#Data Replication in Ceph
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Mastering Ceph Storage Configuration in Proxmox 8 Cluster
Mastering Ceph Storage Configuration in Proxmox 8 Cluster #100daysofhomelab #proxmox8 #cephstorage #CephStorageConfiguration #ProxmoxClusterSetup #ObjectStorageInCeph #CephBlockStorage #CephFileSystem #CephClusterManagement #CephAndProxmoxIntegration
The need for highly scalable storage solutions that are fault-tolerant and offer a unified system is undeniably significant in data storage. One such solution is Ceph Storage, a powerful and flexible storage system that facilitates data replication and provides data redundancy. In conjunction with Proxmox, an open-source virtualization management platform, it can help manage important business…

View On WordPress
#Ceph and Proxmox Integration#Ceph Block Storage#Ceph Cluster Management#Ceph File System#Ceph OSD Daemons#Ceph Storage Configuration#Data Replication in Ceph#High Scalability Storage Solution#Object Storage in Ceph#Proxmox Cluster Setup
0 notes
Text
Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)
In today’s fast-paced cloud-native world, managing storage across containers and Kubernetes platforms can be complex and resource-intensive. Red Hat OpenShift Data Foundation (ODF), formerly known as OpenShift Container Storage (OCS), provides an integrated and robust solution for managing persistent storage in OpenShift environments. One of Red Hat’s key training offerings in this space is the DO370 course – Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation.
In this blog post, we’ll explore the highlights of this course, what professionals can expect to learn, and why ODF is a game-changer for enterprise Kubernetes storage.
What is Red Hat OpenShift Data Foundation?
Red Hat OpenShift Data Foundation is a software-defined storage solution built on Ceph and tightly integrated with Red Hat OpenShift. It provides persistent, scalable, and secure storage for containers, enabling stateful applications to thrive in a Kubernetes ecosystem.
With ODF, enterprises can manage block, file, and object storage across hybrid and multi-cloud environments—without the complexities of managing external storage systems.
Course Overview: DO370
The DO370 course is designed for developers, system administrators, and site reliability engineers who want to deploy and manage Red Hat OpenShift Data Foundation in an OpenShift environment. It is a hands-on lab-intensive course, emphasizing practical experience over theory.
Key Topics Covered:
Introduction to storage challenges in Kubernetes
Deployment of OpenShift Data Foundation
Managing block, file, and object storage
Configuring storage classes and dynamic provisioning
Monitoring, troubleshooting, and managing storage usage
Integrating with workloads such as databases and CI/CD tools
Why DO370 is Essential for Modern IT Teams
1. Storage Made Kubernetes-Native
ODF integrates seamlessly with OpenShift, giving developers self-service access to dynamic storage provisioning without needing to understand the underlying infrastructure.
2. Consistency Across Environments
Whether your workloads run on-prem, in the cloud, or at the edge, ODF provides a consistent storage layer, which is critical for hybrid and multi-cloud strategies.
3. Data Resiliency and High Availability
With Ceph at its core, ODF provides high availability, replication, and fault tolerance, ensuring data durability across your Kubernetes clusters.
4. Hands-on Experience with Industry-Relevant Tools
DO370 includes hands-on labs with tools like NooBaa for S3-compatible object storage and integrates storage into realistic OpenShift use cases.
Who Should Take This Course?
OpenShift Administrators looking to extend their skills into persistent storage.
Storage Engineers transitioning to container-native storage solutions.
DevOps professionals managing stateful applications in OpenShift environments.
Teams planning to scale enterprise workloads that require reliable data storage in Kubernetes.
Certification Pathway
DO370 is part of the Red Hat Certified Architect (RHCA) infrastructure track and is a valuable step for anyone pursuing expert-level certification in OpenShift or storage technologies. Completing this course helps prepare for the EX370 certification exam.
Final Thoughts
As enterprises continue to shift towards containerized and cloud-native application architectures, having a reliable and scalable storage solution becomes non-negotiable. Red Hat OpenShift Data Foundation addresses this challenge, and the DO370 course is the perfect entry point for mastering it.
If you're an IT professional looking to gain expertise in Kubernetes-native storage and want to future-proof your career, Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370) is the course to take. For more details www.hawkstack.com
0 notes
Text
Cloud Native Storage Market Insights: Industry Share, Trends & Future Outlook 2032
TheCloud Native Storage Market Size was valued at USD 16.19 Billion in 2023 and is expected to reach USD 100.09 Billion by 2032 and grow at a CAGR of 22.5% over the forecast period 2024-2032
The cloud native storage market is experiencing rapid growth as enterprises shift towards scalable, flexible, and cost-effective storage solutions. The increasing adoption of cloud computing and containerization is driving demand for advanced storage technologies.
The cloud native storage market continues to expand as businesses seek high-performance, secure, and automated data storage solutions. With the rise of hybrid cloud, Kubernetes, and microservices architectures, organizations are investing in cloud native storage to enhance agility and efficiency in data management.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3454
Market Keyplayers:
Microsoft (Azure Blob Storage, Azure Kubernetes Service (AKS))
IBM, (IBM Cloud Object Storage, IBM Spectrum Scale)
AWS (Amazon S3, Amazon EBS (Elastic Block Store))
Google (Google Cloud Storage, Google Kubernetes Engine (GKE))
Alibaba Cloud (Alibaba Object Storage Service (OSS), Alibaba Cloud Container Service for Kubernetes)
VMWare (VMware vSAN, VMware Tanzu Kubernetes Grid)
Huawei (Huawei FusionStorage, Huawei Cloud Object Storage Service)
Citrix (Citrix Hypervisor, Citrix ShareFile)
Tencent Cloud (Tencent Cloud Object Storage (COS), Tencent Kubernetes Engine)
Scality (Scality RING, Scality ARTESCA)
Splunk (Splunk SmartStore, Splunk Enterprise on Kubernetes)
Linbit (LINSTOR, DRBD (Distributed Replicated Block Device))
Rackspace (Rackspace Object Storage, Rackspace Managed Kubernetes)
Robin.Io (Robin Cloud Native Storage, Robin Multi-Cluster Automation)
MayaData (OpenEBS, Data Management Platform (DMP))
Diamanti (Diamanti Ultima, Diamanti Spektra)
Minio (MinIO Object Storage, MinIO Kubernetes Operator)
Rook (Rook Ceph, Rook EdgeFS)
Ondat (Ondat Persistent Volumes, Ondat Data Mesh)
Ionir (Ionir Data Services Platform, Ionir Continuous Data Mobility)
Trilio (TrilioVault for Kubernetes, TrilioVault for OpenStack)
Upcloud (UpCloud Object Storage, UpCloud Managed Databases)
Arrikto (Kubeflow Enterprise, Rok (Data Management for Kubernetes)
Market Size, Share, and Scope
The market is witnessing significant expansion across industries such as IT, BFSI, healthcare, retail, and manufacturing.
Hybrid and multi-cloud storage solutions are gaining traction due to their flexibility and cost-effectiveness.
Enterprises are increasingly adopting object storage, file storage, and block storage tailored for cloud native environments.
Key Market Trends Driving Growth
Rise in Cloud Adoption: Organizations are shifting workloads to public, private, and hybrid cloud environments, fueling demand for cloud native storage.
Growing Adoption of Kubernetes: Kubernetes-based storage solutions are becoming essential for managing containerized applications efficiently.
Increased Data Security and Compliance Needs: Businesses are investing in encrypted, resilient, and compliant storage solutions to meet global data protection regulations.
Advancements in AI and Automation: AI-driven storage management and self-healing storage systems are revolutionizing data handling.
Surge in Edge Computing: Cloud native storage is expanding to edge locations, enabling real-time data processing and low-latency operations.
Integration with DevOps and CI/CD Pipelines: Developers and IT teams are leveraging cloud storage automation for seamless software deployment.
Hybrid and Multi-Cloud Strategies: Enterprises are implementing multi-cloud storage architectures to optimize performance and costs.
Increased Use of Object Storage: The scalability and efficiency of object storage are driving its adoption in cloud native environments.
Serverless and API-Driven Storage Solutions: The rise of serverless computing is pushing demand for API-based cloud storage models.
Sustainability and Green Cloud Initiatives: Energy-efficient storage solutions are becoming a key focus for cloud providers and enterprises.
Enquiry of This Report: https://www.snsinsider.com/enquiry/3454
Market Segmentation:
By Component
Solution
Object Storage
Block Storage
File Storage
Container Storage
Others
Services
System Integration & Deployment
Training & Consulting
Support & Maintenance
By Deployment
Private Cloud
Public Cloud
By Enterprise Size
SMEs
Large Enterprises
By End Use
BFSI
Telecom & IT
Healthcare
Retail & Consumer Goods
Manufacturing
Government
Energy & Utilities
Media & Entertainment
Others
Market Growth Analysis
Factors Driving Market Expansion
The growing need for cost-effective and scalable data storage solutions
Adoption of cloud-first strategies by enterprises and governments
Rising investments in data center modernization and digital transformation
Advancements in 5G, IoT, and AI-driven analytics
Industry Forecast 2032: Size, Share & Growth Analysis
The cloud native storage market is projected to grow significantly over the next decade, driven by advancements in distributed storage architectures, AI-enhanced storage management, and increasing enterprise digitalization.
North America leads the market, followed by Europe and Asia-Pacific, with China and India emerging as key growth hubs.
The demand for software-defined storage (SDS), container-native storage, and data resiliency solutions will drive innovation and competition in the market.
Future Prospects and Opportunities
1. Expansion in Emerging Markets
Developing economies are expected to witness increased investment in cloud infrastructure and storage solutions.
2. AI and Machine Learning for Intelligent Storage
AI-powered storage analytics will enhance real-time data optimization and predictive storage management.
3. Blockchain for Secure Cloud Storage
Blockchain-based decentralized storage models will offer improved data security, integrity, and transparency.
4. Hyperconverged Infrastructure (HCI) Growth
Enterprises are adopting HCI solutions that integrate storage, networking, and compute resources.
5. Data Sovereignty and Compliance-Driven Solutions
The demand for region-specific, compliant storage solutions will drive innovation in data governance technologies.
Access Complete Report: https://www.snsinsider.com/reports/cloud-native-storage-market-3454
Conclusion
The cloud native storage market is poised for exponential growth, fueled by technological innovations, security enhancements, and enterprise digital transformation. As businesses embrace cloud, AI, and hybrid storage strategies, the future of cloud native storage will be defined by scalability, automation, and efficiency.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#cloud native storage market#cloud native storage market Scope#cloud native storage market Size#cloud native storage market Analysis#cloud native storage market Trends
0 notes
Text
This article intends to cover in detail the installation and configuration of Rook, and how to integrate a highly available Ceph Storage Cluster to an existing kubernetes cluster. I’m performing this process on a recent deployment of Kubernetes in Rocky Linux 8 servers. But it can be used with any other Kubernetes Cluster deployed with Kubeadm or automation tools such as Kubespray and Rancher. In the initial days of Kubernetes, most applications deployed were Stateless meaning there was no need for data persistence. However, as Kubernetes becomes more popular, there was a concern around reliability when scheduling stateful services. Currently, you can use many types of storage volumes including vSphere Volumes, Ceph, AWS Elastic Block Store, Glusterfs, NFS, GCE Persistent Disk among many others. This gives us the comfort of running Stateful services that requires robust storage backend. What is Rook / Ceph? Rook is a free to use and powerful cloud-native open source storage orchestrator for Kubernetes. It provides support for a diverse set of storage solutions to natively integrate with cloud-native environments. More details about the storage solutions currently supported by Rook are captured in the project status section. Ceph is a distributed storage system that provides file, block and object storage and is deployed in large scale production clusters. Rook will enable us to automate deployment, bootstrapping, configuration, scaling and upgrading Ceph Cluster within a Kubernetes environment. Ceph is widely used in an In-House Infrastructure where managed Storage solution is rarely an option. Rook uses Kubernetes primitives to run and manage Software defined storage on Kubernetes. Key components of Rook Storage Orchestrator: Custom resource definitions (CRDs) – Used to create and customize storage clusters. The CRDs are implemented to Kubernetes during its deployment process. Rook Operator for Ceph – It automates the whole configuration of storage components and monitors the cluster to ensure it is healthy and available DaemonSet called rook-discover – It starts a pod running discovery agent on every nodes of your Kubernetes cluster to discover any raw disk devices / partitions that can be used as Ceph OSD disk. Monitoring – Rook enables Ceph Dashboard and provides metrics collectors/exporters and monitoring dashboards Features of Rook Rook enables you to provision block, file, and object storage with multiple storage providers Capability to efficiently distribute and replicate data to minimize potential loss Rook is designed to manage open-source storage technologies – NFS, Ceph, Cassandra Rook is an open source software released under the Apache 2.0 license With Rook you can hyper-scale or hyper-converge your storage clusters within Kubernetes environment Rook allows System Administrators to easily enable elastic storage in your datacenter By adopting rook as your storage orchestrator you are able to optimize workloads on commodity hardware Deploy Rook & Ceph Storage on Kubernetes Cluster These are the minimal setup requirements for the deployment of Rook and Ceph Storage on Kubernetes Cluster. A Cluster with minimum of three nodes Available raw disk devices (with no partitions or formatted filesystems) Or Raw partitions (without formatted filesystem) Or Persistent Volumes available from a storage class in block mode Step 1: Add Raw devices/partitions to nodes that will be used by Rook List all the nodes in your Kubernetes Cluster and decide which ones will be used in building Ceph Storage Cluster. I recommend you use worker nodes and not the control plane machines. [root@k8s-bastion ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8smaster01.hirebestengineers.com Ready control-plane,master 28m v1.22.2 k8smaster02.hirebestengineers.com Ready control-plane,master 24m v1.22.2
