#DirectML
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Text
Latest DirectML boosts AMD GPU AWQ-based LM acceleration

Minimize Memory Usage and Enhance Performance while Running LLMs on AMD Ryzen AI and Radeon Platforms Overview of 4-bit quantization.
AMD and Microsoft have worked closely together to accelerate generative AI workloads on AMD systems over the past year with ONNXRuntime with DirectML. As a follow-up to AMD’s earlier releases, AMD is pleased to announce that they are enabling 4-bit quantization support and acceleration for Large Language Models (LLMs) on discrete and integrated AMD Radeon GPU platforms that are using ONNXRuntime->DirectML in close cooperation with Microsoft.
NEW! Awareness-Based Quantization(AWQ)
Microsoft and AMD are pleased to present Activation-Aware Quantization (AWQ) based LM acceleration enhanced on AMD GPU architectures with the most recent DirectML and AMD driver preview release. When feasible, the AWQ approach reduces weights to 4-bit with little impact on accuracy. This results in a large decrease in the amount of memory required to run these LLM models while also improving performance.
By determining the top 1% of salient weights required to preserve model correctness and quantizing the remaining 99% of weight parameters, the AWQ approach can accomplish this compression while retaining accuracy. Up to three times the memory reduction for the quantized weights/LLM parameters is achieved by using this technique, which determines which weights to quantize from 16-bit to 4-bit based on the actual data distribution in the activations. Compared to conventional weight quantization methods that ignore activation data distributions, it is also possible to preserve model fidelity by accounting for the data distribution in activations.
To obtain a performance boost on AMD Radeon GPUs, AMD driver resident ML layers dequantize the parameters and accelerate on the ML hardware during runtime. This 4-bit AWQ quantization is carried out utilizing Microsoft Olive toolchains for DirectML. Before the model is used for inference, the post-training quantization procedure described below is carried out offline. It was previously impossible to execute these language models (LM) on a device on a system with limited memory, but our technique makes it viable now.
Making Use of Hardware Capabilities
Ryzen AI NPU: Make use of the Neural Processing Unit (NPU) if your Ryzen CPU has one integrated! Specifically engineered to handle AI workloads efficiently, the NPU frees up CPU processing time while utilizing less memory overall.
Radeon GPU: To conduct LLM inference on your Radeon graphics card (GPU), think about utilizing AMD’s ROCm software stack. For the parallel processing workloads typical of LLMs, GPUs are frequently more appropriate, perhaps relieving the CPU of memory pressure.
Software Enhancements:
Quantization: Quantization drastically lowers the memory footprint of the LLM by reducing the amount of bits required to represent weights and activations. AMD [AMD Ryzen AI LLM Performance] suggests 4-bit KM quantization for Ryzen AI systems.
Model Pruning: To minimise the size and memory needs of the LLM, remove unnecessary connections from it PyTorch and TensorFlow offer pruning.
Knowledge distillation teaches a smaller student model to act like a larger teacher model. This may result in an LLM that is smaller and has similar functionality.
Making Use of Frameworks and Tools:
LM Studio: This intuitive software facilitates the deployment of LLMs on Ryzen AI PCs without the need for coding. It probably optimizes AMD hardware’s use of resources.
Generally Suggested Practices:
Select the appropriate LLM size: Choose an LLM that has the skills you require, but nothing more. Bigger models have more memory required.
Aim for optimal batch sizes: Try out various batch sizes to determine the ideal ratio between processing performance and memory utilization.
Track memory consumption: Applications such as AMD Radeon Software and Nvidia System Management Interface (nvidia-smi) can assist in tracking memory usage and pinpointing bottlenecks.
AWQ quantization
4-bit AWQ quantization using Microsoft Olive toolchains for DirectML
4-bit AWQ Quantization: This method lowers the amount of bits in a neural network model that are used to represent activations and weights. It can dramatically reduce the model’s memory footprint.
Microsoft Olive: Olive is a neural network quantization framework that is independent of AMD or DirectML hardware. It is compatible with a number of hardware systems.
DirectML is a Microsoft API designed to run machine learning models on Windows-based devices, with a focus on hardware acceleration for devices that meet the requirements.
