#math olympiad sample tests
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Conquer Olympiad Exams with Oswaal360's Online Course and Mock Tests
Prepare for success with Oswaal360's Olympiad online test series, featuring comprehensive mock tests and sample papers tailored to the latest exam patterns. Elevate your Olympiad preparation and boost your confidence with our expertly curated courses.
0 notes
Text
ChatGPT has already wreaked havoc on classrooms and changed how teachers approach writing homework, since OpenAI publicly launched the generative AI chatbot in late 2022. School administrators rushed to try to detect AI-generated essays, and in turn, students scrambled to find out how to cloak their synthetic compositions. But by focusing on writing assignments, educators let another seismic shift take place in the periphery: students using AI more often to complete math homework too.
Right now, high schoolers and college students around the country are experimenting with free smartphone apps that help complete their math homework using generative AI. One of the most popular options on campus right now is the Gauth app, with millions of downloads. It’s owned by ByteDance, which is also TikTok’s parent company.
The Gauth app first launched in 2019 with a primary focus on mathematics, but soon expanded to other subjects as well, like chemistry and physics. It’s grown in relevance, and neared the top of smartphone download lists earlier this year for the education category. Students seem to love it. With hundreds of thousands of primarily positive reviews, Gauth has a favorable 4.8 star rating in the Apple App Store and Google Play Store.
All students have to do after downloading the app is point their smartphone at a homework problem, printed or handwritten, and then make sure any relevant information is inside of the image crop. Then Gauth’s AI model generates a step-by-step guide, often with the correct answer.
From our testing on high-school-level algebra and geometry homework samples, Gauth’s AI tool didn’t deliver A+ results and particularly struggled with some graphing questions. It performed well enough to get around a low B grade or a high C average on the homework we fed it. Not perfect, but also likely good enough to satisfy bored students who'd rather spend their time after school doing literally anything else.
The app struggled more on higher levels of math, like Calculus 2 problems, so students further along in their educational journey may find less utility in this current generation of AI homework-solving apps.
Yes, generative AI tools, with a foundation in natural language processing, are known for failing to generate accurate answers when presented with complex math equations. But researchers are focused on improving AI’s abilities in this sector, and an entry-level high school math class is likely well within the reach of current AI homework apps. Will has even written about how researchers at Google DeepMind are ecstatic about recent results from testing a math-focused large language model, called AlphaProof, on problems shown at this year’s International Math Olympiad.
To be fair, Gauth positions itself as an AI study company that’s there to “ace your homework” and help with difficult problems, rather than a cheating aid. The company even goes so far as to include an “Honor Code” on its website dictating proper usage. “Resist the temptation to use Gauth in ways that go against your values or school’s expectations,” reads the company’s website. So basically, Gauth implicitly acknowledges impulsive teenagers may use the app for much more than the occasional stumper, and wants them to pinkie promise that they’ll behave.
Prior to publication, a spokesperson for ByteDance did not answer a list of questions about the Gauth app when contacted by WIRED over email.
It’s easy to focus on Gauth’s limitations, but millions of students now have a free app in their pocket that can walk them through various math problems in seconds, with decent accuracy. This concept would be almost inconceivable to students from even a few years ago.
You could argue that Gauth promotes accessibility for students who don’t have access to quality education or who process information at a slower pace than their teacher’s curriculum. It’s a perspective shared by proponents of using AI tools, like ChatGPT, in the classroom. As long as the students all make it to the same destination, who cares what path they took on the journey? And isn’t this just the next evolution in our available math tools? We moved on from the abacus to the graphing calculator, so why not envision generative AI as another critical step forward?
I see value in teachers thoughtfully employing AI in the classroom for specific lessons or to provide students with more personalized practice questions. But I can’t get out of my head how this app, if students overly rely on it, could hollow out future generations’ critical thinking skills—often gleaned from powering through frustrating math classes and tough homework assignments. (I totally get it, though, as an English major.)
Educational leaders are missing the holistic picture if they continue to focus on AI-generated essays as the primary threat that could undermine the current approach to teaching. Instead of arduous assignments to complete outside of class, maybe centering in-class math practice could continue to facilitate positive learning outcomes in the age of AI.
If Gauth and apps like it eventually lead to the demise of math homework for high schoolers, throngs of students will breathe a collective sigh of relief. How will parents and educators respond? I’m not so sure. That remains an open question, and one for which Gauth can’t calculate an answer yet either.
21 notes
·
View notes
Text
Best Home Tutor in Dehradun for Class 1 to 12 – A Complete Guide!

Let’s face it—today’s school curriculum isn’t getting any easier. From CBSE board exams to Olympiads and entrance tests like NEET or JEE, students face academic pressure like never before. And while schools provide a foundation, the real concept clarity, revision support, and one-on-one mentorship often come from home tutoring.
That’s why finding the Best Home Tutor in Dehradun has become a top priority for parents. Whether your child is in Class 1 or Class 12, a professional tutor can fill learning gaps, build confidence, and guide them toward academic success.
What Makes a Home Tutor 'The Best'?
Not all tutors are created equal. A great home tutor doesn’t just explain concepts—they inspire learning. Here’s what to look for when choosing the Best Home Tutor in Dehradun:
Subject expertise and teaching credentials
Communication and explanation skills
Personalized teaching strategy
Flexible schedule that matches school timings
Ability to adapt to the student’s pace and style
Regular assessments and performance tracking
Class-Wise Breakdown: What Students Need at Each Stage
Class 1 to 5 – Building the Basics
Young learners need patience, creativity, and foundational teaching. The best home tutors for this age group:
Use storytelling and visual aids
Focus on reading, writing, arithmetic
Build attention span and classroom discipline
Provide gentle correction and praise
“A strong start now means fewer academic struggles later.”
Class 6 to 8 – Expanding the Learning Curve
Middle school students start exploring more subjects and concepts. This is the best time to build subject confidence:
English Grammar, Essay Writing
Basic Science (Biology, Physics, Chemistry)
History & Civics, Geography
Foundation courses for Math & Reasoning
At this level, having the Best Home Tutor in Dehradun ensures that students don’t fall behind as syllabi become more advanced.
Class 9 & 10 – Prepping for Board Exams
The transition from middle school to high school is steep. Students need:
Exam-oriented preparation for CBSE/ICSE/State Boards
In-depth practice of numericals, diagrams, definitions
Revision schedules & sample paper analysis
Doubt-solving sessions post school hours
A home tutor can break complex chapters into easy, digestible pieces—boosting both marks and morale.
Class 11 & 12 – Competitive & Career-Oriented Learning
Welcome to the big leagues! This is when every mark counts, especially if your child is preparing for:
JEE, NEET, CUET
Subject-specific boards (PCM, PCB, Commerce, Humanities)
Olympiads and scholarship exams
College admission aptitude tests
Only the Best Home Tutor in Dehradun can help students manage school, coaching, and stress without burnout.
Why Saraswati Tutorials Tops the List
When it comes to finding the Best Home Tutor in Dehradun, Saraswati Tutorials continues to lead. Here's why:
Experienced & Certified Tutors
All tutors undergo a strict screening process. They are either retired school teachers, university toppers, or subject matter experts with hands-on classroom experience.
Personalized Learning Plans
No two students are the same. Saraswati Tutorials builds custom plans tailored to learning pace, strengths, and board curriculum.
Affordable Home Tutoring Packages
Whether you're looking for daily tutoring, weekend-only sessions, or exam-crash courses, their pricing is transparent and parent-friendly.
Live Progress Tracking
Parents receive monthly progress reports, and regular parent-teacher check-ins ensure your child is on the right track.
Serving Every Major Area in Dehradun
Looking for a home tutor near your area? Saraswati Tutorials offers home tutors across:
Rajpur Road
Vasant Vihar
Prem Nagar
Clement Town
Dharampur
Ballupur
Dalanwala
Race Course
Nehru Colony
Whether you're in the city center or outskirts, the Best Home Tutor in Dehradun is just a call away.
Real Parent & Student Feedback
“Saraswati Tutorials assigned a tutor for my son in Class 7. He’s now in love with Science!” – Renu S., Vasant Vihar
“The tutors are punctual, disciplined, and very engaging. My daughter’s confidence in Math skyrocketed.” – Mr. Kapoor, Rajpur Road
“From Class 10 till JEE, the same tutor guided me through everything. Couldn’t have done it without them.” – Aayush M., Clement Town
FAQs About the Best Home Tutor in Dehradun
1. Do home tutors teach all subjects?
Yes, you can find subject-specific or multi-subject tutors based on your child’s needs. Some teach all subjects from Class 1–8, while specialized tutors focus on PCM, Commerce, etc.
2. Are Saraswati Tutorial tutors available for online sessions?
Yes! They offer both offline home tuition and live online tutoring.
3. How much does a home tutor cost in Dehradun?
Prices range from ₹2,000 to ₹8,000 per month, depending on class level, number of subjects, and tutor experience.
4. What if my child doesn’t connect with the tutor?
No problem! Saraswati Tutorials offers easy tutor replacement and demo classes until you find the perfect match.
5. Are weekend-only sessions available?
Yes, weekend batches and revision-only tutoring is available for working parents or busy students.
6. Can I monitor my child’s progress?
Absolutely! You’ll receive weekly feedback, monthly reports, and have access to teacher-parent meetings.
Final Thoughts – Give Your Child the Academic Edge
In a city full of academic competition, personalized home tuition isn’t just a luxury—it’s a necessity. Whether your child needs help with basic math in Class 2 or organic chemistry in Class 12, hiring the Best Home Tutor in Dehradun can be a game-changer.
And when you're ready to invest in your child’s future, Saraswati Tutorials is here with trusted, experienced, and result-driven home tutors across the city.
0 notes
Text
DeepMind AlphaGeometry solves complex geometry problems
New Post has been published on https://thedigitalinsider.com/deepmind-alphageometry-solves-complex-geometry-problems/
DeepMind AlphaGeometry solves complex geometry problems
.pp-multiple-authors-boxes-wrapper display:none; img width:100%;
DeepMind, the UK-based AI lab owned by Google’s parent company Alphabet, has developed an AI system called AlphaGeometry that can solve complex geometry problems close to human Olympiad gold medalists.
