#web scraping amazon using python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes
Text
Scrape Product Info, Images & Brand Data from E-commerce | Actowiz
Introduction
In today’s data-driven world, e-commerce product data scraping is a game-changer for businesses looking to stay competitive. Whether you're tracking prices, analyzing trends, or launching a comparison engine, access to clean and structured product data is essential. This article explores how Actowiz Solutions helps businesses scrape product information, images, and brand details from e-commerce websites with precision, scalability, and compliance.
Why Scraping E-commerce Product Data Matters

E-commerce platforms like Amazon, Walmart, Flipkart, and eBay host millions of products. For retailers, manufacturers, market analysts, and entrepreneurs, having access to this massive product data offers several advantages:
- Price Monitoring: Track competitors’ prices and adjust your pricing strategy in real-time.
- Product Intelligence: Gain insights into product listings, specs, availability, and user reviews.
- Brand Visibility: Analyze how different brands are performing across marketplaces.
- Trend Forecasting: Identify emerging products and customer preferences early.
- Catalog Management: Automate and update your own product listings with accurate data.
With Actowiz Solutions’ eCommerce data scraping services, companies can harness these insights at scale, enabling smarter decision-making across departments.
What Product Data Can Be Scraped?

When scraping an e-commerce website, here are the common data fields that can be extracted:
✅ Product Information
Product name/title
Description
Category hierarchy
Product specifications
SKU/Item ID
Price (Original/Discounted)
Availability/Stock status
Ratings & reviews
✅ Product Images
Thumbnail URLs
High-resolution images
Zoom-in versions
Alternate views or angle shots
✅ Brand Details
Brand name
Brand logo (if available)
Brand-specific product pages
Brand popularity metrics (ratings, number of listings)
By extracting this data from platforms like Amazon, Walmart, Target, Flipkart, Shopee, AliExpress, and more, Actowiz Solutions helps clients optimize product strategy and boost performance.
Challenges of Scraping E-commerce Sites

While the idea of gathering product data sounds simple, it presents several technical challenges:
Dynamic Content: Many e-commerce platforms load content using JavaScript or AJAX.
Anti-bot Mechanisms: Rate-limiting, captchas, IP blocking, and login requirements are common.
Frequent Layout Changes: E-commerce sites frequently update their front-end structure.
Pagination & Infinite Scroll: Handling product listings across pages requires precise navigation.
Image Extraction: Downloading, renaming, and storing image files efficiently can be resource-intensive.
To overcome these challenges, Actowiz Solutions utilizes advanced scraping infrastructure and intelligent algorithms to ensure high accuracy and efficiency.
Step-by-Step: How Actowiz Solutions Scrapes E-commerce Product Data

Let’s walk through the process that Actowiz Solutions follows to scrape and deliver clean, structured, and actionable e-commerce data:
1. Define Requirements
The first step involves understanding the client’s specific data needs:
Target websites
Product categories
Required data fields
Update frequency (daily, weekly, real-time)
Preferred data delivery formats (CSV, JSON, API)
2. Website Analysis & Strategy Design
Our technical team audits the website’s structure, dynamic loading patterns, pagination system, and anti-bot defenses to design a customized scraping strategy.
3. Crawler Development
We create dedicated web crawlers or bots using tools like Python, Scrapy, Playwright, or Puppeteer to extract product listings, details, and associated metadata.
4. Image Scraping & Storage
Our bots download product images, assign them appropriate filenames (using SKU or product title), and store them in cloud storage like AWS S3 or GDrive. Image URLs can also be returned in the dataset.
5. Brand Attribution
Products are mapped to brand names by parsing brand tags, logos, and using NLP-based classification. This helps clients build brand-level dashboards.
6. Data Cleansing & Validation
We apply validation rules, deduplication, and anomaly detection to ensure only accurate and up-to-date data is delivered.
7. Data Delivery
Data can be delivered via:
REST APIs
S3 buckets or FTP
Google Sheets/Excel
Dashboard integration
All data is made ready for ingestion into CRMs, ERPs, or BI tools.
Supported E-Commerce Platforms

Actowiz Solutions supports product data scraping from a wide range of international and regional e-commerce websites, including:
Amazon
Walmart
Target
eBay
AliExpress
Flipkart
BigCommerce
Magento
Rakuten
Etsy
Lazada
Wayfair
JD.com
Shopify-powered sites
Whether you're focused on electronics, fashion, grocery, automotive, or home décor, Actowiz can help you extract relevant product and brand data with precision.
Use Cases: How Businesses Use Scraped Product Data

Retailers
Compare prices across platforms to remain competitive and win the buy-box.
🧾 Price Aggregators
Fuel price comparison engines with fresh, accurate product listings.
📈 Market Analysts
Study trends across product categories and brands.
🎯 Brands
Monitor third-party sellers, counterfeit listings, or unauthorized resellers.
🛒 E-commerce Startups
Build initial catalogs quickly by extracting competitor data.
📦 Inventory Managers
Sync product stock and images with supplier portals.
Actowiz Solutions tailors the scraping strategy according to the use case and delivers the highest ROI on data investment.
Benefits of Choosing Actowiz Solutions

✅ Scalable Infrastructure
Scrape millions of products across multiple websites simultaneously.
✅ IP Rotation & Anti-Bot Handling
Bypass captchas, rate-limiting, and geolocation barriers with smart proxies and user-agent rotation.
✅ Near Real-Time Updates
Get fresh data updated daily or in real-time via APIs.
✅ Customization & Flexibility
Select your data points, target pages, and preferred delivery formats.
✅ Compliance-First Approach
We follow strict guidelines and ensure scraping methods respect site policies and data usage norms.
Security and Legal Considerations
Actowiz Solutions emphasizes ethical scraping practices and ensures compliance with data protection laws such as GDPR, CCPA, and local regulations. Additionally:
Only publicly available data is extracted.
No login-restricted or paywalled content is accessed without consent.
Clients are guided on proper usage and legal responsibility for the scraped data.
Frequently Asked Questions
❓ Can I scrape product images in high resolution?
Yes. Actowiz Solutions can extract multiple image formats, including zoomable HD product images and thumbnails.
❓ How frequently can data be updated?
Depending on the platform, we support real-time, hourly, daily, or weekly updates.
❓ Can I scrape multiple marketplaces at once?
Absolutely. We can design multi-site crawlers that collect and consolidate product data across platforms.
❓ Is scraped data compatible with Shopify or WooCommerce?
Yes, we can deliver plug-and-play formats for Shopify, Magento, WooCommerce, and more.
❓ What if a website structure changes?
We monitor site changes proactively and update crawlers to ensure uninterrupted data flow.
Final Thoughts
Scraping product data from e-commerce websites unlocks a new layer of market intelligence that fuels decision-making, automation, and competitive strategy. Whether it’s tracking competitor pricing, enriching your product catalog, or analyzing brand visibility — the possibilities are endless.
Actowiz Solutions brings deep expertise, powerful infrastructure, and a client-centric approach to help businesses extract product info, images, and brand data from e-commerce platforms effortlessly. Learn More
0 notes
Text
Unlock Your Programming Potential with a Python Course in Bangalore
In today’s digital era, learning to code isn’t just for computer scientists — it's an essential skill that opens doors across industries. Whether you're aiming to become a software developer, data analyst, AI engineer, or web developer, Python is the language to start with. If you're located in or near India’s tech capital, enrolling in a Python course in Bangalore is your gateway to building a future-proof career in tech.

