#Unified namespace architecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Why Unified Namespace Architecture Is the Backbone of Industry 4.0 Integration

How to Simplify Data Flow, Empower Teams, and Future-Proof Your Plant
Drowning in Data, Starving for Insight?
You’ve invested in sensors, PLCs, SCADA, MES, and maybe even a few shiny new IIoT platforms. But when your team needs a clear, real-time view of operations across the plant floor… it still feels like you’re piecing together a puzzle with missing pieces.
Each system speaks its own language. Your data is locked in silos. And just trying to answer a simple question like “What’s happening on Line 2?” means logging into three different platforms.
Sound familiar?
That’s where unified namespace architecture comes in — and why more manufacturing leaders are calling it the cornerstone of true Industry 4.0 integration.
What Is a Unified Namespace (UNS)? And Why Does It Matter?
In simple terms, UNS is a single source of truth — a structured, real-time data layer where every device, system, and application publishes and subscribes to live, contextual data.
No more point-to-point integrations. No more fragile data pipelines. Just one cohesive layer of real-time data visibility.
✅ Why It Matters: Instead of building (and constantly maintaining) dozens of connections, you build once — to the UNS. Everything talks through it. It’s cleaner, faster, and infinitely more scalable.
Turning Complexity into Clarity
Without UNS: Your automation engineer is chasing down OPC tags. Your MES vendor wants another custom connector. Your SCADA and ERP are still passing notes via CSV.
With UNS: Everyone — from machines to dashboards to predictive analytics tools — gets their data from one place, in one format, in real time.
✅ The Result? Your plant becomes a data-driven ecosystem, where decision-making is faster, smarter, and aligned.
How It Powers Industry 4.0 Integration
Unified namespace architecture isn’t just an IT convenience — it’s an operational game-changer.
🔹 Connects SCADA and MES systems effortlessly 🔹 Supports modern IIoT architecture with tools like MQTT and Sparkplug B 🔹 Bridges legacy equipment with future-ready applications 🔹 Enables autonomous operations, predictive maintenance, and AI-driven insights
And since it's architected for interoperability, your investments in cloud, automation, and analytics now all work in harmony — not at odds.
Real Impact. Real Results.
We worked with a mid-sized food processing facility recently. They had five systems across two sites, each managed by a different team. Data was delayed, downtime was misdiagnosed, and scaling new lines felt impossible.
INS3 implemented a UNS framework using modern protocols like MQTT and Ignition. Within weeks, their plant teams had:
One unified view of all production lines
Alarms and trends in real time
Seamless SCADA and MES interoperability
A roadmap to scale without rearchitecting systems
The result? 20% faster issue resolution, 40% reduction in reporting lag, and a team that finally felt empowered — not overwhelmed — by their tech stack.
Behind Every Architecture Is a Team That Listens
At INS3, we don’t believe in one-size-fits-all. We believe in partnerships.�� Our engineers walk your floors, ask the right questions, and design around your people, your priorities, your pace.
We bring 30+ years of industrial automation experience, but we lead with empathy — because technology should solve problems, not create more.
You won’t get buzzwords or cookie-cutter solutions. You’ll get resilient architectures, practical innovation, and a team that’s with you for the long haul.
Let’s Build the Backbone of Your Digital Future
Industry 4.0 isn’t about the next flashy tool. It’s about building a connected, future-ready foundation that empowers your team today — and tomorrow.
And that foundation starts with unified namespace architecture.
📞 Let’s talk. One conversation could unlock the clarity you’ve been chasing for years.
0 notes
Text
Migrating Virtual Machines to Red Hat OpenShift Virtualization with Ansible Automation Platform
As enterprises modernize their IT infrastructure, migrating legacy virtual machines (VMs) into container-native platforms has become a strategic priority. Red Hat OpenShift Virtualization provides a powerful solution by enabling organizations to run traditional VMs alongside container workloads on a single, Kubernetes-native platform. When paired with Red Hat Ansible Automation Platform, the migration process becomes more consistent, scalable, and fully automated.
In this article, we explore how Ansible Automation Platform can be leveraged to simplify and accelerate the migration of VMs to OpenShift Virtualization.
Why Migrate to OpenShift Virtualization?
OpenShift Virtualization allows organizations to:
Consolidate VMs and containers on a single platform.
Simplify operations through unified management.
Enable DevOps teams to interact with VMs using Kubernetes-native tools.
Improve resource utilization and reduce infrastructure sprawl.
This hybrid approach is ideal for enterprises that are transitioning to cloud-native architectures but still rely on critical VM-based workloads.
Challenges in VM Migration
Migrating VMs from traditional hypervisors like VMware vSphere, Red Hat Virtualization (RHV), or KVM to OpenShift Virtualization involves several tasks:
Assessing and planning for VM compatibility.
Exporting and transforming VM images.
Reconfiguring networking and storage.
Managing downtime and validation.
Ensuring repeatability across multiple workloads.
Manual migrations are error-prone and time-consuming, especially at scale. This is where Ansible comes in.
Role of Ansible Automation Platform in VM Migration
Ansible Automation Platform enables IT teams to:
Automate complex migration workflows.
Integrate with existing IT tools and APIs.
Enforce consistency across environments.
Reduce human error and operational overhead.
With pre-built Ansible Content Collections, playbooks, and automation workflows, teams can automate VM inventory collection, image conversion, import into OpenShift Virtualization, and post-migration validation.
High-Level Migration Workflow with Ansible
Here's a high-level view of how a migration process can be automated:
Inventory Discovery Use Ansible modules to gather VM data from vSphere or RHV environments.
Image Extraction and Conversion Automate the export of VM disks and convert them to a format compatible with OpenShift Virtualization (QCOW2 or RAW).
Upload to OpenShift Virtualization Use virtctl or Kubernetes API to upload images to OpenShift and define the VM manifest (YAML).
Create VirtualMachines in OpenShift Apply VM definitions using Ansible's Kubernetes modules.
Configure Networking and Storage Attach necessary networks (e.g., Multus, SR-IOV) and persistent storage (PVCs) automatically.
Validation and Testing Run automated smoke tests or application checks to verify successful migration.
Decommission Legacy VMs If needed, automate the shutdown and cleanup of source VMs.
Sample Ansible Playbook Snippet
Below is a simplified snippet to upload a VM disk and create a VM in OpenShift:
- name: Upload VM disk and create VM
hosts: localhost
tasks:
- name: Upload QCOW2 image to OpenShift
command: >
virtctl image-upload pvc {{ vm_name }}-disk
--image-path {{ qcow2_path }}
--pvc-size {{ disk_size }}
--access-mode ReadWriteOnce
--storage-class {{ storage_class }}
--namespace {{ namespace }}
--wait-secs 300
environment:
KUBECONFIG: "{{ kubeconfig_path }}"
- name: Apply VM YAML manifest
k8s:
state: present
definition: "{{ lookup('file', 'vm-definitions/{{ vm_name }}.yaml') }}"
Integrating with Ansible Tower / AAP Controller
For enterprise-scale automation, these playbooks can be run through Ansible Automation Platform (formerly Ansible Tower), offering:
Role-based access control (RBAC)
Job scheduling and logging
Workflow chaining for multi-step migrations
Integration with ServiceNow, Git, or CI/CD pipelines
Red Hat Migration Toolkit for Virtualization (MTV)
Red Hat also offers the Migration Toolkit for Virtualization (MTV), which integrates with OpenShift and can be invoked via Ansible playbooks or REST APIs. MTV supports bulk migrations from RHV and vSphere to OpenShift Virtualization and can be used in tandem with custom automation workflows.
Final Thoughts
Migrating to OpenShift Virtualization is a strategic step toward modern, unified infrastructure. By leveraging Ansible Automation Platform, organizations can automate and scale this migration efficiently, minimizing downtime and manual effort.
Whether you are starting with a few VMs or migrating hundreds across environments, combining Red Hat's automation and virtualization solutions provides a future-proof path to infrastructure modernization.
For more details www.hawkstack.com
0 notes
Text
Best Practices for OpenShift Virtualization in Hybrid Cloud Environments
OpenShift Virtualization enables organizations to run virtual machines (VMs) alongside containerized workloads, offering unparalleled flexibility in hybrid cloud environments. By leveraging OpenShift’s robust Kubernetes platform, businesses can unify their infrastructure and streamline operations. However, adopting best practices is essential to ensure optimal performance, security, and manageability.
1. Plan for Hybrid Cloud Architecture
Assess Workloads: Identify which workloads are best suited for containers versus virtual machines based on performance, latency, and compatibility needs.
Network Configuration: Optimize networking between on-premise and cloud environments to minimize latency and maximize throughput.
Integration: Ensure seamless integration between OpenShift clusters and cloud service providers, such as AWS or Azure.
2. Optimize Resource Allocation
Node Sizing: Allocate sufficient resources (CPU, memory, storage) to nodes hosting virtual machines to avoid contention.
Taints and Tolerations: Use taints and tolerations to segregate VM workloads from containerized workloads when necessary.
Resource Requests and Limits: Set appropriate resource requests and limits for VMs to maintain cluster stability.
3. Leverage OpenShift Features for Management
ImageStreams: Utilize ImageStreams to manage VM images consistently and efficiently.
Namespaces: Organize VMs into namespaces to simplify access control and resource management.
Operators: Use OpenShift Virtualization Operators to automate lifecycle management for VMs.
4. Enhance Security
Isolate Workloads: Use namespaces and network policies to isolate sensitive workloads.
Access Control: Implement Role-Based Access Control (RBAC) to restrict user permissions.
Encryption: Enable encryption for data at rest and in transit.
Compliance: Ensure the hybrid cloud setup adheres to industry standards and compliance requirements like HIPAA or GDPR.
5. Monitor and Optimize Performance
Prometheus and Grafana: Use Prometheus and Grafana for monitoring VM and container performance.
Logging: Centralize logging using OpenShift Logging for better visibility into VM and container activities.
Scaling: Implement auto-scaling policies to manage workload spikes effectively.
6. Automate Deployment and Management
Ansible Playbooks: Use Ansible to automate VM deployments and configurations.
CI/CD Pipelines: Integrate VM deployment into CI/CD pipelines for faster development and testing.
Templates: Create and use VM templates for consistent configurations across the hybrid environment.
7. Ensure Disaster Recovery and Backup
Snapshots: Regularly create snapshots of VMs for quick recovery in case of failures.
Backup Solutions: Implement robust backup strategies for both VMs and containerized workloads.
Failover Testing: Periodically test failover mechanisms to ensure readiness during outages.
8. Continuous Learning and Updating
Stay Updated: Regularly update OpenShift and Virtualization Operators to the latest versions.
Training: Train teams on hybrid cloud best practices and new OpenShift features.
Community Engagement: Engage with the OpenShift community to stay informed about emerging trends and solutions.
By following these best practices, organizations can maximize the potential of OpenShift Virtualization in hybrid cloud environments, achieving improved efficiency, security, and scalability. Whether you’re modernizing legacy applications or deploying cloud-native workloads, OpenShift Virtualization is a powerful tool to bridge the gap between traditional and modern infrastructures.
For more details visit: https://www.hawkstack.com/
0 notes
Text
SYCL 2020’s Five New Features For Modern C++ Programmers

SYCL
For accelerator-using C++ programmers, SYCL 2020 is interesting. People enjoyed contributing to the SYCL standard, a book, and the DPC++ open source effort to integrate SYCL into LLVM. The SYCL 2020 standard included some of the favorite new features. These are Intel engineers’ views, not Khronos’.
Khronos allows heterogeneous C++ programming with SYCL. After SYCL 2020 was finalized in late 2020, compiler support increased.
SYCL is argued in several places, including Considering a Heterogeneous Future for C++ and other materials on sycl.tech. How will can allow heterogeneous C++ programming with portability across vendors and architectures? SYCL answers that question.
SYCL 2020 offers interesting new capabilities to be firmly multivendor and multiarchitecture with to community involvement.
The Best Five
A fundamental purpose of SYCL 2020 is to harmonize with ISO C++, which offers two advantages. First, it makes SYCL natural for C++ programmers. Second, it lets SYCL test multivendor, multiarchitecture heterogeneous programming solutions that may influence other C++ libraries and ISO C++.
Changing the base language from C++11 to C++17 allows developers to use class template argument deduction (CTAD) and deduction guides, which necessitated several syntactic changes in SYCL 2020.
Backends allow SYCL to target more hardware by supporting languages/frameworks other than OpenCL.
USM is a pointer-based alternative to SYCL 1.2.1’s buffer/accessor concept.
A “built-in” library in SYCL 2020 accelerates reductions, a frequent programming style.
The group library abstracts cooperative work items, improving application speed and programmer efficiency by aligning with hardware capabilities (independent of vendor).
Atomic references aligned with C++20 std::atomic_ref expand heterogeneous device memory models.
These enhancements make the SYCL ecosystem open, multivendor, and multiarchitecture, allowing C++ writers to fully leverage heterogeneous computing today and in the future.
Backends
With backends, SYCL 2020 allows implementations in languages/frameworks other than OpenCL. Thus, the namespace has been reduced to sycl::, and the SYCL header file has been relocated from to .
These modifications affect SYCL deeply. Although implementations are still free to build atop OpenCL (and many do), generic backends have made SYCL a programming approach that can target more diverse APIs and hardware. SYCL can now “glue” C++ programs to vendor-specific libraries, enabling developers to target several platforms without changing their code.
SYCL 2020 has true openness, cross-architecture, and cross-vendor.
