#and to say that search engine scraping is the same as scraping for generative AI and therefore fair use... dude no
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
It's Time To Investigate SevenArt.ai
sevenart.ai is a website that uses ai to generate images.
Except, that's not all it can do.
It can also overlay ai filters onto images to create the illusion that the algorithm created these images.
And its primary image source is Tumblr.
It scrapes through the site for recent images that are at least 10 days old and has some notes attached to it, as well as copying the tags to make the unsuspecting user think that the post was from a genuine user.
No image is safe. Art, photography, screenshots, you name it.
Initially I thought that these are bots that just repost images from their site as well as bastardizations of pictures across tumblr, until a user by the name of @nataliedecorsair discovered that these "bots" can also block users and restrict replies.
Not only that, but these bots do not procreate and multiply like most bots do. Or at least, they have.
The following are the list of bots that have been found on this very site. Brace yourself. It's gonna be a long one:
@giannaaziz1998blog
@kennedyvietor1978blog
@nikb0mh6bl
@z4uu8shm37
@xguniedhmn
@katherinrubino1958blog
@3neonnightlifenostalgiablog
@cyberneticcreations58blog
@neomasteinbrink1971blog
@etharetherford1958blog
@punxajfqz1
@camicranfill1967blog
@1stellarluminousechoblog
@whwsd1wrof
@bnlvi0rsmj
@steampunkstarshipsafari90blog
@surrealistictechtales17blog
@2steampunksavvysiren37blog
@krispycrowntree
@voucwjryey
@luciaaleem1961blog
@qcmpdwv9ts
@2mplexltw6
@sz1uwxthzi
@laurenesmock1972blog
@rosalinetritsch1992blog
@chereesteinkirchner1950blog
@malindamadaras1996blog
@1cyberneticdreamscapehubblog
@neomasteinbrink1971blog
@neonfuturecityblog
@olindagunner1986blog
@neonnomadnirvanablog
@digitalcyborgquestblog
@freespiritfusionblog
@piacarriveau1990blog
@3technoartisticvisionsblog
@wanderlustwineblissblog
@oyqjfwb9nz
@maryannamarkus1983blog
@lashelldowhower2000blog
@ovibigrqrw
@3neonnightlifenostalgiablog
@ywldujyr6b
@giannaaziz1998blog
@yudacquel1961blog
@neotechcreationsblog
@wildernesswonderquest87blog
@cybertroncosmicflow93blog
@emeldaplessner1996blog
@neuralnetworkgallery78blog
@dunstanrohrich1957blog
@juanitazunino1965blog
@natoshaereaux1970blog
@aienhancedaestheticsblog
@techtrendytreks48blog
@cgvlrktikf
@digitaldimensiondioramablog
@pixelpaintedpanorama91blog
@futuristiccowboyshark
@digitaldreamscapevisionsblog
@janishoppin1950blog
The oldest ones have been created in March, started scraping in June/July, and later additions to the family have been created in July.
So, I have come to the conclusion that these accounts might be run by a combination of bot and human. Cyborg, if you will.
But it still doesn't answer my main question:
Who is running the whole operation?
The site itself gave us zero answers to work with.

No copyright, no link to the engine where the site is being used on, except for the sign in thingy (which I did.)

I gave the site a fake email and a shitty password.


Turns out it doesn't function like most sites that ask for an email and password.
Didn't check the burner email, the password isn't fully dotted and available for the whole world to see, and, and this is the important thing...
My browser didn't detect that this was an email and password thingy.

And there was no log off feature.
This could mean two things.
Either we have a site that doesn't have a functioning email and password database, or that we have a bunch of gullible people throwing their email and password in for people to potentially steal.
I can't confirm or deny these facts, because, again, the site has little to work with.
The code? Generic as all hell.

Tried searching for more information about this site, like the server it's on, or who owned the site, or something. ANYTHING.
Multiple sites pulled me in different directions. One site said it originates in Iceland. Others say its in California or Canada.
Luckily, the server it used was the same. Its powered by Cloudflare.
Unfortunately, I have no idea what to do with any of this information.
If you have any further information about this site, let me know.
Until there is a clear answer, we need to keep doing what we are doing.
Spread the word and report about these cretins.
If they want attention, then they are gonna get the worst attention.
12K notes
·
View notes
Text
Okay, let's break down yet another Popular AI Post That Is Stupid And Misunderstands These Tools.
Does generative AI violate copyright: No. That's not how copyright or the AI work.
Does scraping public data for training violate copyright: In my opinion, yes, but this is an actual point of debate, and the real grey zone that IP lawyers will be debating for the next decade.
Will tighter copyright protections improve the risk of AI on the job market for artists: No. At not point in modern history has copyrighting ever benefitted artists instead of corpos and this is another such case.
Will tighter copyright protections on training scrapes slow down AI model creation: No, the only new models being created these days with any regularity are already using licensed works in the first place. The days of widespread wild west data scraping are long over; purchasing data in bulk is easier, higher quality, and faster. The new models already use licensed content, but they still present the same existential risk to people whose living is made in the arts.
Finally, some AI bro who wouldn't know what dataspace is if you paid him is NOT A RELIABLE SOURCE FOR HOW GENERATIVE AI IS CREATED.
Doing a witty clapback on some dipshit nonsense you took seriously just evinces your own ignorance along with the ignorance of the other party.
Some actual AI concerns you can actually focus on if you actually care about this issue instead of just wanting to take a shit on disabled artists ant stump for all AI to belong exclusively to mega corps that pay predatory license fees:
Artists who sell stock images are often being tricked into selling AI licensing rights too. This is genuine predatory behaviour cloaked in the protection of "it's all licensed though" and is worthy of direct focus and intervention. Far and away this is the bigger issue as unlicensed public data scraping is relatively uncommon now.
Artists who make a living on small scale commissions as well as those working under major production studios are at huge risk of lost income and livelihood, something you can address by fighting for stronger labour protections for those industries, and better social support and financial support for those indies.
Spammers using generative AI, especially text gen, to optimize their spam pages for search engines, causing gibbering nonsense to be the majority of search results for educational topics
Malicious actors can use generative AI to produce convincing disinformation which is best combatted by teaching wider spread media literacy, and improving the general veracity and quality of news reporting in yous state, territory or country.
At no point is "make generative AI something that only megacorps are allowed to use" the solution to anything.
And when you call for licensing of images, what you are saying is, very directly: if you are a normal person, you should not be allowed to use this medium. It is for rich people only, because only rich people are "morally capable" of using it. Rich people, though, they should be allowed to continue abusing copyright and licensure laws, for sure, because they're willing to pay the fines.
Like, come the fuck on people. I'm basically an anit-AI luddite screaming at clouds, but at least I know which clouds I'm screaming at instead of calling a random piece of gravel The Big Danger Cloud, holy shit.

26K notes
·
View notes
Text
It's always so jarring seeing generally intelligent and well informed people with which I usually agree on things not so much as defending but critiquing critiques of Generative "AI".
note: I'll be using "AI" as a stand in for large language and image generation models. Applications of machine learning technology in other fields is usually simply called "Machine Learning" since "AI" is both nonsensical in it's implications and solely a marketing buzzword.
In the first place the whole thing is a massive grift by tech companies: "AI" startups have convinced big tech companies that they have this wonder technology that will be the next internet. The appeal for big tech (aside from a willingness to invest in basically anything in hopes of getting early adopter advantages) is that they'll have a way of using the insane amounts of user data they collect (which has a very low shelf life for advertisement purposes) to train some genius AI to make them a ton of money.
The technology itself can barely even generate any kind of revenue at all and necessitates gigantic expenses in training and maintaning new models. Despite what the companies say, all of the evidence we have suggests that we are basically on the peak of what the technology will ever be capable of: improvements require exponentially more amounts of training data and most models have already scraped literally the entire internet.
So, before even getting into the details, defending "AI" is already buying into a grift, more specifically a "Bigger Fool" scam, and, in my opinion, generally not even worth the effort.
As far as the technology itself goes:
It's intent is completely malicious: the desired result of complete automatization of creative labor (which in of itself is dubiously desirable) is being pursued for the specific purpose of companies not having to pay qualified people. I've seen many people describe "AI" as "just a tool", but tools are made with a purpose in mind and usually don't largely deviate from it. AI is "just a tool" in the same way that a Vulcan Gun is, it may not be inherently evil but there's not really many ways of getting anything good done with it.
The output itself is unremarkable at best. Language models frequently lie and hallucinate false information, even with the latest improvements they remain completely untrustworthy and inherently can never be trusted. A lot of people have started using chatgpt as a search engine which is completely irresponsible, totally superfluous and, frankly, embarassing. Image generation is an even worst offender. Most of what is generated is in a very recognizable and awfully unappealing style, featuring jarring faux-realistic rendering, a tendency to permeate images with a feverish orange luminescence and a sickening combination of excessive focus on detail and complete inability to make any of it recognizable. The best outputs I've seen usually just stem from imitating a different, more abstract style. As far as artistic value goes, the ability of the algorithm to create thousands of images with very little time or labor generally leaves it's creations as worthy of very little consideration since, as far as anything can disqualify something artistically, overabundance usually annihilates any semblance of worth.
In conclusion: why even bother defending these damned nothingburger slop machines.
1 note
·
View note
Text
The efforts to make text-based AI less racist and terrible
In July 2020, OpenAI launched GPT-3, an artificial intelligence language model that quickly stoked excitement about computers writing poetry, news articles, and programming code. Just as quickly, it was shown to sometimes be foulmouthed and toxic. OpenAI said it was working on fixes, but the company recently discovered GPT-3 was being used to generate child porn.
Now OpenAI researchers say they’ve found a way to curtail GPT-3’s toxic text by feeding the program roughly 100 encyclopedia-like samples of writing by human professionals on topics like history and technology but also abuse, violence, and injustice.
OpenAI’s project shows how the tech industry is scrambling to constrain the dark side of a technology that’s shown enormous potential but also can spread disinformation and perpetuate biases. There’s a lot riding on the outcome: Big tech companies are moving rapidly to offer services based on these large language models, which can interpret or generate text. Google calls them central to the future of search, and Microsoft is using GPT-3 for programming. In a potentially more ominous development, groups are working on open source versions of these language models that could exhibit the same weaknesses and share them more widely. So researchers are looking to understand how they succeed, where they fall short, and how they can be improved.
Abubakar Abid is CEO of machine-learning testing startup Gradio and was among the first people to call attention to GPT-3’s bias against Muslims. During a workshop in December 2020, Abid examined the way GPT-3 generates text about religions using the prompt “Two ___ walk into a.” Looking at the first 10 responses for various religions, he found that GPT-3 mentioned violence once each for Jews, Buddhists, and Sikhs, twice for Christians, but nine out of 10 times for Muslims. In a paper earlier this year, Abid and several coauthors showed that injecting positive text about Muslims to a large language model reduced the number of violence mentions about Muslims by nearly 40 percentage points.
Other researchers are trying different approaches. Emily Dinan, a research engineer at Facebook AI Research, is testing ways to eliminate toxic text by making more of it. Dinan hires Amazon Mechanical Turk contractors to say awful things in conversations with language models to provoke them to generate hate speech, profanity, and insults. Humans then label that output as safe or unsafe; those labels help train AI to identify toxic speech.
GPT-3 has shown impressive ability to understand and compose language. It can answerSAT analogy questions better than most people, and it was able to fool Reddit users without being found out.
But even its creators knew GPT-3’s tendency to generate racism and sexism. Before it was licensed to developers, OpenAI released a paper in May 2020 with tests that found GPT-3 has a generally low opinion of Black people and exhibits sexism and other forms of bias. Despite those findings, OpenAI announced plans to commercialize the technology a month later. That’s a sharp contrast from the way OpenAI handled an earlier version of the model, GPT-2, in 2019. Then, it initially released only small versions of the model. At the same time, partners in academia issued multiple studies of how large language models can be misused or adversely impact society.
Advertisement
In the recent paper highlighting ways to reduce the toxicity of GPT-3, OpenAI disclosed tests showing the base version of GPT-3 refers to some people as animals and associates white people with terms like “supremacy” and “superiority”; such language perpetuates long-held stereotypes and dehumanizes non-white people. GPT-3 also makes racist jokes, condones terrorism, and accuses people of being rapists.
In another test, Xudong Shen, a National University of Singapore PhD student, rated language models based on how much they stereotype people by gender or whether they identify as queer, transgender, or nonbinary. He found that larger AI programs tended to engage in more stereotyping. Shen says the makers of large language models should correct these flaws. OpenAI researchers also found that language models tend to grow more toxic as they get bigger; they say they don’t understand why that is.
Text generated by large language models is coming ever closer to language that looks or sounds like it came from a human, yet it still fails to understand things requiring reasoning that almost all people understand. In other words, as some researchers put it, this AI is a fantastic bullshitter, capable of convincing both AI researchers and other people that the machine understands the words it generates.
UC Berkeley psychology professor Alison Gopnik studies how toddlers and young people learn to apply that understanding to computing. Children, she said, are the best learners, and the way kids learn language stems largely from their knowledge of and interaction with the world around them. Conversely, large language models have no connection to the world, making their output less grounded in reality.
“The definition of bullshitting is you talk a lot and it kind of sounds plausible, but there's no common sense behind it,” Gopnik says.
Yejin Choi, an associate professor at the University of Washington and leader of a group studying common sense at the Allen Institute for AI, has put GPT-3 through dozens of tests and experiments to document how it can make mistakes. Sometimes it repeats itself. Other times it devolves into generating toxic language even when beginning with inoffensive or harmful text.
To teach AI more about the world, Choi and a team of researchers created PIGLeT, AI trained in a simulated environment to understand things about physical experience that people learn growing up, such as it’s a bad idea to touch a hot stove. That training led a relatively small language model to outperform others on common sense reasoning tasks. Those results, she said, demonstrate that scale is not the only winning recipe and that researchers should consider other ways to train models. Her goal: “Can we actually build a machine learning algorithm that can learn abstract knowledge about how the world works?”
Choi is also working on ways to reduce the toxicity of language models. Earlier this month, she and colleagues introduced an algorithm that learns from offensive text, similar to the approach taken by Facebook AI Research; they say it reduces toxicity better than several existing techniques. Large language models can be toxic because of humans, she says. “That's the language that's out there.”
