#hadoop tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
From Math to Machine Learning: A Comprehensive Blueprint for Aspiring Data Scientists
The realm of data science is vast and dynamic, offering a plethora of opportunities for those willing to dive into the world of numbers, algorithms, and insights. If you're new to data science and unsure where to start, fear not! This step-by-step guide will navigate you through the foundational concepts and essential skills to kickstart your journey in this exciting field. Choosing the Best Data Science Institute can further accelerate your journey into this thriving industry.

1. Establish a Strong Foundation in Mathematics and Statistics
Before delving into the specifics of data science, ensure you have a robust foundation in mathematics and statistics. Brush up on concepts like algebra, calculus, probability, and statistical inference. Online platforms such as Khan Academy and Coursera offer excellent resources for reinforcing these fundamental skills.
2. Learn Programming Languages
Data science is synonymous with coding. Choose a programming language – Python and R are popular choices – and become proficient in it. Platforms like Codecademy, DataCamp, and W3Schools provide interactive courses to help you get started on your coding journey.
3. Grasp the Basics of Data Manipulation and Analysis
Understanding how to work with data is at the core of data science. Familiarize yourself with libraries like Pandas in Python or data frames in R. Learn about data structures, and explore techniques for cleaning and preprocessing data. Utilize real-world datasets from platforms like Kaggle for hands-on practice.
4. Dive into Data Visualization
Data visualization is a powerful tool for conveying insights. Learn how to create compelling visualizations using tools like Matplotlib and Seaborn in Python, or ggplot2 in R. Effectively communicating data findings is a crucial aspect of a data scientist's role.
5. Explore Machine Learning Fundamentals
Begin your journey into machine learning by understanding the basics. Grasp concepts like supervised and unsupervised learning, classification, regression, and key algorithms such as linear regression and decision trees. Platforms like scikit-learn in Python offer practical, hands-on experience.
6. Delve into Big Data Technologies
As data scales, so does the need for technologies that can handle large datasets. Familiarize yourself with big data technologies, particularly Apache Hadoop and Apache Spark. Platforms like Cloudera and Databricks provide tutorials suitable for beginners.
7. Enroll in Online Courses and Specializations
Structured learning paths are invaluable for beginners. Enroll in online courses and specializations tailored for data science novices. Platforms like Coursera ("Data Science and Machine Learning Bootcamp with R/Python") and edX ("Introduction to Data Science") offer comprehensive learning opportunities.
8. Build Practical Projects
Apply your newfound knowledge by working on practical projects. Analyze datasets, implement machine learning models, and solve real-world problems. Platforms like Kaggle provide a collaborative space for participating in data science competitions and showcasing your skills to the community.
9. Join Data Science Communities
Engaging with the data science community is a key aspect of your learning journey. Participate in discussions on platforms like Stack Overflow, explore communities on Reddit (r/datascience), and connect with professionals on LinkedIn. Networking can provide valuable insights and support.
10. Continuous Learning and Specialization
Data science is a field that evolves rapidly. Embrace continuous learning and explore specialized areas based on your interests. Dive into natural language processing, computer vision, or reinforcement learning as you progress and discover your passion within the broader data science landscape.

Remember, your journey in data science is a continuous process of learning, application, and growth. Seek guidance from online forums, contribute to discussions, and build a portfolio that showcases your projects. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science. With dedication and a systematic approach, you'll find yourself progressing steadily in the fascinating world of data science. Good luck on your journey!
3 notes
·
View notes
Text
The tech field is still exhibiting strong growth, with a high demand for qualified workers. Yet for recent graduates to land the most highly sought after roles, you’ll want to make sure that your skills are up to scratch. This is an industry that’s constantly evolving along with the rapid explosion of technology, so employees who want better paying jobs and security will need to stay current with the latest innovations. With that in mind, here are five IT skills that students in particular may want to pay attention to. 1. Programming And Coding Perhaps the number one skill that will guarantee you a job in the IT industry straight out of university is the ability to program or code. IT departments all over the world are on the hunt for talented programmers, who are well trained in the latest platforms and can code in multiple languages. Learning programming is very obvious and essential part of successful career in IT industry. There are many popular programming languages to start as a student. You can choose one of your favorite language and pick a good programming book to learn coding. Although coding is seen as something that’s highly technical, even beginners can pick up introductory skills through a number of online courses and tutorials. For example IT courses at training.com.au often start with this basic skill that’s always in high demand. 