#comments and all. something about downloading a python package?
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
i find it so insanely funny when the tech guy is "hacking" something and you see his screen and it's absolutely random code they found somewhere that either makes no sense or is really really simple
#kuu.txt#like i just saw a bash file on the screen omg i'm crying#comments and all. something about downloading a python package?#did they really just print some random help file and called it a day just bc the comments get a cool colour omg#sorry i have trauma with shell scripts and anything linux#programmer yes but a loyal win user <3
7 notes
·
View notes
Text
installation Process..
Hey everyone ,lets began the installation process of python into your system. you can install any version of python and make/developed cool content of program and developed good project into them. so lets began,
STEP 1:
1.1. download the python package of any version, but i suggest to install python current version which is python 3.8. from source. Open a browser window and navigate to the Download at python.org. choose the.
1.2. system environment which is 32bit os of 64bit os. The heading at the top that says Python Releases for Windows or etc os , click on the link for the Latest Python 3 Release - Python 3.x.x.
1.3. Scroll It to the bottom and select either Windows x86-64 executable installer for 64-bit or Windows x86 executable installer for 32-bit..
start download.....
STEP 2:
2.1 Once you have choose and downloaded an installer, simply run it by double-clicking on the downloaded file. A dialog should appear that looks something like this.run the installer.
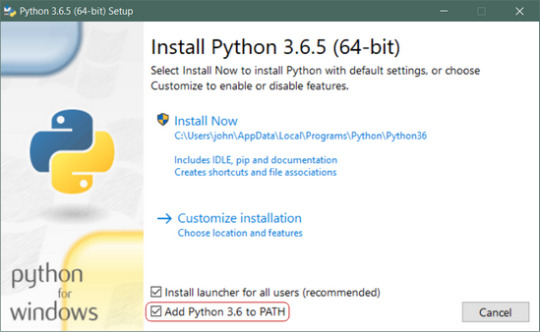
you need have to be check the path which is selected or not, check path after go to next.
2.2. click on install now . its ready to install .
2.3. open the window terminal /command prompt of your system to Check weather its install or not you have type the basic command.
type: python --version

Now its ready . we can do program its perfectly installed
STEP 3:
Now you can also write your program on or test that python is installed or not . go to window start and search or type idle . now open its own shell of python.
STEP 4:
lets create a hello world program into shell . run it
like >>>print(”HELLO world ”)
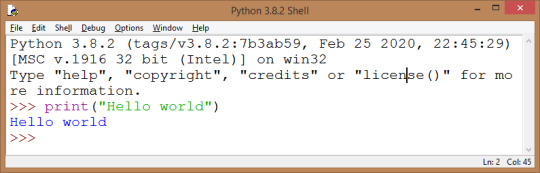
you can also create other program. for practice you can do
1. print a information of yourself your details...
to exit from terminal you can type
>>>exit()
STEP 5:you can also save your program into file using extension // //filename.py
now open shell go to file>>new >> saves with .py its open a blank file write your program into them and save it .you can run this file
using f5 if using idle or you can run the file manual like..
>>goto idle cmd type python filename.py at that folder where save on that path.

so . last its all about installation and your first hello world program. so
please share it , comment it how its , don’t forget to like .. and follow my account Gatepython # share It plz..
1 note
·
View note
Text
Unity With Python

⚡️ A very fast, simple, and general inter-process communication example between Unity3D C# and Python, using ZeroMQ.
PS. It looks slow in the GIF above because I put a delay of one second between each message so that you can see itworking.
Python for Unity facilitates Unity's interaction with various media and entertainment industry applications and ensures that you can integrate Unity into a broader production pipeline seamlessly. Potential benefits of using Python in your Unity project include: Automating scene and sequence assembly in the context of using Unity as a real-time.
The other neat part is that Unity3D can produce binaries for all major platforms. This includes Windows, Linux, MacOS, Android, iOS, and otherx. So not only does this add 3D capabilities to Python, but it also includes multi-platform support. The build process itself is simple and directed by the game engine itself.
Core Pillars
very fast — ZeroMQ is a networking library that allows you to send huge amount of data from server to client in a short period of time. I’m talking about casually sending/receiving 10,000 requests per second.
simple — You don’t have to explicitly open and bind a socket or know anything about low-level networking.
general — You can use this to send/receive any kind of data request. You can send image, video, text, JSON, file, or whatever you want. In this example, we are sending text.
inter-process — The communication is done inside the same machine. Which means very low-latency.
Introduction
Have you ever tried to communicate C# code in Unity3D with Python before but could not find a satisfying solution?
Have you ever tried implementing communication protocol using file read/write and found out that it’s a stupid approach?
Have you ever tried communicating using Web HTTP request and found out that it’s stupidly slow and high latency?
Have you ever tried communicating using socket/TCP/UDP stuff, but it feels like you are reinventing the wheel and youare becoming a network engineer?
Have you ever tried to communicate by emulating a serial port, and found out that it’s not how cool guys do work?
Have you ever tried to send Unity input to python and do some scientific work (maybe even machine learning task)and return the output to Unity?
Have you ever tried to build a .dll from python or even rewrite everything in C# because you don’t know how tocommunicate between python and C# processes?
Have you ever tried to embed IronPython or Python.NET inside Unity but it doesn’t allow you to install youramazing external python libraries? (And its minimal power is pretty ridiculous compared to your external python)
Have you ever tried to export a TensorFlow Protobuf Graph (Deep learning model) and use TensorFlowSharp orOpenCVForUnity to import the graph inside Unity because you want to use the model to predict stuff in Unity, but itdoesn’t allow you to use/utilize your new NVIDIA GeForce RTX 2080Ti, and it’s also hard to code?
Tried MLAgents, anyone?
If you answer Yes to any of these questions but it seems you have found no solutions,then this repository is definitely for you!(If you answered Yes to all questions, you and me are brothers! 😏)
A complex calculation (based on the data received from Unity) is performed in python and it produces a result (action); The result (action) is sent back via TCP to Unity. The character performs the action corresponding to the result. Steps 1-4 are repeated until infinity (unless the client or server stops). I used Keras in Python to design a neural network calculating something like a noise-reducing-function. It works pretty good so far, and now I want to use this network to clean the data inside a Unity-Project of mine. I would not have thought that this could be so difficult.
I’ve tried a lot. With a lot of searching on the internet, I’ve found no solutions that is simple, fast, and generalenough that I can apply to any kind of communication between Python and Unity3D. All I’ve done in the past were simplya hack to either get my scientific computation work in Unity instead of python, or communicate between the processes painfully.
Until I found ZeroMQ approach from this repository(and some head scratching).
Solution Explanation
I’ve built a request-reply pattern of ZeroMQ where Python (server) replies whenever Unity (client) requestsa service from Python.
https://foxgambling694.tumblr.com/post/658010901333606400/visual-studio-c-programming. The idea is to create a separate thread inside Unity that will send a request to python, receive a reply and log the replyto the console.
Getting Started
Clone this repository using git clone https://github.com/off99555/Unity3D-Python-Communication.git command.
Open UnityProject (its dll files are targeting .NET 4.x version) and run Assets/NetMQExample/Scenes/SampleScene.
Run python file PythonFiles/server.py using command python server.py on a command prompt.
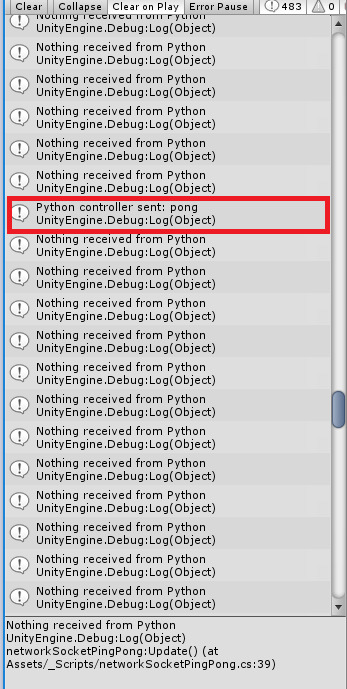
You should start seeing messages being logged inside Unity and the command prompt.
Specifically, Unity will send request with a message Hello 10 times, and Python will simply reply World 10 times.There is a one second sleep between each reply on the server (to simulate long processing time of the request).
Please read the comments inside PythonFiles/server.py and UnityProject/Assets/NetMQExample/Scripts/ and you willunderstand everything more deeply.
The most important thing is that you should follow the 4 getting started steps first. Don’t skip it! ❣️
After you’ve understood most of the stuff but it’s not advanced enough, you should consult the officialØMQ - The Guide.
Requirements
PyZMQ is the Python bindings for ZeroMQ. You can install it usingpip install pyzmq command or see more installation options here orhere.
NetMQ is a native C# port of ZeroMQ. Normally you need to install this usingNuGet package manager inside Visual Studio when you want to build a .NET application, or you could install using.NET CLI. But for this repository here, you don’t need to do any of the installation because we’ve already includedAsyncIO.dll and NetMQ.dll for you inside UnityProject/Assets/NetMQExample/Plugins/ directory.If you want to build your own dll files, please take a look atthis issue.
Known Issues
Based on this issue, the NetMQ implementation is not working nicely with Unity. If you create more than one ZeroMQ client in Unity, the Unity editor will freeze.
Troubleshooting
While both server and client are running and communicating fine, I kill the server process, restart the server, then both server and client seem to not be communicating anymore. Why don’t they continue communicating? Is this a bug?
No, this is the expected behavior of ZeroMQ because of the simplicity of the code. It’s mentioned in the guidehere. If you want to make the code better, which is notthe focus of this example, you can learn more about ZeroMQ as suggested in the screenshot below.
The problem is that when you restart the server, the server won’t reconnect to the old client anymore. You have to restart the client also.
Disclaimer
This repository is designed to be a minimal learning resource for getting started. It’s not a fully working high-level package.After you understand the example, my job is done.
