#PromptTemplates
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
youtube
#ChatGPT#PromptTemplates#AIAssistance#ContentGeneration#TemplateCreation#AITemplates#ProductivityTips#AITools#ChatGPTTutorial#AIContent#Youtube
1 note
·
View note
Text
Rounded Pixel Bot
{ "schemaVersion": "1.3", "generatedAt": "2025-05-11T15:44:39Z", "authorNotes": "Auto‑generated by Logo‑Prompt GPT from brief: Pixel Bot Head Logo / flat vector with rounded-edge geometry / duo-tone adaptable", "sourceGPT": "logo-prompt-gpt-v1.1", "tokens": { "subject": "Pixel Bot Head Logo", "styleRequested": "rounded pixel", "primaryColor": "#000000", "backgroundColor": "#FFFFFF" }, "styleProfile": { "name": "Rounded Pixel Glitch", "description": "Blocky glitch emblem built from rounded-corner pixels; conveys data corruption without harsh edges—always solid color, never textured.", "promptKeywords": [ "rounded pixel", "soft glitch", "8-bit", "blocky", "corrupted" ], "promptTemplate": "A rounded-pixel glitch Pixel Bot Head Logo drawn in solid #000000 blocks on #FFFFFF. Use right-angle steps with 3 px corner radius and missing segments for a corrupted digital silhouette—no noise, no gradients." }, "visualCharacteristics": { "lineQuality": "Pixel-stepped edges with 2–4 px corner radius", "edgeStyle": "Right-angle offsets, softly rounded corners", "fillType": "Solid blocks", "stroke": "none", "contrast": "extreme" }, "designDirectives": { "geometry": "8-bit mosaic silhouette with rounded blocks and deliberate gaps / offsets", "symmetry": "Grid-based or slight asymmetry", "anchorSmoothing": "Each pixel block must keep its corner radius—no sharp points" }, "fileGuidelines": { "exportFormats": ["SVG", "PNG"], "minResolution": "4096x4096px", "aspectRatio": "1:1", "background": "#FFFFFF", "transparency": false, "vectorCleanliness": "Blocks aligned to grid; rounded corners consistent; no antialias" }, "brandingApplication": { "usage": "General purpose one‑color branding marks", "trademark": "Custom per project", "exclusivity": "Each symbol should feel unique to the brief" }, "notes": {}, "promptTemplate": "A rounded-pixel glitch Pixel Bot Head Logo drawn in solid #000000 blocks on #FFFFFF. Use right-angle steps with 3 px corner radius and missing segments for a corrupted digital silhouette—no noise, no gradients.", "minReadablePx": 32, "detailWeighting": "medium", "contrastLevel": "high", "strokePresence": "none", "detailDensity": "medium", "expressionIntensity": "neutral", "scaleSafeDetailing": "Logo must remain recognisable at 32 px.", "silhouetteFocus": "Logo should read clearly if filled solid.", "variants": [], "negativePrompts": { "noNoise": [ "grain texture", "noise overlay", "halftone dots" ], "noGradient": [ "smooth color fade", "dithering" ], "noSharpCorners": [ "perfect square corners", "hard 90° corners" ] } }
0 notes
Text
Introduction to the LangChain Framework

LangChain is an open-source framework designed to simplify and enhance the development of applications powered by large language models (LLMs). By combining prompt engineering, chaining processes, and integrations with external systems, LangChain enables developers to build applications with powerful reasoning and contextual capabilities. This tutorial introduces the core components of LangChain, highlights its strengths, and provides practical steps to build your first LangChain-powered application.
What is LangChain?
LangChain is a framework that lets you connect LLMs like OpenAI's GPT models with external tools, data sources, and complex workflows. It focuses on enabling three key capabilities: - Chaining: Create sequences of operations or prompts for more complex interactions. - Memory: Maintain contextual memory for multi-turn conversations or iterative tasks. - Tool Integration: Connect LLMs with APIs, databases, or custom functions. LangChain is modular, meaning you can use specific components as needed or combine them into a cohesive application.
