#data warehouse migration to aws
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Best Practices for a Smooth Data Warehouse Migration to Amazon Redshift
In the era of big data, many organizations find themselves outgrowing traditional on-premise data warehouses. Moving to a scalable, cloud-based solution like Amazon Redshift is an attractive solution for companies looking to improve performance, cut costs, and gain flexibility in their data operations. However, data warehouse migration to AWS, particularly to Amazon Redshift, can be complex, involving careful planning and precise execution to ensure a smooth transition. In this article, we’ll explore best practices for a seamless Redshift migration, covering essential steps from planning to optimization.
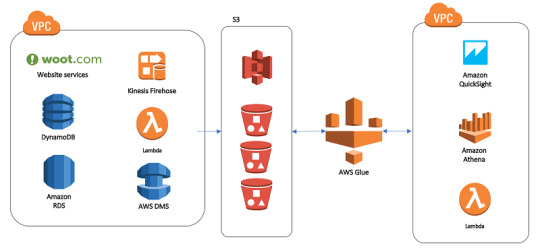
1. Establish Clear Objectives for Migration
Before diving into the technical process, it’s essential to define clear objectives for your data warehouse migration to AWS. Are you primarily looking to improve performance, reduce operational costs, or increase scalability? Understanding the ‘why’ behind your migration will help guide the entire process, from the tools you select to the migration approach.
For instance, if your main goal is to reduce costs, you’ll want to explore Amazon Redshift’s pay-as-you-go model or even Reserved Instances for predictable workloads. On the other hand, if performance is your focus, configuring the right nodes and optimizing queries will become a priority.
2. Assess and Prepare Your Data
Data assessment is a critical step in ensuring that your Redshift data warehouse can support your needs post-migration. Start by categorizing your data to determine what should be migrated and what can be archived or discarded. AWS provides tools like the AWS Schema Conversion Tool (SCT), which helps assess and convert your existing data schema for compatibility with Amazon Redshift.
For structured data that fits into Redshift’s SQL-based architecture, SCT can automatically convert schema from various sources, including Oracle and SQL Server, into a Redshift-compatible format. However, data with more complex structures might require custom ETL (Extract, Transform, Load) processes to maintain data integrity.
3. Choose the Right Migration Strategy
Amazon Redshift offers several migration strategies, each suited to different scenarios:
Lift and Shift: This approach involves migrating your data with minimal adjustments. It’s quick but may require optimization post-migration to achieve the best performance.
Re-architecting for Redshift: This strategy involves redesigning data models to leverage Redshift’s capabilities, such as columnar storage and distribution keys. Although more complex, it ensures optimal performance and scalability.
Hybrid Migration: In some cases, you may choose to keep certain workloads on-premises while migrating only specific data to Redshift. This strategy can help reduce risk and maintain critical workloads while testing Redshift’s performance.
Each strategy has its pros and cons, and selecting the best one depends on your unique business needs and resources. For a fast-tracked, low-cost migration, lift-and-shift works well, while those seeking high-performance gains should consider re-architecting.
4. Leverage Amazon’s Native Tools
Amazon Redshift provides a suite of tools that streamline and enhance the migration process:
AWS Database Migration Service (DMS): This service facilitates seamless data migration by enabling continuous data replication with minimal downtime. It’s particularly helpful for organizations that need to keep their data warehouse running during migration.
AWS Glue: Glue is a serverless data integration service that can help you prepare, transform, and load data into Redshift. It’s particularly valuable when dealing with unstructured or semi-structured data that needs to be transformed before migrating.
Using these tools allows for a smoother, more efficient migration while reducing the risk of data inconsistencies and downtime.
5. Optimize for Performance on Amazon Redshift
Once the migration is complete, it’s essential to take advantage of Redshift’s optimization features:
Use Sort and Distribution Keys: Redshift relies on distribution keys to define how data is stored across nodes. Selecting the right key can significantly improve query performance. Sort keys, on the other hand, help speed up query execution by reducing disk I/O.
Analyze and Tune Queries: Post-migration, analyze your queries to identify potential bottlenecks. Redshift’s query optimizer can help tune performance based on your specific workloads, reducing processing time for complex queries.
Compression and Encoding: Amazon Redshift offers automatic compression, reducing the size of your data and enhancing performance. Using columnar storage, Redshift efficiently compresses data, so be sure to implement optimal compression settings to save storage costs and boost query speed.
6. Plan for Security and Compliance
Data security and regulatory compliance are top priorities when migrating sensitive data to the cloud. Amazon Redshift includes various security features such as:
Data Encryption: Use encryption options, including encryption at rest using AWS Key Management Service (KMS) and encryption in transit with SSL, to protect your data during migration and beyond.
Access Control: Amazon Redshift supports AWS Identity and Access Management (IAM) roles, allowing you to define user permissions precisely, ensuring that only authorized personnel can access sensitive data.
Audit Logging: Redshift’s logging features provide transparency and traceability, allowing you to monitor all actions taken on your data warehouse. This helps meet compliance requirements and secures sensitive information.
7. Monitor and Adjust Post-Migration
Once the migration is complete, establish a monitoring routine to track the performance and health of your Redshift data warehouse. Amazon Redshift offers built-in monitoring features through Amazon CloudWatch, which can alert you to anomalies and allow for quick adjustments.
Additionally, be prepared to make adjustments as you observe user patterns and workloads. Regularly review your queries, data loads, and performance metrics, fine-tuning configurations as needed to maintain optimal performance.
Final Thoughts: Migrating to Amazon Redshift with Confidence
Migrating your data warehouse to Amazon Redshift can bring substantial advantages, but it requires careful planning, robust tools, and continuous optimization to unlock its full potential. By defining clear objectives, preparing your data, selecting the right migration strategy, and optimizing for performance, you can ensure a seamless transition to Redshift. Leveraging Amazon’s suite of tools and Redshift’s powerful features will empower your team to harness the full potential of a cloud-based data warehouse, boosting scalability, performance, and cost-efficiency.
Whether your goal is improved analytics or lower operating costs, following these best practices will help you make the most of your Amazon Redshift data warehouse, enabling your organization to thrive in a data-driven world.
