#create table in apache hive
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Need to move a relational database application to Hadoop? This comprehensive guide introduces you to Apache Hive, Hadoop’s data warehouse infrastructure. You’ll quickly learn how to use Hive’s SQL dialect—HiveQL—to summarize, query, and analyze large datasets stored in Hadoop’s distributed filesystem.This example-driven guide shows you how to set up and configure Hive in your environment, provides a detailed overview of Hadoop and MapReduce, and demonstrates how Hive works within the Hadoop ecosystem. You’ll also find real-world case studies that describe how companies have used Hive to solve unique problems involving petabytes of data.Use Hive to create, alter, and drop databases, tables, views, functions, and indexesCustomize data formats and storage options, from files to external databasesLoad and extract data from tables—and use queries, grouping, filtering, joining, and other conventional query methodsGain best practices for creating user defined functions (UDFs)Learn Hive patterns you should use and anti-patterns you should avoidIntegrate Hive with other data processing programsUse storage handlers for NoSQL databases and other datastoresLearn the pros and cons of running Hive on Amazon’s Elastic MapReduce [ad_2]
0 notes
Text
8 Tools You Will Learn in Data Analytics Courses
Data analytics is one of the fastest-growing fields today, with organizations across industries relying on data-driven insights to make informed decisions. If you're considering a career in data analytics, enrolling in a course will not only equip you with the necessary theoretical knowledge but also provide you with hands-on experience using industry-standard tools. In this blog, we will discuss 8 essential tools you'll learn in a data analytics course that will empower you to unlock the full potential of data and set you on a path to success.
1. Microsoft Excel
Microsoft Excel remains the foundational tool for anyone in data analytics. Although it is often considered basic, Excel has powerful capabilities such as pivot tables, advanced formulas, and data visualization options. In a data analytics course, you'll learn to use Excel to clean, analyze, and visualize data, making it indispensable for entry-level analytics jobs and professionals alike.
2. SQL (Structured Query Language)
SQL is the language used to communicate with databases. It's an essential skill for data analysts as it helps you query large datasets efficiently. With SQL, you can extract, filter, and manipulate data from relational databases, enabling you to draw meaningful insights from raw data. Data analytics courses will teach you the basics of SQL, as well as advanced concepts like joins, subqueries, and aggregation.
3. Tableau
Data visualization is a crucial part of data analysis, and Tableau is one of the most popular tools used to create interactive and visually appealing dashboards. Learning Tableau in your data analytics course will enable you to translate complex data into easy-to-understand visualizations, helping stakeholders make data-driven decisions. It supports drag-and-drop functionality, making it beginner-friendly while offering advanced capabilities for experienced users.
4. Python for Data Analytics
Python is a powerful programming language widely used in data analytics due to its simplicity and versatility. In a data analytics course, you'll learn how to use Python libraries such as Pandas, NumPy, and Matplotlib to clean, analyze, and visualize data. Python’s flexibility makes it a popular choice for working with large datasets, automating data processes, and performing complex statistical analyses.
5. R Programming
R is another programming language tailored for data analysis. It is especially powerful for statistical analysis and data visualization. With R, you can conduct exploratory data analysis (EDA), apply machine learning models, and generate high-quality graphs and charts. A data analytics course will introduce you to R's extensive libraries, such as ggplot2 and dplyr, to work with data efficiently and effectively.
6. Power BI
Power BI is a business analytics tool developed by Microsoft, similar to Tableau. It allows you to transform raw data into interactive visual reports and dashboards. In a data analytics course, you’ll learn to connect Power BI to various data sources, manipulate data, and create insightful reports. Power BI’s integration with other Microsoft products makes it an excellent choice for businesses that rely heavily on Microsoft tools.
7. Google Analytics
For anyone interested in digital marketing analytics, Google Analytics is a must-learn tool. It provides insights into website traffic, user behavior, and performance metrics, helping businesses optimize their online presence. Data analytics courses often cover Google Analytics to help you analyze and interpret website data, track goals, and make data-driven decisions to improve website performance.
8. Hadoop
Hadoop is an open-source framework used for storing and processing large datasets across clusters of computers. It is especially beneficial when dealing with big data. A data analytics course will introduce you to the basics of Hadoop and how it integrates with other tools like Apache Spark and Hive. Learning Hadoop prepares you for handling massive datasets and performing distributed computing, which is becoming increasingly important in the data analytics field.
Why Learn These Tools?
By mastering these 8 tools, you'll be well-equipped to handle real-world data analytics challenges, whether it’s working with small datasets in Excel or processing big data with Hadoop. These tools are widely used in industries such as finance, healthcare, e-commerce, and marketing, making them crucial for any data analytics professional. Additionally, having proficiency in these tools will significantly enhance your career prospects, as they are in high demand across organizations.
Explore More with These YouTube Sessions
Want to deepen your understanding of these tools and their applications in data analytics? Check out these insightful YouTube sessions that delve into the practical aspects of data analytics tools:
Data Analytics Tools Explained
Understanding SQL in Data Analytics
Introduction to Tableau for Data Visualization
Mastering Python for Data Analytics
These sessions offer practical tips and examples to help you get hands-on experience with these tools, enhancing your learning journey in data analytics.
Conclusion
Data analytics is a rewarding career, and mastering the right tools is essential to success in the field. Whether you're just starting or looking to expand your skills, these 8 tools form the backbone of data analytics. Enroll in a data analytics course today, start learning these tools, and open the door to exciting career opportunities in the world of data!
0 notes
Text
Using Amazon Data Firehose For Iceberg Table Replication

Amazon Data Firehose
Dependable real-time stream loading into analytics services, data lakes, and warehouses.
Capturing, transforming, and loading streaming data is simple. With a few clicks, you can create a delivery stream, choose your destination, and begin streaming data in real time.
Provide and scale network, memory, and processing resources automatically without constant management.
