#Best Big Data Hadoop Training California
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Link
SysSigma - Get best big data hadoop tranining in USA with real time experts. Call at +1678-658-8626, [email protected]. Top Hadoop Training USA. Visit https://www.syssigma.com/Training/BigDataHadoop.aspx
#Best Big Data Hadoop Training USA#Best Big Data Hadoop Training#Best Big Data Hadoop Training California#Best Big Data Hadoop Training Texas
0 notes
Text
Important libraries for data science and Machine learning.
Python has more than 137,000 libraries which is help in various ways.In the data age where data is looks like the oil or electricity .In coming days companies are requires more skilled full data scientist , Machine Learning engineer, deep learning engineer, to avail insights by processing massive data sets.
Python libraries for different data science task:
Python Libraries for Data Collection
Beautiful Soup
Scrapy
Selenium
Python Libraries for Data Cleaning and Manipulation
Pandas
PyOD
NumPy
Spacy
Python Libraries for Data Visualization
Matplotlib
Seaborn
Bokeh
Python Libraries for Modeling
Scikit-learn
TensorFlow
PyTorch
Python Libraries for Model Interpretability
Lime
H2O
Python Libraries for Audio Processing
Librosa
Madmom
pyAudioAnalysis
Python Libraries for Image Processing
OpenCV-Python
Scikit-image
Pillow
Python Libraries for Database
Psycopg
SQLAlchemy
Python Libraries for Deployment
Flask
Django
Best Framework for Machine Learning:
1. Tensorflow :
If you are working or interested about Machine Learning, then you might have heard about this famous Open Source library known as Tensorflow. It was developed at Google by Brain Team. Almost all Google’s Applications use Tensorflow for Machine Learning. If you are using Google photos or Google voice search then indirectly you are using the models built using Tensorflow.
Tensorflow is just a computational framework for expressing algorithms involving large number of Tensor operations, since Neural networks can be expressed as computational graphs they can be implemented using Tensorflow as a series of operations on Tensors. Tensors are N-dimensional matrices which represents our Data.
2. Keras :
Keras is one of the coolest Machine learning library. If you are a beginner in Machine Learning then I suggest you to use Keras. It provides a easier way to express Neural networks. It also provides some of the utilities for processing datasets, compiling models, evaluating results, visualization of graphs and many more.
Keras internally uses either Tensorflow or Theano as backend. Some other pouplar neural network frameworks like CNTK can also be used. If you are using Tensorflow as backend then you can refer to the Tensorflow architecture diagram shown in Tensorflow section of this article. Keras is slow when compared to other libraries because it constructs a computational graph using the backend infrastructure and then uses it to perform operations. Keras models are portable (HDF5 models) and Keras provides many preprocessed datasets and pretrained models like Inception, SqueezeNet, Mnist, VGG, ResNet etc
3.Theano :
Theano is a computational framework for computing multidimensional arrays. Theano is similar to Tensorflow , but Theano is not as efficient as Tensorflow because of it’s inability to suit into production environments. Theano can be used on a prallel or distributed environments just like Tensorflow.
4.APACHE SPARK:
Spark is an open source cluster-computing framework originally developed at Berkeley’s lab and was initially released on 26th of May 2014, It is majorly written in Scala, Java, Python and R. though produced in Berkery’s lab at University of California it was later donated to Apache Software Foundation.
Spark core is basically the foundation for this project, This is complicated too, but instead of worrying about Numpy arrays it lets you work with its own Spark RDD data structures, which anyone in knowledge with big data would understand its uses. As a user, we could also work with Spark SQL data frames. With all these features it creates dense and sparks feature label vectors for you thus carrying away much complexity to feed to ML algorithms.
5. CAFFE:
Caffe is an open source framework under a BSD license. CAFFE(Convolutional Architecture for Fast Feature Embedding) is a deep learning tool which was developed by UC Berkeley, this framework is mainly written in CPP. It supports many different types of architectures for deep learning focusing mainly on image classification and segmentation. It supports almost all major schemes and is fully connected neural network designs, it offers GPU as well as CPU based acceleration as well like TensorFlow.
CAFFE is mainly used in the academic research projects and to design startups Prototypes. Even Yahoo has integrated caffe with Apache Spark to create CaffeOnSpark, another great deep learning framework.
6.PyTorch.
Torch is also a machine learning open source library, a proper scientific computing framework. Its makers brag it as easiest ML framework, though its complexity is relatively simple which comes from its scripting language interface from Lua programming language interface. There are just numbers(no int, short or double) in it which are not categorized further like in any other language. So its ease many operations and functions. Torch is used by Facebook AI Research Group, IBM, Yandex and the Idiap Research Institute, it has recently extended its use for Android and iOS.
7.Scikit-learn
Scikit-Learn is a very powerful free to use Python library for ML that is widely used in Building models. It is founded and built on foundations of many other libraries namely SciPy, Numpy and matplotlib, it is also one of the most efficient tool for statistical modeling techniques namely classification, regression, clustering.
Scikit-Learn comes with features like supervised & unsupervised learning algorithms and even cross-validation. Scikit-learn is largely written in Python, with some core algorithms written in Cython to achieve performance. Support vector machines are implemented by a Cython wrapper around LIBSVM.
Below is a list of frameworks for machine learning engineers:
Apache Singa is a general distributed deep learning platform for training big deep learning models over large datasets. It is designed with an intuitive programming model based on the layer abstraction. A variety of popular deep learning models are supported, namely feed-forward models including convolutional neural networks (CNN), energy models like restricted Boltzmann machine (RBM), and recurrent neural networks (RNN). Many built-in layers are provided for users.
