#Linux find file containing string
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
How to Find Files with Specific Text on Linux
15 notes
·
View notes
Text
Linux CLI 41 🐧 regular expressions
New Post has been published on https://tuts.kandz.me/linux-cli-41-%f0%9f%90%a7-regular-expressions/
Linux CLI 41 🐧 regular expressions

youtube
a - regular expressions and POSIX metacharacters 1/2 Regular expressions (regex) are powerful tools for pattern matching and text manipulation. You can use regex with various commands like grep, sed, awk, and even directly in the shell. You can use literal characters(abcdef...) but also metacharacters Basic regex metacharacters (BRE) → ^ $ . [ ] * . → matches any character - f..d matches food but not foot. ^ → matches at the start of the line. ^foo matches lines that start with foo If inside [ ] then means negation - [^0-9] matches any non-digit. $ → matches at the end of the line - bar$ matches lines that end with bar [ ] → matches any characters within the brackets - [aeiou] matches any vowel '*' → matches 0 or more occurrences - fo*d matches fd, food, and fod but not fed b - regular expressions and metacharactes 2/2 Extended regex (ERE) → ( ) ? + | ( ) → grouping and allows for subexpressions and backreferences - (foo)bar matches foobar n → matches exactly n occurrences of the preceding element - o2 matches two o's n,m → matches between n and m occurrences of the preceding element - o1,3 matches one to three o's ? → matches 0 or one occurrence of the preceding element - fo?d matches fd and fod, but not food '+' → matches one or more occurrences of the preceding element - fo+` matches food and fod, but not fd | → alternation/or, matches one of the two expressions - foo|bar matches foo or bar c - regular expressions and POSIX character classes [:alnum:] → matches any alphanumeric character (letters and digits). [:alpha:] → matches any alphabetic character (letter). [:digit:] → matches any digit. [:lower:] → matches any lowercase letter. [:upper:] → matches any uppercase letter. [:blank:] → matches a space or a tab character. [:space:] → matches any whitespace character (spaces, tabs, newlines, etc.). [:graph:] → matches any graphical character (letters, digits, punctuation, and symbols). [:print:] → matches any printable character. [:punct:] → matches any punctuation character. [:xdigit:] → matches any hexadecimal digit (0-9, a-f, A-F). d - regular expressions examples grep -E '[0-9][0-9]' numbers.txt →finds lines containing two consecutive digit grep -E '^[aeiouAEIOU]' vowels.txt →finds lines that start with a vowel (a, e, i, o, u) sed -E 's/f([a-z])o\1d/b&r/' input.txt output.txt → replaces all occurrences of foo with bar awk '/^[0-9]/ && /a/' data.txt → prints lines that start with a number and contain the letter a awk 'gsub(/f([a-z])o\1d/, "b&r"); print' input.txt output.txt →replaces all occurrences of foo with bar grep -E '\.com' domains.txt →finds lines containing the string .com \ → escapes special characters for example \. \\ Regex operations can be slow on large files.
0 notes
Text
This Week in Rust 460
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Security advisories for Cargo (CVE-2022-36113, CVE-2022-36114)
Foundation
Rust Foundation Establishes Security Team to Support and Advance Rust Programming Language
Newsletters
Rust Nigeria Issue #9
Project/Tooling Updates
rust-analyzer changelog #146
IntelliJ Rust Changelog #178
A byte string library for Rust
Pomsky 0.7 released
Slint weekly updates (The GUI framework)
Fang 0.9 - new version of the background processing framework for rust
Fornjot (code-first CAD in Rust) - Weekly Release - 2022-W37
This week in Databend #59: A Modern Cloud Data Warehouse for Everyone
HexoSynth 2022 - Devlog #12 - Documentation for me and you
Observations/Thoughts
You Can't Do That: Abstracting over Ownership in Rust with Higher-Rank Type Bounds. Or Can You?
Security and Correctness in Wasmtime
Attacking Firecracker: AWS' microVM Monitor Written in Rust
&stress about &Strings
A pair of Rust kernel modules
GNU ld Discards Section Containing Code – Section Flags are Important for ELF Files
Use Rust to Reduce the Size of Your SQLite Database
[video] Coroutines: C++ vs Rust - Jonathan Müller - C++ on Sea 2022
[video] Rust on Rails (write code that never crashes)
[video] Let's Code Asteroids in Rust with a First-Time Bevy User
[video] Linux Plumbers Conference 2022 - Rust MC
[video] [series] Rust Day on Google Open Source Live
Rust Walkthroughs
Kernighan software tools in rust
Speeding up incremental Rust compilation with dynamic libraries
Learning Rust by implementing a SHA-1 hash cracker
Chat Blast! A TCP chat server in Rust
Concurrency in RustDb
Beginners guide to Solana NFTs in Rust.
STM32F4 Embedded Rust at the HAL: DMA Controllers
Miscellaneous
[FR] Rejoignez la communauté Rust (et devenez un "rustacé")
[DE] Moderne Spieleprogrammierung mit dem Entity Component System und der Engine Bevy
[DE] Programmieren mit Rust für den FreeBSD-Kernel
Crate of the Week
This week's crate is bstr, a fast and featureful byte-string library.
Thanks to 8573 for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Ockam - Support TCP keepalive for TCP clients
Ockam - Show ockam command help in $PAGER or less (clap based)
Ockam - Implement ockam reset clap command
lib3mf - Help compiling the upstream C++ library on Windows
Artichoke Ruby - Help migrate more path helpers out of its monolith into a support crate.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
324 pull requests were merged in the last week
initial implementation of return-position impl Trait in traits
check that the types in return position impl Trait in traits are well-formed
deny return-position impl Trait in traits for object safety
only encode return-position impl Trait in trait when parent function has a default body
implement std::marker::Tuple, a marker trait for tuples
add inline-llvm option for disabling/enabling LLVM inlining
stabilize raw-dylib for non-x86
equate fn outputs when inferring RPITIT hidden types
allow generators to impl Clone/Copy
avoid infinite loop in function arguments checking
const_generics: correctly deal with bound variables
fix LLVM IR type mismatch
fix ICE in opt_suggest_box_span
fix ICE report flags display
fix ICE, generalize 'move generics to trait' suggestion for >0 non-rcvr arguments
fix RPIT ICE for implicit HRTB when missing dyn
fix code generation of Rvalue::Repeat with 128 bit values
fix compile errors for uwp-windows-msvc targets
normalize before erasing late-bound regions in equal_up_to_regions
recover from using ; as separator between fields
fix the suggestion of format for asm_sub_register
adjust and slightly generalize operator error suggestion
add list of recognized repr attributes to the unrecognized repr error
shrink span for bindings with subpatterns
point at type parameter in plain path expr
point out when a callable is not actually callable because its return is not sized
allow lower_lifetime_binder receive a closure
do not suggest a semicolon for a macro without !
include enum path in variant suggestion
suggest adding array lengths to references to arrays if possible
suggest introducing an explicit lifetime if it does not exist
suggest pub instead of public for const type item
suggest removing unnecessary prefix let in patterns
migrate another part of rustc_infer to session diagnostic
migrate rustc_middle diagnostic
migrate rustc_session to use SessionDiagnostic - Pt. 2
miri: add a Machine hook for inline assembly
shrink PredicateS
shrink hir::Ty and hir::Pat
parameterize ty::Visibility over used ID
allow lint passes to be bound by TyCtxt
track PGO profiles in depinfo
use RelocModel::Pic for UEFI targets
use niche-filling optimization even when multiple variants have data
inline <T as From<T>>::from
lower the assume intrinsic to a MIR statement
compile spin_loop_hint as pause on x86 even without sse2 enabled
reimplement carrying_add and borrowing_sub for signed integers
optimize thread parking on NetBSD
remove &[T] from vec_deque::Drain
the <*const T>::guaranteed_* methods now return an option for the unknown case
use futex-based locks and thread parker on Hermit
hashbrown: add HashSet::raw_table
hashbrown: add RawTable::is_full
git2: implement IntoIterator for Statuses
codegen_gcc: simd: impl extract_element for vector types
cargo: specify the max length for crate name
rustdoc: avoid cleaning modules with duplicate names
rustdoc: correcty handle intra-doc-links to items without HTML page
rustdoc: more accurate struct type
rustdoc: store Variant Fields as their own item
clippy: do not expand macro in nonminimal_bool suggestions
clippy: don't lint large_stack_array inside static items
clippy: don't panic on invalid shift while constfolding
clippy: fix FormatArgsExpn parsing of FormatSpec positions
clippy: fix range_{plus,minus}_one bad suggestions
clippy: fix hang in vec_init_then_push
clippy: rename the arithmetic lint
clippy: suggest unwrap_or_default when closure returns "".to_string
clippy: use visit_expr_field for ParamPosition
clippy: use macro callsite when creating Sugg helper
clippy: make Arithmetic consider literals
clippy: assertions_on_result_states: fix suggestion when assert! is not in a statement
rust-analyzer: add config to unconditionally prefer core imports over std
rust-analyzer: build release artifact against older glibc
rust-analyzer: filter imports on find-all-references
rust-analyzer: new assist: move_format_string_arg
rust-analyzer: remove the toggleInlayHints command from VSCode
rust-analyzer: use proc-macro-srv from sysroot in rust-project.json workspaces
rust-analyzer: make clicking a closing brace inlay hint go to the opening brace
rust-analyzer: add semicolon completion to mod
rust-analyzer: handle lifetime variables in projection normalization
rust-analyzer: handle trait methods as inherent methods for trait-related types
Rust Compiler Performance Triage
From the viewpoint of metrics gathering, this was an absolutely terrible week, because the vast majority of this week's report is dominated by noise. Several benchmarks (html5ever, cranelift-codegen, and keccak) have all been exhibiting bimodal behavior where their compile-times would regress and improve randomly from run to run. Looking past that, we had one small win from adding an inline directive.
