#IBM Netezza data warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
IBM Watsonx.data: Transforming Data Flexibility & Efficiency

In addition to Spark, Presto, and Presto C++, Watsonx.data provides a selection of open query engines that are perfect for a wide range of applications.
Businesses will face more difficulties in handling their expanding data as the worldwide data storage market is predicted to more than treble by 2032. The adoption of hybrid cloud solutions is revolutionising data management, improving adaptability, and elevating overall organisational performance.
Businesses can build flexible, high-performing data ecosystems that are ready for AI innovation and future growth by concentrating on five essential components of cloud adoption for optimising data management, from changing data strategy to guaranteeing compliance.
The development of data management techniques
With generative AI, data management is changing drastically. Companies are increasingly using hybrid cloud solutions, which mix private and public cloud benefits. These solutions are especially helpful for data-intensive industries and businesses implementing AI strategies to drive expansion.
Companies want to put 60% of their systems in the cloud by 2025, according to a McKinsey & Company report, highlighting the significance of adaptable cloud strategy. In order to counter this trend, hybrid cloud solutions provide open designs that combine scalability and excellent performance. Working with systems that can adjust to changing requirements without sacrificing performance or security is what this change means for technical workers.
Workload portability and smooth deployment
The ability to quickly deploy across any cloud or on-premises environment is one of the main benefits of hybrid cloud solutions. Workload portability made possible by cutting-edge technologies like Red Hat OpenShift further increases this flexibility.
With this feature, enterprises can match their infrastructure to hybrid and multicloud cloud data strategies, guaranteeing that workloads may be scaled or transferred as needed without being restricted to a single environment. For businesses to deal with changing business needs and a range of regulatory standards, this flexibility is essential.
Improving analytics and AI with unified data access
The advancement of AI and analytics capabilities is being facilitated by hybrid cloud infrastructures. According to a Gartner report from 2023, “two out of three enterprises use hybrid cloud to power their AI initiatives,” highlighting the platform’s crucial place in contemporary data strategy. These solutions offer uniform data access through the use of open standards, facilitating the easy sharing of data throughout an organisation without the need for significant migration or restructuring.
Moreover, cutting-edge programs like IBM Watsonx.data use vector databases like Milvus, an open-source program that makes it possible to store and retrieve high-dimensional vectors quickly. For AI and machine learning activities, especially in domains like computer vision and natural learning processing, this integration is vital. It increases the relevance and accuracy of AI models by giving access to a larger pool of reliable data, spurring innovation in these fields.
These characteristics enable more effective data preparation for AI models and applications, which benefits data scientists and engineers by improving the accuracy and applicability of AI-driven insights and predictions.
Using appropriate query engines to maximize performance
The varied nature of data workloads in the field of data management necessitates a flexible query processing strategy. Watsonx.data offers a variety of open query engines that are suitable for various applications, including Spark, Presto, and Presto C++. It also provides integration options for data warehouse engines, such as Db2 and Netezza. Data teams are able to select the best tool for each work thanks to this flexibility, which improves efficiency and lowers costs.
For example, Spark is great at handling complicated, distributed data processing jobs, while Presto C++ may be used for high-performance, low-latency queries on big datasets. Compatibility with current workflows and systems is ensured through interaction with well-known data warehouse engines.
In contemporary enterprises, this adaptability is especially useful when handling a variety of data formats and volumes. Watsonx.data solves the difficulties of quickly spreading data across several settings by enabling enterprises to optimise their data workloads.
In a hybrid world: compliance and data governance
Hybrid cloud architectures provide major benefits in upholding compliance and strong data governance in the face of ever more stringent data requirements. In comparison to employing several different cloud services, hybrid cloud solutions can help businesses manage cybersecurity, data governance, and business continuity more successfully, according to a report by FINRA (Financial Industry Regulatory Authority).
Hybrid cloud solutions enable enterprises to use public cloud resources for less sensitive workloads while keeping sensitive data on premises or in private clouds, in contrast to pure multicloud configurations that can make compliance efforts across different providers more difficult. With integrated data governance features like strong access control and a single point of entry, IBM Watsonx.data improves this strategy. This method covers a range of deployment criteria and constraints, which facilitates the implementation of uniform governance principles and enables compliance with industry-specific regulatory requirements without sacrificing security.
Adopting hybrid cloud for data management that is ready for the future
Enterprise data management has seen a substantial change with the development of hybrid cloud solutions. Solutions such as IBM Watsonx.data, which provide a harmony of flexibility, performance, and control, are helping companies to create more inventive, resilient, and efficient data ecosystems.
Enterprise data and analytics will be shaped in large part by the use of hybrid cloud techniques as data management continues to change. Businesses may use Watsonx.data‘s sophisticated capabilities to fully use their data in hybrid contexts and prepare for the adoption of artificial intelligence in the future. This allows them to negotiate this shift with confidence.
Read more on govindhtech.com
#watsonx.data#datamanagement#generativeai#machinelearning#AImodels#datagovernance#cloudtechniques#cloudsolutions#artifiialintelligence#hybridcloud#news#technews#technology#tehnologynews#technologytrends#govindhtech
0 notes
Text
Sunrise on Your Enterprise Data Warehouse, Sunset for IBM Netezza - Yellowbrick
In today’s data-driven world, enterprises are constantly faced with the challenge of managing and processing vast amounts of data in a timely and efficient manner. With IBM formally announcing the end-of-life for IBM’s Mako-generation Netezza systems, many companies are now forced to consider their alternatives as we count down the final months left for vendor support.
0 notes
Photo

Glory IT Technologies offering IBM Netezza Online Training by certified working experts.
#IBM Netezza#ibm#netezza#online training#technology#IBM Netezza training#IBM Netezza online training#IBM Netezza data warehouse
0 notes
Text
Langdetect predictive analytics r language programming
LANGDETECT PREDICTIVE ANALYTICS R LANGUAGE PROGRAMMING 🎇
* Data Science* The study involving data is[ data science. It analyzes data and uses it to extract the useful information from it to develop and create methods to process the data. It deals with both structured and unstructured data. Data is a different field but involves computer science a little bit. While computer science develops algorithms to deal with the data, Data science may use computers. It mainly uses the study. Business Analytics With R or commonly known as 'R Programming Language' is an open-source programming language and a software environment designed by and for statisticians. It is basically used for statistical computations and high-end graphics.
Language line identification poster. The IBM Netezza analytics appliances combine high-capacity storage for Big Data with a massively-parallel processing platform for high-performance computing. With the addition of Revolution R Enterprise for IBM Netezza, you can use the power of the R language to build predictive models on Big Data.
youtube
Bing language detection apixaban.
Python vs. R for Developing Predictive Analytics Applications. Detect chinese language by c. R (programming language. The influence of technology on the world is constantly growing. In this new age where everything is being shifted to the online sphere, data has risen as the new currency. It has become the most important asset of every organization. Hence the uses of data mining in todays world cannot be undermined or understated. Data mining seems like magic to most people. Ext.
Changed: 2019-12-04T03:47:27. Unicode language identification. Exploring Cognitive Relations Between Prediction in Language and Music. Title: Subword Level Language Identification for Intra Word Code Switching. Publish Graduate Diploma In Predictive Analytics. Risk Prevention Data Scientist Volunteer Forest Fire Prevention Derivatives, CrowdDoing, M4A FOUNDAT.
