#Difference between Database and Data Warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
The Difference Between Database and Data Warehouse is that it is designed for real-time operations and transactional processing, storing current data. In contrast, a data warehouse aggregates and organizes large volumes of historical data from various sources, optimizing it for analysis and reporting. While databases focus on day-to-day tasks, data warehouses support strategic decision-making through analytical capabilities. Check here to learn more.
0 notes
Text
Critical Differences: Between Database vs Data Warehouse
Summary: This blog explores the differences between databases and data warehouses, highlighting their unique features, uses, and benefits. By understanding these distinctions, you can select the optimal data management solution to support your organisation’s goals and leverage cloud-based options for enhanced scalability and efficiency.

Introduction
Effective data management is crucial for organisational success in today's data-driven world. Understanding the concepts of databases and data warehouses is essential for optimising data use. Databases store and manage transactional data efficiently, while data warehouses aggregate and analyse large volumes of data for strategic insights.
This blog aims to clarify the critical differences between databases and data warehouses, helping you decide which solution best fits your needs. By exploring "database vs. data warehouse," you'll gain valuable insights into their distinct roles, ensuring your data infrastructure effectively supports your business objectives.
What is a Database?
A database is a structured collection of data that allows for efficient storage, retrieval, and management of information. It is designed to handle large volumes of data and support multiple users simultaneously.
Databases provide a systematic way to organise, manage, and retrieve data, ensuring consistency and accuracy. Their primary purpose is to store data that can be easily accessed, manipulated, and updated, making them a cornerstone of modern data management.
Common Uses and Applications
Databases are integral to various applications across different industries. Businesses use databases to manage customer information, track sales and inventory, and support transactional processes.
In the healthcare sector, databases store patient records, medical histories, and treatment plans. Educational institutions use databases to manage student information, course registrations, and academic records.
E-commerce platforms use databases to handle product catalogues, customer orders, and payment information. Databases also play a crucial role in financial services, telecommunications, and government operations, providing the backbone for data-driven decision-making and efficient operations.
Types of Databases
Knowing about different types of databases is crucial for making informed decisions in data management. Each type offers unique features for specific tasks. There are several types of databases, each designed to meet particular needs and requirements.
Relational Databases
Relational databases organise data into tables with rows and columns, using structured query language (SQL) for data manipulation. They are highly effective for handling structured data and maintaining relationships between different data entities. Examples include MySQL, PostgreSQL, and Oracle.
NoSQL Databases
NoSQL databases are designed to handle unstructured and semi-structured data, providing flexibility in data modelling. They are ideal for high scalability and performance applications like social media and big data. Types of NoSQL databases include:
Document databases (e.g., MongoDB).
Key-value stores (e.g., Redis).
Column-family stores (e.g., Cassandra).
Graph databases (e.g., Neo4j).
In-Memory Databases
In-memory databases store data in the main memory (RAM) rather than on disk, enabling high-speed data access and processing. They are suitable for real-time applications that require low-latency data retrieval, such as caching and real-time analytics. Examples include Redis and Memcached.
NewSQL Databases
NewSQL databases aim to provide the scalability of NoSQL databases while maintaining the ACID (Atomicity, Consistency, Isolation, Durability) properties of traditional relational databases. They are used in applications that require high transaction throughput and firm consistency. Examples include Google Spanner and CockroachDB.
Examples of Database Management Systems (DBMS)
Understanding examples of Database Management Systems (DBMS) is essential for selecting the right tool for your data needs. DBMS solutions offer varied features and capabilities, ensuring better performance, security, and integrity across diverse applications. Some common examples of Database Management Systems (DBMS) are:
MySQL
MySQL is an open-source relational database management system known for its reliability, performance, and ease of use. It is widely used in web applications, including popular platforms like WordPress and Joomla.
PostgreSQL
PostgreSQL is an advanced open-source relational database system that supports SQL and NoSQL data models. It is known for its robustness, extensibility, and standards compliance, making it suitable for complex applications.
MongoDB
MongoDB is a leading NoSQL database that stores data in flexible, JSON-like documents. It is designed for scalability and performance, making it a popular choice for modern applications that handle large volumes of unstructured data.
Databases form the foundation of data management in various domains, offering diverse solutions to meet specific data storage and retrieval needs. By understanding the different types of databases and their applications, organisations can choose the proper database technology to support their operations.
Read More: What are Attributes in DBMS and Its Types?
What is a Data Warehouse?
A data warehouse is a centralised repository designed to store, manage, and analyse large volumes of data. It consolidates data from various sources, enabling organisations to make informed decisions through comprehensive data analysis and reporting.
A data warehouse is a specialised system optimised for query and analysis rather than transaction processing. It is structured to enable efficient data retrieval and analysis, supporting business intelligence activities. The primary purpose of a data warehouse is to provide a unified, consistent data source for analytical reporting and decision-making.
Common Uses and Applications
Data warehouses are commonly used in various industries to enhance decision-making processes. Businesses use them to analyse historical data, generate reports, and identify trends and patterns. Applications include sales forecasting, financial analysis, customer behaviour, and performance tracking.
Organisations leverage data warehouses to gain insights into operations, streamline processes, and drive strategic initiatives. By integrating data from different departments, data warehouses enable a holistic view of business performance, supporting comprehensive analytics and business intelligence.
Key Features of Data Warehouses
Data warehouses offer several key features that distinguish them from traditional databases. These features make data warehouses ideal for supporting complex queries and large-scale data analysis, providing organisations with the tools for in-depth insights and informed decision-making. These features include:
Data Integration: Data warehouses consolidate data from multiple sources, ensuring consistency and accuracy.
Scalability: They are designed to handle large volumes of data and scale efficiently as data grows.
Data Transformation: ETL (Extract, Transform, Load) processes clean and organise data, preparing it for analysis.
Performance Optimisation: Data warehouses enhance query performance using indexing, partitioning, and parallel processing.
Historical Data Storage: They store historical data, enabling trend analysis and long-term reporting.
Read Blog: Top ETL Tools: Unveiling the Best Solutions for Data Integration.
Examples of Data Warehousing Solutions
Several data warehousing solutions stand out in the industry, offering unique capabilities and advantages. These solutions help organisations manage and analyse data more effectively, driving better business outcomes through robust analytics and reporting capabilities. Prominent examples include:
Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It is designed to handle complex queries and large datasets, providing fast query performance and easy scalability.
Google BigQuery
Google BigQuery is a serverless, highly scalable, cost-effective multi-cloud data warehouse that enables super-fast SQL queries using the processing power of Google's infrastructure.
Snowflake
Snowflake is a cloud data platform that provides data warehousing, data lakes, and data sharing capabilities. It is known for its scalability, performance, and ability to handle diverse data workloads.
Key Differences Between Databases and Data Warehouses
Understanding the distinctions between databases and data warehouses is crucial for selecting the right data management solution. This comparison will help you grasp their unique features, use cases, and data-handling methods.

Databases and data warehouses serve distinct purposes in data management. While databases handle transactional data and support real-time operations, data warehouses are indispensable for advanced data analysis and business intelligence. Understanding these key differences will enable you to choose the right solution based on your specific data needs and goals.
Choosing Between a Database and a Data Warehouse

Several critical factors should guide your decision-making process when deciding between a database and a data warehouse. These factors revolve around the nature, intended use, volume, and complexity of data, as well as specific use case scenarios and cost implications.
Nature of the Data
First and foremost, consider the inherent nature of your data. Suppose you focus on managing transactional data with frequent updates and real-time access requirements. In that case, a traditional database excels in this operational environment.
On the other hand, a data warehouse is more suitable if your data consists of vast historical records and complex data models and is intended for analytical processing to derive insights.
Intended Use: Operational vs. Analytical
The intended use of the data plays a pivotal role in determining the appropriate solution. Operational databases are optimised for transactional processing, ensuring quick and efficient data manipulation and retrieval.
Conversely, data warehouses are designed for analytical purposes, facilitating complex queries and data aggregation across disparate sources for business intelligence and decision-making.
Volume and Complexity of Data
Consider the scale and intricacy of your data. Databases are adept at handling moderate to high volumes of structured data with straightforward relationships. In contrast, data warehouses excel in managing vast amounts of both structured and unstructured data, often denormalised for faster query performance and analysis.
Use Case Scenarios
Knowing when to employ each solution is crucial. Use a database when real-time data processing and transactional integrity are paramount, such as in e-commerce platforms or customer relationship management systems. Opt for a data warehouse when conducting historical trend analysis, business forecasting, or consolidating data from multiple sources for comprehensive reporting.