#data warehouse migration to aws#redshift data warehouse#amazon redshift data warehouse#redshift migration#data warehouse to aws migration#data warehouse#aws migration
0 notes
Photo
-SHOOT
Prompt: Root/The Machine/Shaw
... just before Root passed out...Root clenches at the most injured parts of her adomn...a slight of hand and "inserting" a small object into the most life threatening part of her stomach...
When the paramedics...got out of sight....they moved Root from the 'bus and moved to a costmized RV/VAN type....
The Machine replicates and "migrates" upwards in a vein..that takes up to Roots brain and begins to replicates like being an Incratitor and implants themselves all over it's new confines....and starts to use microscopic wiring and placing them...and morphine into identical parts of Roots entire "biosphere"s.. and starts by eradicate the Co-Clear Implant behind her ear external and morph... Into a NEW AND GREATLY parts....and it's NOT JUST THE IMPLANT BEHIND THE EAR. ... it's the entire system....
It's years later.. Root went back to her studio loft... despite The Machine Objections,. .Root found where The Machine has been Embodied into the walls of the warehouse where Shaw shot Root. Inside the walls, the ceiling and the floor.,... And she plugged in the flash drive...too much data shot through Roots system... leaving her unconscious get out of there.. waking to the fingers of the sun peaking over horizon into a field of waving wheat....she escaped to the place she BECAME ROOT....the small town in TX and THAT LIBRARY...TO THE INTERFACE (WHICH CONFUSED ROOT) IN WHICHED SAMANTHA GROVES WAS RE-BORN ROOT... And, when The Machine became vulnerable She'd send Root to another Data-Base.,and start a cascaded failure and blowing ALL THE PHYSICAL PERMITMENTORS TO TO ASH....and wot RE-BOOT after 2-Hours of rest . And, "nuzzles" Ms. Groves awake
Root was in a state of influx of transformation into a NEW AND IMPROVED" versions of, both, The Machine and ROOT...
Years later, Root is ONLY ABLE TO REST 2-HOURS OUT OF A 24-HOURS Days (like fucking Batman)...and she was like a super soldier (see Captain America)...and even though Harold and Sammen are still alive and working their own numbers that The Machine has been send them on....Ms. Groves had her own....more deadly....more dangerous... numbers .... Can see inferno red and x-ray vision... can hear a heart beat around a movie theater right by a speaker and getting into a car...
Years later The Machine interfers does THE #1 Golden Rule.... even though all live is valued. You can NOT make exceptions....and put Roots ..and Harold/Sammen just on a tralimentary... and ALL of them will have to deal with sense of betrayal and Harold Sammen resentment against Root. and when all things are BEGINNING so soothing out ... trust is The less issue. Harold doesn't want to share His Machine with Ms. Groves.. Sammen is seriously self destructive
FYI: FAN ART FANFIC IS FREE USE. NOT FOR PROFIT... AND ARE BASICALLY AU. SINCE THEY REFLECT THE *FANS* "ART"...AND AS LONG AS WE PUT THE. DISCLAIMER*NOT FOR PROFIT*... NONE OF THE*Conceptual OWNERS* OF THE ORIGINAL PROPERTY... THEY WILL BE COOL. BECAUSE FAN ART AND/OR FAN FIC.... BECAUSE IT'S FREE ADVERTISING. IE: CHECK OUT ARIANNA ERGANDA'S REACTION TO HOW OVERWHELMING OF THE FAN ART AND FAN FICTION.. SHE WAS IN AWE. "GELPHIE" ...SHE NEVER SAID STOP.. YOUR MAKING MONEY OFF ME
I have all DEGRASSE AND THE NEXT GENERATION.. FOR FREE DOWNLOAD AND I WATCH THEM. I DON'T HAVE TO PAY...AND I'M NOT MAKING ANY OFF THEM. ID, I SHOWED WITHOUT MAKING ANY MONEY.. IT'S*EDUCATIONAL PURPOSES*. ...BTW: DEGRASSI IS CANADIAN..
AND I WATCH CANON/ 'SHIPs ON YOUTUBE FOR FREE...ON PLAYLIST....OR TUBI....FREEVEE... DISNEY+... HULU... NETFLIX... etc.
I AM NOT EVEN GETTING PAID BY THE POWERS TO BE... FOR FREE ADVERTISING. THAT I JUST DID... NO CONTRACTS. I *ADVERTISE* WITH OUT THE ASPECT OF EVER EXCEPTING PAID.
The rest of the thread is here.
tl;dr: Don’t monetize AO3, kids. You won’t like what happens next.
#sheriff nicole haught#wynonna earp#nicole haught#waverly earp#wayhaught#katherine barrell#wynonna earp vengeance#sheriff forbes#wynonnaearpedit#pride month#default tags#tags are your best friends#[email protected]
87K notes
·
View notes
Text
Accelerating Innovation with Data Engineering on AWS and Aretove’s Expertise as a Leading Data Engineering Company
In today’s digital economy, the ability to process and act on data in real-time is a significant competitive advantage. This is where Data Engineering on AWS and the support of a dedicated Data Engineering Company like Aretove come into play. These solutions form the backbone of modern analytics architectures, powering everything from real-time dashboards to machine learning pipelines.
What is Data Engineering and Why is AWS the Platform of Choice?
Data engineering is the practice of designing and building systems for collecting, storing, and analyzing data. As businesses scale, traditional infrastructures struggle to handle the volume, velocity, and variety of data. This is where Amazon Web Services (AWS) shines.
AWS offers a robust, flexible, and scalable environment ideal for modern data workloads. Aretove leverages a variety of AWS tools—like Amazon Redshift, AWS Glue, and Amazon S3—to build data pipelines that are secure, efficient, and cost-effective.
Core Benefits of AWS for Data Engineering
Scalability: AWS services automatically scale to handle growing data needs.
Flexibility: Supports both batch and real-time data processing.
Security: Industry-leading compliance and encryption capabilities.
Integration: Seamlessly works with machine learning tools and third-party apps.
At Aretove, we customize your AWS architecture to match business goals, ensuring performance without unnecessary costs.
Aretove: A Trusted Data Engineering Company
As a premier Data Engineering Aws , Aretove specializes in end-to-end solutions that unlock the full potential of your data. Whether you're migrating to the cloud, building a data lake, or setting up real-time analytics, our team of experts ensures a seamless implementation.
