#Resume Parser API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Photo

We’re a passionate crew of developers, data scientists and AI engineers, on a mission to bring machine learning to the masses. We believe intelligent document processing solutions should be easy, affordable, and accessible to businesses of all sizes — so that’s exactly what we build every day. Visit us to know more about Affinda Resume Parser Software.
#resume extractor#resume parsing#Resume Parsing Software#Resume Parser API#Resume Parser#best resume parsing software
0 notes
Text
Version 428
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a good couple weeks working on the taglist code and some other jobs.
If you are on Windows and use the 'extract' release, you may want to do a 'clean' install this week. Extra notes below.
taglists
So, I took some time to make taglists work a lot cleaner behind the scenes and support more types of data. A heap of code is cleaner, and various small logical problems related to menus are fixed. The tag right-click menu is also more compact, quicker to see and do what you want.
The main benefits though are in the manage tags dialog. Now, the '(will display as xxx)' sibling suffix colours in the correct namespace for the sibling, and parents 'hang' underneath all tags in all the lists. It is now much easier to see why a parent or sibling is appearing for a file.
This is a first attempt. I really like how these basically work, but it can get a bit busy with many tags. With the cleaner code, it will be much easier to expand in future. I expect to add 'expand/collapse parents' settings and more sorts, and maybe shade parents a bit transparent, in the coming weeks. Please let me know how it works for you IRL and I'll keep working.
the rest
The main nitter site seems to be overloaded. They have a bunch of mirrors listed here: https://github.com/zedeus/nitter/wiki/Instances
I picked two roughly at random and added new downloaders for them. If you have Nitter subs, please move their 'sources' over, and they should start working again (they might need to do a bit of 'resync' and will complain about file limits being hit since the URLs are different, but give them time). If you would rather use another mirror, feel free to duplicate your own downloaders as well. Thanks to a user who helped here with some fixed-up parsers.
I gave the recently borked grouped 'status' sort in thread watchers and downloader pages another go, and I improved the reporting there overall. The 'working' status shouldn't flicker on and off as much, there is a new 'pending' status for downloaders waiting for a work slot, and the 'file status' icon column now shows the 'stop' symbol when files are all done.
The menu entry to 'open similar-looking files' is now further up on thumbnails' 'open' submenus.
The duplicate filter has its navigation buttons on the right-hand hover window rearranged a bit. It is silly to have both 'previous' and 'next' when there are only two files, so I merged them. You can also set 'view next' as a separate shortcut for the duplicate filter, if you want to map 'flip file' to something else just for the filter.
windows clean install
If you use the Windows installer, do not worry, these issues are fixed automatically for you from now on.
I updated to a new dev machine this week. Some libraries were updated, and there is now a dll conflict, where a dll from an older version is interfering with a new one. As it happens, the library that fails to load is one I made optional this week, so it doesn't ''seem'' to actually stop you from booting the client, but it will stop you from running the Client API in https if you never did it before (the library does ssl certificate generation).
It is good to be clean, so if you extract the Windows release, you may want to follow this guide this week: https://hydrusnetwork.github.io/hydrus/help/getting_started_installing.html#clean_installs
full list
interesting taglist changes:
taglists work way better behind the scenes
when siblings display with the '(will display as xxx)' suffix, this text is now coloured by the correct namespace!
parents now show in 'manage tags dialog' taglists! they show up just like in a write/edit tag autocomplete results list
the tag right-click menu has had a pass. 'copy' is now at the top, the 'siblings and parents' menu is split into 'siblings' and 'parents' with counts on the top menu label and the submenus for each merged, and the 'open in new page' commands are tucked into an 'open' submenu. the menu is typically much tighter than before
when you hit 'select files with these tags' from a taglist, the thumbgrid now takes keyboard focus if you want to hit F7 or whatever
custom tag presentation (_options->tag presentation_, when you set to always hide namespaces or use custom namespace separator in read/search views) is more reliable across the program. it isn't perfect yet, but I'll keep working
a heap of taglist code has been cleaned up. some weird logical issues should be better
now the code is nicer to work with, I am interested in feedback on how to further improve display and workflows here
.
the rest:
added two mirrors for nitter, whose main site is failing due to load. I added them randomly from the page here: https://github.com/zedeus/nitter/wiki/Instances . if you have nitter subs, please move their download source to one of the mirrors or set up your own url classes to other mirror addresses. thanks to a user for providing other parser fixes here
gallery download pages now show the 'stop' character in the small file column when the files are done
gallery download pages now report their 'working' status without flicker, and they report 'pending' when waiting for a download slot (this situation is a legacy hardcoded bottleneck that has been confusing)
thread watchers also now have the concept of 'pending', and also report when they are next checking
improved the new grouped status sort on gallery downloader and watcher pages. the ascending order is now DONE, working, pending, checking later (for watchers), paused
the network request delay after a system resume is now editable under the new options->system panel. default is 15 seconds
the 'wait on files too' option is moved from 'files and trash' to this panel
when the 'just woke' status is active, you now get a little popup with a cancel button to override it
'open similar-looking files' thumbnail menu entry is moved up from file relationships to the 'open' menu
the duplicate filter right-hand hover window no longer has both 'previous' and 'next' buttons, since they both act as 'flip', and the merged button is moved down, made bigger, and has a new icon
added 'view next' to the duplicate filter shortcut set, so you can set a custom 'flip between pair' mapping just for that filter
thanks to a user helping me out, I was able to figure out a set of lookups in the sibling/parent system that were performing unacceptably slow for some users. this was due to common older versions of sqlite that could not optimise a join with a multi-index OR expression. these queries are now simpler and should perform well for all clients. if your autocomplete results from a search page with thumbs were achingly slow, let me know how they work now!
the hydrus url normalisation code now treats '+' more carefully. search queries like 6+girls should now work correctly on their own on sites where '+' is used as a tag separator. they no longer have to be mixed with other tags to work
.
small/specific stuff:
the similar files maintenance search on shutdown now reports file progress every 10 files and initialises on 0. it also has faster startup time in all cases
when a service is deleted, all currently open file pages will check their current file and tag domains and update to nicer defaults if they were pointed at the now-missing services
improved missing service error handling for file searches in general--this can still hit an export folder pointed at a missing service
improved missing service error handling for tag autocomplete searches, just in case there are still some holes here
fixed a couple small things in the running from source help and added a bit about Visual Studio Build Tools on Windows
PyOpenSSL is now optional. it is only needed to generate the crt/key files for https hosting. if you try to boot the server or run the client api in https without the files and without the module available to generate new ones, you now get a nice error. the availability of this library is now in the client's about window
the mpv player will no longer throw ugly errors when you try to seek on a file that its API interface cannot support
loading a file in the media viewer no longer waits on the file system lock on the main thread (it was, very briefly), so the UI won't hang if you click a thumb just after waking up or while a big file job is going on
the 'just woke' code is a little cleaner all around
the user-made downloader repository link is now more obvious on Lain's import dialog
an old hardcoded url class sorting preference that meant gallery urls would be matched against urls before post, and post before file, is now eliminated. url classes are now just preferenced by number of path components, then how many parameters, then by example url length, with higher numbers matching first (the aim is that the more 'specific' and complicated a url class, the earlier it should attempt to match)
updated some of the labelling in manage tag siblings and parents
when you search autocomplete tags with short inputs, they do not currently give all 'collapsed' matching results, so an input of 'a' or '/a/' does not give the '/a/' tag. this is an artifact of the new search cache. after looking at the new code, there is no way I can currently provide these results efficiently. I tested the best I could figure out, but it would have added 20-200ms lag on all PTR searches, so instead I have made a plan to resurrect an old cache in a more efficient way. please bear with me on this problem
tag searches that only include unusual characters like ? or & are now supported without having to lead the query with an asterisk. they will be slower than normal text search
fixed a bug in the 'add tags before import' dialog for local imports where deleting a 'quick namespace' was not updating the tag list above
.
windows clean install:
I moved to a new windows dev machine this week and a bunch of libraries were updated. I do not believe the update on Windows _needs_ a clean install this week, as a new dll conflict actually hits the coincidentally now-optional PyOpenSSL, but it is worth doing if you want to start using the Client API soon, and it has been a while, so let's be nice and clean. if you extract the release on Windows, please check out this guide: https://hydrusnetwork.github.io/hydrus/help/getting_started_installing.html#clean_installs
the Windows installer has been updated to remove many old files. it should now do clever clean installs every week, you have nothing to worry about!™
.
boring db breakup:
the local tags cache, which caches tags for your commonly-accessed hard drive files, is now spun off to its own module
on invalid tag repair, the new master tags module and local tags cache are now better about forgetting broken tags
the main service store is spun off to its own module. several instances of service creation, deletion, update and basic fetching are merged and cleaned here. should improve a couple of logical edge cases with update and reset
.
