#mongodb docker volume
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
The Roadmap to Full Stack Developer Proficiency: A Comprehensive Guide
Embarking on the journey to becoming a full stack developer is an exhilarating endeavor filled with growth and challenges. Whether you're taking your first steps or seeking to elevate your skills, understanding the path ahead is crucial. In this detailed roadmap, we'll outline the stages of mastering full stack development, exploring essential milestones, competencies, and strategies to guide you through this enriching career journey.

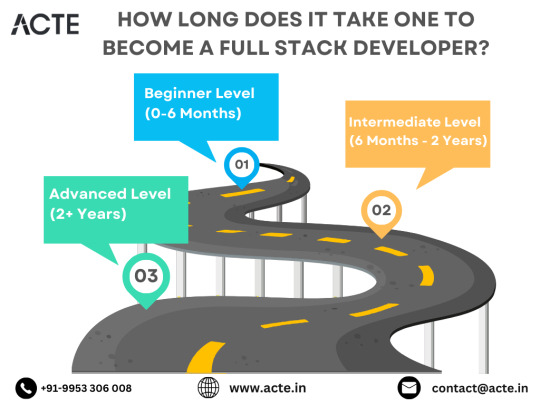
Beginning the Journey: Novice Phase (0-6 Months)
As a novice, you're entering the realm of programming with a fresh perspective and eagerness to learn. This initial phase sets the groundwork for your progression as a full stack developer.
Grasping Programming Fundamentals:
Your journey commences with grasping the foundational elements of programming languages like HTML, CSS, and JavaScript. These are the cornerstone of web development and are essential for crafting dynamic and interactive web applications.
Familiarizing with Basic Data Structures and Algorithms:
To develop proficiency in programming, understanding fundamental data structures such as arrays, objects, and linked lists, along with algorithms like sorting and searching, is imperative. These concepts form the backbone of problem-solving in software development.
Exploring Essential Web Development Concepts:
During this phase, you'll delve into crucial web development concepts like client-server architecture, HTTP protocol, and the Document Object Model (DOM). Acquiring insights into the underlying mechanisms of web applications lays a strong foundation for tackling more intricate projects.
Advancing Forward: Intermediate Stage (6 Months - 2 Years)
As you progress beyond the basics, you'll transition into the intermediate stage, where you'll deepen your understanding and skills across various facets of full stack development.
Venturing into Backend Development:
In the intermediate stage, you'll venture into backend development, honing your proficiency in server-side languages like Node.js, Python, or Java. Here, you'll learn to construct robust server-side applications, manage data storage and retrieval, and implement authentication and authorization mechanisms.
Mastering Database Management:
A pivotal aspect of backend development is comprehending databases. You'll delve into relational databases like MySQL and PostgreSQL, as well as NoSQL databases like MongoDB. Proficiency in database management systems and design principles enables the creation of scalable and efficient applications.
Exploring Frontend Frameworks and Libraries:
In addition to backend development, you'll deepen your expertise in frontend technologies. You'll explore prominent frameworks and libraries such as React, Angular, or Vue.js, streamlining the creation of interactive and responsive user interfaces.
Learning Version Control with Git:
Version control is indispensable for collaborative software development. During this phase, you'll familiarize yourself with Git, a distributed version control system, to manage your codebase, track changes, and collaborate effectively with fellow developers.
Achieving Mastery: Advanced Phase (2+ Years)
As you ascend in your journey, you'll enter the advanced phase of full stack development, where you'll refine your skills, tackle intricate challenges, and delve into specialized domains of interest.
Designing Scalable Systems:
In the advanced stage, focus shifts to designing scalable systems capable of managing substantial volumes of traffic and data. You'll explore design patterns, scalability methodologies, and cloud computing platforms like AWS, Azure, or Google Cloud.
Embracing DevOps Practices:
DevOps practices play a pivotal role in contemporary software development. You'll delve into continuous integration and continuous deployment (CI/CD) pipelines, infrastructure as code (IaC), and containerization technologies such as Docker and Kubernetes.
Specializing in Niche Areas:
With experience, you may opt to specialize in specific domains of full stack development, whether it's frontend or backend development, mobile app development, or DevOps. Specialization enables you to deepen your expertise and pursue career avenues aligned with your passions and strengths.
Conclusion:
Becoming a proficient full stack developer is a transformative journey that demands dedication, resilience, and perpetual learning. By following the roadmap outlined in this guide and maintaining a curious and adaptable mindset, you'll navigate the complexities and opportunities inherent in the realm of full stack development. Remember, mastery isn't merely about acquiring technical skills but also about fostering collaboration, embracing innovation, and contributing meaningfully to the ever-evolving landscape of technology.
#full stack developer#education#information#full stack web development#front end development#frameworks#web development#backend#full stack developer course#technology
9 notes
·
View notes
Text
Docker Tutorial for Beginners: Learn Docker Step by Step
What is Docker?
Docker is an open-source platform that enables developers to automate the deployment of applications inside lightweight, portable containers. These containers include everything the application needs to run—code, runtime, system tools, libraries, and settings—so that it can work reliably in any environment.
Before Docker, developers faced the age-old problem: “It works on my machine!” Docker solves this by providing a consistent runtime environment across development, testing, and production.
Why Learn Docker?
Docker is used by organizations of all sizes to simplify software delivery and improve scalability. As more companies shift to microservices, cloud computing, and DevOps practices, Docker has become a must-have skill. Learning Docker helps you:
Package applications quickly and consistently
Deploy apps across different environments with confidence
Reduce system conflicts and configuration issues
Improve collaboration between development and operations teams
Work more effectively with modern cloud platforms like AWS, Azure, and GCP
Who Is This Docker Tutorial For?