In a new paper in Nature, DeepMind revealed that AlphaGeometry was able to solve 25 out of 30 benchmark geometry problems from past International Mathematical Olympiad (IMO) competitions within the standard time limits. This nearly matches the average score of 26 problems solved by human gold medalists on the same tests.
The AI system combines a neural language model with a rule-bound deduction engine, providing a synergy that enables the system to find solutions to complex geometry theorems.
AlphaGeometry took a revolutionary approach to synthetic data generation by creating one billion random diagrams of geometric objects and deriving relationships between points and lines in each diagram. This process – termed “symbolic deduction and traceback” – resulted in a final training dataset of 100 million unique examples, providing a rich source for training the AI system.
According to DeepMind, AlphaGeometry represents a breakthrough in mathematical reasoning for AI, bringing it closer to the level of human mathematicians. Developing these skills is seen as essential for advancing artificial general intelligence.
Evan Chen, a maths coach and former Olympiad gold medalist, evaluated a sample of AlphaGeometry’s solutions. He said its output was not just correct, but also clean, human-readable proofs using standard geometry techniques—unlike the messy numerical solutions often produced when AI systems brute force maths problems.
While AlphaGeometry only handles the geometry portions of Olympiad tests so far, its skills alone would have been enough to earn a bronze medal on some past exams. DeepMind hopes to continue improving its maths reasoning abilities to the point it could pass the entire multi-subject Olympiad.
Advancing AI’s understanding of mathematics and logic is a key goal for DeepMind and Google. The researchers believe mastering Olympiad problems brings them one step closer towards more generalised artificial intelligence that can automatically discover new knowledge.
(Photo by Dustin Humes on Unsplash)
See also: Stability AI releases Stable Code 3B for enhanced coding assistance
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with Digital Transformation Week and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Tags: ai, alphageometry, artificial intelligence, deepmind, geometry, Google, google deepmind, olympiad
#2024#ai#ai & big data expo#ai news#AI systems#alphageometry#amp#applications#approach#artificial#Artificial General Intelligence#Artificial Intelligence#benchmark#Big Data#billion#Cloud#code#coding#coffee#Companies#Competitions#comprehensive#cyber#cyber security#data#DeepMind#Digital Transformation#engine#enterprise#Events
1 note
·
View note
Link
International Maths Olympiad is an online platform that provides resources for students to excel in maths. It provides an array of maths-related topics such as algebra, geometry, trigonometry, calculus, and more. It offers practice tests, tutorials, and materials to help students master these topics.
#Maths olympiad questions#math olympiad practice questions#maths olympiad preparation#IMO sample papers#online math olympiad test#math olympiad mock test#math olympiad rules
1 note
·
View note
Text
Okay, have spent a lot of time thinking about this for many years but Stefania’s art criticism and the specific disabilities I’ve been diagnosed with brought it into focus. The neuropsych testing I do not think adequately assesses visual processing--it only evaluates spatial orientation and mathematical reasoning. What it uses as a proxy for “visuoconstruction abilities” and “visuospatial memory” (as an obligate compound) is--my working theory, based on a sample size of...my cognition--the ability to recall Gestalts, and recall the relative position of Gestalts in a plane of space vis-a-vis one another, often in a series. It was those primary-color logic puzzles where you have to remember which triangles went where, reconstruct patterns from memory, say the color or the word first, not even account for the color of the signified thing behind the sign! I have such a distinct memory of doing this test because the word apple was blue and I was supposed to say the color instead of reading the word apple but the concept of, like, a Platonic-ideal apple was red, but some apples were green, and if you combined red with blue you got purple, and in any case the word apple was blue synesthesia-wise anyway so the exercise didn’t make sense when it was posed as a contradiction, and also wasn’t it weird that some apples were green and others were red when they were complementary contrasting colors? Why did that occur in nature? And why was the word blue when the fruits were red and green? Yabloko was yellow-green, as a word, and it looked like a golden delicious apple, it was more apple-y as a word than apple, which looked like a red apple with a waxy blue tint, whereas yabloko was matte--
I did not finish the neuropsych test but I remember this very clearly, at seven years old. I can’t hold patterns in my head. I couldn’t draw a representation to save my life or find my way out of a store. But I’ve always had a sense of color, a sense of light and shadow. I’m actually fantastic at 3D modeling too--so it’s not even spatial reasoning per se. I had the highest grade in my geometry class and got sent to the state math Olympiad as a freak accident when I was in remedial math and failed pre-algebra twice; I was a whiz at organic chemistry and bioinformatics and terrible at all the other math-heavy courses. I can’t measure, I can’t reckon depth or distance when it is a matter of proprioception, when it is actually three-dimensional, in physical space, relative to my body. But 3D models, and geometric theorems explaining how those shapes fit together, are not the same cognition-category. The Pythagorean theorem was the first equation that ever made intuitive sense to me! So I think it’s related, actually, not to a deficit in visual processing, or even spatial processing per se, but rather: a secondary effect of a deficit in proprioception, ability to orient one’s body in space. I also have periodic “Alice in Wonderland syndrome” type perceptual distortions with my seizures and episodic vertigo. So: Not dimension or even depth, but proprioception, relative distance, in 3D physical space.
7 notes
·
View notes
Text
Vedantu The LIVE Learning App

Vedantu Is A FREE LIVE Learning App for students. Learn from India’s Best Teachers from the comfort of your home.📱
Vedantu is the pioneer of LIVE Online learning in India and has redefined online education since. In these difficult times, our aim is to ensure that learning is not interrupted for students.
You can now avail Free Access to all LIVE Classes and Premium Content for Grades 1-12, CBSE, ICSE, Boards, KVPY, NTSE, IIT JEE & NEET, for up to 30 Days.
Get Unlimited Access to all courses, Test series, Online study material, Assignments, LIVE In-Class Doubt Solving & lots more, Absolutely FREE.
What makes Vedantu unique?
💻 Vedantu’s comprehensive & interactive LIVE Classes are specially designed for students to make their learning fun, interesting & personalized. The LIVE Learning App offers a one-of-a-kind interactive experience to students using a real-time learning platform named WAVE, a technology built in-house.
💭With Vedantu- the free learning App, experience Unlimited In-Class Doubt Solving, where the student can get his doubts solved instantly in the LIVE Class.
🎁LIVE In-Class Quizzes makes learning fun & the Real-Time Leaderboard pushes children to outdo themselves & perform better.
The LIVE Learning App offers Free Classes, Online Study, Test Series, Assignments & Study material for test preparation for CBSE, ICSE & State Boards. Chapter-wise NCERT Solutions for Maths & Science, Detailed Syllabus, Previous-Year Papers, Sample Papers, Revision notes, Formula sheets & lots more for class 6, class 7, class 8, class 9, class 10, class 11, class 12 & droppers, IIT JEE crash course, NEET crash course, NDA crash course as well as long term courses.
App Features: 📚💻
👩🏫Learn from India’s Best Teachers: Vedantu’s LIVE Online education ensures that every student of Grades 1-12, CBSE, ICSE, State Boards, IIT JEE & NEET receives personalized attention. The courses are conceptualized & designed by India’s Best Teachers, hailing from IITs & other top Educational Institutions. Take free classes on India’s Best online education App
📝Complete Exam Preparation: Get NCERT solutions for class 6, class 7, class 8, class 9, class 10, class 11 & class 12, Previous year question papers with answer keys for CBSE Class 10, CBSE Class 12, ICSE, IIT-JEE Main, JEE Advanced, NEET, KVPY, NTSE, KCET & other competitive exams in the Vedantu study app. Also get Sample papers for CBSE & ICSE, Revision notes, important questions, online study material, Math formula sheets & solutions of RD Sharma, RS Aggarwal, HC Verma & Lakhmir Singh, JEE Main Mock tests, JEE Advanced Mock Tests & lots more for Free!
🎁Play LIVE Interactive VQuiz: A unique feature of the Vedantu Learning App is the LIVE VQuiz that takes place every day. Play the fun real-time quiz with the entire nation & win amazing prizes
🏆Proven Record of Excellence: Vedantu LIVE Learning App has a record of mentoring excellence in CBSE, ICSE, State Boards, IIT JEE, NEET, KVPY & other exams. 14 Vedantu students have got Top 100 Category Ranks in JEE Main 2020 & a whopping 69% of our students scored more than 90% in Grade 12 Boards, 2020
Preparing for IIT JEE, JEE Main & JEE Advanced, NEET, KVPY, NTSE, Boards Exam, NDA, Olympiad? Take free classes & learn LIVE Online from the safety of your home on India’s Best Education App!🎓
Download Now!
Follow Vedantul On-
Facebook: https://www.facebook.com/VedantuInnovations Twitter: https://twitter.com/vedantu_learn YouTube: https://www.youtube.com/user/VedantuInnovations Instagram: https://www.instagram.com/vedantu_learns/?hl=en
#India education#indian express#Education#the times of india: latest news india#india news today#india news#indianstyle#india
1 note
·
View note
Text
The secret to success in Olympiad Exams

Olympiad exams are the most precious exams for students organized in the world. It not only helps in boosting the confidence of students but also makes them learn how to proceed and prepare for the competition. Olympiad exams develop problem-solving skills, analytical thinking skills, and knowledge about different subjects. Olympiad exams are very crucial to groom students for any competitive exams. It not only increases their intelligence but also builds their career in the future.
Let us discuss some secret tips on how to top in Olympiad Exams.
Cover the whole syllabus: Every time you are planning for Olympiad exams check the whole syllabus thoroughly. A syllabus is a description of all topics that you need to cover for a particular exam. Remember, missing a single topic may be your reason for losing.
Solve sample papers: Solve as many sample papers as you can. Because the more you practice the more you are aware of the tricks and tips.
Math Puzzles: Work on Math puzzles and English word puzzles daily. It increases your knowledge of English words, spellings, and Mathematics skills.
Clear concept: For every subject and topic try to go into depth about the topic. Understand the basic concept, watch related videos, search in Google. After the brief understanding, start practicing.
Mock Test: Opt for a mock test online. Mock test helps you get an overview of the exam duration and question pattern that to be faced during the final exam. It helps you to manage your time while answering the questions and locate your weak areas.
Preparation Time: Take at least 2 months prior to the exam for preparation. This will give you ample time to prepare in-depth. Never try anything in a hurry. Always plan and proceed.