Cost Considerations
Finally, weigh the financial aspects of your decision. Databases typically involve lower initial setup costs and are easier to scale incrementally. In contrast, data warehouses may require more substantial upfront investments due to their complex infrastructure and storage requirements.
To accommodate your budgetary constraints, factor in long-term operational costs, including maintenance, storage, and data processing fees.
By carefully evaluating these factors, you can confidently select the database or data warehouse solution that best aligns with your organisation's specific needs and strategic objectives.
Cloud Databases and Data Warehouses
Cloud-based solutions have revolutionised data management by offering scalable, flexible, and cost-effective alternatives to traditional on-premises systems. Here's an overview of how cloud databases and data warehouses transform modern data architectures.
Overview of Cloud-Based Solutions
Cloud databases and data warehouses leverage the infrastructure and services provided by cloud providers like AWS, Google Cloud, and Microsoft Azure. They eliminate the need for physical hardware and offer pay-as-you-go pricing models, making them ideal for organisations seeking agility and scalability.
Advantages of Cloud Databases and Data Warehouses
The primary advantages include scalability to handle fluctuating workloads, reduced operational costs by outsourcing maintenance and updates to the cloud provider and enhanced accessibility for remote teams. Cloud solutions facilitate seamless integration with other cloud services and tools, promoting collaboration and innovation.
Popular Cloud Providers and Services
Leading providers such as AWS with Amazon RDS and Google Cloud's Cloud SQL offer managed database services supporting engines like MySQL, PostgreSQL, and SQL Server. For data warehouses, options like AWS Redshift, Google BigQuery, and Azure Synapse Analytics provide powerful analytical capabilities with elastic scaling and high performance.
Security and Compliance Considerations
Despite the advantages, security remains a critical consideration. Cloud providers implement robust security measures, including encryption, access controls, and compliance certifications (e.g., SOC 2, GDPR, HIPAA).
Organisations must assess data residency requirements and ensure adherence to industry-specific regulations when migrating sensitive data to the cloud.
By embracing cloud databases and data warehouses, organisations can optimise data management, drive innovation, and gain competitive advantages in today's data-driven landscape.
Frequently Asked Questions
What is the main difference between a database and a data warehouse?
A database manages transactional data for real-time operations, supporting sales and inventory management activities. In contrast, a data warehouse aggregates and analyses large volumes of historical data, enabling strategic insights, comprehensive reporting, and business intelligence activities critical for informed decision-making.
When should I use a data warehouse over a database?
Use a data warehouse when your primary goal is to conduct historical data analysis, generate complex queries, and create comprehensive reports. A data warehouse is ideal for business intelligence, trend analysis, and strategic planning, consolidating data from multiple sources for a unified, insightful view of your operations.
How do cloud databases and data warehouses benefit organisations?
Cloud databases and data warehouses provide significant advantages, including scalability to handle varying workloads, reduced operational costs due to outsourced maintenance, and enhanced accessibility for remote teams. They integrate seamlessly with other cloud services, promoting collaboration, innovation, and data management and analysis efficiency.
Conclusion
Understanding the critical differences between databases and data warehouses is essential for effective data management. Databases excel in handling transactional data, ensuring real-time updates and operational efficiency.
In contrast, data warehouses are designed for in-depth analysis, enabling strategic decision-making through comprehensive data aggregation. You can choose the solution that best aligns with your organisation's needs by carefully evaluating factors like data nature, intended use, volume, and cost.
Embracing cloud-based options further enhances scalability and flexibility, driving innovation and competitive advantage in today’s data-driven world. Choose wisely to optimise your data infrastructure and achieve your business objectives.
#Differences Between Database and Data Warehouse#Database vs Data Warehouse#Database#Data Warehouse#data management#data analytics#data storage#data science#pickl.ai#data analyst
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
The rapid growth of data-driven industries has brought about two prominent and in-demand career paths: Data Engineering and Data Science. For international students dreaming of a global tech career, these two fields offer promising opportunities, high salaries, and exciting work environments. But which course should you take abroad? What are the key differences, career paths, skills needed, and best study destinations?
In this blog, we’ll break down the key distinctions between Data Engineering and Data Science, explore which path suits you best, and highlight the best countries and universities abroad to pursue these courses.
What is Data Engineering?
Data Engineering focuses on designing, building, and maintaining data pipelines, systems, and architecture. Data Engineers prepare data so that Data Scientists can analyze it. They work with large-scale data processing systems and ensure that data flows smoothly between servers, applications, and databases.
Key Responsibilities of a Data Engineer:
Developing, testing, and maintaining data pipelines
Building data architectures (e.g., databases, warehouses)
Managing ETL (Extract, Transform, Load) processes
Working with tools like Apache Spark, Hadoop, SQL, Python, and AWS
Ensuring data quality and integrity
What is Data Science?
analysis, machine learning, and data visualization. Data Scientists use data to drive business decisions, create predictive models, and uncover trends.
Key Responsibilities of a Data Scientist:
Cleaning and analyzing large datasets
Building machine learning and AI models
Creating visualizations to communicate findings
Using tools like Python, R, SQL, TensorFlow, and Tableau
Applying statistical and mathematical techniques to solve problems
Which Course Should You Take Abroad?
Choosing between Data Engineering and Data Science depends on your interests, academic background, and long-term career goals. Here’s a quick guide to help you decide:
Take Data Engineering if:
You love building systems and solving technical challenges.
You have a background in software engineering, computer science, or IT.
You prefer backend development, architecture design, and working with infrastructure.
You enjoy automating data workflows and handling massive datasets.
Take Data Science if:
You’re passionate about data analysis, problem-solving, and storytelling with data.
You have a background in statistics, mathematics, computer science, or economics.
You’re interested in machine learning, predictive modeling, and data visualization.
You want to work on solving real-world problems using data.
Top Countries to Study Data Engineering and Data Science
Studying abroad can enhance your exposure, improve career prospects, and provide access to global job markets. Here are some of the best countries to study both courses:
1. Germany
Why? Affordable education, strong focus on engineering and analytics.
Top Universities:
Technical University of Munich
RWTH Aachen University
University of Mannheim
2. United Kingdom
Why? Globally recognized degrees, data-focused programs.
Top Universities:
University of Oxford
Imperial College London
4. Sweden
Why? Innovation-driven, excellent data education programs.
Top Universities:
KTH Royal Institute of Technology
Lund University
Chalmers University of Technology
Course Structure Abroad
Whether you choose Data Engineering or Data Science, most universities abroad offer:
Bachelor’s Degrees (3-4 years):
Focus on foundational subjects like programming, databases, statistics, algorithms, and software engineering.
Recommended for students starting out or looking to build from scratch.
Master’s Degrees (1-2 years):
Ideal for those with a bachelor’s in CS, IT, math, or engineering.
Specializations in Data Engineering or Data Science.
Often include hands-on projects, capstone assignments, and internship opportunities.
Certifications & Short-Term Diplomas:
Offered by top institutions and platforms (e.g., MITx, Coursera, edX).
Helpful for career-switchers or those seeking to upgrade their skills.
Career Prospects and Salaries
Both fields are highly rewarding and offer excellent career growth.
Career Paths in Data Engineering:
Data Engineer
Data Architect
Big Data Engineer
ETL Developer
Cloud Data Engineer
Average Salary (Globally):
Entry-Level: $70,000 - $90,000
Mid-Level: $90,000 - $120,000
Senior-Level: $120,000 - $150,000+
Career Paths in Data Science:
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Research Scientist
AI Engineer
Average Salary (Globally):
Entry-Level: $75,000 - $100,000
Mid-Level: $100,000 - $130,000
Senior-Level: $130,000 - $160,000+
Industry Demand
The demand for both data engineers and data scientists is growing rapidly across sectors like:
E-commerce
Healthcare
Finance and Banking
Transportation and Logistics
Media and Entertainment
Government and Public Policy
Artificial Intelligence and Machine Learning Startups
According to LinkedIn and Glassdoor reports, Data Engineer roles have surged by over 50% in recent years, while Data Scientist roles remain in the top 10 most in-demand jobs globally.
Skills You’ll Learn Abroad
Whether you choose Data Engineering or Data Science, here are some skills typically covered in top university programs:
For Data Engineering:
Advanced SQL
Data Warehouse Design
Apache Spark, Kafka
Data Lake Architecture
Python/Scala Programming
Cloud Platforms: AWS, Azure, GCP
For Data Science:
Machine Learning Algorithms
Data Mining and Visualization
Statistics and Probability
Python, R, MATLAB
Tools: Jupyter, Tableau, Power BI
Deep Learning, AI Basics
Internship & Job Opportunities Abroad
Studying abroad often opens doors to internships, which can convert into full-time job roles.