This flexibility allows the open-source DPC++ compiler effort to support NVIDIA, AMD, and Intel GPUs by implementing SYCL 2020 in LLVM (clang). SYCL 2020 has true openness, cross-architecture, and cross-vendor.
Unified shared memory
Some devices provide CPU-host memory unified views. This unified shared memory (USM) from SYCL 2020 allows a pointer-based access paradigm instead of the buffer/accessor model from SYCL 1.2.1.
Programming with USM provides two benefits. First, USM provides a single address space across host and device; pointers to USM allocations are consistent and may be provided to kernels as arguments. Porting pointer-based C++ and CUDA programs to SYCL is substantially simplified. Second, USM allows shared allocations to migrate seamlessly between devices, enhancing programmer efficiency and compatibility with C++ containers (e.g., std::vector) and algorithms.
Three USM allocations provide programmers as much or as little data movement control as they want. Device allocations allow programmers full control over application data migration. Host allocations are beneficial when data is seldom utilized and transporting it is not worth the expense or when data exceeds device capacity. Shared allocations are a good compromise that immediately migrate to use, improving performance and efficiency.
Reductions
Other C++ reduction solutions, such as P0075 and the Kokkos and RAJA libraries, influenced SYCL 2020.
The reducer class and reduction function simplify SYCL kernel variable expression using reduction semantics. It also lets implementations use compile-time reduction method specialization for good performance on various manufacturers’ devices.
The famous BabelStream benchmark, published by the University of Bristol, shows how SYCL 2020 reductions increase performance. BabelStream’s basic dot product kernel computes a floating-point total of all kernel work items. The 43-line SYCL 1.2.1 version employs a tree reduction in work-group local memory and asks the user to choose the optimal device work-group size. SYCL 2020 is shorter (20 lines) and more performance portable by leaving algorithm and work-group size to implementation.
Group Library
The work-group abstraction from SYCL 1.2.1 is expanded by a sub-group abstraction and a library of group-based algorithms in SYCL 2020.
Sub_group describes a kernel’s cooperative work pieces running “together,” providing a portable abstraction for various hardware providers. Sub-groups in the DPC++ compiler always map to a key hardware concept SIMD vectorization on Intel architectures, “warps” on NVIDIA architectures, and “wavefronts” on AMD architectures enabling low-level performance optimization for SYCL applications.
In another tight agreement with ISO C++, SYCL 2020 includes group-based algorithms based on C++17: all_of, any_of, none_of, reduce, exclusive_scan, and inclusive_scan. SYCL implementations may use work-group and/or sub-group parallelism to produce finely tailored, cooperative versions of these functions since each algorithm is supported at various scopes.
Atomic references
Atomics improved in C++20 with the ability to encapsulate types in atomic references (std::atomic_ref). This design (sycl::atomic_ref) is extended to enable address spaces and memory scopes in SYCL 2020, creating an atomic reference implementation ready for heterogeneous computing.
SYCL follows ISO C++, and memory scopes were necessary for portable programming without losing speed. Don’t disregard heterogeneous systems’ complicated memory topologies.
Memory models and atomics are complicated, hence SYCL does not need all devices to use the entire C++ memory model to support as many devices as feasible. SYCL offers a wide range of device capabilities, another example of being accessible to all vendors.
Beyond SYCL 2020: Vendor Extensions
SYCL 2020’s capability for multiple backends and hardware has spurred vendor extensions. These extensions allow innovation that provides practical solutions for devices that require it and guides future SYCL standards. Extensions are crucial to standardization, and the DPC++ compiler project’s extensions inspired various elements in this article.
Two new DPC++ compiler features are SYCL 2020 vendor extensions.
Group-local Memory at Kernel Scope
Local accessors in SYCL 1.2.1 allow for group-local memory, which must be specified outside of the kernel and sent as a kernel parameter. This might seem weird for programmers from OpenCL or CUDA, thus has created an extension to specify group-local memory in a kernel function. This improvement makes kernels more self-contained and informs compiler optimizations (where local memory is known at compile-time).
FPGA-Specific Extensions
The DPC++ compiler project supports Intel FPGAs. It seems that the modifications, or something similar, can work with any FPGA suppliers. FPGAs are a significant accelerator sector, and nous believe it pioneering work will shape future SYCL standards along with other vendor extension initiatives.
Have introduced FPGA choices to make buying FPGA hardware or emulation devices easier. The latter allows quick prototyping, which FPGA software writers must consider. FPGA LSU controls allow us to tune load/store operations and request a specific global memory access configuration. Also implemented data placement controls for external memory banks (e.g., DDR channel) to tune FPGA designs via FPGA memory channel. FPGA registers allow major tuning controls for FPGA high-performance pipelining.
Summary
Heterogeneity endures. Many new hardware alternatives focus on performance and performance-per-watt. This trend will need open, multivendor, multiarchitecture programming paradigms like SYCL.
The five new SYCL 2020 features assist provide portability and performance mobility. C++ programmers may maximize heterogeneous computing with SYCL 2020.
Read more on Govindhtech.com
#SYCL2020#SYCL#C++#DPC++#OpenCL#SYCL1.2.1#SYCLkernel#CUDA#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
Docker and Kubernetes Online - Visualpath
Kubernetes Concepts and Architecture
Container Orchestration Landscape:
Kubernetes, often abbreviated as K8s, has emerged as the de facto standard for container orchestration. In this article, we will delve into the fundamental concepts and architecture of Kubernetes without delving into intricate coding details. - Docker and Kubernetes Training
Understanding the Basics:
At its core, Kubernetes is an open-source container orchestration platform designed to automate the deployment, scaling, and management of containerized applications. Containers, which encapsulate an application and its dependencies, provide consistency across various environments. - Kubernetes Online Training
Key Concepts:
Nodes and Clusters: Kubernetes operates on a cluster-based architecture, where a cluster is a set of nodes. Nodes are individual machines, either physical or virtual, that collectively form the computing resources of the cluster.
Pods: Pods are the smallest deployable units in Kubernetes. A pod represents a single instance of a running process in a cluster and encapsulates one or more containers. Containers within a pod share the same network namespace, allowing them to communicate easily with each other. - Docker Online Training
Services: Services in Kubernetes provide a stable endpoint for a set of pods, allowing other applications to interact with them. They abstract away the underlying complexity of the pod network, providing a consistent way to access applications.
Deployments: Deployments are a higher-level abstraction that enables declarative updates to applications. They define the desired state of the application and manage the deployment, scaling, and updating of pods.
Architectural Overview:
Control Plane: The control plane is the brain of the Kubernetes cluster, responsible for making global decisions about the cluster (e.g., scheduling), as well as detecting and responding to cluster events (e.g., starting up a new pod when a deployment's replicas field is unsatisfied). - Kubernetes Training Hyderabad
Nodes: Nodes are the worker machines that run containerized applications. Each node has the necessary services to run pods and communicate with the control plane. Key components on nodes include the Kubelet, Container Runtime, and Kube Proxy.
Conclusion:
Kubernetes' power lies in its ability to abstract away the complexity of managing containerized applications, providing a unified and scalable platform for deployment. Understanding its basic concepts and architecture is crucial for anyone involved in deploying and maintaining applications in a containerized environment.
Visualpath is the Leading and Best Institute for learning Docker And Kubernetes Online in Ameerpet, Hyderabad. We provide Docker Online Training Course, you will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit : https://www.visualpath.in/DevOps-docker-kubernetes-training.html
Blog : https://dockerandkubernetesonlinetraining.blogspot.com/
#docker and kubernetes training#docker online training#docker training in hyderabad#kubernetes training hyderabad#docker and kubernetes online training#docker online training hyderabad#kubernetes online training#kubernetes online training hyderabad
0 notes
Text
Sometimes you do need Kubernetes! But how should you decide?

At RisingStack, we help companies to adopt cloud-native technologies, or if they have already done so, to get the most mileage out of them.
Recently, I've been invited to Google DevFest to deliver a presentation on our experiences working with Kubernetes.
Below I talk about an online learning and streaming platform where the decision to use Kubernetes has been contested both internally and externally since the beginning of its development.
The application and its underlying infrastructure were designed to meet the needs of the regulations of several countries:
The app should be able to run on-premises, so students’ data could never leave a given country. Also, the app had to be available as a SaaS product as well.
It can be deployed as a single-tenant system where a business customer only hosts one instance serving a handful of users, but some schools could have hundreds of users.
Or it can be deployed as a multi-tenant system where the client is e.g. a government and needs to serve thousands of schools and millions of users.
The application itself was developed by multiple, geographically scattered teams, thus a Microservices architecture was justified, but both the distributed system and the underlying infrastructure seemed to be an overkill when we considered the fact that during the product's initial entry, most of its customers needed small instances.
Was Kubernetes suited for the job, or was it an overkill? Did our client really need Kubernetes?
Let’s figure it out.
(Feel free to check out the video presentation, or the extended article version below!)
youtube
Let's talk a bit about Kubernetes itself!
Kubernetes is an open-source container orchestration engine that has a vast ecosystem. If you run into any kind of problem, there's probably a library somewhere on the internet that already solves it.
But Kubernetes also has a daunting learning curve, and initially, it's pretty complex to manage. Cloud ops / infrastructure engineering is a complex and big topic in and of itself.
Kubernetes does not really mask away the complexity from you, but plunges you into deep water as it merely gives you a unified control plane to handle all those moving parts that you need to care about in the cloud.
So, if you're just starting out right now, then it's better to start with small things and not with the whole package straight away! First, deploy a VM in the cloud. Use some PaaS or FaaS solutions to play around with one of your apps. It will help you gradually build up the knowledge you need on the journey.
So you want to decide if Kubernetes is for you.
First and foremost, Kubernetes is for you if you work with containers! (It kinda speaks for itself for a container orchestration system). But you should also have more than one service or instance.

Kubernetes makes sense when you have a huge microservice architecture, or you have dedicated instances per tenant having a lot of tenants as well.
Also, your services should be stateless, and your state should be stored in databases outside of the cluster. Another selling point of Kubernetes is the fine gradient control over the network.
And, maybe the most common argument for using Kubernetes is that it provides easy scalability.
Okay, and now let's take a look at the flip side of it.
Kubernetes is not for you if you don't need scalability!
If your services rely heavily on disks, then you should think twice if you want to move to Kubernetes or not. Basically, one disk can only be attached to a single node, so all the services need to reside on that one node. Therefore you lose node auto-scaling, which is one of the biggest selling points of Kubernetes.
For similar reasons, you probably shouldn't use k8s if you don't host your infrastructure in the public cloud. When you run your app on-premises, you need to buy the hardware beforehand and you cannot just conjure machines out of thin air. So basically, you also lose node auto-scaling, unless you're willing to go hybrid cloud and bleed over some of your excess load by spinning up some machines in the public cloud.

If you have a monolithic application that serves all your customers and you need some scaling here and there, then cloud service providers can handle it for you with autoscaling groups.
There is really no need to bring in Kubernetes for that.
Let's see our Kubernetes case-study!
Maybe it's a little bit more tangible if we talk about an actual use case, where we had to go through the decision making process.
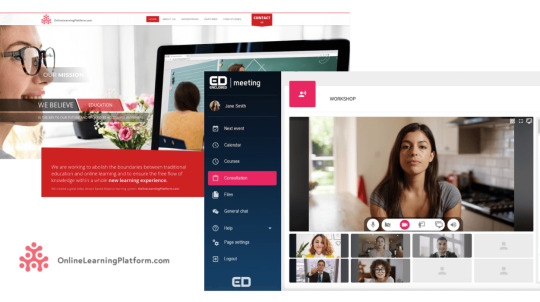
Online Learning Platform is an application that you could imagine as if you took your classroom and moved it to the internet.
You can have conference calls. You can share files as handouts, you can have a whiteboard, and you can track the progress of your students.
This project started during the first wave of the lockdowns around March, so one thing that we needed to keep in mind is that time to market was essential.
In other words: we had to do everything very, very quickly!
This product targets mostly schools around Europe, but it is now used by corporations as well.
So, we're talking about millions of users from the point we go to the market.
The product needed to run on-premise, because one of the main targets were governments.
Initially, we were provided with a proposed infrastructure where each school would have its own VM, and all the services and all the databases would reside in those VMs.
Handling that many virtual machines, properly handling rollouts to those, and monitoring all of them sounded like a nightmare to begin with. Especially if we consider the fact that we only had a couple of weeks to go live.
After studying the requirements and the proposal, it was time to call the client to..
Discuss the proposed infrastructure.
So the conversation was something like this:
"Hi guys, we would prefer to go with Kubernetes because to handle stuff at that scale, we would need a unified control plane that Kubernetes gives us."
"Yeah, sure, go for it."
And we were happy, but we still had a couple of questions:
"Could we, by any chance, host it on the public cloud?"
"Well, no, unfortunately. We are negotiating with European local governments and they tend to be squeamish about sending their data to the US. "
Okay, anyways, we can figure something out...
"But do the services need filesystem access?"
"Yes, they do."
Okay, crap! But we still needed to talk to the developers so all was not lost.
Let's call the developers!
It turned out that what we were dealing with was an usual microservice-based architecture, which consisted of a lot of services talking over HTTP and messaging queues.
Each service had its own database, and most of them stored some files in Minio.