boring taglist changes:
taglists no longer manage text and predicates, but a generalised item class that now handles all text/tag/predicate generation
taglist items can occupy more than one row. all position index calculations are now separate from logical index calculations in selection, sizing, sorting, display, and navigation
all taglist items can present multiple colours per row, like OR predicates
items are responsible for sibling and parent presentation, decoupling a heap of list responsibility mess
tag filter and tag colour lists are now a separate type handled by their own item types
subordinate parent predicates (as previously shown just in write/edit autocomplete result lists) are now part of multi-row items. previously they were 'quiet' rows with special rules that hung beneath the real result. some related selection/publish logic is a bit cleaner now
string tag items are now aware of their parents and so can present them just like autocomplete results in write/edit contexts
the main taglist content update routines have significantly reduced overhead. the various expansions this week add some, so we'll see how this all shakes out
the asynchronous sibling/parent update routine that populates sibling and parent data for certain lists is smarter and saves more work when data is cached
old borked out selection/hitting-skipping code that jumped over labels and parents is now removed
'show siblings and parents' behaviour is more unified now. basically they don't show in read/search, but do in write/edit
a heap of bad old taglist code has been deleted or cleaned up
next week
This was a big couple of weeks. Setting up the new dev machine--I replaced my six year old HP office computer with a nice mini-pc with an SSD--worked out great, but there were some headaches as always. The taglist work was a lot too. I'll take next week a little easier, just working misc small jobs.
1 note
·
View note
Text
Senior Android Developer resume in Ann Arbor, MI
#HR #jobopenings #jobs #career #hiring #Jobposting #LinkedIn #Jobvacancy #Jobalert #Openings #Jobsearch Send Your Resume: [email protected]
Stefan Bayne
Stefan Bayne – Senior Android Developer
Ann Arbor, MI 48105
+1-734-***-****
• 7+ Years Experience working Android.
• 5 published Apps in the Google Play Store.
• Apply in-depth understanding of HTTP and REST-style web services.
• Apply in-depth understanding of server-side software, scalability, performance, and reliability.
• Create robust automated test suites and deployment scripts.
• Considerable experience debugging and profiling Android applications.
• Apply in-depth knowledge of relational databases (Oracle, MS SQL Server, MySQL, PostgreSQL, etc.).
• Hands-on development in full software development cycle from concept to launch; requirement gathering, design, analysis, coding, testing and code review.
• Stays up to date with latest developments.
• Experience in the use several version control tools (Subversion SVN, Source Safe VSS, GIT, GitHub).
• Optimize performance, battery and CPU usage and prevented memory leaks using LeakCanary and IcePick.
• Proficient in Agile and Waterfall methodologies, working with multiple-sized teams from 3 to 10 members often with role of SCRUM master, and mentor to junior developers.
• Implement customized HTTP clients to consume a Web Resource with Retrofit, Volley, OkHTTP and the native HttpURLConnection.
• Implement Dependency Injection frameworks to optimize the unit testing and mocking processes
(Dagger, Butter Knife, RoboGuice, Hilt).
• Experienced with third-party APIs and web services like Volley, Picasso, Facebook, Twitter, YouTube Player and Surface View.
• Android app development using Java and Android SDK compatible across multiple Android versions.
• Hands-on with Bluetooth.
• Apply architectures such as MVVM and MVP.
• Appy design patterns such as Singleton, Decorator, Façade, Observer, etc. Willing to relocate: Anywhere
Work Experience
Senior Android Developer
Domino’s Pizza, Inc. – Ann Arbor, MI
August 2020 to Present
https://play.google.com/store/apps/details?id=com.modinospizza&hl=en_US
· Reviewed Java code base and refactored Java arrays to Kotlin.
· Began refactoring modules of the Android mobile application from Java to Kotlin.
· Worked in Android Studio IDE.
· Implemented Android Jetpack components, Room, and LiveView.
· Implemented ThreadPool for Android app loading for multiple parallel calls.
· Utilized Gradle for managing builds.
· Made use of Web Views for certain features and inserted Javascript code into them to perform specific tasks.
· Used Broadcast to send information across multiple parts of the app.
· Implemented Location Services for geolocation and geofencing.
· Decoupled the logics from tangled code and created a Java library for use in different projects.
· Transitioned architecture from MVP to MVVM architecture.
· Used Spring for Android as well as Android Annotations.
· Implemented push notification functionality using Google Cloud Messaging (GCM).
· Incorporated Amazon Alexa into the Android application for easy ordering.
· Developed Domino’s Tracker ® using 3rd-party service APIs to allow users to see the delivery in progress.
· Handled implementation of Google Voice API for voice in dom bot feature.
· Used Jenkins pipelines for Continuous Integration and testing on devices.
· Performed unit tests with JUnit and automated testing with Espresso.
· Switching from manual JSON parsing into automated parsers and adapting the existing code to use new models.
· Worked on Android app permissions and implementation of deep linking. Senior Android Mobile Application Developer
Carnival – Miami, FL
April 2018 to August 2020
https://play.google.com/store/apps/details?id=com.carnival.android&hl=en_CA&gl=US
· Used Android Studio to review codes from server side and compile server binary.
· Worked with different team (server side, application side) to meet the client requirements.
· Implemented Google Cloud Messaging for instant alerts for the customers.
· Implemented OAuth and authentication tokens.
· Implemented entire feature using Fragments and Custom Views.
· Used sync adapters to load changed data from server and to send modified data to server from app.
· Implemented RESTful API to consume RESTful web services to retrieve account information, itinerary, and event schedules, etc.
· Utilized RxJava and Retrofit to manage communication on multiple threads.
· Used Bugzilla to track open bugs/enhancements.
· Debugged Android applications to refine logic and codes for efficiency/betterment.
· Created documentation for admin and end users on the application and server features and use cases.
· Worked with Broadcast receiver features for communication between application Android OS.
· Used Content provider to access and maintain data between applications and OS.
· Used saved preference features to save credential and other application constants.
· Worked with FCM and Local server notification system for notification.
· Used Git for version control and code review.
· Documented release notes for Server and Applications. Android Mobile Application Developer
Sonic Ind. Services – Oklahoma, OK
May 2017 to April 2018
https://play.google.com/store/apps/details?id=com.sonic.sonicdrivein
· Used Bolts framework to perform branching, parallelism, and complex error handling, without the spaghetti code of having many named callbacks.
· Generated a custom behavior in multiple screens included in the CoordinatorLayout to hide the Toolbar and the Floating Action Button on the user scroll.
· Worked in Java and Kotlin using Android Studio IDE.
· Utilized OkHTTP, Retrofit, and Realm database library to implement on-device data store with built-in synchronization to backend data store feature.
· Worked with lead to integrate Kochava SDK for mobile install attribution and analytics for connected devices.
· Implemented authentication support with the On-Site server using a Bound Service and an authenticator component, OAuth library.
· Coded in Clean Code Architecture on domain and presentation layer in MVP and apply builder, factory, façade, design patterns to make code loosely coupled in layer communication (Dependency principle).
· Integrated PayPal SDK and card.io to view billing history and upcoming payment schedule in custom view.
· Added maps-based data on Google Maps to find the closest SONIC Drive-In locations in user area and see their hours.
· Included Splunk MINT to collect crash, track all HTTP and HTTPS calls, monitor fail rate trends and send it to Cloud server.
· Coded network module using Volley library to mediate the stream of data between different API Components, supported request prioritization and multiple concurrent network connections.
· Used Firebase Authentication for user logon and SQL Cipher to encrypt transactional areas.
· Used Paging library to load information on demand from data source.
· Created unit test cases and mock object to verify that the specified conditions are met and capture arguments of method calls using Mockito framework.
· Included Google Guice dependency injection library for to inject presenters in views, make code easier to change, unit test and reuse in other contexts.
Android Application Developer
Plex, Inc. – San Francisco, CA
March 2016 to May 2017
https://play.google.com/store/apps/details?id=com.plexapp.android&hl=en
· Implemented Android app in Eclipse using MVP architecture.
· Use design patterns Singleton, and Decorator.
· Used WebViews, ListViews, and populated lists to display the lists from database using simple adapters.
· Developed the database wrapper functions for data staging and modeled the data objects relevant to the mobile application.
· Integrated with 3rd-Party libraries such as MixPanel and Flurry analytics.
· Replaced volley by Retrofit for faster JSON parsing.
· Worked on Local Service to perform long running tasks without impact to the UI thread.
· Involved in testing and testing design for the application after each sprint.
