#App Data Extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Mobile App Scraping Services – Scrape Mobile App Data
Cutting-edge mobile app scraping services to collect data from smartphone applications. Get cutstomized mobile app data scrapers and APIs to extract precise data in required format from targeted android, iOS or cross platform apps.
Explore More - https://www.dataseeders.com/mobile-app-scraping-services/
0 notes
Text
Kroger Grocery Data Scraping | Kroger Grocery Data Extraction

Shopping Kroger grocery online has become very common these days. At Foodspark, we scrape Kroger grocery apps data online with our Kroger grocery data scraping API as well as also convert data to appropriate informational patterns and statistics.
#food data scraping services#restaurantdataextraction#restaurant data scraping#web scraping services#grocerydatascraping#zomato api#fooddatascrapingservices#Scrape Kroger Grocery Data#Kroger Grocery Websites Apps#Kroger Grocery#Kroger Grocery data scraping company#Kroger Grocery Data#Extract Kroger Grocery Menu Data#Kroger grocery order data scraping services#Kroger Grocery Data Platforms#Kroger Grocery Apps#Mobile App Extraction of Kroger Grocery Delivery Platforms#Kroger Grocery delivery#Kroger grocery data delivery
2 notes
·
View notes
Text
Realigning Food Delivery Market Moves with Precision Through Glovo Data Scraping

Introduction
This case study highlights how our Glovo Data Scraping solutions empowered clients to monitor food delivery market trends strategically, refine service positioning, and execute agile, data-backed business strategies. Leveraging advanced scraping methodologies, we delivered actionable market intelligence that helped optimize decision-making, elevate competitiveness, and drive profitability.
Our solutions offered a clear strategic edge by enabling end-to-end visibility into the delivery ecosystem to Extract Food Delivery Data. This comprehensive insight allowed clients to fine-tune service models, sharpen market alignment, and achieve consistent revenue growth through accurate competitor benchmarking in the fast-moving food delivery sector.
The Client
A mid-sized restaurant chain operating across 75+ locations with a rapidly expanding digital footprint reached us with a critical operational challenge. Although the brand enjoyed strong recognition, it faced a noticeable drop in customer engagement driven by gaps in delivery service efficiency. To address this, Glovo Data Scraping was identified as a strategic solution, as service inconsistencies directly impacted their revenue goals and competitive position.
With a broad menu and widespread delivery zones, the restaurant struggled to manage delivery logistics, especially during peak hours when quick shifts in demand required fast action. Their manual approach failed to support Real-Time Glovo Data Scraping, leading to missed revenue opportunities and weakening customer loyalty.
Recognizing the need to refine their delivery strategy, the management team saw that without proper visibility into Glovo’s delivery ecosystem, they lacked the insights necessary for efficient operations and practical customer experience management.
Key Challenges Faced by the Client
In their pursuit of stronger delivery market intelligence and a sharper competitive edge, the client faced several operational and strategic hurdles:
Market Insight Shortage
Limited insights into Glovo's platform and competitors made scraping Glovo Delivery Information difficult, preventing effective market analysis necessary for informed business decisions.
Slow Response Adaptation
Reliance on manual weekly evaluations slowed the restaurant chain's ability to act quickly. Without Glovo Delivery Data Extraction, adapting to real-time market changes became a challenge.
Demand Forecasting Gap
Traditional methods failed to account for real-time delivery data. The restaurant chain needed Glovo Product Data Extraction to predict demand and adjust services based on emerging trends accurately.
Manual Process Overload
Labor-intensive processes hindered efficient service decisions. By applying methods to Scrape Glovo For Product Availability And Pricing, the restaurant chain sought automation to optimize service delivery.
Service Consistency Issue
Inconsistent service quality across zones presented a problem. They required Mobile App Scraping Solutions to streamline operations and ensure consistent service delivery across all customer touchpoints.
Key Solutions for Addressing Client Challenges
We implemented cutting-edge solutions to the client's challenges, combining delivery intelligence with advanced analytics.
Delivery Optimization Engine
We built a centralized platform that leverages Real-Time Glovo Delivery Time Data Extraction to collect live data from various restaurants and delivery zones, enabling efficient decision-making.
Competitor Monitoring System
Our system, designed to Extract Restaurant Menus And Prices From Glovo, quickly identifies service gaps when competitors adjust, giving restaurant chains the edge to adapt promptly.
Dynamic Market Signals
By integrating multiple delivery signals, such as peak hours and weather, with Glovo Scraping For Restaurant Delivery Services, we created flexible models that adjust to market fluctuations.
Automated Service Recommender
Using Real-Time Glovo Data Scraping, we implemented an automated engine that generates service suggestions based on customer feedback and competitive positioning, reducing the need for manual input.