Why Python?
Python is one of the most popular and beginner-friendly programming languages in the world. Known for its clean syntax and versatility, Python is used in:
Web development (using Django, Flask)
Data science & machine learning (NumPy, Pandas, Scikit-learn)
Automation and scripting
Game development
IoT applications
Finance and Fintech modeling
Artificial Intelligence (AI) & Deep Learning
Cybersecurity tools
In short, Python is the “Swiss army knife” of programming — easy to learn, powerful to use.
Why Take a Python Course in Bangalore?
Bangalore — India’s leading IT hub — is home to top tech companies like Google, Microsoft, Infosys, Wipro, Amazon, and hundreds of fast-growing startups. The city has a massive demand for Python developers, especially in roles related to data science, machine learning, backend development, and automation engineering.
By joining a Python course in Bangalore, you get:
Direct exposure to real-world projects
Trainers with corporate experience
Workshops with startup founders and hiring partners
Proximity to the best placement opportunities
Peer learning with passionate tech learners
Whether you're a fresher, student, or working professional looking to upskill, Bangalore offers the best environment to learn Python and get hired.
What’s Included in a Good Python Course?
A high-quality Python course in Bangalore typically covers:
✔ Core Python
Variables, data types, loops, and conditionals
Functions, modules, and file handling
Object-Oriented Programming (OOP)
Error handling and debugging
✔ Advanced Python
Iterators, generators, decorators
Working with APIs and databases
Web scraping (with Beautiful Soup and Selenium)
Multi-threading and regular expressions
✔ Real-World Projects
Build a dynamic website using Flask or Django
Create a weather forecasting app
Automate Excel and file management tasks
Develop a chatbot using Python
Analyze datasets using Pandas and Matplotlib
✔ Domain Specializations
Web Development – Django/Flask-based dynamic sites
Data Science – NumPy, Pandas, Matplotlib, Seaborn, Scikit-learn
Machine Learning – Supervised & unsupervised learning models
Automation – Scripts to streamline manual tasks
App Deployment – Heroku, GitHub, and REST APIs
Many training providers also help prepare for Python certifications, such as PCAP (Certified Associate in Python Programming) or Microsoft’s Python certification.
Who Can Join a Python Course?
Python is extremely beginner-friendly. It’s ideal for:
Students (Engineering, BCA, MCA, BSc IT, etc.)
Career switchers from non-tech backgrounds
Working professionals in IT/analytics roles
Startup founders and entrepreneurs
Freelancers and job seekers
There are no prerequisites except basic logical thinking and eagerness to learn.
Career Opportunities after Learning Python
Bangalore has a booming job market for Python developers. Completing a Python course in Bangalore opens opportunities in roles like:
Python Developer
Backend Web Developer
Data Analyst
Data Scientist
AI/ML Engineer
Automation Engineer
Full Stack Developer
DevOps Automation Specialist
According to job portals, Python developers in Bangalore earn ₹5 to ₹15 LPA depending on skillset and experience. Data scientists and ML engineers with Python expertise can earn even higher.
Top Institutes Offering Python Course in Bangalore
You can choose from various reputed institutes offering offline and online Python courses. Some top options include:
Simplilearn – Online + career support
JSpiders / QSpiders – For freshers and job seekers
Intellipaat – Weekend batches with projects
Besant Technologies – Classroom training + placement
Coding Ninjas / UpGrad / Edureka – Project-driven, online options
Ivy Professional School / AnalytixLabs – Python for Data Science specialization
Most of these institutes offer flexible timings, EMI payment options, and placement support.
Why Python is a Must-Have Skill in 2025
Here’s why you can’t ignore Python anymore:
Most taught first language in top universities worldwide
Used by companies like Google, Netflix, NASA, and IBM
Dominates Data Science & AI ecosystems
Huge job demand and salary potential
Enables rapid prototyping and startup MVPs
Whether your goal is to land a job in tech, build a startup, automate tasks, or work with AI models — Python is the key.
Final Thoughts
If you want to break into tech or supercharge your coding journey, there’s no better place than Bangalore — and no better language than Python.
By enrolling in a Python course in Bangalore, you position yourself in the heart of India’s tech innovation, backed by world-class mentorship and career growth.
Ready to transform your future?
Start your Python journey today in Bangalore and code your way to success.
0 notes
Text
The Advantages of Python: A Comprehensive Overview
Python has gained immense popularity in the programming world due to its simplicity, flexibility, and powerful capabilities. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Whether you are a beginner stepping into coding or an experienced developer working on complex projects, Python offers numerous advantages that make it a preferred choice across various industries.
Easy to Learn and Use
Python is known for its clean and readable syntax, making it an excellent choice for beginners. Unlike other programming languages that require complex syntax, Python allows developers to write fewer lines of code while maintaining efficiency. Its simplicity ensures that even those without prior programming experience can quickly grasp the fundamentals and start coding.
Versatile Across Multiple Fields
One of Python’s biggest strengths is its versatility. It is used in web development, data science, artificial intelligence, machine learning, automation, game development, and even cybersecurity. This flexibility allows developers to transition between different domains without having to learn a new language.
Extensive Library and Framework Support
Python offers a vast collection of libraries and frameworks that simplify development tasks. Libraries like NumPy and Pandas are used for data analysis, TensorFlow and PyTorch for machine learning, Flask and Django for web development, and Selenium for automation. These libraries reduce the time and effort needed to build applications, allowing developers to focus on problem-solving.
Strong Community and Learning Resources
Python has a large and active global community that continuously contributes to its growth. Whether you need help debugging code, finding tutorials, or exploring best practices, numerous forums, documentation, and free learning platforms provide valuable support. This makes Python an ideal language for both self-learners and professionals. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

Cross-Platform Compatibility
Python is a cross-platform language, meaning it runs smoothly on Windows, macOS, and Linux without requiring major modifications. This feature enables developers to write code once and deploy it across different operating systems, saving time and effort.
Ideal for Automation and Scripting
Python is widely used for automating repetitive tasks, such as web scraping, file management, and system administration. Businesses leverage Python’s scripting capabilities to improve efficiency and reduce manual workloads. Many developers also use it to automate testing processes, making software development more streamlined.
High Demand in the Job Market
Python is one of the most sought-after programming languages in the job market. Companies across industries, including tech giants like Google, Amazon, and Microsoft, rely on Python for various applications. The demand for Python developers continues to grow, making it a valuable skill for those seeking career advancement.
Integration with Other Technologies
Python seamlessly integrates with other programming languages like C, C++, and Java, making it highly adaptable for different projects. This allows developers to enhance existing applications, optimize performance, and work efficiently with multiple technologies.
Conclusion
Python’s ease of use, versatility, and strong community support make it one of the best programming languages for both beginners and experienced developers. Whether you are interested in software development, data science, artificial intelligence, or automation, Python provides the tools and resources needed to succeed. With its continuous evolution and growing adoption, Python remains a powerful choice for modern programming needs.
#python course#python training#python#technology#tech#python online training#python programming#python online course#python online classes#python certification
0 notes
Text
Building the Perfect Dataset for AI Training: A Step-by-Step Guide

Introduction
As artificial intelligence progressively transforms various sectors, the significance of high-quality datasets in the training of AI systems is paramount. A meticulously curated dataset serves as the foundation for any AI model, impacting its precision, dependability, and overall effectiveness. This guide will outline the crucial steps necessary to create an optimal Dataset for AI Training.
Step 1: Define the Objective
Prior to initiating data collection, it is essential to explicitly outline the objective of your AI model. Consider the following questions:
What specific issue am I aiming to address?
What types of predictions or results do I anticipate?
Which metrics will be used to evaluate success?
Establishing a clear objective guarantees that the dataset is in harmony with the model’s intended purpose, thereby preventing superfluous data collection and processing.
Step 2: Identify Data Sources
To achieve your objective, it is essential to determine the most pertinent data sources. These may encompass:
Open Data Repositories: Websites such as Kaggle, the UCI Machine Learning Repository, and Data.gov provide access to free datasets.
Proprietary Data: Data that is gathered internally by your organization.
Web Scraping: The process of extracting data from websites utilizing tools such as Beautiful Soup or Scrapy.
APIs: Numerous platforms offer APIs for data retrieval, including Twitter, Google Maps, and OpenWeather.
It is crucial to verify that your data sources adhere to legal and ethical guidelines.
Step 3: Collect and Aggregate Data
Upon identifying the sources, initiate the process of data collection. This phase entails the accumulation of raw data and its consolidation into a coherent format.
Utilize tools such as Python scripts, SQL queries, or data integration platforms.
Ensure comprehensive documentation of data sources to monitor quality and adherence to compliance standards.
Step 4: Clean the Data
Raw data frequently includes noise, absent values, and discrepancies. The process of data cleaning encompasses:
Eliminating Duplicates: Remove redundant entries.
Addressing Missing Data: Employ methods such as imputation, interpolation, or removal.
Standardizing Formats: Maintain uniformity in units, date formats, and naming conventions.
Detecting Outliers: Recognize and manage anomalies through statistical techniques or visual representation.
Step 5: Annotate the Data
Data annotation is essential for supervised learning models. This process entails labeling the dataset to establish a ground truth for the training phase.
Utilize tools such as Label Studio, Amazon SageMaker Ground Truth, or dedicated annotation services.
To maintain accuracy and consistency in annotations, it is important to offer clear instructions to the annotators.
Step 6: Split the Dataset
Segment your dataset into three distinct subsets:
Training Set: Generally comprising 70-80% of the total data, this subset is utilized for training the model.
Validation Set: Constituting approximately 10-15% of the data, this subset is employed for hyperparameter tuning and to mitigate the risk of overfitting.
Test Set: The final 10-15% of the data, this subset is reserved for assessing the model’s performance on data that it has not encountered before.
Step 7: Ensure Dataset Diversity
AI models achieve optimal performance when they are trained on varied datasets that encompass a broad spectrum of scenarios. This includes:
Demographic Diversity: Ensuring representation across multiple age groups, ethnic backgrounds, and geographical areas.
Contextual Diversity: Incorporating a variety of conditions, settings, or applications.
Temporal Diversity: Utilizing data gathered from different timeframes.
Step 8: Test and Validate
Prior to the completion of the dataset, it is essential to perform a preliminary assessment to ensure its quality. This assessment should include the following checks:
Equitable distribution of classes.
Lack of bias.
Pertinence to the specific issue being addressed.
Subsequently, refine the dataset in accordance with the findings from the assessment.
Step 9: Document the Dataset
Develop thorough documentation that encompasses the following elements:
Description and objectives of the dataset.
Sources of data and methods of collection.
Steps for preprocessing and data cleaning.
Guidelines for annotation and the tools utilized.
Identified limitations and possible biases.
Step 10: Maintain and Update the Dataset

