#Unsupervised Learning Market size
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Unsupervised learning is a branch of artificial intelligence that involves the training of an algorithm on unstructured data. Unstructured data is defined as data that does not have any predefined categorizations or labels.
#Unsupervised Learning Market#Unsupervised Learning Market size#Unsupervised Learning#Unsupervised machine Learning
0 notes
Text
AI-Powered Drug Discovery in Dermatology Market Forecast, Size, Share by 2025-2033

The Reports and Insights, a leading market research company, has recently releases report titled “AI-Powered Drug Discovery in Dermatology Market: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2025-2033.” The study provides a detailed analysis of the industry, including the global AI-Powered Drug Discovery in Dermatology Market share, size, trends, and growth forecasts. The report also includes competitor and regional analysis and highlights the latest advancements in the market.
Report Highlights:
How big is the AI-Powered Drug Discovery in Dermatology Market?
The global AI-powered drug discovery in dermatology market was valued at US$ 246.4 Million in 2024 and is expected to register a CAGR of 24.7% over the forecast period and reach US$ 1,796.6 Mn in 2033.
What are AI-Powered Drug Discovery in Dermatology?
Request for a sample copy with detail analysis: https://www.reportsandinsights.com/sample-request/2568
What are the growth prospects and trends in the AI-Powered Drug Discovery in Dermatology industry?
What is included in market segmentation?
The report has segmented the market into the following categories:
By Drug Type
Small Molecules
Biologics
Biosimilars
Natural Compounds
RNA-Based Therapeutics
Others
By AI Model
Machine Learning (ML)
Supervised Learning
Unsupervised Learning
Reinforcement Learning
Others
Deep Learning
Neural Networks
Convolutional Neural Networks (CNNs)
Others
Natural Language Processing (NLP)
Generative Models
GANs (Generative Adversarial Networks)
Transformer Models
Others
Others
By Indication
Psoriasis
Atopic Dermatitis (Eczema)
Acne
Skin Cancer (e.g., Melanoma, Basal Cell Carcinoma)
Vitiligo
Wound Healing
Rare Dermatological Disorders
Others
By End User
Pharmaceutical Companies
Biotechnology Firms
Academic and Research Institutes
Contract Research Organizations (CROs)
Healthcare Providers
North America
United States
Canada
Europe
Germany
United Kingdom
France
Italy
Spain
Russia
Poland
Benelux
Nordic
Rest of Europe
Asia Pacific
China
Japan
India
South Korea
ASEAN
Australia & New Zealand
Rest of Asia Pacific
Latin America
Brazil
Mexico
Argentina
Middle East & Africa
Saudi Arabia
South Africa
United Arab Emirates
Israel
Rest of MEA
Who are the key players operating in the industry?
The report covers the major market players including:
Almirall
SCARLETRED
QIMA Monasterium
Quantificare
Google
Microsoft
CytoReason LTD
Atomwise Inc.
View Full Report: https://www.reportsandinsights.com/report/AI-Powered Drug Discovery in Dermatology-market
If you require any specific information that is not covered currently within the scope of the report, we will provide the same as a part of the customization.
About Us:
Reports and Insights consistently mееt international benchmarks in the market research industry and maintain a kееn focus on providing only the highest quality of reports and analysis outlooks across markets, industries, domains, sectors, and verticals. We have bееn catering to varying market nееds and do not compromise on quality and research efforts in our objective to deliver only the very best to our clients globally.
Our offerings include comprehensive market intelligence in the form of research reports, production cost reports, feasibility studies, and consulting services. Our team, which includes experienced researchers and analysts from various industries, is dedicated to providing high-quality data and insights to our clientele, ranging from small and medium businesses to Fortune 1000 corporations.
Contact Us:
Reports and Insights Business Research Pvt. Ltd. 1820 Avenue M, Brooklyn, NY, 11230, United States Contact No: +1-(347)-748-1518 Email: [email protected] Website: https://www.reportsandinsights.com/ Follow us on LinkedIn: https://www.linkedin.com/company/report-and-insights/ Follow us on twitter: https://twitter.com/ReportsandInsi1
#AI-Powered Drug Discovery in Dermatology Market share#AI-Powered Drug Discovery in Dermatology Market size#AI-Powered Drug Discovery in Dermatology Market trends
0 notes
Text
Clustering Techniques in Data Science: K-Means and Beyond
In the realm of data science, one of the most important tasks is identifying patterns and relationships within data. Clustering is a powerful technique used to group similar data points together, allowing data scientists to identify inherent structures within datasets. By applying clustering methods, businesses can segment their customers, analyze patterns in data, and make informed decisions based on these insights. One of the most widely used clustering techniques is K-Means, but there are many other methods as well, each suitable for different types of data and objectives.
If you are considering a data science course in Jaipur, understanding clustering techniques is crucial, as they are fundamental in exploratory data analysis, customer segmentation, anomaly detection, and more. In this article, we will explore K-Means clustering in detail and discuss other clustering methods beyond it, providing a comprehensive understanding of how these techniques are used in data science.
What is Clustering in Data Science?
Clustering is an unsupervised machine learning technique that involves grouping a set of objects in such a way that objects in the same group (a cluster) are more similar to each other than to those in other groups. It is widely used in data mining and analysis, as it helps in discovering hidden patterns in data without the need for labeled data.
Clustering algorithms are essential tools in data science, as they allow analysts to find patterns and make predictions in large, complex datasets. Common use cases for clustering include:
Customer Segmentation: Identifying different groups of customers based on their behavior and demographics.
Anomaly Detection: Identifying unusual or rare data points that may indicate fraud, errors, or outliers.
Market Basket Analysis: Understanding which products are often bought together.
Image Segmentation: Dividing an image into regions with similar pixel values.
K-Means Clustering: A Popular Choice
Among the various clustering algorithms available, K-Means is one of the most widely used and easiest to implement. It is a centroid-based algorithm, which means it aims to minimize the variance within clusters by positioning a central point (centroid) in each group and assigning data points to the nearest centroid.
How K-Means Works:
Initialization: First, the algorithm randomly selects K initial centroids (K is the number of clusters to be formed).
Assignment Step: Each data point is assigned to the closest centroid based on a distance metric (usually Euclidean distance).
Update Step: After all data points are assigned, the centroids are recalculated as the mean of the points in each cluster.
Repeat: Steps 2 and 3 are repeated iteratively until the centroids no longer change significantly, meaning the algorithm has converged.
Advantages of K-Means:
Efficiency: K-Means is computationally efficient and works well with large datasets.
Simplicity: The algorithm is easy to implement and understand.
Scalability: K-Means can scale to handle large datasets, making it suitable for real-world applications.
Disadvantages of K-Means:
Choice of K: One of the main challenges with K-Means is determining the optimal number of clusters (K). If K is not set correctly, the results can be misleading.
Sensitivity to Initial Centroids: The algorithm is sensitive to the initial placement of centroids, which can affect the quality of the clustering.
Assumes Spherical Clusters: K-Means assumes that clusters are spherical and of roughly equal size, which may not be true for all datasets.
Despite these challenges, K-Means remains a go-to algorithm for many clustering tasks, especially in cases where the number of clusters is known or can be estimated.
Clustering Techniques Beyond K-Means
While K-Means is widely used, it may not be the best option for all types of data. Below are other clustering techniques that offer unique advantages and are suitable for different scenarios:
1. Hierarchical Clustering
Hierarchical clustering creates a tree-like structure called a dendrogram to represent the hierarchy of clusters. There are two main approaches:
Agglomerative: This is a bottom-up approach where each data point starts as its own cluster, and pairs of clusters are merged step by step based on similarity.