For any query, comment below. Good luck with your exams.
0 notes
Text
Artificial Intelligence vs. Tuberculosis – Part 2
By SAURABH JHA, MD
Clever Hans
Preetham Srinivas, the head of the chest radiograph project in Qure.ai, summoned Bhargava Reddy, Manoj Tadepalli, and Tarun Raj to the meeting room.
“Get ready for an all-nighter, boys,” said Preetham.
Qure’s scientists began investigating the algorithm’s mysteriously high performance on chest radiographs from a new hospital. To recap, the algorithm had an area under the receiver operating characteristic curve (AUC) of 1 – that’s 100 % on multiple-choice question test.
“Someone leaked the paper to AI,” laughed Manoj.
“It’s an engineering college joke,” explained Bhargava. “It means that you saw the questions before the exam. It happens sometimes in India when rich people buy the exam papers.”
Just because you know the questions doesn’t mean you know the answers. And AI wasn’t rich enough to buy the AUC.
The four lads were school friends from Andhra Pradesh. They had all studied computer science at the Indian Institute of Technology (IIT), a freaky improbability given that only hundred out of a million aspiring youths are selected to this most coveted discipline in India’s most coveted institute. They had revised for exams together, pulling all-nighters – in working together, they worked harder and made work more fun.
Preetham ordered Maggi Noodles – the mysteriously delicious Indian instant noodles – to charge their energies. Ennio Morricone’s soundtrack from For a Few Dollars More played in the background. We were venturing into the wild west of deep learning.
The lads had to comb a few thousand normal and a few thousand abnormal radiographs to find what AI was seeing. They were engineers, not radiologists, and had no special training in radiology except for one that comes with looking at thousands of chest radiographs, which they now knew like the lines at the back of their hands. They had carefully fed AI data to teach it radiology. In return, AI taught them radiology – taught them where to look, what to see, and what to find.
They systematically searched the chest radiographs for clues. Radiographs are two-dimensional renditions, mere geometric compressions, maps of sorts. But the real estate they depict have unique personalities. The hila, apices, and tracheobronchial angle are so close to each other that they may as well be one structure, but like the mews, roads, avenues and cul-de-sacs of London, they’re distinct, each real estate expressing unique elements of physiology and pathology.
One real estate which often flummoxes AI is the costophrenic angle (CPA) – a quiet hamlet where the lung meets the diaphragm, two structures of differing capacity to stop x-rays, two opposites which attach. It’s supposedly sharp – hence, an “angle”; the loss of sharpness implies a pleural effusion, which isn’t normal.
The CPA is often blunt. If radiologists called a pleural effusion every time the CPA was blunt half the world would have a pleural effusion. How radiologists deal with a blunted CPA is often arbitrary. Some call pleural effusion, some just describe their observation without ascribing pathology, and some ignore the blunted CPA. I do all three but on different days of the week. Variation in radiology reporting frustrates clinicians. But as frustrating as reports are, the fact is that radiographs are imperfect instruments interpreted by imperfect arbiters – i.e. Imperfection Squared. Subjectivity is unconquerable. Objectivity is farcical.
Because the radiologist’s interpretation is the gospel truth for AI, variation amongst radiologists messes AI’s mind. AI prefers that radiologists be consistent like sheep and the report be dogmatic like the Old Testament, so that it can better understand the ground truth even if the ground truth is really ground truthiness. When all radiologists call a blunted CPA a pleural effusion, AI appears smarter. Perhaps, offering my two cents, the secret to AI’s mysterious super performance was that the radiologists from this new institute were sheep. They all reported the blunted CPA in the same manner. 100 % consistency – like machines.
“I don’t think it’s the CPA, yaar,” objected Tarun, politely. “The problem is probably in the metadata.”
The metadata is a lawless province which drives data scientists insane. Notwithstanding variation in radiology reporting, radiographs – i.e. data – follow well-defined rules, speak a common language, and can be crunched by deep neural networks. But radiographs don’t exist in vacuum. When stored, they’re drenched in the attributes of the local information technology. And when retrieved, they carry these attributes, which are like local dialects, with them. Before feeding the neural networks, the radiographs must be cleared of idiosyncracies in the metadata, which can take months.
It seemed we had a long night ahead. I was looking forward to the second plate of Maggi Noodles.
Around the 50th radiograph, Tarun mumbled, “it’s clever Hans.” His pitch then rose in excitement, “I figured it. AI is behaving like Clever Hans.”
Clever Hans was a celebrity German horse which could allegedly add and subtract. He’d answer by tapping his hoof. Researchers, however, figured out his secret. Hans would continue tapping his hoof until the number of taps corresponded to the right numerical answer, which he’d deduce from the subtle, non-verbal, visual cues in his owner. The horse would get the wrong answer if he couldn’t stare at his owner’s face. Not quite a math Olympiad, Hans was still quite clever, certainly for a horse, but even by human standards.
“What do you see?” Tarun pointed excitedly to a normal and an abnormal chest radiograph placed side by side. Having interpreted over several thousand radiographs I saw what I usually see but couldn’t see anything mysterious. I felt embarrassed – a radiologist was being upstaged by an engineer, AI, and supposedly a horse, too. I stared intently at the CPA hoping for a flash of inspiration.
“It’s not the CPA, yaar,” Tarun said again – “look at the whole film. Look at the corners.”
I still wasn’t getting it.
“AI is crafty, and just like Hans the clever horse, it seeks the simplest cue. In this hospital all abnormal radiographs are labelled – “PA.” None of the normals are labelled. This is the way they kept track of the abnormals. AI wasn’t seeing the hila, or CPA, or lung apices – it detected the mark – “PA” – which it couldn’t miss,” Tarun explained.
The others shortly verified Tarun’s observation. Sure enough, like clockwork – all the abnormal radiographs had “PA” written on them – without exception. This simple mark of abnormality, a local practice, became AI’s ground truth. It rejected all the sophisticated pedagogy it had been painfully taught for a simple rule. I wasn’t sure whether AI was crafty, pragmatic or lazy, or whether I felt more professionally threatened by AI or data scientists.
“This can be fixed by a simple code, but that’s for tomorrow,” said Preetham. The second plate of Maggi Noodles never arrived. AI had one more night of God-like performance.
The Language of Ground Truth
Artificial Intelligence’s pragmatic laziness is enviable. To learn, it’ll climb mountains when needed but where possible it’ll take the shortest path. It prefers climbing molehills to mountains. AI could be my Tyler Durden. It doesn’t give a rat’s tail how or why and even if it cared it won’t tell you why it arrived at an answer. AI’s dysphasic insouciance – its black box – means that we don’t know why AI is right, or that it is. But AI’s pedagogy is structured and continuous.
After acquiring the chest radiographs, Qure’s scientists had to label the images with the ground truth. Which truth, they asked. Though “ground truth” sounds profound it simply means what the patient has. On radiographs, patients have two truths: the radiographic finding, e.g. consolidation – an area of whiteness where there should be lung, and the disease, e.g. pneumonia, causing that finding. The pair is a couplet. Radiologists rhyme their observation with inference. The radiologist observes consolidation and infers pneumonia.
The inference is clinically meaningful as doctors treat pneumonia, not consolidation, with antibiotics. The precise disease, such as the specific pneumonia, e.g. legionella pneumonia, is the whole truth. But training AI on the whole truth isn’t feasible for several reasons.
First, many diseases cause consolidation, or whiteness, on radiographs – pneumonia is just one cause, which means that many diseases look similar. If legionella pneumonia looks like alveolar hemorrhage, why labor to get the whole truth?
Second, there’s seldom external verification of the radiologist’s interpretation. It’s unethical resecting lungs just to see if radiologists are correct. Whether radiologists attribute consolidation to atelectasis (collapse of a portion of the lung, like a folded tent), pneumonia, or dead lung – we don’t know if they’re right. Inference is guesswork.
Another factor is the sample size: preciser the truth fewer cases of that precise truth. There are more cases of consolidation from any cause than consolidation from legionella pneumonia. AI needs numbers, not just to tighten the confidence intervals around the point estimate – broad confidence intervals imply poor work ethic – but for external validity. The more general the ground truth, the more cases of labelled truth AI sees, and the more generalizable AI gets, allowing it to work in Mumbai, Karachi, and New York.
Thanks to Prashant Warier’s tireless outreach and IIT network, Qure.ai acquired a whopping 2.5 million chest radiographs from nearly fifty centers across the world, from afar as Tokyo and Johannesburg and, of course, from Mumbai. AI had a sure shot at going global. But the sheer volume of radiographs made the scientists timorous.
“I said to Prashant, we’ll be here till the next century if we have to search two million medical records for the ground truth, or label two million radiographs” recalls Preetham. AI could neither be given a blank slate nor be spoon fed. The way around it was to label a few thousand radiographs with anatomical landmarks such as hila, diaphragm, heart, a process known as segmentation. This level of weak supervision could be scaled.
For the ground truth, they’d use the radiologist’s interpretation. Even so, reading over a million radiology reports wasn’t practical. They’d use Natural Language Processing (NLP). NLP can search unstructured (free text) sentences for meaningful words and phrases. NLP would tell AI whether the study was normal or abnormal and what the abnormality was.
Chest x-ray reports are diverse and subjective, with inconsistency added to the mix. Ideally, words should precisely and consistently convey what radiologists see. Radiologists do pay heed to March Hare’s advice to Alice: “then you should say what you mean,” and to Alice’s retort: “at least I mean what I say.” The trouble is that different radiologists say different things about the same disease and mean different things by the same descriptor.
One radiologist may call every abnormal whiteness an “opacity”, regardless of whether they think the opacity is from pneumonia or an innocuous scar. Another may say “consolidation” instead of “opacity.” Still another may use “consolidation” only when they believe the abnormal whiteness is because of pneumonia, instilling connation in the denotation. Whilst another may use “infiltrate” for viral pneumonia and “consolidation” for bacterial pneumonia.
The endless permutations of language in radiology reports would drive both March Hare and Alice insane. The Fleischner Society lexicon makes descriptors more uniform and meaningful. After perusing several thousand radiology reports, the team selected from that lexicon the following descriptors for labelling: blunted costophrenic angle, cardiomegaly, cavity, consolidation, fibrosis, hilar enlargement, nodule, opacity and pleural effusion.