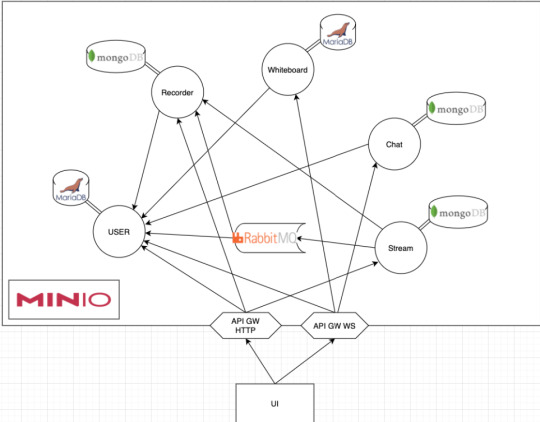
In case you don't know it, Minio is an object storage system that implements the S3 API.
Now that we knew the fine-grained architectural layout, we gathered a few more questions:
"Okay guys, can we move all the files to Minio?"
"Yeah, sure, easy peasy."
So, we were happy again, but there was still another problem, so we had to call the hosting providers:
"Hi guys, do you provide hosted Kubernetes?"
"Oh well, at this scale, we can manage to do that!"
So, we were happy again, but..
Just to make sure, we wanted to run the numbers!
Our target was to be able to run 60 000 schools on the platform in the beginning, so we had to see if our plans lined up with our limitations!
We shouldn't have more than 150 000 total pods!
10 (pod/tenant) times 6000 tenants is 60 000 Pods. We're good!
We shouldn't have more than 300 000 total containers!
It's one container per pod, so we're still good.
We shouldn't have more than 100 pods per node and no more than 5 000 nodes.
Well, what we have is 60 000 pods over 100 pod per node. That's already 6 000 nodes, and that's just the initial rollout, so we're already over our 5 000 nodes limit.

Okay, well... Crap!
But, is there a solution to this?
Sure, it's federation!
We could federate our Kubernetes clusters..
..and overcome these limitations.
We have worked with federated systems before, so Kubernetes surely provides something for that, riiight? Well yeah, it does... kind of.
It's the stable Federation v1 API, which is sadly deprecated.
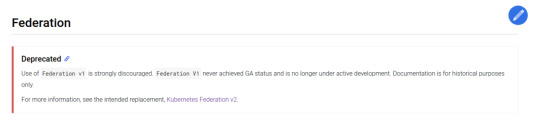
Then we saw that Kubernetes Federation v2 is on the way!
It was still in alpha at the time when we were dealing with this issue, but the GitHub page said it was rapidly moving towards beta release. By taking a look at the releases page we realized that it had been overdue by half a year by then.
Since we only had a short period of time to pull this off, we really didn't want to live that much on the edge.
So what could we do? We could federate by hand! But what does that mean?
In other words: what could have been gained by using KubeFed?
Having a lot of services would have meant that we needed a federated Prometheus and Logging (be it Graylog or ELK) anyway. So the two remaining aspects of the system were rollout / tenant generation, and manual intervention.
Manual intervention is tricky. To make it easy, you need a unified control plane where you can eyeball and modify anything. We could have built a custom one that gathers all information from the clusters and proxies all requests to each of them. However, that would have meant a lot of work, which we just did not have the time for. And even if we had the time to do it, we would have needed to conduct a cost/benefit analysis on it.
The main factor in the decision if you need a unified control plane for everything is scale, or in other words, the number of different control planes to handle.
The original approach would have meant 6000 different planes. That’s just way too much to handle for a small team. But if we could bring it down to 20 or so, that could be bearable. In that case, all we need is an easy mind map that leads from services to their underlying clusters. The actual route would be something like:
Service -> Tenant (K8s Namespace) -> Cluster.
The Service -> Namespace mapping is provided by Kubernetes, so we needed to figure out the Namespace -> Cluster mapping.
This mapping is also necessary to reduce the cognitive overhead and time of digging around when an outage may happen, so it needs to be easy to remember, while having to provide a more or less uniform distribution of tenants across Clusters. The most straightforward way seemed to be to base it on Geography. I’m the most familiar with Poland’s and Hungary’s Geography, so let’s take them as an example.
Poland comprises 16 voivodeships, while Hungary comprises 19 counties as main administrative divisions. Each country’s capital stands out in population, so they have enough schools to get a cluster on their own. Thus it only makes sense to create clusters for each division plus the capital. That gives us 17 or 20 clusters.
So if we get back to our original 60 000 pods, and 100 pod / tenant limitation, we can see that 2 clusters are enough to host them all, but that leaves us no room for either scaling or later expansions. If we spread them across 17 clusters - in the case of Poland for example - that means we have around 3.500 pods / cluster and 350 nodes, which is still manageable.
This could be done in a similar fashion for any European country, but still needs some architecting when setting up the actual infrastructure. And when KubeFed becomes available (and somewhat battle tested) we can easily join these clusters into one single federated cluster.
Great, we have solved the problem of control planes for manual intervention. The only thing left was handling rollouts..
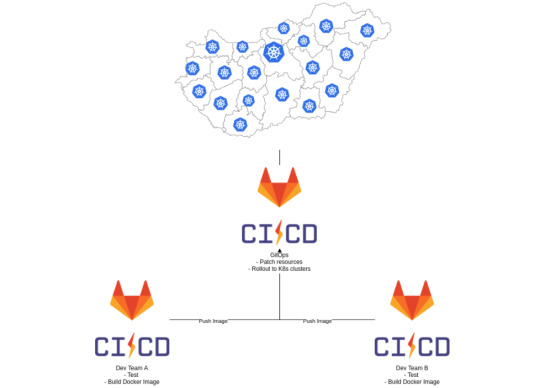
As I mentioned before, several developer teams had been working on the services themselves, and each of them already had their own Gitlab repos and CIs. They already built their own Docker images, so we simply needed a place to gather them all, and roll them out to Kubernetes. So we created a GitOps repo where we stored the helm charts and set up a GitLab CI to build the actual releases, then deploy them.
From here on, it takes a simple loop over the clusters to update the services when necessary.
The other thing we needed to solve was tenant generation.
It was easy as well, because we just needed to create a CLI tool which could be set up by providing the school's name, and its county or state.
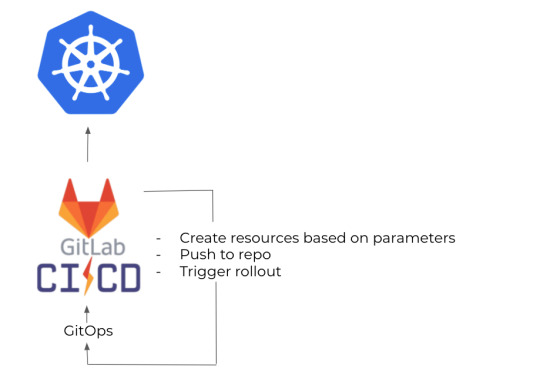
That's going to designate its target cluster, and then push it to our Gitops repo, and that basically triggers the same rollout as new versions.
We were almost good to go, but there was still one problem: on-premises.
Although our hosting providers turned into some kind of public cloud (or something we can think of as public clouds), we were also targeting companies who want to educate their employees.
Huge corporations - like a Bank - are just as squeamish about sending their data out to the public internet as governments, if not more..
So we needed to figure out a way to host this on servers within vaults completely separated from the public internet.
In this case, we had two main modes of operation.
One is when a company just wanted a boxed product and they didn't really care about scaling it.
And the other one was where they expected it to be scaled, but they were prepared to handle this.
In the second case, it was kind of a bring your own database scenario, so you could set up the system in a way that we were going to connect to your database.
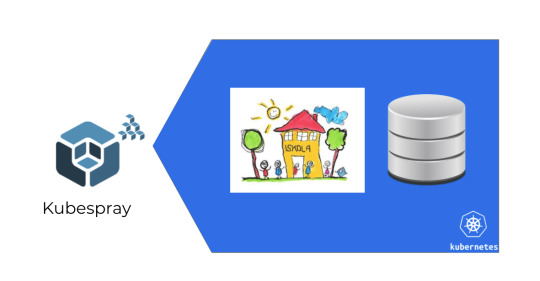
And in the other case, what we could do is to package everything — including databases — in one VM, in one Kubernetes cluster. But! I just wrote above that you probably shouldn't use disks and shouldn't have databases within your cluster, right?
However, in that case, we already had a working infrastructure.
Kubernetes provided us with infrastructure as code already, so it only made sense to use that as a packaging tool as well, and use Kubespray to just spray it to our target servers.
It wasn't a problem to have disks and DBs within our cluster because the target were companies that didn't want to scale it anyway.
So it's not about scaling. It is mostly about packaging!
Previously I told you, that you probably don't want to do this on-premises, and this is still right! If that's your main target, then you probably shouldn't go with Kubernetes.
However, as our main target was somewhat of a public cloud, it wouldn't have made sense to just recreate the whole thing - basically create a new product in a sense - for these kinds of servers.
So as it is kind of a spin-off, it made sense here as well as a packaging solution.
Basically, I've just given you a bullet point list to help you determine whether Kubernetes is for you or not, and then I just tore it apart and threw it into a basket.
And the reason for this is - as I also mentioned:
Cloud ops is difficult!
There aren't really one-size-fits-all solutions, so basing your decision on checklists you see on the internet is definitely not a good idea.
We've seen that a lot of times where companies adopt Kubernetes because it seems to fit, but when they actually start working with it, it turns out to be an overkill.
If you want to save yourself about a year or two of headache, it's a lot better to first ask an expert, and just spend a couple of hours or days going through your use cases, discussing those and save yourself that year of headache.
In case you're thinking about adopting Kubernetes, or getting the most out of it, don't hesitate to reach out to us at [email protected], or by using the contact form below!
Sometimes you do need Kubernetes! But how should you decide? published first on https://koresolpage.tumblr.com/
0 notes
Text
300+ TOP SOAP Interview Questions and Answers
SOAP Interview Questions for freshers experienced :-
1. What is SOAP? SOAP, Simple Object Access Protocol is a communication protocol, a way to structure data before transmitting it, is based on XML standard. It is developed to allow communication between applications of different platforms and programming languages via internet. It can use range of protocols such as HTTP, FTP, SMTP, Post office protocal 3(POP3) to carry documents. Http-Get, Http-Post works with name/value pair which means transferring complex object is not possible with these protocols, whereas SOAP serializes complex structure, such as ASP.NET DataSets, complex arrays, custom types and XML nodes before transmitting and thus allows exchange of complex objects between applications. 2. What is SOAP? Explain its purpose. SOAP is the acronym for Simple Object Access Protocol. XML based messages over a network of computers are exchanged by using SOAP standard, using HTTP. SOAP purpose: A web service needs a combination of XML, HTTP and a protocol which is application-specific. A web service uses XML data for exchanging. The weather service, stock quote service, look up service of postal department are all sending XML messages and receiving an XML reply. This is the pattern that dominates the web services. To perform these web services, SOAP is the reliable protocol. 3. What is the function of SMON? The SMON background process performs all system monitoring functions on the oracle database. Each time oracle is re-started, SMON performs a warm start and makes sure that the transactions that were left incomplete at the last shut down are recovered. SMON performs periodic cleanup of temporary segments that are no longer needed. 4. Give examples where SOAP is used. Remote methods over multiple platforms and technologies are used with HTTP. SOAP is XML based protocol and platform-agnostic. Each application uses different technology. This may cause problems with proxy server and firewalls. SOAP is the solution for this situation. Industries transport the request for finding best route and best cost price. So the application transfers a request to other similar services which uses SOAP. 5. What are the advantages of SOAP? The main advantages of SOAP are given below: SOAP has huge collection of protocols SOAP is an platform and independent. SOAP is an language independent. Most important feature of SOAP is that it has Simple and extensible by nature. 6. Can you explain the role of XML in SOAP? XML use by many large companies due to its open source nature. XML is an standard format than it is accepted by many organization. Their is a wide variety of tools are available on shelves which is use to ease the process of transition to SOAP. Significance of XML is that to reduce the speed and efficiency.Future format of XML is binary XML. 7. How can you explain HTTPS in SOAP? We can say that HTTPS is similar to HTTP But the main difference b/w them is that HTTPS has an additional layer underneath the internet application layer which is use to make encrypted data.HTTPS protocol is much better and widely than other protocols like IOP or DCOM because these procols can filtered by firewalls. HTTP protocol provide us security when we want to transfer secured data by using advocates WS-I method. 8. How you define Transport methods in SOAP? If we wanted to transfer messages from one end to another end using with Internet application layer.Using SOAP we can transport many productsfrom one end to another end.To perform this task without any error we use one of SMTP and HTTP protocols(Used in transfering information). 9. How we can say that SOAP is different from traditional RPC? The main difference b/w SOAP and Traditional RPC are given below: In SOAP we used procedures which has named parameters and order is irrelevant Where as in XML-RPC order is relevant and parameters do not have names. 10. What do you mean by ESB? ESB is stands for Enterprise Service Bus. ESB is standard based which is most important component of Service Oriented Architecture(SOA).Using ESB we can connect applications through service interfaces.

