#Cloud Development
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
September 16th, 2023
Light Thunderstorm Timelapse
Flint Hills, Kansas
Credit: @colonelc45
#my photgraphy#weather#weather photography#storms#thunderstorm#storm clouds#clouds#lightning#thunderstorms#storm photography#cloudphotography#timelapse#lightning storm#storm timelapse#rain#rainstormpics#rain storm#cloud development
4 notes
·
View notes
Text

Transform your business with cloud application development from Implause IT Solutions. We build scalable, secure, and high-performance cloud apps tailored to your needs. Get expert solutions today. Contact us now! https://implauseit.com/
0 notes
Text

Take your business to new heights with the best cloud services in Pune! Whether you're a startup or an established enterprise, our cutting-edge solutions are designed to optimize your operations, enhance scalability, and ensure data security.
Get a Free Quote! ���+91-9975486861 📧[email protected]
For more details, visit https://tinyurl.com/bbz38j38
#Cloud Services Pune#Cloud Development#Cloud Development Company#Cloud Computing#Digital Transformation#Scalar Tech hub#Pune#India
0 notes
Text
Custom Software Development Services - E2W Consulting

Unlock the full potential of your business with Custom Software Development from E2W Consulting. We specialize in creating tailored software solutions designed to meet your unique business needs, streamline operations, and drive growth. From concept to deployment, our expert team ensures innovative, scalable, and secure applications that deliver results. Partner with us to turn your vision into reality—because your business deserves more than off-the-shelf solutions!
1 note
·
View note
Text
Cloud-Based Big Data Development Simplified with Docker

As businesses embrace digital transformation, many tasks have shifted from desktop software to cloud-based applications. Despite this trend, software development IDEs have largely remained desktop-bound. Efforts to create robust online IDEs have been made but lack parity with traditional tools. This limitation highlights a significant gap in the adoption of cloud-based development solutions.
The big data analytics market has experienced explosive growth, with its global size valued at $307.51 billion in 2023. Projections indicate a rise to $348.21 billion in 2024, eventually reaching $924.39 billion by 2032. This growth reflects a remarkable compound annual growth rate (CAGR) of 13.0%. The U.S. market is a key contributor, predicted to achieve $248.89 billion by 2032. Industries increasingly rely on advanced databases, fueling this robust expansion.
The big data and analytics services market continues its rapid ascent, growing from $137.23 billion in 2023 to $154.79 billion in 2024. This represents a CAGR of 12.8%, driven by the proliferation of data and the need for regulatory compliance. Organizations are leveraging big data to gain competitive advantages and ensure smarter decision-making.
Forecasts predict an even faster CAGR of 16.0%, with the market reaching $280.43 billion by 2028. This acceleration is attributed to advancements in AI-driven analytics, real-time data processing, and enhanced cloud-based platforms. Big data privacy and security also play pivotal roles, reflecting the heightened demand for compliance-focused solutions.
Emerging trends in big data highlight the integration of AI and machine learning, which enable predictive and prescriptive analytics. Cloud app development and edge analytics are becoming indispensable as businesses seek agile and scalable solutions. Enhanced data privacy protocols and stringent compliance measures are reshaping the way big data is stored, processed, and utilized.
Organizations leveraging big data are unlocking unparalleled opportunities for growth, innovation, and operational efficiency. With transformative technologies at their fingertips, businesses are better positioned to navigate the data-driven future.
Key Takeaways:
Big data encompasses vast, diverse datasets requiring advanced tools for storage, processing, and analysis.
Docker is a transformative technology that simplifies big data workflows through portability, scalability, and efficiency.
The integration of AI and machine learning in big data enhances predictive and prescriptive analytics for actionable insights.
Cloud environments provide unparalleled flexibility, scalability, and resource allocation, making them ideal for big data development.
Leveraging docker and the cloud together ensures businesses can manage and analyze massive datasets efficiently in a dynamic environment.
What is Big Data?
Big Data encompasses vast, diverse datasets that grow exponentially, including structured, unstructured, and semi-structured information. These datasets, due to their sheer volume, velocity, and variety, surpass the capabilities of traditional data management tools. They require advanced systems to efficiently store, process, and analyze.
The rapid growth of big data is fueled by innovations like connectivity, Internet of Things (IoT), mobility, and artificial intelligence technologies. These advancements have significantly increased data availability and generation, enabling businesses to harness unprecedented amounts of information. However, managing such massive datasets demands specialized tools that process data at high speeds to unlock actionable insights.
Big data plays a pivotal role in advanced analytics, including predictive modeling and machine learning. Businesses leverage these technologies to address complex challenges, uncover trends, and make data-driven decisions. The strategic use of big data allows companies to stay competitive, anticipate market demands, and enhance operational efficiency.
With digital transformation, the importance of big data continues to rise. Organizations now adopt cutting-edge solutions to collect, analyze, and visualize data effectively. These tools empower businesses to extract meaningful patterns and drive innovation, transforming raw data into strategic assets.
How Does Docker Work With AWS?
Docker has revolutionized how applications are developed, deployed, and managed in the dynamic landscape of big data. This guide explores how Docker simplifies big data workflows, providing scalability, flexibility, and efficiency.
Docker uses multiple different environments while building online services:
Amazon Web Services or the servers
Microsoft Azure the code
Google Compute Engine
GitHub for SDK
Dropbox to save files

Step 1: Build Your Big Data Application With a Dockerfile
Begin by developing your big data application using your preferred language and tools. A Dockerfile is essential for packaging your application.
It’s a blueprint that outlines the base image, dependencies, and commands to run your application. For big data applications, the Dockerfile might include libraries for distributed computing like Hadoop and Spark. This ensures seamless functionality across various environments.
Step 2: Build a Big Data Docker Image
The Dockerfile helps create a Docker image, which is a self-sufficient unit containing your application, environment, and dependencies.
For big data, this image ensures compatibility, including tools like Jupyter Notebook, PySpark, or Presto for analytics. Use the following command to create the image: $ docker build -t bigdata-app:latest .
This command builds an image, tags it as ‘bigdata-app:latest’, and prepares it for deployment.