This Docker tutorial is designed for absolute beginners. Whether you're a developer, system administrator, QA engineer, or DevOps enthusiast, you’ll find step-by-step instructions to help you:
Understand the basics of Docker
Install Docker on your machine
Create and manage Docker containers
Build custom Docker images
Use Docker commands and best practices
No prior knowledge of containers is required, but basic familiarity with the command line and a programming language (like Python, Java, or Node.js) will be helpful.
What You Will Learn: Step-by-Step Breakdown
1. Introduction to Docker
We start with the fundamentals. You’ll learn:
What Docker is and why it’s useful
The difference between containers and virtual machines
Key Docker components: Docker Engine, Docker Hub, Dockerfile, Docker Compose
2. Installing Docker
Next, we guide you through installing Docker on:
Windows
macOS
Linux
You’ll set up Docker Desktop or Docker CLI and run your first container using the hello-world image.
3. Working with Docker Images and Containers
You’ll explore:
How to pull images from Docker Hub
How to run containers using docker run
Inspecting containers with docker ps, docker inspect, and docker logs
Stopping and removing containers
4. Building Custom Docker Images
You’ll learn how to:
Write a Dockerfile
Use docker build to create a custom image
Add dependencies and environment variables
Optimize Docker images for performance
5. Docker Volumes and Networking
Understand how to:
Use volumes to persist data outside containers
Create custom networks for container communication
Link multiple containers (e.g., a Node.js app with a MongoDB container)
6. Docker Compose (Bonus Section)
Docker Compose lets you define multi-container applications. You’ll learn how to:
Write a docker-compose.yml file
Start multiple services with a single command
Manage application stacks easily
Real-World Examples Included
Throughout the tutorial, we use real-world examples to reinforce each concept. You’ll deploy a simple web application using Docker, connect it to a database, and scale services with Docker Compose.
Example Projects:
Dockerizing a static HTML website
Creating a REST API with Node.js and Express inside a container
Running a MySQL or MongoDB database container
Building a full-stack web app with Docker Compose
Best Practices and Tips
As you progress, you’ll also learn:
Naming conventions for containers and images
How to clean up unused images and containers
Tagging and pushing images to Docker Hub
Security basics when using Docker in production
What’s Next After This Tutorial?
After completing this Docker tutorial, you’ll be well-equipped to:
Use Docker in personal or professional projects
Learn Kubernetes and container orchestration
Apply Docker in CI/CD pipelines
Deploy containers to cloud platforms
Conclusion
Docker is an essential tool in the modern developer's toolbox. By learning Docker step by step in this beginner-friendly tutorial, you’ll gain the skills and confidence to build, deploy, and manage applications efficiently and consistently across different environments.
Whether you’re building simple web apps or complex microservices, Docker provides the flexibility, speed, and scalability needed for success. So dive in, follow along with the hands-on examples, and start your journey to mastering containerization with Docker tpoint-tech!
0 notes
Text
Create Impactful and Smarter Learning with Custom MERN-Powered LMS Solutions
Introduction
Learning is evolving fast, and modern education businesses need smarter tools to keep up. As online training grows, a robust learning management software becomes essential for delivering courses, tracking progress, and certifying users. The global LMS market is booming – projected to hit about $70+ billion by 2030 – driven by demand for digital learning and AI-powered personalization. Off-the-shelf LMS platforms like Moodle or Canvas are popular, but they may not fit every startup’s unique needs. That’s why custom learning management solutions, built on flexible technology, are an attractive option for forward-looking EdTech companies. In this post, we’ll explore why Custom MERN-Powered LMS Solutions (using MongoDB, Express, React, Node) can create an impactful, smarter learning experience for modern businesses.
Understanding the MERN Stack for LMS Development
The MERN stack combines four open-source technologies: MongoDB (database), Express.js (backend framework), React.js (frontend library), and Node.js (server runtime). Together, they enable developers to write JavaScript across the entire application. For an LMS, MERN’s unified JavaScript stack means faster development and easier maintenance. React’s component-based UI makes creating interactive dashboards and course pages smoother, while Node.js and Express handle data and logic efficiently. Importantly, both Node and MongoDB are built for scale: Node’s non-blocking I/O can handle many users at once, and MongoDB can store huge volumes of course and user data. In practice, MERN apps can be deployed in a microservices or containerized architecture (using Docker/Kubernetes) to ensure high availability. This means your custom LMS can grow with your audience – for example, MongoDB supports sharding so the database can span multiple servers, ensuring the system stays up even if one server fails.
Key Features of Custom MERN-Powered LMS Solutions
A tailored LMS can include all the features your organization needs. Typical components of learning management platforms include:
Course Management: Create, organize, and update courses and modules.
User and Role Management: Register learners, assign roles (students, instructors, admins), and control access.
Interactive Content: Upload videos, presentations, PDFs, and embed quizzes or coding exercises.
Assessments & Certification: Build quizzes, track scores, and automatically issue certificates to successful students.
Discussion Forums & Collaboration: Facilitate peer-to-peer learning with chat, Q&A forums or group projects.
Reporting & Analytics: Dashboard insights into learner progress, completion rates, and engagement.
Integrations: Connect with other tools via APIs – for example, integrating Zoom or MS Teams for live classes, or embedding third-party content libraries.
Branding & Custom Interface: White-label design with your logo and color scheme, for a seamless brand experience.