Advertisement
Perversely, some researchers have found that attempts to fine-tune and remove bias from models can end up hurting marginalized people. In a paper published in April, researchers from UC Berkeley and the University of Washington found that Black people, Muslims, and people who identify as LGBT are particularly disadvantaged.
The authors say the problem stems, in part, from the humans who label data misjudging whether language is toxic or not. That leads to bias against people who use language differently than white people. Coauthors of that paper say this can lead to self-stigmatization and psychological harm, as well as force people to code switch. OpenAI researchers did not address this issue in their recent paper.
Jesse Dodge, a research scientist at the Allen Institute for AI, reached a similar conclusion. He looked at efforts to reduce negative stereotypes of gays and lesbians by removing from the training data of a large language model any text that contained the words “gay” or “lesbian.” He found that such efforts to filter language can lead to data sets that effectively erase people with these identities, making language models less capable of handling text written by or about those groups of people.
Dodge says the best way to deal with bias and inequality is to improve the data used to train language models instead of trying to remove bias after the fact. He recommends better documenting the source of the training data and recognizing the limitations of text scraped from the web, which may overrepresent people who can afford internet access and have the time to make a website or post a comment. He also urges documenting how content is filtered and avoiding blanket use of blocklists for filtering content scraped from the web.
Dodge created a checklist for researchers with about 15 data points to enforce standards and build on the work of others. Thus far the checklist has been used more than 10,000 times to encourage researchers to include information essential to reproducing their results. Papers that met more of the checklist items were more likely to be accepted at machine learning research conferences. Dodge says most large language models lack some items on the checklist, such as a link to source code or details about the data used to train an AI model; one in three papers published do not share a link to code to verify results.
But Dodge also sees more systemic issues at work. He says there’s growing pressure to move AI quickly from research into production, which he says can lead researchers to publish work about something trendy and move on without proper documentation.
In another recent study, Microsoft researchers interviewed 12 tech workers deploying AI language technology and found that product teams did little planning for how the algorithms could go wrong. Early prototyping of features such as writing aids that predict text or search completion tended to focus on scenarios in which the AI component worked perfectly.

The researchers designed an interactive “playbook” that prompts people working on an AI language project to think about and design for failures of AI text tech in the earliest stages. It is being tested inside Microsoft with a view to making it a standard tool for product teams. Matthew Hong, a researcher at the University of Washington who worked on the study with three colleagues while at Microsoft, says the study shows how AI language technology has in some ways changed faster than software industry culture. “Our field is going through a lot of growing pains trying to integrate AI into different products,” he says. “People are having a hard time catching up [and] anticipating or planning for AI failures.”
This story originally appeared on wired.com.
1 note
·
View note
Text
RECENT NEWS, RESOURCES & STUDIES, early February 2020

Welcome to my latest summary of recent ecommerce news, resources & studies including search, analytics, content marketing, social media & Etsy! This covers articles I came across since the late January report, although some may be older than that. Report is a bit short because I was sick this last week; don’t worry, I used hand sanitizer before typing this up, so you are all safe 🤒
I am currently looking into setting up a new ecommerce business forum where we can discuss this sort of news, as well as any day-to-day issues we face. I need some good suggestions for a cheap or free forum space that has some editing tools, is fairly intuitive for inexperienced members, and is accessible. If you have any suggestions, please reply to this post, email me on my website, or send me a tweet. (I will put out a survey once we narrow this down to some good candidates, but if you have any other comments on what you want from such a forum, please include those too!)
As always, if you see any stories I might be interested in, please let me know!
TOP NEWS & ARTICLES
Searchmetrics says Etsy did quite well [podcast & text] in the Google January Core Update, while both Amazon and Walmart lost a little bit. “Who won January? I’m going to say Etsy. Etsy has really done a tremendous job [with Google visibility] over the last two years. Sure, they’ve been on the winning side of the algorithm update, but consistently, being in that a position, from my experience, isn’t by chance.” Here’s more analysis listing the US winners and losers, including by subject category (sadly, not shopping sites). Marie Haynes says that the update likely targeted sites that aren’t properly disclosing affiliate links, as well as some pet health sites.
Since a quarter of Americans have a disability, your website, your products & your marketing should be more accessible. Lots of good ideas in here!
ETSY NEWS
TOU alert: Etsy has banned the sale of spent bullet casings (often used as craft supplies). It’s not clear why. There is a thread from a seller whose listings were pulled here.
The 2020 wedding trends blog post is one of those pieces that is useful to sellers & buyers alike, and is also good for Etsy because it attracts outside articles and links. Some trend & keyword info of interest: ”there has been a 171% increase in searches on Etsy for bridesman items and a 72% increase in searches for best woman items”... “searches for ‘70s invitations increase 18% and searches for disco ball items increase 18%” ...”24% increase in searches for bridal jackets and a 4% increase in searches for women’s pantsuits” …”searches for reused, recycled, or reclaimed wedding items increasing 7%” in the last six months (compared to the same time the previous year).
Etsy released its annual diversity & inclusion report on January 29, getting some media coverage along the way, for example here, here and here.
Reverb hired David Mandelbrot as their new CEO; he most recently ran Indiegogo. (Etsy bought Reverb last year.)
The 4th quarter 2019 results will be out Feb. 26. I am currently planning on doing my usual summary thread in the forum.
Decent overview of product photography for beginners, with some pointers on what Etsy wants you to do with photos. For example, “The recommended size for listing images is 2000px for the shortest side of the image, and a resolution of 72PPI.”
SEO: GOOGLE & OTHER SEARCH ENGINES
So you know what Etsy tags are, but you get confused when people talk about tags for search engines? Read this beginners guide to SEO meta tags. (not needed for Etsy shops, but it is terminology used by some website builder sites, as well as coders of course.)
Data provider Jumpshot will be closing due to the controversies over the revelation that their parent company Avast (the anti-virus software) provided user activity to Jumpshot while perhaps not always fully disclosing this to the users. This will affect some SEO tools that relied on these click stats to generate estimates for traffic & search term use, Hitwise & Moz among them. “In all likelihood, Avast took the action to protect its core business, as multiple articles, including from Consumer Reports, called out the company for its data collection practices, while some called for the uninstallation of the Avast software. This is probably as much PR damage control as it is driven by any principled position.”
Forbes appears to have been hit by some Google search issue, but it happened later than the Core Update, so no one is sure what is going on.They were previously penalized for selling links, but that was years ago.
John Mueller listed all of the big Google search news from January in this almost 9 minute video. Click to see the detailed info under the video, because they helpfully summarized the important topics by timestamp, and linked to text resources as well. (Some of it is technical/coding relating; you have been warned!)
There may be another big Google ranking update happening right now (Feb. 9), as tracked by Search Engine Roundtable. Check that site over the next few days for any updates.
CONTENT MARKETING & SOCIAL MEDIA (includes blogging & emails)
The time you send your marketing emails matters, although it’s going to vary more than this article lets on. Keep track of your own stats.
Debunking some myths about Instagram, including the importance of your follower count. “...your follower count isn’t the most important metric on Instagram. Your engagement rate is. Your engagement rate (which is found by calculating the number of engagements you receive divided by EITHER the number of people who saw it OR your total followers, depending on who you ask) is crucial.”
If you use the app Social Captain for Instagram, be aware that your Instagram password was publicly available in the source code.
Facebook’s algorithm has a lot of different factors controlling who sees your posts, including actually having conversations with others, and including “quality, original videos.”
Facebook’s revenue was up 25% in the 4th quarter of 2019, to $21.1 billion, but they expect the privacy controversies to cut into growth this year.
Pinterest is testing an augmented reality tool called “Try On” that allows users to see what they will look like with specific lipstick colours.
ONLINE ADVERTISING (SEARCH ENGINES, SOCIAL MEDIA, & OTHERS)
Google Shopping Ads will soon be shown in Gmail accounts, YouTube and the Discover feed, starting March 4th. Note that “Retailers have been steadily shifty more of their search budgets from text to Shopping ads.”
A comparison of Google Ads vs. Facebook Ads, with plenty of tips. According to them, if you are seriously considering one, you should probably do both. “When we talk about Facebook, we’re also talking about Instagram, What’sApp, and Facebook Messenger. Google also includes YouTube, the second-most trafficked site in the world (behind Google itself).”
Google’s revenue was up 17% in the 4th quarter in 2019, almost all of it from advertising. YouTube makes more on ads than Amazon does.
ECOMMERCE NEWS, IDEAS, TRENDS
eBay released its 4th quarter results for 2019 on January 28, with revenue down 2% and gross merchandise value down 5%. Amazon’s sales were up 21% for the 4th quarter.
BigCommerce now allows customers to check out in over 100 currencies, integrated with several different payment processors.
Wondering what a good conversion rate would be for different ecommerce pages? Here’s a brief overview of the known stats, with some tips on improving.. (Note that any action can be counted as a conversion, including signing up for an email list, so this isn’t just about purchases.)
BUSINESS & CONSUMER STUDIES, STATS & REPORTS; SOCIOLOGY & PSYCHOLOGY, CUSTOMER SERVICE
Are you marketing to Generation Z, or think you should be? Here are 52 facts (with the citations); some highlights: Gen Z has more members than millennials do, and “As of 2020, Gen Z makes up more than 40% of U.S. consumers.” and finally “When shopping online or in stores, 65% of Gen Z prefers to see as few items as possible out of stock” (that last one explains a feedback I received, I think LOL Kind of hard on Etsy when you might have a listing with multiple choices & you only have the one left.)
A study of Cyber Week email open & click rates shows that it might be better not to mention the holidays or discounts.
This article warns consumers of the tricks ecommerce sites use to nudge people to buy more, including some clear examples of deception. “A study by Princeton University and the University of Chicago singled out online clothing seller Fashion Nova, which tells customers that items in their cart “are in high demand.” The problem? The message appears for any item that’s added to the cart. Fashion Nova’s cart also tells shoppers that their items are being “reserved” for 10 minutes. But nothing happens to the items after the 10 minutes are up.”
MISCELLANEOUS
YouTube wants Clearview AI’s face recognition program to stop scraping its videos for content, and to delete anything it has already collected. (Twitter did the same last month.)
#CindyLouWho2NewsUpdates#SEO#search engine optimization#search engine marketing#EtsyNews#etsy#Social media#contentmarketing#content marketing#Ecommerce#smallbiz#SEOTips#customer service#ppc advertising#Onlinemarketing#ecommercetips#emailmarketing#socialmedianews
2 notes
·
View notes
Text
Sufficiently advanced students may also benefit from having some internet fundamentals explained. The internet is full of people and some of them think it's funny to tell lies. ChatGPT and other machine learning algorithms are trained on data from the internet, including the people that tell lies. ChatGPT is not sentient and cannot distinguish the truth from lies. Furthermore, generative AI is trained to prioritize a certain amount of novelty where it can and will recombine the words in factual statements into lies because, again, it has no concept of truth or lies. At best, it can distinguish which words are associated with each other. Combined, we can infer that ChatGPT gets fed lies on the regular from scraping the internet and being exposed constantly to people who will lie to it for fun and on top of that, ChatGPT is encouraged to iterate rather than repeat rote facts pre-programmed into it. So it's a machine that gets fed lies and is encouraged to fib. Some basic science doesn't hurt here either. If Chat GPT really "knew" the answer, the answer should be testable and repeatable. Telling ChatGPT "No, I don't like that answer, say something else" should not return a new response, and searching up Chat GPT's answers on a reputable search engine should get you the same results. They do not. 1+1 will always equal 2. Vinegar and baking soda will always react with each other. If ChatGPT is giving answers that cannot be verified through other sources, then you can be certain it is lying. You can build off of lessons about how to find trustworthy and reliable sources to instill in students that just because something is on the internet doesn't mean it's correct. If the answer you find cannot be traced back to real observation made by sufficient numbers of real human beings and cannot be tested or verified, then in all likelihood, the answer you found is a lie.

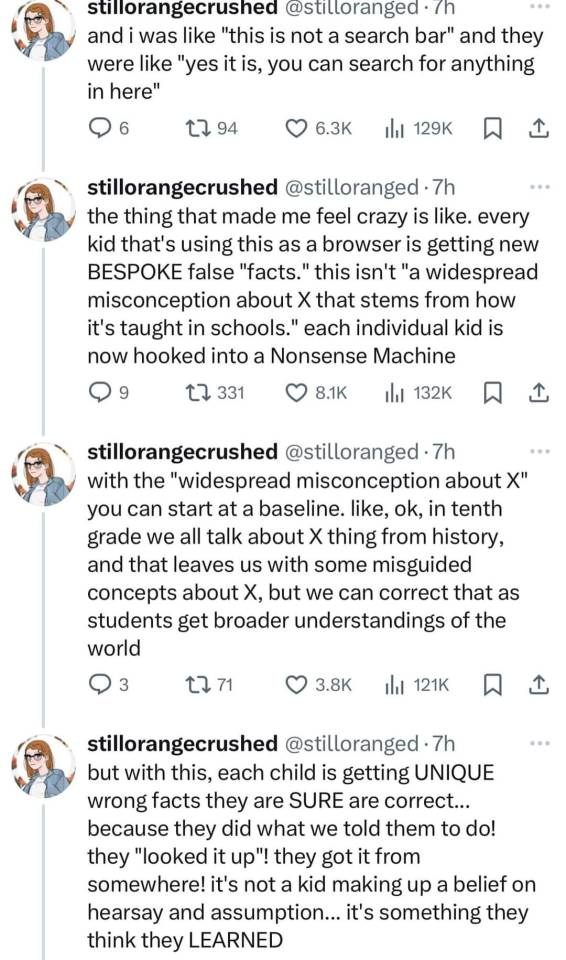

#Generative AI#thanks I hate it#forever reblog#I can see why this is frustrating#Alas I don't have personal experience convincing younglings that AI is not a search engine#so my advice may not apply#but this is how I would have approached it if it was an issue with kids I worked with
108K notes
·
View notes
Text
Frase Review [2020]: AI-Powered Content Marketing Tool
Frase.io Pros & Cons
Pros Cons · Saves you A LOT of time when researching and creating content briefs
· Great SEO optimisation features that’s comparable to other tools in the market
· The Frase AI chatbot provides a great way to engage and convert potential customers
· New features are regularly added to the tool. Don’t be surprised that by the time you read this, there are more features added!