Our services include:
Data Pipeline Development: Build robust ETL/ELT pipelines using AWS Glue and Lambda.
Data Warehousing: Design scalable warehouses with Amazon Redshift for fast querying and analytics.
Real-time Streaming: Implement streaming data workflows with Amazon Kinesis and Apache Kafka.
Data Governance and Quality: Ensure your data is accurate, consistent, and secure.
Case Study: Real-Time Analytics for E-Commerce
An e-commerce client approached Aretove to improve its customer insights using real-time analytics. We built a cloud-native architecture on AWS using Kinesis for stream ingestion and Redshift for warehousing. This allowed the client to analyze customer behavior instantly and personalize recommendations, leading to a 30% boost in conversion rates.
Why Aretove Stands Out
What makes Aretove different is our ability to bridge business strategy with technical execution. We don’t just build pipelines—we build solutions that drive revenue, enhance user experiences, and scale with your growth.
With a client-centric approach and deep technical know-how, Aretove empowers businesses across industries to harness the power of their data.
Looking Ahead
As data continues to fuel innovation, companies that invest in modern data engineering practices will be the ones to lead. AWS provides the tools, and Aretove brings the expertise. Together, we can transform your data into a strategic asset.
Whether you’re starting your cloud journey or optimizing an existing environment, Aretove is your go-to partner for scalable, intelligent, and secure data engineering solutions.
0 notes
Text
Trusted Data Warehouse Consulting Services Experts
Visit us Now -��https://goognu.com/services/data-warehouse-consulting-services
Unlock the full potential of your data with our trusted Data Warehouse Consulting Services. Our team of experts specializes in designing, implementing, and optimizing modern data warehouse solutions that empower your business to make informed decisions backed by real-time insights.
We begin by thoroughly analyzing your existing data landscape to identify gaps, inefficiencies, and opportunities. Whether you're looking to migrate from legacy systems, modernize your data infrastructure, or integrate cloud platforms like AWS, Azure, or Google Cloud, our consultants provide tailored strategies that align with your business goals.
Our services include data warehouse architecture design, ETL/ELT pipeline development, data modeling, performance tuning, and cloud integration. With a focus on scalability and security, we ensure your data warehouse supports current needs while remaining flexible for future growth.
What sets us apart is our commitment to collaboration and results. We work closely with your internal teams to ensure seamless transitions, minimize disruptions, and deliver measurable outcomes. From financial services to retail, healthcare, and beyond, we have delivered robust solutions across diverse industries.
0 notes
Text
Exploring the Role of Azure Data Factory in Hybrid Cloud Data Integration

Introduction
In today’s digital landscape, organizations increasingly rely on hybrid cloud environments to manage their data. A hybrid cloud setup combines on-premises data sources, private clouds, and public cloud platforms like Azure, AWS, or Google Cloud. Managing and integrating data across these diverse environments can be complex.
This is where Azure Data Factory (ADF) plays a crucial role. ADF is a cloud-based data integration service that enables seamless movement, transformation, and orchestration of data across hybrid cloud environments.
In this blog, we’ll explore how Azure Data Factory simplifies hybrid cloud data integration, key use cases, and best practices for implementation.
1. What is Hybrid Cloud Data Integration?
Hybrid cloud data integration is the process of connecting, transforming, and synchronizing data between: ✅ On-premises data sources (e.g., SQL Server, Oracle, SAP) ✅ Cloud storage (e.g., Azure Blob Storage, Amazon S3) ✅ Databases and data warehouses (e.g., Azure SQL Database, Snowflake, BigQuery) ✅ Software-as-a-Service (SaaS) applications (e.g., Salesforce, Dynamics 365)
The goal is to create a unified data pipeline that enables real-time analytics, reporting, and AI-driven insights while ensuring data security and compliance.
2. Why Use Azure Data Factory for Hybrid Cloud Integration?
Azure Data Factory (ADF) provides a scalable, serverless solution for integrating data across hybrid environments. Some key benefits include:
✅ 1. Seamless Hybrid Connectivity
ADF supports over 90+ data connectors, including on-prem, cloud, and SaaS sources.
It enables secure data movement using Self-Hosted Integration Runtime to access on-premises data sources.
✅ 2. ETL & ELT Capabilities
ADF allows you to design Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) pipelines.
Supports Azure Data Lake, Synapse Analytics, and Power BI for analytics.
✅ 3. Scalability & Performance
Being serverless, ADF automatically scales resources based on data workload.
It supports parallel data processing for better performance.
✅ 4. Low-Code & Code-Based Options
ADF provides a visual pipeline designer for easy drag-and-drop development.
It also supports custom transformations using Azure Functions, Databricks, and SQL scripts.
✅ 5. Security & Compliance
Uses Azure Key Vault for secure credential management.
Supports private endpoints, network security, and role-based access control (RBAC).
Complies with GDPR, HIPAA, and ISO security standards.
3. Key Components of Azure Data Factory for Hybrid Cloud Integration
1️⃣ Linked Services
Acts as a connection between ADF and data sources (e.g., SQL Server, Blob Storage, SFTP).
2️⃣ Integration Runtimes (IR)
Azure-Hosted IR: For cloud data movement.
Self-Hosted IR: For on-premises to cloud integration.
SSIS-IR: To run SQL Server Integration Services (SSIS) packages in ADF.
3️⃣ Data Flows
Mapping Data Flow: No-code transformation engine.
Wrangling Data Flow: Excel-like Power Query transformation.
4️⃣ Pipelines
Orchestrate complex workflows using different activities like copy, transformation, and execution.
5️⃣ Triggers
Automate pipeline execution using schedule-based, event-based, or tumbling window triggers.
4. Common Use Cases of Azure Data Factory in Hybrid Cloud
🔹 1. Migrating On-Premises Data to Azure
Extracts data from SQL Server, Oracle, SAP, and moves it to Azure SQL, Synapse Analytics.
🔹 2. Real-Time Data Synchronization
Syncs on-prem ERP, CRM, or legacy databases with cloud applications.
🔹 3. ETL for Cloud Data Warehousing
Moves structured and unstructured data to Azure Synapse, Snowflake for analytics.