Because the MERN stack is so flexible, a custom LMS can add niche features on demand. For instance, you could include gamification (points, badges, leaderboards) to boost engagement, or integrate e-commerce capabilities (Sell courses with Stripe or PayPal). These integrations and customizations may cost extra, but they let you align the system with your exact workflow and goals. In short, a MERN-based LMS can combine the best learning management systems features (like content libraries and mobile responsiveness) while still being fully under your control.
Leveraging AI to Enhance Learning Experiences in Custom MERN-Powered LMS Solutions
AI is transforming how students learn. In a MERN-powered LMS, you can embed AI tools to personalize and streamline education. For example, artificial tutors can adjust to each learner’s pace, and chatbots can answer questions 24/7. AI-driven adaptive learning platforms will tailor lesson plans based on a student’s strengths, weaknesses, and progress. They can suggest next steps or additional resources (“intelligent recommendations”) and even automatically generate or grade quizzes. Similarly, voice and chatbot assistants become “24/7 tutors, answering student queries, explaining concepts, and assisting with assignments,” making education more responsive.
These AI enhancements lead to higher engagement and better outcomes. For instance, personalized content delivery keeps learners motivated, and instant feedback accelerates their progress. Research shows personalization boosts achievement in core subjects, and AI is a key enabler. In practice, a custom MERN LMS could leverage AI services (via APIs or microservices) for recommendation engines, automated content tagging, and data-driven analytics. Over time, the system learns what works best for each user – a truly smarter learning platform that continuously improves itself.
Ensuring Multi-Device Accessibility and Integration Capabilities in Custom MERN-Powered LMS Solutions
Today’s learners switch between laptops, tablets, and phones, so any LMS must be mobile-friendly. A MERN-based platform can be built with responsive design or native mobile apps in mind. The frontend (React) easily adapts layouts for different screen sizes, ensuring the LMS looks and works well on desktops and smartphones. Offline modes (caching content on mobile apps) can be added for uninterrupted access even without internet.
Integration is another must-have. Modern LMS solutions rarely stand alone. A custom MERN LMS can include connectors or plugins for video conferencing (Zoom, Teams), calendars, HR systems, or content libraries. These LMS integrations ensure seamless workflows and a better user experience. For example, automatically syncing course rosters with your HR database saves admin time, and integrating payment gateways lets you monetize courses directly. Overall, a custom MERN LMS can act as a central hub, tying together video calls, documentation, social features, and more into one consistent platform.
Scalability and Deployment Strategies for Custom MERN-Powered LMS Solutions
A key advantage of MERN is scalability. MongoDB and Node.js were designed to grow with your needs. In practice, you would deploy your LMS on cloud infrastructure (AWS, Azure, GCP), using containerization (Docker, Kubernetes) to manage resources. This means you can scale horizontally: spin up more instances of your Node/Express servers or MongoDB shards as the user base grows. For example, MongoDB’s sharding lets the database distribute data across servers, so no single point of failure will crash your app. Likewise, stateless Node servers can be cloned behind a load balancer, handling thousands of concurrent users (ideal for a crash course day!).
For deployment, continuous integration and continuous deployment (CI/CD) pipelines automate updates: changes to code (React components or backend logic) can be tested and released rapidly. This agile pipeline means improvements are delivered safely and often. Cloud hosting also offers global content delivery networks (CDNs) and caching to speed up course content downloads worldwide. In short, a MERN LMS can start small but expand seamlessly – serving a few dozen students or millions – with careful cloud architecture and modern devops practices.
Agile Development Methodology in Custom MERN-Powered LMS Projects
Building a custom LMS with MERN is best done with agile development. Agile (Scrum or Kanban) means working in short sprints and constantly gathering feedback from stakeholders. This approach enables faster delivery of working software by breaking development into smaller iterations and focusing on high-priority features. For an EdTech startup, that means you can release a minimum viable LMS quickly (core courses and user login), then iteratively add features like assessments, forums, or mobile apps, based on user feedback.
Agile also keeps your team aligned with business goals. Regular demos let product leads and instructors see progress early and adjust priorities. The continuous feedback loop means the final LMS better meets expectations and achieves higher satisfaction. Crucially, Agile embraces change: if a new learning requirement or tech emerges, it can be planned into the next sprint. Using Agile in a MERN LMS project helps ensure the platform stays on track with both educational goals and evolving market demands, delivering value early and often.
Pricing Models and Customization Options for MERN-Powered LMS Solutions
Custom LMS pricing varies widely, depending on features and usage. Common models include subscription-based (per-user or per-active-user), pay-per-use, one-time license fees, or even open-source/free solutions. In a custom scenario, you might negotiate a flat development fee plus ongoing support, or an annual per-user fee once the LMS is built.
Be mindful of hidden costs. Beyond base licensing or development, extras often include setup, integrations, and maintenance. For example, integrating your MERN LMS with a CRM, single sign-on, or advanced analytics service usually comes at extra cost. Similarly, hosting fees (cloud servers, bandwidth) and support contracts add to the total. It’s wise to plan for these from the start. The upside is that a custom MERN-powered LMS solution can be tailored – you only pay for exactly the functionality you need, no more. Plus, you avoid paying for unnecessary modules that bloated commercial LMS platforms often include.
