#Find All Substrings of a Given String
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
07/07/2023 || Day 47
LeetCode & Random Rambles
This is a longer one, so more below the cut, but TLDR: buy yourself a whiteboard to help draw things out/make sense of problems.
LeetCode:
Spent 3-4 hours on the Minimum Window Substring question today, which hurt my head but I did it! One problem that I have while working on these problems is figuring out what to keep track of. For example, this question gave us 2 pieces of input; s (which is a string, such as "ABCAAA") and t (which is also a string, but a substring, such as "ABA"). Now, the question asked for us to find the minimum substring of s such that the substring contains all the letters in t, including duplicates in t (which would be "ABCA"). So, I knew I had to keep track of the occurrence of each character in both s and t when the letter is found in both, so I used 2 handy-dandy HashMaps, since I can record the amount of times each character appears in the original string s, and what I've read so far in s. Now, what I failed to realize until later, and what I really didn't want to add until I finally got off my lazy butt and did add, was a mechanism to keep track of whether I've encountered the minimum occurrence of the current letter, as well as all the previous letters. This allows my program to correctly get the minimum substring of s that contains all the letters in t, and if there are more, then that's still ok. Here's a slice of the code that I wrote to fix that problem; basically, seeing if the amount of times I visited a given letter is the same amount as it's supposed to occur. If it is, increase my counter by 1. Then, if the counter is the same number as the size of my total letters (i.e. I've encountered all the letters at least the minimum amount of times), start decreasing my window to find the minimum substring.
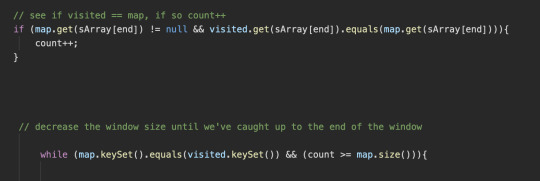
Of course, after adding this mechanism (with a good ol' variable to keep track), things worked out. It's funny, it's like while I'm working on any LeetCode problem and I realize I need to add another mechanism when I'm already knee-deep in my current method, I feel like my brain has to jump over such a high hurdle to get started on adding the thing that will inevitably make things work. It feels like such an mental task...and I'm 90% sure it's my stubbornness. Anyways, with this question done, I've completed the little sliding window section in the 150 LeetCode question list I'm working through. Goodbye sliding window, I'll miss you (not really, but it wasn't that bad).
Also, to everyone who's visual and likes writing things down to work out problems, I HIGHLY recommend getting yourself a whiteboard. I bought one for myself last year and it's the best purchase I've made; I use it so much. Plus, I don't waste paper. (also, playing cards are great for visualizing sorting algorithms).

Random Ramble:
Didn't get into React today, since LeetCode took a lot out of me mentally, but I decided to treat myself and do some art. I'm doing a personal project of drawing each skill tree from the 2nd Ori game, and I don't like working with orange, but I'm happy with how my version turned out! I think I'm still gonna add some stuff/details, but so far so good.

6 notes
·
View notes
Text
hi
Longest Substring Without Repeating Characters Problem: Find the length of the longest substring without repeating characters. Link: Longest Substring Without Repeating Characters
Median of Two Sorted Arrays Problem: Find the median of two sorted arrays. Link: Median of Two Sorted Arrays
Longest Palindromic Substring Problem: Find the longest palindromic substring in a given string. Link: Longest Palindromic Substring
Zigzag Conversion Problem: Convert a string to a zigzag pattern on a given number of rows. Link: Zigzag Conversion
Three Sum LeetCode #15: Find all unique triplets in the array which gives the sum of zero.
Container With Most Water LeetCode #11: Find two lines that together with the x-axis form a container that holds the most water.
Longest Substring Without Repeating Characters LeetCode #3: Find the length of the longest substring without repeating characters.
Product of Array Except Self LeetCode #238: Return an array such that each element is the product of all the other elements.
Valid Anagram LeetCode #242: Determine if two strings are anagrams.
Linked Lists Reverse Linked List LeetCode #206: Reverse a singly linked list.
Merge Two Sorted Lists LeetCode #21: Merge two sorted linked lists into a single sorted linked list.
Linked List Cycle LeetCode #141: Detect if a linked list has a cycle in it.
Remove Nth Node From End of List LeetCode #19: Remove the nth node from the end of a linked list.
Palindrome Linked List LeetCode #234: Check if a linked list is a palindrome.
Trees and Graphs Binary Tree Inorder Traversal LeetCode #94: Perform an inorder traversal of a binary tree.
Lowest Common Ancestor of a Binary Search Tree LeetCode #235: Find the lowest common ancestor of two nodes in a BST.
Binary Tree Level Order Traversal LeetCode #102: Traverse a binary tree level by level.
Validate Binary Search Tree LeetCode #98: Check if a binary tree is a valid BST.
Symmetric Tree LeetCode #101: Determine if a tree is symmetric.
Dynamic Programming Climbing Stairs LeetCode #70: Count the number of ways to reach the top of a staircase.
Longest Increasing Subsequence LeetCode #300: Find the length of the longest increasing subsequence.
Coin Change LeetCode #322: Given a set of coins, find the minimum number of coins to make a given amount.
Maximum Subarray LeetCode #53: Find the contiguous subarray with the maximum sum.
House Robber LeetCode #198: Maximize the amount of money you can rob without robbing two adjacent houses.
Collections and Hashing Group Anagrams LeetCode #49: Group anagrams together using Java Collections.
Top K Frequent Elements LeetCode #347: Find the k most frequent elements in an array.
Intersection of Two Arrays II LeetCode #350: Find the intersection of two arrays, allowing for duplicates.
LRU Cache LeetCode #146: Implement a Least Recently Used (LRU) cache.
Valid Parentheses LeetCode #20: Check if a string of parentheses is valid using a stack.
Sorting and Searching Merge Intervals LeetCode #56: Merge overlapping intervals.
Search in Rotated Sorted Array LeetCode #33: Search for a target value in a rotated sorted array.
Kth Largest Element in an Array LeetCode #215: Find the kth largest element in an array.
Median of Two Sorted Arrays LeetCode #4: Find the median of two sorted arrays.
0 notes
Video
youtube
LEETCODE 1371: SEEN MAP SET AND FORGET PATTERN: FIND SUBSTR WITH EVEN VO...
LeetCode Problem 1371, "Find the Longest Substring Containing Vowels in Even Counts," involves finding the length of the longest substring in a given string where all vowels (a, e, i, o, u) appear an even number of times. The problem can be solved using a bitmasking approach, where each vowel's presence is tracked using a bitmask. The key idea is to store the first occurrence of each bitmask state and check how far you can go from that state without violating the even count condition. By tracking changes in the bitmask as we traverse the string, the solution efficiently finds the longest valid substring.
0 notes
Text
hi
fizzbuzz reverse string implement stack
convert integer to roman numeral longest palindrome substring
design hashset
Java group by sort – multiple comparators example https://leetcode.com/discuss/interview-question/848202/employee-implementation-online-assessment-hackerrank-how-to-solve
SELECT SUBQUERY1.name FROM (SELECT ID,name, RIGHT(name, 3) AS ExtractString FROM students where marks > 75 ) SUBQUERY1 order by SUBQUERY1.ExtractString ,SUBQUERY1.ID asc ;
SELECT *
FROM CITY
WHERECOUNTRYCODE = 'USA' AND POPULATION > 100000;
Regards
Write a simple lambda in Java to transpose a list of strings long value to a list of long reversed. Input: [“1”,”2”,”3”,”4”,”5”] output: [5,4,3,2,1] 2. Write a Java Program to count the number of words in a string using HashMap.
Sample String str = "Am I A Doing the the coding exercise Am" Data model for the next 3 questions:
Write a simple lambda in Java to transpose a list of strings long value to a list of long reversed. Input: [“1”,”2”,”3”,”4”,”5”] output: [5,4,3,2,1] 2. Write a Java Program to count the number of words in a string using HashMap.
Sample String str = "Am I A Doing the the coding exercise Am" Data model for the next 3 questions:
Customer :
CustomerId : int Name : varchar(255)
Account :
AccountId : int CustomerId : int AccountNumber : varchar(255) Balance : int
Transactions : Transactionid : int AccountId: int TransTimestamp : numeric(19,0) Description : varchar(255) Amount(numeric(19,4)) 3. Write a select query to find the most recent 10 transactions. 4. Write a select query, which, given an customer id, returns all the transactions of that customer. 5. What indexes should be created for the above to run efficiently? CustomerId, AccountId 6. Write a program to sort and ArrayList.
Regards
0 notes
Text
Programming: Fuses and place points
The main mechanic is the fuse system which works with the fuse box made from a total of 5 actors.
Fuses
There are 3 fuse types total, though they all operate in basically the same way.
Every fuse has a code given to it on begin play consisting of 3 letters in any combination; R, G and B, these codes are then used to set the colors on the fuse. They also have custom events in order to recode them or recolor them.

Coloring the fuses works by setting the material of the 3 rings on the fuse mesh, the top, middle and bottom.

The coloring is done by taking the corresponding letter in the code by getting a substring, then using a switch on string node to set the ring to the correct material depending on the letter. This is done for all 3 rings.

^ x3
Place points
Place points are used to place objects into.
When a place point is created its mesh and material are set and a tag is added to identify what item can be placed in it.

When an object has been placed, it first goes invisible to prevent Z fighting.
When a correct fuse is placed inside the place point, the place point inherits its code in order to later pass it on to the fuse box however it is also used to short circuit if a fake or faulty fuse is placed inside it, creating an explosion and turning out the lights temporarily.

When a fuse is dropped (or the attach event is triggered), it searches for place points that it is colliding with that have the Fuse tag,
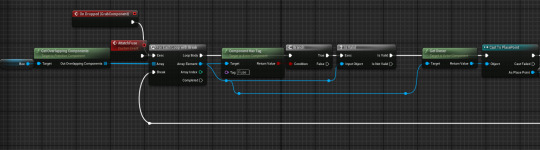
when it finds an empty one, it triggers the fuse placed event with the explosive option on ticked and attaches itself to the place point.

