#kubernetes controller manager logs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Navigating the DevOps Landscape: Opportunities and Roles
DevOps has become a game-changer in the quick-moving world of technology. This dynamic process, whose name is a combination of "Development" and "Operations," is revolutionising the way software is created, tested, and deployed. DevOps is a cultural shift that encourages cooperation, automation, and integration between development and IT operations teams, not merely a set of practises. The outcome? greater software delivery speed, dependability, and effectiveness.

In this comprehensive guide, we'll delve into the essence of DevOps, explore the key technologies that underpin its success, and uncover the vast array of job opportunities it offers. Whether you're an aspiring IT professional looking to enter the world of DevOps or an experienced practitioner seeking to enhance your skills, this blog will serve as your roadmap to mastering DevOps. So, let's embark on this enlightening journey into the realm of DevOps.
Key Technologies for DevOps:
Version Control Systems: DevOps teams rely heavily on robust version control systems such as Git and SVN. These systems are instrumental in managing and tracking changes in code and configurations, promoting collaboration and ensuring the integrity of the software development process.
Continuous Integration/Continuous Deployment (CI/CD): The heart of DevOps, CI/CD tools like Jenkins, Travis CI, and CircleCI drive the automation of critical processes. They orchestrate the building, testing, and deployment of code changes, enabling rapid, reliable, and consistent software releases.
Configuration Management: Tools like Ansible, Puppet, and Chef are the architects of automation in the DevOps landscape. They facilitate the automated provisioning and management of infrastructure and application configurations, ensuring consistency and efficiency.
Containerization: Docker and Kubernetes, the cornerstones of containerization, are pivotal in the DevOps toolkit. They empower the creation, deployment, and management of containers that encapsulate applications and their dependencies, simplifying deployment and scaling.
Orchestration: Docker Swarm and Amazon ECS take center stage in orchestrating and managing containerized applications at scale. They provide the control and coordination required to maintain the efficiency and reliability of containerized systems.
Monitoring and Logging: The observability of applications and systems is essential in the DevOps workflow. Monitoring and logging tools like the ELK Stack (Elasticsearch, Logstash, Kibana) and Prometheus are the eyes and ears of DevOps professionals, tracking performance, identifying issues, and optimizing system behavior.
Cloud Computing Platforms: AWS, Azure, and Google Cloud are the foundational pillars of cloud infrastructure in DevOps. They offer the infrastructure and services essential for creating and scaling cloud-based applications, facilitating the agility and flexibility required in modern software development.
Scripting and Coding: Proficiency in scripting languages such as Shell, Python, Ruby, and coding skills are invaluable assets for DevOps professionals. They empower the creation of automation scripts and tools, enabling customization and extensibility in the DevOps pipeline.
Collaboration and Communication Tools: Collaboration tools like Slack and Microsoft Teams enhance the communication and coordination among DevOps team members. They foster efficient collaboration and facilitate the exchange of ideas and information.
Infrastructure as Code (IaC): The concept of Infrastructure as Code, represented by tools like Terraform and AWS CloudFormation, is a pivotal practice in DevOps. It allows the definition and management of infrastructure using code, ensuring consistency and reproducibility, and enabling the rapid provisioning of resources.

Job Opportunities in DevOps:
DevOps Engineer: DevOps engineers are the architects of continuous integration and continuous deployment (CI/CD) pipelines. They meticulously design and maintain these pipelines to automate the deployment process, ensuring the rapid, reliable, and consistent release of software. Their responsibilities extend to optimizing the system's reliability, making them the backbone of seamless software delivery.
Release Manager: Release managers play a pivotal role in orchestrating the software release process. They carefully plan and schedule software releases, coordinating activities between development and IT teams. Their keen oversight ensures the smooth transition of software from development to production, enabling timely and successful releases.
Automation Architect: Automation architects are the visionaries behind the design and development of automation frameworks. These frameworks streamline deployment and monitoring processes, leveraging automation to enhance efficiency and reliability. They are the engineers of innovation, transforming manual tasks into automated wonders.
Cloud Engineer: Cloud engineers are the custodians of cloud infrastructure. They adeptly manage cloud resources, optimizing their performance and ensuring scalability. Their expertise lies in harnessing the power of cloud platforms like AWS, Azure, or Google Cloud to provide robust, flexible, and cost-effective solutions.
Site Reliability Engineer (SRE): SREs are the sentinels of system reliability. They focus on maintaining the system's resilience through efficient practices, continuous monitoring, and rapid incident response. Their vigilance ensures that applications and systems remain stable and performant, even in the face of challenges.
Security Engineer: Security engineers are the guardians of the DevOps pipeline. They integrate security measures seamlessly into the software development process, safeguarding it from potential threats and vulnerabilities. Their role is crucial in an era where security is paramount, ensuring that DevOps practices are fortified against breaches.
As DevOps continues to redefine the landscape of software development and deployment, gaining expertise in its core principles and technologies is a strategic career move. ACTE Technologies offers comprehensive DevOps training programs, led by industry experts who provide invaluable insights, real-world examples, and hands-on guidance. ACTE Technologies's DevOps training covers a wide range of essential concepts, practical exercises, and real-world applications. With a strong focus on certification preparation, ACTE Technologies ensures that you're well-prepared to excel in the world of DevOps. With their guidance, you can gain mastery over DevOps practices, enhance your skill set, and propel your career to new heights.
11 notes
·
View notes
Text
How a Web Development Company Builds Scalable SaaS Platforms
Building a SaaS (Software as a Service) platform isn't just about writing code—it’s about designing a product that can grow with your business, serve thousands of users reliably, and continuously evolve based on market needs. Whether you're launching a CRM, learning management system, or a niche productivity tool, scalability must be part of the plan from day one.
That’s why a professional Web Development Company brings more than just technical skills to the table. They understand the architectural, design, and business logic decisions required to ensure your SaaS product is not just functional—but scalable, secure, and future-proof.
1. Laying a Solid Architectural Foundation
The first step in building a scalable SaaS product is choosing the right architecture. Most development agencies follow a modular, service-oriented approach that separates different components of the application—user management, billing, dashboards, APIs, etc.—into layers or even microservices.
This ensures:
Features can be developed and deployed independently
The system can scale horizontally (adding more servers) or vertically (upgrading resources)
Future updates or integrations won’t require rebuilding the entire platform
Development teams often choose cloud-native architectures built on platforms like AWS, Azure, or GCP for their scalability and reliability.
2. Selecting the Right Tech Stack
Choosing the right technology stack is critical. The tech must support performance under heavy loads and allow for easy development as your team grows.
Popular stacks for SaaS platforms include:
Frontend: React.js, Vue.js, or Angular
Backend: Node.js, Django, Ruby on Rails, or Laravel
Databases: PostgreSQL or MongoDB for flexibility and performance
Infrastructure: Docker, Kubernetes, CI/CD pipelines for automation
A skilled agency doesn’t just pick trendy tools—they choose frameworks aligned with your app’s use case, team skills, and scaling needs.
3. Multi-Tenancy Setup
One of the biggest differentiators in SaaS development is whether the platform is multi-tenant—where one codebase and database serve multiple customers with logical separation.
A web development company configures multi-tenancy using:
Separate schemas per tenant (isolated but efficient)
Shared databases with tenant identifiers (cost-effective)
Isolated instances for enterprise clients (maximum security)
This architecture supports onboarding multiple customers without duplicating infrastructure—making it cost-efficient and easy to manage.
4. Building Secure, Scalable User Management
SaaS platforms must support a range of users—admins, team members, clients—with different permissions. That’s why role-based access control (RBAC) is built into the system from the start.
Key features include:
Secure user registration and login (OAuth2, SSO, MFA)
Dynamic role creation and permission assignment
Audit logs and activity tracking
This layer is integrated with identity providers and third-party auth services to meet enterprise security expectations.
5. Ensuring Seamless Billing and Subscription Management
Monetization is central to SaaS success. Development companies build subscription logic that supports:
Monthly and annual billing cycles
Tiered or usage-based pricing models
Free trials and discounts
Integration with Stripe, Razorpay, or other payment gateways
They also ensure compliance with global standards (like PCI DSS for payment security and GDPR for user data privacy), especially if you're targeting international customers.
6. Performance Optimization from Day One
Scalability means staying fast even as traffic and data grow. Web developers implement:
Caching systems (like Redis or Memcached)
Load balancers and auto-scaling policies
Asynchronous task queues (e.g., Celery, RabbitMQ)
CDN integration for static asset delivery
Combined with code profiling and database indexing, these enhancements ensure your SaaS stays performant no matter how many users are active.
7. Continuous Deployment and Monitoring
SaaS products evolve quickly—new features, fixes, improvements. That’s why agencies set up:
CI/CD pipelines for automated testing and deployment
Error tracking tools like Sentry or Rollbar
Performance monitoring with tools like Datadog or New Relic
Log management for incident response and debugging
This allows for rapid iteration and minimal downtime, which are critical in SaaS environments.
8. Preparing for Scale from a Product Perspective
Scalability isn’t just technical—it’s also about UX and support. A good development company collaborates on:
Intuitive onboarding flows
Scalable navigation and UI design systems
Help center and chatbot integrations
Data export and reporting features for growing teams
These elements allow users to self-serve as the platform scales, reducing support load and improving retention.
