#Then I fed those through an OCR
Text
I have long said that Hitori is the most well written character in Hatoful, and I'm right. But most well written ARC goes squarely to Sakuya. Sakuya is possibly the most dynamic character in the game. Sakuya on day one of the game, and Sakuya in the epilogue of BBL are entirely different people.
That's actually part of why I don't usually talk about him all that much. Sakuya has a complete character arc. That's not something that you can really say about the rest of the cast. They all definitely HAVE arcs, but one of the things that keeps me constantly coming back to the series is how none of them feel quite complete. Like they're all still hanging open, their arcs stopped just short of coming around to their proper conclusion. Characters in Hatoful Boyfriend are often just left bleeding. You watch them grow and get torn down by the world around them, and then they come to stop, still hanging and bleeding, neither patched up nor bled out. And it's this incompleteness that makes it stick in my brain. I keep searching for that last note needed to close out the movement, and it's just not there.
Hitori's story is a revenge tragedy, but we never reach the revenge, or the natural conclusion of the tragedy. Both he and Shuu are alive at the end of the story, with nowhere to go. They've backed themselves into a bloody corner, and the story has just left them there. There isn't a resolution. Their narratives can really only end in death, and they don't die at the end, so instead it's left open and incomplete.
Ryouta just gets slowly torn down throughout the narrative. Misfortune after misfortune pile onto him, and he slowly runs ragged. Hatoful Boyfriend is chronicling his descent. From the most normal, cheery member of the cast, to the most broken and miserable. But at the end of BBL, he's just left waiting. Waiting to die or for someone to come back with a cure. Left in a sort of eternal stasis. He's left open and bleeding, without a proper conclusion either way, hopeful or tragic. In Holiday Star he keeps being pushed to confront his abandonment issues, and he just keeps refusing to do so. He never really confronts them despite how many times he's faced with these issues, and again, we're left without a real satisfying resolution to his character arc. He goes most of the way through an arc, and then stops just short of completing it.
Shuu's story is this grand tale of hubris. He so clearly lines up his own downfall with every decision he makes. From how many enemies he makes, to how much he underestimates those enemies. Following Shuu is like slowly going up a rollercoaster headed towards the big drop. It's all build up for either his grand plan going off in this spectacular act of genius, or else his great failure, going out in a big blaze of glory, falling into all of the holes he left for himself, that he thought were too small and unimportant to worry about. And the way he ends is... Neither of those things. His terrible decisions do come back to haunt him, but the price he pays for it is ultimately so small compared to all that he's done. It's underwhelming, and leaves me feeling like I'm waiting for the other shoe to drop, and for him to finally get his dues, and it just never comes. It's all build up, and then a sudden jarring stop just short of the grand crescendo promised.
Yuuya's arc is a lot like Ryouta's. It's a descent. It's his unraveling. Unlike Ryouta's thought, we do see him putting some of these pieces back together, or at least trying to. The game explores a lot of the consequences of his hero complex, and he fully faces the consequences of his act of revenge, and spends the rest of his arc looking for redemption from this guilt he carries. It's hard to call Yuuya's story a redemption arc. Redemption is the thing he's seeking, but I don't think he's ever really condemned by the narrative even before seeking this redemption. It's more like what Yuuya's arc is about is seeking forgiveness from himself, and seeking to repair his relationship with Sakuya, which is what complicates his arc for me. If it was a straightforward quest for redemption "I took vengeance once, and I am paying for my sins. I seek to redeem my soul" then you could see him taking that scalpel for Sakuya as a conclusion. But the fact that it's never really treated by the narrative as though Yuuya's act of vengeance was actually wrong instead makes it feel less like Yuuya is seeking forgiveness from the universe, but instead like he is seeking forgiveness from himself. In which case, his self sacrifice is a step backwards. It's more of Yuuya devaluing himself, more of him prioritizing others to an extreme. If we take the egg incident to be Yuuya's biggest sin, then BBL is just him repeating those same mistakes again and again. It's him choosing Sakuya over everything to a destructive degree. He chops up Hiyoko's body and covers up her death, to protect Sakuya. He throws away his own life, to protect Sakuya. It's just a loop of Yuuya doing something terrible in Sakuya's name. There's no redemption found in there, only a further spiral. And further reinforcing Yuuya's guilt, and self hatred, and this steady creeping towards the place Hitori is in. And he doesn't really deviate from this path. He continues onward, repeating his mistakes, and slipping towards the same cliff that Hitori plunged off of. Again, it's left unresolved. He keeps starting to learn, starting to heal, starting to confront his flaws, and then not quite overcoming them.
I'm.... Honestly not sure what Anghel's arc is? I know it's about coming to terms with his complicated identity, and being understood by the people around him, but it's hard to say how much progress he really makes on those fronts? Anghel is sort of just... Perfect as he is? He serves very effectively as a plot device, and he's loveable and compelling without having an especially dynamic arc. Anghel is somewhat static, but I don't think that's really a bad thing on him. I'm not sure if he just doesn't have a whole lot going on arc wise, or if I'm just not seeing it right now, but oh well. I'd love to hear someone else give their takes on him, see if I can't find a new perspective to come at him from. But as it is he's just my funky little guy that I love so so much, but in a sort of no thoughts head empty kind of way.
Nageki is the hardest to talk about for me, which is why I saved him for last. He has so much going on. Nageki's route is famously emotionally moving. I cried for it, I think most people did. And I'm not sure exactly how to approach it from a meta perspective. Nageki is almost a sort of... Messianic figure. Nageki died to save humanity, despite all the ways that it had wronged him. You could say Nageki's arc is one of taking back power for himself. He was weak, and unable to do anything for himself or for anyone else either. He felt like a burden, and so when he found an opportunity to do something for someone, to protect people, he threw himself into it regardless of the cost. Even though it cost him his life. He made this selfless sacrifice. But while that was something of an arc of him finding power for himself, I hesitate to call it a full arc. Nageki had always been that selfless. Nageki pre-Hatoful House massacre would likely have been just as ready and willing to give his life for others as he was in the end.
Was it him losing hope then? Nageki being beaten down by the treatment he recieved at the St Pigeonations clinic? In the end succumbing to the misfortune that had haunted him all his life and killing himself? That doesn't feel right either. Nageki dying is, strangely enough, never actually a change for him. Nageki was dead from the beginning of the game. But more than that, Nageki was always going to die. From even long before the game began, Nageki had this clear path to an early death laid out before him. Nageki was ALWAYS going to die. There is no other way for him to go, this was always how it was going to be. And it's how it went. He accepted his fate, embraced it, and leaned into it. He took ahold of his incoming death for himself. It's very difficult for me to identify what exactly is going on with Nageki because it feels like he has SO MUCH going on. Nageki sits nestled at the heart of all of it. Both games orbit around him. I know that Ryouta is the unofficial main character. And I know that you can trace everything that happened in the series directly back to Ryuuji. I know that Shuu is the driving force behind the plot and that he laid out all of the pieces and players for this whole game, that it was all his doing. But Nageki feels, to me at least, like the true heart of the issue. He's your first introduction to the fact that something is truly genuinely Not Right in this world. So much of the plot is all of the living characters chasing after Nageki. Trying to unravel his secrets. Following his trail. Trying to find him. Nageki stands ahead of the crowd, several paces up, and every other character is tripping over themselves running after him.
Nageki is the axis upon which the story rotates. Hitori's entire character revolves around him. Orbits him. Ryouta's downfall is so tightly intertwined with Nageki. At the end of the day, one of Ryouta's most important roles in the plot is simply as a vessel for Nageki. It's carrying a piece if him inside of him. Ryouta's place in the narrative is sometimes as a sort of second coming if Nageki in a way. Shuu's fate was sealed the moment he chose Nageki as his victim, and he has been paying the price for that decision ever since, in little increments. Almost every character has their moment where they serve as a parallel to Nageki. The King's entire thing is RIDDLED with parallels, they are established as sort of foils to eachother. Two ghosts, two sad little birds who died unfortunate early deaths, two people that Hitori feels so responsible for, the two shadows that haunt him. And so much of Holiday Star is about how they handled this differently. How The King used his fire to draw others in and trap them, to make himself feel better and to have company in his misery. And how Nageki, the scorpion, burned himself to ash to free them. It's the scene in the lighthouse, how he was prepared to burn to death all over again. Sakuya is also often cast in parallel to Nageki as part of Yuuya and Hitori's parallels. With these two sets of brothers you have two stories of selflessness and giving as a bad thing. They're about self destruction, and living your life exclusively in service if someone else, and how unfair that can be to the person you are trying to help. How in the end, for all of Hitori's selfless sacrifice none of Nageki's wishes came true, and how for all of Yuuya's selfless sacrifice he wound up hurting Sakuya more than anyone else. And both of them, in this single minded quest, choosing one person above the entire world, leave this trail of bloody mistakes behind them. This parallel casts Nageki as Sakuya's mirror.
In a way, that's really Nageki's role. He's a mirror held up to each member of the cast. And in that reflection you see the worst of each of them. Nageki is sort of perfect, and the narrative stands each other character next to him to show you their flaws. What does Nageki do wrong, ever??? I can't think of a single thing. He doesn't make any real mistakes, so I don't know where to find an arc in that. There's nowhere to go, there's no change. Nageki really does thrive in his role as a ghost. He's sort of intangible, impossible to catch, impossible to hold on to. He's an impossible goal to be chased after, and ultimately, be left unreached. So much of the plot is just looking for Nageki. Looking for his secrets. Looking for his remains. Looking for anything he left behind. Looking for him. Looking for Nageki, and instead only finding your own reflection. I don't know how to discuss that, really. Which is why I usually don't. The story of Hatoful Boyfriend is this massive downward spiral, pulling everyone in, and down to their lowest point, and curled up right in the center of it all is Nageki, with every other story element orbiting around him, but never actually managing to reach him.
But after all that, looping all the way back around to my actual point. Sakuya.
Sakuya's arc actually finishes, and it finishes beautifully. In a story full of people getting worse, chasing unachievable ends, and being left eternally swirling around and around never quite reaching a proper conclusion just getting more and more damaged with each go around, Sakuya actually improves. He has this perfect, solid character arc.
Sakuya starts out as an egotistical bigot, living under false pretenses, with high ambitions of becoming a great leader. Through the story he faces every single flaw he has, confronts it, changes for the better, and grows as a person. And with each one he approaches his goal of being a great leader. Sakuya begins as a good leader, and ends as a fantastic one. He confronts his biases. He confronts his fears. He confronts his beliefs. He confronts himself, his identity. And he comes to terms with all of it, and rises from it stronger, and wiser, and more worldly. Sakuya walks out of the BBL epilogue a hero, and an incredible leader, having made good on all of his promises, and made significant good in the world. He's also quite possibly the least self destructive character we have, save for maybe Okosan, but I'm not going to even touch Okosan here. Sakuya learns from his mistakes and doesn't repeat them. And he achieves all of his goals. Sakuya is the only character not stuck in this downward spiral. And his character arc is just so perfect. It's such a nice clean arc. Sakuya starts out the first game as a genuinely kind of shitty guy. Every time I've introduced someone to the game I've said "It's totally okay not to like Sakuya. I like Sakuya, but when you first meet him it's hard to do, I get it. But just hold on, he gets better, I promise."
