) (find-word substr)))))
The problem is that there's a lot of words, and many of them are spelled identically. I decided to assign a score to each word based on its length (longer is better), whether it's a preferred spelling of the word, how common the word is and whether it's a particle (which tend to be short and thus need a boost to increase their prominence).
Now we have the following problem: for a sentence, find the set of non-intersecting segments with the maximum total score. Now, you might have better mathematical intuition than I, but my first thought was:
This looks NP-hard, man. This problem has "travelling salesman" written all over it.
My first attempt to crack it was to calculate score per letter for each word and select words with the highest scores. But a counterexample comes to mind rather easily: in a sentence "ABC" with words "AB" (score=5), "BC" (score=5) and "ABC" (score=6), words "AB" and "BC" have a higher score per letter (2.5), but the optimal covering is provided by the word "ABC" with its score per letter a measly 2.
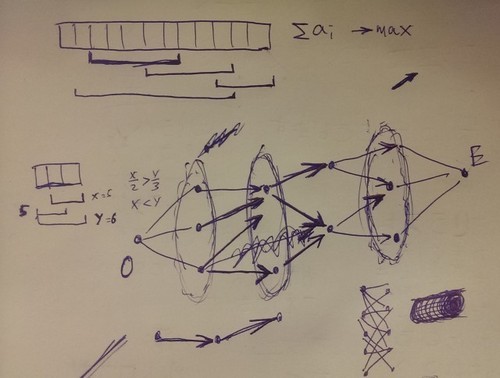
At this point I was working with the most convenient mathematical instrument, which is pen and paper. The breakthrough came when I started to consider a certain relation between two segments: the segment a can be followed by the segment b iff (segment-start b) is greater or equal to (segment-end a). Under this relation our segments form transitive directed acyclic graph. The proof is left as an exercise for the reader. Clearly we just need to do a transitive reduction and use something similar to Dijkstra's algorithm to find the path with the maximal score! This problem is clearly solvable in polynomial time!
Pictured: actual notes drawn by me
In reality the algorithm turns out to be quite simple. Since find-substring-words always returns segments sorted by their start and then by their end, every segment can only be followed by the segments after it. We can then accumulate the largest total score and the path used for it for every segment by using a nested loop:
(defstruct segment start end word (score nil) (accum 0) (path nil)) (defun find-best-path (segments) ;;assume segments are sorted by (start, end) (as is the result of find-substring-words) (let ((best-accum 0) (best-path nil)) (loop for (seg1 . rest) on segments when (> (segment-score seg1) (segment-accum seg1)) do (setf (segment-accum seg1) (segment-score seg1) (segment-path seg1) (list seg1)) (when (> (segment-accum seg1) best-accum) (setf best-accum (segment-accum seg1) best-path (segment-path seg1))) when (> (segment-score seg1) 0) do (loop for seg2 in rest if (>= (segment-start seg2) (segment-end seg1)) do (let ((accum (+ (segment-accum seg1) (segment-score seg2)))) (when (> accum (segment-accum seg2)) (setf (segment-accum seg2) accum (segment-path seg2) (cons seg2 (segment-path seg1))) (when (> accum best-accum) (setf best-accum accum best-path (segment-path seg2))))))) (values (nreverse best-path) best-accum)))
Of course when I actually tried to run this algorithm, SBCL just crashed. How could that be? It took me a while to figure out, but notice how segment-path contains a list that includes the segment itself. A recursive self-referential structure! When SBCL tried to print that in the REPL, it didn't result in dragons flying out of my nose but a crash still happened. Interestingly, Common Lisp has a solution to this: if *print-circle* is set to t, it will actually print the structure using referential tokens. Anyway, I just added the following before returning the result to remove self-references:
(dolist (segment segments) (setf (segment-path segment) nil))
So, did it work? Yes, it did, and the result was impressive! Even though my scoring system is pretty barebones, it's on par or even better than Google Translate's romanization on a few test sentences I tried. I still need to add conjugations, and it can't do personal names at all, but considering how little code there is and the fact that it doesn't even attempt grammatical analysis of the sentence (due to me not knowing the language) I am very happy with the result. Also I plan to add a web interface to it so that it's possible to hover over words and see the translation. That would be pretty useful. The work in progress code is on my Github.