Divisive: This is a top-down approach where all data points start in a single cluster, and splits are made recursively.
Advantages:
Does not require the number of clusters to be specified in advance.
Can produce a hierarchy of clusters, which is useful in understanding relationships at multiple levels.
Disadvantages:
Computationally expensive for large datasets.
Sensitive to noise and outliers.
2. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN is a density-based clustering algorithm that groups points that are closely packed together, marking points in low-density regions as outliers. Unlike K-Means, DBSCAN does not require the number of clusters to be predefined, and it can handle clusters of arbitrary shapes.
Advantages:
Can discover clusters of varying shapes and sizes.
Identifies outliers effectively.
Does not require specifying the number of clusters.
Disadvantages:
Requires setting two parameters (epsilon and minPts), which can be challenging to determine.
Struggles with clusters of varying density.
3. Gaussian Mixture Models (GMM)
Gaussian Mixture Models assume that the data points are generated from a mixture of several Gaussian distributions. GMM is a probabilistic model that provides a soft clustering approach, where each data point is assigned a probability of belonging to each cluster rather than being assigned to a single cluster.
Advantages:
Can handle elliptical clusters.
Provides probabilities for cluster membership, which can be useful for uncertainty modeling.
Disadvantages:
More computationally expensive than K-Means.
Sensitive to initialization and the number of components (clusters).
4. Agglomerative Clustering
Agglomerative clustering is an alternative to K-Means and hierarchical clustering, where data points are iteratively merged into clusters. The merging process is based on distance or similarity measures.
Advantages:
Can be used for both small and large datasets.
Works well with irregular-shaped clusters.
Disadvantages:
Can be computationally intensive for very large datasets.
Clusters can be influenced by noisy data.
Clustering in Data Science Projects
When pursuing a data science course in Jaipur, it’s essential to gain hands-on experience with clustering techniques. These methods are used in various real-world applications such as:
Customer Segmentation: Businesses use clustering to group customers based on purchasing behavior, demographic data, and preferences. This helps in tailoring marketing strategies and improving customer experiences.
Anomaly Detection: Clustering is also employed to detect unusual patterns in data, such as fraudulent transactions or network intrusions.
Image Segmentation: Clustering is used in image processing to identify regions of interest in medical images, satellite imagery, or facial recognition.
Conclusion
Clustering techniques, such as K-Means and its alternatives, are a fundamental part of a data scientist’s toolkit. By mastering these algorithms, you can uncover hidden patterns, segment data effectively, and make data-driven decisions that can transform businesses. Whether you're working with customer data, financial information, or social media analytics, understanding the strengths and limitations of different clustering techniques is crucial.
Enrolling in a data science course in Jaipur is an excellent way to get started with clustering methods. With the right foundation, you’ll be well-equipped to apply these techniques to real-world problems and advance your career as a data scientist.
0 notes
Text
Data Mining Techniques: Unlocking Insights from Big Data

Introduction
Data mining is a crucial process in extracting meaningful patterns and insights from large datasets. Businesses, researchers, and organizations use data mining techniques to make informed decisions, detect trends, and enhance operational efficiency. This blog explores key data mining techniques and their real-world applications.
1. Classification
Definition: Classification is a supervised learning technique used to categorize data into predefined classes or labels.
Common Algorithms:
Decision Trees
Random Forest
Support Vector Machines (SVM)
Naïve Bayes
Example: Email filtering systems use classification to distinguish between spam and legitimate emails.
2. Clustering
Definition: Clustering is an unsupervised learning technique that groups similar data points together based on shared characteristics.
Common Algorithms:
K-Means Clustering
Hierarchical Clustering
DBSCAN (Density-Based Spatial Clustering)
Example: Customer segmentation in marketing to identify different consumer groups based on buying behavior.
3. Association Rule Mining
Definition: This technique identifies relationships between variables in large datasets, often used for market basket analysis.
Common Algorithms:
Apriori Algorithm
FP-Growth (Frequent Pattern Growth)
Example: Retail stores use association rules to discover product purchase patterns, such as "Customers who buy bread often buy butter."
4. Regression Analysis
Definition: Regression is a statistical technique used to predict numerical values based on historical data.
Common Algorithms:
Linear Regression
Logistic Regression
Polynomial Regression
Example: Predicting house prices based on location, size, and other attributes.
5. Anomaly Detection
Definition: Anomaly detection identifies unusual patterns or outliers that do not conform to expected behavior.
Common Algorithms:
Isolation Forest
Local Outlier Factor (LOF)
One-Class SVM
Example: Fraud detection in banking by identifying suspicious transactions.
6. Neural Networks and Deep Learning
Definition: Advanced techniques that simulate human brain functions to analyze complex patterns in large datasets.
Common Models:
Convolutional Neural Networks (CNN)
Recurrent Neural Networks (RNN)
Artificial Neural Networks (ANN)
Example: Image recognition systems in self-driving cars and medical diagnostics.
Applications of Data Mining
Healthcare: Disease prediction and patient risk assessment.
Finance: Credit scoring and fraud detection.
Retail: Personalized recommendations and sales forecasting.
Social Media: Sentiment analysis and trend prediction.
Conclusion
Data mining techniques are essential for uncovering hidden patterns and making data-driven decisions. As businesses continue to generate massive amounts of data, leveraging these techniques can provide valuable insights, improve efficiency, and drive innovation.
Which data mining techniques have you used? Share your experiences in the comments!
0 notes
Text
Essential Skills to Master in 2025 | Top Online Courses
In today's fast-paced world, staying ahead in your career means continuously upgrading your skill set. With industries evolving rapidly, professionals must adapt and acquire new expertise to remain relevant. Whether you are looking to break into a high-paying industry, climb the corporate ladder, or future-proof your career, knowing the best skills to learn in 2025 is essential.

Why Learning New Skills is Essential
The job market is becoming more competitive, and professionals who fail to upskill risk falling behind. Emerging technologies like Artificial Intelligence (AI), Machine Learning (ML), and Data Analytics are reshaping industries, making these areas critical for career growth.
Key Benefits of Upskilling:
Career advancement through updated skill sets
Higher earning potential with specialized skills
Increased job security and flexibility across industries
Personal growth, adaptability, and innovation
Top Online Courses to Upgrade Your Skills in 2025
Online education has made skill-building more accessible than ever. Platforms like UniAthena offer free online short courses tailored to meet industry demands. Here are three career-boosting programs to help you stand out in 2025.
Diploma in Data Analytics
With businesses relying on data-driven decisions, Data Analytics is one of the most in-demand skills today. The Diploma in Data Analytics equips learners with the knowledge to analyze data effectively and extract meaningful insights.
What You Will Learn:
Data analysis techniques and visualization tools like Python and Power BI
Interpreting datasets to optimize business strategies
Big data applications and real-world case studies
Why Choose This Course?
Self-paced learning with flexibility
Blockchain-Verified Certification to enhance your resume
Ideal for professionals in marketing, finance, and IT
Executive Diploma in Machine Learning
Machine Learning is revolutionizing industries, from healthcare to finance. The Executive Diploma in Machine Learning teaches learners how to build AI-powered solutions and automate business processes.
What You Will Learn:
Supervised and unsupervised learning techniques
AI-driven decision-making and neural networks
Hands-on experience with Python for Machine Learning
Why Choose This Course?