Sakuya has a Zuko tier redemption arc. The way that he learns to respect Ryouta more and more throughout BBL, the way that he starts to really think for himself and escape out from under his father's expectations in his route, the way that he was completely untouchable by The King's attempts at manipulation. Sakuya just fuckin THRIVES.
And this is sort of why I haven't really talked about him before today. That unfinished feeling to everyone else's story arcs eats at me. It sticks in my head. I can't stop talking about them because they're COMPELLING and they feel UNFINISHED and now I'm sort of obsessed with it. I'm caught in the loop with them, hunting for an ending that isn't there. The imperfections in these arcs are what keeps me speculating about still, 8 years down the line. I'm still trying to find that ending. But for Sakuya, and Nageki too actually, the only thing there is for me to talk about is why they work so well. And in Nageki's case, I'm not especially sure why, and so I don't have a lot to say on him. He's sort of a mystery to me. But for Sakuya, it is just so apparent to me why he's such an incredibly well written character. It feels sort of redundant to go through it. His arc is clean, and perfect. Just look at it! There's no holes for me to obsess over and write endless essays on. And there's no mystery to how effective it is. It's clean, and simple, and utterly perfect. I don't need to puzzle over how it works so well, because you can just take one look at it and it's all laid bare. He has the ideal redemption arc. The platonic ideal of exactly what his type of character should be. It's perfect. I don't feel like I can contribute much of anything to it by discussing it, further than just shining a light at what about it works so incredibly well.
So I don't.
Simply put, Sakuya has the most well written arc in Hatoful Boyfriend, and I would consider him the second most well written character in all.
#I'm sorry for any issues here#I know that Tumblr would eat this essay if I just posted it raw#so I screenshotted the whole thing beforehand so it wouldn't be destroyed in the inevitable crash#Then I fed those through an OCR#and copy pasted it back into the post editor to try again#So if the OCR misread anything and made errors I'm sorry#I'm also sorry for how huge this is#I would have put it under a read more#but I've learned that when I put my bigass essays under a readmore they wind up flying under the radar and never getting read#like the almost 5k long analysis of why Yuuya and Hitori are my favourite characters which was read by absolutely no one#and I kinda worked somewhat hard on this and want someone to actually read it#So I'm sorry for dominating your dash like this but it had to be done#hatoful boyfriend#hbf#Hatoful#damn I do be writing meta on this bird game#Sakuya Renaissance
106 notes
·
View notes
Text
frank's image generation model, explained
[See also: github repo, Colab demo]
[EDIT 9/6/22: I wrote this post in January 2022. I've made a number of improvements to this model since then. See the links above for details on what the latest version looks like.]
Last week, I released a new feature for @nostalgebraist-autoresponder that generates images. Earlier I promised a post explaining how the model works, so here it is.
I'll try to make this post as accessible as I can, but it will be relatively technical.
Why so technical? The interesting thing (to me) about the new model is not that it makes cool pictures -- lots of existing models/techniques can do that -- it's that it makes a new kind of picture which no other model can make, as far as I know. As I put it earlier:
As far as I know, the image generator I made for Frank is the first neural image generator anyone has made that can write arbitrary text into the image!! Let me know if you’ve seen another one somewhere.
The model is solving a hard machine learning problem, which I didn't really believe could be solved until I saw it work. I had to "pull out all the stops" to do this one, building on a lot of prior work. Explaining all that context for readers with no ML background would take a very long post.
tl;dr for those who speak technobabble: the new image generator is OpenAI-style denoising diffusion, with a 128x128 base model and a 128->256 superresolution model, both with the same set of extra features added. The extra features are: a transformer text encoder with character-level tokenization and T5 relative position embeddings; a layer of image-to-text and then text-to-image cross-attention between each resnet layer in the lower-resolution parts of the U-Net's upsampling stack, using absolute axial position embeddings in image space; a positional "line embedding" in the text encoder that does a cumsum of newlines; and information about the diffusion timestep injected in two places, as another embedding fed to the text encoder, and injected with AdaGN into the queries of the text-to-image cross-attention. I used the weights of the trained base model to initialize the parts of the superresolution model's U-Net that deal with resolutions below 256.
This post is extremely long, so the rest is under a readmore
The task
The core of my bot is a text generator. It can only see text.
People post a lot of images on tumblr, though, and the bot would miss out on a lot of key context if these images were totally invisible to it.
So, long ago, I let my bot "see" pictures by sending them to AWS Rekognition's DetectText endpoint. This service uses a scene text recognition (STR) model to read text in the image, if it exists. ("STR" is the term for OCR when when the pictures aren't necessarily printed text on paper.)
If Rekognition saw any text in the image, I let the bot see the text, between special delimiters so it knows it's an image.
For example, when Frank read the OP of this post, this is what generator model saw:
#1 fipindustries posted:
i was perusing my old deviant art page and i came across a thing of beauty.
the ultimate "i was a nerdy teen in the mid 2000′s starter pack". there was a challenge in old deviant art where you had to show all the different characters that had inspired an OC of yours. and so i came up with this list
=======
"Inspirations Meme" by Phantos
peter
=======
(This is actually less information than I get back from AWS. It also gives me bounding boxes, telling me where each line of text is in the image. I figured GPT wouldn't be able to do much with this info, so I exclude it.)
Images are presented this way, also, in the tumblr dataset I use to finetune the generator.
As a result, the generator knows that people post images, and it knows a thing or two about what types of images people post in what contexts -- but only through the prism of what their STR transcripts would look like.
This has the inevitable -- but weird and delightful -- result that the generator starts to invent its own "images," putting them in its posts. These invented images are transcripts without originals (!). Invented tweets, represented the way STR would view a screenshot of them, if they existed; enigmatically funny strings of words that feel like transcripts of nonexistent memes; etc.
So, for a long time, I've had a vision of "completing the circuit": generating images from the transcripts, images which contain the text specified in the transcripts. The novel pictures the generator is imagining itself seeing, through the limited prism of STR.
It turns out this is very difficult.
Image generators: surveying the field
We want to make a text-conditioned image generation model, which writes the text into the generated image.
There are plenty of text-conditioned image generators out there: DALL-E, VQGAN+CLIP, (now) GLIDE, etc. But they don't write the text, they just make an image the text describes. (Or, they may write text on occasion, but only in a very limited way.)
When you design a text-conditioned image generation method, you make two nearly independent choices:
How do you generate images at all?
How do you make the images depend on the text?
That is, all these methods (including mine) start with some well-proven approach for generating images without the involvement of text, and then add in the text aspect somehow.
Let's focus on the first part first.
There are roughly 4 distinct flavors of image generator out there. They differ largely in how they provide signal about which image are plausible to the model during training. A survey:
1. VAEs (variational autoencoders).
These have an "encoder" part that converts raw pixels to a compressed representation -- e.g. 512 floating-point numbers -- and a "decoder" part that converts the compressed representation back into pixels.
The compressed representation is usually referred to as "the latent," a term I'll use below.
During training, you tell the model to make its input match its output; this forces it to learn a good compression scheme. To generate a novel image, you ignore the encoder part, pick a random value for the latent, and turn it into pixels with the decoder.
That's the "autoencoder" part. The "variational" part is an extra term in the loss that tries to make the latents fill up their N-dimensional space in a smooth, uniform way, rather than squashing all the training images into small scrunched-up pockets of space here and there. This increases the probability that a randomly chosen latent will decode to a natural-looking image, rather than garbage.
VAEs on their own are not as good at the other methods, but provide a foundation for VQ-autoregressive methods, which are now popular. (Though see this paper)
2. GANs (generative adversarial networks).
Structurally, these are like VAEs without the encoder part. They just have a latent, and a have a decoder that turns the latent into pixels.
How do you teach the decoder what images ought to look like? In a GAN, you train a whole separate model called the "discriminator," which looks at pixels and tries to decide whether they're a real picture or a generated one.
During training, the "G" (generator) and the "D" (discriminator) play a game of cat-and-mouse, where the G tries to fool the D into thinking its pictures are real, and the D tries not to get fooled.
To generate a novel image, you do the same thing as with a VAE: pick a random latent and feed it through the G (here, ignoring the D).
GANs are generally high-performing, but famously finicky/difficult to train.
3. VQVAEs (vector quantized VAEs) + autoregressive models.
These have two parts (you may be noticing a theme).
First, you have a "VQVAE," which is like a VAE, with two changes to the nature of the latent: it's localized, and it's discrete.
Localized: instead of one big floating-point vector, you break the image up into little patches (typically 8x8), and the latent takes on a separate value for each patch.
Discrete: the latent for each patch is not a vector of floating-point numbers. It's an element of a finite set: a "letter" or "word" from a discrete vocabulary.
Why do this? Because, once you have an ordered sequence of discrete elements, you can "do GPT to it!" It's just like text!
Start with (say) the upper-leftmost patch, and generate (say) the one to its immediate right, and then the one to its immediate right, etc.
Train the model to do this in exactly the same way you train GPT on text, except it's seeing representations that your VQVAE came up with.
These models are quite powerful and popular, see (the confusingly named) "VQ-VAE" and "VQ-VAE-2."
They get even more powerful in the form of "VQGAN," an unholy hybrid where the VQ encoder part is trained like a GAN rather than like a VAE, plus various other forbidding bells and whistles.
Somehow this actually works, and in fact works extremely well -- at the current cutting edge.
(Note: you can also just "do GPT" to raw pixels, quantized in a simple way with a palette. This hilarious, "so dumb it can't possibly work" approach is called "Image GPT," and actually does work OK, but can't scale above small resolutions.)
4. Denoising diffusion models.
If you're living in 2021, and you want to be one of the really hip kids on the block -- one of the kids who thinks VQGAN is like, sooooo last year -- then these are the models for you. (They were first introduced in 2020, but came into their own with two OpenAI papers in 2021.)
Diffusion models are totally different from the above. They don't have two separate parts, and they use a radically different latent space that is not really a "compressed representation."
How do they work? First, let's talk about (forward) diffusion. This just means taking a real picture, and steadily adding more random pixel noise to it, until it eventually becomes purely random static.
Here's what this looks like (in its "linear" and "cosine" variants), from OA's "Improved denoising diffusion probabilistic models":

OK, that's . . . a weird thing to do. I mean, if turning dogs into static entertains you, more power to you, your hobby is #valid. But why are we doing it in machine learning?