Strategic Adjustment Mechanism
Competitor promotions directly influence our service strategies by using tools to Extract Food Delivery Data, optimizing delivery times and fees while ensuring premium offerings remain profitable.
Cloud-Based Monitoring Hub
A robust Mobile App Scraping Solution enables managers to access and update delivery data remotely, facilitating continuous optimization and transforming strategy management into a dynamic process.
Key Insights Gained from Glovo Data Scraping
Service Elasticity Analysis Revealed delivery time sensitivity across different menu items, offering immediate operational optimization opportunities.
Competitive Positioning Patterns Provided insights into neighborhood-specific delivery differences, supporting targeted service improvements.
Pricing Cycle Optimization Illuminated optimal fee adjustment timing for different meal categories, aiding in more strategic revenue management.
Data-Driven Service Decisions Enabled the implementation of adaptive delivery models based on competitive positioning patterns.
Benefits of Glovo Data Scraping From Retail Scrape
Strategic Boost
By utilizing solutions to Scrape Glovo Delivery Information, the client improved delivery strategies, positioning their services for maximum value, enhancing market responsiveness to competitive shifts.
Loyalty Growth
Using competitor service insights, the client predicted market trends and strengthened customer retention, employing to Extract Glovo Product Data to stay ahead of shifts in demand.
Efficient Operations
The client minimized manual efforts by employing advanced Real-Time Glovo Delivery Time Data Extraction, driving faster decisions and better service while ensuring precise positioning and operational success.
Competitive Edge
With advanced techniques to Scrape Glovo For Product Availability And Pricing, the client gained critical insights into market trends, allowing for service adjustments that boosted profitability in competitive delivery sectors.

Retail Scrape's Glovo Data Scraping solutions revolutionized our approach to delivery market positioning. By gaining comprehensive access to Extract Food Delivery Data insights, we rapidly adjusted our strategy, refined our service models, and achieved a remarkable 37% increase in customer retention.
- Operations Director, Leading Multi-Location Restaurant Chain
Conclusion
Maintaining optimal delivery service positioning is crucial in today's competitive food delivery market. Glovo Data Scraping empowers businesses to monitor competitor services, make informed decisions, and improve market competitiveness.
Our customized solutions offer smooth delivery intelligence and actionable insights, allowing businesses to refine their competitive positioning. With in-depth expertise in Glovo Delivery Data Extraction, we equip businesses with the tools to unlock valuable insights for strategic growth.
Our specialists help evaluate market positioning, refine delivery strategies, and boost profit margins through Real-Time Glovo Data Scraping. Contact Retail Scrape today to minimize service inconsistencies, enhance market positioning, and drive long-term revenue with our advanced food delivery intelligence solutions.
Read more >>https://www.retailscrape.com/glovo-food-delivery-data-scraping-for-market-insights.php
officially published by https://www.retailscrape.com/.
#Glovo data scraping#Glovo delivery data extraction#Scrape Glovo delivery information#Real-time Glovo data scraping#Glovo product data extraction#Extract restaurant menus and prices from Glovo#Real-time Glovo delivery time data extraction#Scrape Glovo for product availability and pricing#Glovo scraping for restaurant delivery services#Extract Food Delivery Data#Mobile App Scraping solution
0 notes
Text
#real estate data scraping services#Zillow scraper#extract property details#track competitor pricing strategies#mobile app scraping#web scraping#instant data scraper
0 notes
Text
🚀 The ChatGPT Desktop App is Changing the Game! 🤯💻 Imagine having an AI assistant that can: ✅ Reply to emails in seconds 📧⏩ ✅ Generate high-quality images with DALL-E 🎨🤩 ✅ Summarize long content instantly 📖📜 ✅ Write HTML/CSS code from screenshots 💻💡 ✅ Translate text across multiple languages 🌍🗣️ ✅ Extract text from images easily 📷📝 ✅ Analyze large datasets from Excel/CSV files 📊📈 👉 This app is designed to save your time. #ChatGPT #ChatGPTDesktopApp #AIProductivity #dalle #TechT
#AI automation#AI content creation#AI email management#AI for business#AI productivity tool#AI social media engagement#automatic code generation#ChatGPT benefits#ChatGPT coding#ChatGPT content summarization#ChatGPT desktop app#ChatGPT email replies#ChatGPT features#ChatGPT for professionals#ChatGPT tools for professionals.#ChatGPT uses#content summarization#DALL-E image generation#data analysis with AI#simplify daily tasks#smart translation#social media automation#text extraction from images
1 note
·
View note
Text
Mobile App Scraping: Unlocking Hidden Data from Apps for Business Growth
0 notes
Text
Ctrip.com is a multinational Travel Company in China. Being China's important traveling service provider, Ctrip provides more than 90 million of comprehensive services like flight ticketing, hotel reservations, registered members, package tours, corporate travel management, and train ticket, dining reservations, and more. Furthermore, both business travelers and leisure that grip the Ctrip associations like to access travel information as well as special discounts from the favored businesses in China.