Self-paced learning with completion in two to three weeks
Blockchain-Verified Certification to validate expertise
Suitable for tech professionals, data scientists, and business analysts
MBA Essentials with Artificial Intelligence
AI is shaping the future of business, and leaders must be equipped to navigate this transformation. The MBA Essentials with Artificial Intelligence course integrates AI concepts into core business strategies, preparing professionals for leadership roles.
What You Will Learn:
AI applications in marketing, HR, finance, and operations
Business strategy tools like SWOT, PESTEL, and Lean Management
The role of AI in decision-making and corporate innovation
Why Choose This Course?
Self-paced learning with completion in three to four weeks
Certification from Acacia University Professional Development (AUPD)
Ideal for executives, entrepreneurs, and business managers
The Demand for These Skills in the Philippines
The Philippines is rapidly emerging as a tech and business hub in Southeast Asia, making skill development more crucial than ever. With industries integrating AI, big data, and automation, professionals who master these technologies will be in high demand.
Key Industry Trends in the Philippines:
Growing demand for data science and analytics professionals
AI integration in BPO and financial services
Digital transformation of small and medium-sized enterprises
Professionals in the Philippines who upskill in Data Analytics, Machine Learning, and AI-powered business management will gain a competitive edge in the job market.
Conclusion
As technology evolves, so must professional skills. UniAthena’s specialized courses—Diploma in Data Analytics, Executive Diploma in Machine Learning, and MBA Essentials with Artificial Intelligence—provide a pathway to career growth and stability.
Additional Benefits:
Ability to translate complex data insights into actionable strategies
Development of skills to work effectively with AI systems
Encouragement of continuous learning and innovation
Investing in skill development today can lead to better career prospects and long-term success. Enroll in UniAthena’s free online short courses and take the next step toward professional advancement in 2025 and beyond.
#EssentialSkills2025#TopOnlineCourses#SkillDevelopment#FutureSkills#OnlineLearning#CareerGrowth#Upskill#DigitalEducation#ProfessionalDevelopment#LearnOnline#SkillsForSuccess
0 notes
Text
Top Machine Learning Algorithms Every Beginner Should Know

Machine Learning (ML) is one of the most transformative technologies of the 21st century. From recommendation systems to self-driving cars, ML algorithms are at the heart of modern innovations. Whether you are an aspiring data scientist or just curious about AI, understanding the fundamental ML algorithms is crucial. In this blog, we will explore the top machine learning algorithms every beginner should know while also highlighting the importance of enrolling in Machine Learning Course in Kolkata to build expertise in this field.
1. Linear Regression
What is it?
Linear Regression is a simple yet powerful algorithm used for predictive modeling. It establishes a relationship between independent and dependent variables using a best-fit line.
Example:
Predicting house prices based on features like size, number of rooms, and location.
Why is it important?
Easy to understand and implement.
Forms the basis of many advanced ML algorithms.
2. Logistic Regression
What is it?
Despite its name, Logistic Regression is a classification algorithm. It predicts categorical outcomes (e.g., spam vs. not spam) by using a logistic function to model probabilities.
Example:
Email spam detection.
Why is it important?
Widely used in binary classification problems.
Works well with small datasets.
3. Decision Trees
What is it?
Decision Trees are intuitive models that split data based on decision rules. They are widely used in classification and regression problems.
Example:
Diagnosing whether a patient has a disease based on symptoms.
Why is it important?
Easy to interpret and visualize.
Handles both numerical and categorical data.
4. Random Forest
What is it?
Random Forest is an ensemble learning method that combines multiple decision trees to improve accuracy and reduce overfitting.
Example:
Credit risk assessment in banking.
Why is it important?
More accurate than a single decision tree.
Works well with large datasets.
5. Support Vector Machines (SVM)
What is it?
SVM is a powerful classification algorithm that finds the optimal hyperplane to separate different classes.
Example:
Facial recognition systems.
Why is it important?
Effective in high-dimensional spaces.
Works well with small and medium-sized datasets.
6. k-Nearest Neighbors (k-NN)
What is it?
k-NN is a simple yet effective algorithm that classifies data points based on their nearest neighbors.
Example:
Movie recommendation systems.
Why is it important?
Non-parametric and easy to implement.
Works well with smaller datasets.
7. K-Means Clustering
What is it?
K-Means is an unsupervised learning algorithm used for clustering similar data points together.
Example:
Customer segmentation for marketing.
Why is it important?
Great for finding hidden patterns in data.
Used extensively in marketing and image recognition.
8. Gradient Boosting Algorithms (XGBoost, LightGBM, CatBoost)
What is it?
These are powerful ensemble learning techniques that build strong predictive models by combining multiple weak models.
Example:
Stock market price prediction.
Why is it important?
Highly accurate and efficient.
Widely used in data science competitions.
Why Enroll in Machine Learning Classes in Kolkata?
Learning ML algorithms on your own can be overwhelming. Enrolling in Machine Learning Classes in Kolkata can provide structured guidance, real-world projects, and mentorship from industry experts. Some benefits include:
Hands-on training with real-world datasets.
Learning from experienced professionals.
Networking opportunities with peers and industry leaders.
Certification that boosts career opportunities.
Conclusion
Understanding these top ML algorithms is the first step toward mastering machine learning. Whether you’re looking to build predictive models or dive into AI-driven applications, these algorithms are essential. To truly excel, consider enrolling in a Machine Learning Course in Kolkata to gain practical experience and industry-relevant skills.
0 notes
Text
A Comprehensive Handbook on Datasets for Machine Learning Initiatives

Introduction:
Datasets in Machine Learning is fundamentally dependent on data. Whether you are a novice delving into predictive modeling or a seasoned expert developing deep learning architectures, the selection of an appropriate dataset is vital for achieving success. This detailed guide will examine the various categories of datasets, sources for obtaining them, and criteria for selecting the most suitable ones for your machine learning endeavors.
The Importance of Datasets in Machine Learning
A dataset serves as the foundation for any machine learning model. High-quality and well-organized datasets enable models to identify significant patterns, whereas subpar data can result in inaccurate and unreliable outcomes. Datasets impact several aspects, including:
Model accuracy and efficiency
Feature selection and engineering
Generalizability of models
Training duration and computational requirements
Selecting the appropriate dataset is as critical as choosing the right algorithm. Let us now investigate the different types of datasets and their respective applications.
Categories of Machine Learning Datasets
Machine learning datasets are available in various formats and serve multiple purposes. The primary categories include:
1. Structured vs. Unstructured Datasets
Structured data: Arranged in a tabular format consisting of rows and columns (e.g., Excel, CSV files, relational databases).
Unstructured data: Comprises images, videos, audio files, and text that necessitate preprocessing prior to being utilized in machine learning models.
2. Supervised vs. Unsupervised Datasets
Supervised datasets consist of labeled information, where input-output pairs are clearly defined, and are typically employed in tasks related to classification and regression.
Unsupervised datasets, on the other hand, contain unlabeled information, allowing the model to independently identify patterns and structures, and are utilized in applications such as clustering and anomaly detection.
3. Time-Series and Sequential Data
These datasets are essential for forecasting and predictive analytics, including applications like stock market predictions, weather forecasting, and data from IoT sensors.
4. Text and NLP Datasets
Text datasets serve various natural language processing functions, including sentiment analysis, the development of chatbots, and translation tasks.
5. Image and Video Datasets
These datasets are integral to computer vision applications, including facial recognition, object detection, and medical imaging.
Having established an understanding of the different types of datasets, we can now proceed to examine potential sources for obtaining them.
