#L2cache
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
AWS C8g & AWS M8g: Efficient High-Performance Computing

Amazon EC2 Instances
Utilize the new Amazon EC2 C8g and M8g instances to run your general-purpose and compute-intensive tasks sustainably. Today Amazon EC2 C8g and M8g instances are now widely available.
AWS C8g
High-performance computing (HPC), batch processing, gaming, video encoding, scientific modeling, distributed analytics, CPU-based machine learning (ML) inference, and ad serving are suited for AWS Graviton4-based C8g instanc
AWS M8g
M8g instances, which are also Graviton4-based, offer the best cost-performance for workloads with a generic purpose. Applications like gaming servers, microservices, application servers, mid-size data storage, and caching fleets are all well suited for M8g instances.
Let’s now have a look at some of the enhancements it has implemented in these two cases. With three times as many vCPUs (up to 48xl), three times as much memory (up to 384GB for C8g and up to 768GB for M8g), seventy-five percent more memory bandwidth, and twice as much L2 cache as comparable 7g instances, C8g and M8g instances offer higher instance sizes. This allows processing larger data sets, increasing workloads, speeding up results turnaround, and lowering TCO.
These instances have up to 50 Gbps network bandwidth and 40 Gbps Amazon EBS capacity, compared to Graviton3-based instances’ 30 Gbps and 20 Gbps. C8g and M8g instances, like R8g instances, have two bare metal sizes (metal-24xl and metal-48xl). You can deploy workloads that gain from direct access to real resources and appropriately scale your instances.
C8g AWS
Important things to know
With pointer authentication capability, separate caches for each virtual CPU, and always-on memory encryption, AWS Graviton4 processors provide improved security.
The foundation of these instances is the AWS Nitro System, a vast array of building blocks that assigns specialized hardware and software to handle many of the conventional virtualization tasks. It reduces virtualization overhead by providing great performance, high availability, and excellent security.
Applications written in popular programming languages such as C/C++, Rust, Go, Java, Python,.NET Core, Node.js, Ruby, and PHP, as well as containerized and microservices-based applications like those running on Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Elastic Container Service (Amazon ECS), are ideally suited for the C8g and M8g instances.
Available right now
The US East (N. Virginia), US East (Ohio), US West (Oregon), and Europe (Frankfurt) AWS Regions currently offer C8g and M8g instances. With Amazon EC2, as usual, you only pay for the resources you utilize. See Amazon EC2 Pricing for additional details. To assist you in moving your applications to Graviton instance types, have a look at the assortment of AWS Graviton resources.
Read more on govindhtech.com
#AWSC8g#AWSM8g#EfficientHigh#PerformanceComputing#L2cache#AmazonEC2#AWSGraviton4based#R8ginstances#AWSNitroSystem#AmazonElasticKubernetesService#Amazon#technology#technews#news#govindhtech
1 note
·
View note
Text
#ProgPoW From the View of an IC Design Engineer
I am an IC design engineer who has also been mining cryptocurrencies since 2014. Although, unlike many other miners from back then, I am not the owner of a large mining farm, I do have a mining setup that makes just enough profit for me to justify the time I spend on it to my wife. Amidst all varying points of views on ProgPoW circulating online, I hope to share those of an IC engineer.
Whether the algorithm is ProgPoW or ETHash, the hashrate is determined by the storage bandwidth of external DRAM. That is,
Hashrate = k*BW
where k is a constant factor and is different for ETHash and ProgPoW
Therefore, to increase the hashrate for ETHash or progPoW, we need to increase the memory bandwidth. In the early years, high-bandwidth memory devices were mainly GDDR5 in graphics cards. Only AMD and Nvidia GPUs could handle such a high-bandwidth memory. So, GPUs from Nvdia or AMD became the most popular for ETHash mining. Now the memory demand for profitably mining ETHash has increased significantly. This demand for high-bandwidth memory has prompted the development of next-generation high-speed memory tech such as GDDR6 and HMB2. In Q4 of 2018, Innosilicon released its GDDR6 IP together with its ETHash mining ASIC. Because of the similarities that exist between the algorithm as well as architecture of ProgPoW and those of ETHash, I believe that Innosilicon’s next ASIC would be tailored for ProgPoW. 3-4 months is sufficient time to design and mass-produce such an ASIC once the parameters of ProgPoW are fixed. I believe that Bitmain is also secretly developing its own GDDR6 IP. Other companies, such as Rambus and eSilicon, have already released IP of GDDR6 and HMB2. I have no doubt that other mining ASIC producers, such as Linzhi and Canaan Creative, will soon adopt GDDR6 or HBM2 in their future generation chips. So, we may see many GDDR6/HBM2 based ASICs for ProgPOW in the near future if ProgPoW is implemented.
