#captcha proxy
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
#proxies#proxy#proxyserver#residential proxy#captcha#web scraping techniques#web scraping tools#web scraping services#datascience#data analytics#automation#algorithm
0 notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text
GSA SER Tutorial GSA Search Engine Ranker SEO GSA SER Tutorial GSA Search Engine Ranker SEO GSA AA List: https://chrispalmer.org Todays walkthrough of GSA SER explains how to maximize the number of backlinks built per hour. I'll cover the types of links to produce, filling out forms quickly, and optimizing GSA SER link-building efforts. Then I'll walk through setting up different types of statuses for submitted and verified links after getting them. I will walk through precise instructions on how to optimize GSA for speed or LPV links per hour and resources. Then how to set the priority of GSA to real time in Windows or VPS in order for it to run faster and create more links. Ill show narrowing down options, such as using proxies and loading them into the GSA . The importance of GSA's captcha breaker, GSA site lists, and link building. Lastly highlight all settings that can improve efficiency while using the tool. Join my channel for members only content and perks: https://www.youtube.com/channel/UC8P0dc0Zn2gf8L6tJi_k6xg/join Chris Palmer SEO Tamaqua PA 18252 (570) 810-1080 https://www.youtube.com/watch?v=MVYJPgW-4uI https://www.youtube.com/watch/MVYJPgW-4uI
#seo#chris palmer seo#marketing#digital marketing#local seo#google maps seo#google my business#google#internet marketing#SEM#bing
3 notes
·
View notes
Text
Reblogging for reference.
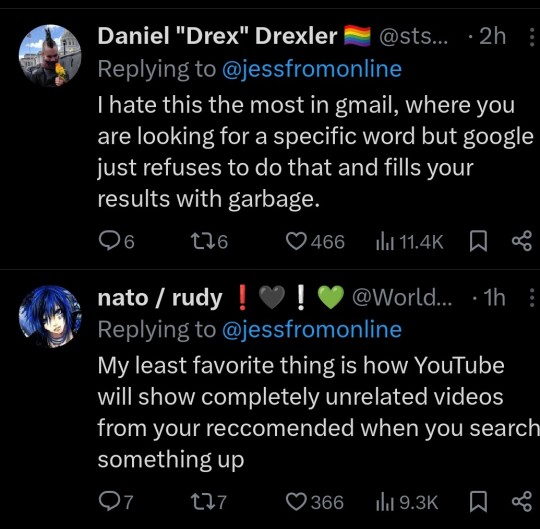
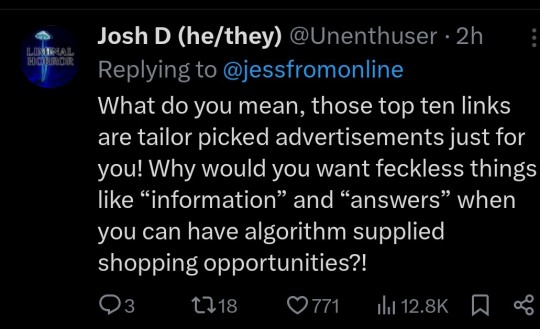
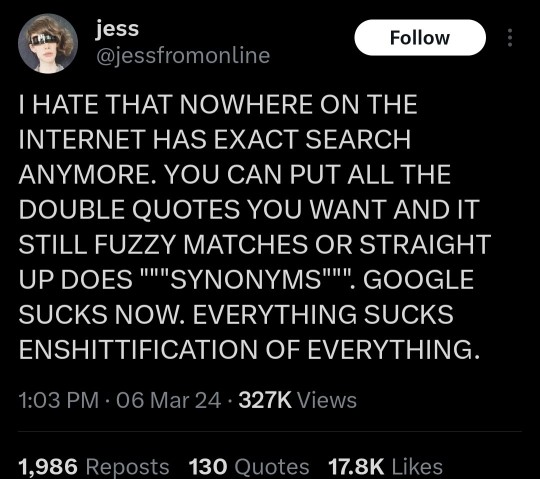
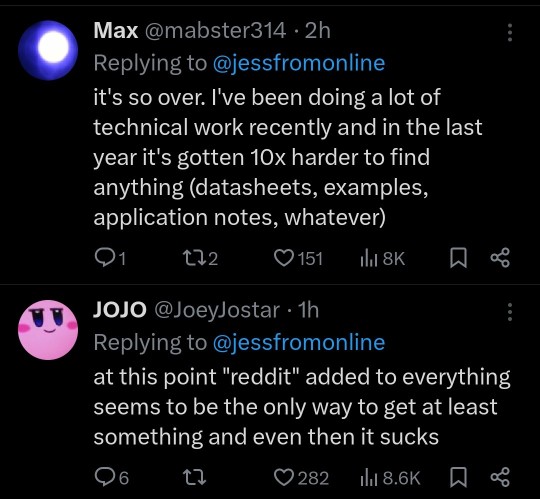
I dislike Duckduckgo because it'll just return zero results if it doesn't like what you're asking (same with Bing, so no surprise there).
This website has a brief rundown of some of the search engines. Not enough people use Mojeek for me to have a sense of whether it is actually private or pretending to be.
Mojeek.com Type: Engine Pro: No JavaScript is required with this completely independent engine. Mojeek gives unique results. Con: It’s not as good at doing conceptual searches on educational topics. Solutions: Use Mojeek when you know what you want.
Qwant Type: Front-end Pro: They are in France and supposedly bound by GDPR Con: Another Bing Front end that’s less honest about being a Bing front end, with annoying captchas for Tor. Qwant also sends data to Microsoft Ads. Source: https://web.archive.org/web/20231107110040/https://about.qwant.com/legal/confidentialite/ France is turning towards tyranny, so I question if GDPR will be upheld with proxy restrictions and digital IDs.
