#amazon scraper python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
News Extract: Unlocking the Power of Media Data Collection
In today's fast-paced digital world, staying updated with the latest news is crucial. Whether you're a journalist, researcher, or business owner, having access to real-time media data can give you an edge. This is where news extract solutions come into play, enabling efficient web scraping of news sources for insightful analysis.

Why Extracting News Data Matters
News scraping allows businesses and individuals to automate the collection of news articles, headlines, and updates from multiple sources. This information is essential for:
Market Research: Understanding trends and shifts in the industry.
Competitor Analysis: Monitoring competitors’ media presence.
Brand Reputation Management: Keeping track of mentions across news sites.
Sentiment Analysis: Analyzing public opinion on key topics.
By leveraging news extract techniques, businesses can access and process large volumes of news data in real-time.
How News Scraping Works
Web scraping involves using automated tools to gather and structure information from online sources. A reliable news extraction service ensures data accuracy and freshness by:
Extracting news articles, titles, and timestamps.
Categorizing content based on topics, keywords, and sentiment.
Providing real-time or scheduled updates for seamless integration into reports.
The Best Tools for News Extracting
Various scraping solutions can help extract news efficiently, including custom-built scrapers and APIs. For instance, businesses looking for tailored solutions can benefit from web scraping services India to fetch region-specific media data.
Expanding Your Data Collection Horizons
Beyond news extraction, companies often need data from other platforms. Here are some additional scraping solutions:
Python scraping Twitter: Extract real-time tweets based on location and keywords.
Amazon reviews scraping: Gather customer feedback for product insights.
Flipkart scraper: Automate data collection from India's leading eCommerce platform.
Conclusion
Staying ahead in today’s digital landscape requires timely access to media data. A robust news extract solution helps businesses and researchers make data-driven decisions effortlessly. If you're looking for reliable news scraping services, explore Actowiz Solutions for customized web scraping solutions that fit your needs.
#news extract#web scraping services India#Python scraping Twitter#Amazon reviews scraping#Flipkart scraper#Actowiz Solutions
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
0 notes
Text
How Can You Scrape Amazon Reviews Quickly And Efficiently?

Struggling to gather valuable customer insights from Amazon reviews? Are you tired of manually copying and pasting reviews one by one?
But what if there was a faster, more innovative way? This blog will guide you through the best practices for scraping Amazon reviews. This will help you unlock a treasure of data, providing you with the potential to improve product quality, refine marketing strategies, and stay ahead of the competition.
What is Amazon Review Scraping?
Amazon customer review scraping automatically extracts customer reviews and their details from Amazon product pages.
Review text What customers say about the product, both positive and negative.
Ratings The star rating assigned by the reviewer
Reviewer details Username, location (if provided), and potentially even purchase history (depending on scraping method).
Date of review When the review was posted.
Benefits of Scraping Amazon Reviews

Scraping Amazon customer reviews can be a powerful tool for businesses and researchers alike. Here are seven key benefits:
Gain Customer Insights
Reviews are full of true customer stories. By scraping them, you can quickly review a lot of information to determine how customers feel, spot frequent issues, and determine which features they like.
Product Improvement
Find out how to improve your or your competitors' products. Look for what customers often like or don't like to help you decide what to do next with your products and how to advertise them.
Market Research
Find out what's currently popular and which products people like in a specific area. By looking at what people say in reviews, you can determine what they want and use this knowledge to decide which products to sell or what moves to make in your business.
Competitive Analysis
See how your products stack up against others. Check out what people say about your competitors to know what they're good at and where they fall short. This can help you find ways to do better than them.
Sentiment Analysis
Look beyond just the number of stars a product gets. By scraping, you can study how customers feel as they write reviews, determining if their thoughts on a product are happy, unhappy, or somewhere in between.
Price Optimization
Look at how the price affects what customers think. Check if reviews get better or worse with different prices to help you decide how much to charge and stay competitive.
Content Creation
Reviews are great for brainstorming marketing ideas. You can quote positive reviews to write attractive product details or customer praise for your website.
How to Scrape Amazon Reviews?
Here's a general overview of how amazon review scraper works:
Choose Your Tools:
There are two main approaches to scraping Amazon reviews:
Web Scraping Libraries Libraries like Beautiful Soup (Python) or Cheerio (JavaScript) allow you to parse HTML content from websites. You can write scripts to extract review data based on specific HTML elements.
Pre-built Scraping Tools Several online tools offer scraping functionalities for Amazon reviews. These tools often have user-friendly interfaces and may require minimal coding knowledge.