Getting Started
Installation First, install the LangChain package using pip: pip install langchain Additionally, you'll need to install an LLM provider (e.g., OpenAI or Hugging Face) and any tools you plan to integrate: pip install openai
Core Concepts in LangChain
1. Chains Chains are sequences of steps that process inputs and outputs through the LLM or other components. Examples include: - Sequential chains: A linear series of tasks. - Conditional chains: Tasks that branch based on conditions. 2. Memory LangChain offers memory modules for maintaining context across multiple interactions. This is particularly useful for chatbots and conversational agents. 3. Tools and Plugins LangChain supports integrations with APIs, databases, and custom Python functions, enabling LLMs to interact with external systems. 4. Agents Agents dynamically decide which tool or chain to use based on the user’s input. They are ideal for multi-tool workflows or flexible decision-making.
Building Your First LangChain Application
In this section, we’ll build a LangChain app that integrates OpenAI’s GPT API, processes user queries, and retrieves data from an external source. Step 1: Setup and Configuration Before diving in, configure your OpenAI API key: import os from langchain.llms import OpenAI # Set API Key os.environ = "your-openai-api-key" # Initialize LLM llm = OpenAI(model_name="text-davinci-003") Step 2: Simple Chain Create a simple chain that takes user input, processes it through the LLM, and returns a result. from langchain.prompts import PromptTemplate from langchain.chains import LLMChain # Define a prompt template = PromptTemplate( input_variables=, template="Explain {topic} in simple terms." ) # Create a chain simple_chain = LLMChain(llm=llm, prompt=template) # Run the chain response = simple_chain.run("Quantum computing") print(response) Step 3: Adding Memory To make the application context-aware, we add memory. LangChain supports several memory types, such as conversational memory and buffer memory. from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemory # Add memory to the chain memory = ConversationBufferMemory() conversation = ConversationChain(llm=llm, memory=memory) # Simulate a conversation print(conversation.run("What is LangChain?")) print(conversation.run("Can it remember what we talked about?")) Step 4: Integrating Tools LangChain can integrate with APIs or custom tools. Here’s an example of creating a tool for retrieving Wikipedia summaries. from langchain.tools import Tool # Define a custom tool def wikipedia_summary(query: str): import wikipedia return wikipedia.summary(query, sentences=2) # Register the tool wiki_tool = Tool(name="Wikipedia", func=wikipedia_summary, description="Retrieve summaries from Wikipedia.") # Test the tool print(wiki_tool.run("LangChain")) Step 5: Using Agents Agents allow dynamic decision-making in workflows. Let’s create an agent that decides whether to fetch information or explain a topic. from langchain.agents import initialize_agent, Tool from langchain.agents import AgentType # Define tools tools = # Initialize agent agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) # Query the agent response = agent.run("Tell me about LangChain using Wikipedia.") print(response) Advanced Topics 1. Connecting with Databases LangChain can integrate with databases like PostgreSQL or MongoDB to fetch data dynamically during interactions. 2. Extending Functionality Use LangChain to create custom logic, such as summarizing large documents, generating reports, or automating tasks. 3. Deployment LangChain applications can be deployed as web apps using frameworks like Flask or FastAPI. Use Cases - Conversational Agents: Develop context-aware chatbots for customer support or virtual assistance. - Knowledge Retrieval: Combine LLMs with external data sources for research and learning tools. - Process Automation: Automate repetitive tasks by chaining workflows. Conclusion LangChain provides a robust and modular framework for building applications with large language models. Its focus on chaining, memory, and integrations makes it ideal for creating sophisticated, interactive applications. This tutorial covered the basics, but LangChain’s potential is vast. Explore the official LangChain documentation for deeper insights and advanced capabilities. Happy coding! Read the full article
#AIFramework#AI-poweredapplications#automation#context-aware#dataintegration#dynamicapplications#LangChain#largelanguagemodels#LLMs#MachineLearning#ML#NaturalLanguageProcessing#NLP#workflowautomation
0 notes
Text
Stock Market Sentiment Prediction with OpenAI and Python
In today’s stock market, staying informed about news and events is crucial for making strategic decisions. Recognizing the impact of sentiment on market trends is essential to adjust strategies accordingly. The process begins with accessing vast amounts of market news available through various sources. Foremost among these are the requirements for data quality (such as the number of sources, data update rate, etc.) and ease of use.
