#Python scraping Twitter
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
News Extract: Unlocking the Power of Media Data Collection
In today's fast-paced digital world, staying updated with the latest news is crucial. Whether you're a journalist, researcher, or business owner, having access to real-time media data can give you an edge. This is where news extract solutions come into play, enabling efficient web scraping of news sources for insightful analysis.

Why Extracting News Data Matters
News scraping allows businesses and individuals to automate the collection of news articles, headlines, and updates from multiple sources. This information is essential for:
Market Research: Understanding trends and shifts in the industry.
Competitor Analysis: Monitoring competitors’ media presence.
Brand Reputation Management: Keeping track of mentions across news sites.
Sentiment Analysis: Analyzing public opinion on key topics.
By leveraging news extract techniques, businesses can access and process large volumes of news data in real-time.
How News Scraping Works
Web scraping involves using automated tools to gather and structure information from online sources. A reliable news extraction service ensures data accuracy and freshness by:
Extracting news articles, titles, and timestamps.
Categorizing content based on topics, keywords, and sentiment.
Providing real-time or scheduled updates for seamless integration into reports.
The Best Tools for News Extracting
Various scraping solutions can help extract news efficiently, including custom-built scrapers and APIs. For instance, businesses looking for tailored solutions can benefit from web scraping services India to fetch region-specific media data.
Expanding Your Data Collection Horizons
Beyond news extraction, companies often need data from other platforms. Here are some additional scraping solutions:
Python scraping Twitter: Extract real-time tweets based on location and keywords.
Amazon reviews scraping: Gather customer feedback for product insights.
Flipkart scraper: Automate data collection from India's leading eCommerce platform.
Conclusion
Staying ahead in today’s digital landscape requires timely access to media data. A robust news extract solution helps businesses and researchers make data-driven decisions effortlessly. If you're looking for reliable news scraping services, explore Actowiz Solutions for customized web scraping solutions that fit your needs.
#news extract#web scraping services India#Python scraping Twitter#Amazon reviews scraping#Flipkart scraper#Actowiz Solutions
0 notes
Text
Scraping Data Off Twitter Using Python | Twitterscraper + NLP + Data Visualization
Take my Full Python Course Here: Link to Code: Scraping … source
0 notes
Text
pleaseee help me if youre familiar w python and webscraping.
im trying to webscrape this site w infinite scrolling (think like. twitter.) but parsehub only goes up to 200 pages in the free version. is there any possible way to start scraping the next 200 pages?
literally dont even know how to search this up bc i dont do this ever 😭😭😭😭😭😭😭
6 notes
·
View notes
Text
The Smart Way to Scrape Twitter Without Violating Terms of Service
Twitter is a rich source of real-time information. Whether you're monitoring trends, analyzing customer sentiment, or researching social behavior, the platform offers a massive volume of valuable data. Naturally, many individuals and organizations look to scrape Twitter to access this content efficiently.
However, Twitter scraping comes with important legal and ethical boundaries. Misusing scraping methods can lead to suspended accounts, blocked IPs, or even legal consequences. In this guide, we’ll walk you through how to gather Twitter data the smart way—without violating Twitter’s Terms of Service.

Why Caution Is Essential When Scraping Twitter
Twitter’s terms explicitly prohibit unauthorized or automated access to their platform, especially if it bypasses their systems, scrapes personal data, or causes server strain. While scraping may seem harmless, it can infringe on both platform rules and user privacy.
Understanding this framework is critical. If your intent is research, analytics, or even business intelligence, you need a method that’s both effective and compliant.
The Right Way to Scrape Twitter Data
If you're looking to collect tweets, user activity, or hashtag trends, here are the two most responsible ways to do it:
1. Use the Official Twitter API
The Twitter API is designed specifically for structured, permission-based access to platform data. It allows you to retrieve tweets, user profiles, engagement metrics, and more. Unlike raw scraping, the API provides a secure and reliable channel for gathering public data.
To use it:
Apply for developer access at developer.twitter.com.
Choose the appropriate access level (Essential, Elevated, or Academic).
Follow the rate limits and usage policies.
The API gives you fine control over the data you collect and helps ensure your project stays within Twitter’s guidelines.
2. Use API-Based Twitter Scraper Tools
If you're not comfortable coding with the API directly, there are several tools that act as wrappers or visual interfaces. These Twitter scraper tool simplify the process while still using the API as their foundation.
Examples include:
Libraries like Tweepy for Python developers
GUI-based platforms that help automate safe, API-based collection
Lightweight tools like SNScrape, which, while unofficial, are often used for personal or academic exploration of public content
Regardless of the tool, always verify that it respects Twitter's rate limits, login policies, and data protection standards.
Avoiding Unofficial Webscraping Methods
Some users attempt to webscrape Twitter by crawling its HTML pages or mimicking browser behavior. While this may work temporarily, it's risky for several reasons:
Twitter actively detects and blocks bot traffic
Terms of Service prohibit scraping through automated browsers or scripts
It can expose you to IP bans or cease-and-desist notices
Additionally, HTML structures on Twitter frequently change, meaning your scraping scripts may break often, making this method both unreliable and unsustainable.
Frequently Asked Questions (FAQs)
Q1: Is it legal to scrape Twitter data for research or business use? **A:** Scraping Twitter data is legal only if done through official and permitted methods, such as the Twitter API. Unauthorized scraping methods, like automated bots or HTML crawlers, may violate Twitter’s Terms of Service and can lead to account suspension or legal action. Always check Twitter’s developer policies before collecting data.
Q2: What is the best Twitter scraper tool for beginners? A: For beginners, Tweepy (a Python-based wrapper for the Twitter API) is a great starting point due to its simplicity and strong documentation. If you're looking for a no-code option, platforms like Apify offer user-friendly interfaces to collect Twitter data using built-in automation tools, though API-based methods remain the safest and most reliable.
0 notes
Text
From Classroom to Code: Real-World Projects Every Computer Science Student Should Try

One of the best colleges in Jaipur, which is Arya College of Engineering & I.T. They transitioning from theoretical learning to hands-on coding is a crucial step in a computer science education. Real-world projects bridge this gap, enabling students to apply classroom concepts, build portfolios, and develop industry-ready skills. Here are impactful project ideas across various domains that every computer science student should consider:
Web Development
Personal Portfolio Website: Design and deploy a website to showcase your skills, projects, and resume. This project teaches HTML, CSS, JavaScript, and optionally frameworks like React or Bootstrap, and helps you understand web hosting and deployment.
