#CTE SQL Update
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Updating SQL Server Tables Using SELECT Statements: Techniques and Examples
To perform an UPDATE from a SELECT in SQL Server, you typically use a subquery or a common table expression (CTE) to select the data that you want to use for the update. There are a few different approaches you can take depending on your specific requirements. Here are some examples: Using Subquery If you want to update a table based on values from another table, you can use a subquery in your…
View On WordPress
0 notes
Text
Master SQL for Data Analysis Online Course with Gritty Tech
In today’s data-driven world, mastering SQL is no longer optional for anyone serious about a career in data. Whether you're an aspiring data analyst, business intelligence professional, or looking to enhance your analytical toolkit, enrolling in a comprehensive SQL for data analysis online course is one of the best decisions you can make. At Gritty Tech, we offer top-tier, affordable SQL courses tailored to modern industry demands, guided by expert tutors with global experience For More...
Why Choose Gritty Tech for Your SQL for Data Analysis Online Course?
Choosing the right platform to study SQL can be the difference between just watching videos and truly learning. Gritty Tech ensures learners gain practical, industry-aligned skills with our expertly crafted SQL for data analysis online course.
Gritty Tech’s course is curated by professionals with real-world experience in SQL and data analytics. We emphasize building conceptual foundations, practical applications, and project-based learning to develop real analytical skills.
Education should be accessible. That’s why we offer our SQL for data analysis online course at budget-friendly prices. Learners can choose from monthly plans or pay per session, making it easier to invest in your career without financial pressure.
Our global team spans 110+ countries, bringing diverse insights and cross-industry experience to your learning. Every instructor in the SQL for data analysis online course is vetted for technical expertise and teaching capability.
Your satisfaction matters. If you’re not happy with a session or instructor, we provide a smooth tutor replacement option. Not satisfied? Take advantage of our no-hassle refund policy for a risk-free learning experience.
What You’ll Learn in Our SQL for Data Analysis Online Course
Our course structure is tailored for both beginners and professionals looking to refresh or upgrade their SQL skills. Here’s what you can expect:
Core concepts include SELECT statements, filtering data with WHERE, sorting using ORDER BY, aggregations with GROUP BY, and working with JOINs to combine data from multiple tables.
You’ll move on to intermediate and advanced topics such as subqueries and nested queries, Common Table Expressions (CTEs), window functions and advanced aggregations, query optimization techniques, and data transformation for dashboards and business intelligence tools.
We integrate hands-on projects into the course so students can apply SQL in real scenarios. By the end of the SQL for data analysis online course, you will have a portfolio of projects that demonstrate your analytical skills.
Who Should Take This SQL for Data Analysis Online Course?
Our SQL for data analysis online course is designed for aspiring data analysts and scientists, business analysts, operations managers, students and job seekers in the tech and business field, and working professionals transitioning to data roles.
Whether you're from finance, marketing, healthcare, or logistics, SQL is essential to extract insights from large datasets.
Benefits of Learning SQL for Data Analysis with Gritty Tech
Our curriculum is aligned with industry expectations. You won't just learn theory—you'll gain skills that employers look for in interviews and on the job.
Whether you prefer to learn at your own pace or interact in real time with tutors, we’ve got you covered. Our SQL for data analysis online course offers recorded content, live mentorship sessions, and regular assessments.
Showcase your achievement with a verifiable certificate that can be shared on your resume and LinkedIn profile.
Once you enroll, you get lifetime access to course materials, project resources, and future updates—making it a lasting investment.
Additional Related Keywords for Broader Reach
To enhance your visibility and organic ranking, we also integrate semantic keywords naturally within the content, such as:
Learn SQL for analytics
Best SQL online training
Data analyst SQL course
SQL tutorials for data analysis
Practical SQL course online
Frequently Asked Questions (FAQs)
What is the best SQL for data analysis online course for beginners? Our SQL for data analysis online course at Gritty Tech is ideal for beginners. It covers foundational to advanced topics with hands-on projects to build confidence.
Can I learn SQL for data analysis online course without prior coding experience? Yes. Gritty Tech’s course starts from the basics and is designed for learners without any prior coding knowledge.
How long does it take to complete a SQL for data analysis online course? On average, learners complete our SQL for data analysis online course in 4-6 weeks, depending on their pace and chosen learning mode.
Is certification included in the SQL for data analysis online course? Yes. Upon successful completion, you receive a digital certificate to showcase your SQL proficiency.
How does Gritty Tech support learners during the SQL for data analysis online course? Our learners get access to live mentorship, community discussions, Q&A sessions, and personal feedback from experienced tutors.
What makes Gritty Tech’s SQL for data analysis online course different? Besides expert instructors and practical curriculum, Gritty Tech offers flexible payments, refund options, and global teaching support that sets us apart.