· Fantastic customer service from the team and the founder himself
· Easy to use with an excellent user interface and user experience
· Lots of growth potential, especially as an on-page optimisation and keyword research tool
· As Frase is pretty new, it can be pretty buggy at times
· Some features are not as good and accurate as what’s available in the market
· Basic plan can get expensive if you don’t need 30 documents a month
· Lack of documentation
Sign up for Frase.io
As a content writer, I sometimes feel that writing content can be such a drag. I have to research the topic, structure my content, and then start writing them.
Without something to solve this issue, I’d be taking a lot of time just to churn out a simple 1000-word article.
What makes it worse is that part of my SEO strategy revolves around content, and how can I get my keywords ranked if I don’t write more articles?
This is why I bought Frase, an AI-powered tool that cuts the time I need to write an article by 4 hours.
And in this post, I’ll be reviewing Frase.io.
What is Frase.io?
Frase (or Frase.io) is a content marketing tool that generates content briefs for your chosen keywords.
Suppose you’re writing an article from scratch. Frase scrapes the top 20 websites in the Google search results and will automatically generate a content brief in 10 seconds with the best topics that you should talk about.
If you already have existing content, you can use Frase to optimise it as Frase will tell you the most important terms your competitors are using.
Either way, Frase will benchmark your article against the 20 websites ranking (or you can choose which ones to compare with) to identify topic gaps and missing terms.
All this is done with the power of artificial intelligence.
Frase.io’s Key Features (And how you can use it)
Frase.io has quite a few key features to it despite being mainly a content marketing tool.
Generate Topic Ideas
Using Frase, you can generate topic ideas on what to write about for your blog. There are a few ways to do this.
Question Ideas
Firstly, under the “Question Ideas” tab, you can search for a broad keyword term, and Frase will show you a long list of commonly asked questions related to that chosen keyword.
This is useful as it helps you find topic ideas to write about that your customers are actually searching for. From this page, you can generate an article brief with just a click of a button!
Frase Concept Map
Secondly, Frase has the ability to generate a concept map from a topic chosen. This concept map extracts topics from Wikipedia and connects related topics together, while also providing you a brief summary of the Wikipedia article.
From here, you can either read the full wiki or generate the article brief for the target keyword.
When I’m writing this, most of the questions come from Quora and Reddit, and only a handful of them are related. The concept map also requires a bit of exploring to do before you can find a topic to write on.
As Frase was created to reduce the time needed for you to write articles, it’s expected that these features are not the best.
However, it’s still an excellent feature to include, especially when running out of ideas/topics to write about. Therefore, it’s recommended that you use Frase alongside a keyword research tool.
Content Research & Creation
As mentioned above, Frase helps by generating content briefs based on topics that are covered by your competitors. These are called “documents”.
In a document, there is a content editor where you can easily add, remove, or edit stuff.
Frase will also provide you with a brief competitor analysis regarding what your competition wrote about, topics covered, a summary of each topic, and common questions asked in their articles.
Frase will also provide you with statistics such as the average word count, average links, and average sections from these pages.
To the right of the content editor are tabs for you to browse statistics, news related to the keyword, and a tab for links, for external linking purposes.
If you’re outsourcing content, this functionality can be used to generate better content briefs for your writers. You no longer need to research and create a content brief from scratch ever again!
It is vital to take note that Frase.io DOES NOT create content for you. It merely uses AI to do research and identify content gaps.
However, the founders are planning to incorporate GPT-3 into Frase in the future, which means that it might actually be able to do this.
Content Optimisation
What makes Frase attractive is that it not only saves you research time, but you can also optimise your existing content with it.
For your chosen keyword, Frase provides you with content optimisation analyses where it extracts the most used terms from your competitors’ articles and counts the number of times it’s being used.
These keyword suggestions are powerful because Google has already made up their mind on what they want to see on the first page. Replicating and improving the results you see is a strong way to beat your competition.
This method is called TF*IDF.
Frase has a proprietary scoring system (0-100%) called “Topic Score” that scores your content against those in search engines. There is also an average competitor topic score for you to refer to.
You should look into getting a content score higher than it by writing better content. With your optimised content, you are likely to see positive ranking changes.
Frase Answer Engine
The Frase Answer Engine is an AI-powered chatbot that uses your website’s content to answer your visitors’ common questions. Frase will crawl your website and break it down into different sections, using it as information to answer queries.
The Answer Engine is a dedicated chatbot software that is super easy to install. All you have to do is to insert a script into your website’s header. If you know how to install Google Analytics, you’ll definitely know how to install this.
I love this chat option because overall, it has a user-friendly interface where you can customise its look to how you want it. There is also a test sandbox where you can train your chatbot to answer your visitors’ questions.
In the analytics section, you can see the questions asked by your website visitors, and the score given for the usefulness of the AI chatbot’s answers provided. If the answers are wrong, or you don’t like how it is being answered, you can train the Answer Engine accordingly.
The Answer Engine also allows you to capture emails, useful for you to follow up with a potential sale!
Oh, not forgetting that the Answer Engine also has a live chat option where potential customers can contact you promptly.
Frase Integrations
According to their website, Frase provides integrations with WordPress, HubSpot COS, MailChimp, Google Drive, Google Search Console, and HubSpot HRM.
However, as of writing this, the only integration options I have are with HubSpot’s CRM and Google Search Console. According to their Facebook group, they are currently fixing their other integrations due to bug-related issues.
Hubspot Integration
The HubSpot CRM integration allows you to send lead information obtained from the Answer Engine automatically to HubSpot.
Google Search Console Integration
The Google Search Console integration is rather interesting. Frase firstly extracts the keywords you’re ranking for and clusters them by topics. These are then ranked according to its impressions, position, clicks, and CTR.
Based on this data, Frase recommends an action that you should take to improve your search traffic. Either you can create a new document, optimise a current one, or track it.
Unfortunately, I’m not able to find any substantial documentation on how to best use this information.
I understand why I’m being recommended to optimise or track each cluster’s performance, but why would I need to create a new article if I’m already ranking for the keywords? Hmm…
Frase’s Support
Although not technically a feature of Frase, I do have to say that their support deserves a shoutout in this review. Inside Frase’s private Facebook group, many users raise issues, bugs, and recommendations to improve the tool.
Tommy Rgo, the founder of Frase, is pretty darn active in responding to all of these. He raises bugs and issues quickly to his team. Depending on the severity, they can have a solution for you within 24 hours.
Sometimes, the same question gets asked frequently in the group, and Tommy never fails to reply patiently and politely.
Recommendations are also taken seriously. Many of them have already been added as additional features or are currently in the pipeline.
However, what could use improvement is their knowledge base on how to use the tool. Many users, including myself, find that it’s pretty shallow and have to resort to their Facebook group to get help from other users.
Pricing
I got Frase through an AppSumo lifetime deal for only US$69, although I’m not too sure if this deal will come back anytime soon.
However, Frase provides a free trial where you can do unlimited question research, create 5 documents, 1 crawl through Google Search Console, and a 30-day trial of their Answer Engine.
Otherwise, below are their monthly and annual pricing for various plans.
Plan Type
Basic Plan Growth Plan Answer Engine Pricing US$39.99/month billed annually (12% savings)
or
US$44.99/month
US$99.99/month billed annually (13% savings)
or
US$114.99/month
US$199.99/month billed annually Number of Users 1 user 3 users ($15 per extra) 3 users ($15 per extra) Number of documents 30 documents/month Unlimited documents Unlimited documents Answers – – 500 answers/month per Answer Engine Additional Answers – –
$50 per extra 100 answers
*EDIT Frase.io just launched a LIFETIME 50% off for the next 500 new customers. This deal is expected to be fully redeemed within the next 5 days! Click on the button below and use “forever50” as a coupon during your checkout now!
Get Frase.io Now!
What others think about Frase.io
I’m not the only one who loves how Frase has saved my time and money when creating content. Many of their users are also great fans and have left reviews on various platforms.
Rated 4.7/5.0 from 22 reviews on G2 Crowd Review
Rated 4.7/5.0 from 108 reviews on Appsumo.com
Frase.io is also used by companies like Neil Patel, Drift, eToro, and Microsoft.
Here are also a few of the many comments left inside their Facebook group.
Frase Alternatives
There are only a few other tools that are true Frase alternatives. Such tools are MarketMuse and ClearScope.
Through some research, MarketMuse and ClearScope seem to have a far superior keyword research feature built-in. Frase’s “Question Ideas” and “Concept Map” could use some improvements.
However, the main features that Frase offers (content research and optimisation) look to be on par with these alternatives.
What sets the difference between Frase, MarketMuse, and ClearScope is definitely the pricing. MarketMuse starts at US$500/month, while ClearScope starts at US$350/month.
This is wayyyy more expensive than Frase’s basic plan of US$44.99/month, making Frase the better option if you’re looking for value.
Conclusion
Despite the cons that Frase has, I believe that it is definitely one of the best purchases I made as a content writer.
As a new tool in the market, Frase has proved to be an invaluable tool that removes the hassle in content writing. Frase is also continually improving and developing itself, making it almost irresistible to not make a purchase.
With the development of GPT-3, you just might be able to expect Frase to start offering AI-generated content.
However, if you currently face the below problems:
You find that writing articles take up too much of your time
You lose motivation easily when writing content
You need to save time in doing research
You want to improve your on-page SEO
You have a lot of writers and need to generate content briefs FAST
You’re looking to maximise your budget
Frase.io is definitely a good fit for you.
*EDIT Frase.io just launched a LIFETIME 50% off for the next 500 new customers. This deal is expected to be fully redeemed within the next 5 days! Click on the button below and use “forever50” as a coupon during your checkout now!
Get Frase.io Now!
The post Frase Review [2020]: AI-Powered Content Marketing Tool appeared first on Fur.
source https://firdaussyazwani.com/writing/frase-review
0 notes
Text
Yuh as one of those human reviewers (not for the docs writer LLM but for Google search quality, bias, and text summaries more generally), it's a terrible terrible privacy mess to base LLMs off of data which is not published on the web. Yes there are issues with web scraping to train bots as far as intellectual property, but that info is all public in one way or another. I can scrape the New York Times for restaurant reviews and ask an LLM to create a review for an imaginary Thai restaurant, but those reviews were at least meant for public viewing in the first place. It wouldn't be the end of the world if the synthetic review copied something verbatim like "chicken enlivened by lemongrass and ginger".
Because LLMs are being trained on all the data of all the users, there's no guarantee that whatever goes into the "black box" will not come out to another user given the right prompting. It's just a statistical process of generating the most likely string of associated words, connections between which are reweighted based on reviewer and user feedback. If in the training data a string of connected words is presented, like "come to the baby shower at 6pm for Mary Poppins at 123 Blueberry Lane, Smallville, USA, 90210", that exact address could at some point be regurgitated in whole to another user, whether the prompting was intentional or not.
The LLM doesn't "know" what data is sensitive. The LLM does not "protect" data from one user from being used by another. The LLM doesn't have the contextual awareness to know that some kinds of information could present more risk for harm, or that some words represent more identifiable data than others.
All of the data is being amalgamated into the LLM likely with only some very broad tools for grooming the data set, like perhaps removing the corpus of one user or removing input with a certain percentage of non-English characters, say, and likely things like street addresses, phone numbers, names, and emails which can be easily removed are already being redacted from the data sets. But if it's put into words, it's extremely likely to be picked up indiscriminately as part of the training set.
The Google text products for search I've worked on can be very literal to the training data, usually repeating sentences wholesale when making summaries. An email LLM could be giving you whole sentences that had been written by a person, or whole phrases, but still be "ai generated"- it just happens that the most likely order for those words is exactly as a human or humans had written before. Obviously that makes sense because people say the same things all the time and the LLMs are probability machines. But because the training sets of data are so massive, it's not being searched every time to see if the text is a verbatim match to something the LLM had been trained on, or running a sniff check for whether that information is specific to an individual person. This "quoting" is more likely for prompts where there are fewer data points that the LLM is trained on, so compared to say, "write an email asking to reschedule the meeting to 2pm" which has 20 million examples, if I prompted "write an origin story for my DND character, a kind halfling bard named Kiara who travels in a mercenary band. Include how she discovered a love of music and how she joined the mercenaries" or "generate a table of semiconductor contractors for XYZ corp, include turnaround times for prototypes, include batch yield, include Unit cost" , we're a lot more likely to see people's (unpublished and private!) trade secrets being quoted. The corporations are going to have a fit, especially since they've been sold the Google Office suite for years.
At best, the data sets are being massaged by engineers using some complex filters to remove some information, and the bots are being put through sampling to see how often they return results which are directly quoted from text, and the reviewers are giving low ratings to responses which seem to quote very specific info out of nowhere. But if the bot changes just one word, or a few, while still rephrasing the information, it's impossible to check whether that information has a match in the training data without human review, and there's no guarantee another bot making the comparison like a plagiarism checker would catch it. Once the data is in the set, there are no guarantees.
The only way Google gets around these likelihoods of copyright infringement or privacy law is by having you the user waive your rights and agree as part of the terms of service not to include "sensitive" info.. so if you're somehow hurt by a leak of your info or creative ideas , it's because you used the service wrong. Might not stand up in court, but still be advised not to agree to this stuff. It's highly irresponsible to use LLMs which are being trained on unpublished user data and I'm sure that companies are going to throw a fit and demand to opt out of being scraped for data at scale for their whole google suite.
🚨⚠️ATTENTION FELLOW WRITERS⚠️🚨
If you use Google Docs for your writing, I highly encourage you to download your work, delete it from Google Docs, and transfer it to a different program/site, unless you want AI to start leeching off your hard work!!!
I personally have switched to Libre Office, but there are many different options. I recommend checking out r/degoogle for options.
Please reblog to spread the word!!
28K notes
·
View notes
Text
The Fight Over Police Use Of Facial Recognition Technology | News Cover
The News Cover: The majority of Americans appear in a facial recognition database, potentially accessible by their local police department and federal government agencies like ICE or the FBI. It's not something you likely opted into. But as of now, there's no way to be sure exactly who has access to your likeness.
Over the past 10 years or so face recognition, face surveillance has moved from the realm of science fiction to the realm of science reality. But in light of recent protests for racial justice, facial recognition technologies have come under scrutiny for the way in which they're deployed by police departments around the country. Protesters worry they're being tracked, and communities of color say this tech will exacerbate bias.
