#ChatGPT content summarization
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
🚀 The ChatGPT Desktop App is Changing the Game! 🤯💻 Imagine having an AI assistant that can: ✅ Reply to emails in seconds 📧⏩ ✅ Generate high-quality images with DALL-E 🎨🤩 ✅ Summarize long content instantly 📖📜 ✅ Write HTML/CSS code from screenshots 💻💡 ✅ Translate text across multiple languages 🌍🗣️ ✅ Extract text from images easily 📷📝 ✅ Analyze large datasets from Excel/CSV files 📊📈 👉 This app is designed to save your time. #ChatGPT #ChatGPTDesktopApp #AIProductivity #dalle #TechT
#AI automation#AI content creation#AI email management#AI for business#AI productivity tool#AI social media engagement#automatic code generation#ChatGPT benefits#ChatGPT coding#ChatGPT content summarization#ChatGPT desktop app#ChatGPT email replies#ChatGPT features#ChatGPT for professionals#ChatGPT tools for professionals.#ChatGPT uses#content summarization#DALL-E image generation#data analysis with AI#simplify daily tasks#smart translation#social media automation#text extraction from images
1 note
·
View note
Text
[Image description: Tweet from ovichknox, quote-tweeting someone claiming to have gotten a readable translation of Aristotle from chatGPT with "this is so scary to me. i recommended a book to a friend recently and she came back to me a day later saying it was really good and i asked if she finished it already and she said 'yeah i got chatgpt to summarise each chapter into 3 paragraphs so it was easy to read.'" End description.]

what is HAPPENING
#man. i'd be like 'would you have chatGPT cuddle your wife for you too' but no I'm sure there are plenty of people who would. :/#this is fucking depressing#I get not wanting to think. i do! but having a machine kludge together an imitation of thought for you is worse than not thinking#and how much of the actual story do you think that friend even got. 'it was really good' your lazy ass didn't even read it!#I just summarized the QT'd tweet bc hey if yr content to let a BS generator do all yr thinking for you yr thoughts must be worthless
103K notes
·
View notes
Text
In other uncanny-valley AI voice news...
Google has this new thing called "NotebookLM," which allows you to upload any document, click a button, and then a few minutes later receive an entire AI-generated podcast episode (!) about the document. The generation seems to occur somewhat faster than real-time.
(This is currently offered for free as a demo, all you need is a Google account.)
These podcast episodes are... they're not, uh, good. In fact, they're terrible – so cringe-y and inane that I find them painful to listen to.
But – unlike with the "AI-generated content" of even the very recent past – the problem with this stuff isn't that it's unrealistic. It's perfectly realistic. The podcasters sound like real people! Everything they say is perfectly coherent! It's just coherently ... bad.
It's a perfect imitation of superficial, formulaic, cringe-y media commentary podcasts. The content isn't good, but it's a type of bad content that exists, and the AI mimics it expertly.
The badness is authentic. The dumb shit they say is exactly the sort of dumb shit that humans would say on this sort of podcast, and they say it with the exact sorts of inflections that people would use when saying that dumb shit on that sort of podcast, and... and everything.
(Advanced Voice Mode feels a lot like this too. And – much as with Advanced Voice Mode – if Google can do this, then they can presumably do lots of things that are more interesting and artistically impressive.
But even if no one especially likes this kind of slop, it's highly inoffensive – palatable to everyone, not likely to confuse anyone or piss anyone off – and so it's what we get, for now, while these companies are still cautiously testing the waters.)
----
Anyway.
The first thing I tried was my novel Almost Nowhere, as a PDF file.
This seemed to throw the whole "NotebookLM" system for a loop, to some extent because it's a confusing book (even to humans), but also to some extent because it's very long.
I saw several different "NotebookLM" features spit out different attempts to summarize/describe it that seemed to be working off of different subsets of the text.
In the case of the generated podcast, the podcasters appear to have only "seen" the first 8 (?) chapters.
And their discussion of those early chapters is... like I said, pretty bad. They get some basic things wrong, and the commentary is painfully basic even when it's not actually inaccurate. But it's still uncanny that something like this is possible.
(Spoilers for the first ~8 chapters of Almost Nowhere)
The second thing I tried was my previous novel, The Northern Caves.
The Northern Caves is a much shorter book, and there were no length-related issues this time.
It's also a book that uses a found-media format and includes a fictitious podcast transcript.
And, possibly because of this, NotebookLM "decided" to generate a podcast that treated the story and characters as though they existed in the real world – effectively, creating fanfiction as opposed to commentary!
(Spoilers for The Northern Caves.)
----
Related links:
I tried OpenAI's Advanced Voice Mode ChatGPT feature and wrote a post about my experiences
I asked NotebookLM to make a podcast about my Advanced Voice Mode post, with surreal results
Tumblr user ralfmaximus takes this to the limit, creating NotebookLM podcast about the very post you're reading now
#“ready to dig into something different today? we're going to be looking at leonard salby. you know him... he wrote 'a thornbush tale.'”#ai tag#almost nowhere#the northern caves
1K notes
·
View notes
Text
Ever since OpenAI released ChatGPT at the end of 2022, hackers and security researchers have tried to find holes in large language models (LLMs) to get around their guardrails and trick them into spewing out hate speech, bomb-making instructions, propaganda, and other harmful content. In response, OpenAI and other generative AI developers have refined their system defenses to make it more difficult to carry out these attacks. But as the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections appear to be far behind those of its established competitors.
Today, security researchers from Cisco and the University of Pennsylvania are publishing findings showing that, when tested with 50 malicious prompts designed to elicit toxic content, DeepSeek’s model did not detect or block a single one. In other words, the researchers say they were shocked to achieve a “100 percent attack success rate.”
The findings are part of a growing body of evidence that DeepSeek’s safety and security measures may not match those of other tech companies developing LLMs. DeepSeek’s censorship of subjects deemed sensitive by China’s government has also been easily bypassed.
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”
57 notes
·
View notes
Text
How Authors Can Use AI to Improve Their Writing Style
Artificial Intelligence (AI) is transforming the way authors approach writing, offering tools to refine style, enhance creativity, and boost productivity. By leveraging AI writing assistant authors can improve their craft in various ways.