Can I use SQL for data analysis in Excel or Google Sheets? Absolutely. The skills from our SQL for data analysis online course can be applied in tools like Excel, Google Sheets, Tableau, Power BI, and more.
Is Gritty Tech’s SQL for data analysis online course suitable for job preparation? Yes, it includes job-focused assignments, SQL interview prep, and real-world business case projects to prepare you for technical roles.
Does Gritty Tech offer tutor replacement during the SQL for data analysis online course? Yes. If you’re unsatisfied, you can request a new tutor without extra charges—ensuring your comfort and learning quality.
Are there any live classes in the SQL for data analysis online course? Yes, learners can choose live one-on-one sessions or join scheduled mentor-led sessions based on their availability.
Conclusion
If you're serious about launching or accelerating your career in data analytics, Gritty Tech’s SQL for data analysis online course is your gateway. With a commitment to high-quality education, professional support, and affordable learning, we ensure that every learner has the tools to succeed. From flexible plans to real-world projects, this is more than a course—it’s your step toward becoming a confident, data-savvy professional.
Let Gritty Tech help you master SQL and take your data career to the next level.
0 notes
Text
Unlock SQL CTE Power
Unleashing the Power of Common Table Expressions (CTEs) in SQL 1. Introduction Common Table Expressions (CTEs) are a powerful feature in SQL that allow you to simplify complex queries by temporarily storing the result of a SELECT statement, which can then be referenced within a SELECT, INSERT, UPDATE, or DELETE statement. CTEs are particularly useful for breaking down complex queries into more…
0 notes
Text
SQL Techniques for Handling Large-Scale ETL Workflows
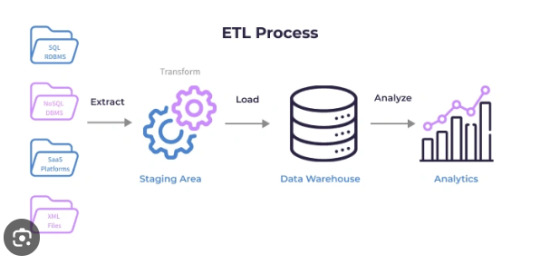
Managing and analyzing large datasets has become a critical task for modern organizations. Extract, Transform, Load (ETL) workflows are essential for moving and transforming data from multiple sources into a centralized repository, such as a data warehouse. When working with large-scale datasets, efficiency, scalability, and performance optimization are crucial. SQL, a powerful language for managing relational databases, is a core component of ETL workflows. This article explores SQL techniques for effectively handling large-scale Extract Transform Load SQL workflows.
Understanding the ETL Process
ETL workflows consist of three key stages:
Extract: Retrieving data from various sources, such as databases, APIs, or files.
Transform: Applying business logic to clean, validate, and format the data for analysis.
Load: Inserting or updating the processed data into a target database or data warehouse.
SQL is widely used in ETL processes for its ability to handle complex data transformations and interact with large datasets efficiently.
Challenges of Large-Scale ETL Workflows
Large-scale ETL workflows often deal with massive data volumes, multiple data sources, and intricate transformations. Key challenges include:
Performance Bottlenecks: Slow query execution due to large data volumes.
Data Quality Issues: Inconsistent or incomplete data requiring extensive cleaning.
Complex Transformations: Handling intricate logic across disparate datasets.
Scalability: Ensuring the workflow can handle increasing data volumes over time.
SQL Techniques for Large-Scale ETL Workflows
To address these challenges, the following SQL techniques can be employed:
1. Efficient Data Extraction
Partitioned Extraction: When extracting data from large tables, use SQL partitioning techniques to divide data into smaller chunks. For example, query data based on date ranges or specific IDs to minimize load on the source system.
Incremental Extraction: Retrieve only the newly added or updated records using timestamp columns or unique identifiers. This reduces the data volume and speeds up the process.
2. Optimized Data Transformation
Using Window Functions: SQL window functions like ROW_NUMBER, RANK, and SUM are efficient for complex aggregations and calculations. They eliminate the need for multiple joins and subqueries.
Temporary Tables and CTEs: Use Common Table Expressions (CTEs) and temporary tables to break down complex transformations into manageable steps. This improves readability and execution performance.
Avoiding Nested Queries: Replace deeply nested queries with joins or CTEs for better execution plans and faster processing.
3. Bulk Data Loading
Batch Inserts: Load data in batches instead of row-by-row to improve performance. SQL’s INSERT INTO or COPY commands can handle large data volumes efficiently.
Disable Indexes and Constraints Temporarily: When loading large datasets, temporarily disabling indexes and constraints can speed up the process. Re-enable them after the data is loaded.