Countries like Germany, Canada, Australia, and the UK allow international students to work part-time during studies and offer post-study work visas. This means you can gain industry experience after graduation.
Additionally, global tech giants like Google, Amazon, IBM, Microsoft, and Facebook frequently hire data professionals across both disciplines.
Final Thoughts: Data Engineering vs Data Science – Which One Should You Choose?
There’s no one-size-fits-all answer, but here’s a quick recap:
Choose Data Engineering if you’re technically inclined, love working on infrastructure, and enjoy building systems from scratch.
Choose Data Science if you enjoy exploring data, making predictions, and translating data into business insights.
Both fields are highly lucrative, future-proof, and in high demand globally. What matters most is your interest, learning style, and career aspirations.
If you're still unsure, consider starting with a general data science or computer science program abroad that allows you to specialize in your second year. This way, you get the best of both worlds before narrowing down your focus.
Need Help Deciding Your Path?
At Cliftons Study Abroad, we guide students in selecting the right course and country tailored to their goals. Whether it’s Data Engineering in Germany or Data Science in Canada, we help you navigate admissions, visa applications, scholarships, and more.
Contact us today to take your first step towards a successful international data career!
0 notes
Text
Difference Between Data Analyst and BI Analyst
In the fast-paced digital age, data is more than just numbers—it’s the foundation of strategic decisions across industries. Within this data-driven ecosystem, two prominent roles often come up: Data Analyst and Business Intelligence (BI) Analyst. Though their responsibilities sometimes intersect, these professionals serve distinct purposes. Understanding the differences between them is crucial for anyone looking to build a career in analytics.
For individuals exploring a career in this field, enrolling in a well-rounded data analyst course in Kolkata can provide a solid stepping stone. But first, let’s dive into what differentiates these two career paths.
Core Focus and Responsibilities
A Data Analyst is primarily responsible for extracting insights from raw data. They gather, process, and examine data to identify patterns and trends that help drive both operational improvements and strategic decision-making. The focus here is largely on data quality, statistical analysis, and deriving insights through quantitative methods.
On the other hand, a BI Analyst is more focused on turning those insights into actionable business strategies. BI Analysts create dashboards, visualize data through tools like Power BI or Tableau, and present their findings to business leaders. Their goal is to help decision-makers understand performance trends, monitor KPIs, and identify opportunities for growth.
In short, data analysts focus more on exploration and deep analysis, whereas BI analysts specialize in communicating the meaning of that data through accessible visuals and reports.
Tools and Technologies
The toolkit of a data analyst usually includes:
SQL for querying databases
Excel for basic data wrangling
Python or R for statistical analysis
Tableau or Power BI for initial visualizations
BI Analysts, while they may use similar tools, concentrate more on:
Dashboard-building platforms like Power BI and Tableau
Data warehouses and reporting tools
Integration with enterprise systems such as ERP or CRM platforms
By starting with a strong technical foundation through a data analyst course in Kolkata, professionals can build the skills needed to branch into either of these specialties.
Skill Sets: Technical vs Business-Centric
Though both roles demand analytical thinking, their required skill sets diverge slightly.
Data Analysts need:
Strong mathematical and statistical knowledge
Data cleaning and transformation abilities
Comfort working with large datasets
Programming skills for automation and modeling
BI Analysts require:
Business acumen to align data with goals
Excellent communication skills
Advanced visualization skills
Understanding of key performance indicators (KPIs)
Aspiring professionals in Kolkata often find that attending an offline data analyst institute in Kolkata provides a more immersive experience in developing both sets of skills, especially with in-person mentoring and interactive learning.
Career Trajectories and Growth
The career paths of data analysts and BI analysts may overlap initially, but they often lead in different directions.
A Data Analyst can progress to roles like:
Data Scientist
Machine Learning Engineer
Quantitative Analyst
Meanwhile, a BI Analyst may evolve into positions such as:
BI Developer
Data Architect
Strategy Consultant
Both paths offer exciting opportunities in industries like finance, healthcare, retail, and tech. The key to progressing lies in mastering both technical tools and business logic, starting with quality training.
The Value of Offline Learning in Kolkata
While online learning is widely available, many learners still value the discipline and clarity that comes with face-to-face instruction. Attending an offline data analyst institute in Kolkata helps bridge the gap between theoretical concepts and practical application. Learners benefit from real-time feedback, collaborative sessions, and guidance that fosters confidence—especially important for those new to data analytics.
DataMites Institute: Your Trusted Analytics Training Partner
When it comes to structured and globally recognized analytics training, DataMites stands out as a top choice for learners across India.
The courses offered by DataMites Institute are accredited by IABAC and NASSCOM FutureSkills, ensuring they align with international industry benchmarks. Students benefit from expert guidance, practical project experience, internship opportunities, and robust placement assistance.
DataMites Institute provides offline classroom training in major cities like Mumbai, Pune, Hyderabad, Chennai, Delhi, Coimbatore, and Ahmedabad—offering learners flexible and accessible education opportunities across India. If you're based in Pune, DataMites Institute provides the ideal platform to master Python and excel in today’s competitive tech environment.
For learners in Kolkata, DataMites Institute represents a trusted gateway to a rewarding analytics career. With a strong emphasis on practical exposure, personalized mentoring, and real-world projects, DataMites Institute empowers students to build confidence and credibility in the field. Whether you're just starting out or looking to upskill, this institute offers the resources and structure to help you succeed in both data and business intelligence roles.
While both Data Analysts and BI Analysts play pivotal roles in transforming data into value, they approach the task from different angles. Choosing between them depends on your interest—whether it lies in deep analysis or strategic reporting. Whichever path you choose, building a strong foundation through a quality training program like that offered by DataMites in Kolkata will set you on the right trajectory.
0 notes
Text
Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer: Choose Your Perfect Data Career!

In today’s rapidly evolving tech world, career opportunities in data-related fields are expanding like never before. However, with multiple roles like Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer, newcomers — and even seasoned professionals — often find it confusing to understand how these roles differ.
At Yasir Insights, we think that having clarity makes professional selections more intelligent. We’ll go over the particular duties, necessary abilities, and important differences between these well-liked Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer data positions in this blog.
Also Read: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Introduction to Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
The Data Science and Machine Learning Development Lifecycle (MLDLC) includes stages like planning, data gathering, preprocessing, exploratory analysis, modelling, deployment, and optimisation. In order to effectively manage these intricate phases, the burden is distributed among specialised positions, each of which plays a vital part in the project’s success.
Data Engineer
Who is a Data Engineer?
The basis of the data ecosystem is built by data engineers. They concentrate on collecting, sanitising, and getting data ready for modelling or further analysis. Think of them as mining precious raw materials — in this case, data — from complex and diverse sources.
Key Responsibilities:
Collect and extract data from different sources (APIS, databases, web scraping).
Design and maintain scalable data pipelines.
Clean, transform, and store data in warehouses or lakes.
Optimise database performance and security.
Required Skills:
Strong knowledge of Data Structures and Algorithms.
Expertise in Database Management Systems (DBMS).
Familiarity with Big Data tools (like Hadoop, Spark).
Hands-on experience with cloud platforms (AWS, Azure, GCP).
Proficiency in building and managing ETL (Extract, Transform, Load) pipelines.
Data Analyst
Who is a Data Analyst?
Data analysts take over once the data has been cleansed and arranged. Their primary responsibility is to evaluate data in order to get valuable business insights. They provide answers to important concerns regarding the past and its causes.
Key Responsibilities:
Perform Exploratory Data Analysis (EDA).
Create visualisations and dashboards to represent insights.
Identify patterns, trends, and correlations in datasets.
Provide reports to support data-driven decision-making.
Required Skills:
Strong Statistical knowledge.
Proficiency in programming languages like Python or R.
Expertise in Data Visualisation tools (Tableau, Power BI, matplotlib).
Excellent communication skills to present findings clearly.
Experience working with SQL databases.
Data Scientist
Who is a Data Scientist?
Data Scientists build upon the work of Data Analysts by developing predictive models and machine learning algorithms. While analysts focus on the “what” and “why,” Data Scientists focus on the “what’s next.”
Key Responsibilities:
Design and implement Machine Learning models.
Perform hypothesis testing, A/B testing, and predictive analytics.
Derive strategic insights for product improvements and new innovations.
Communicate technical findings to stakeholders.
Required Skills:
Mastery of Statistics and Probability.
Strong programming skills (Python, R, SQL).
Deep understanding of Machine Learning algorithms.
Ability to handle large datasets using Big Data technologies.
Critical thinking and problem-solving abilities.