Identify Review Elements
Inspect the HTML structure of an Amazon product page to identify the elements containing review data. This typically includes sections with review text, star ratings, reviewer names (if available), and dates.
Extract the Data
Using Libraries With libraries like Beautiful Soup, you can write code to navigate the HTML structure and extract the desired data points using selectors like CSS selectors or XPath.
Pre-built ToolsThese tools often have built-in functionalities to target specific elements and extract the relevant review data.
Handle pagination
If there are multiple review pages, you'll need to handle pagination to scrape all of them. This might involve finding URLs for subsequent review pages or using features within your amazon review scraper to navigate them automatically.
Store the Data
The scraped data can be stored in various formats like CSV (comma-separated values) or JSON (JavaScript Object Notation) for further analysis or use in other applications.
Methods to Scrape Amazon Reviews Quickly and Effectively
Here are some methods to scrape Amazon reviews quickly and effectively, categorized by their technical complexity:
Pre-built Scraping Tools (Low Technical Knowledge):
Web Scraping Platforms Several online platforms like Reviewgators or Scrapy offer pre-built tools specifically designed for scraping Amazon reviews. These tools are easy to use and don't require much coding skills. You just set up the product link and pick what details you want to gather.
Browser ExtensionsCertain browser extensions offer scraping functionalities for Amazon reviews. These extensions might be a good starting point for simple scraping tasks, but they may need to be improved, and data extraction capabilities may be limitations.
Programming Libraries (Medium Technical Knowledge):
Python Libraries Libraries like Beautiful Soup or Scrapy (Python) allow you to write scripts to parse the HTML content of Amazon product pages. You can leverage these libraries to target specific review data elements using selectors like CSS or XPath. This method offers more control and customization than pre-built tools but requires some programming knowledge.
JavaScript LibrariesLibraries like Cheerio (JavaScript) offer similar functionalities to Python libraries, allowing you to scrape Amazon reviews within a JavaScript environment. This approach might be suitable if you're already working with JavaScript for other purposes.
Web Scraping APIs (Medium to High Technical Knowledge):
Web Scraping APIs Services like Crawlbase or ParseHub offer APIs that allow you to access scraped data from Amazon reviews programmatically. These review scraper APIs handle the complexities of web scraping, like managing user-agent headers, rotating IP addresses, and respecting robots.txt files. This method requires coding knowledge to integrate the amazon review scraper API into your application but offers a robust and scalable solution.
Tips for Faster and More Effective Scraping

By choosing the best practices and following these tips, you can scrape Amazon reviews quickly and effectively, gaining valuable insights for your research or business needs.
Focus on Specific Data Points
Identify the exact review elements you need (text, rating, date) and tailor your scraping process accordingly.
Utilize Rate Limiting
Implement delays between scraping requests to avoid overwhelming Amazon's servers and potential IP blocking.
Handle Pagination Automatically
Use libraries or tools that can automatically navigate through multiple review pages.
Store Data Efficiently
Choose appropriate data formats (CSV, JSON) and consider cloud storage solutions for large datasets.
Respect Amazon's TOS
Always prioritize ethical scraping practices and comply with Amazon's Terms of Service (TOS) and the robots.txt file.
Responsible Scraping
Avoid overloading Amazon's servers and scrape only what you need. Consider using proxy services to rotate your IP address if necessary.
Legal and Ethical Considerations
Research scraping regulations and ensure your use case complies with ethical practices.
Conclusion
Using these scraping methods, you can change how you do research, get important information quickly, and get ahead in your market. It's important to scrape the right way, follow Amazon's ToS, and prioritize ethical practices.
Companies like Reviewsgator provide strong scraping tools and help for businesses big and small that want an easier way. They can deal with the hard parts, so you can use customer reviews to improve your business!
Know more https://www.reviewgators.com/scrape-amazon-reviews-quickly-and-efficiently.php
0 notes
Text
What is E-commerce Price Data Scraping, and Why is it Important for Businesses?
E-commerce price data scraping collects pricing information from various online sources, such as e-commerce websites. This process involves using specialized software tools such as web scrapers or price scrapers to gather pricing data automatically. E-commerce price data scraping is essential for businesses operating in the e-commerce sector, as it provides valuable insights into pricing strategies, market trends, and competitor pricing.
By scraping e-commerce price data, businesses can monitor competitors' prices in real-time, track price trends, and make informed pricing decisions. This data can also be used to optimize pricing strategies, identify pricing opportunities, and improve overall market competitiveness.