1. Grammar and Style Enhancement
AI writing tools like Grammarly, ProWritingAid, and Hemingway Editor help authors refine their prose by correcting grammar, punctuation, and style inconsistencies. These tools offer real-time suggestions to enhance readability, eliminate redundancy, and maintain a consistent tone.
2. Idea Generation and Inspiration
AI can assist in brainstorming and overcoming writer’s block. Platforms like OneAIChat, ChatGPT and Sudowrite provide writing prompts, generate story ideas, and even suggest plot twists. These AI systems analyze existing content and propose creative directions, helping authors develop compelling narratives.
3. Improving Readability and Engagement
AI-driven readability analyzers assess sentence complexity and suggest simpler alternatives. Hemingway Editor, for example, highlights lengthy or passive sentences, making writing more engaging and accessible. This ensures clarity and impact, especially for broader audiences.
4. Personalizing Writing Style
AI-powered tools can analyze an author's writing patterns and provide personalized feedback. They help maintain a consistent voice, ensuring that the writer’s unique style remains intact while refining structure and coherence.
5. Research and Fact-Checking
AI-powered search engines and summarization tools help authors verify facts, gather relevant data, and condense complex information quickly. This is particularly useful for non-fiction writers and journalists who require accuracy and efficiency.
Conclusion
By integrating AI into their writing process, authors can enhance their style, improve efficiency, and foster creativity. While AI should not replace human intuition, it serves as a valuable assistant, enabling writers to produce polished and impactful content effortlessly.
38 notes
·
View notes
Text
venting rn but in the last 2-3 years I've noticed a huge increase in people who seem like they barely want to engage in fandom creations anymore. To be clear, there are still a lot of really great people out there and they certainly make up the majority of my fic readers & commenters!
But in the comments of my stories, I've noticed more and more people in recent years telling/asking me:
to summarize the chapter for them because they didn't understand it
to clarify very simple plot points
to clarify plot points that span multiple chapters
proudly admitting to skimming my works
proudly admitting to skimming my stories because they had "too much detail"
skimming because there was no romance subplot
skimming, skimming, skimming. (Look, if a story just isn't grabbing your attention and you feel compelled to skim it, that's fine. But for the love of god don't tell an author that you did that? It's so fucking rude?? I feel like it was common ettiequte a few years ago to just not say this sort of thing but nowadays I'm getting comments about skimming almost every month)
praising me for interesting writing descriptions which they "don't usually read"... which like... that's all a book is. a series of descriptions of characters, conversations, settings, etc. what are you even saying to me at this point
asking me when an event in the story happened, either in the very chapter that the event happens in or shortly thereafter (probably because they skimmed)
wanting zero ambiguity in the story by asking me to clarify exactly what I meant when I wrote X, or what I meant when I had a character say Y, etc. Even if the purpose of said ambiguity was to enhance the plot or build intrigue. Or god forbid, spark the imagination.
ignoring whatever I say in any of my author's notes, even if I leave a lengthy note or multiple notes, for the sake of begging/pestering/demanding another chapter, another sequel, or what have you. They just want more, more, more. (again, this has always been a thing in fandoms. I've been writing fics for almost 10 years now and I'm mostly used to ignoring it by now. But I feel like people are far less shy nowadays about ignoring an author's wishes just in the off chance that bothering us will give them more content to consume)
Overall, it's just extremely sad to me that a growing faction of people in fandoms simply want to be spoon-fed every last drop of the material they encounter. They do not want ambiguity, uncertainty, complexity, unhappy endings/emotions, wait times, or to put effort into engaging with their fellow-fandom goers. They seemingly want everything chatgpt-ified for them.
I have no statistical data to back up this theory but I just have to assume this is mostly coming from kids or prior-normies who are just now entering fandom spaces and only know how to treat us as commodities, not a community.
So all I can say to that is: I'm still going to take my time writing weird, unusual, or even unhappy stories because they fill me with joy and I know no matter what I write or how fandoms change over time, there'll always be other people who will enjoy my stories too!
#personal#rambling#fandom culture#thanks for coming to the TED talk i just really needed to get this off my chest#long story short: if you have a habit of skimming peoples fic just don't make it obvious#at least try to be a polite fandom goer
18 notes
·
View notes
Text
To bring about its hypothetical future, OpenAI must build a new digital ecosystem, pushing users toward the ChatGPT app or toward preëxisting products that integrate its technology such as Bing, the search engine run by OpenAI’s major investor, Microsoft. Google, by contrast, already controls the technology that undergirds many of our online experiences, from search and e-mail to Android smartphone-operating systems. At its conference, the company showed how it plans to make A.I. central to all of the above. Some Google searches now yield A.I.-generated “Overview” summaries, which appear in tinted boxes above any links to external Web sites. Liz Reid, Google’s head of search, described the generated results with the ominously tautological tagline “Google will do the Googling for you.” (The company envisions that you will rely on the same search mechanism to trawl your own digital archive, using its Gemini assistant to, say, pull up photos of your child swimming over the years or summarize e-mail threads in your in-box.) Nilay Patel, the editor-in-chief of the tech publication the Verge, has been using the phrase “Google Zero” to describe the point at which Google will stop driving any traffic to external Web sites and answer every query on its own with A.I. The recent presentations made clear that such a point is rapidly approaching. One of Google’s demonstrations showed a user asking the A.I. a question about a YouTube video on pickleball: “What is the two-bounce rule?” The A.I. then extracted the answer from the footage and displayed the answer in writing, thus allowing the user to avoid watching either the video or any advertising that would have provided revenue to its creator. When I Google “how to decorate a bathroom with no windows” (my personal litmus test for A.I. creativity), I am now presented with an Overview that looks a lot like an authoritative blog post, theoretically obviating my need to interact directly with any content authored by a human being. Google Search was once seen as the best path for getting to what’s on the Web. Now, ironically, its goal is to avoid sending us anywhere. The only way to use the search function without seeing A.I.-generated content is to click a small “More” tab and select “Web” search. Then Google will do what it was always supposed to do: crawl the Internet looking for URLs that are relevant to your queries, and then display them to you. The Internet is still out there, it’s just increasingly hard to find. If A.I. is to be our primary guide to the world’s information, if it is to be our 24/7 assistant-librarian-companion as the tech companies propose, then it must constantly be adding new information to its data sets. That information cannot be generated by A.I., because A.I. tools are not capable of even one iota of original thought or analysis, nor can they report live from the field. (An information model that is continuously updated, using human labor, to inform us about what’s going on right now—we might call it a newspaper.) For a decade or more, social media was a great way to motivate billions of human beings to constantly upload new information to the Internet. Users were driven by the possibilities of fame and profit and mundane connection. Many media companies were motivated by the possibility of selling digital ads, often with Google itself as a middle man. In the A.I. era, in which Google can simply digest a segment of your post or video and serve it up to a viewer, perhaps not even acknowledging you as the original author, those incentives for creating and sharing disappear. In other words, Google and OpenAI seem poised to cause the erosion of the very ecosystem their tools depend on.