SOAP Interview Questions 11. What is the SOAP? SOAP stands for Simple Object Access Protocol. SOAP is an XML-based protocol for exchanging information between two computers over the internet. It enables you to Remote Procedure Calls (RPC) transported via HTTP. Following are the SOAP characteristics. SOAP is for communication between applications SOAP is a format for sending messages SOAP is designed to communicate via Internet SOAP is platform independent SOAP is language independent SOAP is simple and extensible 12. Where is SOAP used? It is used to exchanges the information between two computers over the internet. For this we used the XML in special format to send and receive the Information. 13. Difference between XML and SOAP? XML is language whereas SOAP is protocol. 14. Difference between JSON and SOAP? JSON is standard to represent human-readable data. SOAP is a protocol specification for transmitting information and calling web services use XML. 15. What are the rules for using SOAP? 16. What is SOAP Envelope Element? 17. What does SOAP Namespace defines? The namespace defines the Envelope as a SOAP Envelope. If a different namespace is used, the application generates an error and discards the message. 18. What is the SOAP encodings? The envelope specified the encoding for the body. This is a method for structuring the request that is suggested within the SOAP specification, known as the SOAP serialization. It's worth noting that one of the biggest technical complaints against SOAP is that it mixes a specification for message transport with a specification for message structure. 19. What does SOAP encodingStyle Attribute defines? The encodingStyle attribute is used to define the data types used in the document(s). This attribute may appear on any SOAP element, and applies to the element's contents and all child element(s). 20. What are the Different Transport Protocols? SOAP, REST, SMTP, raw TCP Socket. 21. What is UML? Unified Modeling Language 22. can we send soap messages with attachments. Yes, We can send photos/Audio/video with soap messages as an attahcment. SOAP messages can be attached with MIME extensions that come in multipart/related. It is used to send messages using the binary data with defined rules. The SOAP message is carried in the body part with the structure that is followed by the message of the SOAP. 23. What is the difference between SOAP and other remote access techniques? SOAP is simple to use and it is non-symetrical whereas DCOM or CORBA is highly popular and usually have complexity in them. It also has the symmetrical nature in it. 24. What are the problems faced by users by using SOAP? There is a problem to use this protocol as firewall is a security mechanism that comes in between. This ock all the ports leaving few like HTTP port 80 and the HTTP port is used by SOAP that bypasses the firewall. It is a serious concern as it can pose difficulties for the users. There are ways like SOAP traffic can be filtered from the firewalls. 25. What is Simple Object Access Protocol (SOAP)? SOAP acts as a medium to provide basic messaging framework. On these basic messaging frameworks abstract layers are built. It transfers messages across the board in different protocols; it also acts as a medium to transmit XML based messages over the network. 26. Give an example about the functioning of SOAP? Consider a real estate database with huge data ranges. If a user wants to search about a particular term, the message with all the required features such as price, availability, place, etc will be returned to the user in an XML formatted document which the user can integrate into third party site for additional performance. 27. Explain about Remote call procedure? Remote call procedure is considered as a very important function in SOAP. In RCP a user (node) sends a request to another node (server) where the information is processes and sent to the user. It immediately sends message across the network. 28. Explain about Transport methods in SOAP? Internet application layer is used to transfer messages from one end to another end. Various products have been transported successfully from one end to another end using SOAP. Both SMTP and HTTP are two successful transport protocols used in transmitting information, but HTTP has gained good ground than HTTP. 29. Explain about HTTPS in SOAP? HTTPS is similar to HTTP but it has an additional layer underneath the internet application layer which makes the data encrypted. This protocol is widely used than IOP or DCOM because those protocols are filtered by firewalls. HTTPS protocol advocates WS-I method to provide security for transmission of secured data. 30. Explain about the role of XML in SOAP? XML is chosen as a standard format because it was already in use by many large companies and immensely due to its open source nature. A wide variety of tools are available on shelves which ease the process of transition to SOAP. XML can significantly reduce the speed and efficiency but binary XML is being considered as a format for future. 31. What is the difference between RPC and Local calls? An important difference between Remote call procedure and local call is that remote call can fail often and this occurs without the knowledge of the user. Local calls are easily handled. Another main difficulty lies with the code writing capability because it is written in a low level language. 32. What are the elements which should be contained in SOAP message? Following elements are contained in the SOAP message. An envelope element which identifies and translates the XML document into a SOAP message. A header element is a must as it should contain header message. A body is required which should contain call and response message. Fault element is required which can communicate about the errors occurred during the process 33. What about the SOAP Envelope element? A SOAP message will have the SOAP element as the root element. SOAP element name space should always have the value of : as that defines the Envelope. 34. What about the actor element? A SOAP message has to travel a very long distance between its client and server but during the process a part of the message may be intended to be deployed to another destination which is made possible by the SOAP elements actor attribute which address the header element to a particular location. 35. What about the SOAP body element? This part of the element will contain the message which is intended for the ultimate delivery point. An element can be described inside the body element as a default namespace which indicates about the error message during the process. SOAP element acts just like a code to be processed during the execution of a certain application. SOAP Questions and Answers Pdf Download Read the full article
0 notes
Text
OPC UA PubSub on a FPGA using open62541
Overview
In a first step a simple OPC UA server was set up on a FPGA (see our previous blog post: OPC UA Server on a FPGA using open62541). As a starting point it would be good to begin with this example since the PubSub description builds up on the basic OPC UA server.
Compared to the Client/Server mechanism, the Publish/Subscribe model is even more interesting in the context of Time Sensitive Networking (TSN). PubSub is defined in Part 14 of the OPC Unified Architecture specification and it allows one-to-many or many-to-many connections. In combination with a TSN sub-layer it can fulfill the real-time requirements for the industry.
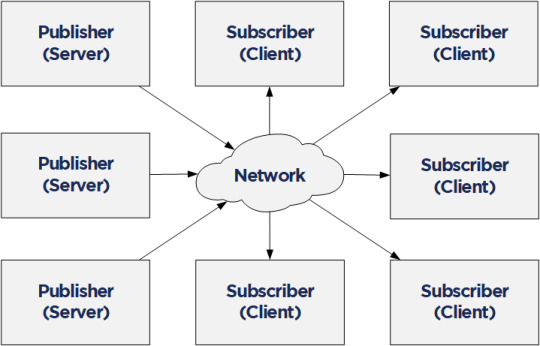
Together with NetTimeLogic’s TSN products or the TSN IIC® Plugfest Application (Talker/Listener) an open62541 PubSub application in a MicroBlaze Softcore can be easily combined. For the future we are targeting to realize the TSN Testbed Interoperability Application with the open62541 OPC UA stack and using NetTimeLogic’s TSN End Node IP core as realtime sub-layer.
The example FPGA project and the application are available here:
https://github.com/NetTimeLogic/opcua/tree/PubSub_example
The open62541 implementation is available here (v1.0rc5):
https://github.com/open62541/open62541/tree/v1.0-rc5
Introduction
Compared to the Client/Server example no changes in the MicroBlaze FPGA design are needed. However, some adjustments in the CMake and BSP for lwip are required.
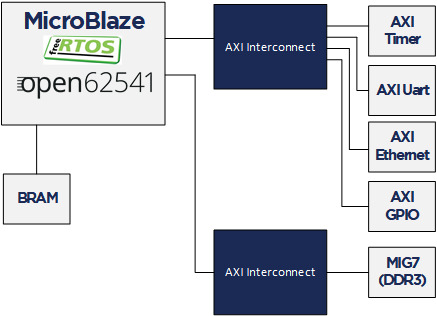
The following implementation is based on the open62541 documentation which describes how to build the library and how to work with Publish/Subscribe. The application creates an OPC UA server thread which is publishing a Dataset. It runs with FreeRTOS and lwip. The FPGA use a MicroBlaze softcore with DDR3, Axi Ethernet Lite, Axi Uart Lite AXI GPIO and AXI Timer. As hardware the same Arty A7-100T development board from DIGILENT as before is used.
Required tools
To build the full project, the following tools are required:
To build the full project following tools are required:
Xilinx Vivado 2019.1
Xilinx SDK 2019.1
CMAKE (Python 2.7.x or 3.x)
UA Expert
Wireshark
BSP adjustments for LWIP
For the simple OPC UA server some adjustments were needed in the lwip BSP of Xilinx SDK.
See Line 10-19: https://github.com/open62541/open62541/blob/master/arch/common/ua_lwip.h
The Pub/Sub functionality need some more adjustments of the BSP. It should be enough to enable the LWIP_IGMP. Nevertheless, it was not possible to generate successfully the BSP again with this option enabled. As a workaround the additional needed defines are added to the already created (in the previous post) open62541 section in the lwip211.tcl (bold) file. This allows to use the standard compilation flow afterwards .
1. Go to:
C:\Xilinx\SDK\2019.1\data\embeddedsw\ThirdParty\sw_services\lwip211_v1_0\data
2. Open the lwip211.tcl
3. Search the proc generate_lwip_opts {libhandle} and go to the end of this procedure
4. Before the line puts $lwipopts_fd “\#endif” add the following code:
#OPEN62541 implementation
set open62541_impl [expr [common::get_property CONFIG.open62541_impl $libhandle] == true]
if {$open62541_impl} {
puts $lwipopts_fd “\#define LWIP_COMPAT_SOCKETS 0”
puts $lwipopts_fd “\#define LWIP_SOCKET 1”
puts $lwipopts_fd “\#define LWIP_DNS 1”
puts $lwipopts_fd “\#define SO_REUSE 1”
puts $lwipopts_fd “\#define LWIP_TIMEVAL_PRIVATE 0”
puts $lwipopts_fd “\#define LWIP_IGMP 1”
puts $lwipopts_fd “\#define LWIP_MULTICAST_TX_OPTIONS 1”
puts $lwipopts_fd “”
}
5. Save the file
After this change and a restart of Xilinx SDK the new option will be visible in the BSP settings GUI of the lwip stack.
Design preparation
For the detailed design preparation steps please check the previous post OPC UA Server on a FPGA using open62541.
Custom information models
In the basic OPC UA server example the default value “reduced” is used as UA_NAMESPACE_ZERO option. For the UA_ENABLE_PUBSUB option it will compile an additional nodeset and datatype file into the name space zero generated file. Depending on what information will be published this might be not enough.
To be on the safe side UA_NAMESPACE_ZERO = “FULL” would be the easiest solution. Since the MicroBlaze CPU is not a very powerful, it is not recommended to use the full namespace. This example would take up to 30 minutes, until the server is up and running! It is highly recommended to use an optimized/customized nodeset for such an application.
https://opcua.rocks/custom-information-models/
XML Nodeset Compiler
Most probably in a final application all the variables/objects etc. are not defined manually in the code. There are different tools (commercial but also open source) available to create this information in a GUI. Out from these tools an XML with the OPC UA Nodeset schema can be exported.
Open62541 provides a compiler which creates C code from the XML Nodeset. This code creates then all the object instances as defined.
The complete documentation can be found here:
https://open62541.org/doc/1.0/nodeset_compiler.html
The compiler result for iicNs.c/h are available in git.
Nodeset in this example
Since this example is targeting for the IIC TSN Testbed application, the Nodeset from there is used. It has the following structure with different types of variables:
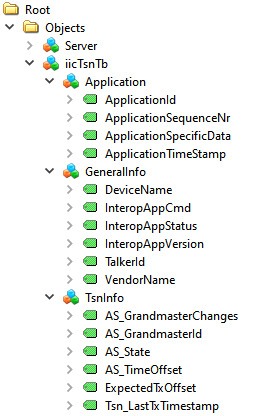
For this Information Model the minimal Nodeset with PubSub is not sufficient, therefore a customized one was created. This can be done as described above, or even simpler, just by using the already precompiled open62541.c/h files
CMAKE
For this example, the open62541 tag v1.0rc5 was used:
https://github.com/open62541/open62541/tree/v1.0-rc5
The easiest way is to work with the CMake GUI. Later it can be used in Xilinx SDK.
If the CMake library build is already available only two adjustments are needed:
UA_ENABLE_PUBSUB = ON
UA_ENABLE_PUBSUB_INFORMATIONMODEL = ON
If a new build is created, CMake for open62541 is used with the following adjustment:
UA_ENABLE_AMALGAMATION = ON
UA_ENABLE_HARDENING = OFF
UA_ENABLE_PUBSUB = ON
UA_ENABLE_PUBSUB_INFORMATIONMODEL = ON
UA_ARCH_EXTRA_INCLUDES = <path to microblaze/include>
UA_ARCH_REMOVE_FLAGS = -Wpedantic -Wno-static-in-inline -Wredundant-decls
CMAKE_C_FLAGS = -Wno-error=format= -mlittle-endian -DconfigUSE_PORT_OPTIMISED_TASK_SELECTION=0 -DconfigAPPLICATION_ALLOCATED_HEAP=3 -DUA_ARCHITECTURE_FREERTOSLWIP
UA_LOGLEVEL = 100 (optional for debugging)
1. Start the CMake GUI
2. Select the correct source code path where the open62541 GIT repository is located and the path where the binaries were built last time:
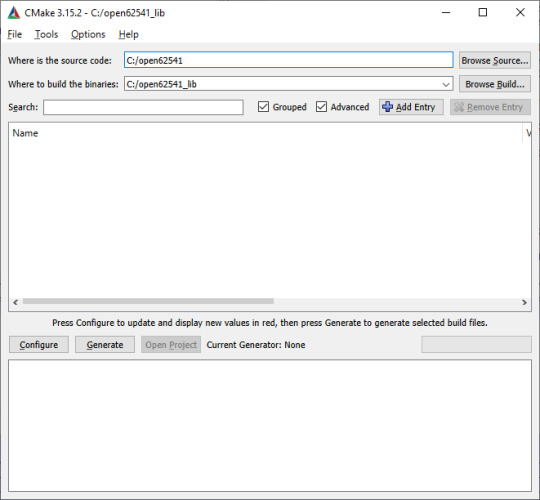
3. Click Configure
4. Change the two parameters:
UA_ENABLE_PUBSUB = ON
UA_ENABLE_PUBSUB_INFORMATIONMODEL = ON
5. Click again on Configure and after that on Generate
6. Generate again the open62541.c/h file in Xilinx SDK.
Make Target->all
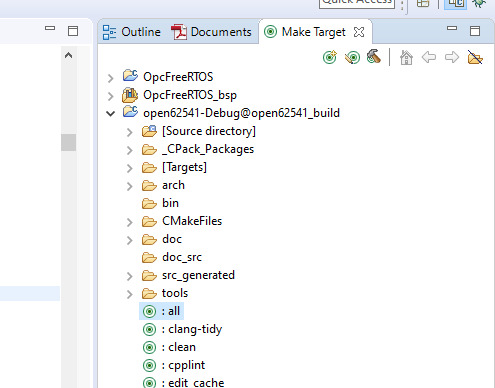
7. The amalgamation files open62541.c/h should have now the PubSub feature included
A pre-generated version of the open62541.c/h files is available on git.