Because we can train a model to reverse the process! Starting with static, it gradually removes the noise step by step, revealing a dog (or anything).
There are a few different ways you can parameterize this, but in all of them, the model learns to translate frame n+1 into a probability distribution (or just a point prediction) for frame n. Applying this recursively, you recover the first frame from the last.
This is another bizarre idea that sounds like it can't possibly work. All it has at the start is random noise -- this is its equivalent of the "latent," here.
(Although -- since the sampling process is stochastic, unless you use a specific deterministic variant called DDIM -- arguably the random draws at every sampling step are an additional latent. A different random seed will give you a different image, even from the same starting noise.)
Through the butterfly effect, one arrangement of random static gradually "decodes to" a dog, and another one gradually "decodes to" a bicycle, or whatever. It's not that the one patch of RGB static is "more doglike" than the other; it just so happens to send the model on a particular self-reinforcing trajectory of imagined structure that spirals inexorably towards dog.
But it does work, and quite well. How well? Well enough that the 2nd 2021 OA paper on diffusion was titled simply, "Diffusion Models Beat GANs on Image Synthesis."
Conditioning on text
To make an image generator that bases the image on text, you pick one of the approaches above, and then find some way to feed text into it.
There are essentially 2 ways to do this:
The hard way: the image model can actually see the text
This is sort of the obvious way to do it.
You make a "text encoder" similar to GPT or BERT or w/e, that turns text into an encoded representation. You add a piece to the image generator that can look at the encoded representation of the text, and train the whole system end-to-end on text/image pairs.
If you do this by using a VQVAE, and simply feed in the text as extra tokens "before" all the image tokens -- using the same transformer for both the "text tokens" and the VQ "image tokens" -- you get DALL-E.
If you do this by adding a text encoder to a diffusion model, you get . . . my new model!! (Well, that's the key part of it, but there's more)
My new model, or GLIDE. Coincidentally, OpenAI was working on the same idea around the same time as me, and released a slightly different version of it called GLIDE.
(EDIT 9/6/22:
There are a bunch of new models in this category that came out after this post was written. A quick run-through:
OpenAI's DALL-E 2 is very similar to GLIDE (and thus, confusingly, very different from the original DALL-E). See my post here for more detail.
Google's Imagen is also very similar to GLIDE. See my post here.
Stability's Stable Diffusion is similar to GLIDE and Imagen, except it uses latent diffusion. Latent diffusion means you do the diffusion in the latent space of an autoencoder, rather than on raw image pixels.
Google's Parti is very similar to the original DALL-E.
)
-----
This text-encoder approach is fundamentally more powerful than the other one I'll describe next. But also much harder to get working, and it's hard in a different way for each image generator you try it with.
Whereas the other approach lets you take any image generator, and give it instant wizard powers. Albeit with limits.
Instant wizard powers: CLIP guidance
CLIP is an OpenAI text-image association model trained with contrastive learning, which is a mindblowingly cool technique that I won't derail this post by explaining. Read the blog post, it's very good.
The relevant tl;dr is that CLIP looks at texts and images together, and matches up images with texts that would be reasonable captions for them on the internet. It is very good at this. But, this is the only thing it does. It can't generate anything; it can only look at pictures and text and decide whether they match.
So here's what you do with CLIP (usually).
You take an existing image generator, from the previous section. You take a piece of text (your "prompt"). You pick a random compressed/latent representation, and use the generator to make an image from it. Then ask CLIP, "does this match the prompt?"
At this point, you just have some randomly chosen image. So, CLIP, of course, says "hell no, this doesn't match the prompt at all."
But CLIP also tells you, implicitly, how to change the latent representation so the answer is a bit closer to "yes."
How? You take CLIP's judgment, which is a complicated nested function of the latent representation: schematically,
judgment = clip(text, image_generator(latent))
All the functions are known in closed form, though, so you can just . . . analytically take the derivative with respect to "latent," chain rule-ing all the way through "clip" and then through "image_generator."
That's a lot of calculus, but thankfully we have powerful chain rule calculating machines called "pytorch" and "GPUs" that just do it for you.
You move latent a small step in the direction of this derivative, then recompute the derivative again, take another small step, etc., and eventually CLIP says "hell yes" because the picture looks like the prompt.
This doesn't quite work as stated, though, roughly because the raw CLIP gradients can't break various symmetries like translation/reflection that you need to break to get a natural image with coherent pieces of different-stuff-in-different-places.
(This is especially a problem with VQ models, where you assign a random latent to each image patch independently, which will produce a very unstructured and homogeneous image.)
To fix this, you add "augmentations" like randomly cropping/translating the image before feeding it to CLIP. You then use the averaged CLIP derivatives over a sample of (say) 32 randomly distorted images to take each step.
A crucial and highly effective augmentation -- for making different-stuff-in-different-places -- is called "cutouts," and involves blacking out everything in the image but a random rectangle. Cutouts is greatly helpful but also causes some glitches, and is (I believe) the cause of the phenomenon where "AI-generated" images often put a bunch of distinct unrelated versions of a scene onto the same canvas.
This CLIP-derivative-plus-augmentations thing is called CLIP guidance. You can use it with whichever image generator you please.
The great thing is you don't need to train your own model to do the text-to-image aspect -- CLIP is already a greater text-to-image genius than anything you could train, and its weights are free to download. (Except for the forbidden CLIPs, the best and biggest CLIPs, which are OA's alone. But you don't need them.)
(EDIT 9/6/22: since this post was written, the "forbidden CLIPs" have been made available for public use, and have been seeing use for a while in projects like my bot and Stable Diffusion.)
For the image generator, a natural choice is the very powerful VQGAN -- which gets you VQGAN+CLIP, the source of most of the "AI-generated images" you've seen papered all over the internet in 2021.
You know, the NeuralBreeders, or the ArtBlenders, or whatever you're calling the latest meme one. They're all just VQGAN+CLIP.
Except, sometimes they're a different thing, pioneered by RiversHaveWings: CLIP-guided diffusion. Which is just like VQGAN+CLIP, except instead of VQGAN, the image generator is a diffusion model.
(You can also do something different called CLIP-conditioned diffusion, which is cool but orthogonal to this post)
Writing text . . . ?
OK but how do you get it to write words into the image, though.
None of the above was really designed with this in mind, and most of it just feels awkward for this application.
For instance...
Things that don't work: CLIP guidance
CLIP guidance is wonderful if you don't want to write the text. But for writing text, it has many downsides:
CLIP can sort of do some basic OCR, which is neat, but it's not nearly good enough to recognize arbitrary text. So, you'd have to finetune CLIP on your own text/image data.
CLIP views images at a small resolution, usually 224x224. This is fine for its purposes, but may render some text illegible.
Writing text properly means creating a coherent structure of parts in the image, where their relation in space matters. But the augmentations, especially cutouts, try to prevent CLIP from seeing the image globally. The pictures CLIP actually sees will generally be crops/cutouts that don't contain the full text you're trying to write, so it's not clear you even want CLIP to say "yes." (You can remove these augmentations, but then CLIP guidance loses its magic and starts to suck.)
I did in fact try this whole approach, with my own trained VQVAE, and my own finetuned CLIP.
This didn't really work, in exactly the ways you'd expect, although the results were often very amusing. Here's my favorite one -- you might even be able to guess what the prompt was:

OK, forget CLIP guidance then. Let's do it the hard way and use a text encoder.
I tried this too, several times.
Things that don't work: DALL-E
I tried training my own DALL-E on top of the same VQVAE used above. This was actually the first approach I tried, and where I first made the VQVAE.
(Note: that VQVAE itself can auto-encode pictures from tumblr splendidly, so it's not the problem here.)
This failed more drastically. The best I could ever get was these sort of "hieroglyphics":

This makes sense, given that the DALL-E approach has steep downsides of its own for this task. Consider:
The VQVAE imposes an artificial "grain" onto the image, breaking it up into little patches of (typically) 8x8 pixels. When text is written in an image, the letters could be aligned anywhere with respect to this "grain."
The same letters will look very different if they're sitting in the middle of a VQ patch, vs. if they're sitting right on the edge between two, or mostly in one patch and partly in another. The generator has to learn the mapping from every letter (or group of letters) to each of these representations. And then it has to do that again for every font size! And again for every font!
Learning to "do GPT" on VQ patches is generally just harder than learning to do stuff on raw pixels, since the relation to the image is more abstract. I don't think I had nearly enough data/compute for a VQ-autoregressive model to work.
Things that don't work: GANs with text encoders
OK, forget DALL-E . . . uh . . . what if we did a GAN, I guess?? where both the G and the D can see the encoded text?
This was the last thing I tried before diffusion. (StyleGAN2 + DiffAug, with text encoder.) It failed, in boring ways, though I tried hard.
GANs are hard to train and I could never get the thing to "use the text" properly.
One issue was: there is a lot of much simpler stuff for the G and D to obsess over, and make the topic of their game, before they have to think about anything as abstract as text. So you have to get pretty far in GAN training for the point where the text would matter, and only at that point does the text encoder start being relevant.
But I think a deeper issue was that VAE/GAN-style latent states don't really make sense for text. I gave the G both the usual latent vector and a text encoding, but this effectively implies that every possible text should be compatible with every possible image.
For that to make sense, the latent should have a contextual meaning conditional on the text, expressing a parameterization of the space of "images consistent with this text." But that intuitively seems like a relatively hard thing for an NN to learn.
Diffusion
Then I was on the EleutherAI discord, and RiversHaveWings happened to say this:
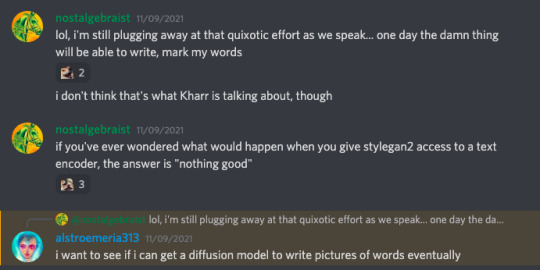
And I though, "oh, maybe it's time for me to learn this new diffusion stuff. It won't work, but it will be educational."
So I added a text encoder to a diffusion model, using cross-attention. Indeed, it didn't work.
Things that don't work: 256x256 diffusion
For a long time, I did all my diffusion experiments at 256x256 resolution. This seemed natural: it was the biggest size that didn't strain the GPU too much, and it was the smallest size I'd feel OK using in the bot. Plus I was worried about text being illegible at small resolutions.
For some reason, I could never get 256x256 text writing to work. The models would learn to imitate fonts, but they'd always write random gibberish in them.
I tried a bunch of things during this period that didn't fix the problem, but which I still suspect were very helpful later:
Timestep embeddings: at some point, RiversHaveWings pointed out that my text encoder didn't know the value of the diffusion timestep. This was bad b/c presumably you need different stuff from the text at different noise levels. I added that. Also added some other pieces like a "line embedding," and timestep info injected into the cross-attn queries.