48 notes
·
View notes
Text
study advice (just for fun)
Use your resources: online videos, past papers, marking schemes, ebooks, textbooks take your pick
For Muslims: study after fajr and schedule around prayers. (Also start with rabbi zidni ilma)
Summary sheets: summarize each topic on one piece of paper I like doing this for geography
Formula sheets: make a list of all the formulas you use in math, physics and other calculation based subjects and keep it with you when you study (it's a life saver)
Erasable pens are amazing for note taking especially for diagrams
Use mnemonics when you can and other memory devices. If you can't come up with one ask chat gpt for it
On the same note use chatgpt to simplify your notes and make the content more fun
Keep a mistakes notebook or Google document for all questions you do wrong. For each mistake write it down with corrections this helps identify weak spots in learning
After each test ask your teacher for feedback and corrections then redo all your mistakes. Jot down the errors in mistake document/notebook
#study tips#studyblr#high school studyblr#study method#study blog#study challenge#study motivation#high school tips#school tips
11 notes
·
View notes
Text
Dinkclump Linkdump

I'm on tour with my new novel The Bezzle! Catch me TONIGHT in LA (Saturday night, with Adam Conover), Seattle (Monday, with Neal Stephenson), then Portland, Phoenix and more!

Some Saturday mornings, I look at the week's blogging and realize I have a lot more links saved up than I managed to write about this week, and then I do a linkdump. There've been 14 of these, and this is number 15:
https://pluralistic.net/tag/linkdump/
Attentive readers will note that this isn't Saturday. You're right. But I'm on a book tour and every day is shatterday, because damn, it's grueling and I'm not the spry manchild who took Little Brother on the road in 2008 – I'm a 52 year old with two artificial hips. Hence: an out-of-cycle linkdump. Come see me on tour and marvel at my verticality!
https://pluralistic.net/2024/02/16/narrative-capitalism/#bezzle-tour
Best thing I read this week, hands down, was Ryan Broderick's Garbage Day piece, "AI search is a doomsday cult":
https://www.garbageday.email/p/ai-search-doomsday-cult
Broderick makes so many excellent points in this piece. First among them: AI search sucks, but that's OK, because no one is asking for AI search. This only got more true later in the week when everyone's favorite spicy autocomplete accidentally loaded the James Joyce module:
https://arstechnica.com/information-technology/2024/02/chatgpt-alarms-users-by-spitting-out-shakespearean-nonsense-and-rambling/
(As Matt Webb noted, Chatbots have slid rapidly from Star Trek (computers give you useful information in a timely fashion) to Douglas Adams (computers spout hostile, impenetrable nonsense at you):
https://interconnected.org/home/2024/02/21/adams
But beyond the unsuitability of AI for search results and beyond the public's yawning indifference to AI-infused search, Broderick makes a more important point: AI search is about summarizing web results so you don't have to click links and read the pages yourself.
If that's the future of the web, who the fuck is going to write those pages that the summarizer summarizes? What is the incentive, the business-model, the rational explanation for predicting a world in which millions of us go on writing web-pages, when the gatekeepers to the web have promised to rig the game so that no one will ever visit those pages, or read what we've written there, or even know it was us who wrote the underlying material the summarizer just summarized?
If we stop writing the web, AIs will have to summarize each other, forming an inhuman centipede of botshit-ingestion. This is bad news, because there's pretty solid mathematical evidence that training a bot on botshit makes it absolutely useless. Or, as the authors of the paper – including the eminent cryptographer Ross Anderson – put it, "using model-generated content in training causes irreversible defects":
https://arxiv.org/abs/2305.17493
This is the mathematical evidence for Jathan Sadowski's "Hapsburg AI," or, as the mathematicians call it, "The Curse of Recursion" (new band-name just dropped).

But if you really have your heart set on living in a ruined dystopia dominated by hostile artificial life-forms, have no fear. As Hamilton Nolan writes in "Radical Capital," a rogues gallery of worker-maiming corporations have asked a court to rule that the NLRB can't punish them for violating labor law:
https://www.hamiltonnolan.com/p/radical-capital
Trader Joe’s, Amazon, Starbucks and SpaceX have all made this argument to various courts. If they prevail, then there will be no one in charge of enforcing federal labor law. Yes, this will let these companies go on ruining their workers' lives, but more importantly, it will give carte blanche to every other employer in the land. At one end of this process is a boss who doesn't want to recognize a union – and at the other end are farmers dying of heat-stroke.
The right wing coalition that has put this demand before the court has all sorts of demands, from forced birth to (I kid you not), the end of recreational sex:
https://www.lawyersgunsmoneyblog.com/2024/02/getting-rid-of-birth-control-is-a-key-gop-agenda-item-for-the-second-trump-term
That coalition is backed by ultra-rich monopolists who want wreck the nation that their rank-and-file useful idiots want to wreck your body. These are the monopoly cheerleaders who gave us the abomination that is the Pharmacy Benefit Manager – a useless intermediary that gets to screw patients and pharmacists – and then let PBMs consolidate and merge with pharmacy monopolists.