Most of the code are just copies from the official ZeroMQ tutorial. I try to make this as simple to grasp as possible,so I only log the message to the console and nothing fancy. This is to minimize the unnecessary learning curve.
TODO
Add a complicated example of how to use it for real
Show how to do this with SocketIO. SocketIO is another approach I found very viable and stable. I use BestHTTP package in Unity for SocketIO client and use python-socketio as SocketIO server. And it does not have the issue of making Unity editor freezes.
Download GitHub for Unity 1.4.0
Our latest release, install manually
Download from Unity Asset Store
Download and install via Unity
By downloading, you agree to the Terms and Conditions.
Free and open source

Is onenote good on ipad. The extension is completely open source. Fix or report bugs. Build the features you need. Be a part of future GitHub for Unity releases.
Ditch the command line
View your project history, experiment in branches, craft a commit from your changes, and push your code to GitHub without leaving Unity.
Stay in sync with your team
Collaborate with other developers, pull down recent changes, and lock files to avoid troublesome merge conflicts.
Authentication and Initialization with GitHub
GitHub authentication is embedded in Unity, including 2FA. And with a click of a button, you can quickly initialize your game’s repository.
Use the GitHub for Unity Extension
Get off of the command line and work exclusively within Unity by downloading and installing the GitHub package!
Download
Unity With Python
Reach out to the GitHub for Unity team
Do you have questions? Feature ideas? Just want to chat with the team? Reach out to us on GitHub by opening a new issue, or by joining one of the chats listed in the project README. You can also email us at [email protected], or tweet at @GitHubUnity
Discuss
Python Unity3d
Code the GitHub for Unity Extension
Contribute to this open source project by reporting or resolving issues or forking the repository to add your own features!
Contribute
0 notes
Text
Extracting Ensoniq SQ-80 Disk Images
Another Ensoniq SQ-80 project - to extract SQ80 disk images on a PC for the purposes of searching contents and extracting patches.
The project came about because I was organising my patches with a view to distributing some of the better ones. I have been using the wonderful SQ8L VST plugin as a librarian. It is not only an excellent emulation of the SQ80, but loads SYSEX dumps and allows the creation of large libraries. I have a lot of patches on disk, and want to make sure some of the ones that have ended up in my banks are not actually 3rd party. Large disks would have been a lot of work to go through manually, sending a SYSEX dump for each bank over MIDI to a computer one by one. As floppy disks start to fail, and floppy disk drives and the computers that they can be installed in become harder to find this is also an insurance policy for archival purposes.
Enter the sq80toolkit by Rainer Buchty. This works really well at what it does, which is make disk images. However, it didn’t have the functionality I needed, namely extracting individual banks/patches as SYSEX data.
So what I needed was a tool that could read the disk images, extract the needed data from them, and convert it to SYSEX format. I have written a command line tool - extract_sq80 - to do this and have open sourced it. It’s in python and should run on just about any platform.
It also enables just about anyone to use the disk images that are available on Rainer’s page (and possibly elsewhere?) without having access to a floppy drive and the increasingly elusive double density 3 1/2″ floppies.
Visit the github to download the extract_sq80 tool here.
A quick step by step HOWTO:
You need a linux PC with a floppy drive in it to install the sq80toolkit on. I have no idea if sq80toolkit will work on a USB floppy drive, but I suspect it might not. I built a legacy hardware linux machine specially for this (which was a reasonable project in itself given failing hardware etc.)
Install the sq80toolkit. I also needed to install ‘fdutils’, which I did using my linux distribution’s package manager. There is a precompiled version of sq80toolkit, but I compiled the tool from source and had to make one change to the source. This was was to remove the check on line 74 of sq80dump.c which sees if the ioctl call fails. It was failing at run time with it on, but worked fine without it. I’m guessing this is something to do with modern linux kernels?
Once sq80toolkit is installed you can extract a disk image using the following command:
sq80dump -if=/dev/fd0 -of=IMAGE_FILE.img
/dev/fd0 indicates which floppy drive contains the disk image, the first one in this case.
The extract_sq80.py tool can be downloaded from the github. It needs python to be installed, but should run without any other dependencies.
You can then use extract_sq80.py to list the contents of the image generated in step 3, and extract whatever you need. It currently doesn’t know anything about sequences, but can extract banks or individual programs, either all at once, or individually. It also has a ‘virtual bank’ mode, where it combines all of the individual programs into banks so that you don’t have to deal with lots of individual programs in separate files. Some example commands are:
extract_sq80.py IMAGE_FILE.img bank --dump syx
which extracts all banks from the image in SYSEX format. Without the '--dump syx' option, it will just list them.
extract_sq80.py IMAGE_FILE.img bank --dump bin -n 2
extracts just the second bank from the image in the binary PCB format used by the SQ80 natively.
extract_sq80.py IMAGE_FILE.img prog --list
lists all of the individual programs in a more human readable format (5 programs per line, rather than one).
extract_sq80.py IMAGE_FILE.img bank --list > IMAGE_FILE_banks.txt
lists all of the banks and save the output to a text file. The --list option when used in bank mode will list all of the programs within each bank as well.
extract_sq80.py IMAGE_FILE.img virtbank -d syx
extracts all of the individual programs in up to 4 “virtual banks”, as sysex files.
extract_sq80.py --help
gives full usage information, so please refer to that for a more complete description.
On Linux, it’s very easy to send the resulting SYSEX files to the synth. I do it like this:
amidi -p hw:2,0,0 -s BANK01.syx
where hw:2,0,0 is the MIDI port, and BANK01.syx is the sysex file dumped by extract_sq80 using the ‘--dump syx’ option.
amidi -l
gives you a list of all the MIDI ports available on your system.
Any number of tools (MIDIOx etc) can be used to do a similar thing on Windows. The SQ8L VST plugin will also read in the .syx files as is.
Please feel free to get in touch with any questions/comments.
0 notes
Text
The best free ebooks resources

What are free ebooks resources?
These resources will provide you a huge online-ebooks. Furthermore, they are completely free! In addition, these resources contain many topics from business to technology ...so on. Besides, some of them are support view on mobile mode and easy to get pdf file.
Where are they store?
You can find these resources below which their full description. Hence, they are very useful for doing research and study and of course they are free for all access, so you can download as many as you want. We list out these to many different categories below for easy to find. Libraries Gutenberg: Project Gutenberg was the first to supply free ebooks, and today they have almost 30,000 free titles in stock. Free-eBooks.net: Besides browsing topics such as biography, fan fiction, games, history, or tutorials, you can submit your own ebook, too. ManyBooks.net: You can conduct an advanced search, type in a title or author, browse categories or select books by language, from Finnish to Bulgarian to Catalan to Swedish. DailyLit: Get free downloads sent to your email by RSS feed. iBiblio: Find archives, ebooks, tutorials, language books, and more from iBiblio. Authorama: This public domain book site has a wide variety of ebooks for free, by Lewis Carroll, Emerson, Kafka, and more. Bartleby: While Bartleby charges for some titles, it has a free ebook store here. bibliomania: You will find over 2,000 classic texts from bibliomania, plus study guides, reference material and more. Baen Free Library: You can download ebooks for HTML, RTF, Microsoft Reader and for Palm, Psion, and Window CE. eReader.com: eReader.com has many classic lit selections for free. Read Print Library: These novels and poems are all free. ebook Directory: From children's books to IT books to literature to reference, you'll find lots of free titles and book packages here. Planet PDF: Planet PDF has made available classic titles like Anna Karenina and Frankenstein for free. Get Free Ebooks: This website has free ebooks in categories from writing to environment to fiction to business, plus features and reviews. Globusz: There are no limits on the number of free books you can download on this online publishing site. eBookLobby: You'll find lost of self-help, hobby and reference books here, plus children's fiction and more. Bookyards: This online "library to the world" has over 17,000 ebooks, plus links to other digital libraries. The Online Books Page: You'll be able to access over 35,000 free ebooks from this site, powered by the University of Pennsylvania. Starry.com: These novels and anthologies were last updated in 2006, but you'll still find an interesting selection of online and virtual novels. eBook Readers Getting reviews and product information for all kinds of ebook readers, including the Kindle, you will have a full reviews before making decisions to purchase something. E-book Reader Matrix: This wiki makes it easy to compare ebook reader sizes, battery life, supported formats, and other qualifications. Amazon Kindle: Learn about, shop, and discover titles for the Kindle here. Abacci eBooks: All the books here are for Microsoft Reader. eBook Reader Review: TopTenReviews lists reader reviews from 2009. List of e-book readers: Learn about all of the different ebook readers from Wikipedia. E-book readers at a glance: This guide reviews and compares the new, cool readers. Free iPhone ebook readers head-to-head: Reality Distortion ranks iPhone ebook readers. About eBooks These links will connect you to ebook news, new title releases, and e-reader information. In addition, these resources support mobile views. TeleRead: This blog shares news stories about ebooks and digital libraries. MobileRead Forums: Learn about new ebook releases, clubs, and readers. E-book News: Technology Today has made room for a whole section on ebook news. Ebook2u.com: Get the latest headlines about readers, troubleshooting, titles, and more. The eBook coach: Learn how to write a successful ebook. Audio and Mobile Getting ebooks on your iPhone, iPod, BlackBerry, Palm, or other mobile device, you have many options to expand your knowledge on mobile devices. Feedbooks: You can download books for any mobile device here. Books in My Phone: Read ebooks on a java-enabled phone when you download them here. You can also manage a reading list. Barnes & Noble eBooks: Get NYT titles, new releases and more for your iPhone, BlackBerry, or computer. MemoWare: Get literature, poetry, and reference books for your PDA. Audible.com: Here you can download books to your iPod or mp3 player. iTunes: iTunes has audiobooks for iPhones and iPods. LibriVox: Get free audio book files on this site, or volunteer to record your narration for other books. eReader.comMobile: Get the mobile-friendly version of eReader.com here. Business and Education Turning to these ebook lists and resources for help with classes and your career is so very important for your personal future plan. Moreover, they are huge and well-organisation. Open Book Project: Students and teachers will find quality free textbooks and materials here. Digital Book