AI models necessitate regular updates to maintain their efficacy. It is essential to implement procedures for:
Regular data collection and enhancement.
Ongoing assessment of relevance and precision.
Version management to document modifications.
Conclusion
Creating an ideal dataset for AI training is a careful endeavor that requires precision, specialized knowledge, and ethical awareness. By adhering to this comprehensive guide, you can develop datasets that enable your AI models to perform at their best and produce trustworthy outcomes.
For additional information on AI training and resources, please visit Globose Technology Solutions.AI.
0 notes
Text

Python: Unlocking Possibilities Beyond Code
Python has earned its place as one of the most powerful and versatile programming languages in the world. While it is celebrated for its simple syntax and robust capabilities, the true magic of Python lies in its ability to empower innovation across a variety of domains. From data science to artificial intelligence, Python's influence extends far beyond the world of coding itself.
In this blog, we will explore the non-technical aspects of Python—its versatility, applications, community, and impact on industries—showcasing why Python is the backbone of the modern digital era.
Why Python Stands Out
Python’s widespread adoption is not just due to its technical features but also its accessibility and adaptability. Let’s examine the key factors that set Python apart:
Ease of Learning Python’s clean and readable syntax makes it beginner-friendly, attracting newcomers to the world of programming. This ease of use also enables non-programmers, such as researchers and analysts, to leverage Python effectively.
Community Support Python boasts one of the largest and most active communities. This global network of developers continuously contributes to its growth by creating libraries, frameworks, and tools that address evolving industry needs.
Cross-Domain Applications Python isn’t limited to a single industry. Its versatility spans across web development, automation, data analysis, artificial intelligence, and even creative fields like game design and music.
Integration with Other Technologies Python plays well with other languages and tools, making it a preferred choice for integrating systems and technologies.
Real-World Applications of Python
Python’s influence is evident in its diverse applications, which make it indispensable for businesses and industries.
Data Science and Analytics Python is the go-to language for data scientists. Its libraries like Pandas, NumPy, and Matplotlib simplify data manipulation, visualization, and analysis. Organizations rely on Python to extract insights from massive datasets, driving informed decision-making.
Artificial Intelligence and Machine Learning Frameworks like TensorFlow and Scikit-learn have made Python a leader in AI and ML development. Companies use these technologies to create smart applications, from chatbots to recommendation systems.
Web Development Python-powered frameworks like Django and Flask have revolutionized web development. These tools enable developers to create secure, scalable, and feature-rich web applications quickly.
Automation Python’s simplicity makes it ideal for automating repetitive tasks. From scraping web data to managing workflows, Python helps businesses save time and resources.
Education Python’s intuitive nature has made it a staple in educational institutions. It’s often used to introduce students to programming concepts due to its simplicity and relevance.
Creative Industries Python has found its place in game development, music production, and even digital art. Tools like Blender and PyGame rely on Python to create immersive experiences.
Python's Role in Shaping Industries
Python’s impact extends to transforming industries by enabling innovation and improving efficiency:
Healthcare Python is used in medical research for analyzing complex datasets, developing diagnostic tools, and even managing hospital systems.
Finance Financial institutions use Python for risk analysis, fraud detection, and algorithmic trading, leveraging its precision and scalability.
E-commerce Platforms like Amazon and Shopify use Python to enhance user experience, optimize search algorithms, and manage large inventories.
Entertainment Streaming giants like Netflix rely on Python for recommendation algorithms and managing content delivery networks.
Manufacturing Python’s role in IoT and predictive maintenance ensures smooth operations and reduces downtime in factories.
The Human Element: Python’s Community
The heart of Python lies in its community. Developers, educators, and enthusiasts worldwide contribute to Python’s success by sharing knowledge, creating resources, and supporting newcomers. The open-source nature of Python ensures its continuous growth and adaptation to new challenges.
Whether through meetups, forums, or conferences like PyCon, Python’s community fosters collaboration and innovation, ensuring the language remains relevant for years to come.
The Future of Python
Python’s journey is far from over. With advancements in technology, Python is set to play a pivotal role in areas such as:
Quantum Computing Python libraries like Cirq and Qiskit are paving the way for quantum computing, unlocking new possibilities in problem-solving.
Sustainability Python’s analytical capabilities can address environmental challenges by optimizing resource use and analyzing climate data.
Education Python will continue to democratize coding education, empowering learners from diverse backgrounds to enter the tech world.
Ethical AI Development Python’s frameworks will contribute to creating transparent and ethical AI systems that align with societal values.
Conclusion
Python is more than just a programming language; it’s a catalyst for innovation and collaboration. Its adaptability, extensive community support, and applications across industries make it a cornerstone of modern technology.
Whether you’re a business aiming to innovate or an individual looking to build a career, Python offers endless opportunities. Its simplicity and versatility ensure that it remains a language not just for coders but for thinkers and creators across the globe.
If you’re ready to embark on this exciting journey, consider learning Python to unlock its full potential and stay ahead in the digital age.
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
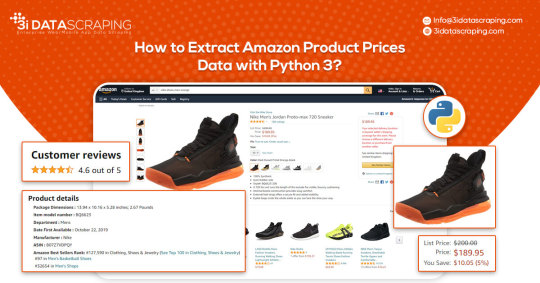
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
A Guide to Web Scraping Amazon Fresh for Grocery Insights