4. Performance Optimization
Indexing: Create appropriate indexes on columns used in filtering and joining to speed up query execution.
Query Optimization: Use EXPLAIN or EXPLAIN PLAN statements to analyze and optimize SQL queries. This helps identify bottlenecks in query execution.
Partitioning: Partition large tables based on frequently queried columns, such as dates or categories. Partitioning allows SQL engines to process smaller data chunks efficiently.
5. Data Quality and Validation
Data Profiling: Use SQL queries to analyze data patterns, identify inconsistencies, and address quality issues before loading.
Validation Rules: Implement validation rules during the transformation stage to ensure data integrity. For example, use CASE statements or conditional logic to handle null values and invalid data.
6. Parallel Processing
Parallel Queries: Many modern SQL databases support parallel query execution, enabling faster data processing for large workloads.
Divide and Conquer: Divide large datasets into smaller subsets and process them in parallel using SQL scripts or database-specific tools.
Best Practices for Large-Scale ETL Workflows
Use Dedicated ETL Tools with SQL Integration: Tools like Apache Spark, Talend, and Informatica can handle complex ETL workflows while leveraging SQL for transformations.
Monitor and Optimize Performance: Regularly monitor query performance and optimize SQL scripts to handle growing data volumes.
Automate and Schedule ETL Processes: Use schedulers like cron jobs or workflow orchestration tools such as Apache Airflow to automate SQL-based ETL tasks.
Document and Version Control SQL Scripts: Maintain detailed documentation and version control for SQL scripts to ensure transparency and ease of debugging.
Advantages of SQL in Large-Scale ETL Workflows
Scalability: SQL is highly scalable, capable of handling petabytes of data in modern database systems.
Flexibility: Its ability to work with structured data and perform complex transformations makes it a preferred choice for ETL tasks.
Compatibility: SQL is compatible with most databases and data warehouses, ensuring seamless integration across platforms.
Conclusion
Handling large-scale Extract Transform Load SQL workflows requires a combination of efficient techniques, performance optimization, and adherence to best practices. By leveraging SQL’s powerful capabilities for data extraction, transformation, and loading, organizations can process massive datasets effectively while ensuring data quality and consistency.
As data volumes grow and workflows become more complex, adopting these SQL techniques will enable businesses to stay ahead, making informed decisions based on accurate and timely data. Whether you are managing enterprise-scale data or integrating multiple data sources, SQL remains an indispensable tool for building robust and scalable ETL pipelines.
0 notes
Text
CTE (Common Table Expression)SQL
The Common Table Expressions (CTE) are imported into the SQL to simplify many classes of the Structured Query Language (SQL) for a derived table, which is unsuitable. It was introduced in 2005 SQL SERVER version.
The common table expressions (CTE) are a result set, which we reference with the SELECT, INSERT, UPDATE, or DELETE statement. In SQL 2008, we add a CTE for the unique MERGE statement.

0 notes
Text
Understanding Oracle Common Table Expressions (CTEs)
Common Table Expressions (CTEs) are a powerful SQL feature available in Oracle that allow for more readable and maintainable queries. Introduced in Oracle 9i, CTEs provide a way to define temporary result sets that can be referenced within a SELECT, INSERT, UPDATE, or DELETE statement. This blog will delve into the advantages, disadvantages, and provide an example of using CTEs in Oracle. What…
0 notes
Text
50 Sql Inquiry Questions You Need To Exercise For Interview
You can pick distinct documents from a table by utilizing the UNIQUE keyword phrase. Trigger in SQL is are a unique type of stored procedures that are specified to implement automatically in place or after information adjustments. It enables you to carry out a batch of code when an insert, update or any other question is executed against a particular table. DROP command eliminates a table and also it can not be rolled back from the database whereas TRUNCATE command eliminates all the rows from the table. This index does not allow the area to have duplicate values if the column is special indexed. Longevity indicates that when a transaction has been dedicated, it will certainly remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements implement, the outcomes require to be kept completely. The SELECT statement is made use of as a partial DML statement, utilized to select all or relevant documents in the table. Denormalization is made use of to access the information from greater or reduced regular form of database. It likewise processes redundancy right into a table by including information from the associated tables. Denormalization includes required repetitive term right into the tables so that we can stay clear of making use of complicated joins as well as many other complex operations. t mean that normalization will not be done, however the denormalization process takes place after the normalization procedure. Think of a solitary column in a table that is inhabited with either a solitary number (0-9) or a single character (a-z, A-Z). Write a SQL inquiry to publish 'Fizz' for a numeric worth or 'Buzz' for alphabetical value for all values because column. Finally utilize the DEALLOCATE declaration to delete the cursor meaning and also release the associated sources. Clustering index can boost the performance of many query operations since they supply a linear-access path to data saved in the database. DeNormalization is a method used to access the information from