Step 3: Run Containers for Big Data Processing
A Docker container is an isolated instance of your image, ideal for running big data tasks without interference.$ docker container run -d -p 8080:80 bigdata-app:latest
This command runs the container in detached mode and maps port 8080 on the host to port 80 in the container.
For big data, containers allow parallel processing, enabling distributed systems to run seamlessly across multiple nodes.
Step 4: Manage Big Data Containers

Docker simplifies the management of containers for complex big data workflows.
Use ‘docker ps’ to view running containers, essential for tracking active data processes.
Use ‘docker ps -a’ to check all containers, including completed tasks.
Use ‘docker stop ’ and ‘docker start ’ to manage container lifecycles.
Use ‘docker rm ’ to remove unused containers and free resources.
Run ‘docker container –help’ to explore advanced options for managing big data processing pipelines.
Step 5: Orchestrate Big Data Workflows with Docker Compose
For complex big data architecture, Docker Compose defines and runs multi-container setups.
Compose files in YAML specify services like Hadoop clusters, Spark worker, or Kafka brokers. This simplifies deployment and ensures services interact seamlessly.```yaml version: '3' services: hadoop-master: image: hadoop-master:latest ports: - "50070:50070" spark-worker: image: spark-worker:latest depends_on: - hadoop-master
On command can spin up your entire big data ecosystem:$ docker-compose up
Step 6: Publish and Share Big Data Docker Images
Publishing Docker images ensures your big data solutions are accessible across teams or environments. Push your image to a registry:$ docker push myregistry/bigdata-app:latest
This step enables distributed teams to collaborate effectively and deploy applications in diverse environments like Kubernetes clusters or cloud platforms.
Step 7: Continuous Iteration for Big Data Efficiency
Big data applications require constant updates to incorporate new features or optimize workflows.
Update your Dockerfile to include new dependencies or scripts for analytics, then rebuild the image: $ docker build -t bigdata-app:v2 .
This interactive approach ensures that your big data solutions evolve while maintaining efficiency and reliability
The Five ‘V’ of Big Data
Not all large datasets qualify as big data. To be clarified as such, the data must exhibit five characteristics. Let’s look deeper into these pillars.
Volume: The Scale of Data
Volume stands as the hallmark of big data. Managing vast amounts of data—ranging from terabytes to petabytes—requires advanced tools and techniques. Traditional systems fall short, while AI-powered analytics handle this scale with ease. Secure storage and efficient organization form the foundation for utilizing this data effectively, enabling large companies to unlock insights from their massive reserves.
Velocity: The Speed of Data Flow
In traditional systems, data entry was manual and time-intensive, delaying insights. Big data redefines this by enabling real-time processing as data is generated, often within milliseconds. This rapid flow empowers businesses to act swiftly—capturing opportunities, addressing customer needs, detecting fraud, and ensuring agility in fast-paced environments.
Veracity: Ensuring Data Quality
Data’s worth lies in its accuracy, relevance, and timeliness. While structured data errors like typos are manageable, unstructured data introduces challenges like bias, misinformation, and unclear origins. Big data technologies address these issues, ensuring high-quality datasets that fuel precise and meaningful insights.
Value: Transforming Data into Insights
Ultimately, big data’s true strength lies in its ability to generate actionable insights. The analytics derived must go beyond intrigue to deliver measurable outcomes, such as enhanced competitiveness, improved customer experiences, and operational efficiency. The right big data strategies translate complex datasets into tangible business value, ensuring a stronger bottom line and resilience.
Understanding Docker Containers: Essential for Big Data Use Cases
Docker containers are revolutionizing how applications are developed, deployed, and managed, particularly in big data environments. Here’s an exploration of their fundamentals and why they are transformative.
What Are Docker Containers?

Docker containers act as an abstraction layer, bundling everything an application needs into a single portable package. This bundle includes libraries, resources, and code, enabling seamless deployment on any system without requiring additional configurations. For big data applications, this eliminates compatibility issues, accelerating development and deployment.
Efficiency in Development and Migration
Docker drastically reduces development time and costs, especially during architectural evolution or cloud migration. It simplifies transitions by packaging all necessary components, ensuring smooth operation in new environments. For big data workflows, Docker’s efficiency helps scale analytics, adapt to infrastructure changes, and support evolving business needs.
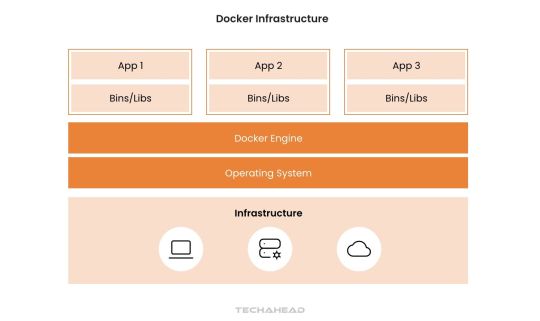
Why the Hype Around Docker?
Docker’s approach to OS-level virtualization and its Platform-as-a-Service (PaaS) nature makes it indispensable. It encapsulates applications into lightweight, executable components that are easy to manage. For big data, this enables rapid scaling, streamlined workflows, and reduced resource usage.
Cross-Platform Compatibility
As an open-source solution, Docker runs on major operating systems like Linux, Windows, and macOS. This cross-platform capability ensures big data applications remain accessible and functional across diverse computing environments. Organizations can process and analyze data without being limited by their operating system.
Docker in Big Data Architecture

Docker’s architecture supports modular, scalable, and efficient big data solutions. By isolating applications within containers, Docker ensures better resource utilization and consistent performance, even under heavy workloads. Its ability to integrate seamlessly into big data pipelines makes it a critical tool for modern analytics.
Docker containers are transforming big data operations by simplifying deployment, enhancing scalability, and ensuring compatibility across platforms. This powerful technology allows businesses to unlock the full potential of their data with unmatched efficiency and adaptability.
Applications of Big Data Across Industries

Big data is transforming industries by enabling businesses to harness data-driven insights for innovation, efficiency, and improved decision-making. Here’s how different sectors are leveraging big data to revolutionize their operations.