5 notes
·
View notes
Text
My little transliterator can't be this CLOS
If you are reading this blog, you are probably able to read Latin script. It is pretty widespread in the world, and used by 70% of the world's population according to Wikipedia. Perhaps, like me, your native language uses a different script. There are many writing systems in the world, some are related, and some are wildly different from each other. Fortunately with the advent of the Internet and tools like Google Translate it is increasingly possible to read text not only in the language you don't understand, but even the languages where you don't even understand their writing system.
Well, Google is Google, but is it possible for a mere mortal to create something like that? Not to translate, but just to present some unknown writing system in your preferred alphabet (the process is called transliteration or transcription)? There's no reason why not.
In this post I'll talk about the process of romanization of Japanese language, which is transcription from Japanese to Latin script. For example "ありがとうございます" is romanized to "arigatō gozaimasu" under Hepburn romanization method (there are many of those).
First off, the basics of Japanese writing are as follows:
There are several scripts used to write in Japanese language.
Hiragana is a syllabary (a writing system where each character represents a syllable) that is used for words of Japanese origin.
Katakana is another syllabary that is used for loan words. Every possible syllable in Japanese language has a hiragana and katakana form, which usually are completely different. Both scripts have about 50 characters in them.
Chinese characters (kanji) are used for words of Japanese and Chinese origin. There are thousands of such characters. Furthermore, most of them could be read in several different ways, which makes transcribing them difficult. We're going to ignore those for now.
If we focus on romanization of hiragana and katakana (both systems are called kana for short) then the process seems pretty simple. It's just a matter of replacing each kana with the syllable it represents, written in roman letters. However there are some characters that do not represent a syllable, but rather modify a syllable before or after that character. This includes sokuon, which doubles the consonant of the next syllable and yoon characters, which are a small version of normal kana and are used to modify a vowel of a preceding syllable.
Ok, so the first thing we must do is to somehow bring order to this madness. Since there is hiragana and katakana version of each character, it doesn't make sense to work with the characters directly. Instead I'm going to replace each character with a keyword.
(defparameter *sokuon-characters* '(:sokuon "っッ")) (defparameter *iteration-characters* '(:iter "ゝヽ" :iter-v "ゞヾ")) (defparameter *modifier-characters* '(:+a "ぁァ" :+i "ぃィ" :+u "ぅゥ" :+e "ぇェ" :+o "ぉォ" :+ya "ゃャ" :+yu "ゅュ" :+yo "ょョ" :long-vowel "ー")) (defparameter *kana-characters* '(:a "あア" :i "いイ" :u "うウ" :e "えエ" :o "おオ" :ka "かカ" :ki "きキ" :ku "くク" :ke "けケ" :ko "こコ" :sa "さサ" :shi "しシ" :su "すス" :se "せセ" :so "そソ" :ta "たタ" :chi "ちチ" :tsu "つツ" :te "てテ" :to "とト" :na "なナ" :ni "にニ" :nu "ぬヌ" :ne "ねネ" :no "のノ" :ha "は" :hha "ハ" :hi "ひヒ" :fu "ふフ" :he "へヘ" :ho "ほホ" :ma "まマ" :mi "みミ" :mu "むム" :me "めメ" :mo "もモ" :ya "やヤ" :yu "ゆユ" :yo "よヨ" :ra "らラ" :ri "りリ" :ru "るル" :re "れレ" :ro "ろロ" :wa "わワ" :wi "ゐヰ" :we "ゑヱ" :wo "を" :wwo "ヲ" :n "んン" :ga "がガ" :gi "ぎギ" :gu "ぐグ" :ge "げゲ" :go "ごゴ" :za "ざザ" :ji "じジ" :zu "ずズ" :ze "ぜゼ" :zo "ぞゾ" :da "だダ" :dji "ぢヂ" :dzu "づヅ" :de "でデ" :do "どド" :ba "ばバ" :bi "びビ" :bu "ぶブ" :be "べベ" :bo "ぼボ" :pa "ぱパ" :pi "ぴピ" :pu "ぷプ" :pe "ぺペ" :po "ぽポ" )) (defparameter *all-characters* (append *sokuon-characters* *iteration-characters* *modifier-characters* *kana-characters*)) (defparameter *char-class-hash* (let ((hash (make-hash-table))) (loop for (class chars) on *all-characters* by #'cddr do (loop for char across chars do (setf (gethash char hash) class))) hash))
(defun get-character-classes (word)
(map 'list (lambda (char) (gethash char *char-class-hash* char)) word))
This creates a hash table that maps every kana to a keyword that describes it and we can now trivially convert a word into a list of "character classes" (or the characters themselves for non-kana characters). Then we need to transform this list into a kind of AST where modifier characters have the role of functions.