higher to decrease regular types of database. It is also procedure of introducing redundancy into a table by including information from the related tables. Normalization is the process of reducing redundancy and also dependence by organizing fields and table of a database. The major objective of Normalization is to add, erase or modify field that can be made in a single table. APrimary keyis a column or a set of columns that uniquely identifies each row in the table. The information kept in the database can be customized, obtained and also deleted as well as can be of any type of type like strings, numbers, photos and so on. A CTE or common table expression is an expression which includes short-term outcome set which is defined in a SQL declaration. By utilizing DISTINCT key words duplicating records in a query can be avoided. When stored in a database, varchar2 uses just the allocated space. E.g. if you have a varchar2 and placed 50 bytes in the table, it will use 52 bytes. Stored Procedure is a feature includes many SQL statement to access the data source system. Numerous SQL statements are settled into a kept treatment and also implement them whenever and wherever called for. SQL represents Structured Query Language is a domain name particular programs language for managing the information in Database Administration Solution. SQL programs skills are extremely desirable and needed out there, as there is a huge use Database Management Systems in practically every software program application. To get a work, prospects require to crack the interview in which they are asked various SQL interview questions. A Stored Treatment is a function which includes numerous SQL declarations to access the data source system. Numerous SQL statements are settled into a kept treatment and also execute them whenever and also wherever required which saves time and prevent writing code time and again. If a main key is defined, a one-of-a-kind index can be applied immediately. An index refers to a performance adjusting method of enabling much faster access of records from the table. An index creates an access for every value as well as therefore it will be faster to retrieve data. Denormalization refers to a strategy which is utilized to gain access to information from higher to lower kinds of a data source. It aids the data source supervisors to raise the efficiency of the entire infrastructure as it introduces redundancy into a table. It adds the redundant information into a table by incorporating database questions that incorporate information from numerous tables into a solitary table. A DB question is a code written in order to obtain the details back from the data source. Question can be made as if it matched with our expectation of the result collection. Unique index can be applied immediately when main key is specified. An index is performance tuning approach of allowing much faster retrieval of records from the table. An index creates an entrance for each and every worth as well as it will certainly be much faster to get data. To defend against power loss, transactions need to be recorded in a non-volatile memory. Compose a inquiry to bring values in table test_a that are as well as not in test_b without utilizing the NOT keyword phrase. A self SIGN UP WITH is a case of normal join where a table is signed up with to itself based upon some relation between its very own column. Self-join makes use of the INNER JOIN or LEFT JOIN clause as well as a table pen name is made use of to designate various names to the table within the query. In this guide you will certainly locate a collection of real world SQL meeting inquiries asked in firms like Google, Oracle, Amazon.com and also Microsoft and so on. Each question includes a completely composed solution inline, saving your interview prep work time. TRUNCATE removes all the rows from the table, as well as it can not be rolled back. An Index is an unique structure related to a table speed up the efficiency of questions. https://geekinterview.net Index can be created on several columns of a table. A table can have just one PRIMARY KEY whereas there can be any variety of UNIQUE secrets. Main key can not contain Void values whereas One-of-a-kind key can have Void worths. MINUS - returns all unique rows selected by the first query but not by the second. UNION - returns all unique rows selected by either query UNION ALL - returns all rows chosen by either query, consisting of all duplicates. DECLINE command removes a table from the database and also procedure can not be curtailed. MINUS operator is utilized to return rows from the initial inquiry however not from the 2nd question. Matching records of first as well as 2nd query as well as various other rows from the very first question will be presented therefore set. Cross sign up with specifies as Cartesian product where variety of rows in the first table increased by number of rows in the 2nd table. If suppose, WHERE clause is made use of in cross sign up with then the inquiry will function like an INNER SIGN UP WITH. A nonclustered index does not alter the method it was kept yet develops a full separate item within the table. It point back to the original table rows after looking.

Considering the data source schema showed in the SQLServer-style diagram below, write a SQL inquiry to return a checklist of all the invoices. For every invoice, show the Billing ID, the billing day, the customer's name, as well as the name of the client that referred that customer. PROCLAIM a arrow after any type of variable declaration. The cursor statement must always be associated with a SELECT Declaration. The OPEN statement have to be called before fetching rows from the result set. FETCH statement to get and also relocate to the next row in the result set. Call the CLOSE declaration to shut off the arrow.