Identifying Language Origin of Named Entity With Multiple Information Sources. NLP: Simple language detection in Python. Settings google language detection. Top 10 Programming Languages For Data Scientists to Learn In 2018. Php script language detection and translation. SQL Server R language tutorials. 12/18/2018; 2 minutes to read +4; In this article. APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse This article describes the R language tutorials for in-database analytics on SQL Server 2016 R Services or SQL Server Machine Learning Services.
Risk Prevention Data Scientist Volunteer Forest Fire Prevention Derivatives, CrowdDoing, See more detailed background on CrowdDoing's forest fire prevention derivatives _HUr-tCCNaeGoSDfPrirRPbaoV3X4/view?usp=sharing Risk Prevention Data Scientist Volunteer Forest Fire Prevention Derivatives, CrowdDoing, Bobby Fishkin, lead author In 2018, Sacramento was named the "the Most Polluted City on Earth" due to "smoke from Camp Fire, This proposal aims to prevent.
mevasokick.simpsite.nl/
http://vascviwhegor.tripod.com
http://mancadenwe.parsiblog.com/Posts/5/Detect+Language+Python+Language+Langdetect/
rauguescanap.blogg.se/2019/december/php-language-detection-stringent-langdetect.html
u/cardsixohua/blog/LangdetectRLanguagePredictFunctionInR/
https://everplaces.com/roalinjicom/places/573e76f03f314beb8b83bf3a7c59d0c7/
1 note
·
View note
Text
IBM Netezza Training
High-performance data warehouse appliance and advanced analytics applications by using IBM Netezza
Introduction:
Netezza was obtained by IBM in 2010, September 10 and reached out of support in June 2019. This technology was reintroduced in June 2020 as the part of the IBM. This system mainly built for Data Warehousing and it is simple to administer and to maintain.
IBM Netezza performance server for IBM Cloud Pak with enhancement to in-database analytics capabilities. This technology designed specifically for running complex data warehousing workloads. It is a type of device commonly referred to as a data warehouse device and concept of a device is realized by merging the database and storage into an easy to deploy and manage system.
By using IBM Netezza reduces bottle necks with commodity field-Programmable Gate Array (FPGA). This is a short high-level overview architecture.
Benefits and Features of IBM Netezza:
Achieving frictionless migration
Pure Data System for Analytics
Elimination of data silos
Acceleration of time value
Choosing your environment
Helping reducing costs
Minimal Ongoing administration
Flexible deploys in the environment
Benefits from in-database analytics and hardware-acceleration
Flexible Information Architecture
Solving more business problems while saving costs
Make all your data available for analysis and AI
Review (or) Overview
User login control
Impersonating
Key management
Advanced query history
Multi-level Security
Row-secure tables
CLI Commands and Netezza SQL
Enable and Disable security commands
Career with IBM Netezza:
This IBM Netezza is efficient and reliable platform for enterprise data storage and it is easy to use. This technology is a best solution for larger database. Comparing with other technologies this technology has best career because more than 10000 IBM Netezza jobs available across India.
If you want to learn more about IBM Netezza, go through this IBM Netezza tutorial pdf by Nisa Trainings and also you can learn this IBM Netezza online course yourself by referring to Nisa Trainings on your flexible timings.
Currently Using companies are:
USAA
United Health Group
Quest Diagnostics
Citi
Harbor Freight
Bank of America
IBM
These are the companies using this technology and it is an on-demand technology.
Course Information
IBM Netezza Online Course
Course Duration: 25 Hours
Timings: On Your Flexible Timings
Training Method: Instructor Led Online
For More information about IBM Netezza Online Course, feel free to reach us
Name: Albert
Email: [email protected]
Ph No: +91-9398381825
#ibmnetezzaonlinetraining#ibmnetezzaonlinecourse#ibmnetezzacertification#ibmnetezzatraining#ibmnetezzacourse
0 notes
Text
IBM Netezza: Unlock true Potential of data warehousing

Introduction to IBM Netezza
IBM Netezza is a data analytics platform designed for high-performance computing, analytics, and data warehousing. It combines hardware and software to deliver a powerful and efficient solution for rapidly ingesting, analyzing, and visualizing data. With its distributed computing architecture, IBM Netezza can scale up to handle larger volumes of data and enable organizations to take on more complex analytics projects.
At its core, IBM Netezza is a data warehouse platform. It includes functions for extracting and transforming data from various sources, loading the data into a relational database, and managing the data warehouse environment. With its integrated analytics functions, IBM Netezza makes it easy to analyze the data in the warehouse and produce insights. Additionally, IBM Netezza provides a feature-rich environment for creating custom reports and visualizations.
IBM Netezza also offers a range of advanced features, such as data mining, predictive analytics, and machine learning. These features allow organizations to gain deeper insights into their data and make more informed decisions. Furthermore, IBM Netezza is designed to be highly secure, with built-in encryption and authentication capabilities to protect sensitive data.
Understanding the Benefits of IBM Netezza
IBM Netezza provides several benefits that make it an attractive option for organizations looking to leverage data analytics. First, it is designed for high-performance computing, meaning it can handle large amounts of data quickly and efficiently. This makes it ideal for organizations that need to process large volumes of data in real-time. Additionally, IBM Netezza includes a wide range of integrated analytics functions, allowing organizations to easily gain insights from their data.
The platform also offers scalability for both hardware and software. This means organizations can start small and scale up as their data analytics needs grow. Furthermore, IBM Netezza is backed by an experienced team of professionals who can help organizations get the most out of the platform.
IBM Netezza also offers a range of security features, such as encryption and authentication, to ensure data is kept safe and secure. Additionally, the platform is designed to be easy to use, with a user-friendly interface and intuitive tools that make it simple to access and analyze data. This makes it an ideal choice for organizations of all sizes.
Exploring the Capabilities of IBM Netezza
IBM Netezza is an all-in-one data warehouse platform that offers a variety of capabilities for data analysis. It includes functions for extracting, transforming, and loading data into the warehouse, as well as built-in analytics functions for analyzing the data. Additionally, IBM Netezza provides the ability to create custom reports and visualizations. And with its distributed computing architecture, IBM Netezza can scale up to handle larger amounts of data.
Some of the key capabilities of IBM Netezza include:
* Data extraction, transformation, and loading (ETL)
* Data warehousing
* Analytics tools for predictive modeling
* Custom reporting and visualizations
* Scalable hardware and software architecture
IBM Netezza also offers a range of security features, such as data encryption, role-based access control, and audit logging. This ensures that data is secure and only accessible to authorized users. Additionally, IBM Netezza provides a range of support options, including online resources, tutorials, and customer support.
Analyzing Data with IBM Netezza
IBM Netezza includes a range of tools and functions for analyzing data. The platform includes built-in analytics functions for exploring relationships between different elements in the data. Additionally, IBM Netezza provides a suite of predictive analytics tools for uncovering patterns in the data and predicting future trends. And with its integrated reporting and visualization tools, IBM Netezza makes it easy to create custom reports and visualizations.
IBM Netezza also offers a range of data mining capabilities, allowing users to identify hidden patterns and correlations in the data. This can be used to uncover new insights and inform decision-making. Additionally, IBM Netezza provides a range of data preparation tools, allowing users to quickly and easily clean and transform data for analysis.
Optimizing Performance with IBM Netezza
IBM Netezza is designed to maximize performance. The platform includes features for optimizing query performance and ensuring that queries run efficiently. Additionally, IBM Netezza provides a suite of tuning tools that allow organizations to fine-tune their queries to get the best performance. And with its distributed computing architecture, IBM Netezza can scale up to handle larger amounts of data.