2. Database Administration Big data is a term that’s thrown around constantly these days, which is why there’s such a need for those skilled with database administration. This type of job involves the ability to sift and analyse high volumes of data, while setting up logical database architecture to keep everything in check. Because data is growing at such a massive speed on a daily basis, the demand for qualified workers will only grow. If you have some experience with wrangling data through your studies, you’ll be well positioned to land a plum role in the organization of your choice. Many beginners may directly get tempted to jump on to Hadoop, however it may be a good idea to understand basic database and relational database storage as a beginner. Majority of corporate software is still running on relational databases like Oracle and MySQL. Though knowing Hadoop may help, it may not be sufficient for excelling in your job. You need larger skill set to be able to manage big data. 3. UX Design Web design today is all about the user experience, or UX. UX designers think about how the eventual user will be able to interact with a system, whether it’s an application or website. They analyse efficiency, testing it to create a more user-friendly experience. It’s a different way of looking at web design that’s becoming increasingly important for all designers to be aware of. Perhaps you already have some web design experience from your foundation courses– adding UX courses to your CV can’t hurt. Knowing about responsive design will also be a help. Checkout some inspirational responsive examples to stay up to date with latest web design trends. Make sure to know how to use the tools for web design. 4. Mobile Expertise App development, mobile marketing, and responsive web design are all hot trends this year, as most companies make the move to create a viable mobile presence. Businesses must have a strong mobile strategy now to compete, and many are moving to the ability to take payments via smartphone or tablet. Mobile and cloud computing are also coming together to form the future of technology, with mobile apps able to be used on numerous devices. A strong understanding of mobile technology and app design will put you ahead of the curve. 5. Networking If you have some experience with the ins and outs of setting up and monitoring a network, you might want to update this skill set to land a job. IT departments in a variety of industries are looking for individuals who are able to handle IP routing, firewall filtering, and other basic networking tasks with ease. Most security
tester and ethical hacker jobs require you to have a in depth understanding of networking concepts. Naturally, needs will vary depending on the type of company you’re thinking of working for. But for students keen on entering the workforce, upskilling in these IT-related areas will put you in a very good position. Can you think of a skill that we missed out?
0 notes
Text
Creating a Scalable Amazon EMR Cluster on AWS in Minutes

Minutes to Scalable EMR Cluster on AWS
AWS EMR cluster
Spark helps you easily build up an Amazon EMR cluster to process and analyse data. This page covers Plan and Configure, Manage, and Clean Up.
This detailed guide to cluster setup:
Amazon EMR Cluster Configuration
Spark is used to launch an example cluster and run a PySpark script in the course. You must complete the “Before you set up Amazon EMR” exercises before starting.
While functioning live, the sample cluster will incur small per-second charges under Amazon EMR pricing, which varies per location. To avoid further expenses, complete the tutorial’s final cleaning steps.
The setup procedure has numerous steps:
Amazon EMR Cluster and Data Resources Configuration
This initial stage prepares your application and input data, creates your data storage location, and starts the cluster.
Setting Up Amazon EMR Storage:
Amazon EMR supports several file systems, but this article uses EMRFS to store data in an S3 bucket. EMRFS reads and writes to Amazon S3 in Hadoop.
This lesson requires a specific S3 bucket. Follow the Amazon Simple Storage Service Console User Guide to create a bucket.
You must create the bucket in the same AWS region as your Amazon EMR cluster launch. Consider US West (Oregon) us-west-2.
Amazon EMR bucket and folder names are limited. Lowercase letters, numerals, periods (.), and hyphens (-) can be used, but bucket names cannot end in numbers and must be unique across AWS accounts.
The bucket output folder must be empty.
Small Amazon S3 files may incur modest costs, but if you’re within the AWS Free Tier consumption limitations, they may be free.
Create an Amazon EMR app using input data:
Standard preparation involves uploading an application and its input data to Amazon S3. Submit work with S3 locations.
The PySpark script examines 2006–2020 King County, Washington food business inspection data to identify the top ten restaurants with the most “Red” infractions. Sample rows of the dataset are presented.
Create a new file called health_violations.py and copy the source code to prepare the PySpark script. Next, add this file to your new S3 bucket. Uploading instructions are in Amazon Simple Storage Service’s Getting Started Guide.
Download and unzip the food_establishment_data.zip file, save the CSV file to your computer as food_establishment_data.csv, then upload it to the same S3 bucket to create the example input data. Again, see the Amazon Simple Storage Service Getting Started Guide for uploading instructions.
“Prepare input data for processing with Amazon EMR” explains EMR data configuration.
Create an Amazon EMR Cluster:
Apache Spark and the latest Amazon EMR release allow you to launch the example cluster after setting up storage and your application. This may be done with the AWS Management Console or CLI.
Console Launch:
Launch Amazon EMR after login into AWS Management Console.
Start with “EMR on EC2” > “Clusters” > “Create cluster”. Note the default options for “Release,” “Instance type,” “Number of instances,” and “Permissions”.
Enter a unique “Cluster name” without <, >, $, |, or `. Install Spark from “Applications” by selecting “Spark”. Note: Applications must be chosen before launching the cluster. Check “Cluster logs” to publish cluster-specific logs to Amazon S3. The default destination is s3://amzn-s3-demo-bucket/logs. Replace with S3 bucket. A new ‘logs’ subfolder is created for log files.