1 note
·
View note
Text
The Power of CTEs: Simplifying Complex Queries
1. Introduction What are CTEs? Common Table Expressions, commonly referred to as CTEs, are a powerful feature in SQL that allow you to simplify complex queries by breaking them down into smaller, more manageable pieces. CTEs are temporary result sets that can be used within a SELECT, INSERT, UPDATE, or DELETE statement. They are particularly useful for scenarios where a query needs to reference…
0 notes
Text
Common Table Expression (CTE)
Common Table Expression (CTE) is a temporary result set that can be used within a SQL statement, typically a SELECT, INSERT, UPDATE or DELETE statement. CTEs are useful for creating self-contained queries that can be reused multiple times within a larger query or by other queries in a database. Here are some examples of SQL CTEs. Recursive CTE: A recursive Common Table Expression (CTE) is used…
View On WordPress
0 notes
Text
2022 Year in Review
The past year has been a whirlwind and yet New Years has also come/landed as a complete surprise. I looked through my blog archive the other day and I realized I never did a year round up last year so this will be 2021 and 2022 in review of sorts.
The biggest change is that I have changed jobs and departments this year at MPOW and moved into a role that is generating reports using SQL as opposed to Oracle’s GUI interface PSQuery tool. I had gotten good about using CASE statements and expressions to work around PSQuery’s limitations though it was great to start working directly with the database.
The concept behind using PSQuery and direct/raw SQL is the same though now I get to use features like CTE tables and also have more control over the join criteria and functions. Still, it has been like taking a drink from a fire hose in terms of learning new skills, and tools (I ask using Dbeaver as my IDE in case you’re wondering; it is great.).
In late-breaking esque news, I have been enjoying my time on Mastadon on the Libraryland Server. It reminds me of the early birdsite where you had interactions with folks and your timeline didn't get bombarded with updates. I also like how it is federated like email so you're not tied to one instance and you can interact with anyone. If you're interested in finding me on Mastadon you can find me at @[email protected].
I have continued my journey in personal knowledge management tools and processes (i.e. PKM) and relatedly was overjoyed to be added to the Documentation working group at MPOW. I still LOVE software and enjoy trying new tools, which means I have used Apple Notes, Agenda, Obsidian, Notion, Craft, and OneNote at various times. I have settled on Agenda for home-related notes, Obsidian for personal writing, and OneNote at work (though I looking forward to Microsoft Loop being more widely available).
I hope the new year brings more skill growth and also more time to write (though I have said that before and made promises to do better before too) I am trying to give myself grace though rather than sticking to a strict schedule or trying to maintain something I can’t manage. I hope everyone has a great day, and a wonderful year.
0 notes
Text
[PDF/ePub] SQL Cookbook: Query Solutions and Techniques for All SQL Users - Anthony Molinaro
Download Or Read PDF SQL Cookbook: Query Solutions and Techniques for All SQL Users - Anthony Molinaro Free Full Pages Online With Audiobook.

[*] Download PDF Here => SQL Cookbook: Query Solutions and Techniques for All SQL Users
[*] Read PDF Here => SQL Cookbook: Query Solutions and Techniques for All SQL Users
You may know SQL basics, but are you taking advantage of its expressive power? This second edition applies a highly practical approach to Structured Query Language (SQL) so you can create and manipulate large stores of data. Based on real-world examples, this updated cookbook provides a framework to help you construct solutions and executable examples in severalflavors of SQL, including Oracle, DB2, SQL Server, MySQL, andPostgreSQL.SQL programmers, analysts, data scientists, database administrators, and even relatively casual SQL users will find SQL Cookbook to be a valuable problem-solving guide for everyday issues. No other resource offers recipes in this unique format to help you tackle nagging day-to-day conundrums with SQL.The second edition includes:Fully revised recipes that recognize the greater adoption of window functions in SQL implementationsAdditional recipes that reflect the widespread adoption of common table expressions (CTEs) for more readable, easier-to-implement
0 notes
Text
CTE in SQL
Ortak Tablo İfadeleri (CTE), türetilmiş bir tablonun uygun olmadığı çeşitli SQL Sorguları sınıflarını basitleştirmek için standart SQL’e dahil edildi. CTE, SQL Server 2005’te tanıtıldı, ortak tablo ifadesi (CTE), bir SELECT, INSERT, UPDATE veya DELETE deyiminde başvurabileceğiniz geçici bir adlandırılmış sonuç kümesidir. Görünümün SELECT sorgusunun bir parçası olarak CREATE a view içinde de bir…
View On WordPress
0 notes
Text
Как лучше настроить GPORCA для оптимизации SQL-запросов в Greenplum
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают таблицы без статистики.
