#AIStack
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text

🧠 One AI App to Replace Them All – Explore the Power of EveryAI
Get it Now>>>
0 notes
Text
Top AI Development Tools Showdown 2025: Which Platform Dominates on Speed, Features & Pricing?
AI developers, listen up! As the race to build smarter, faster, and more cost-efficient models heats up, which AI tool truly delivers in 2025? From Google’s Vertex AI to OpenAI’s ecosystem, this deep-dive compares the top contenders across performance, scalability, integrations, and pricing tiers. Discover which tool gives you the edge – and which might hold you back. The winner might surprise you.
#AItools#AIdevelopment#VertexAI#OpenAI#HuggingFace#MLops#AIstack#AITools2025#TechStackWars#AIengineering#AIDevelopers
0 notes
Text
Intel Extension for Transformers & PyTorch LLM Optimisation

Enhancing deep learning model performance is essential for scalability and efficiency in the rapidly changing field of artificial intelligence. Intel has been in the forefront of creating frameworks and tools to improve AI models’ memory efficiency and speed of execution, especially with Intel Extension for PyTorch and Intel Extension for Transformers.
Comprehending the AI Stack
There are several layers in the AI stack, and each is essential to optimizing LLMs. The hardware layer, which consists of Intel Xeon CPUs, Intel Data Centre GPUs, Intel Arc GPUs, and Intel Gaudi AI accelerators, is fundamental.
The acceleration libraries, such as Intel oneAPI Collective Communications Library (oneCCL) and Intel oneAPI Deep Neural Network Library (oneDNN), sit above this layer and offer optimized kernels with Intel optimized instruction sets for effective processing. The highest layer is made up of resource-efficient frameworks such as PyTorch that interface with the hardware and libraries underneath to optimize model performance.
Important Optimization Methods
Optimizing operators is essential to improving LLM performance. Using enhanced instruction sets such as Intel enhanced Vector Extensions (Intel AVX), Intel Advanced Matrix Extensions (Intel AMX), and Intel Xe Matrix Extensions (Intel XMX), Intel replaces the default operation kernels with highly-optimized Intel oneDNN kernels. The accuracy-flexible design of this optimization ensures that applications can operate at maximum speed and precision by supporting a variety of data types, from FP32 to INT4.
Graph optimizations reduce the amount of memory accesses needed during computation, which further enhances efficiency. For example, memory access times can be reduced by combining layers (e.g., Conv+ReLU+Sum) with bandwidth-limited operations (e.g., activation functions, ReLU, or Tanh).
This method works especially well for models such as ResNet-50, where a large amount of processing time is dedicated to bandwidth-constrained tasks. Specific fusion methods, including as linear post-ops fusion and multi-head attention fusion, are used in the context of LLMs with Intel Extension for PyTorch in JIT/Torch script mode to improve performance.
Memory management is essential for maximizing LLM performance because they frequently require large amounts of memory. By pre-filling key/value pairs before to the onset of autoregressive decoding and utilising pre-allocated buffers throughout the decoding stage, the Segment KV Cache approach maximizes memory use.
This technique increases efficiency by lowering the requirement for in-the-moment memory changes. Similar to this, the Indirect Access KV Cache efficiently manages memory by utilising beam index history and pre-allocated buffers, which lowers the overhead related to memory access during inference.
Model compression uses quantization algorithms, which successively decrease weight and activation precision from FP32 to lower precision forms like INT8 or INT4. This reduction minimizes the size of the model, increases inference speed, and lowers the required for memory bandwidth. Smooth Quant is a post-training quantization technique that shifts the quantization difficulty from activations to weights. This allows for the preservation of model accuracy while mitigating activation outliers and optimizing hardware utilization.
A big part of optimization is also played by custom operators. The goal of weight-only quantization is to increase input and output activation precision by quantizing the model’s weights alone. With minimal influence on accuracy, this technique maximizes computational performance by utilising weight-only quantization-optimized bespoke GEMM (General Matrix Multiply) kernels. Performance can be further optimized by using Explicit SIMD (ESIMD) extensions, which provide more precise control over hardware features.
Intel Extension for PyTorch
APIs for implementing these optimizations on CPU and GPU based training and inference are provided by the Intel Extension for PyTorch. You may make sure that your models are optimized to operate well on Intel hardware by making use of these APIs. To make it easier for developers to execute these optimizations, the extension comes with environment configurations and scripts that are intended to maximize hardware utilization.
Another essential element of Intel’s optimization approach are the Intel Gaudi AI accelerators. Deep learning applications perform better because to the integration of PyTorch with the Intel Gaudi software suite, which effectively transfers neural network topologies onto Gaudi hardware. This integration also supports important kernel libraries and optimizations.
Intel Extension for Transformers
https://community.intel.com/t5/image/serverpage/image-id/56748i59BB048F0E369A11/image-size/large?v=v2&px=999&whitelist-exif-data=Orientation%2CResolution%2COriginalDefaultFinalSize%2CCopyright
Several plugins for widely used pipelines, like audio processing and retrieval-augmented generation (RAG), can be integrated with Neural Chat. By integrating the required optimizations straight into the pipeline setup, it makes the deployment of optimized chatbots easier.
Neural Velocity and Dispersed Interpretation
https://community.intel.com/t5/image/serverpage/image-id/56751iE6BB93D0A520220B/image-size/large?v=v2&px=999&whitelist-exif-data=Orientation%2CResolution%2COriginalDefaultFinalSize%2CCopyright
DeepSpeed
These optimizations are further expanded across numerous nodes or GPUs via Intel’s support for distributed inference via DeepSpeed. DeepSpeed now supports Intel GPUs thanks to the Intel Extension for DeepSpeed. It includes the following parts:
Implementation of the DeepSpeed Accelerator Interface
Implementation of DeepSpeed op builder for XPU
Code for DeepSpeed op builder kernel
With the help of oneCCL, this Intel-optimized extension distributes compute jobs well, lowering memory footprint and increasing throughput overall. Scaling AI applications across heterogeneous computer systems requires this capacity.
Utilising Optimizations in Real-World Applications
It’s actually very easy to implement these optimizations using Intel’s tools, as you can use the extensions for the PyTorch and Transformers frameworks. For example, Intel Extension for Transformers improves model compression methods such as weight-only and smooth quantization right inside the well-known Transformers API. By setting the quantization parameters and using the integrated APIs, you may optimize models with ease.
In a similar vein, the Intel Extension for Transformers and PyTorch offers an adaptable framework for optimizing deep learning models other than LLMs. This update provides GPU-centric capabilities like tensor parallelism and CPU optimizations like NUMA management and graph optimization’s to enable fine-tuning and deployment across a variety of hardware configurations.
In summary
You may significantly increase the effectiveness and performance of your AI models by utilising Intel’s extensive hardware stack, accelerated libraries, and optimized frameworks. These optimizations cut the energy and operating expenses associated with running large-scale AI applications in addition to improving computational performance and reducing latency.
Using the getting started samples from the Intel Extension for PyTorch and Intel Extension for Transformers, you can investigate these optimizations on the Intel Tiber Developer Cloud. You can make sure your LLMs are operating at optimal performance on Intel hardware by incorporating these strategies.
Read more on govindhtech.com
#intelextension#Transformers#PyTorch#llm#Optimisation#learningmodel#aistack#LLMperformanc#cpu#gpu#neuralnetwork#aiapplications#aimodels#Developercloud#inteltiber#technologe#technews#news#govindhtech
0 notes
Text
AI Stack Review – Real Information And Bonus
click here- https://rpreviewer.com/2023/10/03/ai-stack-review-real-information-and-bonus/

