#Systematic Approaches to Learning Algorithms and Machine Inferences
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
please stop playing with that salami
it's not that interesting

144K notes
·
View notes
Text
IEEE Transactions on Artificial Intelligence, Volume 6, Issue 5, May 2025
1) A Comparative Review of Deep Learning Techniques on the Classification of Irony and Sarcasm in Text
Author(s): Leonidas Boutsikaris, Spyros Polykalas
Pages: 1052 - 1066
2) Approaching Principles of XAI: A Systematization
Author(s): Raphael Ronge, Bernhard Bauer, Benjamin Rathgeber
Pages: 1067 - 1079
3) Brain-Conditional Multimodal Synthesis: A Survey and Taxonomy
Author(s): Weijian Mai, Jian Zhang, Pengfei Fang, Zhijun Zhang
Pages: 1080 - 1099
4) Analysis of An Intellectual Mechanism of a Novel Crop Recommendation System Using Improved Heuristic Algorithm-Based Attention and Cascaded Deep Learning Network
Author(s): Yaganteeswarudu Akkem, Saroj Kumar Biswas
Pages: 1100 - 1113
5) Improving String Stability in Cooperative Adaptive Cruise Control Through Multiagent Reinforcement Learning With Potential-Driven Motivation
Author(s): Kun Jiang, Min Hua, Xu He, Lu Dong, Quan Zhou, Hongming Xu, Changyin Sun
Pages: 1114 - 1127
6) A Quantum Multimodal Neural Network Model for Sentiment Analysis on Quantum Circuits
Author(s): Jin Zheng, Qing Gao, Daoyi Dong, Jinhu Lü, Yue Deng
Pages: 1128 - 1142
7) Decoupling Dark Knowledge via Block-Wise Logit Distillation for Feature-Level Alignment
Author(s): Chengting Yu, Fengzhao Zhang, Ruizhe Chen, Aili Wang, Zuozhu Liu, Shurun Tan, Er-Ping Li
Pages: 1143 - 1155
8) CauseTerML: Causal Learning via Term Mining for Assessing Review Discrepancies
Author(s): Wenjie Sun, Chengke Wu, Qinge Xiao, Junjie Jiang, Yuanjun Guo, Ying Bi, Xinyu Wu, Zhile Yang
Pages: 1156 - 1170
9) Unsupervised Learning of Unbiased Visual Representations
Author(s): Carlo Alberto Barbano, Enzo Tartaglione, Marco Grangetto
Pages: 1171 - 1183
10) Herb-Target Interaction Prediction by Multiinstance Learning
Author(s): Yongzheng Zhu, Liangrui Ren, Rong Sun, Jun Wang, Guoxian Yu
Pages: 1184 - 1193
11) Periodic Hamiltonian Neural Networks
Author(s): Zi-Yu Khoo, Dawen Wu, Jonathan Sze Choong Low, Stéphane Bressan
Pages: 1194 - 1202
12) Unsigned Road Incidents Detection Using Improved RESNET From Driver-View Images
Author(s): Changping Li, Bingshu Wang, Jiangbin Zheng, Yongjun Zhang, C.L. Philip Chen
Pages: 1203 - 1216
13) Deep Reinforcement Learning Data Collection for Bayesian Inference of Hidden Markov Models
Author(s): Mohammad Alali, Mahdi Imani
Pages: 1217 - 1232
14) NVMS-Net: A Novel Constrained Noise-View Multiscale Network for Detecting General Image Processing Based Manipulations
Author(s): Gurinder Singh, Kapil Rana, Puneet Goyal, Sathish Kumar
Pages: 1233 - 1247
15) Improved Supervised Machine Learning for Predicting Auto Insurance Purchase Patterns
Author(s): Mourad Nachaoui, Fatma Manlaikhaf, Soufiane Lyaqini
Pages: 1248 - 1258
16) An Intelligent Chatbot Assistant for Comprehensive Troubleshooting Guidelines and Knowledge Repository in Printed Circuit Board Production
Author(s): Supparesk Rittikulsittichai, Thitirat Siriborvornratanakul
Pages: 1259 - 1268
17) Learning to Communicate Among Agents for Large-Scale Dynamic Path Planning With Genetic Programming Hyperheuristic
Author(s): Xiao-Cheng Liao, Xiao-Min Hu, Xiang-Ling Chen, Yi Mei, Ya-Hui Jia, Wei-Neng Chen
Pages: 1269 - 1283
18) Multilabel Black-Box Adversarial Attacks Only With Predicted Labels
Author(s): Linghao Kong, Wenjian Luo, Zipeng Ye, Qi Zhou, Yan Jia
Pages: 1284 - 1297
19) VODACBD: Vehicle Object Detection Based on Adaptive Convolution and Bifurcation Decoupling
Author(s): Yunfei Yin, Zheng Yuan, Yu He, Xianjian Bao
Pages: 1298 - 1308
20) Seeking Secure Synchronous Tracking of Networked Agent Systems Subject to Antagonistic Interactions and Denial-of-Service Attacks
Author(s): Weihao Li, Lei Shi, Mengji Shi, Jiangfeng Yue, Boxian Lin, Kaiyu Qin
Pages: 1309 - 1320
21) Revisiting LARS for Large Batch Training Generalization of Neural Networks
Author(s): Khoi Do, Minh-Duong Nguyen, Nguyen Tien Hoa, Long Tran-Thanh, Nguyen H. Tran, Quoc-Viet Pham
Pages: 1321 - 1333
22) A Stratified Seed Selection Algorithm for K-Means Clustering on Big Data
Author(s): Namita Bajpai, Jiaul H. Paik, Sudeshna Sarkar
Pages: 1334 - 1344
23) Visual–Semantic Fuzzy Interaction Network for Zero-Shot Learning
Author(s): Xuemeng Hui, Zhunga Liu, Jiaxiang Liu, Zuowei Zhang, Longfei Wang
Pages: 1345 - 1359
24) Weakly Correlated Multimodal Domain Adaptation for Pattern Classification
Author(s): Shuyue Wang, Zhunga Liu, Zuowei Zhang, Mohammed Bennamoun
Pages: 1360 - 1372
25) Prompt Customization for Continual Learning
Author(s): Yong Dai, Xiaopeng Hong, Yabin Wang, Zhiheng Ma, Dongmei Jiang, Yaowei Wang
Pages: 1373 - 1385
26) Monocular 3-D Reconstruction of Blast Furnace Burden Surface Based on Cross-Domain Generative Self-Supervised Network
Author(s): Zhipeng Chen, Xinyi Wang, Ling Shen, Jinshi Liu, Jianjun He, Jilin Zhu, Weihua Gui
Pages: 1386 - 1400
27) Energy-Efficient Hybrid Impulsive Model for Joint Classification and Segmentation on CT Images
Author(s): Bin Hu, Zhi-Hong Guan, Guanrong Chen, Jürgen Kurths
Pages: 1401 - 1413
28) Deep Temporally Recursive Differencing Network for Anomaly Detection in Videos
Author(s): Gargi V. Pillai, Debashis Sen
Pages: 1414 - 1428
29) A Hierarchical Cross-Modal Spatial Fusion Network for Multimodal Emotion Recognition
Author(s): Ming Xu, Tuo Shi, Hao Zhang, Zeyi Liu, Xiao He
Pages: 1429 - 1438
30) On the Role of Priors in Bayesian Causal Learning
Author(s): Bernhard C. Geiger, Roman Kern
Pages: 1439 - 1445
0 notes
Text
How to ensure data consistency in machine learning

Machine learning (ML) continues to revolutionize industries across India and the globe. From personalized recommendations to sophisticated financial modeling and advancements in healthcare, the potential is immense. However, beneath the surface of powerful algorithms and impressive predictions lies a critical foundation that often determines success or failure: data consistency.