Conclusion
SaaS platforms are complex ecosystems that require planning, flexibility, and technical excellence. From architecture and authentication to billing and performance, every layer must be built with growth in mind. That’s why startups and enterprises alike trust a Web Development Company to help them design and launch SaaS solutions that can handle scale—without sacrificing speed or security.
Whether you're building your first SaaS MVP or upgrading an existing product, the right development partner can transform your vision into a resilient, scalable reality.
0 notes
Text
Migrating Virtual Machines to Red Hat OpenShift Virtualization with Ansible Automation Platform
As enterprises modernize their infrastructure, migrating traditional virtual machines (VMs) to container-native platforms is no longer just a trend — it’s a necessity. One of the most powerful solutions for this evolution is Red Hat OpenShift Virtualization, which allows organizations to run VMs side-by-side with containers on a unified Kubernetes platform. When combined with Red Hat Ansible Automation Platform, this migration can be automated, repeatable, and efficient.
In this blog, we’ll explore how enterprises can leverage Ansible to seamlessly migrate workloads from legacy virtualization platforms (like VMware or KVM) to OpenShift Virtualization.
🔍 Why OpenShift Virtualization?
OpenShift Virtualization extends OpenShift’s capabilities to include traditional VMs, enabling:
Unified management of containers and VMs
Native integration with Kubernetes networking and storage
Simplified CI/CD pipelines that include VM-based workloads
Reduction of operational overhead and licensing costs
🛠️ The Role of Ansible Automation Platform
Red Hat Ansible Automation Platform is the glue that binds infrastructure automation, offering:
Agentless automation using SSH or APIs
Pre-built collections for platforms like VMware, OpenShift, KubeVirt, and more
Scalable execution environments for large-scale VM migration
Role-based access and governance through automation controller (formerly Tower)
🧭 Migration Workflow Overview
A typical migration flow using Ansible and OpenShift Virtualization involves:
1. Discovery Phase
Inventory the source VMs using Ansible VMware/KVM modules.
Collect VM configuration, network settings, and storage details.
2. Template Creation
Convert the discovered VM configurations into KubeVirt/OVIRT VM manifests.
Define OpenShift-native templates to match the workload requirements.
3. Image Conversion and Upload
Use tools like virt-v2v or Ansible roles to export VM disk images (VMDK/QCOW2).
Upload to OpenShift using Containerized Data Importer (CDI) or PVCs.
4. VM Deployment
Deploy converted VMs as KubeVirt VirtualMachines via Ansible Playbooks.
Integrate with OpenShift Networking and Storage (Multus, OCS, etc.)
5. Validation & Post-Migration
Run automated smoke tests or app-specific validation.
Integrate monitoring and alerting via Prometheus/Grafana.
- name: Deploy VM on OpenShift Virtualization
hosts: localhost
tasks:
- name: Create PVC for VM disk
k8s:
state: present
definition: "{{ lookup('file', 'vm-pvc.yaml') }}"
- name: Deploy VirtualMachine
k8s:
state: present
definition: "{{ lookup('file', 'vm-definition.yaml') }}"
🔐 Benefits of This Approach
✅ Consistency – Every VM migration follows the same process.
✅ Auditability – Track every step of the migration with Ansible logs.
✅ Security – Ansible integrates with enterprise IAM and RBAC policies.
✅ Scalability – Migrate tens or hundreds of VMs using automation workflows.
🌐 Real-World Use Case
At HawkStack Technologies, we’ve successfully helped enterprises migrate large-scale critical workloads from VMware vSphere to OpenShift Virtualization using Ansible. Our structured playbooks, coupled with Red Hat-supported tools, ensured zero data loss and minimal downtime.
🔚 Conclusion
As cloud-native adoption grows, merging the worlds of VMs and containers is no longer optional. With Red Hat OpenShift Virtualization and Ansible Automation Platform, organizations get the best of both worlds — a powerful, policy-driven, scalable infrastructure that supports modern and legacy workloads alike.
If you're planning a VM migration journey or modernizing your data center, reach out to HawkStack Technologies — Red Hat Certified Partners — to accelerate your transformation. For more details��www.hawkstack.com
0 notes
Text
Where Can I Find DevOps Training with Placement Near Me?
Introduction: Unlock Your Tech Career with DevOps Training
In today’s digital world, companies are moving faster than ever. Continuous delivery, automation, and rapid deployment have become the new norm. That’s where DevOps comes in a powerful blend of development and operations that fuels speed and reliability in software delivery.
Have you ever wondered how companies like Amazon, Netflix, or Facebook release features so quickly without downtime? The secret lies in DevOps an industry-demanded approach that integrates development and operations to streamline software delivery. Today, DevOps skills are not just desirable they’re essential. If you’re asking, “Where can I find DevOps training with placement near me?”, this guide will walk you through everything you need to know to find the right training and land the job you deserve.

Understanding DevOps: Why It Matters
DevOps is more than a buzzword it’s a cultural and technical shift that transforms how software teams build, test, and deploy applications. It focuses on collaboration, automation, continuous integration (CI), continuous delivery (CD), and feedback loops.
Professionals trained in DevOps can expect roles like:
DevOps Engineer
Site Reliability Engineer
Cloud Infrastructure Engineer
Release Manager
The growing reliance on cloud services and rapid deployment pipelines has placed DevOps engineers in high demand. A recent report by Global Knowledge ranks DevOps as one of the highest-paying tech roles in North America.
Why DevOps Training with Placement Is Crucial
Many learners begin with self-study or unstructured tutorials, but that only scratches the surface. A comprehensive DevOps training and placement program ensures:
Structured learning of core and advanced DevOps concepts
Hands-on experience with DevOps automation tools
Resume building, interview preparation, and career support
Real-world project exposure to simulate a professional environment
Direct pathways to job interviews and job offers
If you’re looking for DevOps training with placement “near me,” remember that “location” today is no longer just geographic—it’s also digital. The right DevOps online training can provide the accessibility and support you need, no matter your zip code.
Core Components of a DevOps Course Online
When choosing a DevOps course online, ensure it covers the following modules in-depth:
1. Introduction to DevOps Culture and Principles
Evolution of DevOps
Agile and Lean practices
Collaboration and communication strategies
2. Version Control with Git and GitHub
Branching and merging strategies
Pull requests and code reviews
Git workflows in real-world projects
3. Continuous Integration (CI) Tools
Jenkins setup and pipelines
GitHub Actions
Code quality checks and automated builds
4. Configuration Management
Tools like Ansible, Chef, or Puppet
Managing infrastructure as code (IaC)
Role-based access control
5. Containerization and Orchestration
Docker fundamentals
Kubernetes (K8s) clusters, deployments, and services
Helm charts and autoscaling strategies
6. Monitoring and Logging
Prometheus and Grafana
ELK Stack (Elasticsearch, Logstash, Kibana)
Incident alerting systems
7. Cloud Infrastructure and DevOps Automation Tools
AWS, Azure, or GCP fundamentals
Terraform for IaC
CI/CD pipelines integrated with cloud services
Real-World Applications: Why Hands-On Learning Matters
A key feature of any top-tier DevOps training online is its practical approach. Without hands-on labs or real projects, theory can only take you so far.
Here’s an example project structure:
Project: Deploying a Multi-Tier Application with Kubernetes
Such projects help learners not only understand tools but also simulate real DevOps scenarios, building confidence and clarity.
DevOps Training and Certification: What You Should Know
Certifications validate your knowledge and can significantly improve your job prospects. A solid DevOps training and certification program should prepare you for globally recognized exams like:
DevOps Foundation Certification
Certified Kubernetes Administrator (CKA)
AWS Certified DevOps Engineer
Docker Certified Associate
While certifications are valuable, employers prioritize candidates who demonstrate both theoretical knowledge and applied skills. This is why combining training with placement offers the best return on investment.
What to Look for in a DevOps Online Course
If you’re on the hunt for the best DevOps training online, here are key features to consider:
Structured Curriculum
It should cover everything from fundamentals to advanced automation practices.
Expert Trainers
Trainers should have real industry experience, not just academic knowledge.
Hands-On Projects
Project-based assessments help bridge the gap between theory and application.
Flexible Learning
A good DevOps online course offers recordings, live sessions, and self-paced materials.
Placement Support
Look for programs that offer:
Resume writing and LinkedIn profile optimization
Mock interviews with real-time feedback
Access to a network of hiring partners
Benefits of Enrolling in DevOps Bootcamp Online
A DevOps bootcamp online fast-tracks your learning process. These are intensive, short-duration programs designed for focused outcomes. Key benefits include:
Rapid skill acquisition
Industry-aligned curriculum
Peer collaboration and group projects
Career coaching and mock interviews
Job referrals and hiring events
Such bootcamps are ideal for professionals looking to upskill, switch careers, or secure a DevOps role without spending years in academia.
DevOps Automation Tools You Must Learn
Git & GitHub Git is the backbone of version control in DevOps, allowing teams to track changes, collaborate on code, and manage development history. GitHub enhances this by offering cloud-based repositories, pull requests, and code review tools—making it a must-know for every DevOps professional.