Select your two EC2 keys under “Security configuration and permissions”. For the instance profile, choose “EMR_DefaultRole” for Service and “EMR_EC2_DefaultRole” for IAM.
Choose “Create cluster”.
The cluster information page appears. As the EMR fills the cluster, its “Status” changes from “Starting” to “Running” to “Waiting”. Console view may require refreshing. Status switches to “Waiting” when cluster is ready to work.
AWS CLI’s aws emr create-default-roles command generates IAM default roles.
Create a Spark cluster with aws emr create-cluster. Name your EC2 key pair –name, set –instance-type, –instance-count, and –use-default-roles. The sample command’s Linux line continuation characters () may need Windows modifications.
Output will include ClusterId and ClusterArn. Remember your ClusterId for later.
Check your cluster status using aws emr describe-cluster –cluster-id myClusterId>.
The result shows the Status object with State. As EMR deployed the cluster, the State changed from STARTING to RUNNING to WAITING. When ready, operational, and up, the cluster becomes WAITING.
Open SSH Connections
Before connecting to your operating cluster via SSH, update your cluster security groups to enable incoming connections. Amazon EC2 security groups are virtual firewalls. At cluster startup, EMR created default security groups: ElasticMapReduce-slave for core and task nodes and ElasticMapReduce-master for main.
Console-based SSH authorisation:
Authorisation is needed to manage cluster VPC security groups.
Launch Amazon EMR after login into AWS Management Console.
Select the updateable cluster under “Clusters”. The “Properties” tab must be selected.
Choose “Networking” and “EC2 security groups (firewall)” from the “Properties” tab. Select the security group link under “Primary node”.
EC2 console is open. Select “Edit inbound rules” after choosing “Inbound rules”.
Find and delete any public access inbound rule (Type: SSH, Port: 22, Source: Custom 0.0.0.0/0). Warning: The ElasticMapReduce-master group’s pre-configured rule that allowed public access and limited traffic to reputable sources should be removed.
Scroll down and click “Add Rule”.
Choose “SSH” for “Type” to set Port Range to 22 and Protocol to TCP.
Enter “My IP” for “Source” or a range of “Custom” trustworthy client IP addresses. Remember that dynamic IPs may need updating. Select “Save.”
When you return to the EMR console, choose “Core and task nodes” and repeat these steps to provide SSH access to those nodes.
Connecting with AWS CLI:
SSH connections may be made using the AWS CLI on any operating system.
Use the command: AWS emr ssh –cluster-id –key-pair-file <~/mykeypair.key>. Replace with your ClusterId and the full path to your key pair file.
After connecting, visit /mnt/var/log/spark to examine master node Spark logs.
The next critical stage following cluster setup and access configuration is phased work submission.
#AmazonEMRcluster#EMRcluster#DataResources#SSHConnections#AmazonEC2#AWSCLI#technology#technews#technologynews#news#govindhtech
0 notes
Text
🔍 Dive into Data Science: Your Beginner's Guide 🧠
🚀 Kickstart Your Data Science Journey Today! Are you curious about Data Science but don’t know where to begin? We've got you covered!
Our latest blog, "Data Science Tutorial: Learn Data Science From Scratch", is your all-in-one guide to entering one of the most in-demand fields of the 21st century. 📊💡
🔍 In this blog, you’ll learn: ✅ Why Data Science matters in today’s digital world ✅ Who is a Data Scientist and what skills are required ✅ The key components of Data Science – from R Studio to Big Data & Hadoop ✅ Common problems solved using Machine Learning algorithms ✅ Career roles and job trends in the Data Science landscape
Whether you're a beginner or looking to strengthen your foundation, this tutorial will help you understand the tools, concepts, and career opportunities in Data Science.
📖 Read the full blog here: 👉 https://analyticsjobs.in/data-science-tutorial-learn-data-science-from-scratch
#DataScience #MachineLearning #AnalyticsJobs #CareerInDataScience #BigData #DataScienceTutorial #LearnDataScience #ArtificialIntelligence #Hadoop #SparkR

1 note
·
View note
Photo

Hive Tutorial | Hive Course For Beginners | Intellipaat - YouTube ☞ http://go.codetrick.net/d68b7e0dba #bigdata #hadoop
0 notes
Photo

Hive Tutorial | Hive Course For Beginners | Intellipaat - YouTube ☞ http://go.codetrick.net/d68b7e0dba #bigdata #hadoop
0 notes
Video
youtube
🐹Aula 47 – Tutorial Golang – Uso do Recover no Controle de Fluxo 🔧 Aprenda a usar recover() em Go e evite que sua aplicação caia com erros inesperados! Se você estuda programação, algoritmos, ou está mergulhado em projetos com machine learning, Hadoop ou APIs web, vai curtir a nova aula gratuita do Código Fluente. Nesta aula, você aprende a usar recover() — uma função poderosa que trabalha junto com panic e defer no Go para capturar erros críticos e continuar a execução do seu programa. Isso significa mais segurança, estabilidade e controle nos seus projetos, mesmo quando algo dá errado. 💡📌 Veja como aplicar em: – Funções encadeadas – Goroutines – Servidores HTTP Quer aprender na prática e com exemplos reais? É só acessar: 👉 https://www.codigofluente.com.br/aula-47-tutorial-golang-uso-do-recover-no-controle-de-fluxo/ 💻 Conteúdo 100% gratuito e direto ao ponto. Bora codar! #Golang #programação #recover #panic #defer #controledefluxo #códigofluente #backend #machinelearning #Hadoop #algoritmos #dev #go #desenvolvimentoweb
0 notes
Text
Leveraging SAS for Big Data Analytics: A Practical Guide
Big data analytics has become a critical tool for organizations seeking to gain insights from large and complex datasets. From social media trends to IoT sensor data, big data has the potential to revolutionize industries by providing valuable insights that drive decision-making. SAS tutorial offers a comprehensive guide for users looking to leverage SAS’s powerful capabilities for big data analytics, enabling them to handle vast amounts of data with ease.