🔹 4. IoT and Big Data Integration
Collects IoT sensor data, processes it in Azure Data Lake, and visualizes it in Power BI.
🔹 5. Multi-Cloud Data Movement
Transfers data between AWS S3, Google BigQuery, and Azure Blob Storage.
5. Best Practices for Hybrid Cloud Integration Using ADF
✅ Use Self-Hosted IR for Secure On-Premises Data Access ✅ Optimize Pipeline Performance using partitioning and parallel execution ✅ Monitor Pipelines using Azure Monitor and Log Analytics ✅ Secure Data Transfers with Private Endpoints & Key Vault ✅ Automate Data Workflows with Triggers & Parameterized Pipelines
6. Conclusion
Azure Data Factory plays a critical role in hybrid cloud data integration by providing secure, scalable, and automated data pipelines. Whether you are migrating on-premises data, synchronizing real-time data, or integrating multi-cloud environments, ADF simplifies complex ETL processes with low-code and serverless capabilities.
By leveraging ADF’s integration runtimes, automation, and security features, organizations can build a resilient, high-performance hybrid cloud data ecosystem.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
#IfiTechsolutions#DataWarehouseMigration#AzureSQL#CloudMigration#MicrosoftPartner#AzureData#HealthcareAI#RedshiftToAzure#CloudComputing#DataAnalytics#DigitalTransformation
0 notes
Text
Kadel Labs: Leading the Way as Databricks Consulting Partners
Introduction
In today’s data-driven world, businesses are constantly seeking efficient ways to harness the power of big data. As organizations generate vast amounts of structured and unstructured data, they need advanced tools and expert guidance to extract meaningful insights. This is where Kadel Labs, a leading technology solutions provider, steps in. As Databricks Consulting Partners, Kadel Labs specializes in helping businesses leverage the Databricks Lakehouse platform to unlock the full potential of their data.
Understanding Databricks and the Lakehouse Architecture
Before diving into how Kadel Labs can help businesses maximize their data potential, it’s crucial to understand Databricks and its revolutionary Lakehouse architecture.
Databricks is an open, unified platform designed for data engineering, machine learning, and analytics. It combines the best of data warehouses and data lakes, allowing businesses to store, process, and analyze massive datasets with ease. The Databricks Lakehouse model integrates the reliability of a data warehouse with the scalability of a data lake, enabling businesses to maintain structured and unstructured data efficiently.
Key Features of Databricks Lakehouse
Unified Data Management – Combines structured and unstructured data storage.
Scalability and Flexibility – Handles large-scale datasets with optimized performance.
Cost Efficiency – Reduces data redundancy and lowers storage costs.
Advanced Security – Ensures governance and compliance for sensitive data.
Machine Learning Capabilities – Supports AI and ML workflows seamlessly.
Why Businesses Need Databricks Consulting Partners
While Databricks offers powerful tools, implementing and managing its solutions requires deep expertise. Many organizations struggle with:
Migrating data from legacy systems to Databricks Lakehouse.
Optimizing data pipelines for real-time analytics.
Ensuring security, compliance, and governance.
Leveraging machine learning and AI for business growth.
This is where Kadel Labs, as an experienced Databricks Consulting Partner, helps businesses seamlessly adopt and optimize Databricks solutions.
Kadel Labs: Your Trusted Databricks Consulting Partner
Expertise in Databricks Implementation
Kadel Labs specializes in helping businesses integrate the Databricks Lakehouse platform into their existing data infrastructure. With a team of highly skilled engineers and data scientists, Kadel Labs provides end-to-end consulting services, including:
Databricks Implementation & Setup – Deploying Databricks on AWS, Azure, or Google Cloud.
Data Pipeline Development – Automating data ingestion, transformation, and analysis.
Machine Learning Model Deployment – Utilizing Databricks MLflow for AI-driven decision-making.
Data Governance & Compliance – Implementing best practices for security and regulatory compliance.
Custom Solutions for Every Business
Kadel Labs understands that every business has unique data needs. Whether a company is in finance, healthcare, retail, or manufacturing, Kadel Labs designs tailor-made solutions to address specific challenges.
Use Case 1: Finance & Banking
A leading financial institution faced challenges with real-time fraud detection. By implementing Databricks Lakehouse, Kadel Labs helped the company process vast amounts of transaction data, enabling real-time anomaly detection and fraud prevention.
Use Case 2: Healthcare & Life Sciences
A healthcare provider needed to consolidate patient data from multiple sources. Kadel Labs implemented Databricks Lakehouse, enabling seamless integration of electronic health records (EHRs), genomic data, and medical imaging, improving patient care and operational efficiency.
Use Case 3: Retail & E-commerce
A retail giant wanted to personalize customer experiences using AI. By leveraging Databricks Consulting Services, Kadel Labs built a recommendation engine that analyzed customer behavior, leading to a 25% increase in sales.
Migration to Databricks Lakehouse
Many organizations still rely on traditional data warehouses and Hadoop-based ecosystems. Kadel Labs assists businesses in migrating from legacy systems to Databricks Lakehouse, ensuring minimal downtime and optimal performance.
Migration Services Include:
Assessing current data architecture and identifying challenges.
Planning a phased migration strategy.
Executing a seamless transition with data integrity checks.
Training teams to effectively utilize Databricks.
Enhancing Business Intelligence with Kadel Labs
By combining the power of Databricks Lakehouse with BI tools like Power BI, Tableau, and Looker, Kadel Labs enables businesses to gain deep insights from their data.
Key Benefits:
Real-time data visualization for faster decision-making.
Predictive analytics for future trend forecasting.
Seamless data integration with cloud and on-premise solutions.
Future-Proofing Businesses with Kadel Labs
As data landscapes evolve, Kadel Labs continuously innovates to stay ahead of industry trends. Some emerging areas where Kadel Labs is making an impact include:
Edge AI & IoT Data Processing – Utilizing Databricks for real-time IoT data analytics.
Blockchain & Secure Data Sharing – Enhancing data security in financial and healthcare industries.
AI-Powered Automation – Implementing AI-driven automation for operational efficiency.