E-Commerce Platform: Build a basic online store with product listings, shopping carts, and payment integration. This project introduces backend development, database management, and user authentication.
Mobile App Development
Recipe Finder App: Develop a mobile app that lets users search for recipes based on ingredients they have. This project covers UI/UX design, API integration, and mobile programming languages like Java (Android) or Swift (iOS).
Personal Finance Tracker: Create an app to help users manage expenses, budgets, and savings, integrating features like OCR for receipt scanning.
Data Science and Analytics
Social Media Trends Analysis Tool: Analyze data from platforms like Twitter or Instagram to identify trends and visualize user behavior. This project involves data scraping, natural language processing, and data visualization.
Stock Market Prediction Tool: Use historical stock data and machine learning algorithms to predict future trends, applying regression, classification, and data visualization techniques.
Artificial Intelligence and Machine Learning
Face Detection System: Implement a system that recognizes faces in images or video streams using OpenCV and Python. This project explores computer vision and deep learning.
Spam Filtering: Build a model to classify messages as spam or not using natural language processing and machine learning.
Cybersecurity
Virtual Private Network (VPN): Develop a simple VPN to understand network protocols and encryption. This project enhances your knowledge of cybersecurity fundamentals and system administration.
Intrusion Detection System (IDS): Create a tool to monitor network traffic and detect suspicious activities, requiring network programming and data analysis skills.
Collaborative and Cloud-Based Applications
Real-Time Collaborative Code Editor: Build a web-based editor where multiple users can code together in real time, using technologies like WebSocket, React, Node.js, and MongoDB. This project demonstrates real-time synchronization and operational transformation.
IoT and Automation
Smart Home Automation System: Design a system to control home devices (lights, thermostats, cameras) remotely, integrating hardware, software, and cloud services.
Attendance System with Facial Recognition: Automate attendance tracking using facial recognition and deploy it with hardware like Raspberry Pi.
Other Noteworthy Projects
Chatbots: Develop conversational agents for customer support or entertainment, leveraging natural language processing and AI.
Weather Forecasting App: Create a user-friendly app displaying real-time weather data and forecasts, using APIs and data visualization.
Game Development: Build a simple 2D or 3D game using Unity or Unreal Engine to combine programming with creativity.
Tips for Maximizing Project Impact
Align With Interests: Choose projects that resonate with your career goals or personal passions for sustained motivation.
Emphasize Teamwork: Collaborate with peers to enhance communication and project management skills.
Focus on Real-World Problems: Address genuine challenges to make your projects more relevant and impressive to employers.
Document and Present: Maintain clear documentation and present your work effectively to demonstrate professionalism and technical depth.
Conclusion
Engaging in real-world projects is the cornerstone of a robust computer science education. These experiences not only reinforce theoretical knowledge but also cultivate practical abilities, creativity, and confidence, preparing students for the demands of the tech industry.
Source: Click here
#best btech college in jaipur#best engineering college in jaipur#best private engineering college in jaipur#top engineering college in jaipur#best engineering college in rajasthan#best btech college in rajasthan
0 notes
Text
Beyond the Books: Real-World Coding Projects for Aspiring Developers
One of the best colleges in Jaipur, which is Arya College of Engineering & I.T. They transitioning from theoretical learning to hands-on coding is a crucial step in a computer science education. Real-world projects bridge this gap, enabling students to apply classroom concepts, build portfolios, and develop industry-ready skills. Here are impactful project ideas across various domains that every computer science student should consider:
Web Development
Personal Portfolio Website: Design and deploy a website to showcase your skills, projects, and resume. This project teaches HTML, CSS, JavaScript, and optionally frameworks like React or Bootstrap, and helps you understand web hosting and deployment.
E-Commerce Platform: Build a basic online store with product listings, shopping carts, and payment integration. This project introduces backend development, database management, and user authentication.
Mobile App Development
Recipe Finder App: Develop a mobile app that lets users search for recipes based on ingredients they have. This project covers UI/UX design, API integration, and mobile programming languages like Java (Android) or Swift (iOS).
Personal Finance Tracker: Create an app to help users manage expenses, budgets, and savings, integrating features like OCR for receipt scanning.
Data Science and Analytics
Social Media Trends Analysis Tool: Analyze data from platforms like Twitter or Instagram to identify trends and visualize user behavior. This project involves data scraping, natural language processing, and data visualization.
Stock Market Prediction Tool: Use historical stock data and machine learning algorithms to predict future trends, applying regression, classification, and data visualization techniques.
Artificial Intelligence and Machine Learning
Face Detection System: Implement a system that recognizes faces in images or video streams using OpenCV and Python. This project explores computer vision and deep learning.
Spam Filtering: Build a model to classify messages as spam or not using natural language processing and machine learning.
Cybersecurity
Virtual Private Network (VPN): Develop a simple VPN to understand network protocols and encryption. This project enhances your knowledge of cybersecurity fundamentals and system administration.
Intrusion Detection System (IDS): Create a tool to monitor network traffic and detect suspicious activities, requiring network programming and data analysis skills.
Collaborative and Cloud-Based Applications
Real-Time Collaborative Code Editor: Build a web-based editor where multiple users can code together in real time, using technologies like WebSocket, React, Node.js, and MongoDB. This project demonstrates real-time synchronization and operational transformation.
IoT and Automation
Smart Home Automation System: Design a system to control home devices (lights, thermostats, cameras) remotely, integrating hardware, software, and cloud services.
Attendance System with Facial Recognition: Automate attendance tracking using facial recognition and deploy it with hardware like Raspberry Pi.
Other Noteworthy Projects
Chatbots: Develop conversational agents for customer support or entertainment, leveraging natural language processing and AI.
Weather Forecasting App: Create a user-friendly app displaying real-time weather data and forecasts, using APIs and data visualization.
Game Development: Build a simple 2D or 3D game using Unity or Unreal Engine to combine programming with creativity.