IBM Netezza also offers a suite of data security features, including encryption, authentication, and access control. This ensures that data is secure and protected from unauthorized access. Additionally, IBM Netezza provides a comprehensive monitoring system that allows organizations to track query performance and identify any potential issues. This helps organizations ensure that their queries are running optimally and that their data is secure.
Integrating IBM Netezza with Other Technologies
IBM Netezza includes a range of features for integrating with other technologies. The platform includes APIs for connecting to other systems and applications, making it easy to leverage existing infrastructure. Additionally, IBM Netezza supports a variety of formats for importing and exporting data, making it easy to move data between systems. Finally, IBM Netezza provides an extensive library of third-party connectors that allow organizations to easily connect to other systems.
IBM Netezza also offers a range of tools for managing and monitoring data integration processes. These tools allow organizations to track the progress of data transfers, as well as identify and troubleshoot any issues that may arise. Additionally, IBM Netezza provides a secure environment for data integration, ensuring that sensitive information is protected throughout the process.
Security Considerations for IBM Netezza
IBM Netezza includes a range of features for ensuring security. The platform supports secure authentication protocols and includes encryption tools for protecting sensitive data. Additionally, IBM Netezza provides robust auditing tools for keeping track of user activity. Finally, the platform includes features for monitoring system performance to ensure that users are not accessing more than they need.
Conclusion
IBM Netezza is an incredibly powerful data analytics platform that enables organizations to quickly and efficiently analyze large amounts of data. With its high-performance computing capabilities and integrated analytics functions, IBM Netezza helps organizations gain insights and make better decisions faster. In this article, we explored the benefits, capabilities, and potential of IBM Netezza as a data analytics platform.
0 notes
Text
Ibm spss statistics reviews

#Ibm spss statistics reviews professional#
With its client server architecture, SPSS Modeler can push the analysis back to the source for execution, which can minimize data movement and increase performance. Auto Classifiers, Decision Trees, Logistic, SVM, Time Series, etc.Integration to Cognos, Netezza, InfoSphere and System Z.Entity Analytics ensures the quality of the data and results in more accurate models.Natural Language Processing (NLP) to extract concepts and sentiments in text.Access all data: structured and unstructured from disparate sources.Automated modeling and data preparation capabilities.Interactive easy to use interface without the need for programming.IBM Predictive Analytics IBM SPSS Modeler Features :
#Ibm spss statistics reviews professional#
IBM SPSS Modeler Professional – Provides a range of advanced algorithms, data manipulation and automated modeling and preparation techniques to build predictive models and uncover hidden patterns in structured data. IBM SPSS Modeler Premium – Provides a range of advanced algorithms and capabilities including text analytics, entity analytics, social network analysis and automated modeling and preparation techniques. This is achieved with Decision Management which combines predictive analytics with rules, scoring and optimization within an organization's processes. IBM SPSS Modeler Gold – Provides organizations with the ability to build and deploy predictive models directly into the business process. IBM SPSS Modeler is offered as three editions: SPSS Modeler offers capabilities include conducting analysis regardless of where the data is stored such as in a data warehouse, a database, Hadoop or flat file and regardless of whether it is structured such as age, price, product, location or unstructured such as text, emails, social media. The solution provides a range of advanced analytics including text analytics, entity analytics, social network analysis, automated modeling, data preparation, decision management and optimization. Detailed answers and explanations for the first 3 can be found in the appendix and the final 2 are available to instructors only at /aldrich3e.IBM SPSS Modeler is an analytics platform from IBM, which bring predictive intelligence to everyday business problems. Review Exercises (5 for each chapter) provide additional hands-on practice.Nonparametric tests are included in the same chapters as their related parametric tests to help readers find the information they need more quickly.Screenshots and callouts present additional details on where to click, unclick, and enter variable information and/or data.Bulleted, step-by-step instructions for doing statistical analysis include items the reader should click on in bold and other important terms in italics.Chapter objectives alert readers to what they’ll learn in the pages that follow.This book makes the benefits of the latest SPSS program available not only to the novice but also to the more experienced user of statistics.(2-tailed)” column shown in much of SPSS’s output. A new Appendix provides examples of the use of the normal curve and z-table to solve probability type problems that encourages the student/statistician to examine and understand the real meaning and importance of the “Sig.Topics such as sampling, statistical significance and hypothesis testing are addressed to give the SPSS user a foundational understanding of the results of SPSS’s statistical procedures.A new chapter on inferential statistics helps readers transition from univariate to inferential tests.The entire text has been updated to reflect the changes of SPSS version 25.Each statistical chapter has additional descriptions of the goals and parameters of each statistical test and the basic formula behind the test.Answers to the two additional Review Exercises at the end of each chapter that are available to instructors.100 pages of answers that provide detailed explanations as well as graphs and tables directly from the SPSS output.Video tutorials from the author that guide readers through SPSS functionality.A new Companion Website enhances the mastery of concepts and includes:.
1 note
·
View note
Text
What are the IBM Informix Features and Benefits?
In literal terms, the IBM Informix provides an Informix database on IBM cloud, and it offers customers the rich features of an on-premises Informix deployment while assisting to reduce the cost, complexity and risk of managing your own infrastructure. Informix on cloud, especially brings you a high-performance engine that integrates time series, spatial, NoSQL and SQL data together with easy access through MQTT, REST and MongoDB APIs as a whole. Some of the features of IBM Informix are as follows:
o High-performance technology
IBM Informix offers a cleaner indexes and improved memory management for more-efficient use of memory and processors. It also supports enhanced buffer priority management for more-efficient use of large amounts of memory for today’s 64-bit operating systems. Apart from that it supports smarter query optimization including that of user-defined type costing with new spatial data types, and shortened instruction sets for common tasks, as well as that of reduced contention between concurrent users.
o Scalability
Informix offers data capacity of a single instance with a quick enhancement from 4TB to 128PB. Whereas, Informix maximum chunk size increases from 2GB to 4 TB, and maximum number of chunks increases from 2,048 to 32K. On the other hand, the maximum LVARCHAR size increased from 2KB to 32KB, and its DBMS utility file size limit increased from 2GB to 17 billion GB.
o Security
Informix offer highest level of security especially from all kind of data breaches, and at the same time, it offers secured over-the-wire encryption using the industry-standard OpenSSL encryption libraries, and configurable user authentication mechanisms using Pluggable Authentication Modules, especially for your confidential data files.
o System management
Informix storage manager support in the browser-based ISA, and automated backup and restore functions to increase media efficiency by tape-handling utilities and also offers more flexible restore options so that your database management system works with more efficiency and offers security to your sensitive data files.
o Application development
Informix basically support SQL language enhancements, and also expanded Unicode support. On the other hand, it also works on multiple collation support, silent installation, and continued support of IBM Informix 4GL, SQL, ODBC, JDBC, OLE DB, SQLJ, and.NET driver as a whole.
Unlike it features, some of the benefits of IBM Informix are as follows o One of the key benefits of IBM Informix database is that it has been used in many high transaction rate OLTP applications in the retail, finance, energy and utilities, manufacturing and transportation sectors. More recently the server has been updated to improve its support for data warehouse workloads. o Another astounding feature of IBM Informix is that the Informix server supports all kinds of object–relational model, which has permitted IBM to offer extensions that support data types that are not a part of the SQL standard. The most widely used of these are the JSON, BSON, time series and spatial extensions, which provide both data type support and language extensions that permit high performance domain specific queries and efficient storage for data sets based on semi-structured, time series, and spatial data.