Conclusion
For businesses looking to harness the power of data, Kadel Labs stands out as a leading Databricks Consulting Partner. By offering comprehensive Databricks Lakehouse solutions, Kadel Labs empowers organizations to transform their data strategies, enhance analytics capabilities, and drive business growth.
If your company is ready to take the next step in data innovation, Kadel Labs is here to help. Reach out today to explore custom Databricks solutions tailored to your business needs.
0 notes
Text
The demand for SAP FICO vs. SAP HANA in India depends on industry trends, company requirements, and evolving SAP technologies. Here’s a breakdown:
1. SAP FICO Demand in India
SAP FICO (Finance & Controlling) has been a core SAP module for years, used in almost every company that runs SAP ERP. It includes:
Financial Accounting (FI) – General Ledger, Accounts Payable, Accounts Receivable, Asset Accounting, etc.
Controlling (CO) – Cost Center Accounting, Internal Orders, Profitability Analysis, etc.
Why is SAP FICO in demand? ✅ Essential for businesses – Every company needs finance & accounting. ✅ High job availability – Many Indian companies still run SAP ECC, where FICO is critical. ✅ Migration to S/4HANA – Companies moving from SAP ECC to SAP S/4HANA still require finance professionals. ✅ Stable career growth – Finance roles are evergreen.
Challenges:
As companies move to S/4HANA, traditional FICO skills alone are not enough.
Need to upskill in SAP S/4HANA Finance (Simple Finance) and integration with SAP HANA.
2. SAP HANA Demand in India
SAP HANA is an in-memory database and computing platform that powers SAP S/4HANA. Key areas include:
SAP HANA Database (DBA roles)
SAP HANA Modeling (for reporting & analytics)
SAP S/4HANA Functional & Technical roles
SAP BW/4HANA (Business Warehouse on HANA)
Why is SAP HANA in demand? ✅ Future of SAP – SAP S/4HANA is replacing SAP ECC, and all new implementations are on HANA. ✅ High-paying jobs – Technical consultants with SAP HANA expertise earn more. ✅ Cloud adoption – Companies prefer SAP on AWS, Azure, and GCP, requiring HANA skills. ✅ Data & Analytics – Business intelligence and real-time analytics run on HANA.
Challenges:
More technical compared to SAP FICO.
Requires skills in SQL, HANA Modeling, CDS Views, and ABAP on HANA.
Companies still transitioning from ECC, meaning FICO is not obsolete yet.
Mail us on [email protected]
Website: Anubhav Online Trainings | UI5, Fiori, S/4HANA Trainings

0 notes
Text
Best Informatica Cloud Training in India | Informatica IICS
Cloud Data Integration (CDI) in Informatica IICS
Introduction
Cloud Data Integration (CDI) in Informatica Intelligent Cloud Services (IICS) is a powerful solution that helps organizations efficiently manage, process, and transform data across hybrid and multi-cloud environments. CDI plays a crucial role in modern ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) operations, enabling businesses to achieve high-performance data processing with minimal complexity. In today’s data-driven world, businesses need seamless integration between various data sources, applications, and cloud platforms. Informatica Training Online

What is Cloud Data Integration (CDI)?
Cloud Data Integration (CDI) is a Software-as-a-Service (SaaS) solution within Informatica IICS that allows users to integrate, transform, and move data across cloud and on-premises systems. CDI provides a low-code/no-code interface, making it accessible for both technical and non-technical users to build complex data pipelines without extensive programming knowledge.
Key Features of CDI in Informatica IICS
Cloud-Native Architecture
CDI is designed to run natively on the cloud, offering scalability, flexibility, and reliability across various cloud platforms like AWS, Azure, and Google Cloud.
Prebuilt Connectors
It provides out-of-the-box connectors for SaaS applications, databases, data warehouses, and enterprise applications such as Salesforce, SAP, Snowflake, and Microsoft Azure.
ETL and ELT Capabilities
Supports ETL for structured data transformation before loading and ELT for transforming data after loading into cloud storage or data warehouses.
Data Quality and Governance
Ensures high data accuracy and compliance with built-in data cleansing, validation, and profiling features. Informatica IICS Training
High Performance and Scalability
CDI optimizes data processing with parallel execution, pushdown optimization, and serverless computing to enhance performance.
AI-Powered Automation
Integrated Informatica CLAIRE, an AI-driven metadata intelligence engine, automates data mapping, lineage tracking, and error detection.
Benefits of Using CDI in Informatica IICS
1. Faster Time to Insights
CDI enables businesses to integrate and analyze data quickly, helping data analysts and business teams make informed decisions in real-time.
2. Cost-Effective Data Integration
With its serverless architecture, businesses can eliminate on-premise infrastructure costs, reducing Total Cost of Ownership (TCO) while ensuring high availability and security.
3. Seamless Hybrid and Multi-Cloud Integration
CDI supports hybrid and multi-cloud environments, ensuring smooth data flow between on-premises systems and various cloud providers without performance issues. Informatica Cloud Training
4. No-Code/Low-Code Development
Organizations can build and deploy data pipelines using a drag-and-drop interface, reducing dependency on specialized developers and improving productivity.
5. Enhanced Security and Compliance
Informatica ensures data encryption, role-based access control (RBAC), and compliance with GDPR, CCPA, and HIPAA standards, ensuring data integrity and security.
Use Cases of CDI in Informatica IICS
1. Cloud Data Warehousing
Companies migrating to cloud-based data warehouses like Snowflake, Amazon Redshift, or Google BigQuery can use CDI for seamless data movement and transformation.
2. Real-Time Data Integration
CDI supports real-time data streaming, enabling enterprises to process data from IoT devices, social media, and APIs in real-time.
3. SaaS Application Integration
Businesses using applications like Salesforce, Workday, and SAP can integrate and synchronize data across platforms to maintain data consistency. IICS Online Training
4. Big Data and AI/ML Workloads
CDI helps enterprises prepare clean and structured datasets for AI/ML model training by automating data ingestion and transformation.
Conclusion
Cloud Data Integration (CDI) in Informatica IICS is a game-changer for enterprises looking to modernize their data integration strategies. CDI empowers businesses to achieve seamless data connectivity across multiple platforms with its cloud-native architecture, advanced automation, AI-powered data transformation, and high scalability. Whether you’re migrating data to the cloud, integrating SaaS applications, or building real-time analytics pipelines, Informatica CDI offers a robust and efficient solution to streamline your data workflows.