Creating the OPC UA server application
The complete SDK workspace is available on git.
C/C++ Build Settings
For the build there are no new adjustments required. Please take the same build settings as in the previous post for the simple OPC UA Server.
Linker script
The linker script setting for the memory must be increased, In the example we use now:
Heap Size: 20MB
Stack Size: 20MB
OPC UA Server PubSub application
In the Xilinx SDK, the available OpcServer.c can be imported to the OpcServer application project.
In the basic server the thread stack size was defined with 4096. This is not enough anymore and the application will report with the hook functions a StackOverFlow. Therefore, the THREAD_STACKSIZE was increased to 16384.
In a first step the network initialization and the basic OPC UA Server configuration is done. Before the server starts, the PubSub specific setup is needed. The application is targeting to be compatible with the Pub/Sub format for the IIC TSN Testbed interoperability application
Define the PubSub connection
In the PubSub connection mainly the transport profile and the multicast network are defined. For this case we used following settings:
transportProfile: http://opcfoundation.org/UA-Profile/Transport/pubsub-udp-uadp
Network Address URL: opc.udp://224.0.0.22:4840
Add a Publishing dataset
This is the collection of the published fields. All PubSub items are linked to this one.
As PublishedDataSetType the following configuration is used:
publishedDataSetType: UA_PUBSUB_DATASET_PUBLISHEDITEMS
Add fields (variables) to the dataset
Here the variables are added by their NodeIds to the Published data set. Depending on the configuration the order of adding the variables has an impact how the published data will look like.
Additionally, a value is set. It is important that the variables have a value (not NULL). If a variable is empty there is just no content for the DataMessage to publish in the PubSub frame.
Add the writer group
The writer group is the important part when it comes to how the message looks like. The whole configuration for the NetworkMessage Header (Extended) is done here (OPC UA Part 14 Chapter 7.2.2.2).
Open62541 allows the specific configuration with the networkMessageContentMask configuration.
For the IIC TSN Testbed interoperability application following settings will be used:
writerGroupMessage->networkMessageContentMask = (UA_UADPNETWORKMESSAGECONTENTMASK_PUBLISHERID | UA_UADPNETWORKMESSAGECONTENTMASK_GROUPHEADER | UA_UADPNETWORKMESSAGECONTENTMASK_WRITERGROUPID | UA_UADPNETWORKMESSAGECONTENTMASK_GROUPVERSION | UA_UADPNETWORKMESSAGECONTENTMASK_NETWORKMESSAGENUMBER | UA_UADPNETWORKMESSAGECONTENTMASK_SEQUENCENUMBER | UA_UADPNETWORKMESSAGECONTENTMASK_PAYLOADHEADER | UA_UADPNETWORKMESSAGECONTENTMASK_TIMESTAMP);
Beside the NetworkMessage Header also settings like the publishing interval or the encoding MimeType are done here.
Add the dataset writer
This part is the second important part and defines how the DataSetMessage Header looks like (OPC UA Part 14 Chapter 7.2.2.3.4).
With the dataSetMessageContentMask and the dataSetFieldContentMask this can be configured.
For the IIC TSN Testbed interoperability application all this additional information is disabled:
dataSetWriterMessage->dataSetMessageContentMask = UA_UADPDATASETMESSAGECONTENTMASK_NONE;
dataSetWriterConfig.dataSetFieldContentMask = UA_DATASETFIELDCONTENTMASK_NONE;
Start the Server
After all the setup for the variables and the PubSub data set has been done the server is ready to start.
Starting the server takes quite some time with this example. After about two minutes the OPC UA Server starts publishing.
Listen to the OPC UA publisher
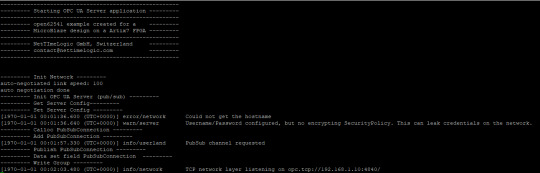
If there is no Subscriber available there are other options to understand a bit how the variables are published. Either the UaExpert can give some information or via Wireshark the real PubSub Frame can be analyzed.
Before a connection to the OPC UA server is possible the application needs to be compiled and started on the FPGA. After a successful start you should see the following printout on in the Terminal:
UA Expert
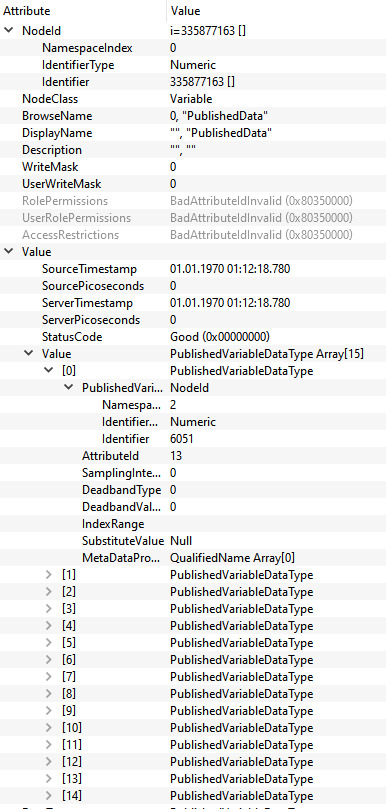
UA Expert is also a helpful tool to check some stuff about PubSub. With the option UA_ENABLE_PUBSUB_INFORMATIONMODEL the published dataset information is available.
All the configured nodes from the previous steps are now visible (UADP Connection, PublishedDataSets, DataSetWriter etc.) as a structure directly from the server.
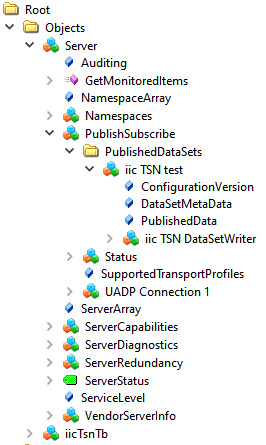
In the Attribute of the object PublishedData all the published variables are visible.
Wireshark
To check if the content of the published frame manually, Wireshark is the simplest way. This sample application uses a publishing interval of 5000 ms, so every 5s a published frame is received in Wireshark.
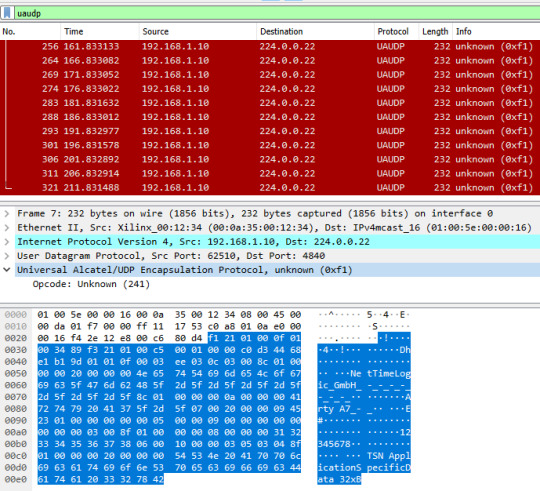
Looking into the encoding of the frame above the following information is published:

Summary
The used version of open62541 (v1.0rc5) allows working with Pub/Sub and allows to do most of the configurations for the header information. However, there were some adaptations required to use it for the IIC TSN Testbed interoperability application.
In our test we saw some problems with some header information.
GroupHeader:
GroupVersion was assigned
SequenceNumber was not assigned
Extended NetworkMessageHeader:
Timestamp was empty
As a workaround we have made some adaptations in the file src/pubsub/ua_pubsub.c by adding some assignments after the following code line:
nm.groupHeader.writerGroupId = wg->config.writerGroupId;
add:
nm.groupHeader.groupVersion = wgm->groupVersion;
nm.groupHeader.sequenceNumber = sequenceNumber;
nm.timestamp = UA_DateTime_now();
With these adjustments it was possible to create the frame as shown in the Wireshark capture.
In a next step we will try to be fully compatible with the IIC TSN Testbed interoperability application and combine it with our TSN core for real time publishing.
0 notes
Photo

New Post has been published on https://warmdevs.com/moving-towards-web3-0-using-blockchain-as-core-tech.html
Moving Towards web3.0 Using Blockchain as Core Tech
The invention of Bitcoin and blockchain technology sets the foundations for the next generations of web applications. The applications which will run on peer to peer network model with existing networking and routing protocols. The applications where centralized Servers would be obsolete and data will be controlled by the entity whom it belongs, i.e., the User.
From Web 1.0 to Web 2.0
As we all know, Web 1.0 was static web, and the majority of the information was static and flat. The major shift happened when user-generated content becomes mainstream. Projects such as WordPress, Facebook, Twitter, YouTube, and others are nominated as Web 2.0 sites where we produce and consume verity of contents such as Video, Audio, Images, etc.
The problem, however, was not the content; it was the architecture. The Centralized nature of Web opens up tons of security threats, data gathering of malicious purpose, privacy intrusion and cost as well.
The invention of Bitcoin and successful use of decentralized, peer to peer, secure network opens up the opportunity to take a step back and redesign the way our web works. The blockchain is becoming the backbone of the new Web, i.e., Web 3.0.
History of blockchain
The invention of blockchain came to the mainstream after the boom of the Bitcoin in 2018. Have a look at the graph below; Bitcoin was at its peak around $20000.
But the technologies that power the blockchain network is not something new. These concepts were researched and developed during the ’90s. Have a look at this timeline.
The concepts, such as proof of work, peer to peer network, public key cryptography and consensus algorithms for distributed computing which powers the blockchain have been researched and developed by various universities and computer scientists during the ’90s.
These algorithms and concepts are mature and battle-tested by various organizations. Satoshi Nakamoto combined these technologies and ideas together and built a decentralized, immutable, peer to peer database primarily used for financial purposes.
Initially, we all thought that blockchain is suitable only for cryptocurrencies and not for other applications. This thought was challenged when Vitalik buterin developed the Etherum cryptocurrency with a new Smart contract feature.
Smart contracts changed everything. The ability to code your own application and run on top of blockchain was the answer to critics who thought that blockchain is only for currencies.
“Cryptocurrency is a small subset of the blockchain, like the Email of the internet.”
The smart contracts open up the wave of new applications. The viral game cryptokitties showcases blockchain can handle large end applications such as games.
Smart contracts are written in Solidity language and can be executed on Etherum network. The protocol and design of Etherum inspired the engineers to build an open source and blockchain agnostic platform to build decentralized applications.
DApps protocols
As I have mentioned earlier, Etherum smart contracts were among the first such technology that can be used to program the decentralized applications. The issue was that smart contracts were written by keeping transactions or money in mind.
Developers need multiple tools to build a full-fledged web application such as storage (database, files, index, etc.), message queues or event queues to facilitate the communication. Etherum address these problems by introducing Etherum Swarm and Etherum Whisper projects.
As you can see in the diagram above, With Etherum Smart contracts for writing contracts and swarm to store files that can be associated with contracts. To make the decentralized apps communicate with each other, Whisper can be used. All of these can run inside the decentralized browser such as Dbrowser.
Swarm is a distributed storage platform for an ethereum stack. The core objective of Swarm is to provide decentralized storage for ethereum public records. Swarm is supposed to save the DApps code base and data associated with it.
Swarm allows public participants to pool their storage and bandwidth resources to make the network robust and get paid in Etherum incentives. Fair deal.
Ethereum whisper, in a nutshell, is a protocol for DApps running on Etherum blockchain to communicate with each other, similar to message queues or event queues. Whisper provides low-level API’s to support communication between DApps. You can learn more about it here.
However, do you sense the limitations here? Well, the main issue is that this is entirely Etherum agnostic, i.e., all apps are written and run on top of Etherum blockchain. This change will increase the size of the chain significantly, and scalability will be an issue.
Other than scalability, adaptability will be an issue as well. We need a smooth shift from the centralized web to decentralized web. A shift where masses do not need to change everything for the sake of the decentralized web.
This is where our new protocol comes in, called the IPFS (Interplanetary file system) stack by Protocols labs.
Protocols labs is dedicated to building the decentralized web which runs in parallel to TCP/IP stack. This will make the shift from existing web to web 3.0 very smooth, and masses do not need to make a significant change to use the web 3.0.
Here is the stack.
Rings a bell? This stack looks pretty similar to TCP/IP protocol layers. Let’s learn about this in detail.
The IPFS stack is divided into three essential layers:
Networking layer.
Data definition and naming layer.
Data layer.
Let’s learn about each of them in detail.
Networking Layer
One of the core challenges in the decentralized web is the peer to peer network and designing the protocols which work in a peer to peer network in parallel to the centralized system.
The Libp2p project addresses this challenge with protocols labs. Libp2p provides the modular stack which one can use to build peer to peer network in conjunction with existing protocols such as WebRTC or any new transport layer protocols. Hence, Libp2p is transported agnostics.
Features of libp2p:
Libp2p is a modular networking stack. You can use all of it or use part of the stack to build your application.