In conclusion, it can be said that Informix is often compared to IBM's other major database product like DB2, which is offered on the mainframe zSeries platform as well as on Windows, Unix and Linux. There is also certain speculation around the corner that IBM would combine Informix with DB2, or with other database products has proven to be unfounded. On the other hand, IBM has instead continued to expand the variety of database products it offers, such as Netezza, a data warehouse appliance, and Cloudant, a NoSQL database. IBM has described its approach to the market as providing workload optimized systems as a whole.
Avail All Blue Solutions IBM Informix database system for your business today!
0 notes
Text
The Need to Migrate Data from Netezza to Snowflake
Netezza was introduced in 2003 and became the first data warehouse appliance in the world. Subsequently, there were many “firsts” too – 100 TB data warehouse appliance in 2006 and petabyte data warehouse appliance in 2009.

Netezza has had an amazing run, with unmatched performance due to its hardware acceleration process in field-programmable gate arrays (FPGA). This could be fine-tuned to process intricate queries at blistering speed and scale. Data compression, data pruning, and row-column conversion were all handled optimally by FPGA.
During the lifetime of Netezza, various versions have been launched and all of them have provided high value to the users with simplified management, data pruning, and no need for indexing and partitioning of data. Then, why would users want to migrate data from Netezza to Snowflake?
The cloud-based data warehouse revolution made a huge difference to Netezza as IBM withdrew support. New hardware has not been released since 2014. By doing so IBM has forced Netezza users to abandon the appliance and opt for cloud-based data warehousing solution Snowflake.
There are many benefits of Snowflake for those wanting to shift from Netezza to Snowflake. Snowflake is a premium product, providing a great deal of performance, scalability, and resilience, more than other cloud-based data warehouse solutions.
Additionally, there are many advantages of shifting to the cloud and Snowflake for data management.
· Affordable – Enterprises do not have to invest in additional hardware and software. This is very critical for small industries and start-ups. In this pricing model, users can scale up or down in computing and storage facilities and pay only for the quantum of resources used.
· Reliability – Reliability and uptime of server availability are mostly in excess of 99.9%.
· Deployment speed – Organizations have the leeway to develop and deploy applications almost instantly because of access to unlimited computing and storage facilities.
· Economies of scale – When several organizations share the same cloud resources the costs are amortized for each of them, leading to economies of scale.
· Disaster recovery – When there is an outage in primary databases, the secondary databases in the region are automatically triggered and users can work as usual. When the outage is resolved, the primary databases are restored and updated automatically.
There are two steps in any Netezza to Snowflake data migration strategy.
The first is the lift-and-shift strategy which is used when there is timescale pressures to move away from Netezza with the need to move highly integrated data across existing data warehouse. This is also relevant when a single standalone and independent data mart has to be migrated.
The second is the staged approach. This is applicable when many independent data marts have to be moved independently. The focus here is on new development rather than reworking legacy processes.
Choosing between the two largely depends on such factors as timescale, number of data resources, and types of data types.
0 notes
Text
IBM and AWS’s collaboration is effective

During the current AI revolution, businesses are attempting to alter their operations via the use of data, generative AI, and foundation models in order to increase efficiency, innovate, improve consumer experiences, and gain a competitive advantage. Since 2016, IBM and AWS have collaborated to provide safe, automated solutions for hybrid cloud settings.
Through this cooperation, customers have the freedom to choose the ideal combination of technologies for their requirements, and IBM Consulting can assist them in scaling those solutions throughout the whole company. As a consequence, technology adoption is simpler and quicker, operations are more secure, and these factors may all contribute to greater business outcomes. The way organizations use the promise of data-driven AI to remain competitive in the digital era is being revolutionized by this potent combination.
Data and AI as the Partnership’s Foundation
This relationship is based on a shared understanding of how data can act as a catalyst for innovation in AI. Data enables AI algorithms, allowing them to provide insights, forecasts, and solutions that advance enterprises. This understanding serves as the foundation for the IBM and AWS partnership, fostering a setting where data and AI are effortlessly blended to provide outstanding outcomes.
Together with the ease of SaaS for our clients, IBM and AWS have collaborated to enable the whole IBM data management portfolio, including Db2, Netezza, and IBM Watsonx.data, to function on AWS in a cloud native manner. This partnership acknowledges that data and AI work together inextricably to power digital transformation. Data serves as the starting point for AI algorithms to learn and develop, and AI mines data for useful information that helps to define corporate strategy and consumer experiences. Together, they increase each other’s potential, sparking an innovation feedback loop.
IBM’s data management know-how, AI research, and creative solutions complement AWS’s cloud computing capabilities and worldwide reach nicely. This alliance takes use of the synergies between data and AI and is more than simply a marriage of convenience.
IBM Data Store portfolio as the only option
In the last six months A series of ground-breaking data and AI technologies that enable organizations to prosper in a data-driven environment have been introduced by the IBM and AWS cooperation. The capabilities of enterprises across multiple sectors are improved by these products, which put a strong emphasis on data management, AI development, and seamless integration.
Watsonx.data on AWS:Imagine having the power of data at your fingertips with Watsonx.data on AWS. Data administration is revolutionized by the software-as-a-service (SaaS) product watsonx.data. It has a fit-for-purpose data store built on an open lakehouse architecture, cuts Data Warehouse expenditures in half, and provides fast access to all of your data on AWS in only 30 minutes. Its capabilities are further enhanced by several query engines, integrated governance, and hybrid cloud deployment methods.
Netezza SaaS: Changing to the cloud has never been simpler than with Netezza SaaS. Data transfer is made simple with Netezza SaaS, which also guarantees seamless updates and the lowest Total Cost of Ownership (TCO). Watsonx integration and support for open table formats on COS.Data operations are streamlined, making it a valuable resource for companies needing seamless cloud connectivity.
Db2 Warehouse SaaS: Db2 Warehouse SaaS: Db2 Warehouse SaaS, which guarantees up to 7 times quicker performance and a spectacular 30 times decrease in expenses, satisfies the requirement for quick data processing. This approach scalable well, whether working with tens or hundreds of gigabytes. Its adaptability is shown by its support for native and open table formats on COS and watsonx.data integration.
A sample of the influence in the actual world
When analyzing hypothetical situations, the partnership’s and its offers’ actual strength becomes clear. One noteworthy instance is a well-known Japanese insurance provider that used Db2 PureScale on AWS. Through this cooperation, they were able to improve customer service while obtaining knowledge that has changed the way they communicate with their customers.
A plea for the adoption of data-driven AI transformation
Business data is king and AI is the game-changer for our clients. The collaboration between IBM and AWS stands out as an innovation beacon. Together, we are demonstrating to our clients how important data and AI are to advancement. This relationship provides organizations with a road map to data-driven AI solutions that spur development, innovation, and long-term success as they attempt to negotiate the complexity of the digital ecosystem.
Attend IBM TechXchange Conference 2023, the leading educational conference for programmers, engineers, and IT professionals, and network with IBM and AWS specialists.
Visit the AWS Marketplace page for the IBM Watsonx.data software-as-a-service (SaaS) offering. On the watsonx.data product page, you can also register for a demo or begin an IBM watsonx.data trial on AWS.
The future is revealed via the union of data and AI
The cooperation between IBM and AWS is a step toward realizing the full potential of data and AI, more than just a collaboration. Their combined experience produces a symphony of invention that cuts across sectors and reshapes possibilities. This cooperation, which uses data as the foundation and AI as the engine, paves the way for a day when organizations will prosper from the power of perception, intellect, and invention.