0 notes
Text
Update 4 on the search for Riot by Orthgirl123:
While looking through my first deviantart account for other fics i remembered, I stumbled across a reposted fanfic of Orthgirl123 on someone else's account. It wasn't Riot but it was from another previous account she had on deviantart before that account got deleted?? The person reposting was a friend of hers and wanted to preserve her story(they only had ch1) until eventually she did come back AS the account I remembered her from.
In the comments, someone else(another friend) mentioned that they actually had that entire fanfiction saved and they could send it to them for the complete reposting. This person that saved the fanfiction, is someone I remember. They were one of the first ppl that greeted me when I joined deviantart and commented on EVERYTHING anyone posted about PaF. They mentioned recently that they like to catch up with older mutuals or ppl they knew on his account.
IM WONDERING IF HE HAS THE FANFIC IM LOOKING FOR!!!!
#im a bit scared to asked the translator after searching more about the fallout they had with SOMEONE#ive just kept searching through more data sets related to dA. I think this person might have it but for real.!! i remember seeing this guy#like on every post ever. they were mutuals or friends and always commented and got replied to back#i think he might have the fanfic. especially bc they mentioned having enjoyed Orthgirl123's stories i think its worth a shot#hopefully they did and still have access to it if so#also ive started asking around on reddit. this fanfic is driving me crazy. i downloaded a translation app to#convert the first 3 chapters back into english but it only accepts like 100 words at a time.#im also comparing the 1st paragraph from the original extraction to the translation to the retranslation to see if the process is working#accurately bc some words change. the reason i like this app im using is bc it lets me use columbian spanish as the text input which is where#the translator is from.#my dark fantasy is that they all find my blog and see how obsessively thorough and devoted i am and feel bad and say 'wow you did all this?'#all while impressed flattered and with every piece of fanworks they made back in 2011 ready to let me read through again#riotfic-search
0 notes
Text
Mobile App Scraping Services - Extract Android and IOS App Data
Gather accurate data from any iOS & Android apps using Our mobile app scraping service to make informed business decisions.
Know More : https://www.crawlxpert.com/mobile-app-scraping-services-extract-android-and-ios-app-data
#Mobile App Scraping Services#Extract Android and IOS App Data#ScrapedatafromiOSandAndroidapps#AndroidandIOSAppDataScraper
0 notes
Text
Exploring the Uber Eats API: A Definitive Guide to Integration and Functionality
In this blog, we delve into the various types of data the Uber Eats API offers and demonstrate how they can be ingeniously harnessed to craft engaging and practical meal-serving apps.
#Uber Eats Data Scraping API#Scrape Uber Eats Data API#Extract Uber Eats Data#Scrape Food Delivery App Data#Food Delivery App Data Scraping
0 notes
Text
Scrape Data from Amazon and Flipkart Mobile Apps
Uncover competitive secrets and market trends by scraping data from Amazon and Flipkart mobile apps. Access valuable insights to fuel your e-commerce success.
know more:
#Extract Data from Amazon Mobile Apps#Extract Data from Flipkart Mobile Apps#collect data from online shopping Applications
0 notes
Text
Large-Scale Web Scraping - Web Scraping at Scale

To make sense of all that information, we need a way to organize it into something meaningful. That is where large-scale web scraping comes to the rescue. It is a process that involves gathering data from websites, particularly those with large amounts of data.
What Is Large-Scale Web Scraping?
Large Scale Web Scraping is scraping web pages and extracting data from them. This can be done manually or with automated tools. The extracted data can then be used to build charts and graphs, create reports and perform other analyses on the data.
It can be used to analyze large amounts of data, like traffic on a website or the number of visitors they receive. In addition, It can also be used to test different website versions so that you know which version gets more traffic than others.
Getting To Know The Client Expectations And Needs
We collect all the data from our clients to analyze the feasibility of the data extraction process for every individual site. If possible, we tell our clients exactly what data can be extracted, how much can be extracted, to what extent it can be extracted, and how much time the process completes.
Constructing Scrapers And Assembling Them Together
For every site allotted to us by our clients, we get a unique scraper built in place so that no one scraper has the burden to go through thousands of sites and millions of data. Moreover, all those scrapers are working in tandem for work to be done rapidly.