Not content with publicly available NLPs, which don’t factor local linguistic culture, the team developed their own NLP. They had two choices – use machine learning to develop the NLP or use humans (programmers) to make the rules. The former is way faster. Preetham opted for the latter because it gave him latitude to incorporate qualifiers in radiology reports such as “vague” and “persistent.” The nuances could come in handy for future iterations.
Starting off with simple rules such as negation detection so that “no abnormality” or “no pneumonia” or “pneumonia unlikely” would be the same as “normal”, then broadening the rules to incorporate synonyms such as “density” and “lesion”, including the protean “prominent”, a word which can mean anything except what it actually means and like “awesome” has been devalued by overuse, the NLP for chest radiograph accrued nearly 2500 rules, rapidly becoming more biblical than the regulations of Obamacare.
The first moment of reckoning arrived: does the NLP even work? Testing the NLP is like testing the tester – if the NLP was grossly inaccurate, the whole project would crash. NLP determines the accuracy of the labelled truth – e.g. whether the radiologist truly said “consolidation” in the report. If NLP correctly picks “consolidation” in nine out of ten reports and doesn’t in one out of ten, the radiograph with “consolidation” but labelled “normal” doesn’t confuse AI. AI can tolerate occasional misclassification; indeed, it thrives on noise. You’re allowed to fool it once, but you can’t fool it too often.
After six months of development, the NLP was tested on 1930 reports to see if it flagged the radiographic descriptors correctly. The reports, all 1930 of them, were manually checked by radiologists blinded to NLP’s answers. The NLP performed respectively, with sensitivities/ specificities for descriptors ranging from 93 % to 100 %.
For “normal”, the most important radiological diagnosis, NLP had a specificity of 100 %. This means that in 10, 000 reports the radiologists called or implied abnormal, none would be falsely extracted by the NLP as “normal.” NLP’s sensitivity for “normal” was 94 %. This means that in 10, 000 reports the radiologist called or implied normal, 600 would be falsely extracted by NLP as “abnormal.” NLP’s accuracy reflected language ambiguity, which is a proxy of radiologist’s uncertainty. Radiologists are less certain and use more weasel words when they believe the radiograph is normal.
Algorithm Academy
After deep learning’s success using Image Net to spot cats and dogs, prominent computer scientists prophesized the extinction of radiologists. If AI could tell cats apart from dogs it could surely read CAT scans. They missed a minor point. The typical image resolution in Image Net is 64 x 64 pixels. The resolution of chest radiographs can be as high as 4096 x 4096 pixels. Lung nodules on chest radiographs are needles in haystacks. Even cats are hard to find.
The other point missed is more subtle. When AI is trying to classify a cat in a picture of a cat on the sofa, the background is irrelevant. AI can focus on the cat and ignore the sofa and the writing on the wall. On chest radiographs the background is both the canvass and the paint. You can’t ignore the left upper lobe just because there’s an opacity in the right lower lobe. Radiologists don’t enjoy satisfaction of search. All lungs must be searched with unyielding visual diligence.
Radiologists maybe awkward people, imminently replaceable, but the human retina is a remarkable engineering feat, evolutionarily extinction-proof, which can discern lot more than fifty shades of gray. For the neural network, 4096 pixels is too much information. Chest radiographs had to be down sampled to 256 pixels. The reduced resolution makes pulmonary arteries look like nodules. Radiologists should be humbled that AI starts at a disadvantage.
Unlike radiologists, AI doesn’t take bathroom breaks or check Twitter. It’s indefatigable. Very quickly, it trained on 50, 000 chest radiographs. Soon AI was ready for the end of semester exam. The validation cases come from the same source as the training cases. Training-validation is a loop. Data scientists look at AI’s performance on validation cases, make tweaks, and give it more cases to train on, check its performance again, make tweaks, and so on.
When asked “is there consolidation?”, AI doesn’t talk but expresses itself in a dimensionless number known as confidence score – which runs between 0 and 1. How AI arrives at a particular confidence score, such as 0.5, no one really understands. The score isn’t a measure of probability though it probably incorporates some probability. Nor does it strictly measure confidence, though it’s certainly a measure of belief, which is a measure of confidence. It’s like asking a radiologist – “how certain are you that this patient has pulmonary edema – throw me a number?” The number the radiologist throws isn’t empirical but is still information.
The confidence score is mysterious but not meaningless. For one, you can literally turn the score’s dial, like adjusting the brightness or contrast of an image, and see the trade-off between sensitivity and specificity. It’s quite a sight. It’s like seeing the full tapestry of radiologists, from the swashbuckling under caller to the “afraid of my shadow” over caller. The confidence score can be chosen to maximize sensitivity or specificity, or using Youden’s index, optimize both.
To correct poor sensitivity and specificity, the scientists looked at cases where the confidence scores were at the extremes, where the algorithm was either nervous or overconfident. AI’s weaknesses were radiologist’s blind spots, such as the lung apices, the crowded bazaar of the hila, and behind the ribs. It can be fooled by symmetry. When the algorithm made a mistake, it’s reward function, also known as loss function, was changed so that it was punished if it made the same mistake and rewarded when it didn’t. Algorithms, who have feelings, too, responded favorably like Pavlov’s dogs, and kept improving.
Validation case. The algorithm called “consolidation” in the left lower lobe. The radiologist called the x-ray normal. The radiologist is the gold standard so this was a false positive.
The Board Exam
After eighteen months of training-validation, and seeing over million radiographs, the second moment of reckoning arrived: the test, the real test, not the mock exam. This important part of algorithm development must be rigorous because if the test is too easy the algorithm can falsely perform. Qure.ai wanted their algorithms validated by independent researchers and that validation published in peer review journals. But it wasn’t Reviewer 2 they feared.
“You want to find and fix the algorithm’s weaknesses before deployment. Because if our customers discover its weaknesses instead of us, we lose credibility,” explained Preetham.
Preetham was alluding to the inevitable drop in performance when algorithms are deployed in new hospitals. A small drop in AUC such as 1-2 %, which doesn’t change clinical management, is fine; a massive drop such as 20 % is embarrassing. What’s even more embarrassing is if AI misses an obvious finding such a bleedingly-obvious consolidation. If radiologists miss obvious findings they could be sued. If the algorithm missed an obvious finding it could lose its jobs, and Qure.ai could lose future contracts. A single drastic error can undo months of hard work. Healthcare is an unforgiving market.
In the beginning of the training, AI missed a 6 cm opacity in the lung, which even toddlers can see. Qure’s scientists were puzzled, afraid, and despondent. It turned out that the algorithm had mistaken the large opacity for a pacemaker. Originally, the data scientists had excluded radiographs with devices so as not to confuse AI. When the algorithm saw what it thought was a pacemaker it remembered the rule, “no devices”, so denied seeing anything. The scientists realized that in their attempt to not confuse AI, they had confused it even more. There was no gain in mollycoddling AI. It needed to see the real world to grow up.
The test cases came from new sources – hospitals in Calcutta, Pune and Mysore. The ground truth was made more stringent. Three radiologists read the radiographs independently. If two called “consolidation” and the third didn’t, the majority prevailed, and the ground truth was “consolidation”. If two radiologists didn’t flag a nodule, and a third did, the ground truth was “no nodule.” For both validation and the test cases, radiologists were the ground truth – AI was prisoner to radiologists’ whims, but by using three radiologists as the ground truth for test cases, the interobserver variability was reduced – the truth, in a sense, was the golden mean rather than consensus.
Test case. Algorithm called “opacity” in the left lower lobe. You can see why – notice the subtle but real increased density in left vs right lower lobe. One radiologist called said “opacity”, two disagreed. This was a false positive.
What’s the minimum number of abnormalities AI needs to see; its numbers needed to learn (NNL)? This depends on several factors – how sensitive you think the algorithm will be, the desired tightness of the confidence interval, desired precision (paucity of false positives) and, crucially, rarity of the abnormality. The rarer the abnormality the more radiographs AI needs to see. To be confident of seeing eighty cases – the NNL was derived from a presumed sensitivity of 80 % – of a specific finding, AI would have to see 15, 000 radiographs. NNL wasn’t a problem in either training or validation – recall, there were 100, 000 radiographs for validation which is a feast even for training. But gathering test cases was onerous and expensive. Radiologists aren’t known to work for free.
Qure’s homegrown NLP flagged chest radiographs with radiology descriptors in the new hospitals. There were normals, too, which were randomly distributed in the test, but the frequency of abnormalities was different from the training cases. In the latter, the frequency reflected actual prevalences of radiographic abnormalities. Natural prevalences don’t guarantee sufficient abnormals in a sample of two thousand. Through a process called “enrichment”, the frequency of each abnormality in the test pool was increased, so that 80 cases each of opacity, nodule, consolidation, etc, were guaranteed in the test.
The abnormals in the test were more frequent than in real life. Contrived? Yes. Unfair? No. In the American board examination, radiologists are shown only abnormal cases.
Like anxious parents, Qure’s scientists waited for the exam result, the AUC.
“We expected sensitivities of 80 %. That’s how we calculated our sample size. A few radiologists advised us that we not develop algorithms for chest radiographs, saying that it was a fool’s errand because radiographs are so subjective. We could hear their warnings.” Preetham recalled with subdued nostalgia.
The AUC for detecting an abnormal chest radiograph was 0.92. Individual radiologists, unsurprisingly, did better as they were part of the truth, after all. As expected, the degree of agreement between radiologists, the inter-observer variability, affected AI’s performance, which was the highest when radiologists were most in agreement, such as when calling cardiomegaly. The radiologists had been instructed to call “cardiomegaly” when the cardiothoracic ratio was greater than 0.5. For this finding, the radiologists agreed 92 % of the time. For normal, radiologists agreed 85 % of the time. For cardiomegaly, the algorithm’s AUC was 0.96. Given the push to make radiology more quantitative and less subjective, these statistics should be borne in mind.