(defun process-modifiers (cc-list) (loop with result for (cc . rest) on cc-list if (eql cc :sokuon) do (push (cons cc (process-modifiers rest)) result) (loop-finish) else if (member cc *modifier-characters*) do (push (list cc (pop result)) result) else do (push cc result) finally (return (nreverse result))))
This is your basic push/nreverse idiom with some extra recursiveness added. Sokuon is applied to everything to the right of it, because I wanted it to have lower precedence, i.e. (:sokuon :ka :+yu) is parsed as (:sokuon (:+yu :ka)) instead of the other way around. Now we can write the outline of our algorithm:
(defun romanize-core (method cc-tree) (with-output-to-string (out) (dolist (item cc-tree) (cond ((null item)) ((characterp item) (princ item out)) ((atom item) (princ (r-base method item) out)) ((listp item) (princ (r-apply (car item) method (cdr item)) out))))))
The functions r-base and r-apply are generic functions that will depend on the method of romanization. Another generic function will be r-simplify that will "pretty up" the result. It is easy to write some reasonable fallback methods for them:
(defgeneric r-base (method item) (:documentation "Process atomic char class") (:method (method item) (string-downcase item))) (defgeneric r-apply (modifier method cc-tree) (:documentation "Apply modifier to something") (:method ((modifier (eql :sokuon)) method cc-tree) (let ((inner (romanize-core method cc-tree))) (if (zerop (length inner)) inner (format nil "~a~a" (char inner 0) inner)))) (:method ((modifier (eql :long-vowel)) method cc-tree) (romanize-core method cc-tree)) (:method ((modifier symbol) method cc-tree) (format nil "~a~a" (romanize-core method cc-tree) (string-downcase modifier)))) (defgeneric r-simplify (method str) (:documentation "Simplify the result of transliteration") (:method (method str) str))
Of course relying on symbol names isn't flexible at all. It's better to have a mapping from each keyword to a string that represents it. This is where we have to resort to classes to store this mapping in a slot.
(defclass generic-romanization () ((kana-table :reader kana-table :initform (make-hash-table)))) (defmethod r-base ((method generic-romanization) item) (or (gethash item (kana-table method)) (call-next-method))) (defmethod r-apply ((modifier symbol) (method generic-romanization) cc-tree) (let ((yoon (gethash modifier (kana-table method)))) (if yoon (let ((inner (romanize-core method cc-tree))) (format nil "~a~a" (subseq inner 0 (max 0 (1- (length inner)))) yoon)) (call-next-method))))
(defmacro hash-from-list (var list)
(alexandria:with-gensyms (hash key val)
`(defparameter ,var
(let ((,hash (make-hash-table)))
(loop for (,key ,val) on ,list
do (setf (gethash ,key ,hash) ,val))
,hash))))
(hash-from-list *hepburn-kana-table*
'(:a "a" :i "i" :u "u" :e "e" :o "o"
:ka "ka" :ki "ki" :ku "ku" :ke "ke" :ko "ko"
:sa "sa" :shi "shi" :su "su" :se "se" :so "so"
:ta "ta" :chi "chi" :tsu "tsu" :te "te" :to "to"
:na "na" :ni "ni" :nu "nu" :ne "ne" :no "no"
:ha "ha" :hha "ha" :hi "hi" :fu "fu" :he "he" :ho "ho"
:ma "ma" :mi "mi" :mu "mu" :me "me" :mo "mo"
:ya "ya" :yu "yu" :yo "yo"