Running The Scrapers By Executing Them Smoothly
It is essential to have the servers and Internet lease lines running all the time so the extraction process is not interrupted. We ensure this through high-end hardware present at our premises costing lacs of rupees so that real-time information is delivered after extraction whenever the client wants. To avoid any blacklisting scenario, we already have proxy servers, many IP addresses, and various secret strategies coming to our rescue.
Quality Checks Scrapers Maintenance Performed On A Regular Basis
After the the automated web data scraping process, we ensure manual quality checks on the extracted or mined data via our QA team, who constantly communicates with the developer’s team for any bugs or errors reported. Additionally, if the scrapers need to be modified per changing site structure or client requirements, we do so without any hassle.
#data extraction#data mining services#webscraping#Large Scale Web Scraping#data scraping services#mobile app scraping
1 note
·
View note
Text
Exploring the Uber Eats API: A Definitive Guide to Integration and Functionality
In this blog, we delve into the various types of data the Uber Eats API offers and demonstrate how they can be ingeniously harnessed to craft engaging and practical meal-serving apps.
#Uber Eats Data Scraping API#Scrape Uber Eats Data API#Extract Uber Eats Data#Scrape Food Delivery App Data#Food Delivery App Data Scraping
0 notes
Text
Scrape Social Media App Data | Social Media Apps Scraping
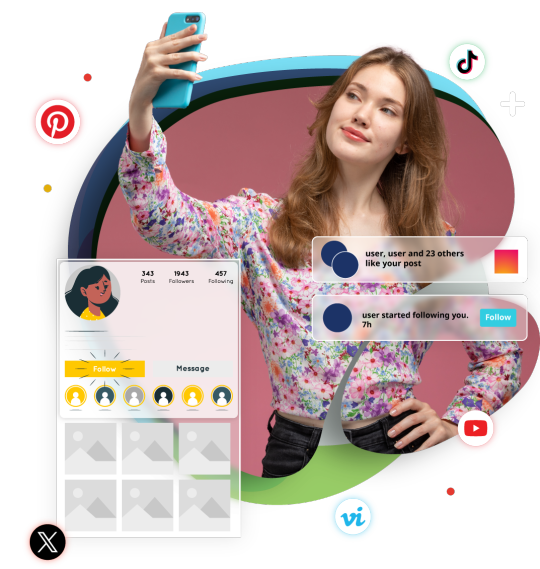
Scrape Social Media App Data today! Our social media app scraping helps you to extract data from popular social media platforms like, Instagram, YouTube, TikTok, Twitter, and Facebook.
#Scrape Social Media App Data#Social Media Apps Scraping#Social Media Apps Scraper#Social Media Apps Data Extraction
0 notes
Text
There Were Always Enshittifiers

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in DC TONIGHT (Mar 4), and in RICHMOND TOMORROW (Mar 5). More tour dates here. Mail-order signed copies from LA's Diesel Books.

My latest Locus column is "There Were Always Enshittifiers." It's a history of personal computing and networked communications that traces the earliest days of the battle for computers as tools of liberation and computers as tools for surveillance, control and extraction:
https://locusmag.com/2025/03/commentary-cory-doctorow-there-were-always-enshittifiers/
The occasion for this piece is the publication of my latest Martin Hench novel, a standalone book set in the early 1980s called "Picks and Shovels":
https://us.macmillan.com/books/9781250865908/picksandshovels
The MacGuffin of Picks and Shovels is a "weird PC" company called Fidelity Computing, owned by a Mormon bishop, a Catholic priest, and an orthodox rabbi. It sounds like the setup for a joke, but the punchline is deadly serious: Fidelity Computing is a pyramid selling cult that preys on the trust and fellowship of faith groups to sell the dreadful Fidelity 3000 PC and its ghastly peripherals.
You see, Fidelity's products are booby-trapped. It's not merely that they ship with programs whose data-files can't be read by apps on any other system – that's just table stakes. Fidelity's got a whole bag of tricks up its sleeve – for example, it deliberately damages a specific sector on every floppy disk it ships. The drivers for its floppy drive initialize any read or write operation by checking to see if that sector can be read. If it can, the computer refuses to recognize the disk. This lets the Reverend Sirs (as Fidelity's owners style themselves) run a racket where they sell these deliberately damaged floppies at a 500% markup, because regular floppies won't work on the systems they lure their parishioners into buying.
Or take the Fidelity printer: it's just a rebadged Okidata ML-80, the workhorse tractor feed printer that led the market for years. But before Fidelity ships this printer to its customers, they fit it with new tractor feed sprockets whose pins are slightly more widely spaced than the standard 0.5" holes on the paper you can buy in any stationery store. That way, Fidelity can force its customers to buy the custom paper that they exclusively peddle – again, at a massive markup.