Getting Started with SAS for Big Data Analytics
SAS is renowned for its ability to process large datasets efficiently. With its sophisticated analytics tools and scalability, SAS allows you to analyze big data and derive actionable insights that drive business success. Whether you are working with structured, unstructured, or semi-structured data, SAS provides the flexibility to handle various types of big data.
The first step in leveraging the SAS tutorial for big data analytics is understanding the architecture of SAS. SAS offers several tools and techniques to manage large datasets, such as SAS Grid Computing and in-memory analytics. These technologies help you store, manage, and analyze big data more efficiently.
One of the key benefits of SAS tutorial for big data analytics is the ability to perform real-time analytics. With real-time processing, you can analyze data as it’s generated, which is crucial for industries like finance, healthcare, and e-commerce. For example, real-time analytics allows financial institutions to monitor transactions for fraud or helps e-commerce companies personalize their customers' shopping experiences.
Key Techniques in Big Data Analytics Using SAS
Data Integration: The first step in big data analytics is integrating data from multiple sources. SAS tutorial provides guidance on using SAS data integration features to connect with databases, cloud platforms, and other big data environments like Hadoop and Spark. This allows you to consolidate and preprocess data from disparate sources.
Data Processing: Once the data is integrated, SAS allows you to clean, filter, and transform it for analysis. With SAS, you can easily manipulate data by removing duplicates, handling missing values, and aggregating data to create meaningful datasets for analysis.
Advanced Analytics: SAS offers a wide range of advanced analytics capabilities that allow you to apply predictive modeling, machine learning algorithms, and statistical analysis to big data. These tools help you uncover hidden patterns and trends that can be used to make data-driven decisions.
Visualization: SAS provides powerful visualization tools that help you communicate your findings effectively. From charts to dashboards, these tools allow you to present big data insights in a clear and meaningful way, making it easier for decision-makers to understand and act on the information.
Scalability: SAS is built to scale, which is particularly important when working with big data. Whether you’re working with terabytes of data or massive datasets in the cloud, SAS ensures that your analytics can keep up with the growing size of your data.
youtube
Benefits of Using SAS for Big Data Analytics
Seamless Integration with Big Data Platforms: SAS integrates effortlessly with big data platforms like Hadoop and Spark, enabling you to process large datasets across multiple systems.
Real-Time Processing: SAS allows for real-time data processing, ensuring that organizations can make timely, data-driven decisions.
Scalable Architecture: SAS’s scalable architecture ensures that your analytics capabilities grow as your data expands, making it suitable for businesses of all sizes.
Comprehensive Analytics: SAS provides a comprehensive suite of analytics tools, from descriptive statistics to advanced machine learning, making it suitable for all types of big data analytics.
Conclusion
By leveraging SAS tutorial for big data analytics, organizations can efficiently process large datasets and derive actionable insights that lead to better decision-making. With SAS’s advanced tools for data integration, processing, and analysis, businesses can harness the power of big data to stay ahead of the competition and drive innovation. Whether you're dealing with structured data or unstructured data, SAS provides the tools to make sense of it all.
#sas tutorial#sas programming tutorial#sas tutorial for beginners#sas programming#Data Analytics#big data analytics#learning sas for big data analytics#Youtube
0 notes
Text
Leverage Apache HBase for Big Data Analytics Best Practices
1. Introduction Overview: Apache HBase is a distributed, scalable, and fault-tolerant database built on top of Apache Hadoop, designed to handle large-scale big data analytics. This tutorial provides a hands-on guide to using HBase for storing, processing, and analyzing large datasets. What You Will Learn: – Core concepts of HBase – How to set up and configure HBase – CRUD (Create, Read,…
0 notes
Text
Lab 2 Convert WordCount to UrlCount
In this lab, you’re going to take WordCount (an existing Hadoop application that is extensively described in the [Hadoop tutorial](https://hadoop.apache.org/docs/r3.0.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html)) and modify it into UrlCount. You can either approach the lab as native Java-hadoop application or use the [Hadoop streaming…
0 notes
Text
What Is The Role of Python in Artificial Intelligence? - Arya College
Importance of Python in AI
Arya College of Engineering & I.T. has many courses for Python which has become the dominant programming language in the fields of Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) due to several compelling factors:
1. Simplicity and Readability
Python's syntax is clear and intuitive, making it accessible for both beginners and experienced developers. This simplicity allows for rapid prototyping and experimentation, essential in AI development where iterative testing is common. The ease of learning Python enables new practitioners to focus on algorithms and data rather than getting bogged down by complex syntax.