We've all heard the adage "Garbage In, Garbage Out" (GIGO). In machine learning, this isn't just a catchy phrase; it's a fundamental truth. Inconsistent data fed into an ML pipeline can lead to models that perform poorly, produce unreliable or biased results, and fail catastrophically when deployed in the real world. Ensuring data consistency isn't a mere 'nice-to-have'; it's an absolute necessity for building robust, reproducible, and trustworthy ML systems.
What Do We Mean by Data Consistency in ML?
Data consistency in the context of machine learning goes beyond simple accuracy. It encompasses several key aspects:
Format Consistency: Ensuring data values adhere to the same format across all datasets. This includes consistent data types (e.g., integers vs. floats), date formats (YYYY-MM-DD vs. DD/MM/YYYY), units (metric vs. imperial), and text encodings (e.g., UTF-8).
Schema Consistency: Maintaining the same set of features (columns), feature names, and data structure across training, validation, testing, and importantly, the live inference data the model will encounter in production.
Value Consistency: Using standardized representations for categorical data (e.g., always using "Maharashtra" not "MH" or "Mah"), consistent handling of missing values (e.g., NaN, null, -1), and applying the same scaling or normalization techniques everywhere.
Temporal Consistency: Ensuring that the time-based relationship between features and the target variable is maintained logically, preventing data leakage from the future into the training set, and accounting for how data characteristics might change over time (concept drift).
Source Consistency: If data is aggregated from multiple sources, ensuring it's joined correctly and harmonized to maintain consistency across common fields.
Why is Data Consistency Paramount for ML?
Inconsistent data can sabotage ML projects in numerous ways:
Poor Model Performance: Models trained on inconsistent data struggle to learn meaningful patterns, leading to low accuracy and poor generalization.
Unreliable Predictions: A model might work during testing but fail in production if the live data format or schema differs slightly from the training data.
Debugging Nightmares: Tracing errors becomes incredibly difficult when you can't be sure if the issue lies in the model logic or inconsistent input data.
Lack of Reproducibility: Experiments become impossible to reproduce if the underlying data or its pre-processing steps change inconsistently.
Bias Amplification: Inconsistent encoding or representation of demographic or other sensitive features can introduce or worsen bias in model outcomes.
Strategies for Ensuring Data Consistency in Your ML Pipelines
Achieving data consistency requires a proactive and systematic approach throughout the ML lifecycle:
Establish Clear Data Schemas & Dictionaries:
Action: Define expected data types, formats, acceptable ranges, allowed categorical values, units, and null representations for every feature before you start coding. Maintain a shared data dictionary.
Why: Provides a single source of truth and enables automated validation.
Implement Robust Data Validation Pipelines:
Action: Use tools (like Great Expectations, Pandera, Cerberus, or custom Python scripts) to automatically validate data against your defined schema at critical points: upon ingestion, after pre-processing, and before model training/inference. Check for type mismatches, out-of-range values, unexpected categories, missing columns, etc.
Why: Catches inconsistencies early, preventing corrupted data from propagating downstream.
Standardize Pre-processing Steps:
Action: Encapsulate all pre-processing logic (imputation, scaling, encoding, feature engineering) into reusable functions or pipelines (e.g., Scikit-learn Pipelines, custom classes). Ensure the exact same pipeline object/code is applied to your training, validation, test, and incoming production data.
Why: Guarantees that transformations are applied identically, preventing discrepancies between training and inference.
Version Control Your Data & Code:
Action: Use Git for your code (including pre-processing scripts and validation rules). Use tools like DVC (Data Version Control) or Git LFS to version control your datasets alongside your code.
Why: Enables reproducibility, allows rollback to previous states, and tracks how data and processing logic evolve together.
Monitor for Data Drift:
Action: Continuously monitor the statistical distribution of data entering your production system. Compare it against the distribution of your training data. Set up alerts for significant deviations (data drift) or changes in the relationship between features and the target (concept drift).
Why: Detects when the production environment no longer matches the training environment, indicating potential inconsistency and the need for model retraining or pipeline updates.
Use Feature Stores (for Mature MLOps):
Action: Implement a feature store – a centralized repository where standardized, pre-computed features are stored and managed. Data science teams consume features directly from the store for both training and inference.
Why: Enforces consistency by design, reduces redundant computation, and facilitates feature sharing across projects.
Foster Documentation and Collaboration:
Action: Clearly document data sources, transformations, validation checks, and known data quirks. Encourage open communication between data engineering, data science, and ML engineering teams.
Why: Ensures everyone understands the data landscape and consistency requirements, preventing misunderstandings and errors.
Building Reliable AI in India
As India continues its rapid growth in AI and ML adoption, embedding these data consistency practices is crucial. Building robust, reliable, and scalable AI solutions demands a rigorous approach to data quality from day one. By prioritizing data consistency, teams can avoid common pitfalls, build more trustworthy models, and accelerate the delivery of impactful ML applications.
Conclusion
Data consistency is not a glamorous topic, but it's the invisible scaffolding that supports successful machine learning projects. By implementing clear schemas, automated validation, standardized pre-processing, version control, drift monitoring, and fostering collaboration, you can build a solid foundation for your models. Investing time and effort in ensuring data consistency isn't just good practice – it's essential for unlocking the true potential of machine learning.
0 notes
Text
A Deep Dive into AWS SageMaker: Your Complete Resource
In today's data-driven world, machine learning (ML) has become a cornerstone for innovation and efficiency across industries. Amazon Web Services (AWS) SageMaker stands out as a powerful platform designed to simplify the complexities of machine learning. In this blog, we will explore AWS SageMaker in detail, covering its features, benefits, and how it can transform your approach to ML.
If you want to advance your career at the AWS Course in Pune, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path.

What is AWS SageMaker?
AWS SageMaker is a fully-managed service that enables developers and data scientists to quickly build, train, and deploy machine learning models. Launched in 2017, SageMaker integrates various tools and services, which streamlines the machine learning workflow. This allows users to focus on developing high-quality models without worrying about the underlying infrastructure.
Key Features of AWS SageMaker
1. Integrated Jupyter Notebooks
SageMaker provides built-in Jupyter notebooks for data exploration and visualization. This feature allows users to prototype and test different algorithms in a user-friendly environment, eliminating the need for external setups.
2. Diverse Algorithms and Frameworks
SageMaker offers a variety of built-in algorithms optimized for speed and efficiency. It also supports popular frameworks, such as TensorFlow, PyTorch, and MXNet, giving users the flexibility to work with their preferred tools.
3. Automated Hyperparameter Tuning
One of SageMaker’s standout features is its automatic hyperparameter tuning, which optimizes model parameters to enhance performance. This automation saves time and improves model accuracy without requiring extensive manual effort.
