#bigdatasearch
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Big Data and Search Technologies
Today, in the era of Big Data, we must acknowledge the need for problem-solving search technologies. Keeping any amount of data is not a big deal: most of the companies can afford it. But it’s obvious, that in order to be successful, organizations need to find their data easily and quickly in order to analyze it. No matter if you have a well-structured or unstructured data: using an enterprise search engine like CybervoreQuery, you will find any amount of data stored anywhere, because it is fast, easy-to-use, and flexible.
The information volume is growing on a monthly basis, and organizations need better tools to find, structure and analyze their data ASAP. Analytics is very important in business, because if you don’t analyse your Big Data… you just have lots of data. If you start to examine your data, you can draw conclusions and draw predictions concerning your business’s next steps, make better decisions. This will result in higher sales and bigger efficiency for your company.
More about Big Data search
0 notes
Text
Big Data Search using ElasticSearch
ElasticSearch built on top of Lucene has come up with an elegant search engine which can solve the Big Data Search problem.
Its basically a solution built from the ground up to be distributed. It also can be used by any other programming language easily, which basically means JSON over HTTP.
It's a Java based solution. ElasticSearch has been architected in such a way that it can easily either start embedded or remote to the Java process, both in distributed mode or in a single node mode.
Another important and fundamental piece of ElasticSearch which has helped solved the scalability problem is by running a “local” index (a shard) on each node, and do map reduce when you execute a search, and routing when you index.
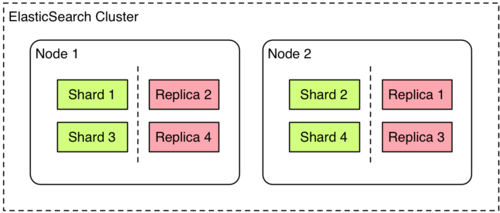
*Image courtesy of François Terrier @ Liip.
A shard is a single Lucene instance. It is a low-level “worker” unit which is managed automatically by elasticsearch. An index is a logical namespace which points to primary and replica shards.
Other than defining the number of primary and replica shards that an index should have, developers never need to refer to shards directly which maintains the vision of really making search easy. Instead, their code only needs to refer to an index. We usually index our searches based on a variation of following parameters : Business Function/ Application Name and Time (Month / Week). Our current volume is too low to put in the actual day as part of the index even though internally Elasticsearch has all that information.
Elasticsearch distributes shards amongst all nodes in the cluster, and can move shards automatically from one node to another in the case of node failure, or the addition of new nodes.
0 notes