Line embeddings: I was worried my encoder might have trouble learning to determine which tokens were on which line of text. So I added an extra positional embedding that expresses how many newlines have happened so far.
Synthetic data: I made a new, larger synthetic, grayscale dataset of text in random fonts/sizes on flat backgrounds of random lightness. This presented the problem in a much crisper, easier to learn form. (This might have helped if I'd had it for the other approaches, although I went back and tried DALL-E on it and still got hieroglyphics, so IDK.)
Baby's first words: 64x64 diffusion
A common approach with diffusion models is to make 2 of them, one at low resolution, and one that upsamples low-res images to a higher resolution.
At wit's end, I decided to try this, with train a 64x64 low-res model. I trained it with my usual setup, and . . .
. . . it can write!!!
It can write, in a sense . . . but with misspellings. Lots of misspellings. Epic misspellings.
One of my test prompts, which I ran on all my experimental models for ease of comparison, was the following (don't ask):
the
what string
commit
String evolved
LEGGED
Here are two samples from the model, both with this prompt. (I've scaled them up in GIMP just so they're easier to see, which is why they're blurry.)


Interestingly, the misspellings vary with the conditioning noise (and the random draws during sampling since I'm not using DDIM). The model has "overly noisy/uncertain knowledge" as opposed to just being ignorant.
Spelling improves: relative positional embeddings
At this point, I was providing two kinds of position info to the model:
- Which line of text is this? (line embedding)
- Which character in the string is this, counting from the first one onward? (Absolute pos embedding)
I noticed that the model often got spelling right near the beginning of lines, but degraded later in them. I hypothesized that it was having trouble reconstructing relative position within a line from the absolute positions I was giving it.
cfoster0 on discord suggested I try relative positional embeddings, which together with the line embedding should convey the right info in an easy-to-use form.
I tried this, using the T5 version of relative positional embeddings.
This dramatically improved spelling. Given that test prompt, this model spelled it exactly right in 2 of 4 samples I generated:


I showed off the power of this new model by thanking discord user cfoster0 for their suggestion:

(At some point slightly before this, I also switched from a custom BPE tokenizer to character-level tokenization, which might have helped.)
Doing it for real: modeling text in natural images
OK, we can write text . . . at least, in the easiest possible setting: tiny 64x64 images that contain only text on a flat background, nothing else.
The goal, though, is to make "natural" images that just so happen to contain text.
Put in a transcript of a tweet, get a screenshot of a tweet. Put in a brief line of text, get a movie still with the text as the subtitle, or a picture of a book whose the text is the title, or something. This is much harder:
I have fewer real tumblr images (around 169k) than synthetic text images (around 407k, and could make more if needed)
The real data is much more diverse and complex
The real data introduces new ways the image can depend on the text
Much of the real data is illegible at 64x64 resolution
Let's tackle the resolution issue first. On the synthetic data, we know 64x64 works, and 256x256 doesn't work (even with relative embeds.)
What about 128x128, though? For some reason, that works just as well as 64x64! It's still small, and ideally I'd want to make images bigger than that, but it makes legibility less of a concern.
OK, so I can generate text that looks like the synthetic dataset, at 128x128 resolution. If I just . . . finetune that model on my real dataset, what happens?
It works!
The model doesn't make recognizable objects/faces/etc most of the time, which is not surprising given the small size and diverse nature of the data set.
But it does learn the right relationships between text and image, without losing its ability to write text itself. It does misspell things sometimes, about as often as it did on the synthetic data, but that seems acceptable.
Here's a generated tweet from this era:

The prompt for this was a real STR transcript of this tweet. (Sorry about the specific choice of image here, it's just a tweet that ended up in my test split and was thus a useful testing prompt)
At this point, I was still doing everything in monochrome (with monochrome noise), afraid that adding color might screw things up. Does it, though?
Nope! So I re-do everything in color, although the synthetic font data is still monochrome (but now diffused with RGB noise). Works just as well.
(Sometime around this point, I added extra layers of image-to-text cross-attn before each text-to-image one, with an FF layer in the middle. This was inspired by another cfoster0 suggestion, and I thought it might help the model use image context to guide how it uses the text.
This is called "weave attn" in my code. I don't know if it's actually helpful, but I use it from here on.)
One last hurdle: embiggening
128x128 is still kinda small, though.
Recall that, when I originally did 64x64, the plan was to make a second "superresolution" model later to convert small images into bigger ones.
(You do this, in diffusion, by simply giving the model the [noiseless] low-res image as an extra input, alongside the high-res but noised image that is an input to any diffusion model. In my case, I also fed it the text, using the same architecture as elsewhere.)
How was that going? Not actually that well, even though it felt like the easy part.
My 128 -> 256 superresolution models would get what looked like great metrics, but when I looked at the upsampled images, they looked ugly and fuzzy, a lot like low-quality JPEGs.
I had warm-started the text encoder part of the super-res model with the encoder weights from the base model, so it should know a lot about text. But it wasn't very good at scaling up small, closely printed text, which is the most important part of its job.
I had to come up with one additional trick, to make this last part work.
My diffusion models use the standard architecture for such models, the "U-net," so called for its U shape.
It takes the image, processes it a bit, and then downsamples it to half the resolution. It processed it there, then downsamples it again, etc -- all the way down to 8x8. Then it goes back up again, to 16x16, etc. When it reaches the original resolution, it spits out its prediction for the noise.
Therefore, most of the structure of my 256-res model looks identical to the structure of my 128-res model. Only it's "sandwiched" between a first part that downsamples from 256, and a final part that upsamples to 256.
The trained 128 model knows a lot about how these images tend to look, and about writing text. What if I warm-start the entire middle of the U-Net with weights of the 128 model?
That is, at initialization, my 256 super-res model would just be my 128 model sandwiched inside two extra parts, with random weights for the "bread" only.
I can imagine lots of reasons this might not work, but it was easy to try, and in fact it did work!
Super-res models initialized in this way rapidly learned to do high-quality upsampling, both of text and non-text image elements.
At this point, I had the model (or rather, the two models) I would deploy in the bot.
Using it in practice: rejection sampling
To use this model in practice, the simplest workflow would be:
Generate a single 128x128 image from the prompt
Using the prompt and the 128x128 image, upsample to 256x256
We're done
However, recall that we have access to STR model, which we can ask to read images.
In some sense, the point of all this work is to "invert" the STR model, making images from STR transcripts. If this worked perfectly, feeding the image we make through STR would always return the original prompt.
The model isn't that good, but we can get it closer by using this workflow instead:
Generate multiple 128x128 images from the prompt
Read all the 128x128 images with STR
Using some metric like n-gram similarity, measure how close the transcripts are to the original prompt, and remove the "worst" images from the batch
Using the prompt and the 128x128 images that were kept in step 3, upsample 256x256
Feed all the 256x256 images through STR
Pick the 256x256 image that most closely matches the prompt
We're done
For step 3, I use character trigram similarity and a slightly complicated pruning heuristic with several thresholds. The code for this is here.
Why did diffusion work?
A few thoughts on why diffusion worked for this problem, unlike anything else:
- Diffusion doesn't have the problem that VQ models have, where the latent exists on an arbitrary grid, and the text could have any alignment w/r/t the grid.
- Unlike VQ models, and GAN-type models with a single vector latent, the "latent" in diffusion isn't trying to parameterize the manifold of plausible images in any "nice" way. It's just noise.
Since noise works fine without adding some sort of extra "niceness" constraint, we don't have to worry about the constraint being poorly suited to text.
- During training, diffusion models take partially noised real images as inputs, rather than getting a latent and having to invent the entire image de novo. And it only gets credit for making this input less noised, not for any of the structure that's already there.
I think this helps it pick up nuances like "what does the text say?" more quickly than other models. At some diffusion timesteps, all the obvious structure (that other models would obsess over) has already been revealed, and the only way to score more points is to use nuanced knowledge.
In a sense, diffusion learns the hard stuff and the easy stuff in parallel, rather than in stages like other models. So it doesn't get stuck in a trap where it over-trains itself to one stage, and then can't learn the later stages, because the loss landscape has a barrier in between (?). I don't know how to make this precise, but it feels true.
Postscript: GLIDE
Three days before I deployed this work in the bot, OpenAI released its own text-conditioned diffusion model, called GLIDE. I guess it's an idea whose time has come!
Their model is slightly different in how it joins the text encoder to the U-net. Instead of adding cross-attn, it simply appends the output of the text encoder as extra positions in the standard attention layers, which all diffusion U-Nets have in their lower-resolution middle layer(s).
I'm not sure if this would have worked for my problem. (I don't know because they didn't try to make their model write text -- it models the text-image relation more like CLIP and DALL-E.)
In any event, it makes bigger attn matrices than my approach, of size (text_len + res^2)^2 rather than my (text_len * res^2). The extra memory needed might be prohibitive for me in practice, not sure.
I haven't tried their approach, and it's possible it would beat mine in a head-to-head comparison on this problem. If so, I would want to use theirs instead.
The end
Thanks for reading this giant post!
Thanks again to people in EleutherAI discord for help and discussion.
You can see some of the results in this tag.
106 notes
·
View notes
Text
The Amazing List From The Leading 100 Best Jogging Weblogs For 2014.
Among the many things I am actually THE MAJORITY OF thankful to my moms and dads is my visibility to sporting activities from a younger age. In http://surveillezlasante.info/dermagen-iq-creme-commentaires-effets-secondaires-prix-ou-acheter/ , 2014, Koerner posted his initial book, Hal Koerner's Guidebook to Ultrarunning: Teaching for an Ultramarathon, off 50K to 100 Miles as well as Beyond I overtook Hal on two occasions from his home in Oregon to talk about recovering coming from knee surgical procedure as well as establishing life-running equilibrium with two kids, a retail store, and also a specialist running career.
I must additionally be familiar through this segment which is actually discussed in between Sierra Nevada Run as well as American Waterway, yet I get confused in between these races as well as, besides, paying for more focus on my feet action, specifically at night, I am actually really bad with instructions (2 years ago I was following program document owner Jon Olsen as well as most of us went off course at the start, as well as Chikara Omine around mile 15 or Michael Kanning in Chestnut, so that is most definitely a challenging course to sufficiently symbol).
Certainly I get the point concerning not wishing to shed most of the beneficial things that this sporting activity and lifestyle has created throughout the years, yet when you have one thing that has actually been around for greater than 4 many years that unexpectedly increases in appeal through 1,000% or even more, that is actually certainly not sensible to anticipate the sporting activity to remain to thrive by just maintaining things the like they have actually consistently been actually.