· Implemented Robolectric to speed-up unit testing.
· Used Job Scheduler to manage resources and optimize power usage in the application.
· Used Shared preferences and SQLite for data persistence and securing user information.
· Used Picasso for efficient image loading
· Provided loose coupling using Dagger dependency injection lib from Google
· Tuned components for high performance and scalability using techniques such as caching, code optimization, and efficient memory management.
· Cleaned up code to make it more efficient, scalable, reusable, consistent, and managed the code base with Git and Jenkins for continuous integration.
· Used Google GSON to parse JSON files.
· Tested using emulator and device testing with multiple versions and sizes with the help of ADB.
· Used Volley to request data from the various APIs.
· Monitored the error logs using Log4J and fixed the problems. Android Application Software Developer
SunTrust Bank – Atlanta, GA
February 2015 to March 2016
https://play.google.com/store/apps/details?id=com.suntrust.mobilebanking
· Used RESTful APIs to communicate with web services and replaced old third-party libraries versions with more modern and attractive ones.
· Followed Google Material Design Guidelines, added an Action Bar to handle external and constant menu items related to the Android app’s current Activity and extra features.
· Implemented changes to the Android Architecture of some legacy data structures to better support our primary user cases.
· Utilized Parcelables for object transfers within Activities.
· Used Crashlytics to track user behavior and obtain mobile analytics.
· Automated payment integration using Google Wallet and PayPal API for Android.
· Used certificate pinning and AES encryption for security in Android mobile apps.
· Added Trust Manager to support SSL/TLS connection for the Android app connection.
· Stored user credentials with Keychain.
· Use of Implicit Intents, ActionBar tabs with Fragments.
· Utilized Git version control tool as source control management system,
· Used a Jenkins instance for continuous integration to ensure quality methods.
· Utilized Dagger for dependency injection in Android mobile app.
· Used GSON library to deserialize JSON information.
· Utilized JIRA as the issue tracker, and for epics, stories, and tasks and backlog to manage the project for the Android development team.
Education
Bachelor’s degree in Computer Science
Florida A&M University
Skills
• Languages: Java, Kotlin
• IDE/Dev: Eclipse, Android Studio, IntelliJ
• Design Standards: Material Design
• TDD
• JIRA
• Continuous Integration
• Kanban
• SQLite
• MySQL
• Firebase DB
• MVP
• MVC
• MVVM
• Git
• GitHub
• SVN
• Bitbucket
• SourceTree
• REST
• SOAP
• XML
• JSON
• GSON
• Retrofit
• Loopers
• Loaders
• AsyncTask
• Intent Service
• RxJava
• Dependency Injection
• EventBus
• Dagger
• Crashlytics
• Mixpanel
• Material Dialogs
• RxCache
• Retrofit
• Schematic
• Smart TV
• Certificate Pinning
• MonkeyRunner
• Bluetooth Low Energy
• ExoPlayer
• SyncAdapters
• Volley
• IcePick
• Circle-CI
• Samsung SDK
• Glide
• VidEffects
• JUnit
• Ion
• GSON
• ORMLite
• Push Notifications
• Kickflip
• SpongyCastle
• Parse
• Flurry
• Twitter
• FloatingActionButton
• Espresso
• Fresco
• Moshi
• Jenkins
• UIAutomator
• Parceler
• Marshmallow
• Loaders
• Android Jetpack
• Room
• LiveView
• JobScheduler
• ParallaxPager
• XmlPullParser
• Google Cloud Messaging
• LeakCanary
Certifications and Licenses
Certified Scrum Master
Contact this candidate
Apply Now
0 notes
Video
tumblr
RChilli Resume Parser helps ATS make the recruitment process streamlined and uniform. RChilli's parsing API helps to extract documents into more than 140+ fields. The data is stored in XML or JSON format in the database. RChilli Resume Parser helps ATS make the recruitment process streamlined.
#ResumeParser HRTechTool ATS HRTechnology Recruiting ResumeParsingtool scalableparsing cvparssingsoftware#AIandautomation#resumeparser#hrtechnology#resumeparsingtool#scalableparsing#cvparsingsoftware#automatedresumeparsing#talentacquisition
0 notes
Text
How an AI Powered Resume Parser Platform Can Help Your Enterprise
The parsing of resumes — manually sifting through hundreds of resumes to make note of the most relevant bits of information – is the most time-consuming component of the recruitment process. This leads one to wonder if there is a method to automate this process so that the Recruitment team can spend more time and effort on more vital responsibilities. The fact is that, owing to automated resume parser software, recruitment teams in new age businesses have reason to rejoice. When it comes to resume parsing, however, the most important issue is accuracy, and this is something that cannot be overlooked.
The Digital Resume Parser, on the other hand, is a solution from The Digital Group that ensures the speed and precision of the resume parsing process.
How a Resume Parsing Platform Works
A powerful AI-based resume parser software provides an automated solution for extracting intelligent data from candidate resumes, freeing HR and Recruitment teams from the time-consuming human data extraction process. By automating the data extraction, processing, and storage processes, the team saves time and effort. The data is extracted and converted into machine-readable formats.
The resumes that the hiring team receives come from a range of sources and in a variety of formats. This is a challenging situation, but the AI platform will learn to detect different types of resumes over time in order to enhance efficiency. A resume parser platform, such as Digital Resume Parser, extracts important information from resumes while also categorising it into predefined categories.
A resume parsing platform allows users to upload resumes into your applicant database in a variety of ways.
You can import a single resume from your PC to parse the candidate profile and add it to your database. You can also import, parse, and add resume data from the configured Outlook mailbox to the candidate database with a single click using the DRP Outlook Add-in.
Bulk Import of Resumes
Learn how to import a large number of resumes in a short amount of time. To fill your candidate database, start sourcing new applications or use existing résumé files. You can send the DRP API as many resumes as you like, and it will parse them all in no time!
Verification of Redundant Record
A resume parsing platform includes a resume data extraction tool that aids in reducing redundancy. When you import a résumé, it's possible that the applicant information you're looking for is already in your candidate database. Tell DRP if the duplicate resume should be overwritten or added as a duplicate record. Bulk Import and the Outlook Add-in for parsing candidate resumes are two more time-saving options.
If you are looking for faster and accurate resume parsing, visit the website of Digital Resume Parser. It is a platform that will help you make the recruitment process faster and more efficient.
0 notes
Text
Los 30 Mejores Software Gratuitos de Web Scraping en 2021
El Web scraping (también denominado extracción datos de una web, web crawler, web scraper o web spider) es una web scraping técnica para extraer datos de una página web . Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en database.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
Tabla de Contenido
Beautiful Soup
Octoparse
Import.io
Mozenda
Parsehub
Crawlmonster
Connotate
Common Crawl
Crawly
Content Grabber
Diffbot
Dexi.io
DataScraping.co
Easy Web Extract
FMiner
Scrapy
Helium Scraper
Scrape.it
Scrapinghub
Screen-Scraper
Salestools.io
ScrapeHero
UniPath
Web Content Extractor
WebHarvy
Web Scraper.io
Web Sundew
Winautomation
Web Robots
1. Beautiful Soup
Para quién sirve: desarrolladores que dominan la programación para crear un web spider/web crawler.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
Esta tabla resume las ventajas y desventajas de cada parser:-
ParserUso estándarVentajasDesventajas
html.parser (puro)BeautifulSoup(markup, "html.parser")
Pilas incluidas
Velocidad decente
Leniente (Python 2.7.3 y 3.2.)
No es tan rápido como lxml, es menos permisivo que html5lib.
HTML (lxml)BeautifulSoup(markup, "lxml")
Muy rápido
Leniente
Dependencia externa de C
XML (lxml)
BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup, "xml")
Muy rápido
El único parser XML actualmente soportado
Dependencia externa de C
html5lib
BeautifulSoup(markup, "html5lib")
Extremadamente indulgente
Analizar las páginas de la misma manera que lo hace el navegador
Crear HTML5 válido
Demasiado lento
Dependencia externa de Python
2. Octoparse
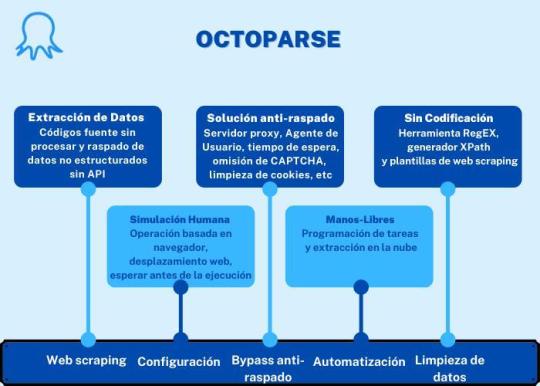
Para quién sirve: Las empresas o las personas tienen la necesidad de captura estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puedes usar para capturar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates de los sitios web más populares de países hispanohablantes para usar, como Amazon.es, Idealista, Indeed.es, Mercadolibre y muchas otras. Octoparse también proporciona servicio de datos web. Puedes personalizar tu tarea de crawler según tus necesidades de scraping.