Mining ASICs can use optimization methods based on GDDR6 and HBM2. Just an example of these methods is having more GDDR6/HBM2 memory banks in ASICs than GPUs. Take Nvidia's 2080. It uses 8 GDDR6s and operates at 14Gbps, giving it a total bandwidth (BW) of 8*14*32/8 = 448Gbps. According to the bandwidth requirement of ProgPoW, the theoretical hashrate should be
hashrate = BW/64/256 = 27.3Mh/s.
Considering the storage efficiency, the actual value should be 25.5Mh/s. An ASIC producer can use the smaller GDDR6 memory banks to gain cost advantages over GPUs. 16 GDDR6 4GB memory banks can be used to achieve a 2x bandwidth advantage, while maintaining GDDR6 costs at almost the same level. In this case, the available bandwidth is 16*14*32/8 = 896Gbps, and the theoretical hashrate is,
hahsrate = 896Gbps/256/64 = 54.6Mh/s
which gives 2x more hashrate advantage. But the silicon area of 4GB GDDR6 is 50% smaller than that of the 8GB GDDR6. So the price of 4GB GDDR6 should be 60% less than the price of 8GB GDDR6. The total cost of GDDR6 is summarized in Table 1 below.
Let’s look into the internal structure of a GPU chip, such as the Nvidia RTX2080, as shown in Figure 1 from Nvidia.

Fig.1: Architecture of Nvidia RTX2080
There are many modules in the RTX2080 chip that occupy a lot of the chip area and are useless for ProgPoW. These include PCIE, NVLINK, L2Cache, 3072 shading units, 64 ROPs, 192 TMUs et. all. An ASIC producer could remove these graphics functions and optimize the same chip area for ProgPOW algorithms, which could reduce the chip area to roughly 1/3rd that of Nvidia’s RTX2080 chip. So, the cost of such an AISC chip would be only 1/3rd that of the RTX2080 because, with the same number of silicon wafers, the number of such ASIC chips that can be produced would be three times more.
And, compared to large chips, small chips have higher yields and lower packaging and testing costs. The yield calculation formula is:
Y = 1/power(1+0.08*die_area)^22.4
For the Nvidia RTX2080 GPU, the die area is 545 mm^2. So the calculated yield of the GPU is 23%. If the area is reduced to 1/3rd, the yield Y will increase by 60%. Low yield will result in a higher cost of the GPU. The cost of such an ASIC would be 1/3*23/60 = 0.13 of that of the GPU. That is a 7.7x more advantage for the ProgPoW ASIC compared to the GPU. Estimating maturity of the GPU, I will keep this advantage limited to 5x for the next calculation. On the system PCB, the ProgPoW ASIC would also have a cost advantage if the ASIC producer were to eliminate the PCIE and complex thermal designs which are required by GPU cards. In an ASIC based mining machine, a large number of ASIC chips and GDDR6, using much simpler and cost-effective heat sink design, would be way more densely packed (and thus shipped). The system cost in a GPU cards may be 50%, but the PCB cost of the ASIC based mining machine can easily be reduced to 30%. I have made the overall cost comparison for GPU and ASICs in Table 1.

