#OpenJDK 21 APT
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
I just cleaned up my setup by removing the Snap version of Java and installing OpenJDK 21 using APT. Much smoother, more compatible, and no path issues. If you're a dev or just tired of Java acting weird—this guide is for you. 💻✨ 👉 Read the full post and fix your setup #today.
#Eclipse Java fix#gist#GitHub#IDE#install Java Ubuntu#Java developer guide#Java IDE compatibility#Java installation Ubuntu#Java runtime environment#linux#Linux development tools#open#open source#OpenJDK#OpenJDK 21 APT#OpenJDK path Ubuntu#remove Snap Java#Ubuntu#Ubuntu Java setup#Ubuntu JDK fix
0 notes
Text
Lib jitsi meet

Lib jitsi meet how to#
Lib jitsi meet install#
You can later exchange the SSL certificate to an officially signed one e.g. This warning appears as the site is currently protected by a self-signed SSL certificate. Open your web browser and type the URL or You will be redirected to the following page: Jitsi Meet is now up and listening on port 443. Select the first option and click on the Ok button to start the installation. You will be asked to select the SSL certificate as shown below: Provide your hostname and click on the OK button.
Lib jitsi meet install#
Next, update the repository and install Jitsi Meet with the following command: sudo apt-get update -yĭuring the installation process, you will need to provide your hostname as shown below: Sudo sh -c "echo 'deb stable/' > /etc/apt//jitsi.list" You can do this by running the following command: wget -qO - | sudo apt-key add. So you will need to add the repository for that. Jitsi Meet Installīy default, Jitsi Meet is not available in the Ubuntu 18.04 default repository. Jun 17 11:56:22 server1 systemd: Started A high performance web server and a reverse proxy server. Jun 17 11:56:21 server1 systemd: Starting A high performance web server and a reverse proxy server. ├─34894 nginx: master process /usr/sbin/nginx -g daemon on master_process on Loaded: loaded (/lib/systemd/system/rvice enabled vendor preset: enabled)Īctive: active (running) since Wed 11:56:22 UTC 12s ago rvice - A high performance web server and a reverse proxy server.:/home/administrator# sudo systemctl status nginx Output: Synchronizing state of rvice with SysV service script with /lib/systemd/systemd-sysv-install.Įxecuting: /lib/systemd/systemd-sysv-install enable nginx Once the Nginx is installed, you can check the Nginx service with the following command: sudo systemctl status nginx You can install it with the following command: Advertisement sudo apt-get install nginx -y So you will need to install it to your system. Jitsi Meet uses Nginx as a reverse proxy. OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode) Once the Java is installed, verify the Java version with the following command: java -version You can install OpenJDK JRE 8 by running the following command: sudo apt-get install -y openjdk-8-jre-headless -y Next, you will need to install Java to your system. Then, verify the hostname with the following command: hostname -f Next, open /etc/hosts file and add FQDN: sudo nano /etc/hostsĪdd the following line: 127.0.1.1 server1 You can do this by running the following command: sudo hostnamectl set-hostname server1 Next, you will need to set up a hostname and FQDN to your system. Once your system is up-to-date, restart your system to apply the changes. Getting Started with installing Jitsi Meet on Ubuntu 20.04īefore starting, update your system with the latest version with the following command: sudo apt-get update -y
Lib jitsi meet how to#
In this tutorial, we will learn how to install the video conferencing service Jitsi Meet on an Ubuntu 20.04 LTS server. You can video chat with the entire team and invite users to a meeting using a simple, custom URL. With Jisti Meet you can stream your desktop or just some windows. The Jitsi Meet client runs in your browser, so you don’t need to install anything on your computer. Vmware horizon client the supplied certificate is expired or not yet valid.Jitsi Meet is a free, open-source, secure, simple, and scalable video conferencing solution that you can use as a standalone application or embed it into your web application.
1 note
·
View note
Text
Как подключить PySpark и Kaggle в Google Colab

Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер.
Google Colab
Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через Google Drive. Это тот же самый Jupyter Notebook, только блокноты хранятся в Google Drive, а выполняются на сервере. В отличие от традиционных инструментов разработки, Jupyter Notebook состоит из ячеек, где можно писать код (чаще всего на Python), запускать и сразу же смотреть результаты. Кроме того, ячейки блокнотов могут содержать не только код, но и текст, формулы, рисунки и видео. Особенную популярность блокноты получили у Data Scientist’ов, поскольку позволяют мгновенно тестировать свои идеи. Но некоторые методы машинного обучения, например, глубокое обучение (Deep Learning), подразумевают большие вычислительные мощности, что не каждый может себе позволить. Поэтому Google Colab также предоставляет GPU, а также TPU — уникальная разработка Google специально для машинного обучения (Machine Learning). Все вычисления происходят на виртуальной машине с операционной системой Ubuntu. Все команды bash также доступны. Примечательно, в ячейках для запуска команд bash перед самой командой ставится восклицательный знак.
Установка PySpark в Google Colab
PySpark прежде всего требует установки самого Spark и платформы Java. Для нашего примера установим свободный JDK (Java development kit) вер��ии 8. А Apache Spark скачаем версии 2.4.6 с Hadoop. Точная ссылка для скачивания доступна на главной странице Apache Software Foundation на вкладке Downloads. Скачанный архив нужно разархивировать командой tar. Вот как это выглядит в Colab: !apt-get install openjdk-8-jdk-headless -qq > /dev/null !wget -q https://downloads.apache.org/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz !tar xf spark-2.4.6-bin-hadoop2.7.tgz После этого в окружение среды нужно указать пути JAVA_HOME и SPARK_HOME на скачанные программы. Поскольку мы напрямую загрузили Spark, то он находится в директории content. Чтобы их добавить воспользуемся модулем os, который предоставляет интерфейс для взаимодействия с файловой системой. Вот так будет выглядеть Python-код: import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["SPARK_HOME"] = "/content/spark-2.4.6-bin-hadoop2.7 Чтобы использовать PySpark как обычную Python-библиотеку, установим findspark, который сделает за нас остальную работу по инициализации: !pip install findspark Вот и все. Осталось только проинициализировать PySpark. Для этого вызывается метод findspark.init(), а дальше создаём точку входа кластера. Следующий код на Python это иллюстрирует: import findspark findspark.init()from pyspark.sql import SparkSession spark = SparkSession.builder.master("local[*]").getOrCreate() Об инициализации Spark-приложения через SparkSession читайте нашу предыдущую статью
Скачиваем датасет Kaggle
Многие Data Scientsist’ы работают с датасетами Kaggle — онлайн-площадке для соревнований по машинному обучению как в рамках конкурсов, так и для личных исследований. Обычно датасеты с Kaggle скачиваются напрямую на компьютер. Потом их загружают либо в Google Colab, либо в Google Drive. Причём если они загружаются с Drive, то придётся также их подгружать в Colab и вводить код доступа. Оба метода достаточно долгие, особенно если файлы большого размера. Поэтому рекомендуется загружать файлы напрямую с Kaggle в Colab через Kaggle API [1]. Для этого, прежде всего необходимо создать аккаунт Kaggle. А затем в настройках аккаунта нужно создать API Token. Рисунок ниже показывает соответствующий раздел. После этого скачается файл kaggle.json, который содержит ваш личный код доступа, поэтому им не стоит делиться со сторонними лицами.

Создание личного API Token Далее требуется загрузить kaggle.json в директорию root. Для этого мы создадим этот файл, а потом добавим содержимое файла. Ниже команды в Colab, где вам нужно будет вставить ваши поля с именем и ключом. Также, чтобы обезопасить свой ключ, мы используем команду chmod. !mkdir /root/.kaggle !touch /root/.kaggle/kaggle.json !echo '{"username":"ИМЯ"}' > /root/.kaggle/kaggle.json !chmod 600 ~/.kaggle/kaggle.json Осталось только скачать какой-нибудь датасет. Например, можно взять датасет с данными о домах Бруклина с 2003 по 2017 года, который весит 234 Мб. А затем скопировать API команду, как это показано на рисунке ниже. Перейти на страницу с датасетом Kaggle.

Копирование API command После вставить скопированную команду в ячейку, не забыв поставить восклицател��ный знак впереди. Он загрузится в архивированном виде, поэтому также следует его разархивировать. !kaggle datasets download -d tianhwu/brooklynhomes2003to2017 !unzip -q brooklynhomes2003to2017.zip А теперь можно приступать к работе со Spark в Google Colab. Так как файл в формате CSV, то мы может его прочитать и вывести первые строчки в Python: data = spark.read.csv( 'brooklyn_sales_map.csv', inferSchema=True, header=True) data.show(5) +---+--------+--------------------+-----------------------+ +---+--------+--------------------+-----------------------+ | 1| 3| DOWNTOWN-METROTECH| 28 COMMERCIAL CO...| | 2| 3|DOWNTOWN-FULTON F...| 29 COMMERCIAL GA...| | 3| 3| BROOKLYN HEIGHTS| 21 OFFICE BUILDINGS| | 4| 3| MILL BASIN| 22 STORE BUILDINGS| | 5| 3| BROOKLYN HEIGHTS| 26 OTHER HOTELS| +---+--------+--------------------+-----------------------+ После выхода из Google Colab состояние обнулится — исчезнет все созданное и загруженное, поэтому при повторном использовании придется снова запустить все ячейки. В следующей статье рассмотрим пример выполнения SQL-операций в PySpark на этом же датасете. А ещё больше подробностей о работе с PySpark и Google Colab вы узнаете на специализированном курсе «Анализ данных с Apache Spark» в нашем лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве. Смотреть расписание Записаться на курс Источники 1. https://github.com/Kaggle/kaggle-api Read the full article
0 notes
Text
Instalar Apache Maven en Debian 10