When a fuse is grabbed and it is inside a place point, the place point will be cleared and lose the fuse's code.

The same thing happens when a fuse is launched out upon a blackout or when a fake or faulty fuse is placed in, along with an impulse being added to throw it.

A fuse can also be broken, which clears its code and makes its lights blink out and die, making it useless.
Fake/faulty fuse explosion

Fuses breaking

Faulty fuse
Faulty fuses work in the exact same way as regular ones with 2 exceptions.
Upon being placed in a place point, its explosive option is set to true, making it blow up.

2. It has a sequence which makes it constantly blink. This is done by randomly selecting which lights on it should be blinking on begin play.
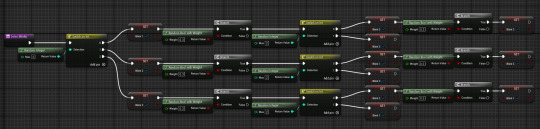
Along with that, unlike in the regular fuse its colors are saved as variables. After doing so, this sequence is played on tick; for every blinking light there is a 10% chance to switch material to either a random color or no light.


Fake fuse
Fake fuses work similarly, but instead of blinking, they have different colors; Cyan, yellow and magenta, using some random chance to mix them in with the regular colors, but always with minimum one incorrect color in order to tell it apart, similar to the faulty fuse which always has at least 1 blinking light, they will also blow up.
Regular fuse on the left, fake on the right.

0 notes
Text
Find All Substrings of a Given String In C#
Find All Substrings of a Given String In C#
Find All Substrings of a Given String In C# Console.Write(“Enter a String : “);string inputString = Console.ReadLine(); Console.WriteLine(“All substrings for given string are : “); for (int i = 0; i < inputString.Length; ++i){StringBuilder subString = new StringBuilder(inputString.Length – i);for (int j = i; j < inputString.Length; ++j){subString.Append(inputString[j]);Console.Write(subString…

View On WordPress
#.NET#c#Coding#Find All Substrings of a Given String#Find All Substrings of a Given String In C#java#Program#program in c#Programming#Technology
0 notes
Text
The Trick for Sql Interview Questions for Experienced Professionals
What You Need to Do to Find Out About Sql Interview Questions for Experienced Professionals Before You're Left Behind They are commands used to combine queries to be able to get outcomes. Scheduled tasks or jobs are used to automate procedures which may be conducted on a scheduled period at a standard interval. The usage of their responses given below and the questions is to guarantee that women and the men who examine them and learn them will secure a comprehension of the XML functionalities supplied by SQL Server. There's a reason for the error read on to understand why. The issue is the SQL Standard says that a column which is not part of the group by clause unless it contained inside an function can't be picked by us. The problem here is that we don't know because we are not with what we are requesting in the SQL particular 19, what will be returned! My problem is that I want to eliminate duplicates in the outcome and don't appear to be able to accomplish this. Whether there aren't any configuration problems that block the server you can start an instance of Microsoft SQL Server by utilizing the configuration startup choice. You will find the questions are not loyal to any right answer but there is always scope for improvement in your reply. It is a simple fact that the aforementioned questions might be answered in a number of other potential ways. Answers are extremely precise. The reply ought to be one. http://bit.ly/2jYDMm8 The issue is that you want to express the reply in your words and imagination will come out in front of their interviewers. Please help me to enhance the answer if you believe so. Do not say yes just to locate the job when the true answer is no. Finding Sql Interview Questions Whizlabs pioneering the internet certification training business aims that will allow you to construct a booming career. Technology is moving at a fast speed. There are several database systems out there, and individuals will be unfamiliar with the ins and out of each one of them. Functions are available in gleaning information regarding the error to aid. The SUBSTR function is utilized to return specific part of series in a string that was particular. Integrity constraints are utilised to ensure accuracy and consistency of information. Taking away the columns that are not determined by constraints that are important that are primary. You'd really like all unmatched and matched information from only one table. https://tinyurl.com/y2emjnh4 There are types of connect that are utilised to recover data and it is contingent on the connection between tables. The New Fuss About Sql Interview Questions for Professionals SQL server can be connected to any database which has OLE-DB supplier to extend a hyperlink. SQL Server from Microsoft is largely supposed to be employed on Windows Systems. Microsoft SQL Server supports varieties of XML indexes. Database is merely an form of information for accessibility, storing, retrieval and managing of information. Oracle database consists of 3 kinds of documents. https://is.gd/kqrdm4 https://annuaire-du-net.com/sql-interview-questions-and-answers/ There are three sorts of sub query 9. There you get the queries for sample data generation so that you can quickly start your SQL interview preparation. There are a great deal of data types extended in PL SQL but mostly you might be using several the ones that are well-known. Things You Should Know About Sql Interview Questions for Professionals You need to see that the assurance level before going into the office. As an applicant, you should concentrate on communicating skills and your own confidence level. It requires skill to make them see it when you're an ideal match. First you need the database abilities and you want the interview skills. The Key to Sql Interview Questions for Professionals By referencing foreign key with another table's key key relationship has to be made between two tables. Database Relationship is understood to be the relation between the tables in a database. You may understand what is SQL in DBMS's function. Thus you have to find out your candidate . Candidates will need to prepare to provide examples from past job experiences, sharing tales which enable the feasible employer to get a comprehension of skillset that is present. The candidate will be able to notify you cursors are utilized to perform processing. Interviewers are going to need to see your coding skills to check your general adaptability. The interviewers desire to feel confident you have the ideal skills, but additionally that your will be a pleasant and productive coworker. Your interviewer will probably have to look at your knowledge to see whether you will name the orders required for programmers. Employers are a lot more likely to respond well to credibility versus perfectionism. They'll want to make certain they're hiring a SQL programmer who is experienced with the set of internet technologies they use in their company, which explains why it's beneficial that you have experience with RDBMSs.
1 note
·
View note
Text
Grep manual

When the -c or –count option is also used, grep does not output a count greater than NUM. When grep stops after NUM matching lines, it outputs any trailing context lines. This enables a calling process to resume a search. If the input is standard input from a regular file, and NUM matching lines are output, grep ensures that the standard input is positioned to just after the last matching line before exiting, regardless of the presence of trailing context lines. ) -m NUM, –max-count= NUM Stop reading a file after NUM matching lines. The scanning will stop on the first match. l, –files-with-matches Suppress normal output instead print the name of each input file from which output would normally have been printed. L, –files-without-match Suppress normal output instead print the name of each input file from which no output would normally have been printed. The deprecated environment variable GREP_COLOR is still supported, but its setting does not have priority. The colors are defined by the environment variable GREP_COLORS. ) –color, –colour Surround the matched (non-empty) strings, matching lines, context lines, file names, line numbers, byte offsets, and separators (for fields and groups of context lines) with escape sequences to display them in color on the terminal. With the -v, –invert-match option (see below), count non-matching lines. General Output Control -c, –count Suppress normal output instead print a count of matching lines for each input file. x, –line-regexp Select only those matches that exactly match the whole line. Word-constituent characters are letters, digits, and the underscore. Similarly, it must be either at the end of the line or followed by a non-word constituent character. The test is that the matching substring must either be at the beginning of the line, or preceded by a non-word constituent character. ) -w, –word-regexp Select only those lines containing matches that form whole words. ) -v, –invert-match Invert the sense of matching, to select non-matching lines. ) -i, –ignore-case Ignore case distinctions in both the PATTERN and the input files. The empty file contains zero patterns, and therefore matches nothing. ) -f FILE, –file= FILE Obtain patterns from FILE, one per line. This is useful to protect patterns beginning with hyphen-minus ( –). Matching Control -e PATTERN, –regexp= PATTERN Use PATTERN as the pattern. This is highly experimental and grep -P may warn of unimplemented features. P, –perl-regexp Interpret PATTERN as a Perl regular expression. ) -G, –basic-regexp Interpret PATTERN as a basic regular expression (BRE, see below). ) -F, –fixed-strings Interpret PATTERN as a list of fixed strings, separated by newlines, any of which is to be matched. Matcher Selection -E, –extended-regexp Interpret PATTERN as an extended regular expression (ERE, see below). This version number should be included in all bug reports (see below). V, –version Print the version number of grep to the standard output stream. Options Generic Program Information –help Print a usage message briefly summarizing these command-line options and the bug-reporting address, then exit. Direct invocation as either egrep or fgrep is deprecated, but is provided to allow historical applications that rely on them to run unmodified. In addition, three variant programs egrep, fgrep and rgrep are available. By default, grep prints the matching lines. Grep searches the named input FILEs (or standard input if no files are named, or if a single hyphen-minus ( –) is given as file name) for lines containing a match to the given PATTERN. You will have to remove those if your input contains more than just the addresses.Grep, egrep, fgrep, rgrep – print lines matching a pattern Synopsis Note however that some of the expressions are used to match only the IP address and therefore contain beginning- ( ^) and end-of-line ( $) characters. You can find lots of IP address regular expressions on the web, see for example this StackOverflow question. grep -o 192.1.* zĪny line starting with 1921 will be matched, and only the matching part will be printed because of the -o switch.* matches anything up to the end of the line, including the empty string. Only 1921 will be matched, and only the matching part will be printed because of the -o switch. Your input does not contain data where this makes any difference. will be matched, and only the matching part will be printed because of the -o switch.
0 notes
Text
CSCD Assignment Recursive Descent Parser Solution
CSCD Assignment Recursive Descent Parser Solution
Implement a class called SubstringTester that uses recursion to generate all substrings of a given String. For example, the substrings of the string “Sluggo” are the 22 strings: Sluggo Slugg Slug Slu Sl S luggo lugg lug lu l uggo ugg ug u ggo gg g go g o “” You are not allowed to use any loops to build the substrings — at least in your final product. You may, however, find it productive to solve…