Table 1: the comparison of GPU and ASIC for ProgPOW
As for the power consumption, the GPU would consume much more power as it can only work at the normal voltage, which is usually 0.8V. However, the ProgPoW ASIC’s power consumption can be reduced by reducing the operating voltage. According to Ohm's law, power is proportional to the square of the voltage:
P = U*I = U^2/R
The voltage of ASICs can easily be reduced to 0.4V, which is 1/2 that of GPU’s. Thus, for the same hashrate, the ProgPoW ASIC would consume only 1/4th the power consumed by the GPU. In other words, the ProgPoW ASIC can have an energy efficiency ratio 4x that of the GPU. Such low-voltage ASIC designs are already utilized by ASIC producers in Bitcoin mining machines and there is no reason to believe that they would not be used in ProgPoW ASICs. The same power-saving can also be achieved in LPDDR4x DRAM, which has a lower power consumption than GDDR6. GDDR6 works at 1.35v, while LPDDR4X works at 0.6V, which is less than half that of the GDDR6. So GDDR6 consumes at least 4x more power than LPDDR4x. So an ASIC with LPDDR4x DRAM has a 4x more power efficiency over a GPU with GDDR6. I have shown this in Table 2.
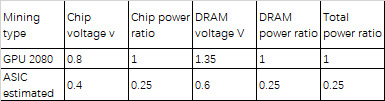
Table 2: Power efficiency comparison of GPU and ASIC with ProgPoW
Furthermore, designing GPUs requires a much higher R&D investment in terms of both human resource and time. Because GPU is a general-purpose acceleration chip, it usually takes about 12 months for a GPU to be designed, fabricated and tested, requiring a lot of hardware simulations and software developing to cover different computing scenarios. But the design and test for ProgPoW's ASICs, are much simpler. A dedicated team of experienced IC designers could take as little as 2 months for design, 6 weeks for fabrication and 2 weeks for testing of ProgPoW ASICs. Thus, it could take only 3 to 4 months for ProgPoW ASICs to be ready for mass production. For ASIC companies, such as Bitmain and Innosilicon, which are already producing ETHash mining ASICs, integrating ProgPoW in their previous designs to produce a ProgPoW ASIC would be even simpler. A GPU producer like Nvidia employs about 8000 people to develop GPUs, which are much more complicated, whereas an ASIC producer like Linzhi only employs a dozen or so people to focus only on ASICs for ETHash mining. The labor costs of these companies company are different by a factor of 100. So ASICs have further advantages in terms of cost and time-to-market than GPU chips.
To summarize, ProgPoW ASICs seems inevitable if ProgPoW were implemented and it would take only 3-4 months for them to hit mass production. Furthermore, they would have at least a 4x advantage in both cost and power efficiency over a GPU for accelerating the ProgPoW algorithm. This would bring us right back to where we started pre-ProgPoW and begs the question: Why ProgPoW or why ASIC-resistance?
1 note
·
View note
Text
Amazon EC2 X8g: Graviton-4 Memory-Optimized AWS Instances
The most affordable price per gigabyte of memory among Graviton4-based EC2 instances is offered by Amazon Elastic Compute Cloud (Amazon EC2) X8g instances, which are driven by the most recent AWS Graviton4 processors. In addition, X8g instances provide up to 60% faster performance than X2gd instances and up to 3TiB of memory. They also offer larger instance sizes with up to three times more memory and vCPUs.
Customers can run memory-intensive workloads like in-memory databases (Redis, Memcached), relational databases (MySQL, PostgreSQL), electronic design automation (EDA) workloads, real-time big data analytics, and real-time caching servers with X8g instances’ increased performance and extra memory. To further optimize their computational infrastructure, X8g instances allow several memory-intensive containerized apps to run on a single instance. With up to 3 TiB of DDR5 memory and up to 192 vCPUs, Graviton-4-powered, memory-optimized X8g instances are now offered in 10 virtual sizes and two bare metal sizes.
With the finest price-performance and scale-up capability of any comparable EC2 Graviton instance to date, this instance is its most energy-efficient to date. These instances are optimized for Electronic Design Automation, in-memory databases & caches, relational databases, real-time analytics, and memory-constrained microservices, and have a memory to virtual CPU ratio of 16 to 1. The instances include with extra AWS Nitro System and Graviton4 security capabilities, and they completely encrypt all high-speed physical hardware interfaces.
This new instances are an even better host for these applications because they come in twelve sizes, giving you the option to scale up (using a larger instance) or scale out (using multiple instances). They also give you more flexibility for memory-bound workloads that are currently running on different instances.