4. Scalable Training and Inference
With SageMaker, users can train models on large datasets quickly using distributed training. Once a model is trained, deploying it for inference is straightforward, allowing for real-time predictions with ease.
5. Model Monitoring and Management
SageMaker includes robust tools for monitoring the performance of models in production. This feature ensures that models remain effective over time, with capabilities for automatic retraining when necessary.
6. SageMaker Studio
SageMaker Studio is an integrated development environment (IDE) that consolidates all aspects of the machine learning workflow. It allows users to build, train, and deploy models while facilitating collaboration among team members.

To master the intricacies of AWS and unlock its full potential, individuals can benefit from enrolling in the AWS Online Training.
Benefits of AWS SageMaker
Cost-Effective Solutions
SageMaker operates on a pay-as-you-go pricing model, allowing businesses to scale their machine learning operations without significant upfront investment. You only pay for the resources you consume.
Accelerated Time to Market
By streamlining the ML lifecycle, SageMaker helps teams transition from experimentation to production faster. This acceleration is crucial for organizations looking to capitalize on AI-driven applications quickly.
Increased Accessibility
The user-friendly interface and comprehensive documentation make SageMaker accessible to users at all skill levels, from novices to experienced data scientists.
Robust Security and Compliance
Being part of the AWS ecosystem, SageMaker benefits from advanced security features and compliance certifications, making it suitable for handling sensitive and regulated data.
Conclusion
AWS SageMaker is a game-changer for organizations aiming to harness the power of machine learning. By simplifying the model-building process and providing a robust set of tools, SageMaker enables businesses to unlock insights from their data efficiently.
Whether you are just starting your machine learning journey or looking to enhance your existing capabilities, AWS SageMaker offers the resources and flexibility you need to succeed. Embracing this powerful platform can lead to innovative solutions, driving growth and competitive advantage in today’s marketplace.
0 notes
Text
Exploring the Future: Pattern Recognition in AI
Summary: Pattern recognition in AI enables machines to interpret data patterns autonomously through statistical, syntactic, and neural network methods. It enhances accuracy, automates complex tasks, and improves decision-making across diverse sectors despite challenges in data quality and ethical concerns.

Introduction
Artificial Intelligence (AI) transforms our world by automating complex tasks, enhancing decision-making, and enabling more innovative technologies. In today's data-driven landscape, AI's significance cannot be overstated. A crucial aspect of AI is pattern recognition, which allows systems to identify patterns and make predictions based on data.
This blog aims to simplify pattern recognition in AI, exploring its mechanisms, applications, and emerging trends. By understanding pattern recognition in AI, readers will gain insights into its profound impact on various industries and its potential for future innovations.
What is Pattern Recognition in AI?
Pattern recognition in AI involves identifying regularities or patterns in data through algorithms and models. It enables machines to discern meaningful information from complex datasets, mimicking human cognitive abilities.
AI systems categorise and interpret patterns by analysing input data to make informed decisions or predictions. This process spans various domains, from image and speech recognition to medical diagnostics and financial forecasting.
Pattern recognition equips AI with recognising similarities or anomalies, facilitating tasks requiring efficient understanding and responding to recurring data patterns. Thus, it forms a foundational aspect of AI's capability to learn and adapt from data autonomously.
How Does Pattern Recognition Work?
Pattern recognition in artificial intelligence (AI) involves systematically identifying and interpreting patterns within data, enabling machines to learn and make decisions autonomously. This process integrates fundamental principles and advanced techniques to achieve accurate results across domains.
Statistical Methods
Statistical methods form the bedrock of pattern recognition, leveraging probability theory and statistical inference to analyse patterns in data. Techniques such as Bayesian classifiers, clustering algorithms, and regression analysis enable machines to discern patterns based on probabilistic models derived from training data.
By quantifying uncertainties and modelling relationships between variables, statistical methods enhance the accuracy and reliability of pattern recognition systems.
Syntactic Methods
Syntactic methods focus on patterns' structural aspects, emphasising grammatical or syntactic rules to parse and recognise patterns. This approach is beneficial in tasks like natural language processing (NLP) and handwriting recognition, where the sequence and arrangement of elements play a crucial role.
Techniques like formal grammars, finite automata, and parsing algorithms enable machines to understand and generate structured patterns based on predefined rules and constraints.
Neural Networks and Deep Learning
Neural networks and Deep Learning have revolutionised pattern recognition by mimicking the human brain's interconnected network of neurons. These models learn hierarchical representations of data through multiple layers of abstraction, extracting intricate features and patterns from raw input.
Convolutional Neural Networks (CNNs) excel in image and video recognition tasks. In contrast, Recurrent Neural Networks (RNNs) are adept at sequential data analysis, such as speech and text recognition. The advent of Deep Learning has significantly enhanced the scalability and performance of pattern recognition systems across diverse applications.
Steps Involved in Pattern Recognition
Understanding the steps involved in pattern recognition is crucial for solving complex problems in AI and Machine Learning. Mastering these steps fosters innovation and efficiency in developing advanced technological solutions. Pattern recognition involves several sequential steps to transform raw data into actionable insights:
Step 1: Data Collection
The process begins with acquiring relevant data from various sources, ensuring a comprehensive dataset that adequately represents the problem domain.
Step 2: Preprocessing
Raw data undergoes preprocessing to clean, normalise, and transform it into a suitable format for analysis. This step includes handling missing values, scaling features, and removing noise to enhance data quality.
Step 3: Feature Extraction
Feature extraction involves identifying and selecting meaningful features or attributes from the preprocessed data that best characterise the underlying patterns. Techniques like principal component analysis (PCA), wavelet transforms, and deep feature learning extract discriminative features essential for accurate classification.
Step 4: Classification
In the classification phase, extracted features categorise or label data into predefined classes or categories. Machine Learning algorithms such as Support Vector Machines (SVMS), Decision Trees, and K-Nearest Neighbours (K-NN) classifiers assign new instances to the most appropriate class based on learned patterns.
Step 5: Post-processing
Post-processing involves refining and validating the classification results, often through error correction, ensemble learning, or feedback mechanisms. Addressing uncertainties and refining model outputs ensures robustness and reliability in real-world applications.
Benefits of Pattern Recognition
Pattern recognition in AI offers significant advantages across various domains. Firstly, it improves accuracy and efficiency by automating the identification and classification of patterns within vast datasets. This capability reduces human error and enhances the reliability of outcomes in tasks such as image recognition or predictive analytics.
Moreover, pattern recognition enables the automation of complex tasks that traditionally require extensive human intervention. By identifying patterns in data, AI systems can autonomously perform tasks like anomaly detection in cybersecurity or predictive maintenance in manufacturing, leading to increased operational efficiency and cost savings.
Furthermore, the technology enhances decision-making by providing insights based on data patterns that humans might overlook. This capability supports businesses in making data-driven decisions swiftly and accurately, thereby gaining a competitive edge in dynamic markets.
Challenges of Pattern Recognition
Despite its benefits, pattern recognition in AI faces several challenges. Data quality and quantity issues pose significant hurdles as accurate pattern recognition relies on large volumes of high-quality data. Here are a few of the challenges:
Data Quality
Noisy, incomplete, or inconsistent data can significantly impact the performance of pattern recognition algorithms. Techniques like outlier detection and data cleaning are crucial for mitigating this challenge.