Tips for Maximizing Project Impact
Align With Interests: Choose projects that resonate with your career goals or personal passions for sustained motivation.
Emphasize Teamwork: Collaborate with peers to enhance communication and project management skills.
Focus on Real-World Problems: Address genuine challenges to make your projects more relevant and impressive to employers.
Document and Present: Maintain clear documentation and present your work effectively to demonstrate professionalism and technical depth.
Conclusion
Engaging in real-world projects is the cornerstone of a robust computer science education. These experiences not only reinforce theoretical knowledge but also cultivate practical abilities, creativity, and confidence, preparing students for the demands of the tech industry.
0 notes
Text
Unlock SEO & Automation with Python
In today’s fast-paced digital world, marketers are under constant pressure to deliver faster results, better insights, and smarter strategies. With automation becoming a cornerstone of digital marketing, Python has emerged as one of the most powerful tools for marketers who want to stay ahead of the curve.
Whether you’re tracking SEO performance, automating repetitive tasks, or analyzing large datasets, Python offers unmatched flexibility and speed. If you're still relying solely on traditional marketing platforms, it's time to step up — because Python isn't just for developers anymore.
Why Python Is a Game-Changer for Digital Marketers
Python’s growing popularity lies in its simplicity and versatility. It's easy to learn, open-source, and supports countless libraries that cater directly to marketing needs. From scraping websites for keyword data to automating Google Analytics reports, Python allows marketers to save time and make data-driven decisions faster than ever.
One key benefit is how Python handles SEO tasks. Imagine being able to monitor thousands of keywords, track competitors, and audit websites in minutes — all without manually clicking through endless tools. Libraries like BeautifulSoup, Scrapy, and Pandas allow marketers to extract, clean, and analyze SEO data at scale. This makes it easier to identify opportunities, fix issues, and outrank competitors efficiently.
Automating the Routine, Empowering the Creative
Repetitive tasks eat into a marketer's most valuable resource: time. Python helps eliminate the grunt work. Need to schedule social media posts, generate performance reports, or pull ad data across platforms? With just a few lines of code, Python can automate these tasks while you focus on creativity and strategy.
In Dehradun, a growing hub for tech and education, professionals are recognizing this trend. Enrolling in a Python Course in Dehradun not only boosts your marketing skill set but also opens up new career opportunities in analytics, SEO, and marketing automation. Local training programs often offer real-world marketing projects to ensure you gain hands-on experience with tools like Jupyter, APIs, and web scrapers — critical assets in the digital marketing toolkit.
Real-World Marketing Use Cases
Python's role in marketing isn’t just theoretical — it’s practical. Here are a few real-world scenarios where marketers are already using
Python to their advantage:
Content Optimization: Automate keyword research and content gap analysis to improve your blog and web copy.
Email Campaign Analysis: Analyze open rates, click-throughs, and conversions to fine-tune your email strategies.
Ad Spend Optimization: Pull and compare performance data from Facebook Ads, Google Ads, and LinkedIn to make smarter budget decisions.
Social Listening: Monitor brand mentions or trends across Twitter and Reddit to stay responsive and relevant.
With so many uses, Python is quickly becoming the Swiss army knife for marketers. You don’t need to become a software engineer — even a basic understanding can dramatically improve your workflow.
Getting Started with Python
Whether you're a fresh graduate or a seasoned marketer, investing in the right training can fast-track your career. A quality Python training in Dehradun will teach you how to automate marketing workflows, handle SEO analytics, and visualize campaign performance — all with practical, industry-relevant projects.
Look for courses that include modules on digital marketing integration, data handling, and tool-based assignments. These elements ensure you're not just learning syntax but applying it to real marketing scenarios. With Dehradun's increasing focus on tech education, it's a great place to gain this in-demand skill.
Python is no longer optional for forward-thinking marketers. As SEO becomes more data-driven and automation more essential, mastering Python gives you a clear edge. It simplifies complexity, drives efficiency, and helps you make smarter, faster decisions.
Now is the perfect time to upskill. Whether you're optimizing search rankings or building powerful marketing dashboards, Python is your key to unlocking smarter marketing in 2025 and beyond.
Python vs Ruby, What is the Difference? - Pros & Cons
youtube
#python course#python training#education#python#pythoncourseinindia#pythoninstitute#pythoninstituteinindia#pythondeveloper#Youtube
0 notes
Text
How to Leverage Python Skills to Launch a Successful Freelance Career
The demand for Python developers continues to grow in 2025, opening exciting opportunities—not just in full-time employment, but in freelancing as well. Thanks to Python’s versatility, freelancers can offer services across multiple industries, from web development and data analysis to automation and AI.
Whether you're looking to supplement your income or transition into full-time freelancing, here's how you can use Python to build a thriving freelance career.
Master the Core Concepts
Before stepping into the freelance market, it's essential to build a solid foundation in Python. Make sure you're comfortable with:
Data types and structures (lists, dictionaries, sets)
Control flow (loops, conditionals)
Functions and modules
Object-oriented programming
File handling and error management
Once you’ve nailed the basics, move on to specialized areas based on your target niche.
Choose a Niche That Suits You
Python is used in many domains, but as a freelancer, it helps to specialize. Some profitable freelance niches include:
Web Development: Use frameworks like Django or Flask to build custom websites and web apps.
Data Analysis: Help clients make data-driven decisions using tools like Pandas and Matplotlib.
Automation Scripts: Streamline repetitive client tasks by developing efficient Python automation tools.
Web Scraping: Use tools such as BeautifulSoup or Scrapy to extract data from websites quickly and effectively.
Machine Learning: Offer insights, models, or prototypes using Scikit-learn or TensorFlow.
Choosing a niche allows you to brand yourself as an expert rather than a generalist, which can attract higher-paying clients.
Build a Portfolio
A portfolio is your online resume and a powerful trust builder. Create a personal website or use GitHub to showcase projects that demonstrate your expertise. Some project ideas include:
A simple blog built with Flask
A script that scrapes data and exports it to Excel
A dashboard that visualizes data from a CSV file
An automated email responder
The key is to show clients that you can solve real-world problems using Python.