SearXNG Type: Software Pro: Self-hosted open source search that pulls results from Brave, Duckduckgo, Qwant, Google, ect. This way you know it’s not browser fingerprinting you or logging. Con: Many of these search engines will block SearX instances
88K notes
·
View notes
Text
LLM Browser: Agentic Browser for AI in the Cloud
Browser for AI Agents. Enable your AI agents to access any website without worrying about captchas, proxies and anti-bot challenges.
At LLM Browser, we believe AI agents should be able to navigate and interact with the web as seamlessly as humans do. Traditional web automation tools fail when faced with modern anti-bot systems, CAPTCHAs, and sophisticated detection mechanisms.
We're building the infrastructure that makes web automation work reliably at scale, enabling AI agents to access information, perform tasks, and interact with any website - just like a human would.
browser for ai
#agentic browser#browser for agents#browser for ai#web browser for ai#llm browser#browser ai#ai browser
0 notes
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes
Text
This New AI Browser Agent Just Changed Everything (And It’s Open Source)
1. Browser Use – The Open-Source Web Agent Powerhouse
Developed by Magnus Müller and Gregor Zunic, Browser Use has become one of the most popular open-source AI agents, amassing over 50,000 stars on GitHub within three months . It allows AI models to seamlessly control browsers, handling tasks like form filling, data scraping, and navigation. The platform offers a hosted version at $30/month, with an open-source core that supports multiple LLMs and features proxy rotation, session persistence, and CAPTCHA handling.
0 notes
Text
How ArcTechnolabs Builds Grocery Pricing Datasets in UK & Australia

Introduction
In 2025, real-time grocery price intelligence is mission-critical for FMCG brands, retailers, and grocery tech startups...
ArcTechnolabs specializes in building ready-to-use grocery pricing datasets that enable fast, reliable, and granular price comparisons...
Why Focus on the UK and Australia for Grocery Price Intelligence?
The grocery and FMCG sectors in both regions are undergoing massive digitization...
Key Platforms Tracked by ArcTechnolabs:

How ArcTechnolabs Builds Pre-Scraped Grocery Pricing Datasets
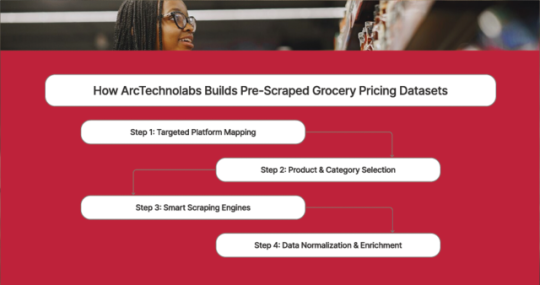
Step 1: Targeted Platform Mapping
UK: Tesco (Superstore), Ocado (Online-only)
AU: Coles (urban + suburban), Woolworths (nationwide chain)
Step 2: SKU Categorization
Dairy
Snacks & Beverages
Staples (Rice, Wheat, Flour)
Household & Personal Care
Fresh Produce (location-based)
Step 3: Smart Scraping Engines
Rotating proxies
Headless browsers
Captcha solvers
Throttling logic
Step 4: Data Normalization & Enrichment
Product names, pack sizes, units, currency
Price history, stock status, delivery time
Sample Dataset: UK Grocery (Tesco vs Sainsbury’s)
ProductTesco PriceSainsbury’s PriceDiscount TescoStock1L Semi-Skimmed Milk£1.15£1.10NoneIn StockHovis Wholemeal Bread£1.35£1.25£0.10In StockCoca-Cola 2L£2.00£1.857.5%In Stock
Sample Dataset: Australian Grocery (Coles vs Woolworths)
Product Comparison – Coles vs Woolworths
Vegemite 380g
--------------------
Coles: AUD 5.20 | Woolworths: AUD 4.99
Difference: AUD 0.21
Discount: No
Dairy Farmers Milk 2L
---------------------------------
Coles: AUD 4.50 | Woolworths: AUD 4.20
Difference: AUD 0.30
Discount: Yes
Uncle Tobys Oats
------------------------------
Coles: AUD 3.95 | Woolworths: AUD 4.10
Difference: -AUD 0.15 (cheaper at Coles)
Discount: No
What’s Included in ArcTechnolabs’ Datasets?
Attribute Overview for Grocery Product Data:
Product Name: Full title with brand and variant
Category/Subcategory: Structured food/non-food grouping
Retailer Name: Tesco, Sainsbury’s, etc.
Original Price: Base MRP
Offer Price: Discounted/sale price
Discount %: Auto-calculated
Stock Status: In stock, limited, etc.
Unit of Measure: kg, liter, etc.
Scrape Timestamp: Last updated time
Region/City: London, Sydney, etc.
Use Cases for FMCG Brands & Retailers
Competitor Price Monitoring – Compare real-time prices across platforms.
Retailer Negotiation – Use data insights in B2B talks.
Promotion Effectiveness – Check if discounts drive sales.
Price Comparison Apps – Build tools for end consumers.
Trend Forecasting – Analyze seasonal price patterns.
Delivery & Formats
Formats: CSV, Excel, API JSON
Frequencies: Real-time, Daily, Weekly
Custom Options: Region, brand, platform-specific, etc.
Book a discovery call today at ArcTechnolabs.com/contact
Conclusion
ArcTechnolabs delivers grocery pricing datasets with unmatched speed, scale, and geographic depth for brands operating in UK and Australia’s dynamic FMCG ecosystem.