Jenkins Jenkins is the most popular open-source automation server used to build and manage continuous integration and continuous delivery (CI/CD) pipelines. It integrates with almost every DevOps tool and helps automate testing, deployment, and release cycles efficiently.
Docker Docker is a game-changer in DevOps. It enables you to containerize applications, ensuring consistency across environments. With Docker, developers can package software with all its dependencies, leading to faster development and more reliable deployments.
Kubernetes Once applications are containerized, Kubernetes helps manage and orchestrate them at scale. It automates deployment, scaling, and load balancing of containerized applications—making it essential for managing modern cloud-native infrastructures.
Ansible Ansible simplifies configuration management and infrastructure automation. Its agentless architecture and easy-to-write YAML playbooks allow you to automate repetitive tasks across servers and maintain consistency in deployments.
Terraform Terraform enables Infrastructure as Code (IaC), allowing teams to provision and manage cloud resources using simple, declarative code. It supports multi-cloud environments and ensures consistent infrastructure with minimal manual effort.
Prometheus & Grafana For monitoring and alerting, Prometheus collects metrics in real-time, while Grafana visualizes them beautifully. Together, they help track application performance and system health essential for proactive operations.
ELK Stack (Elasticsearch, Logstash, Kibana) The ELK stack is widely used for centralized logging. Elasticsearch stores logs, Logstash processes them, and Kibana provides powerful visualizations, helping teams troubleshoot issues quickly.
Mastering these tools gives you a competitive edge in the DevOps job market and empowers you to build reliable, scalable, and efficient software systems.
Job Market Outlook for DevOps Professionals
According to the U.S. Bureau of Labor Statistics, software development roles are expected to grow 25% by 2032—faster than most other industries. DevOps roles are a large part of this trend. Companies need professionals who can automate pipelines, manage scalable systems, and deliver software efficiently.
Average salaries in the U.S. for DevOps engineers range between $95,000 to $145,000, depending on experience, certifications, and location.
Companies across industries—from banking and healthcare to retail and tech—are hiring DevOps professionals for critical digital transformation roles.
Is DevOps for You?
If you relate to any of the following, a DevOps course online might be the perfect next step:
You're from an IT background looking to transition into automation roles
You enjoy scripting, problem-solving, and system management
You're a software developer interested in faster and reliable deployments
You're a system admin looking to expand into cloud and DevOps roles
You want a structured, placement-supported training program to start your career
How to Get Started with DevOps Training and Placement
Step 1: Enroll in a Comprehensive Program
Choose a program that covers both foundational and advanced concepts and includes real-time projects.
Step 2: Master the Tools
Practice using popular DevOps automation tools like Docker, Jenkins, and Kubernetes.
Step 3: Work on Live Projects
Gain experience working on CI/CD pipelines, cloud deployment, and infrastructure management.
Step 4: Prepare for Interviews
Use mock sessions, Q&A banks, and technical case studies to strengthen your readiness.
Step 5: Land the Job
Leverage placement services, interview support, and resume assistance to get hired.
Key Takeaways
DevOps training provides the automation and deployment skills demanded in modern software environments.
Placement support is crucial to transitioning from learning to earning.
Look for comprehensive online courses that offer hands-on experience and job assistance.
DevOps is not just a skill it’s a mindset of collaboration, speed, and innovation.
Ready to launch your DevOps career? Join H2K Infosys today for hands-on learning and job placement support. Start your transformation into a DevOps professional now.
#devops training#DevOps course#devops training online#devops online training#devops training and certification#devops certification training#devops training with placement#devops online courses#best devops training online#online DevOps course#advanced devops course#devops training and placement#devops course online#devops real time training#DevOps automation tools
0 notes
Text
Kubernetes Cluster Management at Scale: Challenges and Solutions
As Kubernetes has become the cornerstone of modern cloud-native infrastructure, managing it at scale is a growing challenge for enterprises. While Kubernetes excels in orchestrating containers efficiently, managing multiple clusters across teams, environments, and regions presents a new level of operational complexity.
In this blog, we’ll explore the key challenges of Kubernetes cluster management at scale and offer actionable solutions, tools, and best practices to help engineering teams build scalable, secure, and maintainable Kubernetes environments.
Why Scaling Kubernetes Is Challenging
Kubernetes is designed for scalability—but only when implemented with foresight. As organizations expand from a single cluster to dozens or even hundreds, they encounter several operational hurdles.
Key Challenges:
1. Operational Overhead
Maintaining multiple clusters means managing upgrades, backups, security patches, and resource optimization—multiplied by every environment (dev, staging, prod). Without centralized tooling, this overhead can spiral quickly.
2. Configuration Drift
Cluster configurations often diverge over time, causing inconsistent behavior, deployment errors, or compliance risks. Manual updates make it difficult to maintain consistency.
3. Observability and Monitoring
Standard logging and monitoring solutions often fail to scale with the ephemeral and dynamic nature of containers. Observability becomes noisy and fragmented without standardization.
4. Resource Isolation and Multi-Tenancy
Balancing shared infrastructure with security and performance for different teams or business units is tricky. Kubernetes namespaces alone may not provide sufficient isolation.
5. Security and Policy Enforcement
Enforcing consistent RBAC policies, network segmentation, and compliance rules across multiple clusters can lead to blind spots and misconfigurations.
Best Practices and Scalable Solutions
To manage Kubernetes at scale effectively, enterprises need a layered, automation-driven strategy. Here are the key components:
1. GitOps for Declarative Infrastructure Management
GitOps leverages Git as the source of truth for infrastructure and application deployment. With tools like ArgoCD or Flux, you can:
Apply consistent configurations across clusters.
Automatically detect and rollback configuration drifts.
Audit all changes through Git commit history.
Benefits:
· Immutable infrastructure
· Easier rollbacks
· Team collaboration and visibility
2. Centralized Cluster Management Platforms
Use centralized control planes to manage the lifecycle of multiple clusters. Popular tools include:
Rancher – Simplified Kubernetes management with RBAC and policy controls.
Red Hat OpenShift – Enterprise-grade PaaS built on Kubernetes.
VMware Tanzu Mission Control – Unified policy and lifecycle management.
Google Anthos / Azure Arc / Amazon EKS Anywhere – Cloud-native solutions with hybrid/multi-cloud support.
Benefits:
· Unified view of all clusters
· Role-based access control (RBAC)
· Policy enforcement at scale
3. Standardization with Helm, Kustomize, and CRDs
Avoid bespoke configurations per cluster. Use templating and overlays:
Helm: Define and deploy repeatable Kubernetes manifests.
Kustomize: Customize raw YAMLs without forking.
Custom Resource Definitions (CRDs): Extend Kubernetes API to include enterprise-specific configurations.
Pro Tip: Store and manage these configurations in Git repositories following GitOps practices.
4. Scalable Observability Stack
Deploy a centralized observability solution to maintain visibility across environments.
Prometheus + Thanos: For multi-cluster metrics aggregation.
Grafana: For dashboards and alerting.
Loki or ELK Stack: For log aggregation.
Jaeger or OpenTelemetry: For tracing and performance monitoring.
Benefits:
· Cluster health transparency
· Proactive issue detection
· Developer fliendly insights
5. Policy-as-Code and Security Automation
Enforce security and compliance policies consistently:
OPA + Gatekeeper: Define and enforce security policies (e.g., restrict container images, enforce labels).
Kyverno: Kubernetes-native policy engine for validation and mutation.
Falco: Real-time runtime security monitoring.
Kube-bench: Run CIS Kubernetes benchmark checks automatically.
Security Tip: Regularly scan cluster and workloads using tools like Trivy, Kube-hunter, or Aqua Security.
6. Autoscaling and Cost Optimization
To avoid resource wastage or service degradation:
Horizontal Pod Autoscaler (HPA) – Auto-scales pods based on metrics.
Vertical Pod Autoscaler (VPA) – Adjusts container resources.
Cluster Autoscaler – Scales nodes up/down based on workload.
Karpenter (AWS) – Next-gen open-source autoscaler with rapid provisioning.
Conclusion
As Kubernetes adoption matures, organizations must rethink their management strategy to accommodate growth, reliability, and governance. The transition from a handful of clusters to enterprise-wide Kubernetes infrastructure requires automation, observability, and strong policy enforcement.
By adopting GitOps, centralized control planes, standardized templates, and automated policy tools, enterprises can achieve Kubernetes cluster management at scale—without compromising on security, reliability, or developer velocity.
0 notes
Text
SRE Roadmap: Your Complete Guide to Becoming a Site Reliability Engineer in 2025
In today’s rapidly evolving tech landscape, Site Reliability Engineering (SRE) has become one of the most in-demand roles across industries. As organizations scale and systems become more complex, the need for professionals who can bridge the gap between development and operations is critical. If you’re looking to start or transition into a career in SRE, this comprehensive SRE roadmap will guide you step by step in 2025.

Why Follow an SRE Roadmap?
The field of SRE is broad, encompassing skills from DevOps, software engineering, cloud computing, and system administration. A well-structured SRE roadmap helps you:
Understand what skills are essential at each stage.
Avoid wasting time on non-relevant tools or technologies.
Stay up to date with industry standards and best practices.
Get job-ready with the right certifications and hands-on experience.