Different Types of E-commerce Websites
Listed below are some of the most popular e-commerce websites
Amazon is a leading e-commerce platform offering a wide range of products. Price scraping on Amazon allows businesses to monitor competitor prices, track market trends, and optimize their pricing strategies.
eBay is a popular online marketplace where users can buy and sell new and used items. Scraping eBay product data helps sellers track competitor pricing, identify profitable niches, and optimize their product listings.
Walmart is a major retailer with a significant online presence. Scraping Walmart's website product data can provide valuable pricing and product information for businesses looking to compete in the retail market.
Target is another prominent retailer offering a variety of products online. Scraping Target's website product data enables businesses to gather pricing data, analyze market trends, and make informed decisions about their product offerings.
How Does E-commerce Product Price Scraping Help Businesses?
E-commerce product price scraping helps businesses by providing insights into competitors' pricing strategies, enabling informed pricing decisions.
Competitor Analysis: E-commerce product price scraping services allow businesses to conduct thorough competitor analysis. By monitoring competitors' pricing strategies, businesses can adjust their prices to stay competitive.
Price Trend Identification: Scraping product prices from e-commerce websites helps businesses identify trends over time. This information is valuable for setting pricing strategies and predicting future price changes.
Promotional Strategy Optimization: Price scraping enables businesses to track competitors' promotional strategies, such as discounts and offers. This information can help businesses optimize their promotional strategies to attract more customers.
Market Entry Planning: Before entering a new market, businesses can use price scraper to gather pricing data from existing competitors. This information helps them develop competitive pricing strategies for the new market.
Product Assortment Planning: Price scraping can also help businesses plan product assortment. By analyzing pricing data for different products, businesses can determine which products to stock and at what price points.
Brand Perception Management: Monitoring product prices in relation to competitors can help businesses manage their brand perception. By offering competitive prices, businesses can position themselves as value-for-money or premium brands.
Dynamic Inventory Pricing: Price scraping services can assist businesses in dynamically pricing their inventory based on factors such as demand, seasonality, and competitor prices. It can help maximize revenue and minimize losses.
Steps to Scrape eBay Product Price Data using Python
This tutorial will demonstrate step-by-step instructions for scraping e-commerce product price data using Python, focusing on eBay as our example. This guide will cover setting up the scraping environment, writing Python code to extract the data, and organizing the scraped data for analysis. Following these steps, you'll learn to efficiently gather pricing information from e-commerce websites for your analysis and decision-making processes.
Here is a more detailed guide on how to scrape eBay product price data using Python for a specific category:
Install Required Libraries: First, install the necessary libraries. You'll need requests, beautifulsoup4, and pandas. Use pip to install them:pip install requests beautifulsoup4 pandas
Import Libraries: Import the required libraries into your Python script:
import requestsfrom bs4 import BeautifulSoup import pandas as pd
Set URL and Headers: Define the URL of the eBay category you want to scrape and set the user-agent header to mimic a web browser:url = 'https://www.ebay.com/b/Cell-Phones-Smartphones/9355/bn_320094' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Apple WebKit/537. 36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
Send a GET Request: Use the requests library to send a GET request to the eBay URL and get the webpage content:response = requests.get (url, headers = headers)
Analyze the HTML Content: Parse the webpage’s HTML content using BeautifulSoup:soup = BeautifulSoup(response.content, 'html.parser')
Find Product Containers: Find all the containers that hold the product information. Inspect the eBay webpage to identify the HTML structure:product_containers = soup.find_all('div', class_='s-item__info')
Extract Product Data: Iterate through each product container and extract relevant data such as product name, price, and URL:product_data = [] for container in product_containers: name = container.find('h3', class_='s-item__title').text price = container.find('span', class_='s-item__price').text url = container.find('a', class_='s-item__link').get('href') product_data.append({'Name': name, 'Price': price, 'URL': url})
Create a DataFrame: Convert the list of product data into a pandas DataFrame for easier manipulation:df = pd.DataFrame(product_data)
Clean the Data: Clean the data as needed. For example, remove non-numeric characters from the price column and convert it to a numeric data type:df['Price'] = df['Price'].str.replace('$', '').astype(float)
Save or Analyze the Data: You can save the scraped data to a CSV file or perform further analysis and visualization using pandas and other libraries.
This detailed guide provides a comprehensive framework for scraping eBay product price data using Python. You can modify the code to scrape other categories on eBay or apply similar techniques to scrape data from other e-commerce websites.