Finance
Big data is a cornerstone of the finance and insurance sectors, enhancing fraud detection and enabling more accurate risk assessments. Predictive analytics help refine credit rankings and brokerage services, ensuring better financial decision-making. Blockchain technology also benefits from big data by streamlining secure transactions and tracking digital assets. Financial institutions use big data to fortify cybersecurity measures and deliver personalized financial recommendations to customers, improving user trust and satisfaction.
Healthcare
Big data is reshaping healthcare app development by equipping hospitals, researchers, and pharmaceutical companies with critical insights. Patient and population data allow for the optimization of treatments, accelerating research on diseases like cancer and Alzheimer’s. Advanced analytics support the development of innovative drugs and help identify trends in population health. By leveraging big data, healthcare providers can predict disease outbreaks and improve preventive care strategies.
Education
In education app development, big data empowers institutions to analyze student behavior and develop tailored learning experiences. This data enables educators to design personalized lesson plans, predict student performance, and enhance engagement. Schools also use big data to monitor resources, optimize budgets, and reduce operational costs, fostering a more efficient educational environment.
Retail
Retailers rely on big data to analyze customer purchase histories and transaction patterns. This data predicts future buying behaviors allowing for personalized marketing strategies and improved customer experiences. Real estate app development uses big data to optimize inventory, pricing, and promotions, staying competitive in a dynamic market landscape.
Government
Governments leverage big data to analyze public financial, health, and demographic data for better policymaking. Insights derived from big data help create responsive legislation, optimize financial operations, and enhance crisis management plans. By understanding citizen needs through data, governments can improve public services and strengthen community engagement.
Marketing
Big data transforms marketing by offering an in-depth understanding of consumer behavior and preferences. Businesses use this data to identify emerging market trends and refine buyer personas. Marketers optimize campaigns and strategies based on big data insights, ensuring more targeted outreach and higher conversion rates.
OTT Channels
Media platforms like Netflix and Hulu exemplify big data’s influence in crafting personalized user experiences. These companies analyze viewing, reading, and listening habits to recommend content that aligns with individual preferences. Big data even informs choices about graphics, titles, and colors, tailoring the content presentation to boost engagement and customer satisfaction.
Big data is not just a technological trend—it’s a transformative force across industries. Organizations that effectively utilize big data gain a competitive edge, offering smarter solutions and creating lasting value for their customers.
Best Practices for Using Docker in Big Data Development

To maximize the potential of Docker for big data development, implementing key strategies can optimize performance, security, and scalability. Below are essential practices for effectively using Docker in big data environments.
Keep Containers Lightweight
Design Docker containers with minimalistic and efficient images to optimize resource consumption. Lightweight containers reduce processing overhead, enabling faster execution of big data workloads. By stripping unnecessary dependencies, you can improve container performance and ensure smoother operations across diverse environments.
Leverage Orchestration Tools
Utilize orchestration platforms like Docker Swarm or Kubernetes to streamline the management of big data workloads. These tools automate deployment, scaling, and load balancing, ensuring that big data applications remain responsive during high-demand periods. Orchestration also simplifies monitoring and enhances fault tolerance.
Automate Deployment and Configuration
Automate the provisioning and setup of Docker containers using tools like Docker Compose or infrastructure-as-code frameworks. Automation reduces manual errors and accelerates deployment, ensuring consistent configurations across environments. This approach enhances the efficiency of big data processing pipelines, especially in dynamic, large-scale systems.
Implement Security Measures
Adopt robust security protocols to protect Docker containers and the big data they process. Use trusted base images, keep Docker components updated, and enforce strict access controls to minimize vulnerabilities. Restrict container privileges to the least necessary level, ensuring a secure environment for sensitive data processing tasks.
Backup and Disaster Recovery
Establish comprehensive backup and disaster recovery plans for data managed within Docker environments. Regularly back up critical big data outputs to safeguard against unexpected failures or data loss. A reliable disaster recovery strategy ensures continuity in big data operations, preserving valuable insights even during unforeseen disruptions.
By adhering to these practices, organizations can fully leverage Docker’s capabilities in big data processing. These strategies enhance operational efficiency, ensure data security, and enable scalability, empowering businesses to drive data-driven innovation with confidence.
Advantages of Using Docker for Big Data Processing

Docker offers a range of benefits that enhance the efficiency and scalability of big data processing environments. By optimizing resource utilization and enabling seamless application deployment. Docker ensures businesses can handle large-scale data operations effectively. Here’s a closer look:
Isolation
Docker provides robust application-level isolation, ensuring each big data development workload operates independently. This isolation prevents conflicts between applications, improving reliability and enabling seamless parallel execution of multiple data-intensive tasks. Businesses can confidently run diverse big data applications without compatibility concerns or interference.
Portability
Docker containers deliver unmatched portability, allowing big data workloads to be deployed across various environments. Whether running on local machines, cloud platforms, or on-premises servers. Docker ensures consistent performance. This portability simplifies cloud migration of big data development workflows between infrastructure, minimizing downtime and operational challenges.
Scalability
With Docker, scaling big data applications becomes effortless through horizontal scaling capabilities. Businesses can quickly deploy multiple containers to distribute workloads, enhancing processing power and efficiency. This scalability ensures organizations can manage fluctuating data volumes, maintaining optimal performance during peak demands.
Resource Efficiency
Docker’s lightweight design optimizes resource utilization, reducing hardware strain while processing large datasets. This efficiency ensures big data workloads can run smoothly without requiring excessive infrastructure investments. Organizations can achieve high-performance data analysis while controlling operational costs.
Version Control
Docker’s versioning features simplify managing containerized big data applications, ensuring reproducibility and traceability. Teams can easily roll back to previous versions if needed, enhancing system reliability and reducing downtime. This capability supports consistent and accurate data processing workflows.
By leveraging Docker, businesses can streamline big data processing operations. The above-mentioned advantages empower businesses to process large datasets effectively, extract actionable insights, and stay competitive in a data-driven world.
Conclusion
This article explores how modern cloud technologies can establish an efficient and scalable development environment. While cloud-based machines may not fully replace traditional computers or laptops, they excel for development tasks requiring access to integrated development environments (IDEs). With today’s high-speed internet, cloud-based development offers seamless and responsive performance for most projects.