4-bit KM Quantization
AMD advises against utilizing AWQ quantization for Ryzen AI systems and instead suggests 4-bit KM quantization. Within the larger field of quantization approaches, KM is a particular quantization scheme.
Olive is not directly related to AMD or DirectML, even if it can be used for quantization. It is an independent tool.
The quantized model for inference might be deployed via DirectML on an AMD-compatible Windows device, but DirectML wouldn’t be used for the quantization process itself.
In conclusion, AMD Ryzen AI uses a memory reduction technique called 4-bit KM quantization. While Olive is a tool that may be used for quantization, it is not directly related to DirectML.
Achievement
Memory footprint reduction on AMD Radeon 7900 XTX systems when compared to executing the 16-bit version of the weight00000s; comparable reduction on AMD Ryzen AI platforms with AMD Radeon 780m.
Read more on Govindhtech.com
0 notes
Text
使用微軟的 DirectML Extension for Automatic1111's SD WebUI 加速 SD v1.5 的圖像生成速度
目前測試預設的 SD v1.5 和 SD v1.4 可以正常的運行,而且算���速度明顯快上不少;SD v2 可以跑最佳化,但是算圖時會發生錯誤。 以下為環境建置方式: 1. 於擴充功能頁籤���網址安裝:https://github.com/microsoft/Stable-Diffusion-WebUI-DirectML 2. 重啟UI完成安裝後,在[Settings 設定] –> [User Interface] 的 [Quicksettings list 快速設定列表],加入 “sd_unet”,套用設定並重新載入UI以啟用 SD Unet 選擇介面。 3. 目前 SD Unet 選單內還沒有模型可以選擇,請切換到 [DirectML] 頁籤,這裡是官方對於該擴充功能的說明,以及運行所需要的套件資訊。 4. 參考說明的 Getting Started 第 1.…
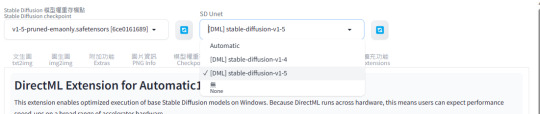
View On WordPress
0 notes
Text
警告やエラーを解決していく その1
## 警告やエラーを解決していく WARNING: you should not skip torch test unless you want CPU to work. F:\StabilityMatrix\Data\Packages\stable-diffusion-webui-directml\venv\lib\site-packages\timm\models\layers\__init__.py:48: FutureWarning: Importing from timm.models.layers is deprecated, please import via timm.layers warnings.warn(f"Importing from {__name__} is deprecated, please import via timm.layers",…
0 notes

Text
Microsoft DirectML ora supporta i PC Copilot+ e WebNN
DirectML è un’API di basso livello che consente agli sviluppatori di eseguire carichi di lavoro di apprendimento automatico su qualsiasi GPU compatibile con DirectX 12 di AMD, Intel e NVIDIA. È stata introdotta per la prima volta in Windows 10, versione 1903. Di recente, Microsoft ha iniziato a supportare le NPU presenti nei moderni SoC in DirectML. Oggi, Microsoft ha annunciato che DirectML ora…
0 notes
Text

十六夜ノノミ Izayoi Nonomi+ Task Report
[Reward] https://wingr.fanbox.cc/posts/6657797 https://subscribestar.adult/posts/1009340 https://discord.com/channels/725318162207473764/725338684311732306/1150230280897036418
Sorry for disappear for almost 10 days. These days I'm studying AI. Yea… I know people don't like it. But I'm curious what can it done.
I switch from NOD-AI to Vlad. After end of Aug reward. I start to setup it. Yea… spent 10 days for this AI coloring.
The process isn't smooth. Even I got suck at --use-directml
Then got suck at inpaint and Img to Img. Keeps "half" and "memory" errors. Outpainting I even can't figure out how to do it till now
Keep error and error and error
For this jumping. I am more stable lora characters , AWW FRESH MEAT X I wanted coloring lineart O
I mentioned before. I won't color all my drawing. Time is limited, can't do everything. For those aren't important sketches. I can make a AI paint ver if you really wanted full color
This Nonomi drawing is supposed for this testing only. I just finished it right now and put into Vlad.