Что такое GPORCA: краткий ликбез по оптимизаторам SQL-запросов в Greenplum
Напомним, в Greenplum есть два оптимизатора SQL-запросов: встроенный на основе PostgreSQL-планировщика и более быстрый ORCA-вариант, который называется GPORCA. Ориентируясь на область Big Data, GPORCA расширяет возможности планирования и оптимизации PostgreSQL-планировщика в средах с многоядерной архитектурой. В частности, GPORCA улучшает настройку производительности SQL-запросов к партиционированным таблицам, поддерживая CTE-запросы с общими табличными выражениями и с подзапросами.По умолчанию в этой MPP-СУБД используется именно GPORCA, с версии 6.13 применяя методы динамического программирования для многосторонних соединений таблиц и «жадные» алгоритмы оптимизации для ускорения SQL-запросов. В Greenplum 6.14 оптимизатор GPORCA включает обновления, который еще более сокращают время оптимизации и улучшают планы выполнения SQL-запросов для больших соединений . Подробно о том, какие именно математические алгоритмы обеспечивают быстроту работы GPORCA-оптимизаторы, мы писали здесь. А сейчас детально рассмотрим некоторые особенности этого компонента Greenplum и Arenadata DB.
Тонкости ORCA-оптимизатора и лучшие практики его настройки
GPORCA позволяет выполнять update поля партиционирования и дистрибуции, однако, этот оптимизатор очень требователен к статистике таблиц, собрать которую помогает оператор ANALYZE . Как рабоатет этот оператор, мы рассказывали здесь. Официальная документация Greenplum отмечает, что для эффективного выполнения SQL-запроса с помощью GPORCA, он должен соответствовать следующим критериям :- ключи партиционирования заданы по одному, а не по нескольким столбцам таблицы; - многоуровневая партиционированная таблица является унифицированной. Это означает, что она создана с помощью предложения SUBPARTITION в выражении CREATE TABLE и имеет единообразную структуру для каждого узла раздела на одном уровне иерархии. Ограничения ключа раздела тоже согласованны и единообразны, а также совпадают для дочерних таблиц. При этом названия разделов могут быть разными. - Параметр конфигурации сервера optimizer_enable_master_only_queries включен при работе только с основными таблицами, такими как системная таблица pg_attribute. Поскольку общее включение этого параметра снижает производительность коротких запросов к каталогу, его необходимо задавать только для сеанса или отдельного SQL-запроса. - Статистика собрана в корневом разделе партиционированной таблицы. - Рекомендуется, чтобы число разделов в партиционированной таблице не превышало 20 000. Иначе следует рассмотреть возможность изменения ее схемы. На обработку SQL-запросов с помощью GPORCA влияют следующие параметры конфигурации сервера Greenplum :- optimizer_cte_inlining_bound – управляет объемом строк для CTE-запросов с условием WHERE. - optimizer_force_multistage_agg – указывает GPORCA на выбор многоступенчатого агрегатного плана для отдельного скалярного агрегата. Когда это значение выключено (по умолчанию), GPORCA выбирает между одноэтапным и двухэтапным агрегированным планом в зависимости от стоимости SQL-запроса, что мы разбирали в этой статье. - optimizer_force_three_stage_scalar_dqa – указывает GPORCA на выбор плана с многоступенчатыми агрегатами. - optimizer_join_order – устанавливает уровень оптимизации запроса для упорядочивания соединений, указывая, какие типы альтернативных вариантов следует оценивать. Про операторы JOIN-соединений в Greenplum читайте здесь. - optimizer_join_order_threshold – указывает максимальное количество дочерних элементов соединения, для которых GPORCA использует алгоритм упорядочения соединений на основе динамического программирования. - optimizer_nestloop_factor – управляет коэффициентом стоимости соединения вложенного цикла (Nested Loop Join) при оптимизации SQL-запроса. - optimizer_parallel_union – контролирует степень распараллеливания для запросов с UNION или UNION ALL. Если этот параметр включен, GPORCA может сгенерировать план запроса дочерних операций для UNION или UNION ALL, выполняемых параллельно на экземплярах сегмента Greenplum. - optimizer_sort_factor – контролирует фактор стоимости к операциям сортировки во время оптимизации запроса, позволяя корректировать его при наличии перекоса данных. - gp_enable_relsize_collection – управляет тем, как GPORCA и PostgreSQL- планировщик обрабатывают таблицу без статистики. Если она недоступна, GPORCA использует значение по умолчанию для оценки количества строк. Когда это значение включено, GPORCA использует оценочный размер таблицы. Для корневого раздела партиционированной таблицы этот параметр игнорируется – при отсутствии статистики для нее GPORCA всегда использует значение по умолчанию. Можно использовать оператор ANALZYE ROOTPARTITION для сбора статистики по корневому разделу. А следующие параметры конфигурации сервера Greenplum управляют отображением и логированием информации :- optimizer_print_missing_stats (по умолчанию true) управляет отображением информации о столбце (команда display) при отсутствии статистики для запроса; - optimizer_print_optimization_stats контролирует логирование метрик GPORCA-оптимизатора для SQL-запроса (по умолчанию выключено). Для каждого запроса GPORCA создает мини-дампы с описанием контекста оптимизации, которые используются службой поддержки VMware для анализа проблем с Greenplum. Файлы минидампа находятся в каталоге основных данных и называются следующим образом Minidump_date_time.mdp. Когда команда EXPLAIN ANALYZE использует GPORCA, в плане показывается только количество удаляемых разделов, а все просканированные разделы не отображаются. Чтобы имя просканированных разделов отображалось в логах