Conclusion
Custom MERN-powered LMS solutions offer a compelling path for EdTech startups and training companies. By leveraging a unified JavaScript stack (MongoDB, Express, React, Node), development teams can deliver a robust LMS learning platform that is modern, scalable, and finely tuned to your audience. These systems combine essential learning management software features (content delivery, assessments, analytics) with cutting-edge enhancements (AI personalization, seamless integrations, multi-device support) – all under your brand. With agile methods, the platform can evolve in step with your needs, while cloud deployment ensures it can grow effortlessly. In short, a custom MERN LMS gives you the best learning management system for your business: a solution built exactly for you. It’s a strategic investment in smarter learning that will pay off in engagement, effectiveness, and flexibility for years to come.
#learning management software#learning management solutions#LMS platforms#best learning management systems#best learning management software#LMS learning platform#Custom MERN-Powered LMS Solutions
0 notes
Text
Big Data Course in Kochi: Transforming Careers in the Age of Information
In today’s hyper-connected world, data is being generated at an unprecedented rate. Every click on a website, every transaction, every social media interaction — all of it contributes to the vast oceans of information known as Big Data. Organizations across industries now recognize the strategic value of this data and are eager to hire professionals who can analyze and extract meaningful insights from it.
This growing demand has turned big data course in Kochi into one of the most sought-after educational programs for tech enthusiasts, IT professionals, and graduates looking to enter the data-driven future of work.
Understanding Big Data and Its Relevance
Big Data refers to datasets that are too large or complex for traditional data processing applications. It’s commonly defined by the 5 V’s:
Volume – Massive amounts of data generated every second
Velocity – The speed at which data is created and processed
Variety – Data comes in various forms, from structured to unstructured
Veracity – Quality and reliability of the data
Value – The insights and business benefits extracted from data
These characteristics make Big Data a crucial resource for industries ranging from healthcare and finance to retail and logistics. Trained professionals are needed to collect, clean, store, and analyze this data using modern tools and platforms.
Why Enroll in a Big Data Course?
Pursuing a big data course in Kochi can open up diverse opportunities in data analytics, data engineering, business intelligence, and beyond. Here's why it's a smart move:
1. High Demand for Big Data Professionals
There’s a huge gap between the demand for big data professionals and the current supply. Companies are actively seeking individuals who can handle tools like Hadoop, Spark, and NoSQL databases, as well as data visualization platforms.
2. Lucrative Career Opportunities
Big data engineers, analysts, and architects earn some of the highest salaries in the tech sector. Even entry-level roles can offer impressive compensation packages, especially with relevant certifications.
3. Cross-Industry Application
Skills learned in a big data course in Kochi are transferable across sectors such as healthcare, e-commerce, telecommunications, banking, and more.
4. Enhanced Decision-Making Skills
With big data, companies make smarter business decisions based on predictive analytics, customer behavior modeling, and real-time reporting. Learning how to influence those decisions makes you a valuable asset.
What You’ll Learn in a Big Data Course
A top-tier big data course in Kochi covers both the foundational concepts and the technical skills required to thrive in this field.
1. Core Concepts of Big Data
Understanding what makes data “big,” how it's collected, and why it matters is crucial before diving into tools and platforms.
2. Data Storage and Processing
You'll gain hands-on experience with distributed systems such as:
Hadoop Ecosystem: HDFS, MapReduce, Hive, Pig, HBase
Apache Spark: Real-time processing and machine learning capabilities
NoSQL Databases: MongoDB, Cassandra for unstructured data handling
3. Data Integration and ETL
Learn how to extract, transform, and load (ETL) data from multiple sources into big data platforms.
4. Data Analysis and Visualization
Training includes tools for querying large datasets and visualizing insights using:
Tableau
Power BI
Python/R libraries for data visualization
5. Programming Skills
Big data professionals often need to be proficient in:
Java
Python
Scala
SQL
6. Cloud and DevOps Integration
Modern data platforms often operate on cloud infrastructure. You’ll gain familiarity with AWS, Azure, and GCP, along with containerization (Docker) and orchestration (Kubernetes).
7. Project Work
A well-rounded course includes capstone projects simulating real business problems—such as customer segmentation, fraud detection, or recommendation systems.
Kochi: A Thriving Destination for Big Data Learning
Kochi has evolved into a leading IT and educational hub in South India, making it an ideal place to pursue a big data course in Kochi.
1. IT Infrastructure
Home to major IT parks like Infopark and SmartCity, Kochi hosts numerous startups and global IT firms that actively recruit big data professionals.
2. Cost-Effective Learning
Compared to metros like Bangalore or Hyderabad, Kochi offers high-quality education and living at a lower cost.
3. Talent Ecosystem
With a strong base of engineering colleges and tech institutes, Kochi provides a rich talent pool and a thriving tech community for networking.
4. Career Opportunities
Kochi’s booming IT industry provides immediate placement potential after course completion, especially for well-trained candidates.
What to Look for in a Big Data Course?
When choosing a big data course in Kochi, consider the following:
Expert Instructors: Trainers with industry experience in data engineering or analytics
Comprehensive Curriculum: Courses should include Hadoop, Spark, data lakes, ETL pipelines, cloud deployment, and visualization tools
Hands-On Projects: Theoretical knowledge is incomplete without practical implementation
Career Support: Resume building, interview preparation, and placement assistance
Flexible Learning Options: Online, weekend, or hybrid courses for working professionals
Zoople Technologies: Leading the Way in Big Data Training
If you’re searching for a reliable and career-oriented big data course in Kochi, look no further than Zoople Technologies—a name synonymous with quality tech education and industry-driven training.
Why Choose Zoople Technologies?
Industry-Relevant Curriculum: Zoople offers a comprehensive, updated big data syllabus designed in collaboration with real-world professionals.