Variability in Patterns
Real-world patterns often exhibit variations and inconsistencies. An algorithm trained on a specific type of pattern might struggle to recognize similar patterns with slight variations.
High Dimensionality
Data with a high number of features (dimensions) can make it difficult for algorithms to identify the most relevant features for accurate pattern recognition. Dimensionality reduction techniques can help address this issue.
Overfitting and Underfitting
An overfitted model might perform well on training data but fail to generalize to unseen data. Conversely, an underfitted model might not learn the underlying patterns effectively. Careful selection and tuning of algorithms are essential to avoid these pitfalls.
Computational Complexity
Some pattern recognition algorithms, particularly deep learning models, can be computationally expensive to train and run, especially when dealing with large datasets. This can limit their applicability in resource-constrained environments.
Limited Explainability
While some algorithms excel at recognizing patterns, they might not be able to explain why they classified a particular data point as belonging to a specific pattern. This lack of interpretability can be a challenge in situations where understanding the reasoning behind the recognition is crucial.
Emerging Technologies and Methodologies

This section highlights how ongoing technological advancements are shaping the landscape of pattern recognition in AI, propelling it towards more sophisticated and impactful applications across various sectors.
Advances in Deep Learning and Neural Networks
Recent advancements in Deep Learning and neural networks have revolutionised pattern recognition in AI. These technologies mimic the human brain's ability to learn and adapt from data, enabling machines to recognise complex patterns with unprecedented accuracy.
Deep Learning, a subset of Machine Learning, uses deep neural networks with multiple layers to automatically extract features from raw data. This approach has significantly improved tasks such as image and speech recognition, natural language processing, and autonomous decision-making.
Role of Big Data and Cloud Computing
The proliferation of Big Data and cloud computing has provided the necessary infrastructure for handling vast amounts of data crucial for pattern recognition. Big Data technologies enable the collection, storage, and processing of massive datasets essential for training and validating complex AI models.
Cloud computing platforms offer scalable resources and computational power, facilitating the deployment and management of AI applications across various industries. This combination of Big Data and cloud computing has democratised access to AI capabilities, empowering organisations of all sizes to leverage advanced pattern recognition technologies.
Integration with Other AI Technologies
Pattern recognition in AI is increasingly integrated with other advanced technologies, such as reinforcement learning and generative models. Reinforcement learning enables AI systems to learn through interaction with their environment, making it suitable for tasks requiring decision-making and continuous learning.
Generative models, such as Generative Adversarial Networks (GANs), create new data instances similar to existing ones, expanding the scope of pattern recognition applications in areas like image synthesis and anomaly detection. These integrations enhance the versatility and effectiveness of AI-powered pattern recognition systems across diverse domains.
Future Trends and Potential Developments
Looking ahead, the future of pattern recognition in AI promises exciting developments. Enhanced interpretability and explainability of AI models will address concerns related to trust and transparency are a few of the many developments. Some other noteworthy developments include:
Domain-Specific AI
We will see a rise in AI models specifically designed for particular domains, such as medical diagnosis, financial forecasting, or autonomous vehicles. These specialized models will be able to leverage domain-specific knowledge to achieve superior performance.
Human-in-the-Loop AI
The future lies in a collaborative approach where AI and humans work together. Pattern recognition systems will provide recommendations and insights, while humans retain the ultimate decision-making power.
Bio-inspired AI
Drawing inspiration from the human brain and nervous system, researchers are developing neuromorphic computing approaches that could lead to more efficient and robust pattern recognition algorithms.
Quantum Machine Learning
While still in its early stages, quantum computing has the potential to revolutionize how we approach complex pattern recognition tasks, especially those involving massive datasets.
Frequently Asked Questions
What is Pattern Recognition in AI?
Pattern recognition in AI refers to the process where algorithms analyse data to identify recurring patterns. It enables machines to learn from examples, categorise information, and predict outcomes, mimicking human cognitive abilities crucial for applications like image recognition and predictive modelling.
How Does Pattern Recognition Work in AI?
Pattern recognition in AI involves statistical methods, syntactic analysis, and neural networks. Statistical methods like Bayesian classifiers analyse probabilities, syntactic methods parse structural patterns, and neural networks learn hierarchical representations. These techniques enable machines to understand data complexity and make informed decisions autonomously.
What are the Benefits of Pattern Recognition in AI?
Pattern recognition enhances accuracy by automating the identification of patterns in large datasets, reducing human error. It automates complex tasks like anomaly detection and predictive maintenance, improving operational efficiency across industries. Moreover, it facilitates data-driven decision-making, providing insights from data patterns that human analysis might overlook.
Conclusion
Pattern recognition in AI empowers machines to interpret and act upon data patterns autonomously, revolutionising industries from healthcare to finance. By leveraging statistical methods, neural networks, and emerging technologies like Deep Learning, AI systems can identify complex relationships and make predictions with unprecedented accuracy.
Despite challenges such as data quality and ethical considerations, ongoing advancements in big data, cloud computing, and integrative AI technologies promise a future where pattern
0 notes
Text
The Essential Toolkit for Navigating the Data Science Landscape
In the dynamic and ever-evolving world of technology, data science has emerged as a pivotal discipline, captivating the attention of organizations across diverse industries. As the demand for data-driven insights continues to grow, the need for skilled data science professionals has become increasingly paramount.
Enhancing your profession at the Data Science Course in Coimbatore requires following a systematic approach and enrolling in an appropriate course that will significantly broaden your learning experience while aligning with your preferences.

Navigating the data science landscape, however, requires more than just technical proficiency. Aspiring data scientists must cultivate a multifaceted skillset that encompasses a deep understanding of mathematical principles, programming expertise, and the ability to extract meaningful insights from complex datasets.
Let's Explore the Essential Toolkit that Every Successful Data Science Professional Must Possess:
Mastering the Foundations of Mathematics and Statistics At the core of data science lies a strong foundation in mathematical and statistical concepts. Aspiring data scientists must demonstrate a firm grasp of probability theory, linear algebra, calculus, and statistical inference. These foundational skills serve as the bedrock for building predictive models, analyzing intricate datasets, and deriving impactful insights.
Proficiency in Programming Languages Data science is a highly technical discipline, and proficiency in at least one or more programming languages is a non-negotiable requirement. Python and R are two of the most widely adopted tools in the data science toolkit, offering robust libraries and frameworks for data manipulation, analysis, and machine learning. Familiarity with SQL is also crucial for working with relational databases and extracting data.
Expertise in Data Wrangling and Transformation In the real world, data is often messy, unstructured, and riddled with inconsistencies. A key skill for data scientists is the ability to wrangle and transform raw data into a format that is suitable for analysis. This process, known as data wrangling or data munging, requires proficiency in techniques like data cleaning, feature engineering, and data normalization.
For people who want to thrive in data science, Data Science Online Training is highly recommended. Look for classes that are compatible with your preferred programming language and learning style.

Understanding of Machine Learning Algorithms At the heart of data science lies the application of machine learning algorithms to extract insights and make predictions from data. Aspiring data scientists should have a solid grasp of supervised and unsupervised learning techniques, including regression, classification, clustering, and neural networks. Familiarity with model evaluation and optimization methods is also essential.