Amazon Machine Learning is a service that makes it easy for developers of all skill levels to use machine learning technology. Amazon Machine Learning provides visualization tools and wizards that guide you through the process of creating machine learning (ML) models without having to learn complex ML algorithms and technology. It connects to data stored in Amazon S3, Redshift, or RDS, and can run binary classification, multiclass categorization, or regression on said data to create a model.
Azure ML Studio allows Microsoft Azure users to create and train models, then turn them into APIs that can be consumed by other services. Users get up to 10GB of storage per account for model data, although you can also connect your own Azure storage to the service for larger models. A wide range of algorithms are available, courtesy of both Microsoft and third parties. You don’t even need an account to try out the service; you can log in anonymously and use Azure ML Studio for up to eight hours.
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license. Models and optimization are defined by configuration without hard-coding & user can switch between CPU and GPU. Speed makes Caffe perfect for research experiments and industry deployment. Caffe can process over 60M images per day with a single NVIDIA K40 GPU.
H2O makes it possible for anyone to easily apply math and predictive analytics to solve today’s most challenging business problems. It intelligently combines unique features not currently found in other machine learning platforms including: Best of Breed Open Source Technology, Easy-to-use WebUI and Familiar Interfaces, Data Agnostic Support for all Common Database and File Types. With H2O, you can work with your existing languages and tools. Further, you can extend the platform seamlessly into your Hadoop environments.
Massive Online Analysis (MOA) is the most popular open source framework for data stream mining, with a very active growing community. It includes a collection of machine learning algorithms (classification, regression, clustering, outlier detection, concept drift detection and recommender systems) and tools for evaluation. Related to the WEKA project, MOA is also written in Java, while scaling to more demanding problems.
MLlib (Spark) is Apache Spark’s machine learning library. Its goal is to make practical machine learning scalable and easy. It consists of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as lower-level optimization primitives and higher-level pipeline APIs.
mlpack, a C++-based machine learning library originally rolled out in 2011 and designed for “scalability, speed, and ease-of-use,” according to the library’s creators. Implementing mlpack can be done through a cache of command-line executables for quick-and-dirty, “black box” operations, or with a C++ API for more sophisticated work. Mlpack provides these algorithms as simple command-line programs and C++ classes which can then be integrated into larger-scale machine learning solutions.
Pattern is a web mining module for the Python programming language. It has tools for data mining (Google, Twitter and Wikipedia API, a web crawler, a HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, clustering, SVM), network analysis and visualization.
Scikit-Learn leverages Python’s breadth by building on top of several existing Python packages — NumPy, SciPy, and matplotlib — for math and science work. The resulting libraries can be used either for interactive “workbench” applications or be embedded into other software and reused. The kit is available under a BSD license, so it’s fully open and reusable. Scikit-learn includes tools for many of the standard machine-learning tasks (such as clustering, classification, regression, etc.). And since scikit-learn is developed by a large community of developers and machine-learning experts, promising new techniques tend to be included in fairly short order.
Shogun is among the oldest, most venerable of machine learning libraries, Shogun was created in 1999 and written in C++, but isn’t limited to working in C++. Thanks to the SWIG library, Shogun can be used transparently in such languages and environments: as Java, Python, C#, Ruby, R, Lua, Octave, and Matlab. Shogun is designed for unified large-scale learning for a broad range of feature types and learning settings, like classification, regression, or explorative data analysis.
TensorFlow is an open source software library for numerical computation using data flow graphs. TensorFlow implements what are called data flow graphs, where batches of data (“tensors”) can be processed by a series of algorithms described by a graph. The movements of the data through the system are called “flows” — hence, the name. Graphs can be assembled with C++ or Python and can be processed on CPUs or GPUs.
Theano is a Python library that lets you to define, optimize, and evaluate mathematical expressions, especially ones with multi-dimensional arrays (numpy.ndarray). Using Theano it is possible to attain speeds rivaling hand-crafted C implementations for problems involving large amounts of data. It was written at the LISA lab to support rapid development of efficient machine learning algorithms. Theano is named after the Greek mathematician, who may have been Pythagoras’ wife. Theano is released under a BSD license.
Torch is a scientific computing framework with wide support for machine learning algorithms that puts GPUs first. It is easy to use and efficient, thanks to an easy and fast scripting language, LuaJIT, and an underlying C/CUDA implementation. The goal of Torch is to have maximum flexibility and speed in building your scientific algorithms while making the process extremely simple. Torch comes with a large ecosystem of community-driven packages in machine learning, computer vision, signal processing, parallel processing, image, video, audio and networking among others, and builds on top of the Lua community.
Veles is a distributed platform for deep-learning applications, and it’s written in C++, although it uses Python to perform automation and coordination between nodes. Datasets can be analyzed and automatically normalized before being fed to the cluster, and a REST API allows the trained model to be used in production immediately. It focuses on performance and flexibility. It has little hard-coded entities and enables training of all the widely recognized topologies, such as fully connected nets, convolutional nets, recurent nets etc.
1 note
·
View note
Text
What Is Data Science In Simple Words?

What Is Data Science?
Data science is defined as the study of data, where it comes from, what it signifies, and the meaning you can extract from it. It combines domain expertise, knowledge of mathematics, statistics, and programming skills. By studying the data, and hidden trends, meanings are uncovered to help businesses make better decisions, innovate and strategize. Data science is applicable across industries such as healthcare, finance, education, logistics, and more. A data science training in California can open up various career paths for you.