Introduction
In the e-commerce landscape, Amazon Fresh stands out as a major player in the grocery delivery sector. Extracting data from Amazon Fresh through web scraping offers valuable insights into:
Grocery pricing and discount patterns
Product availability and regional variations
Delivery charges and timelines
Customer reviews and ratings
Using Amazon Fresh grocery data for scraping helps businesses conduct market research, competitor analysis, and pricing strategies. This guide will show you how the entire process works, from setting up your environment to analyzing the data that have been extracted.
Why Scrape Amazon Fresh Data?
✅ 1. Competitive Pricing Analysis
Track price fluctuations and discounts.
Compare prices with other grocery delivery platforms.
✅ 2. Product Availability and Trends
Monitor product availability by region.
Identify trending or frequently purchased items.
✅ 3. Delivery Time and Fee Insights
Understand delivery fee variations by location.
Track delivery time changes during peak hours.
✅ 4. Customer Review Analysis
Extract and analyze product reviews.
Identify common customer sentiments and preferences.
✅ 5. Supply Chain and Inventory Monitoring
Monitor out-of-stock products.
Analyze restocking patterns and delivery speeds.
Legal and Ethical Considerations
Before starting Amazon Fresh data scraping, it’s important to follow legal and ethical practices:
✅ Respect robots.txt: Check Amazon’s robots.txt file for any scraping restrictions.
✅ Rate Limiting: Add delays between requests to avoid overloading Amazon’s servers.
✅ Data Privacy Compliance: Follow data privacy regulations like GDPR and CCPA.
✅ No Personal Data: Avoid collecting or using personal customer information.
Setting Up Your Web Scraping Environment
1. Tools and Libraries Needed
To scrape Amazon Fresh, you’ll need:
✅ Python: For scripting the scraping process.
✅ Libraries:
requests – To send HTTP requests.
BeautifulSoup – For HTML parsing.
Selenium – For handling dynamic content.
Pandas – For data analysis and storage.
2. Install the Required Libraries
Run the following commands to install the necessary libraries:pip install requests beautifulsoup4 selenium pandas
3. Choose a Browser Driver
Amazon Fresh uses dynamic JavaScript rendering. To extract dynamic content, use ChromeDriver with Selenium.
Step-by-Step Guide to Scraping Amazon Fresh Data
Step 1: Inspecting Amazon Fresh Website Structure
Before scraping, examine the HTML structure of the Amazon Fresh website:
Product names
Prices and discounts
Product categories
Delivery times and fees
Step 2: Extracting Static Data with BeautifulSoup
import requests from bs4 import BeautifulSoup url = "https://www.amazon.com/Amazon-Fresh-Grocery/b?node=16310101" headers = {"User-Agent": "Mozilla/5.0"} response = requests.get(url, headers=headers) soup = BeautifulSoup(response.content, "html.parser") # Extract product titles titles = soup.find_all('span', class_='a-size-medium') for title in titles: print(title.text)
Step 3: Scraping Dynamic Data with Selenium
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service import time # Set up Selenium driver service = Service("/path/to/chromedriver") driver = webdriver.Chrome(service=service) # Navigate to Amazon Fresh driver.get("https://www.amazon.com/Amazon-Fresh-Grocery/b?node=16310101") time.sleep(5) # Extract product names titles = driver.find_elements(By.CLASS_NAME, "a-size-medium") for title in titles: print(title.text) driver.quit()
Step 4: Extracting Product Pricing and Delivery Data
driver.get("https://www.amazon.com/product-page-url") time.sleep(5) # Extract item name and price item_name = driver.find_element(By.ID, "productTitle").text price = driver.find_element(By.CLASS_NAME, "a-price").text print(f"Product: {item_name}, Price: {price}") driver.quit()
Step 5: Storing and Analyzing the Extracted Data
import pandas as pd data = {"Product": ["Bananas", "Bread"], "Price": ["$1.29", "$2.99"]} df = pd.DataFrame(data) df.to_csv("amazon_fresh_data.csv", index=False)
Analyzing Amazon Fresh Data for Business Insights
✅ 1. Pricing Trends and Discount Analysis
Track price changes over time.
Identify seasonal discounts and promotions.
✅ 2. Delivery Fee and Time Insights
Compare delivery fees by region.
Identify patterns in delivery time during peak hours.
✅ 3. Product Category Trends
Identify the most popular grocery items.
Analyze trending products by region.
✅ 4. Customer Review and Rating Analysis
Extract customer reviews for sentiment analysis.
Identify frequently mentioned keywords.
Challenges in Amazon Fresh Scraping and Solutions
Challenge: Dynamic content rendering — Solution: Use Selenium for JavaScript data
Challenge: CAPTCHA verification — Solution: Use CAPTCHA-solving services
Challenge: IP blocking — Solution: Use proxies and user-agent rotation
Challenge: Data structure changes — Solution: Regularly update scraping scripts
Best Practices for Ethical and Effective Scraping
✅ Respect robots.txt: Ensure compliance with Amazon’s web scraping policies.
✅ Use proxies: Prevent IP bans by rotating proxies.
✅ Implement delays: Use time delays between requests.
✅ Data usage: Use the extracted data responsibly and ethically.
Conclusion
Scraping Amazon Fresh gives valuable grocery insights into pricing trends, product availability, and delivery details. This concise but detailed tutorial helps one in extracting the grocery data from Amazon Fresh efficiently for competitive analysis, market research, and pricing strategies.
For large-scale or automated Amazon Fresh-like data scraping, consider using CrawlXpert. CrawlXpert will facilitate your data collection process and give you more time to focus on actionable insights.
Start scrapping Amazon Fresh today to leverage powerful grocery insights!
Know More : https://www.crawlxpert.com/blog/web-scraping-amazon-fresh-for-grocery-insights
0 notes
Text
News Extract: Unlocking the Power of Media Data Collection
In today's fast-paced digital world, staying updated with the latest news is crucial. Whether you're a journalist, researcher, or business owner, having access to real-time media data can give you an edge. This is where news extract solutions come into play, enabling efficient web scraping of news sources for insightful analysis.

Why Extracting News Data Matters
News scraping allows businesses and individuals to automate the collection of news articles, headlines, and updates from multiple sources. This information is essential for:
Market Research: Understanding trends and shifts in the industry.
Competitor Analysis: Monitoring competitors’ media presence.
Brand Reputation Management: Keeping track of mentions across news sites.
Sentiment Analysis: Analyzing public opinion on key topics.
By leveraging news extract techniques, businesses can access and process large volumes of news data in real-time.
How News Scraping Works
Web scraping involves using automated tools to gather and structure information from online sources. A reliable news extraction service ensures data accuracy and freshness by:
Extracting news articles, titles, and timestamps.
Categorizing content based on topics, keywords, and sentiment.
Providing real-time or scheduled updates for seamless integration into reports.
The Best Tools for News Extracting
Various scraping solutions can help extract news efficiently, including custom-built scrapers and APIs. For instance, businesses looking for tailored solutions can benefit from web scraping services India to fetch region-specific media data.
Expanding Your Data Collection Horizons
Beyond news extraction, companies often need data from other platforms. Here are some additional scraping solutions:
Python scraping Twitter: Extract real-time tweets based on location and keywords.
Amazon reviews scraping: Gather customer feedback for product insights.
Flipkart scraper: Automate data collection from India's leading eCommerce platform.
Conclusion
Staying ahead in today’s digital landscape requires timely access to media data. A robust news extract solution helps businesses and researchers make data-driven decisions effortlessly. If you're looking for reliable news scraping services, explore Actowiz Solutions for customized web scraping solutions that fit your needs.
#news extract#web scraping services India#Python scraping Twitter#Amazon reviews scraping#Flipkart scraper#Actowiz Solutions
0 notes
Text
How Can You Scrape Amazon Reviews Quickly And Efficiently?

Struggling to gather valuable customer insights from Amazon reviews? Are you tired of manually copying and pasting reviews one by one?
But what if there was a faster, more innovative way? This blog will guide you through the best practices for scraping Amazon reviews. This will help you unlock a treasure of data, providing you with the potential to improve product quality, refine marketing strategies, and stay ahead of the competition.
What is Amazon Review Scraping?
Amazon customer review scraping automatically extracts customer reviews and their details from Amazon product pages.
Review text What customers say about the product, both positive and negative.
Ratings The star rating assigned by the reviewer
Reviewer details Username, location (if provided), and potentially even purchase history (depending on scraping method).
Date of review When the review was posted.
Benefits of Scraping Amazon Reviews

Scraping Amazon customer reviews can be a powerful tool for businesses and researchers alike. Here are seven key benefits:
Gain Customer Insights
Reviews are full of true customer stories. By scraping them, you can quickly review a lot of information to determine how customers feel, spot frequent issues, and determine which features they like.
Product Improvement
Find out how to improve your or your competitors' products. Look for what customers often like or don't like to help you decide what to do next with your products and how to advertise them.
Market Research
Find out what's currently popular and which products people like in a specific area. By looking at what people say in reviews, you can determine what they want and use this knowledge to decide which products to sell or what moves to make in your business.
Competitive Analysis
See how your products stack up against others. Check out what people say about your competitors to know what they're good at and where they fall short. This can help you find ways to do better than them.
Sentiment Analysis
Look beyond just the number of stars a product gets. By scraping, you can study how customers feel as they write reviews, determining if their thoughts on a product are happy, unhappy, or somewhere in between.
Price Optimization
Look at how the price affects what customers think. Check if reviews get better or worse with different prices to help you decide how much to charge and stay competitive.
Content Creation
Reviews are great for brainstorming marketing ideas. You can quote positive reviews to write attractive product details or customer praise for your website.
How to Scrape Amazon Reviews?
Here's a general overview of how amazon review scraper works:
Choose Your Tools:
There are two main approaches to scraping Amazon reviews:
Web Scraping Libraries Libraries like Beautiful Soup (Python) or Cheerio (JavaScript) allow you to parse HTML content from websites. You can write scripts to extract review data based on specific HTML elements.
Pre-built Scraping Tools Several online tools offer scraping functionalities for Amazon reviews. These tools often have user-friendly interfaces and may require minimal coding knowledge.
Identify Review Elements
Inspect the HTML structure of an Amazon product page to identify the elements containing review data. This typically includes sections with review text, star ratings, reviewer names (if available), and dates.
Extract the Data
Using Libraries With libraries like Beautiful Soup, you can write code to navigate the HTML structure and extract the desired data points using selectors like CSS selectors or XPath.
Pre-built ToolsThese tools often have built-in functionalities to target specific elements and extract the relevant review data.
Handle pagination
If there are multiple review pages, you'll need to handle pagination to scrape all of them. This might involve finding URLs for subsequent review pages or using features within your amazon review scraper to navigate them automatically.
Store the Data
The scraped data can be stored in various formats like CSV (comma-separated values) or JSON (JavaScript Object Notation) for further analysis or use in other applications.
Methods to Scrape Amazon Reviews Quickly and Effectively
Here are some methods to scrape Amazon reviews quickly and effectively, categorized by their technical complexity:
Pre-built Scraping Tools (Low Technical Knowledge):
Web Scraping Platforms Several online platforms like Reviewgators or Scrapy offer pre-built tools specifically designed for scraping Amazon reviews. These tools are easy to use and don't require much coding skills. You just set up the product link and pick what details you want to gather.
Browser ExtensionsCertain browser extensions offer scraping functionalities for Amazon reviews. These extensions might be a good starting point for simple scraping tasks, but they may need to be improved, and data extraction capabilities may be limitations.
Programming Libraries (Medium Technical Knowledge):
Python Libraries Libraries like Beautiful Soup or Scrapy (Python) allow you to write scripts to parse the HTML content of Amazon product pages. You can leverage these libraries to target specific review data elements using selectors like CSS or XPath. This method offers more control and customization than pre-built tools but requires some programming knowledge.
JavaScript LibrariesLibraries like Cheerio (JavaScript) offer similar functionalities to Python libraries, allowing you to scrape Amazon reviews within a JavaScript environment. This approach might be suitable if you're already working with JavaScript for other purposes.
Web Scraping APIs (Medium to High Technical Knowledge):
Web Scraping APIs Services like Crawlbase or ParseHub offer APIs that allow you to access scraped data from Amazon reviews programmatically. These review scraper APIs handle the complexities of web scraping, like managing user-agent headers, rotating IP addresses, and respecting robots.txt files. This method requires coding knowledge to integrate the amazon review scraper API into your application but offers a robust and scalable solution.
Tips for Faster and More Effective Scraping

