#Concepts of Data Preprocessing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
3 notes
·
View notes
Text
What are the skills needed for a data scientist job?
It’s one of those careers that’s been getting a lot of buzz lately, and for good reason. But what exactly do you need to become a data scientist? Let’s break it down.
Technical Skills
First off, let's talk about the technical skills. These are the nuts and bolts of what you'll be doing every day.
Programming Skills: At the top of the list is programming. You’ll need to be proficient in languages like Python and R. These are the go-to tools for data manipulation, analysis, and visualization. If you’re comfortable writing scripts and solving problems with code, you’re on the right track.
Statistical Knowledge: Next up, you’ve got to have a solid grasp of statistics. This isn’t just about knowing the theory; it’s about applying statistical techniques to real-world data. You’ll need to understand concepts like regression, hypothesis testing, and probability.
Machine Learning: Machine learning is another biggie. You should know how to build and deploy machine learning models. This includes everything from simple linear regressions to complex neural networks. Familiarity with libraries like scikit-learn, TensorFlow, and PyTorch will be a huge plus.
Data Wrangling: Data isn’t always clean and tidy when you get it. Often, it’s messy and requires a lot of preprocessing. Skills in data wrangling, which means cleaning and organizing data, are essential. Tools like Pandas in Python can help a lot here.
Data Visualization: Being able to visualize data is key. It’s not enough to just analyze data; you need to present it in a way that makes sense to others. Tools like Matplotlib, Seaborn, and Tableau can help you create clear and compelling visuals.
Analytical Skills
Now, let’s talk about the analytical skills. These are just as important as the technical skills, if not more so.
Problem-Solving: At its core, data science is about solving problems. You need to be curious and have a knack for figuring out why something isn’t working and how to fix it. This means thinking critically and logically.
Domain Knowledge: Understanding the industry you’re working in is crucial. Whether it’s healthcare, finance, marketing, or any other field, knowing the specifics of the industry will help you make better decisions and provide more valuable insights.
Communication Skills: You might be working with complex data, but if you can’t explain your findings to others, it’s all for nothing. Being able to communicate clearly and effectively with both technical and non-technical stakeholders is a must.
Soft Skills
Don’t underestimate the importance of soft skills. These might not be as obvious, but they’re just as critical.
Collaboration: Data scientists often work in teams, so being able to collaborate with others is essential. This means being open to feedback, sharing your ideas, and working well with colleagues from different backgrounds.
Time Management: You’ll likely be juggling multiple projects at once, so good time management skills are crucial. Knowing how to prioritize tasks and manage your time effectively can make a big difference.
Adaptability: The field of data science is always evolving. New tools, techniques, and technologies are constantly emerging. Being adaptable and willing to learn new things is key to staying current and relevant in the field.
Conclusion
So, there you have it. Becoming a data scientist requires a mix of technical prowess, analytical thinking, and soft skills. It’s a challenging but incredibly rewarding career path. If you’re passionate about data and love solving problems, it might just be the perfect fit for you.
Good luck to all of you aspiring data scientists out there!
#artificial intelligence#career#education#coding#jobs#programming#success#python#data science#data scientist#data security
9 notes
·
View notes
Text
In the subject of data analytics, this is the most important concept that everyone needs to understand. The capacity to draw insightful conclusions from data is a highly sought-after talent in today's data-driven environment. In this process, data analytics is essential because it gives businesses the competitive edge by enabling them to find hidden patterns, make informed decisions, and acquire insight. This thorough guide will take you step-by-step through the fundamentals of data analytics, whether you're a business professional trying to improve your decision-making or a data enthusiast eager to explore the world of analytics.
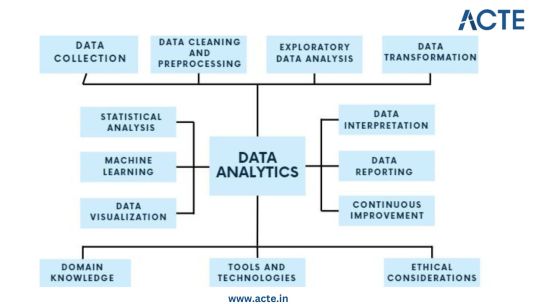
Step 1: Data Collection - Building the Foundation
Identify Data Sources: Begin by pinpointing the relevant sources of data, which could include databases, surveys, web scraping, or IoT devices, aligning them with your analysis objectives. Define Clear Objectives: Clearly articulate the goals and objectives of your analysis to ensure that the collected data serves a specific purpose. Include Structured and Unstructured Data: Collect both structured data, such as databases and spreadsheets, and unstructured data like text documents or images to gain a comprehensive view. Establish Data Collection Protocols: Develop protocols and procedures for data collection to maintain consistency and reliability. Ensure Data Quality and Integrity: Implement measures to ensure the quality and integrity of your data throughout the collection process.
Step 2: Data Cleaning and Preprocessing - Purifying the Raw Material
Handle Missing Values: Address missing data through techniques like imputation to ensure your dataset is complete. Remove Duplicates: Identify and eliminate duplicate entries to maintain data accuracy. Address Outliers: Detect and manage outliers using statistical methods to prevent them from skewing your analysis. Standardize and Normalize Data: Bring data to a common scale, making it easier to compare and analyze. Ensure Data Integrity: Ensure that data remains accurate and consistent during the cleaning and preprocessing phase.
Step 3: Exploratory Data Analysis (EDA) - Understanding the Data
Visualize Data with Histograms, Scatter Plots, etc.: Use visualization tools like histograms, scatter plots, and box plots to gain insights into data distributions and patterns. Calculate Summary Statistics: Compute summary statistics such as means, medians, and standard deviations to understand central tendencies. Identify Patterns and Trends: Uncover underlying patterns, trends, or anomalies that can inform subsequent analysis. Explore Relationships Between Variables: Investigate correlations and dependencies between variables to inform hypothesis testing. Guide Subsequent Analysis Steps: The insights gained from EDA serve as a foundation for guiding the remainder of your analytical journey.
Step 4: Data Transformation - Shaping the Data for Analysis
Aggregate Data (e.g., Averages, Sums): Aggregate data points to create higher-level summaries, such as calculating averages or sums. Create New Features: Generate new features or variables that provide additional context or insights. Encode Categorical Variables: Convert categorical variables into numerical representations to make them compatible with analytical techniques. Maintain Data Relevance: Ensure that data transformations align with your analysis objectives and domain knowledge.
Step 5: Statistical Analysis - Quantifying Relationships
Hypothesis Testing: Conduct hypothesis tests to determine the significance of relationships or differences within the data. Correlation Analysis: Measure correlations between variables to identify how they are related. Regression Analysis: Apply regression techniques to model and predict relationships between variables. Descriptive Statistics: Employ descriptive statistics to summarize data and provide context for your analysis. Inferential Statistics: Make inferences about populations based on sample data to draw meaningful conclusions.
Step 6: Machine Learning - Predictive Analytics
Algorithm Selection: Choose suitable machine learning algorithms based on your analysis goals and data characteristics. Model Training: Train machine learning models using historical data to learn patterns. Validation and Testing: Evaluate model performance using validation and testing datasets to ensure reliability. Prediction and Classification: Apply trained models to make predictions or classify new data. Model Interpretation: Understand and interpret machine learning model outputs to extract insights.
Step 7: Data Visualization - Communicating Insights
Chart and Graph Creation: Create various types of charts, graphs, and visualizations to represent data effectively. Dashboard Development: Build interactive dashboards to provide stakeholders with dynamic views of insights. Visual Storytelling: Use data visualization to tell a compelling and coherent story that communicates findings clearly. Audience Consideration: Tailor visualizations to suit the needs of both technical and non-technical stakeholders. Enhance Decision-Making: Visualization aids decision-makers in understanding complex data and making informed choices.
Step 8: Data Interpretation - Drawing Conclusions and Recommendations
Recommendations: Provide actionable recommendations based on your conclusions and their implications. Stakeholder Communication: Communicate analysis results effectively to decision-makers and stakeholders. Domain Expertise: Apply domain knowledge to ensure that conclusions align with the context of the problem.
