#PythonPractice
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Python Code Practice for Beginners and Beyond
Consistent Python code practice is the best way to improve your skills. Start with simple exercises like string manipulation, loops, and basic math operations. As you progress, try working with more complex concepts like dictionaries, file handling, or algorithms. Use platforms like LeetCode and Codecademy to practice and build confidence.
0 notes
Photo

Converting a Python console calculator to flask web application. This is the third part of our part flask web development series.In this part,we create our calculator functions in the flask view and connect to the web templates form and display the functionality. I have used tailwindcss for creating the templates.Tailwind css makes it easier and have written no single css but it's a smart web page. This part brings the whole web development circle of frontend and back end to one place. Enjoy the reading. #flask #python #tailwindcss #frontenddevelopment #backenddevelooment #flaskwebapps #pythonflaskcalculator #taiwindcssdesign #pythonprojects #pythonpractice #pythonprogramming (at Lilongwe, Malawi) https://www.instagram.com/p/CI3Y4fCh7dN/?igshid=qwnejietgxmi
#flask#python#tailwindcss#frontenddevelopment#backenddevelooment#flaskwebapps#pythonflaskcalculator#taiwindcssdesign#pythonprojects#pythonpractice#pythonprogramming
0 notes
Photo

🔰Write the Python script for above task and post it in below comment section. ➖➖➖➖➖➖➖➖➖➖➖ ✳️ Follow us ✳️ @pyadda @pyadda @pyadda 🔰Turn on post notification. . . . . . . #programmer #programmerlife #pythonpractice #pythonprogrammers #programmerslife #programming #programminglife #computer #pythonprojects #python3 #pythoncode #datascience #algorithms #machinelearning #artificialintelligence #pythonprogramming #pythonprogrammer #pythondeveloper #ai #ml #lockdown #wfm #internship #covid19 (at Mumbai - City of Dreams) https://www.instagram.com/p/CAsq2qxARmp/?igshid=1a8skfogjvs3f
#programmer#programmerlife#pythonpractice#pythonprogrammers#programmerslife#programming#programminglife#computer#pythonprojects#python3#pythoncode#datascience#algorithms#machinelearning#artificialintelligence#pythonprogramming#pythonprogrammer#pythondeveloper#ai#ml#lockdown#wfm#internship#covid19
0 notes
Text
Predicting whether a person is a Regular Smoker or not using the best Decision Tree from the generated Random Forest
As a part of Assignment for Course: Machine Learning Tools
Steps Involved:
Get the Research Data
Identify the Explanatory Variables: Both Categorical and Quantitative
Load the Dataset
Clean the dataset (remove NAs)
Split dataset in 60:40 ratio, 60% for training model and 40% for testing model
Check Accuracy of the Tree with a defined node.
Check whether other trees are required or not?
Define number of Random Trees in Forest = 25
Plot accuracy of each of them
If the accuracy of other trees is similar to the one we got initially, other trees are not really helpful.
Results Explanation:
2745 records were used for training the model
1830 records were used for testing the model
Importance of Explanatory Variables as per the Prediction Model:
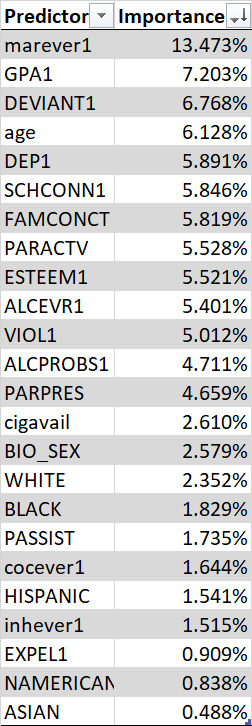
Working Code:
import matplotlib.pylab as plt import numpy as np import pandas as pd import sklearn.metrics # Feature Importance from sklearn.ensemble import ExtraTreesClassifier from sklearn.model_selection import train_test_split # Load the dataset AH_data = pd.read_csv('C:\\Users\\M1049673\\Documents\\PythonPractice\\Coursera\\ML\\Datatree_addhealth.csv') AH_data.replace('?', np.nan, inplace=True) data_clean = AH_data.dropna() print('Datatype Information:\n',data_clean.dtypes) print('\nBasic Data related information:\n',data_clean.describe()) # Split into training and testing sets predictors = data_clean[['BIO_SEX','HISPANIC','WHITE','BLACK','NAMERICAN','ASIAN','age', 'ALCEVR1','ALCPROBS1','marever1','cocever1','inhever1','cigavail','DEP1','ESTEEM1','VIOL1', 'PASSIST','DEVIANT1','SCHCONN1','GPA1','EXPEL1','FAMCONCT','PARACTV','PARPRES']] targets = data_clean.TREG1 pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=.4) print('\nShape of Prediction Train:',pred_train.shape) print('Shape of Prediction Test:',pred_test.shape) print('Shape of Target Train:',tar_train.shape) print('Shape of Target Test:',tar_test.shape) # Build model on training data from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators=25) classifier = classifier.fit(pred_train, tar_train) predictions = classifier.predict(pred_test) print('\nConfusion Matrix:\n',sklearn.metrics.confusion_matrix(tar_test, predictions)) print('Accuracy Score:',sklearn.metrics.accuracy_score(tar_test, predictions)) # fit an Extra Trees model to the data model = ExtraTreesClassifier() model.fit(pred_train, tar_train) # display the relative importance of each attribute print('\nFeatures Importance:',model.feature_importances_) """ Running a different number of trees and see the effect of that on the accuracy of the prediction """ trees = range(25) accuracy = np.zeros(25) for idx in range(len(trees)): classifier = RandomForestClassifier(n_estimators=idx + 1) classifier = classifier.fit(pred_train, tar_train) predictions = classifier.predict(pred_test) accuracy[idx] = sklearn.metrics.accuracy_score(tar_test, predictions) plt.cla() plt.plot(trees, accuracy) plt.show()
Output:
Datatype Information: BIO_SEX float64 HISPANIC float64 WHITE float64 BLACK float64 NAMERICAN float64 ASIAN float64 age float64 TREG1 float64 ALCEVR1 float64 ALCPROBS1 int64 marever1 int64 cocever1 int64 inhever1 int64 cigavail float64 DEP1 float64 ESTEEM1 float64 VIOL1 float64 PASSIST int64 DEVIANT1 float64 SCHCONN1 float64 GPA1 float64 EXPEL1 float64 FAMCONCT float64 PARACTV float64 PARPRES float64 dtype: object
Basic Data related information: BIO_SEX HISPANIC ... PARACTV PARPRES count 4575.000000 4575.000000 ... 4575.000000 4575.000000 mean 1.521093 0.111038 ... 6.290710 13.398033 std 0.499609 0.314214 ... 3.360219 2.085837 min 1.000000 0.000000 ... 0.000000 3.000000 25% 1.000000 0.000000 ... 4.000000 12.000000 50% 2.000000 0.000000 ... 6.000000 14.000000 75% 2.000000 0.000000 ... 9.000000 15.000000 max 2.000000 1.000000 ... 18.000000 15.000000
[8 rows x 25 columns]
Shape of Prediction Train: (2745, 24) Shape of Prediction Test: (1830, 24) Shape of Target Train: (2745,) Shape of Target Test: (1830,)
Confusion Matrix: [[1441 78] [ 190 121]] Accuracy Score: 0.853551912568306
Features Importance: [0.02578917 0.0154114 0.02351627 0.01829161 0.00837805 0.00488314 0.06128191 0.05400669 0.04710931 0.13473079 0.01644478 0.01515276 0.02609708 0.05890997 0.05520846 0.05011535 0.0173519 0.06768484 0.05846291 0.07203345 0.00908774 0.05818886 0.05527677 0.04658681]

0 notes
Photo

🔰Write the Python script for above task and post it in below comment section. ➖➖➖➖➖➖➖➖➖➖➖ ✳️ Follow us ✳️ @pyadda @pyadda @pyadda 🔰Turn on post notification. . . . . . . #programmer #programmerlife #pythonpractice #pythonprogrammers #programmerslife #programming #programminglife #computer #pythonprojects #python3 #pythoncode #datascience #algorithms #machinelearning #artificialintelligence #pythonprogramming #pythonprogrammer #pythondeveloper #ai #ml #lockdown #wfm #internship #covid19 (at Bangalore, India) https://www.instagram.com/p/CAqDMJhApVP/?igshid=1h802tsz6vnpq
#programmer#programmerlife#pythonpractice#pythonprogrammers#programmerslife#programming#programminglife#computer#pythonprojects#python3#pythoncode#datascience#algorithms#machinelearning#artificialintelligence#pythonprogramming#pythonprogrammer#pythondeveloper#ai#ml#lockdown#wfm#internship#covid19
0 notes