Cloud environments provide unparalleled flexibility, making server access and management significantly faster than local setups. Developers can effortlessly scale memory, deploy additional environments, or generate system images with minimal effort. This agility is especially crucial when handling big data projects, which demand vast resources and scalable infrastructures.
The cloud effectively places an entire data center at your fingertips, empowering developers to manage complex tasks efficiently. For big data workflows, this translates into the ability to process and store massive datasets without compromising speed or functionality. Businesses benefit from this scalability, as it aligns with the increasing demand for high-performance analytics and storage.
By leveraging the cloud, developers gain access to state-of-the-art infrastructures that optimize workflow efficiency. The ability to allocate resources, process data, and scale operations dynamically is essential for thriving in today’s data-driven economy.
Source URL: https://www.techaheadcorp.com/blog/developing-for-the-cloud-in-the-cloud-big-data-development-with-docker/
0 notes
Text
#custom app development#cloud devops services#web app development#mobile app development#web application development#cloud development#app development
0 notes
Text
Check out our latest blog on scaling your business with multi-cloud versus hybrid cloud strategies. Discover the unique benefits of each approach and find the best solution to enhance flexibility, scalability, and growth for your organization. Read more now!
0 notes
Text
Accelerating Cloud Development: How AWS DevOps is Revolutionizing Software Delivery in 2024
In 2024, businesses are operating in an era where software delivery needs to be faster, more reliable, and more scalable than ever before. The rise of cloud computing has been central to this transformation, and AWS (Amazon Web Services) DevOps has become a key enabler of these advancements. By combining the power of cloud infrastructure with the agility of DevOps practices, AWS DevOps is revolutionizing how organizations develop, deploy, and manage applications.
What is AWS DevOps?
AWS DevOps refers to the combination of AWS’s cloud computing services and DevOps practices to facilitate faster, more efficient software development and deployment. DevOps is a set of practices that automates and integrates the processes between software development and IT operations teams, enabling them to build, test, and release software more quickly and reliably.
AWS offers a wide range of tools and services that support DevOps practices, including continuous integration and continuous delivery (CI/CD), infrastructure as code (IaC), monitoring, and logging. AWS DevOps helps businesses of all sizes adopt cloud-native technologies and streamline their software development lifecycle (SDLC) to meet the demands of the modern digital landscape.
How AWS DevOps is Revolutionizing Software Delivery in 2024
Accelerating Time-to-Market
In today’s competitive landscape, the ability to deliver new features and updates quickly is crucial for business success. AWS DevOps automates various stages of the SDLC, from code development to deployment, reducing the time it takes to release new software. With AWS services like CodePipeline, CodeDeploy, and CodeBuild, development teams can automate their CI/CD pipelines, ensuring that code is automatically tested and deployed as soon as it’s ready. This eliminates manual steps and accelerates time-to-market, allowing businesses to respond to market demands faster.
Scalability and Flexibility
AWS’s cloud infrastructure provides unparalleled scalability, allowing businesses to scale their applications up or down based on demand. When combined with DevOps practices, AWS enables organizations to dynamically adjust resources, optimize performance, and minimize costs. For example, AWS Elastic Beanstalk automatically handles the deployment, load balancing, scaling, and monitoring of applications, freeing development teams to focus on innovation rather than infrastructure management. This scalability makes AWS DevOps a powerful tool for both startups and large enterprises.
Enhanced Security and Compliance
Security is a top priority in cloud development, and AWS DevOps helps organizations integrate security into every stage of the SDLC. AWS provides a suite of security tools, such as AWS Identity and Access Management (IAM), AWS Shield, and AWS Key Management Service (KMS), which enable teams to enforce security best practices and meet compliance requirements. By incorporating DevSecOps principles, AWS DevOps ensures that security checks are automated and embedded into the CI/CD pipeline, helping organizations identify vulnerabilities early and prevent security breaches.
Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is a core principle of DevOps, and AWS DevOps takes IaC to the next level with services like AWS CloudFormation and AWS CDK (Cloud Development Kit). IaC allows developers to define, provision, and manage infrastructure using code, ensuring consistency and reducing human error. With AWS CloudFormation, teams can create and deploy cloud resources using templates, while AWS CDK provides a higher-level abstraction for defining infrastructure in familiar programming languages. This approach allows for automated, repeatable infrastructure deployments, leading to more reliable and efficient operations.
Monitoring and Logging
Monitoring and logging are essential for maintaining the health and performance of applications in the cloud. AWS DevOps offers powerful monitoring tools, such as Amazon CloudWatch and AWS X-Ray, which provide real-time insights into application performance, resource utilization, and system health. These tools enable teams to detect and resolve issues quickly, minimizing downtime and ensuring a seamless user experience. Automated alerts and dashboards help operations teams stay on top of system performance, while logging services like AWS CloudTrail provide detailed audit logs for security and compliance purposes.
Cost Optimization
Cost efficiency is a critical factor in cloud development, and AWS DevOps enables organizations to optimize their cloud spending. By automating resource provisioning and scaling, AWS DevOps helps businesses ensure that they are only using the resources they need, reducing waste and lowering operational costs. Tools like AWS Cost Explorer and AWS Trusted Advisor provide insights into resource utilization and offer recommendations for optimizing costs. Additionally, the pay-as-you-go pricing model of AWS allows businesses to align their expenses with their actual usage, further enhancing cost efficiency.
Collaborative Development Environment
AWS DevOps fosters a collaborative environment between development and operations teams, breaking down silos and enabling continuous collaboration throughout the SDLC. With services like AWS CodeCommit and AWS CodeStar, teams can work together on code repositories, manage projects, and track progress in real-time. This collaborative approach ensures that everyone is aligned, reducing bottlenecks and improving overall productivity. By integrating with popular DevOps tools like GitHub, Jenkins, and Slack, AWS DevOps creates a seamless development workflow that encourages communication and collaboration.
Real-World Applications of AWS DevOps
AWS DevOps is being adopted by organizations across various industries to drive digital transformation. For example:
E-commerce platforms are using AWS DevOps to continuously deliver new features and updates, ensuring a seamless shopping experience for customers.