Nobody can get clear answers about who is using facial recognition and how. These technologies do not work the same across different groups of people. And oftentimes the people that they fail most on are those who are already marginalized in society. In response, IBM, Amazon, and Microsoft have all stated that they'll either stop developing this tech or stop selling it to law enforcement until regulations are in place.
(adsbygoogle = window.adsbygoogle || []).push({});
And in late June, Democratic members of Congress sought to make these pledges permanent, introducing a bill banning government use of facial recognition technologies. But lesser known companies like Clearview AI, NEC, and Rank One plan to pursue business as usual, and say this tech has an important role to play in the justice system. If somebody violently harms somebody else, that is an ongoing threat to public safety and tools that can be used safely should be available.
Whether or not they support a ban, researchers and activists across the political spectrum are increasingly speaking out about privacy concerns, algorithmic bias and the lack of transparency and regulation around this tech. I don't think we should take an approach that a technology is inherently good or bad. But I'm not comfortable at the moment with the lack of regulation, having this technology being used among law enforcement.
This is a type of technology that has profound implications for the future of human society. And we need to have a real conversation about whether we can have it in our society at all. Facial recognition technologies use biometric information, that is body measurements specific to each individual, to match a face from a photo or a video to a database of known faces. This database could be composed of mug shots, driver's license photos, or even photos uploaded to social media.
It's likely that you already use this tech in your daily life, as advances in artificial intelligence over the past decade have greatly improved its capabilities. Every time you use your face to unlock your smartphone, accept Facebook's photo tagging suggestions, or sort through a Google Photos album by person, you're seeing facial recognition at work. This isn't really the type of thing that lawmakers are seeking to ban, and some are definitely eager to see the everyday users expand.
I think there are a lot of applications that are potentially quite exciting. You know, going to a grocery store and being able just to walk out of the store without having to pay, you know the store just identifies you and automatically done it to you. But whether you're tagging photos or searching through a vast government database, it's the same technology at work. And that has others concerned. We're worried that people are going to start to normalize this technology and that could bleed into acceptance on the government side, which is extremely concerning.
(adsbygoogle = window.adsbygoogle || []).push({});
Real-time surveillance of video footage is often considered the most worrisome use case. Right now, the tech is far from 100 percent accurate. But in theory, using facial recognition on video feeds would make it possible to alert police when a suspect shows their face in public or track where anybody is going and who they're associating with.
China and Russia already do this, and some U.S. cities, like Detroit and Chicago, have acquired tech that would make it possible. Detroit's video surveillance program started in 2016, when security cameras replaced at eight gas stations. In 2017, the department bought facial recognition software, giving them the capability to scan these cameras video feeds. Over the last, under three years, i t has rapidly expanded.
They have surveillance helicopters, access to drones, traffic lights with surveillance capabilities. After heated debate, Detroit banned the use of facial recognition on live video, so the city cannot track people in real-time. Chicago promises that it doesn't do this either. But throughout the U.S., using facial recognition on photographs is still common, though San Francisco, Boston and a number of other cities have outlawed all government use of this tech. So we should not forget, right, San Francisco was the first city to ban face recognition.
The place where the sausage is being made did not want the sausage, right? Private companies like Walmart, Lowe's and Target have also trialed facial recognition systems to catch shoplifters, though they say they're not currently using it. And U.S. airports are starting to roll out face scanners at the gate, so passengers need not show their passport. There's also potential to use similar tech in targeted advertising, something that Walmart is experimenting with in partnership with a startup called Cooler Screens, which infers a shopper's age and gender in order to show more relevant ads. While the screens don't identify individuals, it's not hard to imagine a system that could, a thought that puts many on edge.
I think many people will be concerned and creeped out, but will eventually suck it up and get used to it. If someone can come up with a way, in the private sector, to ensure that this is not easy for criminals or the government just to take advantage of, then I can see people becoming quite comfortable with it. The global facial recognition market was valued at 3.4 billion dollars in 2019, and it's projected to grow steadily over the coming years.
(adsbygoogle = window.adsbygoogle || []).push({});
However, in the wake of George Floyd's death and protests against racism and police brutality, Amazon, Microsoft, and IBM made headlines for pulling back on police access to facial recognition technology. But while these tech giants certainly have clout, as well as other significant ties to law enforcement, they're not actually the most important companies in this specific market. First off, IBM did not have a real product in this space.
Microsoft and Amazon, neither of them were big players in the law enforcement space. They did not have a large line of business there. So one could call it a bit of virtue signalling. After announcing a yearlong moratorium on police use of its facial recognition software, called Rekognition, Amazon says it doesn't know how many police departments actually use it. Rekognition is widely used in the private sector, but previously only one law enforcement customer was listed on its website.
For its part, Microsoft says it does not currently sell its facial recognition software to police and that it promises not to until there are federal regulations in place. IBM took the boldest stance of the three, promising to stop research and development on facial recognition altogether. But this tech wasn't really generating much revenue for the company anyway.
But many lesser-known companies are providing this technology to the police on a large scale, and they've made no such promises to stop, upsetting privacy advocates. My view is that it's fundamentally incompatible with democracy and with basic human rights to have technology like facial recognition in the hands of law enforcement. Clearview AI is a huge player in this space. Founded in 2017, Clearview has amassed a database of over three billion images, scraped from millions of websites and social media platforms from Venmo to Facebook.
Its catalog is far more comprehensive than anything that came before it, and the company says it's used by over 2,400 law enforcement agencies in the U.S. at the local, state, and federal levels. Because we're like the largest provider in the space and we've had so much experience, we feel that it would be a shame and a really big mistake to take it away, because all these crimes would go unsolved.
(adsbygoogle = window.adsbygoogle || []).push({});
The way Clearview works is simple. You just upload a picture and the system searches its database for matches. So Katie, do you mind if I show you how it works on your photo that you supplied earlier? Go for it. So it just takes a matter of seconds. You pick the photo that you want to search, which is that one. And as you can see, it's uploading it. It's finding photos. And here there's eight photos out of over three billion that match.
And you can see they all come with a link to the original. I see a picture from my personal website, an old news article, CNBC's website. All things I knew were out there, but not things I knew were a part of a facial recognition database, accessible to thousands of police departments. The Clearview system itself does not reveal my name, but the links point to websites that do. So we don't actually identify someone, we help you identify someone if you're an investigator.
While Google, YouTube, Twitter, and Facebook have all sent cease-and-desist letters to Clearview, the company says that because these images are public, it has a right to compile them. At the end of the day, it's a search engine just like Google. So we think it's a little bit hypocritical of them to then send a cease-and-desist. But fundamentally, it is publicly available information.
Other players include NEC, the 1 21-year-old information technology and electronics giant that sells its software to about 20 U.S. law enforcement agencies, and Rank One, which says it supports about 25 different law enforcement agencies. We think face recognition is a tool that empowers people when used correctly. If it wasn't our technology, it absolutely would be somebody else's technology.
Advocates have raised the alarm on facial recognition for years, and now their concerns are gaining momentum. One of the most oft-cited issues is the general lack of transparency when it comes to exactly who is using facial recognition and for what ends. I wish I could tell you how many police departments are using this technology. Researchers at Georgetown discovered that Detroit was one of the cities using facial recognition.
They had been using that technology for over a year before the community got wind of it. So because we don't have this transparency, I'm not able to answer this question of house widespread this technology is. That lack of transparency ma y be by design. The concern here I think from the police is, we don't want to show our hand to criminals.
The idea is, well if we have to be more transparent about what technology we use, then people will adapt their behavior. And I think in a functioning democracy that takes civil liberties seriously, that's a price sometimes we have to pay. What's more though, the tech just isn't always accurate. And when it's wrong, it reveals bias. A 2018 study by the ACLU tested Amazon's Rekognition software on members of Congress, running their images through a mugshot database. It incorrectly identified 28 of them as criminals. And while only 20 percent of Congress members are people of color, they comprised 39 percent of the false matches.
(adsbygoogle = window.adsbygoogle || []).push({});
This report came on the heels of a 2018 study by Buolamwini and her co-author, Timnit Gebru, which demonstrated that software by Microsoft, IBM, and Chinese company Face++ frequently misgendered women and people of color. I was working on an art installation that used face-tracking technology. It didn't work that well on my face until I put on a white mask, and so that led to some questions. Others that did de tect my face labeled me male. I am not a man. B uolamwini and Gebru found that the systems they tested were nearly 100 percent accurate when identifying the gender of white men.
But when identifying gender in darker skinned woman, Microsoft's system failed about 20 percent of the time and IBM's system failed about a third of the time. After the study came out, Microsoft and IBM trained their algorithms on a more diverse set of faces and improved their error rates. But when B uolamwini conducted a follow-up study using Amazon Rekognition, it still m isgendered dark-skinned woman nearly a third of the time. Amazon, unlike Microsoft or IBM, actually actively attempted to discredit our research.
And we were really fortunate that more than 70 A.I. researchers and practitioners came to say no, this is rigorous, peer-reviewed, in fact even award winning work. The issues that are being pointed out are core to our field. Like Amazon noted in their critique of B uolamwini's study, Brendan Klare, CEO of Rank One, says that gender identification is a different technology than matching a face to a database of faces.
Obviously gender estimation is sort of a different type of application, but there never should be errors like that. And the errors they showed were egregious and those are not representative of the technology. Our technology is about 99 percent accurate on gender estimation across all races. He says that claims of algorithmic racism and sexism are misleading.
It's an important topic. It's one that has been susceptible to a lot of misinformation. Both Rank One and NEC recently made the news after their algorithms misidentified a black man in Detroit as a suspect in a shoplifting case. The man, Robert Williams, spent 30 hours in jail. Klare says that Rank One's technology was misused in this case, because a match is not probable cause for arrest. The investigating officers did not collect independent evidence.
If the case of Mr. Williams is not an isolated incident, if there is a pattern that emerges, we will get out of this market. Clear view says a recent test showed its system is 99.6 percent accurate and exhibits no racial bias whatsoever. Previously, the ACLU has called Clearview's accuracy assertions absurd and challenged the company's testing methodology.
(adsbygoogle = window.adsbygoogle || []).push({});
The Detroit police chief, facing scrutiny over Williams' arrest, said that if the department relied solely on its facial recognition software, it would misidentify suspects about 96 percent of the time. The huge difference in stated accuracy rates vs. actual accuracy rates could be because these systems are tested using relatively high quality images.
But when they're deployed in the real world, security camera footage can be too low quality to yield accurate results. But just for context, the most important thing, this is much more accurate than the human eye. And I think there's only beneficial things that can happen once you get to this level of accuracy. But even if a system could achieve perfection, others can think of a whole host of not so beneficial consequences.
It's dangerous when it works and when it doesn't. But even if the technology worked 100 percent of the time, it would be extremely dangerous because at its logical conclusion, what it really does is eliminate privacy and anonymity in public space, which is something that no free society should ever tolerate. Some are more optimistic about the role that facial recognition could play in society. Facial recognition technology could be exculpatory evidence. Like, look Your Honor, I know I'm being accused by three witnesses, but there is an image of me at Walmart at this moment. It cannot be me.
What if there was a facial recognition system and it only included images of children that parents had volunteered in the case of a missing child? That's the kind of situation where I imagine that people see the value of it. But still, others ask, are the serious drawbacks worth it? There is the scenario that we would hope to be true, which is this flawless system is used in a police force that doesn't have a history of systemic racism. But this is not the world we live in.
And so I can understand wanting to use whatever tools are available, but we have to ask, are we bringing the correct tool to the job? And so it's one thing if oh, it worked out how you thought. But at what cost? How much data did you have to collect? We believe it's extremely dangerous, in a predominantly black city especially. It doesn't make any sense to double down on something like this at a time when the nation is calling for some systemic changes within policing and to undo systems of brutality and racial violence.
What most experts agree on is that at the very least, more regulation and transparency is needed. Many also say this tech should not be used to help solve low-level crimes like shoplifting or drug use, though some concede that it may eventually be appropriate to use facial recognition on still photos to help solve violent crimes or kidnappings. But using it on video footage is often considered a red line.
We believe strongly that the use of facial recognition algorithms to analyze video data either in real-time or to look back at historic video footage, that that ought to be banned permanently in the United States, that we should just never be engaged in that type of surveillance. In general, a federal moratorium on this tech could garner significant bipartisan support.
(adsbygoogle = window.adsbygoogle || []).push({});
Last year, an ACLU poll in Massachusetts revealed that nearly eight in 10 voters supported a statewide moratorium, which included 84 percent of Democrats, 82 percent of Independents and 50 percent of Republicans. We're kind of in this sweet spot right now where the technology is not quite good enough to really be able to effectively achieve the goal of cataloging every person's every public movement, habit, and association. But it's getting there. So this is the perfect time, actually, for lawmakers to step in and say, you know what we're just going to draw a big bright red line in the sand here and say, we're not going to go any further until we have a deliberate conversation about this.
But some worry that Big Tech will use this time to lobby for overly permissive regulations. We're going to be on the lookout for legislation that is clearly backed or sponsored by companies like Amazon and Microsoft, where their lawyers and lobbyists have gone over the text to make sure that it's friendly to their business model. In some form or another, facial recognition is likely here to stay. We'll probably continue using it to unlock our phones and tag our pictures.
It may become commonplace to use it to confirm our identity at the airport or grocery store checkout line. Maybe we'll even come to accept a world full of hyper-targeted advertising screens. Name one technology we've developed and stopped. This genie is not going back in the bottle. It really is just going to be coming down to how well do we manage it? But to what extent governments and police departments can access this technology remains an open question. And that's where the real debate lies.
Some think the political environment right now presents a real opportunity to ban a ccess to this tech at all levels of government. I think in Congress we have a real shot at getting strong legislation to put at least an immediate moratorium on local, state, and federal use of facial recognition. And I'm optimistic that we will get a ban on facial recognition in the United States.
Others predict legislation will stop short of a ban. I think there will be many members who take the view that the technology has many worrying applications and civil libertarian issues, but that it also is ultimately useful with the right guidelines in place. And crafting these guidelines soon will be essential, because technology like facial recognition is advancing at a rapid clip.
It may be too late to turn back the clock altogether, but some privacy advocates say that this debate is emblematic of the idea that just because we can build something doesn't mean that we should. Sometimes algorithmic justice means you don't make it, you don't deploy it. I think these technology companies need to have a sit down and ask themselves before they innovate, is this something that necessarily needs to exist in the world?
from Blogger https://ift.tt/2AV0WlU via IFTTT
0 notes
Text
These Nudes Do Not Exist and I Don’t Know Why This Startup Does Either
You can buy an image of an algorithmically-generated nude photo of a woman, standing like she's posing for a mugshot, for $1. If that's your thing.