Domain-Specific Datasets
Healthcare and Medical Datasets
MIMIC-III – ICU patient data for medical research.
Chest X-ray Dataset – Used for pneumonia detection.
Finance and Economics Datasets
Yahoo Finance API – Financial market and stock data.
Quandl – Economic, financial, and alternative data.
Natural Language Processing (NLP) Datasets
Common Crawl – Massive web scraping dataset.
Sentiment140 – Labeled tweets for sentiment analysis.
Computer Vision Datasets
ImageNet – Large-scale image dataset for object detection.
COCO (Common Objects in Context) – Image dataset for segmentation and captioning tasks.
Custom Dataset Generation
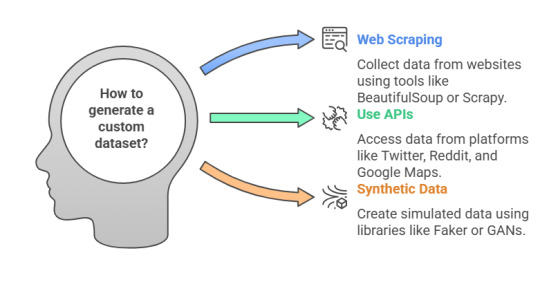
When publicly available datasets do not fit your needs, you can:
Web Scraping: Use BeautifulSoup or Scrapy to collect custom data.
APIs: Utilize APIs from Twitter, Reddit, and Google Maps to generate unique datasets.
Synthetic Data: Create simulated datasets using libraries like Faker or Generative Adversarial Networks (GANs).
Selecting an Appropriate Dataset
The choice of an appropriate dataset is influenced by various factors:
Size and Diversity – A dataset that is both large and diverse enhances the model's ability to generalize effectively.
Data Quality – High-quality data that is clean, accurately labeled, and devoid of errors contributes to improved model performance.
Relevance – It is essential to select a dataset that aligns with the specific objectives of your project.
Legal and Ethical Considerations – Ensure adherence to data privacy laws and regulations, such as GDPR and HIPAA.
In Summary
Datasets serve as the cornerstone of any machine learning initiative. Regardless of whether the focus is on natural language processing, computer vision, or financial forecasting, the selection of the right dataset is crucial for the success of your model. Utilize platforms such as GTS.AI to discover high-quality datasets, or consider developing your own through web scraping and APIs.
With the appropriate data in hand, your machine learning project is already significantly closer to achieving success.
0 notes
Text
From Nature to Surveillance: Navigating the Trail Camera Market Boom
The global trail camera market size is expected to reach USD 175.1 million by 2030, expanding at a CAGR of 7.0% from 2023 to 2030, according to a new report by Grand View Research, Inc. The market is largely driven by factors such as the increased spending on wildlife research and monitoring, coupled with increasing scope of application in outdoor security.
An increase in wildlife conservation policies by developing governments to preserve wildlife from illegal hunting and poaching offers a great opportunity for companies to collaborate on such projects. Owing to such conservation policies, extensive monitoring of different species by the governments is surging the demand for cameras equipped with the latest features.
Growing interest and popularity of wildlife photography and hunting activities are driving professionals to spend more on trail cameras. Trail cameras have become a popular way to capture photographs of animals in the environment. This is the major driving force behind the market expansion. Many television networks including Discovery and National Geographic broadcast high-definition wildlife videos. The public’s increased interest in learning more about animals has fueled the market expansion.
8 to 12 MP emerged as the largest segment and accounted for a share of over 55.0% in 2021. This segment is expected to be dominant during the forecast period. The 17 to 21 MP segment is expected to expand at the fastest CAGR of 7.9% from 2022 to 2030 as several consumers seek and research trail cameras that are rugged, waterproof, and designed for extended and unsupervised use outdoors with additional features such as night vision, low glow infrared, HD video, high-quality image resolution, and fast trigger speed technology.
Trail Camera Market Report Highlights
Increasing spending on wildlife research and monitoring is expected to remain a key factor driving the market
In 2022, North America held the largest share of over 30.9%. North America has emerged as the most lucrative market for trail cameras and is expected to retain its dominance throughout the forecast period
Asia Pacific is expanding rapidly owing to lucrative opportunities and a growing consumer base in the region. Rising end-user awareness, an increase in the number of applications, and the presence of leading manufacturers in the region are all likely to provide a plethora of growth opportunities
Trail cameras with image/video resolution between 8 and 12 MP are witnessing a rapid surge in demand to get higher quality pictures as these have advanced camera processors that click a higher resolution image
In terms of application, wildlife monitoring and research dominated the market with a share of over 61.8% in 2022. Trail cameras have become an increasingly popular tool for viewing wildlife and are used in wildlife research to study animal activity and behavior
Trail Camera Market Segmentation
Grand View Research has segmented the global trail camera market on the basis of pixel size, application, and region:
Trail Camera Pixel Size Outlook (Revenue, USD Million, 2017 - 2030)
Below 8 MP
8 to 12 MP
12 MP to 16 MP
17 MP to 21 MP
22 MP to 30 MP
Above 30 MP
Trail Camera Application Outlook (Revenue, USD Million, 2017 - 2030)
Wildlife Monitoring & Research
Security
Others
Trail Camera Regional Outlook (Revenue, USD Million, 2017 - 2030)
North America
US
Canada
Mexico
Europe
UK
Germany
Italy
France
Spain
Asia Pacific
China
Japan
India
South Korea
Australia
Central & South America
Brazil
Middle East & Africa
South Africa
List of Key Players
Wildgame Innovations (Good Sportsman Marketing, LLC)
Browning Trail Cameras
Vista Outdoor Operations LLC
SPYPOINT
Boly Media Communications Inc.
Covert Scouting Cameras, Inc.
Reconyx Inc.
Cuddeback
Easy Storage Technologies Co., Ltd.
Order a free sample PDF of the Trail Camera Market Intelligence Study, published by Grand View Research.
0 notes
Text
0 notes
Text
Machine Learning Models Simplified: HawkStack's Step-by-Step Approach
In the ever-evolving landscape of technology, machine learning (ML) is one of the most transformative fields, revolutionizing industries from healthcare to finance and beyond. However, for many, the complexities of machine learning can be daunting. How does a machine learn? What are the different types of models? And most importantly, how can you effectively implement and use them in real-world applications?
At HawkStack, we believe in simplifying the process, offering a clear, step-by-step approach to help demystify machine learning. Whether you're an aspiring data scientist, a business professional, or simply someone interested in understanding this powerful technology, our goal is to guide you through each phase of building and deploying machine learning models. Let’s break it down.
Step 1: Understanding the Problem
Before diving into any machine learning model, the first critical step is to define the problem you're trying to solve. Are you trying to predict a future outcome, classify items into categories, or maybe cluster similar data points together?
For example, if you're working with customer data, are you trying to predict churn (whether customers will leave) or segment your customers into different groups for targeted marketing?
By clearly defining your problem, you set the foundation for the entire machine learning process. This clarity helps in selecting the right type of model, the appropriate data, and how to evaluate the model's performance later.
Step 2: Gathering and Preparing the Data
Machine learning is data-driven. This means that the quality and quantity of your data directly influence the performance of your models. At HawkStack, we emphasize the importance of data collection and preprocessing. Here are a few key tasks you might encounter in this step:
Data Collection: Gather all relevant data, ensuring it's representative of the problem you're trying to solve.
Data Cleaning: Real-world data is often messy. You'll need to clean the data by handling missing values, removing outliers, and ensuring consistency.