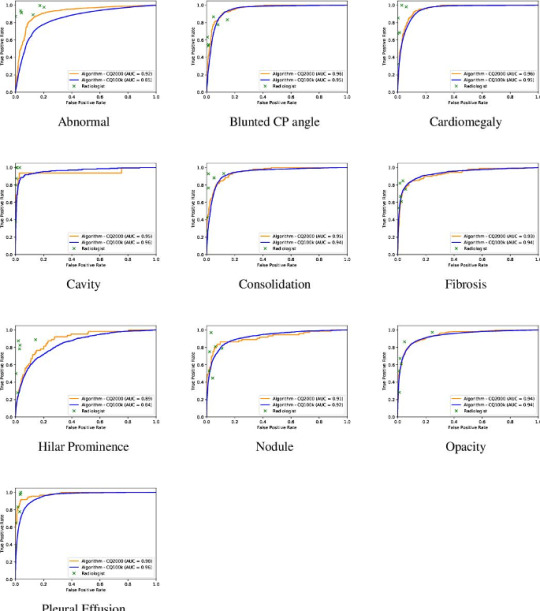
The AUC of algorithm performance in test and validation cases. The individual crosses represent radiologists. Radiologists did better than the algorithm.
For all abnormalities, both measures of diagnostic performance were over 90 %. The algorithm got straight As. In fact, the algorithm performed better on the test (AUC – 0.92) than validation cases (AUC – 0.86) at discerning normal – a testament not to its less-is-more philosophy but the fact that the test sample had fewer gray zone abnormalities, such as calcification of the aortic knob, the type of “abnormality” that some radiologists report and others ignore. This meant that AI’s performance had reached an asymptote which couldn’t be overcome by more data because the more radiographs it saw the more “gray zone” abnormalities it’d see. This curious phenomenon mirrors radiologists’ performance. The more chest radiographs we see the better we get. But we get worse, too, because we know what we don’t know and become more uncertain. After a while there’s little net gain in performance by seeing more radiographs.
Nearly three years after the company was conceived, after several dead ends, and morale-lowering frustrations with the metadata, the chest radiograph algorithm had matured. It was actually not a single algorithm but a bunch of algorithms which helped each other and could be combined into a meta-algorithm. The algorithms moved like bees but functioned like a platoon.
As the team was about to open the champagne, Ammar Jagirdar, Product Manager, had news.
“Guys, the local health authority in Baran, Rajasthan, is interested in our TB algorithm.”
Ammar, a former dentist with a second degree in engineering, also from IIT, isn’t someone you can easily impress. He gave up his lucrative dental practice for a second career because he found shining teeth intellectually bland.
“I was happy with the algorithm performance,” said Ammar, “but having worked in start-ups, I knew that building the product is only 20 % of the task. 80 % is deployment.”
Ammar had underestimated deployment. He had viewed it as an engineering challenge. He anticipated mismatched IT systems which could be fixed by clever codes or I-phone apps. Rajashtan would teach him that the biggest challenge to deployment of algorithms wasn’t the AUC, or clever statisticians arguing endlessly on Twitter about which outcome measures the value of AI, or overfitting. It was a culture of doubt. A culture which didn’t so much fear change as couldn’t be bothered changing. Qure’s youthful scientists, who looked like characters from a Netflix college movie, would have to labor to be taken seriously.
Saurabh Jha (aka @RogueRad) is a contributing editor to The Health Care Blog. This is Part 2 of a 3-part series.
The post Artificial Intelligence vs. Tuberculosis – Part 2 appeared first on The Health Care Blog.
Artificial Intelligence vs. Tuberculosis – Part 2 published first on https://venabeahan.tumblr.com
0 notes
Text
Artificial Intelligence vs. Tuberculosis – Part 2
By SAURABH JHA, MD
Clever Hans
Preetham Srinivas, the head of the chest radiograph project in Qure.ai, summoned Bhargava Reddy, Manoj Tadepalli, and Tarun Raj to the meeting room.
“Get ready for an all-nighter, boys,” said Preetham.
Qure’s scientists began investigating the algorithm’s mysteriously high performance on chest radiographs from a new hospital. To recap, the algorithm had an area under the receiver operating characteristic curve (AUC) of 1 – that’s 100 % on multiple-choice question test.
“Someone leaked the paper to AI,” laughed Manoj.
“It’s an engineering college joke,” explained Bhargava. “It means that you saw the questions before the exam. It happens sometimes in India when rich people buy the exam papers.”
Just because you know the questions doesn’t mean you know the answers. And AI wasn’t rich enough to buy the AUC.
The four lads were school friends from Andhra Pradesh. They had all studied computer science at the Indian Institute of Technology (IIT), a freaky improbability given that only hundred out of a million aspiring youths are selected to this most coveted discipline in India’s most coveted institute. They had revised for exams together, pulling all-nighters – in working together, they worked harder and made work more fun.
Preetham ordered Maggi Noodles – the mysteriously delicious Indian instant noodles – to charge their energies. Ennio Morricone’s soundtrack from For a Few Dollars More played in the background. We were venturing into the wild west of deep learning.
The lads had to comb a few thousand normal and a few thousand abnormal radiographs to find what AI was seeing. They were engineers, not radiologists, and had no special training in radiology except for one that comes with looking at thousands of chest radiographs, which they now knew like the lines at the back of their hands. They had carefully fed AI data to teach it radiology. In return, AI taught them radiology – taught them where to look, what to see, and what to find.
They systematically searched the chest radiographs for clues. Radiographs are two-dimensional renditions, mere geometric compressions, maps of sorts. But the real estate they depict have unique personalities. The hila, apices, and tracheobronchial angle are so close to each other that they may as well be one structure, but like the mews, roads, avenues and cul-de-sacs of London, they’re distinct, each real estate expressing unique elements of physiology and pathology.
One real estate which often flummoxes AI is the costophrenic angle (CPA) – a quiet hamlet where the lung meets the diaphragm, two structures of differing capacity to stop x-rays, two opposites which attach. It’s supposedly sharp – hence, an “angle”; the loss of sharpness implies a pleural effusion, which isn’t normal.
The CPA is often blunt. If radiologists called a pleural effusion every time the CPA was blunt half the world would have a pleural effusion. How radiologists deal with a blunted CPA is often arbitrary. Some call pleural effusion, some just describe their observation without ascribing pathology, and some ignore the blunted CPA. I do all three but on different days of the week. Variation in radiology reporting frustrates clinicians. But as frustrating as reports are, the fact is that radiographs are imperfect instruments interpreted by imperfect arbiters – i.e. Imperfection Squared. Subjectivity is unconquerable. Objectivity is farcical.
Because the radiologist’s interpretation is the gospel truth for AI, variation amongst radiologists messes AI’s mind. AI prefers that radiologists be consistent like sheep and the report be dogmatic like the Old Testament, so that it can better understand the ground truth even if the ground truth is really ground truthiness. When all radiologists call a blunted CPA a pleural effusion, AI appears smarter. Perhaps, offering my two cents, the secret to AI’s mysterious super performance was that the radiologists from this new institute were sheep. They all reported the blunted CPA in the same manner. 100 % consistency – like machines.
“I don’t think it’s the CPA, yaar,” objected Tarun, politely. “The problem is probably in the metadata.”
The metadata is a lawless province which drives data scientists insane. Notwithstanding variation in radiology reporting, radiographs – i.e. data – follow well-defined rules, speak a common language, and can be crunched by deep neural networks. But radiographs don’t exist in vacuum. When stored, they’re drenched in the attributes of the local information technology. And when retrieved, they carry these attributes, which are like local dialects, with them. Before feeding the neural networks, the radiographs must be cleared of idiosyncracies in the metadata, which can take months.
It seemed we had a long night ahead. I was looking forward to the second plate of Maggi Noodles.
Around the 50th radiograph, Tarun mumbled, “it’s clever Hans.” His pitch then rose in excitement, “I figured it. AI is behaving like Clever Hans.”
Clever Hans was a celebrity German horse which could allegedly add and subtract. He’d answer by tapping his hoof. Researchers, however, figured out his secret. Hans would continue tapping his hoof until the number of taps corresponded to the right numerical answer, which he’d deduce from the subtle, non-verbal, visual cues in his owner. The horse would get the wrong answer if he couldn’t stare at his owner’s face. Not quite a math Olympiad, Hans was still quite clever, certainly for a horse, but even by human standards.
“What do you see?” Tarun pointed excitedly to a normal and an abnormal chest radiograph placed side by side. Having interpreted over several thousand radiographs I saw what I usually see but couldn’t see anything mysterious. I felt embarrassed – a radiologist was being upstaged by an engineer, AI, and supposedly a horse, too. I stared intently at the CPA hoping for a flash of inspiration.
“It’s not the CPA, yaar,” Tarun said again – “look at the whole film. Look at the corners.”
I still wasn’t getting it.
“AI is crafty, and just like Hans the clever horse, it seeks the simplest cue. In this hospital all abnormal radiographs are labelled – “PA.” None of the normals are labelled. This is the way they kept track of the abnormals. AI wasn’t seeing the hila, or CPA, or lung apices – it detected the mark – “PA” – which it couldn’t miss,” Tarun explained.
The others shortly verified Tarun’s observation. Sure enough, like clockwork – all the abnormal radiographs had “PA” written on them – without exception. This simple mark of abnormality, a local practice, became AI’s ground truth. It rejected all the sophisticated pedagogy it had been painfully taught for a simple rule. I wasn’t sure whether AI was crafty, pragmatic or lazy, or whether I felt more professionally threatened by AI or data scientists.
“This can be fixed by a simple code, but that’s for tomorrow,” said Preetham. The second plate of Maggi Noodles never arrived. AI had one more night of God-like performance.
The Language of Ground Truth
Artificial Intelligence’s pragmatic laziness is enviable. To learn, it’ll climb mountains when needed but where possible it’ll take the shortest path. It prefers climbing molehills to mountains. AI could be my Tyler Durden. It doesn’t give a rat’s tail how or why and even if it cared it won’t tell you why it arrived at an answer. AI’s dysphasic insouciance – its black box – means that we don’t know why AI is right, or that it is. But AI’s pedagogy is structured and continuous.
After acquiring the chest radiographs, Qure’s scientists had to label the images with the ground truth. Which truth, they asked. Though “ground truth” sounds profound it simply means what the patient has. On radiographs, patients have two truths: the radiographic finding, e.g. consolidation – an area of whiteness where there should be lung, and the disease, e.g. pneumonia, causing that finding. The pair is a couplet. Radiologists rhyme their observation with inference. The radiologist observes consolidation and infers pneumonia.