Index: This site has over 140,000 titles, including textbooks and a pending American Studies collection. Classical Authors Directory: Get lesson plans, audio files, ebooks, and more from authors like Washington Irving, Benjamin Franklin and Homer. The Literature Network: Find classics, from Balzac to Austen to Shakespeare, plus educational resources to go along with the plays, short stories, and novels. OnlineFreeEbooks.net: All kinds of business, hobby, education textbooks, and self-teaching books are available for free on this site. Free Ebooks and Software: Learn how to do your own taxes and more from the books here. eLibrary Business Ebooks: Get emarketing, how-to, and other business ebooks here. Free Business eBooks: This guide has links to all kinds of free business ebooks. Data-Sheet: Data-Sheet finds ebook pdfs. Pdfgeni.com: Type into the search box the type of book you want to read, such as business education or vampire fiction. Ebook Search Engine: Simply type in your search and choose to have results displayed as PDFs or Word documents. Ebook Engine: This engine brings up free ebooks. eBook Search Queen: You can search ebooks by country here. ebookse.com: Browse by category or type your search into the box to bring up your query. Addebook: Free Ebook Search Engine: This tool is Google's ebook search engine. Boocu: Boocu can pull up thousands of ebooks and digital resources. Twitter Keeping up with ebook news, new titles, e-readers, and more by following these Twitter feeds is very well. The social channel is so very important to improve your knowledge. @AnEbookReader: Get tech reviews, accessories news, and more for ereaders and ebooks. LibreDigital: This company helps people find what they want to read and watch, on any medium. @e_reading: This feed comments on Kindle news and more. @RogerSPress: Roger publishes ebooks and has been reading them for 10 years already. @DigiBookWorld: Read about the latest trends in digital publishing. @ebooksstore: Follow @ebooksstore for interesting ebook news and releases. @ebookvine: This feed is all about Kindle. @vooktv: Now you can watch books on high-quality video online. @ebooklibrary: This is a feed for anyone who wants to learn more about free ebooks. @ericrumsey: Eric is a librarian who loves ebooks, his iPhone, and the Internet. @namenick: Nick Name is an ebook addict and mobile fiction writer. @KindleZen: Get the latest in Kindle news and hacks. Tech eBooks Get programming, design, and other tech assistance when you head to these ebook resources. FreeComputerBooks.com: Find magazines and IT books for reference and general interest. OnlineComputerBooks.com: Find free computer ebooks on networking, MySQL, Python, PHP, C++, and more. KnowFree.net: KnowFree has mostly tech books for download, plus some business titles. FreeTechBooks.com: This site has downloads in categories such as artificial intelligence, functional programming, and parallel computing. Tech Books for Free: From the web to computer programming to science, you'll find all sorts of tech ebooks here. Poetry Find poetry ebooks and collections here. everypoet.com: Read classic poetry on this site. PoemHunter.com: Download poems in PDF format here. Poetry: You'll find poetry ebooks for download on this site. Kids Share these interactive ebook resources with young readers. International Children's Digital Library: The ICDL is a colorful site devoted to children's ebooks. ebook88: On this site, there's a Christmas Bookshelf, and plenty of other kids' ebook links. Children's Storybooks Online: Find kids' storybooks, home schooling materials, and more. Tumble Books: This Tumble BookLibrary features fun, animated, talking picture books. Raz-Kids.com: This is another interactive kids' book site that helps kids learn to read. Children's Books Online: the Rosetta Project, Inc.: Here you'll find loads of books and translations for kids. Read.gov: From children's classics to in-progress digital books, Read.gov has excellent ebook resources. Storyline Online: The Screen Actors Guild Foundation presents Storyline Online with streaming videos of actors reading children's books. Miscellaneous From social networking and ebooks to bundles of books, turn here. Scribd: This ebook finder and social network shares what people are currently reading, and lets you upload your own book. Diesel: Diesel has 500,000 ebook store downloads, including custom bundles, mobile downloads, and some free titles. eBooks.com: Get NYT bestsellers for $9.99 each, plus all kinds of academic ebooks, non-fiction, and more.
Final Word
Phew, they are a lot and free. Therefore, they are important and necessary. You can read carefully and find exactly what you want. On the other hand, I will add more content for this topic later, so you can check the updated posts. I hope you enjoy this post and find something is useful for you. Read the full article
0 notes
Text
Learn Enough Docker to be Useful
Docker Images
Recall that a Docker container is a Docker image brought to life. It’s a self-contained, minimal operating system with application code.
The Docker image is created at build time and the Docker container is created at run time.
The Dockerfile is at the heart of Docker. The Dockerfile tells Docker how to build the image that will be used to make containers.
Each Docker image contains a file named Dockerfile with no extension. The Dockerfile is assumed to be in the current working directory when docker build is called to create an image. A different location can be specified with the file flag (-f).
Recall that a container is built from a series of layers. Each layer is read only, except the final container layer that sits on top of the others. The Dockerfile tells Docker which layers to add and in which order to add them.
Each layer is really just a file with the changes since the previous layer. In Unix, pretty much everything is a file.
The base image provides the initial layer(s). A base image is also called a parent image.
When an image is pulled from a remote repository to a local machine only layers that are not already on the local machine are downloaded. Docker is all about saving space and time by reusing existing layers.
A Dockerfile instruction is a capitalized word at the start of a line followed by its arguments. Each line in a Dockerfile can contain an instruction. Instructions are processed from top to bottom when an image is built. Instructions look like this:
FROM ubuntu:18.04 COPY . /app
Only the instructions FROM, RUN, COPY, and ADD create layers in the final image. Other instructions configure things, add metadata, or tell Docker to do something at run time, such as expose a port or run a command.
In this article, I’m assuming you are using a Unix-based Docker image. You can also used Windows-based images, but that’s a slower, less-pleasant, less-common process. So use Unix if you can.
Let’s do a quick once-over of the dozen Dockerfile instructions we’ll explore.
A Dozen Dockerfile Instructions
FROM — specifies the base (parent) image. LABEL —provides metadata. Good place to include maintainer info. ENV — sets a persistent environment variable. RUN —runs a command and creates an image layer. Used to install packages into containers. COPY — copies files and directories to the container. ADD — copies files and directories to the container. Can upack local .tar files. CMD — provides a command and arguments for an executing container. Parameters can be overridden. There can be only one CMD. WORKDIR — sets the working directory for the instructions that follow. ARG — defines a variable to pass to Docker at build-time. ENTRYPOINT — provides command and arguments for an executing container. Arguments persist. EXPOSE — exposes a port. VOLUME — creates a directory mount point to access and store persistent data.
Let’s get to it!
Instructions and Examples
A Dockerfile can be as simple as this single line:
FROM ubuntu:18.04
FROM
A Dockerfile must start with a FROM instruction or an ARG instruction followed by a FROM instruction.
The FROM keyword tells Docker to use a base image that matches the provided repository and tag. A base image is also called a parent image.
In this example, ubuntu is the image repository. Ubuntu is the name of an official Docker repository that provides a basic version of the popular Ubuntu version of the Linux operating system.
Notice that this Dockerfile includes a tag for the base image: 18.04 . This tag tells Docker which version of the image in the ubuntu repository to pull. If no tag is included, then Docker assumes the latest tag, by default. To make your intent clear, it’s good practice to specify a base image tag.
When the Dockerfile above is used to build an image locally for the first time, Docker downloads the layers specified in the ubuntu image. The layers can be thought of as stacked upon each other. Each layer is a file with the set of differences from the layer before it.
When you create a container, you add a writable layer on top of the read-only layers.
Docker uses a copy-on-write strategy for efficiency. If a layer exists at a previous level within an image, and another layer needs read access to it, Docker uses the existing file. Nothing needs to be downloaded.
When an image is running, if a layer needs modified by a container, then that file is copied into the top, writeable layer. Check out the Docker docs here to learn more about copy-on-write.
A More Substantive Dockerfile
Although our one-line image is concise, it’s also slow, provides little information, and does nothing at container run time. Let’s look at a longer Dockerfile that builds a much smaller size image and executes a script at container run time.
FROM python:3.7.2-alpine3.8 LABEL maintainer=" [email protected]" ENV ADMIN="jeff" RUN apk update && apk upgrade && apk add bashCOPY . ./appADD https://raw.githubusercontent.com/discdiver/pachy-vid/master/sample_vids/vid1.mp4 \ /my_app_directory RUN ["mkdir", "/a_directory"]CMD ["python", "./my_script.py"]
Whoa, what’s going on here? Let’s step through it and demystify.
The base image is an official Python image with the tag 3.7.2-alpine3.8. As you can see from its source code, the image includes Linux, Python and not much else. Alpine images are popular because they are small, fast, and secure. However, Alpine images don’t come with many operating system niceties. You must install such packages yourself, should you need them.
LABEL
The next instruction is LABEL. LABEL adds metadata to the image. In this case, it provides the image maintainer’s contact info. Labels don’t slow down builds or take up space and they do provide useful information about the Docker image, so definitely use them. More about LABEL metadata can be found here.
ENV
ENV sets a persistent environment variable that is available at container run time. In the example above, you could use the ADMIN variable when when your Docker container is created.
ENV is nice for setting constants. If you use a constant several places in your Dockerfile and want to change its value at a later time, you can do so in one location.
With Dockerfiles there are often multiple ways to accomplish the same thing. The best method for your case is a matter of balancing Docker conventions, transparency, and speed. For example, RUN, CMD, and ENTRYPOINT serve different purposes, and can all be used to execute commands.
RUN
RUN creates a layer at build-time. Docker commits the state of the image after each RUN.
RUN is often used to install packages into an image. In the example above, RUN apk update && apk upgrade tells Docker to update the packages from the base image. && apk add bash tells Docker to install bash into the image.
apk stands for Alpine Linux package manager. If you’re using a Linux base image in a flavor other than Alpine, then you’d install packages with RUN apt-get instead of apk. apt stand for advanced package tool. I’ll discuss other ways to install packages in a later example.