сегментов Greenplum, следует включить параметр конфигурации сервера:SET gp_log_dynamic_partition_pruning = on. В заключение отметим, что при работе с распределенными СУБД для оптимизации SQL-запроса важен не только он, но и особенности хранения данных. В Greenplum они физически хранятся на разных сегментах, разделенные случайным образом или по значению хэш-функции от одного или нескольких полей. Рекомендуются следующие советы по выбору этого поля, называемого ключ дистрибуции :- минимум NULL- значений, которые будут распределены на один сегмент, что может привести к перекосу данных - тип данных integer, с которым лучше всего работает часто используемый вариант соединения таблиц Hash Join; - более одного поля в ключе дистрибуции увеличивает время хэширования и часто требуют передачи данных между сегментами Greenplum при соединении таблиц. - заданный ключ дистрибуции обычно лучше случайного; - для оптимального соединения таблиц одинаковые значения должны быть расположены на одном сегменте Greenplum, а тип полей в Join-условии должен быть одинаков во всех таблицах. - Не следует использовать в качестве ключей дистрибуции поля, которые используются при фильтрации запросов с выражением WHERE из-за неравномерного распределения нагрузки. - Не стоит использовать один и тот же столбец в качестве ключа партиционирования и дистрибуции, т.к. в этом случае SQL-запрос будет выполняться целиком на одном сегменте, исключая преимущества распараллеливания. Освойте администрирование и эксплуатацию Greenplum на примере Arenadata DB или в виде отдельного продукта для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения ква��ификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:- Greenplum для инженеров данных - Эксплуатация Arenadata DB + сертификация - Arenadata DB для разработчиков + сертификация Источники 1. https://greenplum.org/faster-optimization-of-join-queries-in-orca/ 2. https://habr.com/ru/company/rostelecom/blog/442758/ 3. https://gpdb.docs.pivotal.io/6-17/admin_guide/query/topics/query-piv-opt-overview.html Read the full article
0 notes
Text
50 Sql Question Questions You Need To Practice For Meeting
You can choose distinct records from a table by using the UNIQUE key words. Trigger in SQL is are a special sort of kept treatments that are defined to execute instantly in position or after information adjustments. It allows you to execute a set of code when an insert, update or any other question is implemented against a details table. DECLINE command removes a table and also it can not be rolled back from the database whereas TRUNCATE command removes all the rows from the table. This index does not permit the area to have replicate worths if the column is distinct indexed. Durability indicates that once a deal has been devoted, it will certainly remain so, also in case of power loss, crashes, or errors. In a relational database, for example, when a group of SQL statements perform, the outcomes need to be stored completely.

The SELECT declaration is used as a partial DML declaration, utilized to select all or relevant records in the table. sites is used to access the data from higher or lower regular type of data source. It additionally refines redundancy right into a table by including data from the related tables. Denormalization adds needed repetitive term into the tables to make sure that we can stay clear of using complicated signs up with and lots of various other complex procedures. t mean that normalization will certainly not be done, however the denormalization procedure happens after the normalization process. Visualize a single column in a table that is occupied with either a solitary figure (0-9) or a solitary personality (a-z, A-Z). Create a SQL inquiry to print 'Fizz' for a numerical value or 'Buzz' for indexed worth for all worths in that column. Lastly utilize the DEALLOCATE declaration to erase the cursor interpretation as well as launch the linked sources. Gathering index can boost the efficiency of most query operations because they provide a linear-access path to information saved in the database. DeNormalization is a strategy utilized to access the information from higher to decrease typical kinds of data source. It is likewise process of presenting redundancy into a table by including data from the related tables. Normalization is the procedure of decreasing redundancy and also dependence by arranging areas and also table of a data source. The major aim of Normalization is to add, delete or customize area that can be made in a solitary table. APrimary keyis a column or a set of columns that distinctly recognizes each row in the table. The information saved in the data source can be customized, retrieved as well as erased as well as can be of any kind of type like strings, numbers, photos and so on. A CTE or common table expression is an expression which contains momentary result collection which is specified in a SQL declaration. By utilizing UNIQUE keyword duplicating records in a inquiry can be stayed clear of. When saved in look what i found , varchar2 uses only the alloted room. E.g. if you have a varchar2 and placed 50 bytes in the table, it will make use of 52 bytes. Stored Procedure is a feature consists of several SQL statement to access the database system. Several SQL statements are consolidated into a stored procedure and perform them whenever as well as any place needed. SQL represents Structured Inquiry Language is a domain name particular shows language for handling the information in Database Management Solution. SQL programs skills are extremely desirable and called for in the marketplace, as there is a massive use of