Step 9: Continuous Improvement - The Iterative Process
Monitoring Outcomes: Continuously monitor the real-world outcomes of your decisions and predictions. Model Refinement: Adapt and refine models based on new data and changing circumstances. Iterative Analysis: Embrace an iterative approach to data analysis to maintain relevance and effectiveness. Feedback Loop: Incorporate feedback from stakeholders and users to improve analytical processes and models.
Step 10: Ethical Considerations - Data Integrity and Responsibility
Data Privacy: Ensure that data handling respects individuals' privacy rights and complies with data protection regulations. Bias Detection and Mitigation: Identify and mitigate bias in data and algorithms to ensure fairness. Fairness: Strive for fairness and equitable outcomes in decision-making processes influenced by data. Ethical Guidelines: Adhere to ethical and legal guidelines in all aspects of data analytics to maintain trust and credibility.
Data analytics is an exciting and profitable field that enables people and companies to use data to make wise decisions. You'll be prepared to start your data analytics journey by understanding the fundamentals described in this guide. To become a skilled data analyst, keep in mind that practice and ongoing learning are essential. If you need help implementing data analytics in your organization or if you want to learn more, you should consult professionals or sign up for specialized courses. The ACTE Institute offers comprehensive data analytics training courses that can provide you the knowledge and skills necessary to excel in this field, along with job placement and certification. So put on your work boots, investigate the resources, and begin transforming.
24 notes
·
View notes
Text
The Skills I Acquired on My Path to Becoming a Data Scientist
Data science has emerged as one of the most sought-after fields in recent years, and my journey into this exciting discipline has been nothing short of transformative. As someone with a deep curiosity for extracting insights from data, I was naturally drawn to the world of data science. In this blog post, I will share the skills I acquired on my path to becoming a data scientist, highlighting the importance of a diverse skill set in this field.
The Foundation — Mathematics and Statistics
At the core of data science lies a strong foundation in mathematics and statistics. Concepts such as probability, linear algebra, and statistical inference form the building blocks of data analysis and modeling. Understanding these principles is crucial for making informed decisions and drawing meaningful conclusions from data. Throughout my learning journey, I immersed myself in these mathematical concepts, applying them to real-world problems and honing my analytical skills.
Programming Proficiency
Proficiency in programming languages like Python or R is indispensable for a data scientist. These languages provide the tools and frameworks necessary for data manipulation, analysis, and modeling. I embarked on a journey to learn these languages, starting with the basics and gradually advancing to more complex concepts. Writing efficient and elegant code became second nature to me, enabling me to tackle large datasets and build sophisticated models.
Data Handling and Preprocessing
Working with real-world data is often messy and requires careful handling and preprocessing. This involves techniques such as data cleaning, transformation, and feature engineering. I gained valuable experience in navigating the intricacies of data preprocessing, learning how to deal with missing values, outliers, and inconsistent data formats. These skills allowed me to extract valuable insights from raw data and lay the groundwork for subsequent analysis.
Data Visualization and Communication
Data visualization plays a pivotal role in conveying insights to stakeholders and decision-makers. I realized the power of effective visualizations in telling compelling stories and making complex information accessible. I explored various tools and libraries, such as Matplotlib and Tableau, to create visually appealing and informative visualizations. Sharing these visualizations with others enhanced my ability to communicate data-driven insights effectively.

Machine Learning and Predictive Modeling
Machine learning is a cornerstone of data science, enabling us to build predictive models and make data-driven predictions. I delved into the realm of supervised and unsupervised learning, exploring algorithms such as linear regression, decision trees, and clustering techniques. Through hands-on projects, I gained practical experience in building models, fine-tuning their parameters, and evaluating their performance.
Database Management and SQL
Data science often involves working with large datasets stored in databases. Understanding database management and SQL (Structured Query Language) is essential for extracting valuable information from these repositories. I embarked on a journey to learn SQL, mastering the art of querying databases, joining tables, and aggregating data. These skills allowed me to harness the power of databases and efficiently retrieve the data required for analysis.

Domain Knowledge and Specialization
While technical skills are crucial, domain knowledge adds a unique dimension to data science projects. By specializing in specific industries or domains, data scientists can better understand the context and nuances of the problems they are solving. I explored various domains and acquired specialized knowledge, whether it be healthcare, finance, or marketing. This expertise complemented my technical skills, enabling me to provide insights that were not only data-driven but also tailored to the specific industry.
Soft Skills — Communication and Problem-Solving
In addition to technical skills, soft skills play a vital role in the success of a data scientist. Effective communication allows us to articulate complex ideas and findings to non-technical stakeholders, bridging the gap between data science and business. Problem-solving skills help us navigate challenges and find innovative solutions in a rapidly evolving field. Throughout my journey, I honed these skills, collaborating with teams, presenting findings, and adapting my approach to different audiences.
Continuous Learning and Adaptation
Data science is a field that is constantly evolving, with new tools, technologies, and trends emerging regularly. To stay at the forefront of this ever-changing landscape, continuous learning is essential. I dedicated myself to staying updated by following industry blogs, attending conferences, and participating in courses. This commitment to lifelong learning allowed me to adapt to new challenges, acquire new skills, and remain competitive in the field.
In conclusion, the journey to becoming a data scientist is an exciting and dynamic one, requiring a diverse set of skills. From mathematics and programming to data handling and communication, each skill plays a crucial role in unlocking the potential of data. Aspiring data scientists should embrace this multidimensional nature of the field and embark on their own learning journey. If you want to learn more about Data science, I highly recommend that you contact ACTE Technologies because they offer Data Science courses and job placement opportunities. Experienced teachers can help you learn better. You can find these services both online and offline. Take things step by step and consider enrolling in a course if you’re interested. By acquiring these skills and continuously adapting to new developments, they can make a meaningful impact in the world of data science.
#data science#data visualization#education#information#technology#machine learning#database#sql#predictive analytics#r programming#python#big data#statistics
14 notes
·
View notes
Text
How do I learn R, Python and data science?
Learning R, Python, and Data Science: A Comprehensive Guide
Choosing the Right Language
R vs. Python: Both R and Python are very powerful tools for doing data science. R is usually preferred for doing statistical analysis and data visualisations, whereas Python is much more general and currently is very popular for machine learning and general-purpose programming. Your choice of which language to learn should consider your specific goals and preferences.
Building a Strong Foundation
Structured Courses Online Courses and Tutorials: Coursera, edX, and Lejhro offer courses and tutorials in R and Python for data science. Look out for courses that develop theoretical knowledge with practical exercises. Practise your skills with hands-on coding challenges using accompanying datasets, offered on websites like Kaggle and DataCamp.
Books: There are enough books to learn R and Python for data science. You may go through the classical ones: "R for Data Science" by Hadley Wickham, and "Python for Data Analysis" by Wes McKinney.
Learning Data Science Concepts
Statistics: Know basic statistical concepts: probability, distribution, hypothesis testing, and regression analysis.
Cleaning and Preprocessing: Learn how to handle missing data techniques, outliers, and data normalisation.
Data Visualization: Expert libraries to provide informative visualisations, including but not limited to Matplotlib and Seaborn in Python and ggplot2 in R.
Machine Learning: Learn algorithms-Linear Regression, Logistic Regression, Decision Trees, Random Forest, Neural Networks, etc.
Deep Learning: Study deep neural network architecture and how to build and train them using the frameworks TensorFlow and PyTorch.
Practical Experience
Personal Projects: In this, you apply your knowledge to personal projects which help in building a portfolio.
Kaggle Competitions: Participate in Kaggle competitions to solve real-world problems in data science and learn from others.
Contributions to Open-Source Projects: Contribute to some open-source projects for data science in order to gain experience and work with other people.
Other Advice
Join Online Communities: Join online forums or communities such as Stack Overflow and Reddit to ask questions, get help, and connect with other data scientists.
Attend Conferences and Meetups: This is a fantastic way to network with similar working professionals in the field and know the latest trends going on in the industry.