:ra "ra" :ri "ri" :ru "ru" :re "re" :ro "ro"
:wa "wa" :wi "wi" :we "we" :wo "wo" :wwo "wo"
:n "n"
:ga "ga" :gi "gi" :gu "gu" :ge "ge" :go "go"
:za "za" :ji "ji" :zu "zu" :ze "ze" :zo "zo"
:da "da" :dji "ji" :dzu "zu" :de "de" :do "do"
:ba "ba" :bi "bi" :bu "bu" :be "be" :bo "bo"
:pa "pa" :pi "pi" :pu "pu" :pe "pe" :po "po"
:+a "a" :+i "i" :+u "u" :+e "e" :+o "o"
:+ya "ya" :+yu "yu" :+yo "yo"
))
(defclass generic-hepburn (generic-romanization) ((kana-table :initform (alexandria:copy-hash-table *hepburn-kana-table*))))
I'm going for a rather versatile class hierarchy here, starting with a completely empty kana-table for generic-romanization method, but defining the methods on it that will work for any table. Then I define a class generic-hepburn that will be the basis for different hepburn variations. The table is taken from Wikipedia article on Hepburn romanization, which is pretty detailed. By carefully reading it, we can identify the exceptions that the above functions can't handle. For example a :sokuon before :chi is romanized as "tchi" and not as "cchi" as it would by the simple consonant-doubling method. Another exception is that, for example, :chi followed by :+ya is romanized as "cha", not "chya". CLOS makes it easy to handle these irregularities before passing the torch to a less specific method.
(defmethod r-apply ((modifier (eql :sokuon)) (method generic-hepburn) cc-tree) (if (eql (car cc-tree) :chi) (concatenate 'string "t" (romanize-core method cc-tree)) (call-next-method))) (defmethod r-apply ((modifier (eql :+ya)) (method generic-hepburn) cc-tree) (case (car cc-tree) (:shi "sha") (:chi "cha") ((:ji :dji) "ja") (t (call-next-method)))) ... and the same for :+yu and :+yo
Another thing Hepburn romanizations do is simplifying double vowels like "oo", "ou" and "uu". For example, our generic-hepburn will romanize "とうきょう" as "toukyou", while most people are more familiar with the spelling "Tokyo" or "Tōkyō".
(defun simplify-ngrams (str map) (let* ((alist (loop for (from to) on map by #'cddr collect (cons from to))) (scanner (ppcre:create-scanner (cons :alternation (mapcar #'car alist))))) (ppcre:regex-replace-all scanner str (lambda (match &rest rest) (declare (ignore rest)) (cdr (assoc match alist :test #'equal))) :simple-calls t))) (defclass simplified-hepburn (generic-hepburn) ((simplifications :initform nil :initarg :simplifications :reader simplifications :documentation "List of simplifications e.g. (\"ou\" \"o\" \"uu\" \"u\")" ))) (defmethod r-simplify ((method simplified-hepburn) str) (simplify-ngrams (call-next-method) (simplifications method)))
(defclass traditional-hepburn (simplified-hepburn)
((simplifications :initform '("oo" "ō" "ou" "ō" "uu" "ū"))))
I'm using the "parse tree" feature of CL-PPCRE here to create a complex :alternation regex on the fly and then use regex-replace-all with a custom replacing function. It's probably not the most efficient method, but sometimes outsourcing string manipulations to a well-tested regex engine is the least painful solution. Anyway, we're really close now, and all that's left is to chain up our functions for a useful API.