Source >> https://www.arctechnolabs.com/arctechnolabs-grocery-pricing-datasets-uk-australia.php
#ReadyToUseGroceryPricingDatasets#AustraliaGroceryProductDataset#TimeSeriesUKSupermarketData#WebScrapingGroceryPricesDataset#GroceryPricingDatasetsUKAustralia#RetailPricingDataForQCommerce#ArcTechnolabs
0 notes
Text
How Automated Web Scraping Powers Real-Time Market Intelligence in 2025
In 2025, the race for data-driven dominance has only accelerated. Businesses are no longer just making data-informed decisions—they’re expected to respond to market shifts in real time. The key to unlocking this agility lies in one technology: automated web scraping. From tracking competitor pricing and new product launches to monitoring regional customer sentiment, automated web scraping allows organizations to collect and analyze high-impact data continuously. It's not just about gathering more information; it's about getting the right insights faster and feeding them directly into strategies.

What is Automated Web Scraping?
At its core, web scraping involves extracting data from websites. While manual scraping is possible, it's neither scalable nor consistent for modern enterprise needs. Automated web scraping takes it a step further by using bots, scripts, and intelligent systems to collect data from thousands of web pages simultaneously, without human intervention.
Unlike traditional data gathering, automation enables continuous, real-time access to dynamic web data. Whether it's product listings, stock prices, news articles, or social media trends, automated web scraping allows businesses to stay informed and agile.
Why Real-Time Market Intelligence Matters in 2025
The business landscape in 2025 is dynamic, decentralized, and deeply influenced by digital trends. As consumer behaviors evolve rapidly, staying updated with static reports or slow-moving data sources is no longer sufficient.
Key Reasons Real-Time Intelligence Is a Business Imperative:
Instant Reactions to Consumer Trends: Viral content, influencer campaigns, or trending hashtags can reshape demand within hours.
Hyper-competitive Pricing: E-commerce giants change prices by the hour—being reactive is no longer enough.
Supply Chain Volatility: Real-time monitoring of supplier availability, shipping conditions, and raw material costs is essential.
Localized Customer Preferences: Consumers in different geographies engage differently, tracking regional trends in real-time enables better personalization.
Key Use Cases of Automated Web Scraping for Market Intelligence
1. Competitor Monitoring
Businesses use automated scrapers to track competitor pricing, promotions, and inventory levels in real time. This helps them make dynamic pricing decisions and spot opportunities to win over customers.
2. Product Development Insights
Scraping product reviews, Q&A forums, and social chatter enables product teams to understand what features customers like or miss across similar offerings in the market.
3. Sentiment Analysis
Real-time scraping of reviews, social media, and news comments allows for up-to-date sentiment analysis. Brands can detect PR risks or emerging product issues before they escalate.
4. Localized Trend Tracking
Multilingual and region-based scraping helps companies understand local search trends, demand patterns, and user behavior, essential for international businesses.
5. Financial & Investment Research
Web scraping helps investors gather information on companies, mergers, leadership changes, and market movement without waiting for quarterly reports or outdated summaries.
Challenges in Real-Time Market Data Collection (And How Automation Solves Them)
Despite its power, real-time data scraping comes with technical and operational challenges. However, automation, with the right infrastructure, solves these issues efficiently:
Website Blocking & CAPTCHAs: Many websites implement anti-scraping mechanisms that detect and block bots. Automated tools use rotating IPs, proxy servers, and CAPTCHA solvers to bypass these restrictions ethically.
High Volume of Data: Collecting large datasets from thousands of sources is impractical manually. Automated scraping allows data collection at scale—scraping millions of pages without human effort.
Frequent Web Page Changes: Websites often change layouts, breaking scrapers. Advanced automation frameworks use AI-based parsers and fallback mechanisms to adapt and recover quickly.
Data Formatting and Clean-Up: Raw scraped data is usually unstructured. Automated systems use rule-based or AI-driven cleaning processes to deliver structured, ready-to-use data for analytics tools or dashboards.
Maintaining Compliance: Automation ensures that scraping practices align with privacy regulations (like GDPR) by excluding personal or sensitive data and respecting robots.txt protocols.
Technologies Driving Web Scraping in 2025
The evolution of scraping tech is driven by AI, cloud computing, and data engineering advancements.
AI-Powered Extraction Engines
Modern scrapers now use AI and NLP to not just extract text but understand its context, identifying product specifications, customer emotions, and competitive differentiators.
Headless Browsers & Smart Bots
Tools like headless Chrome replicate human behavior while browsing, making it difficult for sites to detect automation. Bots can now mimic mouse movement, scroll patterns, and form interactions.
Serverless & Scalable Architectures
Cloud-native scraping solutions use auto-scaling functions that grow with demand. Businesses can scrape 10,000 pages or 10 million, with no performance trade-off.
API Integration & Real-Time Feeds
Scraped data can now flow directly into CRM systems, BI dashboards, or pricing engines, offering teams real-time visibility and alerts when anomalies or changes are detected.
How TagX is Redefining Real-Time Market Intelligence
At TagX, we specialize in delivering real-time, high-precision web scraping solutions tailored for businesses looking to gain a data advantage. Our infrastructure is built to scale with your needs—whether you're monitoring 100 products or 1 million.
Here’s how TagX supports modern organizations with market intelligence:
End-to-End Automation: From data extraction to cleaning and structuring, our scraping pipelines are fully automated and monitored 24/7.
Multi-Source Capabilities: We extract data from a variety of sources—ecommerce platforms, social media, job boards, news outlets, and more.