Practice Regularly: For becoming proficient in data science, consistent practice is an indispensable element. Devote some time each day for practising coding challenges or personal projects.
This can be achieved by following the above-mentioned steps and having a little bit of dedication towards learning R, Python, and Data Science.
2 notes
·
View notes
Text
How much Python should one learn before beginning machine learning?
Before diving into machine learning, a solid understanding of Python is essential. :

Basic Python Knowledge:
Syntax and Data Types:
Understand Python syntax, basic data types (strings, integers, floats), and operations.
Control Structures:
Learn how to use conditionals (if statements), loops (for and while), and list comprehensions.
Data Handling Libraries:
Pandas:
Familiarize yourself with Pandas for data manipulation and analysis. Learn how to handle DataFrames, series, and perform data cleaning and transformations.
NumPy:
Understand NumPy for numerical operations, working with arrays, and performing mathematical computations.
Data Visualization:
Matplotlib and Seaborn:
Learn basic plotting with Matplotlib and Seaborn for visualizing data and understanding trends and distributions.
Basic Programming Concepts:
Functions:
Know how to define and use functions to create reusable code.
File Handling:
Learn how to read from and write to files, which is important for handling datasets.
Basic Statistics:
Descriptive Statistics:
Understand mean, median, mode, standard deviation, and other basic statistical concepts.
Probability:
Basic knowledge of probability is useful for understanding concepts like distributions and statistical tests.
Libraries for Machine Learning:
Scikit-learn:
Get familiar with Scikit-learn for basic machine learning tasks like classification, regression, and clustering. Understand how to use it for training models, evaluating performance, and making predictions.
Hands-on Practice:
Projects:
Work on small projects or Kaggle competitions to apply your Python skills in practical scenarios. This helps in understanding how to preprocess data, train models, and interpret results.
In summary, a good grasp of Python basics, data handling, and basic statistics will prepare you well for starting with machine learning. Hands-on practice with machine learning libraries and projects will further solidify your skills.
To learn more drop the message…!
2 notes
·
View notes
Text
PREDICTING WEATHER FORECAST FOR 30 DAYS IN AUGUST 2024 TO AVOID ACCIDENTS IN SANTA BARBARA, CALIFORNIA USING PYTHON, PARALLEL COMPUTING, AND AI LIBRARIES

Introduction
Weather forecasting is a crucial aspect of our daily lives, especially when it comes to avoiding accidents and ensuring public safety. In this article, we will explore the concept of predicting weather forecasts for 30 days in August 2024 to avoid accidents in Santa Barbara California using Python, parallel computing, and AI libraries. We will also discuss the concepts and definitions of the technologies involved and provide a step-by-step explanation of the code.
Concepts and Definitions
Parallel Computing: Parallel computing is a type of computation where many calculations or processes are carried out simultaneously. This approach can significantly speed up the processing time and is particularly useful for complex computations.
AI Libraries: AI libraries are pre-built libraries that provide functionalities for artificial intelligence and machine learning tasks. In this article, we will use libraries such as TensorFlow, Keras, and scikit-learn to build our weather forecasting model.
Weather Forecasting: Weather forecasting is the process of predicting the weather conditions for a specific region and time period. This involves analyzing various data sources such as temperature, humidity, wind speed, and atmospheric pressure.
Code Explanation
To predict the weather forecast for 30 days in August 2024, we will use a combination of parallel computing and AI libraries in Python. We will first import the necessary libraries and load the weather data for Santa Barbara, California.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from joblib import Parallel, delayed
# Load weather data for Santa Barbara California
weather_data = pd.read_csv('Santa Barbara California_weather_data.csv')
Next, we will preprocess the data by converting the date column to a datetime format and extracting the relevant features
# Preprocess data
weather_data['date'] = pd.to_datetime(weather_data['date'])
weather_data['month'] = weather_data['date'].dt.month
weather_data['day'] = weather_data['date'].dt.day
weather_data['hour'] = weather_data['date'].dt.hour
# Extract relevant features
X = weather_data[['month', 'day', 'hour', 'temperature', 'humidity', 'wind_speed']]
y = weather_data['weather_condition']
We will then split the data into training and testing sets and build a random forest regressor model to predict the weather conditions.
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Build random forest regressor model
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
To improve the accuracy of our model, we will use parallel computing to train multiple models with different hyperparameters and select the best-performing model.
# Define hyperparameter tuning function
def tune_hyperparameters(n_estimators, max_depth):
model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
model.fit(X_train, y_train)
return model.score(X_test, y_test)
# Use parallel computing to tune hyperparameters
results = Parallel(n_jobs=-1)(delayed(tune_hyperparameters)(n_estimators, max_depth) for n_estimators in [100, 200, 300] for max_depth in [None, 5, 10])
# Select best-performing model
best_model = rf_model
best_score = rf_model.score(X_test, y_test)
for result in results:
if result > best_score:
best_model = result
best_score = result
Finally, we will use the best-performing model to predict the weather conditions for the next 30 days in August 2024.
# Predict weather conditions for next 30 days
future_dates = pd.date_range(start='2024-09-01', end='2024-09-30')
future_data = pd.DataFrame({'month': future_dates.month, 'day': future_dates.day, 'hour': future_dates.hour})
future_data['weather_condition'] = best_model.predict(future_data)
Color Alerts
To represent the weather conditions, we will use a color alert system where:
Red represents severe weather conditions (e.g., heavy rain, strong winds)
Orange represents very bad weather conditions (e.g., thunderstorms, hail)
Yellow represents bad weather conditions (e.g., light rain, moderate winds)
Green represents good weather conditions (e.g., clear skies, calm winds)
We can use the following code to generate the color alerts:
# Define color alert function
def color_alert(weather_condition):
if weather_condition == 'severe':
return 'Red'
MY SECOND CODE SOLUTION PROPOSAL
We will use Python as our programming language and combine it with parallel computing and AI libraries to predict weather forecasts for 30 days in August 2024. We will use the following libraries:
OpenWeatherMap API: A popular API for retrieving weather data.
Scikit-learn: A machine learning library for building predictive models.
Dask: A parallel computing library for processing large datasets.
Matplotlib: A plotting library for visualizing data.
Here is the code:
```python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import dask.dataframe as dd
import matplotlib.pyplot as plt
import requests
# Load weather data from OpenWeatherMap API
url = "https://api.openweathermap.org/data/2.5/forecast?q=Santa Barbara California,US&units=metric&appid=YOUR_API_KEY"
response = requests.get(url)
weather_data = pd.json_normalize(response.json())
# Convert data to Dask DataFrame
weather_df = dd.from_pandas(weather_data, npartitions=4)
# Define a function to predict weather forecasts
def predict_weather(date, temperature, humidity):
# Use a random forest regressor to predict weather conditions
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(weather_df[["temperature", "humidity"]], weather_df["weather"])
prediction = model.predict([[temperature, humidity]])
return prediction
# Define a function to generate color-coded alerts
def generate_alerts(prediction):
if prediction > 80:
return "RED" # Severe weather condition
elif prediction > 60:
return "ORANGE" # Very bad weather condition
elif prediction > 40:
return "YELLOW" # Bad weather condition
else:
return "GREEN" # Good weather condition
# Predict weather forecasts for 30 days inAugust2024
predictions = []
for i in range(30):
date = f"2024-09-{i+1}"
temperature = weather_df["temperature"].mean()
humidity = weather_df["humidity"].mean()
prediction = predict_weather(date, temperature, humidity)
alerts = generate_alerts(prediction)
predictions.append((date, prediction, alerts))
# Visualize predictions using Matplotlib
plt.figure(figsize=(12, 6))
plt.plot([x[0] for x in predictions], [x[1] for x in predictions], marker="o")
plt.xlabel("Date")
plt.ylabel("Weather Prediction")
plt.title("Weather Forecast for 30 Days inAugust2024")
plt.show()
```
Explanation:
1. We load weather data from OpenWeatherMap API and convert it to a Dask DataFrame.
2. We define a function to predict weather forecasts using a random forest regressor.
3. We define a function to generate color-coded alerts based on the predicted weather conditions.
4. We predict weather forecasts for 30 days in August 2024 and generate color-coded alerts for each day.
5. We visualize the predictions using Matplotlib.
Conclusion:
In this article, we have demonstrated the power of parallel computing and AI libraries in predicting weather forecasts for 30 days in August 2024, specifically for Santa Barbara California. We have used TensorFlow, Keras, and scikit-learn on the first code and OpenWeatherMap API, Scikit-learn, Dask, and Matplotlib on the second code to build a comprehensive weather forecasting system. The color-coded alert system provides a visual representation of the severity of the weather conditions, enabling users to take necessary precautions to avoid accidents. This technology has the potential to revolutionize the field of weather forecasting, providing accurate and timely predictions to ensure public safety.