(defparameter *hepburn-traditional* (make-instance 'traditional-hepburn)) (defvar *default-romanization-method* *hepburn-traditional*) (defun romanize-list (cc-list &key (method *default-romanization-method*)) "Romanize a character class list according to method" (let ((cc-tree (process-modifiers cc-list))) (values (r-simplify method (romanize-core method cc-tree))))) (defun romanize-word (word &key (method *default-romanization-method*)) "Romanize a word according to method" (romanize-list (get-character-classes word) :method method))
>>> (romanize-word "ありがとうございます")
"arigatōgozaimasu"
At my Github you can find an unabridged version of the above code. However there are still some difficult problems with romanization of Japanese that can't be solved as easily. Even leaving kanji aside, the hiragana character は is pronounced either as "ha" or "wa" depending on whether it is used as a particle. For example a common greeting "こんにちは" is romanized as "konnichiwa" and not "konnichiha" because は plays the role of a particle. Which brings us to another problem: there are no spaces between the words, so it's not possible to determine whether は is a part of a word or a standalone particle without a dictionary, and even then it can be ambiguous! I'm ending the post on this note, since I'm still not sure how to solve this. さ��うなら!
2 notes
·
View notes
Text
Living on the edge
Lately my primary Lisp has been a SBCL fork for Windows which is based on SBCL 1.1.4 and is now pretty old. The official release of SBCL for Windows is 1.2.1 so I decided to try it out. The installer managed to delete my old version of SBCL, so there was no way back now. I tried to run it, but it still tried to use .core from the old SBCL. Strange, I'm pretty sure the system environment variables have been updated. Yep, I go to system settings and SBCL_HOME points at the correct directory. I run "cmd" and nope, SBCL_HOME points at the old directory. How could that be? After some mucking about, I save the environment variables again and now it has updated. SBCL now runs from command line. Success?
Ok, so I run SLIME and it tries to use some symbol from SBCL system package which has clearly been removed at some point. My SLIME isn't even that old, last updated in 2013. I actually installed it via Quicklisp, wonder if this will work? I run SBCL from command line and do (ql:update-all-dists). Lots of libraries get updated, including SLIME 2014-08-01. Oh, this is good stuff.
I start up Emacs, load SLIME and face a certain bug I already faced on another computer. At some point SLIME became, let's say, not very compatible with Emacs 24.1 and 24.2 series, because Emacs developers did something with 'cl package and SLIME relies on that change. Guess I'll have to update Emacs too.
As a result I have been forced to update to a shiny new Lisp stack from 2014. To compare, at work we have to use Python 2.6 (released in 2008) and Django 1.3 (released in 2011 and already deprecated). It's actually amazing how many libraries still run on Python 2.6. Meanwhile Common Lisp as the language hasn't changed since like the 80s and yet you must always watch out for compatibility issues! Keep up with the times!
0 notes
Text
Web scraping with Common Lisp: cookies and stuff
It's been a long time since my last post, but let's pick up where I left off.
Read part 1 here!
Often you want to grab some data from a website but you can't just send a get request to a page, you need to log in first. How does the site even know you're logged in? Well, attached to each request is a bunch of cookies, which are essentialy name-value pairs. Moreover, the server's response may update or add new cookies, which are faithfully stored by your browser for some period of time. So when you are logging in to a site the following happens:
You send a POST request with your name and password as parameters.
The server responds by setting up your cookies in a way that allows it to recognize your future requests. Usually it sets a cookie that contains your "session id", which uniquely identifies your current browser session.
When you make any requests after that, the cookie that contains session id is sent along with them, and the server assumes you are logged in.
As you can see, the whole algorithm hinges on the fact that your browser must store and resend the cookie that the server has set up. And when you are making requests through a library or a command-line tool such as curl or wget, the responsibility to store and pass the cookies lies upon you.
Ok, so with Common Lisp we're using the DRAKMA library. By default it will not send any cookies, or do anything with received cookies. However if you pass a special cookie jar object as a keyword parameter to http-request, it will send cookies from it, and update them based on the server's response. If you use the same cookie jar object to POST a login request and later to retrieve some data, usually this will be enough to trick the server into serving you the content behind the authentication wall.