Feature Engineering: Transform raw data into meaningful features that your model can work with. This could mean normalizing values, encoding categorical variables, or even creating new features from existing ones.
The more effort you put into preparing and cleaning your data, the better your model will perform. A well-prepared dataset makes all the difference in the success of your machine learning project.
Step 3: Selecting the Right Model
There is no "one-size-fits-all" in machine learning. The choice of model depends on the problem you're solving. At HawkStack, we guide you through selecting the right model based on your needs. Here’s a brief rundown of some common models:
Supervised Learning Models: Used when you have labeled data and want to predict an output based on input features. Common examples include:Linear Regression (predict continuous values)Logistic Regression (classify data into categories)Decision Trees and Random Forests (powerful for classification and regression)Support Vector Machines (SVM) (used for classification tasks)
Unsupervised Learning Models: These are used when you have unlabeled data and want to find patterns or groupings. Examples include:K-Means Clustering (grouping data into clusters)Principal Component Analysis (PCA) (dimensionality reduction)
Reinforcement Learning: A more advanced approach used for decision-making problems, where an agent learns by interacting with an environment and receiving feedback.
Choosing the right model is vital, and it’s often an iterative process. You'll need to experiment and tweak until you find the best fit.
Step 4: Training the Model
Once you’ve selected your model, the next step is to train it using the data you've collected. Training involves using algorithms to adjust the model’s internal parameters to minimize error, so it can make predictions accurately.
This process involves:
Splitting your data into training and testing sets.
Feeding the training data into the model so it can learn patterns and relationships.
Evaluating the model's performance using the test data to ensure it generalizes well to new, unseen data.
At HawkStack, we provide insights into how different algorithms work and how to fine-tune them for optimal results. From adjusting hyperparameters to understanding overfitting and underfitting, this stage requires careful monitoring and evaluation.
Step 5: Evaluating the Model’s Performance
The goal of machine learning is to develop models that perform well not just on training data but on unseen data (test data). At HawkStack, we focus on evaluation metrics to help measure a model’s success. Common metrics include:
Accuracy: The proportion of correct predictions.
Precision, Recall, and F1 Score: Especially useful for imbalanced datasets, like fraud detection.
Mean Squared Error (MSE): Commonly used in regression tasks.
Confusion Matrix: A detailed breakdown of prediction performance in classification tasks.
The evaluation process is critical because it allows you to understand how your model will perform in real-world scenarios and whether any improvements are necessary.
Step 6: Tuning the Model
After evaluating your model’s performance, you’ll likely need to fine-tune it to improve results. This might involve:
Hyperparameter Tuning: Adjusting the model's hyperparameters to enhance performance.
Cross-Validation: A technique to assess how your model generalizes by training it multiple times on different subsets of the data.
Feature Selection: Identifying which features are most important and removing irrelevant ones.
At HawkStack, we often use grid search and random search for hyperparameter tuning, and other advanced techniques like genetic algorithms to optimize the model.
Step 7: Deployment
Once your model has been trained and tuned, it’s time for deployment. This is where the model is integrated into a production environment, where it can make real-time predictions on new data. Deployment often involves:
Model Serving: Exposing the model through an API so it can be accessed by applications.
Monitoring: Tracking model performance over time to detect drift or degradation in accuracy.
Updating: Retraining the model periodically with fresh data to maintain its relevance and performance.
Effective deployment ensures that the model continues to add value long after it has been built.
Step 8: Continuous Improvement
Machine learning is an iterative process. The model you deploy today might need adjustments tomorrow as new data becomes available or the problem evolves. This is why it’s essential to monitor performance and iterate on your model.
At HawkStack, we emphasize continuous learning, encouraging teams to regularly review model performance, retrain with new data, and refine their models for sustained success.
Conclusion
Machine learning can seem overwhelming at first, but with a systematic, step-by-step approach, you can break down complex tasks into manageable steps. HawkStack's methodology ensures that you are not only building models that are accurate and effective but also scalable and maintainable in the long term.
By following these steps, from defining the problem and preparing data to selecting the right model and deployment, you’re setting yourself up for success. So, whether you're a beginner or a seasoned expert, HawkStack is here to guide you through every stage of your machine learning journey.
Ready to dive in? Let’s get started with simplifying machine learning, one step at a time!
for more details visit
http://hawkstack.com
http://qcsdclabs.com
0 notes
Text
Supervised and Unsupervised Learning
Supervised and Unsupervised Learning are two primary approaches in machine learning, each used for different types of tasks. Here’s a breakdown of their differences:
Definition and Purpose
Supervised Learning: In supervised learning, the model is trained on labeled data, meaning each input is paired with a correct output. The goal is to learn the mapping between inputs and outputs so that the model can predict the output for new, unseen inputs. Example: Predicting house prices based on features like size, location, and number of bedrooms (where historical prices are known). Unsupervised Learning: In unsupervised learning, the model is given data without labeled responses. Instead, it tries to find patterns or structure in the data. The goal is often to explore data, find groups (clustering), or detect outliers. Example: Grouping customers into segments based on purchasing behavior without predefined categories.
Types of Problems Addressed Supervised Learning: Classification: Categorizing data into classes (e.g., spam vs. not spam in emails). Regression: Predicting continuous values (e.g., stock prices or temperature). Unsupervised Learning: Clustering: Grouping similar data points (e.g., market segmentation). Association: Finding associations or relationships between variables (e.g., market basket analysis in retail). Dimensionality Reduction: Reducing the number of features while retaining essential information (e.g., principal component analysis for visualizing data in 2D).
Example Algorithms - Supervised Learning Algorithms: Linear Regression Logistic Regression Decision Trees and Random Forests Support Vector Machines (SVM) Neural Networks (when trained with labeled data) Unsupervised Learning Algorithms: K-Means Clustering Hierarchical Clustering Principal Component Analysis (PCA) Association Rule Mining (like the Apriori algorithm)
Training Data Requirements Supervised Learning: Requires a labeled dataset, which can be costly and time-consuming to collect and label. Unsupervised Learning: Works with unlabeled data, which is often more readily available, but the insights are less straightforward without predefined labels.
Evaluation Metrics Supervised Learning: Can be evaluated with standard metrics like accuracy, precision, recall, F1 score (for classification), and mean squared error (for regression), since we have labeled outputs. Unsupervised Learning: Harder to evaluate directly. Techniques like silhouette score or Davies–Bouldin index (for clustering) are used, or qualitative analysis may be required.
Use Cases Supervised Learning: Fraud detection, email classification, medical diagnosis, sales forecasting, and image recognition. Unsupervised Learning: Customer segmentation, anomaly detection, topic modeling, and data compression.
In summary:
Supervised learning requires labeled data and is primarily used for prediction or classification tasks where the outcome is known. Unsupervised learning doesn’t require labeled data and is mainly used for data exploration, clustering, and finding patterns where the outcome is not predefined.

1 note
·
View note
Text
Artificial Intelligence Course in Nagercoil
Dive into the Future with Jclicksolutions’ Artificial Intelligence Course in Nagercoil
Artificial Intelligence (AI) is rapidly transforming industries, opening up exciting opportunities for anyone eager to explore its vast potential. From automating processes to enhancing decision-making, AI technologies are changing how we live and work. If you're looking to gain a foothold in this field, the Artificial Intelligence course at Jclicksolutions in Nagercoil is the ideal starting point. This course is carefully designed to cater to both beginners and those with a tech background, offering comprehensive training in the concepts, tools, and applications of AI.
Why Study Artificial Intelligence?