Needless to say, printing with these wider sprocket holes causes frequent jams and puts a serious strain on the printer's motors, causing them to burn out at a high rate. That's great news – for Fidelity Computing. It means they get to sell you more overpriced paper so you can reprint the jobs ruined by jams, and they can also sell you their high-priced, exclusive repair services when your printer's motors quit.
Perhaps you're thinking, "OK, but I can just buy a normal Okidata printer and use regular, cheap paper, right?" Sorry, the Reverend Sirs are way ahead of you: they've reversed the pinouts on their printers' serial ports, and a normal printer won't be able to talk to your Fidelity 3000.
If all of this sounds familiar, it's because these are the paleolithic ancestors of today's high-tech lock-in scams, from HP's $10,000/gallon ink to Apple and Google's mobile app stores, which cream a 30% commission off of every dollar collected by an app maker. What's more, these ancient, weird misfeatures have their origins in the true history of computing, which was obsessed with making the elusive, copy-proof floppy disk.
This Quixotic enterprise got started in earnest with Bill Gates' notorious 1976 "open letter to hobbyists" in which the young Gates furiously scolds the community of early computer hackers for its scientific ethic of publishing, sharing and improving the code that they all wrote:
https://en.wikipedia.org/wiki/An_Open_Letter_to_Hobbyists
Gates had recently cloned the BASIC programming language for the popular Altair computer. For Gates, his act of copying was part of the legitimate progress of technology, while the copying of his colleagues, who duplicated Gates' Altair BASIC, was a shameless act of piracy, destined to destroy the nascent computing industry:
As the majority of hobbyists must be aware, most of you steal your software. Hardware must be paid for, but software is something to share. Who cares if the people who worked on it get paid?
Needless to say, Gates didn't offer a royalty to John Kemeny and Thomas Kurtz, the programmers who'd invented BASIC at Dartmouth College in 1963. For Gates – and his intellectual progeny – the formula was simple: "When I copy you, that's progress. When you copy me, that's piracy." Every pirate wants to be an admiral.
For would-be ex-pirate admirals, Gates's ideology was seductive. There was just one fly in the ointment: computers operate by copying. The only way a computer can run a program is to copy it into memory – just as the only way your phone can stream a video is to download it to its RAM ("streaming" is a consensus hallucination – every stream is a download, and it has to be, because the internet is a data-transmission network, not a cunning system of tubes and mirrors that can make a picture appear on your screen without transmitting the file that contains that image).
Gripped by this enshittificatory impulse, the computer industry threw itself headfirst into the project of creating copy-proof data, a project about as practical as making water that's not wet. That weird gimmick where Fidelity floppy disks were deliberately damaged at the factory so the OS could distinguish between its expensive disks and the generic ones you bought at the office supply place? It's a lightly fictionalized version of the copy-protection system deployed by Visicalc, a move that was later publicly repudiated by Visicalc co-founder Dan Bricklin, who lamented that it confounded his efforts to preserve his software on modern systems and recover the millions of data-files that Visicalc users created:
http://www.bricklin.com/robfuture.htm
The copy-protection industry ran on equal parts secrecy and overblown sales claims about its products' efficacy. As a result, much of the story of this doomed effort is lost to history. But back in 2017, a redditor called Vadermeer unearthed a key trove of documents from this era, in a Goodwill Outlet store in Seattle:
https://www.reddit.com/r/VintageApple/comments/5vjsow/found_internal_apple_memos_about_copy_protection/
Vaderrmeer find was a Apple Computer binder from 1979, documenting the company's doomed "Software Security from Apple's Friends and Enemies" (SSAFE) project, an effort to make a copy-proof floppy:
https://archive.org/details/AppleSSAFEProject
The SSAFE files are an incredible read. They consist of Apple's best engineers beavering away for days, cooking up a new copy-proof floppy, which they would then hand over to Apple co-founder and legendary hardware wizard Steve Wozniak. Wozniak would then promptly destroy the copy-protection system, usually in a matter of minutes or hours. Wozniak, of course, got the seed capital for Apple by defeating AT&T's security measures, building a "blue box" that let its user make toll-free calls and peddling it around the dorms at Berkeley:
https://512pixels.net/2018/03/woz-blue-box/
Woz has stated that without blue boxes, there would never have been an Apple. Today, Apple leads the charge to restrict how you use your devices, confining you to using its official app store so it can skim a 30% vig off every dollar you spend, and corralling you into using its expensive repair depots, who love to declare your device dead and force you to buy a new one. Every pirate wants to be an admiral!
https://www.vice.com/en/article/tim-cook-to-investors-people-bought-fewer-new-iphones-because-they-repaired-their-old-ones/
Revisiting the early PC years for Picks and Shovels isn't just an excuse to bust out some PC nostalgiacore set-dressing. Picks and Shovels isn't just a face-paced crime thriller: it's a reflection on the enshittificatory impulses that were present at the birth of the modern tech industry.