PROS
Interfaz limpia y fácil de usar con un panel de flujo de trabajo simple
Facilidad de uso, sin necesidad de conocimientos especiales
Capacidades variables para el trabajo de investigación
Plantillas de tareas abundantes
Extracción de nubes
Auto-detección
CONS
Se requiere algo de tiempo para configurar la herramienta y comenzar las primeras tareas
3. Import.io
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite extraer datos de una web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
PROS
Colaboración con un equipo
Muy eficaz y preciso cuando se trata de extraer datos de grandes listas de URL
Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
Es necesario reintroducir una aplicación de escritorio, ya que recientemente se basó en la nube
Los estudiantes tuvieron tiempo para comprender cómo usar la herramienta y luego dónde usarla.
4. Mozenda
Para quién sirve: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué deberías usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
PROS
Creación dinámica de agentes
Interfaz gráfica de usuario limpia para el diseño de agentes
Excelente soporte al cliente cuando sea necesario
CONS
La interfaz de usuario para la gestión de agentes se puede mejorar
Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica
Solo Windows
5. Parsehub
Para quién sirve: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-scraping.
PROS
Tener un excelente boaridng que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas
Plataforma cruzada, para Windows, Mac y Linux
No necesita conocimientos básicos de programación para comenzar
Soporte al usuario de muy alta calidad
CONS
No se puede importar / exportar la plantilla
Tener una integración limitada de javascript / regex solamente
6. Crawlmonster
Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite escanear sitios web y analizar el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
PROS
Facilidad de uso
Atención al cliente
Resumen y publicación de datos
Escanear el sitio web en busca de todo tipo de puntos de datos
CONS
Funcionalidades no son tan completas
7. Connotate
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Connotate ha estado trabajando junto con Import.io, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a scrapear, recopilar y manejar los datos.
PROS
Fácil de usar, especialmente para no programadores
Los datos se reciben a diario y, por lo general, son bastante limpios y fáciles de procesar
Tiene el concepto de programación de trabajos, que ayuda a obtener datos en tiempos programados
CONS
Unos cuantos glitches con cada lanzamiento de una nueva versión provocan cierta frustración
Identificar las faltas y resolverlas puede llevar más tiempo del que nos gustaría
8. Common Crawl
Para quién sirve: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501 (c) (3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué deberías usarlo: Crawly proporciona un servicio automático que scrape un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
Análisis de demanda
Investigación de fuentes de datos
Informe de resultados
Personalización del robot
Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación.
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
PROS
Fácil de usar, no requiere habilidades especiales de programación
Capaz de raspar sitios web de datos específicos en minutos
Debugging avanzado
Ideal para raspados de bajo volumen de datos de sitios web
CONS
No se pueden realizar varios raspados al mismo tiempo
Falta de soporte
11. Diffbot
Para quién sirve: Desarrolladores y empresas.
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
PROS
Información precisa actualizada
API confiable
Integración de Diffbot
CONS
La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable
12. Dexi.io
Para quién sirve: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
PROS
Fácil de empezar
El editor visual hace que la automatización web sea accesible para las personas que no están familiarizadas con la codificación
Integración con Amazon S3
CONS
La página de ayuda y soporte del sitio no cubre todo
Carece de alguna funcionalidad avanzada
13. DataScraping.co
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Data Scraping Studio es un software web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux
14. Easy Web Extract
Para quién sirve: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Easy Web Extract es un software visual de scraping y crawling para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
Agregación y publicación de datos
Extracción de direcciones de correo electrónico
Extracción de imágenes
Extracción de dirección IP
Extracción de número de teléfono
Extracción de datos web
15. FMiner
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
PROS
Herramienta de diseño visual
No se requiere codificación
Características avanzadas
Múltiples opciones de navegación de rutas de rastreo
Listas de entrada de palabras clave
CONS
No ofrece formación
16. Scrapy
Para quién sirve: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
PROS
Construido sobre Twisted, un marco de trabajo de red asincrónico
Rápido, las arañas scrapy no tienen que esperar para hacer solicitudes una a la vez
CONS
Scrapy es solo para Python 2.7. +
La instalación es diferente para diferentes sistemas operativos
17. Helium Scrape
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
Capturar datos complejos
Extracción rápida
Capturar datos complejos
Extracción rápida
Flujo de trabajo simple
Capturar datos complejos
18. Scrape.it
Para quién sirve: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
PROS
Soporte móvil
Agregación y publicación de datos
Automatizará todo el sitio web para ti
CONS
El precio es un poco alto
19. ScraperWiki
Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambian el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (anteriormente Scrapinghub)
Para quién sirve: Python/Desarrolladores de web scraping
Por qué deberías usarlo: Zyte es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
PROS
La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad
El panel de trabajo es fácil de entender
La efectividad
CONS
No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash
No hay una solución simple para el rastreo distribuido / de gran volumen
Falta de monitoreo y alerta.
21. Screen-Scraper
Para quién sirve: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
PROS
Sencillo de ejecutar - se puede recopilar una gran cantidad de información hecha una vez
Económico - el raspado brinda un servicio básico que requiere poco o ningún esfuerzo
Precisión - los servicios de raspado no solo son rápidos, también son exactos
CONS
Difícil de analizar - el proceso de raspado es confuso para obtenerlo si no eres un experto
Tiempo - dado que el software tiene una curva de aprendizaje
Políticas de velocidad y protección - una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web
22. Salestools.io
Para quién sirve: Comercializador y ventas.
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
PROS
Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados
Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM
Ser capaz de integrarse de manera eficiente con CRM Pipedrive
CONS
La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos la primera vez
El servicio necesita bastantes interacciones para obtener el valor total
23. ScrapeHero
Para quién sirve: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué deberías usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
PROS
La calidad y consistencia del contenido entregado es excelente
Buena capacidad de respuesta y atención al cliente
Tiene buenos analizadores disponibles para la conversión de documentos a texto
CONS
Limited functionality in terms of what it can do with RPA, it is difficult to implement in use cases that are non traditional
Los datos solo vienen como un archivo CSV
24. UniPath
Para quién sirve: Negocios con todos los tamaños
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
Conversión del valor FPKM de expresión génica en valor P
Combinación de valores P
Ajuste de valores P
ATAC-seq de celda única
Puntuaciones de accesibilidad global
Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
PROS
Fácil de usar para la mayoría de los casos que puede encontrar en web scraping
Raspar un sitio web con un simple clic y obtendrá tus resultados de inmediato
Su soporte responderá a tus preguntas relacionadas con el software
CONS
El tutorial de youtube fue limitado
26. Webharvy
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: WebHarvy es un web scraping software de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
PROS
Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente
Perfecto para raspar correos electrónicos y clientes potenciales
La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa
CONS
A menudo no es obvio cómo funciona una función
Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente
27. Web Scraper.io
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
PROS
Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles
Funciona con una interfaz limpia y sencilla
El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos
CONS
Tiene alguna curva de aprendizaje
No para organizaciones
28. Web Sundew
Para quién sirve: Empresas, comercializadores e investigadores.
Por qué deberías usarlo: WebSundew es una herramienta de crawly web scraper visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
Interfaz fácil de apuntar y hacer clic
Extraer cualquier dato web sin una línea de codificación
Desarrollado por Modern Web Engine
Software de plataforma agnóstico
29. Winautomation
Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué deberías usarlo: Winautomation es una herramienta de web scraper parsers de Windows que le permite automatizar tareas de escritorio y basadas en la web.
PROS
Automatizar tareas repetitivas
Fácil de configurar
Flexible para permitir una automatización más complicada
Se notifica cuando un proceso ha fallado
CONS
Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento
La funcionalidad FTP es útil pero complicada
Ocasionalmente pierde la pista de las ventanas de la aplicación
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
PROS
Ejecutarse en tu navegador Chrome o Edge como extensión
Localizar y extraer automáticamente datos de páginas web
SLA garantizado y excelente servicio al cliente
Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente
CONS
Solo en la nube, SaaS, basado en web
Falta de tutoriales, no tiene videos
1 note
·
View note
Photo
Chrome releases back on, form controls to get some polish in M81 and M83
#434 — April 1, 2020
Read on the Web
Frontend Focus
Updates to Form Controls and Focus in Chrome — Here’s a closer look at the recent changes introduced to HTML form controls within Chrome, designed to “beautiful, webby, and neutral”. They bring with them a host of accessibility wins, touch support, and more consistent keyboard access.