Machine Learning Engineer
Who is a Machine Learning Engineer?
Machine Learning Engineers (MLES) take the models developed by Data Scientists and make them production-ready. They ensure models are deployed, scalable, monitored, and maintained effectively in real-world systems.
Key Responsibilities:
Deploy machine learning models into production environments.
Optimise and scale ML models for performance and efficiency.
Continuously monitor and retrain models based on real-time data.
Collaborate with software engineers and data scientists for integration.
Required Skills:
Strong foundations in Linear Algebra, Calculus, and Probability.
Mastery of Machine Learning frameworks (TensorFlow, PyTorch, Scikit-learn).
Proficiency in programming languages (Python, Java, Scala).
Knowledge of Distributed Systems and Software Engineering principles.
Familiarity with MLOps tools for automation and monitoring.
Summary: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Data Engineer
Focus Area: Data Collection & Processing
Key Skills: DBMS, Big Data, Cloud Computing
Objective: Build and maintain data infrastructure
Data Analyst
Focus Area: Data Interpretation & Reporting
Key Skills: Statistics, Python/R, Visualisation Tools
Objective: Analyse data and extract insights
Data Scientist
Focus Area: Predictive Modelling
Key Skills: Machine Learning, Statistics, Data Analysis
Objective: Build predictive models and strategies
Machine Learning Engineer
Focus Area: Model Deployment & Optimisation
Key Skills: ML Frameworks, Software Engineering
Objective: Deploy and optimise ML models in production
Frequently Asked Questions (FAQS)
Q1: Can a Data Engineer become a Data Scientist?
Yes! With additional skills in machine learning, statistics, and model building, a Data Engineer can transition into a Data Scientist role.
Q2: Is coding necessary for Data Analysts?
While deep coding isn’t mandatory, familiarity with SQL, Python, or R greatly enhances a Data Analyst’s effectiveness.
Q3: What is the difference between a Data Scientist and an ML Engineer?
Data Scientists focus more on model development and experimentation, while ML Engineers focus on deploying and scaling those models.
Q4: Which role is the best for beginners?
If you love problem-solving and analysis, start as a Data Analyst. If you enjoy coding and systems, a Data Engineer might be your path.
Published By:
Mirza Yasir Abdullah Baig
Repost This Article and built Your Connection With Others
0 notes
Text
Difference between Database and DBMS

The main difference between a database and a DBMS lies in their purpose and functionality. A database is a structured collection of data that is stored electronically and used for efficient data retrieval, while a DBMS (Database Management System) is a software tool that interacts with the database, enabling users to manage, organize, and manipulate data effectively.
In modern data-driven environments, a database acts as a digital warehouse that stores information, such as user records, sales data, and transaction logs. However, without a DBMS, accessing or modifying this data manually would be complex and error-prone.
A DBMS simplifies database administration through features like data security, backup, concurrency control, and query optimization. It also supports SQL commands for retrieving and updating records, ensuring real-time data access and consistent performance.
0 notes
Text
Exploring the Role of Azure Data Factory in Hybrid Cloud Data Integration

Introduction
In today’s digital landscape, organizations increasingly rely on hybrid cloud environments to manage their data. A hybrid cloud setup combines on-premises data sources, private clouds, and public cloud platforms like Azure, AWS, or Google Cloud. Managing and integrating data across these diverse environments can be complex.
This is where Azure Data Factory (ADF) plays a crucial role. ADF is a cloud-based data integration service that enables seamless movement, transformation, and orchestration of data across hybrid cloud environments.
In this blog, we’ll explore how Azure Data Factory simplifies hybrid cloud data integration, key use cases, and best practices for implementation.
1. What is Hybrid Cloud Data Integration?
Hybrid cloud data integration is the process of connecting, transforming, and synchronizing data between: ✅ On-premises data sources (e.g., SQL Server, Oracle, SAP) ✅ Cloud storage (e.g., Azure Blob Storage, Amazon S3) ✅ Databases and data warehouses (e.g., Azure SQL Database, Snowflake, BigQuery) ✅ Software-as-a-Service (SaaS) applications (e.g., Salesforce, Dynamics 365)
The goal is to create a unified data pipeline that enables real-time analytics, reporting, and AI-driven insights while ensuring data security and compliance.
2. Why Use Azure Data Factory for Hybrid Cloud Integration?
Azure Data Factory (ADF) provides a scalable, serverless solution for integrating data across hybrid environments. Some key benefits include:
✅ 1. Seamless Hybrid Connectivity
ADF supports over 90+ data connectors, including on-prem, cloud, and SaaS sources.
It enables secure data movement using Self-Hosted Integration Runtime to access on-premises data sources.
✅ 2. ETL & ELT Capabilities
ADF allows you to design Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) pipelines.
Supports Azure Data Lake, Synapse Analytics, and Power BI for analytics.
✅ 3. Scalability & Performance
Being serverless, ADF automatically scales resources based on data workload.
It supports parallel data processing for better performance.
✅ 4. Low-Code & Code-Based Options
ADF provides a visual pipeline designer for easy drag-and-drop development.
It also supports custom transformations using Azure Functions, Databricks, and SQL scripts.
✅ 5. Security & Compliance
Uses Azure Key Vault for secure credential management.
Supports private endpoints, network security, and role-based access control (RBAC).
Complies with GDPR, HIPAA, and ISO security standards.
3. Key Components of Azure Data Factory for Hybrid Cloud Integration
1️⃣ Linked Services
Acts as a connection between ADF and data sources (e.g., SQL Server, Blob Storage, SFTP).
2️⃣ Integration Runtimes (IR)
Azure-Hosted IR: For cloud data movement.
Self-Hosted IR: For on-premises to cloud integration.
SSIS-IR: To run SQL Server Integration Services (SSIS) packages in ADF.
3️⃣ Data Flows
Mapping Data Flow: No-code transformation engine.
Wrangling Data Flow: Excel-like Power Query transformation.
4️⃣ Pipelines
Orchestrate complex workflows using different activities like copy, transformation, and execution.
5️⃣ Triggers
Automate pipeline execution using schedule-based, event-based, or tumbling window triggers.
4. Common Use Cases of Azure Data Factory in Hybrid Cloud
🔹 1. Migrating On-Premises Data to Azure
Extracts data from SQL Server, Oracle, SAP, and moves it to Azure SQL, Synapse Analytics.
🔹 2. Real-Time Data Synchronization
Syncs on-prem ERP, CRM, or legacy databases with cloud applications.
🔹 3. ETL for Cloud Data Warehousing
Moves structured and unstructured data to Azure Synapse, Snowflake for analytics.
🔹 4. IoT and Big Data Integration
Collects IoT sensor data, processes it in Azure Data Lake, and visualizes it in Power BI.
🔹 5. Multi-Cloud Data Movement
Transfers data between AWS S3, Google BigQuery, and Azure Blob Storage.
5. Best Practices for Hybrid Cloud Integration Using ADF
✅ Use Self-Hosted IR for Secure On-Premises Data Access ✅ Optimize Pipeline Performance using partitioning and parallel execution ✅ Monitor Pipelines using Azure Monitor and Log Analytics ✅ Secure Data Transfers with Private Endpoints & Key Vault ✅ Automate Data Workflows with Triggers & Parameterized Pipelines
6. Conclusion
Azure Data Factory plays a critical role in hybrid cloud data integration by providing secure, scalable, and automated data pipelines. Whether you are migrating on-premises data, synchronizing real-time data, or integrating multi-cloud environments, ADF simplifies complex ETL processes with low-code and serverless capabilities.
By leveraging ADF’s integration runtimes, automation, and security features, organizations can build a resilient, high-performance hybrid cloud data ecosystem.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
From Silos to Synergy: Real-time data sharing across eco-systems in real time
Despite advancements in data management technologies in recent years, the ability to get true potential of business data continues to evolve. From cumbersome batch processing to complex data formatting and transformations, sharing data across diverse systems and tech stacks is anything but easy or in real time.
This is one (of many!) reasons why we’re starting to see event-driven data automation tools revolutionize how businesses leverage data, especially when it comes to collaborating with strategic business partners and other external parties.
This article investigates common hurdles associated with traditional data sharing, highlighting the benefits of event-driven data automation for multi-party data exchange.
Data-sharing bottlenecks: Time to clear the path
Today’s data-driven economy demands agile data sharing, and relying solely on internal data is no longer sufficient. But while third-party data is essential for personalized experiences, fraud prevention, and lots more, current data-sharing mechanisms often fall short when it comes to exchanging information across diverse systems.
Historically, data exchange is primarily conducted through two methods:
Network data loads: Meticulously formatted data (e.g., CSV files) is transferred in batches between different systems. However, this static approach limits data updates to daily cycles at most, leading to information delays and stale business insights.