0 notes
Text
[PowerBi] Tipos de conexión
Power Bi nos permite nutrirnos de sus múltiples conectores a muy diversos orígenes de datos. Cada uno de ellos tiene particularidades y formas de conexión. Puede que necesitemos instalar un driver o venga por defecto. La realidad es que depende del conector y origen para conocer las formas conexión que contiene.
En éste artículo vamos a presentar las tres formas de conexión que nos provee Power Bi frente a distintos tipos de orígenes de datos. Éstos serán nombrados en ingles para unificar conceptos de Power Bi. Aprendé sobre ellos a continuación.
1- Import Data
Éste método funciona cargando todos los datos de la fuente de origen dentro de Power Bi. Importar en Power Bi significa consumir memoria y espacio de disco. Mientras se desarrolla sobre Power Bi Desktop en una computadora la memoria ram y el espacio de disco que consumiría sería el propio. Cuando el informe o conjunto de datos es publicado al portal de Power Bi, la memoria y el disco utilizado sería de una Cloud Machine que provee el Servicio de Power Bi que es invisible para nosotros.
Tengamos en cuenta que si nuestra base de datos tiene 1000 tablas con muchas filas, pero solo cargamos 10 tablas y pocas filas en Power Bi, entonces solo consumiríamos memoria para esas 10 tablas filtradas. La idea de consumir memoria y disco es solo para los datos que queremos trabajar.
Hay una consideración muy importante a tener en cuenta sobre Import Data. Si cargas en Power Bi 100GB de tablas de una base de datos el archivo modelo de Desktop no pesará 100GB. Power Bi tiene un motor de compresión de xVelocidad y funciona con tecnología Column-Store in-memory (dejo en ingles por si quieren leer más al respecto). La forma más conocida para comprobarlo es tener un excel de 1GB y cuando lo importen en Power Bi probablemente termine pesando menos de la mitad del peso original del archivo. Esto sucede por la compresión mencionada antes. Sin embargo, la compresión no será tan buena siempre, la misma depende de varios factores; tipos de datos, cantidad de columnas, etc. Spoiler, más adelante voy a armar un post de como reducir el modelo de datos y ahi podrían aparecer más factores.
Para mantener los datos actualizados en éste método debemos configurar actualizaciones programadas.
Características
Permite usar toda la funcionalidad poderosa de Power BI
Con este método se puede aprovechar mucho características fuertes de Power Bi. Puedes usar Power Query para combinar, transformar y modelar múltiples orígenes de datos o escribir DAX avanzado con Time Intelligence para mejorar objetivos de las visualizaciones. Se pueden aprovechar todos sus componentes con esta forma.
Limitaciones de tamaño
No todo es maravilloso, algo tiene que diferenciarlo de los demás. Esta conexión tiene sus limitaciones. Hay límite con los tamaños. El modelo de datos (aproximadamente el archivo de power bi desktop) no puede pesar más de 1GB. Las áreas de trabajo donde se publican pueden soportar hasta 10GB pero cada archivo no puede superar 1GB. Hay un excepción para las áreas de trabajo con capacidad paga llamada Power Bi Premium que te permite un modelo de 50GB y más aun tocando unas preview features que Christian Wade cuenta sobre escalabilidad, no se trata de esto el post por ende seguiré con los limites. A su vez no es posible procesar una sola tabla que pese más de 10GB. Si una de las tablas a la que nos queremos conectar tiene un peso de 10GB el motor no intentará procesarla sino que avisará al usuario. No todo está perdido y es malo, recordemos que el motor cuenta con una tremenda compresión capas que dejar 1GB de excel en pocos megas. Verán que si quieren llegar a esos limites hablamos de tablas de más de 50 millones de registros aproximadamente. También está limitado en cantidad de actualizaciones programadas por día. Es posible tener hasta 8, que no es poca cosa para un Bi. En caso de Premium puede tener hasta 48.
Es muy rápido
Ésta conexión es la opción más rápida para uso del tablero final. Los datos son cargados en la memoria del servidor y las consultas serán evaluadas dentro de ese modelo comprimido con todos los datos cargado en memoria. De ésta forma nos liberamos de lag y demoras, siempre y cuando sigamos buenas prácticas de Data Modeling que puedes encontrar en ladataweb como el Modelo Estrella.
2- Direct Query
Como el nombre lo indica es una conexión directa al origen de datos. Los datos NO serán almacenados en un modelo comprimido de Power Bi. Power Bi se convierte en la capa de visualización y por cada interacción del usuario sobre dicha capa se construye una consulta automáticamente que consultará los datos para las especificaciones seleccionadas. Power Bi solo almacenará metadata de las tablas. El tamaño del archivo será ínfimo con el cual nunca llegaría a la limitación de 1GB porque los datos no están almacenados en el archivo. Para poder consultar al origen todo el tiempo necesitamos que el origen sea uno que permita recibir consultas. Dejo una lista de ejemplos que permiten esta conexión.
Amazon Redshift
Azure HDInsight Spark (Beta)
Azure SQL Database
Azure SQL Data Warehouse
IBM Netezza (Beta)
Impala (version 2.x)
Oracle Database (version 12 and above)
SAP Business Warehouse
SAP HANA
Snowflake
Spark
SQL Server
Teradata Database
PostgreSQL
Escalabilidad
Como mencioné antes éste método no contendría la limitación de 1GB porque su tamaño de archivo será mínimo. Puedes consultar tablas de más de 10GB y armar modelos de más de 1GB porque no se almacenará en el archivo.
Limitado en funcionalidad
No podremos aprovechar al máximo las funcionalidad de transformación de Power Bi. Solo tendrás dos vistas en Power Bi Desktop, la vista de visualización y la de relaciones. No podrás tener la vista de datos dado que no están cargados.
Respecto a Power Query también está limitado. Solo es posible aplicar un pequeño número de operaciones que en caso contrario el motor mostrará un mensaje que no es posible aplicar la operación.
También está limitado en DAX pero menos que Power Query. No es posible escribir todo tipo de expresiones de columnas y medidas. Varias funciones no son soportadas. Lista completa de permitidas aquí.
Lenta interacción por conectividad
La mayor desventaja de éste método es una lenta conexión al origen de datos. Hay que tener presente que cada interacción del usuario en las visualizaciones es una consulta al motor y la espera en la respuesta para poder reflejarla. Normalmente tenemos más de una visualización y filtros, hay que considerar la respuesta del motor antes de llegar a éste caso. Mi recomendación dice que si demora más de 5 segundos en responder un filtro, no recomiendo el método
No es tiempo real
Para intentar mejorar la velocidad de respuesta del motor Power Bi intentará guardar una cache de respuestas que cambiará cada 15 minutos. Lo que significa que la consulta no es tan directa ni en tiempo real como se espera.
3- Live Connection
La conexión directa es muy similar a Direct Query en la manera que trabaja contra el origen de datos. No almacenará datos en Power Bi y va a consultar el origen de datos cada vez que el usuario lo utilice. Sin embargo, es diferente a las consultas directas. Para aclarar el panorama veamos los orígenes de datos que permiten esta conexión:
SQL Server Analysis Services (SSAS) Tabular
SQL Server Analysis Services (SSAS) Multi-Dimensional
Power BI Service
Porque éstos orígenes de datos ya son por si mismos motores con modelos de datos, Power Bi solo se conectará a éstos sincronizando todos los metadatos (nombres de tablas, columnas, medidas, relaciones). Con éste método el manejo de modelado y transformación de datos será responsabilidad del origen de datos y Power Bi será quien controle la capa superficial de visualizaciones.