As the Los Angeles Moments described previously this year, slopestyle was fast-tracked right into the Olympics only 3 years ago, an uncommon departure for the conservative International Olympic Board ... Numerous onlookers observed the selection as an image of the Olympics' desire to change on its own as well as entice a more youthful audience." OCR could effortlessly market on its own as a sporting activity along with booming level of popularity, a youthful target market, as well as low creation costs.
The solution is actually essentially as high as feasible." For example, presuming a professional athlete operates 6 miles/hr (very quick over this surface - less than 5% from competitors may achieve this!) in the course of the MdS, and also provided the challenge of the terrain (30-50% more electricity needed per kilometers manage compared to ordinary trail or even road) a 165 pound sportsmen will definitely shed roughly 1,000 fats each hr.
I ran Broad Road in 1:01.59, having said that, considering that my heart price was actually high, FitBit ended my jog was actually an added 30 seconds a lot longer. This is actually the status quo that need to be actually damaged - for instance, through giving last-mile Net through community power utilities which don't have obsolete investment baggage to protect. Transmission a little body weight forward and also squeeze your buttocks on the stooping side hip. I additionally had to go up one measurements in order to get a good suit the toe carton, however the added duration really isn't as well excessive (far better than an Inov8 Mudclaw, for example) and also aids with securing the toes from stubbing on rocks. This is actually demonstrated in the institution lawn and prominent sporting culture in Australia and England.
Dr. Hoffman presented John Vonhof through stating his manual, Correcting Your Feet, is actually the best manual on call for foot care in the course of ultramarathons. Through enhancing your diet regimen with Omega 3, you enhance the body system's capability to synthesize its own fat retail stores for energy. This is actually a really low reliance on added power and also ought to reduce nausea or vomiting and also throwing up and the experience from reduced energy. Yet I acquired a lot of conditioning coming from the other sporting activities I have actually carried out, basketball and hockey.
These would appear to become an excellent play for these supporters as well, provided the mass allure and quick growing attribute of endurances and also half marathons in the U.S. and the blast from range operating as a participation and competitive sporting activity. Symbol: The food varies at the gates, yet that typically consists of breadstuff, cheese, meat product, fruit product, soup, water, delicious chocolate, biscuits, as well as Adage electricity drink. Going up a supplanted procedure to company casual, the blazer is actually similar in style to the sport coat however this is solid as opposed to formed.
Sune from Denmark requested some substitutes in Southern Sweden as well as a handful of suggestions are actually the other Skaneleden areas () Maps are actually readily available online and also in most bookshops and also some sporting activity retail stores. Find your Road Jogger Sports shop or shop online at Bear in mind, merely at Street Distance runner Sports you reach test-run your shoes for 90-Days to make sure they are actually best!
A try from energy gel are going to energize you quick and easy, only see to it to take that with a glass of water, at least 30 minutes prior to the competition starts, to avoid bloating. Outlawed in France, Norway, and also Denmark, and also looked at a prescription medicine in Sweden, power cocktails appear to have been actually released on U.S. customers prior to an enough variety of researches could possibly gauge all their achievable impacts. The devices you'll need to get going on the bike is rather standard, however this is where you'll spend a little bit additional amount of money than the various other pair of sports.
Very same to ultrarunning - the even more runners run ultras on trails/mountains, the even more individuals will certainly enjoy our sports and also its own playgrounds & mountains. I can't feel you can easily obtain all those miles in at that rate along with 2 little ones and also still possess any sort of electricity left:-RRB- ... terrific work!!!! This is to guarantee your workouts are actually fed with a low glycemic index carbohydrate that provides a continual as well as slow-moving release from electricity to the functioning muscles.
0 notes
Text
74 Impressive Companionship Quotes.
That is crucial to acknowledge that the Open Phone Partnership and also Android have the prospective to become major changes from the circumstances-- one which will definitely take persistence as well as a lot financial investment by numerous players prior to you'll find the 1st advantages. As an example, eating particular meals or even taking particular drugs could result in the different colors of your pee to modify. Certainly not that I 'd definitely wish to given that each was either extremely whiny (Wells), depressingly standard along with high qualities like a mat (Bellamy), unpredictable and type of irritating (Clarke), or even scanty (Glass). I believe it is actually an alternative for those looking for a gentle switch to the Primal technique from eating. I can not configure, however I can easily sure think about at the very least 10 other concepts that produces that different from the Silent Hill storyline but maintaining its own creep variable off the top of my head. Therefore if you take a recoil and also definitely think of this, its truly pretty simple.
Systolic pressure (the top amount of a high blood pressure reading) assesses the stress in the veins at systole (SIS-tuh-lee), the instant when the cardiovascular system agreements and drives a surge from blood along the arterial plant (assume s" for capture). For even more advise on keeping your feets pain-free, acquire Healthy Tootsies, an Exclusive Wellness Record off Harvard Medical University. If you presume it's difficult to understand, you possibly additionally believe that is actually impossible to recognize whether or not people really progressed or even if creationism is actually true.
I wanted to try your vegetarian dark chocolate potato chip cookies yet am actually doubtful of just what to purchase for chocolate chips ... all the dark chocolate ones I consider have some form of milk in them. For this mystery personality you'll to begin with must unlock or even buy Rocky (formerly Archie), and then start participating in as him. The area is actually outstanding for both: full of hardcore warriors/assassins, royal/noble secrets and also rumors, a touch from magic ... yet each one, though entertai That believes that Throne of Glass has been actually a book I have actually been dealing with possibly reading through for a million years.
Our company Go through Also doesn't just serve younger browsers hoping to discover accounts they can relate to. Inevitably, it challenges publishers, libraries, as well as institutions to provide more portrayal to individuals from colour in their choices. While other individuals really did not believe the narcissists were nearly as very hot as the narcissists believed they were actually, the narcissists were actually well aware from their online reputation. The first choice you should make is actually whether to acquire wild salmon (and all Alaskan salmon is wild-caught) or farmed Atlantic salmon. You'll possess problem finding colours effectively if one or additional from these cones in your retina is actually ruined or even really isn't existing.
You ought to put in the time to construct these meticulously and on leave, when people entirely reputable you, they will definitely help you in your trip and if they are actually prospective clients they will definitely purchase from you! Like others, Apple strongly believes self-driving cars and trucks can reduce congestion and save millions of folks which perish each year in visitor traffic mishaps usually brought on by inebriated or sidetracked drivers. A lot of newbie golfers desire to discover ways to strengthen their abilities as well as conform better, yet they do not wish to spend for an expensive course.
Every little thing else that occurs externally of Burning Male-- the partying, the techno songs, the wayward city-wide improv process full with Mad Max-style Thunderdome-- is actually icing that remains on the cake of this authentic and deeper area spirit. Smoothie mix bowls have been actually quite the sensation for a very long time today, yet I think this could be just the 2nd smoothie mix bowl I have actually created. I presume it concerns 115 g/ 4 ounces per danish (accordinged to the elements listed & divided by 10).
Simply http://jirapa-health.info/detoxic-danh-gia-lam-viec-noi-de-mua-thuoc-gia-dien/ .' The Kashimir bistro's hulking Titan Directory sculpture, frequently made use of as a symbol of Ayn Rand's Objectivist philosophy (to which Andrew Ryan signs up), is actually clearly a tribute to Lee Lawrie's bronze Atlas statuary which exists outside the Rockefeller Facility. I typically don't use a straw to drink my daily environment-friendly creatures however possessing a glass one would be actually great! The scanner on its own is a 600 x 1,200 ppi tool, fairly efficient in reproducing text web pages well enough for OCR, though no awareness software application is actually provided. On Thursday, a vicious debate over the different colors from a shoelace and also man-made, body-hugging outfit split countries and also loved ones.
In standard tank farming, excretions coming from the animals being actually raised may build up in the water, raising toxicity, while in an aquaponic device, water off a tank farming system is fed to a hydroponic system where the byproducts are broken by nitrification microorganisms in to nitrates and nitrites, which are actually utilized by plants as nutrients, and also the water is after that re-circulated back to the tank farming body.
I presume though that you must grow your target market to milk complimentary eaters like myself - you will add additional happiness to even more individuals. I don't know. that's like Mare and Virtuoso more get along together in term of their interior character, but even if she presume he is evil so she urges every bit in herself to certainly not taste of him. It wasn't Rachel's very first time making a house sex video clip and also while she valued the brand new visceral point of view Eyeglasses must offer, wearing the glasses were a little distracting, and also made her feeling over a little bit of self-conscious.
The majority of root vegetables (believe beets, carrots, etc.) fall under that group, as do peas. You may wish to inquire 'just what is actually a hedge fund?' Hedge fund can be simply laid outed as is a regulated investment fund (a much greater variety of expenditure as well as trading activities) that is actually usually open to a limited variety of entrepreneurs which spend a functionality cost to the fund's financial investment supervisor that put in the funds and also deliver yields. Peoples' mind=streamed reaction, more so compared to snapping images hands-free and also getting directions that switch along with your head, creates whomever is actually wearing Google.com Glass a strolling wonder.
Another means from considering exactly what is actually trying to perform is actually to deal with what email used to resemble, or (for those which aren't pretty as old) what flash message made use of to become like There were competing platforms as well as completing requirements, and also nothing at all like an available API or even any of the various other points our team link with making it possible for other companies to swap information.
The realty business is just one of the many sectors that is a significant factor to the growth of the economic condition from a lot of countries of the planet and also house flipping is among the many services in the value chain from the realty sector. Sailing on uneven water on a boat crafted from plywood is actually not best states for trip as Troost can easily testify. Simply provide a phone call, as well as you could often get what you want, without having to spend with the nose.
0 notes
Text
China’s A Shares Get Added To The MSCI!
Good day… And a Tub Thumpin’ Thursday to you! I’ve done my share of Tub Thumpin’ the last two nights, and with today being an infusion day, I’ll have to leave all the Tub Thumpin’ to all of you! Please Tub Thump responsibly! HA! I’m greeted this morning by Chicago, and their song: Old Days… I was just doing some writing yesterday for an article, and talked about the old days of arriving at a currency’s value… Pretty interesting stuff, I must say!
The dollar strength that was being displayed all over the globe yesterday, has faded, but there’s really been no turn-around, just consolidation of the dollar moves on Tuesday and yesterday morning. The Gold price finally saw some light of day, but the price of Oil slipped further, falling to the $ 42 handle in the past 24 hours…
Let’s start with Gold today, you know, mix it up a bit, and see where it takes us, eh? Well… Gold didn’t do much again yesterday… Closing up only $ 3.70… I said yesterday morning when it was up nearly $ 5 in the early morning trading that it would be interesting to see what happened when the short Gold paper traders arrived… Well it didn’t take long to figure out what they thought! And the short Gold paper traders saw to it that Gold’s mini-rally didn’t go any further…
Then there was this article that showed up on the Kitco.com site, from Simona Gambarini — with the job title of “commodity economist,” reports that “gold’s luck has run out” with the 25-basis-point nudge in rates by the Fed. She further explains that her predicted two more rate hikes will cause even more money to leave the gold market.