Without creating your own processing pipelines, you may dynamically segment streaming data and convert raw streaming data into formats like Apache Parquet.
How it operates
The simplest method for obtaining, transforming, and sending data streams to analytics services, data lakes, and data warehouses in a matter of seconds is offered by Amazon Data Firehose. Setting up a stream with a source, destination, and necessary modifications is necessary in order to use Amazon Data Firehose. The stream is continuously processed by Amazon Data Firehose, which scales automatically according to the volume of data available and provides it in a matter of seconds.
Source
Choose your data stream’s source, such as a stream in Kinesis Data Streams, a topic in Amazon Managed Streaming for Kafka (MSK), or write data using the Firehose Direct PUT API. You can build up a stream from sources like Amazon CloudWatch Logs, AWS WAF web ACL logs, AWS Network Firewall Logs, Amazon SNS, or AWS IoT because Amazon Data Firehose is connected into more than 20 AWS services.
Data Transformation (optional)
Choose whether you wish to decompress the data, execute custom data transformations using your own AWS Lambda function, convert your data stream into formats like Parquet or ORC, or dynamically partition input records based on attributes to send into separate places.
The destination
Choose a destination for your stream, such as Splunk, Snowflake, Amazon Redshift, Amazon OpenSearch Service, Amazon S3, or a custom HTTP endpoint.
Use cases
Flow into warehouses and data lakes
Without creating processing pipelines, stream data into Amazon S3 and transform it into the formats needed for analysis.
Increase security
Use supported Security Information and Event Management (SIEM) solutions to keep an eye on network security in real time and generate warnings when possible threats materialize.
Create applications for ML streaming
To evaluate data and forecast inference endpoints as streams go to their destination, enhance your data streams with machine learning (ML) models.
Use Amazon Data Firehose to replicate database updates to Apache Iceberg tables (in preview)
A new feature in Amazon Data Firehose that records modifications made to databases like PostgreSQL and MySQL and replicates the changes to Apache Iceberg tables on Amazon Simple Storage Service (Amazon S3) is being made available in preview today.
An excellent open-source table format for large data analytics is Apache Iceberg. Open-source analytics engines like Apache Spark, Apache Flink, Trino, Apache Hive, and Apache Impala can operate with the same data simultaneously with Apache Iceberg, which also adds the simplicity and dependability of SQL tables to S3 data lakes.
This new feature offers a straightforward, end-to-end way to stream database updates without affecting database applications’ transaction performance. To transmit change data capture (CDC) updates from your database, you can quickly set up a Data Firehose stream. Data from various databases can now be readily replicated into Iceberg tables on Amazon S3, allowing you to access current data for machine learning (ML) and large-scale analytics applications.
Typical Enterprise clients of Amazon Web Services (AWS) utilize hundreds of databases for transactional applications. They wish to record database changes, such as the addition, modification, or deletion of records in a table, and send the updates to their data warehouse or Amazon S3 data lake in open source table formats like Apache Iceberg so that they can do large-scale analytics and machine learning on the most recent data.
Many clients create extract, transform, and load (ETL) processes to read data from databases on a regular basis in order to accomplish this. However, batch tasks can cause many hours of delay before data is ready for analytics, and ETL readers affect database transaction speed. Customers seek the option to stream database changes in order to lessen the impact on database transaction performance. A change data capture (CDC) stream is the name given to this stream.
Installing and configuring several open-source components is necessary for the initial setup and testing of such systems. Days or weeks may pass. The operational overhead is increased by the engineers’ need to validate and implement open source updates, monitor and manage clusters after setup.
CDC streams from databases can now be continuously replicated to Apache Iceberg tables on Amazon S3 using Amazon Data Firehose’s new data streaming feature. A Data Firehose stream is created by defining its source and destination. An initial data snapshot and all ensuing modifications made to the chosen database tables are captured and continuously replicated by Data Firehose as a data stream. Data Firehose minimizes the impact on database transaction performance by using the database replication log to obtain CDC streams.
AWS Data Firehose automatically splits the data and keeps records until they are sent to their destination, regardless of how frequently the number of database updates changes. Cluster management and fine-tuning, as well as capacity provisioning, are optional. As part of the initial Data Firehose stream creation, Data Firehose can automatically generate Apache Iceberg tables with the same schema as the database tables in addition to the data itself. It can also dynamically develop the target schema, adding additional columns, for example, in response to changes in the source schema.
You don’t need to use open source components, install software upgrades, or pay for overhead because Data Firehose is a fully managed service.
Amazon Data Firehose offers a straightforward, scalable, end-to-end managed solution for delivering CDC streams into your data lake or data warehouse, where you can execute extensive analysis and machine learning applications. It does this by continuously replicating database updates to Apache Iceberg tables in Amazon S3.
Things to be aware of
Here are some other things to be aware of.
The following databases on Amazon RDS and self-managed PostgreSQL and MySQL databases on Amazon EC2 are supported by this new feature:
Amazon Aurora PostgreSQL-Compatible Edition with Amazon RDS for PostgreSQL
Amazon Aurora MySQL-Compatible Edition with Amazon RDS for MySQL
Throughout the trial period and beyond general availability, the team will keep adding support for other databases. They informed me that support for MongoDB, Oracle, and SQL Server databases is already in the works.
Data Firehose connects to databases in your Amazon Virtual Private Cloud (Amazon VPC) via AWS PrivateLink.
You have two options when configuring an Amazon Data Firehose delivery stream: you may define a class of tables and columns using wildcards, or you can specify particular tables and columns. When using wildcards, Data Firehose will automatically construct new tables and columns in the destination if they match the wildcard and are added to the database after the Data Firehose stream is created.
Accessibility
With the exception of the Asia Pacific (Malaysia), AWS GovCloud (US), and China regions, all AWS regions now offer the new data streaming feature.
Amazon Data Firehose pricing
At the start of the preview, there are no fees for your use. In the future, the price will be determined by your actual usage, such as the number of bytes read and supplied. There are no upfront costs or obligations. To learn more, be sure to read the pricing page.
Read more on Govindhtech.com
#AmazonDataFirehose#IcebergTable#Apache#AmazonData#AmazonS3#machinelearning#ML#Cloudcomputing#AWSservices#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
1 note
·
View note
Text
"Apache Spark: The Leading Big Data Platform with Fast, Flexible, Developer-Friendly Features Used by Major Tech Giants and Government Agencies Worldwide."
What is Apache Spark? The Big Data Platform that Crushed Hadoop

Apache Spark is a powerful data processing framework designed for large-scale SQL, batch processing, stream processing, and machine learning tasks. With its fast, flexible, and developer-friendly nature, Spark has become the leading platform in the world of big data. In this article, we will explore the key features and real-world applications of Apache Spark, as well as its significance in the digital age.
Apache Spark defined
Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets. It can distribute data processing tasks across multiple computers, either on its own or in conjunction with other distributed computing tools. This capability is crucial in the realm of big data and machine learning, where massive computing power is necessary to analyze and process vast amounts of data. Spark eases the programming burden of these tasks by offering an easy-to-use API that abstracts away much of the complexities of distributed computing and big data processing.
What is Spark in big data
In the context of big data, the term "big data" refers to the rapid growth of various types of data - structured data in database tables, unstructured data in business documents and emails, semi-structured data in system log files and web pages, and more. Unlike traditional analytics, which focused solely on structured data within data warehouses, modern analytics encompasses insights derived from diverse data sources and revolves around the concept of a data lake. Apache Spark was specifically designed to address the challenges posed by this new paradigm.
Originally developed at U.C. Berkeley in 2009, Apache Spark has become a prominent distributed processing framework for big data. Flexibility lies at the core of Spark's appeal, as it can be deployed in various ways and supports multiple programming languages such as Java, Scala, Python, and R. Furthermore, Spark provides extensive support for SQL, streaming data, machine learning, and graph processing. Its widespread adoption by major companies and organizations, including Apple, IBM, and Microsoft, highlights its significance in the big data landscape.
Spark RDD
Resilient Distributed Dataset (RDD) forms the foundation of Apache Spark. An RDD is an immutable collection of objects that can be split across a computing cluster. Spark performs operations on RDDs in a parallel batch process, enabling fast and scalable parallel processing. The RDD concept allows Spark to transform user's data processing commands into a Directed Acyclic Graph (DAG), which serves as the scheduling layer determining the tasks, nodes, and sequence of execution.
Apache Spark can create RDDs from various data sources, including text files, SQL databases, NoSQL stores like Cassandra and MongoDB, Amazon S3 buckets, and more. Moreover, Spark's core API provides built-in support for joining data sets, filtering, sampling, and aggregation, offering developers powerful data manipulation capabilities.
Spark SQL
Spark SQL has emerged as a vital component of the Apache Spark project, providing a high-level API for processing structured data. Spark SQL adopts a dataframe approach inspired by R and Python's Pandas library, making it accessible to both developers and analysts. Alongside standard SQL support, Spark SQL offers a wide range of data access methods, including JSON, HDFS, Apache Hive, JDBC, Apache ORC, and Apache Parquet. Additional data stores, such as Apache Cassandra and MongoDB, can be integrated using separate connectors from the Spark Packages ecosystem.
Spark SQL utilizes Catalyst, Spark's query optimizer, to optimize data locality and computation. Since Spark 2.x, Spark SQL's dataframe and dataset interfaces have become the recommended approach for development, promoting a more efficient and type-safe method for data processing. While the RDD interface remains available, it is typically used when lower-level control or specialized performance optimizations are required.
Spark MLlib and MLflow
Apache Spark includes libraries for machine learning and graph analysis at scale. MLlib offers a framework for building machine learning pipelines, facilitating the implementation of feature extraction, selection, and transformations on structured datasets. The library also features distributed implementations of clustering and classification algorithms, such as k-means clustering and random forests.
MLflow, although not an official part of Apache Spark, is an open-source platform for managing the machine learning lifecycle. The integration of MLflow with Apache Spark enables features such as experiment tracking, model registries, packaging, and user-defined functions (UDFs) for easy inference at scale.
Structured Streaming
Structured Streaming provides a high-level API for creating infinite streaming dataframes and datasets within Apache Spark. It supersedes the legacy Spark Streaming component, addressing pain points encountered by developers in event-time aggregations and late message delivery. With Structured Streaming, all queries go through Spark's Catalyst query optimizer and can be run interactively, allowing users to perform SQL queries against live streaming data. The API also supports watermarking, windowing techniques, and the ability to treat streams as tables and vice versa.
Delta Lake
Delta Lake is a separate project from Apache Spark but has become essential in the Spark ecosystem. Delta Lake augments data lakes with features such as ACID transactions, unified querying semantics for batch and stream processing, schema enforcement, full data audit history, and scalability for exabytes of data. Its adoption has contributed to the rise of the Lakehouse Architecture, eliminating the need for a separate data warehouse for business intelligence purposes.
Pandas API on Spark
The Pandas library is widely used for data manipulation and analysis in Python. Apache Spark 3.2 introduced a new API that allows a significant portion of the Pandas API to be used transparently with Spark. This compatibility enables data scientists to leverage Spark's distributed execution capabilities while benefiting from the familiar Pandas interface. Approximately 80% of the Pandas API is currently covered, with ongoing efforts to increase coverage in future releases.
Running Apache Spark
An Apache Spark application consists of two main components: a driver and executors. The driver converts the user's code into tasks that can be distributed across worker nodes, while the executors run these tasks on the worker nodes. A cluster manager mediates communication between the driver and executors. Apache Spark can run in a stand-alone cluster mode, but is more commonly used with resource or cluster management systems such as Hadoop YARN or Kubernetes. Managed solutions for Apache Spark are also available on major cloud providers, including Amazon EMR, Azure HDInsight, and Google Cloud Dataproc.
Databricks Lakehouse Platform
Databricks, the company behind Apache Spark, offers a managed cloud service that provides Apache Spark clusters, streaming support, integrated notebook development, and optimized I/O performance. The Databricks Lakehouse Platform, available on multiple cloud providers, has become the de facto way many users interact with Apache Spark.
Apache Spark Tutorials
If you're interested in learning Apache Spark, we recommend starting with the Databricks learning portal, which offers a comprehensive introduction to Apache Spark (with a slight bias towards the Databricks Platform). For a more in-depth exploration of Apache Spark's features, the Spark Workshop is a great resource. Additionally, books such as "Spark: The Definitive Guide" and "High-Performance Spark" provide detailed insights into Apache Spark's capabilities and best practices for data processing at scale.
Conclusion
Apache Spark has revolutionized the way large-scale data processing and analytics are performed. With its fast and developer-friendly nature, Spark has surpassed its predecessor, Hadoop, and become the leading big data platform. Its extensive features, including Spark SQL, MLlib, Structured Streaming, and Delta Lake, make it a powerful tool for processing complex data sets and building machine learning models. Whether deployed in a stand-alone cluster or as part of a managed cloud service like Databricks, Apache Spark offers unparalleled scalability and performance. As companies increasingly rely on big data for decision-making, mastering Apache Spark is essential for businesses seeking to leverage their data assets effectively.
Sponsored by RoamNook
This article was brought to you by RoamNook, an innovative technology company specializing in IT consultation, custom software development, and digital marketing. RoamNook's main goal is to fuel digital growth by providing cutting-edge solutions for businesses. Whether you need assistance with data processing, machine learning, or building scalable applications, RoamNook has the expertise to drive your digital transformation. Visit https://www.roamnook.com to learn more about how RoamNook can help your organization thrive in the digital age.
0 notes
Text
The Ultimate Guide to Becoming an Azure Data Engineer

The Azure Data Engineer plays a critical role in today's data-driven business environment, where the amount of data produced is constantly increasing. These professionals are responsible for creating, managing, and optimizing the complex data infrastructure that organizations rely on. To embark on this career path successfully, you'll need to acquire a diverse set of skills. In this comprehensive guide, we'll provide you with an extensive roadmap to becoming an Azure Data Engineer.
1. Cloud Computing
Understanding cloud computing concepts is the first step on your journey to becoming an Azure Data Engineer. Start by exploring the definition of cloud computing, its advantages, and disadvantages. Delve into Azure's cloud computing services and grasp the importance of securing data in the cloud.
2. Programming Skills
To build efficient data processing pipelines and handle large datasets, you must acquire programming skills. While Python is highly recommended, you can also consider languages like Scala or Java. Here's what you should focus on:
Basic Python Skills: Begin with the basics, including Python's syntax, data types, loops, conditionals, and functions.
NumPy and Pandas: Explore NumPy for numerical computing and Pandas for data manipulation and analysis with tabular data.
Python Libraries for ETL and Data Analysis: Understand tools like Apache Airflow, PySpark, and SQLAlchemy for ETL pipelines and data analysis tasks.
3. Data Warehousing
Data warehousing is a cornerstone of data engineering. You should have a strong grasp of concepts like star and snowflake schemas, data loading into warehouses, partition management, and query optimization.
4. Data Modeling
Data modeling is the process of designing logical and physical data models for systems. To excel in this area:
Conceptual Modeling: Learn about entity-relationship diagrams and data dictionaries.
Logical Modeling: Explore concepts like normalization, denormalization, and object-oriented data modeling.
Physical Modeling: Understand how to implement data models in database management systems, including indexing and partitioning.
5. SQL Mastery
As an Azure Data Engineer, you'll work extensively with large datasets, necessitating a deep understanding of SQL.
SQL Basics: Start with an introduction to SQL, its uses, basic syntax, creating tables, and inserting and updating data.
Advanced SQL Concepts: Dive into advanced topics like joins, subqueries, aggregate functions, and indexing for query optimization.
SQL and Data Modeling: Comprehend data modeling principles, including normalization, indexing, and referential integrity.
6. Big Data Technologies
Familiarity with Big Data technologies is a must for handling and processing massive datasets.
Introduction to Big Data: Understand the definition and characteristics of big data.
Hadoop and Spark: Explore the architectures, components, and features of Hadoop and Spark. Master concepts like HDFS, MapReduce, RDDs, Spark SQL, and Spark Streaming.
Apache Hive: Learn about Hive, its HiveQL language for querying data, and the Hive Metastore.
Data Serialization and Deserialization: Grasp the concept of serialization and deserialization (SerDe) for working with data in Hive.
7. ETL (Extract, Transform, Load)
ETL is at the core of data engineering. You'll need to work with ETL tools like Azure Data Factory and write custom code for data extraction and transformation.
8. Azure Services
Azure offers a multitude of services crucial for Azure Data Engineers.
Azure Data Factory: Create data pipelines and master scheduling and monitoring.
Azure Synapse Analytics: Build data warehouses and marts, and use Synapse Studio for data exploration and analysis.
Azure Databricks: Create Spark clusters for data processing and machine learning, and utilize notebooks for data exploration.
Azure Analysis Services: Develop and deploy analytical models, integrating them with other Azure services.
Azure Stream Analytics: Process real-time data streams effectively.
Azure Data Lake Storage: Learn how to work with data lakes in Azure.
9. Data Analytics and Visualization Tools
Experience with data analytics and visualization tools like Power BI or Tableau is essential for creating engaging dashboards and reports that help stakeholders make data-driven decisions.
10. Interpersonal Skills
Interpersonal skills, including communication, problem-solving, and project management, are equally critical for success as an Azure Data Engineer. Collaboration with stakeholders and effective project management will be central to your role.
Conclusion
In conclusion, becoming an Azure Data Engineer requires a robust foundation in a wide range of skills, including SQL, data modeling, data warehousing, ETL, Azure services, programming, Big Data technologies, and communication skills. By mastering these areas, you'll be well-equipped to navigate the evolving data engineering landscape and contribute significantly to your organization's data-driven success.
Ready to Begin Your Journey as a Data Engineer?
If you're eager to dive into the world of data engineering and become a proficient Azure Data Engineer, there's no better time to start than now. To accelerate your learning and gain hands-on experience with the latest tools and technologies, we recommend enrolling in courses at Datavalley.
Why choose Datavalley?
At Datavalley, we are committed to equipping aspiring data engineers with the skills and knowledge needed to excel in this dynamic field. Our courses are designed by industry experts and instructors who bring real-world experience to the classroom. Here's what you can expect when you choose Datavalley:
Comprehensive Curriculum: Our courses cover everything from Python, SQL fundamentals to Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, Azure Services for DevOps, and DevOps tools.
Hands-On Learning: Our courses include practical exercises, projects, and labs that allow you to apply what you've learned in a real-world context.
Multiple Experts for Each Course: Modules are taught by multiple experts to provide you with a diverse understanding of the subject matter as well as the insights and industrial experiences that they have gained.
Flexible Learning Options: We provide flexible learning options to learn courses online to accommodate your schedule and preferences.
Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
Certification: Upon completing our courses, you'll receive a certification that validates your skills and can boost your career prospects.
On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with up to 3 months of on-call project support.
The world of data engineering is waiting for talented individuals like you to make an impact. Whether you're looking to kickstart your career or advance in your current role, Datavalley's Data Engineer Masters Program can help you achieve your goals.
#datavalley#dataexperts#data engineering#dataexcellence#data engineering course#online data engineering course#data engineering training
0 notes
Text
Extract Transform Load Python

Extract, Transform, Load (ETL) with Python: Streamlining Data Integration and Analysis
In today's data-driven world, businesses and organizations rely on seamless data integration and analysis to make informed decisions. The Extract, Transform, Load Python (ETL) process plays a crucial role in managing and preparing data for analysis. Python, a versatile programming language, provides a powerful and flexible toolkit for implementing ETL workflows.
The ETL process involves three key stages: extraction, transformation, and loading. Let's delve into each stage and explore how Python can simplify and enhance the ETL process.
Extraction: Extraction involves retrieving data from various sources such as databases, files, APIs, or web scraping. Python offers a wide range of libraries and frameworks that facilitate data extraction. For instance, libraries like Pandas, NumPy, and Requests allow users to extract data from files (such as CSV, Excel, or JSON), connect to databases, or interact with web services.
Python's simplicity and versatility make it easy to implement extraction scripts that gather data from different sources. It provides numerous APIs and connectors that simplify data retrieval, whether it's fetching data from social media platforms, e-commerce websites, or IoT devices.
Transformation: The transformation stage involves cleaning, manipulating, and structuring the extracted data to make it suitable for analysis. Python, with its rich ecosystem of data manipulation libraries, offers a seamless environment for data transformation tasks. Libraries like Pandas, NumPy, and SciPy provide powerful functions and methods for handling data cleaning, filtering, aggregation, and joining.
Python's flexibility allows developers to implement custom transformation logic specific to their data requirements. Whether it's handling missing values, normalizing data, or performing advanced statistical operations, Python provides the necessary tools and libraries to streamline the transformation process.
Additionally, Python's support for machine learning and natural language processing (NLP) allows for more advanced transformations. For example, it can be used to perform sentiment analysis, text classification, or image recognition, enriching the data and providing deeper insights.
Loading: The final stage of the ETL process is loading the transformed data into a target system, such as a database, data warehouse, or visualization tool. Python's extensive support for database connectors, such as SQLAlchemy, allows for seamless integration with various database management systems (DBMS). This enables users to efficiently load data into structured tables or create new ones based on the transformed data.
Python's integration capabilities extend to popular data warehousing solutions like Amazon Redshift, Google BigQuery, or Apache Hive. These connections enable users to load transformed data directly into data warehouses for further analysis and reporting.
Moreover, Python's visualization libraries like Matplotlib, Seaborn, and Plotly provide rich options for visualizing and exploring data before loading it into a target system. This allows users to gain insights and identify any anomalies or patterns in the data during the ETL process itself.
Python's ecosystem also includes tools like Airflow and Luigi, which facilitate workflow management and scheduling. These frameworks allow users to orchestrate complex ETL pipelines, ensuring the smooth execution and monitoring of data integration tasks.
The combination of Python's data manipulation capabilities, database connectivity, and visualization tools makes it a versatile choice for ETL processes. Its readability, ease of use, and extensive community support contribute to its popularity among data professionals and developers alike.
In conclusion, the Extract, Transform, Load (ETL) process is a fundamental component of data integration and analysis. Python's versatility and extensive ecosystem of libraries and tools make it an excellent choice for implementing ETL workflows. From data extraction to transformation and loading, Python provides a seamless environment for handling and preparing data for analysis. By harnessing the power of Python, businesses and organizations can streamline their data integration processes, gain valuable insights, and make informed decisions.
1 note
·
View note
Text
Post 50 | HDPCD | Order Hive query output across multiple reducers
Order Hive query output across multiple reducers
Hello, everyone. Welcome to one more tutorial in the HDPCD certification series.
In the last tutorial, we saw how to enable vectorization in Hive.
In this tutorial, we are going to see how to run a subquery within a Hive query.
Let us begin, then.
The following infographics show the step-by-step process of performing this operation.

Apache Hive: Ordering output across multiple reducers
From the…
View On WordPress
#apache hive#apache hive internal and external table#beginners in hadoop#Big Data#big data certification#big data tutorial#bucketed table in hive#certification#certification preparation#certified#compressed data#create database#create external table in hive#create hive bucketed table#create hive table#create sql database#create table in apache hive#create table in hive#created hive bucketed table#csv to hive#data#data ingestion#data loader#Data Loader and Transformer#data loading#data science#data scientist#Data Sources#Data Transformation#Data Transformation using Accure Momentum
0 notes
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
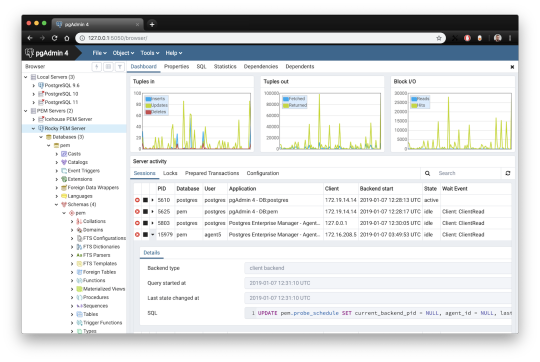
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
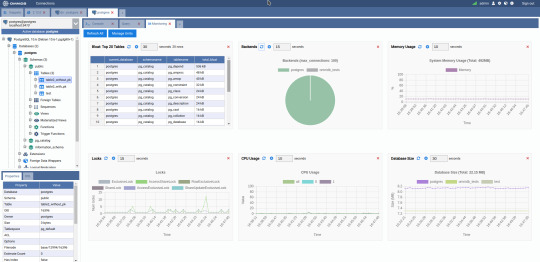
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
Data Disposal - Open Source Java-based Big Data Retention Tool
By Sam Groth, Senior Software Engineer, Verizon Media
Do you have data in Apache Hadoop using Apache HDFS that is made available with Apache Hive? Do you spend too much time manually cleaning old data or maintaining multiple scripts? In this post, we will share why we created and open sourced the Data Disposal tool, as well as, how you can use it.
Data retention is the process of keeping useful data and deleting data that may no longer be proper to store. Why delete data? It could be too old, consume too much space, or be subject to legal retention requirements to purge data within a certain time period of acquisition.
Retention tools generally handle deleting data entities (such as files, partitions, etc.) based on: duration, granularity, or date format.
Duration: The length of time before the current date. For example, 1 week, 1 month, etc.
Granularity: The frequency that the entity is generated. Some entities like a dataset may generate new content every hour and store this in a directory partitioned by date.
Date Format: Data is generally partitioned by a date so the format of the date needs to be used in order to find all relevant entities.
Introducing Data Disposal
We found many of the existing tools we looked at lacked critical features we needed, such as configurable date format for parsing from the directory path or partition of the data and extensible code base for meeting the current, as well as, future requirements. Each tool was also built for retention with a specific system like Apache Hive or Apache HDFS instead of providing a generic tool. This inspired us to create Data Disposal.
The Data Disposal tool currently supports the two main use cases discussed below but the interface is extensible to any other data stores in your use case.
File retention on the Apache HDFS.
Partition retention on Apache Hive tables.
Disposal Process

The basic process for disposal is 3 steps:
Read the provided yaml config files.
Run Apache Hive Disposal for all Hive config entries.
Run Apache HDFS Disposal for all HDFS config entries.
The order of the disposals is significant in that if Apache HDFS disposal ran first, it would be possible for queries to Apache Hive to have missing data partitions.
Key Features
The interface and functionality is coded in Java using Apache HDFS Java API and Apache Hive HCatClient API.
Yaml config provides a clean interface to create and maintain your retention process.
Flexible date formatting using Java's SimpleDateFormat when the date is stored in an Apache HDFS file path or in an Apache Hive partition key.
Flexible granularity using Java's ChronoUnit.
Ability to schedule with your preferred scheduler.
The current use cases all use Screwdriver, which is an open source build platform designed for continuous delivery, but using other schedulers like cron, Apache Oozie, Apache Airflow, or a different scheduler would be fine.
Future Enhancements
We look forward to making the following enhancements:
Retention for other data stores based on your requirements.
Support for file retention when configuring Apache Hive retention on external tables.
Any other requirements you may have.
Contributions are welcome! The Data team located in Champaign, Illinois, is always excited to accept external contributions. Please file an issue to discuss your requirements.
2 notes
·
View notes
Text
Introduction to Spark Course
Software developers that are ready to upgrade their abilities in Big Data must choose to coach in Apache Spark Scala Pune. ETL programmers and data engineers may think about accomplishing this particular practice. This coaching is a good alternative for data professionals and scientists. While this training is chosen by IT professionals, they will get expertise in Spark and Scala. The seasoned business professionals will probably be useful in mastering the technologies through teaching sessions, assignments and lab practices. You will have the ability to score a total of Cloudera Spark evaluation and Hadoop Developer Certification because you register for these training classes. We've experienced professionals from multinational firms who'll clean your doubts. There'll be an increase in your career opportunities as you learn this language. You'll be introduced to Scala and Spark because you pick our Spark courses in Pune. For this reason, you'll be capable of analyzing these languages. As you proceed to another one and complete each module, you'll have the ability to understand the difference between Hadoop Training and Spark. This training has to be helpful to IT professionals to Spark Data aggregation and advancement of performance. By deciding on the training courses, you are going to be prosperous in creating codes. You are able to write spark apps. Substantial data have an impact on the IT company in Pune. Together, together with the processing of real time streaming data the firms are in high contest for the creation of outcomes. Apache Spark seems to be a single technology which accomplishes the requirement with the help of features. Due to that, its own needs are improving in city steadily. There are not any specific eligibility criteria for picking this practice.