Triage done by @pnkfelix. Revision range: e7cdd4c0..17cbdfd0
Summary:
(instructions:u) mean range count Regressions ❌ (primary) 1.1% [0.2%, 6.2%] 26 Regressions ❌ (secondary) 1.9% [0.1%, 5.6%] 34 Improvements ✅ (primary) -1.8% [-29.4%, -0.2%] 42 Improvements ✅ (secondary) -1.3% [-5.3%, -0.2%] 50 All ❌✅ (primary) -0.7% [-29.4%, 6.2%] 68
11 Regressions, 11 Improvements, 13 Mixed; 11 of them in rollups 71 artifact comparisons made in total
Full report here
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
De-RFC: Remove type ascription
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
Rust Style Team
RFC: Statics in patterns
Tracking Issues & PRs
[disposition: close] Loosen shadowing check inside macro contexts (attempt 2).
[disposition: merge] Tracking issue for std::hint::black_box
[disposition: merge] Commit to safety rules for dyn trait upcasting
[disposition: merge] Tracking Issue for constifying some {BTreeMap,Set} functions
[disposition: merge] Tracking Issue for Option::unzip()
[disposition: merge] Tracking issue for map_first_last: first/last methods on BTreeSet and BTreeMap
[disposition: merge] Make Sized coinductive, again
[disposition: merge] Neither require nor imply lifetime bounds on opaque type for well formedness
[disposition: merge] Make typeck aware of uninhabited types
[disposition: merge] Stabilize let else
[disposition: merge] Fix #[derive(Default)] on a generic #[default] enum adding unnecessary Default bounds
New and Updated RFCs
No New or Updated RFCs were created this week.
Upcoming Events
Rusty Events between 2022-09-14 - 2022-10-12 🦀
Virtual
2022-09-14 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2022-09-14 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Introduction to Async in Rust
2022-09-14 | Virtual (Malaysia)| Golang Malaysia
Rust Meetup September 2022
2022-09-15 | Virtual (Columbus, OH, US) | GDG Columbus
Past, Present, and Future of Internet Money! (Custom tokenomics, RUST and CosmWASM library...)
2022-09-15 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2022-09-20 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful: Bencher—Catch Performance Regressions in CI—Everett Pompeii
2022-09-21 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out (Call for Participation)
2022-09-22 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
Rust based Bluetooth tools (BlueR) you can use today
2022-09-22 | Virtual (Tehran, IR) | Iran Rust Meetup
Rust Iran Meetup #9 - Let's Write An Async Executor
2022-09-23 | Virtual (Tokyo, JP) | Rust Tokyo
Rust Tokyo 2022
2022-09-27 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2022-09-28 | Virtual (London, UK) | Rust London User Group
Rust (Hybrid) Hack & Learn September 2022
2022-10-04 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2022-10-05 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2022-10-05 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2022-10-06 | Virtual (Nürnberg, DE) | Rust Nuremberg
Rust Nürnberg online #18
2022-10-08 | Virtual | Rust GameDev
Rust GameDev Monthly Meetup
2022-10-12 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2022-10-12 | Virtual (San Francisco, CA, US) | Microsoft Reactor San Francisco
Getting Started with Rust: Building Rust Projects
Europe
2022-09-15 | Paris, FR | Rust Paris
Rust Paris meetup #52
2022-09-27 | Nijmegen, NL | Rust Nederland
Regular track: Rust at RU
Student track: Rust at RU
2022-09-28 | London, UK + Virtual | Rust London User Group
Rust (Hybrid) Hack & Learn September 2022
2022-09-29 | Amsterdam, NL | Rust Developers Amsterdam Group
Fiberplane Rust Workshop
2022-09-29 | Copenhagen, DK | Copenhagen Rust group
Rust Hack Night #29
2022-09-29 | Enschede, NL | Dutch Rust Meetup
Going full stack on Rust
2022-10-02 | Florence, IT + Virtual | RustLab
RustLab Conference 2022 (Oct 2-4)
2022-10-03 | Stockholm, SE | Stockholm Rust
Rust Meetup @Microsoft Reactor
2022-10-12 | Berlin, DE | Rust Berlin
Rust and Tell - EuroRust B-Sides
North America
2022-09-14 | Austin, TX, US | Rust ATX
Rust Lunch
2022-09-20 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2022-09-22 | Lehi, UT, US | Utah Rust
Game Prototyping with Rusty Engine with Nathan Stocks and Food!
2022-09-29 | Ciudad de México, MX | Rust MX
Nuestra RustMX comunidad tiene página
Oceania
2022-09-14 | Sydney, NSW, AU | Rust Sydney
Rust-Sydney Lightning Talks
2022-09-20 | Phillip, ACT, AU | Canberra Rust User Group
September Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
In Rust We Trust
– Alexander Sidorov on Medium
Thanks to Anton Fetisov for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Linux find file containing string

#LINUX FIND FILE CONTAINING STRING INSTALL#
#LINUX FIND FILE CONTAINING STRING DOWNLOAD#
#LINUX FIND FILE CONTAINING STRING FREE#
Match Alphabetic Characters Using Class.
Match Alphabetic and Numeric Characters Using Class.
Match a Pattern With Specific Characters Using Third Brackets.
Match Specific Digits Using Third Brackets.
Print the Particular Number of Lines After and Before the Matching Lines.
Print the Particular Number of Lines Before the Matching Lines.
Print the Particular Number of Lines After the Matching Lines.
Use of Wildcard to Match the Exact Number of Times.
Use of Wildcard to Match One or More Times.
Use of Wildcard to Match Zero or More Times.
Use of Wildcard to Match a Single Character.
Search Multiple Files in the Current Directory.
Search String With Case Insensitive Match.
The 30 different uses of the “ grep” command are shown in this tutorial with simple examples.
#LINUX FIND FILE CONTAINING STRING FREE#
Alternatively, you can also try other free tools like Ack, The Silver Searcher, Ripgrep, and find command.The “ grep” command displays the matching lines of the file based on the searching string or pattern by default. Search File Contents Using Filters ConclusionĪll the above-mentioned applications are beginner’s friendly, free-to-use and open source to add your own enhancements. Search File Contents Using Midnight CommanderĪs you can see in the above picture, you can also use filters like ignore case, whole words, and regular expression by just checking and unchecking it. To search file content, you can open a search dialog using ALT+SHIFT+? and enter the text in the “Content:” section. Inside the terminal, mc provides a visual representation of the filesystem in which you can navigate either through keyboard or mouse. Search File Contents Using Midnigh Commander
#LINUX FIND FILE CONTAINING STRING INSTALL#
The Midnight Commander is available to install from the default repositories in the most of the Linux distributions. Midnight Commander Install Midnight Commander on Linux If you live in a terminal and still want to search text using GUI way, you can also try Terminal User Interface (TUI) based file manager tool, mc ( midnight commander) – is a visual file manager that is used to search for files. Search for Specific Text in Specific File Types Search Specific Text In Linux Using MC (Midnight Commander) exclude-dir=in -rnwi "linuxshelltips" /home/sarvottam/ “-include”, “-exclude”, and “-exclude-dir” are the options available to add file type and directory filter. To further reduce the search scope, you can also specifically mention the type of file and directories to only look for while searching. Search for Specific Text in Specific File Types It is also worth mentioning that if you search through directories that require root permissions, you need to use the sudo command. Search Text and Print File Names and Line Numbers $ sudo grep -rnwi “linuxshelltips” /home/sarvottam/ List File Names Contains Specific Text in Linux Print File Names and Line Numbers That Contains a Given Stringįurthermore, you can also tweak the output using the following options available for grep: $ grep -rl “linuxshelltips” /home/sarvottam/ If you want to print only file names and hide the text from the output, you can use the '-l' flag. Search Specific Text in Files Find File Names That Contains a Given String $ grep -r “ linuxshelltips” /home/sarvottam/ Here, the '-r' or '-R' flag recursively searches through the all subdirectories inside the specified directory. Now to search and find all files for a given text string in a Linux terminal, you can run the following command. Since almost all unix-like operating systems ship grep utility by default, you don’t need to install it. Search Text Based on File Types Search Specific Text in Linux Using Grep Commandīeside the GUI way, grep is one of the popular command line tools that can be used to search inside file content. You can even add a directory path where you don’t want to search. You can also use file type and modified date filter from the left panel to reduce the search scope. Search Specific Text in Linux Using Catfish Tool It will list down all files containing text along with file size and location. Once installed, you only need to do is enable “ Search file contents”, select directories from the top-left dropdown option, and type the text you want to search for.
#LINUX FIND FILE CONTAINING STRING DOWNLOAD#
If the package is not available, you can download the latest release file, extract the downloaded tar.bz2 file, and run the following command: $ sudo python3 setup.py install On other Linux distributions, you can install it from the default repositories using your package manager.
0 notes
Text
Ichiran@home 2021: the ultimate guide
Recently I’ve been contacted by several people who wanted to use my Japanese text segmenter Ichiran in their own projects. This is not surprising since it’s vastly superior to Mecab and similar software, and is occassionally updated with new vocabulary unlike many other segmenters. Ichiran powers ichi.moe which is a very cool webapp that helped literally dozens of people learn Japanese.
A big obstacle towards the adoption of Ichiran is the fact that it’s written in Common Lisp and people who want to use it are often unfamiliar with this language. To fix this issue, I’m now providing a way to build Ichiran as a command line utility, which could then be called as a subprocess by scripts in other languages.
This is a master post how to get Ichiran installed and how to use it for people who don’t know any Common Lisp at all. I’m providing instructions for Linux (Ubuntu) and Windows, I haven’t tested whether it works on other operating systems but it probably should.
