#Apache Spark
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text


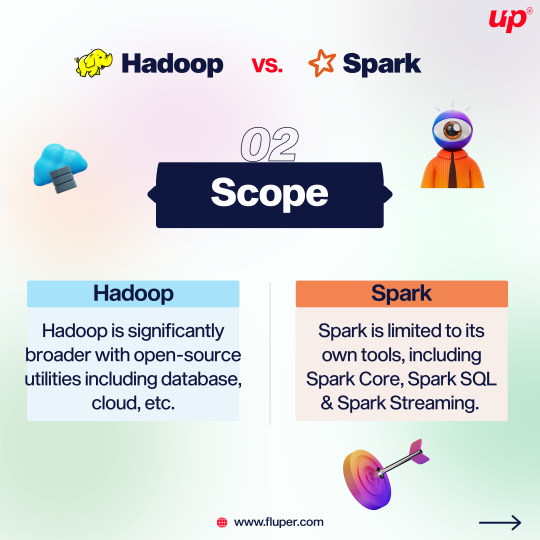




Apache Spark and Apache Hadoop are both popular, open-source data science tools offered by the Apache Software Foundation. . . . . Join the development and support of the community with Fluper, and continue to grow in popularity and features.
2 notes
·
View notes
Text
instagram
#hadoop#alarm#Apache spark#coding#code#machinelearning#programming#datascience#python#programmer#artificialintelligence#deeplearning#ai#Instagram
6 notes
·
View notes
Photo

Hive Tutorial | Hive Course For Beginners | Intellipaat - YouTube ☞ http://go.codetrick.net/d68b7e0dba #bigdata #hadoop
0 notes
Photo

Hive Tutorial | Hive Course For Beginners | Intellipaat - YouTube ☞ http://go.codetrick.net/d68b7e0dba #bigdata #hadoop
0 notes
Text
Supercharge Your Data: Advanced Optimization and Maintenance for Delta Tables in Fabric
Dive into the final part of our series on optimizing data ingestion with Spark in Microsoft Fabric! Discover advanced optimization techniques and essential maintenance strategies for Delta tables to ensure high performance and efficiency in your data Ops
Welcome to the third and final installment of our blog series on optimizing data ingestion with Spark in Microsoft Fabric. In our previous posts, we explored the foundational elements of Microsoft Fabric and Delta Lake, delving into the differences between managed and external tables, as well as their practical applications. Now, it’s time to take your data management skills to the next…
#Advanced Techniques#Apache Spark#Big Data#Cloud Data Management#Data Compaction#Data Efficiency#Data Maintenance#Data management#Data Optimization#Data Performance#Data Retention#Data Scalability#Delta Lake#File Size Optimization#Handling Deletes#Merge Optimization#Microsoft Fabric#Optimize Write#Partition Pruning#Real-Time Data#Schema Evolution#Vacuum Command#Z-Ordering
0 notes
Text
my head hurts should i suffer and choose a nosql database to build my app or should i just "fuck it we ball" and go with postgresql
i mean i have a really structured data but also lots of rows in the tables (like, millions) and potentially a lot of people could use it at the same time and i plan on using spark to analyze stuff?? like will my app survive like that? i don't know shit
#apache spark#nosql#postgresql#of how the tables have turned i post about programming on tumblr#don't ask me why i am doing this if i don't know enough i just want to graduate#i don't even like databases anymore#chatgpt said it's okay to use postgreql and apache spark in this case so it's something#i had to beg it to give me an answer it kept saying “depends on your project blah blah blah”
1 note
·
View note
Text
#learn#free#resource#python#r#postgresql#chatgpt#tableau#power bi#excel#scala#apache spark#shell#git#oracle#programming#software
0 notes
Text
What is Snowpark?