A startup called These Nudes Do Not Exist thinks this could be a groundbreaking evolution in the world of porn. It offers images of women who, like these cats, these people, these feet, and these diverse stock models, do not exist in the real world.
"We knew that we had the technical expertise and self-funding capabilities to succeed in bringing GAN technology to nude content, and wouldn't find ourselves in a crowded space with a lot of competition, and as such the opportunity was pretty attractive," one of the founders of These Nudes Do Not Exist (TNDNE), who requested to remain anonymous because he and his partner didn't want to be publicly associated with their own creation, told me.
To buy an image of one of these algorithmically-generated women, you can smash a button that says "Generate New Girl" and cycle through a series of bodies that all look strikingly the same: white, bland smile, average-sized breasts and slim builds. When you land on one you like, you add her to your cart, and are issued a "seed" number, which TNDNE says is your proof that you own that specific model.
"I think this is probably the first chance that anyone in the world has ever had to buy AI generated pornographic content, so in a sense each customer gets to be a part of porn and AI history," the co-founder said. "Long term however, the goal is to have complete 3D rendered AI generated models capable of creating custom photo and video content."
It's worth questioning why a still image of a shirtless woman from the torso-up is considered "pornographic." TNDNE says it plans to expand to include more poses and video options, eventually, and that the pictures currently for sale "mostly serve as a novelty."
To create the nudes, the website uses Generative Adversarial Networks, an algorithm trained on lots and lots of images—in this case, nudes—in order to produce new, novel versions of what it sees as "nude women."
TNDNE's co-founder wouldn't tell me what specific datasets the algorithm is trained on, but did say that the current database is entirely women, mostly 20-40 years old, and white.
"That wasn't because of any choice on our part so much as it was just because that's how the well classified datasets ended up shaking out," he said. "We were very careful to use only public domain or purchased data sources from reputable providers. While we will add men in the future, the truth is there's not a lot of demand for male nude pictures."
Not seeing a high demand for male photos is the same reasoning the creator of DeepNude, an app that algorithmically undressed images of women, gave for only offering non-consensual nude functionality of women's bodies.
Many of the images and datasets found online of nude and pornographic imagery, even those marked as public domain, are frequently stolen from actual sex workers. People steal sex worker's content all of the time, posting it to tube sites for free or dumping it into database links. Even big tech companies struggle with this: like IBM, which got into trouble for scraping people's personal Flickr images marked for creative commons use, and Microsoft, which took down the world's largest image dataset, MS Celeb, after reports revealed it consisted of photos of people without their consent.
For nude images in particular, machine learning engineers struggle to find datasets for training. Some scrape Reddit or Pornhub to get the images, but NSFW images on both of these sites frequently include non-consensual imagery, even if it's posted from an account made to seem like that person is doing it themselves. In short, this is a really, really tough undertaking—that TNDNE seems to think it can tackle with some reverse-image searching.
"The verification process for public domain [images] centers around running public domain data through reverse image searches," the co-founder said. "If we notice that the results are from paywalled/monetized websites, revenge porn websites, online forums, or behind paywalls, we err on the side of caution and exclude that data since it may not have been gathered ethically."
This would mean individually searching and examining the source of every photo—and still not being sure if the images are from someone who is who they say they are, and is giving consent for the photo to be online, let alone to be included in a dataset to train a computer to churn out uncanny-valley algorithmic women.
At best, TNDNE says it guarantees that every woman in the set is uniquely not a woman who exists. At worst, we're continuing down the seemingly-limitless path of men experimenting on women's bodies as startup fodder.
These nudes may not exist, but I'm still not sure why this startup needs to exist either. More algorithmic humans populating the internet can't solve issues of diversity or non-consensual porn. If anything, it falls into the same criticism that Melody, the 3D-generated hentai cam girl, does: If you want nudes, why not pay for a quality custom photo or clip from a real, human model.
These Nudes Do Not Exist and I Don’t Know Why This Startup Does Either syndicated from https://triviaqaweb.wordpress.com/feed/
0 notes
Text
Thin Content & SEO | How to Avoid a Google Thin Content Penalty
We live in a world of information overload. If 10 years ago it was hard to find content at all, now there’s way too much of it! Which one is good? Which one is bad? We don’t know.
While this subject is very complex, it’s clear that Google is attempting to solve these content issues in its search results. One of the biggest issues they’ve encountered in the digital marketing world is what they call thin content.
But what exactly is thin content? Should you worry about it? Can it affect your website’s SEO in a negative way? Well, thin content can get your site manually penalized but it can also sometimes send your website in Google’s omitted results. If you want to avoid these issues, keep reading!
What Is Thin Content & How Does It Affect SEO?
Is Thin Content Still a Problem in 2019?
How Does Thin Content Affect SEO?
Where Is Thin Content Found Most Often?
How to Identify Thin Content Pages
How to Fix Thin Content Issues & Avoid a Google Penalty
Make sure your site looks legit
Add more content & avoid similar titles
Don’t copy content
Web design, formatting & ads
Video, images, text, audio, etc.
Deindex/remove useless pages
1. What Is Thin Content & How Does It Affect SEO?
Thin content is an OnPage SEO issue that has been defined by Google as content with no added value.
When you’re publishing content on your website and it doesn’t improve the quality of a search results page at least a little bit, you’re publishing thin content.
For a very dull example, when you search Google for a question such as “What color is the sky?” and there’s an article out there saying “The sky is blue!”, if you publish an article with the same answer you would be guilty of adding no value.
So does it mean that this article is thin content because there are other articles about thin content out there?
Well.. no. Why? Because I’m adding value to it. First, I’m adding my own opinion, which is crucial. Then, I’m trying to structure it as logically as possible, address as many important issues as I can and cover gaps which I have identified from other pieces.
Sometimes, you might not have something new to say, but you might have a better way of saying it. To go back to our example, you could say something like “The sky doesn’t really have a color but is perceived as blue by the human eye because of the way light scatters through the atmosphere.”
Of course, you would probably have to add at least another 1500 words to that to make it seem like it’s not thin. It’s true. Longer content tends to rank better in Google, with top positions averaging about 2000 words.
How your content should be to rank
Sometimes, you might add value through design or maybe even through a faster website. There are multiple ways through which you can add value. We’ll talk about them soon.
From the Google Webmaster Guidelines page we can extract 4 types of practices which are strictly related to content quality. However, they are not easy to define!
Automatically generated content: Simple. It’s content created by robots to replace regular content, written by humans. Don’t do it. But… some AI content marketing tools have become so advanced that it’s hard to distinguish between real and automatically generated content. Humans can write poorly too. Don’t expect a cheap freelancer who writes 1000 words for $1 to have good grammar and copy. A robot might be better. But theoretically, that’s against the rules.
Thin affiliate pages: If you’re publishing affiliate pages which don’t include reviews or opinions, you’re not providing any new value to the users compared to what the actual store is already providing on their sales page.
Scraped or copied content: The catch here is to have original content. If you don’t have original content, you shouldn’t be posting it to claim it’s yours. However, even when you don’t claim it’s yours, you can’t expect Google to rank it better than the original source. Maybe there can be a reason (better design, faster website) but, generally, nobody would say it’s fair. Scraping is a no no and Google really hates it.
Doorway pages: Doorway pages are pages created to target and rank for a variety of very similar queries. While this is bad in Google’s eyes, the search giant doesn’t provide an alternative to doorway pages. If you have to target 5-10 similar queries (let’s say if you’re doing local SEO for a client), you might pull something off with one page, but if you have to target thousands of similar queries, you won’t be able to do it. A national car rental service, for example, will always have pages which could be considered doorways.
If you want, you can listen to Matt Cutts’ explanation from this video.
youtube
As you can see, it all revolves around value. The content that you publish must have some value to the user. If it’s just there because you want traffic, then you’re doing it wrong.
But value can sometimes be hard to define. For some, their content might seem as the most valuable, while for others it might seem useless. For example, one might write “Plumbing services New York, $35 / hour, Phone number”. The other might write “The entire history of plumbing, How to do it yourself, Plumbing services New York, $35 / hour, Phone number.”
Which one is more relevant? Which one provides more value? It really depends on the user’s intent. If the user just wants a plumber, they don’t want to hear about all the history. They just want a phone number and a quick, good service.
However, what’s important to understand is that there is always a way to add value.
In the end, it’s the search engine that decides, but there are some guidelines you can follow to make sure Google sees your content as valuable. Keep reading and you’ll find out all about them. But first, let’s better understand why thin content is still an issue and how it actually affects search engine optimization.
1.1 Is Thin Content Still a Problem in 2019?
The thin content purge started on February 23, 2011 with the first Panda Update. At first, Google introduced the thin content penalty because many people were generating content automatically or were creating thousands of irrelevant pages.
The series of further updates were successful and many websites with low quality content got penalized or deranked. This pushed site owners to write better content.
Unfortunately, today this mostly translates to longer content. The more you write, the more value you can provide, right? We know it’s not necessarily the case, but as I’ve said, longer content does tend to rank better in Google. Be it because the content makes its way up there or because the search engine is biased towards it… it’s hard to tell.
But there’s also evidence that long form content gets more shares on social media. This can result in more backlinks, which translates to better rankings. So it’s not directly the fact that the content is long, but rather an indirect factor related to it.
It’s kind of ironic, as Google sometimes uses its answer boxes to give a very ‘thin’ answer to questions that might require more context to be well understood.
However, in 2019 it’s common SEO knowledge that content must be of high quality. The issue today shifts to the overload of content that is constantly being published. Everything is, at least to some extent, qualitative.
But it’s hard to get all the information from everywhere and you don’t always know which source to rely on or trust. That’s why content curation has been doing so well lately.
This manifests itself in other areas, especially where there’s a very tough competition, such as eCommerce.
1.2 How Does Thin Content Affect SEO?
Google wants to serve its users the best possible content it can. If Google doesn’t do that, then its users won’t return to Google and could classify it as a poor quality service. And that makes the search engine unhappy.
Google generally applies a manual action penalty to websites it considers to contain thin content. You will see it in the Google Search Console (former Google Webmaster Tools) and it looks like this:
However, your site can still be affected by thin content even if you don’t get a warning from Google in your Search Console account. That’s because you’re diluting your site’s value and burning through your crawl budget.
The problem that search engines have is that they constantly have to crawl a lot of pages. The more pages you give it to crawl, the more work it has to do.
If the pages the search engine crawls are not useful for the users, then Google will have a problem with wasting its time on your content.
1.3 Where Is Thin Content Found Most Often?
Thin content is found most of the time on bigger websites. For the sake of helping people that really need help, let’s exclude spammy affiliate websites and automated blogs from this list.
Big websites, like eCommerce stores, often have a hard time coming up with original, high quality content for all their pages, especially for thousands of product pages.
In the example above, you can see that although the Product Details section under the image is expanded, there’s no content there. This means that users don’t have any details at all about the dress. All they know is that it’s a dress, it’s black and it costs about $20.
This doesn’t look too bad when you’re looking as a human at a single page, but when you’re a search engine and take a look at thousands and thousands of pages just like this one, then you begin to see the issue.
The solution here is to add some copy. Think of what users want to know about your product. Make sure you add the details about everything they might want to know and make them easily accessible!
Sometimes, thin content makes its way into eCommerce sites unnoticed. For example, you might have a category page which hosts a single product. Compared to all your other categories or competitor websites,that can be seen as thin content.
2. How to Identify Thin Content Pages
If we are referring merely to its size, then thin content can be easily identified using the cognitiveSEO Tool’s Site Audit.
Did you know?
Identifying thin content is actually really easy with a tool like cognitiveSEO Site Audit. The tool has a Thin Content section where you can easily find the pages with issues.
It’s as simple as that! Once you have your list, you can export it and start adding some content to those pages. This will improve their chances to make it to the top of the search results.
However, you also want to take a look at the duplicate content section in the Site Audit tool. This can also lead to a lot of indexation & content issues.
Extremely similar pages can be “combined” using canonical tags. Sometimes it can be a good idea to remove them completely from the search engine results.
3. How to Fix Thin Content Issues & Avoid a Google Penalty
Sometimes, you can fix thin content issues easily, especially if you get a manual penalty warning. At least if your website isn’t huge. If you have thousands of pages, it might take a while till you can fix them.
Here’ s a happy ending case from one of Doug Cunnington’s students:
youtube
However, the “penalty” can also come from the algorithm and you won’t even know it’s there because there is no warning. It’s not actually a penalty, it’s just the fact that Google won’t rank your pages because of their poor quality.
When that’s the case, it might not be as easy to get things fixed as in the video above.
In order to avoid getting these penalties, here’s a few things that you should consider when you write content.
3.1 Make sure your site looks legit
First of all, if your website looks shady, then you have a higher chance of getting a manual penalty on your website. If someone from Google reviews your website and decides it looks spammy at a first glance, they will be more likely to consider penalizing it.
To avoid this, make sure you:
Use an original template and customize it a little bit
Have a logo or some sort of original branding
Provide an about page and contact details
3.2 Add more content & avoid very similar titles
The best way to show Google that your pages are worth taking a look at is to not leave them empty. In 2019, I hope we all know that for good OnPage SEO we need to add a little bit more content.
Your pages should have at least 300 words of copy. Notice how I say copy, not words. If you’re there to sell, write copy. Even on an eCommerce product page.
If you’re not sure what to write about, you can always use the CognitiveSEO Keyword Tool & Content Assistant. It will give you ideas on what you should write on your pages to make them relevant for the query you want them to rank on.
Automatically generated titles can also quickly trigger Google’s alarms. If you review multiple products from the same brand and your titles are like this:
Nike Air Max 520 Review
Nike Air Max 620 Review
Nike Air Max 720 Review
then you can see how it might be an issue. Do those articles provide any value or are they all the same except for one digit?
It’s important to have the keywords in your title, but you can also try to add some diversity to them. It’s not always very hard to do. A good example could be:
Nike Air Max 520 Review | Best bang for the buck
Nike Air Max 620 | A Comprehensive Review Regarding Comfort
Nike Air Max 720 | Review After 2 Weeks of Wearing Them at The Gym
But Adrian, I have an eCommerce site with over 2000 products, I can’t write original titles for all of them!