PostgreSQL
Ichiran uses a PostgreSQL database as a source for its vocabulary and other things. On Linux install postgresql using your preferred package manager. On Windows use the official installer. You should remember the password for the postgres user, or create a new user if you know how to do it.
Download the latest release of Ichiran database. On the release page there are commands needed to restore the dump. On Windows they don't really work, instead try to create database and restore the dump using pgAdmin (which is usually installed together with Postgres). Right-click on PostgreSQL/Databases/postgres and select "Query tool...". Paste the following into Query editor and hit the Execute button.
CREATE DATABASE [database_name] WITH TEMPLATE = template0 OWNER = postgres ENCODING = 'UTF8' LC_COLLATE = 'Japanese_Japan.932' LC_CTYPE = 'Japanese_Japan.932' TABLESPACE = pg_default CONNECTION LIMIT = -1;
Then refresh the Databases folder and you should see your new database. Right-click on it then select "Restore", then choose the file that you downloaded (it wants ".backup" extension by default so choose "Format: All files" if you can't find the file).
You might get a bunch of errors when restoring the dump saying that "user ichiran doesn't exist". Just ignore them.
SBCL
Ichiran uses SBCL to run its Common Lisp code. You can download Windows binaries for SBCL 2.0.0 from the official site, and on Linux you can use the package manager, or also use binaries from the official site although they might be incompatible with your operating system.
However you really want the latest version 2.1.0, especially on Windows for uh... reasons. There's a workaround for Windows 10 though, so if you don't mind turning on that option, you can stick with SBCL 2.0.0 really.
After installing some version of SBCL (SBCL requires SBCL to compile itself), download the source code of the latest version and let's get to business.
On Linux it should be easy, just run
sh make.sh --fancy sudo sh install.sh
in the source directory.
On Windows it's somewhat harder. Install MSYS2, then run "MSYS2 MinGW 64-bit".
pacman -S mingw-w64-x86_64-toolchain make # for paths in MSYS2 replace drive prefix C:/ by /c/ and so on cd [path_to_sbcl_source] export PATH="$PATH:[directory_where_sbcl.exe_is_currently]" # check that you can run sbcl from command line now # type (sb-ext:quit) to quit sbcl sh make.sh --fancy unset SBCL_HOME INSTALL_ROOT=/c/sbcl sh install.sh
Then edit Windows environment variables so that PATH contains c:\sbcl\bin and SBCL_HOME is c:\sbcl\lib\sbcl (replace c:\sbcl here and in INSTALL_ROOT with another directory if applicable). Check that you can run a normal Windows shell (cmd) and run sbcl from it.
Quicklisp
Quicklisp is a library manager for Common Lisp. You'll need it to install the dependencies of Ichiran. Download quicklisp.lisp from the official site and run the following command:
sbcl --load /path/to/quicklisp.lisp
In SBCL shell execute the following commands:
(quicklisp-quickstart:install) (ql:add-to-init-file) (sb-ext:quit)
This will ensure quicklisp is loaded every time SBCL starts.
Ichiran
Find the directory ~/quicklisp/local-projects (%USERPROFILE%\quicklisp\local-projects on Windows) and git clone Ichiran source code into it. It is possible to place it into an arbitrary directory, but that requires configuring ASDF, while ~/quicklisp/local-projects/ should work out of the box, as should ~/common-lisp/ but I'm not sure about Windows equivalent for this one.
Ichiran wouldn't load without settings.lisp file which you might notice is absent from the repository. Instead, there's a settings.lisp.template file. Copy settings.lisp.template to settings.lisp and edit the following values in settings.lisp:
*connection* this is the main database connection. It is a list of at least 4 elements: database name, database user (usually "postgres"), database password and database host ("localhost"). It can be followed by options like :port 5434 if the database is running on a non-standard port.
*connections* is an optional parameter, if you want to switch between several databases. You can probably ignore it.
*jmdict-data* this should be a path to these files from JMdict project. They contain descriptions of parts of speech etc.
ignore all the other parameters, they're only needed for creating the database from scratch
Run sbcl. You should now be able to load Ichiran with
(ql:quickload :ichiran)
On the first run, run the following command. It should also be run after downloading a new database dump and updating Ichiran code, as it fixes various issues with the original JMdict data.
(ichiran/mnt:add-errata)
Run the test suite with
(ichiran/test:run-all-tests)
If not all tests pass, you did something wrong! If none of the tests pass, check that you configured the database connection correctly. If all tests pass, you have a working installation of Ichiran. Congratulations!
Some commands that can be used in Ichiran:
(ichiran:romanize "一覧は最高だぞ" :with-info t) this is basically a text-only equivalent of ichi.moe, everyone's favorite webapp based on Ichiran.
(ichiran/dict:simple-segment "一覧は最高だぞ") returns a list of WORD-INFO objects which contain a lot of interesting data which is available through "accessor functions". For example (mapcar 'ichiran/dict:word-info-text (ichiran/dict:simple-segment "一覧は最高だぞ") will return a list of separate words in a sentence.
(ichiran/dict:dict-segment "一覧は最高だぞ" :limit 5) like simple-segment but returns top 5 segmentations.
(ichiran/dict:word-info-from-text "一覧") gets a WORD-INFO object for a specific word.
ichiran/dict:word-info-str converts a WORD-INFO object to a human-readable string.
ichiran/dict:word-info-gloss-json converts a WORD-INFO object into a "json" "object" containing dictionary information about a word, which is not really JSON but an equivalent Lisp representation of it. But, it can be converted into a real JSON string with jsown:to-json function. Putting it all together, the following code will convert the word 一覧 into a JSON string:
(jsown:to-json (ichiran/dict:word-info-json (ichiran/dict:word-info-from-text "一覧")))
Now, if you're not familiar with Common Lisp all this stuff might seem confusing. Which is where ichiran-cli comes in, a brand new Command Line Interface to Ichiran.
ichiran-cli
ichiran-cli is just a simple command-line application that can be called by scripts just like mecab and its ilk. The main difference is that it must be built by the user, who has already did the previous steps of the Ichiran installation process. It needs to access the postgres database and the connection settings from settings.lisp are currently "baked in" during the build. It also contains a cache of some database references, so modifying the database (i.e. updating to a newer database dump) without also rebuilding ichiran-cli is highly inadvisable.
The build process is very easy. Just run sbcl and execute the following commands:
(ql:quickload :ichiran/cli) (ichiran/cli:build)
sbcl should exit at this point, and you'll have a new ichiran-cli (ichiran-cli.exe on Windows) executable in ichiran source directory. If sbcl didn't exit, try deleting the old ichiran-cli and do it again, it seems that on Linux sbcl sometimes can't overwrite this file for some reason.
Use -h option to show how to use this tool. There will be more options in the future but at the time of this post, it prints out the following:
>ichiran-cli -h Command line interface for Ichiran Usage: ichiran-cli [-h|--help] [-e|--eval] [-i|--with-info] [-f|--full] [input] Available options: -h, --help print this help text -e, --eval evaluate arbitrary expression and print the result -i, --with-info print dictionary info -f, --full full split info (as JSON) By default calls ichiran:romanize, other options change this behavior
Here's the example usage of these switches
ichiran-cli "一覧は最高だぞ" just prints out the romanization
ichiran-cli -i "一覧は最高だぞ" - equivalent of ichiran:romanize :with-info t above
ichiran-cli -f "一覧は最高だぞ" - outputs the full result of segmentation as JSON. This is the one you'll probably want to use in scripts etc.
ichiran-cli -e "(+ 1 2 3)" - execute arbitrary Common Lisp code... yup that's right. Since this is a new feature, I don't know yet which commands people really want, so this option can be used to execute any command such as those listed in the previous section.
By the way, as I mentioned before, on Windows SBCL prior to 2.1.0 doesn't parse non-ascii command line arguments correctly. Which is why I had to include a section about building a newer version of SBCL. However if you use Windows 10, there's a workaround that avoids having to build SBCL 2.1.0. Open "Language Settings", find a link to "Administrative language settings", click on "Change system locale...", and turn on "Beta: Use Unicode UTF-8 for worldwide language support". Then reboot your computer. Voila, everything will work now. At least in regards to SBCL. I can't guarantee that other command line apps which use locales will work after that.
That's it for now, hope you enjoy playing around with Ichiran in this new year. よろしくおねがいします!
6 notes
·
View notes
Text
Version 420
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a great week fixing a whole bunch of bugs.
bugs
I fixed taglist drag-select, which was not moving the to-be selected indices down with the scroll. Sorry for the trouble here. You can now also ctrl+drag-select to deselect.
There was a bug in the new virtual siblings and parents lookup system that meant some grandparents and siblings were not appearing. For instance, for parents, 'samus aran' might have 'metroid', and 'metroid' would have 'nintendo', but 'samus aran' would not have 'nintendo'. Thanks to help from users, I was able to reproduce it and fix the problem. When you update, the client will spend a few seconds regenerating the lookups and finding the missing links. It will queue up a bit more work for the background display sync to do later on. In my test situation, the PTR went from 189,000 sync rows to 192,000.
Autocomplete results in manage tags now list parents beneath every tag they apply to. Previously, parents could only exist in the list once, so they were accidentally de-duping and only ending up beneath the last applicable tag. Now you get plenty.
Also, these 'write' autocomplete results now show sibling and parent data for the tag that matches your input text even if that tag has no count. When that tag has sibling data, all the siblings are loaded as well. This sounds obscure, but you'll notice when you next start entering tags on a service with a lot of siblings. It should make it easier to quick-type complicated tags in manage tags.
Typing to get autocomplete results in search pages with thumbnails is now significantly faster and more responsive when 'searching immediately' is turned on. This routine gathers count-accurate results based on the thumbnails in front of you and then sends that data down to the database for sibling population. This suddenly got laggy with the new virtuals system, but I have improved how it schedules its searches and performs its tag lookups, and it should be much better now.