Online data platforms: While online platforms like CDPs, data lakes, and warehouses offer some potential for data sharing, the reality is that incompatible data stacks frequently create obstacles, requiring significant data formatting and transformation efforts.
Both methods present additional challenges as well. Batch processing is inflexible, making it difficult to accommodate real-time operational or market fluctuations. Transferring large datasets also carries significant security risks, potentially exposing sensitive information. Plus, incompatibility between data stacks can create silos across systems and companies, blocking business leaders from gaining a clear, comprehensive view of information for decision making.
These limitations translate to a host of real-world business challenges, such as:
Downstream disruption: Batch processing in industries such as financial services often leads to delays and lost opportunities. For example, payroll deposits arriving outside designated processing windows can disrupt downstream systems, causing customer frustration and potential financial hardship.
Increased operational costs: The complexities of data transformation and heightened security measures associated with traditional methods drive up costs. In manufacturing and retail, a lack of real-time data visibility exacerbates issues like inventory mismatches, inaccurate demand forecasts, and reactive replenishment strategies, all of which inflate operational expenses.
Poor customer experiences: Customers also face friction when businesses lack real-time data. For example, if a global airline doesn’t have access to up-to-date information, its customers may face limited flight or seating options or missed opportunities on using their miles for upgrades.
Heightened fraud risk: Across industries, delayed detection of fraudulent activities due to batch processing can also increase an organization’s exposure to financial losses.
A new paradigm: Secure, event-driven data sharing
Event-driven data automation is revolutionizing how businesses harness the power of data. End-to-end data automation platforms like Vendia act as a secure intermediary between mixed tech stacks (often with different database solutions), unlocking real-time data sharing.
This means that organizations can instantly analyze data, uncovering previously hidden opportunities and driving proactive strategies faster.
Here's how it breaks the mold:
Event-driven architecture: Data is immediately shared any time a predefined event occurs, eliminating the need for batch processing and ensuring information across business systems is always up-to-date.
Secure direct data transfer: Data moves directly between parties through secure connections, minimizing the attack surface and reducing the risk of exposure during transit.
Read More: https://www.thecioera.com/from-silos-to-synergy--real-time-data-sharing-across-eco-systems-in-real-time/
0 notes
Text
Key Differences Between Data Governance and Data Management
In today’s data-driven world, organizations rely heavily on vast amounts of data to drive business decisions, enhance customer experiences, and improve operational efficiency. However, effectively handling data requires a strategic approach. Two essential concepts in this realm are Data Governance and Data Management. While they are closely related, they serve distinct purposes and involve different processes. In this blog, we will explore the key differences between Data Governance and Data Management and why both are critical for any data-centric organization.
What is Data Governance?
Data Governance refers to the framework of policies, procedures, and standards that ensure data quality, security, compliance, and accountability within an organization. It establishes rules for how data is created, stored, used, and maintained. The primary goal Data Governance of Data Governance is to ensure that data remains accurate, consistent, and protected throughout its lifecycle.
Key Aspects of Data Governance:
Data Ownership & Accountability: Assigning roles and responsibilities to individuals for managing data assets.
Data Policies & Compliance: Ensuring adherence to regulatory requirements such as GDPR, HIPAA, or CCPA.
Data Quality & Integrity: Maintaining high-quality data by defining validation rules and data accuracy standards.
Data Security & Privacy: Implementing measures to prevent unauthorized access and breaches.
Data Stewardship: Monitoring data usage and ensuring compliance with governance policies.
What is Data Management?
Data Management encompasses the processes, tools, and technologies used to collect, store, organize, and maintain data effectively. It involves the operational aspect of handling data across its lifecycle, ensuring accessibility, efficiency, and reliability.
Key Aspects of Data Management:
Data Collection & Integration: Gathering data from multiple sources and consolidating it.
Data Storage & Architecture: Storing data efficiently using databases, data warehouses, or cloud solutions.
Data Processing & Transformation: Cleaning, enriching, and preparing data for analytics.
Data Security & Backup: Implementing safeguards to protect data and ensure disaster recovery.
Data Analytics & Utilization: Using data for reporting, insights, and decision-making.
Key Differences Between Data Governance and Data Management
The primary purpose of Data Governance is to establish rules, policies, and standards for data usage, whereas Data Management focuses on the practical implementation and operation of data processes. While Data Governance ensures data integrity, compliance, and security, Data Management is responsible for collecting, processing, and maintaining data for operational use.
In terms of responsibility, Data Governance is typically overseen by data stewards, governance committees, and compliance teams. On the other hand, Data Management is managed by IT teams, database administrators, and data engineers who handle the day-to-day technical aspects of data.
Key components of Data Governance include policies, accountability, compliance, security, and stewardship, while Data Management involves databases, ETL (Extract, Transform, Load) processes, data warehouses, and analytics. The outcome of Data Governance is trusted, high-quality data that aligns with business rules, whereas Data Management ensures efficiently stored and accessible data for business operations.
Why Organizations Need Both Data Governance and Data Management
Organizations cannot rely on Data Management alone without Data Governance, as it may lead to inconsistent data, compliance risks, and security vulnerabilities. Conversely, Data Governance without Data Management lacks execution, making data policies ineffective. To maximize the value of data, businesses must integrate both strategies to achieve data accuracy, security, and usability.
Benefits of Implementing Both:
Improved Decision-Making: Ensures high-quality, well-managed data for reliable analytics.
Regulatory Compliance: Reduces legal and financial risks by enforcing data policies.
Operational Efficiency: Streamlines data handling processes, reducing redundancies and inefficiencies.
Enhanced Data Security: Protects sensitive information from breaches and unauthorized access.
Conclusion
Understanding the differences between Data Governance and Data Management is essential for organizations aiming to leverage data effectively. While Data Governance establishes the framework and policies for data integrity and compliance, Data Management ensures the proper execution of those policies through operational processes. Together, they create a robust data ecosystem that drives business success, mitigates risks, and ensures data reliability.
Organizations looking to thrive in the digital age must recognize that Data Governance and Data Management are not interchangeable but complementary. By aligning both strategies, businesses can harness the full potential of their data assets and maintain a competitive edge in an increasingly data-driven world.
0 notes
Text
Understanding Data Testing and Its Importance

In today’s data-driven world, businesses rely heavily on accurate and high-quality data to make critical decisions. Data testing is a crucial process that ensures the accuracy, consistency, and reliability of data within databases, data warehouses, and software applications. By implementing robust data testing services, organizations can avoid costly errors, improve decision-making, and enhance operational efficiency.
What is Data Testing?
Data testing is the process of validating data for accuracy, integrity, consistency, and completeness. It involves checking whether the data being used in an application or system meets predefined quality standards. Organizations use data testing to detect discrepancies, missing values, duplicate records, or incorrect formats that can compromise data integrity.
Key Aspects of Data Testing
Data Validation – Ensures that data conforms to predefined rules and constraints.
Data Integrity Testing – Checks for consistency and correctness of data across different databases and systems.
Data Migration Testing – Validates data movement from one system to another without loss or corruption.
ETL Testing – Tests the Extract, Transform, Load (ETL) process to ensure accurate data extraction, transformation, and loading into the target system.
Regression Testing – Ensures that changes in data do not negatively impact the system’s functionality.
Performance Testing – Assesses the speed and reliability of data processes under varying conditions.
Why Are Data Testing Services Essential?
With the exponential growth of data, organizations cannot afford to overlook data quality. Investing in professional data testing services provides several benefits:
Prevention of Data Errors: Identifying and fixing data issues before they impact business processes.
Regulatory Compliance: Ensuring data adheres to industry regulations such as GDPR, HIPAA, and SOX.
Optimized Performance: Ensuring that databases and applications run efficiently with high-quality data.
Enhanced Decision-Making: Reliable data enables better business insights and informed decision-making.
Seamless Data Integration: Ensuring smooth data migration and integration between different platforms.
How to Implement Effective Data Testing?
Define Clear Data Quality Standards: Establish rules and benchmarks for data accuracy, consistency, and completeness.
Automate Testing Where Possible: Leverage automation tools for efficient and accurate data validation.
Conduct Regular Data Audits: Periodic testing helps identify and rectify data anomalies.
Use Robust Data Testing Tools: Tools like Informatica, Talend, and Apache Nifi help streamline the process.
Engage Professional Data Testing Services: Partnering with expert service providers ensures thorough testing and high-quality data.