Conclusion: Scraping prices from eCommerce websites can give businesses valuable insights into market trends, competitor pricing strategies, and consumer behavior. Businesses can automate collecting and analyzing price data by leveraging Python libraries such as requests, beautifulsoup4, and pandas, saving time and resources. However, it's important to note that scraping data from websites should be done ethically and comply with the website's terms of service. With the right approach, scraping prices can help businesses make informed decisions about pricing strategies, product offerings, and overall market positioning, ultimately leading to increased competitiveness and profitability in the eCommerce landscape.
Know More https://www.iwebdatascraping.com/e-commerce-price-data-scraping-for-businesses.php
#ScrapeE-commercePriceData#E-commercePriceDataScraping#ExtractE-commercePriceData#E-commercePriceDataExtractor#E-commercePriceDataCollection#E-commercePriceDataExtension#E-commercePriceDataScraper
0 notes
Text
Check List To Build Amazon Reviews Scraper
Let's dive into the realm of Amazon, a behemoth in the online marketplace sphere renowned for its vast repository of invaluable data for businesses. Whether it's perusing product descriptions or dissecting customer reviews, the potential insights garnered from Amazon's data reservoir are immense. With the aid of web scraping tools, one can effortlessly tap into this trove of information and derive actionable intelligence.
Amazon's staggering fiscal statistics for 2021, showcasing a whopping $125.6 billion in fourth-quarter sales revenue, underscore its unparalleled prominence in the e-commerce landscape. Notably, consumer inclination towards Amazon is strikingly evident, with nearly 90% expressing a preference for purchasing from this platform over others.
A pivotal driving force behind Amazon's soaring sales figures is its treasure trove of customer reviews. Studies reveal that a staggering 73% of consumers are inclined to trust e-commerce platforms boasting positive customer feedback. Consequently, businesses, both budding and established, are increasingly turning to Amazon review scrapers to extract and harness this invaluable data.
The significance of Amazon review data cannot be overstated, particularly for emerging businesses seeking to gain a competitive edge. With over 4,000 items sold per minute in the US alone, these enterprises leverage Amazon review scrapers to glean insights into consumer sentiments and market trends, thereby refining their strategies and offerings.
So, what makes Amazon review scrapers indispensable? These tools serve as a conduit for businesses to decipher product rankings, discern consumer preferences, and fine-tune their marketing strategies. By harnessing review data scraped from Amazon, sellers can enhance their product offerings and bolster customer satisfaction.
Moreover, Amazon review scrapers facilitate comprehensive competitor analysis, enabling businesses to gain a deeper understanding of market dynamics and consumer preferences. Armed with this intelligence, enterprises can tailor their offerings to better resonate with their target audience, thereby amplifying their market presence and competitiveness.
For large-scale enterprises grappling with vast product inventories, monitoring individual product performances can be daunting. However, Amazon web scraping tools offer a solution by furnishing insights into product-specific performance metrics and consumer sentiments, thus empowering businesses to fine-tune their strategies and bolster their online reputation.
Sentiment analysis, another key facet of Amazon review scraping, enables businesses to gauge consumer sentiment towards their products. By parsing through review data, sellers can gain invaluable insights into consumer perceptions and sentiments, thereby informing their decision-making processes and enhancing customer engagement strategies.
Building an effective Amazon review scraper necessitates meticulous planning and execution. From analyzing the HTML structure of target web pages to implementing Scrapy parsers in Python, each step is crucial in ensuring the seamless extraction and organization of review data. Moreover, leveraging essential tools such as Python, ApiScrapy, and a basic understanding of HTML tags is imperative for developing a robust Amazon review scraper.
However, the journey towards scraping Amazon reviews is fraught with challenges. Amazon's stringent security measures, including CAPTCHAS and IP bans, pose formidable obstacles to scraping activities. Additionally, the variability in page structures and the resource-intensive nature of review data necessitate adept handling and sophisticated infrastructure.
In conclusion, the efficacy of Amazon review scraping in driving business growth and informing strategic decisions cannot be overstated. By harnessing the power of web scraping tools and leveraging Amazon's wealth of review data, businesses can gain invaluable insights into consumer preferences, market trends, and competitor landscapes, thereby charting a course towards sustained success and competitiveness in the dynamic e-commerce arena.