An unusual situation with a 'null character' tag that could not be displayed in the client should be better. This tag is detected, the rendering problem caught, and the user notified. The database routine that corrects bad tags now also fixes this tag and forces a tag presentation refresh once it is done.
speed
I spent a bunch of time in the siblings and parents system this week, and autocomplete and tags in general, running profiles on complex data and optimising various calls. I also sped up a critical new optimisation used across the program. Tag searches, autocomplete lookups, tag processing, tag display sync, and anything that runs frequently in small amounts should now be a bit faster. The only thing that may run a bit slower is tag display sync for very complicated tag parent situations, due to the more thorough logic in the fixes above. Thank you to users who helped with profiling here.
Tag display sync now only tries to run every 30 seconds (up from every ~3 seconds) when allowed to run in 'normal' time. It also takes breaks when it thinks a bunch of other work is going on. It was running hotter and faster than we needed, and it made the client too laggy, so I am pulling it back until I can make it more intelligent. I am also considering breaking the main display sync maintenance job into even more granular pieces. I will keep working.
full list
misc:
fixed the bad position indexing when drag-selecting taglists that were scrolled down. this also caused some weird selection when scrolled and clicks included a little mouse movement. sorry for the trouble!
ctrl+drag-select now deselects!
fetching tag autocomplete results when you have thumbnails and 'searching immediately' on, which has been way too slow recently, now cancels much faster. in some large page situations, it was adding multi-second lag on the first character-press. it also runs faster overall
hydrus should now deal better with invalid tags that contain the null character (there it one we know about on the PTR, from a decode of botched Shift JIS, which could crash the client from too many errors during critical paint periods). when a tag like this turns up in a taglist, thumbnail, or canvas background, it now renders as an appropriate 'invalid tag' string, and a one-time 'woah, bad tag, run fix tags now' popup appears
regular tag cleaning now looks for and removes null characters, so all new sources of these bad tags should now be eliminated
_database->check and repair->fix invalid tags_ now fixes tags with the null character. it also fixes tags so broken that after cleaning they have no subtag left. it also now forces a full media tag reload when it is done for all media
the 'regen storage mappings', 'regen display mappings', and repopulate from cache' database routines now have an additional step where you can order them only to work on one tag service, so regenning or repopulating local tags, which usually takes a couple seconds, doesn't need to wait two hours for the PTR to go as well
added some menu help to the 'profile modes' debug menu, and gave 'reducing program lag' help page a pass
fixed virtual display regeneration on service delete
.
parents and siblings:
fixed situations where some grandparent and sibling relationships would not appear in the virtual system. it was a bug when certain links of a multi-part display 'chain' were updated at different times. when repopulating chain data, the sibling and parent update routines now correctly chase their complete chains both when wiping ideal data and repopulating from raw data, hitting all levels of the chain, ensuring to go back up and down chains when there are multiple grandsiblings/children/parents, and chasing parents where one or both members have better siblings. thank you to the several users who reported and helped figure out this problem, which was not simple to reproduce (issue #725)
your ideal display data will be regenerated on update, which should not take more than a couple of seconds. it will likely correct some siblings and add some grandparents to be filled in by the siblings/parents sync. my PTR test environment went up from about 189,000 display rows to 192,000
while sibling and parent lookup is more thorough (and hence more expensive), I also optimised many parts of lookup week. I believe tag display sync and tag processing will be much faster for tags with simple sibling and parent relationships, and slightly slower for tags with complex relationships and many instances to files on your drive. as always, let me know what sort of processing speeds and lag you get, and if you know how to make a db profile, please send them in when it gets bad
when a 'write' autocomplete results list includes parent expansion rows (as in _manage tags_), parents now show duplicated and properly for all the tags that have them, including siblings and other children/grandchildren (previously, a parent label could only exist once in a list, which meant parents were ending up hanging off the last valid tag for which they applied)
'write' autocompletes now show results that exactly match the text entry, and all their siblings, when they do not have count but do have sibling or parent data. so, if you type in 'samus aran', and it has a sibling to 'character:samus aran', but 'samus aran' doesn't actually have count, you now get it and all siblings anyway. this may need tuning, but it solves a persistent and annoying lookup and quick-sibling-access problem in _manage tags_
copying tags and their indented parents now removes the parent indent whitespace
tag sync display now takes way longer breaks (now 30 seconds, was 2.5) between 'normal' background work periods. this thing was hammering people far harder than needed and could clog up db write/commit time and nobble UI responsitivity when big bumps collided
the tag display maintenance manager now also tries to detect when many siblings or parents are streaming in (from a migration or a repository process with a heap of data), and pauses work while that continues
greatly sped up mass imports of sibling and parent data, either from tag migration or big dialog pastes. what was 40 rows/s should now be about 1,000 rows/s
fixed the database menu's 'regenerate tag parents lookup cache', which wasn't hooked up
.
boring changes:
gave tag parents and siblings update, regen, and chain fetch a full pass, correcting bad queries to fix the above, fixing raw pair chain level navigation and parent-sibling idealisation, and optimised these lookups as well
fixed some tag_id vs ideal_tag_id nomenclature (and related bugs) in tag parents cache
optimised 'all known tags' autocomplete count fetching a little. tag autocomplete and search should be a bit faster in this domain
reduced display sync pre-processing overhead by about 30% with a better random pair sampling routine
reduced the overhead of my now very commonly used single integer memory table select optimisation. this now recycles tables after use, which reduces overhead about 50% in small number scenarios. all features of the database will enjoy this speed improvement, particularly small repetitive tag lookup jobs (such as the new display sync and repository tag processing)
reduced overhead on some sibling chain lookup code
reduced overhead on the sibling lookup used by manage tag dialog taglist
reduced overhead on some parent chain lookup code
tiny optimisation on single sibling chain lookup
sped up the ancient OG single tag->tag-id fetching routine, seems to work about twice as fast now
more misc optimisations, mostly list/set/dict comprehension rewriting to reduce overhead, across virtual sibling and parent code
added a full combined siblings and parents unit tests for the main missing parent chain link problem solved this week
added a full combined siblings and parents unit test for large real world data added in multiple pieces
'a file identifier was missing!' critical errors now print a stack trace to the log for further debugging info
updated the 'help my db is broke.txt' document with a couple new comments
next week
I want to do some code cleanup, catching up on bad old code and making the duplicate potentials search non-interrupting. I'll also prototype a database mode that may improve performance on HDDs. Other than that, I want to properly plan and start work on the big network improvements that I will finish the year on.
1 note
·
View note
Text
GNU/Linux most wanted
How can I find the version of Ubuntu that is installed? lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 16.10 Release: 16.10 Codename: yakkety
ref: GNU/Linux most wanted
Handling files and directories Changing directories: cd ~bill (home directory of user bill) Copy files to a directory: cp file1 file2 dir
Copy directories recursively: cp -r source_dir/ dest_dir/ rsync -a source_dir/ dest_dir/ rsync -av --exclude='path/to/exclude' source_dir/ dest_dir
Create a symbolic link: ln -s linked_file link ln -sf linked_file link s: make symbolic links instead of hard links f: remove existing destination files
Rename a file, link or directory: mv source_file dest_file mv -T /path/src /path/dst -T: treate DESTINATION (/path/dst) as a normal file
Remove non-empty directories: rm -rf dir
Remove non-empty directories Recursively: rm -rf `find . -name .git`
Listing files ls l: long listing a: list all files (including hidden files) t: by time (most recent files first) s: by size (biggest files first) r: reverse sort order
List link file recursively: ls -alR | grep "/home/chhuang/500G" -B10 R: recursive
grep B NUM: --before-context=NUM o: only matching 只取出找到的pattern片段 例 dmesg | grep -o 'scsi.*Direct-Access.*ADATA'
awk 以空白做分隔,並列印指定的第幾欄 (從1開始) 例:以空白做分隔,印出第2欄 dmesg | grep -o 'scsi.*Direct-Access.*ADATA' | awk '{print $2}'
How to grep for contents after pattern? https://stackoverflow.com/questions/10358547/how-to-grep-for-contents-after-pattern 取冒號之後的文字:
grep 'potato:' file.txt | sed 's/^.*: //' or
grep 'potato:' file.txt | cut -d\ -f2 or
grep 'potato:' file.txt | awk '{print $2}'
example: Long list with most recent files last: ls -ltr
Displaying file contents Display the first 10 lines of a file: head -10 file
Display the last lines of a file: tail -10 file
********************************************************************************
Looking for files Find *log* files in current (.) directory recursively find . -name "*log*"
Find all the .pdf files in current (.) directory recursively and run a command on each find . -name "*.pdf" -exec xpdf {} ';'
對每個找到的檔案執行xxx.sh find . -type f | xargs -n | xxx.sh
在當前目錄遞迴找某關鍵字,並忽略find和grep警告訊息 find . -type f 2>/dev/null | xargs grep -H keyword_to_find 2>/dev/null > find_result.txt
在當前目錄找某關鍵字 grep -Ire keryword_to_find l: Do not list binary files (--binary-files=without-match) R: Recursively. Follow all symbolic links. -e PATTERN
尋找linked files (並看完整路徑) find . -type l -ls | grep mnt
locate "*pub*"
copy: https://stackoverflow.com/questions/5410757/delete-lines-in-a-text-file-that-contain-a-specific-string Remove the line and print the output to standard out: sed '/pattern to match/d' ./infile
Remove lines with specified pattern directly from the file: sed -i '/pattern to match/d' ./infile
Archiving Create a compressed archive (TApe ARchive): tar jcvf archive.tar.bz2 dir
tar xvf archive.tar.[gz|bz2|lzma|xz] tar jxvf archive.tar.bz2
tar jxvf archive.bz2
c: create t: test x: extract j: on the fly bzip2 (un)compression
tar xvf archive.tar -C /path/to/directory
********************************************************************************
File and partition sizes Show the total size on disk of files or directories (Disk Usage): du -sh dir1 dir2 file1 file2 -s: summarize -h: human
Number of bytes, words and lines in file: wc file (Word Count)
Show the size, total space and free space of the current partition: df -h .