Libp2p provides transport and peer to peer protocols to build large, robust and scalable network application.
Libp2p is transport protocol agnostics. It can work with TCP, UDP, WebRTC, WebSockets, and UDP.
Libp2p offers a number of modules such as transport interface, discovery, distributed hash lookup, peer discovery, and routing.
Libp2p offers built-in encryption to prevent eavesdropping.
Libp2p offers built-in roaming features so that your service can switch networks without any intervention and loss of packets.
Libp2p is the solution upon which the networking layer of peer to peer can be built.
Data definition and naming layer
Content addressing through hashes is widely used in a distributed system. We use hash-based content addressing in Git, cryptocurrencies, etc. The same is also used in peer to peer networking.
IPLD provides a unified namespace for all hash-based protocals. Using IPLD, data can be traversed across various protocols to explore and view the data spread across peer to peer network.
IPNS is a system to create a mutable address to the contents stored on IPFS. The reason why they are mutable because the addresses of the content change every time the content changes.
Data Layer
The topmost layer in this stack is the data layer. Interplanetary file system or IPFS is the peer to peer hypermedia protocol. IPFS provides a way to store and retrieve the data across peer to peer network.
IPFS uses IPNS and Libp2p to create, name and distribute content across peer to peer network.
Anyone can become an IPFS peer and start looking for the content using hashes. IPFS peer does not need to store every data; they only need to store data created by them or the one they have searched in the past.
Features of IPFS:
IPFS provides peer to peer hypermedia protocols for web 3.0.
IPFS can work with existing protocols and browsers. This gives a smooth transition from centralized web to web 3.0.
IPFS uses Libp2p to support peer to peer networking.
IPFS data is cryptographically secure.
IPFS can save tons of bandwidth in streaming services. For in-depth details, read this white paper.
IPFS is under development, and there are some fantastic applications built by developers that are running on top of the IPFS. One of the applications of my choice is d.tube. This is a decentralized version of YouTube with built-in incentive and reward feature provided by Steem blockchain.
IPFS also trying to solve the incentive issue. We can’t expect every person connected to the internet to act as a peer. In order to provide an incentive to those who participate and contribute value to the network, IPFS has created a coin called Filecoin which can be paid to peers in the network by the user.
Conclusion
Decentralized web or Web 3.0 is the future. There is a need to design a robust, secure and peer to peer network to tackle the issue in existing web. Etherum and IPFS are leading the path to develop the development suite for developers like us to start developing core applications that are needed to make a smooth transition from the existing web to decentralized web.
0 notes
Text
Red Hat OpenShift Service Mesh: Simplifying Microservices Networking
Introduction
As organizations embrace microservices architectures, managing service-to-service communication becomes increasingly complex. Traditional networking approaches struggle to handle the dynamic nature of microservices, leading to challenges in security, observability, and traffic management. Red Hat OpenShift Service Mesh provides a robust solution to simplify and streamline these complexities within OpenShift environments.
What is OpenShift Service Mesh?
OpenShift Service Mesh is an enterprise-grade implementation of Istio, Kiali, and Jaeger, integrated into the OpenShift ecosystem. It offers a unified way to manage microservices networking, security, and observability without modifying application code.
Key Components:
Istio: Provides service discovery, traffic management, and security policies.
Kiali: Offers a graphical representation of the service mesh, making it easier to troubleshoot and monitor services.
Jaeger: Enables distributed tracing to track requests as they traverse multiple microservices.
Why Use OpenShift Service Mesh?
1. Enhanced Security
Mutual TLS (mTLS) encryption ensures secure communication between services.
Fine-grained access control using role-based policies.
Automatic certificate management for seamless encryption.
2. Traffic Management
Intelligent routing and load balancing for efficient traffic distribution.
Canary deployments and A/B testing support.
Fault injection and circuit breaking to enhance application resilience.
3. Observability & Monitoring
Real-time service topology visualization with Kiali.
Distributed tracing with Jaeger to debug latency issues.
Built-in metrics collection for performance monitoring.
How OpenShift Service Mesh Works
OpenShift Service Mesh operates as a sidecar proxy model, where an Envoy proxy runs alongside each microservice pod. These proxies handle all network traffic, enforcing security policies, managing traffic flow, and collecting telemetry data.
Deployment Flow:
Install OpenShift Service Mesh Operator from the OpenShift OperatorHub.
Create a Service Mesh Control Plane (SMCP) to configure the mesh.
Onboard Microservices by adding them to the service mesh namespace.
Define Policies for security, routing, and observability.
Real-World Use Cases
Zero-Trust Security: Enforce encryption and authentication between microservices without manual intervention.
Progressive Rollouts: Use traffic shifting for safe deployment strategies.
Performance Optimization: Analyze and optimize microservices latency with real-time insights.
Conclusion
Red Hat OpenShift Service Mesh simplifies the management of microservices networking, enhancing security, observability, and traffic control. As enterprises scale their Kubernetes workloads, integrating a service mesh becomes essential to maintaining reliability and efficiency.
Looking to implement OpenShift Service Mesh in your environment? HawkStack Technologies can help you architect, deploy, and optimize your microservices infrastructure for maximum performance and security.
Stay tuned for more in-depth OpenShift insights on HawkStack.com!
0 notes
Text
OneAPI Math Kernel Library (oneMKL): Intel MKL’s Successor

The upgraded and enlarged Intel oneAPI Math Kernel Library supports numerical processing not only on CPUs but also on GPUs, FPGAs, and other accelerators that are now standard components of heterogeneous computing environments.
In order to assist you decide if upgrading from traditional Intel MKL is the better option for you, this blog will provide you with a brief summary of the maths library.
Why just oneMKL?
The vast array of mathematical functions in oneMKL can be used for a wide range of tasks, from straightforward ones like linear algebra and equation solving to more intricate ones like data fitting and summary statistics.
Several scientific computing functions, including vector math, fast Fourier transforms (FFT), random number generation (RNG), dense and sparse Basic Linear Algebra Subprograms (BLAS), Linear Algebra Package (LAPLACK), and vector math, can all be applied using it as a common medium while adhering to uniform API conventions. Together with GPU offload and SYCL support, all of these are offered in C and Fortran interfaces.
Additionally, when used with Intel Distribution for Python, oneAPI Math Kernel Library speeds up Python computations (NumPy and SciPy).
Intel MKL Advanced with oneMKL
A refined variant of the standard Intel MKL is called oneMKL. What sets it apart from its predecessor is its improved support for SYCL and GPU offload. Allow me to quickly go over these two distinctions.
GPU Offload Support for oneMKL
GPU offloading for SYCL and OpenMP computations is supported by oneMKL. With its main functionalities configured natively for Intel GPU offload, it may thus take use of parallel-execution kernels of GPU architectures.
oneMKL adheres to the General Purpose GPU (GPGPU) offload concept that is included in the Intel Graphics Compute Runtime for OpenCL Driver and oneAPI Level Zero. The fundamental execution mechanism is as follows: the host CPU is coupled to one or more compute devices, each of which has several GPU Compute Engines (CE).
SYCL API for oneMKL
OneMKL’s SYCL API component is a part of oneAPI, an open, standards-based, multi-architecture, unified framework that spans industries. (Khronos Group’s SYCL integrates the SYCL specification with language extensions created through an open community approach.) Therefore, its advantages can be reaped on a variety of computing devices, including FPGAs, CPUs, GPUs, and other accelerators. The SYCL API’s functionality has been divided into a number of domains, each with a corresponding code sample available at the oneAPI GitHub repository and its own namespace.
OneMKL Assistance for the Most Recent Hardware
On cutting-edge architectures and upcoming hardware generations, you can benefit from oneMKL functionality and optimizations. Some examples of how oneMKL enables you to fully utilize the capabilities of your hardware setup are as follows:
It supports the 4th generation Intel Xeon Scalable Processors’ float16 data type via Intel Advanced Vector Extensions 512 (Intel AVX-512) and optimised bfloat16 and int8 data types via Intel Advanced Matrix Extensions (Intel AMX).
It offers matrix multiply optimisations on the upcoming generation of CPUs and GPUs, including Single Precision General Matrix Multiplication (SGEMM), Double Precision General Matrix Multiplication (DGEMM), RNG functions, and much more.
For a number of features and optimisations on the Intel Data Centre GPU Max Series, it supports Intel Xe Matrix Extensions (Intel XMX).
For memory-bound dense and sparse linear algebra, vector math, FFT, spline computations, and various other scientific computations, it makes use of the hardware capabilities of Intel Xeon processors and Intel Data Centre GPUs.
Additional Terms and Context
The brief explanation of terminology provided below could also help you understand oneMKL and how it fits into the heterogeneous-compute ecosystem.
The C++ with SYCL interfaces for performance math library functions are defined in the oneAPI Specification for oneMKL. The oneMKL specification has the potential to change more quickly and often than its implementations.
The specification is implemented in an open-source manner by the oneAPI Math Kernel Library (oneMKL) Interfaces project. With this project, we hope to show that the SYCL interfaces described in the oneMKL specification may be implemented for any target hardware and math library.
The intention is to gradually expand the implementation, even though the one offered here might not be the complete implementation of the specification. We welcome community participation in this project, as well as assistance in expanding support to more math libraries and a variety of hardware targets.
With C++ and SYCL interfaces, as well as comparable capabilities with C and Fortran interfaces, oneMKL is the Intel product implementation of the specification. For Intel CPU and Intel GPU hardware, it is extremely optimized.
Next up, what?
Launch oneMKL now to begin speeding up your numerical calculations like never before! Leverage oneMKL’s powerful features to expedite math processing operations and improve application performance while reducing development time for both current and future Intel platforms.
Keep in mind that oneMKL is rapidly evolving even while you utilize the present features and optimizations! In an effort to keep up with the latest Intel technology, we continuously implement new optimizations and support for sophisticated math functions.
They also invite you to explore the AI, HPC, and Rendering capabilities available in Intel’s software portfolio that is driven by oneAPI.
Read more on govindhtech.com
#FPGAs#CPU#GPU#inteloneapi#onemkl#python#IntelGraphics#IntelTechnology#mathkernellibrary#API#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
Learning about .NET Core futures by poking around at David Fowler's GitHub
David Fowler is the ASP.NET Core Architect (and an amazing highly technical public speaker) and I've learned a lot from watching him code. However, what's the best way for YOU to learn from folks like David if you can't sit on their shoulder? Why, look at their GitHub!
Since .NET Core (and most of Microsoft) is not only open source but also developed in the open now on GitHub, we can actually watch folks in their day to day work as they commit code to projects like the C# compiler, .NET Core, and ASP.NET Core.
Even more interestingly, we can look at David's github here https://github.com/davidfowl and then under Repositories see what he's up to, filter by language and type, and explore!
You can have Private repositories on GitHub, as I do, and as I'm sure David does. But GitHub is a social network for code and it's more fun and a better learning experience when we can see each others code and read it. Read with a critical eye, but without judgment as you may not have all the context that the author does. If you went to my GitHub, https://github.com/shanselman you might be disappointed but you also may be missing the big picture. Just consider that as you Follow people and explore their code.
David is an advanced .NET developer, while, for example, I am comparatively intermediate. So I realize that not all of David's code is FOR me. It's a scratchpad, it's not educational how-to workshops. However, I can get pick up cool idioms, interesting directions the tech may be going, and more importantly - prototypes and spikes. Spikes are folks testing out technical ideas. They may not be complete. In fact, they may never be complete. But some my be harbingers of things to come.
Here's a few things I learned today.
gRPC for .NET Core
For example, at https://github.com/davidfowl/grpc-dotnet I can see David has forked (copied) gRPC for dotnet and his game is working with the gRPC folks to make a fully supported version of gRPC for production workloads with .NET Core! Here are the stated goals:
We plan to implement a fully-managed version of gRPC for .NET that will be built on top of ASP.NET Core HTTP/2 server.
Good integration with the rest of ASP.NET Core ecosystem
High-performance (we plan to utilize some of the cutting edge performance features from ASP.NET Core and in .NET plaform itself)
That sounds cool! I can go learn that gRPC is a modern (google sponsored) Remote Procedure Call framework that can run anywhere. It's used by Netflix and Square and supports basically any languaige and any environment. Nice for this microservice world we are entering and hopefully has learned from the sins of DCOM and CORBA and RMI, because I was there and it sucked.
Nothing to see here but moving to a new JSON serializer
This Web.Framework sounds fun, and I'll be sure to take the description to heart.
You can see David and James Newton-King kicking ideas around as you explore the commit log. However, the most interesting commit IMHO is when David moves this little spike from using JSON.NET (the ubiquitous 3rd party JSON serializer) to the new emerging official System.Text.Json. Here is the commit with unified differences.
It's a small change but it also makes me feel good about the API underneath this new JSON API that's coming. My takeway is that it's not as scary as I'd assumed. Looks like a Good Thing(tm).
Cool!
Multi-Protocol ASP.NET Core
This looks interesting.
"The following sample shows how you can host a TCP server and HTTP server in the same ASP.NET Core application. Under the covers, it's the same server (Kestrel) running different protocols on different ports. The ConnectionHandler is a new primitive introduced in ASP.NET Core 2.1 to support non-HTTP protocols."
I didn't know you could do that! Looks like this sample hasn't changed much since it was conceived of in 2018, but then in the last month it's been updated twice and it appears to be part of a larger, slow-moving architectural issue called Bedrock that's moving forward.
I learned that Kestral (the ASP.NET Core web server) has a "ListenLocalhost" option on its options object!