Exceptional Communication and Storytelling Skills While technical skills are undoubtedly crucial, data scientists must also possess strong communication and storytelling abilities. The ability to effectively present data-driven insights to both technical and non-technical stakeholders is a valuable asset. Data visualization skills, such as creating informative charts and dashboards, can also aid in conveying complex information in a compelling and understandable way.
Navigating the data science landscape requires a multifaceted skillset that seamlessly blends technical expertise with analytical prowess and effective communication. By cultivating this essential toolkit, aspiring data science professionals can position themselves for success in this dynamic and highly sought-after field.
0 notes
Text
Navigating the World of Data Science: A Beginner's Guide
In today's digital age, data is everywhere, and its value is undeniable. From influencing business decisions to shaping public policy, data drives much of what we do. With the increasing reliance on data, the field of data science has emerged as one of the most sought-after and rewarding career paths. However, navigating the vast and complex world of data science can be daunting for beginners. In this beginner's guide, we'll explore what data science is, why it matters, and how you can embark on your journey in this exciting field.
If you're interested in pursuing a career in data science, there are several key things you need to knowEnhancing your career at the Data Science Course in Coimbatore entails taking a systematic strategy and looking into enrolling in a suitable course that will greatly expand your learning journey while harmonizing with your preferences.

Essential Skills for Becoming a Data Scientist
1. Programming Languages
Python: Learn Python programming language, which is widely used in data science for its simplicity and versatility.
R: Familiarize yourself with R programming language, commonly used for statistical analysis and data visualization.
2. Statistics and Mathematics
Probability and Statistics: Understand fundamental concepts of probability theory, statistical inference, and hypothesis testing.
Linear Algebra: Gain proficiency in linear algebra, particularly matrices and vectors, which are essential for machine learning algorithms.
3. Data Wrangling and Cleaning
Data Manipulation: Learn techniques for data wrangling and cleaning, including handling missing values, data normalization, and data transformation.
Data Visualization: Master data visualization libraries like Matplotlib and Seaborn to communicate insights effectively.
4. Machine Learning
Supervised Learning: Understand algorithms for supervised learning tasks such as regression and classification.
Unsupervised Learning: Learn about clustering and dimensionality reduction techniques used in unsupervised learning.
5. Big Data Technologies
SQL: Acquire knowledge of SQL for querying databases and extracting relevant data.
Hadoop and Spark: Familiarize yourself with big data processing frameworks like Hadoop and Spark for handling large datasets.
6. Domain Knowledge
Industry Expertise: Gain domain-specific knowledge in areas like healthcare, finance, or e-commerce to apply data science techniques effectively.
Business Acumen: Understand business objectives and how data science can contribute to solving real-world problems.For those who want to thrive in Data Science, Data Science Online Training is highly suggested. Look for classes that align with your preferred programming language and learning approach
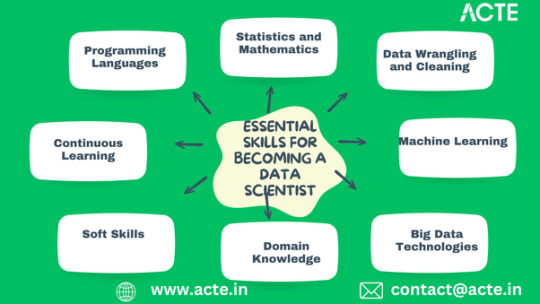
7. Soft Skills
Communication: Develop strong communication skills to convey complex findings to non-technical stakeholders.
Problem-Solving: Cultivate critical thinking and problem-solving skills to tackle diverse data science challenges.
8. Continuous Learning
Stay Updated: Keep abreast of the latest developments in data science by reading research papers, attending conferences, and participating in online courses.
Practice: Continuously practice and apply your skills through projects, competitions, and real-world applications.
Data science offers exciting opportunities for individuals passionate about exploring and analyzing data to derive actionable insights. By developing essential skills, gaining practical experience, and staying updated with industry trends, you can embark on a rewarding journey in the world of data science. Whether you're a recent graduate, a career changer, or someone looking to upskill, the field of data science welcomes diverse backgrounds and experiences. So, roll up your sleeves, dive into the world of data, and unleash the power of insights that drive innovation and change.
0 notes
Text
okay but this is a semi-serious proposal among some researchers
*raises my hand to ask a question* what if we collectively refused to refer to AI as 'AI'? it's not artificial intelligence, artificial intelligence doesn't currently exist, it's just algorithms that use stolen input to reinforce prejudice. what if we protested by using a more accurate name? just spitballing here but what about Automated Biased Output (ABO for short)
31K notes
·
View notes
Text
Mastering Quantitative Analysis: Navigating the World of Data-Driven Decision Making

In the ever-evolving landscape of business, economics, and research, the term "quantitative analysis" has become increasingly prominent. This analytical methodology focuses on the objective measurement and the statistical, mathematical, or numerical analysis of data collected through polls, questionnaires, and surveys, or by manipulating pre-existing statistical data using computational techniques. The essence of quantitative analysis lies in its ability to turn complex phenomena into simple, quantifiable units, which can be systematically measured and analyzed for patterns, trends, and predictions.
The Genesis and Evolution of Quantitative Analysis
Quantitative analysis has its roots in the early methods of statistics and mathematics. However, its real development started with the advent of computers and advanced statistical software, allowing for more complex data analysis than ever before. Today, it encompasses a wide range of statistical and mathematical techniques, from basic models like linear regression to sophisticated algorithms used in machine learning and artificial intelligence.
Applications in Diverse Fields
The utility of quantitative analysis spans across various sectors. In finance, it is used to assess risk, evaluate the performance of stocks, and optimize investment portfolios. In marketing, quantitative techniques help in understanding consumer behavior, market segmentation, and product positioning.
In public health, it assists in analyzing epidemiological data, improving patient outcomes, and policy planning. The field of economics uses quantitative analysis for modeling economic data, forecasting market trends, and informing policy decisions.
Tools and Techniques
Quantitative analysis relies on a plethora of tools and techniques. Statistical software like SPSS, SAS, R, and Python are commonly used for data analysis. These tools offer capabilities for data manipulation, statistical modeling, and visualization, making them indispensable for quantitative analysts. Techniques like regression analysis, hypothesis testing, factor analysis, and time series analysis are some of the fundamental methods used to explore and make inferences from data.
The Importance of Data Quality
The validity of quantitative analysis heavily depends on the quality of data. Data accuracy, completeness, and consistency are critical. Poor data can lead to incorrect conclusions, making data verification and validation an essential step in the quantitative analysis process.
Challenges and Considerations
Quantitative analysis, while powerful, is not without challenges. The interpretation of data can be complex, and the results are often sensitive to the choice of model and assumptions made during the analysis. Additionally, the reliance on numerical data means that qualitative aspects like context, emotion, and subjective experiences are often overlooked.
Ethical and Privacy Concerns
With the rise in data availability, ethical and privacy concerns are paramount. Analysts must ensure data confidentiality, consent, and comply with data protection laws. The misuse of data, especially in sensitive areas like healthcare and finance, can have significant consequences.