Who are Data Scientists?
Data scientists collect data from different sources such as internet searches, commerce sites, surveys, and social media. They use various scientific methods, techniques to store, organize, and analyze data to generate insights, make predictions and devise data-driven solutions.
Data scientists have knowledge about a number of big data platforms and tools, including Pig, Spark, Hive, Hadoop, MapReduce, and programming languages such as Python, SQL, Perl, and Scala; and statistical computing languages, such as R. To gain these skills, you must join the Best Data Science Course in Bay Area.
Data Science Skills
Computer Science: Data scientists should apply different principles of computer science, including database systems, software engineering, numerical analysis, and Artificial Intelligence.
Programming: A Data Scientist must know a few programming languages such as Python, R, and SQL to write algorithms.
Statistics: Statistical techniques help find the hidden pattern and correlation between various features in data.
Machine Learning: Data scientists must know various algorithms to build a model to train the machine.
Soft Skills
Analytical Thinking: A Data Scientist should be able to critically solve business problems.
Interpersonal Skills: A Data Scientist should have excellent communication skills to interact with stakeholders, clients, and colleagues.
Critical Thinking: A Data Scientist should have the critical thinking ability to analyze facts before reaching a conclusion.
Business Instinct: A Data Scientist should be able to understand the problems and communicate solutions.
Applications of Data Science
Healthcare
Finance
Fraud and risk detection
Targeted advertising
Website recommendations
Advanced image recognition
Speech recognition
Augmented reality
Gaming
Email spam filtering
Virtual assistants
Chatbots
Cybersecurity
Robotics
Why is Data Science Important?
Data science is a hot topic as more and more companies realize the value of data. Regardless of industry type or size, organizations that wish to remain competitive need to develop and implement their data science capabilities efficiently. It helps them unveil amazing solutions and well-thought decisions across business verticals. For example, with the help of data science, businesses can understand their customers and offer them customized products and services.
Is Data Science A Good Career?
Data science is a lucrative career to pursue as data science roles are increasing day by day. Data science professionals are demanded in every industry, and if you have the right set of skills, you can apply for any data science role, including data scientist, data analyst, data engineer, business analyst, machine learning engineer, and more. The Best Data Science Course in California can help you prepare for a meaningful and successful data science career. Data science professionals start with higher salaries. According to Glassdoor, Data scientists make an average salary of $117,212 per year.
Source: https://buzztum.com/what-is-data-science-in-simple-words/
0 notes
Text
Is Data Science Training worth it?

As per some research, every day, 2.5 quintillion bytes of data is generated on the internet, which is likely to reach 463 exabytes by 2025. The increase in data volume is exponential, so it calls for vigorous actions to maintain Big Data. As businesses are struggling to deal with the dynamic & complex data types, they look for professional Data Scientists who can process, clean, manage, interpret, & organize the copious amount of data. With the rapid demand for skilled & certified Data Science professionals, there has been a surge in the enrollments of Data Science Bootcamps. However, it is important to determine if immersive training for few months can help you build a successful Data Science career? Let’s get into the core of the matter to understand the true value of Data Science Training.
Benefits of Data Science Training
· Improves Career Path- As we all know that the demand for Data scientists is on the rise in all the dominant industries across the world. A candidate can acquire data science skills, knowledge, & proficiency by taking career-oriented Data science training. Thus, getting trained in Data Science can prepare you for the next step of your professional journey.
· It makes you eligible for the highest-paying jobs- A professionally trained and certified Data Science professional can seize various jobs at tremendously high salary packages. Since the tech field of Big Data & Data Science is ever-expanding, it offers lucrative career opportunities such as:
Ø Data Scientist ($122451 per year)
Ø Data Architect ($101,322 per year)
Ø Data Engineer ($131545 per year)
Ø Data Analyst ($73891 per year)
Ø Business Analyst (78399 per year)
Ø Data Administrator ($96154 per year)
Ø Data Analytics Manager ($113335 per year)
Ø Business Intelligence Manager ($94988 per year)
By the end of Data Science Training in California, you will become qualified to secure any of the above positions.
· Recruitment in Fortune 500 Companies- Nowadays, many top companies like Google, Facebook, Amazon, PayPal, eBay, Apple, & Microsoft are hiring competent Data Scientists. With Data Science training, you can strengthen your professional worth & showcase in-demand skills in your resume, helping you get shortlisted by the Fortune 500 companies.
· Learning from industry-experts- Another benefit of joining one of the best Data Science Bootcamps is learning from experienced trainers who have years of subject expertise. The trained professionals impart additional career tips & share job-related challenges along with hands-on training that prepares you for your future endeavors.
· Individual Assistance- When you sign up for Data Science Training, you will be learning in a batch of 20 or less fellow students, which will provide you enough flexibility to clear your doubts. Moreover, you will get individual attention from the instructors that could facilitate a better learning experience.
· Prowess in other related technologies- Being an interdisciplinary field, Data Science Training in California empowers candidates with other top-level technologies such as Machine Learning, Artificial Intelligence, Hadoop, Business Analyst, Deep Learning, Data Analysts, etc.
Considering the above benefits, one can perceive that Data Science Training is definitely worth it. If you also want to explore this lucrative technology, take the best Data Science Training in California at SynergisticIT.
Also, Read This Blog: Where can you get your Data Science Training Online?