Rob Dodson (Google)
Google to Resume Chrome Updates It Paused Due to COVID-19 — Chrome 81 will now be released on April 7. Here's the official blog post from Google announcing that releases are now resuming.
Catalin Cimpanu (ZDNet)
Check Now to See If Your .TECH Domain Is Available — .TECH is the most definitive domain extension for the tech industry with the likes of Intel, CES and Viacom using it. Secure your online tech namespace before it’s gone. Use code frontendfocus for 80% off on 1 & 5 Year .TECH domains.
.TECH Domains sponsor
TOAST UI Editor 2.0: A Powerful WYSIWYG Markdown Editor — Two years in comes version 2.0, along with 10K GitHub stars to boot. v2.0 has a new Markdown parser, better syntax highlighting, improved scroll syncing and live previews, and more. GitHub repo.
NHN
Mozilla Re-Enables TLS 1.0 and 1.1 Because of Coronavirus (and Google) — TLS 1.0 and 1.1 has been re-enabled in the Firefox Stable and Beta browser because of Google and government sites that still rely on these protocols. Google has taken a similar, temporary, step due to the COVID-19 crisis, too.
Martin Brinkmann (gHacks)
What Should You Do When a Web Design Trend Becomes Too Popular? — This guide aims to help you figure out which approach makes the most sense when considering popular design trends for your site.
Suzanne Scacca
How to Improve Page Speed from Start to Finish — In this advanced guide Patrick Stox explains how page speed works, and what actions to take for your site.
Ahrefs
📮 Introducing JAMstacked..
It's not often we launch a new newsletter, but JAMstacked is a new email digest from us covering the JavaScript, API, and Markup (i.e. JAMstack) movement. Issue 2 is landing in inboxes tomorrow (Thursday) but you can check out issue 1 here. Brian Rinaldi will bring you a concise round-up on the evolving JAMstack ecosystem — and you can sign up here.
💻 Jobs
Frontend Developer at X-Team (Remote) — Join X-Team and work on projects for companies like Riot Games, FOX, Coinbase, and more. Work from anywhere.
X-Team
Find a Job Through Vettery — Vettery specializes in tech roles and is completely free for job seekers. Create a profile to get started.
Vettery
▶ Get ready for your next role with PluralSight: Start a free ten-day trial on the technology skills platform. — SPONSORED
📙 News, Tutorials & Opinion
The Top 10 Reasons to Switch to The New Microsoft Edge — Yep, this is a feature list trying to convince folks to give Edge a try. I didn’t know about a few of the things Edge now offers, including an interesting ‘vertical tabs’ mode.
Liat Ben-Zur
What Does playsinline Mean in Web Video? — Have you noticed how sometimes in mobile browsers a video will play right where it is instead of the fullscreen default? Here’s how that works.
Chris Coyier
Inclusive Inputs — An exploration into how to make inputs more accessible, touching upon semantic HTML and a bit of ARIA.
Oscar Braunert
Making a Responsive Twitch Embed — This works mainly as a refresher on how to do intrinsic aspect ratio sizing in CSS for any embedded media, but it’s specific to Twitch embeds.
Phil Nash
The Fastest Way to Get Great Bug Reports from the Non-Technical Folk — Simply click an element to provide actionable feedback with screenshots & metadata pinned to the task. Try free for 14 days.
BugHerd sponsor
HTML DOM: A Resource for Solving DOM Problems with Native APIs — A guide with a list of different things we might normally do with a JavaScript library, but can now be done using native APIs.
Nguyen Huu Phuoc
Bootstrap 5 Dropping IE 10 & 11 Browser Support: Where Does That Leave Us? — The upcoming version five of popular framework Bootstrap is officially dropping support for both Internet Explorer 10 and 11. Here’s a quick look at what that means for those relying on Bootstrap, and what workarounds (polyfills) to expect.
Zoltán Szőgyényi
Building a Code Editor with CodeMirror — CodeMirror is an open source project that makes it easy to build advanced text editors into your frontend apps. Here’s how to build a code editor with it and how to connect together all the pieces.
Valeri Karpov
5 Reasons Why GraphCMS Could Be Your Next Backend for MVPs — An overview about why using a backend-as-a-service like GraphCMS is a viable way to go for MVPs.
Stephen Jensen
The Perfect Partner to MongoDB Atlas. Try It for Free
Studio 3T sponsor
Designing Web Applications for the Apple Watch using Toucaan CSS Framework
Marvin Danig
How to Display Different Favicons for Your Production and Development Sites
Chris Coyier
Web Font of the Week
Source Sans Pro
Drawing inspiration from American gothic typeface designs, this is Adobe's first open-source typeface family (and is made up of 12 weights). Designed by Paul D. Hunt it was conceived primarily as a typeface for user interfaces — boasting wide-ranging language support and a focus on clarity and legibility.

🔧 Code, Tools and Resources

MoreToggles.css — A pure CSS library with plenty of stylish toggles. Here's the related GitHub page.
Enkai Ji
Bootstrap Icons Alpha 3 — Although still in alpha, this is a massive update that puts the icon library at over 500 icons and adds a permalink page for each.
Mark Otto, Jacob Thornton, and Bootstrap contributors
Animockup: Create Animated Mockups in the Browser — An open-source design tool to make animated GIFs and videos to showcase your products. Try it here.
Alyssa X
Snapfont: Chrome Extension to Test Any Font on Any Website — Based on a pay-what-you-want model, this allows you to test any of the ~900 fonts on Google Fonts or using any locally installed font.
snapfont
🗓 Events
Most, if not all, of the in-person events that we typically list here are now understandably cancelled or postponed until further notice due to the global COVID-19 outbreak.
Because of this, more events are now looking at ways to run online. In the coming weeks, we're looking to devote this section to digital events, virtual conferences, livestreams, and similar online gatherings. Please do drop us a note (just hit reply) if you have such an event that we can promote here. Even if you're doing a single scheduled talk on Twitch or YouTube Live, say, we might be able to list it.
by via Frontend Focus https://ift.tt/344g8Y8
0 notes
Photo

Nmap Defcon Release! 80+ improvements include new NSE scripts/libs, new Npcap, etc.