k8smaster03.hirebestengineers.com Ready control-plane,master 23m v1.22.2 k8snode01.hirebestengineers.com Ready 22m v1.22.2 k8snode02.hirebestengineers.com Ready 21m v1.22.2 k8snode03.hirebestengineers.com Ready 21m v1.22.2 k8snode04.hirebestengineers.com Ready 21m v1.22.2 In my Lab environment, each of the worker nodes will have one raw device – /dev/vdb which we’ll add later. [root@k8s-worker-01 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 253:0 0 40G 0 disk ├─vda1 253:1 0 1M 0 part ├─vda2 253:2 0 1G 0 part /boot ├─vda3 253:3 0 615M 0 part └─vda4 253:4 0 38.4G 0 part / [root@k8s-worker-01 ~]# free -h total used free shared buff/cache available Mem: 15Gi 209Mi 14Gi 8.0Mi 427Mi 14Gi Swap: 614Mi 0B 614Mi The following list of nodes will be used to build storage cluster. [root@kvm-private-lab ~]# virsh list | grep k8s-worker 31 k8s-worker-01-server running 36 k8s-worker-02-server running 38 k8s-worker-03-server running 41 k8s-worker-04-server running Add secondary storage to each node If using KVM hypervisor, start by listing storage pools: $ sudo virsh pool-list Name State Autostart ------------------------------ images active yes I’ll add a 40GB volume on the default storage pool. This can be done with a for loop: for domain in k8s-worker-01..4-server; do sudo virsh vol-create-as images $domain-disk-2.qcow2 40G done Command execution output: Vol k8s-worker-01-server-disk-2.qcow2 created Vol k8s-worker-02-server-disk-2.qcow2 created Vol k8s-worker-03-server-disk-2.qcow2 created Vol k8s-worker-04-server-disk-2.qcow2 created You can check image details including size using qemu-img command: $ qemu-img info /var/lib/libvirt/images/k8s-worker-01-server-disk-2.qcow2 image: /var/lib/libvirt/images/k8s-worker-01-server-disk-2.qcow2 file format: raw virtual size: 40 GiB (42949672960 bytes) disk size: 40 GiB To attach created volume(s) above to the Virtual Machine, run: for domain in k8s-worker-01..4-server; do sudo virsh attach-disk --domain $domain \ --source /var/lib/libvirt/images/$domain-disk-2.qcow2 \ --persistent --target vdb done --persistent: Make live change persistent --target vdb: Target of a disk device Confirm add is successful Disk attached successfully Disk attached successfully Disk attached successfully Disk attached successfully You can confirm that the volume was added to the vm as a block device /dev/vdb [root@k8s-worker-01 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 253:0 0 40G 0 disk ├─vda1 253:1 0 1M 0 part ├─vda2 253:2 0 1G 0 part /boot ├─vda3 253:3 0 615M 0 part └─vda4 253:4 0 38.4G 0 part / vdb 253:16 0 40G 0 disk Step 2: Deploy Rook Storage Orchestrator Clone the rook project from Github using git command. This should be done on a machine with kubeconfig configured and confirmed to be working. You can also clone Rook’s specific branch as in release tag, for example: cd ~/ git clone --single-branch --branch release-1.8 https://github.com/rook/rook.git All nodes with available raw devices will be used for the Ceph cluster. As stated earlier, at least three nodes are required cd rook/deploy/examples/ Deploy the Rook Operator The first step when performing the deployment of deploy Rook operator is to use. Create required CRDs as specified in crds.yaml manifest: [root@k8s-bastion ceph]# kubectl create -f crds.yaml customresourcedefinition.apiextensions.k8s.io/cephblockpools.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephclients.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephclusters.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephfilesystemmirrors.ceph.rook.io created
customresourcedefinition.apiextensions.k8s.io/cephfilesystems.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephnfses.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephobjectrealms.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephobjectstores.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephobjectstoreusers.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephobjectzonegroups.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephobjectzones.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/cephrbdmirrors.ceph.rook.io created customresourcedefinition.apiextensions.k8s.io/objectbucketclaims.objectbucket.io created customresourcedefinition.apiextensions.k8s.io/objectbuckets.objectbucket.io created customresourcedefinition.apiextensions.k8s.io/volumereplicationclasses.replication.storage.openshift.io created customresourcedefinition.apiextensions.k8s.io/volumereplications.replication.storage.openshift.io created customresourcedefinition.apiextensions.k8s.io/volumes.rook.io created Create common resources as in common.yaml file: [root@k8s-bastion ceph]# kubectl create -f common.yaml namespace/rook-ceph created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-object-bucket created serviceaccount/rook-ceph-admission-controller created clusterrole.rbac.authorization.k8s.io/rook-ceph-admission-controller-role created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-admission-controller-rolebinding created clusterrole.rbac.authorization.k8s.io/rook-ceph-cluster-mgmt created clusterrole.rbac.authorization.k8s.io/rook-ceph-system created role.rbac.authorization.k8s.io/rook-ceph-system created clusterrole.rbac.authorization.k8s.io/rook-ceph-global created clusterrole.rbac.authorization.k8s.io/rook-ceph-mgr-cluster created clusterrole.rbac.authorization.k8s.io/rook-ceph-object-bucket created serviceaccount/rook-ceph-system created rolebinding.rbac.authorization.k8s.io/rook-ceph-system created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-system created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-global created serviceaccount/rook-ceph-osd created serviceaccount/rook-ceph-mgr created serviceaccount/rook-ceph-cmd-reporter created role.rbac.authorization.k8s.io/rook-ceph-osd created clusterrole.rbac.authorization.k8s.io/rook-ceph-osd created clusterrole.rbac.authorization.k8s.io/rook-ceph-mgr-system created role.rbac.authorization.k8s.io/rook-ceph-mgr created role.rbac.authorization.k8s.io/rook-ceph-cmd-reporter created rolebinding.rbac.authorization.k8s.io/rook-ceph-cluster-mgmt created rolebinding.rbac.authorization.k8s.io/rook-ceph-osd created rolebinding.rbac.authorization.k8s.io/rook-ceph-mgr created rolebinding.rbac.authorization.k8s.io/rook-ceph-mgr-system created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-mgr-cluster created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-osd created rolebinding.rbac.authorization.k8s.io/rook-ceph-cmd-reporter created Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+ podsecuritypolicy.policy/00-rook-privileged created clusterrole.rbac.authorization.k8s.io/psp:rook created clusterrolebinding.rbac.authorization.k8s.io/rook-ceph-system-psp created rolebinding.rbac.authorization.k8s.io/rook-ceph-default-psp created rolebinding.rbac.authorization.k8s.io/rook-ceph-osd-psp created rolebinding.rbac.authorization.k8s.io/rook-ceph-mgr-psp created rolebinding.rbac.authorization.k8s.io/rook-ceph-cmd-reporter-psp created serviceaccount/rook-csi-cephfs-plugin-sa created serviceaccount/rook-csi-cephfs-provisioner-sa created role.rbac.authorization.k8s.io/cephfs-external-provisioner-cfg created rolebinding.rbac.authorization.k8s.io/cephfs-csi-provisioner-role-cfg created clusterrole.rbac.authorization.k8s.io/cephfs-csi-nodeplugin created
clusterrole.rbac.authorization.k8s.io/cephfs-external-provisioner-runner created clusterrolebinding.rbac.authorization.k8s.io/rook-csi-cephfs-plugin-sa-psp created clusterrolebinding.rbac.authorization.k8s.io/rook-csi-cephfs-provisioner-sa-psp created clusterrolebinding.rbac.authorization.k8s.io/cephfs-csi-nodeplugin created clusterrolebinding.rbac.authorization.k8s.io/cephfs-csi-provisioner-role created serviceaccount/rook-csi-rbd-plugin-sa created serviceaccount/rook-csi-rbd-provisioner-sa created role.rbac.authorization.k8s.io/rbd-external-provisioner-cfg created rolebinding.rbac.authorization.k8s.io/rbd-csi-provisioner-role-cfg created clusterrole.rbac.authorization.k8s.io/rbd-csi-nodeplugin created clusterrole.rbac.authorization.k8s.io/rbd-external-provisioner-runner created clusterrolebinding.rbac.authorization.k8s.io/rook-csi-rbd-plugin-sa-psp created clusterrolebinding.rbac.authorization.k8s.io/rook-csi-rbd-provisioner-sa-psp created clusterrolebinding.rbac.authorization.k8s.io/rbd-csi-nodeplugin created clusterrolebinding.rbac.authorization.k8s.io/rbd-csi-provisioner-role created role.rbac.authorization.k8s.io/rook-ceph-purge-osd created rolebinding.rbac.authorization.k8s.io/rook-ceph-purge-osd created serviceaccount/rook-ceph-purge-osd created Finally deploy Rook ceph operator from operator.yaml manifest file: [root@k8s-bastion ceph]# kubectl create -f operator.yaml configmap/rook-ceph-operator-config created deployment.apps/rook-ceph-operator created After few seconds Rook components should be up and running as seen below: [root@k8s-bastion ceph]# kubectl get all -n rook-ceph NAME READY STATUS RESTARTS AGE pod/rook-ceph-operator-9bf8b5959-nz6hd 1/1 Running 0 45s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/rook-ceph-operator 1/1 1 1 45s NAME DESIRED CURRENT READY AGE replicaset.apps/rook-ceph-operator-9bf8b5959 1 1 1 45s Verify the rook-ceph-operator is in the Running state before proceeding: [root@k8s-bastion ceph]# kubectl -n rook-ceph get pod NAME READY STATUS RESTARTS AGE rook-ceph-operator-76dc868c4b-zk2tj 1/1 Running 0 69s Step 3: Create a Ceph Storage Cluster on Kubernetes using Rook Now that we have prepared worker nodes by adding raw disk devices and deployed Rook operator, it is time to deploy the Ceph Storage Cluster. Let’s set default namespace to rook-ceph: # kubectl config set-context --current --namespace rook-ceph Context "kubernetes-admin@kubernetes" modified. Considering that Rook Ceph clusters can discover raw partitions by itself, it is okay to use the default cluster deployment manifest file without any modifications. [root@k8s-bastion ceph]# kubectl create -f cluster.yaml cephcluster.ceph.rook.io/rook-ceph created For any further customizations on Ceph Cluster check Ceph Cluster CRD documentation. When not using all the nodes you can expicitly define the nodes and raw devices to be used as seen in example below: storage: # cluster level storage configuration and selection useAllNodes: false useAllDevices: false nodes: - name: "k8snode01.hirebestengineers.com" devices: # specific devices to use for storage can be specified for each node - name: "sdb" - name: "k8snode03.hirebestengineers.com" devices: - name: "sdb" To view all resources created run the following command: kubectl get all -n rook-ceph Watching Pods creation in rook-ceph namespace: [root@k8s-bastion ceph]# kubectl get pods -n rook-ceph -w This is a list of Pods running in the namespace after a successful deployment: [root@k8s-bastion ceph]# kubectl get pods -n rook-ceph NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-8vrgj 3/3 Running 0 5m39s csi-cephfsplugin-9csbp 3/3 Running 0 5m39s csi-cephfsplugin-lh42b 3/3 Running 0 5m39s csi-cephfsplugin-provisioner-b54db7d9b-kh89q 6/6 Running 0 5m39s csi-cephfsplugin-provisioner-b54db7d9b-l92gm 6/6 Running 0 5m39s csi-cephfsplugin-xc8tk 3/3 Running 0 5m39s csi-rbdplugin-28th4 3/3 Running 0 5m41s csi-rbdplugin-76bhw 3/3 Running 0 5m41s csi-rbdplugin-7ll7w 3/3 Running 0 5m41s csi-rbdplugin-provisioner-5845579d68-5rt4x 6/6 Running 0 5m40s csi-rbdplugin-provisioner-5845579d68-p6m7r 6/6 Running 0 5m40s csi-rbdplugin-tjlsk 3/3 Running 0 5m41s rook-ceph-crashcollector-k8snode01.hirebestengineers.com-7ll2x6 1/1 Running 0 3m3s rook-ceph-crashcollector-k8snode02.hirebestengineers.com-8ghnq9 1/1 Running 0 2m40s rook-ceph-crashcollector-k8snode03.hirebestengineers.com-7t88qp 1/1 Running 0 3m14s rook-ceph-crashcollector-k8snode04.hirebestengineers.com-62n95v 1/1 Running 0 3m14s rook-ceph-mgr-a-7cf9865b64-nbcxs 1/1 Running 0 3m17s rook-ceph-mon-a-555c899765-84t2n 1/1 Running 0 5m47s rook-ceph-mon-b-6bbd666b56-lj44v 1/1 Running 0 4m2s rook-ceph-mon-c-854c6d56-dpzgc 1/1 Running 0 3m28s rook-ceph-operator-9bf8b5959-nz6hd 1/1 Running 0 13m rook-ceph-osd-0-5b7875db98-t5mdv 1/1 Running 0 3m6s rook-ceph-osd-1-677c4cd89-b5rq2 1/1 Running 0 3m5s rook-ceph-osd-2-6665bc998f-9ck2f 1/1 Running 0 3m3s rook-ceph-osd-3-75d7b47647-7vfm4 1/1 Running 0 2m40s rook-ceph-osd-prepare-k8snode01.hirebestengineers.com--1-6kbkn 0/1 Completed 0 3m14s rook-ceph-osd-prepare-k8snode02.hirebestengineers.com--1-5hz49 0/1 Completed 0 3m14s rook-ceph-osd-prepare-k8snode03.hirebestengineers.com--1-4b45z 0/1 Completed 0 3m14s rook-ceph-osd-prepare-k8snode04.hirebestengineers.com--1-4q8cs 0/1 Completed 0 3m14s Each worker node will have a Job to add OSDs into Ceph Cluster: [root@k8s-bastion ceph]# kubectl get -n rook-ceph jobs.batch NAME COMPLETIONS DURATION AGE rook-ceph-osd-prepare-k8snode01.hirebestengineers.com 1/1 11s 3m46s rook-ceph-osd-prepare-k8snode02.hirebestengineers.com 1/1 34s 3m46s rook-ceph-osd-prepare-k8snode03.hirebestengineers.com 1/1 10s 3m46s rook-ceph-osd-prepare-k8snode04.hirebestengineers.com 1/1 9s 3m46s [root@k8s-bastion ceph]# kubectl describe jobs.batch rook-ceph-osd-prepare-k8snode01.hirebestengineers.com Verify that the cluster CR has been created and active: [root@k8s-bastion ceph]# kubectl -n rook-ceph get cephcluster NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL rook-ceph /var/lib/rook 3 3m50s Ready Cluster created successfully HEALTH_OK
Step 4: Deploy Rook Ceph toolbox in Kubernetes TheRook Ceph toolbox is a container with common tools used for rook debugging and testing. The toolbox is based on CentOS and any additional tools can be easily installed via yum. We will start a toolbox pod in an Interactive mode for us to connect and execute Ceph commands from a shell. Change to ceph directory: cd ~/ cd rook/deploy/examples Apply the toolbox.yaml manifest file to create toolbox pod: [root@k8s-bastion ceph]# kubectl apply -f toolbox.yaml deployment.apps/rook-ceph-tools created Connect to the pod using kubectl command with exec option: [root@k8s-bastion ~]# kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash [root@rook-ceph-tools-96c99fbf-qb9cj /]# Check Ceph Storage Cluster Status. Be keen on the value of cluster.health, it should beHEALTH_OK. [root@rook-ceph-tools-96c99fbf-qb9cj /]# ceph status cluster: id: 470b7cde-7355-4550-bdd2-0b79d736b8ac health: HEALTH_OK services: mon: 3 daemons, quorum a,b,c (age 5m) mgr: a(active, since 4m) osd: 4 osds: 4 up (since 4m), 4 in (since 5m) data: pools: 1 pools, 128 pgs objects: 0 objects, 0 B usage: 25 MiB used, 160 GiB / 160 GiB avail pgs: 128 active+clean List all OSDs to check their current status. They should exist and be up. [root@rook-ceph-tools-96c99fbf-qb9cj /]# ceph osd status ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE 0 k8snode04.hirebestengineers.com 6776k 39.9G 0 0 0 0 exists,up 1 k8snode03.hirebestengineers.com 6264k 39.9G 0 0 0 0 exists,up 2 k8snode01.hirebestengineers.com 6836k 39.9G 0 0 0 0 exists,up 3 k8snode02.hirebestengineers.com 6708k 39.9G 0 0 0 0 exists,up Check raw storage and pools: [root@rook-ceph-tools-96c99fbf-qb9cj /]# ceph df --- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 160 GiB 160 GiB 271 MiB 271 MiB 0.17 TOTAL 160 GiB 160 GiB 271 MiB 271 MiB 0.17 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 32 0 B 0 0 B 0 51 GiB replicapool 3 32 35 B 8 24 KiB 0 51 GiB k8fs-metadata 8 128 91 KiB 24 372 KiB 0 51 GiB k8fs-data0 9 32 0 B 0 0 B 0 51 GiB [root@rook-ceph-tools-96c99fbf-qb9cj /]# rados df POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR device_health_metrics 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B k8fs-data0 0 B 0 0 0 0 0 0 1 1 KiB 2 1 KiB 0 B 0 B k8fs-metadata 372 KiB 24 0 72 0 0 0 351347 172 MiB 17 26 KiB 0 B 0 B replicapool 24 KiB 8 0 24 0 0 0 999 6.9 MiB 1270 167 MiB 0 B 0 B total_objects 32 total_used 271 MiB total_avail 160 GiB total_space 160 GiB Step 5: Working with Ceph Cluster Storage Modes You have three types of storage exposed by Rook: Shared Filesystem: Create a filesystem to be shared across multiple pods (RWX) Block: Create block storage to be consumed by a pod (RWO) Object: Create an object store that is accessible inside or outside the Kubernetes cluster All the necessary files for either storage mode are available in rook/cluster/examples/kubernetes/ceph/ directory. cd ~/ cd rook/deploy/examples 1. Cephfs Cephfs is used to enable shared filesystem which can be mounted with read/write permission from multiple pods.