But there is a nostalgic streak in Picks and Shovels, of course, represented by the other weird PC company in the tale. Computing Freedom is a scrappy PC startup founded by three women who came up as sales managers for Fidelity, before their pangs of conscience caused them to repent of their sins in luring their co-religionists into the Reverend Sirs' trap.
These women – an orthodox lesbian whose family disowned her, a nun who left her order after discovering the liberation theology movement, and a Mormon woman who has quit the church over its opposition to the Equal Rights Amendment – have set about the wozniackian project of reverse-engineering every piece of Fidelity hardware and software, to make compatible products that set Fidelity's caged victims free.
They're making floppies that work with Fidelity drives, and drives that work with Fidelity's floppies. Printers that work with Fidelity computers, and adapters so Fidelity printers will work with other PCs (as well as resprocketing kits to retrofit those printers for standard paper). They're making file converters that allow Fidelity owners to read their data in Visicalc or Lotus 1-2-3, and vice-versa.
In other words, they're engaged in "adversarial interoperability" – hacking their own fire-exits into the burning building that Fidelity has locked its customers inside of:
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
This was normal, back then! There were so many cool, interoperable products and services around then, from the Bell and Howell "Black Apple" clones:
https://forum.vcfed.org/index.php?threads%2Fbell-howell-apple-ii.64651%2F
to the amazing copy-protection cracking disks that traveled from hand to hand, so the people who shelled out for expensive software delivered on fragile floppies could make backups against the inevitable day that the disks stopped working:
https://en.wikipedia.org/wiki/Bit_nibbler
Those were wild times, when engineers pitted their wits against one another in the spirit of Steve Wozniack and SSAFE. That era came to a close – but not because someone finally figured out how to make data that you couldn't copy. Rather, it ended because an unholy coalition of entertainment and tech industry lobbyists convinced Congress to pass the Digital Millennium Copyright Act in 1998, which made it a felony to "bypass an access control":
https://www.eff.org/deeplinks/2016/07/section-1201-dmca-cannot-pass-constitutional-scrutiny
That's right: at the first hint of competition, the self-described libertarians who insisted that computers would make governments obsolete went running to the government, demanding a state-backed monopoly that would put their rivals in prison for daring to interfere with their business model. Plus ça change: today, their intellectual descendants are demanding that the US government bail out their "anti-state," "independent" cryptocurrency:
https://www.citationneeded.news/issue-78/
In truth, the politics of tech has always contained a faction of "anti-government" millionaires and billionaires who – more than anything – wanted to wield the power of the state, not abolish it. This was true in the mainframe days, when companies like IBM made billions on cushy defense contracts, and it's true today, when the self-described "Technoking" of Tesla has inserted himself into government in order to steer tens of billions' worth of no-bid contracts to his Beltway Bandit companies:
https://www.reuters.com/world/us/lawmakers-question-musk-influence-over-verizon-faa-contract-2025-02-28/
The American state has always had a cozy relationship with its tech sector, seeing it as a way to project American soft power into every corner of the globe. But Big Tech isn't the only – or the most important – US tech export. Far more important is the invisible web of IP laws that ban reverse-engineering, modding, independent repair, and other activities that defend American tech exports from competitors in its trading partners.
Countries that trade with the US were arm-twisted into enacting laws like the DMCA as a condition of free trade with the USA. These laws were wildly unpopular, and had to be crammed through other countries' legislatures:
https://pluralistic.net/2024/11/15/radical-extremists/#sex-pest
That's why Europeans who are appalled by Musk's Nazi salute have to confine their protests to being loudly angry at him, selling off their Teslas, and shining lights on Tesla factories:
https://www.malaymail.com/news/money/2025/01/24/heil-tesla-activists-protest-with-light-projection-on-germany-plant-after-musks-nazi-salute-video/164398
Musk is so attention-hungry that all this is as apt to please him as anger him. You know what would really hurt Musk? Jailbreaking every Tesla in Europe so that all its subscription features – which represent the highest-margin line-item on Tesla's balance-sheet – could be unlocked by any local mechanic for €25. That would really kick Musk in the dongle.
The only problem is that in 2001, the US Trade Rep got the EU to pass the EU Copyright Directive, whose Article 6 bans that kind of reverse-engineering. The European Parliament passed that law because doing so guaranteed tariff-free access for EU goods exported to US markets.
Enter Trump, promising a 25% tariff on European exports.
The EU could retaliate here by imposing tit-for-tat tariffs on US exports to the EU, which would make everything Europeans buy from America 25% more expensive. This is a very weird way to punish the USA.