The X8g instances vs X2gd instances
It offer three times as much memory, three times as many virtual CPUs, more than twice as much EBS capacity (40 Gbps vs. 19 Gbps), and twice as much network bandwidth (50 Gbps vs. 25 Gbps) as the previous generation (X2gd) instances.
With 160% more memory bandwidth and twice as much L2 cache per core as the Graviton2 processors in the X2gd instances (2 MiB vs. 1 MiB), the Graviton4 processors within the X8g instances can achieve up to 60% better compute performance.
The 5th generation of AWS Nitro System and Graviton4 processors, which include additional security features like Branch Target Identification (BTI) to protect against low-level attacks that try to disrupt control flow at the instruction level, are used in the construction of the X8g
ENA, ENA Express, and EFA Enhanced Networking are supported by the instances. The following table shows that they support all EBS volume types, including io2 Block Express, EBS General Purpose SSD, and EBS Provisioned IOPS SSD, and that they offer a sizable amount of EBS bandwidth.
Now let’s examine a few use cases and apps that can utilize up to 3 TiB per instance and 16 GiB of RAM per vCPU:
Databases: SAP HANA and SAP Data Analytics Cloud can now manage heavier and more ambitious workloads thanks to X8g instances. When compared to the same workloads operating on Graviton3 instances, SAP has measured up to 25% greater performance for analytical workloads and up to 40% better performance for transactional workloads when running on Graviton4 powered instances. SAP may now use Graviton-based utilization to even larger memory-bound solutions.
Workloads related to Electronic Design Automation (EDA) are essential to the process of developing, testing, confirming, and implementing new chip generations, such as Inferentia, Trainium, Graviton, and those that serve as the foundation for the Nitro System.
In order to take advantage of scalability and elasticity and provide the right amount of compute power for every stage of the design process, AWS and numerous other chip makers have selected the AWS Cloud for these workloads. Because they are not waiting for outcomes, engineers are able to develop more quickly as a result. This is a long-term image from one of the clusters utilized in late 2022 and early 2023 to support Graviton4 development. As you can see, this cluster operates at a very high scale, reaching peaks up to five times the typical usage.
Periodic spikes in daily and weekly activity are evident, followed by an increase in overall usage throughout the tape-out phase. Since the cluster’s instances are on the larger end of the size range, the peaks signify several hundred thousand cores that are operating simultaneously. Without having to make a specific hardware investment, it may achieve unparalleled scalability because to this capacity to spin up compute when needed and down when not.
With the support of the new X8g instances, AWS and its EDA clients will be able to execute even more workloads on Graviton processors, which will save costs and energy consumption while also accelerating the release of new products.
Accessible Right Now
X8g instances are currently offered in On Demand, Spot, Reserved Instance, Savings Plan, Dedicated Instance, and Dedicated Host forms in the US East (North Virginia), US West (Oregon), and Europe (Frankfurt) AWS Regions.
Read more on govindhtech.com
#AmazonEC2X8g#Graviton4Memory#AWSInstances#Graviton3instances#L2cache#DDR5memory#Graviton4basedEC2instances#aws#news#Gravitonprocessors#AWSCloud#ElectronicDesignAutomation#AmazonElasticComputeCloud#EDA#AmazonEC2#technology#technews#govindhtech
1 note
·
View note
Text
Apple MacBook Pro 15" Core i7-8750H 16GB RAM 512GB SSD Radeon Pro Touch Bar 2018
Apple MacBook Pro 15″ Core i7-8750H 16GB RAM 512GB SSD Radeon Pro Touch Bar 2018
HardwareOverview: ModelName:MacBook Pro ModelIdentifier:MacBookPro15,1 ProcessorName:6-Core Intel Core i7 ProcessorSpeed:2.2 GHz Numberof Processors:1 TotalNumber of Cores:6 L2Cache (per Core):256 KB L3Cache:9 MB Hyper-ThreadingTechnology:Enabled Memory:16GB SystemFirmware Version:1715.81.2.0.0 (iBridge: 19.16.10744.0.0,0) OSLoader Version:540.60.2~89 SerialNumber…

View On WordPress
0 notes