By choosing the best practices and following these tips, you can scrape Amazon reviews quickly and effectively, gaining valuable insights for your research or business needs.
Focus on Specific Data Points
Identify the exact review elements you need (text, rating, date) and tailor your scraping process accordingly.
Utilize Rate Limiting
Implement delays between scraping requests to avoid overwhelming Amazon's servers and potential IP blocking.
Handle Pagination Automatically
Use libraries or tools that can automatically navigate through multiple review pages.
Store Data Efficiently
Choose appropriate data formats (CSV, JSON) and consider cloud storage solutions for large datasets.
Respect Amazon's TOS
Always prioritize ethical scraping practices and comply with Amazon's Terms of Service (TOS) and the robots.txt file.
Responsible Scraping
Avoid overloading Amazon's servers and scrape only what you need. Consider using proxy services to rotate your IP address if necessary.
Legal and Ethical Considerations
Research scraping regulations and ensure your use case complies with ethical practices.
Conclusion
Using these scraping methods, you can change how you do research, get important information quickly, and get ahead in your market. It's important to scrape the right way, follow Amazon's ToS, and prioritize ethical practices.
Companies like Reviewsgator provide strong scraping tools and help for businesses big and small that want an easier way. They can deal with the hard parts, so you can use customer reviews to improve your business!
Know more https://www.reviewgators.com/scrape-amazon-reviews-quickly-and-efficiently.php
0 notes
Text
How to Scrape Product Reviews from eCommerce Sites?
Know More>>https://www.datazivot.com/scrape-product-reviews-from-ecommerce-sites.php
Introduction In the digital age, eCommerce sites have become treasure troves of data, offering insights into customer preferences, product performance, and market trends. One of the most valuable data types available on these platforms is product reviews. To Scrape Product Reviews data from eCommerce sites can provide businesses with detailed customer feedback, helping them enhance their products and services. This blog will guide you through the process to scrape ecommerce sites Reviews data, exploring the tools, techniques, and best practices involved.
Why Scrape Product Reviews from eCommerce Sites? Scraping product reviews from eCommerce sites is essential for several reasons:
Customer Insights: Reviews provide direct feedback from customers, offering insights into their preferences, likes, dislikes, and suggestions.
Product Improvement: By analyzing reviews, businesses can identify common issues and areas for improvement in their products.
Competitive Analysis: Scraping reviews from competitor products helps in understanding market trends and customer expectations.
Marketing Strategies: Positive reviews can be leveraged in marketing campaigns to build trust and attract more customers.
Sentiment Analysis: Understanding the overall sentiment of reviews helps in gauging customer satisfaction and brand perception.
Tools for Scraping eCommerce Sites Reviews Data Several tools and libraries can help you scrape product reviews from eCommerce sites. Here are some popular options:
BeautifulSoup: A Python library designed to parse HTML and XML documents. It generates parse trees from page source code, enabling easy data extraction.
Scrapy: An open-source web crawling framework for Python. It provides a powerful set of tools for extracting data from websites.
Selenium: A web testing library that can be used for automating web browser interactions. It's useful for scraping JavaScript-heavy websites.
Puppeteer: A Node.js library that gives a higher-level API to control Chromium or headless Chrome browsers, making it ideal for scraping dynamic content.
Steps to Scrape Product Reviews from eCommerce Sites Step 1: Identify Target eCommerce Sites First, decide which eCommerce sites you want to scrape. Popular choices include Amazon, eBay, Walmart, and Alibaba. Ensure that scraping these sites complies with their terms of service.
Step 2: Inspect the Website Structure Before scraping, inspect the webpage structure to identify the HTML elements containing the review data. Most browsers have built-in developer tools that can be accessed by right-clicking on the page and selecting "Inspect" or "Inspect Element."
Step 3: Set Up Your Scraping Environment Install the necessary libraries and tools. For example, if you're using Python, you can install BeautifulSoup, Scrapy, and Selenium using pip:
pip install beautifulsoup4 scrapy selenium Step 4: Write the Scraping Script Here's a basic example of how to scrape product reviews from an eCommerce site using BeautifulSoup and requests:
Step 5: Handle Pagination Most eCommerce sites paginate their reviews. You'll need to handle this to scrape all reviews. This can be done by identifying the URL pattern for pagination and looping through all pages:
Step 6: Store the Extracted Data Once you have extracted the reviews, store them in a structured format such as CSV, JSON, or a database. Here's an example of how to save the data to a CSV file:
Step 7: Use a Reviews Scraping API For more advanced needs or if you prefer not to write your own scraping logic, consider using a Reviews Scraping API. These APIs are designed to handle the complexities of scraping and provide a more reliable way to extract ecommerce sites reviews data.
Step 8: Best Practices and Legal Considerations Respect the site's terms of service: Ensure that your scraping activities comply with the website’s terms of service.
Use polite scraping: Implement delays between requests to avoid overloading the server. This is known as "polite scraping."
Handle CAPTCHAs and anti-scraping measures: Be prepared to handle CAPTCHAs and other anti-scraping measures. Using services like ScraperAPI can help.
Monitor for changes: Websites frequently change their structure. Regularly update your scraping scripts to accommodate these changes.
Data privacy: Ensure that you are not scraping any sensitive personal information and respect user privacy.
Conclusion Scraping product reviews from eCommerce sites can provide valuable insights into customer opinions and market trends. By using the right tools and techniques, you can efficiently extract and analyze review data to enhance your business strategies. Whether you choose to build your own scraper using libraries like BeautifulSoup and Scrapy or leverage a Reviews Scraping API, the key is to approach the task with a clear understanding of the website structure and a commitment to ethical scraping practices.
By following the steps outlined in this guide, you can successfully scrape product reviews from eCommerce sites and gain the competitive edge you need to thrive in today's digital marketplace. Trust Datazivot to help you unlock the full potential of review data and transform it into actionable insights for your business. Contact us today to learn more about our expert scraping services and start leveraging detailed customer feedback for your success.
#ScrapeProduceReviewsFromECommerce#ExtractProductReviewsFromECommerce#ScrapingECommerceSitesReviews Data#ScrapeProductReviewsData#ScrapeEcommerceSitesReviewsData
0 notes
Text
What is E-commerce Price Data Scraping, and Why is it Important for Businesses?
E-commerce price data scraping collects pricing information from various online sources, such as e-commerce websites. This process involves using specialized software tools such as web scrapers or price scrapers to gather pricing data automatically. E-commerce price data scraping is essential for businesses operating in the e-commerce sector, as it provides valuable insights into pricing strategies, market trends, and competitor pricing.
By scraping e-commerce price data, businesses can monitor competitors' prices in real-time, track price trends, and make informed pricing decisions. This data can also be used to optimize pricing strategies, identify pricing opportunities, and improve overall market competitiveness.
Different Types of E-commerce Websites
Listed below are some of the most popular e-commerce websites
Amazon is a leading e-commerce platform offering a wide range of products. Price scraping on Amazon allows businesses to monitor competitor prices, track market trends, and optimize their pricing strategies.
eBay is a popular online marketplace where users can buy and sell new and used items. Scraping eBay product data helps sellers track competitor pricing, identify profitable niches, and optimize their product listings.
Walmart is a major retailer with a significant online presence. Scraping Walmart's website product data can provide valuable pricing and product information for businesses looking to compete in the retail market.
Target is another prominent retailer offering a variety of products online. Scraping Target's website product data enables businesses to gather pricing data, analyze market trends, and make informed decisions about their product offerings.
How Does E-commerce Product Price Scraping Help Businesses?
E-commerce product price scraping helps businesses by providing insights into competitors' pricing strategies, enabling informed pricing decisions.
Competitor Analysis: E-commerce product price scraping services allow businesses to conduct thorough competitor analysis. By monitoring competitors' pricing strategies, businesses can adjust their prices to stay competitive.
Price Trend Identification: Scraping product prices from e-commerce websites helps businesses identify trends over time. This information is valuable for setting pricing strategies and predicting future price changes.
Promotional Strategy Optimization: Price scraping enables businesses to track competitors' promotional strategies, such as discounts and offers. This information can help businesses optimize their promotional strategies to attract more customers.
Market Entry Planning: Before entering a new market, businesses can use price scraper to gather pricing data from existing competitors. This information helps them develop competitive pricing strategies for the new market.
Product Assortment Planning: Price scraping can also help businesses plan product assortment. By analyzing pricing data for different products, businesses can determine which products to stock and at what price points.
Brand Perception Management: Monitoring product prices in relation to competitors can help businesses manage their brand perception. By offering competitive prices, businesses can position themselves as value-for-money or premium brands.
Dynamic Inventory Pricing: Price scraping services can assist businesses in dynamically pricing their inventory based on factors such as demand, seasonality, and competitor prices. It can help maximize revenue and minimize losses.
Steps to Scrape eBay Product Price Data using Python
This tutorial will demonstrate step-by-step instructions for scraping e-commerce product price data using Python, focusing on eBay as our example. This guide will cover setting up the scraping environment, writing Python code to extract the data, and organizing the scraped data for analysis. Following these steps, you'll learn to efficiently gather pricing information from e-commerce websites for your analysis and decision-making processes.
Here is a more detailed guide on how to scrape eBay product price data using Python for a specific category:
Install Required Libraries: First, install the necessary libraries. You'll need requests, beautifulsoup4, and pandas. Use pip to install them:pip install requests beautifulsoup4 pandas
Import Libraries: Import the required libraries into your Python script:
import requestsfrom bs4 import BeautifulSoup import pandas as pd
Set URL and Headers: Define the URL of the eBay category you want to scrape and set the user-agent header to mimic a web browser:url = 'https://www.ebay.com/b/Cell-Phones-Smartphones/9355/bn_320094' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Apple WebKit/537. 36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
Send a GET Request: Use the requests library to send a GET request to the eBay URL and get the webpage content:response = requests.get (url, headers = headers)
Analyze the HTML Content: Parse the webpage’s HTML content using BeautifulSoup:soup = BeautifulSoup(response.content, 'html.parser')
Find Product Containers: Find all the containers that hold the product information. Inspect the eBay webpage to identify the HTML structure:product_containers = soup.find_all('div', class_='s-item__info')
Extract Product Data: Iterate through each product container and extract relevant data such as product name, price, and URL:product_data = [] for container in product_containers: name = container.find('h3', class_='s-item__title').text price = container.find('span', class_='s-item__price').text url = container.find('a', class_='s-item__link').get('href') product_data.append({'Name': name, 'Price': price, 'URL': url})
Create a DataFrame: Convert the list of product data into a pandas DataFrame for easier manipulation:df = pd.DataFrame(product_data)
Clean the Data: Clean the data as needed. For example, remove non-numeric characters from the price column and convert it to a numeric data type:df['Price'] = df['Price'].str.replace('$', '').astype(float)
Save or Analyze the Data: You can save the scraped data to a CSV file or perform further analysis and visualization using pandas and other libraries.
This detailed guide provides a comprehensive framework for scraping eBay product price data using Python. You can modify the code to scrape other categories on eBay or apply similar techniques to scrape data from other e-commerce websites.
Conclusion: Scraping prices from eCommerce websites can give businesses valuable insights into market trends, competitor pricing strategies, and consumer behavior. Businesses can automate collecting and analyzing price data by leveraging Python libraries such as requests, beautifulsoup4, and pandas, saving time and resources. However, it's important to note that scraping data from websites should be done ethically and comply with the website's terms of service. With the right approach, scraping prices can help businesses make informed decisions about pricing strategies, product offerings, and overall market positioning, ultimately leading to increased competitiveness and profitability in the eCommerce landscape.
Know More https://www.iwebdatascraping.com/e-commerce-price-data-scraping-for-businesses.php
#ScrapeE-commercePriceData#E-commercePriceDataScraping#ExtractE-commercePriceData#E-commercePriceDataExtractor#E-commercePriceDataCollection#E-commercePriceDataExtension#E-commercePriceDataScraper
0 notes
Text
The Advantages of Using Python: A Comprehensive Guide
Python has become one of the most popular programming languages in the world, thanks to its simplicity, versatility, and powerful capabilities. Whether you are a beginner or an experienced developer, Python offers a range of benefits that make it an ideal choice for various applications.
Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