Display these info for all partitions: df -h
********************************************************************************
mount samba in Linux (/etc/fstab)
sudo vi /etc/fstab
//172.16.70.151/your_name /path/to/your/local/directory/ cifs rw,username=your_name,password=your_password,uid=your_uid,gid=your_gid,iocharset=utf8,file_mode=0777,dir_mode=0777,noperm 0 0
Make zip file zip -0r bootanimation.zip desc.txt part0 part1 0: not use any compression r: recursively
start to use screen $ screen And press [space] key to skip the spash list screen(s) you used $ screen -ls There are screens on: 19668.pts-14.Aspire-M7720-build-machine (11/21/2017 05:35:28 PM) (Detached) 2345.pts-19.Aspire-M7720-build-machine (11/17/2017 10:44:58 AM) (Detached) delete a specified screen format: screen -X -S [session id] quit example: $ screen -X -S 2345 quit re-attach a screen $ screen -r or format: screen -r [session id] $ screen -r 19668
force attach to a specified session screen -d -r 19668
for loop END=5 for i in $(seq 1 $END); do echo $i; done
make sequence numbers: for i in {1..4}; do printf "hello '%s'\n" input.mp4 >> list.txt; done
$ for i in {01..05}; do echo "$i"; done 01 02 03 04 05
$ foo=$(printf "%02d" 5) $ echo "${foo}" 05
multimedia: ffmpeg
make mp4 video from bmp files ffmpeg -framerate 60 -i img%03d.bmp -c:v libx264 -pix_fmt yuv420p -crf 0 output_60f.mp4 -crf 0: to create a lossless video
Repeat/loop Input Video with ffmpeg: copy: https://video.stackexchange.com/questions/12905/repeat-loop-input-video-with-ffmpeg This allows you to loop an input without needing to re-encode.
1. Make a text file. Contents of an example text file to repeat 4 times.
file 'input.mp4' file 'input.mp4' file 'input.mp4' file 'input.mp4' Then run ffmpeg:
2. ffmpeg -f concat -i list.txt -c copy output.mp4
dd /data/local/bin/dd 'if=/data/local/tmp/rnd_64M.img' 'of=/mnt/user/rnd_64M.img' 'bs=1024k' 'count=64' 'iflag=fullblock'
/data/local/bin/dd 'if=/mnt/sdc2_mmc/rnd_64M.img' 'of=/mnt/user/rnd.img_64M' 'bs=1024k' 'count=64' 'iflag=direct'
https://community.mellanox.com/s/article/how-to-set-cpu-scaling-governor-to-max-performance--scaling-governor-x
Performance CPU echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu3/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu4/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu5/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu6/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu7/cpufreq/scaling_governor
# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq
3300000
# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
1200000
# cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq
3210156
1 note
·
View note
Text
Something Awesome Project Week 8
Level 25 + 26:
Logging in to bandit26 from bandit25 should be fairly easy… The shell for user bandit26 is not /bin/bash, but something else. Find out what it is, how it works and how to break out of it.
For this level, the ssh key for the next level was in the directory, however when I tried to use it, it kicked me out.
If we cat /etc/passwd | grep bandit26
we get:
bandit26:x:11026:11026:bandit level
26:/home/bandit26:/usr/bin/showtext
which is strange because we should be getting a shell /bin/bash/ not usr/bin/showtext.
looking inside that file we see that:
#!/bin/sh
export TERM=linux
more ~/text.txt
exit 0
So it exists straight away after calling the more function, so we need to make the more function stop. The way to do this is actually by making your terminal window smaller (I never would have thought of this). Once you are in, you can use vim to open the /etc/paww/bandit26 file to get the password.
key 26: 5czgV9L3Xx8JPOyRbXh6lQbmIOWvPT6Z
now that we are in the shell, we can see another setuid executable for bandit27, if we use this to cat etc/bandit_pass/bandit 27 we find the next key.
key 27: 3ba3118a22e93127a4ed485be72ef5ea
Level 27:
Spec: There is a git repository at ssh://bandit27-git@localhost/home/bandit27-git/repo. The password for the user bandit27-git is the same as for the user bandit27.
Clone the repository and find the password for the next level.
After changing into the tmp directory, just
git clone ssh://bandit27-git@localhost/home/bandit27-git/repo
and you have the repo which contains a README file which contains the next key.
key: 0ef186ac70e04ea33b4c1853d2526fa2
Level 28:
Spec: There is a git repository at ssh://bandit28-git@localhost/home/bandit28-git/repo. The password for the user bandit28-git is the same as for the user bandit28. Clone the repository and find the password for the next level.
We would expect it to be somewhat the same as last level, except the readme isn’t so straightforward this time In fact, it’s missing the password. Checking the man page for git, there’s a git diff function, but it can only tell us the difference between commits. Instead I had to use git log to find the commits, then
git diff 073c27c130e6ee407e12faad1dd3848a110c4f95 186a1038cc54d1358d42d468cdc8e3cc28a93fcb (the commit numbers) to find out what was changed between commits.
key: bbc96594b4e001778eee9975372716b2
Level 29:
There is a git repository at ssh://bandit29-git@localhost/home/bandit29-git/repo. The password for the user bandit29-git is the same as for the user bandit29. Clone the repository and find the password for the next level.
This time, after trying what happened in the last exercise, the password was blank. This time we turn to git branches, after identifying the correct branch after using git show-branch –all (dev branch), use git checkout dev and now we are in the dev branch so if we cat the readme, we find the key
key: 5b90576bedb2cc04c86a9e924ce42faf
Level 30:
Spec: There is a git repository at ssh://bandit30-git@localhost/home/bandit30-git/repo. The password for the user bandit30-git is the same as for the user bandit30.
Clone the repository and find the password for the next level.
branches and commits were both dead ends, and I had completely no idea where to look, the readme read: “just an empty file… muahaha” what a taunt!
After looking at the files I found that a file called packed-refs. I don’t really know much in this area of git so I did some research and apparently there are things called tags which are like branches except they are permanent, they capture a point in the repo typically for a version release.
I used git show —name-only secret (the tag name) to find the next key
key: 47e603bb428404d265f59c42920d81e5
Level 31:
Another git exercise.
This time, the readme says this:
This time your task is to push a file to the remote repository.
Details:
File name: key.txt
Content: ‘May I come in?’
Branch: master
I used vim to make a vile with the string “May I come in?”, saved it, and tried to push.
However a .gitignore file was ignoring key.txt so I used rm .gitignore and then pushed it. It worked this time and I got the key.
key: 56a9bf19c63d650ce78e6ec0354ee45e
Level 32:
so straight away I am greeted with a message saying WELCOME TO THE UPPERCASE SHELL… i tried ls, and LS but neither of them helped me, both were converted to LS and i couldn’t find out where i was.
I used $0 to invoke bash again and reset. from there I was able to navigate to the home/bandit32 directory and find the last password
Level 33:
IT’S OVER!
1 note
·
View note
Text
MP3 Cutter, MP3 Joiner, MP3 Splitter, Minimize MP3, Be a part of MP3, Cut up MP3 For Windows 10
Split MP3 file simply. Begin by opening uploading MP3 files to this system. Click on on Import" button after which click on on Import Recordsdata" browse the MP3 file and open with program. This program also supports drag and drop options thus you should use that to add information to the program. Step four Be part of MP3 information Simply click on massive Join!" button on the decrease right nook of the program to hitch mp3 information into one in a flash. Fortunately, many free MP3 music cutters on the market in the market would meet your needs. To save your effort and time, here we're listing the highest 6 free MP3 cutter, together with online MP3 music cutter , that may let you split, join and edit any MP3 audio observe simply with top quality on both Mac and Windows. Free MP3 Cutter Joiner is fairly accurate and has the flexibility to edit recordsdata within one millisecond. This may be very helpful if you wish to do issues like make your personal ringtones. Click Obtain Now on this webpage to save MP3 Merger to a folder. Lastly, go to File> Export Clip> as an MP3 and save your audio file. I then downloaded Audacity and tried merging there. It took longer as a result of I have to manually string the recordsdata collectively, however the brand new merged recordsdata play perfectly on the web site. To start chopping, dicing, and mashing your audio information, try among the greatest free MP3 splitters on the web. MP3 Splitter Joiner adopts superior LAME Encoder, means that you can generate varied qualities of MP3 files. it provides rich choices on your particular requirements. Assist MP3 VBR. Alternate options to Simple MP3 Cutter Joiner Editor for Android, Android Pill, Windows, Mac, Linux and more. Filter by license to find solely free or Open Supply alternate options. This listing contains a complete of 4 apps similar to Easy MP3 Cutter Joiner Editor. MP3splt for Mac is one greatest MP3 Splitter out there in the market for Mac OS. It is open source software program that helps customers to split MP3 files and OggVorbis audio information. It allows users to separate large MP3 information into small information or divide a full album into particular person tracks. It is rather simple to make use of and all it is advisable to do is to pick out a start and the top place for cutting the audio file.

You should utilize MP3 Toolkit to convert audio for cell gadgets, make ringtones, fix tag information, rip Audio CD, document sound or merge audio items to a whole MP3 file. MP3 Splitter & Joiner comes with assist for CUE file, being able to import file information from CUE information. The application will even export the audio file data again to CUE file. Export track info - you possibly can export the tracks in the merge checklist to M3U (.m3u) file. Click 'Save List' button, export the tracks within the merge listing to the file you chose.