SRE Roadmap: Step-by-Step Guide
🔹 Phase 1: Foundation (Beginner Level)
Key Focus Areas:
Linux Fundamentals – Learn the command line, shell scripting, and process management.
Networking Basics – Understand DNS, HTTP/HTTPS, TCP/IP, firewalls, and load balancing.
Version Control – Master Git and GitHub for collaboration.
Programming Languages – Start with Python or Go for scripting and automation tasks.
Tools to Learn:
Git
Visual Studio Code
Postman (for APIs)
Recommended Resources:
"The Linux Command Line" by William Shotts
GitHub Learning Lab
🔹 Phase 2: Core SRE Skills (Intermediate Level)
Key Focus Areas:
Configuration Management – Learn tools like Ansible, Puppet, or Chef.
Containers & Orchestration – Understand Docker and Kubernetes.
CI/CD Pipelines – Use Jenkins, GitLab CI, or GitHub Actions.
Monitoring & Logging – Get familiar with Prometheus, Grafana, ELK Stack, or Datadog.
Cloud Platforms – Gain hands-on experience with AWS, GCP, or Azure.
Certifications to Consider:
AWS Certified SysOps Administrator
Certified Kubernetes Administrator (CKA)
Google Cloud Professional SRE
🔹 Phase 3: Advanced Practices (Expert Level)
Key Focus Areas:
Site Reliability Principles – Learn about SLIs, SLOs, SLAs, and Error Budgets.
Incident Management – Practice runbooks, on-call rotations, and postmortems.
Infrastructure as Code (IaC) – Master Terraform or Pulumi.
Scalability and Resilience Engineering – Understand fault tolerance, redundancy, and chaos engineering.
Tools to Explore:
Terraform
Chaos Monkey (for chaos testing)
PagerDuty / OpsGenie
Real-World Experience Matters
While theory is important, hands-on experience is what truly sets you apart. Here are some tips:
Set up your own Kubernetes cluster.
Contribute to open-source SRE tools.
Create a portfolio of automation scripts and dashboards.
Simulate incidents to test your monitoring setup.
Final Thoughts
Following this SRE roadmap will provide you with a clear and structured path to break into or grow in the field of Site Reliability Engineering. With the right mix of foundational skills, real-world projects, and continuous learning, you'll be ready to take on the challenges of building reliable, scalable systems.
Ready to Get Certified?
Take your next step with our SRE Certification Course and fast-track your career with expert training, real-world projects, and globally recognized credentials.
0 notes
Text
DevOps: Bridging Development & Operations

In the whirlwind environment of software development, getting code quickly and reliably from concept to launch is considered fast work. There has usually been a wall between the "Development" (Dev) and the "Operations" (Ops) teams that has usually resulted in slow deployments, conflicts, and inefficiencies. The DevOps culture and practices have been created as tools to close this gap in a constructive manner by fostering collaboration, automation, and continuous delivery.
DevOps is not really about methodology; it's more of a philosophy whereby developers and operations teams are brought together to collaborate and increase productivity by automation of infrastructure and workflows and continuous assessment of application's performance. Today, it is imperative for any tech-savvy person to have the basic know-how of DevOps methodologies-adopting them-and especially in fast-developing IT corridors like Ahmedabad.
Why DevOps is Crucial in Today's Tech Landscape
It is very clear that the benefits of DevOps have led to its adoption worldwide across industries:
Offering Faster Time-to-Market: DevOps has automated steps, placing even more importance on collaboration, manuals, to finish testing, and to deploy applications very fast.
Ensuring Better Quality and Reliability: With continuous testing, integration, and deployment, we get fewer bugs and more stable applications.
Fostering Collaboration: It removes traditional silos between teams, thus promoting shared responsibility and communication.
Operational Efficiency and Cost-Saving: It automates repetitive tasks, eliminates manual efforts, and reduces errors.
Building Scalability and Resilience: DevOps practices assist in constructing scalable systems and resilient systems that can handle grow-thrust of users.
Key Pillars of DevOps
A few of the essential practices and tools on which DevOps rests:
Continuous Integration (CI): Developers merge their code changes into a main repository on a daily basis, in which automated builds and tests are run to detect integration errors early. Tools: Jenkins, GitLab CI, Azure DevOps.
Continuous Delivery / Deployment: Builds upon CI to automatically build, test, and prepare code changes for release to production. Continuous Deployment then deploys every valid change to production automatically. Tools: Jenkins, Spinnaker, Argo CD.
Infrastructure as Code (IaC): Managing and provisioning infrastructure through code instead of through manual processes. Manual processes can lead to inconsistent setups and are not easily repeatable. Tools: Terraform, Ansible, Chef, Puppet.
Monitoring & Logging: Monitor the performance of applications as well as the health of infrastructure and record logs to troubleshoot and detect issues in the shortest possible time. Tools: Prometheus, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana).
Collaboration and Communication: On the other hand, it is a cultural change towards open communication, working jointly, and feedback loops.
Essential Skills for a DevOps Professional
If you want to become a DevOps Engineer or start incorporating DevOps methodologies into your day-to-day work, these are some skills to consider:
Linux Basics: A good understanding of Linux OS is almost a prerequisite, as most servers run on Linux.
Scripting Languages: Having a working understanding of one or another scripting language (like Python, Bash, or PowerShell) comes in handy in automation.
Cloud Platforms: Working knowledge of cloud providers like AWS, Microsoft Azure, or Google Cloud Platform, given cloud infrastructure is an integral part of deployments nowadays.
Containerization: These include skills on containerization using Docker and orchestration using Kubernetes for application deployment and scaling.
CI/CD Tools: Good use of established CI/CD pipeline tools (Jenkins, GitLab CI, Azure DevOps, etc.).
Version Control: Proficiency in Git through the life of the collaborative code change.
Networking Basics: Understanding of networking protocols and configurations.
Your Path to a DevOps Career
The demand for DevOps talent in India is rapidly increasing.. Since the times are changing, a lot of computer institutes in Ahmedabad are offering special DevOps courses which cover these essential tools and practices. It is advisable to search for programs with lab sessions, simulated real-world projects, and guidance on industry-best practices.
Adopting DevOps is more than just learning new tools; it is a mindset that values efficiency and trust in automation as well as seamless collaboration. With such vital skills, you can act as a critical enabler between development and operations to ensure the rapid release of reliable software, thereby guaranteeing your position as one of the most sought-after professionals in the tech world.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Cloud Cost Optimization: Proven Tactics to Cut Spend Without Sacrificing Performance
Cloud computing offers incredible scalability, flexibility, and performance — but without careful management, costs can spiral out of control. Many businesses discover too late that what starts as a cost-effective solution can quickly become a budgetary burden.
Cloud cost optimization is not just about cutting expenses — it’s about maximizing value. In this blog, we’ll explore proven strategies to reduce cloud spend without compromising performance, reliability, or scalability.
📉 Why Cloud Costs Escalate
Before we dive into tactics, it’s important to understand why cloud bills often balloon:
Overprovisioned resources (more CPU/RAM than needed)
Idle or unused services running 24/7
Lack of visibility into usage patterns
Inefficient storage practices
No tagging or accountability for resource ownership
Ignoring cost-effective services like spot instances
✅ 1. Right-Size Your Resources
Many teams overestimate capacity needs, leaving resources idle.
Optimization Tip: Use tools like AWS Cost Explorer, Azure Advisor, or Google Cloud Recommender to analyze resource utilization and scale down underused instances or switch to smaller configurations.
Examples:
Downgrade from m5.2xlarge to m5.large
Reduce EBS volume sizes
Remove over-provisioned Kubernetes pods
💤 2. Eliminate Idle and Unused Resources
Even seemingly harmless resources like unattached volumes, idle load balancers, and unused snapshots can rack up charges over time.
Optimization Tip: Set up automated scripts or third-party tools (like CloudHealth or Spot.io) to detect and delete unused resources on a regular schedule.
🕒 3. Leverage Auto-Scaling and Scheduled Shutdowns
Not all applications need to run at full capacity 24/7. Auto-scaling ensures resources grow and shrink based on actual demand.
Optimization Tip:
Use auto-scaling groups for web and backend servers
Schedule development and staging environments to shut down after hours
Turn off test VMs or containers on weekends
💲 4. Use Reserved and Spot Instances
On-demand pricing is convenient, but it’s not always cost-effective.
Reserved Instances (RIs): Commit to 1 or 3 years for significant discounts (up to 72%)
Spot Instances: Take advantage of spare capacity at up to 90% lower cost (ideal for batch processing or fault-tolerant apps)
Optimization Tip: Use a blended strategy — combine on-demand, reserved, and spot instances for optimal flexibility and savings.
🗂️ 5. Optimize Storage Costs
Storage often goes unchecked in cloud environments. Tiered storage models offer cost savings based on access frequency.
Optimization Tip:
Move infrequently accessed data to cheaper storage (e.g., S3 Glacier or Azure Archive Storage)
Delete outdated logs or compress large files
Use lifecycle policies to automate archival
🧩 6. Implement Cost Allocation Tags
Tagging resources by project, environment, team, or client provides visibility into who is using what — and how much it costs.
Optimization Tip:
Standardize a tagging policy (e.g., env:production, team:marketing, project:salzen-app)
Use cost reports to hold teams accountable for resource usage
📊 7. Monitor, Alert, and Analyze
Visibility is key to continuous optimization. Without real-time monitoring, overspend can go unnoticed until the bill arrives.