Real-Time Dashboards: Get your data visualized in real-time with integrations into tools like Power BI, Tableau, or your custom analytics stack.
Ethical & Compliant Practices: TagX follows industry best practices and compliance norms, ensuring data is collected legally and responsibly.
Custom-Built Scrapers: Our team builds custom scrapers that adapt to your specific vertical—be it finance, e-commerce, logistics, or media.
Whether you're an emerging tech startup or a growing retail brand, TagX helps you unlock real-time intelligence at scale, so your decisions are always ahead of the market curve.
Future Trends: What’s Next for Web Scraping in Market Intelligence
Context-Aware Web Scrapers
Next-gen scrapers will not only extract data but also interpret intent. For example, detecting a competitor’s product rebranding or analyzing tone shifts in customer reviews.
Multilingual & Cultural Insights
As companies expand globally, scraping in native languages with cultural understanding will become key to local market relevance.
Scraping + LLMs = Strategic Automation
Pairing scraping with Large Language Models (LLMs) will allow businesses to auto-summarize competitive intelligence, write reports, and even suggest strategies based on raw web data.
Predictive Intelligence
The future of scraping isn’t just about gathering data, but using it to forecast trends, demand spikes, and emerging market threats before they happen.
Final Thoughts
In 2025, reacting quickly is no longer enough—you need to anticipate shifts. Automated web scraping provides the speed, scale, and intelligence businesses need to monitor their markets and stay one step ahead. With TagX as your data partner, you don’t just collect data—you gain real-time intelligence you can trust, scale you can rely on, and insights you can act on.
Let’s Make Your Data Smarter, Together. Contact TagX today to explore how automated web scraping can power your next strategic move.
0 notes
Text
Efficient Naver Map Data Extraction for Business Listings

Introduction
In today's competitive business landscape, having access to accurate and comprehensive business data is crucial for strategic decision-making and targeted marketing campaigns. Naver Map Data Extraction presents a valuable opportunity to gather insights about local businesses, consumer preferences, and market trends for companies looking to expand their operations or customer base in South Korea.
Understanding the Value of Naver Map Business Data
Naver is often called "South Korea's Google," dominating the local search market with over 70% market share. The platform's mapping service contains extensive information about businesses across South Korea, including contact details, operating hours, customer reviews, and location data. Naver Map Business Data provides international and local businesses rich insights to inform market entry strategies, competitive analysis, and targeted outreach campaigns.
However, manually collecting this information would be prohibitively time-consuming and inefficient. This is where strategic Business Listings Scraping comes into play, allowing organizations to collect and analyze business information at scale systematically.
The Challenges of Accessing Naver Map Data
Unlike some other platforms, Naver presents unique challenges for data collection:
Language barriers: Naver's interface and content are primarily Korean, creating obstacles for international businesses.
Complex website structure: Naver's dynamic content loading makes straightforward scraping difficult.
Strict rate limiting: Aggressive anti-scraping measures can block IP addresses that require too many requests.
CAPTCHA systems: Automated verification challenges to prevent bot activity.
Terms of service considerations: Understanding the Legal Ways To Scrape Data From Naver Map is essential.
Ethical and Legal Considerations
Before diving into the technical aspects of Naver Map API Scraping, it's crucial to understand the legal and ethical framework. While data on the web is publicly accessible, how you access it matters from legal and ethical perspectives.
To Scrape Naver Map Data Without Violating Terms Of Service, consider these principles:
Review Naver's terms of service and robots.txt file to understand access restrictions.
Implement respectful scraping practices with reasonable request rates.
Consider using official APIs where available.
Store only the data you need and ensure compliance with privacy regulations, such as GDPR and Korea's Personal Information Protection Act.
Use the data for legitimate business purposes without attempting to replicate Naver's services.
Effective Methods For Scraping Naver Map Business Data
There are several approaches to gathering business listing data from Naver Maps, each with advantages and limitations.
Here are the most practical methods:
1. Official Naver Maps API
Naver provides official APIs that allow developers to access map data programmatically. While these APIs have usage limitations and costs, they represent the most straightforward and compliant Naver Map Business Data Extraction method.
The official API offers:
Geocoding and reverse geocoding capabilities.
Local search functionality.
Directions and routing services.
Address verification features.
Using the official API requires registering a developer account and adhering to Naver's usage quotas and pricing structure. However, it provides reliable, sanctioned access to the data without risking account blocks or legal issues.
2. Web Scraping Solutions
When API limitations prove too restrictive for your business needs, web scraping becomes a viable alternative. Naver Map Scraping Tools range from simple script-based solutions to sophisticated frameworks that can handle dynamic content and bypass basic anti-scraping measures.
Key components of an effective scraping solution include:
Proxy RotationRotating between multiple proxy servers is essential to prevent IP bans when accessing large volumes of data. This spreads requests across different IP addresses, making the scraping activity appear more like regular user traffic than automated collection.Commercial proxy services offer:1. Residential proxies that use real devices and ISPs.2. Datacenter proxies that provide cost-effective rotation options.3. Geographically targeted proxies that can access region-specific content.
Request Throttling Implementing delays between requests helps mimic human browsing patterns and reduces server load. Adaptive throttling that adjusts based on server response times can optimize the balance between collection speed and avoiding detection.
Browser Automation Tools like Selenium and Playwright can control real browsers to render JavaScript-heavy pages and interact with elements just as a human user would. This approach is efficient for navigating Naver's dynamic content loading system.
3. Specialized Web Scraping API Services
For businesses lacking technical resources to build and maintain scraping infrastructure, Web Scraping API offers a middle-ground solution. These services handle the complexities of proxy rotation, browser rendering, and CAPTCHA solving while providing a simple API interface to request data.