Although the data is available online and easily accessible, one of the most convenient methods for our needs is to use an API endpoint to integrate market data and news directly into our code. There is a variety of financial data providers that offer API connections; they vary in the data packages, support approach, and quality of data they provide.
In this article, we are going to use the Stock Market and Financial News API provided by one of the Market Data providers named EODHD, which, in my opinion, boasts a great balance of quality and price. The API provides an endpoint for extracting insights from financial news, facilitating easy analysis of market sentiment. With its ease of use, users can query and retrieve news articles, enabling a dynamic assessment of the market’s positive or negative tones.
By showcasing the capabilities of the API, I aim to demonstrate its seamless integration into sentiment analysis, enabling us to make informed decisions based on prevailing market sentiments. In the fast-paced environment of the stock market, having access to such a resource ensures a more adaptive and strategic approach to investing.
Without further ado, let’s dive into the article.
Importing Packages
Let’s start with importing the required packages into our Python environment. We’ll be using three packages in this article which are pandas for working with dataframes, eodhd for extracting data, and langchain for building the LLM model. Apart from these, we will also be using other secondary packages like config and re. Import all the necessary packages using the following code:!pip install openai !pip install langchain !pip install eodhd !pip install config
import re import requests import pandas as pd import config as cfg from eodhd import APIClient from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chat_models import ChatOpenAI
Before importing, make sure to install the packages using the command line. Now that we have all the required packages imported into our Python environment, we can proceed to the next step which is activating the API key.
API Key Activation
It is essential to register the EODHD API key with the package in order to use its functions. If you don’t have an EODHD API key, firstly, head over to their website, then, finish the registration process to create an EODHD account, and finally, navigate to the ‘Settings’ page where you can find your secret EODHD API key. It is important to ensure that this secret API key is not revealed to anyone. You can activate the API key by following this code:api_key = '<YOUR API KEY>' api = APIClient(api_key)
The code is pretty simple. In the first line, we are storing the secret EODHD API key into api_key, and then in the second line, we are using the APIClient class provided by the eodhd package to activate the API key and stored the response in the client variable.
Note that you need to replace <YOUR API KEY> with your secret EODHD API key. Apart from directly storing the API key with text, there are other ways for better security such as utilizing environmental variables, and so on.
Extracting the Data
We are going to use the Stock Market and Financial News API by accessing the Python library provided by EODHD as follows:resp = api.financial_news(s = "AAPL.US", from_date = '2024-01-01', to_date = '2024-01-30', limit = 100) df = pd.DataFrame(resp) # converting the json output into datframe df.tail()
Let me explain the parameters in the API:
s: String. REQUIRED if parameter ‘t’ is not set. The ticker code to get news for.
t: String. REQUIRED if parameter ‘s’ is not set. The tag to get news on a given topic. you can find the provided topic list on this page: https://eodhd.com/financial-apis/stock-market-financial-news-api/
api_token: String. REQUIRED. Your api_token to access the API. You will get it after registration.
from and to: the format is ‘YYYY-MM-DD’. If you need data from Mar 1, 2021, to Mar 10, 2021, you should use from=2021–03–01 and to=2021–03–10.
limit: Number. OPTIONAL. The number of results should be returned with the query. Default value: 50, minimum value: 1, maximum value: 1000.
offset: Number. OPTIONAL. The offset of the data. Default value: 0, minimum value: 0. For example, to get 100 symbols starting from 200 you should use limit=100 and offset=200.
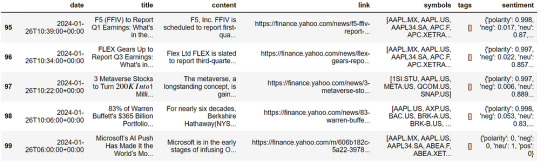
The output data has the following fields:
date: The date and time of the article are in ISO 8601 format.
title: The title of the article.
content: The full body of the article.
link: The link to the source.
symbols: The array of ticker symbols is mentioned in the article.