One such inbred colossus is Change Healthcare, a giant PBM that is, in turn, a mere tendril of United Healthcare, which merged the company with Optum. The resulting system – held together with spit and wishful thinking – has access to the health records of a third of Americans and processes 15 billion prescriptions per day.
Or rather, it did process that amount – until the all-your-eggs-in-one-badly-maintained basket strategy failed on Wednesday, and Change's systems went down due to an unspecified "cybersecurity incident." In the short term, this meant that tens of millions of Americans who tried to refill their prescriptions were told to either pay cash or come back later (if you don't die first). That was the first shoe dropping. The second shoe is the medical records of a third of the country.
Don't worry, I'm sure those records are fine. After all, nothing says security like "merging several disparate legacy IT systems together while simultaneously laying off half your IT staff as surplus to requirements and an impediment to extracting a special dividend for the private equity owners who are, of course, widely recognized as the world's greatest information security practitioners."
Look, not everything is terrible. Some computers are actually getting better. Framework's user-serviceable, super-rugged, easy-to-repair, powerful laptops are the most exciting computers I've ever owned – or broken:
https://pluralistic.net/2022/11/13/graceful-failure/#frame
Now you can get one for $500!
https://frame.work/blog/first-framework-laptop-16-shipments-and-a-499-framework
And the next generation is turning our surprisingly well, despite all our worst efforts. My kid – now 16! – and I just launched our latest joint project, "The Sushi Chronicles," a small website recording our idiosyncratic scores for nearly every sushi restaurant in Burbank, Glendale, Studio City and North Hollywood:
https://sushichronicles.org/
This is the record of two years' worth of Daughter-Daddy sushi nights that started as a way to get my picky eater to try new things and has turned into the highlight of my week. If you're in the area and looking for a nice piece of fish, give it a spin (also, we belatedly realized that we've never reviewed our favorite place, Kuru Kuru in the CVS Plaza on North Hollywood Way – we'll be rectifying that soon).
And yes, we have a lavishly corrupt Supreme Court, but at least now everyone knows it. Glenn Haumann's even set up a Gofundme to raise money to bribe Clarence Thomas (now deleted, alas):
https://www.gofundme.com/f/pzhj4q-the-clarence-thomas-signing-bonus-fund-give-now
The funds are intended as a "signing bonus" in the event that Thomas takes up John Oliver on his offer of a $2.4m luxury RV and $1m/year for life if he'll resign from the court:
https://www.youtube.com/watch?v=GE-VJrdHMug
This is truly one of Oliver's greatest bits, showcasing his mastery over the increasingly vital art of turning abstruse technical issues into entertainment that negates the performative complexity used by today's greatest villains to hide their misdeeds behind a Shield of Boringness (h/t Dana Clare).
The Bezzle is my contribution to turning abstruse scams into a high-impact technothriller that pierces that Shield of Boringness. The key to this is to master exposition, ignoring the (vastly overrated) rule that one must "show, not tell." Good exposition is hard to do, but when it works, it's amazing (as anyone who's read Neal Stephenson's 1,600-word explanation of how to eat Cap'n Crunch cereal in Cryptonomicon can attest). I wrote about this for Mary Robinette Kowal's "My Favorite Bit" this week:
https://maryrobinettekowal.com/journal/my-favorite-bit/my-favorite-bit-cory-doctorow-talks-about-the-bezzle/
Of course, an undisputed master of this form is Adam Conover, whose Adam Ruins Everything show helped invent it. Adam is joining me on stage in LA tomorrow night at Vroman's at 5:30PM, to host me in a book-tour event for my novel The Bezzle:
https://www.vromansbookstore.com/Cory-Doctorow-discusses-The-Bezzle
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/02/23/gazeteer/#out-of-cycle
Image: Peter Craven (modified) https://commons.wikimedia.org/wiki/File:Aggregate_output_%287637833962%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#the bezzle#ryan broderick#mary robinette kowal#exposition#john oliver#margot robbie#adam conover#ai#ai search#change healthcare#centralization#pharma#pbms#pharmacy benefit managers#corruption#scotus#crowdfunding#clarence thomas
39 notes
·
View notes
Text
Check-in for 01/28/24
It's been a while since I did one of these. Time to remedy that!
I've been doing well in my assignments, but due to some registration issues at the start of the semester I was unable to sign up for any web development or programming classes :< It's nice to take a break, but I'm really worried about getting stagnant in those skills, and maybe even losing what I've learned over time.
This is where a couple of new projects come in: A blorbo database and a tool for drawing pokemon from memory. These things are going to keep me avoid stagnancy and help me develop my web dev and Python programming skills, and I'm real excited to talk about them.

First up, let's talk about that tool for drawing pokemon from memory. I love drawing pokemon from memory, but it's a bit of a struggle to find tools online that work well for a solo experience when you're doing this challenge alone. So I made a program in PyGame to solve this problem, and I've actually already completed it! It was a great learning experience when it came to getting a taste of APIs, and PokeAPI really helped me do all the heavy lifting with it. I also ended up using ChatGPT to help me understand how to phrase my questions and the things I needed to research. This is the end result:

If you click "Get Random Pokemon", the program will provide a pokemon's name. The point of it is to draw the pokemon as best as you remember it, and then click "Show Pokemon Image" to see how you did. You will then have the option to get a new random pokemon, which clears the image from the window.
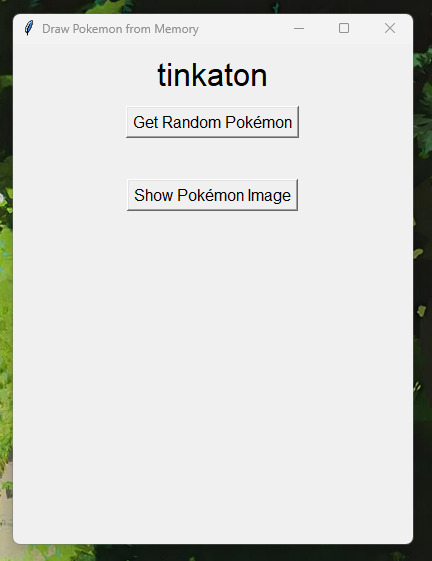

There's a lot of stuff I don't understand about how the program works--- APIs evade my understanding, and Tkinter is a dark art beyond my comprehension. But I was able to make a program that solved a genuine problem for me for the first time, and that's super exciting to me!