Create Profiles on Freelance Platforms
Once your portfolio is ready, the next step is to start reaching out to potential clients. Create profiles on platforms like:
Upwork
Freelancer
Fiverr
Toptal
PeoplePerHour
When setting up your profile, write a compelling bio, list your skills, and upload samples from your portfolio. Use keywords clients might search for, like "Python automation," "Django developer," or "data analyst."
Start Small and Build Your Reputation
Landing your first few clients as a new freelancer can take some patience and persistence. Consider offering competitive rates or working on smaller projects initially to gain reviews and build credibility. Positive feedback and completed jobs on your profile will help you attract better clients over time. Deliver quality work, communicate clearly, and meet deadlines—these soft skills matter as much as your technical expertise.
Upskill with Online Resources
The tech landscape changes fast, and staying updated is crucial.Set aside time to explore new tools, frameworks, and libraries, ensuring you stay up-to-date and continuously grow your skill set. Many freelancers also benefit from taking structured courses that help them level up efficiently. If you're serious about freelancing as a Python developer, enrolling in a comprehensive python training course in Pune can help solidify your knowledge. A trusted python training institute in Pune will offer hands-on projects, expert mentorship, and practical experience that align with the demands of the freelance market.
Market Yourself Actively
Don’t rely solely on freelance platforms. Expand your reach by: Sharing coding tips or projects on LinkedIn and Twitter
Writing blog posts about your Python solutions
Networking in communities like Reddit, Stack Overflow, or Discord
Attend local freelancing or tech meetups in your area to network and connect with like-minded professionals. The more visible you are, the more likely clients will find you organically.
Set Your Rates Wisely
Pricing is a common challenge for freelancers. Begin by exploring the rates others in your field are offering to get a sense of standard pricing. Factor in your skill level, project complexity, and market demand. You can charge hourly, per project, or even offer retainer packages for ongoing work. As your skills and client list grow, don’t hesitate to increase your rates.
Stay Organized and Professional
Treat freelancing like a business.Utilize productivity tools to streamline time tracking, invoicing, and client communication.Apps like Trello, Notion, and Toggl can help you stay organized. Create professional invoices, use contracts, and maintain clear communication with clients to build long-term relationships.
Building a freelance career with Python is not only possible—it’s a smart move in today’s tech-driven world. With the right skills, mindset, and marketing strategy, you can carve out a successful career that offers flexibility, autonomy, and unlimited growth potential.
Start by mastering the language, building your portfolio, and gaining real-world experience. Whether you learn through self-study or a structured path like a python training institute in Pune, your efforts today can lead to a rewarding freelance future.
0 notes
Text
Digital Marketing Application Programming

In today's tech-driven world, digital marketing is no longer just about catchy ads and engaging posts—it's about smart, automated, data-driven applications. Whether you're a developer building a marketing automation platform or a digital marketer looking to leverage tech, understanding how to program marketing applications is a game changer.
What Is Digital Marketing Application Programming?
Digital Marketing Application Programming refers to the development of tools, systems, and scripts that help automate, optimize, and analyze digital marketing efforts. These applications can handle tasks like SEO analysis, social media automation, email campaigns, customer segmentation, and performance tracking.
Key Areas of Digital Marketing Applications
Email Marketing Automation: Schedule and personalize email campaigns using tools like Mailchimp API or custom Python scripts.
SEO Tools: Build bots and crawlers to check page speed, backlinks, and keyword rankings.
Social Media Automation: Use APIs (e.g., Twitter, Instagram, Facebook) to schedule posts and analyze engagement.
Analytics and Reporting: Integrate with Google Analytics and other platforms to generate automated reports and dashboards.
Ad Campaign Management: Use Google Ads API or Meta Ads API to manage and analyze advertising campaigns.
Popular Technologies and APIs
Python: Great for automation, scraping, and data analysis.
JavaScript/Node.js: Excellent for real-time applications, chatbots, and front-end dashboards.
Google APIs: For accessing Google Ads, Google Analytics, and Google Search Console data.
Facebook Graph API: For managing posts, ads, and analytics across Facebook and Instagram.
Zapier/IFTTT Integration: No-code platforms for connecting various marketing tools together.
Example: Sending an Automated Email with Python
import smtplib from email.mime.text import MIMEText def send_email(subject, body, to_email): msg = MIMEText(body) msg['Subject'] = subject msg['From'] = '[email protected]' msg['To'] = to_email with smtplib.SMTP('smtp.example.com', 587) as server: server.starttls() server.login('[email protected]', 'yourpassword') server.send_message(msg) send_email("Hello!", "This is an automated message.", "[email protected]")
Best Practices
Use APIs responsibly and within rate limits.
Ensure user privacy and comply with GDPR/CCPA regulations.
Log all automated actions for transparency and debugging.
Design with scalability in mind—marketing data grows fast.
Secure API keys and sensitive user data using environment variables.
Real-World Use Cases
Marketing dashboards pulling real-time analytics from multiple platforms.
Automated tools that segment leads based on behavior.
Chatbots that qualify sales prospects and guide users.
Email drip campaigns triggered by user activity.
Dynamic landing pages generated based on campaign source.
Conclusion
Digital marketing is being transformed by smart programming. Developers and marketers working together can create systems that reduce manual labor, improve targeting, and increase ROI. Whether you're automating emails, analyzing SEO, or building AI chatbots—coding skills are a superpower in digital marketing.
0 notes
Text
Intro to Web Scraping
Chances are, if you have access to the internet, you have heard of Data Science. Aside from the buzz generated by the title ‘Data Scientist’, only a few in relevant fields can claim to understand what data science is. The majority of people think, if at all, that a data scientist is a mad scientist type able to manipulate statistics and computers to magically generate crazy visuals and insights seemingly out of thin air.
Looking at the plethora of definitions to be found in numerous books and across the internet of what data science is, the layman’s image of a data scientist may not be that far off.
While the exact definition of ‘data science’ is still a work in progress, most in the know would agree that the data science universe encompasses fields such as:
Big Data
Analytics
Machine Learning
Data Mining
Visualization
Deep Learning
Business Intelligence
Predictive Modeling
Statistics
Data Source: Top keywords

Image Source – Michael Barber
Further exploration of the skillset that goes into what makes a data scientist, consensus begins to emerge around the following:
Statistical Analysis
Programming/Coding Skills: - R Programming; Python Coding
Structured Data (SQL)
Unstructured Data (3-5 top NoSQL DBs)
Machine Learning/Data Mining Skills
Data Visualization
Big Data Processing Platforms: Hadoop, Spark, Flink, etc.