And I also packed those testing output (Those not presentable images are removed)
10天來一個帖都沒有,很抱歉。 在趕完8月末的REWARD後我就跳到AI去,一研究就研究了10天了。
嗯,人們不喜歡AI,不過我想知道AI能作到什麼東西。
這10天自然是很不順暢 就一開始時的 --use-directml已經卡了好幾小時
然後重點的IMG 2 IMG和Inpaint又卡。不是half就是memory問題。 OUTPAINT更是現在都未模到要怎麼用
這次研究AI重點 可以輸出LORA版權人物圖,大量肉暴誕 X AI的線稿上色 O
我曾說過了,我不會為每張圖上色。一個人的時間是有限,不可能全都完成的。 那麼那些不太重要的草圖…現在可以用AI上色了。
這次的野乃美是為了這個而作。就是剛剛才弄好…
另外也打包了一堆測試圖 (太爛的我直接丟了)
★ Twitter - https://twitter.com/wingr2000 ★ ★ Discord - http://discord.gg/xtnWz4h ★ ★ If you enjoy my work, supporting me on ★ Fanbox https://wingr.fanbox.cc/
0 notes
Photo

Sometimes you’ll meet people who go ‘pfft, what’s the deal with AI cores in GPUs, they should get rid of it’ without fully understanding what hardware like Tensor cores could do. Sure there’d be the usual nVidia vs AMD camps battling whether DLSS or FSR is better. IMHO, FSR is a cheaper, easier to implement feature that costs next to nothing to implement. DLSS has to be trained months using large data number crunchers to produce good results. But therein lies the conceit: FSR is a fixed algorithm. DLSS is a machine-learning (ML) implementation. Which means it can be trained to be better. A lot better.
Let’s forget about 3D stuff for now and go back to what this blog mainly covers about: old 2D visuals. Currently a lot of emulators have lightweight pixel scalers such as xBRz and HQ4x that attempt to upscale visuals so that they don’t look so square on modern LCD screens. This is because some people were old enough to remember looking at the visuals on CRT screens that were somewhat fuzzy via a combination of phosphor bloom and scanlines. These filters were great when they were introduced in zSNES because it upscaled the lowres console graphics to twice the resolution, but ultimately still displayed on a CRT monitor. In the modern era where HD LCD is the norm, these filters look horrendous. In a twist of irony, many resort to using scanline filters in an attempt to resurrect the original feel of the visuals with varying success.
The past recent years came the introduction of machine learning processing, which utilise neural networks to twist the previous paradigm of having humans come up with the algorithms of how pixels should be upscaled. Instead, the computer itself comes up with the methodology by comparing the input, expected output and its own predictions over a hundred thousand iterations. The result of this can be incredible, depending on what data was fed to the computer to achieve this objective. The downside is this upscaling takes a lot of GPU power, roughly clocking about 5-10 fps for a 4x upscale of a 320x240 pixel visual.
Companies that believe ML is the future commit to allocating a significant chunk of their chip silicone real-estate to AI-centric cores, such as nVidia and Apple (or ARM in general). Meanwhile, AMD is in the firm believe that their Compute Units are sufficient enough to handle ML tasks. However, them dropping out of developing a ML-based upscaler for their GPUs (even with heavy promotion with their X-Box partner Microsoft, supposedly to be done via DirectML) and coming out with FSR instead... puts doubt into this notion.
Nvidia is investing for things to come, despite the initial missteps in ML tech such as the first implementation of DLSS. Right now we already other interesting implementations of ML tech such DLAA and RTX voice, so who knows, when GPUs become fast enough to do 2D ML upscaling at 60fps, then the drivers, libraries, data and models are already ready for mass implementation.
17 notes
·
View notes
Text
Powerful Intel Arc Graphics and DirectML Collaboration

Intel Arc Graphics and Microsoft’s DirectML
The use of generative AI technology is revolutionizing their workflow and opening up new possibilities in a variety of industries, including coding, real-time graphics, and video production. Now Intel and Microsoft are showcasing their collaborative engineering efforts to facilitate cutting-edge generative AI workloads on Intel GPUs running Windows, in conjunction with the Microsoft Ignite developer conference.