Optimization Tip:
Use native tools like AWS Budgets, Azure Cost Management, or GCP Billing Reports
Set budget alerts and forecast future usage
Perform monthly reviews to track anomalies or spikes
🔧 8. Use Third-Party Cost Optimization Tools
Cloud-native tools are great, but third-party solutions provide more advanced analytics, recommendations, and automation.
Popular Options:
CloudHealth by VMware
Apptio Cloudability
Spot by NetApp
Harness Cloud Cost Management
These tools help with governance, forecasting, and even automated resource orchestration.
🧠 Bonus: Adopt a FinOps Culture
FinOps is a financial management discipline that brings together finance, engineering, and product teams to optimize cloud spending collaboratively.
Optimization Tip:
Promote cost-awareness across departments
Make cost metrics part of engineering KPIs
Align cloud budgets with business outcomes
🧭 Final Thoughts
Cloud cost optimization isn’t a one-time project — it’s a continuous, data-driven process. With the right tools, policies, and cultural practices, you can control costs without compromising the performance or flexibility the cloud offers.
Looking to reduce your cloud bill by up to 40%? Salzen Cloud helps businesses implement real-time cost visibility, automation, and cost-optimized architectures. Our experts can audit your cloud setup and design a tailored savings strategy — without disrupting your operations.
0 notes
Text
Effective Kubernetes cluster monitoring simplifies containerized workload management by measuring uptime, resource use (such as memory, CPU, and storage), and interaction between cluster components. It also enables cluster managers to monitor the cluster and discover issues such as inadequate resources, errors, pods that fail to start, and nodes that cannot join the cluster. Essentially, Kubernetes monitoring enables you to discover issues and manage Kubernetes clusters more proactively. What Kubernetes Metrics Should You Measure? Monitoring Kubernetes metrics is critical for ensuring the reliability, performance, and efficiency of applications in a Kubernetes cluster. Because Kubernetes constantly expands and maintains containers, measuring critical metrics allows you to spot issues early on, optimize resource allocation, and preserve overall system integrity. Several factors are critical to watch with Kubernetes: Cluster monitoring - Monitors the health of the whole Kubernetes cluster. It helps you find out how many apps are running on a node, if it is performing efficiently and at the right capacity, and how much resource the cluster requires overall. Pod monitoring - Tracks issues impacting individual pods, including resource use, application metrics, and pod replication or auto scaling metrics. Ingress metrics - Monitoring ingress traffic can help in discovering and managing a variety of issues. Using controller-specific methods, ingress controllers can be set up to track network traffic information and workload health. Persistent storage - Monitoring volume health allows Kubernetes to implement CSI. You can also use the external health monitor controller to track node failures. Control plane metrics - With control plane metrics we can track and visualize cluster performance while troubleshooting by keeping an eye on schedulers, controllers, and API servers. Node metrics - Keeping an eye on each Kubernetes node's CPU and memory usage might help ensure that they never run out. A running node's status can be defined by a number of conditions, such as Ready, MemoryPressure, DiskPressure, OutOfDisk, and NetworkUnavailable. Monitoring and Troubleshooting Kubernetes Clusters Using the Kubernetes Dashboard The Kubernetes dashboard is a web-based user interface for Kubernetes. It allows you to deploy containerized apps to a Kubernetes cluster, see an overview of the applications operating on the cluster, and manage cluster resources. Additionally, it enables you to: Debug containerized applications by examining data on the health of your Kubernetes cluster's resources, as well as any anomalies that have occurred. Create and modify individual Kubernetes resources, including deployments, jobs, DaemonSets, and StatefulSets. Have direct control over your Kubernetes environment using the Kubernetes dashboard. The Kubernetes dashboard is built into Kubernetes by default and can be installed and viewed from the Kubernetes master node. Once deployed, you can visit the dashboard via a web browser to examine extensive information about your Kubernetes cluster and conduct different operations like scaling deployments, establishing new resources, and updating application configurations. Kubernetes Dashboard Essential Features Kubernetes Dashboard comes with some essential features that help manage and monitor your Kubernetes clusters efficiently: Cluster overview: The dashboard displays information about your Kubernetes cluster, including the number of nodes, pods, and services, as well as the current CPU and memory use. Resource management: The dashboard allows you to manage Kubernetes resources, including deployments, services, and pods. You can add, update, and delete resources while also seeing extensive information about them. Application monitoring: The dashboard allows you to monitor the status and performance of Kubernetes-based apps. You may see logs and stats, fix issues, and set alarms.
Customizable views: The dashboard allows you to create and preserve bespoke dashboards with the metrics and information that are most essential to you. Kubernetes Monitoring Best Practices Here are some recommended practices to help you properly monitor and debug Kubernetes installations: 1. Monitor Kubernetes Metrics Kubernetes microservices require understanding granular resource data like memory, CPU, and load. However, these metrics may be complex and challenging to leverage. API indicators such as request rate, call error, and latency are the most effective KPIs for identifying service faults. These metrics can immediately identify degradations in a microservices application's components. 2. Ensure Monitoring Systems Have Enough Data Retention Having scalable monitoring solutions helps you to efficiently monitor your Kubernetes cluster as it grows and evolves over time. As your Kubernetes cluster expands, so will the quantity of data it creates, and your monitoring systems must be capable of handling this rise. If your systems are not scalable, they may get overwhelmed by the volume of data and be unable to offer accurate or relevant results. 3. Integrate Monitoring Systems Into Your CI/CD Pipeline Source Integrating Kubernetes monitoring solutions with CI/CD pipelines enables you to monitor your apps and infrastructure as they are deployed, rather than afterward. By connecting your monitoring systems to your pipeline for continuous integration and delivery (CI/CD), you can automatically collect and process data from your infrastructure and applications as it is delivered. This enables you to identify potential issues early on and take action to stop them from getting worse. 4. Create Alerts You may identify the problems with your Kubernetes cluster early on and take action to fix them before they get worse by setting up the right alerts. For example, if you configure alerts for crucial metrics like CPU or memory use, you will be informed when those metrics hit specific thresholds, allowing you to take action before your cluster gets overwhelmed. Conclusion Kubernetes allows for the deployment of a large number of containerized applications within its clusters, each of which has nodes that manage the containers. Efficient observability across various machines and components is critical for successful Kubernetes container orchestration. Kubernetes has built-in monitoring facilities for its control plane, but they may not be sufficient for thorough analysis and granular insight into application workloads, event logging, and other microservice metrics within Kubernetes clusters.
0 notes
Text
DevOps Landscape: Building Blocks for a Seamless Transition
In the dynamic realm where software development intersects with operations, the role of a DevOps professional has become instrumental. For individuals aspiring to make the leap into this dynamic field, understanding the key building blocks can set the stage for a successful transition. While there are no rigid prerequisites, acquiring foundational skills and knowledge areas becomes pivotal for thriving in a DevOps role.

1. Embracing the Essence of Software Development: At the core of DevOps lies collaboration, making it essential for individuals to have a fundamental understanding of software development processes. Proficiency in coding practices, version control, and the collaborative nature of development projects is paramount. Additionally, a solid grasp of programming languages and scripting adds a valuable dimension to one's skill set.
2. Navigating System Administration Fundamentals: DevOps success is intricately linked to a foundational understanding of system administration. This encompasses knowledge of operating systems, networks, and infrastructure components. Such familiarity empowers DevOps professionals to adeptly manage and optimize the underlying infrastructure supporting applications.
3. Mastery of Version Control Systems: Proficiency in version control systems, with Git taking a prominent role, is indispensable. Version control serves as the linchpin for efficient code collaboration, allowing teams to track changes, manage codebases, and seamlessly integrate contributions from multiple developers.
4. Scripting and Automation Proficiency: Automation is a central tenet of DevOps, emphasizing the need for scripting skills in languages like Python, Shell, or Ruby. This skill set enables individuals to automate repetitive tasks, fostering more efficient workflows within the DevOps pipeline.
5. Embracing Containerization Technologies: The widespread adoption of containerization technologies, exemplified by Docker, and orchestration tools like Kubernetes, necessitates a solid understanding. Mastery of these technologies is pivotal for creating consistent and reproducible environments, as well as managing scalable applications.
6. Unveiling CI/CD Practices: Continuous Integration and Continuous Deployment (CI/CD) practices form the beating heart of DevOps. Acquiring knowledge of CI/CD tools such as Jenkins, GitLab CI, or Travis CI is essential. This proficiency ensures the automated execution of code testing, integration, and deployment processes, streamlining development pipelines.
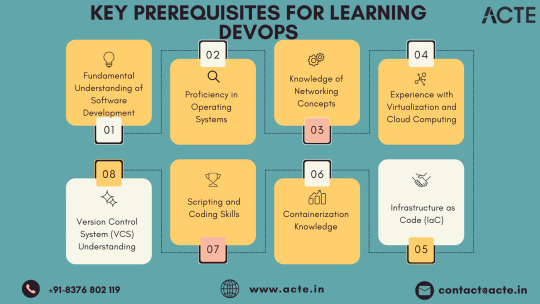
7. Harnessing Infrastructure as Code (IaC): Proficiency in Infrastructure as Code (IaC) tools, including Terraform or Ansible, constitutes a fundamental aspect of DevOps. IaC facilitates the codification of infrastructure, enabling the automated provisioning and management of resources while ensuring consistency across diverse environments.