For organizations seeking to accelerate digital transformation, adopting Informatics’ Cloud Data Integration (CDI) solution is a strategic step toward achieving agility, cost efficiency, and data-driven innovation.
For More Information about Informatica Cloud Online Training
Contact Call/WhatsApp: +91 7032290546
Visit: https://www.visualpath.in/informatica-cloud-training-in-hyderabad.html
#Informatica Training in Hyderabad#IICS Training in Hyderabad#IICS Online Training#Informatica Cloud Training#Informatica Cloud Online Training#Informatica IICS Training#Informatica Training Online#Informatica Cloud Training in Chennai#Informatica Cloud Training In Bangalore#Best Informatica Cloud Training in India#Informatica Cloud Training Institute#Informatica Cloud Training in Ameerpet
0 notes
Text
#ifitechsolutions#HealthcareInnovation#DataWarehouseMigration#HealthTech#DataAnalytics#DigitalTransformation
0 notes
Text
Expert Data Lake Consulting Services for Scalable Solutions
Visit our Website - https://goognu.com/services/data-lake-consulting-services
In today’s data-driven world, businesses need efficient ways to store, manage, and analyze vast amounts of structured and unstructured data. Our Data Lake Consulting Services provide tailored solutions to help organizations implement, optimize, and manage data lakes for maximum performance and scalability.
Our team of experts specializes in designing and deploying cloud-based and on-premises data lakes that enable seamless data integration, real-time analytics, and advanced data governance. We work closely with your business to understand your unique needs, ensuring that your data lake architecture aligns with your operational goals and compliance requirements.
We help organizations leverage powerful tools like AWS Lake Formation, Azure Data Lake, Google Cloud Storage, and Apache Hadoop to build scalable and cost-effective solutions. Whether you're looking to migrate from traditional data warehouses, improve your existing data lake setup, or implement AI-driven analytics, our consulting services ensure a smooth and successful transformation.
With our expertise in data ingestion, metadata management, security, and performance optimization, we help businesses break down data silos and unlock valuable insights. We also provide end-to-end support, from strategy development to implementation and ongoing maintenance, ensuring that your data lake remains a valuable asset for innovation and decision-making.
0 notes
Text
Transforming Business with Goognu Data Lake Consulting Services

Data Lake Consulting Services | Goognu
In today's competitive and data-driven world, businesses rely heavily on the power of data to make informed decisions, optimize operations, and drive innovation. However, effectively managing vast amounts of raw data can be a daunting challenge. This is where Data Lake Consulting Services play a pivotal role. Goognu, a trusted leader in the field, offers unparalleled expertise in designing, implementing, and optimizing data lakes, ensuring businesses can harness the full potential of their data for strategic growth.
What Are Data Lake Consulting Services?
A data lake is a centralized repository designed to store, manage, and process massive volumes of structured, semi-structured, and unstructured data. Unlike traditional data warehouses, data lakes can hold data in its raw form, providing a flexible and scalable solution for organizations. Data Lake Consulting Services guide businesses in establishing these repositories while addressing their unique challenges, from storage and accessibility to analytics and security.
At Goognu, we offer a comprehensive range of Data Lake Consulting Services, tailored to meet the specific needs of each client. With more than 21 years of software engineering experience, 200+ highly skilled data professionals, and partnerships with leading cloud platforms such as AWS, Microsoft Azure, and Google Cloud, Goognu ensures seamless integration, robust performance, and maximum value from your data assets.
Key Offerings of Goognu’s Data Lake Consulting Services
1. Scalable and Cost-Effective Solutions
Businesses today face the challenge of managing exponentially growing data volumes. Goognu’s Data Lake Consulting Services provide cost-effective, scalable solutions that enable organizations to expand their storage capacity as needed without significant upfront investments. By leveraging the expertise of Goognu, businesses can ensure efficient data management that evolves with their needs.
2. Enhanced Data Accessibility
One of the significant benefits of data lakes is the centralization of raw data from multiple sources in a unified repository. Goognu simplifies this process by ensuring seamless data integration, making it accessible to all stakeholders. This fosters a culture of collaboration and supports data-driven decision-making across the organization.
3. Advanced Analytics and Machine Learning
Data lakes provide an ideal environment for deploying machine learning and advanced analytics. Goognu enables businesses to build and train AI models efficiently, thanks to centralized and diverse datasets. These capabilities empower organizations to uncover hidden patterns, generate actionable insights, and create intelligent solutions that drive innovation and improve decision-making.
4. Seamless Cloud Migration
Transitioning data to the cloud is often a critical component of modern data management strategies. Goognu specializes in seamless cloud migration services, ensuring that businesses can move their data to secure and scalable cloud environments without disruptions. Their expertise spans public, private, and hybrid cloud configurations, guaranteeing optimal performance and security.
5. Robust Security and Compliance
Security is a cornerstone of Goognu's Data Lake Consulting Services. Their solutions include fine-grained access controls, identity management, and compliance frameworks tailored to each business's unique requirements. This ensures data protection while maintaining regulatory compliance.
6. Optimized Performance
Goognu team of experts focuses on optimizing data lake infrastructure for better performance, scalability, and availability. By implementing robust scheduling solutions and integrating the right DevOps tools, they ensure uninterrupted data operations and improved efficiency.
Benefits of Partnering with Goognu
Goognu’s extensive experience in Data Lake Consulting Services spans various industries, including financial services, pharmaceuticals, entertainment, and more. Their client-centric approach ensures tailored solutions that address specific challenges while delivering measurable business value.
1. Expertise You Can Trust
With over two decades of experience and 400+ cloud specialists, Goognu brings unmatched expertise to every project. Their team of certified professionals ensures that your data lake is designed and implemented with precision and scalability in mind.
2. Comprehensive Support
Goognu provides end-to-end support for data lake projects, from strategy and design to implementation and maintenance. Their 24/7 assistance ensures that businesses always have access to expert help when needed.
3. Cost Efficiency
By leveraging Goognu’s scalable and optimized solutions, businesses can reduce costs associated with data management. From rightsizing storage to streamlining operational processes, Goognu ensures maximum ROI.