0 notes
Link
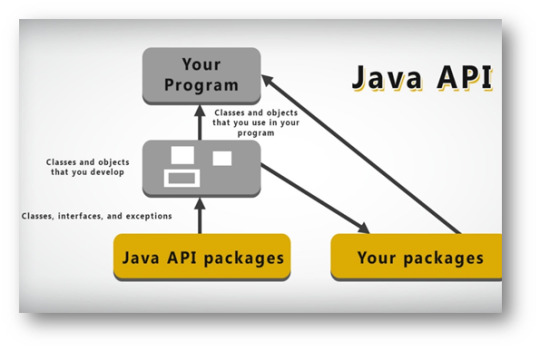
At Synergistic IT we provide you with best course training of Java,J2EE,Full Stack, Big data ,Mern Stack , Azure,Hadoop,and AWS Certification Training in California. Through our training programs, you will be equipped with the knowledge needed to adapt to the dynamic IT industry.
#it staffing company california#java course training in california#Full Stack course training in california#aws certification training in california#aws architect certification training in california#best java training in california
0 notes
Text
Big Data
Rainbow Training Institute provides the best Big Data and Hadoop online training. Enroll for big data Hadoop training in Hyderabad certification, delivered by Certified Big Data Hadoop Experts. Here we are offering big data Hadoop training across global.
Big Data Analytics
Investigation gives an upper hand to organizations. Gartner is foreseeing that organizations that aren't putting vigorously in investigation before the finish of 2020 may not be good to go in 2021. (It is expected private ventures, for example, independently employed jacks of all trades, cultivators, and numerous craftsmen, are excluded from this expectation.)
The constant discourse examination showcase has seen its previously continued selection cycle starting in 2019. The idea of client venture examination is anticipated to develop consistently, with the objective of improving undertaking efficiency and the client experience. Continuous discourse investigation and client venture examination will increase critical ubiquity in 2020.
Nonstop Intelligence
"Nonstop insight" is a framework that has incorporated continuous investigation with business activities. It forms authentic and current data to give basic leadership robotization or basic leadership support. Persistent knowledge use an assortment of advances (improvement, business rule the board, occasion stream handling, expanded investigation, and AI). It prescribes activities dependent on both chronicled and constant data.
Consistent insight vows to give progressively successful client assistance and extraordinary offers intended to entice explicit clients. The innovation can possibly go about as a "center sensory system" for associations, for example, trucking organizations, aircrafts, and railways. These businesses could utilize nonstop knowledge to screen and upgrade planning choices. Persistent insight is a genuinely new innovation, made conceivable by expanded investigation and the advancement of different advances.
Gartner predicts more than 50 percent of new business framework will utilize consistent insight by 2022. This move has begun, and numerous associations will join persistent insight during 2020 to pick up (or keep up) a serious edge.
Increased Analytics
Increased investigation mechanizes the way toward picking up business experiences through cutting edge man-made reasoning and AI. An expanded investigation motor consequently experiences an association's data, cleans it, and breaks down it. As a last advance, it changes over the bits of knowledge into significant strides with little supervision from a tech individual. Enlarged examination can make investigation accessible to littler organizations by making it more easy to understand.
In 2020, expanded investigation will turn into the essential acquisition of organizations managing examination and business insight. Web organizations should anticipate embracing enlarged examination as their foundation abilities develop (or finding a cloud that offers increased investigation). The innovation has upset the examination business by blending man-made brainpower and AI systems to make creating, sharing, and deciphering investigation simpler.
On the Edge
As expressed previously, the IDC has effectively anticipated the IoT will consolidate gushing investigation and AI by 2020 – this pattern will keep on developing.
Investigation Insight predicts the web of things will be converged with data examination in 2020. Gartner is foreseeing the car and venture IoT market will grow to incorporate 5.8 billion endpoints during 2020, ascending by 21 percent from 2019. In enormous specialized associations previously utilizing IoT gadgets, keen business pioneers are actualizing the helping innovation expected to run data examination for greatest proficiency.
The essential objective of consolidating the IoT with AI and data investigation is to improve the adaptability and exactness of reactions made by AI, paying little heed to the circumstance. Furthermore, this sort of framework is as a rule calibrated with the expectations of improving connection with people.
In-Memory Computing
"In-memory registering" depicts the capacity of data inside the irregular access memory (RAM) of explicit committed servers, rather than being put away in muddled social databases running on moderately moderate plate drives. In-memory registering has the additional advantage of helping business clients (counting banks, retailers, and utilities) to recognize designs rapidly and break down gigantic measures of data effectively. The dropping of costs for memory is a central point in the developing enthusiasm of in-memory registering innovation.
In-memory innovation is utilized to perform complex data examinations progressively. It permits its clients to work with Big data sets with a lot more prominent deftness. As indicated by Analytics Insight, in 2020, in-memory processing will pick up fame because of the decreases in expenses of memory.
The issues of utilizing in-memory registering are getting less and less, the aftereffect of new advancements in memory innovation. The innovation gives an amazingly incredible mass-memory to help in preparing superior assignments. It offers quicker CPU execution and quicker stockpiling, while at the same time giving bigger measures of memory.
The GDPR and different Regulations
GDPRwent into full impact in May of 2018. The California Consumer Privacy Act is planned to become effective in January of 2020. Numerous American companies attempt to abstain from managing the new guidelines and have put forth fruitful attempts to square and defer comparable American enactment. These guidelines significantly affect how data is prepared and took care of, just as security and shopper profiling. Numerous associations who offer their data to others are not excited with these new guidelines intended to ensure shopper protection. Patterns of improving shopper protection are not founded on corporate benefits, yet on the wants of web clients to keep up their security.