That’s why I said that content isn’t the only way you can provide value with. If you can’t change the titles and content, improve some other areas.
However, the truth is that there’s someone out there who does optimize and show love to all their titles, even if there are 2000 of them. So why shouldn’t they be rewarded for it?
Usually, very similar titles are a result of content duplication issues. If you have a product that comes in 100 different colors, you don’t necessarily need to have 100 different pages with 100 unique titles and copy. You can just make them 1 single page where users can select their color without having to go to another URL.
Combining pages can also be done via canonical tags, although it’s recommended to only keep this for duplicate content. Pages with different colors can count as duplicate content, as only one word is different, so the similarity is 99.9%.
Make sure that the pages that get canonicalized don’t provide organic search traffic. For example, if people search for “blue dress for ladies” then it’s a good idea to have a separate page that can directly rank for that query instead of canonicalizing it to the black version.
A proper faceted navigation can help you solve all these SEO issues.
3.3 Don’t copy content
Copying content from other websites will definitely make your site look bad in Google’s eyes.
Again, this happens mostly on eCommerce websites, where editors get the descriptions directly from the producer’s official website. Many times they also duplicate pages in order to save time and just change a couple of words.
On the long run, this will definitely get you into duplicate content issues, which can become very hard to fix once they’re out of control. It will also tell Google that your site endorses competitors. By using their copy, you’re considering it valuable, right?
3.4 Web design, formatting & ads
Sometimes, you can identify gaps in web design or formatting. That’s not easy to do, as you’ll have to manually take a look at your competitor’s websites. Here are some questions you should ask yourself:
Are competitors presenting their information in an unpleasant manner? Do they have too many pop-ups, too many ads or very nasty designs?
Then that’s obviously where you can make a difference. This doesn’t give you the right not to have an original copy, but it might have a greater impact.
Source: premiumcoding.com
3.5 Video, images, text, audio, etc.
Big, successful eCommerce businesses which have an entire community supporting them and backing them up have used this technique for a long time: video content.
This might work better in some niches, such as tech. In Romania, cel.ro has a very bad reputation with delivery and quality, yet it still has a decent amount of market share due to its strong video content marketing strategy.
If you want to improve the value of your page, make sure you add images, videos or whatever you think might better serve your user. If you’re a fashion store, images might be your priority, while if you’re an electronics store, the product specifications should be more visible instead.
3.6 Deindex useless pages
Sometimes, when you have a lot of very similar pages that host thin content with no added value, the only viable solution is to remove those pages completely.
This can be done in a number of ways. However, the best ones are:
Removing the content altogether
Using canonical tags to combine them
Using robots.txt & noindex
However, you’ll have to choose carefully which method you use. Remember, you don’t want to remove those pages with search demand from the search engines!
Source: Moz.com
This can determine you to switch the focus from optimizing individual product pages to optimizing category pages.
Conclusion
Thin content is definitely bad for your website. It’s always better to avoid an issue from the beginning than to have to fix it later on. This saves you both time and money.
However, you’ll have to know about these issues early on, before you even start setting up your website and content marketing strategy. Hopefully, this article helped you have a better understanding on the topic.
Have you ever faced thin content issues on your websites in your digital marketing journey? How do you identify it? And how did you solve these content issues? Let us know in the comments section below!
The post Thin Content & SEO | How to Avoid a Google Thin Content Penalty appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
from Marketing https://cognitiveseo.com/blog/22582/thin-content-google-penalty-seo/ via http://www.rssmix.com/
0 notes
Text
Why then, prior to the introduction of venture capital into the machine learning field, do you think academic researchers limited their training data sets to publicly available images and documents which were explicitly free use?
There is a difference between "we believe this would be an illegal use of copyrighted materials" and "we believe SOMEONE MIGHT CLAIM this is an illegal use of copyrighted materials, and we do not have the resources to mount an effective legal defense."
See also: all the fic archive sites that remove fanfic on request of the author/company that controls the IP, despite a total lack of legal precedent for fanfic being copyright infringement, and some pretty solid cases that lean the other direction.
Note the lack of lawsuits against AO3, which will not remove fics for this reason. Neither Disney nor Paramount nor this month's random obsessive author who thinks fanfic about her fake vampire boyfriend is a personal attack, has managed to scrounge up a lawyer that will tackle AO3's claims that no-income fanfic is legal.
Google has won multiple cases about their right to scrape the web to operate a search engine. To do that, they have to make copies of everything. They are using datasets comprised of copyrighted material, and not for academic or nonprofit purposes. And the courts decided, it's okay to make those copies, because the end result is (1) useful to a whole lot of people and (2) very disconnected from the value of the original works.
How disconnected is the value of LLM generative-AI results from the originals? ...that depends. But the average conversation with chatGPT is not infringing on anyone's copyright because it happens to look like a thousand chat exchanges on Twitter, with all the personality and interesting topic details removed.
The problem with LLMs and the art-AI programs is not the copying. It's the results. It's attempting to use the software to remove human creativity and oversight from their business expenses.
Focus on their attempt to cheat the public with shoddy lying chat programs. Focus on the fraud of allowing chatbots to make promises they won't follow through on. Focus on the attempt to charge the public the same price for services when only some of those services cost the company human labor, and other services are provided with "this will probably work fine but if it doesn't you can't hold us responsible for what the bot does." Focus on the fucking deaths caused by software attempting to drive cars.
Don't push for laws asking to make large-scale copying illegal. Push for laws that say "if the bot did it for your company, SOMEONE at your company is liable for damages caused by the bot. That SOMEONE may include programmers, managers, CEOs... it definitely includes the Board."
Making the Board and stockholders directly liable for damages caused by the damn LLM bots will be a lot more effective in curtailing their harms to the creative community, than trying to make data collection illegal.
My hot take is that AI bears all of the hallmarks of an economic bubble but that anti-AI bears all of the hallmarks of a moral panic. I contain multitudes.
9K notes
·
View notes
Text
Thin Content & SEO | How to Avoid a Google Thin Content Penalty
We live in a world of information overload. If 10 years ago it was hard to find content at all, now there’s way too much of it! Which one is good? Which one is bad? We don’t know.
While this subject is very complex, it’s clear that Google is attempting to solve these content issues in its search results. One of the biggest issues they’ve encountered in the digital marketing world is what they call thin content.
But what exactly is thin content? Should you worry about it? Can it affect your website’s SEO in a negative way? Well, thin content can get your site manually penalized but it can also sometimes send your website in Google’s omitted results. If you want to avoid these issues, keep reading!
What Is Thin Content & How Does It Affect SEO?
Is Thin Content Still a Problem in 2019?
How Does Thin Content Affect SEO?
Where Is Thin Content Found Most Often?
How to Identify Thin Content Pages
How to Fix Thin Content Issues & Avoid a Google Penalty
Make sure your site looks legit
Add more content & avoid similar titles
Don’t copy content
Web design, formatting & ads
Video, images, text, audio, etc.
Deindex/remove useless pages
1. What Is Thin Content & How Does It Affect SEO?
Thin content is an OnPage SEO issue that has been defined by Google as content with no added value.
When you’re publishing content on your website and it doesn’t improve the quality of a search results page at least a little bit, you’re publishing thin content.
For a very dull example, when you search Google for a question such as “What color is the sky?” and there’s an article out there saying “The sky is blue!”, if you publish an article with the same answer you would be guilty of adding no value.
So does it mean that this article is thin content because there are other articles about thin content out there?
Well.. no. Why? Because I’m adding value to it. First, I’m adding my own opinion, which is crucial. Then, I’m trying to structure it as logically as possible, address as many important issues as I can and cover gaps which I have identified from other pieces.
Sometimes, you might not have something new to say, but you might have a better way of saying it. To go back to our example, you could say something like “The sky doesn’t really have a color but is perceived as blue by the human eye because of the way light scatters through the atmosphere.”
Of course, you would probably have to add at least another 1500 words to that to make it seem like it’s not thin. It’s true. Longer content tends to rank better in Google, with top positions averaging about 2000 words.
How your content should be to rank
Sometimes, you might add value through design or maybe even through a faster website. There are multiple ways through which you can add value. We’ll talk about them soon.
From the Google Webmaster Guidelines page we can extract 4 types of practices which are strictly related to content quality. However, they are not easy to define!
Automatically generated content: Simple. It’s content created by robots to replace regular content, written by humans. Don’t do it. But… some AI content marketing tools have become so advanced that it’s hard to distinguish between real and automatically generated content. Humans can write poorly too. Don’t expect a cheap freelancer who writes 1000 words for $1 to have good grammar and copy. A robot might be better. But theoretically, that’s against the rules.
Thin affiliate pages: If you’re publishing affiliate pages which don’t include reviews or opinions, you’re not providing any new value to the users compared to what the actual store is already providing on their sales page.
Scraped or copied content: The catch here is to have original content. If you don’t have original content, you shouldn’t be posting it to claim it’s yours. However, even when you don’t claim it’s yours, you can’t expect Google to rank it better than the original source. Maybe there can be a reason (better design, faster website) but, generally, nobody would say it’s fair. Scraping is a no no and Google really hates it.
Doorway pages: Doorway pages are pages created to target and rank for a variety of very similar queries. While this is bad in Google’s eyes, the search giant doesn’t provide an alternative to doorway pages. If you have to target 5-10 similar queries (let’s say if you’re doing local SEO for a client), you might pull something off with one page, but if you have to target thousands of similar queries, you won’t be able to do it. A national car rental service, for example, will always have pages which could be considered doorways.
If you want, you can listen to Matt Cutts’ explanation from this video.
youtube
As you can see, it all revolves around value. The content that you publish must have some value to the user. If it’s just there because you want traffic, then you’re doing it wrong.
But value can sometimes be hard to define. For some, their content might seem as the most valuable, while for others it might seem useless. For example, one might write “Plumbing services New York, $35 / hour, Phone number”. The other might write “The entire history of plumbing, How to do it yourself, Plumbing services New York, $35 / hour, Phone number.”
Which one is more relevant? Which one provides more value? It really depends on the user’s intent. If the user just wants a plumber, they don’t want to hear about all the history. They just want a phone number and a quick, good service.
However, what’s important to understand is that there is always a way to add value.
In the end, it’s the search engine that decides, but there are some guidelines you can follow to make sure Google sees your content as valuable. Keep reading and you’ll find out all about them. But first, let’s better understand why thin content is still an issue and how it actually affects search engine optimization.
1.1 Is Thin Content Still a Problem in 2019?
The thin content purge started on February 23, 2011 with the first Panda Update. At first, Google introduced the thin content penalty because many people were generating content automatically or were creating thousands of irrelevant pages.
The series of further updates were successful and many websites with low quality content got penalized or deranked. This pushed site owners to write better content.
Unfortunately, today this mostly translates to longer content. The more you write, the more value you can provide, right? We know it’s not necessarily the case, but as I’ve said, longer content does tend to rank better in Google. Be it because the content makes its way up there or because the search engine is biased towards it… it’s hard to tell.
But there’s also evidence that long form content gets more shares on social media. This can result in more backlinks, which translates to better rankings. So it’s not directly the fact that the content is long, but rather an indirect factor related to it.
It’s kind of ironic, as Google sometimes uses its answer boxes to give a very ‘thin’ answer to questions that might require more context to be well understood.
However, in 2019 it’s common SEO knowledge that content must be of high quality. The issue today shifts to the overload of content that is constantly being published. Everything is, at least to some extent, qualitative.
But it’s hard to get all the information from everywhere and you don’t always know which source to rely on or trust. That’s why content curation has been doing so well lately.
This manifests itself in other areas, especially where there’s a very tough competition, such as eCommerce.
1.2 How Does Thin Content Affect SEO?
Google wants to serve its users the best possible content it can. If Google doesn’t do that, then its users won’t return to Google and could classify it as a poor quality service. And that makes the search engine unhappy.
Google generally applies a manual action penalty to websites it considers to contain thin content. You will see it in the Google Search Console (former Google Webmaster Tools) and it looks like this:
However, your site can still be affected by thin content even if you don’t get a warning from Google in your Search Console account. That’s because you’re diluting your site’s value and burning through your crawl budget.
The problem that search engines have is that they constantly have to crawl a lot of pages. The more pages you give it to crawl, the more work it has to do.
If the pages the search engine crawls are not useful for the users, then Google will have a problem with wasting its time on your content.
1.3 Where Is Thin Content Found Most Often?
Thin content is found most of the time on bigger websites. For the sake of helping people that really need help, let’s exclude spammy affiliate websites and automated blogs from this list.
Big websites, like eCommerce stores, often have a hard time coming up with original, high quality content for all their pages, especially for thousands of product pages.
In the example above, you can see that although the Product Details section under the image is expanded, there’s no content there. This means that users don’t have any details at all about the dress. All they know is that it’s a dress, it’s black and it costs about $20.
This doesn’t look too bad when you’re looking as a human at a single page, but when you’re a search engine and take a look at thousands and thousands of pages just like this one, then you begin to see the issue.
The solution here is to add some copy. Think of what users want to know about your product. Make sure you add the details about everything they might want to know and make them easily accessible!
Sometimes, thin content makes its way into eCommerce sites unnoticed. For example, you might have a category page which hosts a single product. Compared to all your other categories or competitor websites,that can be seen as thin content.
2. How to Identify Thin Content Pages
If we are referring merely to its size, then thin content can be easily identified using the cognitiveSEO Tool’s Site Audit.
Did you know?
Identifying thin content is actually really easy with a tool like cognitiveSEO Site Audit. The tool has a Thin Content section where you can easily find the pages with issues.
It’s as simple as that! Once you have your list, you can export it and start adding some content to those pages. This will improve their chances to make it to the top of the search results.
However, you also want to take a look at the duplicate content section in the Site Audit tool. This can also lead to a lot of indexation & content issues.
Extremely similar pages can be “combined” using canonical tags. Sometimes it can be a good idea to remove them completely from the search engine results.
3. How to Fix Thin Content Issues & Avoid a Google Penalty
Sometimes, you can fix thin content issues easily, especially if you get a manual penalty warning. At least if your website isn’t huge. If you have thousands of pages, it might take a while till you can fix them.