RUN — and its cousins, CMD and ENTRYPOINT — can be used in exec form or shell form. Exec form uses JSON array syntax like so: RUN ["my_executable", "my_first_param1", "my_second_param2"].
In the example above, we used shell form in the format RUN apk update && apk upgrade && apk add bash.
Later in our Dockerfile we used the preferred exec form with RUN ["mkdir", "/a_directory"] to create a directory. Don’t forget to use double quotes for strings with JSON syntax for exec form!
COPY
The COPY . ./app instruction tells Docker to take the files and folders in your local build context and add them to the Docker image’s current working directory. Copy will create the target directory if it doesn’t exist.
ADD
ADD does the same thing as COPY, but has two more use cases. ADD can be used to move files from a remote URL to a container and ADD can extract local TAR files.
I used ADD in the example above to copy a file from a remote url into the container’s my_app_directory. The Docker docs don’t recommend using remote urls in this manner because you can’t delete the files. Extra files increase the final image size.
The Docker docs also suggest using COPY instead of ADD whenever possible for improved clarity. It’s too bad that Docker doesn’t combine ADD and COPY into a single command to reduce the number of Dockerfile instructions to keep straight 😃.
Note that the ADD instruction contains the \ line continuation character. Use it to improve readability by breaking up a long instruction over several lines.
CMD
CMD provides Docker a command to run when a container is started. It does not commit the result of the command to the image at build time. In the example above, CMD will have the Docker container run the my_script.py file at run time.
A few other things to know about CMD:
Only one CMD instruction per Dockerfile. Otherwise all but the final one are ignored.
CMD can include an executable. If CMD is present without an executable, then an ENTRYPOINT instruction must exist. In that case, both CMD and ENTRYPOINT instructions should be in JSON format.
Command line arguments to docker run override arguments provided to CMD in the Dockerfile.
Ready for more?
Let’s introduce a few more instructions in another example Dockerfile.
FROM python:3.7.2-alpine3.8 LABEL maintainer=" [email protected]"# Install dependencies RUN apk add --update git # Set current working directory WORKDIR /usr/src/my_app_directory # Copy code from your local context to the image working directory COPY . . # Set default value for a variable ARG my_var=my_default_value # Set code to run at container run time ENTRYPOINT ["python", "./app/my_script.py", "my_var"] # Expose our port to the world EXPOSE 8000 # Create a volume for data storage VOLUME /my_volume
Note that you can use comments in Dockerfiles. Comments start with #.
Package installation is a primary job of Dockerfiles. As touched on earlier, there are several ways to install packages with RUN.
You can install a package in an Alpine Docker image with apk. apk is like apt-get in regular Linux builds. For example, packages in a Dockerfile with a base Ubuntu image can be updated and installed like this: RUN apt-get update && apt-get install my_package.
In addition to apk and apt-get, Python packages can be installed through pip, wheel, and conda. Other languages can use various installers.
The underlying layers need to provide the install layer with the the relevant package manger. If you’re having an issue with package installation, make sure the package managers are installed before you try to use them. 😃
You can use RUN with pip and list the packages you want installed directly in your Dockerfile. If you do this concatenate your package installs into a single instruction and break it up with line continuation characters (\). This method provides clarity and fewer layers than multiple RUN instructions.
Alternatively, you can list your package requirements in a file and RUN a package manager on that file. Folks usually name the file requirements.txt. I’ll share a recommended pattern to take advantage of build time caching with requirements.txt in the next article.
WORKDIR
WORKDIR changes the working directory in the container for the COPY, ADD, RUN, CMD, and ENTRYPOINT instructions that follow it. A few notes:
It’s preferable to set an absolute path with WORKDIR rather than navigate through the file system with cd commands in the Dockerfile.
WORKDIR creates the directory automatically if it doesn’t exist.
You can use multiple WORKDIR instructions. If relative paths are provided, then each WORKDIR instruction changes the current working directory.
ARG
ARG defines a variable to pass from the command line to the image at build-time. A default value can be supplied for ARG in the Dockerfile, as it is in the example: ARG my_var=my_default_value.
Unlike ENV variables, ARG variables are not available to running containers. However, you can use ARG values to set a default value for an ENV variable from the command line when you build the image. Then, the ENV variable persists through container run time. Learn more about this technique here.
ENTRYPOINT
The ENTRYPOINT instruction also allows you provide a default command and arguments when a container starts. It looks similar to CMD, but ENTRYPOINT parameters are not overwritten if a container is run with command line parameters.
Instead, command line arguments passed to docker run my_image_name are appended to the ENTRYPOINT instruction’s arguments. For example, docker run my_image bash adds the argument bash to the end of the ENTRYPOINT instruction’s existing arguments.
A Dockerfile should have at least one CMD or ENTRYPOINT instruction.
The Docker docs have a few suggestions for choosing between CMD and ENTRYPOINT for your initial container command:
Favor ENTRYPOINT when you need to run the same command every time.
Favor ENTRYPOINT when a container will be used as an executable program.
Favor CMD when you need to provide extra default arguments that could be overwritten from the command line.
In the example above, ENTRYPOINT ["python", "my_script.py", "my_var"]has the container run the the python script my_script.py with the argument my_var when the container starts running. my_var could then be used by my_script via argparse. Note that my_var has a default value supplied by ARG earlier in the Dockerfile. So if an argument isn’t passed from the command line, then the default argument will be used.
Docker recommends you generally use the exec form of ENTRYPOINT: ENTRYPOINT ["executable", "param1", "param2"]. This form is the one with JSON array syntax.
EXPOSE
The EXPOSE instruction shows which port is intended to be published to provide access to the running container. EXPOSE does not actually publish the port. Rather, it acts as a documentation between the person who builds the image and the person who runs the container.
Use docker run with the -p flag to publish and map one or more ports at run time. The uppercase -P flag will publish all exposed ports.
VOLUME
VOLUME specifies where your container will store and/or access persistent data. Volumes are the topic of a forthcoming article in this series, so we’ll investigate them then.
Let’s review the dozen Dockerfile instructions we’ve explored.
Important Dockerfile Instructions
FROM — specifies the base (parent) image. LABEL —provides metadata. Good place to include maintainer info. ENV — sets a persistent environment variable. RUN —runs a command and creates an image layer. Used to install packages into containers. COPY — copies files and directories to the container. ADD — copies files and directories to the container. Can upack local .tar files. CMD — provides a command and arguments for an executing container. Parameters can be overridden. There can be only one CMD. WORKDIR — sets the working directory for the instructions that follow. ARG — defines a variable to pass to Docker at build-time. ENTRYPOINT — provides command and arguments for an executing container. Arguments persist. EXPOSE — exposes a port. VOLUME — creates a directory mount point to access and store persistent data.
Now you know a dozen Dockerfile instructions to make yourself useful! Here’s a bonus bagel: a cheat sheet with all the Dockerfile instructions. The five commands we didn’t cover are USER, ONBUILD, STOPSIGNAL, SHELL, and HEALTHCHECK. Now you’ve seen their names if you come across them. 😃
Wrap
Dockerfiles are perhaps the key component of Docker to master. I hope this article helped you gain confidence with them. We’ll revisit them in the next article in this series on slimming down images. Follow me to make sure you don’t miss it!
If you found this article helpful, please help others find it by sharing on your favorite social media.
Credit : https://towardsdatascience.com/learn-enough-docker-to-be-useful-b0b44222eef5
0 notes
Text
Top 9 Real World Applications of Python Programming
1. Python Applications
Let’s discuss python applications to that python can accomplish in the world. In this applications of Python programming tutorial, you will know about 9 applications of Python Lets go through these Python applications one by one.
We’ve been learning Python programming over the last two months and we’ve learned quite some useful stuff. But when you can see what you can do with something, it feels powerful. It lends you some actual motivation to keep going.
So, let’s start Python Applications.

2. Web and Internet Development
Python lets you develop a web application without too much trouble. It has libraries for internet protocols like HTML and XML, JSON, e-mail processing, FTP, IMAP, and easy-to-use socket interface. Yet, the package index has more libraries:
Requests – An HTTP client library
BeautifulSoup – An HTML parser
Feedparser – For parsing RSS/Atom feeds
Paramiko – For implementing the SSH2 protocol
Twisted Python – For asynchronous network programming
We also have a gamut of frameworks available. Some of these are- Django, Pyramid. We also get microframeworks like flask and bottle. We’ve discussed these in our write-up on an Introduction to Python Programming. We can also write CGI scripts, and we get advanced content management systems like Plone and Django CMS.
3. Applications of Python Programming in Desktop GUI
Most binary distributions of Python ship with Tk, a standard GUI library. It lets you draft a user interface for an application. Apart from that, some toolkits are available:
wxWidgets
Kivy – for writing multitouch applications
Qt via pyqt or pyside
And then we have some platform-specific toolkits:
GTK+
Microsoft Foundation Classes through the win32 extensions
Delphi
4. Science and Numeric Applications
This is one of the very common applications of python programming. With its power, it comes as no surprise that python finds its place in the scientific community. For this, we have:
SciPy – A collection of packages for mathematics, science, and engineering.
Pandas- A data-analysis and -modeling library
IPython – A powerful shell for easy editing and recording of work sessions. It also supports visualizations and parallel computing.
Software Carpentry Course – It teaches basic skills for scientific computing and running bootcamps. It also provides open-access teaching materials.
Also, NumPy lets us deal with complex numerical calculations.
5. Software Development Application
Software developers make use of python as a support language. They use it for build-control and management, testing, and for a lot of other things:
SCons – for build-control
Buildbot, Apache Gump – for automated and continuous compilation and testing
Roundup, Trac – for project management and bug-tracking.