The GDPR and the California Consumer Privacy Act are intended to put power back in the hands of the buyer. This has been cultivated by perceiving customers as the proprietors of data they make. The GDPR gives purchasers the privilege to expel their data from an association's control.
Associations that apply security guidelines — instead of concentrating on the transient benefits earned from offers of private data — won't need to pay fines to an European nation, or California, for breaking protection guidelines. (What's more, on the off chance that they promote their regard for protection, they may build the reliability of their client base.)
Cloud Usage
The "open cloud" is a PC handling administration offered by outsider contractual worker, for nothing or for an expense. The open cloud is accessible to anybody ready to utilize it. Open cloud utilization keeps on developing, as an ever increasing number of associations go to it for administrations. 41 percent of organizations are relied upon to begin utilizing open cloud stages in 2020.
The cross breed cloud and multi-cloud procedures are turning out to be progressively well known arrangements. Frequently, associations will decide to receive multi-cloud and cross breed systems for taking care of a wide range of distributed computing ventures, contingent upon the undertaking needs. Exploiting the different most appropriate devices and arrangements accessible at various mists permits associations to expand their advantages. Regardless of the advantages, utilizing various mists can make observing costs, administration, and cloud the executives progressively troublesome.
0 notes
Text
Education

It is astounding to realize automotive seo that there are a major number of candidates that are being turned down in most nursing schools. The purpose behind this isn't about the absence of value nursing instruction. It is more looking into the issue of absence of qualified educators. On the off chance that a man would get a quality training, it is imperative that the nursing teachers ought to be trade schools near me sufficient to enable understudies to find out about nursing.
Most schools lament dismissing python certification understudies, yet with the deficiency of instructing staff, that is the main arrangement that they can concoct for the interim. They realize that they can't forfeit the nature of the nursing training just to technical schools near me suit every one of the candidates who need to enlist in the nursing classes.
Quality nursing instructors are business analyst training number one need for nursing schools. The part is exceptionally indispensable for understudies to take in the diverse speculations and applications that they will require. In the event that there are not qualified individuals to instruct the understudies then it can be a major issue later on. Nursing schools ought to put resources bookkeeping classes into selecting and searching for these individuals.
Nursing teachers ought to ecd have great experience. It isn't just about hypotheses however genuine circumstances that future medical caretakers will confront when they go into the nursing business. These teachers could be previous attendants themselves who are searching for a difference in calling yet at the early childhood development same time have the capacity to stay inside the nursing condition.
Beside educator, something houston seo else that will enhance is the satisfactory restorative office for them to exchange the abilities they learned. One miserable reality remained is that there are nursing schools that don't have the sufficient office to their nursing understudies may wind up without some specialized know-hows.
Maybe more than the hardware dallas seo experts or lab offices, the nursing understudies ought to likewise be outfitted with the privilege mental and enthusiastic strength in taking care of the activity. The school can show all the specialized abilities yet they likewise need to center around how understudies can adapt to blunders or oversights in reality. In a school setting high evaluations are given when understudies performed well, perhaps there ought to be an alternative when educators need to train that mix-ups can happen houston seo company and one needs to have readiness to deal with these circumstances.
Youthful youngsters frequently need to emulate their folks or more seasoned kin who likely invest energy in their PCs. Be that as it may, numerous guardians are houston seo consultant reluctant to enable a preschooler to utilize the PC, particularly without the correct supervision. The kinds of recreations accessible for youthful youngsters can likewise be a worry. In the event that you are mindful so as to pick destinations that offer instructive preschool amusements, however, you will have the capacity to offer some career aptitude test incentive to your tyke.
Diversion Value
All kids need to be what career is right for me engaged somehow. In this day and age, the utilization of gadgets is a typical method to keep even youthful youngsters possessed. Notwithstanding, you don't need your kid playing only any amusement. There are instructive diversions that are gone for preschool matured kids. These amusements are a lot of enjoyable to play, enabling your youngster to have a decent time while he is learning imperative data he will escape houston require later in school.
Instructive Value
The essential reason guardians search out instructive preschool diversions is to enable their youngster to master all that they have to prevail in school. In the bmw houston event that you pick only any amusement that is accessible on the web, your youngster will be engaged, yet it won't give him the instructive establishment he needs. For some guardians, this implies investing energy online is an exercise in futility and assets. They would lexus houston preferably their tyke pick up something valuable than play careless amusements.
Time Value
Endeavoring to complete hyundai houston everything around the house with a youthful kid underneath isn't a perfect circumstance. Be that as it may, you would prefer not to stop your preschooler before the TV or PC throughout the day so you can complete things. When you discover quality instructive diversions online for your preschooler, you don't have to feel regretful about putting your kid before the PC for some time so you can vacuum or cook supper. Your kid will honda dealership houston make great utilization of the time, adapting a portion of the essential components of different subjects to prepare him for the forthcoming school years.
When you choose to make jaguar houston utilization of instructive preschool amusements to get your youngster on the PC and to involve his chance, you have to ensure you are picking diversions that will give something back to your kid. Not exclusively do you need your tyke to be engaged, you likewise need him to really get the hang of something amid his play. In the event that he isn't learning while he is playing, you are basically dawdling.