Instalar Apache Maven en Debian 10. Apache Maven es una herramienta especializada en la creación y gestión de proyectos Maven es una herramienta de software para la gestión y construcción de proyectos Java. Su principal beneficio es que estandariza la configuración de nuestro proyecto en todas sus fases, desde la compilación y empaquetado hasta la instalación y administración de las librerías necesarias. Maven fue creado en el 2002 por Jason van Zyl, y es la base de los compiladores IDES actuales, como Eclipse, NetBeans, etc. Antes de comenzar su instalación vemos sus principales características. Excelente sistema de gestión dependencias. Mecanismo de distribución de librerías desde el repositorio local de Maven, hacia los repositorios publicados en Internet o red local. Permite la creación de plugins customizables. Es multi-plataforma. Open Source, el código está disponible para que lo modifiques si es necesario. Los repositorios oficiales y públicos de software libre, ofrecen librerías que toda la comunidad de desarrolladores pueden utilizar. Es compatible con muchos IDEs.
Instalar Apache Maven en Debian 10
Actualizamos el sistema. apt upgrade apt upgrade -y Necesitamos instalar el paquete de desarrollo de java (OpenJDK 11), la herramienta wget y GIT. apt install -y default-jdk apt install -y wget git Apache Maven necesita la variable de entorno $JAVA_HOME, la incluimos en nuestro sistema. echo "export JAVA_HOME=/lib/jvm/default-java" >> /etc/profile
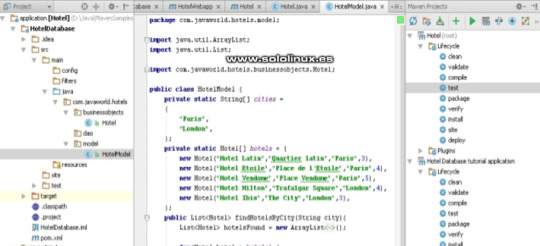
Instalar Apache Maven Bien, ya tenemos nuestro sistema listo para la instalación, comenzamos importando las keys publicas. cd /tmp wget https://www.apache.org/dist/maven/KEYS gpg --import KEYS && rm KEYS Ahora descargamos el archivo binario de la aplicación y el de la firma. Actualmente la ultima versión estable es la 3.6.3, puedes comprobar si existe alguna actualización en su pagina oficial. wget -O maven.tgz https://www-eu.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz wget -O maven.tgz.asc https://www.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz.asc Verificamos el paquete con el archivo de firmas. gpg --verify maven.tgz.asc maven.tgz Descomprimimos el archivo y lo movemos a su directorio final. tar -xzf maven.tgz rm maven.tgz* mv apache-maven* /opt/maven Agregamos /opt/maven/bin a la variable de entorno. echo "export PATH=$PATH:/opt/maven/bin" >> /etc/profile Como punto final debes recargar las variables de entorno. ./etc/profile Verifica que la instalación es correcta. mvn -v ejemplo de salida... Apache Maven 3.6.3 (81f7586969310zs1dc0d5t7yc0dc55gtrd0p519; 2019-12-05T19:17:21+01:00) Maven home: /opt/maven Java version: 11.0.5, vendor: Debian, runtime: /usr/lib/jvm/java-11-openjdk-amd64 Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "4.19.0-6-amd64", arch: "amd64", family: "unix" Ya puedes ejecutar Maven. Si tienes dudas te recomiendo revisar su guía oficial, es muy buena. Espero que este articulo te sea de utilidad, puedes ayudarnos a mantener el servidor con una donación (paypal), o también colaborar con el simple gesto de compartir nuestros artículos en tu sitio web, blog, foro o redes sociales. Read the full article
#/opt/maven/bin#ApacheMaven#Debian10#Eclipse#git#InstalarApacheMaven#JasonvanZyl#java_home#maven#netbeans#opensource#OpenJDK11#wget
0 notes