4. Tailored Solutions for Every Industry
Goognu expertise spans a wide range of industries, enabling them to create customized data lake architectures that address unique challenges and deliver significant business impact.
Major Services Offered
Detailed Data Lake Strategy Consultation: Goognu works closely with businesses to design effective data lake strategies. Their consultative approach ensures that every solution aligns with the client’s goals and operational needs.
Data Lake Implementation with Advanced Analytics: Through well-designed architectures, Goognu transforms raw data into meaningful insights. This empowers organizations to make data-driven decisions and improve overall efficiency.
Deploying Advanced Analytics and Machine Learning: Goognu leverages the latest advancements in containerization and machine learning to build intelligent solutions within the data lake environment.
Seamless Cloud Migration Services: From planning to execution, Goognu ensures smooth transitions to cloud platforms, maintaining high levels of data integrity and security.
Why Choose Goognu for Data Lake Consulting Services?
1. Industry Experience
Goognu has completed over 30 successful data projects, earning a reputation for delivering reliable and innovative solutions. Their portfolio includes leading enterprises and Fortune 500 companies, showcasing their ability to handle complex challenges effectively.
2. Cutting-Edge Tools and Techniques
Goognu stays at the forefront of technological advancements, utilizing advanced tools for big data engineering, analytics, and machine learning. This ensures that their clients remain competitive in an ever-evolving market.
3. Commitment to Security
Data protection and compliance are integral to Goognu’s services. By implementing robust security measures and adhering to industry standards, they provide peace of mind to their clients.
4. Unparalleled Support
Goognu round-the-clock support ensures that clients have access to assistance whenever needed. Their dedication to customer satisfaction sets them apart as a trusted partner.
Conclusion
Goognu’s Data Lake Consulting Services offer businesses a comprehensive solution for managing, storing, and analyzing their data. By partnering with Goognu, organizations can harness the power of their data lakes to drive innovation, optimize operations, and make strategic decisions. With a proven track record of success and a commitment to excellence, Goognu stands as a trusted partner in the journey toward data-driven success.
Let’s Connect
Ready to unlock the full potential of your data? Goognu is here to help. Their team of experienced professionals is committed to providing tailored solutions that meet your unique business needs. Contact them today to schedule a consultation and take the first step toward transforming your data management strategy.
Location: Unit No. 538, JMD Megapolis, Sohna Road, Gurugram-122018
Email: [email protected]
Phone: +91 9971018978
0 notes
Text
5 Obstacles in Big Data and How Amazon Web Services Can Conquer Them

Unlocking big data's potential is vital for every contemporary firm aiming for success. The amount of important information that big data contains about consumer behavior and the opportunity to improve customer experiences, cut expenditures, drive revenue growth, and promote product creation is evident.
However, handling massive data creates numerous issues that require precise attention and experience. Analyzing enormous quantities of data might be difficult, but it is not impossible.
Data Growth
We hear data is growing quickly, and the stats support that. According to Forbes, global data generation, recording, copying, and consumption increased from 1.2 trillion gigabytes to 59 trillion gigabytes between 2010 and 2020.
That’s a lot of data that may be valuable for corporations. But it needs a lot of effort to get value from it. This involves storing it, and data storage isn’t free. Migrating existing servers and storage to a cloud-based environment with AWS consulting services can help, offering software-defined storage solutions and techniques like compression, tiering, and deduplication to optimize space and reduce costs.
Data Integration
From social network sites, emails, and financial reports to gadget sensors, satellite pictures, and delivery receipts, data may flow from just about anywhere. There could be some organization to it. Perhaps some of it lacks structure. And some of it may be semi-structured. Businesses have a daunting task when trying to compile data from disparate sources, ensure compatibility, and provide a single perspective for analysis and report generation.
When it comes to data integration, there are a lot of options. The same is true for platforms and software that automate the process of data integration by linking and directing data from source systems to destination systems. Customized versions may also be developed by data integration architects.
Before you can choose the right data integration technologies and approaches, you need to figure out what your integration needs are and what kind of business profile you have.
The Synchronization of Data
Inaccuracies in analysis might occur if data copies from separate sources are not in sync with one another due to differences in transfer rates and scheduling. The value of data analytics initiatives might be diminished owing to delays in information caused by fixing this misalignment, which disrupts the programs.
There are services available to automate and speed up the data synchronization process, which is excellent news. Data archiving, duplication, and processing via cloud transfer are further features of these systems. For safe and efficient data processing, essential security features, including data-in-transit encryption, data integrity checks, and automated recovery, are necessary.
Ensuring the Safety of Data
Big data is useful for more than just companies. Cybercriminals are very interested in it. Furthermore, they are dogged in their pursuit of stolen data and often succeed in doing so for malicious ends. For these reasons, it may pose problems with data loss prevention, downtime mitigation, and privacy.
It is not that companies do not consider data security. The catch is that they could not realize it calls for a comprehensive strategy that is always evolving to meet new challenges. Addressing the fallout after a data breach should take precedence over efforts to avoid one. It encompasses the whole data lifecycle, from the sites of origin (endpoints) to the storage locations (data warehouses, data lakes) to the people who consume the data (users).
For complete data security, you should implement the following measures:
Protecting and separating data
Control over user identities and permissions for access
Terminal security
Continuous tracking
Strengthening cloud platforms
Network perimeter security
Isolation of security functions
Implementing cloud-optimized frameworks and architectures for data security.
Compliance requirements
Businesses have a significant challenge in complying with data security and privacy rules because of the volume and complexity of data they manage. It is critical to contact professionals as needed and stay current on compliance responsibilities.
Ensuring compliance with regulatory requirements needs the use of precise data. Governance frameworks aid in system integration, giving an auditable picture of data throughout the firm, while automation and duplication simplify reporting and compliance. Management of data pipelines is further simplified by unification.
Amazon Web Services Fixes for Big Data Problems
One way to tackle these 5 big data obstacles is by using AWS data analytics services offered by https://itmagic.pro/. The AWS cloud offers a number of advantages, such as secure infrastructure and the ability to pay for cloud computing as you go.
Data input, synchronization, storage, security, processing, warehousing, orchestration, and visualization are all possible with the help of a wide range of cloud services.