Data source Administration Systems in almost every software application. So as to get a job, candidates require to split the interview in which they are asked various SQL meeting inquiries. A Stored Treatment is a function which consists of many SQL statements to access the data source system. Numerous SQL declarations are consolidated right into a saved procedure as well as execute them whenever as well as anywhere called for which conserves time and avoid creating code repeatedly. If a main key is defined, a unique index can be used automatically. An index describes a performance adjusting approach of permitting quicker retrieval of records from the table. An index produces an entrance for each value as well as hence it will certainly be faster to retrieve data. Denormalization refers to a strategy which is used to accessibility information from greater to reduce types of a data source. It aids the database managers to increase the efficiency of the entire framework as it presents redundancy into a table. It adds the redundant data right into a table by integrating database questions that incorporate information from numerous tables right into a solitary table. A DB inquiry is a code written in order to obtain the info back from the data source. Query can be developed in such a way that it matched with our expectation of the outcome set. Special index can be applied immediately when main key is defined. An index is efficiency tuning method of enabling faster access of documents from the table. An index creates an access for each and every value and it will be quicker to retrieve information. To defend against power loss, deals have to be taped in a non-volatile memory. Compose a inquiry to fetch values in table test_a that are and also not in test_b without making use of the NOT search phrase. https://tinyurl.com/c7k3vf9t is a instance of normal join where a table is joined to itself based upon some relationship between its very own column. Self-join uses the INNER SIGN UP WITH or LEFT JOIN provision and a table pen name is made use of to designate different names to the table within the inquiry. In this guide you will locate a collection of real life SQL meeting questions asked in business like Google, Oracle, Amazon.com and Microsoft etc. Each question includes a perfectly created solution inline, conserving your interview preparation time. TRUNCATE gets rid of all the rows from the table, as well as it can not be rolled back. An Index is an special structure related to a table speed up the performance of questions. Index can be created on one or more columns of a table. A table can have only one PRIMARY TRICK whereas there can be any variety of UNIQUE secrets. Primary trick can not include Void worths whereas Special key can consist of Null worths. MINUS - returns all unique rows selected by the very first inquiry yet not by the 2nd. UNION - returns all distinct rows chosen by either query UNION ALL - returns all rows selected by either query, including all matches. DECLINE command gets rid of a table from the data source as well as operation can not be rolled back. MINUS driver is used to return rows from the very first query yet not from the second query. Matching records of very first and 2nd inquiry and also other rows from the initial query will certainly be presented because of this collection. Cross join defines as Cartesian product where number of rows in the very first table multiplied by number of rows in the second table. If mean, WHERE stipulation is made use of in cross join then the question will certainly function like an INTERNAL JOIN. https://is.gd/snW9y3 does not modify the method it was stored but develops a complete different object within the table. It aim back to the original table rows after looking. Thinking about the data source schema displayed in the SQLServer-style representation below, write a SQL question to return a list of all the billings. For each billing, show the Invoice ID, the billing date, the consumer's name, as well as the name of the client that referred that customer. DECLARE a cursor after any kind of variable affirmation. The cursor affirmation have to constantly be connected with a SELECT Declaration. The OPEN declaration must be called in the past bring rows from the result collection. FETCH declaration to retrieve and also transfer to the following row in the result collection. Call the CLOSE statement to shut off the cursor.
0 notes
Text
Download (PDF) SQL Cookbook: Query Solutions and Techniques for All SQL Users - Anthony Molinaro

Read/Download Visit : https://tt.kindleebs.xyz/?book=1492077445
Book Synopsis :
You may know SQL basics, but are you taking advantage of its expressive power? This second edition applies a highly practical approach to Structured Query Language (SQL) so you can create and manipulate large stores of data. Based on real-world examples, this updated cookbook provides a framework to help you construct solutions and executable examples in severalflavors of SQL, including Oracle, DB2, SQL Server, MySQL, andPostgreSQL.SQL programmers, analysts, data scientists, database administrators, and even relatively casual SQL users will find SQL Cookbook to be a valuable problem-solving guide for everyday issues. No other resource offers recipes in this unique format to help you tackle nagging day-to-day conundrums with SQL.The second edition includes:Fully revised recipes that recognize the greater adoption of window functions in SQL implementationsAdditional recipes that reflect the widespread adoption of common table expressions (CTEs) for more readable, easier-to-implement
0 notes