Experienced Trainers: Learn from data scientists and engineers with years of experience in multinational companies.
Hands-On Training: Their learning model emphasizes practical exposure, with real-time projects and live data scenarios.
Placement Assistance: Zoople has a dedicated team to help students with job readiness—mock interviews, resume support, and direct placement opportunities.
Modern Learning Infrastructure: With smart classrooms, cloud labs, and flexible learning modes, students can learn in a professional, tech-enabled environment.
Strong Alumni Network: Zoople’s graduates are placed in top firms across India and abroad, and often return as guest mentors or recruiters.
Zoople Technologies has cemented its position as a go-to institute for aspiring data professionals. By enrolling in their big data course in Kochi, you’re not just learning technology—you’re building a future-proof career.
Final Thoughts
Big data is more than a trend���it's a transformative force shaping the future of business and technology. As organizations continue to invest in data-driven strategies, the demand for skilled professionals will only grow.
By choosing a comprehensive big data course in Kochi, you position yourself at the forefront of this evolution. And with a trusted partner like Zoople Technologies, you can rest assured that your training will be rigorous, relevant, and career-ready.
Whether you're a student, a working professional, or someone looking to switch careers, now is the perfect time to step into the world of big data—and Kochi is the ideal place to begin.
0 notes
Text
Using Docker in Software Development

Docker has become a vital tool in modern software development. It allows developers to package applications with all their dependencies into lightweight, portable containers. Whether you're building web applications, APIs, or microservices, Docker can simplify development, testing, and deployment.
What is Docker?
Docker is an open-source platform that enables you to build, ship, and run applications inside containers. Containers are isolated environments that contain everything your app needs—code, libraries, configuration files, and more—ensuring consistent behavior across development and production.
Why Use Docker?
Consistency: Run your app the same way in every environment.
Isolation: Avoid dependency conflicts between projects.
Portability: Docker containers work on any system that supports Docker.
Scalability: Easily scale containerized apps using orchestration tools like Kubernetes.
Faster Development: Spin up and tear down environments quickly.
Basic Docker Concepts
Image: A snapshot of a container. Think of it like a blueprint.
Container: A running instance of an image.
Dockerfile: A text file with instructions to build an image.
Volume: A persistent data storage system for containers.
Docker Hub: A cloud-based registry for storing and sharing Docker images.
Example: Dockerizing a Simple Python App
Let’s say you have a Python app called app.py: # app.py print("Hello from Docker!")
Create a Dockerfile: # Dockerfile FROM python:3.10-slim COPY app.py . CMD ["python", "app.py"]
Then build and run your Docker container: docker build -t hello-docker . docker run hello-docker
This will print Hello from Docker! in your terminal.
Popular Use Cases
Running databases (MySQL, PostgreSQL, MongoDB)
Hosting development environments
CI/CD pipelines
Deploying microservices
Local testing for APIs and apps
Essential Docker Commands
docker build -t <name> . — Build an image from a Dockerfile
docker run <image> — Run a container from an image
docker ps — List running containers
docker stop <container_id> — Stop a running container
docker exec -it <container_id> bash — Access the container shell
Docker Compose
Docker Compose allows you to run multi-container apps easily. Define all your services in a single docker-compose.yml file and launch them with one command: version: '3' services: web: build: . ports: - "5000:5000" db: image: postgres
Start everything with:docker-compose up
Best Practices
Use lightweight base images (e.g., Alpine)
Keep your Dockerfiles clean and minimal
Ignore unnecessary files with .dockerignore
Use multi-stage builds for smaller images
Regularly clean up unused images and containers
Conclusion
Docker empowers developers to work smarter, not harder. It eliminates "it works on my machine" problems and simplifies the development lifecycle. Once you start using Docker, you'll wonder how you ever lived without it!
0 notes
Text
A Deep Dive into Modern Backend Development for Web Application
Creating seamless and dynamic web experiences often comes down to what happens behind the scenes. While front-end design captures initial attention, the backend is where much of the magic unfolds — handling data, security, and server logic. This article explores the core concepts of modern backend development, examines how evolving practices can fuel growth, and offers insights on selecting the right tools and partners.
1. Why the Backend Matters
Imagine a beautifully designed website that struggles with slow loading times or frequent errors. Such issues are typically rooted in the server’s logic or the infrastructure behind it. A robust backend ensures consistent performance, efficient data management, and top-tier security — elements that collectively shape user satisfaction.
Moreover, well-designed backend systems are better equipped to handle sudden traffic spikes without sacrificing load times. As online platforms scale, the backend must keep pace, adapting to increased user demands and integrating new features with minimal disruption. This flexibility helps businesses stay agile in competitive environments.
2. Core Components of Backend Development
Server
The engine running behind every web application. Whether you choose shared hosting, dedicated servers, or cloud-based virtual machines, servers host your application logic and data endpoints.
Database
From relational systems like MySQL and PostgreSQL to NoSQL options such as MongoDB, databases store and manage large volumes of information. Choosing the right type hinges on factors like data structure, scalability needs, and transaction speed requirements.
Application Logic
This code handles requests, processes data, and sends responses back to the front-end. Popular languages for writing application logic include Python, JavaScript (Node.js), Java, and C#.
API Layer
Application Programming Interfaces (APIs) form a communication bridge between the backend and other services or user interfaces. RESTful and GraphQL APIs are two popular frameworks enabling efficient data retrieval and interactions.