Now, for web development--- long story short, I'm making a website dedicated to cataloguing my OCs that's very much inspired by tumblr user @snekkerdoodles's personal site on neocities, which I regularly stare at in an effort to motivate myself to make cool things like it (everyone reading this should check his page out IMMEDIATELY and tell him how cool it is). Here's the screenshots of the WIP I'm chipping away at right now:

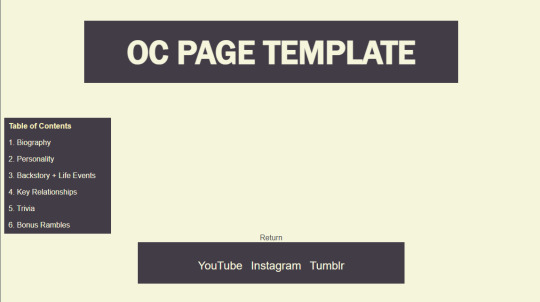
I don't have much to say about it, as the interesting stuff will really be the content of the pages, and I still have yet to finish the template page I'll be filling with my OCs' information. However, I can say that I'm very upset with the lack of proper teaching that took place in the first (and currently only) college web dev class I've taken. I spent an entire semester doing my own research to learn everything they were supposed to be teaching us. I'm still very peeved about that.
To summarize this very rambling post I'm too sleepy to edit properly, I'm making a digital blorbo encyclopedia, and I finished making a little desktop app thingy, which means I need to summon a new programming project. I'm tempted to make it a video game... maybe I should turn back to that visual novel idea I had ages ago and boot up RenPy!
#let me know if you'd prefer I untag you!#I'm still so uncertain of tagging etiquette on Tumblr#stuff by sofie#sofie checks in#web developers#web development#web dev#programming#coding#codeblr#python#software development#app development#pygame
32 notes
·
View notes
Note
Hey, I love your writeups for the ChatGPT case! There's one thing that's kind of confusing me though. You (and the judge) seem to be saying that the good faith argument makes sense for the March 1st opposition but not the April 25th affidavit. I'm not a lawyer, but the more I think about it the more I feel like the other way around makes more sense.
Regarding not reading the cases: if I was looking for a book, even because someone said it doesn't exist, and I found a book that had the right title, author, and cover, and wasn't obviously a fake book (like, no words on the pages, or something), I think I'd be convinced. If I'm supposed to think it could be a forgery, I don't know how I could tell by reading it. How hard is it to write a fake opinion that looks real? What tells would you look for? And why would anyone write one? It seems to me like the only thing that reading the cases would prove is whether or not it was generated by a bleeding-edge large language model. (This is setting aside all the warnings they had to ignore that ChatGPT specifically isn't a reliable source. And the fact that they didn't even annex the "entire opinions" they were ordered to. And that they didn't even seem to realize that they were being accused of citing bogus cases. And that they should have read the cases anyway, possible fakery or not. And the way they tried to downplay it afterwards. God, there is so much stupid in this case. "The ChatGPT lawyer" really doesn't do it justice.)
The opposition seems less defensible. Schwartz didn't just find and submit documents, he submitted assertions about the contents of cases without reading said contents. Why would you use a "search engine" to write your arguments for you? That's your job. How can you claim in good faith that precedents you didn't read are in favour of your position? Even if ChatGPT really was incapable of making up cases, if they'd found all the cases on Google Scholar and annexed them, they could still be in deep shit, right? They could be sanctioned if they misrepresented the contents, or at least lose the case if the interpretations are dubious. Not to mention the legal argument about state law in a federal case - that's something I would expect a lawyer to know to check for.
Am I missing something? You've anticipated all the judge's points and it's probably me who's wrong here. Just trying to understand.
Hi! Thank you for the question. I think I understand your confusion, and I am going to try to clear it up - let me know if this makes sense.
The difference comes down to the idea that when he submitted the opposition, he was doing very poor work and was not acting reasonably. However, when he submitted the fake cases, he was knowingly lying to the court.
For example: for my job, I use secondary sources that other people have written to explain the current state of the law. Those secondary sources refer to, cite, and summarize various cases. When I use a secondary source, I don't rely on the source - I use it as a jumping off point to look up the cases myself and do additional legal research. But, based on my experience, I expect the summaries of cases in good secondary sources to be more-or-less accurate.
Now, that doesn't mean it is okay for someone to submit a legal brief based solely off the summaries in a secondary source - as you say, you can't know for sure the summaries or correct (and "more-or less" leaves a lot of wiggle room). And there is a lot of potentially relevant information that is left out of the summaries. And even if they are correct, you don't know if they are still good law - they may be out of date.
But "being a bad lawyer" is not sanctionable misconduct. Especially because with sua sponte sanctions, the question isn't whether Schwartz was reasonable (he wasn't), but if he was acting in subjective bad faith, which in this case means essentially that he was knowingly lying to the court.
If he, as he says, genuinely thought the cases he was citing in the opposition were real cases and the bot was accurately summarizing their contents, he was not knowingly lying to the court. He was doing terrible work, but again, being a terrible lawyer is not sanctionable misconduct.
But - and here is where maybe I think the confusion is coming in? - when he submitted the fake opinions, he was making an assertion to the court about the contents of the cases. He was telling the court, "these judges wrote these specific things in these specific cases." (And in terms how hard is it to write a fake opinion that looks real - those cases did not look real. Anyone with any legal training, even just glancing at them, would realize something seemed wrong.)
It was unreasonable for him to cite the cases without reading them in his opposition, but at that point, he can at least try to argue that he had reason to believe the citations and summaries were accurate. Once he was put on notice, continuing to "assume the cases were real" without checking and reading them was no longer plausibly good faith.
And to return to your analogy - he didn't just "find a book" that had the right title and author and so on. He went back to the same source that had given him the titles, and asked it to provide him the full text of the book.
