#luceneindexes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Link
Have a huge database and need to access data from it in a short span of time? Meet Lucene.
Lucene works by creating documents of the data from the database, and these documents are stored in an index. When data is required and needs to be searched, it uses the index to get faster results by fetching the required documents.
Read more: https://opspl.com/blog/indexing-and-searching-using-lucene/
0 notes
Text
Big Data Search using ElasticSearch
ElasticSearch built on top of Lucene has come up with an elegant search engine which can solve the Big Data Search problem.
Its basically a solution built from the ground up to be distributed. It also can be used by any other programming language easily, which basically means JSON over HTTP.
It's a Java based solution. ElasticSearch has been architected in such a way that it can easily either start embedded or remote to the Java process, both in distributed mode or in a single node mode.
Another important and fundamental piece of ElasticSearch which has helped solved the scalability problem is by running a “local” index (a shard) on each node, and do map reduce when you execute a search, and routing when you index.
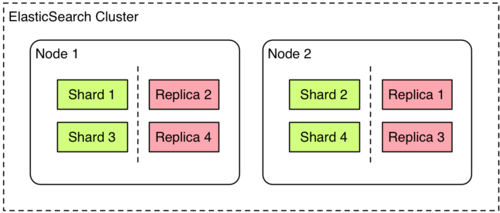
*Image courtesy of François Terrier @ Liip.
A shard is a single Lucene instance. It is a low-level “worker” unit which is managed automatically by elasticsearch. An index is a logical namespace which points to primary and replica shards.
Other than defining the number of primary and replica shards that an index should have, developers never need to refer to shards directly which maintains the vision of really making search easy. Instead, their code only needs to refer to an index. We usually index our searches based on a variation of following parameters : Business Function/ Application Name and Time (Month / Week). Our current volume is too low to put in the actual day as part of the index even though internally Elasticsearch has all that information.
Elasticsearch distributes shards amongst all nodes in the cluster, and can move shards automatically from one node to another in the case of node failure, or the addition of new nodes.
0 notes