I about fell out of my chair folks… As the U.S. economist, Dave Kranzler, responds to the GATA folks, “Hmmm. … “If Gambarini were a true economist, she would have conducted enough research of interest rates to know that every cycle in which the Fed raises the Fed Funds rate is accompanied by a rise in the price of gold. This is because the market perceives the Fed to be “behind the curve” on rising inflation, something to which several Fed heads have alluded.”
I’ll also throw in my two-cents, and say HOGWASH to those two more rate hikes! I’ve said it before and I’ll say it again, by the end of summer the Fed will be putting a halt on their plans to hike rates, and by Rocktober, they will be beginning their reversal that will eventually lead to QE4, and maybe even negative rates! Let’s see what Ms. Gambarini says then about Gold!
Whew! give me a minute while I climb down from the soapbox… OK, I’m back on terra firma now, and ready to talk about something else! The BIG NEWS yesterday involved China, so let’s talk about that for a minute.. I told you a couple of weeks ago that the MSCI (Morgan Stanley Corp Index) International Index was contemplating adding Chinese A share stocks to this index, and I said that they probably would add them, after telling the Chinese no, the previous 3 times they were up for adoption.
This deal comes with some parameters, as only 222 of Big Cap stocks were admitted, and since the Chinese like to “suspend stocks”, any stocks that had been suspended in the past 50 days were excluded. There was no discussion as to how the index would treat the 10% rule that the Chinese have on their stocks… No stock that gains or loses 10% in one day is allowed to trade further that day. But here’s the real benefit for China…
You see, their stocks and currency will get a wider distribution, which has been a goal of the Chinese to gain a wider distribution of their currency for over a decade now. China has a lot of debt problems that they’ve created in creating an infrastructure that’s second to none. Have you seen the new Beijing Airport? They also keep their citizens happy by spending lots of money… And they have something called WMP’s, which is nothing more than a Ponzi scheme, but… China always seems to be able to weather their storms, and while a collapse of the WMP’s could bring on major damage to the economy and China’s reserves, the Gov’t continues to make inroads to having a free floating currency, that will most likely be backed by some percentage of Gold…
Earlier this morning, the Norges Bank met (Norway’s Central Bank) and like I said on Tuesday when I went through the events of the week, the Norges Bank left rates unchanged… But also like I said on Tuesday, Norway has seemed to have weathered the storm from the drop in the price of Oil, which they had leaned on very heavily through the years.
Here’s a comment from the Norges Bank this morning after the announcement of no rate change. “Capacity utilization in the Norwegian economy appears to be higher than envisaged earlier. Inflation is lower than expected and may continue to drift down in the months ahead, but increased activity and receding unemployment suggest that inflation will pick up. Inflation expectations appear to be firmly anchored. Low house price inflation will curb debt accumulation, but it will take time for household vulnerabilities to recede.”
“The Executive Board’s current assessment of the outlook and the balance of risks suggests that the key policy rate will remain at today’s level in the period ahead,” says Governor Øystein Olsen.
The Reserve Bank of New Zealand (RBNZ) also left their Official Cash Rate (OCR) unchanged at 1.75% and in out going RBNZ Gov. Wheeler’s dwindling opportunities to diss kiwi strength, chose to just briefly mention that a weaker kiwi would help rebalance the growth outlook towards the tradables sector. Hmmm… what’s gotten into Wheeler? Has he gotten soft on kiwi strength? I really don’t know, but this is just not like him. Maybe he sees the light at the end of the tunnel, which will come when he steps down from his post in September… Not that I want him to be himself with regards to dissing kiwi strength, I’m just being a Curious George here…
Kiwi did gain some ground after the OCR announcement, and no major dissing of the currency… So, kiwi has that going for it today!
Next week’s article for the Dow Theory Letters is going to be about what I talked about some yesterday, and that will be all about the euro… I’m putting the finishing touches on it today… www.dowtheoryletters.com is the website where these articles will print on Thursdays, but you have to pay for a subscription to the site, which is very good, with different writers each day, and ending the week with the Aden Sisters, so if it floats your boat, set sail my friends!
The U.S. Data Cupboard is still being restocked, but we will see the color of the latest, Leading Indicators Index today… This report and Capacity Utilization are about the only two forward looking pieces of economic data, so I’ll be watching for the data print today… On Tuesday, the U.S. Current Account Deficit for the 1st QTR printed, and printed worse than expected… The forecasters had the deficit around $ 112 Billion, but the actual print was $ 117 Billion!!!!!! UGH, when will the deficit spending every stop? When the wall of debt comes crashing down, that’s when!
To recap… The dollar strength of Tuesday through Wednesday morning faded into consolidation yesterday, and the currencies and metals have won a little of the lost ground back… Both the Norges Bank and the RBNZ left rates unchanged and really didn’t have much to say about their no rate moves either. Strange that RBNZ Gov. Wheeler wasn’t out dissing kiwi strength! Gold finally saw some light of day yesterday, but its gain was kept to just $ 3.70… And the price of Oil slipped further falling to the $ 42 handle…
For what It’s Worth… In 2003, I remember sitting in our convertible mustang, as the three Amigos, Chuck, Duane and Rick were setting out to find Roger Dean Stadium on our first trip to Spring Training together. And Duane asked me what was on my mind regarding the U.S. economy. (now this was long before they realized they should never ask me stuff like that!) And I responded that I had been reading and writing about something that really troubled me, and that was the underfunding that was going on with Pensions.. That’s right I said that in 2003… And I’ve been writing about it since, sounding like a broken record, I guess, but still it goes on and on, and keeps getting larger and larger… Look at Illinois, they’ve now been ordered by a Court to pay bills, but they have no money, and their State Pension is grossly underfunded!
Well, any-old-way you look at it, Chuck was out there seeing stuff that was going to be a problem, long before anyone else did, and that brings me to today’s FWIW… It’s an article on Bloomberg, that talks about GE’s pension shortfall, and when I say shortfall, I’m being kind to GE! You can find the article here: https://www.bloomberg.com/news/articles/2017-06-16/ge-s-31-billion-hangover-immelt-leaves-behind-big-unfunded-tab?utm_source=ST&utm_medium=email&utm_campaign=ShareTrader+AM+Update+for+Saturday+17+June+2017
Or, here’s your snippet: “It’s a problem that Jeffrey Immelt largely ignored as he tried to appease General Electric Co.’s most vocal shareholders.
But it might end up being one of the costliest for John Flannery, GE’s newly anointed CEO, to fix.
At $ 31 billion, GE’s pension shortfall is the biggest among S&P 500 companies and 50 percent greater than any other corporation in the U.S. It’s a deficit that has swelled in recent years as Immelt spent more than $ 45 billion on share buybacks to win over Wall Street and pacify activists like Nelson Peltz.
Part of it has to do with the paltry returns that have plagued pensions across corporate America as ultralow interest rates prevailed in the aftermath of the financial crisis. But perhaps more importantly, GE’s dilemma underscores deeper concerns about modern capitalism’s all-consuming focus on immediate results, which some suggest is short-sighted and could ultimately leave everyone — including shareholders themselves — worse off.”
Chuck again.. well, there’s no reason for me to pile on here… You know when I played football, I was usually the guy that made the first hit and then as we fell to the ground, I got piled on. I always hated that feeling of being at the bottom of a pie of people, especially other football players! Yes, I was what my dad would call, a “pretty good country athlete”, but that was in a different life, for if you’ve seen me in my adult life, I no more look like any kind of athlete! HA! (maybe a Sumo wrestler! HA)
Currencies today 6/22/17… American Style: A$ .7540, kiwi .7253, C$ .7510, euro 1.1165, sterling 1.2665, Swiss $ .9736, … European Style: rand 13.0052, krone 8.4890, SEK 8.7398, HUF 276.65, zloty 3.7957, koruna 23.5154, RUB 59.82, yen 111.33, sing 1.39, HKD 7.8003, INR 64.56, China 6.8287, peso 18.17, BRL 3.3268, Dollar Index 97.55, Oil $ 42.66, 10-year 2.16%, Silver $ 16.59, Platinum $ 927.73, Palladium $ 888.07, and Gold… $ 1,251.60
That’s it for today… Running a bit later this morning, but no biggie! A great day for me yesterday, I was sent the subscriber list for the Pfennig, which means, we can load it up now and maybe by tomorrow, but probably Monday the emailed Pfennig will be going out once again! YAHOO! Things are looking up once again for yours truly… I do have to get a chemo infusion today though, so I’ll deal with that later this morning, and hopefully it doesn’t rain on my parade! Another extra inning win for my beloved Cardinals last night. But like I told my friend Dennis Miller, winning extra inning games against the worse team in baseball, isn’t what I would call “good wins”… But a win is a win, right? Ok.. time to get going. The iPod has reshuffled and we’re being taken to the finish line today by Billy Squier and his song: My Kind Of Lover… I hope you have a Tub Thumpin’ Thursday, and Be Good To Yourself!
Chuck Butler
Daily Pfennig
source http://capitalisthq.com/chinas-a-shares-get-added-to-the-msci/
from CapitalistHQ http://capitalisthq.blogspot.com/2017/06/chinas-shares-get-added-to-msci.html
0 notes
Text
China’s A Shares Get Added To The MSCI!
Good day… And a Tub Thumpin’ Thursday to you! I’ve done my share of Tub Thumpin’ the last two nights, and with today being an infusion day, I’ll have to leave all the Tub Thumpin’ to all of you! Please Tub Thump responsibly! HA! I’m greeted this morning by Chicago, and their song: Old Days… I was just doing some writing yesterday for an article, and talked about the old days of arriving at a currency’s value… Pretty interesting stuff, I must say!
The dollar strength that was being displayed all over the globe yesterday, has faded, but there’s really been no turn-around, just consolidation of the dollar moves on Tuesday and yesterday morning. The Gold price finally saw some light of day, but the price of Oil slipped further, falling to the $ 42 handle in the past 24 hours…
Let’s start with Gold today, you know, mix it up a bit, and see where it takes us, eh? Well… Gold didn’t do much again yesterday… Closing up only $ 3.70… I said yesterday morning when it was up nearly $ 5 in the early morning trading that it would be interesting to see what happened when the short Gold paper traders arrived… Well it didn’t take long to figure out what they thought! And the short Gold paper traders saw to it that Gold’s mini-rally didn’t go any further…
Then there was this article that showed up on the Kitco.com site, from Simona Gambarini — with the job title of “commodity economist,” reports that “gold’s luck has run out” with the 25-basis-point nudge in rates by the Fed. She further explains that her predicted two more rate hikes will cause even more money to leave the gold market.