0 notes
Text

🚀 Elevate Your E-commerce Game with AI Stack! 🤖✨
Tired of the old, complex e-commerce routine? Say hello to AI Stack, your ultimate e-commerce companion! 🛒💼
🔥 Generate high-converting sales funnels effortlessly using AI technology. 🌐 Sell digital, physical, or affiliate products with ease. 🚗 Let AI Stack drive traffic to your funnels – no more expensive ad campaigns! 💰 Say goodbye to hidden monthly fees, keep your profits where they belong. 🏆 Affiliates, get ready to earn commissions and win cash prizes!
Customize, retarget, and streamline your marketing like a pro. With AI Stack, the future of e-commerce is here.
Ready to boost your sales and profitability? 📈 Don't miss out! Try AI Stack today! 💪🔗
#AIStack#Ecommerce#SalesFunnels#ArtificialIntelligence#OnlineBusiness#DigitalMarketing#AffiliateMarketing#Innovation#EcommerceSolutions#MarketingAutomation#TrafficGeneration#ConversionOptimization#ProfitableFunnels#BusinessTools#DigitalProducts#AffiliateCommissions#MarketingStrategies#OnlineRetail#Entrepreneurship#BrandCustomization#CostEffective#techlaunchreviews
0 notes
Text
AI Toolkit for Non-Marketers: Simplifying AI Layers
🚀 Unlock the Power of AI for Your Business! Confused about where to start with Artificial Intelligence? This visual guide breaks down the AI Stack into simple, actionable layers, with tools that even non-marketers can use. 💡 From data collection to AI applications, learn how to choose the right tools to boost your productivity and creativity! 💬 How are you using AI in your business? Share your thoughts in the comments! #AIForBeginners #ArtificialIntelligence #AIStack #MarketingMadeEasy #AIForSmallBusinesses #BusinessGrowth 👉 Check out the full post here:
Artificial Intelligence (AI) is revolutionizing industries, but understanding its intricacies can feel overwhelming. Enter the AI stack—a simplified roadmap that divides AI into manageable layers, each serving a unique purpose. Whether you’re a small business owner, marketer, or entrepreneur, this breakdown will help you navigate AI tools without needing technical expertise. Here’s an actionable…
#ai#AI Chatbot#AI Content Creation#AI Ethics#AI for Email Marketing#AI for Freelancers#AI for Marketing#AI for Non-Techies#AI for Saving Time#AI for Small Business Owners#AI in Social Media Marketing#AI Marketing Essentials#AI Marketing for Beginners#AI Marketing Tips#AI Marketing Trends#AI Marketing Trends AI Tools for 2025#AI Productivity Tools#AI SEO Strategies#AI Simplified for Beginners#AI Social Media Strategies#AI Tools for Everyone#AI Tools for Marketing#AI-Driven Analytics#AI-Generated Content#AI-Powered Campaigns#AI-Powered Success#Beginner Marketing Tips#Beginner’s Guide to AI#Boost Marketing with AI#Content Marketing
0 notes
Text
How Tesla Uses PyTorch