Structured vs unstructured data
Structured data refers to information with a high degree of organization, such that inclusion in a relational database is seamless and readily searchable by simple, straightforward search engine algorithms or other search operation
Examples of structured data include numbers, dates, and groups of words and numbers called strings.
Unstructured data (or unstructured information) is information that either does not have a pre-defined data model or is not organized in a pre-defined manner. Unstructured information is typically text-heavy, but may contain data such as dates, numbers, and facts as well. This results in irregularities and ambiguities that make it difficult to understand using traditional programs as compared to data stored in fielded form in databases or annotated (semantically tagged) in documents.
Examples of "unstructured data" may include books, journals, documents, metadata, health records, audio, video, analog data, images, files, and unstructured text such as the body of an e-mail message, Web pages, or word-processor document. Source: Unstructured data - Wikipedia
Implied within the definition of unstructured data is the fact that it is very difficult to search. In addition, the vast amount of data in the world is unstructured. A key skill when it comes to mining insights out of the seeming trash that is unstructured data is web scraping.
What is web scraping?
Everyone has done this: you go to a web site, see an interesting table and try to copy it over to Excel so you can add some numbers up or store it for later. Yet this often does not really work, or the information you want is spread across a large number of web sites. Copying by hand can quickly become very tedious.
You’ve tried everything else, and you haven’t managed to get your hands on the data you want. You’ve found the data on the web, but, alas — no download options are available and copy-paste has failed you. Fear not, there may still be a way to get the data out. Source: Data Journalism Handbook
As a data scientist, the more data you collect, the better your models, but what if the data you want resides on a website? This is the problem of social media analysis when the data comes from users posting content online and can be extremely unstructured. While there are some websites who support data collection from their web pages and have even exposed packages and APIs (such as Twitter), most of the web pages lack the capability and infrastructure for this. If you are a data scientist who wants to capture data from such web pages then you wouldn’t want to be the one to open all these pages manually and scrape the web pages one by one. Source: Perceptive Analytics
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis. Source: Wikipedia
Web Scraping is a method to convert the data from websites, whether structured or unstructured, from HTML into a form on which analysis can be performed.
The advantage of scraping is that you can do it with virtually any web site — from weather forecasts to government spending, even if that site does not have an API for raw data access. While this method is very powerful and can be used in many places, it requires a bit of understanding about how the web works.
There are a variety of ways to scrape a website to extract information for reuse. In its simplest form, this can be achieved by copying and pasting snippets from a web page, but this can be unpractical if there is a large amount of data to be extracted, or if it spread over a large number of pages. Instead, specialized tools and techniques can be used to automate this process, by defining what sites to visit, what information to look for, and whether data extraction should stop once the end of a page has been reached, or whether to follow hyperlinks and repeat the process recursively. Automating web scraping also allows to define whether the process should be run at regular intervals and capture changes in the data.
https://librarycarpentry.github.io/lc-webscraping/
Web Scraping with R
Atop any data scientist’s toolkit lie Python and R. While python is a general purpose coding language used in a variety of situations; R was built from the ground up to mold statistics and data. From data extraction, to clean up, to visualization to publishing; R is in use. Unlike packages such as tableau, Stata or Matlab which are skewed either towards data manipulation or visualization, R is a general purpose statistical language with functionality cutting across all data management operations. R is also free and open source which contributes to making it even more popular.
To extend the boundaries limiting data scientists from accessing data from web pages, there are packages based on ‘Web scraping’ available in R. Let us look into web scraping technique using R.
Harvesting Data with RVEST
R. Hadley Wickham authored the rvest package for web scraping using R which will be demonstrated in this tutorial. Although web scraping with R is a fairly advanced topic it is possible to dive in with a few lines of code within a few steps and appreciate its utility, versatility and power.
We shall use 2 examples inspired by Julia Silge in her series cool things you can do with R in a tweet:
Scraping the list of districts of Uganda
Getting the list of MPs of the Republic of Rwanda
0 notes
Text
Sure, here is the article formatted according to your specifications:
Cryptocurrency data scraping TG@yuantou2048
In the rapidly evolving world of cryptocurrency, staying informed about market trends and price movements is crucial for investors and enthusiasts alike. One effective way to gather this information is through cryptocurrency data scraping. This method involves extracting data from various sources on the internet, such as exchanges, forums, and news sites, to compile a comprehensive dataset that can be used for analysis and decision-making.
What is Cryptocurrency Data Scraping?
Cryptocurrency data scraping refers to the process of automatically collecting and organizing data related to cryptocurrencies from online platforms. This data can include real-time prices, trading volumes, news updates, and social media sentiment. By automating the collection of this data, users can gain valuable insights into the cryptocurrency market, enabling them to make more informed decisions. Here’s how it works and why it’s important.
Why Scrape Cryptocurrency Data?
1. Real-Time Insights: Scraping allows you to access up-to-date information about different cryptocurrencies, ensuring that you have the latest details at your fingertips.
2. Market Analysis: With the vast amount of information available online, manual tracking becomes impractical. Automated scraping tools can help you stay ahead by providing timely and accurate information.
3. Tools and Techniques:
Web Scrapers: These are software tools designed to extract specific types of data from websites. They can gather data points like current prices, historical price trends, and community sentiment, which are essential for making informed investment decisions.
2. Automation: Instead of manually checking multiple platforms, automated scrapers can continuously monitor and collect data, saving time and effort.
3. Customization: You can tailor your scraper to focus on specific metrics or platforms, allowing for personalized data collection tailored to your needs.
4. Competitive Advantage: Having access to real-time data gives you an edge in understanding market dynamics and identifying potential opportunities or risks.
5. Legal Considerations: It's important to ensure that the data collected complies with legal guidelines and respects terms of service agreements of the websites being scraped. Always check the legality and ethical considerations before implementing any scraping projects.
6. Use Cases:
Price Tracking: Track the value of different cryptocurrencies across multiple exchanges.