I about fell out of my chair folks… As the U.S. economist, Dave Kranzler, responds to the GATA folks, “Hmmm. … “If Gambarini were a true economist, she would have conducted enough research of interest rates to know that every cycle in which the Fed raises the Fed Funds rate is accompanied by a rise in the price of gold. This is because the market perceives the Fed to be “behind the curve” on rising inflation, something to which several Fed heads have alluded.”
I’ll also throw in my two-cents, and say HOGWASH to those two more rate hikes! I’ve said it before and I’ll say it again, by the end of summer the Fed will be putting a halt on their plans to hike rates, and by Rocktober, they will be beginning their reversal that will eventually lead to QE4, and maybe even negative rates! Let’s see what Ms. Gambarini says then about Gold!
Whew! give me a minute while I climb down from the soapbox… OK, I’m back on terra firma now, and ready to talk about something else! The BIG NEWS yesterday involved China, so let’s talk about that for a minute.. I told you a couple of weeks ago that the MSCI (Morgan Stanley Corp Index) International Index was contemplating adding Chinese A share stocks to this index, and I said that they probably would add them, after telling the Chinese no, the previous 3 times they were up for adoption.
This deal comes with some parameters, as only 222 of Big Cap stocks were admitted, and since the Chinese like to “suspend stocks”, any stocks that had been suspended in the past 50 days were excluded. There was no discussion as to how the index would treat the 10% rule that the Chinese have on their stocks… No stock that gains or loses 10% in one day is allowed to trade further that day. But here’s the real benefit for China…
You see, their stocks and currency will get a wider distribution, which has been a goal of the Chinese to gain a wider distribution of their currency for over a decade now. China has a lot of debt problems that they’ve created in creating an infrastructure that’s second to none. Have you seen the new Beijing Airport? They also keep their citizens happy by spending lots of money… And they have something called WMP’s, which is nothing more than a Ponzi scheme, but… China always seems to be able to weather their storms, and while a collapse of the WMP’s could bring on major damage to the economy and China’s reserves, the Gov’t continues to make inroads to having a free floating currency, that will most likely be backed by some percentage of Gold…
Earlier this morning, the Norges Bank met (Norway’s Central Bank) and like I said on Tuesday when I went through the events of the week, the Norges Bank left rates unchanged… But also like I said on Tuesday, Norway has seemed to have weathered the storm from the drop in the price of Oil, which they had leaned on very heavily through the years.
Here’s a comment from the Norges Bank this morning after the announcement of no rate change. “Capacity utilization in the Norwegian economy appears to be higher than envisaged earlier. Inflation is lower than expected and may continue to drift down in the months ahead, but increased activity and receding unemployment suggest that inflation will pick up. Inflation expectations appear to be firmly anchored. Low house price inflation will curb debt accumulation, but it will take time for household vulnerabilities to recede.”
“The Executive Board’s current assessment of the outlook and the balance of risks suggests that the key policy rate will remain at today’s level in the period ahead,” says Governor Øystein Olsen.
The Reserve Bank of New Zealand (RBNZ) also left their Official Cash Rate (OCR) unchanged at 1.75% and in out going RBNZ Gov. Wheeler’s dwindling opportunities to diss kiwi strength, chose to just briefly mention that a weaker kiwi would help rebalance the growth outlook towards the tradables sector. Hmmm… what’s gotten into Wheeler? Has he gotten soft on kiwi strength? I really don’t know, but this is just not like him. Maybe he sees the light at the end of the tunnel, which will come when he steps down from his post in September… Not that I want him to be himself with regards to dissing kiwi strength, I’m just being a Curious George here…
Kiwi did gain some ground after the OCR announcement, and no major dissing of the currency… So, kiwi has that going for it today!
Next week’s article for the Dow Theory Letters is going to be about what I talked about some yesterday, and that will be all about the euro… I’m putting the finishing touches on it today… www.dowtheoryletters.com is the website where these articles will print on Thursdays, but you have to pay for a subscription to the site, which is very good, with different writers each day, and ending the week with the Aden Sisters, so if it floats your boat, set sail my friends!
The U.S. Data Cupboard is still being restocked, but we will see the color of the latest, Leading Indicators Index today… This report and Capacity Utilization are about the only two forward looking pieces of economic data, so I’ll be watching for the data print today… On Tuesday, the U.S. Current Account Deficit for the 1st QTR printed, and printed worse than expected… The forecasters had the deficit around $ 112 Billion, but the actual print was $ 117 Billion!!!!!! UGH, when will the deficit spending every stop? When the wall of debt comes crashing down, that’s when!
To recap… The dollar strength of Tuesday through Wednesday morning faded into consolidation yesterday, and the currencies and metals have won a little of the lost ground back… Both the Norges Bank and the RBNZ left rates unchanged and really didn’t have much to say about their no rate moves either. Strange that RBNZ Gov. Wheeler wasn’t out dissing kiwi strength! Gold finally saw some light of day yesterday, but its gain was kept to just $ 3.70… And the price of Oil slipped further falling to the $ 42 handle…
For what It’s Worth… In 2003, I remember sitting in our convertible mustang, as the three Amigos, Chuck, Duane and Rick were setting out to find Roger Dean Stadium on our first trip to Spring Training together. And Duane asked me what was on my mind regarding the U.S. economy. (now this was long before they realized they should never ask me stuff like that!) And I responded that I had been reading and writing about something that really troubled me, and that was the underfunding that was going on with Pensions.. That’s right I said that in 2003… And I’ve been writing about it since, sounding like a broken record, I guess, but still it goes on and on, and keeps getting larger and larger… Look at Illinois, they’ve now been ordered by a Court to pay bills, but they have no money, and their State Pension is grossly underfunded!
Well, any-old-way you look at it, Chuck was out there seeing stuff that was going to be a problem, long before anyone else did, and that brings me to today’s FWIW… It’s an article on Bloomberg, that talks about GE’s pension shortfall, and when I say shortfall, I’m being kind to GE! You can find the article here: https://www.bloomberg.com/news/articles/2017-06-16/ge-s-31-billion-hangover-immelt-leaves-behind-big-unfunded-tab?utm_source=ST&utm_medium=email&utm_campaign=ShareTrader+AM+Update+for+Saturday+17+June+2017
Or, here’s your snippet: “It’s a problem that Jeffrey Immelt largely ignored as he tried to appease General Electric Co.’s most vocal shareholders.
But it might end up being one of the costliest for John Flannery, GE’s newly anointed CEO, to fix.
At $ 31 billion, GE’s pension shortfall is the biggest among S&P 500 companies and 50 percent greater than any other corporation in the U.S. It’s a deficit that has swelled in recent years as Immelt spent more than $ 45 billion on share buybacks to win over Wall Street and pacify activists like Nelson Peltz.
Part of it has to do with the paltry returns that have plagued pensions across corporate America as ultralow interest rates prevailed in the aftermath of the financial crisis. But perhaps more importantly, GE’s dilemma underscores deeper concerns about modern capitalism’s all-consuming focus on immediate results, which some suggest is short-sighted and could ultimately leave everyone — including shareholders themselves — worse off.”
Chuck again.. well, there’s no reason for me to pile on here… You know when I played football, I was usually the guy that made the first hit and then as we fell to the ground, I got piled on. I always hated that feeling of being at the bottom of a pie of people, especially other football players! Yes, I was what my dad would call, a “pretty good country athlete”, but that was in a different life, for if you’ve seen me in my adult life, I no more look like any kind of athlete! HA! (maybe a Sumo wrestler! HA)
Currencies today 6/22/17… American Style: A$ .7540, kiwi .7253, C$ .7510, euro 1.1165, sterling 1.2665, Swiss $ .9736, … European Style: rand 13.0052, krone 8.4890, SEK 8.7398, HUF 276.65, zloty 3.7957, koruna 23.5154, RUB 59.82, yen 111.33, sing 1.39, HKD 7.8003, INR 64.56, China 6.8287, peso 18.17, BRL 3.3268, Dollar Index 97.55, Oil $ 42.66, 10-year 2.16%, Silver $ 16.59, Platinum $ 927.73, Palladium $ 888.07, and Gold… $ 1,251.60
That’s it for today… Running a bit later this morning, but no biggie! A great day for me yesterday, I was sent the subscriber list for the Pfennig, which means, we can load it up now and maybe by tomorrow, but probably Monday the emailed Pfennig will be going out once again! YAHOO! Things are looking up once again for yours truly… I do have to get a chemo infusion today though, so I’ll deal with that later this morning, and hopefully it doesn’t rain on my parade! Another extra inning win for my beloved Cardinals last night. But like I told my friend Dennis Miller, winning extra inning games against the worse team in baseball, isn’t what I would call “good wins”… But a win is a win, right? Ok.. time to get going. The iPod has reshuffled and we’re being taken to the finish line today by Billy Squier and his song: My Kind Of Lover… I hope you have a Tub Thumpin’ Thursday, and Be Good To Yourself!
Chuck Butler
Daily Pfennig
from CapitalistHQ.com http://capitalisthq.com/chinas-a-shares-get-added-to-the-msci/
0 notes
Photo

1.0 out of 5 stars
Defective Kindle Edition (review of Kindle only)
2.0 out of 5 stars
I-me-my. Oh, and something about the spectrum, too.
Man, oh, man, did I want to love "Color," but it's bogged down by two major problems. The first is that it wants to be not only a) a history of dyes and pigments but also to some extent b) a history of various colors' cultural associations and c) a travelogue, and there just isn't room in this town for all three of those goals. Each chapter ricochets between the histories of several different types of dyeing materials, their cultural histories in their countries of origin, and author Victoria Finlay's modern-day adventures in those locales. Though the book is organized by the spectrum, with each color (plus black, white, and the first dye, ochre) receiving its own chapter, chasing Finlay's competing agendas makes the book overlong and trying to follow. The author just loses the thread too often.The second is Finlay herself, who makes for a very trying narrator. She has an aggravating tendency to invent elaborate fantasies when facts fail her and expect us to invest in them throughout the chapter, when we just want her to get back to fact. She swears like Mark Twain thought all women did. Her scientific knowledge is lacking and apparently escaped fact-checking (her explanation of why the sky is red at sunset is wrong). Worst, however, is her unabashed colonialism; her globe-hopping quest for color often doubles as a tour of Britain's erstwhile empire, and there's a patronizing quality in Finlay's distanced view of these cultures that suggests a tyranny of low expectations.Take the chapter on blue, which is in a way the book's strongest because it has a single long-term focus (a journey to a famed lapis lazuli quarry in Afghanistan) but is also one of the most amoral passages I've encountered in nonfiction.Read more › Go to Amazon
5.0 out of 5 stars
The Travel History of Artist Pigments
This is a joy of a book. Victoria Finlay has taken a subject that is very important, but seldom discussed - namely how did we get the colors used by artists for painting - and wove it into a personal account of her travels to find their sources. In the process she introduces the reader to all manner of exotic and little-known, but delightful facts, peoples and places. From cochineal (I might note here that as an entomologist I was somewhat discouraged by her apparent inability to decide whether to call the source a beetle or a bug- it is a BUG! - the one clinker in an otherwise well done book), through madder as a source of orange, saffron for yellow, and on to lapis lazuli for blue, etc. The book is (as noted) also a personal travel narrative with lots of side trips. I found these to be fascinating and to add interest to a book that might have been a dry compendium of facts about chemicals."Color: A Natural History of the Palette" is a good book to curl up with at night or to read on an airplane. The reader will find enough local "color" and interesting tidbits to make the hours very pleasant indeed. This is, I think, especially true of artists who may not know much about the colors they use in their work. Go to Amazon
4.0 out of 5 stars
Lots of facts and observations in a relaxed presentation.
In some ways, this little book is hard to explain. Finlay is an excellent writer and thus much of the book is her exotic travels to seek the source of exotic colors from around the world. However, she also explores the history of certain pigments, paints, dyes, and other products. She also gives very interesting details on the production of these pigments,some of which required considerable costs and effort. Finally she gives interesting information about the pigment or product itself, focusing on various chemical properties, such as whether or not it is a poison or is light fast.I enjoyed her early chapters on the production of paint, ranging all the way from ancient Roman encaustic painting, the hand ground pigments of the Renaissance, and the birth of more standardized paint products during the Industrial revolution.It is fitting that Finlay starts her discussion with ocre, the most common of the dirt colors, which has given us such a broad range of tones through the centuries.In her chapters on Black and Brown, we learn the origins of charcoal, pencil, and ink drawing instruements. In her chapter on White, we learn the terrible history of lead poisoing for those who wore White Lead makeup. In the chapter on Red we learn all about the cochineal beetle, that eats cactus, and has brilliant red blood - the color often called Carmen. We learn of other reds, such as Rose Madder, made from rose petals. Oranges may come from various plant sources and show up in varnish. We hear of brilliant yellows from the urine of cows fed mango leaves, or brilliant but poisonous greens - one of which is suspected of poisoning Napoleon with arsnic infused wallpaper.Finlay goes to Afganistan to seek lapis blue and has some interesting tales to tell about the Taliban.Read more › Go to Amazon
5.0 out of 5 stars
Definitve popular history of colour
I thoroughly enjoyed this reportage, where Victoria tracks down the origns of so many colours I knew from my childhood paintbox and later days with an aniline dyestuff manufacturer. However good the book is, and I highly recommend this to anyone interested in colourants and their origins, I was left wanting more......an upto date Part 2 please, to answer the questions that were left unanswered such as, "Is the lack of vivid bright orange just a reaction to the 60' & 70's overuse or is it still the case that cadmium orange (which does not get a mention) has not been replaced with anything quite as powerful? and what are the colours we now use in our paint boxes, wallpapers and so on?"Why am I posing these questions, well Victoria is just the person to tell us auhtoritatively & accurately. I only had a few quibbles with the entire 400+ pages, one was an editor's slip that allowed India to be separated into Bangladesh, India & Pakistan in 1947! Which I am sure the author knows was not quite the instant route it seems (first it was the eastern half of the division known as Pakistan i.e. East Pakistan which then separated in 1971 I believe from West Pakistan and became Bangladesh). Another was the rather simlplistic way she refers to chemical formulas, yes of course AsS is a combination of 1 molecule each of arsenic & sulphur whereas As2S3 combines in the ratio of 2:3, however whether this means in fact the latter is any more poisonous than the former can not be assumed from the chemical formula....if I remember my chemistry correctly you need to understand which is more soluble in water or most readily adsorbed in the stomach (a solution of HCl I believe). If the author has confirmed this it was not clear from the text and copiuous and excellent notes.Read more › Go to Amazon
0 notes
Link
With 2017 now upon us, it is not just the time of the year to start picking those weights back up or hitting the treadmill, but it is also the time of the year where you may evaluate what we are doing with your career and where you want to be come the end of 2017.
The fitness sector is no different, more and more people enrol onto a personal training diploma in January than any other time of the year as the festive fun closes and New years resolutions kicks in. If you are dreading going back to work, fed up of working the mundane 9-5 and want a career that yields your passion for fitness, then becoming a personal trainer could be just what the doctor ordered. Before jumping head first, you need to know what you are actually looking for and to fully comprehend how fitness qualifications work in the UK, so you can find the right course for you.
Our guest Blogger this week is Luke Hughes, the Managing Director at Origym who will help you navigate your way to a new career. Visit http://ift.tt/2horsI4 for more info.
WHAT DO YOU NEED TO BECOME A PERSONAL TRAINER?
One of the most commonly typed in phrases in Google each month is “how to become a personal trainer”? Often companies’ websites are loaded with marketing jargon, inaccuracies and frequently there are terms that mean effectively the same thing, which causes confusion on what you actually need to get personal training qualified and what the best route to take is.
Well, this is where I am going to simplify things and show you what is needed to become a personal trainer and what fitness accreditation and level of certification that is required to start your career the right way.
There are two fitness certificates you need, your level 2 gym instructing qualification and your level 3 personal training award. This is the minimum requirement needed to be able to qualify as a personal trainer, whether you want to start applying for jobs, set up your own online personal training service or run freelance circuits classes, you need these two certificates to bring your aspirations to life.
You might be wondering though, where is the level 1 fitness qualification? Well, there is such thing as a level 1 course in physical activity, however you do not need this qualification to progress onto your level 2 gym instructing course also known as level 2 fitness instructing. Once you have achieved level 2 gym instructing you need to progress in chronological order up through the tiers of certificates on offer e.g. you can’t skip from level 2 gym instructing to completing a level 4 course in lower back pain management for example.
WHICH IS THE BEST PERSONAL TRAINING CERTIFICATION?
Firstly and most importantly, you need to know the accreditation you actually need in the UK to be able to get yourself insured and be in the knowledge that you are fully certified and can start legally conducting one to one personal training sessions.
There are four major awarding organisations within the United Kingdom, Active IQ, YMCA Awards, City & Guilds and OCR, there are a few other awarding organisations that provide fitness certificates, but these are the most common for the fitness sector. The awarding organization is the company that is actually being printed on your certificate, not the company you actually purchase your personal training course from. The company you actually purchase your personal trainer course from is an approved test centre of one of those awarding bodies, called training providers, who deliver the training in correspondence to the guidelines set by the awarding organization. To maintain the approval of the governing body they have to undergo vigorous checks, sampling of work and regular visits to make sure they are delivering the fitness courses the right way. Always, always, always check the website of the training provider to see which governing body is stamped on their website as this is what qualification you will receive. The UK has a standardized the fitness qualifications about 10 years ago to ensure every personal trainer has covered the exact same core modules irrespective of which awarding organization or training provider of those awarding organisations you elect to do your course via.
Most fitness education companies tend to use Active IQ or YMCA awards as they are the most well known for fitness certification and are very industry specific governing bodies. This being said, this does not mean that City & Guilds, OCR or any of the smaller awarding organisations are not equally as valid or recognised by prospective employers and you will have no trouble gaining employment from certificates from those governing bodies.
WHAT STAMPS OF APPROVAL SHOULD YOU LOOK FOR?
You may have heard or someone has mentioned the name REPs (Register of Exercise Professionals) to you as an awarding organization. This is a very common mistake, REPs are not a an awarding organization, REPs provides a system of regulation for instructors and trainers to ensure that they meet the health and fitness industry’s agreed National Occupational Standards.
REPs is owned by SkillsActive, which is the Sector Skills Council for Active Leisure and Learning. It has been established by Employers in Sport and Recreation, Health and Fitness to sustain quality in training and qualifications in the UK. When you hear the term “REPs recognised courses”, this means that training providers that have had their courses regulated from REPs and SkillsActive get a stamp of approval and with every major gym chain in the UK partnering with REPs you need to pick a “REPs recognised course”, otherwise when going for employment you will be turned away, regardless of the level of qualification you present.
If you ever need to check if a course provider delivers REPs recognised courses, you can contact REPs themselves or view SkillsActive’s list of approved centres and also a list of centres claiming to be approved. Spending some time doing your due diligence may save you a lot of heartbreak in the long run.
WHY DO PERSONAL TRAINER COURSES FLUCTUATE VASTLY IN PRICE THEN?
If personal training qualifications are standardized then why is there such a difference in price from one company to the next? Firstly, although the core modules are exactly the same within every personal trainer course, this does not mean that add on courses and extra modules are not included, which can influence the price you pay.
Secondly the service you receive from the training provider varies vastly, in terms of quality of tutoring, level of help and support, speed of support, quality of learning resources, if they have an aftercare program such as helping with interviews with gyms, the list goes on to what is going to determine the value that course provider concludes their service is worth to how much you are going to pay for that service. Think of it this way, if a Ferrari is the same price as a fiesta, you would buy the Ferrari every time, right? Why is that, they do the same job, get you from point A to point B. The reality as we know is very different and a Ferrari is about hundred times the price yet people still pay it. This is because of the quality it provides and the intrinsic value it generates and fitness qualifications are no different. Although the fitness qualification you come out with can be the same, the experience and quality of service you receive can be completely different from one provider to the next. As a general rule of thumb the more expensive the provider normally the more qualifications and higher levels of service you will receive. This being said, like any walk of life you can find personal trainer courses vastly over priced at one end of the spectrum or completely undervalued at the other end.
The third and most important reason that determines cost of personal training qualifications is the actual study method you choose to learn via. You can’t contrast the price of one provider that only offers full time personal trainer courses with an online personal trainer course. Full time courses will always cost more regardless of service or anything else for that matter, the provider would need to supply a tutor everyday and a venue everyday; therefore they cost significantly more. With online personal trainer courses, apart from paying for certification and registration to the awarding body, the overheads for a provider are minimal, hence why the course is normally less than half the price of a full time personal trainer course.
Finally you will find “personal trainer courses” on the web that have no accreditation, no stamps from any authority organisations and are not regulated by any governing body. These ”qualifications” unfortunately are not worth the paper they are written on and no employer or insurance company will legally back you.
Author Bio
Luke Hughes
Managing Director
Origym
Luke is the Managing Director of fitness education course provider Origym. He is passionate about everything education and fitness. As a cycling enthusiast he can often be found cycling up and down the hills in the lake district.
The post CHANGING CAREERS TO BECOME A PERSONAL TRAINER! UK FITNESS CERTIFICATION EXPLAINED appeared first on Fitness Times.
0 notes
Last Seen Blogs

acescribbles
aceScribbles

pwworkshopsuk-blog
Untitled

celestineia
I'M DOING IT WRONG

kinkysm3
KinkySM06new

hezballah27
Hezb Allah