Roster of Integrated Development Environments
6. Python Applications in Education
Thanks to its simplicity, brevity, and large community, Python makes for a great introductory programming language. Applications of python programming in education has huge scope as it is a great language to teach in schools or even learn on your own. If you still haven’t begun, we suggest you read up on what we have to say about the white and dark sides of Python. Also, check out Python Features.
7. Python Applications in Business
Python is also a great choice to develop ERP and e-commerce systems:
Tryton – A three-tier, high-level general-purpose application platform.
Odoo – A management software with a range of business applications. With that, it’s an all-rounder and forms a complete suite of enterprise-management applications in-effect.
8. Database Access
This is one of the hottest Python Applications. With Python, you have:
Custom and ODBC interfaces to MySQL, Oracle, PostgreSQL, MS SQL Server, and others. These are freely available for download.
Object databases like Durus and ZODB
Standard Database API
9. Network Programming
With all those possibilities, how would Python slack in network programming? It does provide support for lower-level network programming:
Twisted Python – A framework for asynchronous network programming. We mentioned it in section 2.
An easy-to-use socket interface
10. Games and 3D Graphics
Safe to say, this one is the most interesting. When people hear someone say they’re learning Python, the first thing they get asked is – ‘So, did you make a game yet?’ PyGame, PyKyra are two frameworks for game-development with Python. Apart from these, we also get a variety of 3D-rendering libraries. If you’re one of those game-developers, you can check out PyWeek, a semi-annual game programming contest.
11. Other Python Applications
These are some of the major Python Applications. Apart from what we just discussed, it still finds use in more places:
Console-based Applications
Audio – or Video- based Applications
Applications for Images
Enterprise Applications
3D CAD Applications
Computer Vision (Facilities like face-detection and color-detection)
Machine Learning
Robotics
Web Scraping (Harvesting data from websites)
Scripting
Artificial Intelligence
Data Analysis (The Hottest of Python Applications)
This was all about the Python Applications Tutorial. If you like this tutorial on applications of Python programming comment below.
Why should you Learn python? Refer this link to get your answer.
Ready to install Python? Refer this link Python Installation
12. Conclusion – Python Applications
Python is everywhere and now that we know python Applications. We can do with it, we feel more powerful than ever. If there’s a unique project you’ve made in the Python language.
Share your experience with us in the comments. You can also share your queries regarding Python Application tutorial.
0 notes
Link
via blog.ouseful.info
A handful of brief news-y items…
Netflix Polynote Notebooks
Netflic have announced a new notebook candidate, Polynote [code], capable of running polyglot notebooks (scala, Python, SQL) with fixed cell ordering, variable inspector and WYSIWYG text authoring.
At the moment you need to download and install it yourself (no official Docker container yet?) but from the currently incomplete installation docs, it looks like there may be other routes on the way…
The UI is clean, and whilst perhaps slightly more cluttered than vanilla Jupyter notebooks it’s easier on the eye (to my mind) than JupyterLab.
Cells are code cells or text cells, the text cells offering a WYSIWYG editor view:
One of the things I note is the filetype: .ipynb.
Code cells are sensitive to syntax, with a code completion prompt:
I really struggle with code complete. I can’t write import pandas as pd RETURN because that renders as import pandas as pandas. Instead I have to enter import pandas as pd ESC RETURN.
Running cells are indicated with a green sidebar to the cell (you can get a similar effect in Jupyter notebooks with the multi-outputs extension):
I couldn’t see how to connect to a SQL database, nor did I seem to get an error from running a presumably badly formed SQL query?
The execution model is supposed to enforce linear execution, but I could insert a cell after and unrun cell and get an error from it (so the execution model is not run all cells above either literally, or based on analysis of the programme abstract syntax tree?)
There is a variable inspector, although rather than showing or previewing cell state, you just get a listing of variables and then need to click through to view the value:
I couldn’t see how to render a matplotibl plot:
The IPython magic used in Jupyter notebooks throws an error, for example:
This did make me realise that cell lines are line numbered on one side and there’s a highlight shown on the other side which line errored. I couldn’t seem to click through to raise a more detailed error trace though?
On the topic of charts, if you have a Vega chart spec, you can paste that into a Vega spec type code cell and it will render the chart when you run the cell:
The developers also seem to be engaging with the “open” thing…
Take it for a spin today by heading over to our website or directly to the code and let us know what you think! Take a look at our currently open issues and to see what we’re planning, and, of course, PRs are always welcome!
Streamlit.io
Streamlit.io is another new notebook alternative, pip installable and locally runnable. The model appears to be that you create a Python file and run the streamlit server against that file. Trying to print("Hello World") doesn’t appear to have any effect — so that’s a black mark as far as I’n concerned! — but the display is otherwise very clean.
Hovering top right will raise the context menu (if it’s timed-out itself closed) showing if the source file has recently been saved and not rerun, or allowing you to always rerun the execution each time the file is saved.
I’m not sure if there’s any cacheing of steps that are slow to run if associated code hasn’t changed up to that point in a newly saved file.
Ah, it looks there is…
… and the docs go into further detail, with the use of decorators to support cacheing the output of particular functions.
I need to play with this a bit more, but it looks to me like it’d make for a really interesting VS Code extension. It also has the feel of Scripted Forms, as was, (a range of widgets are available in streamlit as UI components), and R’s Shiny application framework. It also feels like something I guess you could do in Jupyterlab, perhaps with a bit of Jupytext wiring.
In a similar vein, a package called Handout also appeared a few weeks ago, offering the promise of “[t]urn[ing] Python scripts into handouts with Markdown comments and inline figures”. I didnlt spot it in the streamlit UI, but it’d be useful to be able to save or export the rendered streamlit document eg as an HTML file, or even as an ipynb notebook, with run cells, rather than having to save it via the browser save menu?
Wolfram Notebooks
Wolfram have just announced their new, “free” Wolfram Notebooks service, the next step in the evolution of Wolfram Cloud (announcement review], I guess? (I scare-quote “free because, well, Wolfram; you’d also need to carefully think about the “open” and “portable” aspects…
*Actually, I did try to have a play, but I went to the various sites labelled as “Wolfram Notebooks” and I couldn’t actually find a 1-click get started (at all, let alone, for “free”) link button anywhere obvious?
Ah… here we go:
[W]e’ve set it up so that anyone can make their own copy of a published notebook, and start using it; all they need is a (free) Cloud Basic account. And people with Cloud Basic accounts can even publish their own notebooks in the cloud, though if they want to store them long term they’ll have to upgrade their account.
0 notes
Text
Original Post from Rapid7 Author: Josh Frantz
When you have old computers, flash drives, phones, or hard drives that you no longer use, you might take them to a resale shop, thrift store, or recycling center. However, have you ever wondered what happens to these devices and the data within them? Does your data get destroyed, or are your items resold with all your memories and personal data perfectly packaged up for the new owner to access? And, if that data is still available, what happens when someone like me starts shopping at all the thrift stores and resale shops in my area with the sole purpose of seeing how much personal data I can get my hands on?
To find out, I spent six months extracting all the data I could from devices available at businesses that sell refurbished computers or accept donated items to sell after supposedly wiping them. By the end of this experiment, this research revealed that many businesses do not follow through on their guarantee to wipe the data from the devices people hand over to them.
Let’s take a look at how I conducted this experiment, the types of data I discovered, and some methods to ensure all data is safely removed from all your old devices before they leave your possession.
The process
My first step was probably the least interesting part of this experiment: I researched all the businesses that sold refurbished, donated, or used computers around my home in Wisconsin. I visited a total of 31 businesses and bought whatever I could get my hands on for a grand total of around $600. Here is a breakdown of all the devices I purchased:
Device Type Number of Devices Bought Desktop or laptop computer 41 Removable media (such as flash drives and memory cards) 27 Hard disk 11 Cell phone 6
After buying the devices, I took them to my command center (a cool name for my basement) and began the data extraction process. Whenever I brought a computer back, I booted it up to see whether it was bootable and whether it required a password to log in. I wrote a script in PowerShell that would run through and index all the images, documents, saved emails, and conversation histories through instant messengers. It would then zip it up nice and organized on the desktop, and I would pull it off with a USB drive (I know, you were expecting something much fancier). Only one Dell laptop had been erased properly.
With hard disks, most of them were IDE, so I used this IDE toaster to quickly download everything I could—this time, using a Python script to go through all the data and organize it. What I found was that none of the drives were encrypted, and all seemed to function properly (with the exception of one old Hitachi 20GB hard drive that had been wiped).
The cell phones I bought were very old and required three proprietary chargers I had to buy on eBay, putting my total cost around $650 (without factoring in gas, coffee, or my family’s road trip misery). The cell phones didn’t require PINs, and for a few of them, I couldn’t find software to interface with my computer to pull anything off.
I simply plugged in flash drives and memory cards and used that Python script again to organize the data.
Overall, what I found was astounding: Out of the 85 devices I purchased, only two (the Dell laptop and Hitachi hard drive) were erased properly. Additionally, only three of the devices were encrypted.
The data
Armed with a bunch of data and a basement littered with technology older than myself, I developed a plan to sift through all this data for potentially private information. I used pyocr to try to identify Social Security numbers, dates of birth, credit card numbers, and phone numbers on images and PDFs. I then used PowerShell to go through all documents, emails, and text files for the same information. You can find the regular expressions I used to identify the personal information here.
Despite the fact that OCR is not 100% accurate and there could have been data I couldn’t extract from images by themselves or within PDFs, I can verify that the regular expressions used for Social Security numbers, credit cards, dates of birth, and driver’s license numbers were fairly comprehensive.
Below are the final counts on processed data (not including several instances of MSN/AIM conversation history) and which file formats were used to calculate this. I also excluded a few file extensions (such as XML, HTML, and CSS) for brevity and relevance.