Healthcare providers are leveraging AWS DevOps to manage sensitive patient data securely while delivering high-performance telemedicine applications.
Financial services companies are using AWS DevOps to build scalable, secure, and compliant applications that meet regulatory requirements.
These real-world applications highlight the versatility and power of AWS DevOps in driving innovation and operational excellence.
Learn AWS DevOps and MERN Stack Development with Network Rhinos
As the demand for AWS DevOps expertise continues to rise, mastering AWS DevOps can open up exciting career opportunities. If you’re interested in learning AWS DevOps and becoming a cloud development expert, Network Rhinos offers comprehensive training in AWS DevOps course in Chennai and Bangalore.
Our AWS DevOps course is designed to provide hands-on experience with AWS services and DevOps tools, equipping you with the skills to automate software delivery, manage cloud infrastructure, and ensure security and compliance. You’ll learn how to build CI/CD pipelines, implement IaC, and optimize cloud resources, all while gaining insights from industry experts.
Additionally, if you're interested in full-stack development, our MERN Stack developer course covers MongoDB, Express.js, React.js, and Node.js, giving you the skills to build dynamic web applications from start to finish. Whether you choose AWS DevOps, MERN Stack development, or both, Network Rhinos has the courses to help you succeed in today’s cloud-driven world.
Conclusion
AWS DevOps is revolutionizing software delivery in 2024 by enabling faster, more secure, and scalable cloud development. Through automation, scalability, and security integration, AWS DevOps empowers organizations to innovate and meet the demands of the modern digital landscape. As cloud computing continues to evolve, mastering AWS DevOps is becoming essential for developers and IT professionals alike.
If you’re ready to accelerate your cloud development journey, Network Rhinos is here to help. Join our AWS DevOps or MERN Stack developer courses in Chennai or Bangalore and build a successful career in cloud and full-stack development today.
#cloud development#continuous integration (CI)#continuous delivery (CD)#infrastructure as code (IaC)#monitoring and logging#scalability and flexibility#AWS#Devops#amazon web services
1 note
·
View note
Text
Software Product Development Company in India
We build your dreams into reality from Concept to Code: Partner with our software product development experts today for unparalleled success
#software support#cloud development#Zaigo Infotech#software development partner#Software Product Development Company
1 note
·
View note
Text
https://www.yelp.com/biz/codinix-technologies-woodbridge-township
Codinix is a CRM, Cloud Development, Custom Integrations, Microsoft Dynamics, Digital Transformation, Core Development, Zoho, Netsuite, and EDI integrations technology consulting firm focused on CRM implementation and Cloud integration.
#Cloud Development#Custom Integrations#Microsoft Dynamics#Digital Transformation#Core Development#Zoho#Netsuite#EDI integrations#CRM implementation#Cloud integration.
0 notes
Text
Expert Cloud Development Services in Europe
Discover Europe's finest expert cloud development services, offering innovative solutions tailored to your business needs. With a focus on cutting-edge technology and customer satisfaction, these top-tier companies provide robust cloud infrastructure, ensuring seamless integration and scalability.

0 notes
Text

TestDel: Your Gateway to Excellence in Software Testing and Quality Assurance! Our industry-leading solutions ensure maximum user satisfaction and bug-free applications. Join us in shaping the future of seamless software experiences.
Contact us today: [email protected]
Visit our website: www.testdel.com
#software testing#app development#cloud development#microsoft azure#service now#web application development#workday#mobile application development
0 notes
Text
IaaS vs PaaS vs SaaS: Three Options — One Solution or How to Choose Between the Alternatives
Cloud computing offers a plethora of scenarios for business development. It is convenient, easy, and cost-efficient. There is a variety of types of cloud services to choose from, which opens a door to many opportunities. In our blog article, we will look at the most popular services, such as SaaS, PaaS, and IaaS and explore their differences.
#outsourcing#software development#web development#staff augmentation#custom software development#it staff augmentation#custom software solutions#it staffing company#it staff offshoring#custom software#iaas#paas#saas software#saas technology#saas#software as a service#cloud development#cloud computing
0 notes
Text
Cloud-Based Big Data Development Simplified with Docker

As businesses embrace digital transformation, many tasks have shifted from desktop software to cloud-based applications. Despite this trend, software development IDEs have largely remained desktop-bound. Efforts to create robust online IDEs have been made but lack parity with traditional tools. This limitation highlights a significant gap in the adoption of cloud-based development solutions.
The big data analytics market has experienced explosive growth, with its global size valued at $307.51 billion in 2023. Projections indicate a rise to $348.21 billion in 2024, eventually reaching $924.39 billion by 2032. This growth reflects a remarkable compound annual growth rate (CAGR) of 13.0%. The U.S. market is a key contributor, predicted to achieve $248.89 billion by 2032. Industries increasingly rely on advanced databases, fueling this robust expansion.
The big data and analytics services market continues its rapid ascent, growing from $137.23 billion in 2023 to $154.79 billion in 2024. This represents a CAGR of 12.8%, driven by the proliferation of data and the need for regulatory compliance. Organizations are leveraging big data to gain competitive advantages and ensure smarter decision-making.
Forecasts predict an even faster CAGR of 16.0%, with the market reaching $280.43 billion by 2028. This acceleration is attributed to advancements in AI-driven analytics, real-time data processing, and enhanced cloud-based platforms. Big data privacy and security also play pivotal roles, reflecting the heightened demand for compliance-focused solutions.
Emerging trends in big data highlight the integration of AI and machine learning, which enable predictive and prescriptive analytics. Cloud app development and edge analytics are becoming indispensable as businesses seek agile and scalable solutions. Enhanced data privacy protocols and stringent compliance measures are reshaping the way big data is stored, processed, and utilized.
Organizations leveraging big data are unlocking unparalleled opportunities for growth, innovation, and operational efficiency. With transformative technologies at their fingertips, businesses are better positioned to navigate the data-driven future.
Key Takeaways:
Big data encompasses vast, diverse datasets requiring advanced tools for storage, processing, and analysis.
Docker is a transformative technology that simplifies big data workflows through portability, scalability, and efficiency.
The integration of AI and machine learning in big data enhances predictive and prescriptive analytics for actionable insights.