Last week, Tesla Motors made the news for delivering big with its smart summon feature on their cars. The cars can now be made to move around the parking lot with just a click. A myriad of tools and frameworks run in the background which makes Tesla’s futuristic features a great success. One such framework is PyTorch. PyTorch has gained popularity over the past couple of years and it is now powering the fully autonomous objectives of Tesla motors. During a talk for the recently-concluded PyTorch developer conference, Andrej Karpathy, who plays a key role in Tesla’s self-driving capabilities, spoke about how the full AI stack utilises PyTorch in the background. Tesla WorkFlow With PyTorch

via PyTorch Tesla Motors is known for pioneering the self-driving vehicle revolution in the world. They are also known for achieving high reliability in autonomous vehicles without the use of either LIDAR or high definition maps. Tesla cars depend entirely upon computer vision. Tesla is fairly a vertical integrated company and that is also true when it comes to the intelligence of the autopilot. Everything that goes into making Tesla autopilot the best in the world is based on machine learning and the raw video streams that come from 8 cameras around the vehicle. The footage from these cameras is processed through convolutional neural networks(CNNs) for object detection and performing other actions eventually. The collected data is labelled, training is done on on-premise GPU clusters and then it is taken through the entire stack. The networks are run on Tesla’s own custom hardware giving them full control over the lifecycle of all these features, which are deployed to almost 4 million Teslas around the world. For instance, a single frame from the footage of a single camera can contain the following: Road markingsTraffic lightsOverhead signsCrosswalksMoving objectsStatic objectsEnvironment tags So this quickly becomes a multi-task setting. A typical Tesla computer vision workflow would have all these tasks that are connected to a ResNet-50 like shared backbone running roughly on 1000 x 1000 images. Shared because having neural networks for every single task is costly and inefficient. These shared backbone or the networks are called Hydra Nets. There are multiple Hydra Nets for multiple tasks and the information gathered from all these networks can be used to solve recurring tasks. This requires a combination of data-parallel and model-parallel training.
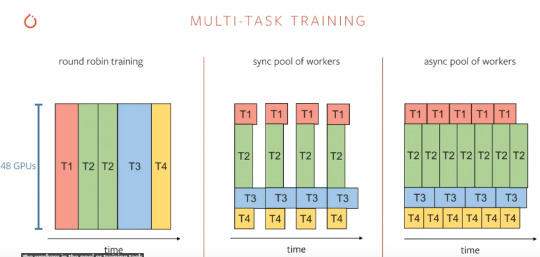
via PyTorch Multi-task training can be done through three main ways as illustrated above. Though round-robin looks straight forward, it is not effective because a pool of workers would be more effective in doing multiple tasks simultaneously. And, the engineers at Tesla find PyTorch to be well suited for carrying out this multitasking. For autopilot, Tesla trains around 48 networks that do 1,000 different predictions and it takes 70,000 GPU hours. Moreover, this training is not a one-time affair but an iterative one and all these workflows should be automated while making sure that these 1,000 different predictions don’t regress over time. Why PyTorch?

Smart summon in action When it comes to machine learning frameworks, TensorFlow and PyTorch are widely popular with the practitioners. No other framework comes even remotely close to what these two products of Google and Facebook respectively, have in store. These frameworks have slowly found their niche within the AI community. PyTorch, especially has become the go-to framework for machine learning researchers. PyTorch citations in papers on ArXiv grew 194% in the first half of 2019 alone while the number of contributors to the platform has grown more than 50%. Companies like Microsoft, Uber, and other organisations across industries are increasingly using it as the foundation for their most important machine learning research and production workloads. And now with the release of PyTorch 1.3, the platform got a much needed boost as it now includes experimental support for features such as seamless model deployment to mobile devices, model quantisation for better performance at inference time, and front-end improvements, like the ability to name tensors and create clearer code with less need for inline comments. The team also has plans in place for launching a number of additional tools and libraries to support model interpretability and bringing multimodal research to production. Additionally, PyTorch team have also collaborated with Google and Salesforce to add broad support for Cloud Tensor Processing Units, providing a significantly accelerated option for training large-scale deep neural networks. These timely releases from PyTorch coincide with the self-imposed deadlines of Elon Musk on his Tesla team. With the success of their Smart summon, Tesla aims to go fully autonomous in the next couple of years and we can safely say that it has rightly chosen PyTorch to do the heavy lifting. Read the full article
0 notes