3. Emerging Trends in Backend Development
Cloud-Native Architectures
Cloud-native applications leverage containerization (Docker, Kubernetes) and microservices, making it easier to deploy incremental changes, scale specific components independently, and limit downtime. This modular approach ensures continuous delivery and faster testing cycles.
Serverless Computing
Platforms like AWS Lambda, Google Cloud Functions, and Azure Functions allow developers to run code without managing servers. By focusing on logic rather than infrastructure, teams can accelerate development, paying only for the computing resources they actually use.
Microservices
Rather than constructing one large, monolithic system, microservices break an application into smaller, independent units. Each service manages a specific function and communicates with others through lightweight protocols. This design simplifies debugging, accelerates deployment, and promotes autonomy among development teams.
Real-Time Communication
From chat apps to collaborative tools, real-time functionality is on the rise. Backend frameworks increasingly support WebSockets and event-driven architectures to push updates instantly, boosting interactivity and user satisfaction.
4. Balancing Performance and Security
The need for speed must not compromise data protection. Performance optimizations — like caching and query optimization — improve load times but must be paired with security measures. Popular practices include:
Encryption: Safeguarding data in transit with HTTPS and at rest using encryption algorithms.
Secure Authentication: Implementing robust user verification, perhaps with JWT (JSON Web Tokens) or OAuth 2.0, prevents unauthorized access.
Regular Audits: Scanning for vulnerabilities and patching them promptly to stay ahead of evolving threats.
Organizations that neglect security can face breaches, data loss, and reputational harm. Conversely, a well-fortified backend can boost customer trust and allow businesses to handle sensitive tasks — like payment processing — without fear.
5. Making the Right Technology Choices
Selecting the right backend technologies for web development hinges on various factors, including project size, performance targets, and existing infrastructure. Here are some examples:
Node.js (JavaScript): Known for event-driven, non-blocking I/O, making it excellent for real-time applications.
Python (Django, Flask): Valued for readability, a large ecosystem of libraries, and strong community support.
Ruby on Rails: Emphasizes convention over configuration, speeding up development for quick MVPs.
Java (Spring): Offers stability and scalability for enterprise solutions, along with robust tooling.
.NET (C#): Integrates deeply with Microsoft’s ecosystem, popular in enterprise settings requiring Windows-based solutions.
Evaluating the pros and cons of each language or framework is crucial. Some excel in rapid prototyping, while others shine in large-scale, enterprise-grade environments.
6. Customizing Your Approach
Off-the-shelf solutions can help businesses get started quickly but may lack flexibility for unique requirements. Customized backend development services often prove essential when dealing with complex workflows, specialized integrations, or a need for extensive scalability.
A tailored approach allows organizations to align every feature with operational goals. This can reduce technical debt — where one-size-fits-all solutions require extensive workarounds — and ensure that the final product supports long-term growth. However, custom builds do require sufficient expertise, planning, and budget to succeed.
7. The Role of DevOps
DevOps practices blend development and operations, boosting collaboration and streamlining deployment pipelines. Continuous Integration (CI) and Continuous Deployment (CD) are common components, automating tasks like testing, building, and rolling out updates. This not only reduces human error but also enables teams to push frequent, incremental enhancements without risking application stability.
Infrastructure as Code (IaC) is another DevOps strategy that uses configuration files to manage environments. This approach eliminates the guesswork of manual setups, ensuring consistent conditions across development, staging, and production servers.
8. Measuring Success and Ongoing Improvement
A robust backend setup isn’t a one-time project — it’s a continuous journey. Monitoring key performance indicators (KPIs) like uptime, response times, and error rates helps identify problems before they escalate. Logging tools (e.g., ELK stack) and application performance monitoring (APM) tools (e.g., New Relic, Datadog) offer deep insights into system performance, user behavior, and resource allocation.
Regular reviews of these metrics can inform incremental improvements, from refactoring inefficient code to scaling up cloud resources. This iterative process not only keeps your application running smoothly but also maintains alignment with evolving market demands.
Conclusion
From blazing-fast load times to rock-solid data integrity, a well-crafted backend paves the way for exceptional digital experiences. As businesses continue to evolve in competitive online spaces, adopting modern strategies and frameworks can yield remarkable benefits. Whether leveraging serverless architectures or working with microservices, organizations that prioritize performance, security, and scalability remain better positioned for future growth.
0 notes
Text
Big Data and Data Engineering
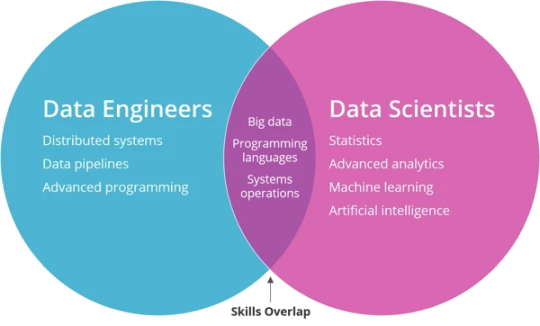
Big Data and Data Engineering are essential concepts in modern data science, analytics, and machine learning.
They focus on the processes and technologies used to manage and process large volumes of data.
Here’s an overview:
What is Big Data? Big Data refers to extremely large datasets that cannot be processed or analyzed using traditional data processing tools or methods.
It typically has the following characteristics:
Volume:
Huge amounts of data (petabytes or more).
Variety:
Data comes in different formats (structured, semi-structured, unstructured). Velocity: The speed at which data is generated and processed.
Veracity: The quality and accuracy of data.
Value: Extracting meaningful insights from data.
Big Data is often associated with technologies and tools that allow organizations to store, process, and analyze data at scale.