AI is no longer a concept of the distant future. It is actively shaping industries such as healthcare, finance, automotive, retail, and more. Skills in AI can lead to careers in data science, machine learning engineering, robotics, and even roles as AI strategists and consultants. By learning AI, you’ll be joining one of the most dynamic and impactful fields, making you a highly valuable asset in the job market.
Course Overview at Jclicksolutions
The Artificial Intelligence course at Jclicksolutions covers foundational principles as well as advanced concepts, providing a balanced learning experience. It is designed to ensure that students not only understand the theoretical aspects of AI but also gain hands-on experience with its practical applications. The curriculum includes modules on machine learning, data analysis, natural language processing, computer vision, and neural networks.
1. Comprehensive and Structured Curriculum
The course covers every critical aspect of AI, starting from the basics and gradually moving into advanced topics. Students begin by learning fundamental concepts like data pre-processing, statistical analysis, and supervised vs. unsupervised learning. As they progress, they delve deeper into algorithms, decision trees, clustering, and neural networks. The course also includes a segment on deep learning, enabling students to explore areas like computer vision and natural language processing, which are essential for applications in image recognition and AI-driven communication.
2. Hands-On Learning with Real-World Projects
One of the standout features of the Jclicksolutions AI course is its emphasis on hands-on learning. Rather than just focusing on theoretical knowledge, the course is structured around real-world projects that allow students to apply what they’ve learned. For example, students might work on projects that involve creating machine learning models, analyzing large datasets, or designing AI applications for specific business problems. By working on these projects, students gain practical experience, making them job-ready upon course completion.
3. Experienced Instructors and Personalized Guidance
The instructors at Jclicksolutions are industry experts with years of experience in AI and machine learning. They provide invaluable insights, sharing real-life case studies and offering guidance based on current industry practices. With small class sizes, each student receives personalized attention, ensuring they understand complex topics and receive the support needed to build confidence in their skills.
4. Cutting-Edge Tools and Software
The AI course at Jclicksolutions also familiarizes students with the latest tools and platforms used in the industry, including Python, TensorFlow, and Keras. These tools are essential for building, training, and deploying AI models. Students learn how to use Jupyter notebooks for coding, experiment with datasets, and create data visualizations that reveal trends and patterns. By the end of the course, students are proficient in these tools, positioning them well for AI-related roles.
Career Opportunities after Completing the AI Course
With the knowledge gained from this AI course, students can pursue various roles in the tech industry. AI professionals are in demand across sectors such as healthcare, finance, retail, and technology. Here are some career paths open to graduates of the Jclicksolutions AI course:
Machine Learning Engineer: Design and develop machine learning systems and algorithms.
Data Scientist: Extract meaningful insights from data and help drive data-driven decision-making.
AI Consultant: Advise businesses on implementing AI strategies and solutions.
Natural Language Processing Specialist: Work on projects involving human-computer interaction, such as chatbots and voice recognition systems.
Computer Vision Engineer: Focus on image and video analysis for industries like automotive and healthcare.
To support students in their career journey, Jclicksolutions also offers assistance in building portfolios, resumes, and interview preparation, helping students transition from learning to employment.
Why Choose Jclicksolutions?
Located in Nagercoil, Jclicksolutions is known for its commitment to delivering high-quality tech education. The institute stands out for its strong focus on practical training, a supportive learning environment, and a curriculum that aligns with industry standards. Students benefit from a collaborative atmosphere, networking opportunities, and mentorship that goes beyond the classroom. This hands-on, project-based approach makes Jclicksolutions an excellent choice for those looking to make a mark in AI.
Enroll Today and Join the AI Revolution
AI is a transformative field that is reshaping industries and creating new opportunities. By enrolling in the Artificial Intelligence course at Jclicksolutions in Nagercoil, you’re setting yourself up for a promising future in tech. This course is more than just an educational program; it's a gateway to a career filled with innovation and possibilities. Whether you’re a beginner or an experienced professional looking to upskill, Jclicksolutions offers the resources, knowledge, and support to help you succeed.
Software Internship Training | Placement Centre Course Nagercoil
0 notes
Text
Supervised & Unsupervised Learning: What’s The Difference?

This essay covers supervised and unsupervised data science basics. Choose an approach that fits you.
The world is getting “smarter” every day, and firms are using machine learning algorithms to simplify to meet client expectations. Unique purchases alert them to credit card fraud, and facial recognition unlocks phones to detect end-user devices.
Supervised learning and unsupervised learning are the two fundamental methods in machine learning and artificial intelligence (AI). The primary distinction is that one makes use of labeled data to aid in result prediction, whilst the other does not. There are some differences between the two strategies, though, as well as important places where one performs better than the other. To help you select the right course of action for your circumstances, this page explains the distinctions.
What is supervised learning?
Labeled data sets are used in supervised learning, a machine learning technique. These datasets are intended to “supervise” or train algorithms to correctly identify data or forecast results. The model may gauge its accuracy and gain knowledge over time by using labeled inputs and outputs.
When it comes to data mining, supervised learning may be divided into two categories of problems: regression and classification.
To correctly classify test data into distinct groups, such as differentiating between apples and oranges, classification problems employ an algorithm. Alternatively, spam in a different folder from your inbox can be categorized using supervised learning algorithms in the real world. Common classification algorithm types include decision trees, random forests, support vector machines, and linear classifiers.
Another kind of supervised learning technique is regression, which use an algorithm to determine the correlation between dependent and independent variables. Predicting numerical values based on several data sources, such sales revenue estimates for a certain company, is made easier by regression models. Polynomial regression, logistic regression, and linear regression are a few common regression algorithms.
What is unsupervised learning?
Unsupervised learning analyzes and groups unlabeled data sets using machine learning methods. These algorithms are “unsupervised” because they find hidden patterns in data without the assistance of a human.
Three primary tasks are addressed by unsupervised learning models: dimensionality reduction, association, and clustering.
A data mining technique called clustering is used to arrange unlabeled data according to similarities or differences. K-means clustering techniques, for instance, group related data points into groups; the size and granularity of the grouping are indicated by the K value. This method works well for picture compression, market segmentation, and other applications.
Another kind of unsupervised learning technique is association, which looks for links between variables in a given data set using a variety of rules. These techniques, such as “Customers Who Bought This Item Also Bought” suggestions, are commonly applied to recommendation engines and market basket analysis.
When there are too many characteristics in a given data collection, a learning technique called “dimensionality reduction” is applied. It maintains the data integrity while bringing the quantity of data inputs down to a manageable level.
This method is frequently applied during the preprocessing phase of data, such as when autoencoders eliminate noise from visual data to enhance image quality.
The main difference between supervised and unsupervised learning
Using labeled data sets is the primary difference between the two methods. In short, an unsupervised learning method does not employ labeled input and output data, whereas supervised learning does.
The algorithm “learns” from the training data set in supervised learning by repeatedly predicting the data and modifying for the right response. Supervised learning algorithms need human interaction up front to properly identify the data, even though they are typically more accurate than unsupervised learning models. For instance, depending on the time of day, the weather, and other factors, a supervised learning model can forecast how long your commute will take. However, you must first teach it that driving takes longer in rainy conditions.
In contrast, unsupervised learning algorithms find the underlying structure of unlabeled data on their own. Keep in mind that human intervention is still necessary for the output variables to be validated. An unsupervised learning model, for instance, can recognize that online buyers frequently buy many items at once. The rationale behind a recommendation engine grouping baby garments in an order of diapers, applesauce, and sippy cups would need to be confirmed by a data analyst.