Do you need to minimize and get out the excellent part in an audio file? Do you want to be a part of a whole lot of audio information into one file? Please test MP3 Cutter Joiner. MuseTips Free MP3 Cutter and Editor is presently at v2.7.zero (changelog at - ). Step 2. Click on Add audio" after which add the MP3 audio you need to cut up. To resolve this drawback simply add filesize % splitval to splitsize. This manner you will not be lacking any bytes. The information from 1 to splitval - 1 may have the identical dimension, the final file will be smaller. The Merger lets you take a number of audio info, rearrange them in no matter order you need, then export it as a single combined audio file. That means, I not at all have to open GarageBand or every other multi-monitor mp3 merge files audio software program program. You'll be able to decrease audio recordsdata into MP3 or mix totally totally different MP3 into one file with ease.
Fastened a bug associated to adding multiple information utilizing the dialog box. When the process completes, it can present a link to obtain the combination. Apart from combing audio files , http://www.mergemp3.com/ the crossfade function of makes the merged songs circulation one into another seamlessly. After all in case you needed to separate up an mp3 file just to switch it (and to not play again the break up portions), you would use a generic file splitting utility after which the binary copy method you have used to reassemble the mp3. The ultimate however not the least, MP3 Splitter is Windows 10 applicable and works with Residence home windows 7 (sixty 4-bit and mp3 merge files 32-bit). Direct WAV MP3 Splitter is a product developed by Pistonsoft. This website should not be instantly affiliated with Pistonsoft All emblems, registered emblems, product names and firm names or logos talked about herein are the property of their respective homeowners.
1 note
·
View note
Text
How to find all files containing specific text on Linux

Finding a File Containing a Particular Text String In Linux Server
9 notes
·
View notes
Text
Something awesome: progress update
Feeling sleepy...

From the time of my last blogpost, till now (11:15pm) I’ve been working on writing the first chapter of my how-to-guide which mainly covers an introduction to programming for beginner students. I’ve also included the writeups to picoCTF challenges which I have previously completed for the appropriate module
I’ve written about 1.5k words, which for those who are interested can be read below.
Before we begin…
Introduction to programming
A key skill to learn before we dive head-first into the other concepts covered in this guide, we should probably first learn about our environment!
For those who think ‘airport’ when they hear the word terminal or ‘snail’ when they hear the word shell, you should definitely read this part before getting started with any of the other modules. For those who are already quite confident with navigating their way through the Linux environment, feel free to skip ahead!
Let’s start with a quick summary of some of the key things you should know:
What is a terminal?
The terminal is the main way that we, as users, interact with the computer. It normally looks like a black screen with white font. To uss the terminal, you type in specific commands which the computer interprets in order to run certain operations.
Of course, in order to use the terminal you have to know the commands!
Some basic terminal commands:
I like to compare using the terminal like using a normal file explorer. We double-click
folders (also called directories) to enter them, and double-clicking files opens them. We can create new folders, new files by right-clicking then pressing the appropriate button. All of this can be done through the terminal - you just have to know the right commands.
cd - stands for ‘change directory’. This command is used like ‘cd <name-of-directory>’ in order to change into the specified directory
If you just type in cd or ‘cd ~’ you should change to your home directory
You can use ‘cd ..’ to change into the previous directory you were in
pwd - stands for ‘print working directory’
ls - used to list all the files in your current directory.
mkdir - stands for ‘make directory’. Basically is the equivalent of the ‘new folder’ button in a normal file explorer. You can use it like ‘mkdir <name-of-directory>’ to make a folder with the specified name.
./ - this little ‘./’ is very powerful! If we have executable files or files that we can’t normally open, we can run them by doing ‘./<name-of-executable>’
man - stands for ‘manual’. Think about this as your help guide for any command you want to learn more about. Use it by typing in ‘man <name-of-command>’.
Other useful commands:
rm - stands for ‘remove’. Used like ‘rm <name-of-file-to-be-removed>’
whoami - displays information about the user
cat - one of cat’s applications is to view the contents of a file without actually having to open it. Use it like ‘cat <name-of-file>’ to have the contents of the specified file be displayed in the terminal
strings - strings basically finds printable strings or sentences in an object, or other binary files. Use it like ‘strings <name-of-file>’.
grep - grep is a way for us to find the existence of certain patterns or words in a file. You can use it like ‘grep <word/pattern> <name-of-file>’ to return every instance of the word/pattern in the specified file
nc - nc or netcat is a tool that can help you read or write data over the internet. It has a lot of uses, but for the context of picoCTF we’ll mainly be using to access the challenges. Use it like ‘nc <destination> <port>’. An example of how we could use it for picoCTF is detailed below
ssh - basically a way for us to safely access remote servers. Use it like ‘ssh <user>@<host>’, where <user> refers to the account you want to access and <host> is the domain or IP address of the computer you are trying to access.
You can find more info about SSH here: https://www.hostinger.com/tutorials/ssh-tutorial-how-does-ssh-work
A more comprehensive guide containing explanations about a wider variety of commands can be found here.
What is a programming language?
So sure, we’ve learnt how to make our way through a terminal, but what about code? How do we write and run it? In terms of writing code, there are many varied programming languages, each with their own rules and different features that we can use. For readers who’ve never coded before in their life, now would be a fantastic time to learn one!
A lot of the concepts are common in programming languages, so it doesn’t particularly matter which one you start with. However, I would definitely recommend Python, as it is quite user-friendly. This is a great place to start learning.
What is a text editor?
To summarise quickly, basically we write programs saved in a certain type of file based on what language they are written. These files can be changed and edited using what are called text editors. There are many different ones- some are inherent to your terminal like ‘vim’ or ‘nano’ and are quite simplistic. Others you can download online and include cool features like autocompleting variable names and structuring your code for you.
Whatever text editor you choose to use is completely based on your preferences! Use whatever is comfortable for you and supports your writing of code
How do we run code?
Now that you’ve written your first program in a text editor, in your chosen programming language what do we actually do with it? Some programming languages like C or Java need to have their files be ‘compiled’ before we can actually run them. This basically means translating the code we write into a form that the computer can interpret. Other languages like Python don’t require this extra step, and can be run easily.
picoCTF writeups - Hideout:
This chapter’s challenges can all be found under the ‘hideout’ module in the 2018 picoCTF. The below examples detail some of the ways we can apply what has been described above.
net cat
Using netcat (nc) will be a necessity throughout your adventure. Can you connect to 2018shell.picoctf.com at port 49387 to get the flag?
As we described above, we can use nc like ‘nc <destination> <port>’. Hence, we simply do ‘nc 2018shell.pico.ctf.com 49387’ to connect to the remote service. The flag should be displayed on your terminal which is: picoCTF{NEtcat_iS_a_NEcESSiTy_8b6a1fbc}
grep 1
Can you find the flag in file [1] ? This would be really obnoxious to look through by hand, see if you can find a faster way. You can also find the file in /problems/grep-1_4_0431431e36a950543a85426d0299343e on the shell server.
Although you could just look the whole file to manually find the flag, we can use one of the handy commands we learnt about earlier! As described in the above guide, we can use grep like ‘grep <word/pattern> <name-of-file>’. We can utilise the fact that every flag inpicoCTF is formatted in the same way, by doing ‘grep picoCTF file’ to retrieve our flag which is: picoCTF{grep_and_you_will_find_cdf2e7c2}
sshkeyz
As nice as it is to use our webshell, sometimes its helpful to connect directly to our machine. To do so, please add your own public key to ~/.ssh/authorized_keys, using the webshell. The flag is in the ssh banner which will be displayed when you login remotely with ssh to with your username.
You can connect to the picoCTF server by doing ‘ssh <username>@2018shell1.picoctf.com’ in your terminal. The output should look somewhat similar to below:
$ ssh [email protected]
The authenticity of host '2018shell1.picoctf.com (18.223.208.176)' can't be established.
ECDSA key fingerprint is SHA256:zCX5ip3tx1RMbsJBc70jEazd+gAFzlbC1Q2iDI8LA/k.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '2018shell1.picoctf.com,18.223.208.176' (ECDSA) to the list of known hosts.
picoCTF{who_n33ds_p4ssw0rds_38dj21}
Thus we can see our flag, which is: picoCTF{who_n33ds_p4ssw0rds_38dj21}
strings
Can you find the flag in this file [1] without actually running it? You can also find the file in /problems/strings_0_bf57524acf558aca2081eb97ece8e2ee on the shell server.
As we detailed above, we can use string like ‘strings <name-of-file>’. To get all the printable lines in the ‘strings’ file we can use the strings command, together with grep to get the flag! By doing ‘strings strings | grep picoCTF’ we retrieve our flag which is: picoCTF{sTrIngS_sAVeS_Time_3f712a28}
what base is this
To be successful on your mission, you must be able to read data represented in different ways, such as hexadecimal or binary. Can you get the flag from this program to prove you are ready? Connect with nc 2018shell.picoctf.com 15853.