Conclusion
In an era where data fuels business success, ensuring its accuracy and reliability is paramount. Data testing services play a crucial role in maintaining data integrity and enhancing operational efficiency. Organizations that invest in proper data testing can mitigate risks, improve compliance, and make data-driven decisions with confidence. Prioritizing data testing today means securing a smarter and more efficient business future.
0 notes
Text
Navigating the Data World: A Deep Dive into Architecture of Big Data Tools

In today’s digital world, where data has become an integral part of our daily lives. May it be our phone’s microphone, websites, mobile applications, social media, customer feedback, or terms & conditions – we consistently provide “yes” consents, so there is no denying that each individual's data is collected and further pushed to play a bigger role into the decision-making pipeline of the organizations.
This collected data is extracted from different sources, transformed to be used for analytical purposes, and loaded in another location for storage. There are several tools present in the market that could be used for data manipulation. In the next sections, we will delve into some of the top tools used in the market and dissect the information to understand the dynamics of this subject.
Architecture Overview
While researching for top tools, here are a few names that made it to the top of my list – Snowflake, Apache Kafka, Apache Airflow, Tableau, Databricks, Redshift, Bigquery, etc. Let’s dive into their architecture in the following sections:
Snowflake
There are several big data tools in the market serving warehousing purposes for storing structured data and acting as a central repository of preprocessed data for analytics and business intelligence. Snowflake is one of the warehouse solutions. What makes Snowflake different from other solutions is that it is a truly self-managed service, with no hardware requirements and it runs completely on cloud infrastructure making it a go-to for the new Cloud era. Snowflake uses virtual computing instances and a storage service for its computing needs. Understanding the tools' architecture will help us utilize it more efficiently so let’s have a detailed look at the following pointers:

Image credits: Snowflake
Now let’s understand what each layer is responsible for. The Cloud service layer deals with authentication and access control, security, infrastructure management, metadata, and optimizer manager. It is responsible for managing all these features throughout the tool. Query processing is the compute layer where the actual query computation happens and where the cloud compute resources are utilized. Database storage acts as a storage layer for storing the data.
Considering the fact that there are a plethora of big data tools, we don’t shed significant light on the Apache toolkit, this won’t be justice done to their contribution. We all are familiar with Apache tools being widely used in the Data world, so moving on to our next tool Apache Kafka.
Apache Kafka
Apache Kafka deserves an article in itself due to its prominent usage in the industry. It is a distributed data streaming platform that is based on a publish-subscribe messaging system. Let’s check out Kafka components – Producer and Consumer. Producer is any system that produces messages or events in the form of data for further processing for example web-click data, producing orders in e-commerce, System Logs, etc. Next comes the consumer, consumer is any system that consumes data for example Real-time analytics dashboard, consuming orders in an inventory service, etc.
A broker is an intermediate entity that helps in message exchange between consumer and producer, further brokers have divisions as topic and partition. A topic is a common heading given to represent a similar type of data. There can be multiple topics in a cluster. Partition is part of a topic. Partition is data divided into small sub-parts inside the broker and every partition has an offset.
Another important element in Kafka is the ZooKeeper. A ZooKeeper acts as a cluster management system in Kafka. It is used to store information about the Kafka cluster and details of the consumers. It manages brokers by maintaining a list of consumers. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occur, the ZooKeeper sends notifications to Apache Kafka. Zookeeper has a master-slave that handles all the writes, and the rest of the servers are the followers who handle all the reads.
In recent versions of Kafka, it can be used and implemented without Zookeeper too. Furthermore, Apache introduced Kraft which allows Kafka to manage metadata internally without the need for Zookeeper using raft protocol.

Image credits: Emre Akin
Moving on to the next tool on our list, this is another very popular tool from the Apache toolkit, which we will discuss in the next section.
Apache Airflow
Airflow is a workflow management system that is used to author, schedule, orchestrate, and manage data pipelines and workflows. Airflow organizes your workflows as Directed Acyclic Graph (DAG) which contains individual pieces called tasks. The DAG specifies dependencies between task execution and task describing the actual action that needs to be performed in the task for example fetching data from source, transformations, etc.
Airflow has four main components scheduler, DAG file structure, metadata database, and web server. A scheduler is responsible for triggering the task and also submitting the tasks to the executor to run. A web server is a friendly user interface designed to monitor the workflows that let you trigger and debug the behavior of DAGs and tasks, then we have a DAG file structure that is read by the scheduler for extracting information about what task to execute and when to execute them. A metadata database is used to store the state of workflow and tasks. In summary, A workflow is an entire sequence of tasks and DAG with dependencies defined within airflow, a DAG is the actual data structure used to represent tasks. A task represents a single unit of DAG.

As we received brief insights into the top three prominent tools used by the data world, now let’s try to connect the dots and explore the Data story.
Connecting the dots
To understand the data story, we will be taking the example of a use case implemented at Cubera. Cubera is a big data company based in the USA, India, and UAE. The company is creating a Datalake for data repository to be used for analytical purposes from zero-party data sources as directly from data owners. On an average 100 MB of data per day is sourced from various data sources such as mobile phones, browser extensions, host routers, location data both structured and unstructured, etc. Below is the architecture view of the use case.

Image credits: Cubera
A node js server is built to collect data streams and pass them to the s3 bucket for storage purposes hourly. While the airflow job is to collect data from the s3 bucket and load it further into Snowflake. However, the above architecture was not cost-efficient due to the following reasons:
AWS S3 storage cost (for each hour, typically 1 million files are stored).
Usage costs for ETL running in MWAA (AWS environment).
The managed instance of Apache Airflow (MWAA).
Snowflake warehouse cost.
The data is not real-time, being a drawback.
The risk of back-filling from a sync-point or a failure point in the Apache airflow job functioning.
The idea is to replace this expensive approach with the most suitable one, here we are replacing s3 as a storage option by constructing a data pipeline using Airflow through Kafka to directly dump data to Snowflake. The following is a newfound approach, as Kafka works on the consumer-producer model, snowflake works as a consumer here. The message gets queued on the Kafka topic from the sourcing server. The Kafka for Snowflake connector subscribes to one or more Kafka topics based on the configuration information provided via the Kafka configuration file.

Image credits: Cubera
With around 400 million profile data directly sourced from individual data owners from their personal to household devices as Zero-party data, 2nd Party data from various app partnerships, Cubera Data Lake is continually being refined.
Conclusion
With so many tools available in the market, choosing the right tool is a task. A lot of factors should be taken into consideration before making the right decision, these are some of the factors that will help you in the decision-making – Understanding the data characteristics like what is the volume of data, what type of data we are dealing with - such as structured, unstructured, etc. Anticipating the performance and scalability needs, budget, integration requirements, security, etc.
This is a tedious process and no single tool can fulfill all your data requirements but their desired functionalities can make you lean towards them. As noted earlier, in the above use case budget was a constraint so we moved from the s3 bucket to creating a data pipeline in Airflow. There is no wrong or right answer to which tool is best suited. If we ask the right questions, the tool should give you all the answers.
Join the conversation on IMPAAKT! Share your insights on big data tools and their impact on businesses. Your perspective matters—get involved today!
0 notes
Text
Implementing the Tableau to Power BI Migration: A Strategic Approach for Transition
migrating from Tableau to Power BI offers organizations an opportunity to unlock new levels of analytics performance, cost-efficiency, and integration within the Microsoft ecosystem. However, transitioning from one BI tool to another is a complex process that requires careful planning and execution. In this guide, we explore the essential steps and strategies for a successful Tableau to Power BI migration, ensuring smooth data model conversion, optimized performance, robust security implementation, and seamless user adoption. Whether you're looking to modernize your analytics environment or improve cost management, understanding the key components of this migration is crucial to achieving long-term success.
Understanding the Tableau to Power BI migration Landscape
When planning a Tableau to Power BI migration , organizations must first understand the fundamental differences between these platforms. The process requires careful consideration of various factors, including data architecture redesign and cross-platform analytics transition. A successful Tableau to Power BI migration starts with a thorough assessment of your current environment.
Strategic Planning and Assessment
The foundation of any successful Tableau to Power BI migration lies in comprehensive planning. Organizations must conduct a thorough migration assessment framework to understand their current Tableau implementation. This involves analyzing existing reports, dashboards, and data sources while documenting specific requirements for the transition.
Technical Implementation Framework
Data Architecture and Integration
The core of Tableau to Power BI migration involves data model conversion and proper database connection transfer. Organizations must implement effective data warehouse integration strategies while ensuring proper data gateway configuration. A successful Tableau to Power BI migration requires careful attention to ETL process migration and schema migration planning.