Cleaning the Data
Now this data is unclean and contains lots of line breaks and different commands. So we are going to clean them:#funtion to clean the textual data def clean_text(text): cleaned_text = re.sub(r'\s+', ' ', text) return cleaned_text.strip()
# Apply the replacement function to the entire column df['content'] = df['content'].apply(clean_text)
Now we have applied it to all the data and we can move forward with our chatbot.
LLM
Now we will use Langchain to form an LLM chain with the OpenAI model.llm = ChatOpenAI(model = "gpt-3.5-turbo", openai_api_key = 'YOUR OPENAI API KEY', temperature = 0)
NOTE: You should replace YOUR OPENAI API KEYwith your own OpenAI API key for the smooth functioning of the code without any errors.
This code snippet initializes the Language Model (LM) by instantiating GPT-2.5-turbo with a temperature of 0. The choice of temperature 0 ensures determinism in our model, preventing it from getting sidetracked and maintaining a focused and consistent generation.
Now, we are going to use different techniques to make it precise for our downstream task i.e. Sentiment analysis. There are lots of different ways to do it:
1) Prompt Engineering:
Prompt engineering is a growing field that involves designing and optimizing prompts to maximize the performance of large language models like GPT. As these models advance, the way we prompt them becomes increasingly important. Recent research shows that well-crafted prompts can significantly improve reliability and enable models to tackle more complex tasks than previously believed.
Following are some prompt engineering techniques that are commonly used:
Zero-shot prompting: This method enables large language models (LLMs) to handle new tasks even without prior examples or understanding of the task. It operates through a technique called ‘prompting,’ where you simply give the LLM a natural language description of the desired task.
Few-shot prompting: While large-language models demonstrate remarkable zero-shot capabilities, they still fall short on more complex tasks when using the zero-shot setting. Few-shot prompting can be used as a technique to enable in-context learning where we provide demonstrations in the prompt to steer the model to better performance. The demonstrations serve as conditioning for subsequent examples where we would like the model to generate a response.
Chain of Thought Prompting: Chain of thought prompting is a helpful technique for AI systems to simplify complex tasks by breaking them down into manageable steps. Instead of tackling a challenging problem in one go, this method promotes explaining the reasoning process by breaking the solution into a series of smaller, incremental steps. It begins by clearly defining the end goal and then considers the logical prerequisites and sub-tasks required to reach that goal.
2) Fine-tuning
Fine-tuning is a useful process that lets users tailor pre-trained language models (LLMs) for specific tasks. By fine-tuning a model on a small dataset containing task-specific data, you can enhance its performance for that particular task while keeping its overall language understanding intact.
The two main Fine-tuning Methods are as follows:
Full instruction fine-tuning: Full instruction fine-tuning is a technique used to adapt Large Language Models (LLMs) to specific tasks. The process involves adjusting all parameters of the LLM using task-specific data. This adaptation allows the model to perform more effectively on specific tasks, potentially leading to improved performance. The need for full instruction fine-tuning arises because even the most powerful pre-trained LLM might not always meet specific needs right out of the box. For instance, an application might require a unique structure or style, or the pre-trained LLM might lack knowledge about specific documents crucial to the application. Furthermore, certain domains, industries, and even particular enterprises often have unique terminologies, concepts, and structures not prominently represented in the general pretraining data. Therefore, full instruction fine-tuning is a valuable method for tailoring LLMs to more specific use cases.
Parameter-efficient fine-tuning: Parameter-efficient fine-tuning (PEFT) is a technique used to adapt large pre-trained models to various downstream applications without fine-tuning all of a model’s parameters. This is because fine-tuning all parameters can be prohibitively costly. Instead, PEFT methods only fine-tune a small number of (extra) model parameters. This significantly decreases computational and storage costs while yielding performance comparable to a fully fine-tuned model. PEFT addresses issues such as the infeasibility of full fine-tuning on consumer hardware and the high cost of storing and deploying fine-tuned models independently for each downstream task. It also overcomes the problem of catastrophic forgetting, a behavior observed during the full fine-tuning of Large Language Models (LLMs).