This guide explores the key advantages of using Python and why it is a preferred language for developers across industries.
1. Easy to Learn and Readable Syntax
One of the main reasons for Python’s widespread adoption is its simple and readable syntax. Unlike other programming languages that use complex structures, Python follows a clean and easy-to-understand format. This makes it an excellent choice for beginners while also allowing experienced developers to write clear and maintainable code.
2. Versatile and Widely Used
Python is not limited to a single field—it is used across various domains, including:
Web Development – Popular frameworks like Django and Flask allow developers to create robust web applications.
Data Science and Machine Learning – Python’s libraries like Pandas, NumPy, TensorFlow, and Scikit-learn make it the go-to language for data analysis and AI.
Automation and Scripting – Python is widely used to automate repetitive tasks, such as data entry and web scraping.
Cybersecurity – Ethical hackers and security analysts use Python for penetration testing and threat analysis.
Game Development – Libraries like Pygame help in developing simple to complex games.
3. Large Collection of Libraries and Frameworks
Python provides a vast ecosystem of libraries and frameworks that simplify coding and accelerate development. Some of the most commonly used ones include:
NumPy and Pandas – For data manipulation and analysis
Matplotlib and Seaborn – For data visualization
TensorFlow and PyTorch – For machine learning and deep learning
Django and Flask – For web development
Requests and BeautifulSoup – For web scraping
These pre-built libraries save developers time and effort by providing ready-to-use functionalities. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