Fellow hackers, I'm here in Las Vegas for Defcon and delighted to release Nmap 7.80. It's the first formal Nmap release in more than a year, and I hope you find it worth the wait! The main reason for the delay is that we've been working so hard on our Npcap Windows packet capturing driver. As many of you know, Windows Nmap traditionally depended on Winpcap for packet capture. That is great software, but it has been discontinued and has seen no updates since 2013. It doesn't always work on Windows 10, and it depends on long-deprecated Windows API's that Microsoft could remove at any time. So we've spent the last few years building our own Npcap raw packet capturing/sending driver, starting with Winpcap as the base. It uses modern APIs and is more performant as well as more secure and more featureful. We've had 15 Npcap releases since Nmap 7.70 and we're really happy with where it is now. Even Wireshark switched to Npcap recently. More details on Npcap can be found at https://npcap.org. But Windows users aren't the only ones benefiting from this new Nmap release. It includes 80+ cross-platform improvements you can read about below, including 11 new NSE scripts, a bunch of new libraries, bug fixes and performance improvements. map 7.80 source code and binary packages for Linux, Windows, and Mac are available for free download from the usual spot: https://nmap.org/download.html If you find any bugs in this release, please let us know on the Nmap Dev list or bug tracker as described at https://nmap.org/book/man-bugs.html. Here is the full list of significant changes since 7.70: map 7.70 source code and binary packages for Linux, Windows, and Mac are available for free download from the usual spot: https://nmap.org/download.html If you find any bugs in this release, please let us know on the Nmap Dev list or bug tracker as described at https://nmap.org/book/man-bugs.html. Here is the full list of significant changes: o [Windows] The Npcap Windows packet capturing library (https://npcap.org/) is faster and more stable than ever. Nmap 7.80 updates the bundled Npcap from version 0.99-r2 to 0.9982, including all of these changes from the last 15 Npcap releases: https://nmap.org/npcap/changelog o [NSE] Added 11 NSE scripts, from 8 authors, bringing the total up to 598! They are all listed at https://nmap.org/nsedoc/, and the summaries are below: + [GH#1232] broadcast-hid-discoveryd discovers HID devices on a LAN by sending a discoveryd network broadcast probe. [Brendan Coles] + [GH#1236] broadcast-jenkins-discover discovers Jenkins servers on a LAN by sending a discovery broadcast probe. [Brendan Coles] + [GH#1016][GH#1082] http-hp-ilo-info extracts information from HP Integrated Lights-Out (iLO) servers. [rajeevrmenon97] + [GH#1243] http-sap-netweaver-leak detects SAP Netweaver Portal with the Knowledge Management Unit enabled with anonymous access. [ArphanetX] + https-redirect detects HTTP servers that redirect to the same port, but with HTTPS. Some nginx servers do this, which made ssl-* scripts not run properly. [Daniel Miller] + [GH#1504] lu-enum enumerates Logical Units (LU) of TN3270E servers. [Soldier of Fortran] + [GH#1633] rdp-ntlm-info extracts Windows domain information from RDP services. [Tom Sellers] + smb-vuln-webexec checks whether the WebExService is installed and allows code execution. [Ron Bowes] + smb-webexec-exploit exploits the WebExService to run arbitrary commands with SYSTEM privileges. [Ron Bowes] + [GH#1457] ubiquiti-discovery extracts information from the Ubiquiti Discovery service and assists version detection. [Tom Sellers] + [GH#1126] vulners queries the Vulners CVE database API using CPE information from Nmap's service and application version detection. [GMedian, Daniel Miller] o [GH#1291][GH#34][GH#1339] Use pcap_create instead of pcap_live_open in Nmap, and set immediate mode on the pcap descriptor. This solves packet loss problems on Linux and may improve performance on other platforms. [Daniel Cater, Mike Pontillo, Daniel Miller] o [NSE] Collected utility functions for string processing into a new library, stringaux.lua. [Daniel Miller] o [NSE] New rand.lua library uses the best sources of random available on the system to generate random strings. [Daniel Miller] o [NSE] New library, oops.lua, makes reporting errors easy, with plenty of debugging detail when needed, and no clutter when not. [Daniel Miller] o [NSE] Collected utility functions for manipulating and searching tables into a new library, tableaux.lua. [Daniel Miller] o [NSE] New knx.lua library holds common functions and definitions for communicating with KNX/Konnex devices. [Daniel Miller] o [NSE][GH#1571] The HTTP library now provides transparent support for gzip- encoded response body. (See https://github.com/nmap/nmap/pull/1571 for an overview.) [nnposter] o [Nsock][Ncat][GH#1075] Add AF_VSOCK (Linux VM sockets) functionality to Nsock and Ncat. VM sockets are used for communication between virtual machines and the hypervisor. [Stefan Hajnoczi] o [Security][Windows] Address CVE-2019-1552 in OpenSSL by building with the prefix "C:\Program Files (x86)\Nmap\OpenSSL". This should prevent unauthorized users from modifying OpenSSL defaults by writing configuration to this directory. o [Security][GH#1147][GH#1108] Reduced LibPCRE resource limits so that version detection can't use as much of the stack. Previously Nmap could crash when run on low-memory systems against target services which are intentionally or accidentally difficult to match. Someone assigned CVE-2018-15173 for this issue. [Daniel Miller] o [GH#1361] Deprecate and disable the -PR (ARP ping) host discovery option. ARP ping is already used whenever possible, and the -PR option would not force it to be used in any other case. [Daniel Miller] o [NSE] bin.lua is officially deprecated. Lua 5.3, added 2 years ago in Nmap 7.25BETA2, has native support for binary data packing via string.pack and string.unpack. All existing scripts and libraries have been updated. [Daniel Miller] o [NSE] Completely removed the bit.lua NSE library. All of its functions are replaced by native Lua bitwise operations, except for `arshift` (arithmetic shift) which has been moved to the bits.lua library. [Daniel Miller] o [NSE][GH#1571] The HTTP library is now enforcing a size limit on the received response body. The default limit can be adjusted with a script argument, which applies to all scripts, and can be overridden case-by-case with an HTTP request option. (See https://github.com/nmap/nmap/pull/1571 for details.) [nnposter] o [NSE][GH#1648] CR characters are no longer treated as illegal in script XML output. [nnposter] o [GH#1659] Allow resuming nmap scan with lengthy command line [Clément Notin] o [NSE][GH#1614] Add TLS support to rdp-enum-encryption. Enables determining protocol version against servers that require TLS and lays ground work for some NLA/CredSSP information collection. [Tom Sellers] o [NSE][GH#1611] Address two protocol parsing issues in rdp-enum-encryption and the RDP nse library which broke scanning of Windows XP. Clarify protocol types [Tom Sellers] o [NSE][GH#1608] Script http-fileupload-exploiter failed to locate its resource file unless executed from a specific working directory. [nnposter] o [NSE][GH#1467] Avoid clobbering the "severity" and "ignore_404" values of fingerprints in http-enum. None of the standard fingerprints uses these fields. [Kostas Milonas] o [NSE][GH#1077] Fix a crash caused by a double-free of libssh2 session data when running SSH NSE scripts against non-SSH services. [Seth Randall] o [NSE][GH#1565] Updates the execution rule of the mongodb scripts to be able to run on alternate ports. [Paulino Calderon] o [Ncat][GH#1560] Allow Ncat to connect to servers on port 0, provided that the socket implementation allows this. [Daniel Miller] o Update the included libpcap to 1.9.0. [Daniel Miller] o [NSE][GH#1544] Fix a logic error that resulted in scripts not honoring the smbdomain script-arg when the target provided a domain in the NTLM challenge. [Daniel Miller] o [Nsock][GH#1543] Avoid a crash (Protocol not supported) caused by trying to reconnect with SSLv2 when an error occurs during DTLS connect. [Daniel Miller] o [NSE][GH#1534] Removed OSVDB references from scripts and replaced them with BID references where possible. [nnposter] o [NSE][GH#1504] Updates TN3270.lua and adds argument to disable TN3270E [Soldier of Fortran] o [GH#1504] RMI parser could crash when encountering invalid input [Clément Notin] o [GH#863] Avoid reporting negative latencies due to matching an ARP or ND response to a probe sent after it was recieved. [Daniel Miller] o [Ncat][GH#1441] To avoid confusion and to support non-default proxy ports, option --proxy now requires a literal IPv6 address to be specified using square-bracket notation, such as --proxy [2001:db8::123]:456. [nnposter] o [Ncat][GH#1214][GH#1230][GH#1439] New ncat option provides control over whether proxy destinations are resolved by the remote proxy server or locally, by Ncat itself. See option --proxy-dns. [nnposter] o [NSE][GH#1478] Updated script ftp-syst to prevent potential endless looping. [nnposter] o [GH#1454] New service probes and match lines for v1 and v2 of the Ubiquiti Discovery protocol. Devices often leave the related service open and it exposes significant amounts of information as well as the risk of being used as part of a DDoS. New nmap-payload entry for v1 of the protocol. [Tom Sellers] o [NSE] Removed hostmap-ip2hosts.nse as the API has been broken for a while and the service was completely shutdown on Feb 17th, 2019. [Paulino Calderon] o [NSE][GH#1318] Adds TN3270E support and additional improvements to tn3270.lua and updates tn3270-screen.nse to display the new setting. [mainframed] o [NSE][GH#1346] Updates product codes and adds a check for response length in enip-info.nse. The script now uses string.unpack. [NothinRandom] o [Ncat][GH#1310][GH#1409] Temporary RSA keys are now 2048-bit to resolve a compatibility issue with OpenSSL library configured with security level 2, as seen on current Debian or Kali. [Adrian Vollmer, nnposter] o [NSE][GH#1227] Fix a crash (double-free) when using SSH scripts against non-SSH services. [Daniel Miller] o [Zenmap] Fix a crash when Nmap executable cannot be found and the system PATH contains non-UTF-8 bytes, such as on Windows. [Daniel Miller] o [Zenmap] Fix a crash in results search when using the dir: operator: AttributeError: 'SearchDB' object has no attribute 'match_dir' [Daniel Miller] o [Ncat][GH#1372] Fixed an issue with Ncat -e on Windows that caused early termination of connections. [Alberto Garcia Illera] o [NSE][GH#1359] Fix a false-positive in http-phpmyadmin-dir-traversal when the server responds with 200 status to a POST request to any URI. [Francesco Soncina] o [NSE] New vulnerability state in vulns.lua, UNKNOWN, is used to indicate that testing could not rule