Development and Conversion Process
During the Tableau to Power BI migration, special attention must be paid to DAX formula conversion and LOD expression transformation. The process includes careful handling of calculated field migration and implementation of proper parameter configuration transfer. Organizations should establish a robust development environment setup to ensure smooth transitions.
Performance Optimization Strategy
A critical aspect of Tableau to Power BI migration involves implementing effective performance tuning methods. This includes establishing proper query performance optimization techniques and memory usage optimization strategies. Organizations must focus on resource allocation planning and workload distribution to maintain optimal performance.
Security Implementation
Security remains paramount during Tableau to Power BI migration. Organizations must ensure proper security model transfer and implement robust access control implementation. The process includes setting up row-level security migration and establishing comprehensive data protection protocols.
User Management and Training
Successful Tableau to Power BI migration requires careful attention to user access migration and license transfer process. Organizations must implement effective group policy implementation strategies while ensuring proper user mapping strategy execution. This includes developing comprehensive user training materials and establishing clear knowledge transfer plans.
Testing and Quality Assurance
Implementing thorough migration testing protocols ensures successful outcomes. Organizations must establish comprehensive validation framework setup procedures and implement proper quality assurance methods. This includes conducting thorough user acceptance testing and implementing effective dashboard testing strategy procedures.
Maintenance and Support Planning
Post-migration success requires implementing effective post-migration monitoring systems and establishing proper system health checks. Organizations must focus on performance analytics and implement comprehensive usage monitoring setup procedures to ensure continued success.
Ensuring Long-term Success and ROI
A successful Tableau to Power BI migration requires ongoing attention to maintenance and optimization. Organizations must establish proper maintenance scheduling procedures and implement effective backup procedures while ensuring comprehensive recovery planning.
Partner with DataTerrain for Migration Excellence
At DataTerrain, we understand the complexities of Tableau to Power BI migration. Our team of certified professionals brings extensive experience in managing complex migrations, ensuring seamless transitions while maintaining business continuity. We offer:
Comprehensive Migration Services: Our expert team handles every aspect of your migration journey, from initial assessment to post-migration support.
Technical Excellence: With deep expertise in both Tableau and Power BI, we ensure optimal implementation of all technical components.
Proven Methodology: Our structured approach, refined through numerous successful migrations, ensures predictable outcomes and minimal disruption.
Transform your business intelligence capabilities with DataTerrain's expert Tableau to Power BI migration services. Contact us today for a free consultation and discover how we can guide your organization through a successful migration journey.
1 note
·
View note
Text
Maximizing Business Operations with Data Pipeline and Data Pipeline API
In the age of data today, organizations have to process and integrate large amounts of data to make effective business decisions. Match Data Pro LLC is an expert in sophisticated data pipeline solutions and data pipeline API integration, guaranteeing smooth data flow between multiple systems. Data pipeline solutions allow businesses to automate data transfer, enhance operational effectiveness, and store high-quality, structured data for analytics and decision-making.
What is a Data Pipeline?
A data pipeline is a computerized process that transports, converts, and aggregates data from multiple sources to a target location, including a data warehouse, analytics tool, or cloud storage system. Data pipelines guarantee that organizations have the ability to process raw data into actionable intelligence in real-time or batch modes.
Advantages of a Data Pipeline:
Automated Data Movement: Removes the need for human intervention in moving data, lowering errors and inefficiencies.
Real-Time Data Processing: Facilitates quicker decision-making with real-time information.
Scalability: Scales with growing data volumes and business requirements.
Data Consistency: Provides accurate and consistent data across multiple platforms.
Seamless Integration: Integrates different data sources, such as databases, cloud applications, and third-party systems.
Match Data Pro LLC offers sophisticated data pipeline solutions to meet various industry needs, ensuring smooth data orchestration and management.
Understanding Data Pipeline API
A data pipeline API is an application programming interface used to programatically build, manage, and automate data pipelines. Through the use of APIs, companies are able to connect data pipelines to current applications, tailor workflows, and streamline data processing operations.
Main Features of a Data Pipeline API:
Adaptable Data Integration: Links disparate data sources, such as structured and unstructured data.
Automated Scheduling of Data: Supports timed or real-time data processing.
Secure Data Transfers: Ensures encrypted and compliant data movement.
Scalable Infrastructure: Handles high-volume data processing with low latency.
Error Handling and Monitoring: Offers real-time alerts and logging for data pipeline management.
At Match Data Pro LLC, our data pipeline API solutions assist businesses in accelerating their data workflows, increasing automation, and gaining improved insights from their datasets.
How Data Pipeline and Data Pipeline API Work Together
The integration of data pipeline solutions and data pipeline API technology enables companies to build a solid data infrastructure. These solutions, combined, enable:
Automated Data Ingestion: Retrieves data from various sources and transfers it to storage or processing systems.
Data Transformation: Cleans, enriches, and formats the data prior to analysis.
Data Synchronization: Manages real-time or batch updates across different platforms.
API-Based Control: Enables developers to programatically alter and optimize pipelines.
Error Recovery Mechanisms: Avoids loss of data and ensures integrity during transfers.
Industry Applications of Data Pipeline and Data Pipeline API
These technologies are used by organizations in various industries to improve their data management methods. Some of the major applications are:
1. Finance & Banking
Handling real-time transactional data.
Identifying fraudulent transactions through real-time monitoring.
Merging customer financial information for customized services.
2. Healthcare
Merging patient records across various hospitals and clinics.
Automating insurance claims processing.
Improving medical research with organized datasets.
3. Retail & E-Commerce
Syncing inventory data across online and offline channels.
Monitoring customer activity and sales patterns.
Automating order fulfillment operations.
4. Technology & SaaS
Gathering and analyzing user behavior data to enhance products.
Streamlining cloud-based data management.
Automating software performance monitoring and reporting.
Why Match Data Pro LLC for Data Pipeline Solutions?
Match Data is a leading data pipeline and data pipeline API provider that streamlines business data management. The following are the reasons why clients rely on our expertise:
Advanced Automation: Minimizes the need for manual intervention and maximizes efficiency.
Customizable Workflows: Adapts solutions to individual business needs.
Scalable Architecture: Accommodates both small businesses and large-scale businesses.
Secure Data Processing: Aligns with industry regulations on data security and privacy.
Expert Support: Provides expert technical support for smooth implementation.
Conclusion
In a data-driven world, efficient data pipeline solutions and data pipeline API technology can make a huge difference to business operations. Match Data Pro LLC enables businesses with state-of-the-art data management capabilities, guaranteeing error-free integration, automation, and processing speed.
0 notes
Text
The Role of Ask On Data’s Chat-Based GenAI in Modern Data Engineering
Data engineering is evolving at an incredible pace, driven by the need for faster, more efficient ways to manage and process vast amounts of data. Traditionally, data engineering tasks such as ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) required significant manual effort, with data engineers performing repetitive tasks to integrate, transform, and load data into systems like data lakes and data warehouses. However, with the advent of powerful Open Source GenAI powered chat-based Data Engineering tool like Ask On Data, this process is being revolutionized.
Ask On Data integrates NLP with GenAI, offering a conversational interface that streamlines the data engineering process. By leveraging LLMs (Large Language Models), Ask On Data allows users to interact with data workflows using plain, intuitive language, rather than writing complex code. This marks a significant shift from manual, code-heavy processes to automated, AI-powered interactions. The tool is designed for data engineers and even non-technical stakeholders, making data management accessible to a broader audience.
Chat-Based Data Engineering: Bridging the Gap
One of the standout features of Ask On Data is its chat-based interface. In a typical data engineering workflow, engineers would write scripts and queries to extract data from various sources, transform it into a usable format, and load it into a data warehouse or data lake. With Ask On Data, the entire process becomes more efficient and intuitive. Users can simply input commands or ask questions in natural language—such as "Load customer data from this database to the data lake"—and Ask On Data automates the rest. This NLP based Data Engineering Tool streamlines what was once a tedious manual process into a simple, conversational interaction.
Transforming Data: NLP Based ETL and Data Integration
Ask On Data’s core strength lies in its ability to perform advanced data transformation and data integration tasks without requiring deep technical expertise. As an NLP based ETL Tool, Ask On Data leverages the capabilities of GenAI to understand natural language requests, interpret them, and transform data accordingly. For instance, a user might request, "Transform raw sales data into monthly revenue metrics," and the tool will automatically handle the extraction, transformation, and loading of that data into the desired format.
The tool also supports seamless integration between different data systems. Whether you're working with a data lake or a data warehouse, Ask On Data ensures that data is efficiently transferred, transformed, and loaded without the complexity of manual scripting. This capability is crucial for modern enterprises that rely on both structured and unstructured data across multiple platforms.