Basically this challenge wants us to convert between different bases of numbers. It requires you to:
Convert from binary to ASCII
Convert from hex to ASCII
Convert from octal to ASCII
I used the following tools to complete the challenge:
https://www.rapidtables.com/convert/number/binary-to-ascii.html
https://www.rapidtables.com/convert/number/ascii-hex-bin-dec-converter.html
http://www.unit-conversion.info/texttools/octal/
1 note
·
View note
Text
Offline Password Cracking · Total OSCP Guide
⭐ ⏩⏩⏩️ DOWNLOAD LINK 🔥🔥🔥 CrackStation uses massive pre-computed lookup tables to crack password hashes. These tables store a mapping between the hash of a password. OnlineHashCrack is a powerful hash cracking and recovery online service for MD5 NTLM Wordpress Joomla SHA1 MySQL OSX WPA, PMKID, Office Docs, Archives, PDF. Decrypt and crack your MD5, SHA1, SHA, MySQL, and NTLM hashes for free online. We also support Bcrypt, SHA, Wordpress and many more. A tool for automating cracking methodologies through Hashcat from the TrustedSec team. hashing automation functions fingerprint hash combinator brute-force. Hash-Buster is an automated tool developed in the Python Language which cracks all types of hashes in seconds. Hash-Buster tool can. What is a Hash function? · Input refers to the message that will be hashed. · The hash function is the encryption algorithm like MD5 and SHA Crack Hashes From the /etc/shadow File in Linux The /etc/shadow file stores the garbled or hashed values of all user's passwords on Linux. Although the hashing algorithms cannot be reversed, password hashes could be cracked. Hackers can generate hashes from a dictionary of strings that are commonly. How to crack passwords and speed up your code, all with the power of hashing. Hashing is an important topic for programmers and computer. Check out the MS docs on how NT or LM Hashes are Lastly a very tough hash to computationally crack is the cached domain credentials on a. Password Hashing and Cracking. Trial and error attacks on passwords take place in two ways: On-line trial-and-error attempts against the site itself. How Attackers Crack Password Hashes¶ · Select a password you think the victim has chosen (e.g. ) · Calculate the hash · Compare the hash you calculated. Example MD5 hash: “secret” -> 5ebeecd0e0f08eabd2a6ee Collisions are so unlikely they're not worth worrying about. This is nothing to do with hash. Hash Crack contains all the tables, commands, online resources, and more to complete your cracking security kit. This version expands on techniques to extract. If the hash matches, then the user is authenticated and can access the system. Rainbow tables are used to crack the password in short amount of time as compared. In cryptanalysis and computer security, password cracking is the process of recovering to check them against an available cryptographic hash of the password. Password hash cracking is a method of attacking dumped hash to find flaws in Password hashing crack technique is only possible in cipher text the only. Hashing is a one way encryption. Meaning, you cannot get the original text back from the hash. Now in information security, passwords are recommended to be. We might find passwords or other credentials in databases. These are often hashed, so we need to first identify which hash it is and then try to crack it. Password hash cracking rigs can be expensive to buy, especially if they are going to be running idle most of the time. Cloud computing offers a.
Password Hashing and Cracking – Lesson Title
CrackStation - Online Password Hash Cracking - MD5, SHA1, Linux, Rainbow Tables, etc.
Decrypt MD5, SHA1, MySQL, NTLM, SHA, SHA, Wordpress, Bcrypt hashes for free online
Online Password Hash Crack - MD5 NTLM Wordpress Joomla WPA PMKID, Office, iTunes, Archive, ..
How to Use hashcat to Crack Hashes on Linux
hash-cracker · GitHub Topics · GitHub
Hash-Buster v - Crack Hashes In Seconds - GeeksforGeeks
Password cracking - Wikipedia
Password Storage - OWASP Cheat Sheet Series
Offline Password Cracking · Total OSCP Guide
1 note
·
View note
Text
Password cracking - Wikipedia
⭐ ⏩⏩⏩️ DOWNLOAD LINK 🔥🔥🔥 CrackStation uses massive pre-computed lookup tables to crack password hashes. These tables store a mapping between the hash of a password. OnlineHashCrack is a powerful hash cracking and recovery online service for MD5 NTLM Wordpress Joomla SHA1 MySQL OSX WPA, PMKID, Office Docs, Archives, PDF. Decrypt and crack your MD5, SHA1, SHA, MySQL, and NTLM hashes for free online. We also support Bcrypt, SHA, Wordpress and many more. A tool for automating cracking methodologies through Hashcat from the TrustedSec team. hashing automation functions fingerprint hash combinator brute-force. Hash-Buster is an automated tool developed in the Python Language which cracks all types of hashes in seconds. Hash-Buster tool can. What is a Hash function? · Input refers to the message that will be hashed. · The hash function is the encryption algorithm like MD5 and SHA Crack Hashes From the /etc/shadow File in Linux The /etc/shadow file stores the garbled or hashed values of all user's passwords on Linux. Although the hashing algorithms cannot be reversed, password hashes could be cracked. Hackers can generate hashes from a dictionary of strings that are commonly. How to crack passwords and speed up your code, all with the power of hashing. Hashing is an important topic for programmers and computer. Check out the MS docs on how NT or LM Hashes are Lastly a very tough hash to computationally crack is the cached domain credentials on a. Password Hashing and Cracking. Trial and error attacks on passwords take place in two ways: On-line trial-and-error attempts against the site itself. How Attackers Crack Password Hashes¶ · Select a password you think the victim has chosen (e.g. ) · Calculate the hash · Compare the hash you calculated. Example MD5 hash: “secret” -> 5ebeecd0e0f08eabd2a6ee Collisions are so unlikely they're not worth worrying about. This is nothing to do with hash. Hash Crack contains all the tables, commands, online resources, and more to complete your cracking security kit. This version expands on techniques to extract. If the hash matches, then the user is authenticated and can access the system. Rainbow tables are used to crack the password in short amount of time as compared. In cryptanalysis and computer security, password cracking is the process of recovering to check them against an available cryptographic hash of the password. Password hash cracking is a method of attacking dumped hash to find flaws in Password hashing crack technique is only possible in cipher text the only. Hashing is a one way encryption. Meaning, you cannot get the original text back from the hash. Now in information security, passwords are recommended to be. We might find passwords or other credentials in databases. These are often hashed, so we need to first identify which hash it is and then try to crack it. Password hash cracking rigs can be expensive to buy, especially if they are going to be running idle most of the time. Cloud computing offers a.
Password Hashing and Cracking – Lesson Title
CrackStation - Online Password Hash Cracking - MD5, SHA1, Linux, Rainbow Tables, etc.
Decrypt MD5, SHA1, MySQL, NTLM, SHA, SHA, Wordpress, Bcrypt hashes for free online
Online Password Hash Crack - MD5 NTLM Wordpress Joomla WPA PMKID, Office, iTunes, Archive, ..
How to Use hashcat to Crack Hashes on Linux
hash-cracker · GitHub Topics · GitHub
Hash-Buster v - Crack Hashes In Seconds - GeeksforGeeks
Password cracking - Wikipedia
Password Storage - OWASP Cheat Sheet Series
Offline Password Cracking · Total OSCP Guide
1 note
·
View note
Text
Password Storage - OWASP Cheat Sheet Series
⭐ ⏩⏩⏩️ DOWNLOAD LINK 🔥🔥🔥 CrackStation uses massive pre-computed lookup tables to crack password hashes. These tables store a mapping between the hash of a password. OnlineHashCrack is a powerful hash cracking and recovery online service for MD5 NTLM Wordpress Joomla SHA1 MySQL OSX WPA, PMKID, Office Docs, Archives, PDF. Decrypt and crack your MD5, SHA1, SHA, MySQL, and NTLM hashes for free online. We also support Bcrypt, SHA, Wordpress and many more. A tool for automating cracking methodologies through Hashcat from the TrustedSec team. hashing automation functions fingerprint hash combinator brute-force. Hash-Buster is an automated tool developed in the Python Language which cracks all types of hashes in seconds. Hash-Buster tool can. What is a Hash function? · Input refers to the message that will be hashed. · The hash function is the encryption algorithm like MD5 and SHA Crack Hashes From the /etc/shadow File in Linux The /etc/shadow file stores the garbled or hashed values of all user's passwords on Linux. Although the hashing algorithms cannot be reversed, password hashes could be cracked. Hackers can generate hashes from a dictionary of strings that are commonly. How to crack passwords and speed up your code, all with the power of hashing. Hashing is an important topic for programmers and computer. Check out the MS docs on how NT or LM Hashes are Lastly a very tough hash to computationally crack is the cached domain credentials on a. Password Hashing and Cracking. Trial and error attacks on passwords take place in two ways: On-line trial-and-error attempts against the site itself. How Attackers Crack Password Hashes¶ · Select a password you think the victim has chosen (e.g. ) · Calculate the hash · Compare the hash you calculated. Example MD5 hash: “secret” -> 5ebeecd0e0f08eabd2a6ee Collisions are so unlikely they're not worth worrying about. This is nothing to do with hash. Hash Crack contains all the tables, commands, online resources, and more to complete your cracking security kit. This version expands on techniques to extract. If the hash matches, then the user is authenticated and can access the system. Rainbow tables are used to crack the password in short amount of time as compared. In cryptanalysis and computer security, password cracking is the process of recovering to check them against an available cryptographic hash of the password. Password hash cracking is a method of attacking dumped hash to find flaws in Password hashing crack technique is only possible in cipher text the only. Hashing is a one way encryption. Meaning, you cannot get the original text back from the hash. Now in information security, passwords are recommended to be. We might find passwords or other credentials in databases. These are often hashed, so we need to first identify which hash it is and then try to crack it. Password hash cracking rigs can be expensive to buy, especially if they are going to be running idle most of the time. Cloud computing offers a.
Password Hashing and Cracking – Lesson Title
CrackStation - Online Password Hash Cracking - MD5, SHA1, Linux, Rainbow Tables, etc.
Decrypt MD5, SHA1, MySQL, NTLM, SHA, SHA, Wordpress, Bcrypt hashes for free online
Online Password Hash Crack - MD5 NTLM Wordpress Joomla WPA PMKID, Office, iTunes, Archive, ..