View On WordPress
0 notes
Text
Normal Expressions With JavaScript

advent
regular expressions (RegExp) are a very useful and powerful part of JavaScript. The purpose of a RegExp is to determine whether or not a given string fee is valid, based on a set of rules.
Too many tutorials don't really educate you the way to write ordinary expressions. They certainly provide you with a few examples, most of which might be unluckily very tough to understand, after which never give an explanation for the details of ways the RegExp works. in case you've been pissed off through this as nicely, you then've come to the right vicinity! these days, you're going to virtually discover ways to write everyday expressions.
To find out how they work, we are going to begin with a completely simple example after which usually upload to the rules of the RegExp. With every rule that we upload, i can provide an explanation for the brand new rule and what it provides to the RegExp.
A RegExp is clearly a fixed of regulations to decide whether a string is valid. permit's count on that we've got an internet page where our customers enter their date of delivery. we can use a JSON Formatter ordinary expression in JavaScript to validate whether or not the date that they input is in a valid date layout. after all, we don't need them to enter some thing that is not a date.
Substring search
initially, allow's write a RegExp that requires our customers to go into a date that includes this cost: "MAR-sixteen-1981". word that they can input something they need, so long as the cost consists of MAR-16-1981 someplace within the value. for instance, this would also be legitimate with this expression: take a look at-MAR-16-1981-greater.
below is the HTML and JavaScript for a web page with a shape that lets in our customers to go into their date of birth.
characteristic validateDateFormat(inputString) {
var rxp = new RegExp(/MAR-sixteen-1981/);
var result = rxp.test(inputString);
if (end result == false) {
alert("Invalid Date format");
}
return end result;
}
be aware of the following key pieces of this code:
1. when the post button is clicked, our JavaScript function is called. If the price fails our take a look at, we display an alert pop-up container with an blunders message. on this state of affairs, the characteristic also returns a fake value. This guarantees that the form doesn't get submitted.
2. note that we're the usage of the RegExp JavaScript item. This item provides us with a "check" method to determine if the cost passes our ordinary expression rules.
precise suit search
The RegExp above lets in any cost that consists of MAR-sixteen-1981. subsequent, permit's expand on our regular expression to best allow values that same MAR-16-1981 precisely. There are matters we need to feature to our normal expression. the primary is a caret ^ at the start of the everyday expression. the second one is a dollar signal $ on the quit of the expression. The caret ^ calls for that the value we are testing cannot have any characters preceding the MAR-sixteen-1981 value. The dollar signal $ requires that the cost can't have any trailing characters after the MAR-sixteen-1981 value. right here's how our regular expression seems with those new rules. This ensures that the price entered have to be exactly MAR-16-1981.
/^MAR-sixteen-1981$/
man or woman Matching
we have already discovered a way to validate string values that either contain a certain substring or are equal to a sure price with a normal expression. however, for our HTML shape, we likely do not want to require our clients to enter an actual date. it's much more likely that we need them to go into any date, as long as it meets positive layout regulations. to start with, let's have a look at editing the RegExp in order that any 3 letters may be entered (not just "MAR"). let's additionally require that these letters be entered in uppercase. here's how this rule seems whilst added to our everyday expression.
/^[A-Z]{3}-sixteen-1981$/
All we've carried out is changed "MAR" with [A-Z]{three} which says that any letter between A and Z may be entered three instances. allow's examine a few versions of the character matching rules to learn about a few different approaches that we are able to in shape patterns of characters.
the rule of thumb above simplest allows 3 uppercase characters. What if you desired to permit 3 characters that could be uppercase or lowercase (i.e. case-insensitive)? here's how that rule could appearance in a regular expression.
/^[A-Za-z]{3}-sixteen-1981$/
next, let's alter our rule to allow three or extra characters. The {3} quantifier says that precisely three characters need to be entered for the month. we will allow three or extra characters via converting this quantifier to {3,}.
/^[A-Za-z]{3,}-16-1981$/
If we want to allow one or greater characters, we will virtually use the plus-signal + quantifier.
/^[A-Za-z]+-sixteen-1981$/
degrees
till now, we've got exact degrees of letters [A-Z] and numbers [0-9]. There are a selection of techniques for writing stages inside everyday expressions. you could specify more than a few [abc] to fit a or b or c. you can also specify a number of [^abc] to healthy anything that is not an a or b or c.
1 note
·
View note
Text
Find the Longest Word
Introduction
Keeping in line with the previous post in which we have explored a novel solution to the FizzBuzz challenge, here we will have a look at another basic programming challenge: to find the longest word for a given input string. In its simplest solution, this challenge requires a basic understanding of loops; particularly how the iterator binding behaves. However, I will also be providing two more alternatives which use .reduce() and .sort(), respectively.
As in the previous post, I will first introduce solutions which are standard for this exercise, then show a novel approach which I devised.
Basics
Regardless of the approach, the first step in this challenge is always to apply the .split() method to the input.
The .split() method divides a string object into an ordered list of substrings, places these into an array, and finally returns the array.
The split (or division) is performed by virtue of the parameter (so-called separator) provided in the method call. It is common for the parameters provided to be either (’’) or (’ ‘). Please note that there is a subtle, yet fundamental difference in the two. The former returns individual characters from an input string, whereas the latter returns individual words from a string. You may also pass a regular expression as separator.
For Loop
The most popular approach to this problem starts by declaring a binding with the let keyword, to which we assign the split of the input string so that it returns the individual words.
We then declare a further ‘counter’ binding to which we assign the value ‘0’. Through this binding we will keep track of the word counter through every iteration in the loop. Finally, we declare ‘result’, the value of which is an empty string which will later take on the value of the longest word.
We iterate through the entire length of the split string, then branch into a conditional statamente based on the comparison of the iterator and the counter, which is 0 at the beginning; counter then takes on the value of the .length property of the iterator. The loop continues until the highest value is found.
Finally, within the conditional statement nested inside the loop, result takes on the value of the longest iterator string and is returned by the function.

For the input:
findLongestWord(”All along the undertow, is strengthening its hold! ”);
The output should be:
strengthening
What is the type of result and why? How can the code be changed so that it returns the result along with the word count?
Reduce (found at FreeCodeCamp)
The .reduce() method works by boiling down a collection of values into a single value. It does so by executing a user-supplied iteratee callback function on each element of the array, in order, passing in the return value from the calculation on the preceding element. The parameters to be passed to the iteratee function are articulate and the functioning of the method complex, so I’ll just recommend you read the relevant documentation.
For our purposes, let’s simply keep in mind we are using the first two of the four possible parameters to be passed to the iteratee function, namely previousValue and currentValue, as referred to in the documentation.

As in the previous solution, we declare a binding which holds the split of the input string; however, in this solution, we may go one step further and apply the .reduce() method directly. The .reduce() method takes an iteratee function as a parameter, which in turn takes two paramaters, longest and currentWord. Furthermore, we provide an optional initial state as a second parameter to the .reduce() method in the form of an empty string. This allows us to have the iteration performed by the iteratee function take on the value of the longest string through the empty string, which is determined by a simple comparison written with the ternary operator syntax.
Finally, we return the longest word.
For the input:
“Halleluja , Winnie Pooh! ”
The output should be:
Halleluja
Sort (partially inspired by FreeCodeCamp)
So far we have returned only the longest word in a string. Let’s have a look at a different approach by returning an array of sorted results in descending order.
We begin with the same approach as in the previous solution, only this time we call the .sort() method on the split string. The first point to keep in mind in this approach is that we need to sort the output in descending order so it will return the longest word first. We do this by having the function parameter within the .sort() method the length of the second parameter provided to the function parameter minus the first parameter (i.e. b.length - a.length).
Finally, we return the longest word.
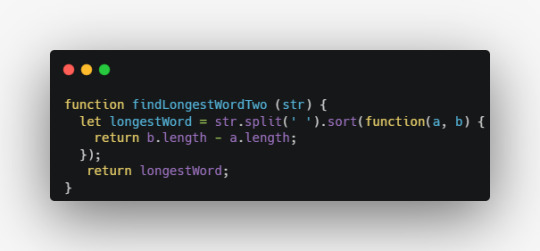
The output for:
findLongestWordOne('Howdy, Winnie Pooh! That is a beautiful honey pot.')
Will look like this:
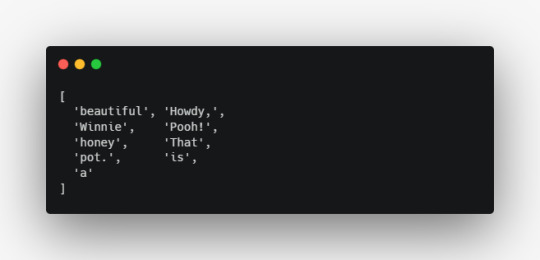
Conclusion
Finding the longest word in a string is an interesting challenge which can be solved with several approaches and has the benefit of walking you through a series of methods to solve it. In my final solution I provided an additional gimmick on top of the traditional approach which returns a neatly sorted array of results.
Consider that another popular approach is to simply return the .length property of the longest word, i.e. the number of characters of the longest word. How might we achieve this?
Thank you for reading, let me know your thoughts!
0 notes
Text
Again XOR problem
You may have solved a lot of problems related to XOR and we are sure that you liked them, so here is one more problem for you. You are given a binary string SS of length NN. Let string TT be the result of taking the XOR of all substrings of size KK of SS. You need to find the number of 1 bits in TT. Note: A substring is a continuous part of string which can be obtained by deleting some (may be…
View On WordPress
0 notes
Text
JavaScript String
charAt: The value of Characters of a string starts with index 0. CharAt () is used to find a specific character in this string.
Example: string.charAt(index);
Concat: concat () is a string method. It is used to connect multiple strings together. concat () combines multiple strings together to provide a new string result.
Example: string.concat(value1, value2, ... value_n);
Includes: includes () This is used to determine if there is a specific item in an array. Provides false values if the item is not true.
Example: var orders_today = ['Strawberry', 'Chocolate', 'Chocolate', 'Raspberry', 'Vanilla', 'Vanilla', 'Double Chocolate Deluxe'];
console.log(orders_today.includes('Double Chocolate Deluxe'));
endsWith: endsWith () is used to determine whether a string ends with a certain sequence of characters. And endsWith () is called by a specific instance of the string class.
Example: var totn_string = 'TechOnTheNet';
console.log(totn_string.endsWith('Net'));
console.log(totn_string.endsWith('net'));
indexOf: indexOf () Returns the first presence position of a certain value on a string. The indexOf () method is case sensitive. The indexOf () method returns -1 if the first presence position of a certain value is not found.
Example: let text = "Hello world, welcome to the universe.";
text.indexOf("e");
lastIndexOf: lastIndexOf () provides a list of the last event of the specified value within the calling string object, searches back from romIndex but returns -1 if the value is not found.
Example: const paragraph = 'The quick brown fox jumps over the lazy dog. If the dog barked, was it really lazy?';
const searchTerm = 'dog';
console.log(`The index of the first "${searchTerm}" from the end is ${paragraph.lastIndexOf(searchTerm)}`);
Replace: The function of replace () is to match a specific string of a pattern and replace it with a new string instead.
Example: const p = 'The quick brown fox jumps over the lazy dog. If the dog reacted, was it really lazy?';
console.log(p.replace('dog', 'monkey'));
Slice: Slice () works according to the values of the index. Slice () will output everything from the array except the index value that will be given.
Example: const animals = ['ant', 'bison', 'camel', 'duck', 'elephant'];
console.log(animals.slice(2));
Expected output: Array ["camel", "duck", "elephant"]
Split: With a split () the strings of a string can be listed separately. And provides these substrings in the form of split () objects.
Example: const str = 'The quick brown fox jumps over the lazy dog.';
const words = str.split(' ');
console.log(words[3]);
Expected output: "fox"
startsWith: startsWith () This means that if a string starts with a letter from a particular string it will give false if it starts then true.
Example: const str1 = 'Saturday night plans';
console.log(str1.startsWith('Sat'));
//Expected output: true
Substr: substr () is used to extract a substring from a string. A substring is extracted from a string using the index value in substr ().
Example: const str = 'Mozilla';
console.log(str.substr(1, 2));
//Expected output: "oz"
toLowerCase: toLowerCase () is used to lowercase all strings.
Example: const sentence = 'The quick brown fox jumps over the lazy dog.';
console.log(sentence.toLowerCase());
//Expected output: "the quick brown fox jumps over the lazy dog."
toUppercase: toUppercase () is used to uppercase all strings.
Example: const sentence = 'The quick brown fox jumps over the lazy dog.';
console.log(sentence.toUpperCase());
//Expected output: "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG."
Trim: trim () is used to remove whitespace from both ends of a string. trim () removes whitespace from both ends and renders it without changing the original string.
Example: const greeting = ' Hello world! ';
console.log(greeting);
//Expected output: " Hello world! ";
console.log(greeting.trim());
//Expected output: "Hello world!";
trimStart: trimStart () is used to remove whitespace on the left side of a string only. trim () only relocates whitespace on the left without changing the original string.
Example: const greeting = ' Hello world! ';
console.log(greeting);
// Expected output: " Hello world! ";
console.log(greeting.trimStart());
// Expected output: "Hello world! ";
trimEnd: trimEnd () is used to remove whitespace on the right side of a string only. trim () only removes the whitespace on the right and replaces it without changing the original string.
Example: const greeting = ' Hello world! ';
console.log(greeting);
// Expected output: " Hello world! ";
console.log(greeting.trimEnd());
// Expected output: " Hello world!";
1 note
·
View note
Text
Concatenation of all combinations of words
Concatenation of all combinations of words
Given a string s and some strings words of the same length. Find all the starting positions of the substrings in s that can be formed by concatenating all the strings in words. Note that the substrings must exactly match the strings in words, and there can be no other characters in the middle, but there is no need to consider the order of the strings in words. An easy solution can be achieved in…