Images (JPEG, TIFF, GIF, BMP, PNG, BPG, SVG) Documents (DOC, DOCX, PDF, CSV, TXT, RTF, ODT) Emails (PST, MSG, DBX, EMLX) 214,019 3,406 148,903
As you can see, many files were found. The best (or worst) part about this is that I extracted a lot of personally identifiable information (PII). Here is the breakdown of unique values for every set:
Type of PII Unique Value Email address 611 Date of birth 50 SSN 41 Credit card number 19 Driver’s license number 6 Passport number 2
Surprisingly, most of the credit card numbers were from scans or images of the front and/or back of the card. The two passport numbers were also scanned into the computer.
The price
Researching further, I realized just how cheap it is to buy people’s information on the Darknet. Social Security numbers only fetch around $1 apiece, while full documents (dox) fetch around $3 each. No matter how we calculate the value of the data gathered, we would never recoup our initial investment of around $600.
This raises a fascinating point: Data leakage/extraction is so common that it has driven down the cost of the data itself. I saw several dumps of Social Security numbers on the Darknet for even less than $1 each.
How to safely dispose of your technology
When donating or selling your technology, you should be sure to wipe it yourself rather than relying on the seller to do it for you. There are several great guides available for wiping your computers, phones, and tablets, so we won’t dive too deep into that topic here.
However, if you are planning on recycling your technology, the following are some ways to make sure your data is irretrievable by destroying the device (or storage disk) irrevocably:
Hammer
Incineration (be careful of toxic by-products)
Industrial shredding
Drill/drill press
Acid
Electrolysis
Microwaves
Thermite
If using any of these methods, you’re going to need to secure your location and wear reasonable safety gear (at a minimum, appropriate goggles and gloves). Once your safety situation is handled, secure destruction can be loads of fun.
Below is one video that shows how to use thermite to destroy a desktop PC:
Realistically, unless you physically destroy a device, forensic experts can potentially extract data from it. If you’re worried about potential data exfiltration, it’s best to err on the side of caution and destroy it. However, wiping your device is usually enough, and can be a very easy and relatively painless process using the guides above.
All kidding aside, if you’re looking to wipe a hard disk drive, DBAN is your best option, and there is a very handy guide here on how to do that. Please note that this will not work for solid-state drives for RAID arrays. If you’re looking to wipe solid-state drives or multiple disks in a RAID, PartedMagic works really well, and there is an easy-to-follow guide here.
In conclusion
If you’re worried about your data ending up in the wrong person’s hands, destroy the data. If you wish to do a good deed and donate your technology so others can benefit, make sure it’s at least wiped to an acceptable standard. Even if you get it in writing that your data will be erased, there’s no good way to know whether that’s actually true unless you perform the wipe yourself. If this research was any indication, it likely isn’t being wiped in a reasonably secure way.
Thanks for reading, and be sure to leave any feedback below in the comments!
#gallery-0-5 { margin: auto; } #gallery-0-5 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-0-5 img { border: 2px solid #cfcfcf; } #gallery-0-5 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
Go to Source Author: Josh Frantz Buy One Device, Get Data Free: Private Information Remains on Donated Tech Original Post from Rapid7 Author: Josh Frantz When you have old computers, flash drives, phones, or hard drives that you no longer use, you might take them to a resale shop, thrift store, or recycling center.
0 notes
Text
What makes ArcGIS Pro so… ‘Pro’?
I think I can speak for all members of the ArcGIS Pro team when I say, one of the most common questions we get is “What is so special about ArcGIS Pro?” In the moment, it is pretty easy to rattle off the top few things that come to mind, but this really doesn’t do Pro due justice. There are so many things that are already special and the list is only growing.
We wanted to compile a list of some things we think are advancements in ArcGIS Pro. We know the list isn’t exhaustive by any means, but that’s where you come in! Please leave a comment below letting us know what you think is an advancement in Pro.
We asked the Desktop development team to contribute their ideas. Here is the list!
.
3D
One of the biggest strengths of ArcGIS Pro is its 3D integration. 3D is a great way to analyze and visualize data and Pro makes it much easier to do. 3D capabilities in Pro include
- Linked 2D and 3D views
- Convert between 2D and 3D in the click of a button
Animations
Another great way to visualize data is through animations. Animations are user-created simulations that walk-through camera keyframes of your maps. This functionality is available in ArcScene, but it is just better and more powerful in ArcGIS Pro, not to mention really easy to use.
I wanted to explore animations before I posted this blog because I had never done it before and after about an hour of messing around I came up with this video…
It’s not very pretty, but it’s pretty good for just an hour of trying something new! It just goes to show how easy it is.
For a more ‘aesthetic’ example click here.
Charts
Charts are another feature that were available in ArcMap but are more powerful in ArcGIS Pro. Charting capabilities are enhanced with multi-series support, filtering by map extent and selection as well as time and range sliders. Line charts also support advanced time aggregation. In Pro you can create many kinds of charts and insert them on your layouts. The charts remain live and update as your data updates.
Developer
Pro makes it easier than ever to download and install additional Python libraries using Conda and the Python Package Manager. This takes the guess work out of finding libraries that are compatible with your version of Python. Due to the new organization of ArcGIS Pro (projects, maps, etc.) ArcPy has changed a little bit, but it is easier and once again more powerful in ArcGIS Pro. Pro also provides improved database schema creating tools.
Editing
There are some major advancements within editing in ArcGIS Pro. Here are some that we came up with
- No need to start/stop editing
- On-the-map interactive annotation editing
- Group Templates
- Contextual editing
- Editing Grid
- Element Snapping
- The extents from elements on the page can act as natural snapping positions allowing you to easily set up a well-organized layout
- CAD-like editing feedback
- Edit in 2D and see results in 3D or vice versa.
Geoprocessing
ModelBuilder in ArcGIS Pro has a plethora of enhancements including search and filtering to find specific model elements, grouping which allows you to select multiple elements and collapse them into one label-able item, and improved selection and connection tools.
Along with the new and improved ModelBuilder functionality, there are a lot of new geoprocessing tools that are specific to ArcGIS Pro and other old tools that have been ‘beefed up’ in Pro.
Layouts
Being able to have multiple layouts in one project in Pro really optimizes workflows and improves data organization. Enhanced features within layouts in ArcGIS Pro are listed below.
- Layouts have their own table of contents – North Arrow, legend, etc. are all objects in the table of contents.
- Feedback when resizing elements – When you add a new element, or resize an existing element you get a feedback box telling you the exact x,y size of the element.
- Map extents are uncoupled from layout map frames – In ArcMap when you change the extent of your map, you can inadvertently change the extent of the map in the layout. This can be bad if the map you want to print has a specific extent that needs to be kept. To change the extent of a map frame in Pro, you must intentionally Activate that map. Then you can reposition it, and Close Activation to maintain the extent.
- Printer page sizes decoupled from the page – In ArcMap your page size is coupled to the page sizes in your installed printers. If you send a map to a friend who doesn’t have the same page sizes on their printer it can inadvertently change the size of your page. In Pro, we have decoupled this so you won’t accidentally cause your page size to change.
- Improved gird and graticules user experience – There are many enhancements to the grid and graticule experience in ArcGIS Pro, including the ability to format grid labels in many ways.
- Insert Multiple Guides – You can add more than one layout guide to the page at a time. You can add them horizontally, vertically, or in both directions and add them in the center, offset from the edges, or evenly spaced to create a grid.
Organization
ArcGIS Pro has a project based structure. This makes it much easier to organize work as you can have multiple maps and layouts in a single project. Project templates also make it easier to repeat projects with new data. With the 2.0 release of Pro, ‘Project favorites‘ allow for easy access of frequently-used folder, database, and server connections to any project.
Performance
It’s just fast… it’s a 64 bit, multi-threaded application.
Symbology
These are some of the symbology advancements in ArcGIS Pro
- Smart mapping UI for authoring symbology
- Apply Transparency to Graphics and Text – Any color in ArcGIS pro can be transparent. You can use this to make any graphic or piece of text in your layout transparent.
- More symbology types and richer symbology options
- Unclassed colors symbology – no more spending time trying to figure out the best classification system.
Tools
Many system tools in ArcGIS Pro are enhanced to support interactive feature input. Only custom-built tools could leverage similar capabilities in ArcMap.
Also, analysis capabilities from ArcGIS Enterprise (Standard Feature Analysis tools, GeoAnalytics tools, and Raster Analysis tools) are only available in ArcGIS Pro.
UI
ArcGIS Pro’s user interface is definitely an advancement. Here are some things about the UI that make it advanced
- Context-based ‘smart UI’
- No more remembering which toolbar to enable to get to a tool
- No more giant pick lists of layers to change simple things like transparency.
- On-screen navigation control (for 2D and 3D)
Other Unique Features
Like I mentioned above, this list is not exhaustive, but some other unique features of ArcGIS Pro include
- Export of PDF – now supports native transparency (no more jaggies)
- New ‘range slider’ for interactive and dynamic filtering across multiple layers
- Integration with ArcGIS Online in terms of both adding data from the Living Atlas and other sources and sharing maps with AGOL.
- New advances in space time pattern mining are only available in ArcGIS Pro
- ArcGIS Pro has geo-enrichment capabilities through the Enrich Layer geoprocessing tool.
- Tasks
- R-bridge
.
Did we capture everything? What do you think is better in Pro? Leave a comment below and add to our list!
.
- Tylor the ArcGIS Pro Intern
.
from ArcGIS Blog http://ift.tt/2uJpWrW
0 notes
Text
How is the await field in iostat calculated?
PART 1: 15 seconds of await
One of our customers was running some third party monitoring software, which was reporting very occasional spikes of many seconds (6-15 seconds)worth of await on their local disk. Looking at the datadog code, we can see that the python is really just running iostat and capturing the output:
if Platform.is_linux(): stdout, _, _ = get_subprocess_output(['iostat', '-d', '1', '2', '-x', '-k'], self.logger)
From the man page, the options iostat is running with are:
-x Display extended statistics. This option works with post 2.5 kernels since it needs /proc/diskstats file or a mounted sysfs to get the statistics. This option may also work with older kernels (e.g. 2.4) only if extended statistics are available in /proc/partitions (the kernel needs to be patched for that).