Snowpark is an open-source programming model and language. It aims to simplify the process of writing and executing data processing tasks on various data platforms. Snowpark provides a unified interface for developers to write code in their preferred languages, such as:
Java
Scala
Python.
This makes it seamlessly integrate with the underlying data processing frameworks.
In this microblog, we will explore Snowpark's key features and delve into its significant advantages.
Key Features of Snowpark
Here are the top 3 key features of Snowpark:
Polyglot Support: Snowpark supports multiple programming languages. Thus, allowing developers to code in their preferred language and leverage their existing skills.
Seamless Integration: Snowpark integrates with popular frameworks like Apache Spark. This provides a unified interface for developers to access the full capabilities of these frameworks in their chosen language.
Interactive Development: Snowpark offers a REPL (Read-Eval-Print Loop) environment for interactive code development. This enables faster iteration, prototyping, and debugging with instant feedback.
So, Snowpark allows developers to leverage their language skills and work more flexibly, unlike Spark or PySpark. Furthermore, discover the unique advantages of Snowpark and know about the difference it makes.
Advantages of Implementing Snowpark
Here are the advantages of Snowpark over other programming models:
Language Flexibility: Snowpark stands out by providing polyglot support. Thus, allowing developers to write code in their preferred programming language. In contrast, Spark and PySpark primarily focus on Scala and Python. Snowpark's language flexibility enables organizations to leverage their existing language skills and choose the most suitable language.
Ease of Integration: It seamlessly integrates with frameworks like Apache Spark. This integration enables developers to harness the power of Spark's distributed computing capabilities while leveraging Snowpark's language flexibility. In comparison, Spark and PySpark offer a narrower integration scope which limits the choice of languages.
Interactive Development Environment: Snowpark provides an interactive development environment. This environment allows developers to write, test, and refine code iteratively, offering instant feedback. In contrast, Spark and PySpark lack this built-in interactive environment, potentially slowing down the development process.
Expanded Use Cases: While Spark and PySpark primarily target data processing tasks, Snowpark offers broader applicability. It supports diverse use cases such as data transformations, analytics, and machine learning. This versatility allows organizations to leverage Snowpark across a wider range of data processing scenarios, enabling comprehensive solutions and flexibility.
Increased Developer Productivity: Snowpark's language flexibility and interactive environment boost developer productivity. Developers can work in their preferred programming language, receive real-time feedback, and streamline the development process. In contrast, Spark and PySpark's language constraints may hinder productivity due to the need to learn new languages or adapt to limited options.
Therefore, Snowpark revolutionizes big data processing by offering a versatile platform that supports multiple programming languages. By adopting Snowpark, developers can enhance their efficiency in executing data processing tasks.
This powerful tool has the potential to drive innovation. It can also streamline development efforts and open exciting new opportunities for businesses. Also, stay updated with Nitor Infotech’s latest tech blogs.
#snowpark#snowflake#blog#Bigdata#data processing services#Data transformation#Apache Spark#Open-source#nitorinfotech#big data analytics#automation#software services
0 notes
Text
Are you looking to build a career in Big Data Analytics? Gain in-depth knowledge of Hadoop and its ecosystem with expert-led training at Sunbeam Institute, Pune – a trusted name in IT education.
Why Choose Our Big Data Hadoop Classes?
🔹 Comprehensive Curriculum: Covering Hadoop, HDFS, MapReduce, Apache Spark, Hive, Pig, HBase, Sqoop, Flume, and more. 🔹 Hands-on Training: Work on real-world projects and industry use cases to gain practical experience. 🔹 Expert Faculty: Learn from experienced professionals with real-time industry exposure. 🔹 Placement Assistance: Get career guidance, resume building support, and interview preparation. 🔹 Flexible Learning Modes: Classroom and online training options available. 🔹 Industry-Recognized Certification: Boost your resume with a professional certification.
Who Should Join?
✔️ Freshers and IT professionals looking to enter the field of Big Data & Analytics ✔️ Software developers, system administrators, and data engineers ✔️ Business intelligence professionals and database administrators ✔️ Anyone passionate about Big Data and Machine Learning

#Big Data Hadoop training in Pune#Hadoop classes Pune#Big Data course Pune#Hadoop certification Pune#learn Hadoop in Pune#Apache Spark training Pune#best Big Data course Pune#Hadoop coaching in Pune#Big Data Analytics training Pune#Hadoop and Spark training Pune
0 notes
Text
Anais Dotis-Georgiou, Developer Advocate at InfluxData – Interview Series
New Post has been published on https://thedigitalinsider.com/anais-dotis-georgiou-developer-advocate-at-influxdata-interview-series/
Anais Dotis-Georgiou, Developer Advocate at InfluxData – Interview Series
Anais Dotis-Georgiou is a Developer Advocate for InfluxData with a passion for making data beautiful with the use of Data Analytics, AI, and Machine Learning. She takes the data that she collects, does a mix of research, exploration, and engineering to translate the data into something of function, value, and beauty. When she is not behind a screen, you can find her outside drawing, stretching, boarding, or chasing after a soccer ball.
InfluxData is the company building InfluxDB, the open source time series database used by more than a million developers around the world. Their mission is to help developers build intelligent, real-time systems with their time series data.
Can you share a bit about your journey from being a Research Assistant to becoming a Lead Developer Advocate at InfluxData? How has your background in data analytics and machine learning shaped your current role?
I earned my undergraduate degree in chemical engineering with a focus on biomedical engineering and eventually worked in labs performing vaccine development and prenatal autism detection. From there, I began programming liquid-handling robots and helping data scientists understand the parameters for anomaly detection, which made me more interested in programming.
I then became a sales development representative at Oracle and realized that I really needed to focus on coding. I took a coding boot camp at the University of Texas in data analytics and was able to break into tech, specifically developer relations.
I came from a technical background, so that helped shape my current role. Even though I didn’t have development experience, I could relate to and empathize with people who had an engineering background and mind but were also trying to learn software. So, when I created content or technical tutorials, I was able to help new users overcome technical challenges while placing the conversation in a context that was relevant and interesting to them.
Your work seems to blend creativity with technical expertise. How do you incorporate your passion for making data ‘beautiful’ into your daily work at InfluxData?
Lately, I’ve been more focused on data engineering than data analytics. While I don’t focus on data analytics as much as I used to, I still really enjoy math—I think math is beautiful, and will jump at an opportunity to explain the math behind an algorithm.
InfluxDB has been a cornerstone in the time series data space. How do you see the open source community influencing the development and evolution of InfluxDB?
InfluxData is very committed to the open data architecture and Apache ecosystem. Last year we announced InfluxDB 3.0, the new core for InfluxDB written in Rust and built with Apache Flight, DataFusion, Arrow, and Parquet–what we call the FDAP stack. As the engineers at InfluxData continue to contribute to those upstream projects, the community continues to grow and the Apache Arrow set of projects gets easier to use with more features and functionality, and wider interoperability.
What are some of the most exciting open-source projects or contributions you’ve seen recently in the context of time series data and AI?
It’s been cool to see the addition of LLMs being repurposed or applied to time series for zero-shot forecasting. Autolab has a collection of open time series language models, and TimeGPT is another great example.
Additionally, various open source stream processing libraries, including Bytewax and Mage.ai, that allow users to leverage and incorporate models from Hugging Face are pretty exciting.
How does InfluxData ensure its open source initiatives stay relevant and beneficial to the developer community, particularly with the rapid advancements in AI and machine learning?
InfluxData initiatives remain relevant and beneficial by focusing on contributing to open source projects that AI-specific companies also leverage. For example, every time InfluxDB contributes to Apache Arrow, Parquet, or DataFusion, it benefits every other AI tech and company that leverages it, including Apache Spark, DataBricks, Rapids.ai, Snowflake, BigQuery, HuggingFace, and more.
Time series language models are becoming increasingly vital in predictive analytics. Can you elaborate on how these models are transforming time series forecasting and anomaly detection?
Time series LMs outperform linear and statistical models while also providing zero-shot forecasting. This means you don’t need to train the model on your data before using it. There’s also no need to tune a statistical model, which requires deep expertise in time series statistics.
However, unlike natural language processing, the time series field lacks publicly accessible large-scale datasets. Most existing pre-trained models for time series are trained on small sample sizes, which contain only a few thousand—or maybe even hundreds—of samples. Although these benchmark datasets have been instrumental in the time series community’s progress, their limited sample sizes and lack of generality pose challenges for pre-training deep learning models.
That said, this is what I believe makes open source time series LMs hard to come by. Google’s TimesFM and IBM’s Tiny Time Mixers have been trained on massive datasets with hundreds of billions of data points. With TimesFM, for example, the pre-training process is done using Google Cloud TPU v3–256, which consists of 256 TPU cores with a total of 2 terabytes of memory. The pre-training process takes roughly ten days and results in a model with 1.2 billion parameters. The pre-trained model is then fine-tuned on specific downstream tasks and datasets using a lower learning rate and fewer epochs.
Hopefully, this transformation implies that more people can make accurate predictions without deep domain knowledge. However, it takes a lot of work to weigh the pros and cons of leveraging computationally expensive models like time series LMs from both a financial and environmental cost perspective.
This Hugging Face Blog post details another great example of time series forecasting.
What are the key advantages of using time series LMs over traditional methods, especially in terms of handling complex patterns and zero-shot performance?
The critical advantage is not having to train and retrain a model on your time series data. This hopefully eliminates the online machine learning problem of monitoring your model’s drift and triggering retraining, ideally eliminating the complexity of your forecasting pipeline.
You also don’t need to struggle to estimate the cross-series correlations or relationships for multivariate statistical models. Additional variance added by estimates often harms the resulting forecasts and can cause the model to learn spurious correlations.
Could you provide some practical examples of how models like Google’s TimesFM, IBM’s TinyTimeMixer, and AutoLab’s MOMENT have been implemented in real-world scenarios?
This is difficult to answer; since these models are in their relative infancy, little is known about how companies use them in real-world scenarios.
In your experience, what challenges do organizations typically face when integrating time series LMs into their existing data infrastructure, and how can they overcome them?
Time series LMs are so new that I don’t know the specific challenges organizations face. However, I imagine they’ll confront the same challenges faced when incorporating any GenAI model into your data pipeline. These challenges include:
Data compatibility and integration issues: Time series LMs often require specific data formats, consistent timestamping, and regular intervals, but existing data infrastructure might include unstructured or inconsistent time series data spread across different systems, such as legacy databases, cloud storage, or real-time streams. To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data.
Model scalability and performance: Time series LMs, especially deep learning models like transformers, can be resource-intensive, requiring significant compute and memory resources to process large volumes of time series data in real-time or near-real-time. This would require teams to deploy models on scalable platforms like Kubernetes or cloud-managed ML services, leverage GPU acceleration when needed, and utilize distributed processing frameworks like Dask or Ray to parallelize model inference.
Interpretability and trustworthiness: Time series models, particularly complex LMs, can be seen as “black boxes,” making it hard to interpret predictions. This can be particularly problematic in regulated industries like finance or healthcare.
Data privacy and security: Handling time series data often involves sensitive information, such as IoT sensor data or financial transaction data, so ensuring data security and compliance is critical when integrating LMs. Organizations must ensure data pipelines and models comply with best security practices, including encryption and access control, and deploy models within secure, isolated environments.
Looking forward, how do you envision the role of time series LMs evolving in the field of predictive analytics and AI? Are there any emerging trends or technologies that particularly excite you?
A possible next step in the evolution of time series LMs could be introducing tools that enable users to deploy, access, and use them more easily. Many of the time series LMs I’ve used require very specific environments and lack a breadth of tutorials and documentation. Ultimately, these projects are in their early stages, but it will be exciting to see how they evolve in the coming months and years.
Thank you for the great interview, readers who wish to learn more should visit InfluxData.
#access control#ai#algorithm#Analytics#anomaly detection#Apache#Apache Spark#architecture#autism#background#Beauty#benchmark#best security#bigquery#billion#Biomedical engineering#Blog#Building#chemical#Chemical engineering#Cloud#cloud storage#coding#Community#Companies#complexity#compliance#content#creativity#data
0 notes
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
Unlock Powerful Data Strategies: Master Managed and External Tables in Fabric Delta Lake
Are you ready to unlock powerful data strategies and take your data management skills to the next level? In our latest blog post, we dive deep into mastering managed and external tables in Delta Lake within Microsoft Fabric.
Welcome to our series on optimizing data ingestion with Spark in Microsoft Fabric. In our first post, we covered the capabilities of Microsoft Fabric and its integration with Delta Lake. In this second installment, we dive into mastering Managed and External tables. Choosing between managed and external tables is a crucial decision when working with Delta Lake in Microsoft Fabric. Each option…
#Apache Spark#Big Data#Cloud Data Management#Data Analytics#Data Best Practices#Data Efficiency#Data Governance#Data Ingestion#Data Insights#Data management#Data Optimization#Data Strategies#Data Workflows#Delta Lake#External Tables#Managed Tables#microsoft azure#Microsoft Fabric#Real-Time Data
0 notes
Text

Big Data Battle Alert! Apache Spark vs. Hadoop: Which giant rules your data universe? Spark = Lightning speed (100x faster in-memory processing!) Hadoop = Batch processing king (scalable & cost-effective).Want to dominate your data game? Read more: https://bit.ly/3F2aaNM
0 notes