#Flololle
Text
PyChang Pix2Pix를 이용한 해금 연주 음원 생성
1. 만들게 된 이유
1) 여러 가상악기, 음향 플러그인 들에 AI를 접목하고 있는 현재 상황에서, 국악기에도 딥러닝을 적용해 보고자 하는 시도
2) 기존 보컬 음성 합성 모델인 PyChang이 일반적인 악기 소리도 잘 합성해 주는지 실험
3) 개인 포트폴리오 제작
2. 개요
2.1 Pix2Pix
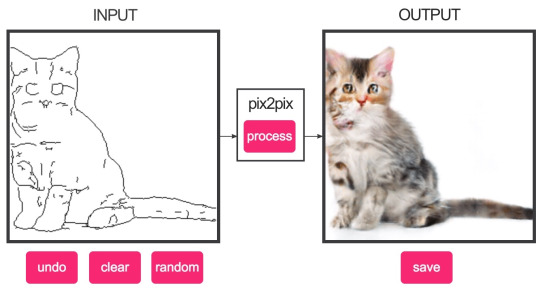
이미지 대 이미지 변환을 수행하는 인공지능입니다. 일반적으로 간단하고 만들기 쉬운 이미지를 입력하면, 복잡하고 어려운 이미지를 출력해 주는 식입니다. 모델의 학습에는 GAN 이라고 하는, 이미지 생성기와 참거짓 판단기가 서로 경쟁하면서 학습해나가는 방식을 이용합니다.
Pix2Pix의 예제 코드는 텐서플로우 웹페이지에 있고, 저는 이 코드를 활용하여 일찍이 PyChang이라는 간단한 음성 생성 모델을 만들어 둔 바 있습니다.
2.2 PyChang
Pix2Pix와 같은 원리로 돌아가는, MIDI 파일과 문자열(가사)을 바탕으로 음성(보컬)을 생성해 주는 모델입니다. PyChang의 모델 생성부는 위의 Pix2Pix의 모델 생성과 완전히 동일하다고 해도 될 정도입니다. 반면 만들어진 모델을 바탕으로 한 음성 생성은 다음과 같은 순서로 이루어지는데요,
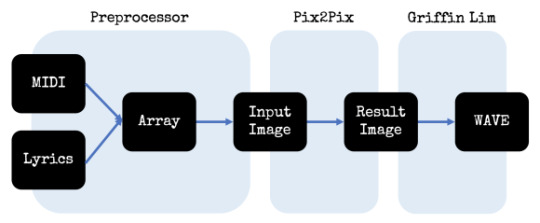
이 순서도에서 실제 인공지능 모델이 쓰이는 곳은 Input image를 Result image로 변환해주는 Pix2Pix 부분뿐입니다. 나머지는 포맷 변환 혹은 기존에 잘 알려진 '그리핀림' 이라는 방식으로 이미지와 파형을 만들어냅니다.
3. 데이터셋
총 두 종류의 데이터셋을 사용했습니다. 일반적으로 음성 생성에서는 결과 데이터의 일관성을 위해 한 종류의 데이터셋만을 사용하게 됩니다만 해금 음원 자료 자체가 부족한 상황이라 본의 아니게 섞어 사용하게 되었습니다.
각 데이터셋의 출처는 다음과 같습니다.
1: 공유마당 해금 효과음 (총 50개) - 쓸 수 없는 것들을 쳐내고 짧은 음원들을 묶으니 25개의 데이터만이 남았습니다.
2: 국립국악원 디지털음원 해금 (총 45개) - 긴 음원들을 학습에 필요한 형식으로 잘라 편집하니 62개의 데이터가 만들어졌습니다. 다운로드 받아 두었지만 아직 전처리를 하지 않은 음원들도 있으니 이걸 바탕으로 좀 더 버전업을 할 수 있는 상태입니다.
4. 전처리
모델을 만들기 위해 컴퓨터가 읽어올 수 있을 정도로 파일들을 만져 주어야 합니다. 보통 전처리를 완료하고 나면 음원 파일, 미디 파일, 텍스트 파일 세 개가 저장됩니다.
4.1 음원(.wav)
텐서플로우 기반 머신러닝을 위해서는 파일 길이가 전부 일정해야 합니다.. 이게 요새(스테이블 디퓨전 같은 것)는 안 그렇긴 합니다만… 스테이블 디퓨전 코드 자체가 공개되어 있는 물건이 아니라고 알고 있으니까요….
PyChang에서 지원하는 15초짜리 음원으로 자를 것은 자르고 합칠 것은 합쳐 줍니다. 이때 각 음원에 음정의 처음부터 끝까지가 잘리지 않고 담겨있을 필요는 없습니다. 잘려도 괜찮습니다.. 어차피 학습과정에서 5초 단위로 끊게 되어있어서요. 오히려 필요한 작업입니다.
4.2 미디(.mid)
학습과정에서 필요한 것은 아닙니다. PyChang에서는 Input Data로 Array 형식의 텍스트 파일만을 지원하는데 이 Array 형식의 텍스트 파일을 쉽게 만들기 위한 것이 바로 미디 파일입니다.
가장 정석적인 것은 미디 파일을 먼저 만들고 이에 맞추어서 연주하는 것입니다만 아무래도 사람이 기계처럼 연주할 수는 없으니 연주되어 있는 음원 파일을 분석하여 미디 파일로 뽑아내는 것이 더욱 정확합니다. 로직에서 Flex Pitch 기능을 이용하면 생각보다 손쉽게 할 수 있습니다.