-k Display statistics in kilobytes per second instead of blocks per second. Data displayed are valid only with kernels 2.4 and later.
-d Display the device utilization report.
The '1' and '2' will mean that iostat runs every one second, and will return two results before exiting. iostat with the -x flag will read from /proc/diskstats by default (it says it can also use sysfs, but a look at the code shows that /proc/diskstats is preferred when available). /proc/diskstats is a file containing a set of incrementing counters with various disk statistics. The first set of output from iostat will be statistics since the system was booted (as per the man page), and the second result will be statistics collected during the interval since the previous report. This will give us output like this:
# iostat -d -k -x 1 2 Linux 2.6.32-642.6.2.el6.x86_64 (linux-test2) 01/26/2017 _x86_64_ (1 CPU) Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvdb 0.01 0.02 0.00 0.00 0.05 0.09 69.08 0.00 31.58 3.05 53.63 0.74 0.00 xvda 0.00 1.40 0.05 1.22 1.10 10.49 18.18 0.00 0.66 0.62 0.67 0.13 0.02 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 xvda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
The first thing to do to try and investigate the issue was to try and replicate the results using iostat ourselves. We ran the following in a while loop:
# while true; do date >> /var/log/iostat.log ; iostat -d 1 2 -x -k >> /var/log/iostat.log; sleep 1; done
After running that for a while, we calculated the min, max and average values that iostat logged for await:
# cat /var/log/iostat.log | grep "dm-2" | awk '{print $10}' | sort -V | awk 'NR == 1 { max=$1; min=$1; sum=0 } { if ($1>max) max=$1; if ($1<min) min=$1; sum+=$1;} END {printf "Min: %d\tMax: %d\tAverage: %f\n", min, max, sum/NR}'
The results looked something like this:
Min: 0 Max: 15506 Average: 1.862469
Suspiciously the max was indeed showing 15506ms. Given that iostat is running every second, 15000ms (15 seconds!) of await is logically impossible. But in case the customer pressed further, the next question is what actually is await? A quick google around the internet doesn't show us exactly how it's calculated, so that means we need to go to the source.
PART 2: Obtaining the source code
The iostat program is part of a package included in the 'sysstat' package. The customer was running sysstat-9.0.4-27.el6.x86_64. The first thing to do was to download the source RPM for this version; it's not sufficient to browse the latest code repository online since software can change significantly from version to version. We found the SRPM on the red hat website and downloaded it on a test machine, and installed it.
# wget http://ftp.redhat.com/pub/redhat/linux/enterprise/6Server/en/os/SRPMS/sysstat-9.0.4-27.el6.src.rpm # rpm -Uvh sysstat-9.0.4-27.el6.src.rpm # cd rpmbuild
Looking in the SOURCES directory, there is some code and a bunch of .patch files. If we wanted to look at the source for the program as it was installed on disk, we would need to apply the patch files to the original source. We can do this with rpmbuild. From the relevant section of the rpmbuild man page:
-bp Executes the "%prep" stage from the spec file. Normally this involves unpacking the sources and applying any patches.
Before we can apply the patch files, we need to install some dependencies. We got an error for missing dependencies when trying to build the package initially which told us which dependencies were missing - gettext and if.h (which a yum whatprovides shows is provided by the gettext and kernel-devel package respectively):
# yum install kernel-devel gettext
Finally we can run rpmbuild.
# rpmbuild -bp SPECS/sysstat.spec
Once this finished, we can find the patched source for the version of sysstat we care about in the ~/rpmbuild/BUILD/sysstat-9.0.4 directory. From the naming of the files, the one we want is iostat.c.
PART 3: Reading the source
Since this is quite a short piece of code (~2000 lines), the first step is to go through and read the comments, functions and variable naming to get a broad picture for what we're looking at. Initially the first thing that sticks out is the write_ext_stat function - the comment above it reads this:
/* *************************************************************************** * Display extended stats, read from /proc/{diskstats,partitions} or /sys. * * IN: * @curr Index in array for current sample statistics. * @itv Interval of time. * @fctr Conversion factor. * @shi Structures describing the devices and partitions. * @ioi Current sample statistics. * @ioj Previous sample statistics. *************************************************************************** */ void write_ext_stat(int curr, unsigned long long itv, int fctr, struct io_hdr_stats *shi, struct io_stats *ioi, struct io_stats *ioj)
That looks like what we want. Looking at the code, we can see pretty clearly where the iostats output is printed when displaying extended stats:
/* DEV rrq/s wrq/s r/s w/s rsec wsec rqsz qusz await svctm %util */ printf("%-13s %8.2f %8.2f %7.2f %7.2f %8.2f %8.2f %8.2f %8.2f %7.2f %6.2f %6.2f\n", devname, S_VALUE(ioj->rd_merges, ioi->rd_merges, itv), S_VALUE(ioj->wr_merges, ioi->wr_merges, itv), S_VALUE(ioj->rd_ios, ioi->rd_ios, itv), S_VALUE(ioj->wr_ios, ioi->wr_ios, itv), ll_s_value(ioj->rd_sectors, ioi->rd_sectors, itv) / fctr, ll_s_value(ioj->wr_sectors, ioi->wr_sectors, itv) / fctr, xds.arqsz, S_VALUE(ioj->rq_ticks, ioi->rq_ticks, itv) / 1000.0, xds.await, /* The ticks output is biased to output 1000 ticks per second */ xds.svctm, /* Again: Ticks in milliseconds */ xds.util / 10.0);
The part we care about is the await part, which is the third column from the right. As above, we can see that what's printed for the await column is "xds.await". Looking a bit further up the function, we can see that xds is likely set here:
compute_ext_disk_stats(&sdc, &sdp, itv, &xds);
The iostat.c file doesn't contain this function, but a quick grep over the source directory shows that the definition is present in common.c:
/* *************************************************************************** * Compute "extended" device statistics (service time, etc.). * * IN: * @sdc Structure with current device statistics. * @sdp Structure with previous device statistics. * @itv Interval of time in jiffies. * * OUT: * @xds Structure with extended statistics. *************************************************************************** */ void compute_ext_disk_stats(struct stats_disk *sdc, struct stats_disk *sdp, unsigned long long itv, struct ext_disk_stats *xds)
Within this function, we can see that await is set based on some arithmetic using various variables, like this:
/* * Kernel gives ticks already in milliseconds for all platforms * => no need for further scaling. */ xds->await = (sdc->nr_ios - sdp->nr_ios) ? ((sdc->rd_ticks - sdp->rd_ticks) + (sdc->wr_ticks - sdp->wr_ticks)) / ((double) (sdc->nr_ios - sdp->nr_ios)) : 0.0;
From the above, it's important for us to know a few pieces of information:
What is nr_ios?
What is rd_ticks?
What is wr_ticks?
What is sdc?
What is sdp?
What is the ? operator?
The sdc and sdp questions can be answered by the comment above the compute_ext_disk_stats function:
* @sdc Structure with current device statistics. * @sdp Structure with previous device statistics.
The next question - what nr_ios actually is - can be obtained back in the write_ext_stat function. There, we have some lines of code which look like this:
sdc.nr_ios = ioi->rd_ios + ioi->wr_ios; sdp.nr_ios = ioj->rd_ios + ioj->wr_ios;
It appears then that nr_ios is the sum of rd_ios and wr_ios.
The remainder of the information can be obtained back in iostat.c. We know from the man page that extended disk stats rely on the /proc/diskstats file. A quick search for this shows a function called read_diskstats_stat:
/* *************************************************************************** * Read stats from /proc/diskstats. * * IN: * @curr Index in array for current sample statistics. *************************************************************************** */ void read_diskstats_stat(int curr)
This function will parse the contents of /proc/diskstats. The important part of this function:
/* major minor name rio rmerge rsect ruse wio wmerge wsect wuse running use aveq */ i = sscanf(line, "%u %u %s %lu %lu %llu %u %lu %lu %llu %u %u %u %u", &major, &minor, dev_name, &rd_ios, &rd_merges_or_rd_sec, &rd_sec_or_wr_ios, &rd_ticks_or_wr_sec, &wr_ios, &wr_merges, &wr_sec, &wr_ticks, &ios_pgr, &tot_ticks, &rq_ticks); ... sdev.rd_ticks = rd_ticks_or_wr_sec;
Documentation on sscanf and % format specifiers is here:
https://linux.die.net/man/3/sscanf https://www.le.ac.uk/users/rjm1/cotter/page_30.htm
From the sscanf man page:
The scanf() family of functions scans input according to format as described below. This format may contain conversion specifications; the results from such conversions, if any, are stored in the locations pointed to by the pointer arguments that follow format.
So the first field of each line is an int and will be read into &major, the second field of each line is an int and will be read into &minor, the third field of each line is a char array and will be read into dev_name, and so on.
From the above, now we know that rd_ios, wr_ios, rd_ticks and wr_ticks directly correlate to fields in /proc/diskstats. We can get a plain English description of what each field in the /proc/diskstats file means by reading the kernel documentation, here: https://www.kernel.org/doc/Documentation/ABI/testing/procfs-diskstats
From cross referencing the variable names above against the fields in the kernel documentation, we can get a plaintext description of what these variables actually are.
rd_ios = field 4. In English, "reads completed successfully"
rd_ticks = field 7. In English, "time spent reading (ms)"
wr_ios = field 8. In English, "writes completed"
wr_ticks = field 11. In English, "time spent writing (ms)"
Now we know all of the information we need to work out what await actually is. A summary:
sdc - Structure with current device statistics
sdp - Structure with previous device statistics
nr_ios - The sum of reads and writes completed successfully (fields 4 and 8 in /proc/diskstats)
rd_ticks - Time spent reading in ms (field 7 in /proc/diskstats)
wr_ticks - Time spent writing in ms (field 11 in /proc/diskstats)
Back to the await calculation, we can see that it's set to this:
xds->await = (sdc->nr_ios - sdp->nr_ios) ? ((sdc->rd_ticks - sdp->rd_ticks) + (sdc->wr_ticks - sdp->wr_ticks)) / ((double) (sdc->nr_ios - sdp->nr_ios)) : 0.0;
One last bit of key information: in C, what you're looking at here with the "?" is a conditional operator (sometimes called a ternary operator). It evaluates to its second argument if the first argument evaluates to true. It evaluates to its third argument (the bit after the :) if the first argument evaluates to false. In English, if there is no difference between the current count for number of I/Os and the previous counter it means there was no disk activity, so set await to 0.0. Otherwise, set await to:
((sdc->rd_ticks - sdp->rd_ticks) + (sdc->wr_ticks - sdp->wr_ticks)) / ((double) (sdc->nr_ios - sdp->nr_ios))
Rewriting that in English:
await = (The difference between the time spent reading in ms plus the time spent writing in milliseconds), divided by (the number of writes completed plus the number of reads completed)
Therefore:
await is the time performing read/write operations divided by the number of read/write operations performed.