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
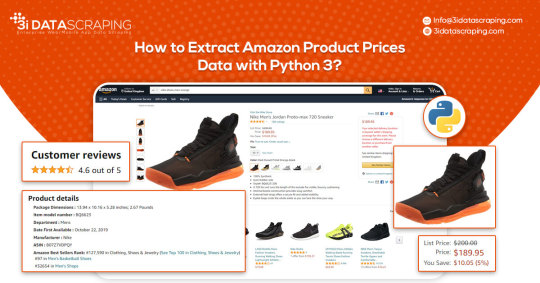
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Develop your own Amazon product scraper bot in Python
How to scrape data from amazon.com? Scraping amazon products details benefits to lots of things as product details, images, pricing, stock, rating, review, etc and it analyzes how particular brand being popular on amazon and competitive analysis. Read more
1 note
·
View note
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text

Scrape Amazon Product Data Even if You Don't Know How to Code
One way to scrape Amazon product data is by writing a code, preferably in JavaScript or Python.
But you don't have to do that.
You can use ScrapeHero Cloud to extract Amazon product details within a few clicks.
0 notes
Text
A Beginner's Guide to Amazon Data Scraping

Are you looking to gather data from Amazon for your next project? Whether you're a data scientist, marketer, or researcher, scraping data from Amazon can provide valuable insights into product trends, pricing, reviews, and more. In this guide, we'll walk you through the basics of Amazon data scraping and provide some tips to get started.
What Is Amazon Data Scraping?
Data scraping, also known as web scraping, involves extracting data from websites. In the context of Amazon, data scraping refers to gathering information such as product details, prices, reviews, ratings, and other data points from the Amazon website. This data can be used for a variety of purposes, including market research, price tracking, sentiment analysis, and competitive analysis.
Legal Considerations
Before diving into Amazon data scraping, it's important to understand the legal and ethical implications. Amazon's terms of service strictly prohibit scraping their website without explicit permission. Violating these terms can result in your IP address being banned from the site. Always ensure you are complying with Amazon's policies and applicable laws.
If you plan to scrape data from Amazon, consider obtaining explicit consent or using an authorized data provider. Additionally, be mindful of ethical data scraping practices, such as respecting the site's rate limits and not causing undue strain on their servers.
Getting Started with Amazon Data Scraping
Here’s a beginner's guide to help you start scraping data from Amazon:
Step 1: Choose a Web Scraping Tool or Library
The first step is to choose a web scraping tool or library that suits your needs. Popular choices include:
BeautifulSoup: A Python library that makes it easy to parse HTML and XML documents.
Scrapy: A powerful Python framework specifically designed for web scraping.
Selenium: A browser automation tool that can be used for scraping dynamic websites.
Puppeteer: A Node.js library that controls a headless browser and is ideal for scraping websites with JavaScript-heavy content.
Step 2: Identify the Data You Want to Scrape
Determine the type of data you want to scrape from Amazon. Common data points include:
Product details: Title, description, images, and specifications.
Prices: Current price, sale price, and discount information.
Reviews and ratings: Customer reviews, star ratings, and review counts.
Seller information: Seller name, feedback rating, and contact information.
Step 3: Scrape the Data
Once you have chosen a tool and identified the data you want to scrape, follow these steps to start the scraping process:
Set up your scraper: Initialize your web scraping tool and configure it with the target URL(s).
Extract data: Use selectors to target specific elements on the page (e.g., product titles, prices, or reviews).
Store data: Save the extracted data in a format that suits your needs (e.g., CSV, JSON, or a database).
Step 4: Handle Dynamic Content
Amazon's website may contain dynamic content that requires special handling:
JavaScript-rendered content: Use tools like Selenium or Puppeteer to interact with the page and wait for JavaScript to load the content.
Pagination: Amazon may display products across multiple pages. Implement pagination handling to scrape data from all pages.
Step 5: Maintain Your Scraper
Amazon frequently updates its website, so your scraper may need adjustments over time. Monitor changes to the website's structure and adjust your scraper accordingly.
Tips for Successful Amazon Data Scraping
Use User-Agent Rotation: To avoid detection and being blocked, rotate your User-Agent string to mimic different web browsers.
Respect Rate Limits: Adhere to the rate limits set by Amazon to avoid overloading their servers.
Monitor Changes: Keep an eye on changes to Amazon's website layout and structure, as this can affect your scraper's functionality.
Conclusion
Amazon data scraping can provide valuable insights for your projects, but it requires careful planning and execution. By following the steps outlined in this guide and adhering to legal and ethical standards, you can successfully scrape data from Amazon and unlock a wealth of information for your work. Happy scraping!