View On WordPress
0 notes
Text
Parameter expansion
POSIX Bracket Expressions
http://www.regular-expressions.info/posixbrackets.html
Noted for me, view source at: http://wiki.bash-hackers.org/syntax/pe
====== Parameter expansion ======
{{keywords>bash shell scripting expansion substitution text variable parameter mangle substitute change check defined null array arrays}}
===== Introduction =====
One core functionality of Bash is to manage **parameters**. A parameter is an entity that stores values and is referenced by a **name**, a **number** or a **special symbol**. * parameters referenced by a name are called **variables** (this also applies to [[syntax:arrays|arrays]]) * parameters referenced by a number are called **positional parameters** and reflect the arguments given to a shell * parameters referenced by a **special symbol** are auto-set parameters that have different special meanings and uses
**Parameter expansion** is the procedure to get the value from the referenced entity, like expanding a variable to print its value. On expansion time you can do very nasty things with the parameter or its value. These things are described here.
**If you saw** some parameter expansion syntax somewhere, and need to check what it can be, try the overview section below!
**Arrays** can be special cases for parameter expansion, every applicable description mentions arrays below. Please also see the [[syntax:arrays|article about arrays]].
For a more technical view what a parameter is and which types exist, [[dict:terms:parameter | see the dictionary entry for "parameter"]].
===== Overview ===== Looking for a specific syntax you saw, without knowing the name? * [[#simple_usage | Simple usage]] * ''$PARAMETER'' * ''${PARAMETER}'' * [[#indirection | Indirection]] * ''${!PARAMETER}'' * [[#case_modification | Case modification ]] * ''${PARAMETER^}'' * ''${PARAMETER^^}'' * ''${PARAMETER,}'' * ''${PARAMETER,,}'' * ''${PARAMETER~}'' * ''${PARAMETER~~}'' * [[#variable_name_expansion | Variable name expansion]] * ''${!PREFIX*}'' * ''${!PREFIX@}'' * [[#substring_removal | Substring removal]] (also for **filename manipulation**!) * ''${PARAMETER#PATTERN}'' * ''${PARAMETER##PATTERN}'' * ''${PARAMETER%PATTERN}'' * ''<nowiki>${PARAMETER%%PATTERN}</nowiki>'' * [[#search_and_replace | Search and replace]] * ''${PARAMETER/PATTERN/STRING}'' * ''<nowiki>${PARAMETER//PATTERN/STRING}</nowiki>'' * ''${PARAMETER/PATTERN}'' * ''<nowiki>${PARAMETER//PATTERN}</nowiki>'' * [[#string_length | String length ]] * ''${#PARAMETER}''
* [[#substring_expansion | Substring expansion]]
* ''${PARAMETER:OFFSET}''
* ''${PARAMETER:OFFSET:LENGTH}''
* [[#use_a_default_value | Use a default value]]
* ''${PARAMETER:-WORD}''
* ''${PARAMETER-WORD}''
* [[#assign_a_default_value | Assign a default value]]
* ''${PARAMETER:=WORD}''
* ''${PARAMETER=WORD}''
* [[#use_an_alternate_value | Use an alternate value]]
* ''${PARAMETER:+WORD}''
* ''${PARAMETER+WORD}''
* [[#display_error_if_null_or_unset | Display error if null or unset]]
* ''${PARAMETER:?WORD}''
* ''${PARAMETER?WORD}''
===== Simple usage =====
''$PARAMETER''
''${PARAMETER}''
The easiest form is to just use a parameter's name within braces. This is identical to using ''$FOO'' like you see it everywhere, but has the advantage that it can be immediately followed by characters that would be interpreted as part of the parameter name otherwise. Compare these two expressions (''WORD="car"'' for example), where we want to print a word with a trailing "s":
<code>
echo "The plural of $WORD is most likely $WORDs"
echo "The plural of $WORD is most likely ${WORD}s"
</code>
__Why does the first one fail?__ It prints nothing, because a parameter (variable) named "''WORDs''" is undefined and thus printed as "" (//nothing//). Without using braces for parameter expansion, Bash will interpret the sequence of all valid characters from the introducing "''$''" up to the last valid character as name of the parameter. When using braces you just force Bash to **only interpret the name inside your braces**.
Also, please remember, that **parameter names are** (like nearly everything in UNIX(r)) **case sentitive!**
The second form with the curly braces is also needed to access positional parameters (arguments to a script) beyond ''$9'':
<code>
echo "Argument 1 is: $1"
echo "Argument 10 is: ${10}"
</code>
==== Simple usage: Arrays ====
See also the [[syntax:arrays|article about general array syntax]]
For arrays you always need the braces. The arrays are expanded by individual indexes or mass arguments. An individual index behaves like a normal parameter, for the mass expansion, please read the article about arrays linked above.
* ${array[5]}
* ${array[*]}
* ${array[@]}
===== Indirection =====
''${!PARAMETER}''
In some cases, like for example
<code>
${PARAMETER}
${PARAMETER:0:3}
</code>
you can instead use the form
<code>${!PARAMETER}</code>
to enter a level of indirection. The referenced parameter is not ''PARAMETER'' itself, but the parameter whose name is stored as the value of ''PARAMETER''. If the parameter ''PARAMETER'' has the value "''TEMP''", then ''${!PARAMETER}'' will expand to the value of the parameter named ''TEMP'':
<code>
read -rep 'Which variable do you want to inspect? ' look_var
printf 'The value of "%s" is: "%s"\n' "$look_var" "${!look_var}"
</code>
Of course the indirection also works with special variables:
<code>
# set some fake positional parameters
set one two three four
# get the LAST argument ("#" stores the number of arguments, so "!#" will reference the LAST argument)
echo ${!#} </code>
You can think of this mechanism as being roughly equivalent to taking any parameter expansion that begins with the parameter name, and substituting the ''!PARAMETER'' part with the value of PARAMETER.
<code> echo "${!var^^}" # ...is equivalent to eval 'echo "${'"$var"'^^}"' </code>
It was an unfortunate design decision to use the ''!'' prefix for indirection, as it introduces parsing ambiguity with other parameter expansions that begin with ''!''. Indirection is not possible in combination with any parameter expansion whose modifier requires a prefix to the parameter name. Specifically, indirection isn't possible on the ''${!var@}'', ''${!var*}'', ''${!var[@]}'', ''${!var[*]}'', and ''${#var}'' forms. This means the ''!'' prefix can't be used to retrieve the indices of an array, the length of a string, or number of elements in an array indirectly (see [[syntax/arrays#indirection]] for workarounds). Additionally, the ''!''-prefixed parameter expansion conflicts with ksh-like shells which have the more powerful "name-reference" form of indirection, where the exact same syntax is used to expand to the name of the variable being referenced.
Indirect references to [[syntax:arrays|array names]] are also possible since the Bash 3 series (exact version unknown), but undocumented. See [[syntax/arrays#indirection]] for details.
Chet has added an initial implementation of the ksh ''nameref'' declaration command to the git devel branch. (''declare -n'', ''local -n'', etc, will be supported). This will finally address many issues around passing and returning complex datatypes to/from functions.
===== Case modification =====
''${PARAMETER^}''
''${PARAMETER^^}''
''${PARAMETER,}''
''${PARAMETER,,}''
''${PARAMETER~}''
''${PARAMETER~~}''
These expansion operators modify the case of the letters in the expanded text.
The ''^'' operator modifies the first character to uppercase, the '','' operator to lowercase. When using the double-form (''^^'' and '',,''), all characters are converted.
<wrap center round info 60%>
The (**currently undocumented**) operators ''~'' and ''~~'' reverse the case of the given text (in ''PARAMETER'').''~'' reverses the case of first letter of words in the variable while ''~~'' reverses case for all.Thanks to ''Bushmills'' and ''geirha'' on the Freenode IRC channel for this finding.
</wrap>
__**Example: Rename all ''*.txt'' filenames to lowercase**__
<code>
for file in *.txt; do
mv "$file" "${file,,}"
done
</code>
__**Note:**__ The feature worked word-wise in Bash 4 RC1 (a modification of a parameter containing ''hello world'' ended up in ''Hello World'', not ''Hello world''). In the final Bash 4 version it works on the whole parameter, regardless of something like "words". IMHO a technically cleaner implementation. Thanks to Chet.
==== Case modification: Arrays ====
For [[syntax:arrays|array]] expansion, the case modification applies to **every expanded element, no matter if you expand an individual index or mass-expand** the whole array using ''@'' or ''*'' subscripts. Some examples:
Assume: ''array=(This is some Text)''
* ''echo "${array[@],}"''
* => ''this is some text''
* ''echo "${array[@],,}"''
* => ''this is some text''
* ''echo "${array[@]^}"''
* => ''This Is Some Text''
* ''echo "${array[@]^^}"''
* => ''THIS IS SOME TEXT''
* ''echo "${array[2]^^}"''
* => ''TEXT''
===== Variable name expansion =====
''${!PREFIX*}''
''${!PREFIX@}''
This expands to a list of all set **variable names** beginning with the string ''PREFIX''. The elements of the list are separated by the first character in the ''IFS''-variable (<space> by default).
This will show all defined variable names (not values!) beginning with "BASH":
<code>
$ echo ${!BASH*}
BASH BASH_ARGC BASH_ARGV BASH_COMMAND BASH_LINENO BASH_SOURCE BASH_SUBSHELL BASH_VERSINFO BASH_VERSION
</code>
This list will also include [[syntax:arrays|array names]].
===== Substring removal =====
''${PARAMETER#PATTERN}''
''${PARAMETER##PATTERN}''
''${PARAMETER%PATTERN}''