The Future of Quantitative Analysis
The future of quantitative analysis is intertwined with advancements in technology. Big data, artificial intelligence, and machine learning are pushing the boundaries of what can be quantified and analyzed. These technologies enable the analysis of unstructured data, like text and images, opening new avenues for quantitative research.
Quantitative Analysis in Education
In education, quantitative analysis is gaining importance. It helps in assessing student performance, evaluating educational policies, and understanding learning behaviors. This data-driven approach can lead to more effective educational strategies and policies.
Quantitative vs. Qualitative Analysis
While quantitative analysis provides a numerical insight, qualitative analysis offers depth and context. A combined approach, known as mixed methods research, leverages the strengths of both, providing a more holistic understanding of the research subject.
Conclusion
Quantitative analysis is a critical tool in modern decision-making. Its ability to provide clear, objective, and data-driven insights makes it invaluable across various fields. However, it is essential to use this tool judiciously, considering the quality of data, the appropriateness of methods, and the ethical implications.
As we move forward, the integration of new technologies and methodologies will undoubtedly expand the scope and impact of quantitative analysis, making it an even more potent instrument in understanding and shaping the world around us.
1 note
·
View note
Text
💫 Let’s forget the term AI. Let’s call them Systematic Approaches to Learning Algorithms and Machine Inferences (SALAMI). – Quinta’s weblog
0 notes
Text
so you're saying you like you SALAMI spicy?


they're outsourcing degradation kinks to AI
14K notes
·
View notes
Text
Artificial Intelligence is dead. Long live Systematic Approaches to Learning Algorithms and Machine Inferences.
1 note
·
View note
Text
One potential tonic against this fallacy is to follow an Italian MP's suggestion and replace "AI" with "SALAMI" ("Systematic Approaches to Learning Algorithms and Machine Inferences"). It's a lot easier to keep a clear head when someone asks you, "Is this SALAMI intelligent? Can this SALAMI write a novel? Does this SALAMI deserve human rights?"
from Cory Doctorow’s - Pluralistic: The AI hype bubble is the new crypto hype bubble
0 notes
Text
Data Science Institutes in Hyderabad
This effect is known as “algorithmic bias” and is turning into a standard problem for data scientists. Google didn’t go out of its way to be racist, Facebook didn’t intend to get users arrested and IBM et al didn’t resolve to make their facial recognition software program blind to black ladies. They were ‘victim’ of the setting their AI realized from and the adverse impact on people’s lives was collateral injury of this limitation. But the GAFA aren’t the only ones struggling to navigate the risks of at-scale AI and one can simply discover a plethora of examples of discriminatory data science. Take the work coming out of the MIT Media Lab for instance, where Joy Buolamwini confirmed in early 2018 that three of the newest gender-recognition AIs, from IBM, Microsoft
Statistical, similarity-based, and causal notions of equity are reviewed and contrasted in the way they apply in instructional contexts. Recommendations for coverage makers and builders of instructional technology offer steerage for the way to promote algorithmic equity in schooling. Concerns in regards to the societal influence of AI-based providers and systems has inspired governments and other organisations all over the world to suggest AI policy frameworks to handle fairness, accountability, transparency and related topics. To obtain the aims of those frameworks, the information and software program engineers who construct machine-learning systems require data about a wide selection of relevant supporting tools and strategies. In this paper we provide an summary of applied sciences that assist building trustworthy machine learning methods, i.e., techniques whose properties justify that people place belief in them. We argue that four classes of system properties are instrumental in reaching the coverage aims, namely equity, explainability, auditability and safety & safety . We discuss how these properties have to be thought-about across all levels of the machine learning life cycle, from information assortment by way of run-time mannequin inference.
Latest evaluation reveals that Lenovo face recognition engine achieves higher efficiency of racial fairness over opponents in phrases of multiple metrics. In addition, it additionally presents post-processing technique of bettering fairness in accordance with totally different issues and criteria. A current line of analysis highlights the existence of systematic biases hidden behind machine studying models' perceived objectivity (O'Neil 2016;Danks and London 2017). Researchers demonstrated how biased algorithms may negatively have an effect on judicial selections (Angwin et al. 2017), and create and improve existing disparities (Crawford 2013;Rhue 2019). Moreover, people had been additionally documented to be cautious about recommendations which are the outcomes of algorithmic calculation after seeing the algorithms err (Dietvorst et al. 2015;Prahl and Van Swol 2017).
Aequitas was created by the Center for Data Science and Public Policy on the University of Chicago. Despite all these complexities, nonetheless, current authorized standards can present an excellent baseline for organizations seeking to combat unfairness of their AI. These standards acknowledge the impracticality of a one-size-fits-all approach to measuring unfair outcomes. As a result, the question these standards ask just isn't merely “is disparate impact occurring? Instead, present requirements mandate what amounts to 2 essential requirements for regulated firms.
Second, we carry out an empirical research of different equity processors in a profit-oriented credit score scoring setup utilizing seven real-world data units. The empirical outcomes substantiate the analysis of equity measures, establish extra and fewer appropriate choices to implement honest credit score scoring, and clarify the profit-fairness trade-off in lending decisions. Specifically, we find that multiple equity standards could be roughly happy at once and determine separation as a proper criterion for measuring the fairness of a scorecard.
Regulatory sandboxes are perceived as one strategy for the creation of momentary reprieves from regulation to allow the technology and rules surrounding its use to evolve collectively. These policies might apply to algorithmic bias and different areas where the know-how in query has no analog lined by existing rules. Even in a extremely regulated industry, the creation of sandboxes the place innovations could be examined alongside with lighter contact laws can yield advantages.
We then created a taxonomy for fairness definitions that machine studying researchers have defined to avoid the present bias in AI techniques. In addition to that, we examined totally different domains and subdomains in AI displaying what researchers have noticed with regard to unfair outcomes within the state-of-the-art methods and methods they have tried to address them. There are still many future instructions and options that may be taken to mitigate the issue of bias in AI systems. We are hoping that this survey will inspire researchers to tackle these points in the close to future by observing present work in their respective fields. In the present era, individuals and society have grown more and more reliant on Artificial Intelligence applied sciences. Discussions about whether or not we must always trust AI have repeatedly emerged lately and in plenty of quarters, together with industry, academia, health care, companies, and so forth.
We summarize earlier efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a significant focus on the viewers for which explainability is sought. We then propose and focus on a couple of taxonomy of current contributions related to the explainability of various Machine Learning models, including these aimed at Deep Learning strategies for which a second taxonomy is constructed. This literature analysis serves because the background for a sequence of challenges faced by XAI, such as the crossroads between data fusion and explainability.