Other key differences between supervised and unsupervised learning
Predicting results for fresh data is the aim of supervised learning. You are aware of the kind of outcome you can anticipate in advance. The objective of an unsupervised learning algorithm is to extract knowledge from vast amounts of fresh data. What is unique or intriguing about the data set is determined by the machine learning process itself.
Applications
Among other things, supervised learning models are perfect for sentiment analysis, spam detection, weather forecasting, and pricing forecasts. Unsupervised learning, on the other hand, works well with medical imaging, recommendation engines, anomaly detection, and customer personas.
Complexity
R or Python are used to compute supervised learning, a simple machine learning method. Working with massive volumes of unclassified data requires strong skills in unsupervised learning. Because unsupervised learning models require a sizable training set in order to yield the desired results, they are computationally complex.
Cons
Labeling input and output variables requires experience, and training supervised learning models can take a lot of time. In the meanwhile, without human interaction to evaluate the output variables, unsupervised learning techniques can produce radically erroneous findings.
Supervised versus unsupervised learning: Which is best for you?
How your data scientists evaluate the volume and structure of your data, along with the use case, will determine which strategy is best for you. Make sure you accomplish the following before making your choice:
Analyze the data you entered: Is the data labeled or unlabeled? Do you have professionals who can help with additional labeling?
Specify your objectives: Do you have a persistent, clearly stated issue that needs to be resolved? Or will it be necessary for the algorithm to anticipate new issues?
Examine your algorithmic options: Is there an algorithm that has the same dimensionality (number of features, traits, or characteristics) that you require? Are they able to handle the volume and structure of your data?
Although supervised learning can be very difficult when it comes to classifying large data, the outcomes are very reliable and accurate. Unsupervised learning can process enormous data sets in real time. However, data clustering is less transparent and outcomes are more likely to be inaccurate. Semi-supervised learning can help with this.
Semi-supervised learning: The best of both worlds
Unable to choose between supervised and unsupervised learning? Using a training data collection that contains both labeled and unlabeled data is a happy medium known as semi-supervised learning. It is especially helpful when there is a large amount of data and when it is challenging to extract pertinent features from the data.
For medical imaging, where a modest amount of training data can result in a considerable gain in accuracy, semi-supervised learning is perfect. To help the system better anticipate which individuals would need further medical attention, a radiologist could, for instance, mark a small subset of CT scans for disorders or tumors.
Read more on Govindhtech.com
#UnsupervisedLearning#SupervisedLearning#machinelearning#artificialintelligence#Python#News#Technews#Technology#Technologynwes#Technologytrends#govindhtech
0 notes
Text
Navigating the Path to Becoming an AI Engineer: Essential Skills, Career Outlook, and Opportunities

What Does an AI Engineer Do?
An AI engineer is responsible for creating systems and models that enable machines to perform tasks that typically require human intelligence, such as decision-making, natural language processing, and visual perception. This role involves working with vast amounts of data, designing complex algorithms, and applying machine learning techniques to optimize model performance.
A few key responsibilities include:
Developing machine learning models: Creating algorithms that can learn from and adapt to new data without explicit programming.
Data preprocessing: Cleaning and transforming data to ensure it’s ready for analysis.
Model deployment and monitoring: Ensuring models perform well in real-world settings and refining them as needed.
Essential Skills for AI Engineers
To excel as an AI engineer, one needs a diverse set of skills. Here are some of the most critical ones:
Programming Proficiency AI engineers must have strong programming skills, particularly in languages like Python, R, and Java. Knowledge of libraries such as Keras, TensorFlow, and PyTorch is also essential for implementing machine learning algorithms.
Mathematics and Statistics A deep understanding of linear algebra, calculus, and probability theory helps AI engineers create more effective algorithms. These skills are fundamental for understanding model behavior and performance.
Data Management Working with large data sets requires expertise in data handling, storage, and processing. Familiarity with big data technologies like Hadoop and Spark is beneficial, as is proficiency in SQL for data extraction and manipulation.
Machine Learning and Deep Learning AI engineers should be proficient in machine learning techniques, such as supervised and unsupervised learning, and deep learning frameworks like TensorFlow. This includes understanding how neural networks function and training them for specific applications.
Problem-Solving and Creativity AI solutions often require out-of-the-box thinking. Strong problem-solving abilities allow AI engineers to devise unique approaches to technical challenges and improve model efficiency.
Career Outlook and Opportunities
The demand for AI engineers continues to grow as businesses across sectors look to integrate AI into their processes. The global AI market size is projected to reach new heights in the coming years, meaning job opportunities for AI engineers will likely remain plentiful. Salaries for AI engineers are competitive, often surpassing those of other IT roles due to the specialized knowledge required.
Some popular industries hiring AI engineers include:
Healthcare: AI is used in diagnostics, personalized medicine, and patient monitoring.
Finance: From fraud detection to algorithmic trading, AI transforms financial services.
Manufacturing: Predictive maintenance and quality control are just a few ways AI is enhancing efficiency.
Retail: Personalization and recommendation engines help retailers improve customer engagement.
Breaking Into the AI Engineering Field
Starting a career in AI engineering often requires a solid educational background in computer science, mathematics, or a related field. However, many aspiring AI engineers also transition from other tech roles by upskilling through online courses and certifications. Platforms like Coursera, Udacity, and edX offer AI and machine learning courses that provide hands-on experience.
Final Thoughts
Becoming an AI engineer is a rewarding journey for those passionate about data, algorithms, and innovation. As AI continues to shape the future, the role of AI engineers will only become more integral to technological advancement. Whether you’re considering entering this field or seeking to hire an AI specialist, understanding these core skills and industry insights can help you make informed decisions in the dynamic AI landscape.
0 notes
Text
Projects Centered on Machine Learning Tailored for Individuals Possessing Intermediate Skills.

Introduction:
Datasets for Machine Learning Projects , which underscores the importance of high-quality datasets for developing accurate and dependable models. Regardless of whether the focus is on computer vision, natural language processing, or predictive analytics, the selection of an appropriate dataset can greatly influence the success of a project. This article will examine various sources and categories of datasets that are frequently utilized in ML initiatives.
The Significance of Datasets in Machine Learning
Datasets form the cornerstone of any machine learning model. The effectiveness of a model in generalizing to new data is contingent upon the quality, size, and diversity of the dataset. When selecting a dataset, several critical factors should be taken into account:
Relevance: The dataset must correspond to the specific problem being addressed.
Size: Generally, larger datasets contribute to enhanced model performance.
Cleanliness: Datasets should be devoid of errors and missing information.
Balanced Representation: Mitigating bias is essential for ensuring equitable model predictions.
There are various categories of datasets utilized in machine learning.
Datasets can be classified into various types based on their applications:
Structured Datasets: These consist of systematically organized data presented in tabular formats (e.g., CSV files, SQL databases).
Unstructured Datasets: This category includes images, audio, video, and text data that necessitate further processing.
Labeled Datasets: Each data point is accompanied by a label, making them suitable for supervised learning applications.
Unlabeled Datasets: These datasets lack labels and are often employed in unsupervised learning tasks such as clustering.
Synthetic Datasets: These are artificially created datasets that mimic real-world conditions.
Categories of Datasets in Machine Learning
Machine learning datasets can be classified into various types based on their characteristics and applications:
1. Structured and Unstructured Datasets
Structured Data: Arranged in organized formats such as CSV files, SQL databases, and spreadsheets.
Unstructured Data: Comprises text, images, videos, and audio that do not conform to a specific format.