Kids are being presented to scratch and dent appliances PCs from early ages, figuring out how to utilize them in their day by day lives. This has turned out to be essential in light of the expanded utilization of PCs in numerous everyday issues. This implies guardians and instructors are continually searching for training recreations online to enable them to supplement learning in a fun, intelligent way. For whatever length of time that you set aside the opportunity to pick quality diversions, you will enable your youngster to learn.
Read Reviews
A standout amongst other wtw5000dw approaches to check the nature of the instructive web based amusements you are thinking about is to peruse audits left by others. Some of the time instructive diversions are a considerable measure of good times for the children however really contain minimal instructive esteem, making the time spent on them futile. Whenever guardians or instructors leave great audits for a site that offers instructive diversions, you can whirlpool cabrio washer make sure your tyke will really pick up something while he is playing.
Play Yourself
It might appear to be senseless to wrs325fdam play instruction diversions online yourself, however it can enable you to measure the nature of the amusements on a site. On the off chance that you would prefer not to attempt the diversions out yourself, sit with your tyke while he plays so you can see the recreations for yourself. Diversions that are too simple for your youngster or don't appear to train anything ought to be maintained a strategic distance from so you can System network training benefit as much as possible from the opportunity.
Peruse the Site
Regardless of whether you big data hadoop training don't play the recreations or don't have room schedule-wise to watch for an extensive stretch of time, you can set your psyche quiet by perusing through the site itself. Take a gander at the subjects they offer, and in addition the sorts of recreations. When you are endeavoring to locate the best quality instructive recreations for your kid, it can turn out to be anything but difficult to disregard ensuring they are a good time for your kid. Checking to guarantee the site offers cell phone repair training online recreations your kid will appreciate will build the odds of progress.
Discovering quality sites that offer instruction recreations online will enable you to give your youngster a more prominent open door at accomplishment in school. To figure out which locales offer the best amusements, set aside the opportunity to search out audits for the site, and also to play the diversions yourself. Perusing the site to perceive what they offer will likewise cell phone repair training enable you to decide whether the site is a solid match for your kid. Regardless of whether you just watch your kid play for some time, you will get a decent vibe for the nature of the diversions.
Progressing training is compulsory in relatively every calling nowadays. Each permit write has particular tenets and controls in the United States for the operators to submit to. These laws are set up for the benefit of the operator and the buyer. On the off chance that specialists were not required to finish their proceeding with training courses they most likely would not do it and they would fall behind on new items accessible to their customers. All the more imperatively, experts could fall behind on new laws and controls being ignored the years. For example, on the off chance that somebody has been authorized to specialize in legal matters throughout the previous thirty years and they have never done proceeding with instruction they might infringe upon the law and not know it!
Each state and calling has distinctive necessities for proceeding with instruction. For example, in Florida protection operators need to finish no less than three long stretches of Senior Suitability proceeding with training at regular intervals. This is a A+ certification training required course do to the senior misbehavior suits that have been on the ascent as of late. Morals is likewise an exceptionally prevalent course that most states require a specialist to take each consistence period. Morals manages making the best decision and helping your customers accomplish their money related objectives, not yours. Settling on moral choices is critical in each calling. In the territory of California each operator offering long haul mind protection to the elderly are additionally required to take no less than three long stretches of proceeding with training credits in long haul mind protection like clockwork. As should be obvious, each state and permit write require distinctive courses particular to what line of business they are in.
A significant number of your credits can be finished either on the web or in a classroom. Each state and permit compose has their own particular standards the licensee must take after. For example, in the province of Illinois a protection operator must do their three hour morals prerequisite in a classroom while the territory of California enables you to do the majority of your proceeding with training on the web. On the off chance that you have any inquiries on how long you owe, it is prescribed to contact your state office for a point by point rundown of courses you have to take and how they should be finished. You can likewise call an endorsed proceeding with instruction supplier and they ought to have the capacity to look into your record and help you with obtaining your courses. Continuously make a point to satisfy your necessities by the due date to stay away from any state fines.
Following quite a long while of being a RN, one would think what is in store for what's to come. Are there different professions that one can consider in the event that one needs a difference in vocation way other than being a RN? It isn't tied in with leaving the nursing calling altogether it is only that one needs to discover a choice to encourage the vocation or perhaps some adjustment in the earth is expected to energize or locate the correct point of view.
On the off chance that a man is considering leaving the nursing calling one can consider seeking after an extraordinary profession as a RN instructor. Obviously not every person will be suited for this sort of attempted, there are sure characteristics that one must have keeping in mind the end goal to prevail in this way.
Energetic
Much the same as in any endeavor or objective, one needs to have enthusiasm. Enthusiasm is synonymous to commitment. This implies the medical attendant teacher is focused on instructing new attendants to accomplish their objective and remaining with them until the finish of the course. Energy additionally intends to pass on to these new understudies how critical their calling is and it isn't only a vocation yet a calling that they ought to be glad to do notwithstanding when difficulties arise.
Persistent
A RN instructor is an educator that needs to indicate tolerance to the understudy and also herself. It's anything but a medium-term achievement; one needs to encounter troubles with the understudies and the progress of working in a healing facility to being an instructor. There will be hardships ahead yet it will be simpler to hold up under in the event that one practices tolerance and continuance.