WebHost.CreateDefaultBuilder(args) .ConfigureServices(services => { // This shows how a custom framework could plug in an experience without using Kestrel APIs directly services.AddFramework(new IPEndPoint(IPAddress.Loopback, 8009)); }) .UseKestrel(options => { // TCP 8007 options.ListenLocalhost(8007, builder => { builder.UseConnectionHandler<MyEchoConnectionHandler>(); }); // HTTP 5000 options.ListenLocalhost(5000); // HTTPS 5001 options.ListenLocalhost(5001, builder => { builder.UseHttps(); }); }) .UseStartup<Startup>();
I can see here that TCP port 8007 is customer and uses a custom ConnectionHandler which I also didn't know existed! I can then look at the implementation of that handler and it's cool how clean the API is. You can get the result cleanly off the Transport buffer. You're doing low-level TCP but it doesn't feel low level.
using System.Threading.Tasks; using Microsoft.AspNetCore.Connections; using Microsoft.Extensions.Logging; namespace KestrelTcpDemo { public class MyEchoConnectionHandler : ConnectionHandler { private readonly ILogger<MyEchoConnectionHandler> _logger; public MyEchoConnectionHandler(ILogger<MyEchoConnectionHandler> logger) { _logger = logger; } public override async Task OnConnectedAsync(ConnectionContext connection) { _logger.LogInformation(connection.ConnectionId + " connected"); while (true) { var result = await connection.Transport.Input.ReadAsync(); var buffer = result.Buffer; foreach (var segment in buffer) { await connection.Transport.Output.WriteAsync(segment); } if (result.IsCompleted) { break; } connection.Transport.Input.AdvanceTo(buffer.End); } _logger.LogInformation(connection.ConnectionId + " disconnected"); } } }
Pretty slick. This just echos what is sent to that port but not only has it educated me about a thing I didn't know about, it's something I can mentally file away until I need it!
All of these things I learned in just 30 minutes of exploring someone's public repository.
What kinds of code do you like to read and what have you learned from just poking around?
Sponsor: Get the latest JetBrains Rider for remote debugging via SSH, SQL injections, a new Search Everywhere popup, and improved Unity support.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
December 06, 2019 at 10:00PM - Reactive JavaScript Course & eBook Bundle (94% discount) Ashraf
Reactive JavaScript Course & eBook Bundle (94% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
JavaScript is the browser language that supports object-oriented, imperative, and functional programming styles, focusing on website behavior. JavaScript provides web developers with the knowledge to program more intelligently and idiomatically—and this course will help you explore the best practices for building an original, functional, and useful cross-platform library. At course’s end, you’ll be equipped with all the knowledge, tips, and hacks you need to stand out in the advanced world of web development.
Access 39 lectures & over 4 hours of content 24/7
Get a foundational knowledge of OOP coding
Explore naming convention best practices for primitive variables, constructors, methods & properties
Learn about creating global namespace & pure JavaScript onload script
Walk through cross-browser compatibility
Learn how the onload & DOMContentLoaded events are triggered
Use querySelectorAll method & dynamically load scripts using a script loader
Build up the instructor’s library by integrating code, methods & logic
Design patterns are intelligent, reusable strategies for solving common problems faced by developers. For web developers working with JavaScript, design patterns provide a tested, methodical plan of attack for tackling challenges that arise in real-world application development. This course will immerse you in the world of intelligent JavaScript programming, helping you learn how to mobilize design patterns and understand key programming concepts and common solutions to frequently occurring programming problems.
Access 26 lectures & 3 hours of content 24/7
Explore 20 different design patterns & the internal logic of each
Discuss the conceptual logic behind design patterns & the major pattern types
Dive into real-world case studies to build a mock application w/ in-built issues that design patterns can solve
Expand into core design patterns underlying the major pattern types
In this comprehensive course, you’ll get a comprehensive introduction to reactive programming and become more familiar with APIs. Responsive applications are dependent on reactive programming, and the concepts you’ll be introduced to here will help you construct streamlined, constantly updating apps that users will love.
Access 28 lectures & 2.5 hours of content 24/7
Start studying Reactive programming & Rx in depth
Get introduced to Rx concepts & similar APIs across many languages
Build a stopwatch app & an autocomplete search box w/ Rx
Create operators & perform various operations such as transform, filter, combine, & error handling
Building a website or mobile app using modern technologies can be a daunting task. Choosing and installing the tools alone can take hours of frustration, and code might not be very efficient. But with the MEAN stack at your aid, you can make the most of JavaScript to create websites and apps that are high-performing and easy on you. This course gives you a start-to-finish solution for using modern technologies, writing high-quality code, and deploying a live website with the MEAN stack.
Access 55 lectures & 4 hours of content 24/7
Use the mean-seed Yeoman generator to equip yourself w/ all the modern tools & workflows
Learn best practices of using Angular directives & writing automated tests right from the start
Get a scaffolded-out, functioning website & then add in custom code & tests to bring it live
Go further w/ GruntJS commands to build & test an application
Explore the three core front-end languages: HTML, CSS, & JavaScript
Build a full stack application complete w/ a database layer, back-end server, & front-end client
Angular 2 promises cross-platform coding, greater development efficiency, better speed and performance, and incredible tooling to create applications for both mobile and desktop. This course delivers an early deep dive into the architectural aspects of Angular 2 development, and imparts the knowledge you need to understand it comprehensively and put into practice the key concepts powering the framework.
Access 27 lectures & 3 hours of content 24/7
Apply Angular 2 concepts to an application that grows in complexity throughout the course
Discover how to present data to users while also ensuring that their interactions on the UI are handled by the presentation layer of your app
Look at business logic needs so your system behaves correctly
Create forms w/ ease & smoothly handle validation
Merge development aspects w/ reactive & asynchronous programming
React and React Native allow you to build cross-platform desktop and mobile applications using Facebook’s innovative UI libraries. Combined with the Flux data architecture and Relay, you can now create powerful and feature-complete applications from one code base. In this three part book, you’ll start crafting composable UIs using React, build Native UIs using React Native, and create React applications that run on every platform.
Craft reusable React components
Control navigation using the React router to help keep your UI in sync w/ URLs
Build isomorphic web applications using Node.js
Use the Flexbox layout model to create responsive mobile designs
Leverage the native APIs of Android & iOS to build engaging applications w/ React Native
Respond to gestures in a way that’s intuitive for the user
Use Relay to build a unified data architecture for your React UIs
Angular 2 introduces an entirely new way to build applications. It wholly embraces all the newest concepts that are built into the next generation of browsers, and cuts away all the fat and bloat from Angular 1. This book plunges directly into the heart of all the most important Angular 2 concepts for you to conquer, as well as demonstrates how the framework embraces a range of new web technologies such as ES6 and TypeScript syntax, among others.
Understand how to best move an Angular 1 application to Angular 2
Build a solid foundational understanding of the core elements of Angular 2 such as components, forms, & services
Gain an ability to wield complex topics such as Observables & Promises
Properly implement applications utilizing advanced topics such as dependency injection
Know how to maximize the performance of Angular 2 applications
Understand the best ways to take an Angular 2 application from TypeScript in a code editor to a fully function application served on your site
Get to know the best practices when organizing & testing a large Angular 2 application
The principles of asynchronous event-driven programming are perfect for today’s web, where efficient real-time applications and scalability are at the forefront. Server-side JavaScript has been here since the ’90s but Node gets it right. Beginning with adopting debugging tips and tricks of the trade and learning how to write your own modules, this ebook covers fundamentals of streams, security, databases, and much more with Node.js.
Rapidly become proficient at debugging Node.js programs
Write & publish your own Node.js modules
Become deeply acquainted w/ Node.js core APIs
Use web frameworks such as Express, Hapi, & Koa for accelerated web application development
Apply Node.js streams for low-footprint infinite-capacity data processing
Fast-track performance knowledge & optimization abilities
Compare & contrast various persistence strategies, including database integrations w/ MongoDB, MySQL/MariaDB, Postgres, Redis, & LevelDB
Grasp & apply critically essential security concepts
Understand how to use Node w/ best-of-breed deployment technologies: Docker, Kubernetes, & AWS
from Active Sales – SharewareOnSale https://ift.tt/2xCrOjy https://ift.tt/eA8V8J via Blogger https://ift.tt/2DYgC5u #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
300+ TOP WCF Interview Questions and Answers
WCF Interview Questions and Answers for freshers experienced :-
1. What is WCF? WCF stands for Windows Communication Foundation. It is a Software development kit for developing services on Windows. WCF is introduced in .NET 3.0. in the System.ServiceModel namespace. WCF is based on basic concepts of Service oriented architecture (SOA) 2. What is endpoint in WCF service? The endpoint is an Interface which defines how a client will communicate with the service. It consists of three main points: Address,Binding and Contract. 3. Explain Address,Binding and contract for a WCF Service? Address:Address defines where the service resides. Binding:Binding defines how to communicate with the service. Contract:Contract defines what is done by the service. 4. What are the various address format in WCF? a)HTTP Address Format:--> http://localhost: b)TCP Address Format:--> net.tcp://localhost: c)MSMQ Address Format:--> net.msmq://localhost: 5. What are the types of binding available in WCF? A binding is identified by the transport it supports and the encoding it uses. Transport may be HTTP,TCP etc and encoding may be text,binary etc. The popular types of binding may be as below: a)BasicHttpBinding b)NetTcpBinding c)WSHttpBinding d)NetMsmqBinding 6. What are the types of contract available in WCF? The main contracts are: Service Contract: Describes what operations the client can perform. Operation Contract : defines the method inside Interface of Service. Data Contract: Defines what data types are passed Message Contract: Defines wheather a service can interact directly with messages 7. What are the various ways of hosting a WCF Service? a)IIS b)Self Hosting c)WAS (Windows Activation Service) 8. What is the proxy for WCF Service? A proxy is a class by which a service client can Interact with the service. By the use of proxy in the client application we are able to call the different methods exposed by the service 9. How can we create Proxy for the WCF Service? We can create proxy using the tool svcutil.exe after creating the service. We can use the following command at command line. svcutil.exe *.wsdl *.xsd /language:C# /out:SampleProxy.cs /config:app.config 11.What is DataContract and ServiceContract?Explain Data represented by creating DataContract which expose the data which will be transefered /consumend from the serive to its clients. **Operations which is the functions provided by this service. To write an operation on WCF,you have to write it as an interface,This interface contains the "Signature" of the methods tagged by ServiceContract attribute,and all methods signature will be impelemtned on this interface tagged with OperationContract attribute.and to implement these serivce contract you have to create a class which implement the interface and the actual implementation will be on that class. Code Below show How to create a Service Contract: Code: Public Interface IEmpOperations { Decimal Get EmpSal(int EmpId); } Class MyEmp: IEmpOperations { Decimal Get EmpSal() { // Implementation of this method. } } 12. What is Windows card space? Windows card space is a central part of Microsoft's effort to create an identify met system, or a unified, secure and interoperable identify layer for the internet. 13. What are the main components of WCF? There are three main components of WCF: Service class Hosting environment End point 14. What are the advantages of hosting WCF Services in IIS as compared to self hosting? There are two main advantages of using IIS over self hosting. Automatic activation Process recycling 15. What is .NET 3.0? In one simple equation .NET 3.0 = .NET 2.0 + Windows Communication Foundation + Windows Presentation Foundation + Windows Workflow Foundation + Windows Card Space. 16. What is the difference between WCF and Web Services? Web services can only be invoked by HTTP. While Services or a WCF component can be invoked by any protocol and any transport type. Second web services are not flexible. However Services are flexible. If you make a new version of the service then you need to just expose a new end. Therefore services are agile and which is a very practical approach looking at the current business trends. 17. What are the different bindings supported by WCF? WCF includes predefined bindings. Basic Http binding WsHttp binding NetTcp Binding Netnamed pipes binding Net MSMQ binding 18. Can we have two way communications in MSMQ? Yes 19. What are dead letter queues? The main use of queue is that you do not need the client and the server running at one time. Therefore it is possible that a message will lie in queue for long time until the server or client picks it up. But there are scenarios where a message is no use after a certain time. 20. what are the various ways of hosting a WCF service? There are three major ways to host a WCF service : Self-hosting the service in his own application domain. This we have already covered in the first section. The service comes in to existence when you create the object of Service Host class and the service closes when you call the Close of the Service Host class. Host in application domain or process provided by IIS Server. Host in Application domain and process provided by WAS (Windows Activation Service) Server 21. What are the core security features that WCF addresses? Confidentiality Integrity Authentication Authorization 22. What is SOA? SOA is a collection of well defined services, where each individual service can be modified independently of other services to help respond to the ever evolving market conditions of a business. 23. What is the difference between transport level and message level security? Transport level security happens at the channel level. Transport level security is the easiest to implement as it happens at the communication level. WCF uses transport protocols like TCP, HTTP, MSMQ etc and every of these protocols have their own security mechanisms. Message level security is implemented with message data itself. 24. What is service and client in perspective of data communication? A service is a unit of functionality exposed to the world. The client of a service is merely the party consuming the service. 25. What is bindings? A binding defines how an endpoint communicates to the world. A binding defines the transport (such as HTTP or TCP) and the encoding being used (such as text or binary). A binding can contain binding elements that specify details like the security mechanisms used to secure messages, or the message pattern used by an endpoint. 26. What are the advantages of WCF? WCF is interoperable with other services when compared to .Net Remoting,where the client and service have to be .Net. WCF services provide better reliability and security in compared to ASMX web services. In WCF, there is no need to make much change in code for implementing the security model and changing the binding. WCF has integrated logging mechanism, changing the configuration file settings will provide this functionality. 