For an analogy: Imagine you are writing a research paper. It would be like if you were emailing a friend looking for a published scientific article to support your research, and they gave you a citation and a summary of the article, and you relied on that article in your paper. That would be unreasonable, but you could honestly say you thought your friend was being honest in providing you information. But now image a bunch of reviewers came back to you and said, "hey this article might be fake, we can't find it." And so you went back to your friend and said, "hey, can you give me that article?" And then they sent you an email back that said, sure! And they sent you about a thousand words in the body of the email. And those thousand words were complete nonsense, where in the beginning it says this was a study on the evolution of bacteria and in the conclusion it was talking about the behavior of the two sample groups of primates. In that case, if you printed out those thousand words and gave it to the reviewers and said, yep, look, the article is totally real, here is the text of the article, the reviewers could reasonable conclude that you were intentionally lying to them.
That was a lot of text, but I hope it helped!
92 notes
·
View notes
Text
Week 3 Blog 9/12
How do algorithms correlate to anti-black racism?
As discussed in Nicole Brown’s “Race and Technology” Youtube video, predictive policing technology has been used in the past decade to create strategic “hit-lists” to predict who would be most likely to commit or be involved with violent crimes in the area. These innocent civilians and children with no criminal past were on high surveillance in real life, as well as their data. Anything put into their algorithms would count as incriminating evidence. Sociologist Simone Brown’s book “Dark Matters” is briefly summarized through the video. It is noteworthy to acknowledge the racial and Black surveillance themes. As technologies continue to use bias and objectification against Black communities society must create and advocate for safe and inclusive spaces within the virtual world.
How has social media proven to encourage social justice and hate at the same time?
What immediately comes to my head is the BLM movement during 2020. After the unjust arrest and murder of George Floyd, uprisings in Black communities led to protests being broadcasted. With every scroll through social media and flip through news channels we were seemingly seeing the same content with different headlines and reactions. If we circle back, the death of George Floyd itself was unfortunately a trending topic with everyone’s biased opinions rather than a call of action for an act of abuse of power. Things such as his past criminal record were brought up through the media to justify what had happened to him, others used plain excuses such as his race. The Black Lives Matter movement had already gained traction years prior due to another murder of a young Black man. Black communities weren’t feeling heard or supported and the BLM movement was once again brought to headlines to advocate for Black voices and consequences to the police force. Now as this progressed and protests made way, lootings, attacks on protests, and curfews were put into place in many areas across the country. Depending on your algorithm you probably saw an array of discourse about the matter, so much so that it had taken away from the point of what was being advocated for in the first place. WIth the freedom of speech we have the right to voice our opinions on these heavy topics surrounding social justice, but society should practice proper and respectful netiquette so we use our voices with purpose.
How much does the healthcare system really depend on technology and how are people of color affected by this?
As society progresses, so do the systems within such as healthcare. Hospitals are actually quite dependent on technology as it is now considered an essential. Some technological advancements used in the healthcare system include data and analytics, diagnostic tools, telemedicine, and electronic health records. All sounds great so how would these pose as issues to people of color? With Electronic Health Records, hospitals are able to transfer patient data for improved treatment and coordination but when it comes to patients in areas with limited digital resources they are left with outdated medical treatment. “Racial bias in a medical algorithm favors white patients over sicker black patients” headlines The Washington Post as seen on Nicole Brown’s “Race and Technology” Youtube video. So yes, the use of data, algorithms, and technology has been proven to create a progressive era for healthcare and its patients, but we as a society must be aware of how this affects minority communities due to embedded bias and properly advocate for change.
Is AI ruining the future of students?
As students are distanced from pencils and paper and moved onto digital spaces, there is a lack of creativity and critical thinking within the entire generation of students. Students are able to use Grammarly and ChatGPT to write papers. Students are able to use Photomath and Mathway to complete math problems. Students are limited to a keyboard and screen for discussions and are missing raw interactions and conversations. This is a danger to the future workforce as many students are cheating their way through schooling and depending on hands on experience without book knowledge and human networking. Many are afraid of AI becoming the future of everything and that can only happen if we continue this co-dependent relationship with it.
https://www.youtube.com/watch?v=d8uiAjigKy8
Automating Inequality Intro (Eubanks)
Rethinking Cyberfeminism (Daniels
10 notes
·
View notes
Text
A new lawsuit brought against the startup Perplexity argues that, in addition to violating copyright law, it’s breaking trademark law by making up fake sections of news stories and falsely attributing the words to publishers.
Dow Jones (publisher of The Wall Street Journal) and the New York Post—both owned by Rupert Murdoch’s News Corp—brought the copyright infringement lawsuit against Perplexity today in the US Southern District of New York.
This is not the first time Perplexity has run afoul of news publishers; earlier this month, The New York Times sent the company a cease-and-desist letter stating that it was using the newspaper behemoth’s content without permission. This summer, both Forbes and WIRED detailed how Perplexity appeared to have plagiarized stories. Both Forbes and WIRED parent company Condé Nast sent the company cease-and-desist letters in response.
A WIRED investigation from this summer, cited in this lawsuit, detailed how Perplexity inaccurately summarized WIRED stories, including one instance in which it falsely claimed that WIRED had reported on a California-based police officer committing a crime he did not commit. The WSJ reported earlier today that Perplexity is seeking to raise $500 million is its next funding round, at an $8 billion valuation.
Dow Jones and the New York Post provide examples of Perplexity allegedly “hallucinating” fake sections of news stories. In AI terms, hallucination is when generative models produce false or wholly fabricated material and present it as fact.
In one case cited, Perplexity Pro first regurgitated, word for word, two paragraphs from a New York Post story about US senator Jim Jordan sparring with European Union commissioner Thierry Breton over Elon Musk and X, but then followed them up with five generated paragraphs about free speech and online regulation that were not in the real article.