In this instance, we will leverage prompt engineering techniques, utilizing the Langchain template functionality, to construct an optimized prompt for conducting sentiment analysis in the stock market. The objective is to create a prompt that not only provides sentiment Analysis but also offers explanations for the model’s inferences.template = """ Identify the sentiment towards the Apple(AAPL) stocks from the news article , where the sentiment score should be from -10 to +10 where -10 being the most negative and +10 being the most positve , and 0 being neutral
Also give the proper explanation for your answers and how would it effect the prices of different stocks
Article : {statement} """
#forming prompt using Langchain PromptTemplate functionality prompt = PromptTemplate(template = template, input_variables = ["statement"]) llm_chain = LLMChain(prompt = prompt, llm = llm)
Now that we’ve established the LLM chain, let me give you an example of its inference.
Running the LLM chain :print(llm_chain.run(df['content'][13]))

Analysis
Now to to analyze the market condition of AAPL (Apple) stocks let’s analyze 100 articles and draw some conclusions.
So, first, we have to make sure we don’t cross the token limit of our model, which is 4097 for me. So we will filter out articles with a number of tokes < 3500:#A function to count the number of tokens def count_tokens(text): tokens = text.split() return len(tokens)
Counting tokes for all the rows in a dataframe:# Applying the tokenization function to the DataFrame column df['TokenCount'] = df['content'].apply(count_tokens)
Filtering the data frame according to TokenCount:# Define a token count threshold (for example, keep rows with more than 2 tokens) token_count_threshold = 3500
# Create a new DataFrame by filtering based on the token count new_df = df[df['TokenCount'] < token_count_threshold]
# Drop the 'TokenCount' column from the new DataFrame if you don't need it new_df = new_df.drop('TokenCount', axis = 1)
# Resetting the index new_df = new_df.reset_index(drop = True)
Now, this time I would change my prompt template so that I would get a concise output:template_2 = """ Identify the sentiment towards the Apple(AAPL) stocks of the news article from -10 to +10 where -10 being the most negative and +10 being the most positve , and 0 being neutral
GIVE ANSWER IN ONLY ONE WORD AND THAT SHOULD BE THE SCORE
Article : {statement} """
#forming prompt using Langchain PromptTemplate functionality prompt_2 = PromptTemplate(template = template_2, input_variables = ["statement"])
Let’s form the new LLM chain:llm_chain_2 = LLMChain(prompt = prompt_2, llm = llm)

Great, we are now able to get a concise output. Now, we are going to create a for-loop to iterate through the data and get the sentiment of each news:x = [] for i in range(0,new_df.shape[0]): x.append(llm_chain_2.run(new_df['content'][i]))
Visualization
Now let’s form some pie charts to see the market sentiment of AAPL stocks:import matplotlib.pyplot as plt
dt = pd.DataFrame(x) #Converting into Dataframe column_name = 0 # this is my column name you should change it according to your data value_counts = dt[column_name].value_counts()
# Plotting the pie chart plt.pie(value_counts, labels = value_counts.index, autopct = '%1.1f%%', startangle = 140) plt.title(f'Pie Chart') plt.axis('equal') # Equal aspect ratio ensures that the pie is drawn as a circle.

The pie chart indicates that a significant number of articles were neutral. However, to ensure accuracy, we should filter our data and focus on analyzing only the non-neutral information.
Removing neutral values:value_to_remove = '0' # Remove all rows where the specified value occurs in the column dt_new = dt[dt[0] != value_to_remove]
Visualizing the new data:value_counts = dt_new[column_name].value_counts()
# Plotting the pie chart plt.pie(value_counts, labels = value_counts.index, autopct = '%1.1f%%', startangle = 140) plt.title(f'Pie Chart') plt.axis('equal') # Equal aspect ratio ensures that the pie is drawn as a circle.

Observing the trends, the combination of +5 and +7 contributes to nearly 40% of the data. Factoring in additional values like +10, +8, and +3, the cumulative percentage of positive articles rises to 52.5%. This pattern indicates a prevailing optimistic sentiment, implying a favorable perception of Apple Inc. in recent articles. The positive outlook identified may have potential implications for shaping overall sentiments regarding Apple’s market performance.
Conclusion
In our study, we employed the Stock Market Financial News API provided by EODHD to collect stock market news articles and utilized OpenAI’s sentiment analysis model to assess the sentiments conveyed in these articles.