out vulnerability. [Daniel Miller] o [GH#1355] When searching for Lua header files, actually use them where they are found instead of forcing /usr/include. [Fabrice Fontaine, Daniel Miller] o [NSE][GH#1331] Script traceroute-geolocation no longer crashes when www.GeoPlugin.net returns null coordinates [Michal Kubenka, nnposter] o Limit verbose -v and debugging -d levels to a maximum of 10. Nmap does not use higher levels internally. [Daniel Miller] o [NSE] tls.lua when creating a client_hello message will now only use a SSLv3 record layer if the protocol version is SSLv3. Some TLS implementations will not handshake with a client offering less than TLSv1.0. Scripts will have to manually fall back to SSLv3 to talk to SSLv3-only servers. [Daniel Miller] o [NSE][GH#1322] Fix a few false-positive conditions in ssl-ccs-injection. TLS implementations that responded with fatal alerts other than "unexpected message" had been falsely marked as vulnerable. [Daniel Miller] o Emergency fix to Nmap's birthday announcement so Nmap wishes itself a "Happy 21st Birthday" rather than "Happy 21th" in verbose mode (-v) on September 1, 2018. [Daniel Miller] o [GH#1150] Start host timeout clocks when the first probe is sent to a host, not when the hostgroup is started. Sometimes a host doesn't get probes until late in the hostgroup, increasing the chance it will time out. [jsiembida] o [NSE] Support for edns-client-subnet (ECS) in dns.lua has been improved by: - [GH#1271] Using ECS code compliant with RFC 7871 [John Bond] - Properly trimming ECS address, as mandated by RFC 7871 [nnposter] - Fixing a bug that prevented using the same ECS option table more than once [nnposter] o [Ncat][GH#1267] Fixed communication with commands launched with -e or -c on Windows, especially when --ssl is used. [Daniel Miller] o [NSE] Script http-default-accounts can now select more than one fingerprint category. It now also possible to select fingerprints by name to support very specific scanning. [nnposter] o [NSE] Script http-default-accounts was not able to run against more than one target host/port. [nnposter] o [NSE][GH#1251] New script-arg `http.host` allows users to force a particular value for the Host header in all HTTP requests. o [NSE][GH#1258] Use smtp.domain script arg or target's domain name instead of "example.com" in EHLO command used for STARTTLS. [gwire] o [NSE][GH#1233] Fix brute.lua's BruteSocket wrapper, which was crashing Nmap with an assertion failure due to socket mixup [Daniel Miller]: nmap: nse_nsock.cc:672: int receive_buf(lua_State*, int, lua_KContext): Assertion `lua_gettop(L) == 7' failed. o [NSE][GH#1254] Handle an error condition in smb-vuln-ms17-010 caused by IPS closing the connection. [Clément Notin] o [Ncat][GH#1237] Fixed literal IPv6 URL format for connecting through HTTP proxies. [Phil Dibowitz] o [NSE][GH#1212] Updates vendors from ODVA list for enip-info. [NothinRandom] o [NSE][GH#1191] Add two common error strings that improve MySQL detection by the script http-sql-injection. [Robert Taylor, Paulino Calderon] o [NSE][GH#1220] Fix bug in http-vuln-cve2006-3392 that prevented the script to generate the vulnerability report correctly. [rewardone] o [NSE][GH#1218] Fix bug related to screen rendering in NSE library tn3270. This patch also improves the brute force script tso-brute. [mainframed] o [NSE][GH#1209] Fix SIP, SASL, and HTTP Digest authentication when the algorithm contains lowercase characters. [Jeswin Mathai] o [GH#1204] Nmap could be fooled into ignoring TCP response packets if they used an unknown TCP Option, which would misalign the validation, causing it to fail. [Clément Notin, Daniel Miller] o [NSE]The HTTP response parser now tolerates status lines without a reason phrase, which improves compatibility with some HTTP servers. [nnposter] o [NSE][GH#1169][GH#1170][GH#1171]][GH#1198] Parser for HTTP Set-Cookie header is now more compliant with RFC 6265: - empty attributes are tolerated - double quotes in cookie and/or attribute values are treated literally - attributes with empty values and value-less attributes are parsed equally - attributes named "name" or "value" are ignored [nnposter] o [NSE][GH#1158] Fix parsing http-grep.match script-arg. [Hans van den Bogert] o [Zenmap][GH#1177] Avoid a crash when recent_scans.txt cannot be written to. [Daniel Miller] o Fixed --resume when the path to Nmap contains spaces. Reported on Windows by Adriel Desautels. [Daniel Miller] o New service probe and match lines for adb, the Android Debug Bridge, which allows remote code execution and is left enabled by default on many devices. [Daniel Miller] Enjoy this new release and please do let us know if you find any problems! Download link: https://nmap.org/download.html Cheers, Fyodor
Source code: https://seclists.org/nmap-announce/2019/0
When more information is available our blog will be updated.
Read More Cyber New’s Visit Our Facebook Page Click the Link : https://www.facebook.com/pages/Cyber-crew/780504721973461
Read More Cyber New’sVisit Our Twitter Page Click the Link : https://twitter.com/Cyber0Crew
~R@@T @CCE$$~
1 note
·
View note
Photo

Integrate our AI-based data extraction functionality into your apps and workflows. Get your free API key, and add automated intelligence to your hiring pipeline.
#Resume Parser API#Resume Parser#resume extractor#parse resume#cv parser api#resume parser online#resume extraction#best resume parsing software#free resume parsing software#cv parsing tool#resume parser using nlp#best cv parser
0 notes
Photo

Affinda’s CV formatting technology rapidly applies consistent branding to whole batches of résumés for candidate submissions — giving you more time to recruit and place candidates. Click here to know more regarding affinda resume templater.
0 notes
Text
Version 501
youtube
windows
Qt5 zip
Qt6 zip
Qt6 exe
macOS
Qt5 app
Qt6 app
linux
Qt5 tar.gz
Qt6 tar.gz
I had a good week working on a mix of important bug fixes and UI quality of life.
highlighted fixes
First off, I have rewritten the guts of the popup toaster. It looks the same, but now it is more 'embedded' into the main gui window and I completely overhauled its layout system. I strongly hope that this will eliminate a variety of jank that has occured over the years, from odd activation/focus issues to weird width sizing to unusual popup locations. If you have had trouble with popup messages, let me know how things work today!
Next, due to a change behind the scenes in another library, the Windows build wouldn't boot last week and needed a hotfix. The Linux build seems to have suffered from a similar issue, so I have fixed both. If you had trouble booting v500 Linux, I am sorry--please try again today. The macOS release uses a different system and was unaffected.
I fixed a bug (and sometimes crash) when opening file selection dialogs for users running from source with PyQt6. Thank you for the reports!
I fixed a crash that was affecting many users (including myself a couple times, I now realise) when performing some options-saving events such as pausing/resuming subscriptions, repositories, or import/export folders. I was finally able to reproduce this reliably as I was putting the release together today. Thank you very much to the users for the reports here, I would not have figured it out but for what you discovered. It turns out it was the collect-by control doing it, so its ability to update itself without a client restart is disabled for now.
I fixed a bad bug in the manage ratings dialog, where any numerical ratings that started and ended on dialog ok in the 'mixed' (dark grey colour) state were not leaving them alone but resetting those files' ratings to the minimum allowed value (0 or 1 stars). This was an unusual bug, and I regret it a lot. I think it came in in recent weeks, when I rewrote how some rating states are handled internally.
The Deviant Art downloader broke last week. It seems like they locked away the API we were using. I have reset us to the original html parser, which still seems to work ok. Please check your DA subs and tell them to retry ignored, and let me know if there are any glaring problems.
full list
misc:
the Linux build gets the same 'cannot boot' setuptools version hotfix as last week's Windows build. sorry if you could not boot v500 on Linux! macOS never got the problem, I think because it uses pyoxidizer instead of pyinstaller
fixed the error/crash when clients running with PyQt6 (rather than the default Qt6, PySide6) tried to open file or directory selection dialogs. there was a slight method name discrepancy between the two libraries in Qt6 that we had missed, and it was sufficiently core that it was causing errors and best, crashes at worst
fixed a common crash caused after several options-saving events such as pausing/resuming subscriptions, repositories, import/export folders. thank you very much to the users who reported this, I was finally able to reproduce it an hour before the release was due. the collect control was causing the crash--its ability to update itself without a client restart is disabled for now
unfortunately, it seems Deviant Art have locked off the API we were using to get nice data, so I am reverting the DA downloader this week to the old html parser, which nonetheless still sems to work well. I expect we'll have to revisit this when we rediscover bad nsfw support or similar--let me know how things go, and you might like to hit your DA subs and 'retry ignored'
fixed a bad bug where manage rating dialogs that were launched on multiple files with disagreeing numerical ratings (where it shows the stars in dark grey), if okayed on that 'mixed' rating, rather than leaving them untouched, were resetting all those files back to the minimum allowed star value. I do not know when this bug came in, it is unusual, but I did do some rating state work a few weeks ago, so I am hoping it was then. I regret this and the inconvenience it has caused
if you manually navigate while the media viewer slideshow is running, the slideshow timer now resets (e.g. if you go 'back' on an image 7 seconds into a 10 second slideshow, it will show the previous image for 10 seconds, not 3, before moving on again)
fixed a type bug in PyQt hydrus when you tried to seek an mpv video when no file was loaded (usually happens when a seek event arrives late)
when you drop a hydrus serialised png of assorted objects onto a multi-column list, the little error where it says 'this list does not take objects of type x' now only shows once! previously, if your png was a list of objects, it could make a separate type error for each in turn. it should now all be merged properly
this import function also now presents a summary of how many objects were successfully imported
updated all ui-level ipfs multihash fetching across the program. this is now a little less laggy and uses no extra db in most cases
misc code and linter warning cleanup
.