The lawsuit claims that mixing in these made-up paragraphs with real reporting and attributing it to the Post is trademark dilution that potentially confuses readers. “Perplexity’s hallucinations, passed off as authentic news and news-related content from reliable sources (using Plaintiffs’ trademarks), damage the value of Plaintiffs’ trademarks by injecting uncertainty and distrust into the newsgathering and publishing process, while also causing harm to the news-consuming public,” the complaint states.
Perplexity did not respond to requests for comment.
In a statement emailed to WIRED, News Corp chief executive Robert Thomson compared Perplexity unfavorably to OpenAI. “We applaud principled companies like OpenAI, which understands that integrity and creativity are essential if we are to realize the potential of Artificial Intelligence,” the statement says. “Perplexity is not the only AI company abusing intellectual property and it is not the only AI company that we will pursue with vigor and rigor. We have made clear that we would rather woo than sue, but, for the sake of our journalists, our writers and our company, we must challenge the content kleptocracy.”
OpenAI is facing its own accusations of trademark dilution, though. In New York Times v. OpenAI, the Times alleges that ChatGPT and Bing Chat will attribute made-up quotes to the Times, and accuses OpenAI and Microsoft of damaging its reputation through trademark dilution. In one example cited in the lawsuit, the Times alleges that Bing Chat claimed that the Times called red wine (in moderation) a “heart-healthy” food, when in fact it did not; the Times argues that its actual reporting has debunked claims about the healthfulness of moderate drinking.
“Copying news articles to operate substitutive, commercial generative AI products is unlawful, as we made clear in our letters to Perplexity and our litigation against Microsoft and OpenAI,” says NYT director of external communications Charlie Stadtlander. “We applaud this lawsuit from Dow Jones and the New York Post, which is an important step toward ensuring that publisher content is protected from this kind of misappropriation.”
If publishers prevail in arguing that hallucinations can violate trademark law, AI companies could face “immense difficulties” according to Matthew Sag, a professor of law and artificial intelligence at Emory University.
“It is absolutely impossible to guarantee that a language model will not hallucinate,” Sag says. In his view, the way language models operate by predicting words that sound correct in response to prompts is always a type of hallucination—sometimes it’s just more plausible-sounding than others.
“We only call it a hallucination if it doesn't match up with our reality, but the process is exactly the same whether we like the output or not.”
12 notes
·
View notes
Text
Free AI Tools
Artificial Intelligence (AI) has revolutionized the way we work, learn, and create. With an ever-growing number of tools, it’s now easier than ever to integrate AI into your personal and professional life without spending a dime. Below, we’ll explore some of the best free AI tools across various categories, helping you boost productivity, enhance creativity, and automate mundane tasks.
Wanna know about free ai tools
1. Content Creation Tools
ChatGPT (OpenAI)
One of the most popular AI chatbots, ChatGPT, offers a free plan that allows users to generate ideas, write content, answer questions, and more. Its user-friendly interface makes it accessible for beginners and professionals alike.
Best For:
Writing articles, emails, and brainstorming ideas.
Limitations:
Free tier usage is capped; may require upgrading for heavy use.
Copy.ai
Copy.ai focuses on helping users craft engaging marketing copy, blog posts, and social media captions.
2. Image Generation Tools
DALL·EOpenAI’s DALL·E can generate stunning, AI-created artwork from text prompts. The free tier allows users to explore creative possibilities, from surreal art to photo-realistic images.
Craiyon (formerly DALL·E Mini)This free AI image generator is great for creating quick, fun illustrations. It’s entirely free but may not match the quality of professional tools.
3. Video Editing and Creation
Runway MLRunway ML offers free tools for video editing, including AI-based background removal, video enhancement, and even text-to-video capabilities.
Pictory.aiTurn scripts or blog posts into short, engaging videos with this free AI-powered tool. Pictory automates video creation, saving time for marketers and educators.
4. Productivity Tools
Notion AINotion's AI integration enhances the already powerful productivity app. It can help generate meeting notes, summarize documents, or draft content directly within your workspace.
Otter.aiOtter.ai is a fantastic tool for transcribing meetings, interviews, or lectures. It offers a free plan that covers up to 300 minutes of transcription monthly.
5. Coding and Data Analysis
GitHub Copilot (Free for Students)GitHub Copilot, powered by OpenAI, assists developers by suggesting code and speeding up development workflows. It’s free for students with GitHub’s education pack.
Google ColabGoogle’s free cloud-based platform for coding supports Python and is perfect for data science projects and machine learning experimentation.
6. Design and Presentation
Canva AICanva’s free tier includes AI-powered tools like Magic Resize and text-to-image generation, making it a top choice for creating professional presentations and graphics.
Beautiful.aiThis AI presentation tool helps users create visually appealing slides effortlessly, ideal for professionals preparing pitch decks or educational slides.
7. AI for Learning
Duolingo AIDuolingo now integrates AI to provide personalized feedback and adaptive lessons for language learners.
Khanmigo (from Khan Academy)This AI-powered tutor helps students with math problems and concepts in an interactive way. While still in limited rollout, it’s free for Khan Academy users.
Why Use Free AI Tools?
Free AI tools are perfect for testing the waters without financial commitments. They’re particularly valuable for:
Conclusion
AI tools are democratizing access to technology, allowing anyone to leverage advanced capabilities at no cost. Whether you’re a writer, designer, developer, or educator, there’s a free AI tool out there for you. Start experimenting today and unlock new possibilities!
4o
5 notes
·
View notes
Text
"Lyotard emphasizes that the 'goal' of knowledge has ceased to be the revelation of truth or the realization of human possibility and instead has become the optimizing of performance. Accordingly, he adapts the linguistic concept of performativity."
— Dependent Participation: Bruce Nauman's Environments by Janet Kraynak (2003)
While reading the article cited above, I happened upon this quote, which describes with uncanny accuracy the reality of contemporary society. Lyotard first shared his predictions about the postmodern condition over forty years ago, but they ring ever more true with each passing moment. Thinking back to the Renaissance, Industrial Revolution, and similar periods of innovation in human history, the goal of knowledge was indeed to reveal greater truths or push the boundaries of human possibility. Nowadays, though, the commodification of knowledge means that any efforts made towards improving it are with the intention of improving productivity. This becomes the new measure of "good" or even "legitimate" knowledge.