Update the filesystem.yaml file by setting data pool name, replication size e.t.c. [root@k8s-bastion ceph]# vim filesystem.yaml apiVersion: ceph.rook.io/v1 kind: CephFilesystem metadata: name: k8sfs namespace: rook-ceph # namespace:cluster Once done with modifications let Rook operator create all the pools and other resources necessary to start the service: [root@k8s-bastion ceph]# kubectl create -f filesystem.yaml cephfilesystem.ceph.rook.io/k8sfs created Access Rook toolbox pod and check if metadata and data pools are created. [root@k8s-bastion ceph]# kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash [root@rook-ceph-tools-96c99fbf-qb9cj /]# ceph fs ls name: k8sfs, metadata pool: k8sfs-metadata, data pools: [k8sfs-data0 ] [root@rook-ceph-tools-96c99fbf-qb9cj /]# ceph osd lspools 1 device_health_metrics 3 replicapool 8 k8fs-metadata 9 k8fs-data0 [root@rook-ceph-tools-96c99fbf-qb9cj /]# exit Update the fsName and pool name in Cephfs Storageclass configuration file: $ vim csi/cephfs/storageclass.yaml parameters: clusterID: rook-ceph # namespace:cluster fsName: k8sfs pool: k8fs-data0 Create StorageClass using the command: [root@k8s-bastion csi]# kubectl create -f csi/cephfs/storageclass.yaml storageclass.storage.k8s.io/rook-cephfs created List available storage classes in your Kubernetes Cluster: [root@k8s-bastion csi]# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 97s Create test PVC and Pod to test usage of Persistent Volume. [root@k8s-bastion csi]# kubectl create -f csi/cephfs/pvc.yaml persistentvolumeclaim/cephfs-pvc created [root@k8s-bastion ceph]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE cephfs-pvc Bound pvc-fd024cc0-dcc3-4a1d-978b-a166a2f65cdb 1Gi RWO rook-cephfs 4m42s [root@k8s-bastion csi]# kubectl create -f csi/cephfs/pod.yaml pod/csicephfs-demo-pod created PVC creation manifest file contents: --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: cephfs-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: rook-cephfs Checking PV creation logs as captured by the provisioner pod: [root@k8s-bastion csi]# kubectl logs deploy/csi-cephfsplugin-provisioner -f -c csi-provisioner [root@k8s-bastion ceph]# kubectl get pods | grep csi-cephfsplugin-provision csi-cephfsplugin-provisioner-b54db7d9b-5dpt6 6/6 Running 0 4m30s csi-cephfsplugin-provisioner-b54db7d9b-wrbxh 6/6 Running 0 4m30s If you made an update and provisioner didn’t pick you can always restart the Cephfs Provisioner Pods: # Gracefully $ kubectl delete pod -l app=csi-cephfsplugin-provisioner # Forcefully $ kubectl delete pod -l app=csi-cephfsplugin-provisioner --grace-period=0 --force 2. RBD Block storage allows a single pod to mount storage (RWO mode). Before Rook can provision storage, a StorageClass and CephBlockPool need to be created [root@k8s-bastion ~]# cd [root@k8s-bastion ~]# cd rook/deploy/examples [root@k8s-bastion csi]# kubectl create -f csi/rbd/storageclass.yaml cephblockpool.ceph.rook.io/replicapool created storageclass.storage.k8s.io/rook-ceph-block created [root@k8s-bastion csi]# kubectl create -f csi/rbd/pvc.yaml persistentvolumeclaim/rbd-pvc created List StorageClasses and PVCs: [root@k8s-bastion csi]# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 49s rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 6h17m
[root@k8s-bastion csi]# kubectl get pvc rbd-pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE rbd-pvc Bound pvc-c093e6f7-bb4e-48df-84a7-5fa99fe81138 1Gi RWO rook-ceph-block 43s Deploying multiple apps We will create a sample application to consume the block storage provisioned by Rook with the classic wordpress and mysql apps. Both of these apps will make use of block volumes provisioned by Rook. [root@k8s-bastion ~]# cd [root@k8s-bastion ~]# cd rook/deploy/examples [root@k8s-bastion kubernetes]# kubectl create -f mysql.yaml service/wordpress-mysql created persistentvolumeclaim/mysql-pv-claim created deployment.apps/wordpress-mysql created [root@k8s-bastion kubernetes]# kubectl create -f wordpress.yaml service/wordpress created persistentvolumeclaim/wp-pv-claim created deployment.apps/wordpress created Both of these apps create a block volume and mount it to their respective pod. You can see the Kubernetes volume claims by running the following: [root@k8smaster01 kubernetes]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE cephfs-pvc Bound pvc-aa972f9d-ab53-45f6-84c1-35a192339d2e 1Gi RWO rook-cephfs 2m59s mysql-pv-claim Bound pvc-4f1e541a-1d7c-49b3-93ef-f50e74145057 20Gi RWO rook-ceph-block 10s rbd-pvc Bound pvc-68e680c1-762e-4435-bbfe-964a4057094a 1Gi RWO rook-ceph-block 47s wp-pv-claim Bound pvc-fe2239a5-26c0-4ebc-be50-79dc8e33dc6b 20Gi RWO rook-ceph-block 5s Check deployment of MySQL and WordPress Services: [root@k8s-bastion kubernetes]# kubectl get deploy wordpress wordpress-mysql NAME READY UP-TO-DATE AVAILABLE AGE wordpress 1/1 1 1 2m46s wordpress-mysql 1/1 1 1 3m8s [root@k8s-bastion kubernetes]# kubectl get svc wordpress wordpress-mysql NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE wordpress LoadBalancer 10.98.120.112 80:32046/TCP 3m39s wordpress-mysql ClusterIP None 3306/TCP 4m1s Retrieve WordPress NodePort and test URL using LB IP address and the port. NodePort=$(kubectl get service wordpress -o jsonpath='.spec.ports[0].nodePort') echo $NodePort Cleanup Storage test PVC and pods [root@k8s-bastion kubernetes]# kubectl delete -f mysql.yaml service "wordpress-mysql" deleted persistentvolumeclaim "mysql-pv-claim" deleted deployment.apps "wordpress-mysql" deleted [root@k8s-bastion kubernetes]# kubectl delete -f wordpress.yaml service "wordpress" deleted persistentvolumeclaim "wp-pv-claim" deleted deployment.apps "wordpress" deleted # Cephfs cleanup [root@k8s-bastion kubernetes]# kubectl delete -f ceph/csi/cephfs/pod.yaml [root@k8s-bastion kubernetes]# kubectl delete -f ceph/csi/cephfs/pvc.yaml # RBD Cleanup [root@k8s-bastion kubernetes]# kubectl delete -f ceph/csi/rbd/pod.yaml [root@k8s-bastion kubernetes]# kubectl delete -f ceph/csi/rbd/pvc.yaml Step 6: Accessing Ceph Dashboard The Ceph dashboard gives you an overview of the status of your Ceph cluster: The overall health The status of the mon quorum The sstatus of the mgr, and osds Status of other Ceph daemons View pools and PG status Logs for the daemons, and much more. List services in rook-ceph namespace: [root@k8s-bastion ceph]# kubectl get svc -n rook-ceph NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE csi-cephfsplugin-metrics ClusterIP 10.105.10.255 8080/TCP,8081/TCP 9m56s csi-rbdplugin-metrics ClusterIP 10.96.5.0 8080/TCP,8081/TCP 9m57s rook-ceph-mgr ClusterIP 10.103.171.189 9283/TCP 7m31s rook-ceph-mgr-dashboard ClusterIP 10.102.140.148 8443/TCP 7m31s
rook-ceph-mon-a ClusterIP 10.102.120.254 6789/TCP,3300/TCP 10m rook-ceph-mon-b ClusterIP 10.97.249.82 6789/TCP,3300/TCP 8m19s rook-ceph-mon-c ClusterIP 10.99.131.50 6789/TCP,3300/TCP 7m46s From the output we can confirm port 8443 was configured. Use port forwarding to access the dashboard: $ kubectl port-forward service/rook-ceph-mgr-dashboard 8443:8443 -n rook-ceph Forwarding from 127.0.0.1:8443 -> 8443 Forwarding from [::1]:8443 -> 8443 Now, should be accessible over https://locallhost:8443 Login username is admin and password can be extracted using the following command: kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="['data']['password']" | base64 --decode && echo Access Dashboard with Node Port To create a service with the NodePort, save this yaml as dashboard-external-https.yaml. # cd # vim dashboard-external-https.yaml apiVersion: v1 kind: Service metadata: name: rook-ceph-mgr-dashboard-external-https namespace: rook-ceph labels: app: rook-ceph-mgr rook_cluster: rook-ceph spec: ports: - name: dashboard port: 8443 protocol: TCP targetPort: 8443 selector: app: rook-ceph-mgr rook_cluster: rook-ceph sessionAffinity: None type: NodePort Create a service that listens on Node Port: [root@k8s-bastion ~]# kubectl create -f dashboard-external-https.yaml service/rook-ceph-mgr-dashboard-external-https created Check new service created: [root@k8s-bastion ~]# kubectl -n rook-ceph get service rook-ceph-mgr-dashboard-external-https NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE rook-ceph-mgr-dashboard-external-https NodePort 10.103.91.41 8443:32573/TCP 2m43s In this example, port 32573 will be opened to expose port 8443 from the ceph-mgr pod. Now you can enter the URL in your browser such as https://[clusternodeip]:32573 and the dashboard will appear. Login with admin username and password decoded from rook-ceph-dashboard-password secret. kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="['data']['password']" | base64 --decode && echo Ceph dashboard view: Hosts list: Bonus: Tearing Down the Ceph Cluster If you want to tear down the cluster and bring up a new one, be aware of the following resources that will need to be cleaned up: rook-ceph namespace: The Rook operator and cluster created by operator.yaml and cluster.yaml (the cluster CRD) /var/lib/rook: Path on each host in the cluster where configuration is cached by the ceph mons and osds All CRDs in the cluster. [root@k8s-bastion ~]# kubectl get crds NAME CREATED AT apiservers.operator.tigera.io 2021-09-24T18:09:12Z bgpconfigurations.crd.projectcalico.org 2021-09-24T18:09:12Z bgppeers.crd.projectcalico.org 2021-09-24T18:09:12Z blockaffinities.crd.projectcalico.org 2021-09-24T18:09:12Z cephclusters.ceph.rook.io 2021-09-30T20:32:10Z clusterinformations.crd.projectcalico.org 2021-09-24T18:09:12Z felixconfigurations.crd.projectcalico.org 2021-09-24T18:09:12Z globalnetworkpolicies.crd.projectcalico.org 2021-09-24T18:09:12Z globalnetworksets.crd.projectcalico.org 2021-09-24T18:09:12Z hostendpoints.crd.projectcalico.org 2021-09-24T18:09:12Z imagesets.operator.tigera.io 2021-09-24T18:09:12Z installations.operator.tigera.io 2021-09-24T18:09:12Z ipamblocks.crd.projectcalico.org 2021-09-24T18:09:12Z ipamconfigs.crd.projectcalico.org 2021-09-24T18:09:12Z ipamhandles.crd.projectcalico.org 2021-09-24T18:09:12Z ippools.crd.projectcalico.org 2021-09-24T18:09:12Z
kubecontrollersconfigurations.crd.projectcalico.org 2021-09-24T18:09:12Z networkpolicies.crd.projectcalico.org 2021-09-24T18:09:12Z networksets.crd.projectcalico.org 2021-09-24T18:09:12Z tigerastatuses.operator.tigera.io 2021-09-24T18:09:12Z Edit the CephCluster and add the cleanupPolicy kubectl -n rook-ceph patch cephcluster rook-ceph --type merge -p '"spec":"cleanupPolicy":"confirmation":"yes-really-destroy-data"' Delete block storage and file storage: cd ~/ cd rook/deploy/examples kubectl delete -n rook-ceph cephblockpool replicapool kubectl delete -f csi/rbd/storageclass.yaml kubectl delete -f filesystem.yaml kubectl delete -f csi/cephfs/storageclass.yaml Delete the CephCluster Custom Resource: [root@k8s-bastion ~]# kubectl -n rook-ceph delete cephcluster rook-ceph cephcluster.ceph.rook.io "rook-ceph" deleted Verify that the cluster CR has been deleted before continuing to the next step. kubectl -n rook-ceph get cephcluster Delete the Operator and related Resources kubectl delete -f operator.yaml kubectl delete -f common.yaml kubectl delete -f crds.yaml Zapping Devices # Set the raw disk / raw partition path DISK="/dev/vdb" # Zap the disk to a fresh, usable state (zap-all is important, b/c MBR has to be clean) # Install: yum install gdisk -y Or apt install gdisk sgdisk --zap-all $DISK # Clean hdds with dd dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync # Clean disks such as ssd with blkdiscard instead of dd blkdiscard $DISK # These steps only have to be run once on each node # If rook sets up osds using ceph-volume, teardown leaves some devices mapped that lock the disks. ls /dev/mapper/ceph-* | xargs -I% -- dmsetup remove % # ceph-volume setup can leave ceph- directories in /dev and /dev/mapper (unnecessary clutter) rm -rf /dev/ceph-* rm -rf /dev/mapper/ceph--* # Inform the OS of partition table changes partprobe $DISK Removing the Cluster CRD Finalizer: for CRD in $(kubectl get crd -n rook-ceph | awk '/ceph.rook.io/ print $1'); do kubectl get -n rook-ceph "$CRD" -o name | \ xargs -I kubectl patch -n rook-ceph --type merge -p '"metadata":"finalizers": [null]' done If the namespace is still stuck in Terminating state as seen in the command below: $ kubectl get ns rook-ceph NAME STATUS AGE rook-ceph Terminating 23h You can check which resources are holding up the deletion and remove the finalizers and delete those resources. kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -n rook-ceph From my output the resource is configmap named rook-ceph-mon-endpoints: NAME DATA AGE configmap/rook-ceph-mon-endpoints 4 23h Delete the resource manually: # kubectl delete configmap/rook-ceph-mon-endpoints -n rook-ceph configmap "rook-ceph-mon-endpoints" deleted Recommended reading: Rook Best Practices for Running Ceph on Kubernetes
0 notes
Text
How to Deploy a Ceph Storage to Bare Virtual Machines

Ceph is a freely available storage platform that implements object storage on a single distributed computer cluster and provides interfaces for object-, block- and file-level storage. Ceph aims primarily for completely distributed operation without a single point of failure. Ceph storage manages data replication and is generally quite fault-tolerant. As a result of its design, the system is both self-healing and self-managing.