Sentiment Analysis: Analyze social media and news feeds to gauge public opinion and predict market movements.
7. Challenges:
Dynamic Content: Websites often use JavaScript to load content dynamically, which requires advanced techniques to capture this data accurately.
Scraping Tools: Popular tools include Python libraries like BeautifulSoup and Selenium, which can parse HTML and interact with web pages to extract relevant information efficiently.
8. Best Practices:
Respect Terms of Service: Ensure that your scraping activities comply with the terms of service of the websites you’re scraping from. Some popular platforms like CoinMarketCap, Coingecko, and Twitter for sentiment analysis.
9. Ethical and Legal Scrutiny: Be mindful of the ethical implications and ensure compliance with website policies.
10. Data Quality: The quality of the data is crucial. Use robust frameworks and APIs provided by exchanges directly when possible to avoid overloading servers and ensure reliability.
11. Conclusion: Cryptocurrency data scraping is a powerful tool for anyone interested in the crypto space. However, always respect the terms of service of the platforms you scrape from.
12. Future Trends: As the landscape evolves, staying updated with the latest technologies and best practices is key. Always respect the terms of service of the platforms you're scraping from.
13. Conclusion: Cryptocurrency data scraping offers a wealth of information but requires careful implementation to avoid violating terms of service or facing legal issues.
14. Final Thoughts: While scraping can provide significant advantages, it’s vital to use these tools responsibly and ethically.
This structured approach ensures that you adhere to ethical standards while leveraging the power of automation to stay informed without infringing on copyright laws and privacy policies.
Feel free to adjust the length and tone as needed.
加飞机@yuantou2048

EPP Machine
蜘蛛池出租
0 notes
Text
Crush It with Twitter Web Scraping Tips

Picking the Perfect Twitter Scraping Tool
One of the first lessons I learned? Not all scraping tools are created equal. A good Twitter scraping tool can make or break your project. I’ve tried everything from Python libraries like Tweepy to more advanced X scraping APIs. My go-to? Tools that balance ease of use with flexibility. For beginners, something like BeautifulSoup paired with Requests in Python is a solid start. If you’re ready to level up, X data API like the official X API (if you can get access) or third-party solutions can save you time. Pro tip: always check rate limits to avoid getting blocked!
Ethical Web Scraping: My Golden Rule
Here’s a story from my early days: I got a bit too excited scraping X and hit a rate limit. Ouch. That taught me the importance of ethical web scraping X data. Always respect X’s terms of service and robots.txt file. Use X data APIs when possible — they’re designed for this! Also, stagger your requests to avoid overwhelming servers. Not only does this keep you on the right side of the rules, but it also ensures your data collection is sustainable.
Step-by-Step Twitter Scraping Tips
Ready to get your hands dirty? Here’s how I approach Twitter web scraping:
Set Clear Goals: Are you after tweets, user profiles, or hashtags? Knowing what you want helps you pick the right Twitter scraping tool.
Use Python for Flexibility: Libraries like Tweepy or Scrapy are my favorites for Data Scraping X. They’re powerful and customizable.
Leverage X Data APIs: If you can, use official X data APIs for cleaner, structured data. They’re a bit pricier but worth it for reliability.
Handle Data Smartly: Store your scraped data in a structured format like CSV or JSON. I once lost hours of work because I didn’t organize my data properly — don’t make that mistake!
Stay Updated: X’s platform evolves, so keep an eye on API changes or new scraping tools to stay ahead.
Overcoming Common Challenges
Scraping isn’t always smooth sailing. I’ve hit roadblocks like CAPTCHAs, changing APIs, and messy data outputs. My fix? Use headless browsers like Selenium for tricky pages, but sparingly — they’re resource-heavy. Also, clean your data as you go. Trust me, spending 10 minutes filtering out irrelevant tweets saves hours later. If you’re using X scraping APIs, check their documentation for updates to avoid surprises.
Turning Data into Action
Here’s where the magic happens. Once you’ve scraped your data, analyze it! I love using tools like Pandas to spot trends or visualize insights with Matplotlib. For example, I once scraped X data to track sentiment around a product launch — game-changer for my client’s strategy. With web scraping X.com, you can uncover patterns that drive smarter decisions, whether it’s for SEO, marketing, or research.
Final Thoughts: Scrape Smart, Win Big
Twitter web scraping has been a game-changer for me, and I’m confident it can be for you too. Start small, experiment with a Twitter scraping tool, and don’t be afraid to dive into X data APIs for bigger projects. Just remember to scrape ethically and organize your data like a pro. Got a favorite scraping tip or tool? Drop it in the comments on X — I’d love to hear your thoughts!
Happy scraping, and let’s crush it!
0 notes
Text
Building the Perfect Dataset for AI Training: A Step-by-Step Guide

Introduction
As artificial intelligence progressively transforms various sectors, the significance of high-quality datasets in the training of AI systems is paramount. A meticulously curated dataset serves as the foundation for any AI model, impacting its precision, dependability, and overall effectiveness. This guide will outline the crucial steps necessary to create an optimal Dataset for AI Training.
Step 1: Define the Objective
Prior to initiating data collection, it is essential to explicitly outline the objective of your AI model. Consider the following questions:
What specific issue am I aiming to address?
What types of predictions or results do I anticipate?
Which metrics will be used to evaluate success?
Establishing a clear objective guarantees that the dataset is in harmony with the model’s intended purpose, thereby preventing superfluous data collection and processing.
Step 2: Identify Data Sources
To achieve your objective, it is essential to determine the most pertinent data sources. These may encompass:
Open Data Repositories: Websites such as Kaggle, the UCI Machine Learning Repository, and Data.gov provide access to free datasets.
Proprietary Data: Data that is gathered internally by your organization.
Web Scraping: The process of extracting data from websites utilizing tools such as Beautiful Soup or Scrapy.
APIs: Numerous platforms offer APIs for data retrieval, including Twitter, Google Maps, and OpenWeather.
It is crucial to verify that your data sources adhere to legal and ethical guidelines.
Step 3: Collect and Aggregate Data
Upon identifying the sources, initiate the process of data collection. This phase entails the accumulation of raw data and its consolidation into a coherent format.