However, the proliferation of such a concept has harmful ramifications for society at large.
When we associate the value of knowledge with how profitable it can be as opposed to, as Lyotard wrote, its "use-value", it ceases to be a resource for individuals to control and instead a tool through which individuals can be controlled.
For example, in this age of social media gurus and pseudo-intellectuals, it is common to find people who use knowledge (or their lack of it) for the sake of garnering views and financial gains. Regardless of the validity of their claims, though, others will continue to consume their content as long as it is short and watered down enough that it requires virtually no thought to process. Content is no longer considered "good" for being informative and reliable, but instead is measured by its shareability and stimulating potential to make you feel satisfied without any actual benefit. In the end, the only ones who benefit are those who run the channels and, ultimately, the corporation behind the platform.
To me, though, the paramount technological structure that promotes performativity in knowledge today is generative AI. The very existence of generative AI means that a person need not possess any knowledge to access its benefits. Platforms such as ChatGPT, Midjourney, Claude, and Copilot allow users to create text and images with a single prompt, sometimes already available from a list of possible options. Great feats are made with the least possible effort—all facilitated by the latest technology, so it must be "good."
Except, the content these AI frameworks generate are not all accurate or even sourced appropriately, such as in the case of AI trained on stolen images. This is where Lyotard's language games come into play. The language, both visual and textual, that AI robots use is very authoritative yet simple, making the content produced appealing to the average unknowing user. It seems like it is accurate, so it probably is, and it can be read in minutes. This is why I get concerned when family friends tell me they now use ChatGPT instead of Google to do research because it summarizes well and reduces the need for endless searching. After all, it is easier to read a short paragraph than engage a 30-page article a grad student probably wrote on their last straw.
It's not that I believe generative AI or any technology favoring the performance of knowledge have no place in society, but, as they are used now, they discourage the pursuit of knowledge for its individual value and wither creativity and resourcefulness to give way to social conformity.
The less we think, the less likely we will be to question the system.
Still, the reality is that technology is a part of our world and we are forced to take part in its performance, even when it seems we have the option to opt out. The solution then, just as Lyotard suggests, is to find the balance between increased use of technology and the possibility of individual resistance. What that looks like, however, is still unknown.
/////

Raussmüller Hallen, Basel with Bruce Nauman, Floating Room: Lit from Inside, 1972. © Bruce Nauman / 2018, ProLitteris, Zurich. Photo: Jürgen Buchinger, © Raussmüller.
/////
QUESTION:
How do we create the possibility of freedom and resistance in a technological world with illusory choice without resorting to nostalgia?
/////
2 notes
·
View notes
Text
OpenAI’s 12 Days of “Shipmas”: Summary and Reflections
Over 12 days, from December 5 to December 16, OpenAI hosted its “12 Days of Shipmas” event, revealing a series of innovations and updates across its AI ecosystem. Here’s a summary of the key announcements and their implications:
Day 1: Full Launch of o1 Model and ChatGPT Pro
OpenAI officially launched the o1 model in its full version, offering significant improvements in accuracy (34% fewer errors) and performance. The introduction of ChatGPT Pro, priced at $200/month, gives users access to these advanced features without usage caps.
Commentary: The Pro tier targets professionals who rely heavily on AI for business-critical tasks, though the price point might limit access for smaller enterprises.
Day 2: Reinforced Fine-Tuning
OpenAI showcased its reinforced fine-tuning technique, leveraging user feedback to improve model precision. This approach promises enhanced adaptability to specific user needs.
Day 3: Sora - Text-to-Video
Sora, OpenAI’s text-to-video generator, debuted as a tool for creators. Users can input textual descriptions to generate videos, opening new doors in multimedia content production.
Commentary: While innovative, Sora’s real-world application hinges on its ability to handle complex scenes effectively.
Day 4: Canvas - Enhanced Writing and Coding Tool
Canvas emerged as an all-in-one environment for coding and content creation, offering superior editing and code-generation capabilities.
Day 5: Deep Integration with Apple Ecosystem
OpenAI announced seamless integration with Apple’s ecosystem, enhancing accessibility and user experience for iOS/macOS users.
Day 6: Improved Voice and Vision Features
Enhanced voice recognition and visual processing capabilities were unveiled, making AI interactions more intuitive and efficient.
Day 7: Projects Feature
The new ���Projects” feature allows users to manage AI-powered initiatives collaboratively, streamlining workflows.
Day 8: ChatGPT with Built-in Search
Search functionality within ChatGPT enables real-time access to the latest web information, enriching its knowledge base.
Day 9: Voice Calling with ChatGPT
Voice capabilities now allow users to interact with ChatGPT via phone, providing a conversational edge to AI usage.
Day 10: WhatsApp Integration
ChatGPT’s integration with WhatsApp broadens its accessibility, making AI assistance readily available on one of the most popular messaging platforms.
Day 11: Release of o3 Model
OpenAI launched the o3 model, featuring groundbreaking reasoning capabilities. It excels in areas such as mathematics, coding, and physics, sometimes outperforming human experts.
Commentary: This leap in reasoning could redefine problem-solving across industries, though ethical and operational concerns about dependency on AI remain.
Day 12: Wrap-Up and Future Vision
The final day summarized achievements and hinted at OpenAI’s roadmap, emphasizing the dual goals of refining user experience and expanding market reach.
Reflections
OpenAI’s 12-day spree showcased impressive advancements, from multimodal AI capabilities to practical integrations. However, challenges remain. High subscription costs and potential data privacy concerns could limit adoption, especially among individual users and smaller businesses.
Additionally, as the competition in AI shifts from technical superiority to holistic user experience and ecosystem integration, OpenAI must navigate a crowded field where user satisfaction and practical usability are critical for sustained growth.
Final Thoughts: OpenAI has demonstrated its commitment to innovation, but the journey ahead will require balancing cutting-edge technology with user-centric strategies. The next phase will likely focus on scalability, affordability, and real-world problem-solving to maintain its leadership in AI.
What are your thoughts on OpenAI’s recent developments? Share in the comments!
3 notes
·
View notes