4. High Demand and Career Growth
Python developers are in high demand across multiple industries, including finance, healthcare, e-commerce, and technology. Many top companies like Google, Facebook, Netflix, and Amazon rely on Python for various applications. Learning Python opens doors to lucrative job opportunities and career advancement.
5. Cross-Platform Compatibility
Python is a cross-platform language, meaning that code written in Python can run on different operating systems such as Windows, macOS, and Linux with minimal modifications. This flexibility makes it an excellent choice for developers working on multiple platforms.
6. Strong Community Support
With a vast and active community, Python developers can find support through online forums, documentation, and open-source projects. Whether you need troubleshooting help or advanced coding solutions, Python’s community is always ready to assist.
7. Excellent for Automation
Python’s simplicity and scripting capabilities make it an excellent choice for automating repetitive tasks. Many IT professionals and software testers use Python to automate processes such as file management, data extraction, and system monitoring.
8. Scalability and Performance
Python is highly scalable, making it suitable for both small projects and large-scale enterprise applications. With optimization techniques and integrations like Cython, JIT compilers, and multiprocessing, Python can handle performance-intensive tasks efficiently.
Conclusion
Python’s ease of use, versatility, and powerful libraries make it one of the best programming languages for developers of all skill levels. Whether you are building websites, analyzing data, automating tasks, or working on artificial intelligence, Python provides the tools and resources to help you succeed.
If you are considering learning Python, now is the perfect time to start. With its growing demand and wide range of applications, mastering Python can open up exciting career opportunities.
0 notes
Text
Check List To Build Amazon Reviews Scraper
Let's dive into the realm of Amazon, a behemoth in the online marketplace sphere renowned for its vast repository of invaluable data for businesses. Whether it's perusing product descriptions or dissecting customer reviews, the potential insights garnered from Amazon's data reservoir are immense. With the aid of web scraping tools, one can effortlessly tap into this trove of information and derive actionable intelligence.
Amazon's staggering fiscal statistics for 2021, showcasing a whopping $125.6 billion in fourth-quarter sales revenue, underscore its unparalleled prominence in the e-commerce landscape. Notably, consumer inclination towards Amazon is strikingly evident, with nearly 90% expressing a preference for purchasing from this platform over others.
A pivotal driving force behind Amazon's soaring sales figures is its treasure trove of customer reviews. Studies reveal that a staggering 73% of consumers are inclined to trust e-commerce platforms boasting positive customer feedback. Consequently, businesses, both budding and established, are increasingly turning to Amazon review scrapers to extract and harness this invaluable data.
The significance of Amazon review data cannot be overstated, particularly for emerging businesses seeking to gain a competitive edge. With over 4,000 items sold per minute in the US alone, these enterprises leverage Amazon review scrapers to glean insights into consumer sentiments and market trends, thereby refining their strategies and offerings.
So, what makes Amazon review scrapers indispensable? These tools serve as a conduit for businesses to decipher product rankings, discern consumer preferences, and fine-tune their marketing strategies. By harnessing review data scraped from Amazon, sellers can enhance their product offerings and bolster customer satisfaction.
Moreover, Amazon review scrapers facilitate comprehensive competitor analysis, enabling businesses to gain a deeper understanding of market dynamics and consumer preferences. Armed with this intelligence, enterprises can tailor their offerings to better resonate with their target audience, thereby amplifying their market presence and competitiveness.
For large-scale enterprises grappling with vast product inventories, monitoring individual product performances can be daunting. However, Amazon web scraping tools offer a solution by furnishing insights into product-specific performance metrics and consumer sentiments, thus empowering businesses to fine-tune their strategies and bolster their online reputation.
Sentiment analysis, another key facet of Amazon review scraping, enables businesses to gauge consumer sentiment towards their products. By parsing through review data, sellers can gain invaluable insights into consumer perceptions and sentiments, thereby informing their decision-making processes and enhancing customer engagement strategies.
Building an effective Amazon review scraper necessitates meticulous planning and execution. From analyzing the HTML structure of target web pages to implementing Scrapy parsers in Python, each step is crucial in ensuring the seamless extraction and organization of review data. Moreover, leveraging essential tools such as Python, ApiScrapy, and a basic understanding of HTML tags is imperative for developing a robust Amazon review scraper.
However, the journey towards scraping Amazon reviews is fraught with challenges. Amazon's stringent security measures, including CAPTCHAS and IP bans, pose formidable obstacles to scraping activities. Additionally, the variability in page structures and the resource-intensive nature of review data necessitate adept handling and sophisticated infrastructure.
In conclusion, the efficacy of Amazon review scraping in driving business growth and informing strategic decisions cannot be overstated. By harnessing the power of web scraping tools and leveraging Amazon's wealth of review data, businesses can gain invaluable insights into consumer preferences, market trends, and competitor landscapes, thereby charting a course towards sustained success and competitiveness in the dynamic e-commerce arena.
0 notes
Text
How to Extract Amazon Reviews: Navigating Code and No-Code Solutions

How to Extract Amazon Reviews: Navigating Code and No-Code Solutions
Oct 20, 2023
Introduction
In the dynamic landscape of e-commerce, Amazon reviews serve as invaluable sources of insights, influencing purchasing decisions and providing crucial feedback for both consumers and sellers. Extracting this wealth of information can be approached through two distinct avenues: code-based and no-code solutions. In this guide, we embark on a journey to unravel the intricacies of Amazon review extraction, exploring the depths of coding methodologies and user-friendly no-code alternatives.
Code-based solutions involve:
Leveraging programming languages like Python.
Utilizing tools like BeautifulSoup and Scrapy to navigate Amazon's web structure.
Programmatically fetching review data.
We'll delve into the intricacies of these scripts, providing step-by-step instructions to empower those with coding prowess.
For those seeking a more accessible route, no-code solutions offer a compelling alternative. Platforms like Mobile App Scraping provide intuitive interfaces for users with varying technical backgrounds to scrape Amazon reviews effortlessly. We'll navigate through these user-friendly tools, illustrating how anyone, regardless of coding expertise, can extract valuable insights from Amazon's extensive review database.
Whether you're a seasoned coder or a novice seeking simplicity, this guide equips you with the knowledge to extract Amazon reviews effectively, opening the door to a wealth of consumer sentiments and market intelligence.
Understanding The Basics
In e-commerce, scraping Amazon reviews has become a pivotal practice for businesses and consumers. Understanding the significance of this process is crucial for unlocking valuable insights that can shape purchasing decisions and refine product offerings.
Amazon reviews encompass a wealth of information, providing a multifaceted view of customer experiences. Firstly, product feedback serves as a direct line of communication from consumers to sellers, offering insights into the strengths and weaknesses of a product. Positive feedback highlights features that resonate with customers, acting as an endorsement for potential buyers. Conversely, negative feedback pinpoints areas of improvement and potential pain points that need addressing.
Ratings, another critical component of Amazon reviews, distill customer satisfaction into a numerical form. These aggregate scores offer a quick snapshot of a product's overall reception, aiding consumers in making informed choices amid a sea of options.
Beyond the quantitative aspects, customer sentiments expressed in reviews offer qualitative insights. Understanding the emotions and opinions of users provides businesses with a nuanced understanding of their audience, helping them tailor products and services to meet consumer expectations.
Scraping Amazon reviews unveils a treasure trove of information encompassing product performance, user satisfaction, and sentiments — insights instrumental in refining marketing strategies, enhancing product development, and ultimately fostering a symbiotic relationship between sellers and consumers.
Code Approach
Python and BeautifulSoup
Python, coupled with the BeautifulSoup library, forms a robust duo for web scraping, offering a powerful combination for extracting Amazon review data. Here's a step-by-step guide to help you navigate through the process:
Environment Setup
Begin by ensuring Python is installed on your system. You can install BeautifulSoup using pip:pip install beautifulsoup4
Library Installation
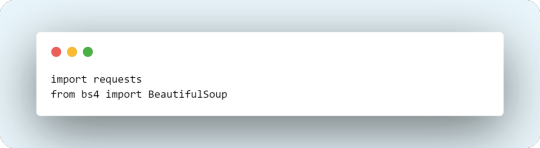
Amazon URL Retrieval

Parsing HTML
Utilize BeautifulSoup to parse the HTML content:soup = BeautifulSoup(response.text, 'html.parser')
Locating Review Elements
Inspect the HTML structure of the page to identify the elements containing review data. Use BeautifulSoup's methods to navigate through the document and locate these elements.
Data Extraction

Data Storage
Depending on your needs, store the extracted data in a suitable format, such as a CSV file or a database.
By following these steps, you can harness the power of Python and BeautifulSoup to scrape Amazon reviews efficiently, providing a foundation for insightful analysis and data-driven decision-making.
Scrapy Framework
The Scrapy framework stands out as a sophisticated and advanced option for scraping Amazon reviews, offering a comprehensive toolkit that streamlines the entire process. Unlike simple scripts, Scrapy provides a robust, extensible architecture specifically designed for web crawling and data extraction.
Installation and Project Initialization
Start by installing Scrapy using pip:pip install scrapy
Initiate a Scrapy project with the command:Initiate a Scrapy project with the command:
Spider Creation
Define a spider within the project to specify how to navigate and extract data from Amazon's pages. Scrapy's spider simplifies the process of traversing links, making it highly efficient for scraping multiple pages.
XPath and Selectors
Scrapy utilizes XPath selectors, offering a powerful and flexible way to navigate HTML and XML documents. This enables precise targeting of elements containing Amazon review data.
Item Pipelines
The framework incorporates item pipelines that facilitate the processing and storage of scraped data. Define custom pipelines to handle extracted Amazon review information seamlessly.
Concurrency and Speed
Scrapy is built for performance, employing asynchronous processing to enhance speed. This is particularly beneficial when scraping large volumes of data, such as extensive Amazon review pages.
Middleware and Extensions
Leverage Scrapy's middleware and extensions to implement custom functionalities and address specific challenges during the scraping process. This adaptability makes Scrapy well-suited for complex scraping scenarios.
Built-in Logging and Error Handling
Scrapy comes with built-in logging and error handling mechanisms, providing developers with insights into the scraping process and making it easier to troubleshoot issues.
By utilizing the Scrapy framework, developers can harness a powerful toolset to streamline the extraction of Amazon review data. Its advanced features and flexibility make it particularly effective for large-scale scraping projects, providing a solid foundation for extracting valuable insights from Amazon's diverse and dynamic review ecosystem.
No-Code Approach
Introduction to No-Code Tools