Benefits of using specialized scraping APIs include:
Reduced development and maintenance overhead.
Built-in compliance with best practices.
Scalable infrastructure that adapts to project needs.
Regular updates to counter anti-scraping measures.
Structuring Your Naver Map Data Collection Process
Regardless of the method chosen, a systematic approach to Naver Map Data Extraction will yield the best results. Here's a framework to guide your collection process:
1. Define Clear Data Requirements
Before beginning any extraction project, clearly define what specific business data points you need and why.
This might include:
Business names and categories.
Physical addresses and contact information.
Operating hours and service offerings.
Customer ratings and review content.
Geographic coordinates for spatial analysis.
Precise requirements prevent scope creep and ensure you collect only what's necessary for your business objectives.
2. Develop a Staged Collection Strategy
Rather than attempting to gather all data at once, consider a multi-stage approach:
Initial broad collection of business identifiers and basic information.
Categorization and prioritization of listings based on business relevance.
Detailed collection focusing on high-priority targets.
Periodic updates to maintain data freshness.
This approach optimizes resource usage and allows for refinement of collection parameters based on initial results.
3. Implement Data Validation and Cleaning
Raw data from Naver Maps often requires preprocessing before it becomes business-ready.
Common data quality issues include:
Inconsistent formatting of addresses and phone numbers.
Mixed language entries (Korean and English).
Duplicate listings with slight variations.
Outdated or incomplete information.
Implementing automated validation rules and manual spot-checking ensures the data meets quality standards before analysis or integration with business systems.
Specialized Use Cases for Naver Product Data Scraping
Beyond basic business information, Naver's ecosystem includes product listings and pricing data that can provide valuable competitive intelligence.
Naver Product Data Scraping enables businesses to:
Monitor competitor pricing strategies.
Identify emerging product trends.
Analyze consumer preferences through review sentiment.
Track promotional activities across the Korean market.
This specialized data collection requires targeted approaches that navigate Naver's shopping sections and product detail pages, often necessitating more sophisticated parsing logic than standard business listings.
Data Analysis and Utilization
The actual value of Naver Map Business Data emerges during analysis and application. Consider these strategic applications:
Market Penetration AnalysisBy mapping collected business density data, companies can identify underserved areas or regions with high competitive saturation. This spatial analysis helps optimize expansion strategies and resource allocation.
Competitive BenchmarkingAggregated ratings and review data provide insights into competitor performance and customer satisfaction. This benchmarking helps identify service gaps and opportunities for differentiation.
Lead Generation and OutreachFiltered business contact information enables targeted B2B marketing campaigns, partnership initiatives, and sales outreach programs tailored to specific business categories or regions.
How Retail Scrape Can Help You?

We understand the complexities involved in Naver Map API Scraping and the strategic importance of accurate Korean market data. Our specialized team combines technical expertise with deep knowledge of Korean digital ecosystems to deliver reliable, compliance-focused data solutions.
Our approach to Naver Map Business Data Extraction is built on three core principles:
Compliance-First Approach: We strictly adhere to Korean data regulations, ensuring all activities align with platform guidelines for ethical, legal scraping.
Korea-Optimized Infrastructure: Our tools are designed for Korean platforms, offering native language support and precise parsing for Naver’s unique data structure.
Insight-Driven Delivery: Beyond raw data, we offer value-added intelligence—market insights, tailored reports, and strategic recommendations to support your business in Korea.
Conclusion
Harnessing the information available through Naver Map Data Extraction offers significant competitive advantages for businesses targeting the Korean market. Organizations can develop deeper market understanding and more targeted business strategies by implementing Effective Methods For Scraping Naver Map Business Data with attention to legal compliance, technical best practices, and strategic application.
Whether you want to conduct market research, generate sales leads, or analyze competitive landscapes, the rich business data available through Naver Maps can transform your Korean market operations. However, the technical complexities and compliance considerations make this a specialized undertaking requiring careful planning and execution.
Need expert assistance with your Korean market data needs? Contact Retail Scrape today to discuss how our specialized Naver Map Scraping Tools and analytical expertise can support your business objectives.
Source : https://www.retailscrape.com/efficient-naver-map-data-extraction-business-listings.php
Originally Published By https://www.retailscrape.com/
#NaverMapDataExtraction#BusinessListingsScraping#NaverBusinessData#SouthKoreaMarketAnalysis#WebScrapingServices#NaverMapAPIScraping#CompetitorAnalysis#MarketIntelligence#DataExtractionSolutions#RetailDataScraping#NaverMapBusinessListings#KoreanBusinessDataExtraction#LocationDataScraping#NaverMapsScraper#DataMiningServices#NaverLocalSearchData#BusinessIntelligenceServices#NaverMapCrawling#GeolocationDataExtraction#NaverDirectoryScraping
0 notes
Text
Extract Amazon Product Prices with Web Scraping | Actowiz Solutions
Introduction
In the ever-evolving world of e-commerce, pricing strategy can make or break a brand. Amazon, being the global e-commerce behemoth, is a key platform where pricing intelligence offers an unmatched advantage. To stay ahead in such a competitive environment, businesses need real-time insights into product prices, trends, and fluctuations. This is where Actowiz Solutions comes into play. Through advanced Amazon price scraping solutions, Actowiz empowers businesses with accurate, structured, and actionable data.
Why extract Amazon Product Prices?

Price is one of the most influential factors affecting a customer’s purchasing decision. Here are several reasons why extracting Amazon product prices is crucial:
Competitor Analysis: Stay informed about competitors’ pricing.
