#CacheManagement
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
How to Increase Battery Life on Android

Increase Battery Life on Android: Image By Christopher Kidobi
Maximizing Your Android's Battery Life: Tips and Tricks for the Modern User
Your Android phone is a technological marvel, but what use is it if the battery dies halfway through the day? With countless apps, updates, and features available on our devices, it's essential to understand which of these have the most impact on battery life and how we can make smarter choices for longer-lasting power. Let's break it down: 1. Screen Brightness: Light on Battery, Heavy on Power Dimming the screen or enabling adaptive brightness is one of the most direct ways to improve battery longevity. The brighter your screen, the faster your battery depletes. 2. Notifications: Less is More Every time your phone buzzes with an app update, it's using power. Restrict notifications for apps that aren’t crucial. Trust us; not every app deserves to interrupt your day. 3. Battery Saver Mode: Your Low-Power Lifeline Battery Saver mode is Android's built-in feature for those critical battery moments. It minimizes background activities and offers a simpler interface to conserve what's left of your battery. 4. Background Activities: It’s What's Behind That Counts Hidden from view, many apps are hard at work. Dive into your settings and limit unnecessary background processes. A little effort can bring considerable energy savings. 5. Know Your Apps: The Power Players Regularly monitor which apps are the main culprits of battery drain. If an app seems too power-hungry, it's time for a rethink. Could there be a more efficient alternative? 6. Update and Elevate: The Fresh Approach Keeping your apps updated is not only about the latest features. More often than not, these updates include fixes and optimizations that boost battery efficiency. 7. Dark Mode: Easy on the Eyes and Battery For OLED or AMOLED screen users, dark mode isn't just a visual preference; it’s a battery saver. These screens consume less power displaying darker colors. 8. Location, Location, Location While location services enhance app functionality, not all apps need to know where you are. Fine-tune these settings to strike a balance between functionality and battery preservation. 9. Smart Connectivity: Only Connect When Necessary Turning off Wi-Fi, Bluetooth, or mobile data when they're not in use can be a game-changer. And if you're in a low-signal area, airplane mode can prevent battery drain from signal searching. 10. Sync Wisely Limit how often your apps sync data. Few apps require constant updates; for others, occasional syncing will do the trick. 11. Wi-Fi Over Mobile Data: A Power-Friendly Choice Given a choice between Wi-Fi and mobile data, always opt for Wi-Fi. It's generally gentler on your battery. 12. Widgets: Keep It Simple While widgets can offer quick info at a glance, they can also be silent battery drainers. Keep only the essential ones and remove the rest. 13. Sleep Tight: Faster Sleep Settings Trim down the time it takes for your phone to sleep after use. The quicker it rests, the more battery you save. 14. Cache In On Savings Regularly clearing your app cache can not only free up space but also potentially reduce unexpected battery drains. 15. Beware of Rogue Apps Always source your apps from reputable platforms and be on the lookout for any app that seems excessively power-hungry. When in doubt, uninstall. Also Read: How to clear cache on Android Futures of Increase Battery Life on Android - Adaptive AI Integration: Future Android systems will likely use more advanced artificial intelligence to learn user behavior, thereby optimizing battery usage based on individual patterns. - Advanced Dark Modes: As OLED and AMOLED screens become more common, advanced dark modes that further reduce power consumption might be developed. - Context-Aware Battery Management: Systems might adjust battery usage based on the user's context. For instance, saving more power during a user's typical sleep hours. - Better Background Management: Enhanced algorithms to determine which background processes are truly essential, leading to even fewer unnecessary background activities. - Integration with IoT: As homes and devices get smarter, Android devices might optimize battery based on surrounding connected devices. Also Read: How to Remove Bloatware on Android? 5 Simple Steps Benefits of Increase Battery Life on Android - Extended Battery Lifespan: By managing charge cycles more effectively, the overall lifespan of the battery could be improved. - Improved Device Performance: Less unnecessary background activity means more resources for the tasks you're actively engaging in. - Seamless User Experience: With adaptive features, the user won’t need to manually adjust settings as frequently. - Cost Savings: Optimizing battery usage can reduce the frequency of battery replacements or even device replacements. - Environmental Impact: Longer-lasting devices and batteries lead to less electronic waste. Optimizing your Android battery life is a blend of understanding its functions and adopting good habits. Armed with these tips, you're well on your way to making the most of your device throughout the day. Happy optimizing! Frequently Asked Questions (FAQs) Q1: What is Adaptive Brightness and how does it save battery? A1: Adaptive Brightness is a feature that automatically adjusts the screen brightness based on your environment and usage patterns. It can save battery by using only as much backlight as necessary, depending on the ambient light and your preferences. Q2: How often should I update my apps for better battery performance? A2: Regular updates are recommended. Developers constantly release optimizations and bug fixes that can enhance battery efficiency. Ideally, you should check for updates every couple of weeks. Q3: Is Dark Mode beneficial for all screen types? A3: Dark Mode is especially beneficial for OLED and AMOLED screens since these displays consume less power for dark pixels. However, the benefits might be minimal for LCD screens. Q4: How do I know if an app is draining too much battery? A4: Navigate to Settings > Battery. Here, you can see a breakdown of battery usage by app. If an app you don't use often shows high battery consumption, it might be worth investigating. Q5: Will constantly turning Wi-Fi and Bluetooth on and off affect my device? A5: Frequently toggling Wi-Fi and Bluetooth won't harm your device. However, the small battery savings from turning them off might be offset by the power used to turn them back on, especially if done very frequently in short intervals. Q6: What's the difference between clearing app cache and app data? A6: Clearing the app cache removes temporary files which might speed up your device and resolve minor glitches. Clearing app data, on the other hand, removes all files, settings, and accounts associated with the app. The latter is more drastic and will reset the app to its initial state. Q7: Can rogue apps damage my battery permanently? A7: While rogue apps can drain your battery faster, they're unlikely to cause permanent damage. However, consistently running your battery down to 0% or exposing it to extreme temperatures can be harmful in the long run. Q8: How does Battery Saver Mode differ from regular usage? A8: Battery Saver Mode reduces device performance, limits background processes, and may reduce features like vibration or location services to conserve power. It provides an essential, lower-power mode to extend battery life when needed. Q9: How can I ensure my app notifications aren’t draining my battery? A9: Limit notifications to only essential apps. Each notification can wake up your screen and use power. Go to Settings > Apps & notifications > > Notifications to manage these settings for individual apps. Q10: Why should I choose Wi-Fi over mobile data? A10: Wi-Fi is generally more power-efficient than mobile data. Cellular data requires your device to communicate with cell towers, which can be a more power-intensive process, especially if the signal is weak. https://howtoin1minute.com/ Read the full article
#Technology#Android#AppUpdates#BackgroundProcesses#BatteryLifespan#BatteryOptimization#CacheManagement#ConnectivityManagement#DarkMode#howto#LocationServices
0 notes
Text
Using Splunk SmartStore with MinIO
Update - MinIO now provide a guide for setting up Splunk SmartStore with MinIO
Your Splunk server is gobbling up disk space and you don’t want to upgrade your disks. What to do?
My initial solution was to use frozen buckets to limit data retention by setting the following in ~splunk/etc/system/local/indexes.conf:
[default] coldToFrozenDir = /opt/frozen-archives frozenTimePeriodInSecs = 39000000
Any buckets older than the frozen time period would be moved into this frozen-archives directory, from where I would periodically archive them to another machine, from which they would be completely inaccessible but I felt a little better knowing that they hadn't just been deleted.
Eventually due to increasing data volumes, I found that I was still running low on disk space. The next option was to split indexes up and apply different retention policues to these. There are some log data which are useful for short term investigations, but I don't need much retention. These were set to just erase data after the frozen time period. Eventually I started running out of disk space again!
A while back, Splunk added support for Amazon S3 storage using something called SmartStore, which copies warm buckets to remote storage. It can then evict them from the local index at its leisure, and then bring them back when they are needed. This sounds like just what I want! I had a heck of a time getting it working though.
The first problem was that I wanted to use MinIO instead of Amazon S3. S3 is pretty inexpensive, but in this case I had another 'storage' VPS at the same hosting provider with plenty of disk space and free gigabit intra-VPS transmit. Here's how I got it working!
On the storage server
Download minio
Create configuration for it:
MINIO_VOLUMES="/home/minio/data" MINIO_OPTS="--address 127.0.0.1:9000 --compat" MINIO_ACCESS_KEY=??? MINOI_SECRET_KEY=???