Ceph has loads of benefits and great features, but the main drawback is that you have to host and manage it yourself. In this post, we'll check two different approaches of virtual machine deployment with Ceph.
Anatomy of a Ceph cluster
Before we dive into the actual deployment process, let's see what we'll need to fire up for our own Ceph cluster.
There are three services that form the backbone of the cluster
ceph monitors (ceph-mon) maintain maps of the cluster state and are also responsible for managing authentication between daemons and clients
managers (ceph-mgr) are responsible for keeping track of runtime metrics and the current state of the Ceph cluster
object storage daemons (ceph-osd) store data, handle data replication, recovery, rebalancing, and provide some ceph monitoring information.
Additionally, we can add further parts to the cluster to support different storage solutions
metadata servers (ceph-mds) store metadata on behalf of the Ceph Filesystem
rados gateway (ceph-rgw) is an HTTP server for interacting with a Ceph Storage Cluster that provides interfaces compatible with OpenStack Swift and Amazon S3.
There are multiple ways of deploying these services. We'll check two of them:
first, using the ceph/deploy tool,
then a docker-swarm based vm deployment.
Let's kick it off!
Ceph Setup
Okay, a disclaimer first. As this is not a production infrastructure, we’ll cut a couple of corners.
You should not run multiple different Ceph demons on the same host, but for the sake of simplicity, we'll only use 3 virtual machines for the whole cluster.
In the case of OSDs, you can run multiple of them on the same host, but using the same storage drive for multiple instances is a bad idea as the disk’s I/O speed might limit the OSD daemons’ performance.
For this tutorial, I've created 4 EC2 machines in AWS: 3 for Ceph itself and 1 admin node. For ceph-deploy to work, the admin node requires passwordless SSH access to the nodes and that SSH user has to have passwordless sudo privileges.
In my case, as all machines are in the same subnet on AWS, connectivity between them is not an issue. However, in other cases editing the hosts file might be necessary to ensure proper connection.
Depending on where you deploy Ceph security groups, firewall settings or other resources have to be adjusted to open these ports
22 for SSH
6789 for monitors
6800:7300 for OSDs, managers and metadata servers
8080 for dashboard
7480 for rados gateway
Without further ado, let's start deployment.
Ceph Storage Deployment
Install prerequisites on all machines
$ sudo apt update $ sudo apt -y install ntp python
For Ceph to work seamlessly, we have to make sure the system clocks are not skewed. The suggested solution is to install ntp on all machines and it will take care of the problem. While we're at it, let's install python on all hosts as ceph-deploy depends on it being available on the target machines.
Prepare the admin node
$ ssh -i ~/.ssh/id_rsa -A [email protected]
As all the machines have my public key added to known_hosts thanks to AWS, I can use ssh agent forwarding to access the Ceph machines from the admin node. The first line ensures that my local ssh agent has the proper key in use and the -A flag takes care of forwarding my key.
$ wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add - echo deb https://download.ceph.com/debian-nautilus/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list $ sudo apt update $ sudo apt -y install ceph-deploy
We'll use the latest nautilus release in this example. If you want to deploy a different version, just change the debian-nautilus part to your desired release (luminous, mimic, etc.).
$ echo "StrictHostKeyChecking no" | sudo tee -a /etc/ssh/ssh_config > /dev/null
OR
$ ssh-keyscan -H 10.0.0.124,10.0.0.216,10.0.0.104 >> ~/.ssh/known_hosts
Ceph-deploy uses SSH connections to manage the nodes we provide. Each time you SSH to a machine that is not in the list of known_hosts (~/.ssh/known_hosts), you'll get prompted whether you want to continue connecting or not. This interruption does not mesh well with the deployment process, so we either have to use ssh-keyscan to grab the fingerprint of all the target machines or disable the strict host key checking outright.
10.0.0.124 ip-10-0-0-124.eu-north-1.compute.internal ip-10-0-0-124 10.0.0.216 ip-10-0-0-216.eu-north-1.compute.internal ip-10-0-0-216 10.0.0.104 ip-10-0-0-104.eu-north-1.compute.internal ip-10-0-0-104
Even though the target machines are in the same subnet as our admin and they can access each other, we have to add them to the hosts file (/etc/hosts) for ceph-deploy to work properly. Ceph-deploy creates monitors by the provided hostname, so make sure it matches the actual hostname of the machines otherwise the monitors won't be able to join the quorum and the deployment fails. Don't forget to reboot the admin node for the changes to take effect.
$ mkdir ceph-deploy $ cd ceph-deploy
As a final step of the preparation, let's create a dedicated folder as ceph-deploy will create multiple config and key files during the process.
Deploy resources
$ ceph-deploy new ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
The command ceph-deploy new creates the necessary files for the deployment. Pass it the hostnames of the monitor nodes, and it will create cepf.conf and ceph.mon.keyring along with a log file.
The ceph-conf should look something like this
[global] fsid = 0572e283-306a-49df-a134-4409ac3f11da mon_initial_members = ip-10-0-0-124, ip-10-0-0-216, ip-10-0-0-104 mon_host = 10.0.0.124,10.0.0.216,10.0.0.104 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx
It has a unique ID called fsid, the monitor hostnames and addresses and the authentication modes. Ceph provides two authentication modes: none (anyone can access data without authentication) or cephx (key based authentication).
The other file, the monitor keyring is another important piece of the puzzle, as all monitors must have identical keyrings in a cluster with multiple monitors. Luckily ceph-deploy takes care of the propagation of the key file during virtual deployments.
$ ceph-deploy install --release nautilus ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
As you might have noticed so far, we haven't installed ceph on the target nodes yet. We could do that one-by-one, but a more convenient way is to let ceph-deploy take care of the task. Don't forget to specify the release of your choice, otherwise you might run into a mismatch between your admin and targets.
$ ceph-deploy mon create-initial
Finally, the first piece of the cluster is up and running! create-initial will deploy the monitors specified in ceph.conf we generated previously and also gather various key files. The command will only complete successfully if all the monitors are up and in the quorum.
$ ceph-deploy admin ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
Executing ceph-deploy admin will push a Ceph configuration file and the ceph.client.admin.keyring to the /etc/ceph directory of the nodes, so we can use the ceph CLI without having to provide the ceph.client.admin.keyring each time to execute a command.
At this point, we can take a peek at our cluster. Let's SSH into a target machine (we can do it directly from the admin node thanks to agent forwarding) and run sudo ceph status.
$ sudo ceph status cluster: id: 0572e283-306a-49df-a134-4409ac3f11da health: HEALTH_OK services: mon: 3 daemons, quorum ip-10-0-0-104,ip-10-0-0-124,ip-10-0-0-216 (age 110m) mgr: no daemons active osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs:
Here we get a quick overview of what we have so far. Our cluster seems to be healthy and all three monitors are listed under services. Let's go back to the admin and continue adding pieces.
$ ceph-deploy mgr create ip-10-0-0-124
For luminous+ builds a manager daemon is required. It's responsible for monitoring the state of the Cluster and also manages modules/plugins.
Okay, now we have all the management in place, let's add some storage to the cluster to make it actually useful, shall we?
First, we have to find out (on each target machine) the label of the drive we want to use. To fetch the list of available disks on a specific node, run
$ ceph-deploy disk list ip-10-0-0-104
Here's a sample output:
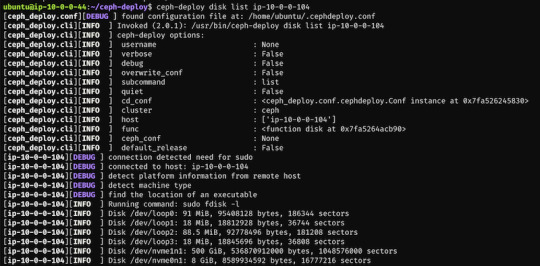
$ ceph-deploy osd create --data /dev/nvme1n1 ip-10-0-0-124 $ ceph-deploy osd create --data /dev/nvme1n1 ip-10-0-0-216 $ ceph-deploy osd create --data /dev/nvme1n1 ip-10-0-0-104
In my case the label was nvme1n1 on all 3 machines (courtesy of AWS), so to add OSDs to the cluster I just ran these 3 commands.
At this point, our cluster is basically ready. We can run ceph status to see that our monitors, managers and OSDs are up and running. But nobody wants to SSH into a machine every time to check the status of the cluster. Luckily there's a pretty neat dashboard that comes with Ceph, we just have to enable it.
...Or at least that's what I thought. The dashboard was introduced in luminous release and was further improved in mimic. However, currently we're deploying nautilus, the latest version of Ceph. After trying the usual way of enabling the dashboard via a manager
$ sudo ceph mgr module enable dashboard
we get an error message saying Error ENOENT: all mgr daemons do not support module 'dashboard', pass --force to force enablement.
Turns out, in nautilus the dashboard package is no longer installed by default. We can check the available modules by running
$ sudo ceph mgr module ls
and as expected, dashboard is not there, it comes in a form a separate package. So we have to install it first, luckily it's pretty easy.
$ sudo apt install -y ceph-mgr-dashboard
Now we can enable it, right? Not so fast. There's a dependency that has to be installed on all manager hosts, otherwise we get a slightly cryptic error message saying Error EIO: Module 'dashboard' has experienced an error and cannot handle commands: No module named routes.
$ sudo apt install -y python-routes
We're all set to enable the dashboard module now. As it's a public-facing page that requires login, we should set up a cert for SSL. For the sake of simplicity, I've just disabled the SSL feature. You should never do this in production, check out the official docs to see how to set up a cert properly. Also, we'll need to create an admin user so we can log in to our dashboard.
$ sudo ceph mgr module enable dashboard $ sudo ceph config set mgr mgr/dashboard/ssl false $ sudo ceph dashboard ac-user-create admin secret administrator
By default, the dashboard is available on the host running the manager on port 8080. After logging in, we get an overview of the cluster status, and under the cluster menu, we get really detailed overviews of each running daemon.
If we try to navigate to the Filesystems or Object Gateway tabs, we get a notification that we haven't configured the required resources to access these features. Our cluster can only be used as a block storage right now. We have to deploy a couple of extra things to extend its usability.
Quick detour: In case you're looking for a company that can help you with Ceph, or DevOps in general, feel free to reach out to us at RisingStack!
Using the Ceph filesystem
Going back to our admin node, running
$ ceph-deploy mds create ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
will create metadata servers, that will be inactive for now, as we haven’t enabled the feature yet. First, we need to create two RADOS pools, one for the actual data and one for the metadata.
$ sudo ceph osd pool create cephfs_data 8 $ sudo ceph osd pool create cephfs_metadata 8
There are a couple of things to consider when creating pools that we won’t cover here. Please consult the documentation for further details.
After creating the required pools, we’re ready to enable the filesystem feature
$ sudo ceph fs new cephfs cephfs_metadata cephfs_data
The MDS daemons will now be able to enter an active state, and we are ready to mount the filesystem. We have two options to do that, via the kernel driver or as FUSE with ceph-fuse.
Before we continue with the mounting, let’s create a user keyring that we can use in both solutions for authorization and authentication as we have cephx enabled. There are multiple restrictions that can be set up when creating a new key specified in the docs. For example:
$ sudo ceph auth get-or-create client.user mon 'allow r' mds 'allow r, allow rw path=/home/cephfs' osd 'allow rw pool=cephfs_data' -o /etc/ceph/ceph.client.user.keyring
will create a new client key with the name user and output it into ceph.client.user.keyring. It will provide write access for the MDS only to the /home/cephfs directory, and the client will only have write access within the cephfs_data pool.
Mounting with the kernel
Now let’s create a dedicated directory and then use the key from the previously generated keyring to mount the filesystem with the kernel.
$ sudo mkdir /mnt/mycephfs $ sudo mount -t ceph 13.53.114.94:6789:/ /mnt/mycephfs -o name=user,secret=AQBxnDFdS5atIxAAV0rL9klnSxwy6EFpR/EFbg==
Attaching with FUSE
Mounting the filesystem with FUSE is not much different either. It requires installing the ceph-fuse package.
$ sudo apt install -y ceph-fuse
Before we run the command we have to retrieve the ceph.conf and ceph.client.user.keyring files from the Ceph host and put the in /etc/ceph. The easiest solution is to use scp.
$ sudo scp [email protected]:/etc/ceph/ceph.conf /etc/ceph/ceph.conf $ sudo scp [email protected]:/etc/ceph/ceph.client.user.keyring /etc/ceph/ceph.keyring
Now we are ready to mount the filesystem.