2. Data Engineering:
Overview Data Engineering is the process of designing, building, and managing the systems and infrastructure required to collect, store, process, and analyze data.
The goal is to make data easily accessible for analytics and decision-making.
Key areas of Data Engineering:
Data Collection:
Gathering data from various sources (e.g., IoT devices, logs, APIs). Data Storage: Storing data in data lakes, databases, or distributed storage systems. Data Processing: Cleaning, transforming, and aggregating raw data into usable formats.
Data Integration:
Combining data from multiple sources to create a unified dataset for analysis.
3. Big Data Technologies and Tools
The following tools and technologies are commonly used in Big Data and Data Engineering to manage and process large datasets:
Data Storage:
Data Lakes: Large storage systems that can handle structured, semi-structured, and unstructured data. Examples include Amazon S3, Azure Data Lake, and Google Cloud Storage.
Distributed File Systems:
Systems that allow data to be stored across multiple machines. Examples include Hadoop HDFS and Apache Cassandra.
Databases:
Relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra, HBase).
Data Processing:
Batch Processing: Handling large volumes of data in scheduled, discrete chunks.
Common tools:
Apache Hadoop (MapReduce framework). Apache Spark (offers both batch and stream processing).
Stream Processing:
Handling real-time data flows. Common tools: Apache Kafka (message broker). Apache Flink (streaming data processing). Apache Storm (real-time computation).
ETL (Extract, Transform, Load):
Tools like Apache Nifi, Airflow, and AWS Glue are used to automate data extraction, transformation, and loading processes.
Data Orchestration & Workflow Management:
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. Kubernetes and Docker are used to deploy and scale applications in data pipelines.
Data Warehousing & Analytics:
Amazon Redshift, Google BigQuery, Snowflake, and Azure Synapse Analytics are popular cloud data warehouses for large-scale data analytics.
Apache Hive is a data warehouse built on top of Hadoop to provide SQL-like querying capabilities.
Data Quality and Governance:
Tools like Great Expectations, Deequ, and AWS Glue DataBrew help ensure data quality by validating, cleaning, and transforming data before it’s analyzed.
4. Data Engineering Lifecycle
The typical lifecycle in Data Engineering involves the following stages: Data Ingestion: Collecting and importing data from various sources into a central storage system.
This could include real-time ingestion using tools like Apache Kafka or batch-based ingestion using Apache Sqoop.
Data Transformation (ETL/ELT): After ingestion, raw data is cleaned and transformed.
This may include:
Data normalization and standardization. Removing duplicates and handling missing data.
Aggregating or merging datasets. Using tools like Apache Spark, AWS Glue, and Talend.
Data Storage:
After transformation, the data is stored in a format that can be easily queried.
This could be in a data warehouse (e.g., Snowflake, Google BigQuery) or a data lake (e.g., Amazon S3).
Data Analytics & Visualization:
After the data is stored, it is ready for analysis. Data scientists and analysts use tools like SQL, Jupyter Notebooks, Tableau, and Power BI to create insights and visualize the data.
Data Deployment & Serving:
In some use cases, data is deployed to serve real-time queries using tools like Apache Druid or Elasticsearch.
5. Challenges in Big Data and Data Engineering
Data Security & Privacy:
Ensuring that data is secure, encrypted, and complies with privacy regulations (e.g., GDPR, CCPA).
Scalability:
As data grows, the infrastructure needs to scale to handle it efficiently.
Data Quality:
Ensuring that the data collected is accurate, complete, and relevant. Data
Integration:
Combining data from multiple systems with differing formats and structures can be complex.
Real-Time Processing:
Managing data that flows continuously and needs to be processed in real-time.
6. Best Practices in Data Engineering Modular Pipelines:
Design data pipelines as modular components that can be reused and updated independently.
Data Versioning: Keep track of versions of datasets and data models to maintain consistency.
Data Lineage: Track how data moves and is transformed across systems.
Automation: Automate repetitive tasks like data collection, transformation, and processing using tools like Apache Airflow or Luigi.
Monitoring: Set up monitoring and alerting to track the health of data pipelines and ensure data accuracy and timeliness.
7. Cloud and Managed Services for Big Data
Many companies are now leveraging cloud-based services to handle Big Data:
AWS:
Offers tools like AWS Glue (ETL), Redshift (data warehousing), S3 (storage), and Kinesis (real-time streaming).
Azure:
Provides Azure Data Lake, Azure Synapse Analytics, and Azure Databricks for Big Data processing.
Google Cloud:
Offers BigQuery, Cloud Storage, and Dataflow for Big Data workloads.
Data Engineering plays a critical role in enabling efficient data processing, analysis, and decision-making in a data-driven world.

0 notes
Text
How to Create a Binance Clone: A Comprehensive Guide for Developers
Binance is one of the world's leading cryptocurrency exchanges, providing a platform to buy, sell, and trade a wide variety of cryptocurrencies. creating a binance clone is an ambitious project that involves understanding both the core features of the exchange and the complex technologies required to manage secure financial transactions.
This guide will cover the features, technology stack, and step-by-step process required to develop a Binance clone.
1. Understanding the main features of Binance
Before diving into development, it is important to identify the key features of Binance that make it popular:
spot trading: The main feature of Binance where users can buy and sell cryptocurrencies.
Forward trading: Allows users to trade contracts based on the price of the cryptocurrency rather than the asset.
expressed: Users can lock their cryptocurrencies in exchange for rewards.