On the other hand, not that Trump has announced that the terms of US free trade deals are optional (for the US, at least), there's no reason not to delete Article 6 of the EUCD, and all the other laws that prevent European companies from jailbreaking iPhones and making their own App Stores (minus Apple's 30% commission), as well as ad-blockers for Facebook and Instagram's apps (which would zero out EU revenue for Meta), and, of course, jailbreaking tools for Xboxes, Teslas, and every make and model of every American car, so European companies could offer service, parts, apps, and add-ons for them.
When Jeff Bezos launched Amazon, his war-cry was "your margin is my opportunity." US tech companies have built up insane margins based on the IP provisions required in the free trade treaties it signed with the rest of the world.
It's time to delete those IP provisions and throw open domestic competition that attacks the margins that created the fortunes of oligarchs who sat behind Trump on the inauguration dais. It's time to bring back the indomitable hacker spirit that the Bill Gateses of the world have been trying to extinguish since the days of the "open letter to hobbyists." The tech sector built a 10 foot high wall around its business, then the US government convinced the rest of the world to ban four-metre ladders. Lift the ban, unleash the ladders, free the world!
In the same way that futuristic sf is really about the present, Picks and Shovels, an sf novel set in the 1980s, is really about this moment.
I'm on tour with the book now – if you're reading this today (Mar 4) and you're in DC, come see me tonight with Matt Stoller at 6:30PM at the Cleveland Park Library:
https://www.loyaltybookstores.com/picksnshovels
And if you're in Richmond, VA, come down to Fountain Bookshop and catch me with Lee Vinsel tomorrow (Mar 5) at 7:30PM:
https://fountainbookstore.com/events/1795820250305

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/03/04/object-permanence/#picks-and-shovels
#pluralistic#picks and shovels#history#web theory#marty hench#martin hench#red team blues#locus magazine#drm#letter to computer hobbyists#bill gates#computer lib#science fiction#crime fiction#detective fiction
498 notes
·
View notes
Note
Is AWAY using it's own program or is this just a voluntary list of guidelines for people using programs like DALL-E? How does AWAY address the environmental concerns of how the companies making those AI programs conduct themselves (energy consumption, exploiting impoverished areas for cheap electricity, destruction of the environment to rapidly build and get the components for data centers etc.)? Are members of AWAY encouraged to contact their gov representatives about IP theft by AI apps?
What is AWAY and how does it work?
AWAY does not "use its own program" in the software sense—rather, we're a diverse collective of ~1000 members that each have their own varying workflows and approaches to art. While some members do use AI as one tool among many, most of the people in the server are actually traditional artists who don't use AI at all, yet are still interested in ethical approaches to new technologies.
Our code of ethics is a set of voluntary guidelines that members agree to follow upon joining. These emphasize ethical AI approaches, (preferably open-source models that can run locally), respecting artists who oppose AI by not training styles on their art, and refusing to use AI to undercut other artists or work for corporations that similarly exploit creative labor.
Environmental Impact in Context
It's important to place environmental concerns about AI in the context of our broader extractive, industrialized society, where there are virtually no "clean" solutions:
The water usage figures for AI data centers (200-740 million liters annually) represent roughly 0.00013% of total U.S. water usage. This is a small fraction compared to industrial agriculture or manufacturing—for example, golf course irrigation alone in the U.S. consumes approximately 2.08 billion gallons of water per day, or about 7.87 trillion liters annually. This makes AI's water usage about 0.01% of just golf course irrigation.
Looking into individual usage, the average American consumes about 26.8 kg of beef annually, which takes around 1,608 megajoules (MJ) of energy to produce. Making 10 ChatGPT queries daily for an entire year (3,650 queries) consumes just 38.1 MJ—about 42 times less energy than eating beef. In fact, a single quarter-pound beef patty takes 651 times more energy to produce than a single AI query.
Overall, power usage specific to AI represents just 4% of total data center power consumption, which itself is a small fraction of global energy usage. Current annual energy usage for data centers is roughly 9-15 TWh globally—comparable to producing a relatively small number of vehicles.
The consumer environmentalism narrative around technology often ignores how imperial exploitation pushes environmental costs onto the Global South. The rare earth minerals needed for computing hardware, the cheap labor for manufacturing, and the toxic waste from electronics disposal disproportionately burden developing nations, while the benefits flow largely to wealthy countries.
While this pattern isn't unique to AI, it is fundamental to our global economic structure. The focus on individual consumer choices (like whether or not one should use AI, for art or otherwise,) distracts from the much larger systemic issues of imperialism, extractive capitalism, and global inequality that drive environmental degradation at a massive scale.
They are not going to stop building the data centers, and they weren't going to even if AI never got invented.