But extra citizen-centered applications, such because the Boston’s Street Bump App, which is developed to detect potholes on roads are also probably discriminatory. By relying on the usage of a smartphone, the App, risks rising the social divide between neighborhoods with the next number of older or much less prosperous residents and people more wealthy areas with more young smartphone homeowners . In the context of civil rights law, discrimination refers to unfair or unequal treatment of individuals based mostly on member- ship to a class or a minority, with out regard to individ- ual merit. A recurring theme in many papers was that legislation always lacks behind technological developments and that while gaps in authorized protection are somehow systemic , an overarching authorized resolution to all unfair discriminatory outcomes of knowledge mining isn't possible . There is an pressing need for company organizations to be more proactive in guaranteeing fairness and non-discrimination as they leverage AI to enhance productivity and performance. One potential answer is by having an AI ethicist in your growth staff to detect and mitigate moral risks early in your project before investing a lot of money and time. In data mining we frequently need to be taught from biased knowledge, as a outcome of, for instance, information comes from totally different batches or there was a gender or racial bias in the assortment of social information. In some purposes it may be necessary to explicitly management this bias in the fashions we learn from the information. This paper is the primary to study studying linear regression models under constraints that control the biasing impact of a given attribute corresponding to gender or batch quantity. We present how propensity modeling can be used for factoring out the a part of the bias that can be justified by externally offered explanatory attributes.
Many papers claimed that automatic choice making and profiling are reshaping the idea of discrimination, past legally accepted definitions. Some articles have also identified that ideas like “identity” and “group” are being transformed by knowledge mining applied sciences. De Vries argued that individual identification is more and more shaped by profiling algorithms and ambient intelligence in terms of elevated grouping created in accordance with algorithms’ arbitrary correlations, which kind people into a virtual, probabilistic “community “or “crowd” . to that group, the explanations behind their affiliation with that group and, most importantly, the consequences of being part of that group . The first is the concept of border , which is now not a physical and static divider between international locations but has turn out to be a pervasive and
Classification algorithms using CNN normally make use of totally different methods to take care of knowledge imbalance, similar to pre-processing , inprocessing to address discrimination in the course of the mannequin coaching phase , or post-processing, that processes the info after the model is educated . These de-biasing approaches are widely used particularly in the course of the task of picture classification, such as gender estimation .
The reasons for these algorithm-based biases are varied, however they can have a profound impact on the validity of the conclusions, together with inadequate drawback specification, model misspecification errors, using biased proxies for goal variables of curiosity, and using misguided coaching knowledge to create predictive fashions. In many cases, biases in the data might outcome from corresponding biases in human habits and social coverage. Machine Learning, AI and Data Science based mostly predictive instruments are being more and more utilized in problems that may have a drastic influence on people’s lives in policy areas such as legal justice, education, public well being, workforce development and social providers. Recent work has raised issues on the danger of unintended bias in these fashions, affecting individuals from certain teams unfairly.
Learn more about data science course in hyderabad with placements
Navigate to Address:
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081 0
99899 94319
Read more :
>Know About Data Science
>Is Data Science A Game Changer ?
>How programming concepts are crucial to Data Science
>Why should you pursue a career in Data Science
>How Data Science is related to our social visibility
>How Data Science and designs can be combined
>Data Science and Data Mining ultimate differences
>Powerful methods for Data Science workflows
>How Data Analytics and fire systems are related
>Which one should you choose for your business Business Analytics or Data Analytics
0 notes
Text
Researcher Emily M. Bender favors an alternative abbreviation proposed by a former member of the Italian Parliament: “Systematic Approaches to Learning Algorithms and Machine Inferences,” or SALAMI.
Then people would be out here asking, “Is this SALAMI intelligent? Can this SALAMI write a novel? Does this SALAMI deserve human rights?”
calling chatgpt “AI” feels exactly the same to me as calling those motorized skateboards “hoverboards”
34K notes
·
View notes
Text
The Unreasonable Importance of Data Preparation in 2020
youtube
The Unreasonable Importance of Data Preparation in 2020
In a world focused on buzzword-driven models and algorithms, you’d be forgiven for forgetting about the unreasonable importance of data preparation and quality: your models are only as good as the data you feed them.
This is the garbage in, garbage out principle: flawed data going in leads to flawed results, algorithms, and business decisions. If a self-driving car’s decision-making algorithm is trained on data of traffic collected during the day, you wouldn’t put it on the roads at night.
To take it a step further, if such an algorithm is trained in an environment with cars driven by humans, how can you expect it to perform well on roads with other self-driving cars?
Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and data collected incorrectly, more of which we’ll address below.
When executives ask me how to approach an AI transformation, I show them Monica Rogati’s AI Hierarchy of Needs, which has AI at the top, and everything is built upon the foundation of data (Rogati is a data science and AI advisor, former VP of data at Jawbone, and former LinkedIn data scientist):
AI Hierarchy of Needs 2020
Image courtesy of Monica Rogati, used with permission.
Why is high-quality and accessible data foundational?
If you’re basing business decisions on dashboards or the results of online experiments, you need to have the right data.
On the machine learning side, we are entering what Andrei Karpathy, director of AI at Tesla, dubs the Software 2.0 era, a new paradigm for software where machine learning and AI require less focus on writing code and more on configuring, selecting inputs, and iterating through data to create higher level models that learn from the data we give them.
In this new world, data has become a first-class citizen, where computation becomes increasingly probabilistic and programs no longer do the same thing each time they run.
The model and the data specification become more important than the code.
Collecting the right data requires a principled approach that is a function of your business question.
Data collected for one purpose can have limited use for other questions.
The assumed value of data is a myth leading to inflated valuations of start-ups capturing said data. John Myles White, data scientist and engineering manager at Facebook, wrote:
The biggest risk I see with data science projects is that analyzing data per se is generally a bad thing.
Generating data with a pre-specified analysis plan and running that analysis is good. Re-analyzing existing data is often very bad.”
John is drawing attention to thinking carefully about what you hope to get out of the data, what question you hope to answer, what biases may exist, and what you need to correct before jumping in with an analysis[1].
With the right mindset, you can get a lot out of analyzing existing data—for example, descriptive data is often quite useful for early-stage companies[2].
Not too long ago, “save everything” was a common maxim in tech; you never knew if you might need the data. However, attempting to repurpose pre-existing data can muddy the water by shifting the semantics from why the data was collected to the question you hope to answer. In particular, determining causation from correlation can be difficult.
For example, a pre-existing correlation pulled from an organization’s database should be tested in a new experiment and not assumed to imply causation[3], instead of this commonly encountered pattern in tech:
A large fraction of users that do X do Z Z is good Let’s get everybody to do X
Correlation in existing data is evidence for causation that then needs to be verified by collecting more data.
The same challenge plagues scientific research. Take the case of Brian Wansink, former head of the Food and Brand Lab at Cornell University, who stepped down after a Cornell faculty review reported he “committed academic misconduct in his research and scholarship, including misreporting of research data, problematic statistical techniques [and] failure to properly document and preserve research results.” One of his more egregious errors was to continually test already collected data for new hypotheses until one stuck, after his initial hypothesis failed[4]. NPR put it well: “the gold standard of scientific studies is to make a single hypothesis, gather data to test it, and analyze the results to see if it holds up. By Wansink’s own admission in the blog post, that’s not what happened in his lab.” He continually tried to fit new hypotheses unrelated to why he collected the data until he got a null hypothesis with an acceptable p-value—a perversion of the scientific method.
Data professionals spend an inordinate amount on time cleaning, repairing, and preparing data
Before you even think about sophisticated modeling, state-of-the-art machine learning, and AI, you need to make sure your data is ready for analysis—this is the realm of data preparation. You may picture data scientists building machine learning models all day, but the common trope that they spend 80% of their time on data preparation is closer to the truth.
common trope that data scientists spend 80% of their time on data preparation 2020
This is old news in many ways, but it’s old news that still plagues us: a recent O’Reilly survey found that lack of data or data quality issues was one of the main bottlenecks for further AI adoption for companies at the AI evaluation stage and was the main bottleneck for companies with mature AI practices.