How to Use hashcat to Crack Hashes on Linux
hash-cracker · GitHub Topics · GitHub
Hash-Buster v - Crack Hashes In Seconds - GeeksforGeeks
Password cracking - Wikipedia
Password Storage - OWASP Cheat Sheet Series
Offline Password Cracking · Total OSCP Guide
1 note
·
View note
Text
Offline Password Cracking · Total OSCP Guide
⭐ ⏩⏩⏩️ DOWNLOAD LINK 🔥🔥🔥 CrackStation uses massive pre-computed lookup tables to crack password hashes. These tables store a mapping between the hash of a password. OnlineHashCrack is a powerful hash cracking and recovery online service for MD5 NTLM Wordpress Joomla SHA1 MySQL OSX WPA, PMKID, Office Docs, Archives, PDF. Decrypt and crack your MD5, SHA1, SHA, MySQL, and NTLM hashes for free online. We also support Bcrypt, SHA, Wordpress and many more. A tool for automating cracking methodologies through Hashcat from the TrustedSec team. hashing automation functions fingerprint hash combinator brute-force. Hash-Buster is an automated tool developed in the Python Language which cracks all types of hashes in seconds. Hash-Buster tool can. What is a Hash function? · Input refers to the message that will be hashed. · The hash function is the encryption algorithm like MD5 and SHA Crack Hashes From the /etc/shadow File in Linux The /etc/shadow file stores the garbled or hashed values of all user's passwords on Linux. Although the hashing algorithms cannot be reversed, password hashes could be cracked. Hackers can generate hashes from a dictionary of strings that are commonly. How to crack passwords and speed up your code, all with the power of hashing. Hashing is an important topic for programmers and computer. Check out the MS docs on how NT or LM Hashes are Lastly a very tough hash to computationally crack is the cached domain credentials on a. Password Hashing and Cracking. Trial and error attacks on passwords take place in two ways: On-line trial-and-error attempts against the site itself. How Attackers Crack Password Hashes¶ · Select a password you think the victim has chosen (e.g. ) · Calculate the hash · Compare the hash you calculated. Example MD5 hash: “secret” -> 5ebeecd0e0f08eabd2a6ee Collisions are so unlikely they're not worth worrying about. This is nothing to do with hash. Hash Crack contains all the tables, commands, online resources, and more to complete your cracking security kit. This version expands on techniques to extract. If the hash matches, then the user is authenticated and can access the system. Rainbow tables are used to crack the password in short amount of time as compared. In cryptanalysis and computer security, password cracking is the process of recovering to check them against an available cryptographic hash of the password. Password hash cracking is a method of attacking dumped hash to find flaws in Password hashing crack technique is only possible in cipher text the only. Hashing is a one way encryption. Meaning, you cannot get the original text back from the hash. Now in information security, passwords are recommended to be. We might find passwords or other credentials in databases. These are often hashed, so we need to first identify which hash it is and then try to crack it. Password hash cracking rigs can be expensive to buy, especially if they are going to be running idle most of the time. Cloud computing offers a.
Password Hashing and Cracking – Lesson Title
CrackStation - Online Password Hash Cracking - MD5, SHA1, Linux, Rainbow Tables, etc.
Decrypt MD5, SHA1, MySQL, NTLM, SHA, SHA, Wordpress, Bcrypt hashes for free online
Online Password Hash Crack - MD5 NTLM Wordpress Joomla WPA PMKID, Office, iTunes, Archive, ..
How to Use hashcat to Crack Hashes on Linux
hash-cracker · GitHub Topics · GitHub
Hash-Buster v - Crack Hashes In Seconds - GeeksforGeeks
Password cracking - Wikipedia
Password Storage - OWASP Cheat Sheet Series
Offline Password Cracking · Total OSCP Guide
1 note
·
View note
Text
Previewing images in and out of SLIME REPL
As any Common Lisp coder knows, a REPL is an incredibly useful tool. It can be used not just for development, but for running all sorts of tasks. Personally, I don’t bother making my Lisp tools into executable scripts and just run them directly from SLIME. As such, any operation that requires leaving the REPL is quite inconvenient. For me, one such operation was viewing image files, for example in conjunction with my match-client:match tool. So lately I’ve been researching various methods to incorporate this functionality into the normal REPL workflow. Below, I present 3 methods that can be used to achieve this.
Open in external program
This one’s easy. When you want to view a file, launch an external process with your favorite image viewer. On Windows a shell command consisting of the image filename would launch the associated application, on Linux it’s necessary to provide the name of the image viewer.
(defvar *image-app* nil) ;; set it to '("eog") or something (defun view-file-native (file) (let ((ns (uiop:native-namestring file))) (uiop:launch-program (if *image-app* (append *image-app* (list ns)) (uiop:escape-shell-token ns)))))
Note that uiop:launch-program is used instead of uiop:run-program. The difference is that launch- is non-blocking - you can continue to work in your REPL while the image is displayed, whereas run- will not return until you close the image viewer.
Also note that when the first argument to run/launch-program is a string, it is not escaped, so I have to do it manually. And if the first argument is a list, it must be a program and a list of its arguments, so merely using (list ns) wouldn't work on Windows.
Inline image in REPL
The disadvantage of the previous method is that the external program might steal focus, appear on top of your REPL and disrupt your workflow. And it’s well known that Emacs can do everything, including viewing images, so why not use that?
In fact, SLIME has a plugin specifically for displaying images in REPL, slime-media. However it's difficult to find any information on how to use it. Eventually I figured out that SWANK (SLIME's CL backend) needs to send an event :write-image with appropriate arguments and slime-media’s handler will display it right in the REPL. The easiest way is to just send the file path. The second argument is the resulting image’s string value. If you copy-paste (sorry, “kill-yank”) it in the repl, it would act just like if you typed this string.
(swank::send-to-emacs '(:write-image "/path/to/test.png" "test"))
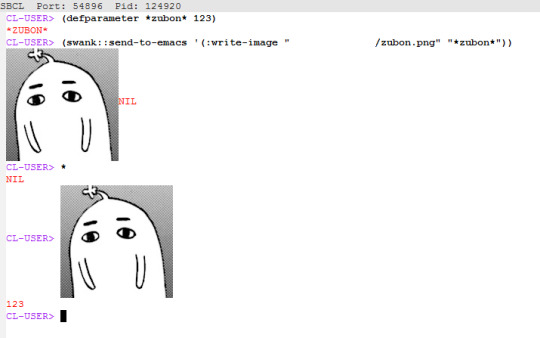
You can even send raw image data using this method. I don’t have anything on hand to generate raw image data so here’s some code that reads from a file, converts it to a base64 string and sends it over SWANK.
(with-open-file (in "/path/to/test.png" :direction :input :element-type '(unsigned-byte 8)) (let* ((arr (make-array (file-length in) :element-type '(unsigned-byte 8))) (b64 (progn (read-sequence arr in) (cl-base64:usb8-array-to-base64-string arr)))) (swank::send-to-emacs `(:write-image ((:data ,b64 :type swank-io-package::png)) "12345"))))
Note that the first argument to :write-image must be a list with a single element, which is itself a plist containing :data and :type keys. :data must be a base64-encoded raw image data. :type must be a symbol in swank-io-package. It's not exactly convenient, so if you're going to use this functionality a helper function/macro might be necessary.
Image in a SLIME popup buffer
Inline images are not always convenient. They can't be resized, and will take up as much space as is necessary to display them. Meanwhile EMACS itself has a built-in image viewer (image-mode) which can fit images to width or height of a buffer. And SLIME has a concept of a "popup buffer" which is for example used by macroexpander (C-c C-m) to display the result of a macro expansion in a separate window.
Interestingly, slime-media.el defines an event :popup-buffer but it seems impossible to trigger it from SWANK. It is however a useful code reference for how to create the popup buffer in ELisp. This time we won't bother with "events" and just straight up execute some ELisp code using swank::eval-in-emacs. However by default, this feature is disabled on Emacs-side, so you'll have to set Emacs variable slime-enable-evaluate-in-emacs to t in order for this method to work.
Also Emacs must be compiled with ImageMagick for the resizing functionality to work.
Anyway, the code to view file in the popup buffer looks like this:
(defun view-file-slime (file &key (bufname "*image-viewer*")) (let ((ns (namestring file))) (swank::eval-in-emacs `(progn (slime-with-popup-buffer (,bufname :connection t :package t) (insert-image (create-image ,ns)) (image-mode) (setf buffer-file-name ,ns) (not-modified) (image-toggle-display-image)) ;; try to resize the image after the buffer is displayed (with-current-buffer ,bufname (image-toggle-display-image)))))) ))
Arriving to this solution has required reading image-mode's source code to understand what exactly makes image-mode behave just like if the image file was opened in Emacs via C-x C-f. First off, image-mode can be a major and a minor mode - and the minor mode is not nearly as useful. slime-with-popup-buffer has a :mode keyword argument but it would cause image-mode to be set before the image is inserted, and it will be a minor mode in this case! Therefore (image-mode) must be called after insert-image.
Next, the buffer must satisfy several conditions in order to get image data from the filename and not from the buffer itself. Technically it shouldn't be necessary, but I couldn't get auto resizing to work when data-p is true. So I set buffer-file-name to image's filename and set not-modified flag on.
Next, image-toggle-display-image is called to possibly resize the image according to image-mode settings. It’s called outside of slime-with-popup-buffer for the following reason: the buffer might not yet be visible and have any specific dimensions assigned to it, and therefore resizing will do nothing.
Here's an example of how calling this function looks in Emacs.

The position of the popup buffer depends on whether the original Emacs window is wide enough or not. I think it looks better when it's divided vertically. Use M-x image-transform-fit-to-height or M-x image-transform-fit-to-width to set up the auto-resizing method (it gets remembered for future images). Unfortunately there's no way to fit both height and width, at least with vanilla Emacs. I prefer fit-to-width because in case the image is too tall, it is possible to scroll the image vertically with M-PgDn and M-PgUp from the other buffer. Unlike other image-mode buffers, this buffer supports a shortcut q to close itself, as well as various SLIME shortcuts, for example C-c C-z to return to the REPL.
That’s it for now, hope you enjoyed this overview and if you happen to know a better way to display images in Emacs, I would be interested to hear about it.
4 notes
·
View notes