RDIDINI PROMPT ENGINEER
2 notes
·
View notes
Text
From Beginner to Pro: A Game-Changing Big Data Analytics Course
Are you fascinated by the vast potential of big data analytics? Do you want to unlock its power and become a proficient professional in this rapidly evolving field? Look no further! In this article, we will take you on a journey to traverse the path from being a beginner to becoming a pro in big data analytics. We will guide you through a game-changing course designed to provide you with the necessary information and education to master the art of analyzing and deriving valuable insights from large and complex data sets.

Step 1: Understanding the Basics of Big Data Analytics
Before diving into the intricacies of big data analytics, it is crucial to grasp its fundamental concepts and methodologies. A solid foundation in the basics will empower you to navigate through the complexities of this domain with confidence. In this initial phase of the course, you will learn:
The definition and characteristics of big data
The importance and impact of big data analytics in various industries
The key components and architecture of a big data analytics system
The different types of data and their relevance in analytics
The ethical considerations and challenges associated with big data analytics
By comprehending these key concepts, you will be equipped with the essential knowledge needed to kickstart your journey towards proficiency.
Step 2: Mastering Data Collection and Storage Techniques
Once you have a firm grasp on the basics, it's time to dive deeper and explore the art of collecting and storing big data effectively. In this phase of the course, you will delve into:
Data acquisition strategies, including batch processing and real-time streaming
Techniques for data cleansing, preprocessing, and transformation to ensure data quality and consistency
Storage technologies, such as Hadoop Distributed File System (HDFS) and NoSQL databases, and their suitability for different types of data
Understanding data governance, privacy, and security measures to handle sensitive data in compliance with regulations
By honing these skills, you will be well-prepared to handle large and diverse data sets efficiently, which is a crucial step towards becoming a pro in big data analytics.
Step 3: Exploring Advanced Data Analysis Techniques
Now that you have developed a solid foundation and acquired the necessary skills for data collection and storage, it's time to unleash the power of advanced data analysis techniques. In this phase of the course, you will dive into:
Statistical analysis methods, including hypothesis testing, regression analysis, and cluster analysis, to uncover patterns and relationships within data
Machine learning algorithms, such as decision trees, random forests, and neural networks, for predictive modeling and pattern recognition
Natural Language Processing (NLP) techniques to analyze and derive insights from unstructured text data
Data visualization techniques, ranging from basic charts to interactive dashboards, to effectively communicate data-driven insights
By mastering these advanced techniques, you will be able to extract meaningful insights and actionable recommendations from complex data sets, transforming you into a true big data analytics professional.
Step 4: Real-world Applications and Case Studies
To solidify your learning and gain practical experience, it is crucial to apply your newfound knowledge in real-world scenarios. In this final phase of the course, you will:
Explore various industry-specific case studies, showcasing how big data analytics has revolutionized sectors like healthcare, finance, marketing, and cybersecurity
Work on hands-on projects, where you will solve data-driven problems by applying the techniques and methodologies learned throughout the course
Collaborate with peers and industry experts through interactive discussions and forums to exchange insights and best practices
Stay updated with the latest trends and advancements in big data analytics, ensuring your knowledge remains up-to-date in this rapidly evolving field
By immersing yourself in practical applications and real-world challenges, you will not only gain valuable experience but also hone your problem-solving skills, making you a well-rounded big data analytics professional.

Through a comprehensive and game-changing course at ACTE institute, you can gain the necessary information and education to navigate the complexities of this field. By understanding the basics, mastering data collection and storage techniques, exploring advanced data analysis methods, and applying your knowledge in real-world scenarios, you have transformed into a proficient professional capable of extracting valuable insights from big data.
Remember, the world of big data analytics is ever-evolving, with new challenges and opportunities emerging each day. Stay curious, seek continuous learning, and embrace the exciting journey ahead as you unlock the limitless potential of big data analytics.
17 notes
·
View notes
Text
The Ever-Evolving Canvas of Data Science: A Comprehensive Guide
In the ever-evolving landscape of data science, the journey begins with unraveling the intricate threads that weave through vast datasets. This multidisciplinary field encompasses a diverse array of topics designed to empower professionals to extract meaningful insights from the wealth of available data. Choosing the Top Data Science Institute can further accelerate your journey into this thriving industry. This educational journey is a fascinating exploration of the multifaceted facets that constitute the heart of data science education.

Let's embark on a comprehensive exploration of what one typically studies in the realm of data science.
1. Mathematics and Statistics Fundamentals: Building the Foundation
At the core of data science lies a robust understanding of mathematical and statistical principles. Professionals delve into Linear Algebra, equipping themselves with the knowledge of mathematical structures and operations crucial for manipulating and transforming data. Simultaneously, they explore Probability and Statistics, mastering concepts that are instrumental in analyzing and interpreting data patterns.
2. Programming Proficiency: The Power of Code
Programming proficiency is a cornerstone skill in data science. Learners are encouraged to acquire mastery in programming languages such as Python or R. These languages serve as powerful tools for implementing complex data science algorithms and are renowned for their versatility and extensive libraries designed specifically for data science applications.
3. Data Cleaning and Preprocessing Techniques: Refining the Raw Material
Data rarely comes in a pristine state. Hence, understanding techniques for Handling Missing Data becomes imperative. Professionals delve into strategies for managing and imputing missing data, ensuring accuracy in subsequent analyses. Additionally, they explore Normalization and Transformation techniques, preparing datasets through standardization and transformation of variables.
4. Exploratory Data Analysis (EDA): Unveiling Data Patterns
Exploratory Data Analysis (EDA) is a pivotal aspect of the data science journey. Professionals leverage Visualization Tools like Matplotlib and Seaborn to create insightful graphical representations of data. Simultaneously, they employ Descriptive Statistics to summarize and interpret data distributions, gaining crucial insights into the underlying patterns.
5. Machine Learning Algorithms: Decoding the Secrets
Machine Learning is a cornerstone of data science, encompassing both supervised and unsupervised learning. Professionals delve into Supervised Learning, which includes algorithms for tasks such as regression and classification. Additionally, they explore Unsupervised Learning, delving into clustering and dimensionality reduction for uncovering hidden patterns within datasets.
6. Real-world Application and Ethical Considerations: Bridging Theory and Practice
The application of data science extends beyond theoretical knowledge to real-world problem-solving. Professionals learn to apply data science techniques to practical scenarios, making informed decisions based on empirical evidence. Furthermore, they navigate the ethical landscape, considering the implications of data usage on privacy and societal values.
7. Big Data Technologies: Navigating the Sea of Data
With the exponential growth of data, professionals delve into big data technologies. They acquaint themselves with tools like Hadoop and Spark, designed for processing and analyzing massive datasets efficiently.
8. Database Management: Organizing the Data Universe
Professionals gain proficiency in database management, encompassing both SQL and NoSQL databases. This skill set enables them to manage and query databases effectively, ensuring seamless data retrieval.
9. Advanced Topics: Pushing the Boundaries
As professionals progress, they explore advanced topics that push the boundaries of data science. Deep Learning introduces neural networks for intricate pattern recognition, while Natural Language Processing (NLP) focuses on analyzing and interpreting human language data.