0 notes
Text
How To Create An Amazon Price Tracker With Python For Real-Time Price Monitoring
How To Create An Amazon Price Tracker With Python For Real-Time Price Monitoring?
In today's world of online shopping, everyone enjoys scoring the best deals on Amazon for their coveted electronic gadgets. Many of us maintain a wishlist of items we're eager to buy at the perfect price. With intense competition among e-commerce platforms, prices are constantly changing.
The savvy move here is to stay ahead by tracking price drops and seizing those discounted items promptly. Why rely on commercial Amazon price tracker software when you can create your solution for free? It is the perfect opportunity to put your programming skills to the test.
Our objective: develop a price tracking tool to monitor the products on your wishlist. You'll receive an SMS notification with the purchase link when a price drop occurs. Let's build your Amazon price tracker, a fundamental tool to satisfy your shopping needs.
About Amazon Price Tracker
An Amazon price tracker is a tool or program designed to monitor and track the prices of products listed on the Amazon online marketplace. Consumers commonly use it to keep tabs on price fluctuations for items they want to purchase. Here's how it typically works:
Product Selection: Users choose specific products they wish to track. It includes anything on Amazon, from electronics to clothing, books, or household items.
Price Monitoring: The tracker regularly checks the prices of the selected products on Amazon. It may do this by web scraping, utilizing Amazon's API, or other methods
Price Change Detection: When the price of a monitored product changes, the tracker detects it. Users often set thresholds, such as a specific percentage decrease or increase, to trigger alerts.
Alerts: The tracker alerts users if a price change meets the predefined criteria. This alert can be an email, SMS, or notification via a mobile app.
Informed Decisions: Users can use these alerts to make informed decisions about when to buy a product based on its price trends. For example, they may purchase a product when the price drops to an acceptable level.
Amazon price trackers are valuable tools for savvy online shoppers who want to save money by capitalizing on price drops. They can help users stay updated on changing market conditions and make more cost-effective buying choices.
Methods
Let's break down the process we'll follow in this blog. We will create two Python web scrapers to help us track prices on Amazon and send price drop alerts.
Step 1: Building the Master File
Our first web scraper will collect product name, price, and URL data. We'll assemble this information into a master file.
Step 2: Regular Price Checking
We'll develop a second web scraper to check the prices and perform hourly checks periodically. This Python script will compare the current prices with the data in the master file.
Step 3: Detecting Price Drops
Since Amazon sellers often use automated pricing, we expect price fluctuations. Our script will specifically look for significant price drops, let's say more than a 10% decrease.
Step 4: Alert Mechanism
Our script will send you an SMS price alert if a substantial price drop is detected. It ensures you'll be informed when it's the perfect time to grab your desired product at a discounted rate.
Let's kick off the process of creating a Python-based Amazon web scraper. We focus on extracting specific attributes using Python's requests, BeautifulSoup, and the lxml parser, and later, we'll use the csv library for data storage.
Here are the attributes we're interested in scraping from Amazon:
Product Name
Sale Price (not the listing price)
To start, we'll import the necessary libraries:
In the realm of e-commerce web scraping, websites like Amazon often harbor a deep-seated aversion to automated data retrieval, employing formidable anti-scraping mechanisms that can swiftly detect and thwart web scrapers or bots. Amazon, in particular, has a robust system to identify and block such activities. Incorporating headers into our HTTP requests is an intelligent strategy to navigate this challenge.
Now, let's move on to assembling our bucket list. In my instance, we've curated a selection of five items that comprise my personal bucket list, and we've included them within the program as a list. If your bucket list is more extensive, storing it in a text file and subsequently reading and processing the data using Python is prudent.
We will create two functions to extract Amazon pricing and product names that retrieve the price when called. For this task, we'll rely on Python's BeautifulSoup and lxml libraries, which enable us to parse the webpage and extract the e-commerce product data. To pinpoint the specific elements on the web page, we'll use Xpaths.
To construct the master file containing our scraped data, we'll utilize Python's csv module. The code for this process is below.
Here are a few key points to keep in mind:
The master file consists of three columns: product name, price, and the product URL.
We iterate through each item on our bucket list, parsing the necessary information from their URLs.
To ensure responsible web scraping and reduce the risk of detection, we incorporate random time delays between each request.
Once you execute the code snippets mentioned above, you'll find a CSV file as "master_data.csv" generated. It's important to note that you can run this program once to create the master file.
To develop our Amazon price tracking tool, we already have the essential master data to facilitate comparisons with the latest scraped information. Now, let's craft the second script, which will extract data from Amazon and perform comparisons with the data stored in the master file.