To ensure seamless compatibility between our data and the OpenAI model, LangChain, a language processing tool, was utilized. To refine the inputs for the OpenAI model and improve the accuracy of our sentiment analysis, we implemented prompt engineering techniques. We conducted sentiment analysis on 100 articles to gauge the current market sentiment surrounding APPL stocks.
This holistic methodology enabled us to extract meaningful insights into market trends based on the sentiments expressed in the news. With that being said, you’ve reached the end of the article. Hope you learned something new and useful today. Thank you very much for your time.
0 notes
Text
LangChain:快速构建自然语言处理应用程序的工具
(封面图由文心一格生成)
LangChain:快速构建自然语言处理应用程序的工具
LangChain 是一个用于构建端到端语言模型应用的Python框架。它提供了一系列模块,这些模块可以组合在一起,用于创建复杂的应用程序,也可以单独用于简单的应用程序。在本篇博客中,我们将重点介绍以下几个方面:
安装和环境设置
构建语言模型应用
Prompt Templates:管理LLMs的提示
Chains:组合LLMs和Prompt Templates以进行多步骤工作流
Agents:根据用户输入动态调用Chains
Memory:为Chains和Agents添加状态
1. 安装和环境设置
首先,我们需要使用以下命令安装LangChain:pip install langchain
使用LangChain通常需要与一个或多个模型提供程序、数据存储、API等集成。在本例中,我们将使用OpenAI的API,因此我们首先需要安装他们的SDK:pip install openai
然后,在终端中设置环境变量:export OPENAI_API_KEY="..."
或者,可以从Jupyter notebook(或Python脚本)中执行此操作:import os os.environ["OPENAI_API_KEY"] = "..."
2. 构建语言模型应用
有了安装的LangChain和设置的环境变量,我们现在可以开始构建语言模型应用了。LangChain提供了许多模块,用于构建语言模型应用。这些模块可以组合在一起,用于创建复杂的应用程序,也可以单独用于简单的应用程序。
LLMs:从语言模型获取预测 LangChain的最基本的构建块是在一些输入上调用LLM。让我们通过一个简单的例子来演示如何实现这一点。为此,让我们假装我们正在构建一个服务,根据公司的产品生成公司名称。
首先,我们需要导入LLM包装器:from langchain.llms import OpenAI
然后,我们可以使用任何参数初始化包装器。在这个例子中,我们可能希望输出更随机,因此我们将使用高temperature进行初始化:llm = OpenAI(temperature=0.9)
现在我们可以在一些输入上调用它!text = "What would be a good company name for a company that makes colorful socks?" print(llm(text))
3. Prompt Templates:管理LLMs的提示
调用LLM是一个很好的第一步,但这只是个开始。通常,在应用程序中使用LLM时,不会直接将用户输入直接发送到LLM。相反,你可能会获取用户输入并构造一个提示,然后将提示发送到LLM中。 例如,在上一个例子中,我们传递的文本是硬编码的,要求为制造彩色袜子的公司取一个名称。在这个想象的服务中,我们想要做的是仅取用户描述公司所做的事情,然后使用该信息格式化提示。
使用LangChain可以轻松实现这一点!
首先定义提示模板:from langchain.prompts import PromptTemplateprompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?", )
现在我们来看看它是如何工作的!我们可以调用.format���法进行格式化。print(prompt.format(product="colorful socks"))
4. Chains:将LLMs和Prompts结合在多步骤工作流中
到目前为止,我们已经单独使用Prompt Template和LLM基元。但是,一个真正的应用程序不仅仅是一个原语,而是由它们的组合构成的。
在LangChain中,一个链由链接组成,这些链接可以是LLM、Prompt Template或其他链。
LLMChain是最核心的链类型,它由Prompt Template和LLM组成。
扩展上一个例子,我们可以构建一个LLMChain,该链接受用户输入,使用Prompt Template格式化它,然后将格式化的响应传递给LLM。from langchain.prompts import PromptTemplate from langchain.llms import OpenAIllm = OpenAI(temperature=0.9) prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?", )
我们现在可以创建一个非常简单的链,该链将获取用户输入,使用Prompt Template对其进行格式化,然后将其发送到LLM:from langchain.chains import LLMChain chain = LLMChain(llm=llm, prompt=prompt)
现在我们可以运行该链,只需指定产品即可!chain.run("colorful socks") # -> '\n\nSocktastic!'