Intel Arc GPUs: Designed for AI workloads of the future
With the release of its Intel Arc A-Series graphics cards last year, Intel made a foray into the discrete GPU market. The Intel Arc A770 GPU, the flagship model in this family, has 16GB of high-bandwidth GDDR6 memory in addition to Intel Xe Matrix Extensions, a potent AI acceleration technology (Intel XMX.) The customized XMX array provides exceptional performance for applications requiring generative AI, particularly for matrix multiplication.
Subsequently, Intel and Microsoft have collaborated to enhance DirectML compatibility with Intel Arc graphics solutions, ranging from the Intel Arc A770 GPU to the Intel Arc GPUs integrated into the next Core Ultra mobile CPUs (also known as Meteor Lake).
Olive tweaks and additional
Ensuring that the models fit and perform effectively within the limitations of consumer PC system settings is one of the challenges developers have when delivering AI capabilities to client systems. Microsoft published the open-source Olive model optimization tool last year to aid in addressing this difficulty. Olive has just been upgraded with enhancements centered around some of the most fascinating new artificial intelligence models, such as the Llama 2 big language model from Meta and the Stable Diffusion XL text-to-image generator from Stability AI.
We discovered that the Olive-optimized version of Stable Diffusion 1.5 works on the Intel Arc A770 GPU via the ONNX Runtime with the DirectML execution provider at a performance that is twice as fast as the default model, demonstrating the potential of this tool.
Although there is a significant improvement, our work didn’t end there. For all generative AI tasks, a wide range of operators are optimized by Intel’s graphics driver. Our driver has a highly optimized version of the multi-head attention (MHA) metacommand, which significantly enhances efficiency by extracting even more from models such as Stable Diffusion. Consequently, our most recent driver outperforms the previous one by up to 36% in Stable Diffusion 1.5 on the Intel Arc A770 GPU.
The net effect is a cumulative acceleration of the Intel Arc A770’s Stable Diffusion 1.5 by up to 2.7 times.
Additionally, the Olive-optimized versions of Llama 2 and Stable Diffusion XL are now functionally supported by this new driver, and further optimizations for all three of these models are on the horizon.
Next, what?
Since many years ago, Intel has collaborated with developers to offer enhanced AI capabilities on our platforms. The work encompasses a variety of end-user apps, such as powerful suites for content production including Adobe Creative Cloud, the AI-enhanced portfolio from Topaz Labs, and Blackmagic DaVinci Resolve. With the use of our Intel Xe Super Sampling (XeSS) AI-based upscaling technology, we have also assisted game creators in providing improved gaming experiences in a number of well-known games. We’re going to keep driving the AI PC revolution on Windows 11 and beyond, together with Microsoft and the developer community!
Read more on Govindhtech.com
0 notes
Text
Stable Diffusion - 修改 Default 預設值
Stable Diffusion Web UI 的 UI 和 算圖相關的設定,分別放在根目錄的 ui-config.json 和 config.json,編輯前者便能要修改 UI 上的預設值如常見的圖像寬高、取樣方法、步驟… 等等。(與 Stable Diffusion Web UI DirectML 通用) 以修改txt2img文生圖的Width寬度預設值為例,用記事本等文字編輯器打開ui-config.json後搜尋”txt2img/Width”便能查到該預設值(相同關鍵字的參數大部分都放在一起,要人工查找也是可以),編輯存檔後即可。如果想要驗證確認,除了Stable Diffusion關閉重開外,也可以點選[設定 Settings]的[重新載入UI Reload UI]來快速生效。

View On WordPress
0 notes
Text
#WindowsML – Create Native AI apps for #Hololens #Windows10
#WindowsML – Create Native AI apps for #Hololens #Windows10
Hi!