The main reason is that the Hadoop system is dependent upon a simple programming model (MapReduce) plus it enables a figuring arrangement that's flexible, flexible, attribute tolerant and fiscally savvy. Here, the principal concern will be to maintain pace in preparing extensive datasets so far as holding time up amongst holding and questions time up to conduct the app. Scala helps to Know the idea of Key-Value set in RDDs, and studying Spark create operations faster, various surgeries of RDD, MapReduce interactive surgeries, fine & coarse update, Spark heap. Working together with RDDs in Spark, to secure more knowledge of the way Spark overcomes the drawbacks of working MapReduce, knowing in-memory MapReduce,interactive surgeries on MapReduce, Spark heap, fine semi coarse-grained upgrade, Spark stack,SparkHadoop YARN, HDFS Revision, YARN Revision, the summary of Spark and the manner it is much better Hadoop, deploying Spark without Hadoop,Spark background , Cloudera distribution. Introducing Scala and setup of Scala for Big Data programs and Apache Spark analytics Spark installation guide,Spark configuration, memory management, executor memory , working together with Spark Shell, the notion of Resilient Distributed Datasets (RDD), learning how to execute operational programming at Spark, the structure of Spark. To Writing and Deploying Spark Software Pattern Matching firstly we will need to Learning about Spark SQL, the circumstance of SQL at Spark for supplying structured information processing, JSON assist in Spark SQL, working with XML info, parquet files, generating HiveContext, composing Data markup into Hive, analyzing JDBC documents, understanding the Data Frames in Spark, creating Information Frames, manual inferring of schema, working with CSV files, analyzing JDBC tables, Information markup to JDBC, user defined functions in Spark SQL, shared variable and accumulators, learning how to question and transform data in Statistics Frames, the manner Data Frame provides the advantage of Spark RDD and Spark SQL, deploying Hive on Spark as the execution engine.
1 note
·
View note
Link
In this Apache Hadoop tutorial you will learn Hadoop from the basics to pursue a big data Hadoop job role. Through this tutorial you will know the Hadoop architecture, its main components like HDFS, MapReduce, HBase, Hive, Pig, Sqoop, Flume, Impala, Zookeeper and more. You will also learn Hadoop installation, how to create a multi-node Hadoop cluster and deploy it successfully. Learn Big Data Hadoop from Intellipaat Hadoop training and fast-track your career.
Hadoop Tutorial – Learn Hadoop from Experts
In this Apache Hadoop tutorial you will learn Hadoop from the basics to pursue a big data Hadoop job role. Through this tutorial you will know the Hadoop architecture, its main components like HDFS, MapReduce, HBase, Hive, Pig, Sqoop, Flume, Impala, Zookeeper and more. You will also learn Hadoop installation, how to create a multi-node Hadoop cluster and deploy it successfully. Learn Big Data Hadoop from Intellipaat Hadoop training and fast-track your career.
Overview of Apache Hadoop
As Big Data has taken over almost every industry vertical that deals with data, the requirement for effective and efficient tools for processing Big Data is at an all-time high. Hadoop is one such tool that has brought a paradigm shift in this world. Thanks to the robustness that Hadoop brings to the table, users can process Big Data and work around it with ease. The average salary of a Hadoop Administrator which is in the range of US$130,000 is also very promising.
Become a Spark and Hadoop Developer by going through this online Big Data Hadoop training!
Watch this Hadoop Tutorial for Beginners video before going further on this Hadoop tutorial.
Apache Hadoop is a Big Data ecosystem consisting of open source components that essentially change the way large datasets are analyzed, stored, transferred and processed. Contrasting to traditional distributed processing systems, Hadoop facilitates multiple kinds of analytic workloads on same datasets at the same time.
Qualities That Make Hadoop Stand out of the Crowd
Single namespace by HDFS makes content visible across all the nodes
Easily administered using High-Performance Computing (HPC)
Querying and managing distributed data are done using Hive
Pig facilitates analyzing the large and complex datasets on Hadoop
HDFS is designed specially to give high throughput instead of low latency.
Interested in learning Hadoop? Click here to learn more from this Big Data Hadoop Training in London!
What is Apache Hadoop?
Apache Hadoop is an open-source data platform or framework developed in Java, dedicated to store and analyze the large sets of unstructured data.
With the data exploding from digital mediums, the world is getting flooded with cutting-edge big data technologies. However, Apache Hadoop was the first one which caught this wave of innovation.
Recommended Audience
Intellipaat’s Hadoop tutorial is designed for Programming Developers and System Administrators
Project Managers eager to learn new techniques of maintaining large datasets
Experienced working professionals aiming to become Big Data Analysts
Mainframe Professionals, Architects & Testing Professionals
Entry-level programmers and working professionals in Java, Python, C++, eager to learn the latest Big Data technology.
If you have any doubts or queries related to Hadoop, do post them on Big Data Hadoop and Spark Community!
Originally published at www.intellipaat.com on August 12, 2019
1 note
·
View note
Text
Datagrip sql

Datagrip sql driver#
Datagrip sql full#
Datagrip sql software#
Datagrip sql trial#
Datagrip sql full#
The SQL syntax is standard Spark SQL so we are free to use the full capabilities of the language. This style of working makes it really easy to explore our data as we're building our pipelines. Click on a table to view the records from that component.The DataGrip catalog should be filled in, with each Dataflow should be present as a different schema with each component mapped as a table.
Datagrip sql trial#
DOWNLOAD A 30-DAY TRIAL FOR DATAGRIP One of the most important activities for anyone working with databases is writing SQL. It supports PostgreSQL, MySQL, SQL Server, Oracle, and many other databases. It even analyzes your existing databases and helps you write. DataGrip is a universal tool for dealing with databases. It has auto completion support for SQL language. Although this article will go through the setup. DataGrip is a SQL database IDE from JetBrains. Click the database connection, select “ All schemas”, then hit the "Refresh" icon. Using Ascends JDBC / ODBC Connection, developers can query Ascend directly from SQL tools like DataGrip.
By default DataGrip does not include any schemas.
Switch to the Options tab to enable the connection as "Read-only".
Test the connection to ensure the setup is correct.
Enter the Username and Password from an API Token linked to a Service Account.
Fill in the host with your Ascend domain in the format.