Good quality datasets are all alike, but every low-quality dataset is low-quality in its own way[5]. Data can be low-quality if:
It doesn’t fit your question or its collection wasn’t carefully considered; It’s erroneous (it may say “cicago” for a location), inconsistent (it may say “cicago” in one place and “Chicago” in another), or missing; It’s good data but packaged in an atrocious way—e.g., it’s stored across a range of siloed databases in an organization; It requires human labeling to be useful (such as manually labeling emails as “spam” or “not” for a spam detection algorithm).
This definition of low-quality data defines quality as a function of how much work is required to get the data into an analysis-ready form. Look at the responses to my tweet for data quality nightmares that modern data professionals grapple with.
The importance of automating data preparation
Most of the conversation around AI automation involves automating machine learning models, a field known as AutoML.
This is important: consider how many modern models need to operate at scale and in real time (such as Google’s search engine and the relevant tweets that Twitter surfaces in your feed). We also need to be talking about automation of all steps in the data science workflow/pipeline, including those at the start. Why is it important to automate data preparation?
It occupies an inordinate amount of time for data professionals. Data drudgery automation in the era of data smog will free data scientists up for doing more interesting, creative work (such as modeling or interfacing with business questions and insights). “76% of data scientists view data preparation as the least enjoyable part of their work,” according to a CrowdFlower survey.
A series of subjective data preparation micro-decisions can bias your analysis. For example, one analyst may throw out data with missing values, another may infer the missing values. For more on how micro-decisions in analysis can impact results, I recommend Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results[6] (note that the analytical micro-decisions in this study are not only data preparation decisions).
Automating data preparation won’t necessarily remove such bias, but it will make it systematic, discoverable, auditable, unit-testable, and correctable. Model results will then be less reliant on individuals making hundreds of micro-decisions.
An added benefit is that the work will be reproducible and robust, in the sense that somebody else (say, in another department) can reproduce the analysis and get the same results[7];
For the increasing number of real-time algorithms in production, humans need to be taken out of the loop at runtime as much as possible (and perhaps be kept in the loop more as algorithmic managers): when you use Siri to make a reservation on OpenTable by asking for a table for four at a nearby Italian restaurant tonight, there’s a speech-to-text model, a geographic search model, and a restaurant-matching model, all working together in real time.
No data analysts/scientists work on this data pipeline as everything must happen in real time, requiring an automated data preparation and data quality workflow (e.g., to resolve if I say “eye-talian” instead of “it-atian”).
The third point above speaks more generally to the need for automation around all parts of the data science workflow. This need will grow as smart devices, IoT, voice assistants, drones, and augmented and virtual reality become more prevalent.
Automation represents a specific case of democratization, making data skills easily accessible for the broader population. Democratization involves both education (which I focus on in my work at DataCamp) and developing tools that many people can use.
Understanding the importance of general automation and democratization of all parts of the DS/ML/AI workflow, it’s important to recognize that we’ve done pretty well at democratizing data collection and gathering, modeling[8], and data reporting[9], but what remains stubbornly difficult is the whole process of preparing the data.
Modern tools for automating data cleaning and data preparation
We’re seeing the emergence of modern tools for automated data cleaning and preparation, such as HoloClean and Snorkel coming from Christopher Ré’s group at Stanford.
HoloClean decouples the task of data cleaning into error detection (such as recognizing that the location “cicago” is erroneous) and repairing erroneous data (such as changing “cicago” to “Chicago”), and formalizes the fact that “data cleaning is a statistical learning and inference problem.”
All data analysis and data science work is a combination of data, assumptions, and prior knowledge. So when you’re missing data or have “low-quality data,” you use assumptions, statistics, and inference to repair your data.
HoloClean performs this automatically in a principled, statistical manner. All the user needs to do is “to specify high-level assertions that capture their domain expertise with respect to invariants that the input data needs to satisfy. No other supervision is required!”
The HoloClean team also has a system for automating the “building and managing [of] training datasets without manual labeling” called Snorkel. Having correctly labeled data is a key part of preparing data to build machine learning models[10].
As more and more data is generated, manually labeling it is unfeasible.
Snorkel provides a way to automate labeling, using a modern paradigm called data programming, in which users are able to “inject domain information [or heuristics] into machine learning models in higher level, higher bandwidth ways than manually labeling thousands or millions of individual data points.”
Researchers at Google AI have adapted Snorkel to label data at industrial/web scale and demonstrated its utility in three scenarios: topic classification, product classification, and real-time event classification.
Snorkel doesn’t stop at data labeling. It also allows you to automate two other key aspects of data preparation:
Data augmentation—that is, creating more labeled data. Consider an image recognition problem in which you are trying to detect cars in photos for your self-driving car algorithm.
Classically, you’ll need at least several thousand labeled photos for your training dataset. If you don’t have enough training data and it’s too expensive to manually collect and label more data, you can create more by rotating and reflecting your images.
Discovery of critical data subsets—for example, figuring out which subsets of your data really help to distinguish spam from non-spam.
These are two of many current examples of the augmented data preparation revolution, which includes products from IBM and DataRobot.
The future of data tooling and data preparation as a cultural challenge
So what does the future hold? In a world with an increasing number of models and algorithms in production, learning from large amounts of real-time streaming data, we need both education and tooling/products for domain experts to build, interact with, and audit the relevant data pipelines.
We’ve seen a lot of headway made in democratizing and automating data collection and building models. Just look at the emergence of drag-and-drop tools for machine learning workflows coming out of Google and Microsoft.
As we saw from the recent O’Reilly survey, data preparation and cleaning still take up a lot of time that data professionals don’t enjoy. For this reason, it’s exciting that we’re now starting to see headway in automated tooling for data cleaning and preparation. It will be interesting to see how this space grows and how the tools are adopted.
A bright future would see data preparation and data quality as first-class citizens in the data workflow, alongside machine learning, deep learning, and AI. Dealing with incorrect or missing data is unglamorous but necessary work.
It’s easy to justify working with data that’s obviously wrong; the only real surprise is the amount of time it takes. Understanding how to manage more subtle problems with data, such as data that reflects and perpetuates historical biases (for example, real estate redlining) is a more difficult organizational challenge.
This will require honest, open conversations in any organization around what data workflows actually look like.
The fact that business leaders are focused on predictive models and deep learning while data workers spend most of their time on data preparation is a cultural challenge, not a technical one. If this part of the data flow pipeline is going to be solved in the future, everybody needs to acknowledge and understand the challenge.
Original Source: The unreasonable importance of data preparation
Curated On: https://www.cashadvancepaydayloansonline.com/
The post The Unreasonable Importance of Data Preparation in 2020 appeared first on Cash Advance Payday Loans Online | Instant Payday Loans Online 2020.
source https://www.cashadvancepaydayloansonline.com/the-unreasonable-importance-of-data-preparation-in-2020/?utm_source=rss&utm_medium=rss&utm_campaign=the-unreasonable-importance-of-data-preparation-in-2020
0 notes