(let ((cookie-jar (make-instance 'drakma:cookie-jar))) (drakma:http-request login-url :method :post :parameters login-parameters :cookie-jar cookie-jar) (drakma:http-request data-url :cookie-jar cookie-jar))
I think it's annoying to always write ":cookie-jar cookie-jar" for every request, so in my library webgunk a special variable *webgunk-cookie-jar* is passed as the requests' cookie jar (it's nil by default). So you can instead:
(let ((*webgunk-cookie-jar* (make-instance 'drakma:cookie-jar))) (http-request login-url :method :post :parameters login-parameters) (http-request data-url))
Special variables are sure handy. In webgunk/modules I created an object-oriented API that uses this feature and webgunk/reddit is a simple reddit browser based on it. Here's the code for authorization:
(defmethod authorize ((obj reddit-browser) &key login password) (let ((login-url "https://ssl.reddit.com/api/login")) (with-cookie-jar obj (http-request login-url :method :post :parameters `(("api_type" . "json") ("user" . ,login) ("passwd" . ,password))))))
where with-cookie-jar is just
(defmacro with-cookie-jar (obj &body body) `(let ((*webgunk-cookie-jar* (get-cookie-jar ,obj))) ,@body))
Note that logging in isn't always as easy. Sometimes the server's procedure for setting the cookies is rather tricky (e.g. involving Javascript and redirects). However you almost always can trick the server that you're logged in by logging in with your browser and then copying the cookie values from your browser (this is known as session hijacking, except you're only hijacking your own session so it's ok).
For example, I used to play an online game called SaltyBet, in which you place imaginary money bets on which character will win in a fight. The outcome could be predicted by analyzing the past fights of each character. After losing a million of SaltyBucks due to suboptimal betting, I have built a system that would collect the results of past fights from SaltyBet's own website, calculate and display the stats for each character and also show their most recent fights, and the biggest upsets that they have been involved in. This was incredibly effective and I was able to recoup my lost money twice over!
But anyway, the data was available only to paid members so I needed to log in to scrape it. And the method described above did not work. In the end what worked was a simple:
(defparameter *cookies* '(("PHPSESSID" . "4s5u76vufh0gt9hs6mrmjpioi0") ("__cfduid" . "dc683e3c2eb82b6c050c1446d5aa203dd1376731139271"))) (defmethod authorize ((obj saltybet-browser) &key) (clear-cookies obj) (loop for (name . value) in *cookies* do (add-cookie obj (make-instance 'drakma:cookie :name name :value value :domain ".saltybet.com"))))
How did I get these values? I just copy-pasted them from my Firefox! They were good for a few days, so it wasn't much hassle at all. Sometimes a stupid solution is the most effective one.
2 notes
·
View notes
Text
Web scraping with Common Lisp: introduction
Web scraping is the process of collecting data from websites. There is a lot of data publically accessible on the Internet and sometimes you want to do something with that data programmatically. Instead of manually copying and pasting stuff from websites to some sort of spreadsheet, you might as well write a script that does it for you. The process depends on the way the data is embedded into a target website. In the usual case you have to perform the following:
Use a web client to download the contents of a webpage.
Convert these contents (a string) into some sort of internal representation in your programming language (usually a tree of HTML elements).
Find and extract the data you need.
Common Lisp has necessary libraries for each of those steps, but not a one single library to put everything together, which is why I threw together Webgunk, which is a mish-mash of various libraries and helper functions to make web scraping easier. It doesn't have a stable API or anything and I'm still adding new things to it.
Web client
Edi Weitz's DRAKMA is the most popular HTTP client for Common Lisp, and it works fine in practice. One small problem I had with it is that its http-request function sometimes returns a string, and sometimes an octet array. Either way, I like strings much more, so I wrote a wrapper around it using FLEXI-STREAMS:
(defun http-request (uri &rest args) "A wrapper around DRAKMA:HTTP-REQUEST which converts octet array which it sometimes returns to normal string" (let* ((result-mv (multiple-value-list (apply #'drakma:http-request uri `(,@args :cookie-jar ,*webgunk-cookie-jar*)))) (result (car result-mv))) (apply #'values (if (and (arrayp result) (equal (array-element-type result) '(unsigned-byte 8))) (flexi-streams:octets-to-string result) result) (cdr result-mv))))
You might notice it preserves all the secondary return values as well.
Parsing HTML
I'm using Closure HTML parser (not to be confused with 1000 other things called Clo[s/j/z]ure) to convert the resulting string into a Lispy representation of DOM tree (CXML-DOM).