The inference is clinically meaningful as doctors treat pneumonia, not consolidation, with antibiotics. The precise disease, such as the specific pneumonia, e.g. legionella pneumonia, is the whole truth. But training AI on the whole truth isn’t feasible for several reasons.
First, many diseases cause consolidation, or whiteness, on radiographs – pneumonia is just one cause, which means that many diseases look similar. If legionella pneumonia looks like alveolar hemorrhage, why labor to get the whole truth?
Second, there’s seldom external verification of the radiologist’s interpretation. It’s unethical resecting lungs just to see if radiologists are correct. Whether radiologists attribute consolidation to atelectasis (collapse of a portion of the lung, like a folded tent), pneumonia, or dead lung – we don’t know if they’re right. Inference is guesswork.
Another factor is the sample size: preciser the truth fewer cases of that precise truth. There are more cases of consolidation from any cause than consolidation from legionella pneumonia. AI needs numbers, not just to tighten the confidence intervals around the point estimate – broad confidence intervals imply poor work ethic – but for external validity. The more general the ground truth, the more cases of labelled truth AI sees, and the more generalizable AI gets, allowing it to work in Mumbai, Karachi, and New York.
Thanks to Prashant Warier’s tireless outreach and IIT network, Qure.ai acquired a whopping 2.5 million chest radiographs from nearly fifty centers across the world, from afar as Tokyo and Johannesburg and, of course, from Mumbai. AI had a sure shot at going global. But the sheer volume of radiographs made the scientists timorous.
“I said to Prashant, we’ll be here till the next century if we have to search two million medical records for the ground truth, or label two million radiographs” recalls Preetham. AI could neither be given a blank slate nor be spoon fed. The way around it was to label a few thousand radiographs with anatomical landmarks such as hila, diaphragm, heart, a process known as segmentation. This level of weak supervision could be scaled.
For the ground truth, they’d use the radiologist’s interpretation. Even so, reading over a million radiology reports wasn’t practical. They’d use Natural Language Processing (NLP). NLP can search unstructured (free text) sentences for meaningful words and phrases. NLP would tell AI whether the study was normal or abnormal and what the abnormality was.
Chest x-ray reports are diverse and subjective, with inconsistency added to the mix. Ideally, words should precisely and consistently convey what radiologists see. Radiologists do pay heed to March Hare’s advice to Alice: “then you should say what you mean,” and to Alice’s retort: “at least I mean what I say.” The trouble is that different radiologists say different things about the same disease and mean different things by the same descriptor.
One radiologist may call every abnormal whiteness an “opacity”, regardless of whether they think the opacity is from pneumonia or an innocuous scar. Another may say “consolidation” instead of “opacity.” Still another may use “consolidation” only when they believe the abnormal whiteness is because of pneumonia, instilling connation in the denotation. Whilst another may use “infiltrate” for viral pneumonia and “consolidation” for bacterial pneumonia.
The endless permutations of language in radiology reports would drive both March Hare and Alice insane. The Fleischner Society lexicon makes descriptors more uniform and meaningful. After perusing several thousand radiology reports, the team selected from that lexicon the following descriptors for labelling: blunted costophrenic angle, cardiomegaly, cavity, consolidation, fibrosis, hilar enlargement, nodule, opacity and pleural effusion.
Not content with publicly available NLPs, which don’t factor local linguistic culture, the team developed their own NLP. They had two choices – use machine learning to develop the NLP or use humans (programmers) to make the rules. The former is way faster. Preetham opted for the latter because it gave him latitude to incorporate qualifiers in radiology reports such as “vague” and “persistent.” The nuances could come in handy for future iterations.
Starting off with simple rules such as negation detection so that “no abnormality” or “no pneumonia” or “pneumonia unlikely” would be the same as “normal”, then broadening the rules to incorporate synonyms such as “density” and “lesion”, including the protean “prominent”, a word which can mean anything except what it actually means and like “awesome” has been devalued by overuse, the NLP for chest radiograph accrued nearly 2500 rules, rapidly becoming more biblical than the regulations of Obamacare.
The first moment of reckoning arrived: does the NLP even work? Testing the NLP is like testing the tester – if the NLP was grossly inaccurate, the whole project would crash. NLP determines the accuracy of the labelled truth – e.g. whether the radiologist truly said “consolidation” in the report. If NLP correctly picks “consolidation” in nine out of ten reports and doesn’t in one out of ten, the radiograph with “consolidation” but labelled “normal” doesn’t confuse AI. AI can tolerate occasional misclassification; indeed, it thrives on noise. You’re allowed to fool it once, but you can’t fool it too often.
After six months of development, the NLP was tested on 1930 reports to see if it flagged the radiographic descriptors correctly. The reports, all 1930 of them, were manually checked by radiologists blinded to NLP’s answers. The NLP performed respectively, with sensitivities/ specificities for descriptors ranging from 93 % to 100 %.
For “normal”, the most important radiological diagnosis, NLP had a specificity of 100 %. This means that in 10, 000 reports the radiologists called or implied abnormal, none would be falsely extracted by the NLP as “normal.” NLP’s sensitivity for “normal” was 94 %. This means that in 10, 000 reports the radiologist called or implied normal, 600 would be falsely extracted by NLP as “abnormal.” NLP’s accuracy reflected language ambiguity, which is a proxy of radiologist’s uncertainty. Radiologists are less certain and use more weasel words when they believe the radiograph is normal.
Algorithm Academy
After deep learning’s success using Image Net to spot cats and dogs, prominent computer scientists prophesized the extinction of radiologists. If AI could tell cats apart from dogs it could surely read CAT scans. They missed a minor point. The typical image resolution in Image Net is 64 x 64 pixels. The resolution of chest radiographs can be as high as 4096 x 4096 pixels. Lung nodules on chest radiographs are needles in haystacks. Even cats are hard to find.
The other point missed is more subtle. When AI is trying to classify a cat in a picture of a cat on the sofa, the background is irrelevant. AI can focus on the cat and ignore the sofa and the writing on the wall. On chest radiographs the background is both the canvass and the paint. You can’t ignore the left upper lobe just because there’s an opacity in the right lower lobe. Radiologists don’t enjoy satisfaction of search. All lungs must be searched with unyielding visual diligence.
Radiologists maybe awkward people, imminently replaceable, but the human retina is a remarkable engineering feat, evolutionarily extinction-proof, which can discern lot more than fifty shades of gray. For the neural network, 4096 pixels is too much information. Chest radiographs had to be down sampled to 256 pixels. The reduced resolution makes pulmonary arteries look like nodules. Radiologists should be humbled that AI starts at a disadvantage.
Unlike radiologists, AI doesn’t take bathroom breaks or check Twitter. It’s indefatigable. Very quickly, it trained on 50, 000 chest radiographs. Soon AI was ready for the end of semester exam. The validation cases come from the same source as the training cases. Training-validation is a loop. Data scientists look at AI’s performance on validation cases, make tweaks, and give it more cases to train on, check its performance again, make tweaks, and so on.
When asked “is there consolidation?”, AI doesn’t talk but expresses itself in a dimensionless number known as confidence score – which runs between 0 and 1. How AI arrives at a particular confidence score, such as 0.5, no one really understands. The score isn’t a measure of probability though it probably incorporates some probability. Nor does it strictly measure confidence, though it’s certainly a measure of belief, which is a measure of confidence. It’s like asking a radiologist – “how certain are you that this patient has pulmonary edema – throw me a number?” The number the radiologist throws isn’t empirical but is still information.
The confidence score is mysterious but not meaningless. For one, you can literally turn the score’s dial, like adjusting the brightness or contrast of an image, and see the trade-off between sensitivity and specificity. It’s quite a sight. It’s like seeing the full tapestry of radiologists, from the swashbuckling under caller to the “afraid of my shadow” over caller. The confidence score can be chosen to maximize sensitivity or specificity, or using Youden’s index, optimize both.
To correct poor sensitivity and specificity, the scientists looked at cases where the confidence scores were at the extremes, where the algorithm was either nervous or overconfident. AI’s weaknesses were radiologist’s blind spots, such as the lung apices, the crowded bazaar of the hila, and behind the ribs. It can be fooled by symmetry. When the algorithm made a mistake, it’s reward function, also known as loss function, was changed so that it was punished if it made the same mistake and rewarded when it didn’t. Algorithms, who have feelings, too, responded favorably like Pavlov’s dogs, and kept improving.
Validation case. The algorithm called “consolidation” in the left lower lobe. The radiologist called the x-ray normal. The radiologist is the gold standard so this was a false positive.
The Board Exam
After eighteen months of training-validation, and seeing over million radiographs, the second moment of reckoning arrived: the test, the real test, not the mock exam. This important part of algorithm development must be rigorous because if the test is too easy the algorithm can falsely perform. Qure.ai wanted their algorithms validated by independent researchers and that validation published in peer review journals. But it wasn’t Reviewer 2 they feared.
“You want to find and fix the algorithm’s weaknesses before deployment. Because if our customers discover its weaknesses instead of us, we lose credibility,” explained Preetham.
Preetham was alluding to the inevitable drop in performance when algorithms are deployed in new hospitals. A small drop in AUC such as 1-2 %, which doesn’t change clinical management, is fine; a massive drop such as 20 % is embarrassing. What’s even more embarrassing is if AI misses an obvious finding such a bleedingly-obvious consolidation. If radiologists miss obvious findings they could be sued. If the algorithm missed an obvious finding it could lose its jobs, and Qure.ai could lose future contracts. A single drastic error can undo months of hard work. Healthcare is an unforgiving market.
In the beginning of the training, AI missed a 6 cm opacity in the lung, which even toddlers can see. Qure’s scientists were puzzled, afraid, and despondent. It turned out that the algorithm had mistaken the large opacity for a pacemaker. Originally, the data scientists had excluded radiographs with devices so as not to confuse AI. When the algorithm saw what it thought was a pacemaker it remembered the rule, “no devices”, so denied seeing anything. The scientists realized that in their attempt to not confuse AI, they had confused it even more. There was no gain in mollycoddling AI. It needed to see the real world to grow up.