Set up a systemd unit file for it
Set up nginx as a reverse proxy. This is mainly so that I can use certbot and Let's Encrypt:
server { listen 9001 ssl http2; listen [::]:9001 ssl http2; server_name minio.example.com; ssl_certificate /etc/letsencrypt/live/minio.example.com/fullchain.pem; # managed by Certbot ssl_certificate_key /etc/letsencrypt/live/minio.example.com/privkey.pem; # managed by Certbot ignore_invalid_headers off; # Allow any size file to be uploaded. # Set to a value such as 1000m; to restrict file size to a specific value client_max_body_size 0; # To disable buffering proxy_buffering off; location / { proxy_set_header Host $http_host; proxy_pass http://localhost:9000; # health_check uri=/minio/health/ready; } }
On the Splunk server
In indexes.conf, configure a remote store:
[volume:remote_store] storageType = remote path = s3://splunk/ # Replace splunk with whatever you want to call it remote.s3.access_key = # from minio's configuration remote.s3.secret_key = # from minio's configuration remote.s3.endpoint = https://minio.example.com:9001/ remote.s3.auth_region = us-east-1
Add some file to the MinIO container (I think you can just copy something in there manually on the filesystem) and then confirm that Splunk can see the file:
~splunk/bin/splunk cmd splunkd rfs -- ls --starts-with volume:remote_store
Then you can add the following for a specific index
[fooindex] remotePath = volume:remote_store/fooindex # The following two lines are apparently required, but ignored coldPath = $SPLUNK_DB/main/colddb thawedPath = $SPLUNK_DB/main/thaweddb
Restart Splunk
Monitor splunkd.log for activity by S3Client, BucketMover, and CacheManager
The configuration settings are a bit opaque and confusing. As far as I can tell, it will just start uploading warm buckets as it feels like it, and then evict them on a least recently used basis when you get close to your minimum free disk space.
Gotchas
Do not apply a remotePath to the [default] index. I did this (by mistake) and while data started uploading happily, it seemed like the frozen time retention policies of different indexes started to stomp over each other, so files were frozen (actually - deleted) from remote storage, probably according to the retention policy of the index with the smallest retention time. This was a bit of a disaster. It might work if you do remotePath=volume:remote_store/$_index_name.
It seems like Splunk requires MinIO to be run with the --compat parameter. I had a lot of trouble getting it to work without that.
MinIO isn't quite as full-featured as S3 - if you want to have different access keys for different users/purposes, I guess you're meant to run another instance of the servers. I wasted a lot of time trying to set up different keys and access levels, all of which kind of look like they are supported but don't really work the way you expect.
0 notes
Text
CacheManage
CacheManage for Android.
from The Android Arsenal http://ift.tt/2z0W0pU
1 note
·
View note
Text
Running an Infinispan server using Testcontainers
Recently I discovered a library called Testcontainers. I already wrote about using it on my current project here. It helps you to run software that your application depends on in a test context by providing an API to start docker containers. It’s implemented as a JUnit 4 rule currently, but you can also use it manually with JUnit 5. Native support for JUnit 5 is on the roadmap for the next major release. Testcontainers comes with a few pre-configured database- and selenium-containers, but most importantly it also provides a generic container that you can use to start whatever docker image you need to.
In my current project we are using Infinispan for distributed caching. For some of our integration tests caching is disabled, but others rely on a running Infinispan instance. Up until now we are using a virtual machine to run Infinispan and other software on developer machines and build servers. The way we are handling this poses a few problems and isolated Infinispan instances would help mitigate these. This post shows how you can get Infinispan running in a generic container. I’ll also try to come up with a useful abstraction that makes running Infinispan as a test container easier.
Configuring a generic container for Infinispan
Docker Hub provides a readymade Infinispan image: jboss/infinispan-server. We’ll be using the latest version at this time, which is 9.1.3.Final. Our first attempt to start the server using Testcontainers looks like this:
@ClassRule public static GenericContainer infinispan = new GenericContainer("jboss/infinispan-server:9.1.3.Final"); @Before public void setup(){ cacheManager = new RemoteCacheManager(new ConfigurationBuilder() .addServers(getServerAddress()) .version(ProtocolVersion.PROTOCOL_VERSION_26) .build()); } @Test public void should_be_able_to_retrieve_a_cache() { assertNotNull(cacheManager.getCache()); } private String getServerAddress() { return infinispan.getContainerIpAddress() + ":" + infinispan.getMappedPort(11222); }
You can see a few things here:
We’re configuring our test class with a class rule that will start a generic container. As a parameter, we use the name of the infinispan docker image alongside the required version. You could also use latest here.
There’s a setup method that creates a RemoteCacheManager to connect to the Infinispan server running inside the docker container. We extract the network address from the generic container and retrieve the container IP address and the mapped port number for the hotrod port in getServerAddress()
Then there’s a simple test that will make sure we are able to retrieve an unnamed cache from the server.
Waiting for Infinispan
If we run the test, it doesn’t work and throws a TransportException, though. It mentions an error code that hints at a connection problem. Looking at other pre-configured containers, we see that they have some kind of waiting strategy in place. This is important so that the test only starts after the container has fully loaded. The PostgreSQLContainer waits for a log message, for example. There’s other wait strategies available and you can implement your own, as well. One of the default strategies is the HostPortWaitStrategy and it seems like a straightforward choice. With the Infinispan image at least, it doesn’t work though: one of the commands that is used to determine the readiness of the tcp port has a subtle bug in it and the other relies on the netcat command line tool being present in the docker image. We’ll stick to the same approach as the PostgreSQLContainer rule and check for a suitable log message to appear on the container’s output. We can determine a message by manually starting the docker container on the command line using:
docker run -it jboss/infinispan-server:9.1.3.Final.
The configuration of our rule then changes to this:
@ClassRule public static GenericContainer container = new GenericContainer("jboss/infinispan-server:9.1.3.Final") .waitingFor(new LogMessageWaitStrategy() .withRegEx(".*Infinispan Server.*started in.*\\s"));
After this change, the test still doesn’t work correctly. But at least it behaves differently: It waits for a considerable amount of time and again throws a TransportException before the test finishes. Since the underlying TcpTransportFactory swallows exceptions on startup and returns a cache object anyway, the test will still be green. Let’s address this first. I don’t see a way to ask the RemoteCacheManager or the RemoteCache about the state of the connection, so my approach here is to work with a timeout:
private ExecutorService executorService = Executors.newCachedThreadPool(); @Test public void should_be_able_to_retrieve_a_cache() throws Exception { Future> result = executorService.submit(() -> cacheManager.getCache()); assertNotNull(result.get(1500, TimeUnit.MILLISECONDS)); }
The test will now fail should we not be able to retrieve the cache within 1500 milliseconds. Unfortunatly, the resulting TimeoutException will not be linked to the TransportException, though. I’ll take suggestions for how to better write a failing test and leave it at that, for the time being.
Running Infinispan in standalone mode
Looking at the stacktrace of the TransportException we see the following output:
INFO: ISPN004006: localhost:33086 sent new topology view (id=1, age=0) containing 1 addresses: [172.17.0.2:11222] Dez 14, 2017 19:57:43 AM org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory updateTopologyInfo INFO: ISPN004014: New server added(172.17.0.2:11222), adding to the pool.
It looks like the server is running in clustered mode and the client gets a new server address to talk to. The IP address and port number seem correct, but looking more closely we notice that the hotrod port 11222 refers to a port number inside the docker container. It is not reachable from the host. That’s why Testcontainers gives you the ability to easily retrieve port mappings. We already use this in our getServerAddress() method. Infinispan, or rather the hotrod protocol, however is not aware of the docker environment and communicates the internal port to the cluster clients overwriting our initial configurtation.
To confirm this analysis we can have a look at the output of the server when we start the image manually:
19:12:47,368 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (MSC service thread 1-6) ISPN000078: Starting JGroups channel clustered 19:12:47,371 INFO [org.infinispan.CLUSTER] (MSC service thread 1-6) ISPN000094: Received new cluster view for channel cluster: [9621833c0138|0] (1) [9621833c0138] ... Dez 14, 2017 19:12:47,376 AM org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory updateTopologyInfo INFO: ISPN004016: Server not in cluster anymore(localhost:33167), removing from the pool.
The server is indeed starting in clustered mode and the documentation on Docker Hub also confirms this. For our tests we need a standalone server though. On the command line we can add a parameter when starting the container (again, we get this from the documentation on Docker Hub):
$ docker run -it jboss/infinispan-server:9.1.3.Final standalone
The output now tells us that Infinispan is no longer running in clustered mode. In order to start Infinispan as a standalone server using Testcontainers, we need to add a command to the container startup. Once more we change the configuration of the container rule:
@ClassRule public static GenericContainer container = new GenericContainer("jboss/infinispan-server:9.1.3.Final") .waitingFor(new LogMessageWaitStrategy() .withRegEx(".*Infinispan Server.*started in.*\\s")) .withCommand("standalone");
Now our test now has access to an Infinispan instance running in a container.
Adding a specific configuration
The applications in our project use different caches, these can be configured in the Infinispan standalone configuration file. For our tests, we need them to be present. One solution is to use the .withClasspathResourceMapping() method to link a configuration file from the (test-)classpath into the container. This configuration file contains the cache configurations. Knowing the location of the configuration file in the container, we can once again change the testcontainer configuration:
public static GenericContainer container = new GenericContainer("jboss/infinispan-server:9.1.3.Final") .waitingFor(new LogMessageWaitStrategy() .withRegEx(".*Infinispan Server.*started in.*\\s")) .withCommand("standalone") .withClasspathResourceMapping( "infinispan-standalone.xml", "/opt/jboss/infinispan-server/standalone/configuration/standalone.xml", BindMode.READ_ONLY); @Test public void should_be_able_to_retrieve_a_cache() throws Exception { Future> result = executorService.submit(() -> cacheManager.getCache("testCache")); assertNotNull(result.get(1500, TimeUnit.MILLISECONDS)); }
Now we can retrieve and work with a cache from the Infinispan instance in the container.
Simplifying the configuration
You can see how it can be a bit of a pain getting an arbitrary docker image to run correctly using a generic container. For Infinispan we now know what we need to configure. But I really don’t want to think of all this every time I need an Infinispan server for a test. However, we can create our own abstraction similar to the PostgreSQLContainer. It contains the configuration bits that we discovered in the first part of this post and since it is an implementation of a GenericContainer, we can also use everything that’s provided by the latter.
public class InfinispanContainer extends GenericContainer { private static final String IMAGE_NAME = "jboss/infinispan-server"; public InfinispanContainer() { this(IMAGE_NAME + ":latest"); } public InfinispanContainer(final String imageName) { super(imageName); withStartupTimeout(Duration.ofMillis(20000)); withCommand("standalone"); waitingFor(new LogMessageWaitStrategy().withRegEx(".*Infinispan Server.*started in.*\\s")); } }
In our tests we can now create an Infinispan container like this:
@ClassRule public static InfinispanContainer infinispan = new InfinispanContainer();
That’s a lot better than dealing with a generic container.
Adding easy cache configuration
You may have noticed that I left out the custom configuration part here. We can do better by providing builder methods to create caches programatically using the RemoteCacheManager. Creating a cache is as easy as this:
cacheManager.administration().createCache("someCache", null);
In order to let the container automatically create caches we facilitate the callback method containerIsStarted(). We can overload it in our abstraction, create a RemoteCacheManager and use its API to create caches that we configure upfront:
... private RemoteCacheManager cacheManager; private Collection cacheNames; ... public InfinispanContainer withCaches(final Collection cacheNames) { this.cacheNames = cacheNames; return this; } @Override protected void containerIsStarted(final InspectContainerResponse containerInfo) { cacheManager = new RemoteCacheManager(new ConfigurationBuilder() .addServers(getServerAddress()) .version(getProtocolVersion()) .build()); this.cacheNames.forEach(cacheName -> cacheManager.administration().createCache(cacheName, null)); } public RemoteCacheManager getCacheManager() { return cacheManager; }
You can also retrieve the CacheManager from the container and use it in your tests. There’s also a problem with this approach: you can only create caches through the API if you use Hotrod protocol version 2.0 or above. I’m willing to accept that as it makes the usage in test really comfortable:
@ClassRule public static InfinispanContainer infinispan = new InfinispanContainer() .withProtocolVersion(ProtocolVersion.PROTOCOL_VERSION_21) .withCaches("testCache"); @Test public void should_get_existing_cache() { assertNotNull(infinispan.getCacheManager().getCache("testCache")); }
If you need to work with a protocol verision below 2.0, you can still use the approach from above, linking a configuration file into the container.
Conclusion
While it sounds very easy to run any docker image using Testcontainers, there’s a lot of configuration details to know, depending on the complexity of the software that you need to run. In order to effectivly work with such a container, it’s a good idea to encapsulate this in your own specific container. Ideally, these containers will end up in the Testcontainers repository and others can benefit of your work as well. I hope this will be useful for others, if you want to see the full code, have look at this repository.
The post Running an Infinispan server using Testcontainers appeared first on codecentric AG Blog.
Running an Infinispan server using Testcontainers published first on http://ift.tt/2fA8nUr
0 notes
Text
Running an Infinispan server using Testcontainers
Recently I discovered a library called Testcontainers. I already wrote about using it on my current project here. It helps you to run software that your application depends on in a test context by providing an API to start docker containers. It’s implemented as a JUnit 4 rule currently, but you can also use it manually with JUnit 5. Native support for JUnit 5 is on the roadmap for the next major release. Testcontainers comes with a few pre-configured database- and selenium-containers, but most importantly it also provides a generic container that you can use to start whatever docker image you need to.
In my current project we are using Infinispan for distributed caching. For some of our integration tests caching is disabled, but others rely on a running Infinispan instance. Up until now we are using a virtual machine to run Infinispan and other software on developer machines and build servers. The way we are handling this poses a few problems and isolated Infinispan instances would help mitigate these. This post shows how you can get Infinispan running in a generic container. I’ll also try to come up with a useful abstraction that makes running Infinispan as a test container easier.
Configuring a generic container for Infinispan
Docker Hub provides a readymade Infinispan image: jboss/infinispan-server. We’ll be using the latest version at this time, which is 9.1.3.Final. Our first attempt to start the server using Testcontainers looks like this:
@ClassRule public static GenericContainer infinispan = new GenericContainer("jboss/infinispan-server:9.1.3.Final"); @Before public void setup(){ cacheManager = new RemoteCacheManager(new ConfigurationBuilder() .addServers(getServerAddress()) .version(ProtocolVersion.PROTOCOL_VERSION_26) .build()); } @Test public void should_be_able_to_retrieve_a_cache() { assertNotNull(cacheManager.getCache()); } private String getServerAddress() { return infinispan.getContainerIpAddress() + ":" + infinispan.getMappedPort(11222); }
You can see a few things here:
We’re configuring our test class with a class rule that will start a generic container. As a parameter, we use the name of the infinispan docker image alongside the required version. You could also use latest here.
There’s a setup method that creates a RemoteCacheManager to connect to the Infinispan server running inside the docker container. We extract the network address from the generic container and retrieve the container IP address and the mapped port number for the hotrod port in getServerAddress()
Then there’s a simple test that will make sure we are able to retrieve an unnamed cache from the server.
Waiting for Infinispan
If we run the test, it doesn’t work and throws a TransportException, though. It mentions an error code that hints at a connection problem. Looking at other pre-configured containers, we see that they have some kind of waiting strategy in place. This is important so that the test only starts after the container has fully loaded. The PostgreSQLContainer waits for a log message, for example. There’s other wait strategies available and you can implement your own, as well. One of the default strategies is the HostPortWaitStrategy and it seems like a straightforward choice. With the Infinispan image at least, it doesn’t work though: one of the commands that is used to determine the readiness of the tcp port has a subtle bug in it and the other relies on the netcat command line tool being present in the docker image. We’ll stick to the same approach as the PostgreSQLContainer rule and check for a suitable log message to appear on the container’s output. We can determine a message by manually starting the docker container on the command line using:
docker run -it jboss/infinispan-server:9.1.3.Final.
The configuration of our rule then changes to this:
@ClassRule public static GenericContainer container = new GenericContainer("jboss/infinispan-server:9.1.3.Final") .waitingFor(new LogMessageWaitStrategy() .withRegEx(".*Infinispan Server.*started in.*\\s"));
After this change, the test still doesn’t work correctly. But at least it behaves differently: It waits for a considerable amount of time and again throws a TransportException before the test finishes. Since the underlying TcpTransportFactory swallows exceptions on startup and returns a cache object anyway, the test will still be green. Let’s address this first. I don’t see a way to ask the RemoteCacheManager or the RemoteCache about the state of the connection, so my approach here is to work with a timeout:
private ExecutorService executorService = Executors.newCachedThreadPool(); @Test public void should_be_able_to_retrieve_a_cache() throws Exception { Future> result = executorService.submit(() -> cacheManager.getCache()); assertNotNull(result.get(1500, TimeUnit.MILLISECONDS)); }
The test will now fail should we not be able to retrieve the cache within 1500 milliseconds. Unfortunatly, the resulting TimeoutException will not be linked to the TransportException, though. I’ll take suggestions for how to better write a failing test and leave it at that, for the time being.
Running Infinispan in standalone mode
Looking at the stacktrace of the TransportException we see the following output:
INFO: ISPN004006: localhost:33086 sent new topology view (id=1, age=0) containing 1 addresses: [172.17.0.2:11222] Dez 14, 2017 19:57:43 AM org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory updateTopologyInfo INFO: ISPN004014: New server added(172.17.0.2:11222), adding to the pool.
It looks like the server is running in clustered mode and the client gets a new server address to talk to. The IP address and port number seem correct, but looking more closely we notice that the hotrod port 11222 refers to a port number inside the docker container. It is not reachable from the host. That’s why Testcontainers gives you the ability to easily retrieve port mappings. We already use this in our getServerAddress() method. Infinispan, or rather the hotrod protocol, however is not aware of the docker environment and communicates the internal port to the cluster clients overwriting our initial configurtation.
To confirm this analysis we can have a look at the output of the server when we start the image manually:
19:12:47,368 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (MSC service thread 1-6) ISPN000078: Starting JGroups channel clustered 19:12:47,371 INFO [org.infinispan.CLUSTER] (MSC service thread 1-6) ISPN000094: Received new cluster view for channel cluster: [9621833c0138|0] (1) [9621833c0138] ... Dez 14, 2017 19:12:47,376 AM org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory updateTopologyInfo INFO: ISPN004016: Server not in cluster anymore(localhost:33167), removing from the pool.
The server is indeed starting in clustered mode and the documentation on Docker Hub also confirms this. For our tests we need a standalone server though. On the command line we can add a parameter when starting the container (again, we get this from the documentation on Docker Hub):
$ docker run -it jboss/infinispan-server:9.1.3.Final standalone
The output now tells us that Infinispan is no longer running in clustered mode. In order to start Infinispan as a standalone server using Testcontainers, we need to add a command to the container startup. Once more we change the configuration of the container rule:
@ClassRule public static GenericContainer container = new GenericContainer("jboss/infinispan-server:9.1.3.Final") .waitingFor(new LogMessageWaitStrategy() .withRegEx(".*Infinispan Server.*started in.*\\s")) .withCommand("standalone");
Now our test now has access to an Infinispan instance running in a container.
Adding a specific configuration
The applications in our project use different caches, these can be configured in the Infinispan standalone configuration file. For our tests, we need them to be present. One solution is to use the .withClasspathResourceMapping() method to link a configuration file from the (test-)classpath into the container. This configuration file contains the cache configurations. Knowing the location of the configuration file in the container, we can once again change the testcontainer configuration:
public static GenericContainer container = new GenericContainer("jboss/infinispan-server:9.1.3.Final") .waitingFor(new LogMessageWaitStrategy() .withRegEx(".*Infinispan Server.*started in.*\\s")) .withCommand("standalone") .withClasspathResourceMapping( "infinispan-standalone.xml", "/opt/jboss/infinispan-server/standalone/configuration/standalone.xml", BindMode.READ_ONLY); @Test public void should_be_able_to_retrieve_a_cache() throws Exception { Future> result = executorService.submit(() -> cacheManager.getCache("testCache")); assertNotNull(result.get(1500, TimeUnit.MILLISECONDS)); }
Now we can retrieve and work with a cache from the Infinispan instance in the container.
Simplifying the configuration
You can see how it can be a bit of a pain getting an arbitrary docker image to run correctly using a generic container. For Infinispan we now know what we need to configure. But I really don’t want to think of all this every time I need an Infinispan server for a test. However, we can create our own abstraction similar to the PostgreSQLContainer. It contains the configuration bits that we discovered in the first part of this post and since it is an implementation of a GenericContainer, we can also use everything that’s provided by the latter.
public class InfinispanContainer extends GenericContainer { private static final String IMAGE_NAME = "jboss/infinispan-server"; public InfinispanContainer() { this(IMAGE_NAME + ":latest"); } public InfinispanContainer(final String imageName) { super(imageName); withStartupTimeout(Duration.ofMillis(20000)); withCommand("standalone"); waitingFor(new LogMessageWaitStrategy().withRegEx(".*Infinispan Server.*started in.*\\s")); } }
In our tests we can now create an Infinispan container like this:
@ClassRule public static InfinispanContainer infinispan = new InfinispanContainer();
That’s a lot better than dealing with a generic container.
Adding easy cache configuration
You may have noticed that I left out the custom configuration part here. We can do better by providing builder methods to create caches programatically using the RemoteCacheManager. Creating a cache is as easy as this:
cacheManager.administration().createCache("someCache", null);
In order to let the container automatically create caches we facilitate the callback method containerIsStarted(). We can overload it in our abstraction, create a RemoteCacheManager and use its API to create caches that we configure upfront:
... private RemoteCacheManager cacheManager; private Collection cacheNames; ... public InfinispanContainer withCaches(final Collection cacheNames) { this.cacheNames = cacheNames; return this; } @Override protected void containerIsStarted(final InspectContainerResponse containerInfo) { cacheManager = new RemoteCacheManager(new ConfigurationBuilder() .addServers(getServerAddress()) .version(getProtocolVersion()) .build()); this.cacheNames.forEach(cacheName -> cacheManager.administration().createCache(cacheName, null)); } public RemoteCacheManager getCacheManager() { return cacheManager; }
You can also retrieve the CacheManager from the container and use it in your tests. There’s also a problem with this approach: you can only create caches through the API if you use Hotrod protocol version 2.0 or above. I’m willing to accept that as it makes the usage in test really comfortable:
@ClassRule public static InfinispanContainer infinispan = new InfinispanContainer() .withProtocolVersion(ProtocolVersion.PROTOCOL_VERSION_21) .withCaches("testCache"); @Test public void should_get_existing_cache() { assertNotNull(infinispan.getCacheManager().getCache("testCache")); }
If you need to work with a protocol verision below 2.0, you can still use the approach from above, linking a configuration file into the container.
Conclusion
While it sounds very easy to run any docker image using Testcontainers, there’s a lot of configuration details to know, depending on the complexity of the software that you need to run. In order to effectivly work with such a container, it’s a good idea to encapsulate this in your own specific container. Ideally, these containers will end up in the Testcontainers repository and others can benefit of your work as well. I hope this will be useful for others, if you want to see the full code, have look at this repository.
The post Running an Infinispan server using Testcontainers appeared first on codecentric AG Blog.
Running an Infinispan server using Testcontainers published first on http://ift.tt/2vCN0WJ
0 notes
Text
Apache JMeter updated to version 3.3, mix and match cloud services with Manifold and more
Apache JMeter updated to version 3.3, mix and match cloud services with Manifold and more
Apache JMeter 3.3 released
Open source software foundation Apache has released Apache JMeter 3.3, the latest version of their application testing software, bringing new features and bug fixes to the utility.
Highlighted changes to JMeter include support for decompression of the Brotli format in the HTTP Sampler, complete support for Vary headers in the CacheManager, latency computation in the…
View On WordPress
0 notes
Text
Multi Tiered Caching - Using in-process Cache in front of Distributed Cache
Via http://ift.tt/2oehwBA
Why Multi Tiered Caching? To improve application's performance, we usually cache data in distributed cache like redis/memcached or in-process cache like EhCache. Each have its own strengths and weaknesses: In-Process Cache is faster but it's hard to maintain consistency and can't store a lot of data; This can be easily solved when using a distributed cache, but it's slower due to network latency and serialization and deserialization.
In some cases, we may want to use both: mainly use a distributed cache to cache data, but also cache data that is small and doesn't change often (or at all) such as configuration in in-process cache.
The Implementation
Spring uses CacheManager to determine which cache implementation to use.
We define our own MultiTieredCacheManager and MultiTieredCache like below.
public class MultiTieredCacheManager extends AbstractCacheManager { private final List<CacheManager> cacheManagers; /** * @param cacheManagers - the order matters, when fetch data, it will check the first one if not * there, will check the second one, then back-fill the first one */ public MultiTieredCacheManager(final List<CacheManager> cacheManagers) { this.cacheManagers = cacheManagers; } @Override protected Collection<? extends Cache> loadCaches() { return new ArrayList<>(); } @Override protected Cache getMissingCache(final String name) { return new MultiTieredCache(name, cacheManagers); } } public class MultiTieredCache implements Cache { private static final Logger logger = LoggerFactory.getLogger(MultiTieredCache.class); private final List<Cache> caches = new ArrayList<>(); private final String name; public MultiTieredCache(final String name, @Nonnull final List<CacheManager> cacheManagers) { this.name = name; for (final CacheManager cacheManager : cacheManagers) { caches.add(cacheManager.getCache(name)); } } @Override public ValueWrapper get(final Object key) { ValueWrapper result = null; final List<Cache> cachesWithoutKey = new ArrayList<>(); for (final Cache cache : caches) { result = cache.get(key); if (result != null) { break; } else { cachesWithoutKey.add(cache); } } if (result != null) { for (final Cache cache : cachesWithoutKey) { cache.put(key, result.get()); } } return result; } @Override public <T> T get(final Object key, final Class<T> type) { T result = null; final List<Cache> noThisKeyCaches = new ArrayList<>(); for (final Cache cache : caches) { result = cache.get(key, type); if (result != null) { break; } else { noThisKeyCaches.add(cache); } } if (result != null) { for (final Cache cache : noThisKeyCaches) { cache.put(key, result); } } return result; } @Override public void put(final Object key, final Object value) { caches.forEach(cache -> cache.put(key, value)); } @Override public void evict(final Object key) { caches.forEach(cache -> cache.evict(key)); } @Override public void clear() { caches.forEach(cache -> cache.clear()); } @Override public String getName() { return name; } @Override public Object getNativeCache() { return this; } } @Configuration @EnableCaching public class CacheConfig extends CachingConfigurerSupport { @Bean @Primary public CacheManager cacheManager(EhCacheCacheManager ehCacheCacheManager, RedisCacheManager redisCacheManager) { if (!cacheEnabled) { return new NoOpCacheManager(); } // Be careful when make change - the order matters ArrayList<CacheManager> cacheManagers = new ArrayList<>(); if (ehCacheEnabled) { cacheManagers.add(ehCacheCacheManager); } if (redisCacheEnabled) { cacheManagers.add(redisCacheManager); } return new MultiTieredCacheManager(cacheManagers); } @Bean(name = EH_CACHE_CACHE_MANAGER) public EhCacheCacheManager ehCacheCacheManager() { final EhCacheManagerFactoryBean ehCacheManagerFactoryBean = new EhCacheManagerFactoryBean(); ehCacheManagerFactoryBean.setConfigLocation(new ClassPathResource("ehcache.xml")); ehCacheManagerFactoryBean.setShared(true); ehCacheManagerFactoryBean.afterPropertiesSet(); final EhCacheManagerWrapper ehCacheManagerWrapper = new EhCacheManagerWrapper(); ehCacheManagerWrapper.setCacheManager(ehCacheManagerFactoryBean.getObject()); return ehCacheManagerWrapper; } @Bean(name = "redisCacheManager") public RedisCacheManager redisCacheManager(final RedisTemplate<String, Object> redisTemplate) { final RedisCacheManager redisCacheManager = new RedisCacheManager(redisTemplate, Collections.<String>emptyList(), true); redisCacheManager.setDefaultExpiration(DEFAULT_CACHE_EXPIRE_TIME_IN_SECOND); redisCacheManager.setExpires(expires); redisCacheManager.setLoadRemoteCachesOnStartup(true); return redisCacheManager; } }
Misc Others things we can do when use multi (tiered) cache in CacheManager:
- We can use cache name prefix to determine which cache to use. - We can add logic to only cache some kinds of data in specific cache.
From lifelongprogrammer.blogspot.com
0 notes
Text
How to clear cache on Android
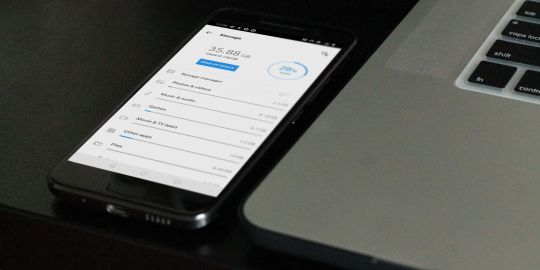
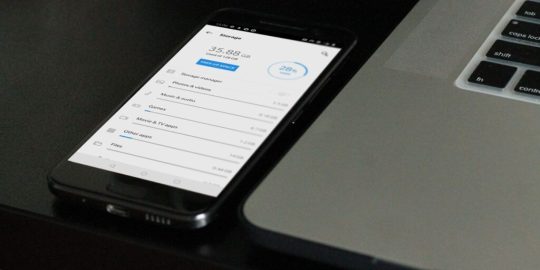
How to Clear Cache on Android? Unlock the Speed Boost Now!
Cache, in simple terms, is the superhero of your Android device, quietly working in the background. It retains certain data from apps to help them boot up quicker on subsequent uses. Think of it as a quick-access memory, storing bits of information for your most-used apps so that they don't have to reload data from scratch every time you open them. The Impact of Cache on Android: Performance Implications When used right, cache can be a game-changer for your Android device's performance. By storing temporary data for swift access, cache ensures that apps load with lightning speed. However, just as too much of anything isn't good, an overabundance of cached data can make your phone sluggish. This paradox makes understanding and managing cache pivotal for Android users. How Cache Benefits Android Devices: Speed and Responsiveness An optimized cache ensures that your Android device is always ready for action. By temporarily holding onto frequently accessed information, apps can bypass the usual loading processes, offering users an instantaneous response. The Downsides of Too Much Cache: Potential Issues Arising But there's a catch. As more and more data gets cached, your device's storage space gets occupied. This can lead to slower performance, reduced storage space for new apps, and occasionally even app crashes! How to Clear Cache on Android? Step-by-Step Procedure https://www.youtube.com/watch?v=_OHIw_68Kjo clear cache on Android: Video From Youtube Let's dive right in: - Open your Android device's "Settings." - Scroll down and select "Storage." - Here, you'll find an option named "Cached Data." - Tapping on it will give you an option to clear it. Hit "OK," and voila! Remember, this will clear the cache for ALL apps. If you want to clear cache for specific apps, keep reading! Clearing App-Specific Cache: Picking Out Troublesome Apps https://www.youtube.com/watch?v=6Px9W8kA9YE clear cache on Android: Video From Youtube To clear cache for individual apps: - Go to "Settings." - Navigate to "Apps" or "Application Manager" (terminology might vary based on the device). - Select the desired app. - Hit "Storage" and then "Clear Cache." Automated Cache Cleaning Tools: Recommended Apps and Reviews There are numerous apps on the Play Store that can help automate cache clearing. Apps like "CCleaner" and "Clean Master" are quite popular. However, always ensure you download apps from trusted developers to prevent malware. Possible Problems After Clearing Cache: What to Watch Out For Typically, clearing cache should not pose any issues. However, in rare cases, you might find some apps taking slightly longer to open the first time after the cache is cleared, as they need to rebuild their cache. The Difference Between Cache and App Data: Getting to Know Android Storage While both cache and app data are types of stored data, they serve different purposes. Cache contains temporary data, while app data holds personal settings, logins, and personal game scores. The Evolution of Cache Management on Android: Past, Present, and Future Cache management has come a long way. Earlier Android versions required frequent manual cache clearing. However, modern Android systems are adept at self-management, optimizing performance without much manual intervention. How Often Should You Clear Cache? Maintenance Tips There's no one-size-fits-all answer. For most users, clearing cache once every few months is sufficient. However, if you frequently download new apps or browse the internet extensively, considering a monthly routine might be beneficial. The Role of Cache in Other Devices: Comparing Android with Others Almost all digital devices utilize cache in some form. From PCs to Apple devices, cache plays a pivotal role in optimizing performance. The management and clearing processes, however, vary widely. Clearing Cache vs. Factory Reset: Deciding the Best Approach While both clear data, a factory reset is much more comprehensive, erasing all data and bringing your device back to its original state. Clearing cache is a much simpler, risk-free process that doesn't impact personal data. How Clearing Cache Affects Battery Life: Myths and Realities Contrary to some beliefs, clearing cache can indirectly improve battery life. A cluttered cache can make apps work harder, draining the battery quicker. By clearing it, apps run more efficiently, consuming less power. Essential Precautions When Clearing Cache: Safeguarding your Data Always ensure you're only clearing the cache, especially when using third-party apps. Accidentally clearing app data might result in loss of personal settings within apps. Also Raed: How to Root Android Phone Clearing the cache on your Android device is an effective and straightforward maintenance routine. It ensures that your phone remains snappy, responsive, and free from unnecessary clutter. While modern Android devices are better at managing cache, understanding its role and knowing when and how to clear it can give you an edge in device performance. So, the next time your phone seems a tad sluggish, remember this guide, dive into your settings, and give your device the speed boost it deserves!
Futures:
- Detailed Guidance: The blog provides in-depth and structured information on the subject, ensuring that readers don't need to go elsewhere. - Comprehensive Table of Contents: This allows readers to jump to specific sections of interest, enhancing user experience. - Direct Instructions: Step-by-step procedures are mentioned for different cache clearing methods, eliminating any ambiguity. - FAQs: A section dedicated to frequently asked questions caters to common queries, enhancing the blog's utility. - Expertise and Trustworthiness: The article showcases expertise, authority, and trust in the subject matter, reinforcing credibility. - Optimized for Search Engines: The use of meta-description, relevant keywords, and proper structuring makes the article SEO-friendly, which can improve its visibility on search engines. - Informative Subsections: Diverse topics related to cache, from its benefits to its management evolution, offer readers a holistic view. Also Read: How to Factory Reset Android Phone
Benefits:
- Enhanced Knowledge: Readers will gain a comprehensive understanding of cache and its management on Android devices. - Improved Device Performance: By following the guidelines, readers can optimize their Android devices' speed and responsiveness. - Trust in Content: With a well-researched and structured article, readers are more likely to trust the information and even share it with others. - Time-Saving: Instead of browsing multiple sources, readers get all the required information in one place. - Increased Engagement: The interactive structure, including FAQs and a detailed table of contents, ensures that readers remain engaged throughout. - Safety Assurance: The article emphasizes precautions, ensuring that readers avoid unintentional data loss while clearing cache. - Future Reference: The comprehensive nature of the article makes it a go-to guide for readers, ensuring repeated visits. Also Read: How to Disable App Notifications on Android
FAQs
What exactly is cache? Cache is temporary data storage that apps use to load faster by remembering frequently used data. Why do I need to clear cache on Android? Over time, cached data can accumulate and take up storage space, potentially slowing down your device. Clearing it can help optimize performance. Does clearing cache delete photos? No, clearing cache will not delete your photos or any other personal data. Can I choose specific apps to clear cache from? Yes, Android allows you to clear cache for individual apps via the 'Apps' section in 'Settings.' Will my phone be faster after clearing cache? While clearing cache can optimize performance, the noticeable speed difference may vary based on how cluttered the cache was. Is it safe to clear cache on Android? Absolutely! It's a risk-free way to free up storage space and improve performance. Read the full article
#Android#AndroidCache#AndroidMaintenance#AndroidPerformance#AppData#BatteryLife#CacheBenefits#CacheManagement#ClearCache#DeviceOptimization#howto#StorageManagement#Techhow-to#Technology#TechMinds
0 notes
Link
From http://ift.tt/1ajReyV
Why Multi Tiered Caching? To improve application's performance, we usually cache data in distributed cache like redis/memcached or in-process cache like EhCache. Each have its own strengths and weaknesses: In-Process Cache is faster but it's hard to maintain consistency and can't store a lot of data; This can be easily solved when using a distributed cache, but it's slower due to network latency and serialization and deserialization.
In some cases, we may want to use both: mainly use a distributed cache to cache data, but also cache data that is small and doesn't change often (or at all) such as configuration in in-process cache.
The Implementation
Spring uses CacheManager to determine which cache implementation to use.
We define our own MultiTieredCacheManager and MultiTieredCache like below.
public class MultiTieredCacheManager extends AbstractCacheManager { private final List<CacheManager> cacheManagers; /** * @param cacheManagers - the order matters, when fetch data, it will check the first one if not * there, will check the second one, then back-fill the first one */ public MultiTieredCacheManager(final List<CacheManager> cacheManagers) { this.cacheManagers = cacheManagers; } @Override protected Collection<? extends Cache> loadCaches() { return new ArrayList<>(); } @Override protected Cache getMissingCache(final String name) { return new MultiTieredCache(name, cacheManagers); } } public class MultiTieredCache implements Cache { private static final Logger logger = LoggerFactory.getLogger(MultiTieredCache.class); private final List<Cache> caches = new ArrayList<>(); private final String name; public MultiTieredCache(final String name, @Nonnull final List<CacheManager> cacheManagers) { this.name = name; for (final CacheManager cacheManager : cacheManagers) { caches.add(cacheManager.getCache(name)); } } @Override public ValueWrapper get(final Object key) { ValueWrapper result = null; final List<Cache> cachesWithoutKey = new ArrayList<>(); for (final Cache cache : caches) { result = cache.get(key); if (result != null) { break; } else { cachesWithoutKey.add(cache); } } if (result != null) { for (final Cache cache : cachesWithoutKey) { cache.put(key, result.get()); } } return result; } @Override public <T> T get(final Object key, final Class<T> type) { T result = null; final List<Cache> noThisKeyCaches = new ArrayList<>(); for (final Cache cache : caches) { result = cache.get(key, type); if (result != null) { break; } else { noThisKeyCaches.add(cache); } } if (result != null) { for (final Cache cache : noThisKeyCaches) { cache.put(key, result); } } return result; } @Override public void put(final Object key, final Object value) { caches.forEach(cache -> cache.put(key, value)); } @Override public void evict(final Object key) { caches.forEach(cache -> cache.evict(key)); } @Override public void clear() { caches.forEach(cache -> cache.clear()); } @Override public String getName() { return name; } @Override public Object getNativeCache() { return this; } } @Configuration @EnableCaching public class CacheConfig extends CachingConfigurerSupport { @Bean @Primary public CacheManager cacheManager(EhCacheCacheManager ehCacheCacheManager, RedisCacheManager redisCacheManager) { if (!cacheEnabled) { return new NoOpCacheManager(); } // Be careful when make change - the order matters ArrayList<CacheManager> cacheManagers = new ArrayList<>(); if (ehCacheEnabled) { cacheManagers.add(ehCacheCacheManager); } if (redisCacheEnabled) { cacheManagers.add(redisCacheManager); } return new MultiTieredCacheManager(cacheManagers); } @Bean(name = EH_CACHE_CACHE_MANAGER) public EhCacheCacheManager ehCacheCacheManager() { final EhCacheManagerFactoryBean ehCacheManagerFactoryBean = new EhCacheManagerFactoryBean(); ehCacheManagerFactoryBean.setConfigLocation(new ClassPathResource("ehcache.xml")); ehCacheManagerFactoryBean.setShared(true); ehCacheManagerFactoryBean.afterPropertiesSet(); final EhCacheManagerWrapper ehCacheManagerWrapper = new EhCacheManagerWrapper(); ehCacheManagerWrapper.setCacheManager(ehCacheManagerFactoryBean.getObject()); return ehCacheManagerWrapper; } @Bean(name = "redisCacheManager") public RedisCacheManager redisCacheManager(final RedisTemplate<String, Object> redisTemplate) { final RedisCacheManager redisCacheManager = new RedisCacheManager(redisTemplate, Collections.<String>emptyList(), true); redisCacheManager.setDefaultExpiration(DEFAULT_CACHE_EXPIRE_TIME_IN_SECOND); redisCacheManager.setExpires(expires); redisCacheManager.setLoadRemoteCachesOnStartup(true); return redisCacheManager; } }
Misc Others things we can do when use multi (tiered) cache in CacheManager:
- We can use cache name prefix to determine which cache to use. - We can add logic to only cache some kinds of data in specific cache.
0 notes
Text
Caching Data in Spring Using Redis
Via http://ift.tt/2jM8cW4
The Scenario We would like to cache Cassandra data to Redis for better read performance. Cache Configuration To make data in Redis more readable and easy for troubleshooting and debugging, we use GenericJackson2JsonRedisSerializer to serialize value as Json data in Redis, use StringRedisSerializer to serialize key. To make GenericJackson2JsonRedisSerializer work, we also configure objectMapper to store type info: objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); We configured cacheManager to store null value. - We use the configuration-driven approach and have a lot of configurations; We define default configuration values in property files. In the code, it first read from db and if null then read from property files. This makes us want to cache null value. We also use SpEL to set different TTL for different cache. redis.expires={configData:XSeconds, userSession: YSeconds}
@Configuration @EnableCaching public class RedisCacheConfig extends CachingConfigurerSupport { @Value("${redis.hostname}") String redisHostname; @Value("${redis.port}") int redisPort; @Value("#{${redis.expires}}") private Map<String, Long> expires; @Bean public JedisConnectionFactory redisConnectionFactory() { final JedisConnectionFactory redisConnectionFactory = new JedisConnectionFactory(); redisConnectionFactory.setHostName(redisHostname); redisConnectionFactory.setPort(redisPort); redisConnectionFactory.setUsePool(true); return redisConnectionFactory; } @Bean public ObjectMapper objectMapper() { final ObjectMapper objectMapper = Util.createFailSafeObjectmapper(); objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); return objectMapper; } @Bean("redisTemplate") public RedisTemplate<String, Object> genricJacksonRedisTemplate(final JedisConnectionFactory cf, final ObjectMapper objectMapper) { final RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setHashKeySerializer(new StringRedisSerializer()); redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)); redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)); redisTemplate.setConnectionFactory(cf); return redisTemplate; } @Bean public CacheManager cacheManager(final RedisTemplate<String, Object> redisTemplate) { final RedisCacheManager cacheManager = new RedisCacheManager(redisTemplate, Collections.<String>emptyList(), true); cacheManager.setDefaultExpiration(86400); cacheManager.setExpires(expires); cacheManager.setLoadRemoteCachesOnStartup(true); return cacheManager; } }
Cache CassandraRepository
@Repository @CacheConfig(cacheNames = Util.CACHE_CONFIG) public interface ConfigurationDao extends CassandraRepository<Configuration> { @Query("Select * from configuration where name=?0") @Cacheable Configuration findByName(String name); @Query("Delete from configuration where name=?0") @CacheEvict void delete(String name); @Override @CacheEvict(key = "#p0.name") void delete(Configuration config); /* * Check http://ift.tt/1LItlnQ * about what #p0 means */ @Override @SuppressWarnings("unchecked") @CachePut(key = "#p0.name") Configuration save(Configuration config); /* * This API doesn't work very well with cache - as spring cache doesn't support put or evict * multiple keys. Call save(Configuration config) in a loop instead. */ @Override @CacheEvict(allEntries = true) @Deprecated <S extends Configuration> Iterable<S> save(Iterable<S> configs); /* * This API doesn't work very well with cache - as spring cache doesn't support put or evict * multiple keys. Call delete(Configuration config) in a loop instead. */ @Override @CacheEvict(allEntries = true) @Deprecated void delete(Iterable<? extends Configuration> configs); }
Admin API to Manage Cache We inject CacheManager to add or evict data from Redis. But to scan all keys in a cache(like: cofig), I need to use stringRedisTemplate.opsForZSet() to get keys of the cache: - as the value in the cache (config), its value is a list of string keys. So here I need use StringRedisTemplate to read it. After get the keys, I use redisTemplate.opsForValue().multiGet to get their values. - I will update this post if I find some better ways to do this.
public class CacheResource { private static final String REDIS_CACHE_SUFFIX_KEYS = "~keys"; @Autowired @Qualifier("redisTemplate") RedisTemplate<String, Object> redisTemplate; @Autowired @Qualifier("stringRedisTemplate") StringRedisTemplate stringRedisTemplate; @Autowired private CacheManager cacheManager; /** * If sessionId is not null, return its associated user info.<br> * It also returns other cached data: they are small data. * * @return */ @GetMapping(produces = MediaType.APPLICATION_JSON_VALUE, path = "/cache") public Map<String, Object> get(@RequestParam("sessionIds") final String sessionIds, @RequestParam(name = "getConfig", defaultValue = "false") final boolean getConfig) { final Map<String, Object> resultMap = new HashMap<>(); if (getConfig) { final Set<String> configKeys = stringRedisTemplate.opsForZSet().range(Util.CACHE_CONFIG_DAO + REDIS_CACHE_SUFFIX_KEYS, 0, -1); final List<Object> objects = redisTemplate.opsForValue().multiGet(configKeys); resultMap.put(Util.CACHE_CONFIG + REDIS_CACHE_SUFFIX_KEYS, objects); } if (StringUtils.isNotBlank(sessionIds)) { final Map<String, Object> sessionIdToUsers = new HashMap<>(); final Long totalUserCount = stringRedisTemplate.opsForZSet().size(Util.CACHE_USER + REDIS_CACHE_SUFFIX_KEYS); sessionIdToUsers.put("totalUserCount", totalUserCount); final ArrayList<String> sessionIdList = Lists.newArrayList(Util.COMMA_SPLITTER.split(sessionIds)); final List<Object> sessionIDValues = redisTemplate.opsForValue().multiGet(sessionIdList); for (int i = 0; i < sessionIdList.size(); i++) { sessionIdToUsers.put(sessionIdList.get(i), sessionIDValues.get(i)); } resultMap.put(Util.CACHE_USER + REDIS_CACHE_SUFFIX_KEYS, sessionIdToUsers); } return resultMap; } @DeleteMapping("/cache") public void clear(@RequestParam("removeSessionIds") final String removeSessionIds, @RequestParam(name = "clearSessions", defaultValue = "false") final boolean clearSessions, @RequestParam(name = "clearConfig", defaultValue = "false") final boolean clearConfig) { if (clearConfig) { final Cache configCache = getConfigCache(); configCache.clear(); } final Cache userCache = getUserCache(); if (clearSessions) { userCache.clear(); } else if (StringUtils.isNotBlank(removeSessionIds)) { final ArrayList<String> sessionIdList = Lists.newArrayList(Util.COMMA_SPLITTER.split(removeSessionIds)); for (final String sessionId : sessionIdList) { userCache.evict(sessionId); } } } /** * Only handle client() data - as other caches such as configuration we can use server side api * to update them */ @PutMapping("/cache") public void addOrupdate(...) { if (newUserSessions == null) { return; } final Cache userCache = getUserCache(); // userCache.put to add key, value } private Cache getConfigCache() { return cacheManager.getCache(Util.CACHE_CONFIG_DAO); } private Cache getUserCache() { return cacheManager.getCache(Util.CACHE_USER); } }
StringRedisTemplate
@Bean("stringRedisTemplate") public StringRedisTemplate stringRedisTemplate(final JedisConnectionFactory cf, final ObjectMapper objectMapper) { final StringRedisTemplate redisTemplate = new StringRedisTemplate(); redisTemplate.setConnectionFactory(cf); return redisTemplate; }
Misc - If you want to disable cache in some env, use NoOpCacheManager.
From lifelongprogrammer.blogspot.com
0 notes
Link
From http://ift.tt/1ajReyV
The Scenario We would like to cache Cassandra data to Redis for better read performance. Cache Configuration To make data in Redis more readable and easy for troubleshooting and debugging, we use GenericJackson2JsonRedisSerializer to serialize value as Json data in Redis, use StringRedisSerializer to serialize key. To make GenericJackson2JsonRedisSerializer work, we also configure objectMapper to store type info: objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); We configured cacheManager to store null value. - We use the configuration-driven approach and have a lot of configurations; We define default configuration values in property files. In the code, it first read from db and if null then read from property files. This makes us want to cache null value. We also use SpEL to set different TTL for different cache. redis.expires={configData:XSeconds, userSession: YSeconds}
@Configuration @EnableCaching public class RedisCacheConfig extends CachingConfigurerSupport { @Value("${redis.hostname}") String redisHostname; @Value("${redis.port}") int redisPort; @Value("#{${redis.expires}}") private Map<String, Long> expires; @Bean public JedisConnectionFactory redisConnectionFactory() { final JedisConnectionFactory redisConnectionFactory = new JedisConnectionFactory(); redisConnectionFactory.setHostName(redisHostname); redisConnectionFactory.setPort(redisPort); redisConnectionFactory.setUsePool(true); return redisConnectionFactory; } @Bean public ObjectMapper objectMapper() { final ObjectMapper objectMapper = Util.createFailSafeObjectmapper(); objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); return objectMapper; } @Bean("redisTemplate") public RedisTemplate<String, Object> genricJacksonRedisTemplate(final JedisConnectionFactory cf, final ObjectMapper objectMapper) { final RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setHashKeySerializer(new StringRedisSerializer()); redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)); redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)); redisTemplate.setConnectionFactory(cf); return redisTemplate; } @Bean public CacheManager cacheManager(final RedisTemplate<String, Object> redisTemplate) { final RedisCacheManager cacheManager = new RedisCacheManager(redisTemplate, Collections.<String>emptyList(), true); cacheManager.setDefaultExpiration(86400); cacheManager.setExpires(expires); cacheManager.setLoadRemoteCachesOnStartup(true); return cacheManager; } }
Cache CassandraRepository
@Repository @CacheConfig(cacheNames = Util.CACHE_CONFIG) public interface ConfigurationDao extends CassandraRepository<Configuration> { @Query("Select * from configuration where name=?0") @Cacheable Configuration findByName(String name); @Query("Delete from configuration where name=?0") @CacheEvict void delete(String name); @Override @CacheEvict(key = "#p0.name") void delete(Configuration config); /* * Check http://ift.tt/1LItlnQ * about what #p0 means */ @Override @SuppressWarnings("unchecked") @CachePut(key = "#p0.name") Configuration save(Configuration config); /* * This API doesn't work very well with cache - as spring cache doesn't support put or evict * multiple keys. Call save(Configuration config) in a loop instead. */ @Override @CacheEvict(allEntries = true) @Deprecated <S extends Configuration> Iterable<S> save(Iterable<S> configs); /* * This API doesn't work very well with cache - as spring cache doesn't support put or evict * multiple keys. Call delete(Configuration config) in a loop instead. */ @Override @CacheEvict(allEntries = true) @Deprecated void delete(Iterable<? extends Configuration> configs); }
Admin API to Manage Cache We inject CacheManager to add or evict data from Redis. But to scan all keys in a cache(like: cofig), I need to use stringRedisTemplate.opsForZSet() to get keys of the cache: - as the value in the cache (config), its value is a list of string keys. So here I need use StringRedisTemplate to read it. After get the keys, I use redisTemplate.opsForValue().multiGet to get their values. - I will update this post if I find some better ways to do this.
public class CacheResource { private static final String REDIS_CACHE_SUFFIX_KEYS = "~keys"; @Autowired @Qualifier("redisTemplate") RedisTemplate<String, Object> redisTemplate; @Autowired @Qualifier("stringRedisTemplate") StringRedisTemplate stringRedisTemplate; @Autowired private CacheManager cacheManager; /** * If sessionId is not null, return its associated user info.<br> * It also returns other cached data: they are small data. * * @return */ @GetMapping(produces = MediaType.APPLICATION_JSON_VALUE, path = "/cache") public Map<String, Object> get(@RequestParam("sessionIds") final String sessionIds, @RequestParam(name = "getConfig", defaultValue = "false") final boolean getConfig) { final Map<String, Object> resultMap = new HashMap<>(); if (getConfig) { final Set<String> configKeys = stringRedisTemplate.opsForZSet().range(Util.CACHE_CONFIG_DAO + REDIS_CACHE_SUFFIX_KEYS, 0, -1); final List<Object> objects = redisTemplate.opsForValue().multiGet(configKeys); resultMap.put(Util.CACHE_CONFIG + REDIS_CACHE_SUFFIX_KEYS, objects); } if (StringUtils.isNotBlank(sessionIds)) { final Map<String, Object> sessionIdToUsers = new HashMap<>(); final Long totalUserCount = stringRedisTemplate.opsForZSet().size(Util.CACHE_USER + REDIS_CACHE_SUFFIX_KEYS); sessionIdToUsers.put("totalUserCount", totalUserCount); final ArrayList<String> sessionIdList = Lists.newArrayList(Util.COMMA_SPLITTER.split(sessionIds)); final List<Object> sessionIDValues = redisTemplate.opsForValue().multiGet(sessionIdList); for (int i = 0; i < sessionIdList.size(); i++) { sessionIdToUsers.put(sessionIdList.get(i), sessionIDValues.get(i)); } resultMap.put(Util.CACHE_USER + REDIS_CACHE_SUFFIX_KEYS, sessionIdToUsers); } return resultMap; } @DeleteMapping("/cache") public void clear(@RequestParam("removeSessionIds") final String removeSessionIds, @RequestParam(name = "clearSessions", defaultValue = "false") final boolean clearSessions, @RequestParam(name = "clearConfig", defaultValue = "false") final boolean clearConfig) { if (clearConfig) { final Cache configCache = getConfigCache(); configCache.clear(); } final Cache userCache = getUserCache(); if (clearSessions) { userCache.clear(); } else if (StringUtils.isNotBlank(removeSessionIds)) { final ArrayList<String> sessionIdList = Lists.newArrayList(Util.COMMA_SPLITTER.split(removeSessionIds)); for (final String sessionId : sessionIdList) { userCache.evict(sessionId); } } } /** * Only handle client() data - as other caches such as configuration we can use server side api * to update them */ @PutMapping("/cache") public void addOrupdate(...) { if (newUserSessions == null) { return; } final Cache userCache = getUserCache(); // userCache.put to add key, value } private Cache getConfigCache() { return cacheManager.getCache(Util.CACHE_CONFIG_DAO); } private Cache getUserCache() { return cacheManager.getCache(Util.CACHE_USER); } }
StringRedisTemplate
@Bean("stringRedisTemplate") public StringRedisTemplate stringRedisTemplate(final JedisConnectionFactory cf, final ObjectMapper objectMapper) { final StringRedisTemplate redisTemplate = new StringRedisTemplate(); redisTemplate.setConnectionFactory(cf); return redisTemplate; }
Misc - If you want to disable cache in some env, use NoOpCacheManager.
0 notes
Text
Spring @Cacheable Not Working - How to Troubleshoot and Solve it
Via http://ift.tt/2jayQYh
The Scenario Spring cache abstraction annotation is easy to add cache abilty to the application: Just define CacheManager in confutation, then use annotations: @Cacheable, @CachePut, @CacheEvict to use and maintain the cache. But what to do if the cache annotation seems doesn't work? How we know cache doesn't work? Logging We can change the log level to print database query in the log. For Cassandra, we can change log level of com.datastax.driver.core.RequestHandler to TRACE. Debug We can set a breakpoint at CacheAspectSupport.execute. If cache works, when we call a method annotated with cache annotation, it will not directly call the method, instead it will be intercepted and hit the breakpoint. Test Possible Reasons 1. The class using cache annotation inited too early Please check Bean X of type Y is not eligible for getting processed by all BeanPostProcessors for detailed explanation How to troubleshoot Add a breakpoint at the default constructor of the bead (add one if not exist), then from the stack trace we can figure out why and which bean (or configuration class) causes this bean to be created. Using ObjectFactory or other approaches to break the eager dependency, restart and check again util the cached method works as expected. Also check whether there is log like: Bean of type is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2. Calling cached method in same class Solutions: - Using self inject or applicationContext.getBean then use the bean to call cached method - Using @Scope(proxyMode = ScopedProxyMode.TARGET_CLASS)
From lifelongprogrammer.blogspot.com
0 notes
Link
From http://ift.tt/1ajReyV
The Scenario Spring cache abstraction annotation is easy to add cache abilty to the application: Just define CacheManager in confutation, then use annotations: @Cacheable, @CachePut, @CacheEvict to use and maintain the cache. But what to do if the cache annotation seems doesn't work? How we know cache doesn't work? Logging We can change the log level to print database query in the log. For Cassandra, we can change log level of com.datastax.driver.core.RequestHandler to TRACE. Debug We can set a breakpoint at CacheAspectSupport.execute. If cache works, when we call a method annotated with cache annotation, it will not directly call the method, instead it will be intercepted and hit the breakpoint. Test Possible Reasons 1. The class using cache annotation inited too early Please check Bean X of type Y is not eligible for getting processed by all BeanPostProcessors for detailed explanation How to troubleshoot Add a breakpoint at the default constructor of the bead (add one if not exist), then from the stack trace we can figure out why and which bean (or configuration class) causes this bean to be created. Using ObjectFactory or other approaches to break the eager dependency, restart and check again util the cached method works as expected. Also check whether there is log like: Bean of type is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2. Calling cached method in same class Solutions: - Using self inject or applicationContext.getBean then use the bean to call cached method - Using @Scope(proxyMode = ScopedProxyMode.TARGET_CLASS)
0 notes