Devoted
Devotion is tied in with giving your everything to the learning and showing part, all things considered, One needs to learn new things regardless of whether you have various years being a RN. Keep in mind that being a medical caretaker is not the same as being an attendant instructor. You likewise must be committed in instructing the medical attendant understudies all you know to set them up for what lies ahead. You will experience understudies who will battle and in light of the devotion that you will shower upon them, you will enable them to overcome the shortcomings and help them prevail to be incredible medical caretakers later on.
Medical attendant teachers are as yet a developing calling. Ideally, later on the attendants will understand this is a suitable way to take since they can contribute well to the achievement of the medical caretaker understudies.

0 notes
Text
Data Scientist Vs. Data Analytics - What is the Big Data Difference
New Post has been published on http://jobsinthefuture.com/index.php/2017/10/16/data-scientist-vs-data-analytics-what-is-the-big-data-difference/
Data Scientist Vs. Data Analytics - What is the Big Data Difference
Updated October 16, 2017
Jobs related to data science are booming right now with the tech industry growing at a rapid pace, but there is a lot of confusion between the Role of a Data Scientist and a Data Analyst…
I am going to QUICKLY breakdown the difference for you so that you can get started right away with your career in the Data Analytics industry!
First of all what is data analytics…
Data analytics is the extraction a large, large, large amounts of data that are stored within a data base. This data comes from a multiplicity of places all over the world via website traffic, in-store and online purchases, social media activity, traffic patterns, etc, etc, etc…. the list could go on and on.
Basically everything we do is being collected to be used as data to advertise to us, keep us safer when we are driving, or help us find the restaurant we want to eat at.
Now to The Role of Data Scientist – The IT Rock Star!
Data Scientists are the top professionals in their industry. They usually hold a Masters Degree in some relative Computer Science degree or even a PhD. They understand, very well, data from a business point of view and he/she can make accurate prediction of the data to advise clients on their next big business move! Data scientists have a solid foundation of computer applications, modeling, statistics and math!
Highly Advanced in coding (Python, MySQL, R, JavaScript, etc…
Ability to do high levels of math quickly
Fantastic Statistical Analysis Abilities
Great Communication Skill: Written and Oral
And they have a brilliant Knack for communicating between the IT world and the Business Professionals.
Starting Salary: $115,000
The Role of Data Analyst
A Data Analyst is very important in the world of data science. They are in charge of collecting, organizing, and and obtaining statistical information from a large amount of data sets (Data sets are very large pools of data that must be searched in order to find the data that is relevant to a specific study). They are also the ones responsible for formulating all of their findings into an accurate report of powerpoint presentation to give to their client or internal team.
Strong Understanding of Hadoop Based Analytics (Program to help extract data from large data sets and the analyze the data)
Familiar with data analytics in a business setting
Must have data storing a retrieval skills
Proficiency in decision making
Have the ability to transform data into understandable presentation
Starting Salary: $60,000
Educational Resources to Get Started Now!
Start By Learning Python with this Free Course from EdX
Free is Good, But A Guided Course is Going to Set You on the Best path to success in Data Analytics!
Start a Full Mastery Course in Data Analytics for a Step by Step Guide to Success!
This program will walk you through 12 courses and give you excellency in 27 new skills
If you want to take you data analyst skills to the next level take the Micro Masters from the University of California San Diego.
Learn From A Highly Qualified Institution Online!
This Course From UC San Diego will be elemental in boosting your data analyst capabilities. Note: be prepared for this course! It is full of amazing insight to the world of Data Analytics!
Don’t wait any longer… These jobs are available but they will be going quickly when more people realize the amazing opportunity of Data Analytics.
Start your Career Training in Data Analytics Now! ===>
0 notes
Text
An Intro to Predictive Analytics – Business 2 Community
When organizations want to make data-driven predictions about future events, they rely on predictive analytics. Driven by the explosion of big data, predictive analytics is fast becoming an important part of many industries and functions. In this article, we’ll take a look at the technology that makes predictive analytics possible and explore just a few of the ways organizations can use it to gain insights into the future.
What Is Predictive Analytics?
At its heart, predictive analytics is about using historical data to make predictions. Your credit score is a good example of predictive analytics in everyday life. That score is based on your past credit history and is used to predict how likely you are to repay your debts. While predictive analytics has been used for decades in the financial services industry, it’s only just recently become an important tool in other industries. The advancement of data collection and processing technologies has made it possible to apply predictive analytics to nearly every aspect of business, from logistics to sales to HR.
While predictive analytics has been used for years in financial services, it’s now an integral part of many industries and businesses. The massive increase in data collection abilities coupled with the widespread availability of commodity hardware are the two trends that have made the spread of predictive modeling a reality.
Building a Model
At the heart of predictive analytics is the model. While the statistical techniques used to create a model depend on the specific task, they fall into two broad types. The first is the regression model, which is used to gauge the correlation between specific variables and outcomes. The resulting coefficients give you a quantified measure of that relationship, in effect, how likely a given outcome is based on a set of variables. The other type of model is the classification model. Where regression models assign a likelihood to an event, classification models predict whether something belongs in one category or another (e.g. whether a customer is a “regular” or an “occasional” buyer).
To start, let’s take an example of something an organization might want to predict: Say we’re a music streaming service and we want to know whether one of our users will like a given new song. Taste is of course subjective and hard to measure, but we can identify some variables that are probably related to whether someone will like a song or not. The trick is to identify what variables are relevant and how heavily to weight each of them. To do that, we can turn to regression analysis, which is a statistical method for finding the relationship between different variables.