$ sudo mkdir cephfs $ sudo ceph-fuse -m 13.53.114.94:6789 cephfs
Using the RADOS gateway
To enable the S3 management feature of the cluster, we have to add one final piece, the rados gateway.
$ ceph-deploy rgw create ip-10-0-0-124
For the dashboard, it's required to create a radosgw-admin user with the system flag to enable the Object Storage management interface. We also have to provide the user's access_key and secret_key to the dashboard before we can start using it.
$ sudo radosgw-admin user create --uid=rg_wadmin --display-name=rgw_admin --system $ sudo ceph dashboard set-rgw-api-access-key <access_key> $ sudo ceph dashboard set-rgw-api-secret-key <secret_key>
Using the Ceph Object Storage is really easy as RGW provides an interface identical to S3. You can use your existing S3 requests and code without any modifications, just have to change the connection string, access, and secret keys.
Ceph Storage Monitoring
The dashboard we’ve deployed shows a lot of useful information about our cluster, but monitoring is not its strongest suit. Luckily Ceph comes with a Prometheus module. After enabling it by running:
$ sudo ceph mgr module enable prometheus
A wide variety of metrics will be available on the given host on port 9283 by default. To make use of these exposed data, we’ll have to set up a prometheus instance.
I strongly suggest running the following containers on a separate machine from your Ceph cluster. In case you are just experimenting (like me) and don’t want to use a lot of VMs, make sure you have enough memory and CPU left on your virtual machine before firing up docker, as it can lead to strange behaviour and crashes if it runs out of resources.
There are multiple ways of firing up Prometheus, probably the most convenient is with docker. After installing docker on your machine, create a prometheus.yml file to provide the endpoint where it can access our Ceph metrics.
# /etc/prometheus.yml scrape_configs: - job_name: 'ceph' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['13.53.114.94:9283]
Then launch the container itself by running:
$ sudo docker run -p 9090:9090 -v /etc/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
Prometheus will start scraping our data, and it will show up on its dashboard. We can access it on port 9090 on its host machine. Prometheus dashboard is great but does not provide a very eye-pleasing dashboard. That’s the main reason why it’s usually used in pair with Graphana, which provides awesome visualizations for the data provided by Prometheus. It can be launched with docker as well.
$ sudo docker run -d -p 3000:3000 grafana/grafana
Grafana is fantastic when it comes to visualizations, but setting up dashboards can be a daunting task. To make our lives easier, we can load one of the pre-prepared dashboards, for example this one.
Ceph Deployment: Lessons Learned & Next Up
CEPH can be a great alternative to AWS S3 or other object storages when running in the public operating your service in the private cloud is simply not an option. The fact that it provides an S3 compatible interface makes it a lot easier to port other tools that were written with a “cloud first” mentality. It also plays nicely with Prometheus, thus you don’t need to worry about setting up proper monitoring for it, or you can swap it a more simple, more battle-hardened solution such as Nagios.
In this article, we deployed CEPH to bare virtual machines, but you might need to integrate it into your Kubernetes or Docker Swarm cluster. While it is perfectly fine to install it on VMs next to your container orchestration tool, you might want to leverage the services they provide when you deploy your CEPH cluster. If that is your use case, stay tuned for our next post covering CEPH where we’ll take a look at the black magic required to use CEPH on Docker Swarm and Kubernetes.
In the next CEPH tutorial which we'll release next week, we're going to take a look at valid ceph storage alternatives with Docker or with Kubernetes.
PS: Feel free to reach out to us at RisingStack in case you need help with Ceph or Ops in general!
How to Deploy a Ceph Storage to Bare Virtual Machines published first on https://koresolpage.tumblr.com/
0 notes
Text
Ceph Storage Solutions Market 2020: Emerging Trends, Global Demand And Sales To 2027
Ceph is a free software platform that enables highly scalable object, block, and file-based storage under one comprehensive system. The cluster of Ceph are designed in such a way that it can run on commodity hardware with the help of CRUSH, which is a hash based algorithm. The CRUSH algorithm makes sure that all the data is accurately distributed across the cluster and all cluster nodes can rightly fit in as well as retrieve data quickly without any constraints. Thus, Ceph not only stores large amounts of data but also simplifies access to the same.
The Ceph RADOS block device in the Ceph storage system is a type of a disk that is attached to a virtual machine or bare-metal Linux-based servers. The Ceph block device leverages the capability of reliable autonomic distributed object store (RADOS) which is a software that facilitates block storage capabilities such as snapshotting and replication. On the whole, Ceph’s functioning as a storage system is effective and simple. Hence, it is deployed by many hosting and IT solution providers for their clients.
Get Sample Copy of the Report to understand the structure of the complete report (Including Full TOC, Table & Figures): https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=44015
Data is growing at a tremendous rate; therefore, enterprises need a solution that can store large volume of data effectively. Storing data efficiently has long been a major challenge for enterprises all around the globe. Ceph storage is an effective solution that can cater to the problem of large amounts of data storage. Ceph provides dynamic storage clusters. Most storage applications do not make the most of the CPU and RAM available in a typical commodity server; however, Ceph storage optimally uses the existing IT infrastructure. Right from rebalancing the clusters to recovering from errors and faults, Ceph offloads work from clients by using distributed computing power of Ceph’s OSD (Object Storage Daemon) to perform the required work. Ceph is scalable, reliable, and easy to manage. It allows organizations to scale without affecting their capital expenditure (CAPEX) or operating expenditure (OPEX). Ceph has therefore transformed IT organizations when it comes to data storage. Ceph runs on any commodity hardware without any vendor lock-in. As a software-defined storage solution, it provides flexibility in hardware selection as well. This has made it quite popular among web professionals.
In addition to the above mentioned advantages, Ceph provides many other advantages such as data safety– Ceph makes each data update transparent to clients. Moreover, it also lets users know that the updated data is securely replicated on a disk and therefore is able to survive power or other failures. Failure detection is another advantage of the Ceph storage solution. Spotting errors or failures at the right time is highly important while securing data. However, this can get difficult with too many clusters on a large scale. OSDs (Object Storage Daemons) in a Ceph distributed file system can self-report in such cases. Thus, Ceph monitoring detects irregularities if any, in a distributive environment. Also, this distributed detection helps in quick detection and resolving inconsistencies. Ceph storage solution also has the capability of cluster recovery and updates in case of OSD failures and when OSD cluster maps undergo changes. In order to provide fast recovery, OSD maintains a version number for each object and a log for recent changes.
Request For Covid19 Impact Analysis Across Industries And Markets – https://www.transparencymarketresearch.com/sample/sample.php?flag=covid19&rep_id=44015
Global companies are investing in providing Ceph based storage solutions. Since, Ceph is open source, it has enabled large number of big vendors to provide Ceph based software- defined storage solutions. This in turn means that the Ceph based solution is expected to witness promising growth in the coming years among enterprises as well as government organizations.
Some of the prominent players providing Ceph based software defined storage solutions are Red Hat Inc., Fujitsu, Cleversafe (IBM Corporation), Hewlett Packard Enterprise (HPE), SUSE Enterprise Storage, SanDisk, Dell Inc,. and Samsung Group.
The report offers a comprehensive evaluation of the market. It does so via in-depth qualitative insights, historical data, and verifiable projections about market size. The projections featured in the report have been derived using proven research methodologies and assumptions. By doing so, the research report serves as a repository of analysis and information for every facet of the market, including but not limited to: Regional markets, technology, types, and applications.
The study is a source of reliable data on:
Market segments and sub-segments
Market trends and dynamics
Supply and demand
Market size
Current trends/opportunities/challenges
Competitive landscape
Technological breakthroughs
Value chain and stakeholder analysis
The regional analysis covers:
North America (U.S. and Canada)
Latin America (Mexico, Brazil, Peru, Chile, and others)
Western Europe (Germany, U.K., France, Spain, Italy, Nordic countries, Belgium, Netherlands, and Luxembourg)
Eastern Europe (Poland and Russia)
Asia Pacific (China, India, Japan, ASEAN, Australia, and New Zealand)
Middle East and Africa (GCC, Southern Africa, and North Africa)
The report has been compiled through extensive primary research (through interviews, surveys, and observations of seasoned analysts) and secondary research (which entails reputable paid sources, trade journals, and industry body databases). The report also features a complete qualitative and quantitative assessment by analyzing data gathered from industry analysts and market participants across key points in the industry’s value chain.
Customization of the Report: This report can be customized as per your needs for additional data or countries. – https://www.transparencymarketresearch.com/sample/sample.php?flag=CR&rep_id=44015
Related Reports Press-Release –
https://www.prnewswire.com/news-releases/blockchain-technology-market-to-rise-at-a-phenomenal-58-9-cagr-till-2024-rising-adoption-of-cryptocurrency-to-fuel-growth—tmr-300814667.html
https://www.prnewswire.com/news-releases/automotive-lighting-market-to-reach-us46-372-7-mn-by-2025–new-regulations-regarding-road-safety-to-drive-growth—tmr-300840622.html
About Us
Transparency Market Research is a next-generation market intelligence provider, offering fact-based solutions to industry leaders, consultants, and strategy professionals.
Our reports are single-point solutions for industries to grow, evolve, and mature. Our significant-time data collection methods along with ability to track more than one million high growth niche products are aligned with your aims. The detailed and proprietary statistical models used by our analysts offer insights for making right decision in the shortest span of time. For organizations that require specific but comprehensive information we offer customized solutions through adhoc reports. These demands are delivered with the perfect combination of right sense of fact-oriented problem solving methodologies and leveraging existing data repositories.
TMR believes that unison of solutions for client-specific problems with right methodology of research is the key to help enterprises reach right decision.
U.S. Office Contact
90 State Street, Suite 700 Albany, NY 12207 Tel: +1-518-618-1030 USA – Canada Toll Free: 866-552-3453 Email: [email protected] Website: https://www.transparencymarketresearch.com
0 notes
Text
Ceph Storage Solutions Market Leading Players Envisioned By The Analysts Forecast
Ceph is a free software platform that enables highly scalable object, block, and file-based storage under one comprehensive system. The cluster of Ceph are designed in such a way that it can run on commodity hardware with the help of CRUSH, which is a hash based algorithm. The CRUSH algorithm makes sure that all the data is accurately distributed across the cluster and all cluster nodes can rightly fit in as well as retrieve data quickly without any constraints. Thus, Ceph not only stores large amounts of data but also simplifies access to the same.
The Ceph RADOS block device in the Ceph storage system is a type of a disk that is attached to a virtual machine or bare-metal Linux-based servers. The Ceph block device leverages the capability of reliable autonomic distributed object store (RADOS) which is a software that facilitates block storage capabilities such as snapshotting and replication. On the whole, Ceph’s functioning as a storage system is effective and simple. Hence, it is deployed by many hosting and IT solution providers for their clients.
Data is growing at a tremendous rate; therefore, enterprises need a solution that can store large volume of data effectively. Storing data efficiently has long been a major challenge for enterprises all around the globe. Ceph storage is an effective solution that can cater to the problem of large amounts of data storage. Ceph provides dynamic storage clusters. Most storage applications do not make the most of the CPU and RAM available in a typical commodity server; however, Ceph storage optimally uses the existing IT infrastructure. Right from rebalancing the clusters to recovering from errors and faults, Ceph offloads work from clients by using distributed computing power of Ceph’s OSD (Object Storage Daemon) to perform the required work. Ceph is scalable, reliable, and easy to manage. It allows organizations to scale without affecting their capital expenditure (CAPEX) or operating expenditure (OPEX). Ceph has therefore transformed IT organizations when it comes to data storage. Ceph runs on any commodity hardware without any vendor lock-in. As a software-defined storage solution, it provides flexibility in hardware selection as well. This has made it quite popular among web professionals.
Looking for exclusive market insights from business experts? Request a Sample Report
In addition to the above mentioned advantages, Ceph provides many other advantages such as data safety– Ceph makes each data update transparent to clients. Moreover, it also lets users know that the updated data is securely replicated on a disk and therefore is able to survive power or other failures. Failure detection is another advantage of the Ceph storage solution. Spotting errors or failures at the right time is highly important while securing data. However, this can get difficult with too many clusters on a large scale. OSDs (Object Storage Daemons) in a Ceph distributed file system can self-report in such cases. Thus, Ceph monitoring detects irregularities if any, in a distributive environment. Also, this distributed detection helps in quick detection and resolving inconsistencies. Ceph storage solution also has the capability of cluster recovery and updates in case of OSD failures and when OSD cluster maps undergo changes. In order to provide fast recovery, OSD maintains a version number for each object and a log for recent changes.
Global companies are investing in providing Ceph based storage solutions. Since, Ceph is open source, it has enabled large number of big vendors to provide Ceph based software- defined storage solutions. This in turn means that the Ceph based solution is expected to witness promising growth in the coming years among enterprises as well as government organizations.
0 notes
Text
DevOps Engineer
DevOps Engineer – 89091 Organization: EB-Environ Genomics & Systems Bio Lawrence Berkeley National Laboratory s (LBNL, https://www.lbl.gov/ ) Environmental Genomics & Systems Biology Division ( https://ift.tt/2gqwKPK ) has an opening for a DevOps Engineer to join the Knowledgebase (KBase) team. Designed to meet the key challenges of systems biology (predicting and ultimately designing biological function), KBase integrates numerous biological datasets and analysis tools into a unified, extensible system that allows researchers to collaboratively generate and test hypotheses about biological functions. Under general instruction, you will work on the core development and production infrastructure of a multi-site scientific platform working on hardware and software installation, configuration and maintenance. The KBase software stack is complex and modern, using containerization and continuous integration and deployment. The position will help continue the automation of on-premise environment to maximize uptime, scalability and agility. This position will be hired at a level commensurate with the business needs; and skills, knowledge, and abilities of the successful candidate. What You Will Do:
Participate in the operation and continued development of the KBase platform. Documentation of issues, procedures, and practices. Support engineers and user support staff in diagnosing operational issues. Understand and effectively use existing configuration management and orchestration tools such as scripts and Rancher. Understand existing short shell and python scripts, and write short scripts for process automation and monitoring of services. Work with version control tools such as git for auditable configuration management.
Additional Responsibilities as needed:
Independently resolve minor service outages. Independently develop/improve tools for more complex automation involving CI/CD and container orchestration. Write effective scripts supporting automation and reporting. Work with engineers and support staff to diagnose operational issues and suggest improvements and mitigations to avoid recurrence.