27. Define service contracts? Service contracts define the operations that a service will perform when executed. They tell the outside world a lot about the service such as message data types, operation locations, the protocols the client will need in order to communicate with the service, and the operations the service provides. 28. Define message contracts? Message contracts allow the control of SOAP messages that are produced and consumed by WCF. Basically it boils down to being able to customize the format of contract parameters and the placing of elements within a SOAP message, or in other words, having control of the structure as well as the contents of a SOAP message. 29. Define data contracts? Data contracts specifically define the data that is being exchanged between a client and service. The data contract is an agreement, meaning that the client and the service must agree on the data contract in order for the exchange of data to take place. 30. Define transaction? A transaction is a collection or group of one or more units of operation executed as a whole. Another way to say it is that transactions provide a way to logically group single pieces of work and execute them as a single unit, or transaction. 31. What is address in WCF? Address is a way of letting client know that where a service is located. In WCF, every service is associated with a unique address. 32. What are the types of bindings in WCF? Basic binding TCP binding Peer network binding IPC binding Web Service (WS) binding Federated WS binding Duplex WS binding MSMQ binding MSMQ integration binding 33. What are different elements of WCF Srevices Client configuration file? WCF Services client configuration file contains endpoint, address, binding and contract. 34. What are the features of WCF? Transactions : A transaction is a unit of work. A transaction ensures that everything within that transaction either succeeds as a whole or fails as whole. Hosting : WCF hosting allows services to be hosted in a handful of different environments, such as Windows NT Services, Windows Forms, and console applications, and well as IIS (Internet Information Services) and Windows Activation Services (WAS). Security : WCF also enables you to integrate your application into an existing security infrastructure, including those that extend beyond the standard Windows-only environments by using secure SOAP messages. Queuing : WCF enables queuing by providing support for the MSMQ transport. 35. Explain WCF contracts? Contracts in Windows Communication Foundation provide the interoperability they need to communicate with the client. It is through contracts that clients and services agree as to the types of operations and structures they will use during the period that they are communicating back and forth. Without contracts, no work would be accomplished because no agreement would happen. Three basic contracts are used to define a Windows Communication Foundation service : Service Contract : Defines the methods of a service, that is, what operations are available on the endpoint to the client. Data Contract : Defines the data types used by the available service methods. Message Contract : Provides the ability to control the message headers during the creation of a message. 36. What is the use of SessionMode? The SessionMode attribute specifies the type of support for reliable sessions that a contract requires or supports. The value of this parameter comes from the Session Mode enumeration. 37. What are the types of messaging programs? In WCF, different types of applications can send and receive messages. Clients Services Intermediaries 38. What is transfer security? Transfer Security is responsible for providing message integrity, confidentiality, and authentication Each of these were defined previously. Windows Communication Foundation builds on this security to include quite a few modes of transfer security. 39. What are the types of messaging patterns? Messaging patterns basically describe how programs exchange messages. When a program sends a message, it must conform to one of several patterns in order for it to successfully communicate with the destination program. There are three basic messaging patterns that programs can use to exchange messages. Simplex Duplex Request Reply 40. What is the difference between WCF Service and Web Service? Web service is a part of WCF. WCF offers much more flexibility and portability to develop a service when comparing to web service. The following point provides the detailed differences between them : Hosting : Webservices can be host in IIS, whereas WCF services can be hosted in IIS, Windows Activation Service, Self Hosting. Encoding : Webservices uses XML 1.0, MTOM(Message Transmission Optimization Mechanism), DIME, Custom. WCF uses XML 1.0, MTOM, Binary, Custom. Transports : Webservices can be accessed using HTTP, TCP, Custom. WCF services can be accessed using HTTP, TCP, Named Pipes, MSMQ, P2P, Custom. Protocols : Webservices uses Security porotocols only. Whereas WCF services uses Security, Reliable Messaging, Transactions protocols. WCF Questions and Answers Pdf Download Read the full article
0 notes
Photo

New Post has been published on https://warmdevs.com/moving-towards-web3-0-using-blockchain-as-core-tech.html
Moving Towards web3.0 Using Blockchain as Core Tech
The invention of Bitcoin and blockchain technology sets the foundations for the next generations of web applications. The applications which will run on peer to peer network model with existing networking and routing protocols. The applications where centralized Servers would be obsolete and data will be controlled by the entity whom it belongs, i.e., the User.
From Web 1.0 to Web 2.0
As we all know, Web 1.0 was static web, and the majority of the information was static and flat. The major shift happened when user-generated content becomes mainstream. Projects such as WordPress, Facebook, Twitter, YouTube, and others are nominated as Web 2.0 sites where we produce and consume verity of contents such as Video, Audio, Images, etc.
The problem, however, was not the content; it was the architecture. The Centralized nature of Web opens up tons of security threats, data gathering of malicious purpose, privacy intrusion and cost as well.
The invention of Bitcoin and successful use of decentralized, peer to peer, secure network opens up the opportunity to take a step back and redesign the way our web works. The blockchain is becoming the backbone of the new Web, i.e., Web 3.0.
History of blockchain
The invention of blockchain came to the mainstream after the boom of the Bitcoin in 2018. Have a look at the graph below; Bitcoin was at its peak around $20000.
But the technologies that power the blockchain network is not something new. These concepts were researched and developed during the ’90s. Have a look at this timeline.
The concepts, such as proof of work, peer to peer network, public key cryptography and consensus algorithms for distributed computing which powers the blockchain have been researched and developed by various universities and computer scientists during the ’90s.
These algorithms and concepts are mature and battle-tested by various organizations. Satoshi Nakamoto combined these technologies and ideas together and built a decentralized, immutable, peer to peer database primarily used for financial purposes.
Initially, we all thought that blockchain is suitable only for cryptocurrencies and not for other applications. This thought was challenged when Vitalik buterin developed the Etherum cryptocurrency with a new Smart contract feature.
Smart contracts changed everything. The ability to code your own application and run on top of blockchain was the answer to critics who thought that blockchain is only for currencies.
“Cryptocurrency is a small subset of the blockchain, like the Email of the internet.”
The smart contracts open up the wave of new applications. The viral game cryptokitties showcases blockchain can handle large end applications such as games.
Smart contracts are written in Solidity language and can be executed on Etherum network. The protocol and design of Etherum inspired the engineers to build an open source and blockchain agnostic platform to build decentralized applications.
DApps protocols
As I have mentioned earlier, Etherum smart contracts were among the first such technology that can be used to program the decentralized applications. The issue was that smart contracts were written by keeping transactions or money in mind.
Developers need multiple tools to build a full-fledged web application such as storage (database, files, index, etc.), message queues or event queues to facilitate the communication. Etherum address these problems by introducing Etherum Swarm and Etherum Whisper projects.
As you can see in the diagram above, With Etherum Smart contracts for writing contracts and swarm to store files that can be associated with contracts. To make the decentralized apps communicate with each other, Whisper can be used. All of these can run inside the decentralized browser such as Dbrowser.
Swarm is a distributed storage platform for an ethereum stack. The core objective of Swarm is to provide decentralized storage for ethereum public records. Swarm is supposed to save the DApps code base and data associated with it.
Swarm allows public participants to pool their storage and bandwidth resources to make the network robust and get paid in Etherum incentives. Fair deal.
Ethereum whisper, in a nutshell, is a protocol for DApps running on Etherum blockchain to communicate with each other, similar to message queues or event queues. Whisper provides low-level API’s to support communication between DApps. You can learn more about it here.
However, do you sense the limitations here? Well, the main issue is that this is entirely Etherum agnostic, i.e., all apps are written and run on top of Etherum blockchain. This change will increase the size of the chain significantly, and scalability will be an issue.
Other than scalability, adaptability will be an issue as well. We need a smooth shift from the centralized web to decentralized web. A shift where masses do not need to change everything for the sake of the decentralized web.
This is where our new protocol comes in, called the IPFS (Interplanetary file system) stack by Protocols labs.
Protocols labs is dedicated to building the decentralized web which runs in parallel to TCP/IP stack. This will make the shift from existing web to web 3.0 very smooth, and masses do not need to make a significant change to use the web 3.0.
Here is the stack.
Rings a bell? This stack looks pretty similar to TCP/IP protocol layers. Let’s learn about this in detail.
The IPFS stack is divided into three essential layers:
Networking layer.
Data definition and naming layer.
Data layer.
Let’s learn about each of them in detail.
Networking Layer
One of the core challenges in the decentralized web is the peer to peer network and designing the protocols which work in a peer to peer network in parallel to the centralized system.
The Libp2p project addresses this challenge with protocols labs. Libp2p provides the modular stack which one can use to build peer to peer network in conjunction with existing protocols such as WebRTC or any new transport layer protocols. Hence, Libp2p is transported agnostics.
Features of libp2p:
Libp2p is a modular networking stack. You can use all of it or use part of the stack to build your application.
Libp2p provides transport and peer to peer protocols to build large, robust and scalable network application.
Libp2p is transport protocol agnostics. It can work with TCP, UDP, WebRTC, WebSockets, and UDP.
Libp2p offers a number of modules such as transport interface, discovery, distributed hash lookup, peer discovery, and routing.
Libp2p offers built-in encryption to prevent eavesdropping.
Libp2p offers built-in roaming features so that your service can switch networks without any intervention and loss of packets.
Libp2p is the solution upon which the networking layer of peer to peer can be built.
Data definition and naming layer
Content addressing through hashes is widely used in a distributed system. We use hash-based content addressing in Git, cryptocurrencies, etc. The same is also used in peer to peer networking.
IPLD provides a unified namespace for all hash-based protocals. Using IPLD, data can be traversed across various protocols to explore and view the data spread across peer to peer network.
IPNS is a system to create a mutable address to the contents stored on IPFS. The reason why they are mutable because the addresses of the content change every time the content changes.
Data Layer
The topmost layer in this stack is the data layer. Interplanetary file system or IPFS is the peer to peer hypermedia protocol. IPFS provides a way to store and retrieve the data across peer to peer network.
IPFS uses IPNS and Libp2p to create, name and distribute content across peer to peer network.
Anyone can become an IPFS peer and start looking for the content using hashes. IPFS peer does not need to store every data; they only need to store data created by them or the one they have searched in the past.
Features of IPFS:
IPFS provides peer to peer hypermedia protocols for web 3.0.
IPFS can work with existing protocols and browsers. This gives a smooth transition from centralized web to web 3.0.
IPFS uses Libp2p to support peer to peer networking.
IPFS data is cryptographically secure.
IPFS can save tons of bandwidth in streaming services. For in-depth details, read this white paper.
IPFS is under development, and there are some fantastic applications built by developers that are running on top of the IPFS. One of the applications of my choice is d.tube. This is a decentralized version of YouTube with built-in incentive and reward feature provided by Steem blockchain.
IPFS also trying to solve the incentive issue. We can’t expect every person connected to the internet to act as a peer. In order to provide an incentive to those who participate and contribute value to the network, IPFS has created a coin called Filecoin which can be paid to peers in the network by the user.
Conclusion
Decentralized web or Web 3.0 is the future. There is a need to design a robust, secure and peer to peer network to tackle the issue in existing web. Etherum and IPFS are leading the path to develop the development suite for developers like us to start developing core applications that are needed to make a smooth transition from the existing web to decentralized web.
0 notes
Text
ICT Innovations
ICT Innovations is a software development company having experienced and dedicated professionals with expertise in LAMP Stack and computer telephony integration (CTI). ICT Innovations has strong knowledge of Open Source communications technologies and applications such as Asterisk, Freeswitch, Drupal, Plivo,voip, Elastix and OpenSIPS/ Kamailio.
Products
ICTBroadcast
ICTBroadcast is a multi-tenant unified communications telemarketing autodialer software solution. It supports Voice broadcasting, SMS broadcasting, Email broadcasting & Fax broadcasting. It is suitable for small business owners, enterprises and Internet telephony service providers. ICTBroadcast is a smart auto dialer software with advanced autodialing multilingual supported features. ICTBroadcast is being offered in two editions , ICTBroadcast Enterprise Edition suitable for organizations / enterprises for their own telemarketing and mass communication needs and ICTBroadcast Service Provider Edition suitable for Internet telephony services providers (ITSP) / carriers to offer hosted telemarketing / mass communications services to their customers and integrate it with their existing infrastructure.
ICTFAX
ICTFAX is an Open Source (GPL v 3) multi-user, web based software solution for service providers based on Open Source Spandsp, Drupal and ICTCore Framework. ICTFAX is an email to fax , web to fax gateway, it supports G.711 faxing, PSTN faxing and T.38 origination and termination. Released new version of ICTCore V 0.7.5 on March 12, 2017 with following improments
Twig based template added for gateway configurations and Application data
Data and Token libraries updated
Sip, SMTP and SMPP added as provider sub-type
Multi tasking support improved for Task and Schedule
Namespaces and PSR-4 based auto-loading support added
PhpUnit support added for unit testing
Services
Consultancy services
ICTInnovations offer consultancy services to its clients and work with them to fully understand their exact business requirements. ICTInnovations customize, develop, migrate, integrate and provide network architecture and deployment plans to our international client base.
Support services
ICTInnovations provide support services for Open Source communications technologies such as Asterisk, Freeswitch, OpenSIPS, Plivo and Drupal.
Integration and Development
ICTInnovations offer services to allow the integration of Open Source telephony projects and components into any existing network. ICT Innovations can provide a complete business solution per each individual client's requirement. We will develop tailored API's on request to integrate Open Source VoIP projects with your existing communications infrastructure. ... from Updates & News http://www.voip-info.org/wiki/view/ICT+Innovations
0 notes