2. Extensive Libraries and Frameworks
Python boasts a rich ecosystem of libraries specifically designed for AI and ML tasks. Libraries such as TensorFlow, Keras, PyTorch, sci-kit-learn, NumPy, and Pandas provide pre-built functions that facilitate complex computations, data manipulation, and model training. This extensive support reduces development time significantly, allowing developers to focus on building models rather than coding from scratch.
3. Strong Community Support
The active Python community contributes to its popularity by providing a wealth of resources, tutorials, and forums for troubleshooting. This collaborative environment fosters learning and problem-solving, which is particularly beneficial for newcomers to AI. Community support also means that developers can easily find help when encountering challenges during their projects.
4. Versatility Across Applications
Python is versatile enough to be used in various applications beyond AI, including web development, data analysis, automation, and more. This versatility makes it a valuable skill for developers who may want to branch into different areas of technology. In AI specifically, Python can handle tasks ranging from data preprocessing to deploying machine learning models.
5. Data Handling Capabilities
Python excels at data handling and processing, which are crucial in AI projects. Libraries like Pandas and NumPy allow efficient manipulation of large datasets, while tools like Matplotlib and Seaborn facilitate data visualization. The ability to preprocess data effectively ensures that models are trained on high-quality inputs, leading to better performance.
6. Integration with Other Technologies
Python integrates well with other languages and technologies, making it suitable for diverse workflows in AI projects. It can work alongside big data tools like Apache Spark or Hadoop, enhancing its capabilities in handling large-scale datasets. This interoperability is vital as AI applications often require the processing of vast amounts of data from various sources.
How to Learn Python for AI
Learning Python effectively requires a structured approach that focuses on both the language itself and its application in AI:
1. Start with the Basics
Begin by understanding Python's syntax and basic programming concepts:
Data types: Learn about strings, lists, tuples, dictionaries.
Control structures: Familiarize yourself with loops (for/while) and conditionals (if/else).
Functions: Understand how to define and call functions.
2. Explore Key Libraries
Once comfortable with the basics, delve into libraries essential for AI:
NumPy: For numerical computations.
Pandas: For data manipulation and analysis.
Matplotlib/Seaborn: For data visualization.
TensorFlow/Keras/PyTorch: For building machine learning models.
3. Practical Projects
Apply your knowledge through hands-on projects:
Start with simple projects like linear regression or classification tasks using datasets from platforms like Kaggle.
Gradually move to more complex projects involving neural networks or natural language processing.
4. Online Courses and Resources
Utilize online platforms that offer structured courses:
Websites like Coursera, edX, or Udacity provide courses specifically focused on Python for AI/ML.
YouTube channels dedicated to programming can also be valuable resources.
5. Engage with the Community
Join forums like Stack Overflow or Reddit communities focused on Python and AI:
Participate in discussions or seek help when needed.
Collaborate on open-source projects or contribute to GitHub repositories related to AI.
6. Continuous Learning
AI is a rapidly evolving field; therefore:
Stay updated with the latest trends by following relevant blogs or research papers.
Attend workshops or webinars focusing on advancements in AI technologies.
By following this structured approach, you can build a solid foundation in Python that will serve you well in your journey into artificial intelligence and machine learning.
0 notes
Text
Why Python is the Best Choice for Data Analytics in 2025
In 2025, data analytics continues to drive business decisions, making it one of the most sought-after skills in the tech industry. Among the many programming languages available, Python stands out as the best choice for data analytics. With its simplicity, extensive libraries, and strong community support, Python empowers data analysts to process, visualize, and extract insights from data efficiently. If you are looking to advance your career in data analytics, enrolling in a Python training in Hyderabad can be a game-changer.
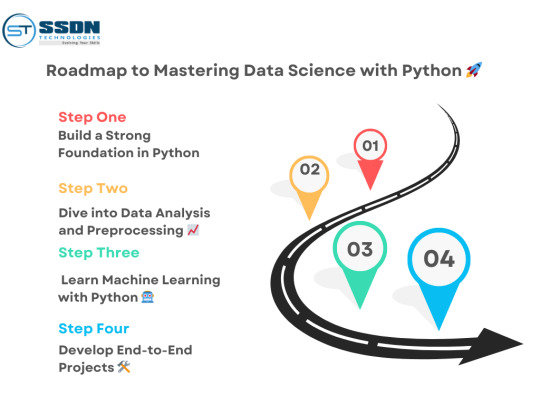
Why Python for Data Analytics?