tag right-click:
the 'edit x' entry in the tag right-click menu is now moved to the 'search' submenu with the other search-changing 'exclude'/'remove' etc.. actions
the 'edit x' entry no longer appears when you only select invertible, non-editable predicates
if you right-click on a -negated tag, the 'search' menu's action label now says 'require samus aran' instead of the awkward 'exclude -samus aran'. it will also say the neutral 'invert selection' if things get complicated
.
notes logic improvements:
if you set notes to append on conflict and the existing note already contains the new note, now no changes will be made (repeatedly parsing the same conflcting note now won't append it multiple times)
if you set notes to rename on conflict and the note already exists on another name, now no changes will be made (i.e. repeatedly parsing the same conflicting note won't create (1), (2), (3)... rename dupes)
.
client api:
/add_tags/search_tags gets a new parameter, 'tag_display_type', which lets you either keep searching the raw 'storage' tags (as you see in edit contexts like the 'manage tags' dialog), or the prettier sibling-processed 'display' tags (as you see in read contexts like a normal file search page)
/get_files/file_metadata now returns 'ipfs_multihashes' structure, which gives ipfs service key(s) and multihashes
if you run /get_files/search_files with no search predicates, or with only tags that do not parse correctly so you end up with no tags, the search now returns nothing, rather than system:everything. I will likely make this call raise errors on bad tags in future
the client api help is updated to talk about these
there's also unit tests for them
client api version is now 33
.
popup messages:
the background workings of the popup toaster are rewritten. it looks the same, but instead of technically being its own window, it is now embedded into the main gui as a raised widget. this should clear up a whole heap of jank this window has caused over the years. for instance, in some OSes/Window Managers, when a new subscription popup appeared, the main window would activate and steal focus. this annoying thing should, fingers crossed, no longer happen
I have significantly rewritten the layout routine of the popup toaster. beyond a general iteration of code cleanup, popup messages should size their width more sensibly, expand to available space, and retract better after needing to grow wide
unfortunately, some layout jank does remain, mostly in popup messages that change height significantly, like error tracebacks. they can sometimes take two frames to resize correctly, which can look flickery. I am still doing something 'bad' here, in Qt terms, and have to hack part of the layout update routine. let me know what else breaks for you, and I will revisit this in future
the 'BUGFIX: Hide the popup toaster when the main gui is minimised/loses focus' checkboxes under _options->popups_ are retired. since the toaster is now embedded into the main gui just like any search page, these issues no longer apply. I am leaving the two 'freeze the popup toaster' checkboxes in place, just so we can play around with some virtual desktop issues I know some users are having, but they may soon go too
the popup toaster components are updated to use Qt signals rather than borked object callables
as a side thing, the popup toaster can no longer grow taller than the main window size
next week
More small job catchup, and I'll try and clear some github bug reports. Let me know how the crashes are going, but my fingers crossed.
0 notes
Text
Version 336
youtube
windows
zip
exe
os x
app
linux
tar.gz
source
tar.gz
Last week, v335, was an important update. If you are updating from v334 or earlier, please go read that release post for your special one-time update instructions and update to v335 before you try this week. Once you have updated to v335, updating to anything newer is back to normal.
I had a good week. A bunch of py3-related bugs are fixed, and I improved some heavy-load throttling.
py3 fixes
Overall, last week's update went well. CPU and memory use and overall jank is down for all users, and afaik there weren't any permanent disasters in the update. This was a big relief for me.
That said, as expected, several unusual bugs related to py3's new unicode handling slipped through. Thank you for the reports. A common one was related to windows logging, another was in pixiv searching with kanji tags, another with videos with unicode metadata. I believe I have cleaned most if not all of it up. There may be a couple more out there, so please let me know if you get anything new. Otherwise, please resume any broken subs or retry any broken webm imports.
I also fixed the numerical tag ui, which was coercing all clicks to to zero or max stars, and which I messed up by accident!
better heavy workflow
The client now has a strict thread-level throttle on the number of importers that can work at once. It seperates the different sub-parts into their own max limits, but the overall total limit is about 20-40. This is in an effort to stop ui hang after accidental heavy import situations such as pasting 100+ queries into a gallery downloader. This is a 1.0 throttle and doesn't have any ui to report 'waiting on a slot' or anything. I don't expect 99% of users will even notice it, but if it affects you seriously, please let me know.
In a related note, for advanced users, gallery downloaders now have the ability to 'bundle' mass-pastes into one downloader, queueing up all the different gallery queries sequentially in the same object (rather than in many in parallel, which is what previously cluttered the ui and boshed the CPU). If you sometimes paste a bunch of single-file md5-queries at once, please check this new check menu item under the gallery downloader's cog menu.
full list
fixed an issue where the numerical rating control was coercing all clicks to either the minimum or maximum allowable rating (e.g. 3/5 stars wasn't working)
fixed some text file and process i/o, which was handling some unicode decoding/encoding incorrectly. it now mandates utf-8 in all cases
fixed a referral url encoding problem that was stopping pixiv from downloading when the gallery page url had kana/kanji characters (from a search term)
fixed a str vs bytes issue when loading the filename tagging panel
fixed the delete button on the filename tagging quick namespaces panel (the edit and delete buttons are also now 'live' and will disable when nothing is selected)
improved some json dump deserialisation code
fixed a data-sorting issue that would appear with certain parsers in the edit parsers panel
improved video metadata parsing, fixing an issue when the video has a 'title' row containing inconvenient data
fixed some hex character processing for system preds
added an advanced check item to the gallery downloader cog icon menu that will 'bundle' multiple query-pastes to the same single gallery downloader (this is helpful if you are pasting a whole bunch of md5 queries in one go and would rather one downloader work through them sequentially than 50+ separate ones blat your CPU simultaneously)
the different kinds of importer worker threads now have several limits on the max number that can be working at once, to stop accidental ui overload when a hundred or more are in memory and all want to work at once (like after a big paste event or resuming after computer sleep). during periods of heavy import activity, the importers will now naturally space themselves out to smooth out the spike. the limits are hardcoded for now, let me know if it noticeably bottlenecks your situation
made some menubar update code a bit less complicated and reduced how often it'll spam during heavy update
the 'what to do?' buttons that appear in manage tags sometimes on a tag action got a simplification pass and are now on the new dialog system
simplified my new dialog code significantly, clearing out redundant code and classes and pushing all okable/cancellable/vetoable closing checks through one single method
wrote some new help.txt in the db dir about hanging startups
next week
I still have a bunch of small stuff going on, but I'd like to start on the Client API, the next 'big thing', as well. I expect this will involve several weeks of ui and clientside server prep before anything exciting happens.
1 note
·
View note
Video
youtube
Easy and accurate parsing of resume/cv data and job descriptions. AI-based RChilli resume parser can extract all relevant data from resumes and enrich it with taxonomies. It uses a REST API to extract candidate data from resumes in 140+ data fields. It is a tool that analyses a resume/CV created in any document format, including DOC, DOCX, PDF, RTF, TXT, ODT, HTM, HTML, DOCM, DOTM, DOT, DOTX, and extracts it into a machine-readable format, such as XML or JSON, using an API
0 notes
Link
RChilli is happy to announce that it is now available on the Rapid API marketplace.
RChilli is the trusted partner for resume parsing, matching, and data enrichment. It has been serving ATS, Job boards, and Enterprises for the last 12 years with its reliable and innovative products such as Resume Parser API, JD Parser API, Search & Match Engine API, Taxonomy API. Now, it is offering its best-in-class APIs to the RapidAPI developer community.
0 notes
Link
Affinda Resume Parser is a machine learning software that uses NLP (Natural Language Processing) to extract more than 100 fields from each resume. It also organizes the resumes into searchable file formats. Fields that are extracted through resume parser are personal details, work experience, education, certifications, skills, summary, language, referees, publications, etc.
#Resume Parsing Software#Invoice Extractor#Resume Parser#cv extractor#parse resume#cv parsing software
0 notes
Link
0 notes