Dynamic Pricing: Adjust your prices in real time based on market trends.
Market Research: Understand consumer behavior through price trends.
Inventory & Repricing Strategy: Align stock and pricing decisions with demand.
With Actowiz Solutions’ Amazon scraping services, you get access to clean, structured, and timely data without violating Amazon’s terms.
How Actowiz Solutions Extracts Amazon Price Data

Actowiz Solutions uses advanced scraping technologies tailored for Amazon’s complex site structure. Here’s a breakdown:
1. Custom Scraping Infrastructure
Actowiz Solutions builds custom scrapers that can navigate Amazon’s dynamic content, pagination, and bot protection layers like CAPTCHA, IP throttling, and JavaScript rendering.
2. Proxy Rotation & User-Agent Spoofing
To avoid detection and bans, Actowiz employs rotating proxies and multiple user-agent headers that simulate real user behavior.
3. Scheduled Data Extraction
Actowiz enables regular scheduling of price scraping jobs — be it hourly, daily, or weekly — for ongoing price intelligence.
4. Data Points Captured
The scraping service extracts:
Product name & ASIN
Price (MRP, discounted, deal price)
Availability
Ratings & Reviews
Seller information
Real-World Use Cases for Amazon Price Scraping

A. Retailers & Brands
Monitor price changes for own products or competitors to adjust pricing in real-time.
B. Marketplaces
Aggregate seller data to ensure competitive offerings and improve platform relevance.
C. Price Comparison Sites
Fuel your platform with fresh, real-time Amazon price data.
D. E-commerce Analytics Firms
Get historical and real-time pricing trends to generate valuable reports for clients.
Dataset Snapshot: Amazon Product Prices

Below is a snapshot of average product prices on Amazon across popular categories:
Product CategoryAverage Price (USD)Electronics120.50Books15.75Home & Kitchen45.30Fashion35.90Toys & Games25.40Beauty20.60Sports50.10Automotive75.80
Benefits of Choosing Actowiz Solutions

1. Scalability: From thousands to millions of records.
2. Accuracy: Real-time validation and monitoring ensure data reliability.
3. Customization: Solutions are tailored to each business use case.
4. Compliance: Ethical scraping methods that respect platform policies.
5. Support: Dedicated support and data quality teams
Legal & Ethical Considerations

Amazon has strict policies regarding automated data collection. Actowiz Solutions follows legal frameworks and deploys ethical scraping practices including:
Scraping only public data
Abiding by robots.txt guidelines
Avoiding high-frequency access that may affect site performance
Integration Options for Amazon Price Data

Actowiz Solutions offers flexible delivery and integration methods:
APIs: RESTful APIs for on-demand price fetching.
CSV/JSON Feeds: Periodic data dumps in industry-standard formats.
Dashboard Integration: Plug data directly into internal BI tools like Tableau or Power BI.
Contact Actowiz Solutions today to learn how our Amazon scraping solutions can supercharge your e-commerce strategy.Contact Us Today!
Conclusion: Future-Proof Your Pricing Strategy
The world of online retail is fast-moving and highly competitive. With Amazon as a major marketplace, getting a pulse on product prices is vital. Actowiz Solutions provides a robust, scalable, and ethical way to extract product prices from Amazon.
Whether you’re a startup or a Fortune 500 company, pricing intelligence can be your competitive edge. Learn More
#ExtractProductPrices#PriceIntelligence#AmazonScrapingServices#AmazonPriceScrapingSolutions#RealTimeInsights
0 notes
Text
What are Traffic Bots?
Ever wondered about "traffic bots"? 🤔 They're automated tools that generate website visits, sometimes for good reasons like testing site performance, but often for shady stuff like faking engagement or ad clicks. 🤖 While some bots are helpful (like search engine crawlers), malicious ones can mess with your analytics, cost you ad money, and even get your site penalized by search engines! 📉
The tricky part is that some bots are super sneaky, mimicking human behavior and using proxies to hide. So, how do you protect your site and ensure your traffic is real? It involves things like analyzing traffic sources, using CAPTCHAs, and deploying web application firewalls.
Want to stop worrying about fake traffic and focus on attracting real customers? At Digi Dervish, we specialize in organic digital marketing strategies that bring genuine human visitors to your website. Let us help you grow your business authentically! ✨ Visit our website to learn more!
#TrafficBots#WebTraffic#SEO#DigitalMarketing#BotDetection#WebsiteAnalytics#AdFraud#OrganicGrowth#SearchEngineOptimization#WebsiteSecurity#OnlineBusiness#MarketingStrategy#DigiDervish#GrowYourBusiness#TechTips#ContentMarketing#SocialMediaMarketing
1 note
·
View note
Text
What are traffic bots?
Ever wondered about "traffic bots"? 🤔 They're automated tools that generate website visits, sometimes for good reasons like testing site performance, but often for shady stuff like faking engagement or ad clicks. 🤖 While some bots are helpful (like search engine crawlers), malicious ones can mess with your analytics, cost you ad money, and even get your site penalized by search engines! 📉
The tricky part is that some bots are super sneaky, mimicking human behavior and using proxies to hide. So, how do you protect your site and ensure your traffic is real? It involves things like analyzing traffic sources, using CAPTCHAs, and deploying web application firewalls.
Want to stop worrying about fake traffic and focus on attracting real customers? At Digi Dervish, we specialize in organic digital marketing strategies that bring genuine human visitors to your website. Let us help you grow your business authentically! ✨ Visit our website to learn more!