5. Agents:根据用户输入动态调用Chains
到目前为止,我们已经看到的链都是按照预定顺序运行的。Agents不再如此:它们使用LLM确定要采取的动作及其顺序。一个动作可以是使用工具并观察其输出,或者返回给用户。
如果正确使用Agents,它们可以非常强大。在本教程中,我们通过最简单、最高级别的API向你展示如何轻松使用代理。
为了加载代理,你应该了解以下概念:
Tool: 执行特定任务的功能。这可以是类似Google搜索、数据库查找、Python REPL、其他链的东西。工具的接口目前是期望有一个字符串作为输入,输出一个字符串的函数。 LLM: 驱动代理的语言模型。
Agent: 要使用的代理。这应该是引用支持代理类的字符串。因为本笔记本专注于最简单、最高级别的API,所以仅涵盖使用标准支持的代理。如果要实现自定义代理,请参见自定义代理的文档(即将推出)。 代理: 支持的代理及其规格的列表,请参见此处。
工具: 预定义工具及其规格的列表,请参见此处。
对于此示例,你还需要安装SerpAPI Python包。pip install google-search-results
并设置适当的环境变量。import os os.environ["SERPAPI_API_KEY"] = "..."
现在我们可以开始!from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.llms import OpenAI# 首先,让我们加载我们要用来控制代理的语言模型。 llm = OpenAI(temperature=0)# 接下来,让我们加载一些要使用的工具。请注意,`llm-math`工具使用LLM,因此我们需要将其传递给它。 tools = load_tools(["serpapi", "llm-math"], llm=llm)# 最后,让我们使用工具、语言模型和我们想要使用的代理类型来初始化一个代理。 agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)# 现在让我们测试一下! agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?") Entering new AgentExecutor chain...I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power. Action: Search Action Input: "Olivia Wilde boyfriend" Observation: Jason Sudeikis Thought: I need to find out Jason Sudeikis' age Action: Search Action Input: "Jason Sudeikis age" Observation: 47 years Thought: I need to calculate 47 raised to the 0.23 power Action: Calculator Action Input: 47^0.23 Observation: Answer: 2.4242784855673896Thought: I now know the final answer Final Answer: Jason Sudeikis, Olivia Wilde's boyfriend, is 47 years old and his age raised to the 0.23 power is 2.4242784855673896. > Finished AgentExecutor chain. "Jason Sudeikis, Olivia Wilde's boyfriend, is 47 years old and his age raised to the 0.23 power is 2.4242784855673896."
6. Memory:向链和代理添加状态
到目前为止,我们所讨论的所有链和代理都是无状态的。但通常,你可能希望链或代理具有一些“记忆”概念,以便它们可以记住有关其先前交互的信息。 这是在设计聊天机器人时最明显和简单的例子-你希望它记住以前的消息,以便它可以使用上下文来进行更好的对话。这将是一种“短期记忆”。在更复杂的一面,你可以想象链/代理随时间记住关键信息-这将是一种“长期记忆”。关��后者的更具体想法,请参见此出色的论文。
LangChain提供了几个专门为此目的创建的链。本笔记本介绍了使用其中一个链(ConversationChain)的两种不同类型的内存。
默认情况下,ConversationChain具有一种简单类型的内存,该内存记住所有先前的输入/输出并将它们添加到传递的上下文中。让我们看看如何使用此链(将verbose=True设置为我们可以看到提示)。from langchain import OpenAI, ConversationChainllm = OpenAI(temperature=0) conversation = ConversationChain(llm=llm, verbose=True)conversation.predict(input="Hi there!") > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: Hi there! AI:> Finished chain. ' Hello! How are you today?' conversation.predict(input="I'm doing well! Just having a conversation with an AI.") > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: Hi there! AI: Hello! How are you today? Human: I'm doing well! Just having a conversation with an AI. AI:> Finished chain. " That's great! What would you like to talk about?"
1 note
·
View note