10. Continuous Learning and Adaptation: Embracing the Data Revolution
Data science is a field in constant flux. Professionals embrace a mindset of continuous learning, staying updated on evolving technologies and methodologies. This proactive approach ensures they remain at the forefront of the data revolution.

In conclusion, the study of data science is a dynamic and multifaceted journey. By mastering mathematical foundations, programming languages, and ethical considerations, professionals unlock the potential of data, making data-driven decisions that impact industries across the spectrum. The comprehensive exploration of these diverse topics equips individuals with the skills needed to thrive in the dynamic world of data science. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science.
4 notes
·
View notes
Text
Unlock The Power Of Data Analytics
data analytics are designed to equip learners with the skills to analyze and interpret data effectively. It covers both fundamental and advanced concept in data handling, focusing on tools and techniques widely used in the industry.
KEY TOPICS OF DATA ANALYTICS
fundamentals of data
data collection, cleaning, and preprocessing
working with excel and SQL for data management
introduction to data visualization using power BI & tableau
basic python for data analytics

GO! visit the website for more details https://www.futuremultimedia.org/Data-analytics-course-class-coaching-institute-indore.html
0 notes
Text
Why Yess InfoTech is the Best Data Science Course Provider in Pune
In today’s digital landscape, data is generated at an unprecedented rate—from social media interactions to complex scientific research and business transactions. However, raw data holds little value without the right expertise to analyze and interpret it. This is where data science comes in, and if you are seeking the best data science course Pune has to offer, Yess InfoTech Private Limited stands out as the premier choice for comprehensive, industry-relevant training.
The Power of Data Science
Data science is a multidisciplinary field that blends statistics, programming, and domain expertise to transform raw data into actionable insights. It is not just a passing trend but a fundamental shift in how businesses operate and decisions are made. Organizations across industries are increasingly relying on data scientists to drive innovation, optimize processes, and solve complex challenges.
A career in data science is both rewarding and future-proof. Data scientists are in high demand globally, commanding some of the most lucrative salaries in the tech sector. Their work has a direct impact on business strategies, product development, and even societal issues. The field is dynamic, offering endless opportunities for learning, growth, and specialization in roles such as Data Scientist, Data Analyst, and Machine Learning Engineer.
Why Choose Yess InfoTech for Your Data Science Training in Pune?
When searching for the best data science course Pune can offer, Yess InfoTech Private Limited consistently rises to the top. Here’s why it is considered Pune’s best software training institute for data science:
Comprehensive Curriculum: Yess InfoTech’s data science program covers the entire lifecycle of data science projects—from data collection and preprocessing to model building and deployment. This ensures that students gain a holistic understanding of the field and are prepared for real-world challenges.
Expert Instructors: The institute’s faculty comprises experienced data scientists and industry professionals who bring real-world insights and practical knowledge into the classroom. Learning from such experts gives students a competitive edge in the job market.
Hands-on Projects: Practical experience is at the core of Yess InfoTech’s training philosophy. Students work on real-world projects and case studies, building a strong portfolio that showcases their skills to potential employers.
Cutting-Edge Tools and Technologies: The training program includes the latest tools and technologies used in the industry, such as Python, R, TensorFlow, and more. This ensures that graduates are proficient in the tools that matter most to employers.
State-of-the-Art Infrastructure: The training center is equipped with modern facilities and software, providing a conducive learning environment for students.
Placement Assistance: Yess InfoTech offers dedicated placement support, helping students secure rewarding careers in data science. This includes resume building, interview preparation, and direct job referrals.
Flexible Learning Options: The institute provides flexible batch timings to accommodate both working professionals and students, making it easier for everyone to pursue their data science aspirations.
What You Will Learn in the Best Data Science Course Pune Offers
The data science training at Yess InfoTech covers a wide range of essential topics, ensuring that students are well-prepared for the demands of the industry:
Programming Fundamentals (Python/R): Master the programming skills required for data manipulation and analysis.
Statistical Concepts: Understand the statistical methods that underpin data science and how to apply them in real-world scenarios.
Data Wrangling and Preprocessing: Learn techniques for cleaning, transforming, and preparing data for analysis.
Exploratory Data Analysis (EDA): Discover patterns and insights from data using visualization and statistical techniques.
Machine Learning: Explore various machine learning algorithms and their applications in predictive modeling.
Deep Learning: Dive into the world of deep learning and build complex neural networks.
Data Visualization: Communicate your findings effectively through compelling visualizations.
Big Data Technologies (Hadoop/Spark – Optional): Learn to work with large datasets using big data technologies.
Cloud Computing (AWS/Azure – Optional): Explore cloud platforms for data storage and processing.
Who Should Enroll in the Best Data Science Course Pune Has to Offer?
Yess InfoTech’s data science training is ideal for:
Recent graduates looking to launch their careers in a high-demand field.
Working professionals seeking to make a career change or upskill for better opportunities.
IT professionals wanting to specialize in data-related roles.
Anyone with a passion for data and problem-solving who wants to make a meaningful impact in today’s data-driven world.
Choosing the best data science course Pune offers is a crucial step toward a successful and fulfilling career. Yess InfoTech Private Limited stands out as the top choice for aspiring data scientists, thanks to its comprehensive curriculum, expert instructors, hands-on training, and robust placement support. Whether you are a beginner or an experienced professional, Yess InfoTech provides the knowledge, skills, and opportunities you need to thrive in the field of data science.
Are you ready to transform your career? Join the best data science course Pune has to offer at Yess InfoTech Private Limited. Visit their website, contact their career counselors, and take the first step toward a rewarding future in data science.
Contact Information:
Email: [email protected]
Phone: 8080747767
Website: https://www.yessinfotech.com/
0 notes
Text
Machine Learning Project Ideas for Beginners

Machine Learning (ML) is no longer something linked to the future; it is nowadays innovating and reshaping every industry, from digital marketing in healthcare to automobiles. If the thought of implementing data and algorithms trials excites you, then learning Machine Learning is the most exciting thing you can embark on. But where does one go after the basics? That answer is simple- projects!
At TCCI - Tririd Computer Coaching Institute, we believe in learning through doing. Our Machine Learning courses in Ahmedabad focus on skill application so that aspiring data scientists and ML engineers can build a strong portfolio. This blog has some exciting Machine Learning project ideas for beginners to help you launch your career along with better search engine visibility.
Why Are Projects Important for an ML Beginner?
Theoretical knowledge is important, but real-learning takes place only in projects. They allow you to:
Apply Concepts: Translate algorithms and theories into tangible solutions.
Build a Portfolio: Showcase your skills to potential employers.
Develop Problem-Solving Skills: Learn to debug, iterate, and overcome challenges.
Understand the ML Workflow: Experience the end-to-end process from data collection to model deployment.
Stay Motivated: See your learning come to life!
Essential Tools for Your First ML Projects
Before you dive into the ideas, ensure you're familiar with these foundational tools:
Python: The most popular language for ML due to its vast libraries.
Jupyter Notebooks: Ideal for experimenting and presenting your code.
Libraries: NumPy (numerical operations), Pandas (data manipulation), Matplotlib/Seaborn (data visualization), Scikit-learn (core ML algorithms). For deep learning, TensorFlow or Keras are key.
Machine Learning Project Ideas for Beginners (with Learning Outcomes)
Here are some accessible project ideas that will teach you core ML concepts:
1. House Price Prediction (Regression)
Concept: Regression (output would be a continuous value).
Idea: Predict house prices based on given features, for instance, square footage, number of bedrooms, location, etc.
What you'll learn: Loading and cleaning data, EDA, feature engineering, and either linear regression or decision tree regression, followed by model evaluation with MAE, MSE, and R-squared.
Dataset: There are so many public house price datasets set available on Kaggle (e.g., Boston Housing, Ames Housing).
2. Iris Flower Classification (Classification)
Concept: Classification (predicting a categorical label).
Idea: Classify organisms among three types of Iris (setosa, versicolor, and virginica) based on sepal and petal measurements.