#TrafficBots#WebTraffic#SEO#DigitalMarketing#BotDetection#WebsiteAnalytics#AdFraud#OrganicGrowth#SearchEngineOptimization#WebsiteSecurity#OnlineBusiness#MarketingStrategy#DigiDervish#GrowYourBusiness#TechTips#ContentMarketing#SocialMediaMarketing
0 notes
Text

Ever wondered about "traffic bots"? 🤔 They're automated tools that generate website visits, sometimes for good reasons like testing site performance, but often for shady stuff like faking engagement or ad clicks. 🤖 While some bots are helpful (like search engine crawlers), malicious ones can mess with your analytics, cost you ad money, and even get your site penalized by search engines! 📉
The tricky part is that some bots are super sneaky, mimicking human behavior and using proxies to hide. So, how do you protect your site and ensure your traffic is real? It involves things like analyzing traffic sources, using CAPTCHAs, and deploying web application firewalls.
Want to stop worrying about fake traffic and focus on attracting real customers? At Digi Dervish, we specialize in organic digital marketing strategies that bring genuine human visitors to your website. Let us help you grow your business authentically! ✨ Visit our website to learn more!
#TrafficBots#WebTraffic#SEO#DigitalMarketing#BotDetection#WebsiteAnalytics#AdFraud#OrganicGrowth#SearchEngineOptimization#WebsiteSecurity#OnlineBusiness#MarketingStrategy#DigiDervish#GrowYourBusiness#TechTips#ContentMarketing#SocialMediaMarketing
1 note
·
View note
Text
Overcoming Bot Detection While Scraping Menu Data from UberEats, DoorDash, and Just Eat
Introduction
In industries where menu data collection is concerned, web scraping would serve very well for us: UberEats, DoorDash, and Just Eat are the some examples. However, websites use very elaborate bot detection methods to stop the automated collection of information. In overcoming these factors, advanced scraping techniques would apply with huge relevance: rotating IPs, headless browsing, CAPTCHA solving, and AI methodology.
This guide will discuss how to bypass bot detection during menu data scraping and all challenges with the best practices for seamless and ethical data extraction.
Understanding Bot Detection on Food Delivery Platforms
1. Common Bot Detection Techniques
Food delivery platforms use various methods to block automated scrapers:
IP Blocking – Detects repeated requests from the same IP and blocks access.
User-Agent Tracking – Identifies and blocks non-human browsing patterns.
CAPTCHA Challenges – Requires solving puzzles to verify human presence.
JavaScript Challenges – Uses scripts to detect bots attempting to load pages without interaction.
Behavioral Analysis – Tracks mouse movements, scrolling, and keystrokes to differentiate bots from humans.
2. Rate Limiting and Request Patterns
Platforms monitor the frequency of requests coming from a specific IP or user session. If a scraper makes too many requests within a short time frame, it triggers rate limiting, causing the scraper to receive 403 Forbidden or 429 Too Many Requests errors.
3. Device Fingerprinting
Many websites use sophisticated techniques to detect unique attributes of a browser and device. This includes screen resolution, installed plugins, and system fonts. If a scraper runs on a known bot signature, it gets flagged.
Techniques to Overcome Bot Detection
1. IP Rotation and Proxy Management
Using a pool of rotating IPs helps avoid detection and blocking.
Use residential proxies instead of data center IPs.
Rotate IPs with each request to simulate different users.
Leverage proxy providers like Bright Data, ScraperAPI, and Smartproxy.
Implement session-based IP switching to maintain persistence.
2. Mimic Human Browsing Behavior
To appear more human-like, scrapers should:
Introduce random time delays between requests.
Use headless browsers like Puppeteer or Playwright to simulate real interactions.
Scroll pages and click elements programmatically to mimic real user behavior.
Randomize mouse movements and keyboard inputs.
Avoid loading pages at robotic speeds; introduce a natural browsing flow.
3. Bypassing CAPTCHA Challenges
Implement automated CAPTCHA-solving services like 2Captcha, Anti-Captcha, or DeathByCaptcha.
Use machine learning models to recognize and solve simple CAPTCHAs.
Avoid triggering CAPTCHAs by limiting request frequency and mimicking human navigation.
Employ AI-based CAPTCHA solvers that use pattern recognition to bypass common challenges.
4. Handling JavaScript-Rendered Content
Use Selenium, Puppeteer, or Playwright to interact with JavaScript-heavy pages.
Extract data directly from network requests instead of parsing the rendered HTML.
Load pages dynamically to prevent detection through static scrapers.
Emulate browser interactions by executing JavaScript code as real users would.
Cache previously scraped data to minimize redundant requests.
5. API-Based Extraction (Where Possible)
Some food delivery platforms offer APIs to access menu data. If available:
Check the official API documentation for pricing and access conditions.
Use API keys responsibly and avoid exceeding rate limits.
Combine API-based and web scraping approaches for optimal efficiency.
6. Using AI for Advanced Scraping
Machine learning models can help scrapers adapt to evolving anti-bot measures by:
Detecting and avoiding honeypots designed to catch bots.
Using natural language processing (NLP) to extract and categorize menu data efficiently.
Predicting changes in website structure to maintain scraper functionality.
Best Practices for Ethical Web Scraping
While overcoming bot detection is necessary, ethical web scraping ensures compliance with legal and industry standards:
Respect Robots.txt – Follow site policies on data access.
Avoid Excessive Requests – Scrape efficiently to prevent server overload.
Use Data Responsibly – Extracted data should be used for legitimate business insights only.
Maintain Transparency – If possible, obtain permission before scraping sensitive data.
Ensure Data Accuracy – Validate extracted data to avoid misleading information.