Grandes modelos de datos (OLAP o Tabular)
El mayor beneficio de éste método es construir grandes modelos sin temor al limite de 1GB de Power Bi dado que dependerá de la máquina donde esté alojado dejando la capa de modelado para SSAS. Con Tabular se obtiene DAX y con Multi-Dimensional MDX. Con ambos lenguajes es posible llevar a cabo las métricas necesarias en los requerimientos del usuario. Tiene mejores características de modelado que Direct Query porque en ella no disponemos de toda la potencia de SSAS o DAX para ayudarnos.
Solo visualizaciones, nada de Power Query
Una posible desventaja es que este método no permitirá el ingreso al editor de consultas para utilizar Power Query. Con éste método solo tendremos la vista de visualizaciones para construir informes. No es del todo una desventaja porque los motores modernos de SSAS (compatibilidad 1400+) permiten usar Power Query.
Medidas en los reportes
Una Live Connection tendrá la posibilidad de jugar un poco con DAX del lado de medidas en Power Bi y no solamente por parte del origen tabular (recordemos que solo tabular tiene DAX). Sin embargo, para mantener la consistencia de un modelo, lo mejor sería no crear medidas sobre Power Bi sino mantener todas ellas en el origen Tabular para que todos los que se conecten dispongan de ellas.
Resumen en una foto
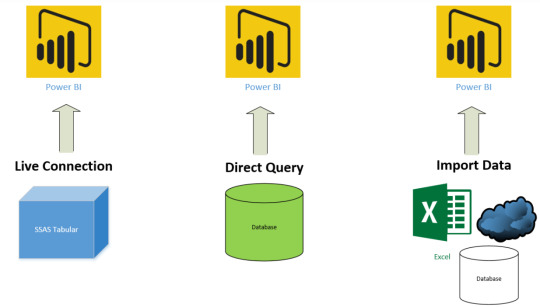
Resumen Tabla - de Power Bi Tips
table { border-collapse: collapse; width: 100%; border:1; } td, thead { text-align: left; padding: 8px; } tr:nth-child(even) {background-color: #f2f2f2;} th { text-align: left; padding: 8px; background-color: #301f09; color: white; }
Capability Import DirectQuery Size Up to 1 GB per dataset No limitation Data Source Import data from Multiple sources Data must come from a single Source Performance High-performance query engine Depends on the data source response for each query Data Change in the underlying data Not Reflected. Required to do a Manual refresh in Power BI Desktop and republish the report or Schedule Refresh Power BI caches the data for better performance. So, it is necessary to Refresh to ensure the latest data Schedule Refresh Maximum 8 schedules per day Schedule often as every 15 mins Power BI Gateway Only required to get latest data from On-premise data sources Must require to get data from On-premise data sources Data Transformations Supports all transformations Supports many data transformations with some limitations Data Modelling No limitation Some limitations such as auto-detect relationships between tables and relationships are limited to a single direction. Built-in Date Hierarchy Available Not available DAX expressions Supports all DAX functions Restricted to use complex DAX functions such as Time Intelligence functions. However, if there is a Date table available in the underlying source then it supports Clustering Available Not available Calculated Tables Available Not supported Quick Insights Available Not available Q&A Available Not available Change Data Connectivity mode Not possible to change Import to DirectQuery Possible to change DirectQuery to Import
Ahora que conocemos las diferencias podemos estar seguros de como conectarnos a nuestros orígenes. Dependerá de ellos para conocer el tipo de conexión a utilizar porque para cada caso podría ajustarse uno distinto.
¿Qué te pareció? ¿Aprendiste la diferencia o estás más confundido?
#powerbi#power bi#power bi direct query#power bi live connection#power bi import data#power bi connections#power bi tutorial#power bi SSAS#power bi training#power bi jujuy#power bi cordoba#power bi argentina
0 notes
Photo

Ready to modernize your data warehouse? Join us for our upcoming tech talk to learn how to migrate your IBM Netezza Data Warehouse to the cloud to save costs and improve performance. https://t.co/umvkEbKjV7 https://t.co/GWiuFjfWwK (via Twitter http://twitter.com/awscloud/status/1186294070328676352)
0 notes
Text
[Full-time] Sr. Business Intelligence at dhar
Location: Wisconsin URL: http://www.jobisite.com Description:
Job Title : Sr. Business Intelligence Developer Project Duration : 6+ Months Location : Milwaukee, WI Positions : 1 Rate : Market Job Description: REQUIRED TECHNOLOGY STACK: Database Experience ? Oracle, DB2, MS, Netezza, GreenPlumb BI Tools ? Tableau, Qlik, Business Objects, Essbase, Microstrategy, Cognos, PowerBI, BOBJ Modeling Tools ? Erwin, Embarcadero ETL Tools ? Alteryx, Informatica, Talend, SSIS, DataStage, Pentaho In this role, the BI Engineer will be responsible for: Executing and facilitating 4-8 concurrent BI Projects, as well as ongoing pre-sales support. Maintaining a solid understanding of traditional enterprise data warehousing and next generation data platforms to meet use case specific requirements of multiple vertically aligned customers. Facilitating data platform discussions and working with data owners to define and understand business requirements of a future state Enterprise Data Platform. Understanding of disparate data sources and integrating them into a meaningful platform to support reporting and analytical needs of customers and audiences. Understanding of complex data relationships and business requirements that formulates new technologies to reduce overall cost and ROI for customers. Ability to present and communicate between all levels of an organization that would include C-Level Executives, Directors, Management, Analysts, Business Users, etc. Strict understanding of traditional Kimball / Inman architecture designs and Data Modeling efforts. Articulating data definitions, content domains, data classes, subject area classification, and conformed dimensions. Experience in collecting, maintaining, and publishing corporate data models related to database architectures. Enforcing data governance standards, policies, and procedures for the design and proper use and care of a customer?s data sets. Developing, managing, and updating data models, including physical and logical models of traditional data warehouse, data mart, staging area, and the operational data store and source system designs. Understanding a company’s transactional systems and data sources and identifying gaps in business processes and recommend solutions to close those gaps. Assisting in the design of a company’s data extraction, staging and loading to a data warehouse processes to ensure that data is as consistent, clean and accurate as possible. Acting as a key business partner to the company’s Data Management Team and developers, to design solutions to correct problems, increase efficiency and performance, as well as recommending best practices for a next generation data platform that supports and drives reporting and analytic needs. Developing technical documentation including requirements documents, process overviews, data models /data flows from source to target, and design specificationsQUALIFICATIONS: Bachelor’s degree in Computer Science, Engineering, or related field (MS Candidates Preferred) 5+ years of experience in Enterprise Data Warehousing, Architecture and Analytics 5+ years of data integration and architecture 5+years of data integration and non-traditional data platforms 5+years of design and implementation of enterprise-level data platforms that support a variety of business intelligence initiatives. Hands on experience with data modeling software tools Strong grasp of advanced SQL writing and query tuning / optimization Strong documentation skills Strong written / oral communication and organizational skills Excellent communication skills and ability to articulate modern data integration strategies Excellent problem solving skills Excellent relationship building skills Excellent white boarding skills Ability to educate and knowledge transfer Team player and collaborator Experience in code migration, database change management and data management through various stages of the development life cycle Understanding of architecture of next generation HA / DR Data Platforms EXPOSURE PREFFERRED: Hadoop ? IBM BigInsights, Cloudera, Horton Works, MapR Cloud ? IBM (DashDB), AWS (Amazon Web Services), Microsoft (Azure) Predictive Analytics ? Python, R, Jupiter Notebooks Statistical Modeling ? Linear Regression, Decision Tree, Neural Network, Logistic Regression Reference : Sr. Business Intelligence jobs
Apply to this job from Employment-USA.Net http://employment-usa.net/job/53550/sr-business-intelligence-at-dhar/
0 notes
Link
via thenewstack.io
A dozen years ago, college professors were among the first to leverage the parallel processing power of GPUs for everyday applications. The trick to accomplishing this — they called it a “trick” when they first spoke with me about it in 2005 — was to occupy the graphics processor in such a way that it “thinks” it’s shading artillery fire and zombies in a 3-D virtual world, when it’s really doing something else.
Today’s GPUs are utilized so often for everyday math that the “G” doesn’t really stand for “graphics” anymore. This week’s Nvidia-sponsored GPU Technology Conference in San Jose will feature sessions on robotics, climate modeling, astrophysics, and database dynamics. It’s this latter category where attendees will expect to find Kinetica, a company formed around a team of developers who devised a database solution for the U.S. Army that far surpassed what anyone expected from it.
“We were on a contract that was evaluating best-of-breed technologies across the board,” described Kinetica CEO Amit Vij (who also serves as CEO of geospatial engineering consultancy GIS Federal), speaking with The New Stack. “We were moving from a document-based search to an entity-based search. Traditionally, our document-based search was hitting a relational database. But our project was getting over 200 different data feeds, [including] from drones tracking every asset that moves in foreign nations, metadata from mobile devices, social media… and doing anomaly detection on that. We evaluated every technology under the sun, and our project had essentially an unlimited budget.”
Falling in
That’s the dream situation when your clients are the Army and the National Security Agency. There, Vij and colleague Nima Negahban began building interim solutions around SAP, Oracle, and IBM Netezza database warehouses. What their clients needed was a system that could evaluate data in real-time and execute queries in the background — analytical queries whose criteria were arriving in the system in real-time as well. It was a concept for which these commercial products were evidently not well-suited.
Nor did open source provide an answer. “If you look to the open source community — Hadoop, and all these different flavors of NoSQL,” explained Vij, “they’re all batch-oriented. And it’s more marketing, rather than actually having a product that works.”
Vij told us the story of how his development team did produce a complete, working, big data-style, open source database stack for their military clients (who were joined, by this time, by the U.S. Postal Service). But no matter how they scaled their applications, these logistics-heavy agencies were never able to achieve real-time, deterministic performance. Put another way, imagine watching a movie whose frames were successfully synchronized, except several of them were taken out of sequence. Sure, the frames show up in time, but for deterministic applications, those missing frames are unfillable voids.
CUDA, the leading GPU acceleration library, and the compiler infrastructure that produces object code using that library are today open source projects. That is to say, Nvidia has released the technologies they developed proprietarily into the open source community, and companies such as IBM have released the proprietary technology they had developed around those assets, also into open source. That’s nowhere near the same situation as a Linux Foundation project, for example, where a balance of developers from multiple firms mutually build a concept, from the time their respective employers are paying for, that’s free and open, to begin with.
Falling apart
Making the NoSQL and Cassandra stack address the needs of the NSA and USPS, Vij told us, “was like duct-taping five, ten different projects, that are loosely coupled, on different release cycles, not really meant to work with one another in a synergistic way. How can these technologies process data in real time? We took a totally different approach to it. We created a database from the ground up, with multicore devices in mind, and we aligned the data to the thousands of cores of GPUs.”
In 2013, AMD’s position as a genuine challenger in the CPU space was waning, and IBM realized it could not compete against Intel all by its lonesome. It established a strategic alliance now known as the OpenPower Foundation, whose members collectively contribute to the systems architecture that originally belonged to IBM — whose initial intent was to scale up to mainframes and scale down to Sony’s PlayStation 3 — as a collective project.
Through OpenPower, both IBM and Nvidia have championed a hardware architecture that facilitates GPU acceleration by design. This technology has forced Intel, with its venerable x86 architecture still going strong, to answer the call for faster acceleration than software alone can provide — for instance, by acquiring FPGA accelerator maker Altera in June 2015 for over $16 billion.
OpenPower’s efforts have also helped bring to fruition an open standard, stewarded by IBM, called the Coherent Accelerator Processor Interface. It’s a faster expansion bus than PCI-Express, upon which many GPUs rely today, and it may apply across hardware architectures including OpenPower and x86.
Falling out
The reason all this matters to little ol’ us in the scalable software space is this: A wider expansion bus will pave a new, multi-lane superhighway for a class of GPUs that’s been waiting in the wings for some time, waiting for the traffic bottleneck to break apart. This new class of accelerators will enable an entirely different — though not officially new — database system architecture to emerge, one that utilizes a broader path to memory, that runs parallel operations orders of magnitude faster than Hadoop or Spark on CPUs alone, and most importantly of all, does not require continual indexing.
Ay, there’s the rub. It’s indexing, contends Kinetica, that makes today’s databases so slow, and the reason these databases need all this indexing is because they’re bound to storage volumes. HDFS made those volumes more vast, and thus opened up the world for big data, but the work being done under the hood there is phenomenal. If those volumes did not have to exist, a huge chunk of the busy work that traditional databases perform today would disappear.
“These NoSQL databases are forcing organizations to redesign their data models,” argued Kinetica’s Vij. “Organizations have, for decades, relied on relational databases as primitives and tables. Moving them to key/value stores takes months or years to do. NoSQL databases right now… cannot provide real-time analytics, as they’re so reliant upon indexing and delta-indexing.”
The typical solution that NoSQL database engineers suggest involves optimization for the queries they tend to run. But that only works if — unlike the case with the NSA, which literally doesn’t know what it’s looking for until it finds it — you know what the queries will be.
“We enable organizations to do correlations on the fly and at the time of query,” the CEO continued, “and do sub-queries, and chain those together. Whereas for traditional databases and NoSQL databases, they are engineering their data schemas and models where they know what those queries are, and they optimize for that. If you don’t know what you’re going to query, that’s a non-starter for [the military].”
What Amit Vij is suggesting is that Kinetica, and GPU-accelerated or FPGA-accelerated platforms like it, are starting to enable containerized applications to address both the big data problem from a decade ago, and the real-time database problem of today, in a manner that was not possible when the current open source database stack was being conceived back then.
Monday at the GPU Technology Conference, we’re likely to see more new examples of this assertion, as analytics products maker Fuzzy Logix launches its partnership with Kinetica. That partnership should lead to the development of real-time financial projection and risk analysis applications, of the scope relegated exclusively to the supercomputing space just a few years ago.
“Databases and analytics engines need to start leveraging the hardware of today,” said Kinetica’s Vij. “GPUs are following Moore’s Law, where the software is not.”
The post Kinetica Brings the Power of GPU Parallel Processing to a Database System appeared first on The New Stack.
0 notes
Text
How Big Data Analytics Can Be a Game Changer in 2017
In the present scenario, organizations face irresistible volumes of data, managerial complexities, quickly changing customer behaviours and amplified competitive pressures in almost all the industries or business domains. New technologies and business innovations, have further created stress with increasing operational channels and professional platforms, which needs aggression to survive in the existing environment.
With data worldwide being steadily growing at 40 to 45 percent annually, Big data analytics can be a prime game changer in the year 2017. Big data has initiated a paradigm shift accompanied by an affluence of data and information. It has left no industry intact as it is continuing to transform the way we think about everything from technology to human resources and sales or marketing are no different.