''<nowiki>${PARAMETER%%PATTERN}</nowiki>''
This one can **expand only a part** of a parameter's value, **given a pattern to describe what to remove** from the string. The pattern is interpreted just like a pattern to describe a filename to match (globbing). See [[syntax:pattern | Pattern matching]] for more.
Example string (//just a quote from a big man//):
<code>
MYSTRING="Be liberal in what you accept, and conservative in what you send"
</code>
==== From the beginning ====
''${PARAMETER#PATTERN}'' and ''${PARAMETER##PATTERN}''
This form is to remove the described [[syntax:pattern | pattern]] trying to **match it from the beginning of the string**.
The operator "''#''" will try to remove the shortest text matching the pattern, while "''##''" tries to do it with the longest text matching. Look at the following examples to get the idea (matched text <del>marked striked</del>, remember it will be removed!):
^Syntax^Result^
|''${MYSTRING#* }''|<del>Be </del>liberal in what you accept, and conservative in what you send|
|''${MYSTRING##* }''|<del>Be liberal in what you accept, and conservative in what you </del>send|
==== From the end ====
''${PARAMETER%PATTERN}'' and ''<nowiki>${PARAMETER%%PATTERN}</nowiki>''
In the second form everything will be the same, except that Bash now tries to match the pattern from the end of the string:
^Syntax^Result^
|''${MYSTRING% *}''|Be liberal in what you accept, and conservative in what you<del> send</del>|
|''<nowiki>${MYSTRING%% *}</nowiki>''|Be<del> liberal in what you accept, and conservative in what you send</del>|
==== Common use ====
__**How the heck does that help to make my life easier?**__
Well, maybe the most common use for it is to **extract parts of a filename**. Just look at the following list with examples:
* **Get name without extension**
* ''${FILENAME%.*}''
* => ''bash_hackers<del>.txt</del>''
* **Get extension**
* ''${FILENAME##*.}''
* => ''<del>bash_hackers.</del>txt''
* **Get directory name**
* ''${PATHNAME%/*}''
* => ''/home/bash<del>/bash_hackers.txt</del>''
* **Get filename**
* ''${PATHNAME##*/}''
* => ''<del>/home/bash/</del>bash_hackers.txt''
These are the syntaxes for filenames with a single extension. Depending on your needs, you might need to adjust shortest/longest match.
==== Substring removal: Arrays ====
As for most parameter expansion features, working on [[syntax:arrays|arrays]] **will handle each expanded element**, for individual expansion and also for mass expansion.
Simple example, removing a trailing ''is'' from all array elements (on expansion):
Assume: ''array=(This is a text)''
* ''echo "${array[@]%is}"''
* => ''Th a text''
* (it was: ''Th<del>is</del> <del>is</del> a text'')
All other variants of this expansion behave the same.
===== Search and replace =====
''${PARAMETER/PATTERN/STRING}''
''<nowiki>${PARAMETER//PATTERN/STRING}</nowiki>''
''<nowiki>${PARAMETER/PATTERN}</nowiki>''
''<nowiki>${PARAMETER//PATTERN}</nowiki>''
This one can substitute (//replace//) a substring [[syntax:pattern | matched by a pattern]], on expansion time. The matched substring will be entirely removed and the given string will be inserted. Again some example string for the tests:
<code>
MYSTRING="Be liberal in what you accept, and conservative in what you send"
</code>
The two main forms only differ in **the number of slashes** after the parameter name: ''${PARAMETER/PATTERN/STRING}'' and ''<nowiki>${PARAMETER//PATTERN/STRING}</nowiki>''
The first one (//one slash//) is to only substitute **the first occurrence** of the given pattern, the second one (//two slashes//) is to substitute **all occurrences** of the pattern.
First, let's try to say "happy" instead of "conservative" in our example string:
<code>
${MYSTRING//conservative/happy}
</code>
=> ''Be liberal in what you accept, and <del>conservative</del>happy in what you send''
Since there is only one "conservative" in that example, it really doesn't matter which of the two forms we use.
Let's play with the word "in", I don't know if it makes any sense, but let's substitute it with "by".
__**First form: Substitute first occurrence**__
<code>${MYSTRING/in/by}</code>
=> ''Be liberal <del>in</del>by what you accept, and conservative in what you send''
__**Second form: Substitute all occurrences**__
<code>${MYSTRING//in/by}</code>
=> ''Be liberal <del>in</del>by what you accept, and conservative <del>in</del>by what you send''
__**Anchoring**__
Additionally you can "anchor" an expression:
A ''#'' (hashmark) will indicate that your expression is matched against the beginning portion of the string, a ''%'' (percent-sign) will do it for the end portion.
<code>MYSTRING=xxxxxxxxxx
echo ${MYSTRING/#x/y} # RESULT: yxxxxxxxxx
echo ${MYSTRING/%x/y} # RESULT: xxxxxxxxxy</code>
If the replacement part is completely omitted, the matches are replaced by the nullstring, i.e., they are removed. This is equivalent to specifying an empty replacement:
<code>
echo ${MYSTRING//conservative/}
# is equivalent to
echo ${MYSTRING//conservative}
</code>
==== Search and replace: Arrays ====
This parameter expansion type applied to [[syntax:arrays|arrays]] **applies to all expanded elements**, no matter if an individual element is expanded, or all elements using the mass expansion syntaxes.
A simple example, changing the (lowercase) letter ''t'' to ''d'':
Assume: ''array=(This is a text)''
* ''echo "${array[@]/t/d}"''
* => ''This is a dext''
* ''echo "${array[@]<nowiki>//</nowiki>t/d}"''
* => ''This is a dexd''
===== String length =====
''${#PARAMETER}''
When you use this form, the length of the parameter's value is expanded. Again, a quote from a big man, to have a test text:
<code>MYSTRING="Be liberal in what you accept, and conservative in what you send"</code>
Using echo ''${#MYSTRING}''...
=> ''64''
The length is reported in characters, not in bytes. Depending on your environment this may not always be the same (multibyte-characters, like in UTF8 encoding).
There's not much to say about it, mh?
==== (String) length: Arrays ====
For [[syntax:arrays|arrays]], this expansion type has two meanings:
* For **individual** elements, it reports the string length of the element (as for every "normal" parameter)
* For the **mass subscripts** ''@'' and ''*'' it reports the number of set elements in the array
Example:
Assume: ''array=(This is a text)''
* ''echo ${#array[1]}''
* => 2 (the word "is" has a length of 2)
* ''echo ${#array[@]}''
* => 4 (the array contains 4 elements)
__**Attention:**__ The number of used elements does not need to conform to the highest index. Sparse arrays are possible in Bash, that means you can have 4 elements, but with indexes 1, 7, 20, 31. **You can't loop through such an array with a counter loop based on the number of elements!**
===== Substring expansion =====
''${PARAMETER:OFFSET}''
''${PARAMETER:OFFSET:LENGTH}''
This one can expand only a **part** of a parameter's value, given a **position to start** and maybe a **length**. If ''LENGTH'' is omitted, the parameter will be expanded up to the end of the string. If ''LENGTH'' is negative, it's taken as a second offset into the string, counting from the end of the string.
''OFFSET'' and ''LENGTH'' can be **any** [[syntax:arith_expr | arithmetic expression]]. **Take care:** The ''OFFSET'' starts at 0, not at 1!
Example string (a quote from a big man):
''MYSTRING="Be liberal in what you accept, and conservative in what you send"''
==== Using only Offset ====
In the first form, the expansion is used without a length value, note that the offset 0 is the first character:
<code>echo ${MYSTRING:34}</code>
=> ''<del>Be liberal in what you accept, and </del>conservative in what you send''
==== Using Offset and Length ====
In the second form we also give a length value:
<code>echo ${MYSTRING:34:13}</code>
=> ''<del>Be liberal in what you accept, and </del>conservative<del> in what you send</del>''
==== Negative Offset Value ====
If the given offset is negative, it's counted from the end of the string, i.e. an offset of -1 is the last character. In that case, the length still counts forward, of course. One special thing is to do when using a negative offset: You need to separate the (negative) number from the colon:
<code>
${MYSTRING: -10:5}
${MYSTRING:(-10):5}
</code>
Why? Because it's interpreted as the parameter expansion syntax to [[syntax:pe#use_a_default_value | use a default value]].
==== Negative Length Value ====
If the ''LENGTH'' value is negative, it's used as offset from the end of the string. The expansion happens from the first to the second offset then:
<code>
echo "${MYSTRING:11:-17}"
</code>
=> ''<del>Be liberal </del>in what you accept, and conservative<del> in what you send</del>''
This works since Bash 4.2-alpha, see also [[scripting:bashchanges]].
==== Substring/Element expansion: Arrays ====
For [[syntax:arrays|arrays]], this expansion type has again 2 meanings:
* For **individual** elements, it expands to the specified substring (as for every “normal” parameter)
* For the **mass subscripts** ''@'' and ''*'' it mass-expands individual array elements denoted by the 2 numbers given (//starting element//, //number of elements//)
Example:
Assume: ''array=(This is a text)''
* ''echo ${array[0]:2:2}''
* => ''is'' (the "is" in "This", array element 0)
* ''echo ${array[@]:1:2}''
* => ''is a'' (from element 1 inclusive, 2 elements are expanded, i.e. element 1 and 2)
===== Use a default value =====
''${PARAMETER:-WORD}''
''${PARAMETER-WORD}''