Challenges and Solutions for Long-Term Scraping Success
1. Managing Dynamic Website Changes
Food delivery platforms frequently update their website structure. Strategies to mitigate this include:
Monitoring website changes with automated UI tests.
Using XPath selectors instead of fixed HTML elements.
Implementing fallback scraping techniques in case of site modifications.
2. Avoiding Account Bans and Detection
If scraping requires logging into an account, prevent bans by:
Using multiple accounts to distribute request loads.
Avoiding excessive logins from the same device or IP.
Randomizing browser fingerprints using tools like Multilogin.
3. Cost Considerations for Large-Scale Scraping
Maintaining an advanced scraping infrastructure can be expensive. Cost optimization strategies include:
Using serverless functions to run scrapers on demand.
Choosing affordable proxy providers that balance performance and cost.
Optimizing scraper efficiency to reduce unnecessary requests.
Future Trends in Web Scraping for Food Delivery Data
As web scraping evolves, new advancements are shaping how businesses collect menu data:
AI-Powered Scrapers – Machine learning models will adapt more efficiently to website changes.
Increased Use of APIs – Companies will increasingly rely on API access instead of web scraping.
Stronger Anti-Scraping Technologies – Platforms will develop more advanced security measures.
Ethical Scraping Frameworks – Legal guidelines and compliance measures will become more standardized.
Conclusion
Uber Eats, DoorDash, and Just Eat represent great challenges for menu data scraping, mainly due to their advanced bot detection systems. Nevertheless, if IP rotation, headless browsing, solutions to CAPTCHA, and JavaScript execution methodologies, augmented with AI tools, are applied, businesses can easily scrape valuable data without incurring the wrath of anti-scraping measures.
If you are an automated and reliable web scraper, CrawlXpert is the solution for you, which specializes in tools and services to extract menu data with efficiency while staying legally and ethically compliant. The right techniques, along with updates on recent trends in web scrapping, will keep the food delivery data collection effort successful long into the foreseeable future.
Know More : https://www.crawlxpert.com/blog/scraping-menu-data-from-ubereats-doordash-and-just-eat
#ScrapingMenuDatafromUberEats#ScrapingMenuDatafromDoorDash#ScrapingMenuDatafromJustEat#ScrapingforFoodDeliveryData
0 notes
Text
Intuitive Powerful Visual Web Scraper - WebHarvy can automatically scrape Text, Images, URLs & Emails from websites, and save the scraped content in various formats. WebHarvy Web Scraper can be used to scrape data from www.yellowpages.com. Data fields such as name, address, phone number, website URL etc can be selected for extraction by just clicking on them! - Point and Click Interface WebHarvy is a visual web scraper. There is absolutely no need to write any scripts or code to scrape data. You will be using WebHarvy's in-built browser to navigate web pages. You can select the data to be scraped with mouse clicks. It is that easy ! - Scrape Data Patterns Automatic Pattern Detection WebHarvy automatically identifies patterns of data occurring in web pages. So if you need to scrape a list of items (name, address, email, price etc) from a web page, you need not do any additional configuration. If data repeats, WebHarvy will scrape it automatically. - Export scraped data Save to File or Database You can save the data extracted from web pages in a variety of formats. The current version of WebHarvy Web Scraper allows you to export the scraped data as an XML, CSV, JSON or TSV file. You can also export the scraped data to an SQL database. - Scrape data from multiple pages Scrape from Multiple Pages Often web pages display data such as product listings in multiple pages. WebHarvy can automatically crawl and extract data from multiple pages. Just point out the 'link to the next page' and WebHarvy Web Scraper will automatically scrape data from all pages. - Keyword based Scraping Keyword based Scraping Keyword based scraping allows you to capture data from search results pages for a list of input keywords. The configuration which you create will be automatically repeated for all given input keywords while mining data. Any number of input keywords can be specified. - Scrape via proxy server Proxy Servers To scrape anonymously and to prevent the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers. Either a single proxy server address or a list of proxy server addresses may be used. - Category Scraping Category Scraping WebHarvy Web Scraper allows you to scrape data from a list of links which leads to similar pages within a website. This allows you to scrape categories or subsections within websites using a single configuration. - Regular Expressions WebHarvy allows you to apply Regular Expressions (RegEx) on Text or HTML source of web pages and scrape the matching portion. This powerful technique offers you more flexibility while scraping data. - WebHarvy Support Technical Support Once you purchase WebHarvy Web Scraper you will receive free updates and free support from us for a period of 1 year from the date of purchase. Bug fixes are free for lifetime. WebHarvy 7.7.0238 Released on May 19, 2025 - Updated Browser WebHarvy’s internal browser has been upgraded to the latest available version of Chromium. This improves website compatibility and enhances the ability to bypass anti-scraping measures such as CAPTCHAs and Cloudflare protection. - Improved ‘Follow this link’ functionality Previously, the ‘Follow this link’ option could be disabled during configuration, requiring manual steps like capturing HTML, capturing more content, and applying a regular expression to enable it. This process is now handled automatically behind the scenes, making configuration much simpler for most websites. - Solved Excel File Export Issues We have resolved issues where exporting scraped data to an Excel file could result in a corrupted output on certain system environments. - Fixed Issue related to changing pagination type while editing configuration Previously, when selecting a different pagination method during configuration, both the old and new methods could get saved together in some cases. This issue has now been fixed. - General Security Updates All internal libraries have been updated to their latest versions to ensure improved security and stability. Sales Page:https://www.webharvy.com/ DOWNLOAD LINKS & INSTRUCTIONS: Sorry, You need to be logged in to see the content. Please Login or Register as VIP MEMBERS to access. Read the full article
0 notes