(defun parse-url (url &rest args) "Parse HTTP request response to CXML-DOM" (let ((response (apply #'http-request url args))) (chtml:parse response (cxml-dom:make-dom-builder))))
Finding your data
It is possible to use the standartized DOM API to find the required elements in the resulting tree (and it's worth knowing it), but really, most of the time you want to just use a CSS selector to grab the elements you need. This is where CSS-SELECTORS library comes in handy.
(let ((document (parse-url "http://www.google.com/search?q=something"))) (css:query "h3.r a" document))
returns a list of links from a Google search.
Extracting your data
Getting a text value of a HTML element isn't as easy as you might think. Because it can have other elements inside of it, you must recursively walk and join all the text nodes. There are also a bunch of rules regarding whitespace which must be stripped correctly from the resulting string.
This is what the function node-text in Webgunk does:
(defun node-text (node &rest args &key test (strip-whitespace t)) (let (values result) (when (or (not test) (funcall test node)) (dom:do-node-list (node (dom:child-nodes node)) (let ((val (case (dom:node-type node) (:element (apply #'node-text node args)) (:text (dom:node-value node))))) (push val values)))) (setf result (apply #'concatenate 'string (nreverse values))) (if strip-whitespace (strip-whitespace result) result)))
It calls strip-whitespace which is just a bunch of regex replacements (see full source code here).
Another place where the data can be hidden is HTML attributes. Fortunately, dom:get-attribute pretty much solves this problem. For example: (dom:get-attribute link "href") returns href attribute of a node.
That's it for today. In the next installment I'll probably discuss authentication and other fun stuff you can do.
5 notes
·
View notes
Text
Print a tree in Common Lisp (really cheaply)
Just a cheap way to print a tree structure to your REPL.
(defun print-tree (tree &optional (offset 0)) (loop for node in tree do (terpri) (loop repeat offset do (princ " |")) (format t "-~a" (car node)) (print-tree (cdr node) (1+ offset)))) >>> (print-tree '(("branch1" ("node1") ("node2")) ("branch2" ("subbranch" ("node3") ("node4")) ("node5")))) -branch1 |-node1 |-node2 -branch2 |-subbranch | |-node3 | |-node4 |-node5
1 note
·
View note
Text
GIMP scripting with Script-Fu: namespaces
A popular open-source image editor GIMP can be scripted using several programming languages, usually Scheme or Python. Scheme interpreter is called Script-Fu and is based on Tinyscheme dialect which implements a subset of R5RS standard, as well as some extensions (like macros).
GIMP docs have a decent tutorial to get started, and the library of GIMP-specific functions is well documented via Procedure Browser (pdb). However many things about the language itself are shrouded in mystery. Tinyscheme documentation is rather sparse and there exist hidden features that aren't obvious. This is the first post in the series of posts exploring these hidden features.
Namespaces
When you write a script it is natural to create a bunch of helper functions. At the time I was writing Animstack, I didn't realize, but functions defined at toplevel are shared between all scripts. This isn't as nice as you might think, because an independent script might totally overwrite your function leading to bugs. When I was writing my second script, BgMask, I took this into account and started giving prefixes to all my helper functions (their names mostly start with "bgmask-"). However this too is a suboptimal solution. What I really wanted was namespaces. And suprisingly, Tinyscheme actually does have them!
(define my-namespace (make-environment ;;; define your functions here (define (my-function arg) ...) (define (blah-blah img drw ....) ... (my-function ...)) )) (define script-fu-blah-blah my-namespace::blah-blah) ;;; register your script here
Inside make-environment you can define as many functions as you want and they will not clash with similarly named functions in other scripts (as long as the namespaces are named differently!) Outside of it, use double-colon syntax to access symbols defined in the environment. Pretty cool, huh? Why doesn't Javascript have something like this?
0 notes
Text
Future topics
This is my programming blog. I am the author of Animstack and other less interesting stuff. As you can guess from the blog's title, I like Lisp and interactive programming. For my day job I program in Python. By the way, I am for hire ;)
web scraping in Common Lisp
programming Script-Fu scripts for GIMP
other stuff, but mostly Lisp
0 notes