A couple of weeks ago I wrote about a new feature in Windows 10 to be able to use ML models natively in W10 Apps. For me, that would mean a breakthrough in the entire Windows 10 Device ecosystem. In example, as we already know, the new version of Hololens incorporates a chip specially dedicated to AI tasks (DNN specifically), so I assumed that in Hololens V2 we could start using Windows ML…
View On WordPress
#DirectML#English Post#HoloLens#Machine Learning#ONNX#Unity3D#Visual Studio 2017#Windows 10#Windows Machine Learning#WinML
0 notes
Text
Intel MacでAMD GPUを使ってStableDiffusionを動かす
前回の記事で、Intel Mac に AUTOMATIC1111 版 Stable Diffusin をインストールする方法をご紹介しました。 https://gift-by-gifted.com/stablediffusion-3/ しかし、Intel CPU と AMD Radeon GPU 搭載の Mac では GPU を使用できず、CPU だけで画像を生成するため、非常に効率の悪いものでした。 最近、DirectML を使って AMD Radeon GPU でも Stable Diffusion が動作するフォーク版がテストながら発表されていますので、それを使って、やや強引な方法ながら動かしてみます。 ブートキャンプの用意 macOS の Stable Diffusion では DirectML はサポートされていないので、強引ながらブートキャンプで Windows…

View On WordPress
0 notes
Photo

Intel Releases Graphics Driver 100.6577 (DCH)
Download Here
Release Notes
Highlights:
Launch Day support for Dirt Rally 2.0
Support added for Civilisation VI: Gathering Storm
Support added for Apex Legends
Gaming Highlights:
Support added for:
Onimusha: Warlords (UHD 620 or higher recommend)
Unruly Heroes (UHD 620 or higher recommend)
Corda Octave (UHD 620 or higher recommend)
Ace Combat 7: Skies Unknown (UHD 630 or higher recommended)
Apex Legends (UHD 630 or higher recommended)
Civilisation VI: Gathering Storm playability improvements for 6th gen and higher
Performance Improvements on Arma 3 for 6th gen and higher
Developer Highlights:
DirectML Metacommands - this driver release contains functional fixes and performance improvements while adding support for few features:
Improved GPU frequency ramp speed giving performance boost to Metacommand enabled workloads
Support for Softplus activation
Support for fused operations to improve performance.
Support for Pooling Metacommand - this operation now uses metacommands for both FP32 and FP16 datatypes and is common in many topologies like Squeezenet, Resnet , Inception etc.
Enables Indigo benchmark application to run.
Adds compiler API for DX11 and DX12 shaders to allow compiling shaders offline to analyze the ISA (native code) generated. This can run independently of the runtime driver and is expected to understand shader performance.
Key issues fixed:
Intermittent crashes in Cinema4D, CIV VI: Gathering Storm And vkQuake2
Graphics anomalies in Final Fantasy XV and Microsoft Edge
OpenGL stability fixes
Internal panels showing black screen after driver installation
Content protection not resuming after waking from sleep
Rotation not being persistent when swapping displays in multi monitor setups
Aspect ratio options not being available in Graphics control panel for HDMI monitors
Garbage may be seen while using Multi stream transport monitors
Key Issues:
Minor Graphics anomalies may be observed in BFV (DX11), Apex Legends(6th Gen only), Arma 3 (6th gen only), Re-legion and other games
Intermittent crashes or hangs occurring in Crackdown 3 and other games
Corruptions may be seen in video recorded by Cyberlink screen recorder
Color band may be be observed on either side of Netflix playback on HDR displays
1 note
·
View note
Text
Use DirectML to train PyTorch machine learning models on a PC
Use DirectML to train PyTorch machine learning models on a PC
Machine learning is an increasingly important tool for developers, providing a way to build applications that can deliver a wide range of prediction-based tasks. In the past you might have had to build a complex rules engine, using numeric techniques to deliver the required statistical models. Now you can work with a ML platform to build, train, and test models for your applications. We call ML…
View On WordPress
0 notes
Text
Intel Core Ultra 5 225 Specs, Performance, and Price

Core Ultra 5 225 is a desktop processor. Arrow Lake is an Intel Core Ultra Processor (Series 2). The processor is considered to be top-tier and great for gaming with a good visual card.
Threads and Core Architecture
The processor has 10 cores and 10 threads.
The cores fall into two categories:
P-cores: six threads and six cores. Their base frequency is 3.3 GHz and turbo frequency is 4.9 GHz.
E-cores, efficient cores: Four cores, four threads. They have 2.7 GHz base frequency and 4.4 GHz turbo frequency.
The cache
The processor includes 20 MB Intel Smart Cache.
A detailed cache breakdown by core type follows:
CPU Performance Package: Instruction L1 6 x 64 KB, L1 data cache 6 x 48 KB, L2 cache 6 x 3072 KB, and L3 cache 20 MB.