8. Fostering a Collaborative Mindset: Effective communication and collaboration skills are non-negotiable in the DevOps sphere. The ability to seamlessly collaborate with cross-functional teams, spanning development, operations, and various stakeholders, lays the groundwork for a culture of collaboration essential to DevOps success.
9. Navigating Monitoring and Logging Realms: Proficiency in monitoring tools such as Prometheus and log analysis tools like the ELK stack is indispensable for maintaining application health. Proactive monitoring equips teams to identify issues in real-time and troubleshoot effectively.
10. Embracing a Continuous Learning Journey: DevOps is characterized by its dynamic nature, with new tools and practices continually emerging. A commitment to continuous learning and adaptability to emerging technologies is a fundamental trait for success in the ever-evolving field of DevOps.
In summary, while the transition to a DevOps role may not have rigid prerequisites, the acquisition of these foundational skills and knowledge areas becomes the bedrock for a successful journey. DevOps transcends being a mere set of practices; it embodies a cultural shift driven by collaboration, automation, and an unwavering commitment to continuous improvement. By embracing these essential building blocks, individuals can navigate their DevOps journey with confidence and competence.
5 notes
·
View notes
Text
Cloud Migration Strategy: A Comprehensive Guide to Seamless IT Transformation
In today’s fast-paced digital world, businesses are increasingly adopting cloud technologies to gain flexibility, scalability, and cost-efficiency. However, moving IT systems and critical applications from on-premises infrastructure to the cloud requires careful planning and execution. This is where a well-defined cloud migration strategy becomes essential. At PufferSoft, we understand the complexities of this transition and help organizations craft and implement the right strategy to ensure a smooth and secure migration.
What Is a Cloud Migration Strategy?
A cloud migration strategy is a detailed plan that outlines how an organization will move its IT resources, including web servers, databases, enterprise applications, and critical IT functions, to cloud platforms such as AWS or Azure. This strategy covers everything from assessing the existing infrastructure to designing, deploying, and managing cloud environments. A successful migration strategy minimizes downtime, controls costs, and maximizes the benefits of cloud adoption.
Why Is a Cloud Migration Strategy Important?
Without a clear cloud migration strategy, companies risk facing disruptions, security vulnerabilities, and inflated costs during the migration process. A solid strategy ensures:
Seamless migration of all IT components, including web servers, databases, Microsoft enterprise applications, disaster recovery, backup, and logging systems.
Adoption of scalable and flexible cloud solutions that grow with your business.
Enhanced security and compliance through best practices and continuous monitoring.
Optimized cloud costs by identifying unnecessary expenses and right-sizing resources.
Implementation of modern DevOps practices such as Kubernetes and CI/CD pipelines for faster deployment and innovation.
Key Elements of a Cloud Migration Strategy
At PufferSoft, our approach to cloud migration involves several critical elements that together form a robust cloud migration strategy:
Assessment and Planning We begin by thoroughly assessing your current IT landscape. This includes understanding your applications, workloads, dependencies, and business objectives. From there, we design a migration roadmap that aligns with your specific needs.
Choosing the Right Cloud Platform We specialize in both AWS and Azure, selecting the platform best suited for your workloads. Our expertise in cloud services ensures that your systems are designed for optimal performance, cost-efficiency, and security.
Migration Execution Using proven tools and methodologies, we migrate your web servers, databases, enterprise applications, and critical IT functions like disaster recovery and backup. We ensure that the migration is seamless and causes minimal disruption to your operations.
Kubernetes and DevOps Integration We leverage Kubernetes for container orchestration and integrate CI/CD pipelines to automate your software delivery process. This modern approach improves scalability and accelerates innovation.
Security and Compliance Security is a top priority. Our team deploys fully redundant and secure cloud architectures with backup and disaster recovery. We also provide auditing services to help you secure cloud resources and comply with industry regulations.
24/7 Cloud Management and Support Post-migration, we offer round-the-clock monitoring and management services. This ensures your cloud infrastructure is always optimized, secure, and performing at its best.
Benefits of Implementing a Cloud Migration Strategy
A thoughtfully executed cloud migration strategy offers numerous benefits to organizations:
Improved Agility: Quickly scale resources up or down based on demand.
Cost Efficiency: Pay only for the resources you use, avoiding costly overprovisioning.
Enhanced Security: Implement robust security controls tailored to your environment.
Business Continuity: Ensure data protection and disaster recovery with redundant cloud setups.
Innovation Acceleration: Leverage DevOps and automation tools to speed up development cycles.
Why Partner with PufferSoft for Your Cloud Migration Strategy?
At PufferSoft, we bring extensive expertise in cloud migration and management. We help businesses move all their IT systems—including web servers, databases, Microsoft enterprise applications, and critical functions like disaster recovery and backup—to the cloud securely and efficiently. Our specialists are skilled in Kubernetes, DevOps, and Terraform, allowing us to deliver fully redundant, secure, and scalable cloud solutions tailored to your unique requirements.
Our comprehensive cloud services include design, deployment, migration, integration, development, and 24/7 management. We also provide auditing to help you secure your cloud environment and optimize costs, ensuring you get the best return on your cloud investment.
Conclusion
Developing and executing a robust cloud migration strategy is crucial for businesses looking to harness the power of the cloud while minimizing risks. Whether you are migrating legacy systems, enterprise applications, or critical IT functions, having a trusted partner like PufferSoft ensures a smooth transition and ongoing success in the cloud. With our expertise in AWS, Azure, Kubernetes, and DevOps, we help you transform your IT landscape into a secure, scalable, and cost-effective cloud environment.
If you are ready to take the next step in your cloud journey, contact PufferSoft today to develop a tailored cloud migration strategy that meets your business goals.
0 notes
Text
Integrating ROSA Applications with AWS Services (CS221)
In today's rapidly evolving cloud-native landscape, enterprises are looking for scalable, secure, and fully managed Kubernetes solutions that work seamlessly with existing cloud infrastructure. Red Hat OpenShift Service on AWS (ROSA) meets that demand by combining the power of Red Hat OpenShift with the scalability and flexibility of Amazon Web Services (AWS).
In this blog post, we’ll explore how you can integrate ROSA-based applications with key AWS services, unlocking a powerful hybrid architecture that enhances your applications' capabilities.
📌 What is ROSA?
ROSA (Red Hat OpenShift Service on AWS) is a managed OpenShift offering jointly developed and supported by Red Hat and AWS. It allows you to run containerized applications using OpenShift while taking full advantage of AWS services such as storage, databases, analytics, and identity management.
🔗 Why Integrate ROSA with AWS Services?
Integrating ROSA with native AWS services enables:
Seamless access to AWS resources (like RDS, S3, DynamoDB)
Improved scalability and availability
Cost-effective hybrid application architecture
Enhanced observability and monitoring
Secure IAM-based access control using AWS IAM Roles for Service Accounts (IRSA)
🛠️ Key Integration Scenarios
1. Storage Integration with Amazon S3 and EFS
Applications deployed on ROSA can use AWS storage services for persistent and object storage needs.
Use Case: A web app storing images to S3.
How: Use OpenShift’s CSI drivers to mount EFS or access S3 through SDKs or CLI.
yaml
Copy
Edit
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc
resources:
requests:
storage: 5Gi
2. Database Integration with Amazon RDS
You can offload your relational database requirements to managed RDS instances.
Use Case: Deploying a Spring Boot app with PostgreSQL on RDS.
How: Store DB credentials in Kubernetes secrets and use RDS endpoint in your app’s config.
env
Copy
Edit
SPRING_DATASOURCE_URL=jdbc:postgresql://<rds-endpoint>:5432/mydb
3. Authentication with AWS IAM + OIDC
ROSA supports IAM Roles for Service Accounts (IRSA), enabling fine-grained permissions for workloads.
Use Case: Granting a pod access to a specific S3 bucket.
How:
Create an IAM role with S3 access
Associate it with a Kubernetes service account
Use OIDC to federate access
4. Observability with Amazon CloudWatch and Prometheus
Monitor your workloads using Amazon CloudWatch Container Insights or integrate Prometheus and Grafana on ROSA for deeper insights.
Use Case: Track application metrics and logs in a single AWS dashboard.
How: Forward logs from OpenShift to CloudWatch using Fluent Bit.
5. Serverless Integration with AWS Lambda
Bridge your ROSA applications with AWS Lambda for event-driven workloads.
Use Case: Triggering a Lambda function on file upload to S3.
How: Use EventBridge or S3 event notifications with your ROSA app triggering the workflow.
🔒 Security Best Practices
Use IAM Roles for Service Accounts (IRSA) to avoid hardcoding credentials.
Use AWS Secrets Manager or OpenShift Vault integration for managing secrets securely.
Enable VPC PrivateLink to keep traffic within AWS private network boundaries.
🚀 Getting Started
To start integrating your ROSA applications with AWS:
Deploy your ROSA cluster using the AWS Management Console or CLI
Set up AWS CLI & IAM permissions
Enable the AWS services needed (e.g., RDS, S3, Lambda)
Create Kubernetes Secrets and ConfigMaps for service integration
Use ServiceAccounts, RBAC, and IRSA for secure access
🎯 Final Thoughts
ROSA is not just about running Kubernetes on AWS—it's about unlocking the true hybrid cloud potential by integrating with a rich ecosystem of AWS services. Whether you're building microservices, data pipelines, or enterprise-grade applications, ROSA + AWS gives you the tools to scale confidently, operate securely, and innovate rapidly.
If you're interested in hands-on workshops, consulting, or ROSA enablement for your team, feel free to reach out to HawkStack Technologies – your trusted Red Hat and AWS integration partner.
💬 Let's Talk!
Have you tried ROSA yet? What AWS services are you integrating with your OpenShift workloads? Share your experience or questions in the comments!
For more details www.hawkstack.com
0 notes
Text
DevOps Course Online for Beginners and Professionals
Introduction: Why DevOps Skills Matter Today
In today's fast-paced digital world, businesses rely on faster software delivery and reliable systems. DevOps, short for Development and Operations, offers a practical solution to achieve this. It’s no longer just a trend; it’s a necessity for IT teams across all industries. From startups to enterprise giants, organizations are actively seeking professionals with strong DevOps skills.
Whether you're a beginner exploring career opportunities in IT or a seasoned professional looking to upskill, DevOps training online is your gateway to success. In this blog, we’ll walk you through everything you need to know about enrolling in a DevOps course online, from fundamentals to tools, certifications, and job placements.
What Is DevOps?
Definition and Core Principles
DevOps is a cultural and technical movement that unites software development and IT operations. It aims to shorten the software development lifecycle, ensuring faster delivery and higher-quality applications.
Core principles include:
Automation: Minimizing manual processes through scripting and tools
Continuous Integration/Continuous Deployment (CI/CD): Rapid code integration and release
Collaboration: Breaking down silos between dev, QA, and ops
Monitoring: Constant tracking of application performance and system health
These practices help businesses innovate faster and respond quickly to customer needs.
Why Choose a DevOps Course Online?
Accessibility and Flexibility
With DevOps training online, learners can access material anytime, anywhere. Whether you're working full-time or managing other responsibilities, online learning offers flexibility.
Updated Curriculum
A high-quality DevOps online course includes the latest tools and techniques used in the industry today, such as:
Jenkins
Docker
Kubernetes
Git and GitHub
Terraform
Ansible
Prometheus and Grafana
You get hands-on experience using real-world DevOps automation tools, making your learning practical and job-ready.
Job-Focused Learning
Courses that offer DevOps training with placement often include resume building, mock interviews, and one-on-one mentoring, equipping you with everything you need to land a job.
Who Should Enroll in a DevOps Online Course?
DevOps training is suitable for:
Freshers looking to start a tech career
System admins upgrading their skills
Software developers wanting to automate and deploy faster
IT professionals interested in cloud and infrastructure management
If you're curious about modern IT processes and enjoy problem-solving, DevOps is for you.
What You’ll Learn in a DevOps Training Program
1. Introduction to DevOps Concepts
DevOps lifecycle
Agile and Scrum methodologies
Collaboration between development and operations teams
2. Version Control Using Git
Git basics and repository setup
Branching, merging, and pull requests
Integrating Git with DevOps pipelines
3. CI/CD with Jenkins
Pipeline creation
Integration with Git
Automating builds and test cases
4. Containerization with Docker
Creating Docker images and containers
Docker Compose and registries
Real-time deployment examples
5. Orchestration with Kubernetes
Cluster architecture
Pods, services, and deployments
Scaling and rolling updates
6. Configuration Management with Ansible
Writing playbooks
Managing inventories
Automating infrastructure setup
7. Infrastructure as Code with Terraform
Deploying cloud resources
Writing reusable modules
State management and versioning
8. Monitoring and Logging
Using Prometheus and Grafana
Alerts and dashboards
Log management practices
This hands-on approach ensures learners are not just reading slides but working with real tools.
Real-World Projects You’ll Build
A good DevOps training and certification program includes projects like:
CI/CD pipeline from scratch
Deploying a containerized application on Kubernetes
Infrastructure provisioning on AWS or Azure using Terraform
Monitoring systems with Prometheus and Grafana
These projects simulate real-world problems, boosting both your confidence and your resume.
The Value of DevOps Certification
Why It Matters
Certification adds credibility to your skills and shows employers you're job-ready. A DevOps certification can be a powerful tool when applying for roles such as:
DevOps Engineer
Site Reliability Engineer (SRE)
Build & Release Engineer
Automation Engineer
Cloud DevOps Engineer
Courses that include DevOps training and placement also support your job search with interview preparation and job referrals.
Career Opportunities and Salary Trends
High Demand, High Pay
According to industry reports, DevOps engineers are among the highest-paid roles in IT. Average salaries range from $90,000 to $140,000 annually, depending on experience and region.
Industries hiring DevOps professionals include:
Healthcare
Finance
E-commerce
Telecommunications
Software as a Service (SaaS)
With the right DevOps bootcamp online, you’ll be prepared to meet these opportunities head-on.
Step-by-Step Guide to Getting Started
Step 1: Assess Your Current Skill Level
Understand your background. If you're a beginner, start with fundamentals. Professionals can skip ahead to advanced modules.
Step 2: Choose the Right DevOps Online Course
Look for these features:
Structured curriculum
Hands-on labs
Real-world projects
Mentorship
DevOps training with placement support
Step 3: Build a Portfolio
Document your projects on GitHub to show potential employers your work.
Step 4: Get Certified
Choose a respected DevOps certification to validate your skills.
Step 5: Apply for Jobs
Use placement support services or apply directly. Showcase your portfolio and certifications confidently.
Common DevOps Tools You’ll Master
Tool
Use Case
Git
Source control and version tracking
Jenkins
CI/CD pipeline automation
Docker
Application containerization
Kubernetes
Container orchestration
Terraform
Infrastructure as Code
Ansible
Configuration management
Prometheus
Monitoring and alerting
Grafana
Dashboard creation for system metrics
Mastering these DevOps automation tools equips you to handle end-to-end automation pipelines in real-world environments.
Why H2K Infosys for DevOps Training?
H2K Infosys offers one of the best DevOps training online programs with:
Expert-led sessions
Practical labs and tools
Real-world projects
Resume building and interview support
DevOps training with placement assistance
Their courses are designed to help both beginners and professionals transition into high-paying roles smoothly.
Key Takeaways
DevOps combines development and operations for faster, reliable software delivery
Online courses offer flexible, hands-on learning with real-world tools
A DevOps course online is ideal for career starters and upskillers alike
Real projects, certifications, and placement support boost job readiness
DevOps is one of the most in-demand and well-paying IT domains today
Conclusion
Ready to build a future-proof career in tech? Enroll in H2K Infosys’ DevOps course online for hands-on training, real-world projects, and career-focused support. Learn the tools that top companies use and get placement-ready today.
#devops training#devops training online#devops online training#devops training and certification#devops training with placement#devops online course#best devops training online#devops training and placement#devops course online#devops bootcamp online#DevOps automation tools
0 notes
Text
"Frontend Flair to Backend Brains: Your Code-to-Cloud Journey"
In today’s digital world, the gap between an idea and a fully functional online product is narrowing faster than ever. Whether you're crafting visually stunning interfaces or architecting robust server logic, the journey from code to cloud is one every modern developer must master. This evolution—from eye-catching frontends to intelligent backends—is not just a career path but a craft. Welcome to the full spectrum: Frontend Flair to Backend Brains.
The Rise of Full Stack Development
Full stack development has emerged as one of the most sought-after skill sets in the tech industry. It empowers developers to build end-to-end applications that operate seamlessly across both the client and server sides. What once required separate roles for frontend and backend specialists can now be handled by a single skilled full stack developer.
Full stack professionals possess a unique blend of skills:
Frontend Mastery: Expertise in HTML, CSS, JavaScript, and frameworks like React or Angular to build responsive and interactive user interfaces.
Backend Logic: Proficiency in server-side languages such as Java, Python, or Node.js, enabling them to manage data, authentication, and business logic.
Database Integration: Familiarity with both SQL and NoSQL databases like MySQL or MongoDB.
DevOps & Cloud Deployment: Understanding of CI/CD pipelines, containerization (Docker), and platforms like AWS, Azure, or Google Cloud.
By mastering these areas, developers can confidently take an idea from its earliest wireframe to a fully deployed application, accessible to users around the globe.
Java Certificate: A Launchpad to Backend Excellence
While full stack development spans a wide array of technologies, strong backend fundamentals are key to building scalable, efficient applications. Java continues to be a mainstay in enterprise software and backend services, thanks to its reliability, security, and cross-platform capabilities.
Earning a Java certificate can be a significant boost for aspiring developers looking to strengthen their backend proficiency. Here’s how:
Structured Learning: A Java certification program ensures comprehensive coverage of core concepts including OOP (Object-Oriented Programming), exception handling, multithreading, and file I/O.
Industry Recognition: It serves as a credential that validates your skill level to employers, helping you stand out in a competitive market.
Problem-Solving Skills: The certification process hones your ability to write efficient and clean code, an essential trait for backend development.
Whether you're transitioning into backend work or enhancing your existing expertise, a Java certificate acts as a reliable stepping stone.
From Code to Cloud: Building Real-World Applications
The journey doesn’t stop with writing code. Deploying your application to the cloud is where theory meets reality. The modern developer's toolkit includes:
Version Control (e.g., Git/GitHub)
CI/CD Pipelines (e.g., Jenkins, GitHub Actions)
Containerization (Docker, Kubernetes)
Monitoring & Logging (Prometheus, Grafana, ELK Stack)
Cloud Providers (AWS, Google Cloud, Azure)
By integrating these tools into your workflow, you ensure your applications are scalable, maintainable, and ready for production.
Why This Journey Matters
Bridging frontend creativity with backend logic isn't just about versatility—it's about creating holistic solutions that perform beautifully and reliably. As organizations increasingly move their operations online, the demand for developers who can think in terms of both design and infrastructure is at an all-time high.
In Summary:
Full stack development enables end-to-end product building, from user interface to server-side logic.
A Java certificate validates your backend expertise and helps build a strong programming foundation.
Understanding deployment, DevOps, and cloud ecosystems is crucial for bringing your code into the real world.
The journey from "Frontend Flair to Backend Brains" isn't linear—it's dynamic, hands-on, and constantly evolving. With the right skills and mindset, you can bring your code from your local machine to the cloud, shaping the digital experiences of tomorrow.
0 notes
Text
Why GPU PaaS Is Incomplete Without Infrastructure Orchestration and Tenant Isolation
GPU Platform-as-a-Service (PaaS) is gaining popularity as a way to simplify AI workload execution — offering users a friendly interface to submit training, fine-tuning, and inferencing jobs. But under the hood, many GPU PaaS solutions lack deep integration with infrastructure orchestration, making them inadequate for secure, scalable multi-tenancy.
If you’re a Neocloud, sovereign GPU cloud, or an enterprise private GPU cloud with strict compliance requirements, you are probably looking at offering job scheduling of Model-as-a-Service to your tenants/users. An easy approach is to have a global Kubernetes cluster that is shared across multiple tenants. The problem with this approach is poor security as the underlying OS kernel, CPU, GPU, network, and storage resources are shared by all users without any isolation. Case-in-point, in September 2024, Wiz discovered a critical GPU container and Kubernetes vulnerability that affected over 35% of environments. Thus, doing just Kubernetes namespace or vCluster isolation is not safe.
You need to provision bare metal, configure network and fabric isolation, allocate high-performance storage, and enforce tenant-level security boundaries — all automated, dynamic, and policy-driven.
In short: PaaS is not enough. True GPUaaS begins with infrastructure orchestration.
The Pitfall of PaaS-Only GPU Platforms
Many AI platforms stop at providing:
A web UI for job submission
A catalog of AI/ML frameworks or models
Basic GPU scheduling on Kubernetes
What they don’t offer:
Control over how GPU nodes are provisioned (bare metal vs. VM)
Enforcement of north-south and east-west isolation per tenant
Configuration and Management of Infiniband, RoCE or Spectrum-X fabric
Lifecycle Management and Isolation of External Parallel Storage like DDN, VAST, or WEKA
Per-Tenant Quota, Observability, RBAC, and Policy Governance
Without these, your GPU PaaS is just a thin UI on top of a complex, insecure, and hard-to-scale backend.
What Full-Stack Orchestration Looks Like
To build a robust AI cloud platform — whether sovereign, Neocloud, or enterprise — the orchestration layer must go deeper.
How aarna.ml GPU CMS Solves This Problem
aarna.ml GPU CMS is built from the ground up to be infrastructure-aware and multi-tenant-native. It includes all the PaaS features you would expect, but goes beyond PaaS to offer:
BMaaS and VMaaS orchestration: Automated provisioning of GPU bare metal or VM pools for different tenants.
Tenant-level network isolation: Support for VXLAN, VRF, and fabric segmentation across Infiniband, Ethernet, and Spectrum-X.
Storage orchestration: Seamless integration with DDN, VAST, WEKA with mount point creation and tenant quota enforcement.
Full-stack observability: Usage stats, logs, and billing metrics per tenant, per GPU, per model.
All of this is wrapped with a PaaS layer that supports Ray, SLURM, KAI, Run:AI, and more, giving users flexibility while keeping cloud providers in control of their infrastructure and policies.
Why This Matters for AI Cloud Providers
If you're offering GPUaaS or PaaS without infrastructure orchestration:
You're exposing tenants to noisy neighbors or shared vulnerabilities
You're missing critical capabilities like multi-region scaling or LLM isolation
You’ll be unable to meet compliance, governance, and SemiAnalysis ClusterMax1 grade maturity
With aarna.ml GPU CMS, you deliver not just a PaaS, but a complete, secure, and sovereign-ready GPU cloud platform.
Conclusion
GPU PaaS needs to be a complete stack with IaaS — it’s not just a model serving interface!
To deliver scalable, secure, multi-tenant AI services, your GPU PaaS stack must be expanded to a full GPU cloud management software stack to include automated provisioning of compute, network, and storage, along with tenant-aware policy and observability controls.
Only then is your GPU PaaS truly production-grade.
Only then are you ready for sovereign, enterprise, and commercial AI cloud success.
To see a live demo or for a free trial, contact aarna.ml
This post orginally posted on https://www.aarna.ml/
0 notes
Text
Microsoft Introduces Agentic DevOps for Software Development

DevOps agent
Agentic DevOps: Microsoft Azure and GitHub Copilot for software development
Agentic DevOps: Microsoft's Next Software Development Trend at Build 2025
Microsoft launched Agentic DevOps, a new technique that leverages intelligent agents to rethink application creation and maintenance, marking a major milestone in the software development lifecycle. Agentic DevOps, the “next evolution of DevOps,” envisions AI agents working with developers and each other to automate and optimise the software lifecycle.
As it celebrates its 51st anniversary, the company is reimagining its founding as a “software factory” developed by developers for developers. The idea is to help engineers “break free from the grind,” restoring the “joy, your flow, and the magic of building” lost in rising demands, complexity, and technological debt. Besides coding, developers spend a lot of time designing systems, going through documentation, troubleshooting, refactoring, and fighting legacy code.
Agentic workflows are offered by GitHub Copilot, which is crucial to this shift. GitHub Copilot, already used by 15 million developers to speed up development, is expanding beyond code completion to enable agentic workflows, which help teams move from idea to production faster, improve code quality, collaborate faster, fortify security, pay off technical debt, and maintain app smoothness.
Microsoft is making GitHub Copilot available to all Visual Studio Code users to promote openness and community-driven innovation.
The Agentic DevOps announcement includes new developer-focused agents. A new coding agent elevates GitHub Copilot from pair programming to “peer” status in the development team. This agent can manage complex, multi-step coding jobs with other agents. Developers may assign it code reviews, test authoring, issue solutions, and full specification implementation.
It works across files and recommends terminal commands from a single prompt. Popular code editors including Microsoft Visual Studio Code, JetBrains, Eclipse, and Xcode offer “Agent mode”. Due to its audit logs and branch controls, this agent's suggested changes must be evaluated before deployment.
New Azure Site Reliability Engineering (SRE) Agents go beyond development. A 24/7 production system monitor spares developers of late-night warnings. It automatically diagnoses and fixes problems. The SRE Agent evaluates application health and performance in Azure Kubernetes Service (AKS), Azure App Service, serverless, and databases using Microsoft's worldwide experience.
It can solve problems itself or guide developers through root cause analysis. Note that repair items and remedial activities are documented as GitHub issues for team follow-up. Resilient, self-healing technologies allow teams to relax and focus, recover faster, and have fewer wake-up calls.
Agentic DevOps aims to address technical debt. With mainframe modernisation imminent, GitHub Copilot is offering new app modernisation services to help developers update stacks, focussing on legacy Java and.NET workloads. These features enable code assessments, dependency updates, and remediation by providing visibility and control over changes and automatically building and executing update plans. The goal is to produce cost-effective, safe, and stable apps so developers can focus on innovation rather than the past.
Azure's platform supports these capabilities with AI + machine learning services like Azure AI Foundry and Azure OpenAI in Foundry Models, containers (Azure Kubernetes Service, Azure App Service), databases (Azure Cosmos DB, Azure DB for PostgreSQL), and monitoring (Azure Monitor). Azure AI Foundry is a “AI App and agent factory” that lets you test cutting-edge models from several providers in the GitHub workflow with a new native integration. This integration lets GitHub Actions users invoke, compare, and exchange models via a single API.
Microsoft calls Agentic DevOps “as transformative as the shift to the cloud” and “seismic shift.” It promises to minimise friction, simplify processes, and rewrite decades-old cost structures that hampered teams. Agentic DevOps automates monotonous tasks to free developers to create the future and enhance productivity.
Microsoft Build 2025 guests are encouraged to explore this future with talks on agentic AI, GitHub Copilot, faster Azure development, app modernisation with AI, and agent mode in action.
#AgenticDevOps#GitHubCopilot#VisualStudio#MicrosoftBuild2025#AIAgentic#MicrosoftAzureandGitHubCopilot#technology#technews#technologynews#news#govindhtech
0 notes