If you encounter difficult connecting, you will likely need to download the Hive Standalone JAR for 2.3.7 from Maven Central and use that JAR instead of the one embedded in DataGrip.
Datagrip sql driver#
The Apache Hive Driver that ships with DataGrip is version 3 and Spark is only compatible up to version 2.3.7. For the data source type, prefer Apache Spark if present, otherwise use Apache Hive. "You get what you pay for" - The paid tools are worth the cost if you can use it to full extent. You can get a connection to SQLite going very easily though, and unlike other databases it doesn't require a server per se (or to be more correct the server is self contained in the driver). To create an instance, run SqlLocalDB create 'DEVELOPMENT' 14.0 -s. A cross-platform IDE that is aimed at DBAs and developers working with SQL databases. You will see a list of available LocalDB instances on the server. What is DataGrip A database IDE for professional SQL developers. Locate SqllocalDB.exe and run the SqllocalDB.exe i command in a terminal. And as a first step, check if your LocalDB instance is ready for a connection. dBeaver - SSMS, Azure Data Studio, Oracle development studio - Snowflake UI, GBQ Builtin UI DataGrip is still a great tool for learning SQL, but there's generally some additional setup involved in getting a server running that they simply don't cover. You can easily connect to your LocalDB instance with DataGrip. The tools native to the system are more than enough. Select the Databricks driver that you added in the preceding step. On the Data Sources tab, click the + ( Add) button. VSCode - Pycharm + DataGripįree tools should not be ignored as they get the job done well. Use DataGrip to connect to the cluster or SQL warehouse that you want to use to access the databases in your Databricks workspace. This means, the development environment should cater to general needs and/or scripting. I'll summarize some of the response:įor general DE needs, a scripted approach seems to be consensus.
Datagrip sql software#
MY RECOMMENDED READING LIST FOR SOFTWARE DEVEL. Toad, data grip, dbeaver etc.Īny recommendations / opinions on IDE & why?Įdit: Thanks for the feedback. Wondering if you should buy Jetbrains DataGrip Learn if its worth the price tag in this super quick review. I have been using sublime and atom as text editors with syntax highlighting but I have been looking into full fledged IDEs e.g. Just curious about the IDE's that other people use.
0 notes
Link
0 notes
Text
Post 49 | HDPCD | Using a subquery within a Hive query
Using a subquery within a Hive query
Hello, everyone. Welcome to one more tutorial in the HDPCD certification series.
In the last tutorial, we saw how to enable vectorization in Hive.
In this tutorial, we are going to see how to run a subquery within a Hive query.
Let us begin, then.

Apache Hive: Running subquery within a query
As you can see from the above screenshot, the process of performing this objective follows the following…
View On WordPress
#apache hive#apache hive internal and external table#basic sql#Big Data#big data certification#big data tutorial#bucketed table in hive#compressed data#create database#create external table in hive#create hive bucketed table#create hive table#create sql database#create sql table#create table in apache hive#create table in hive#created hive bucketed table#csv to hive#data#data ingestion#data loader#Data Loader and Transformer#data loading#data science#data scientist#Data Sources#Data Transformation#Data Transformation using Accure Momentum#data transformation using apache pig#Data Transformation using Momentum
0 notes
Text
Azure Synapse Analytics
The smooth and successful execution of businesses requires the integration of several valuable services and analytical systems. Data lakes and data warehouses are two such critical analytical systems that organizations need. However, using the services separately can be a hassle for your company.
Instead, if you have a cloud-based platform where you can achieve the functions of both the warehouse and the data lakes, you can work more freely. This is where the Microsoft Azure Synapse comes into the picture. It works as a data warehouse but has several other features that make it a smart choice for data analysis.
What Is Synapse Analytics?
Azure synapse analytics is a multipurpose and unlimited analytics service that is also cloud-based. Its key components include Spark, Synapse SQL pools, and Synapse Pipelines. It provides a common platform for Big Data analytics and data warehousing. In addition to its many functionalities, synapse allows the re-creating of data through snapshots that help in data recovery.
It has the capability to save, process, and query non-relational data. It facilitates machine learning and has business intelligence integrations. Being embedded with Microsoft technologies, it supports more integrations. It also allows organizations to use its features as per their requirements and pay only for what they use.
Uses of Azure Synapse Analytics
The features that Microsoft Azure Synapse is loaded with give plenty of reasons to organizations to use it. Some of the common uses that the synapse can be put to are discussed here.
● Managing Datasets - Together with Azure Data Analytics, the synapse helps in processing unstructured data or a set consisting of both unstructured and structured data. This task is achieved Azure Data bricks, Azure Data Lakes Analytics, Spark, and Hive LLAP. When synapse deals with structured data, it works at high speed and computes heavy read operations.
● Analyzing Real-Time Data - Synapse enables the ingestion of real-time data using Stream Analytics. Its HTAP implementation technology combines with Synapse Link to support the real-time analysis of operational data without bringing any negative impact on the operational systems.
● Multiple Integrations - The Azure synapse integrates well with the features of Microsoft applications. This allows organizations to enjoy the services of both the synapse and the Microsoft.
● Managing Complex Queries - Synapse has an MPP architecture that enables managing huge datasets. It achieves this task while its data analytics is still operational.
● Data Warehousing - Synapse supports a complete data warehousing that facilitates stored procedures and relational data models. The Data Warehouse is also called SQL Pool. It allows the loading of Dimension or Fact tables. It also lets users pause the SQL Pool and enhance performance by increasing computation.
● Supports Machine Learning - Synapse enables the use of machine learning Apache Spark MLlib. Using the Machine Learning Studio, users can create their ML Models.
Thus, the Azure Synapse is a platform that enables the accomplishment of various tasks. It has features that are suitable for data engineers, data analysts as well as data scientists. It allows organizations to assess their business performances on a real-time basis. It also makes the process of collating and managing data hassle-free.
0 notes