If the parameter ''PARAMETER'' is unset (never was defined) or null (empty), this one expands to ''WORD'', otherwise it expands to the value of ''PARAMETER'', as if it just was ''${PARAMETER}''. If you omit the '':'' (colon), like shown in the second form, the default value is only used when the parameter was **unset**, not when it was empty.
<code>
echo "Your home directory is: ${HOME:-/home/$USER}."
echo "${HOME:-/home/$USER} will be used to store your personal data."
</code>
If ''HOME'' is unset or empty, everytime you want to print something useful, you need to put that parameter syntax in.
<code>
#!/bin/bash
read -p "Enter your gender (just press ENTER to not tell us): " GENDER
echo "Your gender is ${GENDER:-a secret}."
</code>
It will print "Your gender is a secret." when you don't enter the gender. Note that the default value is **used on expansion time**, it is **not assigned to the parameter**.
==== Use a default value: Arrays ====
For [[syntax:arrays|arrays]], the behaviour is very similar. Again, you have to make a difference between expanding an individual element by a given index and mass-expanding the array using the ''@'' and ''*'' subscripts.
* For individual elements, it's the very same: If the expanded element is ''NULL'' or unset (watch the '':-'' and ''-'' variants), the default text is expanded
* For mass-expansion syntax, the default text is expanded if the array
* contains no element or is unset (the '':-'' and ''-'' variants mean the **same** here)
* contains only elements that are the nullstring (the '':-'' variant)
In other words: The basic meaning of this expansion type is applied as consistent as possible to arrays.
Example code (please try the example cases yourself):
<code>
####
# Example cases for unset/empty arrays and nullstring elements
####
### CASE 1: Unset array (no array)
# make sure we have no array at all
unset array
echo ${array[@]:-This array is NULL or unset}
echo ${array[@]-This array is NULL or unset}
### CASE 2: Set but empty array (no elements)
# declare an empty array
array=()
echo ${array[@]:-This array is NULL or unset}
echo ${array[@]-This array is NULL or unset}
### CASE 3: An array with only one element, a nullstring
array=("")
echo ${array[@]:-This array is NULL or unset}
echo ${array[@]-This array is NULL or unset}
### CASE 4: An array with only two elements, a nullstring and a normal word
array=("" word)
echo ${array[@]:-This array is NULL or unset}
echo ${array[@]-This array is NULL or unset}
</code>
===== Assign a default value =====
''${PARAMETER:=WORD}''
''${PARAMETER=WORD}''
This one works like the [[syntax:pe#use_a_default_value | using default values]], but the default text you give is not only expanded, but also **assigned** to the parameter, if it was unset or null. Equivalent to using a default value, when you omit the '':'' (colon), as shown in the second form, the default value will only be assigned when the parameter was **unset**.
<code>
echo "Your home directory is: ${HOME:=/home/$USER}."
echo "$HOME will be used to store your personal data."
</code>
After the first expansion here (''${HOME:=/home/$USER}''), ''HOME'' is set and usable.
Let's change our code example from above:
<code>
#!/bin/bash
read -p "Enter your gender (just press ENTER to not tell us): " GENDER
echo "Your gender is ${GENDER:=a secret}."
echo "Ah, in case you forgot, your gender is really: $GENDER"
</code>
==== Assign a default value: Arrays ====
For [[syntax:arrays|arrays]] this expansion type is limited. For an individual index, it behaves like for a "normal" parameter, the default value is assigned to this one element. The mass-expansion subscripts ''@'' and ''*'' **can not be used here** because it's not possible to assign to them!
===== Use an alternate value =====
''${PARAMETER:+WORD}''
''${PARAMETER+WORD}''
This form expands to nothing if the parameter is unset or empty. If it is set, it does not expand to the parameter's value, **but to some text you can specify**:
<code>
echo "The Java application was installed and can be started.${JAVAPATH:+ NOTE: JAVAPATH seems to be set}"
</code>
The above code will simply add a warning if ''JAVAPATH'' is set (because it could influence the startup behaviour of that imaginary application).
Some more unrealistic example... Ask for some flags (for whatever reason), and then, if they were set, print a warning and also print the flags:
<code>
#!/bin/bash
read -p "If you want to use special flags, enter them now: " SPECIAL_FLAGS
echo "The installation of the application is finished${SPECIAL_FLAGS:+ (NOTE: there are special flags set: $SPECIAL_FLAGS)}."
</code>
If you omit the colon, as shown in the second form (''${PARAMETER+WORD}''), the alternate value will be used if the parameter is set (and it can be empty)! You can use it, for example, to complain if variables you need (and that can be empty) are undefined:
<code>
# test that with the three stages:
# unset foo
# foo=""
# foo="something"
if [[ ${foo+isset} = isset ]]; then
echo "foo is set..."
else
echo "foo is not set..."
fi
</code>
==== Use an alternate value: Arrays ====
Similar to the cases for [[syntax:arrays|arrays]] to expand to a default value, this expansion behaves like for a "normal" parameter when using individual array elements by index, but reacts differently when using the mass-expansion subscripts ''@'' and ''*'':
* For individual elements, it's the very same: If the expanded element is **not** NULL or unset (watch the :+ and + variants), the alternate text is expanded
* For mass-expansion syntax, the alternate text is expanded if the array
* contains elements where min. one element is **not** a nullstring (the :+ and + variants mean the same here)
* contains **only** elements that are **not** the nullstring (the :+ variant)
For some cases to play with, please see the code examples in the [[#use_a_default_valuearrays|description for using a default value]].
===== Display error if null or unset =====
''${PARAMETER:?WORD}''
''${PARAMETER?WORD}''
If the parameter ''PARAMETER'' is set/non-null, this form will simply expand it. Otherwise, the expansion of ''WORD'' will be used as appendix for an error message:
<code>
$ echo "The unset parameter is: ${p_unset?not set}"
bash: p_unset: not set
</code>
After printing this message,
* an interactive shell has ''$?'' to a non-zero value
* a non-interactive shell exits with a non-zero exit code
The meaning of the colon ('':'') is the same as for the other parameter expansion syntaxes: It specifies if
* only unset or
* unset and empty parameters
are taken into account.
===== Code examples =====
==== Substring removal ====
Removing the first 6 characters from a text string:
<code>
STRING="Hello world"
# only print 'Hello'
echo "${STRING%??????}"
# only print 'world'
echo "${STRING#??????}"
# store it into the same variable
STRING=${STRING#??????}
</code>
===== Bugs and Portability considerations =====
* **Fixed in 4.2.36** ([[ftp://ftp.cwru.edu/pub/bash/bash-4.2-patches/bash42-036 | patch]]). Bash doesn't follow either POSIX or its own documentation when expanding either a quoted ''"$@"'' or ''"${arr[@]}"'' with an adjacent expansion. ''"$@$x"'' expands in the same way as ''"$*$x"'' - i.e. all parameters plus the adjacent expansion are concatenated into a single argument. As a workaround, each expansion needs to be quoted separately. Unfortunately, this bug took a very long time to notice.<code>
~ $ set -- a b c; x=foo; printf '<%s> ' "$@$x" "$*""$x" "$@""$x"
<a b cfoo> <a b cfoo> <a> <b> <cfoo>
</code>
* Almost all shells disagree about the treatment of an unquoted ''$@'', ''${arr[@]}'', ''$*'', and ''${arr[*]}'' when [[http://mywiki.wooledge.org/IFS | IFS]] is set to null. POSIX is unclear about the expected behavior. A null IFS causes both [[syntax:expansion:wordsplit | word splitting]] and [[syntax:expansion:globs | pathname expansion]] to behave randomly. Since there are few good reasons to leave ''IFS'' set to null for more than the duration of a command or two, and even fewer to expand ''$@'' and ''$*'' unquoted, this should be a rare issue. **Always quote them**!<code>
touch x 'y z'
for sh in bb {{d,b}a,{m,}k,z}sh; do
echo "$sh"
"$sh" -s a 'b c' d \* </dev/fd/0
done <<\EOF
${ZSH_VERSION+:} false && emulate sh
IFS=
printf '<%s> ' $*
echo
printf "<%s> " $@
echo
EOF
</code><code>
bb
<ab cd*>
<ab cd*>
dash
<ab cd*>
<ab cd*>
bash
<a> <b c> <d> <x> <y z>
<a> <b c> <d> <x> <y z>
mksh
<a b c d *>
<a b c d *>
ksh
<a> <b c> <d> <x> <y z>
<a> <b c> <d> <x> <y z>
zsh
<a> <b c> <d> <x> <y z>
<a> <b c> <d> <x> <y z>
</code>When ''IFS'' is set to a non-null value, or unset, all shells behave the same - first expanding into separate args, then applying pathname expansion and word-splitting to the results, except for zsh, which doesn't do pathname expansion in its default mode.
* Additionally, shells disagree about various wordsplitting behaviors, the behavior of inserting delimiter characters from IFS in ''$*'', and the way adjacent arguments are concatenated, when IFS is modified in the middle of expansion through side-effects.<code>
for sh in bb {{d,b}a,po,{m,}k,z}sh; do
printf '%-4s: ' "$sh"
"$sh" </dev/fd/0
done <<\EOF
${ZSH_VERSION+:} false && emulate sh
set -f -- a b c
unset -v IFS
printf '<%s> ' ${*}${IFS=}${*}${IFS:=-}"${*}"
echo
EOF
</code><code>
bb : <a b cabc> <a-b-c>
dash: <a b cabc> <a-b-c>
bash: <a> <b> <ca> <b> <c-a b c>
posh: <a> <b> <ca b c> <a-b-c>
mksh: <a> <b> <ca b c> <a-b-c>
ksh : <a> <b> <ca> <b> <c> <a b c>
zsh : <a> <b> <ca> <b> <c> <a-b-c>
</code>ksh93 and mksh can additionally achieve this side effect (and others) via the ''${ cmds;}'' expansion. I haven't yet tested every possible side-effect that can affect expansion halfway through expansion that way.