Open Source and Customization: A Key Advantage
Another major advantage of Ask On Data is its open-source nature. Many businesses face challenges with proprietary tools due to high licensing costs and limited customization options. Ask On Data, being an open-source solution, enables organizations to customize the platform according to their specific needs, enhancing flexibility and reducing costs. Organizations can modify workflows, add new functionalities, or integrate the tool with existing systems to fit their data engineering requirements. This open-source flexibility, combined with the power of GenAI, makes Ask On Data an invaluable tool for teams seeking efficiency, scalability, and innovation in their data processes.
Revolutionizing the Future of Data Engineering
By combining the power of GenAI and LLMs with the simplicity of a chat-based interface, Ask On Data is leading the charge in modernizing data engineering. Tasks that traditionally took hours or days can now be performed in minutes with far fewer errors. From data extraction to data transformation and data loading, Ask On Data automates the labor-intensive steps of data engineering, allowing teams to focus on high-value activities like analyzing and interpreting data.
Conclusion
Ask On Data represents the future of data engineering, where automation, AI, and natural language interfaces converge to make complex workflows more accessible and efficient. By eliminating manual coding and streamlining the entire ETL process, Ask On Data is not just a tool but a paradigm shift in how businesses manage and process data in the era of big data and AI. For companies seeking a powerful, open-source solution that integrates data lakes, data warehouses, and advanced data transformation tasks, Ask On Data offers an invaluable, future-ready tool for any data engineering team.
0 notes
Text
What is the difference between SAP S-4HANA and SAP ERP?
The primary difference between SAP S/4HANA and SAP ERP lies in their architecture, performance, and overall capabilities. SAP S/4HANA is the next generation of SAP ERP solutions, designed to leverage the in-memory computing capabilities of SAP HANA for faster processing, simplified data models, and a modern user experience. Here’s a breakdown of their key differences:
1. Technology and Performance
SAP ERP: The traditional SAP ERP (also known as SAP ECC) uses older database technologies and relies on relational databases, which can be slower when dealing with large amounts of data. While reliable, it’s not optimized for real-time processing or handling vast datasets efficiently.
SAP S/4HANA: S/4HANA is built on SAP HANA, an in-memory database that allows data to be processed in real-time. This drastically improves the speed of operations, reporting, and decision-making. In-memory computing removes the need for separate data warehouses or batch processes, making S/4HANA much faster than SAP ERP.
2. User Experience
SAP ERP: The user interface of SAP ERP is more traditional and can be quite complex for new users. While functional, the experience can feel outdated compared to more modern systems.
SAP S/4HANA: S/4HANA provides a modern, intuitive user interface based on SAP Fiori, which is more user-friendly, visually appealing, and easier to navigate. It is designed for mobile use as well, making it more adaptable across different devices.
3. Data Model
SAP ERP: SAP ERP uses a complex and fragmented data model with multiple systems and layers. This structure can lead to inefficiencies and slower processing, as data often needs to be aggregated from different sources.
SAP S/4HANA: The data model in S/4HANA is simplified, reducing redundancies and offering a more streamlined approach to data management. This allows for better performance and more accurate real-time insights.
4. Deployment Options
SAP ERP: Typically, SAP ERP is deployed on-premise, which means companies need to manage their own infrastructure, including servers and databases.
SAP S/4HANA: S/4HANA offers more flexibility, supporting both on-premise and cloud deployments. This means businesses can choose the most appropriate infrastructure for their needs, whether it’s on their own servers or hosted in the cloud.
5. Real-Time Data Processing
SAP ERP: Due to its older technology, SAP ERP processes data in batches, which can result in delays in reporting and decision-making. Businesses might need to wait for data to be processed before gaining insights.
SAP S/4HANA: One of the standout features of S/4HANA is its ability to process data in real-time, thanks to the in-memory computing capabilities of SAP HANA. This means faster access to analytics, reporting, and data-driven insights.
6. Cost of Ownership
SAP ERP: The cost of ownership for SAP ERP can be higher due to the need for complex infrastructure, customization, and maintenance. As the system is based on older technology, upgrades and system changes can be costly and time-consuming.
SAP S/4HANA: While the initial investment for S/4HANA can be higher, it offers lower long-term maintenance costs. Its simplified architecture reduces the complexity of system updates and maintenance, and its real-time data processing and cloud compatibility can reduce infrastructure and operational costs over time.
7. Customization and Flexibility
SAP ERP: SAP ERP offers significant customization options, making it suitable for businesses with very specific requirements. However, these customizations often lead to higher implementation and maintenance costs.
SAP S/4HANA: S/4HANA offers flexibility through its modular structure, but with a simpler data model, it reduces the need for excessive customization. As businesses grow, they can more easily scale and adapt to new processes without the heavy customization required by traditional ERP systems.
Conclusion
In essence, SAP S/4HANA represents a modern, streamlined version of SAP ERP, offering superior performance, a more intuitive user interface, real-time data processing, and better flexibility. However, businesses that are already using SAP ERP and have extensive customizations may need to carefully plan their transition to SAP S/4HANA to ensure a smooth migration.
If you’re starting fresh or looking for a future-proof ERP solution, SAP S/4HANA is likely the best choice, as it supports emerging technologies, cloud solutions, and real-time analytics. On the other hand, companies with a well-established SAP ERP system may continue using it for the foreseeable future, though it may become more challenging to keep up with technological advancements.
0 notes
Text
Introduction to Data Lakes and Data Warehouses

Introduction
Businesses generate vast amounts of data from various sources.
Understanding Data Lakes and Data Warehouses is crucial for effective data management.
This blog explores differences, use cases, and when to choose each approach.
1. What is a Data Lake?
A data lake is a centralized repository that stores structured, semi-structured, and unstructured data.
Stores raw data without predefined schema.
Supports big data processing and real-time analytics.
1.1 Key Features of Data Lakes
Scalability: Can store vast amounts of data.
Flexibility: Supports multiple data types (JSON, CSV, images, videos).
Cost-effective: Uses low-cost storage solutions.
Supports Advanced Analytics: Enables machine learning and AI applications.
1.2 Technologies Used in Data Lakes
Cloud-based solutions: AWS S3, Azure Data Lake Storage, Google Cloud Storage.
Processing engines: Apache Spark, Hadoop, Databricks.
Query engines: Presto, Trino, Amazon Athena.
1.3 Data Lake Use Cases
✅ Machine Learning & AI: Data scientists can process raw data for model training. ✅ IoT & Sensor Data Processing: Real-time storage and analysis of IoT device data. ✅ Log Analytics: Storing and analyzing logs from applications and systems.
2. What is a Data Warehouse?
A data warehouse is a structured repository optimized for querying and reporting.
Uses schema-on-write (structured data stored in predefined schemas).
Designed for business intelligence (BI) and analytics.
2.1 Key Features of Data Warehouses
Optimized for Queries: Structured format ensures faster analysis.
Supports Business Intelligence: Designed for dashboards and reporting.
ETL Process: Data is transformed before loading.
High Performance: Uses indexing and partitioning for fast queries.
2.2 Technologies Used in Data Warehouses
Cloud-based solutions: Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse.
Traditional databases: Teradata, Oracle Exadata.
ETL Tools: Apache Nifi, AWS Glue, Talend.
2.3 Data Warehouse Use Cases
✅ Enterprise Reporting: Analyzing sales, finance, and marketing data. ✅ Fraud Detection: Banks use structured data to detect anomalies. ✅ Customer Segmentation: Retailers analyze customer behavior for personalized marketing.
3. Key Differences Between Data Lakes and Data Warehouses
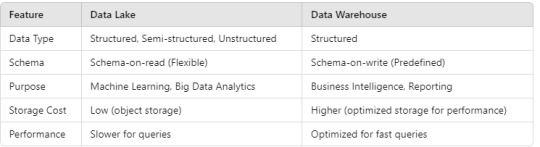
4. Choosing Between a Data Lake and Data Warehouse
Use a Data Lake When:
You have raw, unstructured, or semi-structured data.
You need machine learning, IoT, or big data analytics.
You want low-cost, scalable storage.
Use a Data Warehouse When:
You need fast queries and structured data.
Your focus is on business intelligence (BI) and reporting.
You require data governance and compliance.
5. The Modern Approach: Data Lakehouse
Combines benefits of Data Lakes and Data Warehouses.
Provides structured querying with flexible storage.
Popular solutions: Databricks Lakehouse, Snowflake, Apache Iceberg.
Conclusion
Data Lakes are best for raw data and big data analytics.
Data Warehouses are ideal for structured data and business reporting.
Hybrid solutions (Lakehouses) are emerging to bridge the gap.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes