#JSON merge patch
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Okay so. Project Special K and how I found myself stuck on a project once again.
As I've said earlier, I need something to import model data. I was thinking glTF but this requires JSON and the only glTF importing library I could find specifically uses RapidJSON. I can't get patch support for RapidJSON to work, be it 6902 Patch or 7396 Merge Patch, so that's a deal breaker.
I see three options.
Use the next best format, something binary perhaps that doesn't require a separate parser library, but still supports what I need and can be exported to/from in Blender. I've done Wavefront OBJ before but that doesn't support jack.
Use lazy-glTF + RapidJSON specifically and only for model loading, use SimpleJSON + my patch extension for everything else.
Forget about 3D, switch to using only sprites. But that brings a host of other issues that using 3D would cover in the first place.
Thoughts? Format suggestions? Anything?
6 notes
·
View notes
Text
Tìm hiểu về chuẩn JSON Merge Patch cùng Hằng béo
— Anh Tèo này, dạo này em hay làm với Fredrik, thấy hắn code sáng ghê. — Code như nào mà sáng? — README viết rất kĩ, code có design pattern rõ ràng, comment đầy đủ. Ngoài ra còn đúng chuẩn nữa. — Chuẩn? Chuẩn gì? — Ví dụ gần nhất là chuẩn RFC7396: JSON Merge Patch Continue reading Tìm hiểu về chuẩn JSON Merge Patch cùng Hằng béo

View On WordPress
0 notes
Text
This Week in Rust 480
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.67.0
Help test Cargo's new index protocol
Foundation
Rust Foundation Annual Report 2022
Newsletters
This Month in Rust GameDev #41 - December 2022
Project/Tooling Updates
Scaphandre 0.5.0, to measure energy consumption of IT servers and computers, is released : windows compatibility (experimental), multiple sensors support, and much more...
IntelliJ Rust Changelog #187
rust-analyzer changelog #166
argmin 0.8.0 and argmin-math 0.3.0 released
Fornjot (code-first CAD in Rust) - Weekly Release - The Usual Rabbit Hole
One step forward, an easier interoperability between Rust and Haskell
Managing complex communication over raw I/O streams using async-io-typed and async-io-converse
Autometrics - a macro that tracks metrics for any function & inserts links to Prometheus charts right into each function's doc comments
Observations/Thoughts
Ordering Numbers, How Hard Can It Be?
Next Rust Compiler
Forking Chrome to render in a terminal
40x Faster! We rewrote our project with Rust!
Moving and re-exporting a Rust type can be a major breaking change
What the HAL? The Quest for Finding a Suitable Embedded Rust HAL
Some Rust breaking changes don't require a major version
Crash! And now what?
Rust Walkthroughs
Handling Integer Overflow in Rust
Rust error handling with anyhow
Synchronizing state with Websockets and JSON Patch
Plugins for Rust
[series] Protohackers in Rust, Part 00: Dipping the toe in async and Tokio
Building gRPC APIs with Rust using Tonic
Miscellaneous
Rust's Ugly Syntax
[video] Rust's Witchcraft
[DE] CodeSandbox: Nun auch für die Rust-Entwicklung
Crate of the Week
This week's crate is symphonia, a collection of pure-Rust audio decoders for many common formats.
Thanks to Kornel for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
diesel - Generate matching SQL types for Mysql enums
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
377 pull requests were merged in the last week
move format_args!() into AST (and expand it during AST lowering)
implement Hash for proc_macro::LineColumn
add help message about function pointers
add hint for missing lifetime bound on trait object when type alias is used
add suggestion to remove if in let..else block
assume MIR types are fully normalized in ascribe_user_type
check for missing space between fat arrow and range pattern
compute generator saved locals on MIR
core: support variety of atomic widths in width-agnostic functions
correct suggestions for closure arguments that need a borrow
detect references to non-existant messages in Fluent resources
disable ConstGoto opt in cleanup blocks
don't merge vtables when full debuginfo is enabled
fix def-use dominance check
fix thin archive reading
impl DispatchFromDyn for Cell and UnsafeCell
implement simple CopyPropagation based on SSA analysis
improve proc macro attribute diagnostics
insert whitespace to avoid ident concatenation in suggestion
only compute mir_generator_witnesses query in drop_tracking_mir mode
preserve split DWARF files when building archives
recover from more const arguments that are not wrapped in curly braces
reimplement NormalizeArrayLen based on SsaLocals
remove overlapping parts of multipart suggestions
special-case deriving PartialOrd for enums with dataless variants
suggest coercion of Result using ?
suggest qualifying bare associated constants
suggest using a lock for *Cell: Sync bounds
teach parser to understand fake anonymous enum syntax
use can_eq to compare types for default assoc type error
use proper InferCtxt when probing for associated types in astconv
use stable metric for const eval limit instead of current terminator-based logic
remove optimistic spinning from mpsc::SyncSender
stabilize the const_socketaddr feature
codegen_gcc: fix/signed integer overflow
cargo: cargo add check [dependencies] order without considering the dotted item
cargo: avoid saving the same future_incompat warning multiple times
cargo: fix split-debuginfo support detection
cargo: make cargo aware of dwp files
cargo: mention current default value in publish.timeout docs
rustdoc: collect rustdoc-reachable items during early doc link resolution
rustdoc: prohibit scroll bar on source viewer in Safari
rustdoc: use smarter encoding for playground URL
rustdoc: add option to include private items in library docs
fix infinite loop in rustdoc get_all_import_attributes function
rustfmt: don't wrap comments that are part of a table
rustfmt: fix for handling empty code block in doc comment
clippy: invalid_regex: show full error when string value doesn't match source
clippy: multiple_unsafe_ops_per_block: don't lint in external macros
clippy: improve span for module_name_repetitions
clippy: missing config
clippy: prevents len_without_is_empty from triggering when len takes arguments besides &self
rust-analyzer: adding section for Visual Studio IDE Rust development support
rust-analyzer: don't fail workspace loading if sysroot can't be found
rust-analyzer: improve "match to let else" assist
rust-analyzer: show signature help when typing record literal
rust-analyzer: ide-assists: unwrap block when it parent is let stmt
rust-analyzer: fix config substitution failing extension activation
rust-analyzer: don't include lifetime or label apostrophe when renaming
rust-analyzer: fix "add missing impl members" assist for impls inside blocks
rust-analyzer: fix assoc item search finding unrelated definitions
rust-analyzer: fix process-changes not deduplicating changes correctly
rust-analyzer: handle boolean scrutinees in match <-> if let replacement assists better
rust-analyzer: substitute VSCode variables more generally
Rust Compiler Performance Triage
Overall a positive week, with relatively few regressions overall and a number of improvements.
Triage done by @simulacrum. Revision range: c8e6a9e..a64ef7d
Summary:
(instructions:u) mean range count Regressions ❌ (primary) 0.6% [0.6%, 0.6%] 1 Regressions ❌ (secondary) 0.3% [0.3%, 0.3%] 1 Improvements ✅ (primary) -0.8% [-2.0%, -0.2%] 27 Improvements ✅ (secondary) -0.9% [-1.9%, -0.5%] 11 All ❌✅ (primary) -0.8% [-2.0%, 0.6%] 28
2 Regressions, 4 Improvements, 6 Mixed; 2 of them in rollups 44 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Create an Operational Semantics Team
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Stabilize feature cstr_from_bytes_until_nul
[disposition: merge] Support true and false as boolean flag params
[disposition: merge] Implement AsFd and AsRawFd for Rc
[disposition: merge] rustdoc: compute maximum Levenshtein distance based on the query
New and Updated RFCs
[new] Permissions
[new] Add text for the CFG OS Version RFC
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
Feature: Help test Cargo's new index protocol
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-02-01 - 2023-03-01 🦀
Virtual
2023-02-01 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
New Year Virtual Social + Share
2023-02-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-02-01 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Reactor New York and Microsoft Reactor San Francisco
Primeros pasos con Rust: QA y horas de comunidad | New York Mirror | San Francisco Mirror
2023-02-01 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2023-02-06 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Reactor New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Implementación de tipos y rasgos genéricos | New York Mirror | San Francisco Mirror
2023-02-07 | Virtual (Beijing, CN) | WebAssembly and Rust Meetup (Rustlang)
Monthly WasmEdge Community Meeting, a CNCF sandbox WebAssembly runtime
2023-02-07 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-02-07 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Reactor New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Módulos, paquetes y contenedores de terceros | New York Mirror | San Francisco Mirror
2023-02-08 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-02-08 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco
Primeros pasos con Rust: QA y horas de comunidad | New York Mirror | San Francisco Mirror
2023-02-09 | Virtual (Nürnberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-02-11 | Virtual | Rust GameDev
Rust GameDev Monthly Meetup
2023-02-13 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Escritura de pruebas automatizadas | New York Mirror | San Francisco Mirror
2023-02-14 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2023-02-14 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-02-14 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Creamos un programa de ToDos en la línea de comandos | San Francisco Mirror | New York Mirror
2023-02-14 | Virtual (Saarbrücken, DE) | Rust-Saar
Meetup: 26u16
2023-02-15 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US; São Paulo, BR) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco and Microsoft Reactor São Paulo
Primeros pasos con Rust: QA y horas de comunidad | San Francisco Mirror | New York Mirror | São Paulo Mirror
2023-02-15 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-02-21 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2023-02-23 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
Tock, a Rust based Embedded Operating System
2023-02-23 | Virtual (Kassel, DE) | Java User Group Hessen
Eine Einführung in Rust (Stefan Baumgartner)
2023-02-28 | Virtual (Berlin, DE) | Open Tech School Berlin
Rust Hack and Learn
2023-02-28 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-03-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
Asia
2023-02-01 | Kyoto, JP | Kansai Rust
Rust talk: How to implement Iterator on tuples... kind of
2023-02-20 | Tel Aviv, IL | Rust TLV
February Edition - Redis and BioCatch talking Rust!
Europe
2023-02-02 | Berlin, DE | Prenzlauer Berg Software Engineers
PBerg engineers - inaugural meetup; Lukas: Serverless APIs using Rust and Azure functions (Fee)
2023-02-02 | Hamburg, DE | Rust Meetup Hamburg
Rust Hack & Learn February 2023
2023-02-02 | Lyon, FR | Rust Lyon
Rust Lyon meetup #01
2023-02-04 | Brussels, BE | FOSDEM
FOSDEM 2023 Conference: Rust devroom
2023-02-09 | Lille, FR | Rust Lille
Rust Lille #2
2023-02-15 | London, UK | Rust London User Group
Rust Nation Pre-Conference Reception with The Rust Foundation
2023-02-15 | Trondheim, NO | Rust Trondheim
Rust New Year's Resolution Bug Hunt
2023-02-16, 2023-02-17 | London, UK | Rust Nation UK
Rust Nation '23
2023-02-18 | London, UK | Rust London User Group
Post-Conference Rust in Enterprise Brunch Hosted at Red Badger
2023-02-21 | Zurich, CH | Rust Zurich
Practical Cryptography - February Meetup (Registration opens 7 Feb 2023)
2023-02-23 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #33
North America
2023-02-09 | Mountain View, CA, US | Mountain View Rust Study Group
Rust Study Group at Hacker Dojo
2023-02-09 | New York, NY, US | Rust NYC
A Night of Interop: Rust in React Native & Rust in Golang (two talks)
2023-02-13 | Minneapolis, MN, US | Minneapolis Rust Meetup
Happy Hour and Beginner Embedded Rust Hacking Session (#3!)
2023-02-21 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-02-23 | Lehi, UT, US | Utah Rust
Upcoming Event
Oceania
2023-02-28 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2023-03-01 | Sydney, NSW, AU | Rust Sydney
🦀 Lightning Talks - We are back!
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Compilers are an error reporting tool with a code generation side-gig.
– Esteban Küber on Hacker News
Thanks to Stefan Majewsky for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
ESP32: JSON Merge Patch
ESP32: JSON Merge Patch
Introduction In this tutorial we are going to check how to use the Nlohmann/json library to apply the JSON merge patch operation to an object. We will be using the ESP32 and the Arduino core. The JSON merge patch operation (RFC here) allows to describe a set of modifications to be applied to a source JSON object [1]. These modifications are described using a syntax that closely mimics the…
View On WordPress
0 notes
Text
Merging Tool For Mac

This Mac dev tool has been recommended for its ease of use as well as its integration into the command line. Xcode is an integrated development environment that offers a comprehensive set of Mac developer tools - everything programmers need to build great applications for Mac, iPhone, iPad, Apple TV, and Apple Watch.
Oct 22,2019 • Filed to: Edit PDF
When you have two or more different PDF files that you would like to bring together, you may need a PDF editor that can combine PDF online. When you merge two or more PDF files, their pages will appear in a certain order depending on which file will be first, and which ones follow. Some tools will allow you to reorder the pages once you have merged the files, while others will not. If you do not have a PDF editor on your desktop, you can try some of those that are found online. There are certain sites that have dedicated themselves just to merging PDF files. In this article, you will come to see 5 of these online tools that you can use to merge your PDF files. If you are desktop users, please try to use PDFelement Pro.
Part 1. Top 5 Tools to Combine PDF Online on Mac
1. PDF Merge
PDF Merge is a secure online facility for merging PDF files. You can merge up to 10 different files in the order that you want them to appear after they have been merged. All you have to do is upload the filers and then click on “Merge” once you are done. Your PDF files will be merged within a few minutes. Since you are merging our files on a web browser, the tool will work on all operating systems. The beauty of the site is their efforts to maintain the security of all files. They use a secure merging system and all files are expunged from their servers within one hour.
Pros:
It is easy to use and fast.
It is a secure way of merging your files.
You get your merged document within a few minutes.
Cons:
Meld is a visual diff and merge tool targeted at developers. Meld helps you compare files, directories, and version controlled projects. It provides two- and three-way comparison of both files and directories, and has support for many popular version control systems. Meld helps you review code changes and understand patches.
KDiff3 is a diff and merge program that. Compares or merges two or three text input files or directories, shows the differences line by line and character by character (!), provides an automatic merge-facility and; an integrated editor for comfortable solving of merge-conflicts.
It does not work well with slow Internet connections, with uploads being stopped in the middle and one has to start all over again.
2. SmallPDF
SmallPDF is a great PDF merging tool for Mac. It allows you to drag and drop your PDF files, and then arrange them in the order that you want them to be. The pages will follow the same order. It has the ability to reorder pages, but that can only be done after you have received the merged file. The tool will also give you a preview of your merged PDF file, so you see how it will look before you commit it for merging. The [processing of the PDF files is done on the Cloud so your resources on the computer are not affected at all.
Pros:
It allows you to review the merged files before they are merged.
It does the processing in the cloud to save your computer resources.
The service is safe and secure.
It works across all operating systems so anyone can use it.
It can combine PDF files from other online storage facilities like Google Drive and Dropbox.
Cons:
Photo Merging App For Mac
There are none at the moment.
Diff Tool For Mac Free
3. DocuPub
DocuPub is a free online PDF merging tool, which enables you to combine PDF online. Where many other free online merging tools require that the files to be merged to be in PDF format, Docupub will take files of multiple formats and then combine them all into one PDF file. This is great for people who have to merge several formats into one paper. You may have an Excel spreadsheet and a Word document that you would like merged into one PDF file, and this is the best tool to do this quickly and securely. All you have to do is to click on the “Choose File” button to add any type of file. However, you cannot upload files that are larger than 10MB.
Pros:
Can merge files from several formats at once.
There is no limit to the number of files one can add.
The site is safe and secure so you have no worry.
Cons:
Maximum file size is 10 MB which may affect your work.
4. FoxyUtils
The PDF Shaper is a great free online PDF merging tool, which allows you to merge files from several different formats. The tool is found on the cloud so none of the resources on your computer will be used in the conversion and subsequent merging. Te interface is very easy to work with, and you just add the files in the order that you want them to be merged. You simply have to drag the files onto the page and they will be uploaded. Once they are uploaded, you have the option of changing the order in which they will be merged. You also get to see how many pages the final file will have.
Pros:
It can merge files from several different formats at the same time.
You can change the order of the files before you merge them.
The site has wonderful security measures.
All operations are handled in the cloud.
Cons:
You can only perform 5 operations in a day.
5. PDFJoin
PDFJoin is PDF tool that can also be used to combine PDF online. This means that you can upload files of different formats and they will be converted before they are joined into one single PDF file. You can upload a maximum of 20 different files of any size. The site is safe and secure and all files uploaded are deleted within an hour. The simple user interface makes it easy to upload, arrange and merge the files. When uploaded, you can still change the order that you want the files to be in. Similarly the whole system is encrypted for added security.
Pros:
It is a safe and secure site so sensitive information is not leaked.
Offers a lot of space for merging 20 files.
Easy interface makes it simple to merge files.
Cons:
The limit of 20 files may not be good for people who have many small files to combine into one.
Part 2. The Best PDF Combiner
PDFelement Pro is a versatile tool that you can use to merge your PDF files on your desktop. With the help of this PDF cmbiner you can also rearrange the pages of the new file.
Easy steps to Edit PDF Text in PDFelement Pro
Step 1: Download and install PDFelement Pro.
Step 2: Click on 'Combine File' button to import PDF files to the program.
Step 3: Add files on the new open Window and click on the 'Combine' button to start combining PDF files.
Why Choose PDFelement Pro to Combine PDF Files
With PDFelement Pro you can extract pages from different PDF files and then rearrange them before merging them into one file. You may also merge the files, edit the pages, and then save to a new PDF file. This is a powerful PDF editing tool, and here are some of the main features below.
Key Features of PDFelement Pro
Creation of PDF forms – With this tool, you can create your own original forms and not go getting templates from the Internet. You may also fill and edit forms from other sites.
Create and convert – if you are feeling creative, you can build a PDF file right from the bottom. You can also create a document in another software and the convert it to PDF.
Fantastic user interface – you will find it very easy o use since the interface is intuitive and easy to follow.
Digital signature – use your own unique digital ID to mark your documents. You will also add security to your PDF file.
Edit & OCR – you can now create documents from scanned pages. With OCR, you will have the scanned images turned into text within no time.
0 Comment(s)
Tower comes with integrations for many Diff and Merge tools. If, however, your tool of choice is not included, you will be able to write a custom integration file.

Configuring Your Tool of Choice
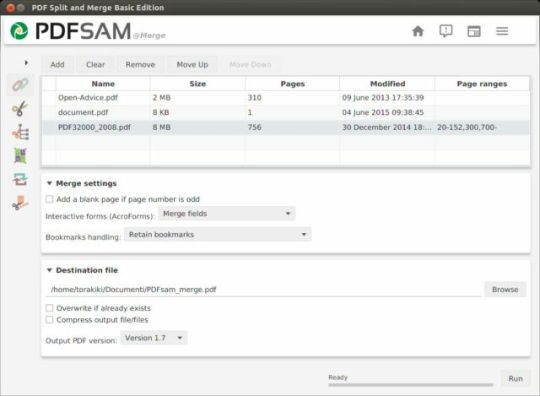
It might be that your favorite diff or merge tool is not among the applications that Tower supports by default. In that case, you can write your own configuration file named 'CompareTool.json' and put it into '%LOCALAPPDATA%fournovaTowerSettingsCompareTools'. The configuration has to be in valid JSON format and looks like this:
Except for the DisplayName, all values can be either empty or omitted altogether. Please make sure to properly escape commands and paths, as they're enclosed in '.
You can find the configuration files for Comparetools shipped with Tower in TowerInstallationPathCompareTools and use them as reference. Should you want to override a shipped configuration, simply copy it to the folder in AppData.
Detailed description for the entries
KeyTypeDefault`DisplayName`stringnone, required!The name shown in Tower's preferences `MinimumVersion`String'The minimum version, is displayed yet not validated `SupportsDiffChangeset`bool`false`The Tool can group multiple `git difftool` calls in one Window/Workspace `SupportsDirectoryDiff`bool`false`The tool supports calls with the `--dir-diff` flag from Git Difftool `DiffToolArguments`stringdoesn't support diffingThe arguments used to call the tool for diffing `MergeToolArguments`stringdoesn't support mergingThe arguments use to call the tool for merging `ApplicationRegistryIdentifiers`stringdon't search in registryRegistry entries pointing to the tool's executable `ApplicationPaths`stringdon't search in filesystemFilesystem locations pointing to the tool's executable
Not all tools support both diffing and merging. Please consult your external tool's manual or support team if you are not sure if it supports both.
0 notes
Text
How to deal with API clients, the lazy way — from code generation to release management
This post is from Massimiliano Pippi, Senior Software Engineer at Arduino.
The Arduino IoT Cloud platform aims to make it very simple for anyone to develop and manage IoT applications and its REST API plays a key role in this search for simplicity. The IoT Cloud API at its core consists of a set of endpoints exposed by a backend service, but this alone is not enough to provide a full-fledge product to your users. What you need on top of your API service are:
Good documentation explaining how to use the service.
A number of plug-and-play API clients that can be used to abstract the API from different programming languages.
Both those features are difficult to maintain because they get outdated pretty easily as your API evolves but clients are particularly challenging: they’re written in different programming languages and for each of those you should provide idiomatic code that works and is distributed according to best practices defined by each language’s ecosystem.
Depending on how many languages you want to support, your engineering team might not have the resources needed to cover them all, and borrowing engineers from other teams just to release a specific client doesn’t scale much.
Being in this exact situation, the IoT Cloud team at Arduino had no other choice than streamlining the entire process and automate as much as we could. This article describes how we provide documentation and clients for the IoT Cloud API.
Clients generation workflow
When the API changes, a number of steps must be taken in order to ship an updated version of the clients, as it’s summarized in the following drawing.
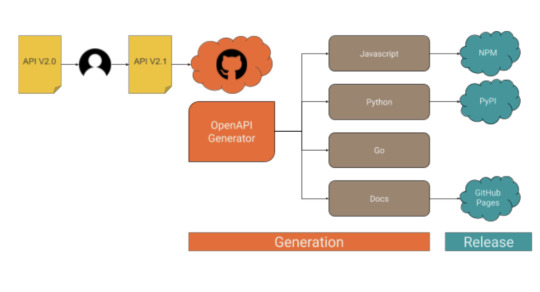
As you can see, what happens after an engineer releases an updated version of the API essentially boils down to the following macro steps:
1. Fresh code is generated for each supported client. 2. A new version of the client is released to the public.
The generation process
Part 1: API definition
Every endpoint provided by the IoT Cloud API is listed within a Yaml file in OpenAPI v3 format, something like this (the full API spec is here):
/v2/things/{id}/sketch: delete: operationId: things_v2#deleteSketch parameters: - description: The id of the thing in: path name: id required: true schema: type: string responses: "200": content: application/json: schema: $ref: '#/components/schemas/ArduinoThing' description: OK "401": description: Unauthorized "404": description: Not Found
The format is designed to be human-readable, which is great because we start from a version automatically generated by our backend software that we manually fine-tune to get better results from the generation process. At this stage, you might need some help from the language experts in your team in order to perform some trial and error and determine how good the generated code is. Once you’ve found a configuration that works, operating the generator doesn’t require any specific skill, the reason why we were able to automate it.
Part 2: Code generation
To generate the API clients in different programming languages we support, along with API documentation we use a CLI tool called openapi-generator. The generator parses the OpenAPI definition file and produces a number of source code modules in a folder on the filesystem of your choice. If you have more than one client to generate, you will notice very soon how cumbersome the process can get: you might need to invoke openapi-generator multiple times, with different parameters, targeting different places in the filesystem, maybe different git repositories; when the generation step is done, you have to go through all the generated code, add it to version control, maybe tag, push to a remote… You get the gist.
To streamline the process described above we use another CLI tool, called Apigentools, which wraps the execution of openapi-generator according to a configuration you can keep under version control. Once Apigentools is configured, it takes zero knowledge of the toolchain to generate the clients – literally anybody can do it, including an automated pipeline on a CI system.
Part 3: Automation
Whenever the API changes, the OpenAPI definition file hosted in a GitHub repository is updated accordingly, usually by one of the backend engineers of the team. A Pull Request is opened, reviewed and finally merged on the master branch. When the team is ready to generate a new version of the clients, we push a special git tag in semver format and a GitHub workflow immediately starts running Apigentools, using a configuration stored in the same repository. If you look at the main configuration file, you might notice for each language we want to generate clients for, there’s a parameter called ‘github_repo_name’: this is a killer feature of Apigentools that let us push the automation process beyond the original plan. Apigentools can output the generated code to a local git repository, adding the changes in a new branch that’s automatically created and pushed to a remote on GitHub.
The release process
To ease the release process and to better organize the code, each API client has its own repo: you’ll find Python code in https://github.com/arduino/iot-client-py, Go code in https://github.com/arduino/iot-client-go and so on and so forth. Once Apigentools finishes its run, you end up with new branches containing the latest updates pushed to each one of the clients’ repositories on GitHub. As the branch is pushed, another GitHub workflow starts (see the one from the Python client as an example) and opens a Pull Request, asking to merge the changes on the master branch. The maintainers of each client receive a Slack notification and are asked to review those Pull Requests – from now on, the process is mostly manual.
It doesn’t make much sense automate further, mainly for two reasons:
Since each client has its own release mechanism: Python has to be packaged in a Wheel and pushed to PyPI, Javascript has to be pushed to NPM, for Golang a tag is enough, docs have to be made publicly accessible.
We want to be sure a human validates the code before it’s generally available through an official release.
Conclusions
We’ve been generating API clients for the IoT Cloud API like this for a few months, performing multiple releases for each supported programming language and we now have a good idea of the pros and cons of this approach.
On the bright side:
The process is straightforward, easy to read, easy to understand.
The system requires very little knowledge to be operated.
The time between a change in the OpenAPI spec and a client release is within minutes.
We had an engineer working two weeks to set up the system and the feeling is that we’re close to paying off that investment if we didn’t already.
On the not-so-bright side:
If operating the system is trivial, debugging the pipeline if something goes awry requires a high level of skill to deep dive into the tools described in this article.
If you stumble upon a weird bug on openapi-generator and the bug doesn’t get attention, contributing patches upstream might be extremely difficult because the codebase is complex.
Overall we’re happy with the results and we’ll keep building up features on top of the workflow described here. A big shoutout to the folks behind openapi-generator and Apigentools!
How to deal with API clients, the lazy way — from code generation to release management was originally published on PlanetArduino
0 notes
Text
Best of Google Database
New Post has been published on https://is.gd/42EFDP
Best of Google Database

Google Cloud Database By
Google provides 2 different types of databases i.e google database
Relational
No-SQL/ Non-relational
Google Relational Database
In this google have 2 different products .
Cloud SQL
Cloud Spanner
Common uses of this relational database are like below
Compatibility
Transactions
Complex queries
Joins
Google No-SQL/ Non-relational Database
In this google provide 4 different types of product or databases
Cloud BigTable
Cloud Firestore
Firebase Realtime database
Cloud Memorystore
Common uses cases for this is like below
TimeSeries data
Streaming
Mobile
IoT
Offline sync
Caching
Low latency
Google relational Databases
Cloud SQL
It is Google fully managed service that makes easy to setup MySQL, PostgreSQL and SQL server databases in the cloud.
Cloud SQL is a fully-managed database service that makes easy to maintain, Manage and administer database servers on the cloud.
The Cloud SQL offers high performance, high availability, scalability, and convenience.
This Cloud SQL takes care of managing database tasks that means you only need to focus on developing an application.
Google manage your database so we can focus on our development task. Cloud SQL is perfect for a wide variety of applications like geo-hospital applications, CRM tasks, an eCommerce application, and WordPress sites also.
Features of Cloud SQL
Focus on our application: managing database is taken care of by google so we can focus on only application development.
Simple and fully managed: it is easy to use and it automates all backups, replication, and patches and updates are having 99.955 of availability anywhere in the world. The main feature of Cloud SQL is automatic fail-over provides isolation from many types of infrastructure hardware and software. It automatically increases our storage capacity if our database grows.
Performance and scalability: it provides high performance and scalability up to 30 TB of storage capacity and 60,000 IOPS and 416Gb of ram per instance. Having 0 downtimes.
Reliability and Security: As it is google so security issue is automatically resolved but the data is automatically encrypted and Cloud SQL is SSAE 16, ISO 27001 and PCI DSS v3.0 compliant and supports HIPAA compliance so you can store patient data also in Cloud SQL.
Cloud SQL Pricing:
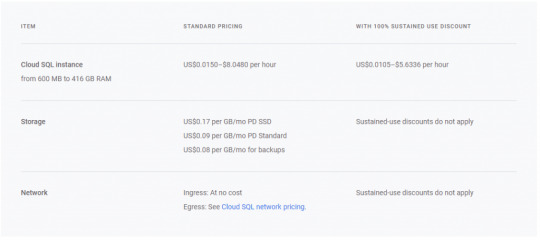
Google Cloud SQL Pricing -Image From Official Google Site
Cloud Spanner
It is a fully managed scalable relational database service for regional and global application data.
Cloud spanner is the first database who takes advantage of relational database and non-relational database.
It is enterprise-grade, globally distributed and strongly consistent database service which built for cloud and it combines benefits of relational and non-relational horizontal scale.
By using this combination you can deliver high-performance transactions and strong consistency across rows, regions and continent.
Cloud spanner have high availability of 99.999% it has no planned downtime and enterprise-grade security.
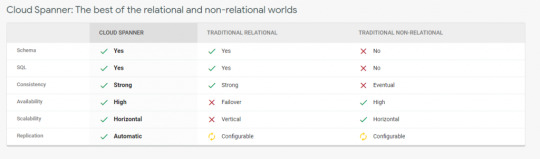
Google Cloud Spanner Features:- Image from official google site
Features of Cloud Spanner:
Scale+SQL:– in today’s world most database fail to deliver consistency and scale but at their, Cloud Spanner comes what it means? It means Cloud Spanner provides you advantage of relational database structure and not relational database scale and performance feature with external consistency across rows, regions and continents.
Cloud spanner scales it horizontally and serves data with low latency and along with that it maintains transactional consistency and industry-leading availability means 99.999%. It can scale up arbitrarily large database size means what It provides it avoids rewrites and migrations.
Less Task– it means google manage your database maintenance instead of you. If you want to replicate your database in a few clicks only you can do this.
Launch faster: it Is relational database with full relational semantics and handles schema changes it has no downtime. This database is fully tested by google itself for its mission-critical applications.
Security and Control:- encryption is by-default and audit logging, custom manufactured hardware and google owned and controlled global network.
Multi-language support means support c#, Go, Java, Php, Python and Ruby.
Pricing for Cloud Spanner:
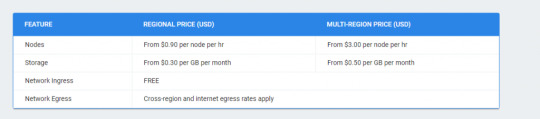
Google Cloud Spanner Pricing – Image from official google site
Non-relational Database by Google
BigTable
This Bigtable database is created by Google, it is compressed, high performance and proprietary data storage system which is created by Google and is built on top of google file system, LevelDB and other few google technologies.
This database development is starting in 2004 and now it is widely used by google like web indexing,google maps, google book search and google earth, blogger, google code, youtube.
The google is designed its own database because they need high scalability and better control over performance.
Bigtable is like wide column store. It maps 2 arbitrary string values which are row key and column key and timestamp for 3-dimensional mappings into an arbitrary byte array.
Remember it is not a relational database and it is more kind of sparse, distributed multi-dimensional sorted map.
BigTable is designed to scale in petabyte range across hundreds and thousands of machines and also to add additional commodity hardware machines is very easy in this and there is no need for reconfiguration.
Ex.
Suppose google copy of web can be stored in BigTable where row key is what is domain URL and Bigtable columns describe various properties of a web page and every column holds different versions of webpage.
He columns can have different timestamped versions of describing different copies of web page and it stores timestamp page when google retrieves that page or fetch that page.
Every cell in Bigtable has zero or timestamped versions of data.
In short, Bigtable is like a map-reduce worker pool.
A google cloud Bigtable is a petabyte-scale, fully managed and it is NoSQL database service provided by Google and it is mainly for large analytical and operational workloads.
Features Of Google Cloud BigTable:
It is having low latency and massively scalable NoSQL. It is mainly ideal for ad tech, fin-tech, and IoT. By using replication it provides high availability, higher durability, and resilience in the face of zonal failures. It is designed for storage for machine learning applications.
Fast and Performant
Seamless scaling and replication
Simple and integrated- it means it integrates easily with popular big data tools like Hadoop, cloud dataflow and Cloud Dataproc also support HBase API.
Fully Managed- means google manage the database and configuration related task and developer needs only focus on development.
Charges for BigTable- server: us-central
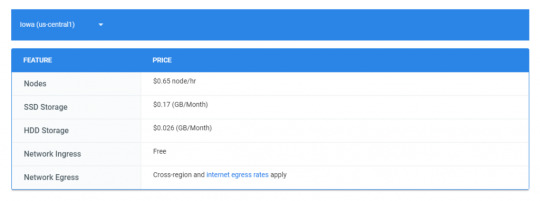
Google Bigtable Pricing- Image from official google site
Cloud Firestore
It is mainly serverless. Cloud Firestore is fast and serverless and fully managed and cloud-native NoSQL. It is document database which simplifies our storing data, syncing data and querying data from your IoT devices, mobile devices or web at global scale. It also provides offline support and its security features and integration with firebase and googles cloud platform.
Cloud Firestore features are below:
You can increase your development velocity with serverless: Is a cloud-native database and Cloud Firestore provides automatic scaling solution and it takes that advantage from googles powerful infrastructure. It provides live synchronization and offline support and also supports ACID properties for hundreds of documents and collections. From your mobile you can directly talk with cloud Firestore.
Synchronization of data on different devices: Suppose client use the different platform of your app means mobile, tab, desktop and when it do changes one device it will automatically reflected other devices with refresh or firing explicit query from user. Also if your user does offline changes and after while he comes back these changes sync when he is online and reflected across.
Simple and effortless: Is robust client libraries. By using this you can easily update and receive new data. You can scale easily as your app grows.
Enterprise-grade and scalable NoSQL: It is fast and managed NoSQL cloud database. It scales by using google infrastructure with horizontal scaling. It has built-in security access controls for data and simple data validations.
Pricing of Google Cloud Firestore:
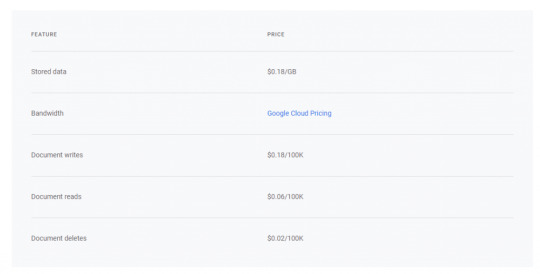
Google Cloud Firestore Pricing – Image from official googles site
FireBase
By tag line, it stores and sync data real-time. It stores data in JSON format. Different devices can access the same database.
It is also optimized for offline use and is having strong user-based security. This is also cloud-hosted database with a NoSQL database. It syncs In real-time across all clients and remains available if you go offline.
Capabilities of FireBase:
Realtime
Offline
Accessible from client devices
Scales across multiple databases: Means if you have blaze plan and your app go grow very fast and you need to scale your database so you can do in same firebase project with multiple database instances.
Firebase allows you to access the database from client-side code directly. Data is persisted locally and offline also in this realtime events are continuous fires by using this end-user experiences realtime responsiveness. When the client disconnected data is stored locally and when he comes online then it syncs with local data changes and merges automatically conflicts.
Firebase designed only to allow operations that can execute quickly.
Pricing of Firebase
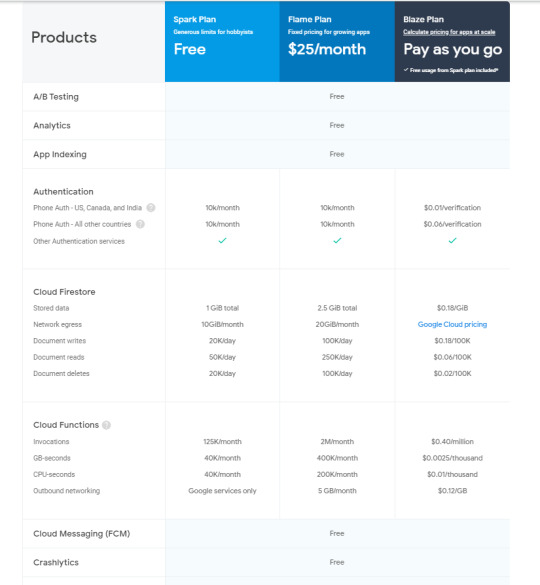
Google Firebase pricing-image from official google site
Cloud MemoryStores
This is an in-memory data store service for Redis. It is fully managed in-memory data store service which is built for scalability, security and highly available infrastructure which is managed by Google.
It is very much compatible with Redis protocol so it allows easy migration with zero code changes. When you want to store your app data in sub-millisecond then you can use this.
Features of Cloud memory stores:
It has the power of open-source Redis database and googles provide high availability, failure and monitoring is done by google
Scale as per your need:- by using this sub-millisecond latency and throughput achieve. It supports instances up to 300 Gb and network throughput 12 Gbps.
It is highly available- 99.9% availability
Google grade security
This is fully compatible with Redis protocol so your open-source Redis move to cloud memory store without any code change by using simple import and export feature.
Price for Cloud MemoryStore:
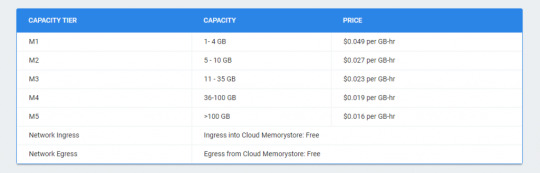
Google Cloud Memorystore price – image from official site of google
0 notes
Text
Version 242
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week, getting a lot done. I've fixed a bunch of bugs and the new dupe stuff now shows something interesting.
This is a big release. tl;dr is that I am firing on all cylinders but sankaku downloading is broken for now. On v245, the hydrus network protocol will update, so check back in around then if you try to upload some tags and get an error.
you can now see some duplicates
I've polished all the duplicate code. Maintenance and searches run smarter and faster and you can control what gets run in idle time (including finding potential duplicate pairs) using the cog icon on the duplicates page.
You can also finally see some duplicates! I've added a prototype 'show some pairs' button that'll show you a random group of pairs just as simple thumbnails. I would like to eventually have a more contextual presentation for the future filter, but do check this out--I think it is pretty neat seeing the different kinds of dupes there are.
The only real job left for duplicates is to make the ui workflow to quickly process them. I would continue to appreciate your feedback now and as it rolls out. You will probably be telling the client 'file A is (no different to|better than|an alternate of) file B' and telling it to merge tags and ratings and optionally deleting bad files.
The feedback from last week was very helpful. Most users are seeing lots of duplicate pairs--typically, the raw number found is about 5-20% of total files (For my 290k client, I have something like 28k 'exact match' duplicate pairs). I dreaded this at first, thinking this would mean a huge workload, but as I thought about it more, I realised this number is inflated--if two files look similar, they make one pair, but if three look similar, there are three pairs discovered, and four make six, five ten, and so on. If you have ten or twenty files that all look the same, this will inflate the 'potential duplicates' number significantly. My workflow will use a bit of logic to collapse these redundant pairs (if you say A is better than B and B is better than C, it can infer that A is better than C).
Anyway, the duplicate stuff is going great, is the main point. It is almost at 1.0.
some downloader issues
The sankaku downloader exploded this week. Several users reported that it gives 503 errors. I looked into it, and I think the problem is due to cloudflare. Either sankaku have chosen to increase their protection level or some anti-DDoS system is kicking in automatically, but the upshot is that hydrus isn't being polite and browser-like enough about its requests so cloudflare is blocking it. Several other script-based downloaders have apparently been similarly affected.
I have paused all sankaku subscriptions and removed the sankaku downloader for new users for now. If the problem magically fixes itself, then we can go back, but I suspect the ultimate solution here is to wait for the downloader overhaul, which I will be working on after this dupe stuff, which will make hydrus act much more like a nice browser and respond more professionally to various server requests and error states.
In a not-dissimilar vein, I have removed the danbooru entry for new users and removed the hentai foundry unnamespaced tag parser. Danbooru has been giving sample sized files for a while, and the artist-created hentai foundry unnamespaced tags are frequently complete garbage. Both issues will be more tacklable under the new downloader engine, so please hang in there until then.
bandwidth limits and network upgrade
My PTR server is probably going to hit 256GB bandwidth (my limit on how much I can give it) for the month in the next couple of days. This is a nice problem, as it means it is doing a lot and lots of people are syncing with it, but it has happened quicker than I expected.
I re-tested the bandwidth exceeded error code this week, but I can't be absolutely confident it will look completely pretty in the real world when it happens. Your sync downloads should pause silently, but I think you'll get an error popup if you try to upload tags. Please wait until the 1st of Feb for the clock to reset.
I have had this problem in the back of my mind for a while. As I've said before, the system that worked for 10 million tags is struggling at 114 million. The update system is very inefficient. There is a longer term plan in the works to P2P a lot of this stuff, but I also have a plan to reduce bandwidth significantly. With this bandwidth problem, I have decided to move this latter overhaul up and also do some other important code and database cleanup.
So, while I will do some general tying-off work next week, for v244 I will concentrate on reducing the size of the database and then in v245 I will overhaul the update protocol. I expect to get about a 30% reduction in db size and quite a bit more on the network end. After that, I will be back to finishing off the dupe stuff.
misc stuff
I have fixed the garbage gif rendering on Windows. It was a build problem.
You can now assign a shortcut to an 'unclose_page' action. It undoes the last page close, and for new users defaults to Ctrl+U.
You can now sort thumbnails by width, height, ratio, and num_pixels!
As I've talked about in recent releases, the hydrus client-server interaction is now exclusively https.
If you import files with neighbouring .txt files and have the original files set to be deleted on successful import, the .txt files will now also be deleted.
When exporting neighbouring .txt files, you will be asked to select which tag services' tags you wish to include!
full list
optimised 'exact match' similar file queries to run a lot faster
optimised similar file queries in general, particularly for larger cycle queries
optimised hamming distance calculation, decreasing time by roughly 45%!
the similar files tree maintenance idle job will not trigger while there are phashes still to regenerate (this was redundantly and annoyingly blatting the new dupes page as soon as phash regen was paused)
removed similar files tree maintenance entry from db->maintain menu, as it can be done better from the new dupes page
adjusted the duplicate search and file phash regen progress gauges to reflect total number of files in cache, not the current batch job
all maintenance jobs on the duplicates search page will now save their progress (and free up a hanging gui) every 30 seconds
the duplicates page's cog menu button now lets you put phash regen and tree rebalancing on the normal idle routine, defaulting both to off
the cog menu can also put duplicate searching on idle time!
added a very rough 'just show me some pairs!' button to the dupe page--it is pretty neat to finally see what is going on
I may have reduced the memory use explosion some users are getting during file phash regen maintenance
wrote an unclose_page action and added it to the shortcuts options panel--it undoes the last page close, if one exists. ctrl+u will be the default for new users, but existing users have to add it under options
added ascending/descending sort choices for width, height, ratio, and num_pixels
the client can no longer talk to old http hydrus network servers--everything is now https
in prep for a later network version update, the client now supports gzipped network strings (which compress json a lot better than the old lz4 compression)
fixed gif rendering in the Windows build--I forgot to update a build script dll patch for the new version of opencv
the export file dialog's neighbouring .txt taglist file stuff now allows you to select a specific combination of tag services
if an hdd import's original file is due to be deleted, any existing neighbouring taglist .txt file will now also be deleted
the inter-thread messaging system has a new simple way of reporting download progress on an url
the handful of things that create a downloading popup (like the youtube downloader) now use this new download reporting system
sankaku seems to be 503-broke due to cloudflare protection--I have paused all existing sankaku subscriptions and removed the sankaku entry for new users (pending a future fix on my or their end)
I've also removed danbooru for new users for now--someone can fix the long-running sample size file issue in the new downloader engine
removed unnamespaced tag support from the hentai-foundry parser--maybe someone can try to fix that mess in the new downloader engine
menubuttons can now handle boolean check menu items that are tied straight into hydrus's options
menus launched from the newer frame and dialog code will now correctly display their help text on the main gui frame's statusbar! (at least on Windows! Linux and OS X remain borked!)
fixed a unicode error parsing bug in the gallery downloader
the server stop (or restart) command now correctly uses https!
the server test code now works on https as appropriate
fixed some misc server test code
misc fixes
misc cleanup
misc layout cleanup
next week
I had actually already scheduled a smaller network improvement for v245 before this bandwidth issue came up, so that's why I am sticking with that for the bigger overhaul. I think the db collapse (which is best done beforehand) will take a week, so I still have next week spare. I will try to tie-off the biggest outstanding cleanup and fixing jobs and not burn myself out so I can concentrate for two weeks.
1 note
·
View note
Text
Yesterday I replaced the RapidJSON in Project Special K with the SimpleJSON I already had in another C++ toy project, after discovering a somewhat simpler variation on JSON patch formats (RFC 7396 JSON Merge Patch opposed to 6902 JSON Patch) but found that the way RapidJSON worked made it next to impossible for me to implement.
I got walled by adding/replacing into arrays and 7396 doesn't support such an operation to begin with so that would simplify the job as well as the patch files.
Now, RFC 8396 does not require 6901 JSON Pointer, unlike 6902, support for which came free with RapidJSON. But why did I use RapidJSON in the first place? Because glTF importing requires JSON and lazy-gltf2 uses RapidJSON specifically.
I could use assimp instead I guess but that seems way overkill?
So I spent last night adapting everything to use SimpleJSON, added RFC 7396 support (though "remove if value is null" is missing right now) and got back to the point where I left off before.
Now I have some choices to consider.
Rework lazy-gltf2 to use SimpleJSON instead of RapidJSON. May find out there's no pointer support and lazy-gltf2 requires it.
Use assimp, end up with an external dependency that carries its own JSON parser but is also way too much for what I need.
Stop using C++, go back to C#, and find out that all the glTF importers available out there are all meant for VS2019 or later and won't compile on 2015, and/or use Newtonsoft JSON while I have a perfectly good library of my implementation right here with passable pointer and patch support.
Stop using C++, go back to C#, write my own glTF importer bound to my own JSON library.
Give the fuck up.
Sometimes I hate my special interests.
4 notes
·
View notes
Quote
The long awaited support for .NET Core 3.1 on AWS Lambda has finally been released. My Twitter bot runs on .NET Core 2.1 in a Lambda function and I have been meaning to update it to .NET Core 3.1 since the beginning. So let's do just that! I'll be following the steps on the announcement blog post to migrate to 3.1. Project file First up, the TargetFrameowrk in the project file (csproj) needs to be updated, so let's do that: netcoreapp3.1 ... CloudFormation template The runtime also needs to be updated in my CloudFormation template: ... Resources: Retweet: .... Properties: ... Runtime: dotnetcore3.1 ... CodeBuild script I'm using AWS CodeBuild for CI, and I should also update the .NET version that is used to build the app: version: 0.2 phases: install: runtime-versions: dotnet: 3.1 ... Note: I had to update my CodeBuild image to aws/codebuild/standard:4.0 as this is the version they added support for 3.1 in. See this comment for more details. NuGet packages The last step for my project is to update any NuGet packages to the latest versions. For that, I'll use the very helpful .NET Tool dotnet-outdated, which can automatically update package versions for you: $ dotnet-outdated src/DotNetTwitterBot/DotNetTwitterBot.csproj -u » DotNetTwitterBot [.NETCoreApp,Version=v3.1] AWSSDK.SecretsManager 3.3.101.72 -> 3.3.102.18 Version color legend: : Major version update or pre-release version. Possible breaking changes. : Minor version update. Backwards-compatible features added. : Patch version update. Backwards-compatible bug fixes. Upgrading package AWSSDK.SecretsManager... Project DotNetTwitterBot [.NETCoreApp,Version=v3.1] upgraded successfully Elapsed: 00:00:26.1976434 New features There are lots of new features that come with .NET Core 3.1 that can be utilised in AWS Lambda, such as: New Lambda JSON serializer ReadyToRun for better cold start performance Updated AWS Mock .NET Lambda Test Tool But, I thought to leave these for other blog posts. Cool! That's it for my app then. Let's merge this into master and see how it goes! Summary In this post, we updated my Twitter bot app from .NET Core 2.1 to 3.1. This was pretty straight forward, just updating a the version in a few files and updating some NuGet packages. It was a very painless exercise and I recommend everyone do it for their apps; there's lots of performance improvements in 3.1 so if all of our code runs faster, that hopefully a lot of CO2 we could be saving!
http://damianfallon.blogspot.com/2020/04/updating-aws-lambda-app-to-from-net.html
0 notes
Text
API Development and Routing with Node.js and Express
This article will be looking at how we can handle API routes inside of a Node.js and Express project. As always, we’ll start with a brand new Express project and progressively enhance it from the ground up.
🐊 Alligator.io recommends �
Learn Node, a video course by Wes Bos
ⓘ About this affiliate link
What exactly are routes?
Routes are ways that we can handle user navigation to various URLs throughout our application. For example, if we wanted to greet a user with a Hello, World! message on the home page, we may do something like this:
const express = require('express') const app = express() app.get('/', function (req, res) { res.send('Hello, World!') })
Without jumping into too much detail at this point, it’s important to understand that we’re not just limited to get responses. We can use other HTTP request methods such as post, put, delete, merge, patch and various others. You can see a full list of potential routing methods here: Express routing methods
So, you could imagine if we wanted to give a different response to the /about page of our application, we’d do something extremely similar:
const express = require('express') const app = express() app.get('/', function (req, res) { res.send('Hello, World!') }) app.get('/about', function (req, res) { res.send('About, World!') })
Project setup
Now that you understand the basics, let’s start to investigate these concepts further as we create our own Express application that involves multiple routes.
Ensure you have Node.js installed from Node.js prior to following the next steps. Run the following in your terminal:
# Create a new folder for our project # here we call it node-express-routing, # but you can give it any name you'd like $ mkdir node-express-routing # Change directory $ cd node-express-routing # Initialise a new Node project with defaults $ npm init -y # Create our entry file $ touch index.js # Install Express $ npm install express --save # nodemon will also come in handy $ npm install -D nodemon
I like to use nodemon to continually restart the Node.js project whenever our index.js or other JavaScript file(s) change. It’s usually a good idea to create a script that runs this inside of your project like so:
{ "name": "node-express-routing", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "start": "nodemon" }, "keywords": [], "author": "Paul Halliday", "license": "MIT" }
We can now run npm start or yarn start and our project will be up and running inside of the terminal.
Routes Within Express
We can now create our Express application and have it run on a port that we specify:
index.js
const express = require('express'); const app = express(); const PORT = 3000; app.listen(PORT, () => console.log(`Express server currently running on port ${PORT}`));
Our application is loaded on http://localhost:3000. If we navigate to that inside of your browser, you’ll notice that we get the following error:
Your first route
That’s because we haven’t specified a default GET route for /, the home page. Let’s do that:
app.get(`/`, (request, response) => { response.send('Hello, /'); });
We’re using app.get('/') to specify that we’d like to create a route handler for the / route. At this point, we have access to the request and response variables.
The request variable contains information about the request, for example, if we log out the request.url we’ll see / in the console:
app.get(`/`, (request, response) => { console.log(request.url); response.send('Hello, /'); });
We can do much more with request and I advise you to look into the documentation on this for further information: Request documentation
We’re able to respond back to the HTTP request with response. Although we’re simply sending plain text back to the browser at this stage, we can also modify this to send HTML instead:
app.get(`/`, (request, response) => { response.send(` <div> <h1>Todo List</h1> <ul> <li style="text-decoration:line-through">Learn about Express routing</li> <li style="text-decoration:line-through">Create my own routes</li> </ul> </div> `); });
This works because response.send() can take in either a Buffer object, a String, a JavaScript object, or an Array. Express handles these inputs differently and changes the Content-Type header to match, as ours is a String type, it’s set to text/html. If you’d like more information on this, check out the documentation here: response.send documentation
Working with Endpoints Using Postman
How do we investigate our route in detail? Well, we could use curl to interface with our API at the command line:
$ curl http://localhost:3000 <div> <h1>Todo List</h1> <ul> <li style="text-decoration:line-through">Learn about Express routing</li> <li style="text-decoration:line-through">Create my own routes</li> </ul> </div>
curl is absolutely a great way to work with our API, but I prefer using Postman. It’s a graphical tool that provides us with powerful features related to API development and design.
Download Postman for your environment by navigating to Postman downloads. You should then be able to test our application by pointing it to our URLs:
We’re making a new request at http://localhost:3000 and can see the response Body, Headers, Cookies and so on. We’ll be using this to test this and other HTTP verbs throughout the rest of the article.
GET, POST, PUT and DELETE with data
We now have a basic understanding of how to create a new route using the HTTP GET verb. Let’s look at how we can take advantage of the various route types with local data. We’ll start with route parameters:
Route parameters
Create a new route at app.get('/accounts') and app.get('/accounts/:id') with some mock data:
let accounts = []; app.get(`/accounts`, (request, response) => { response.json(accounts); }); app.get(`/accounts/:id`, (request, response) => { const accountId = Number(request.params.id); const getAccount = accounts.find((account) => account.id === accountId); if (!getAccount) { response.status(500).send('Account not found.') } else { response.json(getAccount); } });
We’re now able to use our API to filter for /accounts/:id. When we describe a route that has a :parameterName, Express will consider this as a user inputted parameter and match for that.
As a result of this, if we query for http://localhost:3000/accounts we get all of the accounts in our array:
[ { "id": 1, "username": "paulhal", "role": "admin" }, { "id": 2, "username": "johndoe", "role": "guest" }, { "id": 3, "username": "sarahjane", "role": "guest" } ]
If we instead request http://localhost:3000/accounts/3, we only get one account that matches the id parameter:
{ "id": 3, "username": "sarahjane", "role": "guest" }
Adding the bodyParser Middleware
Let’s add a new route using app.post which uses the request body to add new items to our array. In order to parse the incoming body content, we’ll need to install and set up the body-parser middleware:
$ npm install --save body-parser
Next, tell Express we want to use bodyParser:
const bodyParser = require('body-parser'); const app = express(); app.use(bodyParser.urlencoded({ extended: false })); app.use(bodyParser.json());
POST
If we define the app.post('/accounts') route, we’ll be able to push the incoming body content into our accounts array and return the set:
app.post(`/accounts`, (request, response) => { const incomingAccount = request.body; accounts.push(incomingAccount); response.json(accounts); })
We can use Postman to send a POST request to http://localhost/3000/accounts with the following JSON body content:
{ "id": 4, "username": "davesmith", "role": "admin" }
As we’re returning the new accounts with response.json(accounts) the returned body is:
[ { "id": 1, "username": "paulhal", "role": "admin" }, { "id": 2, "username": "johndoe", "role": "guest" }, { "id": 3, "username": "sarahjane", "role": "guest" }, { "id": 4, "username": "davesmith", "role": "admin" } ]
PUT
We can edit/update a particular account by defining a put route. This is similar to what we have done with other routes thus far:
app.put(`/accounts/:id`, (request, response) => { const accountId = Number(request.params.id); const body = request.body; const account = accounts.find((account) => account.id === accountId); const index = accounts.indexOf(account); if (!account) { response.status(500).send('Account not found.'); } else { const updatedAccount = { ...account, ...body }; accounts[index] = updatedAccount; response.send(updatedAccount); } });
We’re now able to change items inside of the accounts array. It’s a simple implementation that just combines / overwrites the initial object with the new addition.
If we set the request URL to http://localhost:3000/accounts/1 and JSON request body to:
{ "role": "guest" }
We can see both by the response body and making a GET request to http://localhost:3000/accounts that the role has been updated to guest from admin:
{ "id": 1, "username": "paulhal", "role": "guest" }
DELETE
Items can be deleted using app.delete. Let’s take a look at how we can implement this inside of our application:
app.delete(`/accounts/:id`, (request, response) => { const accountId = Number(request.params.id); const newAccounts = accounts.filter((account) => account.id != accountId); if (!newAccounts) { response.status(500).send('Account not found.'); } else { accounts = newAccounts; response.send(accounts); } });
Once again, if we send a DELETE request to http://localhost:3000/accounts/1 this will remove the account with the id of 1 from the accounts array.
We can confirm that this works as intended by making a GET request to http://localhost:3000/accounts.
Summary
Phew! This article looked at how we can use Express to create common API routes using HTTP verbs such as GET, POST, PUT, and DELETE.
Further improvements to this would be to include more data validation, security, and the use of a remote database instead of local state. Stay tuned for future articles where we tackle that!
via Alligator.io https://ift.tt/2T309lT
0 notes
Photo

Get to Know JSON Merge Patch: JSON-P 1.1 Overview Series - Enterprise Java JSON https://t.co/68s8MYT4VA #Java #JavaEE #Java9
0 notes
Link
Salesforceを使ったプロジェクトを最近久しぶりにやっています。その中でSalesforceの ISVパートナーになり開発したアプリケーションをAppExchange (Salesforce Store) で配布しようと考えています。その道程の中での気づきや学びを共有していきます。 結論から言うと CIもCD も出来るけど CD に関してはちょっとクセあり?まずは、CDについて解説したいと思います。CIは次回以降解説します。 環境としては GitHub, Salesforce Developer Experience, と Cloud Build を使います。 さて、ソースコードの統合がCIによってうまくいくと今度は本番環境に対してデプロイを高度に自動化していくことになります。これがまさにCD (Continuous Deployment)でやる部分です。(Delivery までではなく、Deploymentまでがやりたいことです。) 目次 管理パッケージをどうやってSalesforceでデプロイするか?開発したコードを本番環境にデプロイするには、AppExchangeの場合だと、それをパッケージ化して、最新パッケージを顧客の環境にインストールすることによって実現します。 もちろんAppExchangeで配布しているアプリケーションなので、たくさんのSalesforce 組織に対してパッケージがインストールされている状態においてもスケーラブルに高度に制御して行きたいと思います。 2nd Gen Managed Package (第二世代管理パッケージ) についてSalesforceでパッケージを作るのは従来とても自動化出来るような作業じゃありませんでした。UI上から人間がコンポーネントを一つずつチェックするようなイメージです。ヒューマンエラーが発生して当たり前の世界です。これが今では第一世代管理パッケージと呼ばれる古い方法です。プロの開発者はもうこれを使うのをやめましょう。(キッパリ) 説明は省きますが、今回はCLIで自動化が可能な第二世代管理パッケージを使います。詳しくはこちら。 パッケージとバージョンのライフサイクル 実態としてソースコード (メタデータ)が含まれるのはバージョンの方です。パッケージはAppExchangeでリスティングする単位を表すのでただの箱です。パッケージに紐付く形で無数のバージョンがあり、その中で安定しているバージョンをリリース (Promote、昇格とも言う)して、本番環境にデプロイします。 ちなみにリリースされていないバージョンの事をBetaバージョンといいます。 パッケージとバージョンの作り方前提条件: DevHub組織が作られている (sfdx clientでデフォルトになっている) 名前空間組織が作られている DevHub組織が名前空間組織を認識しているまずはパッケージを作ります。コマンド一発で出来ます。 sfdx force:package:create --name PACKAGE_NAME \ --packagetype Managed --path force-app/0Ho から始まるパッケージIDが作成されたはずです。そのIDにAliasとしてsfdx-package.json に記録しておきましょう。 次にそのパッケージに紐づくバージョンを作ります。 VERSION_NUM=1.0.0 sfdx force:package:version:create --package "PACKAGE_NAME" \ --installationkeybypass \ --definitionfile config/project-scratch-def.json \ --codecoverage --versionname="ver $VERSION_NUM" \ --versionnumber=$VERSION_NUM.NEXTちなみに二回目以降にバージョンを作成をして、そのバージョンで既存のお客様をアップデートさせる場合はAncestor IDを sfdx-project.json で指定してあげる必要があります。sfdx コマンドのオプションとして指定が出来ないようなので、毎回 JSONファイルを編集する必要があるのが微妙ですね。特に自動化する時に。。。 { "packageDirectories": [ { "path": "force-app", "default": true, "package": "PACKAGE_NAME", "ancestorId": "04t3h000004bchBAAQ" } ], "namespace": "YOUR_NAMESPACE", "sfdcLoginUrl": "https://login.salesforce.com", "sourceApiVersion": "48.0", "packageAliases": { "PACKAGE_NAME": "0Hoxxxxxxxxxxxxxxxx" } }パッケージのバージョンを作成とインストール時の制約この辺の制約は結構複雑です。調べ始めていて意味不明のエラーで何度も挫けそうになりました。あまり文献としてまとまっていなかったように思うので、ここにまとめます。あとに続く開発者の肥やしになればと・・・ パッケージのバージョンを作る際にバージョン番号を命名してあげることがあります。しかし、Git Tagの様にに任意の文字列でつけることが出来ません。 MAJOR.MINOR.PATCH.BUILDで、バージョン番号は必ず構成されます。任意の文字列を名付ける事は出来なくて、ネーミングとアップグレードにはかなり厳密なルールがあります。Buildいらなくない? と思いましたが、Versionは一度作ると消せないので、あるのだと思います。 パッケージバージョン作成時の制約網羅的なものではないと思いますが、パッケージを作成する際の制約事項をまとめました。 • Build バージョンは一つしかPromote (Release) することが出来ない。 例) 1.0.0.1 を Promoteしたら 1.0.0.2 は Promote 出来ない。 • Patch バージョンは、Security Reviewを通っていないと作れない。 例) 1.0.0.1 → 1.0.1.1 はSecurity Reviewをパスしないと作れない • Build バージョンは同じAncestor IDを持っている必要がある 例) 1.0.0.1 と 1.0.0.2 は同じAncestor IDを指定しないと行けない • 破壊的な変更がある場合は Ancestryを分けなければならない。 例) 1.0.0.1 → 1.1.0.1 の移行で DummyController.cls を削除した場合、1.1.0.1 のAncestor IDで1.0.0.1を指定することが出来ない。Ancestorがないバージョンを作らなければならない。Security Reviewに通ってないとPatch バージョンが作れないので、デバッグしただけ、見た目変えただけ、とかでもMinor バージョンを上げないといけない・・・ということが発生します。これはかなりイケてないです。(semantic versioning) あと第二世代管理パッケージではソースコードを消せません (破壊的な変更)。クラスやLightning Componentを作ったあとに削除して新しいバージョンを作ろうとするとエラーが出ます。詳しくはこちら 使わなくなったクラスや、Lightning Component、Lighting App、Connected Appなどが消せないとソースコードのボリュームが無駄に増えて非衛生的ですし、何よりもチームメイトが混乱してしまいます。苦肉の策ですが、削除が出来ない代わりにゴミ箱フォルダーをソースコードに作ってそこに入れてゴミコードであることの意思表示をしています。これ本当にどうにかして欲しいです。 パッケージバージョンを組織��インストールする際の制約• Betaパッケージはアップグレード出来ない。 • バージョンはアップグレードのみ可能。 例) 1.0.1.2 から 1.0.0.1 には戻せない。 • 古いパッケージからアップグレードする際は、直系の子孫じゃないとアップグレードが出来ない。3つ目がものすごくややこしくて鬼門です。ここを次に丁寧に説明します。ちなみに「直系の子孫」は、僕が勝手に作った言葉です。 直系の子孫の定義Major / Minor バージョンのリリースを上位パッケージ (Ancestor ID) で数珠つなぎにして一直線に並べたものと考えればわかりやすいと思います。例えばこの図の様なバージョン構成です。 1人で、1機能ずつ開発したらこんな感じになると思います。この場合、上から下の方向であれば全ての組み合わせでアップグレードが出来ます。 ----------------- なお、直系の子孫かどうかの判断に Patch / Build バージョンは関係ありません。 例えばこの様な場合は、1.0.1.1 も 1.0.2.1も直系とみなされます。よって、例えば 1.0.1.1 から 1.1.0.1アップグレードすることは可能です。 ----------------- さて、多くの開発者にとって混乱を招きやすいのはこのパターンだと思います。 0.2.0.1 を上位に持つ系統が2つ出来ました。(今まで伝統的に長男が家業を継いで来た一族である世代で長女も暖簾分けしてもらって同時に継いだイメージ?) ただしこの場合、系統をまたいだアップグレードは出来ません。例えば 1.3.0.1 から 1.4.0.1 はアップグレード出来ません。アップグレードするならばアンインストールして再インストールしか方法がありません。 ----------------- 応用ですが、以下の様な2つ系統があり、なおかつパッチバージョンがある場合のことも想定してみます。 1.2.1.1 から 1.4.0.1 はアップグレードは出来ませんが、 1.2.1.1 から 1.3.0.1 はアップグレード可能です。 Salesforce の Branch != Git の Branchこのようにツリー形式でバージョニングする事をSalesforceではBranchと呼びます。 名前で誤解をしていたので理解するのにとても苦労したのですがSalesforce の Branch は Merge が出来ません。なので一度系統が分かれてしまったら二度と元に戻ることが出来ません。元に戻すにはパッケージをアンインストールして、最新のバージョンを再インストールするしか方法がありません。 感想複数の機能を同時に複数の組織で開発して、終わったらマージして一つのパッケージに・・・といったデプロイ手法を考えていたのですが、 2nd Generation Packagingは残念ながらこの��な開発は出来ないようです。これは正直期待していたのでちょっと残念です。という点で今回は一番やりたかったCDが出来ませんでした。 まとめ (ベストプラクティス)Git を使って複数の機能を複数人で作っている場合、Git で複数のfeature branchを使いながら開発をする事になると思います。Feature branchからパッケージバージョンを作る事はやめましょう。系統が複数できて、マスターにマージができなくなる自体が発生します。 パッケージバージョンを作るのは、必ずMaster Branchから作るべきです。例えばGitHubを使っている場合であれば Release の機能を使ってパッケージバージョンを作るのがもっとも良いと思います。 そうすればパッケージバージョンはGitHubのリリースと同期することになり、見通しが良くなります。Ancestryのツリーが一本になりAbandoned Packageがなくなり、全ての組織が最新パッケージにアップグレード出来るようになります。 大分長くなってしまったので、今回は制限についての正しい情報についての解説と出来なかった事とそれからの示唆をまとめた投稿になりました。 ぶっちゃけまだまだ課題はありますが、Salesforceも大分、昔に比べるとモダンな開発がしやすくなって来たと思います。 次回は、Cloud Buildを使いながら、どのようにデプロイしていくかを書こうと思います。 もしよかったらスキとSalesforce開発者へ拡散お願いします。
0 notes
Text
Get to Know JSON Merge Patch: JSON-P 1.1 Overview Series
JSON Processing 1.1 JSON Merge Patch Overview @JSONProcessing @Java_EE @Java #JavaEE8 #JavaEE #JakartaEE #JSONP
Java EE 8 includes an update to the JSON Processing API and brings it up to date with the latest IEFT standards for JSON. They are:
JSON Pointer RFC 6901
JSON Patch RFC 6902
JSON Merge Patch RFC 7396
I will cover these topics in this mini-series.
Getting Started
To get started with JSON-P you will need the following dependencies from the Maven central repository.
javax.json javax.json-api…
View On WordPress
0 notes
Text
SSTIC 2017 Wrap-Up Day #3
Here is my wrap-up for the last day. Hopefully, after the yesterday’s social event, the organisers had the good idea to start later… The first set of talks was dedicated to presentation tools.
The first slot was assigned to Florian Maury, Sébastien Mainand: “Réutilisez vos scripts d’audit avec PacketWeaver”. When you are performed audit, the same tasks are already performed. And, as we are lazy people, Florian & Sébastien’s idea was to automate such tasks. They can be to get a PCAP, to use another tool like arpspoof, to modify packets using Scapy, etc… The chain can quickly become complex. By automating, it’s also more easy to deploy a proof-of-concept or a demonstration. The tool used a Metasploit-alike interface. You select your modules, you execute them but you can also chain them: the output of script1 is used as input of script2. The available modules are classified par ISO layer:
app_l7
datalink_l2
network_l3
phy_l1
transport_l4
The tool is available here.
The second slot was about “cpu_rec.py”. This tool has been developed to help in the reconnaissance of architectures in binary files. A binary file contains instructions to be executed by a CPU (like ELF or PE files). But not only files. It is also interesting to recognise firmware’s or memory dumps. At the moment, cpu_rec.py recognise 72 types of architectures. The tool is available here.
And we continue with another tool using machine learning. “Le Machine Learning confronté aux contraintes opérationnelles des systèmes de détection” presented by Anaël Bonneton and Antoine Husson. The purpose is to detect intrusions based on machine learning. The classic approach is to work with systems based on signatures (like IDS). Those rules are developed by experts but can quickly become obsolete to detect newer attacks. Can machine learning help? Anaël and Antoine explained the tool that that developed (“SecuML”) but also the process associated with it. Indeed, the tool must be used in a first phase to learning from samples. The principle is to use a “classifier” that takes files in input (PDF, PE, …) and return the conclusions in output (malicious or not malicious). The tool is based on the scikit-learn Python library and is also available here.
Then, Eric Leblond came on stage to talk about… Suricata of course! His talk title was “À la recherche du méchant perdu”. Suricata is a well-known IDS solution that don’t have to be presented. This time, Eric explained a new feature that has been introduced in Suricata 4.0. A new “target” keyword is available in the JSON output. The idea arise while a blue team / read team exercise. The challenge of the blue team was to detect attackers and is was discovered that it’s not so easy. With classic rules, the source of the attack is usually the source of the flow but it’s not always the case. A good example of a web server returned an error 4xx or 5xx. In this case, the attacker is the destination. The goal of the new keyword is to be used to produce better graphs to visualise attacks. This patch must still be approved and merge in the code. It will also required to update the rules.
The next talk was the only one in English: “Deploying TLS 1.3: the great, the good and the bad: Improving the encrypted web, one round-trip at a time” by Filippo Valsorda & Nick Sullivan. After a brief review of the TLS 1.2 protocol, the new version was reviewed. You must know that, if TLS 1.0, 1.1 and 1.2 were very close to each others, TLS 1.3 is a big jump!. Many changes in the implementation were reviewed. If you’re interested here is a link to the specifications of the new protocol.
After a talk about crypto, we switched immediately to another domain which also uses a lot of abbreviations: telecommunications. The presentation was performed by Olivier Le Moal, Patrick Ventuzelo, Thomas Coudray and was called “Subscribers remote geolocation and tracking using 4G VoLTE enabled Android phone”. VoLTE means “Voice over LTE” and is based on VoIP protocols like SIP. This protocols is already implemented by many operators around the world and, if your mobile phone is compatible, allows you to perform better calls. But the speakers found also some nasty stuff. They explained how VoLTE is working but also how it can leak the position (geolocalization) of your contact just by sending a SIP “INVITE” request.
To complete the first half-day, a funny presentation was made about drones. For many companies, drones are seen as evil stuff and must be prohibited to fly over some places. The goal of the presented tool is just to prevent drones to fly over a specific place and (maybe) spy. There are already solutions for this: DroneWatch, eagles, DroneDefender or SkyJack. What’s new with DroneJack? It focuses on drones communicating via Wi-Fi (like the Parrot models). Basically, a drone is a flying access point. It is possible to detected them based on their SSID’s and MAC addresses using a simple airodump-ng. Based on the signal is it also possible to estimate how far the drone is flying. As the technologies are based on Wi-Fi there is nothing brand new. If you are interested, the research is available here.
When you had a lunch, what do you do usually? You brush your teeth. Normally, it’s not dangerous but if your toothbrush is connected, it can be worse! Axelle Apvrille presented her research about a connected toothbrush provided by an health insurance company in the USA. The device is connected to a smart phone using a BTLE connection and exchange a lot of data. Of course, without any authentication or any other security control. The toothbrush even continues to expose his MAC address via bluetooth all the tile (you have to remove the battery to turn it off). Axelle did not attached the device itself with reverse the mobile application and the protocol used to communicate between the phone and the brush. She wrote a small tool to communicate with the brush. But she also write an application to simulate a rogue device and communicate with the mobile phone. The next step was of course to analyse the communication between the mobile app and the cloud provided by the health insurance. She found many vulnerabilities to lead to the download of private data (up to picture of kids!). When she reported the vulnerability, her account was just closed by the company! Big fail! If you pay your insurance less by washing your teeth correctly, it’s possible to send fake data to get a nice discount. Excellent presentation from Axelle…
To close the event, the ANSSI came on stage to present a post-incident review of the major security breach that affected the French TV channel TV5 in 2015. Just to remember you, the channel was completely compromised up to affecting the broadcast of programs for several days. The presentation was excellent for everybody interested in forensic investigation and incident handling. In a first part, the timeline of all events that lead to the full-compromise were reviewed. To resume, the overall security level of TV5 was very poor and nothing fancy was used to attack them: contractor’s credentials used, lack of segmentation, default credentials used, expose RDP server on the Internet etc. An interesting fact was the deletion of firmwares on switches and routers that prevented them to reboot properly causing a major DoS. They also deleted VM’s. The second part of the presentation was used to explain all the weaknesses and how to improve / fix them. It was an awesome presentation!
My first edition of SSTIC is now over but I hope not the last one!
[The post SSTIC 2017 Wrap-Up Day #3 has been first published on /dev/random]
from Xavier
0 notes