Here’ s a happy ending case from one of Doug Cunnington’s students:
youtube
However, the “penalty” can also come from the algorithm and you won’t even know it’s there because there is no warning. It’s not actually a penalty, it’s just the fact that Google won’t rank your pages because of their poor quality.
When that’s the case, it might not be as easy to get things fixed as in the video above.
In order to avoid getting these penalties, here’s a few things that you should consider when you write content.
3.1 Make sure your site looks legit
First of all, if your website looks shady, then you have a higher chance of getting a manual penalty on your website. If someone from Google reviews your website and decides it looks spammy at a first glance, they will be more likely to consider penalizing it.
To avoid this, make sure you:
Use an original template and customize it a little bit
Have a logo or some sort of original branding
Provide an about page and contact details
3.2 Add more content & avoid very similar titles
The best way to show Google that your pages are worth taking a look at is to not leave them empty. In 2019, I hope we all know that for good OnPage SEO we need to add a little bit more content.
Your pages should have at least 300 words of copy. Notice how I say copy, not words. If you’re there to sell, write copy. Even on an eCommerce product page.
If you’re not sure what to write about, you can always use the CognitiveSEO Keyword Tool & Content Assistant. It will give you ideas on what you should write on your pages to make them relevant for the query you want them to rank on.
Automatically generated titles can also quickly trigger Google’s alarms. If you review multiple products from the same brand and your titles are like this:
Nike Air Max 520 Review
Nike Air Max 620 Review
Nike Air Max 720 Review
then you can see how it might be an issue. Do those articles provide any value or are they all the same except for one digit?
It’s important to have the keywords in your title, but you can also try to add some diversity to them. It’s not always very hard to do. A good example could be:
Nike Air Max 520 Review | Best bang for the buck
Nike Air Max 620 | A Comprehensive Review Regarding Comfort
Nike Air Max 720 | Review After 2 Weeks of Wearing Them at The Gym
But Adrian, I have an eCommerce site with over 2000 products, I can’t write original titles for all of them!
That’s why I said that content isn’t the only way you can provide value with. If you can’t change the titles and content, improve some other areas.
However, the truth is that there’s someone out there who does optimize and show love to all their titles, even if there are 2000 of them. So why shouldn’t they be rewarded for it?
Usually, very similar titles are a result of content duplication issues. If you have a product that comes in 100 different colors, you don’t necessarily need to have 100 different pages with 100 unique titles and copy. You can just make them 1 single page where users can select their color without having to go to another URL.
Combining pages can also be done via canonical tags, although it’s recommended to only keep this for duplicate content. Pages with different colors can count as duplicate content, as only one word is different, so the similarity is 99.9%.
Make sure that the pages that get canonicalized don’t provide organic search traffic. For example, if people search for “blue dress for ladies” then it’s a good idea to have a separate page that can directly rank for that query instead of canonicalizing it to the black version.
A proper faceted navigation can help you solve all these SEO issues.
3.3 Don’t copy content
Copying content from other websites will definitely make your site look bad in Google’s eyes.
Again, this happens mostly on eCommerce websites, where editors get the descriptions directly from the producer’s official website. Many times they also duplicate pages in order to save time and just change a couple of words.
On the long run, this will definitely get you into duplicate content issues, which can become very hard to fix once they’re out of control. It will also tell Google that your site endorses competitors. By using their copy, you’re considering it valuable, right?
3.4 Web design, formatting & ads
Sometimes, you can identify gaps in web design or formatting. That’s not easy to do, as you’ll have to manually take a look at your competitor’s websites. Here are some questions you should ask yourself:
Are competitors presenting their information in an unpleasant manner? Do they have too many pop-ups, too many ads or very nasty designs?
Then that’s obviously where you can make a difference. This doesn’t give you the right not to have an original copy, but it might have a greater impact.
Source: premiumcoding.com
3.5 Video, images, text, audio, etc.
Big, successful eCommerce businesses which have an entire community supporting them and backing them up have used this technique for a long time: video content.
This might work better in some niches, such as tech. In Romania, cel.ro has a very bad reputation with delivery and quality, yet it still has a decent amount of market share due to its strong video content marketing strategy.
If you want to improve the value of your page, make sure you add images, videos or whatever you think might better serve your user. If you’re a fashion store, images might be your priority, while if you’re an electronics store, the product specifications should be more visible instead.
3.6 Deindex useless pages
Sometimes, when you have a lot of very similar pages that host thin content with no added value, the only viable solution is to remove those pages completely.
This can be done in a number of ways. However, the best ones are:
Removing the content altogether
Using canonical tags to combine them
Using robots.txt & noindex
However, you’ll have to choose carefully which method you use. Remember, you don’t want to remove those pages with search demand from the search engines!
Source: Moz.com
This can determine you to switch the focus from optimizing individual product pages to optimizing category pages.
Conclusion
Thin content is definitely bad for your website. It’s always better to avoid an issue from the beginning than to have to fix it later on. This saves you both time and money.
However, you’ll have to know about these issues early on, before you even start setting up your website and content marketing strategy. Hopefully, this article helped you have a better understanding on the topic.
Have you ever faced thin content issues on your websites in your digital marketing journey? How do you identify it? And how did you solve these content issues? Let us know in the comments section below!
The post Thin Content & SEO | How to Avoid a Google Thin Content Penalty appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
0 notes
Text
Thin Content & SEO | How to Avoid a Google Thin Content Penalty
We live in a world of information overload. If 10 years ago it was hard to find content at all, now there’s way too much of it! Which one is good? Which one is bad? We don’t know.
While this subject is very complex, it’s clear that Google is attempting to solve these content issues in its search results. One of the biggest issues they’ve encountered in the digital marketing world is what they call thin content.
But what exactly is thin content? Should you worry about it? Can it affect your website’s SEO in a negative way? Well, thin content can get your site manually penalized but it can also sometimes send your website in Google’s omitted results. If you want to avoid these issues, keep reading!
What Is Thin Content & How Does It Affect SEO?
Is Thin Content Still a Problem in 2019?
How Does Thin Content Affect SEO?
Where Is Thin Content Found Most Often?
How to Identify Thin Content Pages
How to Fix Thin Content Issues & Avoid a Google Penalty
Make sure your site looks legit
Add more content & avoid similar titles
Don’t copy content
Web design, formatting & ads
Video, images, text, audio, etc.
Deindex/remove useless pages
1. What Is Thin Content & How Does It Affect SEO?
Thin content is an OnPage SEO issue that has been defined by Google as content with no added value.
When you’re publishing content on your website and it doesn’t improve the quality of a search results page at least a little bit, you’re publishing thin content.
For a very dull example, when you search Google for a question such as “What color is the sky?” and there’s an article out there saying “The sky is blue!”, if you publish an article with the same answer you would be guilty of adding no value.
So does it mean that this article is thin content because there are other articles about thin content out there?
Well.. no. Why? Because I’m adding value to it. First, I’m adding my own opinion, which is crucial. Then, I’m trying to structure it as logically as possible, address as many important issues as I can and cover gaps which I have identified from other pieces.
Sometimes, you might not have something new to say, but you might have a better way of saying it. To go back to our example, you could say something like “The sky doesn’t really have a color but is perceived as blue by the human eye because of the way light scatters through the atmosphere.”
Of course, you would probably have to add at least another 1500 words to that to make it seem like it’s not thin. It’s true. Longer content tends to rank better in Google, with top positions averaging about 2000 words.
How your content should be to rank
Sometimes, you might add value through design or maybe even through a faster website. There are multiple ways through which you can add value. We’ll talk about them soon.
From the Google Webmaster Guidelines page we can extract 4 types of practices which are strictly related to content quality. However, they are not easy to define!
Automatically generated content: Simple. It’s content created by robots to replace regular content, written by humans. Don’t do it. But… some AI content marketing tools have become so advanced that it’s hard to distinguish between real and automatically generated content. Humans can write poorly too. Don’t expect a cheap freelancer who writes 1000 words for $1 to have good grammar and copy. A robot might be better. But theoretically, that’s against the rules.
Thin affiliate pages: If you’re publishing affiliate pages which don’t include reviews or opinions, you’re not providing any new value to the users compared to what the actual store is already providing on their sales page.
Scraped or copied content: The catch here is to have original content. If you don’t have original content, you shouldn’t be posting it to claim it’s yours. However, even when you don’t claim it’s yours, you can’t expect Google to rank it better than the original source. Maybe there can be a reason (better design, faster website) but, generally, nobody would say it’s fair. Scraping is a no no and Google really hates it.
Doorway pages: Doorway pages are pages created to target and rank for a variety of very similar queries. While this is bad in Google’s eyes, the search giant doesn’t provide an alternative to doorway pages. If you have to target 5-10 similar queries (let’s say if you’re doing local SEO for a client), you might pull something off with one page, but if you have to target thousands of similar queries, you won’t be able to do it. A national car rental service, for example, will always have pages which could be considered doorways.
If you want, you can listen to Matt Cutts’ explanation from this video.
youtube
As you can see, it all revolves around value. The content that you publish must have some value to the user. If it’s just there because you want traffic, then you’re doing it wrong.
But value can sometimes be hard to define. For some, their content might seem as the most valuable, while for others it might seem useless. For example, one might write “Plumbing services New York, $35 / hour, Phone number”. The other might write “The entire history of plumbing, How to do it yourself, Plumbing services New York, $35 / hour, Phone number.”
Which one is more relevant? Which one provides more value? It really depends on the user’s intent. If the user just wants a plumber, they don’t want to hear about all the history. They just want a phone number and a quick, good service.
However, what’s important to understand is that there is always a way to add value.
In the end, it’s the search engine that decides, but there are some guidelines you can follow to make sure Google sees your content as valuable. Keep reading and you’ll find out all about them. But first, let’s better understand why thin content is still an issue and how it actually affects search engine optimization.
1.1 Is Thin Content Still a Problem in 2019?
The thin content purge started on February 23, 2011 with the first Panda Update. At first, Google introduced the thin content penalty because many people were generating content automatically or were creating thousands of irrelevant pages.
The series of further updates were successful and many websites with low quality content got penalized or deranked. This pushed site owners to write better content.
Unfortunately, today this mostly translates to longer content. The more you write, the more value you can provide, right? We know it’s not necessarily the case, but as I’ve said, longer content does tend to rank better in Google. Be it because the content makes its way up there or because the search engine is biased towards it… it’s hard to tell.
But there’s also evidence that long form content gets more shares on social media. This can result in more backlinks, which translates to better rankings. So it’s not directly the fact that the content is long, but rather an indirect factor related to it.
It’s kind of ironic, as Google sometimes uses its answer boxes to give a very ‘thin’ answer to questions that might require more context to be well understood.
However, in 2019 it’s common SEO knowledge that content must be of high quality. The issue today shifts to the overload of content that is constantly being published. Everything is, at least to some extent, qualitative.
But it’s hard to get all the information from everywhere and you don’t always know which source to rely on or trust. That’s why content curation has been doing so well lately.
This manifests itself in other areas, especially where there’s a very tough competition, such as eCommerce.
1.2 How Does Thin Content Affect SEO?
Google wants to serve its users the best possible content it can. If Google doesn’t do that, then its users won’t return to Google and could classify it as a poor quality service. And that makes the search engine unhappy.
Google generally applies a manual action penalty to websites it considers to contain thin content. You will see it in the Google Search Console (former Google Webmaster Tools) and it looks like this:
However, your site can still be affected by thin content even if you don’t get a warning from Google in your Search Console account. That’s because you’re diluting your site’s value and burning through your crawl budget.
The problem that search engines have is that they constantly have to crawl a lot of pages. The more pages you give it to crawl, the more work it has to do.
If the pages the search engine crawls are not useful for the users, then Google will have a problem with wasting its time on your content.
1.3 Where Is Thin Content Found Most Often?
Thin content is found most of the time on bigger websites. For the sake of helping people that really need help, let’s exclude spammy affiliate websites and automated blogs from this list.
Big websites, like eCommerce stores, often have a hard time coming up with original, high quality content for all their pages, especially for thousands of product pages.
In the example above, you can see that although the Product Details section under the image is expanded, there’s no content there. This means that users don’t have any details at all about the dress. All they know is that it’s a dress, it’s black and it costs about $20.
This doesn’t look too bad when you’re looking as a human at a single page, but when you’re a search engine and take a look at thousands and thousands of pages just like this one, then you begin to see the issue.
The solution here is to add some copy. Think of what users want to know about your product. Make sure you add the details about everything they might want to know and make them easily accessible!
Sometimes, thin content makes its way into eCommerce sites unnoticed. For example, you might have a category page which hosts a single product. Compared to all your other categories or competitor websites,that can be seen as thin content.
2. How to Identify Thin Content Pages
If we are referring merely to its size, then thin content can be easily identified using the cognitiveSEO Tool’s Site Audit.
Did you know?
Identifying thin content is actually really easy with a tool like cognitiveSEO Site Audit. The tool has a Thin Content section where you can easily find the pages with issues.
It’s as simple as that! Once you have your list, you can export it and start adding some content to those pages. This will improve their chances to make it to the top of the search results.
However, you also want to take a look at the duplicate content section in the Site Audit tool. This can also lead to a lot of indexation & content issues.
Extremely similar pages can be “combined” using canonical tags. Sometimes it can be a good idea to remove them completely from the search engine results.
3. How to Fix Thin Content Issues & Avoid a Google Penalty
Sometimes, you can fix thin content issues easily, especially if you get a manual penalty warning. At least if your website isn’t huge. If you have thousands of pages, it might take a while till you can fix them.
Here’ s a happy ending case from one of Doug Cunnington’s students:
youtube
However, the “penalty” can also come from the algorithm and you won’t even know it’s there because there is no warning. It’s not actually a penalty, it’s just the fact that Google won’t rank your pages because of their poor quality.
When that’s the case, it might not be as easy to get things fixed as in the video above.
In order to avoid getting these penalties, here’s a few things that you should consider when you write content.
3.1 Make sure your site looks legit
First of all, if your website looks shady, then you have a higher chance of getting a manual penalty on your website. If someone from Google reviews your website and decides it looks spammy at a first glance, they will be more likely to consider penalizing it.
To avoid this, make sure you:
Use an original template and customize it a little bit
Have a logo or some sort of original branding
Provide an about page and contact details
3.2 Add more content & avoid very similar titles
The best way to show Google that your pages are worth taking a look at is to not leave them empty. In 2019, I hope we all know that for good OnPage SEO we need to add a little bit more content.