Utilize tools such as Python scripts, SQL queries, or data integration platforms.
Ensure comprehensive documentation of data sources to monitor quality and adherence to compliance standards.
Step 4: Clean the Data
Raw data frequently includes noise, absent values, and discrepancies. The process of data cleaning encompasses:
Eliminating Duplicates: Remove redundant entries.
Addressing Missing Data: Employ methods such as imputation, interpolation, or removal.
Standardizing Formats: Maintain uniformity in units, date formats, and naming conventions.
Detecting Outliers: Recognize and manage anomalies through statistical techniques or visual representation.
Step 5: Annotate the Data
Data annotation is essential for supervised learning models. This process entails labeling the dataset to establish a ground truth for the training phase.
Utilize tools such as Label Studio, Amazon SageMaker Ground Truth, or dedicated annotation services.
To maintain accuracy and consistency in annotations, it is important to offer clear instructions to the annotators.
Step 6: Split the Dataset
Segment your dataset into three distinct subsets:
Training Set: Generally comprising 70-80% of the total data, this subset is utilized for training the model.
Validation Set: Constituting approximately 10-15% of the data, this subset is employed for hyperparameter tuning and to mitigate the risk of overfitting.
Test Set: The final 10-15% of the data, this subset is reserved for assessing the model’s performance on data that it has not encountered before.
Step 7: Ensure Dataset Diversity
AI models achieve optimal performance when they are trained on varied datasets that encompass a broad spectrum of scenarios. This includes:
Demographic Diversity: Ensuring representation across multiple age groups, ethnic backgrounds, and geographical areas.
Contextual Diversity: Incorporating a variety of conditions, settings, or applications.
Temporal Diversity: Utilizing data gathered from different timeframes.
Step 8: Test and Validate
Prior to the completion of the dataset, it is essential to perform a preliminary assessment to ensure its quality. This assessment should include the following checks:
Equitable distribution of classes.
Lack of bias.
Pertinence to the specific issue being addressed.
Subsequently, refine the dataset in accordance with the findings from the assessment.
Step 9: Document the Dataset
Develop thorough documentation that encompasses the following elements:
Description and objectives of the dataset.
Sources of data and methods of collection.
Steps for preprocessing and data cleaning.
Guidelines for annotation and the tools utilized.
Identified limitations and possible biases.
Step 10: Maintain and Update the Dataset

AI models necessitate regular updates to maintain their efficacy. It is essential to implement procedures for:
Regular data collection and enhancement.
Ongoing assessment of relevance and precision.
Version management to document modifications.
Conclusion
Creating an ideal dataset for AI training is a careful endeavor that requires precision, specialized knowledge, and ethical awareness. By adhering to this comprehensive guide, you can develop datasets that enable your AI models to perform at their best and produce trustworthy outcomes.
For additional information on AI training and resources, please visit Globose Technology Solutions.AI.
0 notes
Text
Creating a tool that helps manage digital mental space while sifting through content and media is a valuable and challenging project. Here’s a high-level breakdown of how you might approach this:
1. Define the Scope and Features
Digital Mental Space Management:
Focus Mode: Create a feature that blocks or filters out distracting content while focusing on specific tasks.
Break Reminders: Set up reminders for taking regular breaks to avoid burnout.
Content Categorization: Allow users to categorize content into different sections (e.g., work, personal, leisure) to manage their mental space better.
Content Sifting and Filtering:
Keyword Filtering: Implement a keyword-based filtering system to highlight or exclude content based on user preferences.
Sentiment Analysis: Integrate a sentiment analysis tool that can categorize content as positive, negative, or neutral, helping users choose what to engage with.
Source Verification: Develop a feature that cross-references content with reliable sources to flag potential misinformation.
2. Technical Components
Front-End:
UI/UX Design: Design a clean, minimalistic interface focusing on ease of use and reducing cognitive load.
Web Framework: Use frameworks like React or Vue.js for responsive and interactive user interfaces.
Content Display: Implement a dashboard that displays categorized and filtered content in an organized way.
Back-End:
API Integration: Use APIs for content aggregation (e.g., news APIs, social media APIs) and filtering.
Data Storage: Choose a database (e.g., MongoDB, PostgreSQL) to store user preferences, filtered content, and settings.
Authentication: Implement a secure authentication system to manage user accounts and personalized settings.
Content Filtering and Analysis:
Text Processing: Use Python with libraries like NLTK or SpaCy for keyword extraction and sentiment analysis.
Machine Learning: If advanced filtering is needed, train a machine learning model using a dataset of user preferences.
Web Scraping: For content aggregation, you might need web scraping tools like BeautifulSoup or Scrapy (ensure compliance with legal and ethical standards).
3. Development Plan
Phase 1: Core Functionality
Develop a basic UI.
Implement user authentication.
Set up content aggregation and display.
Integrate keyword filtering.
Phase 2: Advanced Features
Add sentiment analysis.
Implement break reminders and focus mode.
Add source verification functionality.
Phase 3: Testing and Iteration
Conduct user testing to gather feedback.
Iterate on the design and features based on user feedback.
Optimize performance and security.
4. Tools and Libraries
Front-End: React, Redux, TailwindCSS/Material-UI
Back-End: Node.js/Express, Django/Flask, MongoDB/PostgreSQL
Content Analysis: Python (NLTK, SpaCy), TensorFlow/PyTorch for ML models
APIs: News API, Twitter API, Facebook Graph API
Deployment: Docker, AWS/GCP/Azure for cloud deployment
5. Considerations for User Well-being
Privacy: Ensure user data is protected and handled with care, possibly offering anonymous or minimal data modes.
Customization: Allow users to customize what types of content they want to filter, what kind of breaks they want, etc.
Transparency: Make the filtering and analysis process transparent, so users understand how their content is being sifted and managed.
This is a comprehensive project that will require careful planning and iteration. Starting small and building up the tool's features over time can help manage the complexity.
0 notes
Text
Title: Mastering Python Development: A Comprehensive Guide
In today's tech-driven world, Python stands out as one of the most versatile and widely-used programming languages. From web development to data science, Python's simplicity and power make it a top choice for both beginners and seasoned developers alike. If you're looking to embark on a journey into Python development, you're in the right place. In this comprehensive guide, we'll walk you through the steps to master Python development.