4.3 Array(.txt)
미디 파일을 불러와 가사를 입력하여 Array 형태로 내보내는 것인데, 여기에서 변환 가능합니다. 단, 저는 악기 연주 음원을 만들고 있으므로 주법을 마킹하는 용도로 가사 부분을 활용했습니다. 즉 바이브레이션이 없는 음은 a, 바이브레이션이 심한 음은 i, 위에서 아래로 내리꽂는 음은 u… 와 같은 식입니다. (저는 a, i, u 세 종류만 사용했습니다.)
5. 학습 및 모델 구축
여기까지 준비가 다 되었다면 완성된 파일들을 가지고 학습을 진행합니다. Colab을 사용했습니다. 학습은 제가 하는 게 아니기 때문에 별 말 하지 않겠습니다. 처음에는 epoch를 600번으로 잡아 돌려 주었고, 40000스텝 근처에서 로스가 다시 꺾어지는 것 같아 멈춰주었습니다.
6. 음성 생성 및 결과
이렇게 만들어진 모델로 음성을 생성해 보았습니다. 모델이 학습될 동안 여러 곡을 MIDI로 따고, 텍스트를 통해 꾸밈음 등을 입력해 주었습니다. 그리고 학습이 끝나자마자 바로 변환해 보았습니다! 이렇게 생성된 결과가, 메인 웹페이지에 올라가 있는 음원들입니다.
7. 개선 방향
모델을 딱히 개선해야 할 필요는 못 느끼겠어요 이게 최선입니다.. 정말 여러모로 해 보았는데 GAN을 가지고 이것보다 잘 나오긴 힘듭니다.
나머지는 데이터의 숫자가 늘어나고 높은 퀄리티의 입력 데이터가 주어진다면 어떻게든 되는 것 같지만, 현재로서 가장 어려운 것은 바로 바이브레이션 구간이라고 생각합니다. 의외로 바이브레이션 생성을 잘 못하더군요...
그래서 지금 당장 개선할 수 있는 거라면, 데이터셋 자체를 많게는 200개 정도까지 늘리는 것이 목표입니다. 아까 1시간을 이야기 했는데, 1시간이면 240개 정도의 데이터를 확보할 수 있는 시간입니다. (그리고 아직 보컬로도 1시간짜리 데이터셋 활용해본 적 없습니다)
데이터셋 개수가 많아지게 되면 학습 자체도 더 잘 되지만, 학습에 방해되는 데이터를 쳐낼 수 있는 것도 장점입니다. 실제로 저도 데이터셋 ~50개 대까지는 학습에 방해되는 데이터도 데이터라고 안고 갔는데, ~60개로 만들면서 전부 쳐냈습니다. 솔직히 말하자면 공유마당의 해금 데이터는 정말 '효과음'이 필요한 사람을 타겟으로 한 거라 음성 생성에는 오히려 방해가 되는 음원도 더러 있습니다. 막판에는 이걸 다 쳐내고 깔끔한 데이터만으로 학습을 진행하는 것을 목표로 합니다.
현재 1600Hz 구간의 음량이 과하게 높은 현상이 발생하고 있는데 이 점도 문제점일 수 있습니다. 이게 해금 자체의 음색일 수 있어 원본이랑 비교가 필요하긴 합니다만, 음원을 받아와 믹싱하는 단계에서 이퀄라이저로 이 부분을 내려주어야 더 자연스러운 해금 소리가 났던 것과, 마스터링 단계에서 이퀄라이저를 켜보니 이 부분의 파형이 튀었던 것을 고려해 보면 아예 음원 다운로드 전에 일괄적으로 내려주는 것도 괜찮아 보입니다.
0 notes
Text
Erhu: AI Generated Sound
- Datasets: (Purchased, model training is okay but not allowed to release it)
- Length of Datasets: 15 secs × 74 sets
- Method: Pix2Pix PyChang
Haegeum: AI Generated Sound
- Datasets: Korea Copyright Commission
- CHOI Taeyeong(최태영), National Gugak Center / CC-BY Licence - Length of Datasets: 15 secs × 87 sets - Method: Pix2Pix PyChang
Original: 不忘 - 王一博
1 note
·
View note
Text
한국어판 블로그를 개설했습니다!