What Is Required:
Bachelor s degree in Computer Science, Bioinformatics or related field and a minimum of 2 years professional experience in a DevOps role (DevOps Engineer, Systems Engineer, Site Reliability Engineer, Systems Administrator or similar) or equivalent work experience. Experience with Linux administration, including performance monitoring and troubleshooting, networking, storage hardware and software (LSI, LVM, NFS), security, service administration (systemctl, nginx), and DNS administration (BIND). Experience with virtualization and container technology such as Docker and associated tools (e.g. docker-compose) and KVM. Experience with container orchestration platforms such as Rancher, Kubernetes, Openshift. Experience with data stores (MongoDB, Ceph or other blob stores, S3 API, ElasticSearch, ArangoDB, MariaDB), including replication, redundancy, backups, and recovery Experience with scripting in Python, bash, or similar languages. Experience with monitoring tools such as Nagios or Check_MK. Experience with web services and protocols (REST, JSON-RPC). Experience with version control, such as Git, GitHub or GitLab. Ability to work collaboratively with people of diverse backgrounds. Excellent writing, interpersonal communication, and analytical skills.
Additional Desired Qualifications:
Master s degree in Computer Science or related field and minimum of 3 years related experience or equivalent work experience. Experience with Linux administration of Linux clusters using tools such as pdsh and configuration management tools such as Salt Stack, Ansible, Chef or Puppet Demonstrated ability to independently create new services and new application stacks using container orchestration platforms such as Rancher, Kubernetes, Openshift Demonstrated ability to upgrade/update and migrate data stores (MongoDB, Ceph or other blob stores, S3 API, ElasticSearch, ArangoDB, MariaDB) Demonstrated ability to independently write automation and monitoring scripts of at least 100 lines, and the ability to understand and update scripts of up to 300 lines Demonstrated experience using version control systems to manage configuration Experience working in an academic or research environment Experience with hardware support (replacing drives, hands-on maintenance/recovery) Experience with cloud computing (GCP, AWS) Experience with workflow or batch scheduling (Condor, Slurm) Experience with Continuous Integration/Continuous Deployment pipelines Experience with dynamic HTTP proxy software (Traefik) Knowledge of computational biology.
The posting shall remain open until the position is filled. Notes:
This is a full time, 1 year, term appointment with the possibility of extension or conversion to Career appointment based upon satisfactory job performance, continuing availability of funds and ongoing operational needs. Full-time, M-F, exempt (monthly paid) from overtime pay. Salary is commensurate with experience. This position may be subject to a background check. Any convictions will be evaluated to determine if they directly relate to the responsibilities and requirements of the position. Having a conviction history will not automatically disqualify an applicant from being considered for employment. Work will be primarily performed at West Berkeley Biocenter (Potter St.) Bldg. 977, 717 Potter St., Berkeley, CA.
How To Apply Apply directly online at https://ift.tt/2RRmSTs and follow the on-line instructions to complete the application process. Berkeley Lab (LBNL, https://www.lbl.gov/ ) addresses the world s most urgent scientific challenges by advancing sustainable energy, protecting human health, creating new materials, and revealing the origin and fate of the universe. Founded in 1931, Berkeley Lab s scientific expertise has been recognized with 13 Nobel prizes. The University of California manages Berkeley Lab for the U.S. Department of Energy s Office of Science. Working at Berkeley Lab has many rewards including a competitive compensation program, excellent health and welfare programs, a retirement program that is second to none, and outstanding development opportunities. To view information about the many rewards that are offered at Berkeley Lab- Click Here ( https://hr.lbl.gov/ ). Equal Employment Opportunity: Berkeley Lab is an Equal Opportunity/Affirmative Action Employer. All qualified applicants will receive consideration for employment without regard to race, color, religion, sex, sexual orientation, gender identity, national origin, disability, age, or protected veteran status. Berkeley Lab is in compliance with the Pay Transparency Nondiscrimination Provision ( https://ift.tt/2x1A8st ) under 41 CFR 60-1.4. Click here ( https://ift.tt/2khmEGu ) to view the poster and supplement: “Equal Employment Opportunity is the Law.” – provided by Dice
from Berkeley Job Site https://ift.tt/2tHZIH7 via IFTTT
0 notes
Text
Ceph Storage Solutions Market: Key Players and Production Information analysis
Ceph is a free software platform that enables highly scalable object, block, and file-based storage under one comprehensive system. The cluster of Ceph are designed in such a way that it can run on commodity hardware with the help of CRUSH, which is a hash based algorithm. The CRUSH algorithm makes sure that all the data is accurately distributed across the cluster and all cluster nodes can rightly fit in as well as retrieve data quickly without any constraints. Thus, Ceph not only stores large amounts of data but also simplifies access to the same.
The Ceph RADOS block device in the Ceph storage system is a type of a disk that is attached to a virtual machine or bare-metal Linux-based servers. The Ceph block device leverages the capability of reliable autonomic distributed object store (RADOS) which is a software that facilitates block storage capabilities such as snapshotting and replication. On the whole, Ceph’s functioning as a storage system is effective and simple. Hence, it is deployed by many hosting and IT solution providers for their clients.
Request For Report Brochure https://www.transparencymarketresearch.com/sample/sample.php?flag=B&rep_id=44015
Data is growing at a tremendous rate; therefore, enterprises need a solution that can store large volume of data effectively. Storing data efficiently has long been a major challenge for enterprises all around the globe. Ceph storage is an effective solution that can cater to the problem of large amounts of data storage. Ceph provides dynamic storage clusters. Most storage applications do not make the most of the CPU and RAM available in a typical commodity server; however, Ceph storage optimally uses the existing IT infrastructure.
Right from rebalancing the clusters to recovering from errors and faults, Ceph offloads work from clients by using distributed computing power of Ceph’s OSD (Object Storage Daemon) to perform the required work. Ceph is scalable, reliable, and easy to manage. It allows organizations to scale without affecting their capital expenditure (CAPEX) or operating expenditure (OPEX). Ceph has therefore transformed IT organizations when it comes to data storage. Ceph runs on any commodity hardware without any vendor lock-in. As a software-defined storage solution, it provides flexibility in hardware selection as well. This has made it quite popular among web professionals.
In addition to the above mentioned advantages, Ceph provides many other advantages such as data safety– Ceph makes each data update transparent to clients. Moreover, it also lets users know that the updated data is securely replicated on a disk and therefore is able to survive power or other failures. Failure detection is another advantage of the Ceph storage solution. Spotting errors or failures at the right time is highly important while securing data.
However, this can get difficult with too many clusters on a large scale. OSDs (Object Storage Daemons) in a Ceph distributed file system can self-report in such cases. Thus, Ceph monitoring detects irregularities if any, in a distributive environment. Also, this distributed detection helps in quick detection and resolving inconsistencies. Ceph storage solution also has the capability of cluster recovery and updates in case of OSD failures and when OSD cluster maps undergo changes. In order to provide fast recovery, OSD maintains a version number for each object and a log for recent changes.
Get Report TOC, Figures and Tables https://www.transparencymarketresearch.com/sample/sample.php?flag=T&rep_id=44015
Global companies are investing in providing Ceph based storage solutions. Since, Ceph is open source, it has enabled large number of big vendors to provide Ceph based software- defined storage solutions. This in turn means that the Ceph based solution is expected to witness promising growth in the coming years among enterprises as well as government organizations.
Some of the prominent players providing Ceph based software defined storage solutions are Red Hat Inc., Fujitsu, Cleversafe (IBM Corporation), Hewlett Packard Enterprise (HPE), SUSE Enterprise Storage, SanDisk, Dell Inc,. and Samsung Group.
0 notes
Text
Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)
As organizations continue their journey into cloud-native and containerized applications, the need for robust, scalable, and persistent storage solutions has never been more critical. Red Hat OpenShift, a leading Kubernetes platform, addresses this need with Red Hat OpenShift Data Foundation (ODF)—an integrated, software-defined storage solution designed specifically for OpenShift environments.
In this blog post, we’ll explore how the DO370 course equips IT professionals to manage enterprise-grade Kubernetes storage using OpenShift Data Foundation.
What is OpenShift Data Foundation?
Red Hat OpenShift Data Foundation (formerly OpenShift Container Storage) is a unified and scalable storage solution built on Ceph, NooBaa, and Rook. It provides:
Block, file, and object storage
Persistent volumes for containers
Data protection, encryption, and replication
Multi-cloud and hybrid cloud support
ODF is deeply integrated with OpenShift, allowing for seamless deployment, management, and scaling of storage resources within Kubernetes workloads.
Why DO370?
The DO370: Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation course is designed for OpenShift administrators and storage specialists who want to gain hands-on expertise in deploying and managing ODF in enterprise environments.
Key Learning Outcomes:
Understand ODF Architecture Learn how ODF components work together to provide high availability and performance.
Deploy ODF on OpenShift Clusters Hands-on labs walk through setting up ODF in a variety of topologies, from internal mode (hyperconverged) to external Ceph clusters.
Provision Persistent Volumes Use Kubernetes StorageClasses and dynamic provisioning to provide storage for stateful applications.
Monitor and Troubleshoot Storage Issues Utilize tools like Prometheus, Grafana, and the OpenShift Console to monitor health and performance.
Data Resiliency and Disaster Recovery Configure mirroring, replication, and backup for critical workloads.
Manage Multi-cloud Object Storage Integrate NooBaa for managing object storage across AWS S3, Azure Blob, and more.
Enterprise Use Cases for ODF
Stateful Applications: Databases like PostgreSQL, MongoDB, and Cassandra running in OpenShift require reliable persistent storage.
AI/ML Workloads: High throughput and scalable storage for datasets and model checkpoints.
CI/CD Pipelines: Persistent storage for build artifacts, logs, and containers.
Data Protection: Built-in snapshot and backup capabilities for compliance and recovery.
Real-World Benefits
Simplicity: Unified management within OpenShift Console.
Flexibility: Run on-premises, in the cloud, or in hybrid configurations.
Security: Native encryption and role-based access control (RBAC).
Resiliency: Automatic healing and replication for data durability.
Who Should Take DO370?
OpenShift Administrators
Storage Engineers
DevOps Engineers managing persistent workloads
RHCSA/RHCE certified professionals looking to specialize in OpenShift storage
Prerequisite Skills: Familiarity with OpenShift (DO180/DO280) and basic Kubernetes concepts is highly recommended.
Final Thoughts
As containers become the standard for deploying applications, storage is no longer an afterthought—it's a cornerstone of enterprise Kubernetes strategy. Red Hat OpenShift Data Foundation ensures your applications are backed by scalable, secure, and resilient storage.
Whether you're modernizing legacy workloads or building cloud-native applications, DO370 is your gateway to mastering Kubernetes-native storage with Red Hat.
Interested in Learning More?
📘 Join HawkStack Technologies for instructor-led or self-paced training on DO370 and other Red Hat courses.
Visit our website for more details - www.hawkstack.com
0 notes
Text
The Ceph Foundation and Building a Community: an Interview with SUSE
by Petros Koutoupis
On November 12 at the OpenStack Summit in Berlin, Germany, the Linux foundation formally announced the Ceph Foundation. Present at this same summit were key individuals from SUSE and the SUSE Enterprise Storage team. For those less familiar with the SUSE Enterprise Storage product line, it is entirely powered by Ceph technology.
With Ceph, data is treated and stored like objects. This is unlike traditional (and legacy) data storage solutions, where data is written to and read from the storage volumes via sectors and at sector offsets (often referred to as blocks). When dealing with large amounts of large data, treating them as objects is the way to do it. It's also much easier to manage. In fact, this is how the cloud functions—with objects. This object-drive model enables Ceph for simplified scalability to meet consumer demand easily. These objects are replicated across an entire cluster of nodes, giving Ceph its fault-tolerance and further reducing single points of failure. The parent company of the project and its technology was acquired by Red Hat, Inc., in April 2014.
I was fortunate in that I was able to connect with a few key SUSE representatives for a quick Q & A, as it relates to this recent announcement. I spoke with Lars Marowsky-Brée, SUSE Distinguished Engineer and member of the governing board of the Ceph Foundation; Larry Morris, Senior Product Manager for SUSE Enterprise Storage; Sanjeet Singh, Solutions Owner for SUSE Enterprise Storage; and Michael Dilio, Product and Solutions Marketing Manager for SUSE Enterprise Storage.
Petros Koutoupis: How has IBM's recent Red Hat, Inc., acquisition announcement affected the Ceph project, and do you believe this is what led to the creation of the Ceph Foundation?
SUSE: With Ceph being an Open Source community project, there is no anticipated effect on the Ceph project as a result of the pending IBM acquisition of Red Hat. Discussions and planning of the Ceph foundation have been going on for some time and were not a result of the acquisition announcement.
PK: For some time, SUSE has been fully committed to the Ceph project and has even leveraged the same technology in its SUSE Enterprise Storage offering. Will these recent announcements impact both the offering and the customers using it?
SUSE: The Ceph Foundation news is a validation of the vibrancy of the Ceph community. There are 13 premier members, with SUSE being a founding and premier member.