1. Easy to Learn and Use
Python's simple syntax makes it beginner-friendly, allowing professionals from non-programming backgrounds to learn it quickly. Unlike other languages that require extensive coding, Python offers a concise and readable approach, making data analysis easier and more efficient.
2. Rich Ecosystem of Libraries
Python provides a vast range of libraries specifically designed for data analytics, including:
Pandas – For data manipulation and analysis
NumPy – For numerical computing
Matplotlib & Seaborn – For data visualization
Scikit-learn – For machine learning
TensorFlow & PyTorch – For AI-driven analytics
These libraries simplify complex tasks and help analysts derive meaningful insights from large datasets.
3. Versatility and Scalability
Python is not just limited to data analytics; it is widely used in web development, AI, and automation. This versatility allows professionals to integrate data analytics with other technologies, making it a preferred choice for businesses.
4. Strong Community Support
With a vast community of developers, Python users have access to extensive documentation, forums, and online tutorials. If you encounter any issues while working with Python, you can quickly find solutions and best practices through community discussions.
5. Integration with Big Data and Cloud Technologies
Python seamlessly integrates with big data technologies like Hadoop and Apache Spark, making it an excellent choice for handling massive datasets. Additionally, Python is compatible with cloud platforms such as AWS and Azure, which are essential for modern data analytics solutions.
Career Opportunities in Python-Based Data Analytics
The demand for skilled data analysts proficient in Python is on the rise. Companies across industries are looking for professionals who can analyze and interpret data effectively. Some of the top job roles include:
Data Analyst
Business Intelligence Analyst
Data Engineer
Machine Learning Engineer
AI Specialist
If you want to build a successful career in data analytics, enrolling in a Python course in Hyderabad will equip you with the necessary skills and industry-relevant knowledge.
How to Learn Python for Data Analytics?
To master Python for data analytics, follow these steps:
Enroll in a Structured Course – Join a Python training in Hyderabad that offers hands-on projects and real-world case studies.
Practice with Real Datasets – Work with publicly available datasets to gain practical experience.
Master Data Visualization – Learn tools like Matplotlib and Seaborn to present data insights effectively.
Explore Machine Learning – Get familiar with Scikit-learn and TensorFlow to enhance your data analysis skills.
Build a Portfolio – Showcase your projects on platforms like GitHub and Kaggle to attract job opportunities.
Conclusion
Python continues to dominate the data analytics industry in 2025, offering ease of use, extensive libraries, and strong career prospects. Whether you are a beginner or an experienced professional, mastering Python can unlock numerous opportunities in data analytics. If you are ready to take the next step, consider enrolling in a Python classes in Hyderabad and start your journey toward a successful career in data analytics.
Website : www.ssdntech.com Contact Us : +91 9999111686
#python training in hyderabad#python course in hyderabad#python classes in hyderabad#python Certification in hyderabad#best python institute in hyderabad
0 notes
Text
Hadoop is the most used opensource big data platform. Over the last decade, it has become a very large ecosystem with dozens of tools and projects supporting it. Most information technology companies have invested in Hadoop based data analytics and this has created a huge job market for Hadoop engineers and analysts. Hadoop is a large-scale system that requires Map Reduce programmers, data scientists, and administrators to maintain it. Getting a Hadoop job may seem difficult but not impossible. There are hundreds of useful free resources available online that can help you learn it on your own. Many programmers have switched to data scientist role by simply self-learning Hadoop development. I am a Cloudera certified Hadoop developer since 2008 and I have hand-curated this list of resources for all Hadoop aspirants to learn faster. Hadoop Beginners Tutorials: Simple and Easy to Follow Hadoop requires a lot of prior knowledge of computer science. It may be overwhelming for a total beginner to start using it. I would recommend to take small steps and learn part of it at a time. Try to apply what you learn using a simple project. The pre-bundled distributions of Hadoop are, the best way to avoid complicated setup. You can use Cloudera or Hortonworks bundled packages to quick start your experiments. At first, you need no create a large Hadoop cluster. Even doing a one or two node cluster would be sufficient to verify your learnings. Apache Hadoop - Tutorial 24 Hadoop Interview Questions & Answers for MapReduce developers | FromDev Hadoop Tutorial - YDN Hadoop Tutorial for Beginners: Hadoop Basics Hadoop Tutorial – Learn Hadoop from experts – Intellipaat Free Hadoop Tutorial: Master BigData Hadoop Tutorial Apache Hadoop 2.9.2 – MapReduce Tutorial Learn Hadoop Tutorial - javatpoint Hadoop Tutorial | Getting Started With Big Data And Hadoop | Edureka Hadoop Tutorial for Beginners | Learn Hadoop from A to Z - DataFlair Map Reduce - A really simple introduction « Kaushik Sathupadi Running Hadoop On Ubuntu Linux (Single-Node Cluster) Learn Hadoop Online for Free with Big Data and Map Reduce Cloudera Essentials for Apache Hadoop | Cloudera OnDemand Hadoop Video Tutorials To Watch and Learn Video tutorials are also available for learning Hadoop. There are dozens of beginners video tutorials on Youtube and other websites. Some of the most popular ones are listed below. Hadoop Tutorials Beginners - YouTube Apache Hadoop Tutorial | Hadoop Tutorial For Beginners | Big Data Hadoop | Hadoop Training | Edureka - YouTube Big Data Hadoop Tutorial Videos - YouTube Demystifying Hadoop 2.0 - Playlist Full - YouTube Hadoop Architecture Tutorials Playlist - YouTube Hadoop Tutorials - YouTube Durga Hadoop - YouTube Big Data & Hadoop Tutorials - YouTube Hadoop Tutorials for Beginners - YouTube Big Data and Hadoop Tutorials - YouTube Big Data Hadoop Tutorial Videos | Simplilearn - YouTube Hadoop Training Tutorials - Big Data, Hadoop Big Data,Hadoop Tutorials for Beginners - YouTube Hadoop Training and Tutorials - YouTube Hadoop Tutorials - YouTube Best Hadoop eBooks and PDF to Learn Looking for a PDF downloadable for Hadoop learning? Below list has plenty of options for you from various sources on the internet. Apache Hadoop Tutorial Mapreduce Osdi04 Book Mapreduce Book Final Hadoop The Definitive Guide Hadoop Mapreduce Cookbook Bigdata Hadoop Tutorial Hadoop Books Hadoop In Practice Hadoop Illuminated Hdfs Design Hadoop Real World Solutions Cookbook Hadoop Explained Hadoop With Python Apache Hadoop Tutorial Best Free Mongodb Tutorials Pdf Hadoop Cheatsheets and Quick Reference Resources Hadoop has many commands, memorizing those may take time. You can use a simple cheat sheet that can be used as a quick reference. I recommend you to print one of your favorite cheat sheets and stick it on your desk pinboard. This way you can easily lookup for commands as you work.
Commands Manual Hadoop Hdfs Commands Cheatsheet Hadoop For Dummies Cheat Sheet - dummies Hadoop Deployment Cheat Sheet | Jethro Hdfs Cheatsheet HDFS Cheat Sheet - DZone Big Data Big Data Hadoop Cheat Sheet - Intellipaat Hadoop Websites and Blogs To Learn On Web This is a list of blogs and websites related to Hadoop. These can be handy to keep your knowledge on Hadoop up to date with the latest industry trends. Hadoop Eco System - Hadoop Online Tutorials Big Data Hadoop Tutorial for Beginners- Hadoop Installation,Free Hadoop Online Tutorial Hadoop Tutorial – Getting Started with HDP - Hortonworks Hortonworks Sandbox Tutorials for Apache Hadoop | Hortonworks Hadoop – An Apache Hadoop Tutorials for Beginners - TechVidvan Hadoop Tutorial -- with HDFS, HBase, MapReduce, Oozie, Hive, and Pig Free Online Video Tutorials, Online Hadoop Tutorials, HDFS Video Tutorials | hadooptutorials.co.in Free Hadoop Training Hadoop Fundamentals - Cognitive Class Hadoop Courses | Coursera hadoop Courses | edX MapR Training Options | MapR Hadoop Forums and Discussion Boards To Get Help Looking for help related to Hadoop, you may be lucky if you go online. Many people are willing to help with Hadoop related queries. Below forums are very active with high participation from hundreds of people. Official Apache Hadoop Mailing list Frequent 'Hadoop' Questions - Stack Overflow Forums - Hadoop Forum Hadoop Courses and Training (Including Paid Options) Hadoop courses may not be free but have been proven very useful for quickly learning from experts. The courses can exhaustive, however, it may give you a faster learning curve and greater confidence. There are many costly courses available, my recommendation will be to try out the free courses first and then invest wisely into areas where you need to learn more. Apache Hadoop training from Cloudera University - Following are the key things to notice about this training. Expert trainers Good place for networking for fellow Hadoop engineers. Usually in-person training. It may be costly as an individual, but if you get corporate sponsorship this is probably the best option. This is the Most popular choice for corporate training. Live Training - Hortonworks - Following are the key things to notice about this training. Another good option for corporate level training. Expert trainers. Usually in-person training. It may be costly. Big Data Training - Education Services - US and Canada | HPE™ Big Data Hadoop Training | Hadoop Certification Online Course - Simplilearn Hadoop Tutorial Training Certification - Paid but a cheaper option. Search for ProTech Courses - Hadoop courses are offered at a physical training. TecheTraining Learning Hadoop - Hadoop Training Course on LinkedIn that can be free with a one month trial. Please share your experience If you know about more training options or have any feedback about any training listed here. Summary I have created this huge list of Hadoop tutorials to help learn faster. At first, it may become overwhelming to jump onto any tutorial and start learning, however, I would encourage you to no give up on learning. My recommendation to beginners will be to start small and no give up. Based on the couple hour spent every day you may be able to learn Hadoop ecosystem in a matter of a few weeks. I hope you find this resource page useful. Please mention in comments, If you find something useful that is not listed on this page.