Cloud environments provide unparalleled flexibility, scalability, and resource allocation, making them ideal for big data development.
Leveraging docker and the cloud together ensures businesses can manage and analyze massive datasets efficiently in a dynamic environment.
What is Big Data?
Big Data encompasses vast, diverse datasets that grow exponentially, including structured, unstructured, and semi-structured information. These datasets, due to their sheer volume, velocity, and variety, surpass the capabilities of traditional data management tools. They require advanced systems to efficiently store, process, and analyze.
The rapid growth of big data is fueled by innovations like connectivity, Internet of Things (IoT), mobility, and artificial intelligence technologies. These advancements have significantly increased data availability and generation, enabling businesses to harness unprecedented amounts of information. However, managing such massive datasets demands specialized tools that process data at high speeds to unlock actionable insights.
Big data plays a pivotal role in advanced analytics, including predictive modeling and machine learning. Businesses leverage these technologies to address complex challenges, uncover trends, and make data-driven decisions. The strategic use of big data allows companies to stay competitive, anticipate market demands, and enhance operational efficiency.
With digital transformation, the importance of big data continues to rise. Organizations now adopt cutting-edge solutions to collect, analyze, and visualize data effectively. These tools empower businesses to extract meaningful patterns and drive innovation, transforming raw data into strategic assets.
How Does Docker Work With AWS?
Docker has revolutionized how applications are developed, deployed, and managed in the dynamic landscape of big data. This guide explores how Docker simplifies big data workflows, providing scalability, flexibility, and efficiency.
Docker uses multiple different environments while building online services:
Amazon Web Services or the servers
Microsoft Azure the code
Google Compute Engine
GitHub for SDK
Dropbox to save files
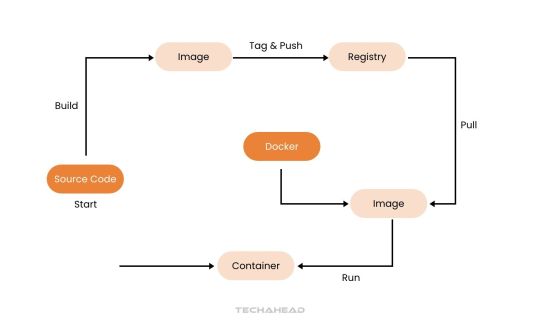
Step 1: Build Your Big Data Application With a Dockerfile
Begin by developing your big data application using your preferred language and tools. A Dockerfile is essential for packaging your application.
It’s a blueprint that outlines the base image, dependencies, and commands to run your application. For big data applications, the Dockerfile might include libraries for distributed computing like Hadoop and Spark. This ensures seamless functionality across various environments.
Step 2: Build a Big Data Docker Image
The Dockerfile helps create a Docker image, which is a self-sufficient unit containing your application, environment, and dependencies.
For big data, this image ensures compatibility, including tools like Jupyter Notebook, PySpark, or Presto for analytics. Use the following command to create the image:
$ docker build -t bigdata-app:latest .
This command builds an image, tags it as ‘bigdata-app:latest’, and prepares it for deployment.
Step 3: Run Containers for Big Data Processing
A Docker container is an isolated instance of your image, ideal for running big data tasks without interference.
$ docker container run -d -p 8080:80 bigdata-app:latest
This command runs the container in detached mode and maps port 8080 on the host to port 80 in the container.
For big data, containers allow parallel processing, enabling distributed systems to run seamlessly across multiple nodes.
Step 4: Manage Big Data Containers
Docker simplifies the management of containers for complex big data workflows.
Use ‘docker ps’ to view running containers, essential for tracking active data processes.
Use ‘docker ps -a’ to check all containers, including completed tasks.
Use ‘docker stop ’ and ‘docker start ’ to manage container lifecycles.
Use ‘docker rm ’ to remove unused containers and free resources.
Run ‘docker container –help’ to explore advanced options for managing big data processing pipelines.
Step 5: Orchestrate Big Data Workflows with Docker Compose
For complex big data architecture, Docker Compose defines and runs multi-container setups.
Compose files in YAML specify services like Hadoop clusters, Spark worker, or Kafka brokers. This simplifies deployment and ensures services interact seamlessly.
```yaml
version: '3'
services:
hadoop-master:
image: hadoop-master:latest
ports:
- "50070:50070"
spark-worker:
image: spark-worker:latest
depends_on:
- hadoop-master
On command can spin up your entire big data ecosystem:$ docker-compose up
Step 6: Publish and Share Big Data Docker Images
Publishing Docker images ensures your big data solutions are accessible across teams or environments. Push your image to a registry:
$ docker push myregistry/bigdata-app:latest
This step enables distributed teams to collaborate effectively and deploy applications in diverse environments like Kubernetes clusters or cloud platforms.
Step 7: Continuous Iteration for Big Data Efficiency
Big data applications require constant updates to incorporate new features or optimize workflows.
Update your Dockerfile to include new dependencies or scripts for analytics, then rebuild the image:
$ docker build -t bigdata-app:v2 .
This interactive approach ensures that your big data solutions evolve while maintaining efficiency and reliability
The Five ‘V’ of Big Data
Not all large datasets qualify as big data. To be clarified as such, the data must exhibit five characteristics. Let’s look deeper into these pillars.
Volume: The Scale of Data
Volume stands as the hallmark of big data. Managing vast amounts of data—ranging from terabytes to petabytes—requires advanced tools and techniques. Traditional systems fall short, while AI-powered analytics handle this scale with ease. Secure storage and efficient organization form the foundation for utilizing this data effectively, enabling large companies to unlock insights from their massive reserves.
Velocity: The Speed of Data Flow
In traditional systems, data entry was manual and time-intensive, delaying insights. Big data redefines this by enabling real-time processing as data is generated, often within milliseconds. This rapid flow empowers businesses to act swiftly—capturing opportunities, addressing customer needs, detecting fraud, and ensuring agility in fast-paced environments.
Veracity: Ensuring Data Quality
Data’s worth lies in its accuracy, relevance, and timeliness. While structured data errors like typos are manageable, unstructured data introduces challenges like bias, misinformation, and unclear origins. Big data technologies address these issues, ensuring high-quality datasets that fuel precise and meaningful insights.