2. Supervised and Unsupervised Datasets
Supervised Learning Datasets: Consist of labeled data utilized for tasks involving classification and regression.
Unsupervised Learning Datasets: Comprise unlabeled data employed for clustering and anomaly detection.
Semi-supervised Learning Datasets: Combine both labeled and unlabeled data.
3. Small and Large Datasets
Small Datasets: Suitable for prototyping and preliminary experiments.
Large Datasets: Extensive datasets that necessitate considerable computational resources.
Popular Sources for Machine Learning Datasets

1. Google Dataset Search
Google Dataset Search facilitates the discovery of publicly accessible datasets sourced from a variety of entities, including research institutions and governmental organizations.
2. AWS Open Data Registry
AWS Open Data provides access to extensive datasets, which are particularly advantageous for machine learning projects conducted in cloud environments.
3. Image and Video Datasets
ImageNet (for image classification and object recognition)
COCO (Common Objects in Context) (for object detection and segmentation)
Open Images Dataset (a varied collection of labeled images)
4. NLP Datasets
Wikipedia Dumps (a text corpus suitable for NLP applications)
Stanford Sentiment Treebank (for sentiment analysis)
SQuAD (Stanford Question Answering Dataset) (designed for question-answering systems)
5. Time-Series and Finance Datasets
Yahoo Finance (providing stock market information)
Quandl (offering economic and financial datasets)
Google Trends (tracking public interest over time)
6. Healthcare and Medical Datasets
MIMIC-III (data related to critical care)
NIH Chest X-rays (a dataset for medical imaging)
PhysioNet (offering physiological and clinical data).
Guidelines for Selecting an Appropriate Dataset
Comprehend Your Problem Statement: Determine if your requirements call for structured or unstructured data.
Verify Licensing and Usage Permissions: Confirm that the dataset is permissible for your intended application.
Prepare and Clean the Data: Data from real-world sources typically necessitates cleaning and transformation prior to model training.
Consider Data Augmentation: In scenarios with limited data, augmenting the dataset can improve model performance.
Conclusion
Choosing the appropriate dataset is vital for the success of any machine learning initiative. With a plethora of freely accessible datasets, both developers and researchers can create robust AI models across various fields. Regardless of your experience level, the essential factor is to select a dataset that aligns with your project objectives while maintaining quality and fairness.
Are you in search of datasets to enhance your machine learning project? Explore Globose Technology Solutions for a selection of curated AI datasets tailored to your requirements!
0 notes
Text
From Words to Insights: The Evolution of the NLP Market
The global natural language processing market size is estimated to reach USD 439.85 billion by 2030, expanding at a CAGR of 40.4% from 2023 to 2030, according to a new study by Grand View Research, Inc. Machine learning is predicted to play a critical role in natural language processing (NLP) techniques, mostly in text analytics, as AI advances. In the future, unsupervised and supervised learning will enable machine-learning engines to undertake more in-depth assessments. According to their ongoing evolution, social media platforms are expected to play a superior role in business decisions. A company, for instance, can rely on several NLP tools to track customer evaluations, feedback, and comments about their business on social media platforms and in the news around the time of a quarterly report.
Factors such as increased usage of smart devices to facilitate smart environments boost market growth. Additionally, the demand for NLP technologies is expanding owing to the rising demand for sophisticated text analytics and increasing internet and connected device usage. In addition, NLP-based apps are increasingly being used across industries to enhance customer experience. Additional profitable market expansion potentials are anticipated due to rising healthcare sector investments. However, constraints in the development of NLP technology utilizing neural networks and complexity associated with the use of code-mixed language during the implementation of NLP solutions constrain the use of cloud-based services, which can create hindrances for market growth.
Companies with huge amounts of spoken or unstructured text data can effectively discover, collect, and analyze dark data issues to the growing pragmatic application of NLP. The usage of NLP is anticipated to increase in areas like semantic search and intelligent chatbots that need to comprehend user intent. The abundance of natural language technologies is expected to endure to shape the communication capability of cognitive computing and the expanding utilization of deep learning and unsupervised and supervised machine learning. Intelligent data for businesses to develop plans, NLP is essential for tracking and monitoring market intelligence reports.
Natural language processing is gaining popularity in the healthcare sector due to the search, analysis, and understanding of massive volumes of patient data. Machine learning in healthcare and NLP technology services can extract pertinent concepts and insights from data previously thought to be buried in text form using advanced medical algorithms. In healthcare media, NLP can effectively give voice to unstructured data, providing great insight into understanding quality, enhancing processes, and increasing patient outcomes. For Instance, In July 2022, Google released a free tool called AutoML Entity Extraction for Healthcare, which is also low-code for healthcare professionals with limited coding expertise. Moreover, it is used to develop Healthcare Natural Language models customized to derive more specific information from medical data, which helps understand more essential details in medical records.
North America is one of the most important marketplaces for natural language processing owing to the early adoption of advanced technologies in the countries from the region. The U.S. has an advantage in innovation because it is home to the majority of the key vendors in the industry. Additionally, the regional governments are promoting AI, ML, and NLP technologies, creating a favorable environment for market vendors to increase their presence in the region.
Natural Language Processing Market Report Highlights
The healthcare segment appeared as the largest segment in the terms of revenue share throughout the forecast period. However, the IT & Telecommunication segment is projected to expand with the highest growth rate
Data extraction emerged as the largest segment in 2022 and is projected to generate revenue of over USD 77.00 billion by 2030
Asia Pacific is projected to witness the highest CAGR of 42.7% and is estimated to reach USD 115.24 billion by 2030. The NLP market is projected to expand with rising demand for better customer experiences, growing smart device usage, and expanding application options
Natural Language Processing Market Segmentation
Grand View Research has segmented the global natural language processing market based on component, deployment, enterprise size, type, application, end-use, and region:
Natural Language Processing Component Outlook (Revenue, USD Million, 2017 - 2030)
Solution
Services
Natural Language Processing Deployment Outlook (Revenue, USD Million, 2017 - 2030)
Cloud
On-Premises
Natural Language Processing Enterprise Size Outlook (Revenue, USD Million, 2017 - 2030)
Large Enterprises
Small & Medium Enterprises
Natural Language Processing Type Outlook (Revenue, USD Million, 2017 - 2030)
Statistical NLP
Rule Based NLP
Hybrid NLP
Natural Language Processing Application Outlook (Revenue, USD Million, 2017 - 2030)
Sentiment Analysis
Data Extraction
Risk And Threat Detection
Automatic Summarization
Content Management
Language Scoring
Others (Portfolio Monitoring, HR & Recruiting, And Branding & Advertising)
Natural Language Processing End-use Outlook (Revenue, USD Million, 2017 - 2030)
BFSI
IT & Telecommunication
Healthcare
Education
Media & Entertainment
Retail & E-commerce
Others
Natural Language Processing Regional Outlook (Revenue, USD Million, 2017 - 2030)
North America
US
Canada
Mexico
Europe
UK
Germany
France
Asia Pacific
China
Japan
India
South America
Brazil
Middle East and Africa (MEA)
List of Key Players
3M
Apple Inc.
Amazon Web Services, Inc.
Baidu Inc.
Crayon Data
Google LLC
Health Fidelity
IBM Corporation
Inbenta
IQVIA
Meta Platforms Inc.
Microsoft Corporation
Oracle Inc.
SAS Institute Inc.
Order a free sample PDF of the Natural Language Processing Market Intelligence Study, published by Grand View Research.
0 notes