PART 4: Conclusion
We know that in the 1000ms between iostat runs, there can not possibly be more than 1000ms worth of reading/writing done. If iostat is sampling 1 second apart, it's impossible for there to be a 15,000ms await. iostat is returning incorrect results. The customer should upgrade to a later version of sysstat, and if the bug persists then we should try and reproduce it, and then open a support case with Red Hat to get it fixed.
0 notes
Text
The best free ebooks resources

What are free ebooks resources?
These resources will provide you a huge online-ebooks. Furthermore, they are completely free! In addition, these resources contain many topics from business to technology ...so on. Besides, some of them are support view on mobile mode and easy to get pdf file.
Where are they store?
You can find these resources below which their full description. Hence, they are very useful for doing research and study and of course they are free for all access, so you can download as many as you want. We list out these to many different categories below for easy to find. Libraries Gutenberg: Project Gutenberg was the first to supply free ebooks, and today they have almost 30,000 free titles in stock. Free-eBooks.net: Besides browsing topics such as biography, fan fiction, games, history, or tutorials, you can submit your own ebook, too. ManyBooks.net: You can conduct an advanced search, type in a title or author, browse categories or select books by language, from Finnish to Bulgarian to Catalan to Swedish. DailyLit: Get free downloads sent to your email by RSS feed. iBiblio: Find archives, ebooks, tutorials, language books, and more from iBiblio. Authorama: This public domain book site has a wide variety of ebooks for free, by Lewis Carroll, Emerson, Kafka, and more. Bartleby: While Bartleby charges for some titles, it has a free ebook store here. bibliomania: You will find over 2,000 classic texts from bibliomania, plus study guides, reference material and more. Baen Free Library: You can download ebooks for HTML, RTF, Microsoft Reader and for Palm, Psion, and Window CE. eReader.com: eReader.com has many classic lit selections for free. Read Print Library: These novels and poems are all free. ebook Directory: From children's books to IT books to literature to reference, you'll find lots of free titles and book packages here. Planet PDF: Planet PDF has made available classic titles like Anna Karenina and Frankenstein for free. Get Free Ebooks: This website has free ebooks in categories from writing to environment to fiction to business, plus features and reviews. Globusz: There are no limits on the number of free books you can download on this online publishing site. eBookLobby: You'll find lost of self-help, hobby and reference books here, plus children's fiction and more. Bookyards: This online "library to the world" has over 17,000 ebooks, plus links to other digital libraries. The Online Books Page: You'll be able to access over 35,000 free ebooks from this site, powered by the University of Pennsylvania. Starry.com: These novels and anthologies were last updated in 2006, but you'll still find an interesting selection of online and virtual novels. eBook Readers Getting reviews and product information for all kinds of ebook readers, including the Kindle, you will have a full reviews before making decisions to purchase something. E-book Reader Matrix: This wiki makes it easy to compare ebook reader sizes, battery life, supported formats, and other qualifications. Amazon Kindle: Learn about, shop, and discover titles for the Kindle here. Abacci eBooks: All the books here are for Microsoft Reader. eBook Reader Review: TopTenReviews lists reader reviews from 2009. List of e-book readers: Learn about all of the different ebook readers from Wikipedia. E-book readers at a glance: This guide reviews and compares the new, cool readers. Free iPhone ebook readers head-to-head: Reality Distortion ranks iPhone ebook readers. About eBooks These links will connect you to ebook news, new title releases, and e-reader information. In addition, these resources support mobile views. TeleRead: This blog shares news stories about ebooks and digital libraries. MobileRead Forums: Learn about new ebook releases, clubs, and readers. E-book News: Technology Today has made room for a whole section on ebook news. Ebook2u.com: Get the latest headlines about readers, troubleshooting, titles, and more. The eBook coach: Learn how to write a successful ebook. Audio and Mobile Getting ebooks on your iPhone, iPod, BlackBerry, Palm, or other mobile device, you have many options to expand your knowledge on mobile devices. Feedbooks: You can download books for any mobile device here. Books in My Phone: Read ebooks on a java-enabled phone when you download them here. You can also manage a reading list. Barnes & Noble eBooks: Get NYT titles, new releases and more for your iPhone, BlackBerry, or computer. MemoWare: Get literature, poetry, and reference books for your PDA. Audible.com: Here you can download books to your iPod or mp3 player. iTunes: iTunes has audiobooks for iPhones and iPods. LibriVox: Get free audio book files on this site, or volunteer to record your narration for other books. eReader.comMobile: Get the mobile-friendly version of eReader.com here. Business and Education Turning to these ebook lists and resources for help with classes and your career is so very important for your personal future plan. Moreover, they are huge and well-organisation. Open Book Project: Students and teachers will find quality free textbooks and materials here. Digital Book Index: This site has over 140,000 titles, including textbooks and a pending American Studies collection. Classical Authors Directory: Get lesson plans, audio files, ebooks, and more from authors like Washington Irving, Benjamin Franklin and Homer. The Literature Network: Find classics, from Balzac to Austen to Shakespeare, plus educational resources to go along with the plays, short stories, and novels. OnlineFreeEbooks.net: All kinds of business, hobby, education textbooks, and self-teaching books are available for free on this site. Free Ebooks and Software: Learn how to do your own taxes and more from the books here. eLibrary Business Ebooks: Get emarketing, how-to, and other business ebooks here. Free Business eBooks: This guide has links to all kinds of free business ebooks. Data-Sheet: Data-Sheet finds ebook pdfs. Pdfgeni.com: Type into the search box the type of book you want to read, such as business education or vampire fiction. Ebook Search Engine: Simply type in your search and choose to have results displayed as PDFs or Word documents. Ebook Engine: This engine brings up free ebooks. eBook Search Queen: You can search ebooks by country here. ebookse.com: Browse by category or type your search into the box to bring up your query. Addebook: Free Ebook Search Engine: This tool is Google's ebook search engine. Boocu: Boocu can pull up thousands of ebooks and digital resources. Twitter Keeping up with ebook news, new titles, e-readers, and more by following these Twitter feeds is very well. The social channel is so very important to improve your knowledge. @AnEbookReader: Get tech reviews, accessories news, and more for ereaders and ebooks. LibreDigital: This company helps people find what they want to read and watch, on any medium. @e_reading: This feed comments on Kindle news and more. @RogerSPress: Roger publishes ebooks and has been reading them for 10 years already. @DigiBookWorld: Read about the latest trends in digital publishing. @ebooksstore: Follow @ebooksstore for interesting ebook news and releases. @ebookvine: This feed is all about Kindle. @vooktv: Now you can watch books on high-quality video online. @ebooklibrary: This is a feed for anyone who wants to learn more about free ebooks. @ericrumsey: Eric is a librarian who loves ebooks, his iPhone, and the Internet. @namenick: Nick Name is an ebook addict and mobile fiction writer. @KindleZen: Get the latest in Kindle news and hacks. Tech eBooks Get programming, design, and other tech assistance when you head to these ebook resources. FreeComputerBooks.com: Find magazines and IT books for reference and general interest. OnlineComputerBooks.com: Find free computer ebooks on networking, MySQL, Python, PHP, C++, and more. KnowFree.net: KnowFree has mostly tech books for download, plus some business titles. FreeTechBooks.com: This site has downloads in categories such as artificial intelligence, functional programming, and parallel computing. Tech Books for Free: From the web to computer programming to science, you'll find all sorts of tech ebooks here. Poetry Find poetry ebooks and collections here. everypoet.com: Read classic poetry on this site. PoemHunter.com: Download poems in PDF format here. Poetry: You'll find poetry ebooks for download on this site. Kids Share these interactive ebook resources with young readers. International Children's Digital Library: The ICDL is a colorful site devoted to children's ebooks. ebook88: On this site, there's a Christmas Bookshelf, and plenty of other kids' ebook links. Children's Storybooks Online: Find kids' storybooks, home schooling materials, and more. Tumble Books: This Tumble BookLibrary features fun, animated, talking picture books. Raz-Kids.com: This is another interactive kids' book site that helps kids learn to read. Children's Books Online: the Rosetta Project, Inc.: Here you'll find loads of books and translations for kids. Read.gov: From children's classics to in-progress digital books, Read.gov has excellent ebook resources. Storyline Online: The Screen Actors Guild Foundation presents Storyline Online with streaming videos of actors reading children's books. Miscellaneous From social networking and ebooks to bundles of books, turn here. Scribd: This ebook finder and social network shares what people are currently reading, and lets you upload your own book. Diesel: Diesel has 500,000 ebook store downloads, including custom bundles, mobile downloads, and some free titles. eBooks.com: Get NYT bestsellers for $9.99 each, plus all kinds of academic ebooks, non-fiction, and more.
Final Word
Phew, they are a lot and free. Therefore, they are important and necessary. You can read carefully and find exactly what you want. On the other hand, I will add more content for this topic later, so you can check the updated posts. I hope you enjoy this post and find something is useful for you. Read the full article
0 notes