Now, we need to test our assumptions. For example: we might assume that genre, year of release, and tempo are relevant attributes that determine whether a user will like a given song. Given that user’s past listening behaviors, we can figure out if and how those variables are related. Let’s say we find out that genre is strongly correlated, tempo is somewhat correlated, and year of release isn’t correlated at all. We can now weight the first two factors in our recommendations, but not the third, to give us our predictive model.
Typically, these models are developed with the aid of machine learning techniques, using real-world data sets to train models. These models can be periodically re-trained and improved as more data is gathered. Processing tools like Hadoop’s MapReduce and Spark allow organizations to process huge volumes of data in regularly scheduled batches or (in the case of Spark Streaming) continuously.
Languages, Tools, and Skills of Predictive Analytics
As we’ve seen, predictive analytics isn’t a single skill–it’s a combination of disciplines, including statistical analysis, predictive modeling, data mining, machine learning, visualization, and more, in addition to the engineering skills that may be required to gather and process the data. In this section, we’ll briefly look at some of the top programming languages and tools used by data scientists when working on predictive analytics.
Data scientists have a number of options when it comes to programming languages and libraries. Java, R, Python, and Scala are all popular choices with a number of high-quality open-source libraries for common predictive analytics tasks, from machine learning to data mining and visualization. Which one is best for your project will depend on what your team is used to working with and what your specific goals are. Java and Python are generally thought to be best-suited to building production apps, while R is favored for heavy-duty analytics work. Scala is increasingly popular, especially with teams who need a highly scalable language and who work with Apache Spark.
That said, there are a number of business intelligence (BI) tools that support some degree of predictive analytics. Since they focus on ad-hoc queries and visualizations, they’re often geared toward Marketing, Sales, and related teams, rather than production-oriented developers. Below, we take a look at three of the most popular options and what sets each of them apart:
Tableau is a BI and analytics platform that specializes in rich visualizations. It can connect to literally hundreds of different data sources, including Excel, SAP, Salesforce, SQL databases, AWS, JSON files, Google Analytics, and more. Another factor driving Tableau’s popularity is its ease-of-use–users won’t need to learn any technical languages, and its drag-and-drop visualizations make it easy to quickly generate ad-hoc analyses. If visualizations and an easy learning curve are important considerations for your project, Tableau might be a natural choice.
Microsoft Power BI is meant to be a cost-effective and scalable BI tool. It lacks some of the analytics and visualization capabilities that Tableau has, but it boasts more complete R integrations, as well as real-time streaming capabilities. As a Microsoft product, it also plays well with Excel and Microsoft Azure, which could be a big advantage for certain enterprise teams.
QlikView is an analytics-focused tool that also comes with robust API support. Unlike other analytics platforms, Qlikview processes data using system RAM. By processing data “in-memory,” QlikView is able to achieve much greater speeds than systems built on traditional relational databases. (This is the same technology used by Apache Spark to achieve real-time analysis.)
Common Applications
Customer Relationship Management (CRM). How do you get customers to stick around longer? How do you get your most loyal customers to spend more? These are questions that CRM can help answer. Using a combination of regression analysis and clustering techniques, CRM tools can separate your customers into cohorts based on their demographics and where they are in the customer lifecycle, allowing you to target your marketing efforts in ways that are most likely to be effective.
Detecting outliers and fraud. Where most predictive analytics applications look for underlying patterns, anomaly detection looks for items that stick out. Financial services have been using it to detect fraud for years, but the same statistical techniques are useful for other applications as well, including medical and pharmaceutical research.
Anticipating demand. An important but difficult task for every business is predicting demand for new products and services. Historically, these kinds of predictions were made using time-series data to make general forecasts, but now retailers are able to anonymized search data to predict sales of a given product down to the regional level. Amazon has even patented a process it calls “anticipatory shipping,” which aims to ship products it expects customers to buy before they’ve even placed an order.
Improving processes. For manufacturers, energy producers, and other businesses that rely on complex and sensitive machinery, predictive analytics can improve efficiency by anticipating what machines and parts are likely to require maintenance. Using historical performance data and real-time sensor data, these predictive models can improve performance and reduce downtime while helping to avert the kinds of major work stoppages that can occur when major systems unexpectedly fail.
Building recommendation engines. Personalized recommendations are relied on by streaming services, online retailers, dating services, and others to increase user loyalty and engagement. Collaborative filtering techniques use a combination of past behavior and similarity to other users to produce recommendations, while content-based filtering assigns characteristics to items and recommends new items based on their similarity to past items.
Improving time-to-hire and retention. Even HR departments are beginning to use predictive analytics to improve their hiring and management policies. For example, companies can use data from the HR systems to optimize their hiring process and identify successful candidates who might be overlooked by human screeners. Additionally, some departments are using a mix of performance data and personality profiles to identify when employees are likely to leave or anticipate potential conflicts so that they can be proactively resolved.
Get work done—anytime, anywhere. Create an awesome job post on Upwork and get started today.
Author: Tyler Keenan
Tyler is an Upwork author who writes about all things related to data and design. Based in Berkeley, California, he’s written and edited article- and book-length projects for a variety of clients, from fiction writers to academics to startup founders. He’s a passionate defender of Oxford commas, en-dashes, and using plain… View full profile ›
More by this author:
Follow Tyler Keenan:
Let’s block ads! (Why?)
Originally posted on http://ift.tt/2mDg5ML
The post An Intro to Predictive Analytics – Business 2 Community appeared first on Big Data News Magazine.
from An Intro to Predictive Analytics – Business 2 Community
0 notes