In this tracker script, we'll introduce two additional libraries:
The Pandas library will be instrumental for data manipulation and analysis, enabling us to work with the extracted data efficiently.
The Twilio library: We'll utilize Twilio for SMS notifications, allowing us to receive price alerts on our mobile devices.
Pandas: Pandas is a powerful open-source Python library for data analysis and manipulation. It's renowned for its versatile data structure, the pandas DataFrame, which facilitates the handling of tabular data, much like spreadsheets, within Python scripts. If you aspire to pursue a career in data science, learning Pandas is essential.
Twilio: Regarding programmatically sending SMS notifications, Twilio's APIs are a top choice. We opt for Twilio because it provides free credits, which suffice for our needs.
To streamline the scraper and ensure it runs every hour, we aim to automate the process. Given my full-time job, manually initiating the program every two hours is impractical. We prefer to set up a schedule that triggers the program's execution hourly.
To verify the program's functionality, manually adjust the price values within the master data file and execute the tracker program. You'll observe SMS notifications as a result of these modifications.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.
Know More: https://www.iwebdatascraping.com/amazon-price-tracker-with-python-for-real-time-price-monitoring.php
0 notes
Text
Your Essential Guide to Building an Amazon Reviews Scraper
Amazon is a massive online marketplace, and it holds a treasure trove of data that's incredibly valuable for businesses. Whether it's product descriptions or customer reviews, you can tap into this data goldmine using a web scraping tool to gain valuable insights. These scraping tools are designed to quickly extract and organize data from specific websites. Just to put things into perspective, Amazon raked in a staggering $125.6 billion in sales revenue in the fourth quarter of 2020!
The popularity of Amazon is astounding, with nearly 90% of consumers preferring it over other websites for product purchases. A significant driver behind Amazon's sales success is its extensive collection of customer reviews. In fact, 73% of consumers say that positive customer reviews make them trust an eCommerce website more. This wealth of product review data on Amazon offers numerous advantages. Many small and mid-sized businesses, aiming for more than 4,000 items sold per minute in the US, look to leverage this data using an Amazon reviews scraper. Such a tool can extract product review information from Amazon and save it in a format of your choice.

Why Use an Amazon Reviews Scraper?
The authenticity and vastness of Amazon reviews make a scraper an ideal tool to analyze trends and market conditions thoroughly. Businesses and sellers can employ an Amazon reviews scraper to target the products in their inventory. They can scrape Amazon reviews from product pages and store them in a format that suits their needs. Here are some key benefits:

1. Find Customer Opinions: Amazon sellers can scrape reviews to understand what influences a product's ranking. This insight allows them to develop strategies to boost their rankings further, ultimately improving their products and customer service.
2. Collect Competing Product Reviews: By scraping Amazon review data, businesses can gain a better understanding of what aspects of products have a positive or negative impact. This knowledge helps them make informed decisions to capture the market effectively.
3. Online Reputation Marketing: Large companies with extensive product inventories often struggle to track individual product performance. However, Amazon web scraping tools can extract specific product information, which can then be analyzed using sentiment analysis tools to measure consumer sentiment.
4. Sentiment Analysis: The data collected with an Amazon reviews scraper helps identify consumer emotions toward a product. This helps prospective buyers gauge the general sentiment surrounding a product before making a purchase. Sellers can also assess how well a product performs in terms of customer satisfaction.
Checklist for Building an Amazon Reviews Scraper
Building an effective Amazon reviews scraper requires several steps to be executed efficiently. While the core coding is done in Python, there are other critical steps to follow when creating a Python Amazon review scraper. By successfully completing this checklist, you'll be able to scrape Amazon reviews for your desired products effectively:
a. Analyze the HTML Structure: Before coding an Amazon reviews scraper, it's crucial to understand the HTML structure of the target web pages. This step helps identify patterns that the scraper will use to extract data.
b. Implement Scrapy Parser in Python: After analyzing the HTML structure, code your Python Amazon review scraper using Scrapy, a web crawling framework. Scrapy will visit target web pages and extract the necessary information based on predefined rules and criteria.
c. Collect and Store Information: After scraping review data from product pages, the Amazon web scraping tools need to save the output data in a format such as CSV or JSON.