<마법소녀 마도카 마기카> 일러스트로부터.
Flololle의 인공지능 얼후 & 해금 음원 및 캐릭터 개발과 관련된 여러 가지 사담을 보다 편하게 올리는 곳이 필요해서 한국어판 블로그를 개설했습니다.
웬만한 것은 연합우주에 올리고 텀블러에서는 영어로만 진행하려고 했는데 역시 어렵더군요.
여기에서는 뒷사람의 성격도 드러내고.. 아무튼 편하게 편하게 운영할 겁니다.
Flololle(플로롤), 뭐 하는 프로젝트인가요?
제가 개발하고 있던 AI 음성 합성 엔진 프로젝트가 있었습니다. 주로 사람의 음성을 변환하는 것을 목적으로 개발하고 있었어요. 사정이 있어서 잠깐 쉬고 있었지만요. 그리고 목소리 녹음도 잠시 불가능해진 상태였습니다.
그런데 여기에 악기 소리를 돌려 보면 어떨까 하는 생각이 들었습니다. 현대 음악을 창작하는 데 일반적으로 많이 사용하는 악기는 이미 가상악기로 많이 나와 있습니다. 그리고 보통 음정과 박자를 정해두면(약간의 오토메이션도 포함) 별 무리 없이 쓸만한 소리를 얻을 수 있었습니다.
그런데 국악기 같은 경우에는 가상악기도 여러 종류가 있지 않은데다, 소리가 일정하면 특유의 국악기스러움이 묻어나지 않는다고 해야할까요, 뭔가 변수가 많은 편이었습니다. 대금이나 해금 같은 게 그런 느낌이었어요. 그래서 국악기 음성 합성을 해보자고 결정하고, 우선은 해금 음원 배포(가상악기는 아니니까요 아무래도 ㅎㅎ..)를 목표로 잡게 되었습니다.
처음에는 이 해금 소리가 상당히 빈약했었고, 이걸 조금이라도 보완하기 위해 데모 파일에 로직 프로의 기본 가상악기 중 하나인 얼후 화음을 첨가했습니다. 얼후가 까랑까랑한 소리보다는 부드러운 소리에 가까운 느낌이라 곡과 해금사이를 잘 메꿔준다는 느낌을 받았습니다.
그래서 그 상태로 클라리스의 ⟨ALIVE⟩를 커버했고, 그 다음에 유이카의 <좋아하니까.> 를 커버했습니다. 전자의 ⟨ALIVE⟩가 <리코리스 리코일> 의 오프닝 테마였던만큼 <리코리코>에 나오는 캐릭터들이 각자 해금과 얼후를 연주하는 장면을 첨가했는데, 이 컨셉이 너무 마음에 들어 이런 느낌을 유지하자고 생각했고, <좋아하니까.> 에 이르러서는 사용할 만한 캐릭터가 없자 영상에 오리지널 캐릭터를 추가하게 됩니다.
그렇게 추가된 캐릭터가 현재의 이지이, 유아란입니다. 이 캐릭터에 설정을 붙이고, 음원 배포 시 홍보모델로 쓰면 괜찮을 것 같다고 생각했습니다. 여기까지 오자 '어라... 그러면 얼후는...?' 이라는 생각이 들었고, 기왕 AI 음성합성을 할 거면 얼후도 AI로 해보자 싶어 지금 상태까지 오게 되었습니다.
이 모든 과정이 일주일도 안 걸렸네요... 앞으로 하고 싶은 건 음원을 계속 개발하면서 캐릭터들의 설정도 머리에 입력해 두고, 간단한 낙서나 데모 음원 같은 것을 꾸준히 공하며 홍보하는 것입니다... 사실 프로젝트의 제대로 된 시동은 아직 걸리지 않았습니다. 한달 정도는 해보고 그때도 흥미가 안 떨어진다면 본격적으로 시작해 볼 생각입니다.
0 notes
Text
[WIP] 인연 - 231014
Erhu: AI Generated Sound
- Datasets: (Purchased)
- Length of Datasets: 15 secs × 43 sets
- Method: Pix2Pix PyChang
Haegeum: AI Generated Sound
- Datasets: Korea Copyright Commission - CHOI Taeyeong(최태영), National Gugak Center / CC-BY Licence
- Length of Datasets: 15 secs × 87 sets
- Method: Pix2Pix PyChang
Original: 인연 - 이선희
1 note
·
View note


Text

The first Illustration of Aran(left) and Zhiyi(right)!
0 notes
Text
[WIP] 好きだから。 - 231003
Erhu: Logic Pro X
Haegeum: AI Generated Sound
- Datasets: Korea Copyright Commission - CHOI Taeyeong(최태영), National Gugak Center / CC-BY Licence
- Length of Datasets: 15 secs × 87 sets
- Epochs : 500
- Method: Pix2Pix PyChang
Original: Yuika
1 note
·
View note
Last Seen Blogs

limbo-acessory
Лимбо Аксессуары

loszera
YO BITCH

ashchristina
persephone

doctordragon
"gender? I don't even know her!" flavor nonbinary

freakyfernando135
freaky fernando 135