No-code tools have emerged as game-changers in web scraping, offering accessible and user-friendly solutions for individuals and businesses seeking to extract valuable data without coding expertise. One such tool in this paradigm is Mobile App Scraping, which empowers users to effortlessly scrape Amazon reviews and glean meaningful insights, all through an intuitive and code-free interface.
These no-code tools simplify the traditionally complex process of web scraping by replacing lines of code with visual elements and straightforward configurations. With Mobile App Scraping, users can navigate the Amazon review landscape seamlessly without writing a single line of code. The platform typically employs a visual workflow where users can specify the target data elements, define extraction rules, and set parameters with simple drag-and-drop actions.
Their democratizing effect on data extraction makes no-code tools like Mobile App Scraping genuinely revolutionary. Users with diverse backgrounds, including marketers, analysts, and business owners, can harness the power of web scraping without needing intricate coding skills. This democratization ensures that the benefits of Amazon review scraping, including enhanced market insights and competitive analysis, are accessible to a broader audience, fostering a more inclusive and data-driven landscape.
Using Mobile App Scraping

Using Mobile App Scraping for Amazon review scraping is a straightforward process that empowers users to extract valuable insights without delving into complex coding. Follow this walkthrough to navigate through the steps seamlessly:
Setting Up the Workflow
Launch Mobile App Scraping and create a new project.
Choose the target platform (in this case, Amazon) and specify the type of data you want to scrape (Amazon reviews).
Configuring Data Extraction
Enter the Amazon product page URL from which you wish to extract reviews.
Use the visual interface to identify and select the elements containing review data, such as user comments, ratings, and timestamps.
Configure extraction rules by simply dragging and dropping elements onto the workflow canvas.
Handling Pagination (if necessary)
If Amazon reviews span multiple pages, configure pagination settings to ensure the tool navigates through all relevant pages.
Mobile App Scraping typically provides an intuitive way to handle pagination, allowing users to set up automated workflows for seamless data extraction.
Running the Extraction
Execute the workflow to initiate the scraping process.
Observe Mobile App Scraping as it automatically navigates through the specified pages, extracting the defined data elements.
Exporting Results
Once the scraping is complete, export the results in your preferred format, such as CSV or Excel.
Mobile App Scraping often offers straightforward export options, ensuring that the extracted Amazon review data is readily available for further analysis.
By following these steps, users can leverage the power of Mobile App Scraping to efficiently and effortlessly scrape Amazon reviews, gaining actionable insights to inform business strategies and decision-making. The no-code approach ensures accessibility for users with varying technical backgrounds, making the process inclusive and user-friendly.
Best Practices And Ethical Considerations
Best Practices and Ethical Considerations in web scraping are critical to ensure responsible and lawful data extraction. Adhering to ethical standards promotes a positive reputation and helps maintain a fair and open internet ecosystem. Here are key considerations:
Respect Website Terms of Service
Continually review and comply with the terms of service of the website you're scraping, including Amazon. Websites may have specific rules regarding automated access and data extraction.
Avoid Excessive Requests
Implement rate-limiting to avoid overwhelming the target website's servers with too many requests. Excessive requests can lead to server strain and potential service disruptions.
Use Robots.txt
Check for and respect the guidelines outlined in a website's robots.txt file. This file often indicates which parts of the site are off-limits for web crawlers or scrapers.
User-Agent Identification
Identify your scraper through a user-agent string. This allows website administrators to understand the source of the requests and facilitates communication if issues arise.
Data Privacy
Do not scrape sensitive personal information without explicit consent. Respect user privacy by avoiding data extraction that could lead to the identification of individuals.
Abide by Legal Guidelines
Please familiarize yourself with the legal landscape surrounding web scraping, as it can vary by jurisdiction. Some websites explicitly prohibit scraping in their terms of service, while others may have legal precedents protecting their data.
Monitor Changes
Regularly check the target website for any changes in its structure or terms of service. Adjust your scraping practices accordingly to maintain compliance.
Handle Cookies Responsibly
If your scraping involves handling cookies, ensure you comply with applicable data protection laws. Be transparent about cookie usage and offer users the option to opt-out.
Provide Attribution
If applicable, give proper attribution to the source website when using scraped data. This helps maintain transparency and acknowledges the efforts of the original content creators.
Be Mindful of Impact
Avoid scraping data in a way that could negatively impact the performance or functionality of the target website. Responsible scraping should not disrupt the user experience for others.
By adhering to these best practices and ethical considerations, web scrapers can contribute to a responsible and sustainable online environment while still extracting valuable data for legitimate purposes.
Challenges And Solutions
Like any web scraping endeavor, Amazon review scraping comes with its challenges. Addressing these challenges is crucial for a successful and sustainable scraping process. Here are common challenges and solutions:
Dynamic Content
Challenge: Amazon pages often load dynamic content, making capturing all relevant data challenging.
Solution: Use tools or libraries that handle dynamic content, such as Selenium. Simulate user interactions to ensure all elements are loaded before scraping.
CAPTCHA Challenges

Challenge: CAPTCHA mechanisms can hinder automated scraping by requiring human verification.
Solution: Implement tools that can handle CAPTCHAs, or consider using headless browsers with user emulation to bypass CAPTCHA checks.
Anti-Scraping Measures
Challenge: Websites like Amazon may employ anti-scraping measures to detect and block automated bots.
Solution: Rotate IP addresses, use proxies, and employ random delays between requests to mimic human-like behavior and avoid detection.
Changes in Website Structure
Challenge: Amazon frequently updates its website structure, leading to broken scrapers.
Solution: Regularly monitor and update your scraping script to accommodate changes in the website structure. Use version control to track changes over time.
Pagination Handling
Challenge: Amazon reviews are often paginated, making scraping beyond the first page challenging.
Solution: Implement logic to handle pagination. Extract and follow links to subsequent pages systematically to collect a comprehensive dataset.
IP Blocking
Challenge: Amazon may block or limit access from specific IP addresses if it detects scraping activity.
Solution: Use a pool of rotating IP addresses or proxies to prevent IP blocking. Employ IP rotation strategies to avoid raising suspicion.
Legal and Ethical Concerns
Challenge: There are legal and ethical considerations when scraping data from Amazon.
Solution: Adhere to Amazon's terms of service, respect website policies, and ensure compliance with relevant laws. Scraping should be conducted responsibly and ethically.
Handling Large Datasets
Challenge: Scraping many reviews can result in a massive, challenging dataset.
Solution: Implement efficient data storage methods, such as databases, and consider limiting the number of reviews to scrape based on project needs.
Bypassing Rate Limits
Challenge: Websites may have rate limits to prevent abuse, leading to blocked access.
Solution: Implement a rate-limiting strategy to ensure your scraper makes only a few requests in a short period. Respect the site's guidelines to avoid being blocked.
By proactively addressing these challenges with appropriate solutions, your Amazon review scraping efforts can remain effective, resilient, and aligned with ethical and legal standards. Regular monitoring and adaptation to changes in the web landscape are vital to maintaining a successful scraping workflow.
Conclusion
Whether you opt for a code-based or a no-code approach, scraping Amazon reviews offers a gateway to a wealth of valuable insights. Code-based methodologies, exemplified by Python and BeautifulSoup or the advanced Scrapy framework, provide powerful customization for those with coding expertise. On the other hand, no-code tools like Mobile App Scraping offer a simplified, accessible alternative, enabling users to extract Amazon review data without programming skills effortlessly.
The critical takeaway is to choose the method that aligns with your technical expertise and project requirements. The code-based route may be suitable if you're well-versed in coding and require intricate customization. Alternatively, if simplicity and accessibility are paramount, no-code tools offer a user-friendly avenue for data extraction.
Embrace the vast opportunities that Amazon review data presents for informed decision-making. Whether you're a developer, marketer, or business owner, unlocking the insights within Amazon reviews can empower you to refine strategies, enhance products, and gain a competitive edge.
Explore the possibilities with Mobile App Scraping, offering an intuitive no-code solution. Seize the opportunity to effortlessly scrape Amazon reviews, gain actionable insights, and make informed decisions. Empower your projects with Mobile App Scraping today and embark on a journey of data-driven success.
know more: https://www.mobileappscraping.com/extract-amazon-reviews.php
#AmazonReviewDataScraping#ScrapeAmazonReviewAppsData#AmazonReviewDataExtraction#AmazonReviewAppsDataCollection#ExtractAmazonReviewsData#EcommerceDataScraping
0 notes