Essential Tools for Building an Amazon Reviews Scraper
When building an Amazon web scraper, you'll need various tools essential to the process of scraping Amazon reviews. Here are the basic tools required:
a. Python: Python's ease of use and extensive library support make it an ideal choice for building an Amazon reviews scraper.
b. Scrapy: Scrapy is a Python web crawling framework that allows you to write code for the Amazon reviews scraper. It provides flexibility in defining how websites will be scraped.
c. HTML Knowledge: A basic understanding of HTML tags is essential for deploying an Amazon web scraper effectively.
d. Web Browser: Browsers like Google Chrome and Mozilla Firefox are useful for identifying HTML tags and elements that the Amazon scraping tool will target.
Challenges in Scraping Amazon Reviews
Scraping reviews from Amazon can be challenging due to various factors:
a. Detection of Bots: Amazon can detect the presence of scraper bots and block them using CAPTCHAS and IP bans.
b. Varying Page Structures: Product pages on Amazon often have different structures, leading to unknown response errors and exceptions.
c. Resource Requirements: Due to the massive size of Amazon's review data, scraping requires substantial memory resources and high-performance network connections.
d. Security Measures: Amazon employs multiple security protocols to block scraping attempts, including content copy protection, JavaScript rendering, and user-agent validation.
How to Scrape Amazon Reviews Using Python

To build an Amazon web scraper using Python, follow these steps:
1. Environment Creation: Establish a virtual environment to isolate the scraper from other processes on your machine.
2. Create the Project: Use Scrapy to create a project that contains all the necessary components for your Amazon reviews scraper.
3. Create a Spider: Define how the scraper will crawl and scrape web pages by creating a Spider.
4. Identify Patterns: Inspect the target web page in a browser to identify patterns in the HTML structure.
5. Define Scrapy Parser in Python: Write the logic for scraping Amazon reviews and implement the parser function to identify patterns on the page.
6. Store Scraped Results: Configure the Amazon reviews scraper to save the extracted review data in CSV or JSON formats.
Using an Amazon reviews scraper provides businesses with agility and automation to analyze customer sentiment and market trends effectively. It empowers sellers to make informed decisions and respond quickly to changes in the market. By following these steps and leveraging the right tools, you can create a powerful Python Amazon review scraper to harness the valuable insights locked within Amazon's reviews.
0 notes
Text
How Web Scraping Services Help E-commerce Industry
Web scraping services will not only help you to develop a powerful business strategy backed by predictive analysis but also help you to be aware of customers’ expectations in advance. Nowadays, data is not only the most valuable asset in any industry but also the new currency for businessmen. In today’s complex and unprecedented business world, the success of any business hinges upon its ability to effectively collect, analyze, and utilize data and information. But how can this necessary data be extracted and gathered quickly and effectively? That’s where web scraping services India come to the rescue.
Here are a few ways web scraping services can help the e-commerce industry:
For Real-Time Tracking of Your Competitors’ Prices Developing an effective pricing strategy is very important for any e-commerce business. However, an effective pricing strategy can only be developed based on your competitors’ pricing information. Hence, you need to monitor your competitors’ prices in real-time to adjust your pricing.
If offering lower prices is not possible due to your supplier, you may decide to scrape pricing data from your supplier’s site and compare it with pricing from other suppliers. Check sample data of product pricing using amazon data scraper for getting idea about data.
To Gain Product Performance Intelligence One way to leave your competitors in the dust is knowing how your products are performing against your competitors’ products and whether your products are lagging or not.
Web scraping services in india will also help e-commerce traders to have an idea of what promotions and customer retention strategies their competitors are using that they can also implement to drive their business.
To Obtain Product Data from Supplier Websites The e-commerce industry relies on several different suppliers i.e. e-commerce business owners obtain their products from different suppliers. Some of these suppliers have APIs which enable e-commerce business owners to access product data and features.
However, not all suppliers have APIs. Hence, the need for web scraping services to access these product lists, features, and other information relating to the products
To Conduct Sentiment Analysis However, e-commerce business owners have a great chance of monitoring customer behavior and responses online via reviews and feedback and use these reviews to align their business goals.
Web scraping services will help you to obtain data that you can use to know what your customers like, dislike, or are saying about your products. This data will enable you to improve your service.
To Predict Market Trends Lastly, web scraping services offer the benefit of market prediction. Web scraping services can help you to obtain user data that can be used to track customer’s buying habits to plan your future marketing campaign strategy.
Conclusion Obtaining and utilizing information is very important for the e-commerce industry. Obtaining this information in large quantities and a meaningful and useful format can be a daunting task.
However, with web scraping services, you can easily obtain this information according to your requirements. Furthermore, interested to learn web scraping using Python then watch this channel and get python script free.
1 note
·
View note