Creative Tools and Environmental Impact
In actuality, all creative practices have some sort of environmental impact in an industrialized society:
Digital art software (such as Photoshop, Blender, etc) generally uses 60-300 watts per hour depending on your computer's specifications. This is typically more energy than dozens, if not��hundreds, of AI image generations (maybe even thousands if you are using a particularly low-quality one).
Traditional art supplies rely on similar if not worse scales of resource extraction, chemical processing, and global supply chains, all of which come with their own environmental impact.
Paint production requires roughly thirteen gallons of water to manufacture one gallon of paint.
Many oil paints contain toxic heavy metals and solvents, which have the potential to contaminate ground water.
Synthetic brushes are made from petroleum-based plastics that take centuries to decompose.
That being said, the point of this section isn't to deflect criticism of AI by criticizing other art forms. Rather, it's important to recognize that we live in a society where virtually all artistic avenues have environmental costs. Focusing exclusively on the newest technologies while ignoring the environmental costs of pre-existing tools and practices doesn't help to solve any of the issues with our current or future waste.
The largest environmental problems come not from individual creative choices, but rather from industrial-scale systems, such as:
Industrial manufacturing (responsible for roughly 22% of global emissions)
Industrial agriculture (responsible for roughly 24% of global emissions)
Transportation and logistics networks (responsible for roughly 14% of global emissions)
Making changes on an individual scale, while meaningful on a personal level, can't address systemic issues without broader policy changes and overall restructuring of global economic systems.
Intellectual Property Considerations
AWAY doesn't encourage members to contact government representatives about "IP theft" for multiple reasons:
We acknowledge that copyright law overwhelmingly serves corporate interests rather than individual creators
Creating new "learning rights" or "style rights" would further empower large corporations while harming individual artists and fan creators
Many AWAY members live outside the United States, many of which having been directly damaged by the US, and thus understand that intellectual property regimes are often tools of imperial control that benefit wealthy nations
Instead, we emphasize respect for artists who are protective of their work and style. Our guidelines explicitly prohibit imitating the style of artists who have voiced their distaste for AI, working on an opt-in model that encourages traditional artists to give and subsequently revoke permissions if they see fit. This approach is about respect, not legal enforcement. We are not a pro-copyright group.
In Conclusion
AWAY aims to cultivate thoughtful, ethical engagement with new technologies, while also holding respect for creative communities outside of itself. As a collective, we recognize that real environmental solutions require addressing concepts such as imperial exploitation, extractive capitalism, and corporate power—not just focusing on individual consumer choices, which do little to change the current state of the world we live in.
When discussing environmental impacts, it's important to keep perspective on a relative scale, and to avoid ignoring major issues in favor of smaller ones. We promote balanced discussions based in concrete fact, with the belief that they can lead to meaningful solutions, rather than misplaced outrage that ultimately serves to maintain the status quo.
If this resonates with you, please feel free to join our discord. :)
Works Cited:
USGS Water Use Data: https://www.usgs.gov/mission-areas/water-resources/science/water-use-united-states
Golf Course Superintendents Association of America water usage report: https://www.gcsaa.org/resources/research/golf-course-environmental-profile
Equinix data center water sustainability report: https://www.equinix.com/resources/infopapers/corporate-sustainability-report
Environmental Working Group's Meat Eater's Guide (beef energy calculations): https://www.ewg.org/meateatersguide/
Hugging Face AI energy consumption study: https://huggingface.co/blog/carbon-footprint
International Energy Agency report on data centers: https://www.iea.org/reports/data-centres-and-data-transmission-networks
Goldman Sachs "Generational Growth" report on AI power demand: https://www.goldmansachs.com/intelligence/pages/gs-research/generational-growth-ai-data-centers-and-the-coming-us-power-surge/report.pdf
Artists Network's guide to eco-friendly art practices: https://www.artistsnetwork.com/art-business/how-to-be-an-eco-friendly-artist/
The Earth Chronicles' analysis of art materials: https://earthchronicles.org/artists-ironically-paint-nature-with-harmful-materials/
Natural Earth Paint's environmental impact report: https://naturalearthpaint.com/pages/environmental-impact
Our World in Data's global emissions by sector: https://ourworldindata.org/emissions-by-sector
"The High Cost of High Tech" report on electronics manufacturing: https://goodelectronics.org/the-high-cost-of-high-tech/
"Unearthing the Dirty Secrets of the Clean Energy Transition" (on rare earth mineral mining): https://www.theguardian.com/environment/2023/apr/18/clean-energy-dirty-mining-indigenous-communities-climate-crisis
Electronic Frontier Foundation's position paper on AI and copyright: https://www.eff.org/wp/ai-and-copyright
Creative Commons research on enabling better sharing: https://creativecommons.org/2023/04/24/ai-and-creativity/
217 notes
·
View notes