* As previously mentioned, the Bash form of indirection by prefixing a parameter expansion with a ''!'' conflicts with the same syntax used by mksh, zsh, and ksh93 for a different purpose. Bash will "slightly" modify this expansion in the next version with the addition of namerefs.
* Bash (and most other shells) don't allow .'s in identifiers. In ksh93, dots in variable names are used to reference methods (i.e. "Discipline Functions"), attributes, special shell variables, and to define the "real value" of an instance of a class.
* In ksh93, the ''_'' parameter has even more uses. It is used in the same way as ''self'' in some object-oriented languages; as a placeholder for some data local to a class; and also as the mechanism for class inheritance. In most other contexts, ''_'' is compatible with Bash.
* Bash only evaluates the subscripts of the slice expansion (''${x:y:z}'') if the parameter is set (for both nested expansions and arithmetic). For ranges, Bash evaluates as little as possible, i.e., if the first part is out of range, the second won't be evaluated. ksh93 and mksh always evaluate the subscript parts even if the parameter is unset. <code>
$ bash -c 'n="y[\$(printf yo >&2)1]" m="y[\$(printf jo >&2)1]"; x=(); echo "${x[@]:n,6:m}"' # No output
$ bash -c 'n="y[\$(printf yo >&2)1]" m="y[\$(printf jo >&2)1]"; x=([5]=hi); echo "${x[@]:n,6:m}"'
yo
$ bash -c 'n="y[\$(printf yo >&2)1]" m="y[\$(printf jo >&2)1]"; x=([6]=hi); echo "${x[@]:n,6:m}"'
yojo
$ bash -c 'n="y[\$(printf yo >&2)1]" m="y[\$(printf jo >&2)1]"; x=12345; echo "${x:n,5:m}"'
yojo
$ bash -c 'n="y[\$(printf yo >&2)1]" m="y[\$(printf jo >&2)1]"; x=12345; echo "${x:n,6:m}"'
yo
</code>
==== Quote Nesting ====
* In most shells, when dealing with an "alternate" parameter expansion that expands to multiple words, and nesting such expansions, not all combinations of nested quoting are possible.
<code>
# Bash
$ typeset -a a=(meh bleh blerg) b
$ IFS=e
$ printf "<%s> " "${b[@]-"${a[@]}" "${a[@]}"}"; echo # The entire PE is quoted so Bash considers the inner quotes redundant.
<meh> <bleh> <blerg meh> <bleh> <blerg>
$ printf "<%s> " "${b[@]-${a[@]} ${a[@]}}"; echo # The outer quotes cause the inner expansions to be considered quoted.
<meh> <bleh> <blerg meh> <bleh> <blerg>
$ b=(meep beep)
$ printf "<%s> " "${b[@]-"${a[@]}" "${a[@]}"}" "${b[@]-${a[@]} ${a[@]}}"; echo # Again no surprises. Outer quotes quote everything recursively.
<meep> <beep> <meep> <beep>
</code>
Now lets see what can happen if we leave the outside unquoted.
<code>
# Bash
$ typeset -a a=(meh bleh blerg) b
$ IFS=e
$ printf "<%s> " ${b[@]-"${a[@]}" "${a[@]}"}; echo # Inner quotes make inner expansions quoted.
<meh> <bleh> <blerg meh> <bleh> <blerg>
$ printf "<%s> " ${b[@]-${a[@]} ${a[@]}}; echo' # No quotes at all wordsplits / globs, like you'd expect.
<m> <h> <bl> <h> <bl> <rg m> <h> <bl> <h> <bl> <rg>
</code>
This all might be intuitive, and is the most common implementation, but this design sucks for a number of reasons. For one, it means Bash makes it absolutely impossible to expand any part of the inner region //unquoted// while leaving the outer region quoted. Quoting the outer forces quoting of the inner regions recursively (except nested command substitutions of course). Word-splitting is necessary to split words of the inner region, which cannot be done together with outer quoting. Consider the following (only slightly far-fetched) code:
<code>
# Bash (non-working example)
unset -v IFS # make sure we have a default IFS
if some crap; then
typeset -a someCmd=(myCmd arg1 'arg2 yay!' 'third*arg*' 4)
fi
someOtherCmd=mycommand
typeset -a otherArgs=(arg3 arg4)
# What do you think the programmer expected to happen here?
# What do you think will actually happen...
"${someCmd[@]-"$someOtherCmd" arg2 "${otherArgs[@]}"}" arg5
</code>
This final line is perhaps not the most obvious, but I've run into cases were this type of logic can be desirable and realistic. We can deduce what was intended:
* If ''someCmd'' is set, then the resulting expansion should run the command: ''"myCmd" "arg1" "arg2 yay!" "third*arg*" "4" "arg5"''
* Otherwise, if ''someCmd'' is not set, expand ''$someOtherCmd'' and the inner args, to run a different command: ''"mycommand" "arg2" "arg3" "arg4" "arg5"''.
Unfortunately, it is impossible to get the intended result in Bash (and most other shells) without taking a considerably different approach. The only way to split the literal inner parts is through word-splitting, which requires that the PE be unquoted. But, the only way to expand the outer expansion correctly without word-splitting or globbing is to quote it. Bash will actually expand the command as one of these:
<code>
# The quoted PE produces a correct result here...
$ bash -c 'typeset -a someCmd=(myCmd arg1 "arg2 yay!" "third*arg*" 4); printf "<%s> " "${someCmd[@]-"$someOtherCmd" arg2 "${otherArgs[@]}"}" arg5; echo'
<myCmd> <arg1> <arg2 yay!> <third*arg*> <4> <arg5>
# ...but in the opposite case the first 3 arguments are glued together. There are no workarounds.
$ bash -c 'typeset -a otherArgs=(arg3 arg4); someOtherCmd=mycommand; printf "<%s> " "${someCmd[@]-"$someOtherCmd" arg2 "${otherArgs[@]}"}" arg5; echo'
<mycommand arg2 arg3> <arg4> <arg5>
# UNLESS! we unquote the outer expansion allowing the inner quotes to
# affect the necessary parts while allowing word-splitting to split the literals:
$ bash -c 'typeset -a otherArgs=(arg3 arg4); someOtherCmd=mycommand; printf "<%s> " ${someCmd[@]-"$someOtherCmd" arg2 "${otherArgs[@]}"} arg5; echo'
<mycommand> <arg2> <arg3> <arg4> <arg5>
# Success!!!
$ bash -c 'typeset -a someCmd=(myCmd arg1 "arg2 yay!" "third*arg*" 4); printf "<%s> " ${someCmd[@]-"$someOtherCmd" arg2 "${otherArgs[@]}"} arg5; echo'
<myCmd> <arg1> <arg2> <yay!> <third*arg*> <4> <arg5>
# ...Ah f^^k. (again, no workaround possible.)
</code>
=== The ksh93 exception ===
To the best of my knowledge, ksh93 is the only shell that acts differently. Rather than forcing nested expansions into quoting, a quote at the beginning and end of the nested region will cause the quote state to reverse itself within the nested part. I have no idea whether it's an intentional or documented effect, but it does solve the problem and consequently adds a lot of potential power to these expansions.
All we need to do is add two extra double-quotes:
<code>
# ksh93 passing the two failed tests from above:
$ ksh -c 'otherArgs=(arg3 arg4); someOtherCmd="mycommand"; printf "<%s> " "${someCmd[@]-""$someOtherCmd" arg2 "${otherArgs[@]}""}" arg5; echo'
<mycommand> <arg2> <arg3> <arg4> <arg5>
$ ksh -c 'typeset -a someCmd=(myCmd arg1 "arg2 yay!" "third*arg*" 4); printf "<%s> " "${someCmd[@]-""$someOtherCmd" arg2 "${otherArgs[@]}""}" arg5; echo'
<myCmd> <arg1> <arg2 yay!> <third*arg*> <4> <arg5>
</code>
This can be used to control the quote state of any part of any expansion to an arbitrary depth. Sadly, it is the only shell that does this and the difference may introduce a possible compatibility problem.
===== See also =====
* Internal: [[syntax:expansion:intro | Introduction to expansion and substitution]]
* Internal: [[syntax:arrays|Arrays]]
* Dictionary, internal: [[dict:terms:parameter]]
2 notes
·
View notes
Text
What is RegEx? Regular Expression in Python & Meta Characters
What is RegEx?
A regular expression (regex, regexp, or re) is a special sequence of characters that helps you match or find other strings or sets of strings, using a specialized syntax held in a pattern. Regular expression patterns are assembled into a set of byte codes which are then executed by a matching engine written in C. Regular expressions are widely used in the world of UNIX.
Now let’s understand simple basic regular expression through the following image.
The caret sign (^) serves two purposes. Here, in this figure, it’s checking for the string that doesn’t contain upper case, lower case, digits, underscore and space in the strings. In short, we can say that it is simply matching for special characters in the given string. If we use caret outside the square brackets, it will simply check for the starting of the string.
An example of a "proper" email-matching regex (like the one in the exercise), see below:
import re input_user = input("enter your email address: ") m = re.match( '(?=.*\d)(?=.*[a-z])(?=.*\W)',input_user) if m: print("Email is valid:") else: print("email is not valid:")
The most common usages of regular expressions are:
Search a string (search and match)
Finding a string (findall)
Break string into substrings (split)
Replace part of a string (sub)
'Re' Module
The module 're' gives full assistance for Perl-like regular expressions in Python. The re module raises the exception re.error if an error occurs while compiling or using a regular expression.
Now if we talk about the 're' module, the re module gives an interface to the regular expression engine, that permits you to arrange REs into objects and then perform with the matches. A regular expression is simply a sequence of characters that define a search pattern. Pythons’ built-in 're' module provides excellent support for the regular expressions with a modern and complete regex flavor.
Now, let’s understand everything about regular expressions and how they can be implemented in python. The very first step would be to import 're' module which provides all the necessary functionalities to play with. It can be done by the following statement in any of the IDE’s.
import re
Meta Characters
Metacharacters are characters or we can say it's a sequence of such characters, that holds a unique meaning specifically in a computing application. These characters have special meaning just like a '*' in wild cards. Some set of characters might be used to represent other characters, like an unprintable character or any logical operation. They are also known as “operators” and are mostly used to give rise to an expression that can represent a required character in a string or a file.
Below is the list of the metacharacters, and how to use such characters in the regular expression or regex like;
. ^ $ * + ? { } [ ] \ | ( )
Initially, the metacharacters we are going to explain are [ and ]. It’s used for specifying the class of the character which is a set of characters that you wish to match.
Characters can be listed individually here, or the range of characters can be indicated by giving two characters and separating them by a '-'. For instance, [abc] will match any of the characters a, b, or c; we can say in another way to express the same set of characters i.e. [a-c]. If you wanted to match only lowercase letters, your RE would be [a-z].
Let’s understand what these characters illuminate:
Here, [abc] will match if the string you are trying to match contains any of the a, b or c.
You can also specify a range of characters using - inside square brackets.
[a-e] is the same as [abcde].
[1-4] is the same as [1234].
[0-9] is the same as [0123---9]
You can complement (invert) the character set by using the caret ^ symbol at the start of a square-bracket.
[^abc] means any character except a or b or c.
[^0-9] means any non-digit character.
The basic usages of commonly used metacharacters are shown in the following table:
For example, \$a match if a string contains $ followed by a. Here, $ is not interpreted by a RegEx engine in a special way.
s = re.search('\w+$','789Welcome67 to python') Output: 'python'
\ is used to match a character having special meaning. For example: '.' matches '.', '+'matches '+' etc.
We need to use '\' to match. Regex recognizes common escape sequences such as \n for newline, \t for tab, \r for carriage-return, \nnn for a up to 3-digit octal number, \xhh for a two-digit hex code, \uhhhh for a 4-digit Unicode, \uhhhhhhhh for a 8-digit Unicode.
The following code example will show you the regex '.' function:
s = re.match('........[a-zA-Z0-9]','Welcome to python') Output: 'Welcome t'
Other Special Sequences
There are some Special sequences that make commonly used patterns easier to write. Below is a list of such special sequences:
Understanding special sequences with examples
\A - Matches if the specified characters are at the start of a string.
s = re.search('\A\d','789Welcome67 to python') Output: '7'
\b - Matches if the specified characters are at the beginning or end of a word.
a = re.findall(r'\baa\b', "bbb aa \\bash\baaa") Output: ['aa']
\B - Opposite of \b. Matches if the specified characters are not at the beginning or end of a word.
a = re.findall('[\B]+', "BBB \\Bash BaBe BasketBall") Output: ['BBB', 'B', 'B', 'B', 'B', 'B']
\d - Matches any decimal digit. Equivalent to [0-9]
a = re.match('\d','1Welco+me to python11') Output: '1'
\D - Matches any non-decimal digit. Equivalent to [^0-9]
a = re.match('\D','Wel12co+me to python11') Output: 'W'
\s - Matches where a string contains any white space character. Equivalent to [ \t\n\r\f\v].
a = re.match('\s',' Wel12co+me to python11') Output: ' '
\S - Matches where a string contains any non-white space character. Equivalent to [^ \t\n\r\f\v].
a = re.match('/S','W el12co+me to python11') Output: 'W'
\w - Matches any alphanumeric character (digits and alphabets). Equivalent to [a-zA-Z0-9_]. By the way, underscore _ is also considered an alphanumeric character.
a = re.match('[\w]','1Welco+me to python11') Output: '1'
\W - Matches any non-alphanumeric character. Equivalent to [^a-zA-Z0-9_]
s = re.match('[\W]','@@Welcome to python') Output: '@'
\Z - Matches if the specified characters are at the end of a string.
s = re.search('\w\Z','789Welcome67 to python') Output: 'n'
Module- Level Functions
'Re' module provides so many top level functions & among them primarily used functions are: match(), search(), findall(), sub(), split(), compile().
These functions are responsible for taking arguments, primarily, regular expression pattern as the first argument and the string where regex has to be applied to be the second. It returns either None or a match object instance. They store the compiled object in a cache for the purpose of making future calls using the same regular expressions and avoiding the need to parse the pattern again and again.
We will explain some of these functions in the below section.
1. re.match() - The match() function is used to match the beginning of the string. In the following example, the match() function will match the first letter of the given string whether it is a digit, lowercase or uppercase letter (underscores included).
a = re.match('[0-9_a-zA-Z-]','Welcome to programming') Output: 'W'
If we add ‘+' outside the character set, it will check for the repeatability of the given characters in 'RE'. In the following example, '+' checks about one or more repetitions of uppercase, lowercase, and digits (underscore included, white spaces excluded).
a = re.match('[_0-9A-Za-z-]+','Welcome to programming') Output: 'Welcome'
'*' is a quantifier that is responsible for matching the regex preceding it 0 or more times. In short, we can say it matches any character zero or more times. Let's understand via the below given example. In the given string ('Welcome to programming'), '*' will match for characters given in the regex as long as possible.
a = re.match('[_A-Z0-9a-z-]*','Welcome to programming') Output: 'Welcome'
If we add '*' inside the character set, the regex will check for the presence of '*' at the beginning of the string. Since in the following example '*' is not present at the beginning of the string, so it will result in 'W'.
a = re.match('[_A-Z0-9a-z-*]','Welcome to programming') Output: 'W'
Using quantifier '?' matches zero or one of whatever precedes it. In the following example '?' matches uppercase or lowercase characters including underscore as well at the beginning of the string.
a = re.match('[_A-Za-z-]?','Welcome to programming') Output: 'W'
There's 're' module function that offers you the set of functions that mainly allows you to search a string for a match. Let’s understand what these functions perform.
2. re. search()- It is mainly used to search the pattern in a text. The function re. search() takes a regex pattern and a string and searches for that particular pattern within the string. In that case, if the search is successful, search() returns a match object or None otherwise. The syntax of re. search is as follows:
a = re.search(pattern, string)
You can better understand the following example.
a = re.search('come', 'welcome to programming') Output: <_sre.SRE_Match object; span=(3, 7), match='come'>
3. re. findall()- Returns a list containing all matches. The function re. findall() is used when you want to iterate over the lines of a file or string, it will return a list of all the matches in a single step. The string is scanned left-to-right, and matches are returned in the order that found. The syntax of re. findall() is as follows:
a = re.findall(pattern, string)
Below is an example of re. findall() function.
a = re.findall('prog','welcome to programming') Output: ['prog']
4. re. split () - Returns a list where the string has been split at each match. Split string by the occurrences of pattern. The syntax of re. split is given below:
a = re.split(pattern, string)
Look at the following example re. split() function:
a = re.split('[\W]+','welcome to programming') Output: ['welcome', 'to', 'programming
a = re.split('\s','Hello how are you') Output: ['Hello', 'how', 'are', 'you']
b = re.split('\d','hello1i am fine') Output: 'hello', 'i am fine']
5. re. sub() - It replaces one or many matches with a string. It is used to replace sub strings and it will replace the matches in string with replacing value. The syntax of re. sub() is as follows:
a = re.sub(pattern, replacing value, string)
The following example replaces all the digits in the given string with an empty string.
m = re.sub('[0-9]','','Welcome to python1234. Coding3456.') Output: 'Welcome to python. Coding.'
6. re. compile() - We can compile pattern into the pattern objects all with the help of function re.compile(), and which contains various methods for operations such as searching for pattern matches or performing string substitutions.
In the following example, the compile function compiles the regex function mentioned and then the code asks the user to enter a name. If the user types/inputs any digit or other special characters, the compile results won't match and it will again ask the user for input. It will continue doing this unless and until the user inputs a name containing characters only.
name_check = re.compile(r"[^A-Za-zs.]") name = input("Please, enter your name: ") while name_check.search(name): print("please enter your name correctly!") name = input("Please, enter your name: ")
The output of the following code is as follows:
Please, enter your name: 1234 please enter your name correctly! Please, enter your name: 5678 Name is provided correctly please enter your name correctly! Please, enter your name: john Name is provided correctly
Wrapping Up
Now that we have a rough understanding of what RegEx is, how regex works in python, further we can move onto something more technical. It's time to get a small project up and running.
0 notes