What you'll learn: Some basic data analysis and classification algorithms (Logistic Regression, K-Nearest Neighbors, Support Vector Machines, Decision Trees), code toward confusion matrix and accuracy score.
Dataset: It happens to be a classical dataset directly available inside Scikit-learn.
3. Spam Email Detector (Natural Language Processing - NLP)
Concept: Text Classification, NLP.
Idea: Create a model capable of classifying emails into "spam" versus "ham" (not spam).
What you'll learn: Text preprocessing techniques such as tokenization, stemming/lemmatization, stop-word removal; feature extraction from text, e.g., Bag-of-Words or TF-IDF; classification using Naive Bayes or SVM.
Dataset: The UCI Machine Learning Repository contains a few spam datasets.
4. Customer Churn Prediction (Classification)
Concept: Classification, Predictive Analytics.
Idea: Predict whether a customer will stop using a service (churn) given the usage pattern and demographics.
What you'll learn: Handling imbalanced datasets (since churn is usually rare), feature importance, applying classification algorithms (such as Random Forest or Gradient Boosting), measuring precision, recall, and F1-score.
Dataset: Several telecom-or banking-related churn datasets are available on Kaggle.
5. Movie Recommender System (Basic Collaborative Filtering)
Concept: Recommender Systems, Unsupervised Learning (for some parts) or Collaborative Filtering.
Idea: Recommend movies to a user based on their past ratings or ratings from similar users.
What you'll learn: Matrix factorization, user-item interaction data, basic collaborative filtering techniques, evaluating recommendations.
Dataset: MovieLens datasets (small or 100k version) are excellent for this.
Tips for Success with Your ML Projects
Start Small: Do not endeavor to build the Google AI in your Very First Project. Instead focus on grasping core concepts.
Understand Your Data: Spend most of your time cleaning it or performing exploratory data analysis. Garbage in, garbage out, as the data thinkers would say.
Reputable Resources: Use tutorials, online courses, and documentation (say, Scikit-learn docs).
Join Communities: Stay involved with fellow learners in forums like Kaggle or Stack Overflow or in local meetups.
Document Your Work: Comment your code and use a README for your GitHub repository describing your procedure and conclusions.
Embrace Failure: Every error is an opportunity to learn.
How TCCI - Tririd Computer Coaching Institute Can Help
Venturing into Machine Learning can be challenging and fulfilling at the same time. At TCCI, our programs in Machine Learning courses in Ahmedabad are created for beginners and aspiring professionals, in which we impart:
A Well-Defined Structure: Starting from basics of Python to various advanced ML algorithms.
Hands-On Training: Guided projects will allow you to build your portfolio, step by-step.
An Expert Mentor: Work under the guidance of full-time data scientists and ML engineers.
Real-World Case Studies: Learn about the application of ML in various industrial scenarios.
If you are considering joining a comprehensive computer classes in Ahmedabad to start a career in data science or want to pursue computer training for further specialization in Machine Learning, TCCI is the place to be.
Are You Ready to Build Your First Machine Learning Project?
The most effective way to learn Machine Learning is to apply it. Try out these beginner-friendly projects and watch your skills expand.
Contact us
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Skills You'll Master in an Artificial Intelligence Classroom Course in Bengaluru
Artificial Intelligence (AI) is revolutionizing industries across the globe, and Bengaluru, the Silicon Valley of India, is at the forefront of this transformation. As demand for skilled AI professionals continues to grow, enrolling in an Artificial Intelligence Classroom Course in Bengaluru can be a strategic move for both aspiring tech enthusiasts and working professionals.
This blog explores the critical skills you’ll develop in a classroom-based AI program in Bengaluru, helping you understand how such a course can empower your career in the AI-driven future.
Why Choose an Artificial Intelligence Classroom Course in Bengaluru?
Bengaluru is home to a thriving tech ecosystem with thousands of startups, MNCs, R&D centers, and innovation hubs. Opting for a classroom-based AI course in Bengaluru offers several advantages:
In-person mentorship from industry experts and certified trainers
Real-time doubt resolution and interactive learning environments
Access to AI-focused events, hackathons, and networking meetups
Hands-on projects with local companies or institutions for practical exposure
A classroom setting adds structure, discipline, and immediate feedback, which online formats often lack.
Core Skills You’ll Master in an Artificial Intelligence Classroom Course in Bengaluru
Let’s explore the most important skills you can expect to acquire during a comprehensive AI classroom course:
1. Python Programming for AI
Python is the backbone of AI development. Most Artificial Intelligence Classroom Courses in Bengaluru begin with a strong foundation in Python.
You’ll learn:
Python syntax, functions, and object-oriented programming
Data structures like lists, dictionaries, tuples, and sets
Libraries essential for AI: NumPy, Pandas, Matplotlib, Scikit-learn
Code optimization and debugging techniques
This foundational skill allows you to transition easily into more complex AI frameworks and data workflows.
2. Mathematics for AI and Machine Learning
Understanding the mathematical concepts behind AI models is essential. A good AI classroom course in Bengaluru will cover:
Linear algebra: vectors, matrices, eigenvalues
Probability and statistics: distributions, Bayes theorem, hypothesis testing
Calculus: derivatives, gradients, optimization
Discrete mathematics for logical reasoning and algorithm design
These mathematical foundations help you understand the internal workings of machine learning and deep learning models.
3. Data Preprocessing and Exploratory Data Analysis (EDA)
Before building models, you must work with data—cleaning, transforming, and visualizing it.
Skills you’ll develop:
Handling missing data and outliers
Data normalization and encoding techniques
Feature engineering and dimensionality reduction
Data visualization with Seaborn, Matplotlib, and Plotly
These skills are crucial in solving real-world business problems using AI.
4. Machine Learning Algorithms and Implementation
One of the core parts of any Artificial Intelligence Classroom Course in Bengaluru is mastering machine learning.
You will learn:
Supervised learning: Linear Regression, Logistic Regression, Decision Trees
Unsupervised learning: K-Means Clustering, PCA
Model evaluation: Precision, Recall, F1 Score, ROC-AUC
Cross-validation and hyperparameter tuning
By the end of this module, you’ll be able to build, train, and evaluate machine learning models on real datasets.
5. Deep Learning and Neural Networks
Deep learning is a critical AI skill, especially in areas like computer vision, NLP, and recommendation systems.
Topics covered:
Artificial Neural Networks (ANN) and their architecture
Activation functions, loss functions, and optimization techniques
Convolutional Neural Networks (CNN) for image processing
Recurrent Neural Networks (RNN) for sequence data
Using frameworks like TensorFlow and PyTorch
This hands-on module helps students build and deploy deep learning models in production
6. Natural Language Processing (NLP)
NLP is increasingly used in chatbots, voice assistants, and content generation.
In a classroom AI course in Bengaluru, you’ll gain:
Text cleaning and preprocessing (tokenization, stemming, lemmatization)
Sentiment analysis and topic modeling
Named Entity Recognition (NER)
Working with tools like NLTK, spaCy, and Hugging Face
Building chatbot and language translation systems
These skills prepare you for jobs in AI-driven communication and language platforms.
7. Computer Vision
AI’s ability to interpret visual data has applications in facial recognition, medical imaging, and autonomous vehicles.
Skills you’ll learn:
Image classification, object detection, and segmentation
Using OpenCV for computer vision tasks
CNN architectures like VGG, ResNet, and YOLO
Transfer learning for advanced image processing
Computer vision is an advanced AI field where hands-on learning adds immense value, and Bengaluru’s tech-driven ecosystem enhances your project exposure.
8. Model Deployment and MLOps Basics
Knowing how to build a model is half the journey; deploying it is the other half.
You’ll master:
Model packaging using Flask or FastAPI
API integration and cloud deployment
Version control with Git and GitHub
Introduction to CI/CD and containerization with Docker
This gives you the ability to take your AI projects from notebooks to live platforms.
9. Capstone Projects and Industry Exposure
Most Artificial Intelligence Classroom Courses in Bengaluru culminate in capstone projects that solve real-world problems.
You’ll work on:
Domain-specific AI projects (healthcare, finance, retail, etc.)