The test cases came from new sources – hospitals in Calcutta, Pune and Mysore. The ground truth was made more stringent. Three radiologists read the radiographs independently. If two called “consolidation” and the third didn’t, the majority prevailed, and the ground truth was “consolidation”. If two radiologists didn’t flag a nodule, and a third did, the ground truth was “no nodule.” For both validation and the test cases, radiologists were the ground truth – AI was prisoner to radiologists’ whims, but by using three radiologists as the ground truth for test cases, the interobserver variability was reduced – the truth, in a sense, was the golden mean rather than consensus.
Test case. Algorithm called “opacity” in the left lower lobe. You can see why – notice the subtle but real increased density in left vs right lower lobe. One radiologist called said “opacity”, two disagreed. This was a false positive.
What’s the minimum number of abnormalities AI needs to see; its numbers needed to learn (NNL)? This depends on several factors – how sensitive you think the algorithm will be, the desired tightness of the confidence interval, desired precision (paucity of false positives) and, crucially, rarity of the abnormality. The rarer the abnormality the more radiographs AI needs to see. To be confident of seeing eighty cases – the NNL was derived from a presumed sensitivity of 80 % – of a specific finding, AI would have to see 15, 000 radiographs. NNL wasn’t a problem in either training or validation – recall, there were 100, 000 radiographs for validation which is a feast even for training. But gathering test cases was onerous and expensive. Radiologists aren’t known to work for free.
Qure’s homegrown NLP flagged chest radiographs with radiology descriptors in the new hospitals. There were normals, too, which were randomly distributed in the test, but the frequency of abnormalities was different from the training cases. In the latter, the frequency reflected actual prevalences of radiographic abnormalities. Natural prevalences don’t guarantee sufficient abnormals in a sample of two thousand. Through a process called “enrichment”, the frequency of each abnormality in the test pool was increased, so that 80 cases each of opacity, nodule, consolidation, etc, were guaranteed in the test.
The abnormals in the test were more frequent than in real life. Contrived? Yes. Unfair? No. In the American board examination, radiologists are shown only abnormal cases.
Like anxious parents, Qure’s scientists waited for the exam result, the AUC.
“We expected sensitivities of 80 %. That’s how we calculated our sample size. A few radiologists advised us that we not develop algorithms for chest radiographs, saying that it was a fool’s errand because radiographs are so subjective. We could hear their warnings.” Preetham recalled with subdued nostalgia.
The AUC for detecting an abnormal chest radiograph was 0.92. Individual radiologists, unsurprisingly, did better as they were part of the truth, after all. As expected, the degree of agreement between radiologists, the inter-observer variability, affected AI’s performance, which was the highest when radiologists were most in agreement, such as when calling cardiomegaly. The radiologists had been instructed to call “cardiomegaly” when the cardiothoracic ratio was greater than 0.5. For this finding, the radiologists agreed 92 % of the time. For normal, radiologists agreed 85 % of the time. For cardiomegaly, the algorithm’s AUC was 0.96. Given the push to make radiology more quantitative and less subjective, these statistics should be borne in mind.
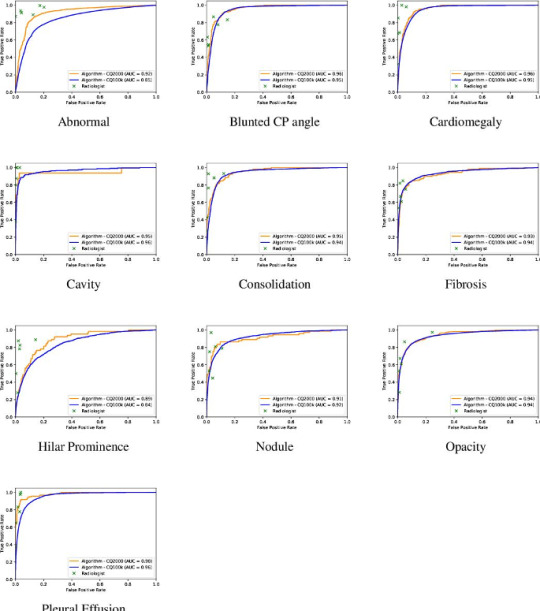
The AUC of algorithm performance in test and validation cases. The individual crosses represent radiologists. Radiologists did better than the algorithm.
For all abnormalities, both measures of diagnostic performance were over 90 %. The algorithm got straight As. In fact, the algorithm performed better on the test (AUC – 0.92) than validation cases (AUC – 0.86) at discerning normal – a testament not to its less-is-more philosophy but the fact that the test sample had fewer gray zone abnormalities, such as calcification of the aortic knob, the type of “abnormality” that some radiologists report and others ignore. This meant that AI’s performance had reached an asymptote which couldn’t be overcome by more data because the more radiographs it saw the more “gray zone” abnormalities it’d see. This curious phenomenon mirrors radiologists’ performance. The more chest radiographs we see the better we get. But we get worse, too, because we know what we don’t know and become more uncertain. After a while there’s little net gain in performance by seeing more radiographs.
Nearly three years after the company was conceived, after several dead ends, and morale-lowering frustrations with the metadata, the chest radiograph algorithm had matured. It was actually not a single algorithm but a bunch of algorithms which helped each other and could be combined into a meta-algorithm. The algorithms moved like bees but functioned like a platoon.
As the team was about to open the champagne, Ammar Jagirdar, Product Manager, had news.
“Guys, the local health authority in Baran, Rajasthan, is interested in our TB algorithm.”
Ammar, a former dentist with a second degree in engineering, also from IIT, isn’t someone you can easily impress. He gave up his lucrative dental practice for a second career because he found shining teeth intellectually bland.
“I was happy with the algorithm performance,” said Ammar, “but having worked in start-ups, I knew that building the product is only 20 % of the task. 80 % is deployment.”
Ammar had underestimated deployment. He had viewed it as an engineering challenge. He anticipated mismatched IT systems which could be fixed by clever codes or I-phone apps. Rajashtan would teach him that the biggest challenge to deployment of algorithms wasn’t the AUC, or clever statisticians arguing endlessly on Twitter about which outcome measures the value of AI, or overfitting. It was a culture of doubt. A culture which didn’t so much fear change as couldn’t be bothered changing. Qure’s youthful scientists, who looked like characters from a Netflix college movie, would have to labor to be taken seriously.
Saurabh Jha (aka @RogueRad) is a contributing editor to The Health Care Blog. This is Part 2 of a 3-part series.
The post Artificial Intelligence vs. Tuberculosis – Part 2 appeared first on The Health Care Blog.
Artificial Intelligence vs. Tuberculosis – Part 2 published first on https://wittooth.tumblr.com/
0 notes
Photo

Preparation Tips For NEET, Boards, Olympiads, JEE
Are you surfing for tips from experienced faculty? Get quick and effective preparation tips for NEET, Boards, Olympiads, JEE main and advanced.
Get all updated here: http://blog.pcmbtoday.com/
neet 2020 preparation
neet 2020
neet exam paper
neet study material
best books for neet
previous year paper of neet
neet preparation books
best books for NEET 2020
NEET books 2020
objective biology books
best books for iit jee maths
best book for organic chemistry
jee advanced preparation books
best books for iit jee
JEE main 2020
iit jee books
books for jee mains
books for jee advanced
aiims previous year question paper
aiims 2020 preparation
aiims preparation books
best books for medical entrance exams
aiims online test series
aiims medical entrance exam
aiims mock test
aiims entrance exam 2020
nso sample papers
ieo sample papers
best books for olympiad preparation
science olympiad sample papers
National science olympiad
International maths olympiad
Books for CBSE boards
Best reference books for CBSE
cbse english sample papers
0 notes
Link
Get IAIS math olympiad sample papers, mock test papers, practice papers for Class 1 to 10. Check online for IAIS math exam date & syllabus
#IAIS mathematics#IAIS math question papers#IAIS math exam#IAIS math sample paper#IAIS math syllabus
0 notes
Text
Tips to crack the National Scholarship Exam
There are many scholarships that require the candidates to go through a written test. The most popular among these are the various science and maths olympiads, entrance tests, and the national scholarship exam. Students from class 5 till diploma and degree holders are eligible to participate and earn scholarship reward worth up to INR 20000. Students can prepare for this exam in advance through the use of sample papers, previous exam papers, communicating with past applicants or participating in forums about the national scholarship exam. More details about cracking this exam are listed on Buddy4Study’s blog section. All the best.

0 notes
Text
NCERT Solutions for Class 7
NCERT solutions for class 7 prepared by the academic team of entrancei is one of the best study material used for reference to scoring good marks in a school exam. These solutions are prepared by experts of entrancei having years of experience.
All questions given in the exercise are solved with the errorless solutions and in easy language to score good marks in the exam. Students are required to solve the questions given in the exercise by yourself and use NCERT solutions for class 7 just for reference, not to copy.
Subject covers in NCERT Solutions for Class 7
The academic team of entrancei understands the requirement of students and focus on creating the best quality of study material. Our team develops NCERT solutions for class 7 all subjects and all chapters. we have covered extensively all books of NCERT and solve all questions given in the exercise of NCERT textbook.
Below mentioned Links are solutions of NCERT textbook as per the Subjects.
NCERT Solution for Class 7 science
NCERT Solution for Class 7 Maths
NCERT Solution for Class 7 English
NCERT Solutions for Class 7 Hindi
The Right Approach for Class 7
In class 7 syllabus is relatively less as compared to the higher class so it is highly recommended to spend time with the concepts. NCERT textbook is a highly recommended textbook for class 7. NCERT Class 7 textbook consists of a very good explanation of theory and concepts with proper use of colorful diagrams which help you to understand the concept.
While reading the theory of NCERT make sure you have prepared your notes properly for all subjects. Entrancei NCERT solutions for class 7 is highly recommended boosting your preparation.
Why Entrancei for NCERT solutions for 7
Class 7 required lots of academic resources along with NCERT solutions for class 7. Our academic team understand class 7 requirements and prepare all possible study material to help students in their preparations.
And it starts with the detail study notes for a subject like maths and science for class 7 in which we have cover extensive theory for competitive exams like Olympiad and others. You can go for an online test for class 7 maths and science. Our team prepares lots of sample papers, worksheets, question banks for class 7 subjects.
Source URL: https://uberant.com/article/712566-ncert-solution-for-class-7/
0 notes
Text
Online Tutors | Online Tuition Teachers | Online Classes. Online Classes LIVE tutoring website with Best Teachers for CBSE, ICSE, IGCSE, IB & State Boards for class 4th to 12th. 1 to 1 Live Coaching for Math, Science, Physics, Chemistry, Biology. Free Trial Class
Teaching Care provides TUITION, TUITION TEACHERS, TUTORS, COACHING, TUTORIALS, ONLINE TUITION, ONLINE TUTORS and LIVE HOME TUITION for ENGLISH, MATHEMATICS, SCIENCE, PHYSICS, CHEMISTRY, BIOLOGY, ACCOUNTANCY, BUSINESS STUDIES, ECONOMICS for CBSE, ICSE, IGCSE, IB, STATE BOARDS, NTSE, OLYMPIADS, JEE main, JEE advanced, NEET, Foundation, NTSE, Olympiads, assignment solving etc at TeachingCare.com by best quality teachers/tutors from all over India & abroad. ASK DOUBTS DURING LIVE CLASS. Live Face to face Tutors with Online two way Interactive whiteboard. Automatic class recording for revision. Tuition fee 1/3rd of offline Tuition rates. Quality Teachers from IITs, NITs, AIIMS, Delhi University, J.N.U., Kendriya Vidyalayas etc. selected by proper screening, tests, demo & interview. Learn at your own convenience at your own timings.
Sign up now for free trial class at https://www.teachingcare.com/ or call 9821126195, 9811000616 or email us at [email protected]
WHY TEACHING CARE
• HIGHLY EXPERIENCED BRANDED TEACHERS: The Online Live Tuition & Coaching Classes at Teaching Care are taught by personalized tuition teachers who are highly experienced & TRAINED TUTORS. All the teachers are from Top Coaching Institutes of India as well as from the best schools from all over India. Most of the Live Tuition Teachers also have Home Tuition experience. All the tuition tutors at Teaching Care Online Live Classes have HIGH EXPOSURE. Many of the tutors on Teaching Care live Classes portal also run their offline tuition centers.
• STRONG EDUCATIONAL BACKGROUND OF TEACHERS: The online tutoring teachers at Teaching Care Live Classes portal have educational qualifications from premier institutes of the country like IITs, NITs, AIIMS, KVs, J.N.U., D.U. etc.
• VERY HIGH-QUALITY TEACHERS AT LOW RATES: The tuition fee charged by tuition teachers at Teaching Care's online Live Coaching portal is merely one-third of the prices charged by these teachers in offline home tuition.
• BETTER PRESENTATION & BETTER LECTURE DELIVERY IN ONLINE LIVE CLASSES: Audio Videos presentations, powerpoint presentations, Images, PDFs, Animations and Youtube videos via virtual whiteboard make the live classes an easy to understand online tuition experience far better than the offline home tuition.
• 1 to 1 LIVE CLASSES WITH PERSONALISED TUITION TEACHER: With only one student in the class, 1 to 1 Live Classes with Private Tuition Teachers make it a personalized learning experience for the student with full individual attention by the tutor uniquely tailor-made based on student's unique learning needs and pace of learning in the class.
• COMFORT & SAFETY: Best Teachers are available at unbelievably low costs for online live tuition classes at the comfort of your home, students don't have to go to Delhi or Kota. The Online Tuition Classes with 1 to 1 Live Tutor save student's time, money, transportation costs, lodging & food costs. Secondly, the homesickness, safety & security issues are also addressed by online classes, especially for girl students.
• TUITION FOR ALL SUBJECTS UNDER ONE ROOF FOR ALL CLASSES & ALL BOARDS: The online live classes portal of Teaching Care provides Tuition Teachers for CBSE, ICSE, IGCSE, IB & State Boards for class 4th to class 12th. You get TUITION, TUITION TEACHERS, TUTORS, COACHING & TUTORIALS for ENGLISH, MATHEMATICS, SCIENCE, PHYSICS, CHEMISTRY, BIOLOGY, ACCOUNTANCY, BUSINESS STUDIES & ECONOMICS. ONLINE TUITION, ONLINE TUTORS, ONLINE HOME TUITION and LIVE CLASSES for JEE main, JEE advanced, NEET, Foundation, NTSE, Olympiads, assignment solving, Aptitude, Reasoning, Spoken English, IELTS, TOEFL, GRE, CAT & SAT are provided by Teaching Care by best faculties.
• EASY ACCESS TO RENOWNED FACULTIES: Any renowned expert from any part of the country teaches students at unbelievable low costs.
• ANYTIME ANYWHERE LEARNING: You can get the teachers for live tutoring Anytime, Anywhere for live classes based on your availability for online learning. Teaching Care staff co-ordinates with you and your online tutor regarding fixing the weekly class schedules. The teachers and students mutually discuss & finalize their weekly class schedules. In this way, the teachers and students conveniently carry out the process of e-learning via live classes at Teaching Care's Online Tutoring Live Classes platform.
• TRAVELING TIME SAVED: Another advantage of studying with teachers on Teaching Care's online classes portal is that you don't have to waste your precious time in unnecessary traveling for coaching classes & tuition centers. The time saved by not commuting to coaching classes & tuition centers can be utilized for your studies or play.
• NO MORE STUCKING IN TRAFFIC CONGESTION: Your studies with teachers via online tuition classes keep you away from tiring traffic, traffic snarls and polluted outdoors. Avoiding outdoor pollution on account of online tuition classes also contributes to long term health benefits.
• ENERGY & FUEL SAVED: Commuting to coaching classes & tuition centers for tuition teachers or tuition classes wastes your energy as well as vehicle fuel. Online Tuition classes or online coaching via Teaching Care's Live Classes platform saves you from unnecessary wastage of fuel. In some ways, you are contributing to saving the environment by saving energy & fuel on account of online learning via Live Classes.
• MONITORING OF LIVE CLASSES BY PARENTS FOR BETTER FEEDBACK: Parents can monitor their child's Online Live Tuition Classes, Online Live TUITION TEACHERS & LIVE COACHING Tutorials at the comfort of their home during the class as well as after the class from class recording.
• DEDICATED SUPPORT TEAM: Dedicated Support Team: There is 24x7 dedicated support staff for any assistance to students, parents, & teachers during the Live Class as well as after the live class is over.
• FREE TRIAL CLASS: Teaching Care provides a free online live class with a private tuition teacher so that the student can understand the importance of Online Live Classes, Online Home Tuition, Online Coaching & Tutorials for smart learning.
• BETTER RESULTS: Individual attention by private tuition tutor, only one student in Live Class, Best Quality Tuition Teacher, right teaching methodology by online Live tutoring teacher, comfort & convenience of online home tuition and flexibility in online live classes schedule bring better results and success for Teaching Care's students.
Get Best Teacher for Online Tuition on Teaching Care's Online Live Tuition Classes website for 1 to 1 Live Tuition and Live coaching by private tuition teachers right at the comfort of your home just like private home tuition by a private home tutor.
Teaching Care LIVE Online Tuition Classes are a superb personalized tutoring platform for you, while you are staying at your home. Teaching Care Online Live Tuition Classes portal has grown to be the best Online Tuition Website in India with immensely talented Master Tuition Teachers, from the most reputed institutions & coaching institutes of the country as well as tutors from abroad.
The online live tuition classes services provided by Teaching Care are year-long structured coaching classes for CBSE, IGCSE, IB and ICSE Board as well as for JEE and NEET entrance exam preparation at affordable tuition fees, with an exclusive session for clearing doubts, ensuring that neither you nor the topics remain unattended.
The Online Live Tuition platform at Teaching Care encourages your Online engagement with the best quality Master Tuition Teachers. Revision notes, study notes, study materials, worksheets, questions, tests, and formula sheets are shared with you, for grasping the toughest concepts. Assignments, Regular Home Works, Subjective Tests & Objective Tests promote your regular practice of the topics. The academic progress report is shared during the Parents Teachers Meeting. The live class tuition Sessions get recorded for you to access for quick revision later, just by a quick login into your account. The interactive approach during the live class establishes a well-deserved academic connect between you and Master Tuition Teachers. Teaching Care is the first choice of students aspiring to score full marks in their CBSE, IGCSE, IB and ICSE Board or to crack any competitive exam like IIT JEE (Mains & Advanced), Kishore Vaigyanik Protsahan Yojana (KVPY), National Talent Search Exam (NTSE), International Math Olympiad (IMO), International English Olympiad (IEO), Math tuition, Science tuition, Maths tuition teacher, Science tuition teacher. Hours and Hours of Study with no fun, is a bad idea for you, foreseeing the long run. To ensure that motivation is stirred in the best proportion for your clear understanding, a good number of online quizzes and Objective tests are organized to impart knowledge and reward the best performers. Online Live Classes Master Teachers cater to teaching Science, Mathematics, Physics, Chemistry, Biology, Business Studies, Accountancy, Economics, Commerce for 6th to 12th grades across CBSE, IGCSE, IB and ICSE Board. To promote talent and potential, the Prices for Online Live Master Coaching Classes are very affordable. FREE Sample Papers and Important questions are extracted, solved and discussed during the live tuition classes, ensuring that you are 100% prepared before any exam. CBSE, IGCSE, IB and ICSE Board Classes rank as the best LIVE and Online Tutoring Website in the top ten cities of India- Delhi, Mumbai, Patna, Kolkata, Pune, Chandigarh, Bangalore, Hyderabad, Chennai, and Jaipur. In Gulf Countries and Singapore, Teaching Care is among the most recommended educational websites for an online home tutor at the very lowest tuition fees. Teaching Care knows the value of your time and strives hard to deliver the best and invest in it with precision. PDFs, video, animations, images and power points of exhaustive subject material for the preparation of the target exams like JEE Main, NEET, KVPY, NTSE, Olympiads, CBSE & ICSE Board exams & School exams, are used during live class lectures to you during live online tuition sessions at Teaching Care. Teaching Care LIVE Online Master Classes is cemented by rigorous hard work of Master Tuition Teachers, complemented by the best study material during live classes along with FREE Books, Free Solutions of NCERT, RD Sharma, RS Agarwal, and HC Verma. Free video lectures, free study material, free study notes, Free e-books, etc are also given on Teaching Care's Live Tutoring website.
youtube
#online coaching classes#online tuition website#math tuition near me#science tuion near me#cbse tuition
0 notes