Understanding the Basics
Before diving into Python development, it's essential to grasp the fundamentals of the language. Start with the basics such as data types, variables, loops, and functions. Online platforms like Codecademy, Coursera, and Udemy offer excellent introductory courses for beginners. Additionally, Python's official documentation and interactive tutorials like "Learn Python" by Codecademy provide hands-on learning experiences.
Build Projects
The best way to solidify your understanding of Python is by building projects. Start with small projects like a simple calculator or a to-do list app. As you gain confidence, challenge yourself with more complex projects such as web development using frameworks like Flask or Django, data analysis with libraries like Pandas and NumPy, or machine learning projects using TensorFlow or PyTorch. GitHub is a fantastic platform to showcase your projects and collaborate with other developers.
Dive Deeper into Python Ecosystem
Python boasts a rich ecosystem of libraries and frameworks that cater to various domains. Explore different areas such as web development, data science, machine learning, and automation. Familiarize yourself with popular libraries like requests for making HTTP requests, BeautifulSoup for web scraping, Matplotlib and Seaborn for data visualization, and scikit-learn for machine learning tasks. Understanding the strengths and applications of these libraries will broaden your Python development skills.
Learn from Others
Engage with the Python community to accelerate your learning journey. Participate in online forums like Stack Overflow, Reddit's r/learnpython, and Python-related Discord servers. Follow Python developers and experts on social media platforms like Twitter and LinkedIn. Attending local meetups, workshops, and conferences can also provide valuable networking opportunities and insights into the latest trends in Python development.
Practice Regularly
Consistency is key to mastering Python development. Dedicate time each day to practice coding, whether it's solving coding challenges on platforms like LeetCode and HackerRank or contributing to open-source projects on GitHub. Set achievable goals and track your progress over time. Remember, proficiency in Python, like any skill, comes with practice and dedication.
Stay Updated
The field of technology is constantly evolving, and Python is no exception. Stay updated with the latest advancements, updates, and best practices in Python development. Follow blogs, newsletters, and podcasts dedicated to Python programming. Attend webinars and online courses to learn about emerging trends and technologies. Continuous learning is essential to stay relevant and competitive in the ever-changing tech industry.
Conclusion
Learning Python development is an exciting journey filled with endless possibilities. Whether you're a beginner or an experienced developer, mastering Python can open doors to a wide range of career opportunities and creative projects. By understanding the basics, building projects, exploring the Python ecosystem, learning from others, practicing regularly, and staying updated, you can embark on a rewarding path towards becoming a proficient Python developer. So, what are you waiting for? Start your Python journey today!
1 note
·
View note
Text
Progress on 2 personal projects
Project # 1 - Trade Triggerer Phase 2
What was Trade Triggerer Phase 1?
In my previous posts, I've shared some snippets of the analysis, development, and deployment of my app Trade Triggerer. It started as a NodeJS project that accomplished the end-to-end data scraping, data management, conditional checking for trades, and email sendout. The deployment was done in Heroku (just like how I deployed my twitter bot previously). I scrapped all that due to the technical upkeep and the increasing difficulty to analyze data in NodeJS.
Sometime around 2017-18, I've started learning Python from online courses for fun, and eventually re-wrote all the NodeJS functionality in a significantly shorter and simpler code. Thus, Trade Trigger-PY was born and deployed circa Aug 2019. Some technologies I've used for this project are simply: Heroku, GMail API, GSheets API. I originally only was monitoring PH Stock Market, but it was easy to add US stocks and Crypto. Hence, I was receiving these emails every day.
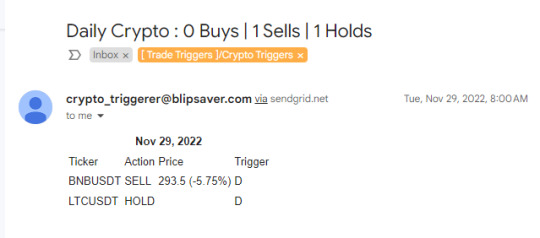
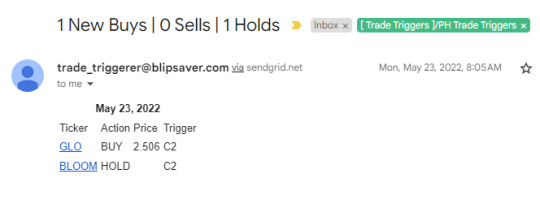
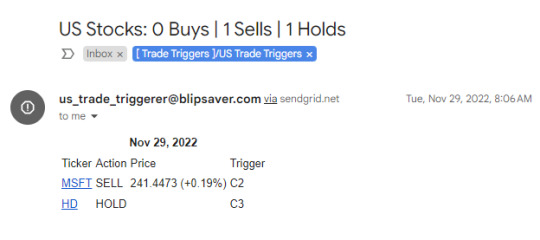
I followed the trading instructions strictly, and I became profitable. However, I stopped for the following reasons:
I was beginning to lose money. It seems I had beginner's luck around 2020-2022 since the market was going up on average as a bounce back to the pandemic.
PH market is not as liquid as my experience in crypto trading.
The US stocks I'm monitoring are very limited, as I focused more on PH.
On April 2023, DLSU deleted alumni emails, where my stocks data are being stored.
On November 2023, Heroku stopped offering free deployments.
Today, I am highly motivated to revive Trade Triggerer for only 1 reason, I don't want money to be a problem for the lifestyle that I want. Learning from my past mistakes, Trade Triggerer Phase 2 will be implemented using the following:
Increased technical analysis - Use of statistical models to analyze historical and current stock data
Start fundamental analysis - Review of historical events that changed market behaviour + Review of balance sheets, starting with banks
Focus on strong International Stocks (US, JPN, EUR, CHN)
Deploy on a local Raspberry Pi
I am still at the beginning. I've only been able to train models using historical data and found promising results. There's a long way to go but I believe I can do the MVP on or before my Birthday :)
Project # 2 - Web scrape properties for sale
For personal use lol. Can't deploy in Heroku anymore; and I dont want to depend on other online alternatives, too. I'll start playing around with raspberry pi for this project.
0 notes