Team collaborations and hackathons
Presentations and peer reviews
Real-time feedback from mentors
Such exposure builds your portfolio and boosts employability in the AI job market.
10. Soft Skills and AI Ethics
Technical skills alone aren’t enough. A good AI course in Bengaluru also helps you build:
Critical thinking and problem-solving
Communication and teamwork
Awareness of bias, fairness, and transparency in AI
Responsible AI development practices
These skills make you a more well-rounded AI professional who can navigate technical and ethical challenges.
Benefits of Learning AI in Bengaluru’s Classroom Setting
Mentorship Access: Bengaluru’s AI mentors often have real industry experience from companies like Infosys, TCS, Accenture, and top startups.
Networking Opportunities: Classroom courses create peer learning environments, alumni networks, and connections to hiring partners.
Hands-On Labs: Physical infrastructure and lab access in a classroom setting support hands-on model building and experimentation.
Placement Assistance: Most top institutes in Bengaluru offer resume workshops, mock interviews, and direct placement support.
Final Thoughts
A well-structured Artificial Intelligence Classroom Course in Bengaluru offers more than just theoretical knowledge—it delivers practical, hands-on, and industry-relevant skills that can transform your career. From Python programming and machine learning to deep learning, NLP, and real-world deployment, you’ll master the full AI development lifecycle.
Bengaluru’s ecosystem of innovation, startups, and tech talent makes it the perfect place to start or advance your AI journey. If you’re serious about becoming an AI professional, investing in a classroom course here could be your smartest move.
Whether you're starting from scratch or looking to specialize, the skills you gain from an AI classroom course in Bengaluru can prepare you for roles such as Machine Learning Engineer, AI Developer, Data Scientist, Computer Vision Specialist, or NLP Engineer—positions that are not just in demand, but also high-paying and future-proof.
#Best Data Science Courses in Bengaluru#Artificial Intelligence Course in Bengaluru#Data Scientist Course in Bengaluru#Machine Learning Course in Bengaluru
0 notes
Text
Which Is Better for Your Business: Fine-Tuning or Full LLM Development?
In today’s AI-powered business landscape, organizations across industries are racing to implement Large Language Models (LLMs) to streamline operations, automate workflows, and elevate customer experiences. However, a critical decision stands in their way: Should you fine-tune an existing open-source LLM, or build a proprietary model from scratch?

This question isn't just technical—it's strategic. Your choice can impact cost, scalability, accuracy, security, and competitive advantage. Understanding the pros and cons of both paths is essential for making a future-proof investment.
This blog breaks down everything you need to know about fine-tuning versus full LLM development, helping you decide which approach best fits your business goals, resources, and risk appetite.
Understanding the Two Approaches
Before diving into comparisons, let’s clarify what each term means in practical terms.
What Is Fine-Tuning?
Fine-tuning refers to taking a pre-trained LLM (like LLaMA, Mistral, or Falcon) and customizing it with your own data or specific use case in mind. The base model already understands general language structure and concepts. Your job is to tweak it for better performance in a particular domain—say, legal, healthcare, finance, or customer support.
Fine-tuning can range from light instruction tuning to domain adaptation and alignment with enterprise tone and brand guidelines.
What Is Full LLM Development?
Full development, on the other hand, means creating a custom LLM from the ground up. This involves collecting vast datasets, training deep neural networks, optimizing architecture, and managing infrastructure. While this approach is resource-intensive, it offers total control and maximum flexibility in model behavior, ethics, and performance.
Business Use Case Alignment: When to Choose What?
Your business’s needs should drive the decision between fine-tuning and full-scale development. Here’s how to evaluate each option based on use case scenarios:
Opt for Fine-Tuning If:
You need faster time-to-market
Your use case involves adding domain expertise to an existing general-purpose model
Budget is a concern, but you still want performance gains
Your data is limited, proprietary, or sensitive but doesn't require building a model from scratch
For example, a legal tech firm fine-tuning a LLaMA model with thousands of case law documents can achieve high accuracy in contract analysis without needing a fully custom LLM.
Choose Full Development If:
You want complete control over architecture, behavior, and output
You operate in a highly regulated or data-sensitive industry
You're building a long-term product or platform that needs proprietary IP
Your business goal is to lead innovation in AI—not just use it
A global bank or government agency building its own model to maintain full data sovereignty and compliance with internal security frameworks would benefit more from full development.
Cost Comparison: Fine-Tuning vs Full LLM Development
Fine-Tuning: Cost-Efficient Customization
Fine-tuning costs are significantly lower than full model development. Most of the compute-intensive training is already done. Your budget mainly goes toward:
Data preprocessing
Model training on GPUs for a few hours to days
Evaluation and deployment
Typical costs can range from $10,000 to $100,000 depending on scale and domain complexity.
Full Development: High Upfront Investment
Training an LLM from scratch is a massive undertaking. It involves:
Building or sourcing a multi-billion token dataset
Training on clusters of GPUs (often across thousands of hours)
Hiring expert ML engineers and researchers
Managing infrastructure, storage, and performance tuning
Development costs often exceed $1 million and can go much higher for models with over 10B parameters. However, it results in complete ownership and differentiated IP.
Time to Deploy: Speed vs Control
Fine-Tuning: Rapid Iteration and Deployment
One of the biggest advantages of fine-tuning is speed. A fine-tuned model can be ready in days or weeks, making it ideal for startups, product pilots, or iterative testing. Open-source base models are readily available, and most of the work lies in preparing training data and running experiments.
Full LLM Development: Long-Term Commitment
Developing a model from scratch is a multi-month to multi-year journey. You need time to clean and curate data, design the architecture, train the model in phases, and go through rigorous evaluation before production deployment. This approach is best suited for enterprises with long-term AI roadmaps and ample resources.
Performance and Precision: Tailoring Language Understanding
Fine-Tuning: Specialized but Limited
Fine-tuning allows you to adjust a model’s behavior, vocabulary, and domain knowledge. It’s particularly effective in handling jargon, customer intent, and industry-specific nuances. However, you’re still bound by the limitations of the base model’s structure and training scope. For instance, a fine-tuned LLaMA model might still hallucinate or make generalizations not suitable for compliance-heavy contexts.
Full Development: Deep Customization and IP
When you build from scratch, you choose your architecture, training methods, and dataset composition. You can design your model for multilingual tasks, low-resource languages, memory optimization, or ethical alignment. The result is an LLM uniquely aligned with your business logic, which is nearly impossible with a generic foundation model.
Data Privacy and Compliance: A Key Differentiator
Fine-Tuning: Controlled Input, Shared Base
When using open-source models, you’re still dealing with externally trained weights, which may include data biases or uncertain data provenance. While fine-tuning on private datasets can help, it doesn’t eliminate inherent risks if the base model was trained on questionable sources.
Full Development: Total Data Sovereignty
With full development, you control every aspect of the data pipeline. You decide what goes into your training set, allowing you to ensure full GDPR, HIPAA, or ISO compliance. If your business handles sensitive medical, legal, or financial records, this can be a deciding factor.
Scalability and Maintenance
Fine-Tuning: Easier to Update and Iterate
Fine-tuned models are lightweight and easier to manage. You can periodically re-train them with new data, track performance, and improve accuracy over time. Many organizations maintain continuous integration pipelines to fine-tune their models every few weeks or months based on fresh input.
Full Development: High Maintenance, High Payoff
Custom-built LLMs require a dedicated MLOps infrastructure. Updates involve retraining or partial training with additional data, along with monitoring for bias, drift, and performance. However, the long-term payoff is massive if you’re building AI as a core product rather than just a tool.
Intellectual Property and Competitive Edge
Fine-Tuning: Shared Models, Differentiated Use
Fine-tuning helps create unique applications, but your core model is still public or open-source. This can limit defensibility if competitors use similar base models.
Full Development: Proprietary Advantage
When you build from scratch, you own the architecture, training methodology, and output behavior. This can serve as a strong moat, especially in industries like fintech, healthcare, or cybersecurity where innovation is key to maintaining market leadership.