Value: Transforming Data into Insights
Ultimately, big data’s true strength lies in its ability to generate actionable insights. The analytics derived must go beyond intrigue to deliver measurable outcomes, such as enhanced competitiveness, improved customer experiences, and operational efficiency. The right big data strategies translate complex datasets into tangible business value, ensuring a stronger bottom line and resilience.
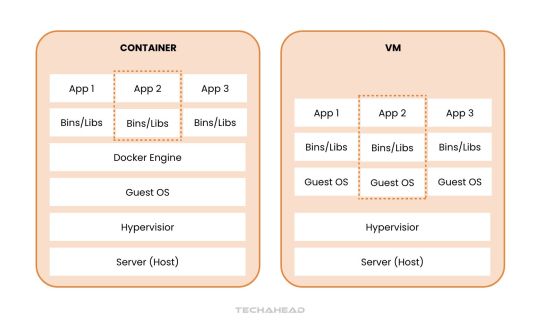
Understanding Docker Containers: Essential for Big Data Use Cases
Docker containers are revolutionizing how applications are developed, deployed, and managed, particularly in big data environments. Here’s an exploration of their fundamentals and why they are transformative.
What Are Docker Containers?
Docker containers act as an abstraction layer, bundling everything an application needs into a single portable package. This bundle includes libraries, resources, and code, enabling seamless deployment on any system without requiring additional configurations. For big data applications, this eliminates compatibility issues, accelerating development and deployment.
Efficiency in Development and Migration
Docker drastically reduces development time and costs, especially during architectural evolution or cloud migration. It simplifies transitions by packaging all necessary components, ensuring smooth operation in new environments. For big data workflows, Docker’s efficiency helps scale analytics, adapt to infrastructure changes, and support evolving business needs.
Why the Hype Around Docker?
Docker’s approach to OS-level virtualization and its Platform-as-a-Service (PaaS) nature makes it indispensable. It encapsulates applications into lightweight, executable components that are easy to manage. For big data, this enables rapid scaling, streamlined workflows, and reduced resource usage.
Cross-Platform Compatibility
As an open-source solution, Docker runs on major operating systems like Linux, Windows, and macOS. This cross-platform capability ensures big data applications remain accessible and functional across diverse computing environments. Organizations can process and analyze data without being limited by their operating system.
Docker in Big Data Architecture
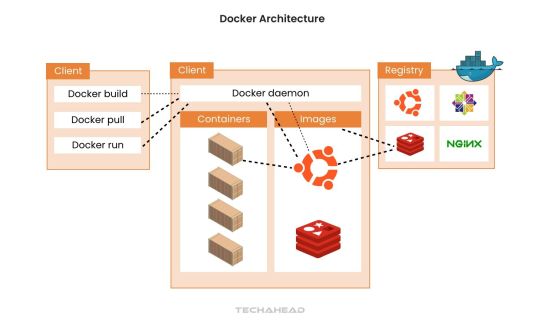
Docker’s architecture supports modular, scalable, and efficient big data solutions. By isolating applications within containers, Docker ensures better resource utilization and consistent performance, even under heavy workloads. Its ability to integrate seamlessly into big data pipelines makes it a critical tool for modern analytics.
Docker containers are transforming big data operations by simplifying deployment, enhancing scalability, and ensuring compatibility across platforms. This powerful technology allows businesses to unlock the full potential of their data with unmatched efficiency and adaptability.
Applications of Big Data Across Industries
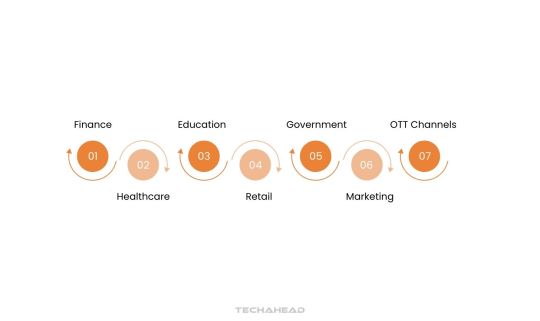
Big data is transforming industries by enabling businesses to harness data-driven insights for innovation, efficiency, and improved decision-making. Here’s how different sectors are leveraging big data to revolutionize their operations.
Finance
Big data is a cornerstone of the finance and insurance sectors, enhancing fraud detection and enabling more accurate risk assessments. Predictive analytics help refine credit rankings and brokerage services, ensuring better financial decision-making. Blockchain technology also benefits from big data by streamlining secure transactions and tracking digital assets. Financial institutions use big data to fortify cybersecurity measures and deliver personalized financial recommendations to customers, improving user trust and satisfaction.
Healthcare
Big data is reshaping healthcare app development by equipping hospitals, researchers, and pharmaceutical companies with critical insights. Patient and population data allow for the optimization of treatments, accelerating research on diseases like cancer and Alzheimer’s. Advanced analytics support the development of innovative drugs and help identify trends in population health. By leveraging big data, healthcare providers can predict disease outbreaks and improve preventive care strategies.
Education
In education app development, big data empowers institutions to analyze student behavior and develop tailored learning experiences. This data enables educators to design personalized lesson plans, predict student performance, and enhance engagement. Schools also use big data to monitor resources, optimize budgets, and reduce operational costs, fostering a more efficient educational environment.
Retail
Retailers rely on big data to analyze customer purchase histories and transaction patterns. This data predicts future buying behaviors allowing for personalized marketing strategies and improved customer experiences. Real estate app development uses big data to optimize inventory, pricing, and promotions, staying competitive in a dynamic market landscape.
Government
Governments leverage big data to analyze public financial, health, and demographic data for better policymaking. Insights derived from big data help create responsive legislation, optimize financial operations, and enhance crisis management plans. By understanding citizen needs through data, governments can improve public services and strengthen community engagement.
Marketing
Big data transforms marketing by offering an in-depth understanding of consumer behavior and preferences. Businesses use this data to identify emerging market trends and refine buyer personas. Marketers optimize campaigns and strategies based on big data insights, ensuring more targeted outreach and higher conversion rates.
OTT Channels
Media platforms like Netflix and Hulu exemplify big data’s influence in crafting personalized user experiences. These companies analyze viewing, reading, and listening habits to recommend content that aligns with individual preferences. Big data even informs choices about graphics, titles, and colors, tailoring the content presentation to boost engagement and customer satisfaction.
Big data is not just a technological trend—it’s a transformative force across industries. Organizations that effectively utilize big data gain a competitive edge, offering smarter solutions and creating lasting value for their customers.
Best Practices for Using Docker in Big Data Development
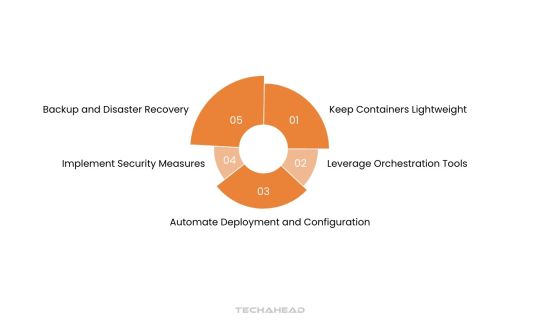
To maximize the potential of Docker for big data development, implementing key strategies can optimize performance, security, and scalability. Below are essential practices for effectively using Docker in big data environments.
Keep Containers Lightweight
Design Docker containers with minimalistic and efficient images to optimize resource consumption. Lightweight containers reduce processing overhead, enabling faster execution of big data workloads. By stripping unnecessary dependencies, you can improve container performance and ensure smoother operations across diverse environments.
Leverage Orchestration Tools
Utilize orchestration platforms like Docker Swarm or Kubernetes to streamline the management of big data workloads. These tools automate deployment, scaling, and load balancing, ensuring that big data applications remain responsive during high-demand periods. Orchestration also simplifies monitoring and enhances fault tolerance.
Automate Deployment and Configuration
Automate the provisioning and setup of Docker containers using tools like Docker Compose or infrastructure-as-code frameworks. Automation reduces manual errors and accelerates deployment, ensuring consistent configurations across environments. This approach enhances the efficiency of big data processing pipelines, especially in dynamic, large-scale systems.
Implement Security Measures
Adopt robust security protocols to protect Docker containers and the big data they process. Use trusted base images, keep Docker components updated, and enforce strict access controls to minimize vulnerabilities. Restrict container privileges to the least necessary level, ensuring a secure environment for sensitive data processing tasks.
Backup and Disaster Recovery
Establish comprehensive backup and disaster recovery plans for data managed within Docker environments. Regularly back up critical big data outputs to safeguard against unexpected failures or data loss. A reliable disaster recovery strategy ensures continuity in big data operations, preserving valuable insights even during unforeseen disruptions.
By adhering to these practices, organizations can fully leverage Docker’s capabilities in big data processing. These strategies enhance operational efficiency, ensure data security, and enable scalability, empowering businesses to drive data-driven innovation with confidence.
Advantages of Using Docker for Big Data Processing

Docker offers a range of benefits that enhance the efficiency and scalability of big data processing environments. By optimizing resource utilization and enabling seamless application deployment. Docker ensures businesses can handle large-scale data operations effectively. Here’s a closer look:
Isolation
Docker provides robust application-level isolation, ensuring each big data development workload operates independently. This isolation prevents conflicts between applications, improving reliability and enabling seamless parallel execution of multiple data-intensive tasks. Businesses can confidently run diverse big data applications without compatibility concerns or interference.
Portability
Docker containers deliver unmatched portability, allowing big data workloads to be deployed across various environments. Whether running on local machines, cloud platforms, or on-premises servers. Docker ensures consistent performance. This portability simplifies cloud migration of big data development workflows between infrastructure, minimizing downtime and operational challenges.
Scalability
With Docker, scaling big data applications becomes effortless through horizontal scaling capabilities. Businesses can quickly deploy multiple containers to distribute workloads, enhancing processing power and efficiency. This scalability ensures organizations can manage fluctuating data volumes, maintaining optimal performance during peak demands.
Resource Efficiency
Docker’s lightweight design optimizes resource utilization, reducing hardware strain while processing large datasets. This efficiency ensures big data workloads can run smoothly without requiring excessive infrastructure investments. Organizations can achieve high-performance data analysis while controlling operational costs.
Version Control
Docker’s versioning features simplify managing containerized big data applications, ensuring reproducibility and traceability. Teams can easily roll back to previous versions if needed, enhancing system reliability and reducing downtime. This capability supports consistent and accurate data processing workflows.
By leveraging Docker, businesses can streamline big data processing operations. The above-mentioned advantages empower businesses to process large datasets effectively, extract actionable insights, and stay competitive in a data-driven world.
Conclusion
This article explores how modern cloud technologies can establish an efficient and scalable development environment. While cloud-based machines may not fully replace traditional computers or laptops, they excel for development tasks requiring access to integrated development environments (IDEs). With today’s high-speed internet, cloud-based development offers seamless and responsive performance for most projects.
Cloud environments provide unparalleled flexibility, making server access and management significantly faster than local setups. Developers can effortlessly scale memory, deploy additional environments, or generate system images with minimal effort. This agility is especially crucial when handling big data projects, which demand vast resources and scalable infrastructures.
The cloud effectively places an entire data center at your fingertips, empowering developers to manage complex tasks efficiently. For big data workflows, this translates into the ability to process and store massive datasets without compromising speed or functionality. Businesses benefit from this scalability, as it aligns with the increasing demand for high-performance analytics and storage.
By leveraging the cloud, developers gain access to state-of-the-art infrastructures that optimize workflow efficiency. The ability to allocate resources, process data, and scale operations dynamically is essential for thriving in today’s data-driven economy.
Source URL: https://www.techaheadcorp.com/blog/developing-for-the-cloud-in-the-cloud-big-data-development-with-docker/
0 notes
Text

CodeStore is a trusted cloud app development company in India, specializing in building secure, flexible, and scalable cloud-based applications.
0 notes
Text
Explore how AI is transforming cloud computing by enhancing efficiency and security. Learn how AI-driven technologies optimize cloud operations, automate processes, and protect data, driving innovation and providing smarter solutions for modern businesses.
0 notes