Go to Full Article
http://bit.ly/2BL0cvU via @johanlouwers . follow me also on twitter
0 notes
Text
Seagate St2000nm0008 Enterprise Capacity V51 2tb 7200rpm Sata-6gbps 128mb Buffer 512n 35inch Hard Disk Drive With Mfg Warranty
ST2000NM0008 GENERAL INFORMATION : MANUFACTURER : SEAGATE MANUFACTURER MODEL : ST2000NM0008 PRODUCT LINE : ENTERPRISE CAPACITY V.5.1 PRODUCT NAME : ENTERPRISE CAPACITY V.5.1 2TB HARD DRIVE BEST-FIT APPLICATIONS : HYPERSCALE APPLICATIONS/CLOUD DATA CENTRES WITH REPLICATED STORAGE SCALE-OUT DATA CENTRES AND BIG DATA ANALYTICS LEGACY MAINSTREAM APPLICATIONS REQUIRING 512N BLOCK SIZE HIGH-CAPACITY DENSITY RAID STORAGE MAINSTREAM ENTERPRISE EXTERNAL STORAGE ARRAYS (SAN, NAS, DAS) DISTRIBUTED FILE SYSTEMS, INCLUDING HADOOP AND CEPH ENTERPRISE BACKUP AND RESTORE - D2D, VIRTUAL TAPE CENTRALISED SURVEILLANCE KEY FEATURES : STORAGE CAPACITY : 2 TB ENCLOSURE : INTERNAL INTERFACE : SATA-6GBPS BYTES PER SECTOR : 512N DRIVE DIMENSIONS : 3.5 INCH MTBF : 2 MILLION HOURS SUPERPARITY : YES HUMIDITY SENSOR : YES SUPER PARITY : YES LOW HALOGEN : YES POWERCHOICE TECHNOLOGY : YES SD&D FIRMWARE SECURITY : YES DRIVE PERFORMANCE : MAX. SUSTAINED TRANSFER RATE OD : 194 MBPS AVERAGE LATENCY : 4.16 MS INTERFACE PORTS : SINGLE ROTATION VIBRATION @ 1500 HZ (RAD/S): 12.5 BUFFER : 128 MB ROTATIONAL SPEED : 7200 RPM PHYSICAL : DIMENSIONS (L X W X H) : 147.0 X 101.6 X 26.1 MM WEIGHT : 550 G CONDITION : WITH MFG WARRANTY. Click to buy: Seagate St2000nm0008 Enterprise Capacity V51 2tb 7200rpm Sata-6gbps 128mb Buffer 512n 35inch Hard Disk Drive With Mfg Warranty from Mac Palace Products Feed http://bit.ly/2EQkzfh
0 notes
Text
The Dynamic volume provisioning in Kubernetes allows storage volumes to be created on-demand, without manual Administrator intervention. When developers are doing deployments without dynamic provisioning, cluster administrators have to manually make calls to their cloud or storage provider to create new storage volumes, from where the PersistentVolumes are created. This guide will discuss how you can achieve Dynamic Volume Provisioning on Kubernetes by using GlusterFS distributed storage solution and Heketi RESTful management interface. It is expected you have deployed Heketi and GlusterFS scale-out network-attached storage file system. For Ceph, check: Ceph Persistent Storage for Kubernetes with Cephfs Persistent Storage for Kubernetes with Ceph RBD How Dynamic Provisioning is configured in Kubernetes In Kubernetes, dynamic volume provisioning is based on the API object StorageClass from the API group storage.k8s.io. As a cluster administrator, you’ll define as many StorageClass objects as needed, each specifying a volume plugin ( provisioner) that provisions a volume and the set of parameters to pass to that provisioner when provisioning. So below are the steps you’ll use to configure Dynamic Volume Provisioning on Kubernetes using Gluster and Heketi API. Setup GlusterFS and Heketi It is expected you have a running Gluster and Heketi before you continue with configurations on the Kubernetes end. Refer to our guide below on setting them up. Setup GlusterFS Storage With Heketi on CentOS 8 / CentOS 7 At the moment we only have guide for CentOS, but we’re working on a deployment guide for Ubuntu/Debian systems. For containerized setup, check: Setup Kubernetes / OpenShift Dynamic Persistent Volume Provisioning with GlusterFS and Heketi Once the installation is done, proceed to step 2: Create StorageClass Object on Kubernetes We need to create a StorageClass object to enable dynamic provisioning for container platform users. The StorageClass objects define which provisioner should be used and what parameters should be passed to that provisioner when dynamic provisioning is invoked. Check your Heketi Cluster ID $ heketi-cli cluster list Clusters: Id:b182cb76b881a0be2d44bd7f8fb07ea4 [file][block] Create Kubernetes Secret Get a base64 format of your Heketi admin user password. $ echo -n "PASSWORD" | base64 Then create a secret with the password for accessing Heketi. $ vim gluster-secret.yaml apiVersion: v1 kind: Secret metadata: name: heketi-secret namespace: default type: "kubernetes.io/glusterfs" data: # echo -n "PASSWORD" | base64 key: cGFzc3dvcmQ= Where: cGFzc3dvcmQ= is the output of echo command. Create the secret by running the command: $ kubectl create -f gluster-secret.yaml Confirm secret creation. $ kubectl get secret NAME TYPE DATA AGE heketi-secret kubernetes.io/glusterfs 1 1d Create StorageClass Below is a sample StorageClass for GlusterFS using Heketi. $ cat glusterfs-sc.yaml kind: StorageClass apiVersion: storage.k8s.io/v1beta1 metadata: name: gluster-heketi provisioner: kubernetes.io/glusterfs reclaimPolicy: Delete volumeBindingMode: Immediate allowVolumeExpansion: true parameters: resturl: "http://heketiserverip:8080" restuser: "admin" secretName: "heketi-secret" secretNamespace: "default" volumetype: "replicate:2" volumenameprefix: "k8s-dev" clusterid: "b182cb76b881a0be2d44bd7f8fb07ea4" Where: gluster-heketi is the name of the StorageClass to be created. The valid options for reclaim policy are Retain, Delete or Recycle. The Delete policy means that a dynamically provisioned volume is automatically deleted when a user deletes the corresponding PersistentVolumeClaim. The volumeBindingMode field controls when volume binding and dynamic provisioning should occur.
Valid options are Immediate & WaitForFirstConsumer. The Immediate mode indicates that volume binding and dynamic provisioning occurs once the PersistentVolumeClaim is created. The WaitForFirstConsumer mode delays the binding and provisioning of a PersistentVolume until a Pod using the PersistentVolumeClaim is created. The resturl is the URL of your heketi endpoint heketi-secret is the secret created for Heketi credentials. default is the name of namespace where secret was created replicate:2 indicated the default replication factor for Gluster Volumes created. For more HA, use 3. volumenameprefix: By default dynamically provisioned volumes have the naming schema of vol_UUID format. We have provided a desired volume name from storageclass. So the naming scheme will be: volumenameprefix_Namespace_PVCname_randomUUID b182cb76b881a0be2d44bd7f8fb07ea4 is the ID of the cluster obtained from the command heketi-cli cluster list Another parameter that can be set is: volumeoptions: "user.heketi.zone-checking strict" The default setting/behavior is: volumeoptions: "user.heketi.zone-checking none" This forces Heketi to strictly place replica bricks in different zones. The required minimum number of nodes required to be present in different zones is 3 if the replica value is set to 3. Once the file is created, run the following command to create the StorageClass object. $ kubectl create -f gluster-sc.yaml Confirm StorageClass creation. $ kubectl get sc NAME PROVISIONER AGE glusterfs-heketi kubernetes.io/glusterfs 1d local-storage kubernetes.io/no-provisioner 30d Step 2: Create PersistentVolumeClaim Object When a user is requesting dynamically provisioned storage, a storage class should be included in the PersistentVolumeClaim. Let’s create a 1GB request for storage: $ vim glusterfs-pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-pvc annotations: volume.beta.kubernetes.io/storage-class: gluster-heketi spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi Create object: $ kubectl create --save-config -f glusterfs-pvc.yaml Confirm: $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE glusterfs-pvc Bound pvc-34b9b5e9-fbde-11e9-943f-00505692ee7e 1Gi RWX glusterfs-heketi 1d After creation, you can use it in your deployments. To use the volume we reference the PVC in the YAML file of any Pod/Deployment like this for example: apiVersion: v1 kind: Pod metadata: name: gluster-pod labels: name: gluster-pod spec: containers: - name: gluster-pod image: busybox command: ["sleep", "60000"] volumeMounts: - name: gluster-vol mountPath: /usr/share/busybox readOnly: false volumes: - name: gluster-vol persistentVolumeClaim: claimName: glusterfs-pvc That’s it for today. You should have a working Dynamic Volume Provisioning With Heketi & GlusterFS for your Kubernetes platform.
0 notes
Text
How to Deploy a Ceph Storage to Bare Virtual Machines

Ceph is a freely available storage platform that implements object storage on a single distributed computer cluster and provides interfaces for object-, block- and file-level storage. Ceph aims primarily for completely distributed operation without a single point of failure. It manages data replication and is generally quite fault-tolerant. As a result of its design, the system is both self-healing and self-managing.
Ceph has loads of benefits and great features, but the main drawback is that you have to host and manage it yourself. In this post, we'll check two different approaches of deploying Ceph.
Anatomy of a Ceph cluster
Before we dive into the actual deployment process, let's see what we'll need to fire up for our own Ceph cluster.
There are three services that form the backbone of the cluster
monitors (ceph-mon) maintain maps of the cluster state and are also responsible for managing authentication between daemons and clients
managers (ceph-mgr) are responsible for keeping track of runtime metrics and the current state of the Ceph cluster
object storage daemons (ceph-osd) store data, handle data replication, recovery, rebalancing, and provide some monitoring information
Additionally, we can add further parts to the cluster to support different storage solutions
metadata servers (ceph-mds) store metadata on behalf of the Ceph Filesystem
rados gateway (ceph-rgw) is an HTTP server for interacting with a Ceph Storage Cluster that provides interfaces compatible with OpenStack Swift and Amazon S3.
There are multiple ways of deploying these services. We'll check two of them:
first, using the ceph/deploy tool,
then a docker-swarm based deployment.
Let's kick it off!
Ceph Setup
Okay, a disclaimer first. As this is not a production infrastructure, we’ll cut a couple of corners.
You should not run multiple different Ceph demons on the same host, but for the sake of simplicity, we'll only use 3 VMs for the whole cluster.
In the case of OSDs, you can run multiple of them on the same host, but using the same storage drive for multiple instances is a bad idea as the disk’s I/O speed might limit the OSD daemons’ performance.
For this tutorial, I've created 4 EC2 machines in AWS: 3 for Ceph itself and 1 admin node. For ceph-deploy to work, the admin node requires passwordless SSH access to the nodes and that SSH user has to have passwordless sudo privileges.
In my case, as all machines are in the same subnet on AWS, connectivity between them is not an issue. However, in other cases editing the hosts file might be necessary to ensure proper connection.
Depending on where you deploy Ceph security groups, firewall settings or other resources have to be adjusted to open these ports
22 for SSH
6789 for monitors
6800:7300 for OSDs, managers and metadata servers
8080 for dashboard
7480 for rados gateway
Without further ado, let's start deployment.
Ceph Storage Deployment
Install prerequisites on all machines
$ sudo apt update $ sudo apt -y install ntp python
For Ceph to work seamlessly, we have to make sure the system clocks are not skewed. The suggested solution is to install ntp on all machines and it will take care of the problem. While we're at it, let's install python on all hosts as ceph-deploy depends on it being available on the target machines.
Prepare the admin node
$ ssh -i ~/.ssh/id_rsa -A [email protected]
As all the machines have my public key added to known_hosts thanks to AWS, I can use ssh agent forwarding to access the Ceph machines from the admin node. The first line ensures that my local ssh agent has the proper key in use and the -A flag takes care of forwarding my key.
$ wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add - echo deb https://download.ceph.com/debian-nautilus/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list $ sudo apt update $ sudo apt -y install ceph-deploy
We'll use the latest nautilus release in this example. If you want to deploy a different version, just change the debian-nautilus part to your desired release (luminous, mimic, etc.).
$ echo "StrictHostKeyChecking no" | sudo tee -a /etc/ssh/ssh_config > /dev/null
OR
$ ssh-keyscan -H 10.0.0.124,10.0.0.216,10.0.0.104 >> ~/.ssh/known_hosts
Ceph-deploy uses SSH connections to manage the nodes we provide. Each time you SSH to a machine that is not in the list of known_hosts (~/.ssh/known_hosts), you'll get prompted whether you want to continue connecting or not. This interruption does not mesh well with the deployment process, so we either have to use ssh-keyscan to grab the fingerprint of all the target machines or disable the strict host key checking outright.
10.0.0.124 ip-10-0-0-124.eu-north-1.compute.internal ip-10-0-0-124 10.0.0.216 ip-10-0-0-216.eu-north-1.compute.internal ip-10-0-0-216 10.0.0.104 ip-10-0-0-104.eu-north-1.compute.internal ip-10-0-0-104
Even though the target machines are in the same subnet as our admin and they can access each other, we have to add them to the hosts file (/etc/hosts) for ceph-deploy to work properly. Ceph-deploy creates monitors by the provided hostname, so make sure it matches the actual hostname of the machines otherwise the monitors won't be able to join the quorum and the deployment fails. Don't forget to reboot the admin node for the changes to take effect.
$ mkdir ceph-deploy $ cd ceph-deploy
As a final step of the preparation, let's create a dedicated folder as ceph-deploy will create multiple config and key files during the process.
Deploy resources
$ ceph-deploy new ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
The command ceph-deploy new creates the necessary files for the deployment. Pass it the hostnames of the monitor nodes, and it will create cepf.conf and ceph.mon.keyring along with a log file.
The ceph-conf should look something like this
[global] fsid = 0572e283-306a-49df-a134-4409ac3f11da mon_initial_members = ip-10-0-0-124, ip-10-0-0-216, ip-10-0-0-104 mon_host = 10.0.0.124,10.0.0.216,10.0.0.104 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx
It has a unique ID called fsid, the monitor hostnames and addresses and the authentication modes. Ceph provides two authentication modes: none (anyone can access data without authentication) or cephx (key based authentication).
The other file, the monitor keyring is another important piece of the puzzle, as all monitors must have identical keyrings in a cluster with multiple monitors. Luckily ceph-deploy takes care of the propagation of the key file during deployment.
$ ceph-deploy install --release nautilus ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
As you might have noticed so far, we haven't installed ceph on the target nodes yet. We could do that one-by-one, but a more convenient way is to let ceph-deploy take care of the task. Don't forget to specify the release of your choice, otherwise you might run into a mismatch between your admin and targets.
$ ceph-deploy mon create-initial
Finally, the first piece of the cluster is up and running! create-initial will deploy the monitors specified in ceph.conf we generated previously and also gather various key files. The command will only complete successfully if all the monitors are up and in the quorum.
$ ceph-deploy admin ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
Executing ceph-deploy admin will push a Ceph configuration file and the ceph.client.admin.keyring to the /etc/ceph directory of the nodes, so we can use the ceph CLI without having to provide the ceph.client.admin.keyring each time to execute a command.
At this point, we can take a peek at our cluster. Let's SSH into a target machine (we can do it directly from the admin node thanks to agent forwarding) and run sudo ceph status.
$ sudo ceph status cluster: id: 0572e283-306a-49df-a134-4409ac3f11da health: HEALTH_OK services: mon: 3 daemons, quorum ip-10-0-0-104,ip-10-0-0-124,ip-10-0-0-216 (age 110m) mgr: no daemons active osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs:
Here we get a quick overview of what we have so far. Our cluster seems to be healthy and all three monitors are listed under services. Let's go back to the admin and continue adding pieces.
$ ceph-deploy mgr create ip-10-0-0-124
For luminous+ builds a manager daemon is required. It's responsible for monitoring the state of the Cluster and also manages modules/plugins.
Okay, now we have all the management in place, let's add some storage to the cluster to make it actually useful, shall we?
First, we have to find out (on each target machine) the label of the drive we want to use. To fetch the list of available disks on a specific node, run
$ ceph-deploy disk list ip-10-0-0-104
Here's a sample output:
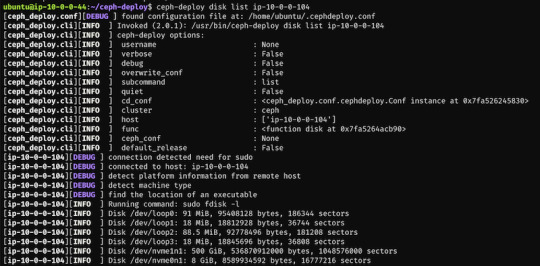
$ ceph-deploy osd create --data /dev/nvme1n1 ip-10-0-0-124 $ ceph-deploy osd create --data /dev/nvme1n1 ip-10-0-0-216 $ ceph-deploy osd create --data /dev/nvme1n1 ip-10-0-0-104
In my case the label was nvme1n1 on all 3 machines (courtesy of AWS), so to add OSDs to the cluster I just ran these 3 commands.
At this point, our cluster is basically ready. We can run ceph status to see that our monitors, managers and OSDs are up and running. But nobody wants to SSH into a machine every time to check the status of the cluster. Luckily there's a pretty neat dashboard that comes with Ceph, we just have to enable it.
...Or at least that's what I thought. The dashboard was introduced in luminous release and was further improved in mimic. However, currently we're deploying nautilus, the latest version of Ceph. After trying the usual way of enabling the dashboard via a manager
$ sudo ceph mgr module enable dashboard
we get an error message saying Error ENOENT: all mgr daemons do not support module 'dashboard', pass --force to force enablement.
Turns out, in nautilus the dashboard package is no longer installed by default. We can check the available modules by running
$ sudo ceph mgr module ls
and as expected, dashboard is not there, it comes in a form a separate package. So we have to install it first, luckily it's pretty easy.
$ sudo apt install -y ceph-mgr-dashboard
Now we can enable it, right? Not so fast. There's a dependency that has to be installed on all manager hosts, otherwise we get a slightly cryptic error message saying Error EIO: Module 'dashboard' has experienced an error and cannot handle commands: No module named routes.
$ sudo apt install -y python-routes
We're all set to enable the dashboard module now. As it's a public-facing page that requires login, we should set up a cert for SSL. For the sake of simplicity, I've just disabled the SSL feature. You should never do this in production, check out the official docs to see how to set up a cert properly. Also, we'll need to create an admin user so we can log in to our dashboard.
$ sudo ceph mgr module enable dashboard $ sudo ceph config set mgr mgr/dashboard/ssl false $ sudo ceph dashboard ac-user-create admin secret administrator
By default, the dashboard is available on the host running the manager on port 8080. After logging in, we get an overview of the cluster status, and under the cluster menu, we get really detailed overviews of each running daemon.
If we try to navigate to the Filesystems or Object Gateway tabs, we get a notification that we haven't configured the required resources to access these features. Our cluster can only be used as a block storage right now. We have to deploy a couple of extra things to extend its usability.
Quick detour: In case you're looking for a company that can help you with Ceph, or DevOps in general, feel free to reach out to us at RisingStack!
Using the Ceph filesystem
Going back to our admin node, running
$ ceph-deploy mds create ip-10-0-0-124 ip-10-0-0-216 ip-10-0-0-104
will create metadata servers, that will be inactive for now, as we haven’t enabled the feature yet. First, we need to create two RADOS pools, one for the actual data and one for the metadata.
$ sudo ceph osd pool create cephfs_data 8 $ sudo ceph osd pool create cephfs_metadata 8
There are a couple of things to consider when creating pools that we won’t cover here. Please consult the documentation for further details.
After creating the required pools, we’re ready to enable the filesystem feature
$ sudo ceph fs new cephfs cephfs_metadata cephfs_data
The MDS daemons will now be able to enter an active state, and we are ready to mount the filesystem. We have two options to do that, via the kernel driver or as FUSE with ceph-fuse.
Before we continue with the mounting, let’s create a user keyring that we can use in both solutions for authorization and authentication as we have cephx enabled. There are multiple restrictions that can be set up when creating a new key specified in the docs. For example:
$ sudo ceph auth get-or-create client.user mon 'allow r' mds 'allow r, allow rw path=/home/cephfs' osd 'allow rw pool=cephfs_data' -o /etc/ceph/ceph.client.user.keyring
will create a new client key with the name user and output it into ceph.client.user.keyring. It will provide write access for the MDS only to the /home/cephfs directory, and the client will only have write access within the cephfs_data pool.
Mounting with the kernel
Now let’s create a dedicated directory and then use the key from the previously generated keyring to mount the filesystem with the kernel.
$ sudo mkdir /mnt/mycephfs $ sudo mount -t ceph 13.53.114.94:6789:/ /mnt/mycephfs -o name=user,secret=AQBxnDFdS5atIxAAV0rL9klnSxwy6EFpR/EFbg==
Attaching with FUSE
Mounting the filesystem with FUSE is not much different either. It requires installing the ceph-fuse package.
$ sudo apt install -y ceph-fuse
Before we run the command we have to retrieve the ceph.conf and ceph.client.user.keyring files from the Ceph host and put the in /etc/ceph. The easiest solution is to use scp.
$ sudo scp [email protected]:/etc/ceph/ceph.conf /etc/ceph/ceph.conf $ sudo scp [email protected]:/etc/ceph/ceph.client.user.keyring /etc/ceph/ceph.keyring
Now we are ready to mount the filesystem.
$ sudo mkdir cephfs $ sudo ceph-fuse -m 13.53.114.94:6789 cephfs
Using the RADOS gateway
To enable the S3 management feature of the cluster, we have to add one final piece, the rados gateway.
$ ceph-deploy rgw create ip-10-0-0-124
For the dashboard, it's required to create a radosgw-admin user with the system flag to enable the Object Storage management interface. We also have to provide the user's access_key and secret_key to the dashboard before we can start using it.
$ sudo radosgw-admin user create --uid=rg_wadmin --display-name=rgw_admin --system $ sudo ceph dashboard set-rgw-api-access-key <access_key> $ sudo ceph dashboard set-rgw-api-secret-key <secret_key>
Using the Ceph Object Storage is really easy as RGW provides an interface identical to S3. You can use your existing S3 requests and code without any modifications, just have to change the connection string, access, and secret keys.
Ceph Storage Monitoring
The dashboard we’ve deployed shows a lot of useful information about our cluster, but monitoring is not its strongest suit. Luckily Ceph comes with a Prometheus module. After enabling it by running:
$ sudo ceph mgr module enable prometheus
A wide variety of metrics will be available on the given host on port 9283 by default. To make use of these exposed data, we’ll have to set up a prometheus instance.
I strongly suggest running the following containers on a separate machine from your Ceph cluster. In case you are just experimenting (like me) and don’t want to use a lot of VMs, make sure you have enough memory and CPU left on your VM before firing up docker, as it can lead to strange behaviour and crashes if it runs out of resources.
There are multiple ways of firing up Prometheus, probably the most convenient is with docker. After installing docker on your machine, create a prometheus.yml file to provide the endpoint where it can access our Ceph metrics.
# /etc/prometheus.yml scrape_configs: - job_name: 'ceph' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['13.53.114.94:9283]
Then launch the container itself by running:
$ sudo docker run -p 9090:9090 -v /etc/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
Prometheus will start scraping our data, and it will show up on its dashboard. We can access it on port 9090 on its host machine. Prometheus dashboard is great but does not provide a very eye-pleasing dashboard. That’s the main reason why it’s usually used in pair with Graphana, which provides awesome visualizations for the data provided by Prometheus. It can be launched with docker as well.
$ sudo docker run -d -p 3000:3000 grafana/grafana
Grafana is fantastic when it comes to visualizations, but setting up dashboards can be a daunting task. To make our lives easier, we can load one of the pre-prepared dashboards, for example this one.
Ceph Deployment: Lessons Learned & Next Up
CEPH can be a great alternative to AWS S3 or other object storages when running in the public operating your service in the private cloud is simply not an option. The fact that it provides an S3 compatible interface makes it a lot easier to port other tools that were written with a “cloud first” mentality. It also plays nicely with Prometheus, thus you don’t need to worry about setting up proper monitoring for it, or you can swap it a more simple, more battle-hardened solution such as Nagios.
In this article, we deployed CEPH to bare VMs, but you might need to integrate it into your Kubernetes or Docker Swarm cluster. While it is perfectly fine to install it on VMs next to your container orchestration tool, you might want to leverage the services they provide when you deploy your CEPH cluster. If that is your use case, stay tuned for our next post covering CEPH where we’ll take a look at the black magic required to use it on Kubernetes and Docker Swarm.
In the next article which we'll release next week, we're going to take a look at valid ceph storage alternatives with Docker or with Kubernetes.
PS: Feel free to reach out to us at RisingStack in case you need help with Ceph or Ops in general!
Hey Friends! The pace on the RisingStack blog was a little slow this summer, but WE'RE BACK! 🥳👽🤘 We just released a longform howto article on deploying a @Ceph storage to bare VM's. Take a look, we would love to get some feedback! 👇👇https://t.co/vTKdA4w5jI
— RisingStack 👉 Node.js, K8S & Microservices (@RisingStack) September 23, 2019
How to Deploy a Ceph Storage to Bare Virtual Machines published first on https://koresolpage.tumblr.com/
0 notes
Text
Ceph Storage Solutions Market to Undertake Strapping Growth During 2019-2027
Ceph is a free software platform that enables highly scalable object, block, and file-based storage under one comprehensive system. The cluster of Ceph are designed in such a way that it can run on commodity hardware with the help of CRUSH, which is a hash based algorithm. The CRUSH algorithm makes sure that all the data is accurately distributed across the cluster and all cluster nodes can rightly fit in as well as retrieve data quickly without any constraints. Thus, Ceph not only stores large amounts of data but also simplifies access to the same.
The Ceph RADOS block device in the Ceph storage system is a type of a disk that is attached to a virtual machine or bare-metal Linux-based servers. The Ceph block device leverages the capability of reliable autonomic distributed object store (RADOS) which is a software that facilitates block storage capabilities such as snapshotting and replication. On the whole, Ceph’s functioning as a storage system is effective and simple. Hence, it is deployed by many hosting and IT solution providers for their clients.
Get Sample Copy of the Report to understand the structure of the complete report (Including Full TOC, Table & Figures): https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=44015
Data is growing at a tremendous rate; therefore, enterprises need a solution that can store large volume of data effectively. Storing data efficiently has long been a major challenge for enterprises all around the globe. Ceph storage is an effective solution that can cater to the problem of large amounts of data storage. Ceph provides dynamic storage clusters. Most storage applications do not make the most of the CPU and RAM available in a typical commodity server; however, Ceph storage optimally uses the existing IT infrastructure. Right from rebalancing the clusters to recovering from errors and faults, Ceph offloads work from clients by using distributed computing power of Ceph’s OSD (Object Storage Daemon) to perform the required work. Ceph is scalable, reliable, and easy to manage. It allows organizations to scale without affecting their capital expenditure (CAPEX) or operating expenditure (OPEX). Ceph has therefore transformed IT organizations when it comes to data storage. Ceph runs on any commodity hardware without any vendor lock-in. As a software-defined storage solution, it provides flexibility in hardware selection as well. This has made it quite popular among web professionals.
In addition to the above mentioned advantages, Ceph provides many other advantages such as data safety– Ceph makes each data update transparent to clients. Moreover, it also lets users know that the updated data is securely replicated on a disk and therefore is able to survive power or other failures. Failure detection is another advantage of the Ceph storage solution. Spotting errors or failures at the right time is highly important while securing data. However, this can get difficult with too many clusters on a large scale. OSDs (Object Storage Daemons) in a Ceph distributed file system can self-report in such cases. Thus, Ceph monitoring detects irregularities if any, in a distributive environment. Also, this distributed detection helps in quick detection and resolving inconsistencies. Ceph storage solution also has the capability of cluster recovery and updates in case of OSD failures and when OSD cluster maps undergo changes. In order to provide fast recovery, OSD maintains a version number for each object and a log for recent changes.
Request For Covid19 Impact Analysis Across Industries And Markets – https://www.transparencymarketresearch.com/sample/sample.php?flag=covid19&rep_id=44015
Global companies are investing in providing Ceph based storage solutions. Since, Ceph is open source, it has enabled large number of big vendors to provide Ceph based software- defined storage solutions. This in turn means that the Ceph based solution is expected to witness promising growth in the coming years among enterprises as well as government organizations.
Some of the prominent players providing Ceph based software defined storage solutions are Red Hat Inc., Fujitsu, Cleversafe (IBM Corporation), Hewlett Packard Enterprise (HPE), SUSE Enterprise Storage, SanDisk, Dell Inc,. and Samsung Group.
The report offers a comprehensive evaluation of the market. It does so via in-depth qualitative insights, historical data, and verifiable projections about market size. The projections featured in the report have been derived using proven research methodologies and assumptions. By doing so, the research report serves as a repository of analysis and information for every facet of the market, including but not limited to: Regional markets, technology, types, and applications.
The study is a source of reliable data on:
Market segments and sub-segments
Market trends and dynamics
Supply and demand
Market size
Current trends/opportunities/challenges
Competitive landscape
Technological breakthroughs
Value chain and stakeholder analysis
The regional analysis covers:
North America (U.S. and Canada)
Latin America (Mexico, Brazil, Peru, Chile, and others)
Western Europe (Germany, U.K., France, Spain, Italy, Nordic countries, Belgium, Netherlands, and Luxembourg)
Eastern Europe (Poland and Russia)
Asia Pacific (China, India, Japan, ASEAN, Australia, and New Zealand)
Middle East and Africa (GCC, Southern Africa, and North Africa)
The report has been compiled through extensive primary research (through interviews, surveys, and observations of seasoned analysts) and secondary research (which entails reputable paid sources, trade journals, and industry body databases). The report also features a complete qualitative and quantitative assessment by analyzing data gathered from industry analysts and market participants across key points in the industry’s value chain.
Customization of the Report: This report can be customized as per your needs for additional data or countries. – https://www.transparencymarketresearch.com/sample/sample.php?flag=CR&rep_id=44015
About Us
Transparency Market Research is a next-generation market intelligence provider, offering fact-based solutions to industry leaders, consultants, and strategy professionals.
Our reports are single-point solutions for industries to grow, evolve, and mature. Our significant-time data collection methods along with ability to track more than one million high growth niche products are aligned with your aims. The detailed and proprietary statistical models used by our analysts offer insights for making right decision in the shortest span of time. For organizations that require specific but comprehensive information we offer customized solutions through adhoc reports. These demands are delivered with the perfect combination of right sense of fact-oriented problem solving methodologies and leveraging existing data repositories.
TMR believes that unison of solutions for client-specific problems with right methodology of research is the key to help enterprises reach right decision.
U.S. Office Contact
90 State Street, Suite 700 Albany, NY 12207 Tel: +1-518-618-1030 USA – Canada Toll Free: 866-552-3453 Email: [email protected] Website: https://www.transparencymarketresearch.com
0 notes