Conclusion: Strategic Choice, Not Just Technical
The decision between fine-tuning and full LLM development isn’t about which is “better” in absolute terms—it’s about what’s better for your business.
Fine-tuning is faster, cheaper, and perfectly suited for organizations looking to adopt AI with limited resources or time constraints. It allows for domain adaptation without the complexity of full-scale model engineering.
Full LLM development is a strategic investment that pays off with unmatched control, privacy, and long-term differentiation. It’s ideal for companies building AI as a core capability or navigating complex regulatory environments.
Ultimately, your decision should reflect your goals: Are you deploying AI to enhance existing processes, or are you building something entirely new with it?
0 notes
Text
ChatGPT & Data Science: Your Essential AI Co-Pilot

The rise of ChatGPT and other large language models (LLMs) has sparked countless discussions across every industry. In data science, the conversation is particularly nuanced: Is it a threat? A gimmick? Or a revolutionary tool?
The clearest answer? ChatGPT isn't here to replace data scientists; it's here to empower them, acting as an incredibly versatile co-pilot for almost every stage of a data science project.
Think of it less as an all-knowing oracle and more as an exceptionally knowledgeable, tireless assistant that can brainstorm, explain, code, and even debug. Here's how ChatGPT (and similar LLMs) is transforming data science projects and how you can harness its power:
How ChatGPT Transforms Your Data Science Workflow
Problem Framing & Ideation: Struggling to articulate a business problem into a data science question? ChatGPT can help.
"Given customer churn data, what are 5 actionable data science questions we could ask to reduce churn?"
"Brainstorm hypotheses for why our e-commerce conversion rate dropped last quarter."
"Help me define the scope for a project predicting equipment failure in a manufacturing plant."
Data Exploration & Understanding (EDA): This often tedious phase can be streamlined.
"Write Python code using Pandas to load a CSV and display the first 5 rows, data types, and a summary statistics report."
"Explain what 'multicollinearity' means in the context of a regression model and how to check for it in Python."
"Suggest 3 different types of plots to visualize the relationship between 'age' and 'income' in a dataset, along with the Python code for each."
Feature Engineering & Selection: Creating new, impactful features is key, and ChatGPT can spark ideas.
"Given a transactional dataset with 'purchase_timestamp' and 'product_category', suggest 5 new features I could engineer for a customer segmentation model."
"What are common techniques for handling categorical variables with high cardinality in machine learning, and provide a Python example for one."
Model Selection & Algorithm Explanation: Navigating the vast world of algorithms becomes easier.
"I'm working on a classification problem with imbalanced data. What machine learning algorithms should I consider, and what are their pros and cons for this scenario?"
"Explain how a Random Forest algorithm works in simple terms, as if you're explaining it to a business stakeholder."
Code Generation & Debugging: This is where ChatGPT shines for many data scientists.
"Write a Python function to perform stratified K-Fold cross-validation for a scikit-learn model, ensuring reproducibility."
"I'm getting a 'ValueError: Input contains NaN, infinity or a value too large for dtype('float64')' in my scikit-learn model. What are common reasons for this error, and how can I fix it?"
"Generate boilerplate code for a FastAPI endpoint that takes a JSON payload and returns a prediction from a pre-trained scikit-learn model."
Documentation & Communication: Translating complex technical work into understandable language is vital.
"Write a clear, concise docstring for this Python function that preprocesses text data."
"Draft an executive summary explaining the results of our customer churn prediction model, focusing on business impact rather than technical details."
"Explain the limitations of an XGBoost model in a way that a non-technical manager can understand."
Learning & Skill Development: It's like having a personal tutor at your fingertips.
"Explain the concept of 'bias-variance trade-off' in machine learning with a practical example."
"Give me 5 common data science interview questions about SQL, and provide example answers."
"Create a study plan for learning advanced topics in NLP, including key concepts and recommended libraries."
Important Considerations and Best Practices
While incredibly powerful, remember that ChatGPT is a tool, not a human expert.
Always Verify: Generated code, insights, and especially factual information must always be verified. LLMs can "hallucinate" or provide subtly incorrect information.
Context is King: The quality of the output directly correlates with the quality and specificity of your prompt. Provide clear instructions, examples, and constraints.
Data Privacy is Paramount: NEVER feed sensitive, confidential, or proprietary data into public LLMs. Protecting personal data is not just an ethical imperative but a legal requirement globally. Assume anything you input into a public model may be used for future training or accessible by the provider. For sensitive projects, explore secure, on-premises or private cloud LLM solutions.
Understand the Fundamentals: ChatGPT is an accelerant, not a substitute for foundational knowledge in statistics, machine learning, and programming. You need to understand why a piece of code works or why an an algorithm is chosen to effectively use and debug its outputs.
Iterate and Refine: Don't expect perfect results on the first try. Refine your prompts based on the output you receive.
ChatGPT and its peers are fundamentally changing the daily rhythm of data science. By embracing them as intelligent co-pilots, data scientists can boost their productivity, explore new avenues, and focus their invaluable human creativity and critical thinking on the most complex and impactful challenges. The future of data science is undoubtedly a story of powerful human-AI collaboration.
0 notes
Text
From Algorithms to Ethics: Unraveling the Threads of Data Science Education
In the rapidly advancing realm of data science, the curriculum serves as a dynamic tapestry, interweaving diverse threads to provide learners with a comprehensive understanding of data analysis, machine learning, and statistical modeling. Choosing the Best Data Science Institute can further accelerate your journey into this thriving industry. This educational journey is a fascinating exploration of the multifaceted facets that constitute the heart of data science education.

1. Mathematics and Statistics Fundamentals:
The journey begins with a deep dive into the foundational principles of mathematics and statistics. Linear algebra, probability theory, and statistical methods emerge as the bedrock upon which the entire data science edifice is constructed. Learners navigate the intricate landscape of mathematical concepts, honing their analytical skills to decipher complex datasets with precision.
2. Programming Proficiency:
A pivotal thread in the educational tapestry is the acquisition of programming proficiency. The curriculum places a significant emphasis on mastering programming languages such as Python or R, recognizing them as indispensable tools for implementing the intricate algorithms that drive the field of data science. Learners cultivate the skills necessary to translate theoretical concepts into actionable insights through hands-on coding experiences.
3. Data Cleaning and Preprocessing Techniques:
As data scientists embark on their educational voyage, they encounter the art of data cleaning and preprocessing. This phase involves mastering techniques for handling missing data, normalization, and the transformation of datasets. These skills are paramount to ensuring the integrity and reliability of data throughout the entire analysis process, underscoring the importance of meticulous data preparation.
4. Exploratory Data Analysis (EDA):
A vivid thread in the educational tapestry, exploratory data analysis (EDA) emerges as the artist's palette. Visualization tools and descriptive statistics become the brushstrokes, illuminating patterns and insights within datasets. This phase is not merely about crunching numbers but about understanding the story that the data tells, fostering a deeper connection between the analyst and the information at hand.
5. Machine Learning Algorithms:
The heartbeat of the curriculum pulsates with the study of machine learning algorithms. Learners traverse the expansive landscape of supervised learning, exploring regression and classification methodologies, and venture into the uncharted territories of unsupervised learning, unraveling the mysteries of clustering algorithms. This segment empowers aspiring data scientists with the skills needed to build intelligent models that can make predictions and uncover hidden patterns within data.
6. Real-world Application and Ethical Considerations:
As the educational journey nears its culmination, learners are tasked with applying their acquired knowledge to real-world scenarios. This application is guided by a strong ethical compass, with a keen awareness of the responsibilities that come with handling data. Graduates emerge not only as proficient data scientists but also as conscientious stewards of information, equipped to navigate the complex intersection of technology and ethics.

In essence, the data science curriculum is a meticulously crafted symphony, harmonizing mathematical rigor, technical acumen, and ethical mindfulness. The educational odyssey equips learners with a holistic skill set, preparing them to navigate the complexities of the digital age and contribute meaningfully to the ever-evolving field of data science. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science.
3 notes
·
View notes