0 notes
Text

Hadoop . . . for more information and tutorial https://bit.ly/4hPFcGk check the above link
0 notes
Text
Why Java is the Best Language to Learn First
In the ever-expanding world of programming languages, choosing the right one to start with is crucial for building a solid foundation. Among countless options, Java has consistently been one of the top recommendations for beginners. But what makes it the best language to learn first? Let’s uncover the reasons that make Java a standout choice for aspiring programmers.

Enrolling in a Java Course in Pune significantly enhances one’s ability to leverage Java’s capabilities effectively. Understanding its primary advantages is crucial for developers and businesses considering its adoption.
1. Beginner-Friendly Yet Powerful
Java strikes the perfect balance between simplicity and functionality. Its syntax is straightforward and easy to read, making it approachable for beginners. At the same time, Java is powerful enough to build everything from simple apps to complex enterprise systems, allowing learners to grow with the language.
Clear and Intuitive Syntax
Java’s syntax is logical and similar to natural language, making it easier for new coders to grasp programming concepts without feeling overwhelmed.
Guided Learning Through Errors
One of Java’s standout features is its detailed error messages. Beginners can quickly identify and fix mistakes, turning errors into valuable learning experiences.
2. Foundation for Object-Oriented Programming (OOP)
Java is a fully object-oriented language, introducing learners to essential OOP concepts like inheritance, polymorphism, encapsulation, and abstraction. These principles are not only fundamental to Java but also to many other modern programming languages, giving you transferable skills.
Real-Life Problem Solving
Learning OOP with Java helps students approach problem-solving like a developer, breaking down complex challenges into manageable components.
3. Platform Independence
Java’s "Write Once, Run Anywhere" (WORA) philosophy allows the same program to run seamlessly on multiple platforms. This feature not only showcases Java’s versatility but also teaches learners the importance of cross-platform compatibility in software development.
Practical Applications
From Windows to macOS to Linux, beginners can test and run their programs without worrying about platform-specific restrictions.
4. Wide Range of Applications
One of the biggest advantages of learning Java is its versatility. As a beginner, you can explore various domains without switching languages:
Web Development: Java frameworks like Spring and Hibernate power countless web applications.
Mobile Development: It’s a go-to language for building Android apps.
Game Development: Java’s libraries and frameworks make it suitable for game programming. Consider enrolling in the Java Online Certification Training to fully harness Java’s capabilities and become proficient in web automation.
Big Data: Tools like Apache Hadoop and Spark rely heavily on Java.
This diversity allows beginners to experiment and discover their interests while using the same language.
5. Rich Ecosystem and Strong Community Support
Learning Java means stepping into a world with abundant resources.
Documentation: Java’s official documentation is detailed and beginner-friendly.
Online Tutorials: From blogs to YouTube channels, there’s no shortage of free Java tutorials.
Community Help: Java boasts a massive community of developers who are eager to help on platforms like Stack Overflow, Reddit, and GitHub.
This strong support system ensures beginners never feel stuck.
6. Prepares You for Future Technologies
Learning Java is not just about understanding a language; it’s about equipping yourself for future opportunities.
Transition to Advanced Skills
Once you master the basics, Java opens doors to advanced topics such as:
Android Development: Java is the backbone of Android applications.
Cloud Computing: Java is widely used in cloud platforms like AWS and Google Cloud.
Enterprise Solutions: Major companies rely on Java for large-scale, robust systems.
By starting with Java, you’re setting yourself up for a seamless transition into these high-demand fields.
7. Safe and Secure
Java prioritizes security, a critical aspect of modern programming. Its built-in security features, such as bytecode verification and sandboxing, teach beginners the importance of safe coding practices early on.
8. Encourages Problem-Solving and Creativity
Java encourages learners to think critically and solve problems logically. With simple tools and concepts, you can build exciting projects like:
Basic calculator applications
Interactive games
Inventory management systems
These projects not only strengthen your understanding but also make learning Java fun and rewarding.
Conclusion: Why Java Deserves the Spotlight
Java isn’t just another programming language; it’s a launchpad for your programming journey. Its beginner-friendly nature, coupled with its powerful features and versatility, makes it the best choice for anyone stepping into the world of coding.
By learning Java first, you’re not just acquiring a skill—you’re building a solid foundation for a thriving career in technology. Whether your goal is to create apps, dive into web development, or explore emerging fields, Java is the perfect companion to help you get started.
So, take the leap, start your Java journey, and unlock a world of endless opportunities!
0 notes