Good CPU Package: L1 Instruction Four 64 KB cache, four 32 KB effective L1 data cache, and one 4096 KB effective L2 cache.
Power and socket
This CPU uses FCLGA1851 sockets.
Thermal design power averages 65 W.
Maximum turbo power is 121 W.
Memory Aid
Memory is limited to 192 GB.
At 6400 MT/s, it supports DDR5 memory.
It supports dual-channel RAM.
Built-in graphics and display
The two-Xe-core processor has Intel Graphics.
Intel Graphics on-board graphics card ID is 0x7D67.
It supports four screens.
On-board graphics outputs include eDP 1.4b, DisplayPort 2.1, and HDMI 2.1.
The graphics card supports OpenGL 4.5 and DirectX 12.0.
Base frequency is 300 MHz and maximum dynamic frequency is 1800 MHz for on-board graphics.
Intel AI Boost Proficiency
The processor has Intel AI Boost NPU.
NPU can reach 13 TOPs.
The CPU, NPU, and GPU offer 23 TOPs of processor performance.
The CPU supports WebNN, ONNX RT, Windows ML, OpenVINO, and DirectML AI frameworks.
The NPU supports WebNN, ONNX RT, Windows ML, OpenVINO, and DirectML AI frameworks.
Sparsity is supported.
Compatible with Windows Studio effects.
CPU and GPU support Intel Deep Learning Boost (DL Boost).
Other Tech and Features
Intel Graphics and AI Boost are included.
PCI Express slots 4.0 and 5.0 are supported and it has 24 lanes.
Instruction sets supported are SSE4.1, SSE4.2, and AVX 2.0.
Compatible with Scalability 1S.
Idle States, Execute Disable Bit, Improved Intel SpeedStep Technology, Secure Key, Turbo Boost 2.0, Trusted Execution, Quick Sync Video, Intel AES-NI, and Thermal Monitoring are features.
We support Intel VT-x, VT-d, and VT-x with EPT.
Intel 64, Speed Shift Technology, OS Guard, Boot Guard, VMD, MBE, Thunderbolt 4, Thread Director, CET, and Standard Manageability are further features.
Maximum operating temperature is 105 °C.
Advantages
Performance-Efficient Cores: The hybrid architecture balances power and performance well.
Integration of AI acceleration features improves AI performance.
Integrating graphics eliminates the need for a discrete GPU for daily work.
Disadvantages
Limited Graphics Performance: Advanced gaming or intensive graphical tasks may exceed integrated graphics.
This processor cannot be overclocked because it is not K series.
Video editing, 3D rendering
The CPU handles video editing and 3D graphics well for entry-level to mid-range applications. A PC with a dedicated graphics card is better for professional applications that require high GPU performance.
Intel Ultra 5 225 video game performance
The Intel Core Ultra 5 225 can play light and moderate games at lower settings with its Intel Graphics. For top-tier gaming, use a discrete GPU.
Intel Core Ultra 5 225 cost
According to Intel's MSRP, the Intel Core Ultra 5 225 will cost $246 USD when packed. MSRP for tray variant is $236.
Remember that seller, location, and market can alter retail prices. Whether it's pre-built or combined with other parts affects its price.
For more details visit govindhtech.com
#IntelCoreUltra5225#IntelCoreUltra#CoreUltra5225#IntelCoreUltra5225processor#Ultra5225#IntelCoreUltra5225price#technology#technews#technologynews#news#govindhtech
0 notes
Text
pip 常用指令
以下是 Python 安裝後自帶的套件管理程式 pip 的常用指令: 查看 pip 的版本(參數有區分大小寫):pip -V 更新 pip 自己:python.exe -m pip install –upgrade pip 查閱已安裝的套件:pip list 安裝或更新指定套件:pip install {套件名稱} 常用套件 NumPy 大量的數學函數,是大部分資料分析套件的必要基礎套件:pip install numpy PyTorch 類神經網路運算的常用套件(需要搭配支援CUDA的nVidia顯示晶片) pip install torch PyTorch with DirectML 透過微軟的 DirectML 讓支援 DirectX 12 的顯示晶片能使用 PyTorchpip install torch-directml 安裝或更新指定套件指定版本:pip…
View On WordPress
0 notes