0 notes
Text
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗘𝗧𝗟?
Extract, Transform, Load (ETL) is a data integration process that involves:
𝟭. 𝗘𝘅𝘁𝗿𝗮𝗰𝘁: This step involves extracting data from various heterogeneous sources. These sources include databases, flat files, APIs, or other data storage mechanisms.
𝟮. 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺: Once the data is extracted, it often needs to be transformed into a format suitable for analysis or reporting. This transformation can involve various operations such as:
🔹 Cleaning the data (e.g., removing duplicates or correcting errors).
🔹 Enriching the data (e.g., combining it with other sources).
🔹 Aggregating or summarizing data.
🔹 Converting data types or formats.
🔹 Applying business rules or calculations.
𝟯. 𝗟𝗼𝗮𝗱: The final step is to load the transformed data into a target system, often a data warehouse, data mart, or another database. This system is then used for business intelligence, reporting, or further analysis.
Some everyday use cases for ETL are:
𝟭. 𝗗𝗮𝘁𝗮 𝗪𝗮𝗿𝗲𝗵𝗼𝘂𝘀𝗶𝗻𝗴: ETL processes are fundamental to data warehousing. They pull data from various operational systems, transform it, and then load it into a data warehouse for analysis.
𝟮. 𝗗𝗮𝘁𝗮 𝗠𝗶𝗴𝗿𝗮𝘁𝗶𝗼𝗻: When businesses change or upgrade their systems, they often need to move data from one system or format to another. ETL processes can help with this migration.
𝟯. 𝗗𝗮𝘁𝗮 𝗜𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗶𝗼𝗻: Companies often have data spread across multiple systems. ETL can integrate this data to provide a unified view.
𝟰. 𝗕𝘂𝘀𝗶𝗻𝗲𝘀𝘀 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 𝗮𝗻𝗱 𝗥𝗲𝗽𝗼𝗿𝘁𝗶𝗻𝗴: For meaningful BI and reporting, data must often be cleaned, transformed, and integrated. ETL processes facilitate this.
𝟱. 𝗗𝗮𝘁𝗮 𝗟𝗮𝗸𝗲 𝗣𝗼𝗽𝘂𝗹𝗮𝘁𝗶𝗼𝗻: ETL processes can populate data lakes with structured and unstructured data from various sources.
Some standard 𝗘𝗧𝗟 𝘁𝗼𝗼𝗹𝘀 are Microsoft SSIS, Talend, Oracle Data Integrator, Apache NiFi, and AWS Glue.
There is also a bit different approach nowadays, called 𝗘𝗟𝗧 (𝗘𝘅𝘁𝗿𝗮𝗰𝘁, 𝗟𝗼𝗮𝗱, 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺). This is a data integration approach where raw data is extracted from various sources, loaded directly into a data warehouse or big data platform, and finally transformed within that target system.

0 notes
Text
The demand for SAP FICO vs. SAP HANA in India depends on industry trends, company requirements, and evolving SAP technologies. Here’s a breakdown:
1. SAP FICO Demand in India
SAP FICO (Finance & Controlling) has been a core SAP module for years, used in almost every company that runs SAP ERP. It includes:
Financial Accounting (FI) – General Ledger, Accounts Payable, Accounts Receivable, Asset Accounting, etc.
Controlling (CO) – Cost Center Accounting, Internal Orders, Profitability Analysis, etc.
Why is SAP FICO in demand? ✅ Essential for businesses – Every company needs finance & accounting. ✅ High job availability – Many Indian companies still run SAP ECC, where FICO is critical. ✅ Migration to S/4HANA – Companies moving from SAP ECC to SAP S/4HANA still require finance professionals. ✅ Stable career growth – Finance roles are evergreen.
Challenges:
As companies move to S/4HANA, traditional FICO skills alone are not enough.
Need to upskill in SAP S/4HANA Finance (Simple Finance) and integration with SAP HANA.
2. SAP HANA Demand in India
SAP HANA is an in-memory database and computing platform that powers SAP S/4HANA. Key areas include:
SAP HANA Database (DBA roles)
SAP HANA Modeling (for reporting & analytics)
SAP S/4HANA Functional & Technical roles
SAP BW/4HANA (Business Warehouse on HANA)
Why is SAP HANA in demand? ✅ Future of SAP – SAP S/4HANA is replacing SAP ECC, and all new implementations are on HANA. ✅ High-paying jobs – Technical consultants with SAP HANA expertise earn more. ✅ Cloud adoption – Companies prefer SAP on AWS, Azure, and GCP, requiring HANA skills. ✅ Data & Analytics – Business intelligence and real-time analytics run on HANA.
Challenges:
More technical compared to SAP FICO.
Requires skills in SQL, HANA Modeling, CDS Views, and ABAP on HANA.
Companies still transitioning from ECC, meaning FICO is not obsolete yet.
Mail us on [email protected]
Website: Anubhav Online Trainings | UI5, Fiori, S/4HANA Trainings

0 notes
Text
Benefits of Snowflake for enterprise database management
The importance of data for businesses cannot be overstated as the world continues to run on data-intensive, hyper-connected and real-time applications.
Businesses of all scale and capabilities rely on data to make future decisions and derive useful insights to create growth.
However, with the rising volume, complexity and dependency on data rich applications and platforms, it has become imperative for companies and enterprises to make use of scalable, flexible and robust tools and technologies.

This is where database management solutions help businesses implement data pipelines for storing, modifying and analysing data in real-time.
Although there are many tools and solutions to make use of real-time data processing and analysis, not all tools are created equal.
While many companies rely on legacy systems like Microsoft SQL server to power a wide range of applications, modern day businesses are increasingly adapting to cloud-based data warehousing platforms.
One such name in the database management sphere is called Snowflake which is a serverless, cloud-native infrastructure as a service platform.
Snowflake supports Microsoft Azure, Google Cloud and Amazon AWS and is fully scalable to meet your computing and data processing needs.
If you are interested in leveraging the power and capabilities of Snowflake’s cloud based data warehousing solution, it’s time to prepare for migrating your existing SQL server to Snowflake with the help of tools like Bryteflow. Bryteflow allows fully automated, no-code replication of SQL server database to a Snowflake data lake or data warehouse.
0 notes