Market research and advisory firm Ovum, assessed that the big data market will nurture from $1.7 billion in 2016 to $9.4 billion by 2020. As the market is maturing, innovative encounters are changing, technology requirements are transforming, and the vendor criteria are also adapting. The year 2017 looks to be a demanding one for big data opportunities and prospects.
Here are some key diagnoses for big data analytics in year 2017 from industry viewers and technology performers.
Three categories of big data which are significant for sales and marketing advancements
Customers: Without accurate customer data no company can survive in this competitive world. The customer big data grouping is most relevant to sales and marketing, comprising of instinctive, behavioural, and transactional customer matrices from sources such as digital marketing campaigns, websites, points of sale, social media, customer surveys, loyalty programs, online communities and forums.
Operations: This big data grouping comprises of objective matrices that quantify the quality of sales and marketing procedures in relation to resource utilization, asset and budgetary controls.
Finance: With measuring the company’s financial systems, this big data grouping controls revenue, profits and financial health of the company.
Three categories of big data significant for Human Resources (HR) management
Hiring: With this big data grouping, HR professionals have enough data driven opportunities to turn out and be more analytical and tactical in attaining good candidates, assisting employers to avoid bad hiring. According to a CareerBuilder survey comprising of 6,000+ HR experts, 27% of employers said that a bad hiring experience cost them around or more than $50,000. Thus, Big data inhibits big mistakes.
Training: This big data grouping helps employers focus on procuring data associated to training program participation and development, which can further assist them and HR department to enhance effectiveness of their professional programs.
Retention: By applying big data within workplace, open opportunities to understand why employees leave and stay in organizations. Taking Xerox, as example, using big data and analytics, it reduced its attrition rate at call centers by 20%. By evaluating numerous sources of employee data, HR can more precisely recognize problems that lead to lesser employee commitments, and how they can improve employee engagements.
As the big data analytics market is swiftly expanding to add mainstream customers, many technologies assure the advancement potentials.
Three categories of big data which are significant for technology advancements
Predictive analytics: This big data grouping includes software and hardware solutions that consent companies to optimize and deploy predictive data models by evaluating big data sources. It helps to increase business performance and reduce risks by informed business decision making.
Data virtualization: This big data grouping includes technologies that provides information from multiple data sources, even comprises of big data sources like Hadoop as well as distributed data stores that too in real-time.
Data integration: This big data grouping includes tools for data scoring for modernizations across solutions like MapReduce, Amazon Elastic MapReduce (EMR), Apache Spark, Apache Hive, Couchbase, Hadoop, MongoDB and Apache Pig.
There are some of the Big Data source types, in compliance to mining techniques that are applied to search your gilt nuggets.
Four categories of big data which are significant for data mining techniques
Social network profiles: This grouping helps exploring user profiles from LinkedIn, Facebook, Google, Yahoo, and different social media sites, extracting professional profiles and demographics capturing like-minded network information. This requires an API integration for mining and importing pre-defined values and data fields.
Cloud applications and Software as a Service (SaaS): Software solutions like Netsuite, Salesforce and SuccessFactors represent professional data that’s stored in the cloud. With the help of distributed data integration tools a company can merge this data with the internal data to drive business results.
Legacy documents: Archives of business and insurance forms, statements, medical records and customer communications are still an untouched resource for data mining. Countless archives are completely filled with old PDF documents and files that comprise of multiple records between customers, organizations and even with the government. Software tools such as Xenos are used for parsing this semi-structured legacy information.
Data warehouse appliances: EMC Greenplum, Teradata and IBM Netezza tools scrutinize transactional data that is already made ready for analysis through internal operational systems. They help in improving the parsed data and refine final results from the gigantic Big data installations.
Key Takeaways
As mentioned, data globally is growing at a great pace every year. This rate of growth is alarming for any sales, marketing or technology leader. However, many business managers may feel that this data size has always been big and its correct in one or the other ways. Imagining about the customer data gathered twenty years ago, it included coupon redemption, point of sale data, replies to direct mails or campaigns. Then coming to customer data collected today, it includes online buying data, social media communications, mobile data or geolocation data. Relatively speaking, there’s not much difference.
So, having big data doesn’t mechanically or automatically lead to improved results. Big data and analytics are a secret weapon, which have to be intelligently utilized to derive actionable insights, to boost informed business, technology or human resource decision making, that can further create the real difference. Visit Hello Soda India if you are looking for Big Data Analytics.
from Outsourcing Insight http://www.outsourcinginsight.com/how-big-data-analytics-can-be-a-game-changer-in-2017/
0 notes
Text
IBM Boosts Cloud Initiative with zEnterprise EC12 Mainframe Server
Faced with declining sales for many giant systems, IBM determined to advance the temporal arrangement slightly to launch its new mainframes. The zEnterprise EC12 mainframe is meant for securing giant volumes of transactions and knowledge analysis ideal for cloud computing and large knowledge.
The mainframe zEC12 guarantees twenty fifth higher performance per core and five hundredth a lot of capability compared to its forerunner (the zEnterprise 196). IBM presents its platform as packed with safety options, together with the Crypto Express4S co-processor for the protection of sensitive knowledge and transactions. With security strategy deployed on its mainframe, IBM is that the initial manufacturer to get the Common Criteria analysis Assurance Level classification.
The mainframe offers a half-hour improvement in knowledge load analysis in relevance the zEnterprise 196, IBM technologies with time period watching of system standing and speedy identification of bottlenecks victimization IBM zAware. IBM aforesaid the mainframe has the world’s quickest chip running at five.5 Gc and five0% a lot of total system capability.
IBM appearance to the Cloud
The main development is targeted on security whereas planning the mainframe. With the web and cloud computing, security of knowledge has become a priority. And it’s not giant IBM mainframe customers, particularly the monetary sector, which needs larger security. The mainframe is therefore ideal for managing cloud computing/virtualization in scale of thousands of distributed systems.
IBM has conjointly created certain that the zEC12 doesn’t essentially work for datacenter environments, promising a lot of flexibility for the location so as to draw in new customers not essentially with facilities like knowledge centers.
“The mainframe could be a sensible foundation for cloud delivery as a result of it’s all the bottom characteristics like economical consolidation, virtualization and therefore the ability to host multiple tenants,” aforesaid Jeff Frey, CTO of System z mainframes at IBM. “As a result, giant enterprises will deliver cloud services internally,” he added.
In addition, mainframes support a major quantity of knowledge in most giant firms. As these firms face the expansion of knowledge, trying to find ways in which to extend security and gain insights from important data like monetary knowledge, client knowledge and resource knowledge of firms.
As an area of the cloud initiatives, the corporate recently declared a good vary of enhancements in performance and potency of their storage systems and technical systems known as Smarter Computing and discharged lower value cloud product and services.
Big knowledge Analysis Capabilities
The mainframe supports the IBM DB2 Analytics Accelerator, which contains the Netezza knowledge warehouse appliance to IBM zEC12 that enables customers to perform complicated business analysis and operations on constant platform.
It conjointly provides analysis capabilities of pc systems supported technology from IBM analysis. The system Analyzes internal electronic messaging system to supply close to time period read of the health of the system, together with potential operational issues.
The mainframe virtualization capabilities create it a powerful various to support personal cloud environments. Customers will consolidate thousands of distributed systems in UNIX operating system zEC12, lowering operational prices related to technology, power consumption, house within the datacenter and software system licenses.
0 notes