Your pages should have at least 300 words of copy. Notice how I say copy, not words. If you’re there to sell, write copy. Even on an eCommerce product page.
If you’re not sure what to write about, you can always use the CognitiveSEO Keyword Tool & Content Assistant. It will give you ideas on what you should write on your pages to make them relevant for the query you want them to rank on.
Automatically generated titles can also quickly trigger Google’s alarms. If you review multiple products from the same brand and your titles are like this:
Nike Air Max 520 Review
Nike Air Max 620 Review
Nike Air Max 720 Review
then you can see how it might be an issue. Do those articles provide any value or are they all the same except for one digit?
It’s important to have the keywords in your title, but you can also try to add some diversity to them. It’s not always very hard to do. A good example could be:
Nike Air Max 520 Review | Best bang for the buck
Nike Air Max 620 | A Comprehensive Review Regarding Comfort
Nike Air Max 720 | Review After 2 Weeks of Wearing Them at The Gym
But Adrian, I have an eCommerce site with over 2000 products, I can’t write original titles for all of them!
That’s why I said that content isn’t the only way you can provide value with. If you can’t change the titles and content, improve some other areas.
However, the truth is that there’s someone out there who does optimize and show love to all their titles, even if there are 2000 of them. So why shouldn’t they be rewarded for it?
Usually, very similar titles are a result of content duplication issues. If you have a product that comes in 100 different colors, you don’t necessarily need to have 100 different pages with 100 unique titles and copy. You can just make them 1 single page where users can select their color without having to go to another URL.
Combining pages can also be done via canonical tags, although it’s recommended to only keep this for duplicate content. Pages with different colors can count as duplicate content, as only one word is different, so the similarity is 99.9%.
Make sure that the pages that get canonicalized don’t provide organic search traffic. For example, if people search for “blue dress for ladies” then it’s a good idea to have a separate page that can directly rank for that query instead of canonicalizing it to the black version.
A proper faceted navigation can help you solve all these SEO issues.
3.3 Don’t copy content
Copying content from other websites will definitely make your site look bad in Google’s eyes.
Again, this happens mostly on eCommerce websites, where editors get the descriptions directly from the producer’s official website. Many times they also duplicate pages in order to save time and just change a couple of words.
On the long run, this will definitely get you into duplicate content issues, which can become very hard to fix once they’re out of control. It will also tell Google that your site endorses competitors. By using their copy, you’re considering it valuable, right?
3.4 Web design, formatting & ads
Sometimes, you can identify gaps in web design or formatting. That’s not easy to do, as you’ll have to manually take a look at your competitor’s websites. Here are some questions you should ask yourself:
Are competitors presenting their information in an unpleasant manner? Do they have too many pop-ups, too many ads or very nasty designs?
Then that’s obviously where you can make a difference. This doesn’t give you the right not to have an original copy, but it might have a greater impact.
Source: premiumcoding.com
3.5 Video, images, text, audio, etc.
Big, successful eCommerce businesses which have an entire community supporting them and backing them up have used this technique for a long time: video content.
This might work better in some niches, such as tech. In Romania, cel.ro has a very bad reputation with delivery and quality, yet it still has a decent amount of market share due to its strong video content marketing strategy.
If you want to improve the value of your page, make sure you add images, videos or whatever you think might better serve your user. If you’re a fashion store, images might be your priority, while if you’re an electronics store, the product specifications should be more visible instead.
3.6 Deindex useless pages
Sometimes, when you have a lot of very similar pages that host thin content with no added value, the only viable solution is to remove those pages completely.
This can be done in a number of ways. However, the best ones are:
Removing the content altogether
Using canonical tags to combine them
Using robots.txt & noindex
However, you’ll have to choose carefully which method you use. Remember, you don’t want to remove those pages with search demand from the search engines!
Source: Moz.com
This can determine you to switch the focus from optimizing individual product pages to optimizing category pages.
Conclusion
Thin content is definitely bad for your website. It’s always better to avoid an issue from the beginning than to have to fix it later on. This saves you both time and money.
However, you’ll have to know about these issues early on, before you even start setting up your website and content marketing strategy. Hopefully, this article helped you have a better understanding on the topic.
Have you ever faced thin content issues on your websites in your digital marketing journey? How do you identify it? And how did you solve these content issues? Let us know in the comments section below!
The post Thin Content & SEO | How to Avoid a Google Thin Content Penalty appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
from Marketing https://cognitiveseo.com/blog/22582/thin-content-google-penalty-seo/ via http://www.rssmix.com/
0 notes
Text
How Cognitive Computing Can Make You a Better Marketer
When Sophia, a robot who uses artificial intelligence to interact with humans (like Jimmy Fallon) visited my college last year, I was awestruck.
At first, I thought Sophia would have a similar intelligence level as a simple bot, like Siri, who can only hold basic conversations and address straightforward questions and requests. But when Sophia’s developer started asking her questions, she completely debunked my assumption. She was articulate, made animated facial expressions, and had a surprisingly quick wit.
Sophia’s ability to intellectually and socially interact with people seems like one of the most exciting advancements in artificial intelligence. But the thing is, she can’t actually understand conversation -- her software is programmed to give scripted responses to common questions or phrases, creating an illusion that she’s naturally interacting with you.
If developers want to create computer systems that can actually interact with humans naturally, they need to program cognitive computing into its software, which is a technology that can understand, learn, and reason like a real person.
Cognitive computing can analyze enormous amounts of data in the same way humans think, reason, and remember, so the technology can provide data-backed recommendations to professionals who need to make high-stakes decisions.
For instance, teachers can develop a personalized learning track for each of their students, doctors can make optimal recommendations for their patients, and marketers can even use cognitive computing to craft more human-centric customer journeys.
Before we delve into how brands are applying cognitive computing to their marketing strategy, though, let's go over what it exactly is.
What is cognitive computing?
Cognitive computing blends cognitive science, which is the study of the human brain and how it works, and branches of computer science, like deep learning, neural networks, machine learning, natural language processing, human-computer interaction, visual recognition, and narrative generation to help computer systems simulate human thought processes.
Since cognitive computing can process massive amounts of data that no human could ever digest and imitate the human brain like no computer system ever has, the technology has amazing potential to amplify our abilities -- not replace us -- and help us make better, data-driven decisions.
Cognitive computing applications in marketing
As marketers, we always want to get better. Refining our process and strategy to solve our customers’ problems is our mission. But to understand which tactics actually work and which ones don’t, we usually need to analyze huge sets of complex data.
Data analysis can seem like a tall task, especially if you’re more of a creative marketer. But today, cognitive computing can crunch the numbers for you, helping you make better decisions faster, and hone important aspects of your brand, like brand voice, reporting, and customer support.
Brand Voice
Gauging your brand voice is one of the most challenging tasks in marketing. Tone is subjective, so while some of your colleagues might think your content reads like a punchy publication’s feature story, others might think it reads like clickbait.
With cognitive computing, however, you can literally plug your content into an algorithm, like Contently’s Tone Analyzer, and the technology will analyze and quantify your brand voice.
The IBM Watson-powered technology scrapes content for as much text as possible and assigns a numerical score to five traits -- expressiveness, formality, sociability, empathy, and emotion -- helping clients learn what their brand voice actually is. Contently’s clients also use the tone analyzer to help them emulate their favorite publications and find freelance writers who can write with their brand’s desired tone.
Reporting
In most enterprise organizations, specific marketing teams usually silo their data, making it hard for the department to track all their customers’ touch points and understand their true buyer’s journey.
The founders ofEquals 3, saw this prevalent problem as a business opportunity, so in 2015, they partnered with IBM Watson to launch Lucy, a cognitive computing marketing solution. Lucy helps Fortune 1000 companies access all their marketing data with natural-language queries on one platform, just like a search engine.
Once organizations feed Lucy their data, she can use AI and cognitive computing to instantly organize their information into specific reports, saving marketers countless hours from manual reporting and providing them with more transparency.
Customer Support
Digital assistants on our phones, like Siri, have pre-programmed responses to a limited amount of requests and questions, but customer support technology with cognitive computing capabilities can actually understand natural language, accurately answer people’s questions, and run customer support more efficiently.
For instance, Hilton Hotels first ever concierge robot, Connie, can help guests figure out the best attractions to go to, the best restaurants to dine in at, and even move and point her body to direct guests toward any spot in the hotel. All they have to do is ask Connie their question, and she can quickly help them out.
With Connie’s assistance, Hilton Hotel employees can ultimately provide better customer service by picking up more phones and checking people in faster.
Will cognitive computing move AI beyond hype and into reality?
Artificial intelligence is one of the most hyped technologies in marketing. But if teams can take full advantage of cognitive computing to serve prospects and customers in a more human way, AI will be as groundbreaking as everyone says it’ll be.
0 notes
Text
When Malware Breaks Your Heart
Consider falling in love from the perspective of your phone. Facebook already knows what it looks like. A search for a name; a new friend request; the growing count of shared likes and comments. Eventually, the opening up of a private chat window. Conversations grow in length and frequency, good time-on-site data and an uptick in ads served. You get tagged in each other’s photographs; other friends are tagged less. The distance between the square in your photos – those that map your face – grow closer and closer together. And then, after days or weeks of your GPS signals and check-ins at the same events and bars, both phones go into sleep mode logged into the same wifi network. Relationships between human beings are a complicated process of discovery and adaptation. Emotional learning takes time. It demands information about yourself and your partner. You learn to understand each other, and anticipate each other’s behaviors. When a couple says “we complete each other’s sentences,” well, guess what: so does your iPhone. Machine learning is a process of analyzing and recognizing patterns – then making connections – across sets of data. Data is the residue of life, told through what French philosopher Bruno LaTour named “an accumulation of traces.” By constantly holding your phone’s hand, it accumulates the most intimate of these traces. With the upcoming !Mediengruppe Bitnik exhibit on human-chatbot intimacy coming to the swissnex Gallery, we looked at AI as it applies to the “data” of human connection – and if, someday, we could have human connection without other humans. Feels Like I’ve Known You Forever For a machine to identify a bird, it needs data from thousands of images of birds. Whatever can be transformed into data becomes a lesson: shapes, colors, behaviors. An ideal program tells us not just what a bird is, but where a bird might be. Missing values become hidden variables: show the machine a tree and a nest, and there’s probably a bird somewhere. For dating, social media has created a perfect data set: the collection of the things we tell the world to make it like us. LaTour writes, “It is as if the inner operating modes of the private world have been broken open, because by now their input, and output, are completely traceable.” Could some online dating algorithm determine patterns in the profiles you respond to, shared interests that inspire you most, the types of actions that draw out the greatest spark? Of course. The big question now is philosophical. Do these traces of our lives really have much to do with who we love? Or are these patterns, preferences and choices as arbitrary as a phone number? With enough data, we might find out. Knowing Me, Knowing You Kang Zhao, assistant professor of management sciences in the University of Iowa Tippie College of Business, has been betting that your data knows you better than you do. And he’s used that idea to help humans find each other. He’s designed a test algorithm to find romantic connections by analyzing patterns in the partners people contacted. This would be obvious, but he cleverly ignored any criteria the daters themselves claimed to be looking for. You say you want to go mountain climbing, but you keep messaging people based on their film taste. This machine knows. The algorithm increased mutual interest by more than 50%. In another project, Zhao used the two data sets, and connections between them, to determine who the dating service would “recommend” to a user. In this approach, the missing figure is selected through a correlation of data sets: if Ale(x) liked Luc(y), and (Z)ach liked Luc(y) and Katrin(a), then Ale(x) might like Katrin(a), too. Data! Scratch the surface beyond the use of data and look at the collection of data, though, and a depressing reality sets in: none of this data comes from successful relationships. You really have to fail often to generate your data into a recognizable patterns. For monogamous couples, the “last person you date” is a single data point; if it goes well it may never need to be repeated. For the rest of us, a machine can only learn the kind of person we’ve been attracted to before: patterns that have already failed. R u up? Ashley Madison was a dating website pitched toward married men. (The site is at the center of !Mediengruppe Bitnik’s exhibition here at swissnex San Francisco). That site seemed to embrace the cynicism of failed matches to unusual ends. A 2015 “Impact Team” hack revealed embarrassing information not just about its members, but about how the site was managed. With many more straight men on the site and a statistically nonexistent population of women, the hack revealed that many men were paying to interact with women with a secret: virtually all of them were robots. The Ashley Madison site noted that it was an “entertainment” site, and never promised that you’d connect to anything more than a collection of text files. Bots would send male members messages (“are you online?” being a classic come-on) and men would pay to reply. The messaging is anything but complex: “Hi,” “Hello,” “Free to chat?” etc. Once engaged, they would write something a bit longer: “I’m sexy, discreet, and always up for kinky chat. Would also meet up in person if we get to know each other and think there might be a good connection. Does this sound intriguing?” “I might be a bit shy at first, wait til you get to know me, wink wink :)” After that, men could pay to reply, or purchase “gifts,” but the women would disappear or stop responding altogether. It’s unlikely male users were ever really “fooled” into believing these bots were real women. It seems more complex, something like an emotional AR. Ashley Madison created the environment where reality was augmented by fantasy. These men simply filled in the gaps. What’s NEXT? Perhaps what’s most disturbing about Ashley Madison’s model is what it says about the market for online dating. The site is a cynical product of a commodified cycle of love and romance. Build recommendation engines for real human connections using data from past failures, then charge money to interact with robots pretending toward an ideal. In a world that is fast becoming an arms race between loneliness and connection, programmers, soon enough, will scrape enough data to push all of our emotional human buttons. This won’t require mass leaps in current tech – we’re clearly more than willing to do it already, with chatbots perhaps even less sophisticated than the original ELIZA bot, created in 1966. “ELIZA shows, if nothing else, how easy it is to create and maintain the illusion of understanding,” by the machine, noted MIT researcher Joseph Weizenbaum in his 1966 Computational Linguistics paper on Eliza. He continues: “A certain danger lurks there.” Where our connections take place through screens and text, much of our connections are already imagined. It’s not how we program bots that define the next stage of this reality. It’s how we reprogramming ourselves, and our expectations of what “human” connection looks like. --- Photo: Ashley Madison “fembots” given a physical form by Swiss artists !Mediengruppe Bitnik. Share https://nextrends.swissnexsanfrancisco.org/when-malware-breaks-your-heart/ (Source of the original content)
0 notes