Peer-to-Peer (P2P) Trading: Binance allows users to buy and sell directly with each other.
wallet management: A secure and easy way for users to store and withdraw cryptocurrencies.
security features: Includes two-factor authentication (2FA), cold storage, and encryption to ensure secure transactions.
market data: Real-time updates on cryptocurrency prices, trading volumes and other market analysis.
API for trading:For advanced users to automate their trading strategies and integrate with third-party platforms.
2. Technology Stack to Build a Binance Clone
Building a Binance clone requires a strong technology stack, as the platform needs to handle millions of transactions, provide real-time market data, and ensure high-level security. Here is a recommended stack:
front end: React or Angular for building the user interface, ensuring it is interactive and responsive.
backend: Node.js with Express to handle user authentication, transaction management, and API requests. Alternatively, Python can be used with Django or Flask for better management of numerical data.
database: PostgreSQL or MySQL for relational data storage (user data, transaction logs, etc.). For cryptocurrency data, consider using a NoSQL database like MongoDB.
blockchain integration: Integrate with blockchain networks, like Bitcoin, Ethereum, and others, to handle cryptocurrency transactions.
websocket: To provide real-time updates on cryptocurrency prices and trades.
cloud storage: AWS, Google Cloud, or Microsoft Azure for secure file storage, especially for KYC documents or transaction logs.
payment gateway: Integrate with payment gateways like Stripe or PayPal to allow fiat currency deposits and withdrawals.
Security: SSL encryption, 2FA (Google Authenticator or SMS-based), IP whitelisting, and cold wallet for cryptocurrency storage.
Containerization and Scaling: Use Docker for containerization, Kubernetes for orchestration, and microservices to scale and handle traffic spikes.
crypto api: For real-time market data, price alerts and order book management. APIs like CoinGecko or CoinMarketCap can be integrated.
3. Designing the User Interface (UI)
The UI of a cryptocurrency exchange should be user-friendly, easy to navigate, and visually appealing. Here are the key components to focus on:
dashboard: A simple yet informative dashboard where users can view their portfolio, balance, recent transactions and price trends.
trading screen: An advanced trading view with options for spot trading, futures trading, limit orders, market orders and more. Include charts, graphs and candlestick patterns for real-time tracking.
account settings: Allow users to manage their personal information, KYC documents, two-factor authentication, and security settings.
Deposit/Withdrawal Screen: An interface for users to deposit and withdraw both fiat and cryptocurrencies.
Transaction History: A comprehensive history page where users can track all their deposits, withdrawals, trades and account activities.
Order Book and Market Data: Display buy/sell orders, trading volume and price charts in real time.
4. Key Features for Implementation
The key features that need to be implemented in your Binance clone include:
User Registration and Authentication: Users should be able to sign up via email or social login (Google, Facebook). Implement two-factor authentication (2FA) for added security.
KYC (Know Your Customer): Verify the identity of users before allowing them to trade or withdraw large amounts. You can integrate KYC services using third-party providers like Jumio or Onfido.
spot and futures trading: Implement spot and futures trading functionality where users can buy, sell or trade cryptocurrencies.
Order Types: Include different order types such as market orders, limit orders and stop-limit orders for advanced trading features.
real time data feed: Use WebSockets to provide real-time market data including price updates, order book and trade history.
wallet management: Create secure wallet for users to store their cryptocurrencies. You can use hot wallets for frequent transactions and cold wallets for long-term storage.
deposit and withdrawal system: Allow users to deposit and withdraw both fiat and cryptocurrencies. Make sure you integrate with a trusted third-party payment processor for fiat withdrawals.
Security: Implement multi-layered security measures like encryption, IP whitelisting, and DDoS protection. Cold storage for large amounts of cryptocurrencies and real-time fraud monitoring should also be prioritized.
5. Blockchain Integration
One of the most important aspects of building a Binance clone is integrating the right blockchain network for transaction processing. You will need to implement the following:
blockchain nodes: Set up nodes for popular cryptocurrencies like Bitcoin, Ethereum, Litecoin, etc. to process transactions and verify blocks.
smart contracts: Use smart contracts for secure transactions, especially for tokenized assets or ICOs (Initial Coin Offerings).
cryptocurrency wallet: Develop wallet solutions supporting major cryptocurrencies. Make sure wallets are secure and easy to use for transactions.
6. Security measures
Security is paramount when building a cryptocurrency exchange, and it is important to ensure that your platform is protected from potential threats. Here are the key security measures to implement:
ssl encryption: Encrypt all data exchanged between the server and the user's device.
Two-Factor Authentication (2FA): Implement Google Authenticator or SMS-based 2FA for user login and transaction verification.
Cold room: Store most user funds in cold storage wallets to reduce the risk of hacks.
anti phishing: Implement anti-phishing features to protect users from fraudulent websites and attacks.
audit trails: Keep detailed logs of all transactions and account activities for transparency and security audits.
7. Monetization Strategies for Your Binance Clone
There are several ways to earn from Binance clone:
trading fees: Charge a small fee (either fixed or percentage-based) for each trade made on the platform.
withdrawal fee: Charge a fee for cryptocurrency withdrawals or fiat withdrawals from bank accounts.
margin trading: Provide margin trading services for advanced users and charge interest on borrowed funds.
token lists: Charge projects a fee for listing their tokens on their platform.
Affiliate Program: Provide referral links for users to invite others to join the platform, thereby earning a percentage of their trading fees.
8. Challenges in creating a Binance clone
Creating a Binance clone is not without challenges:
Security: Handling the security of users' funds and data is important, as crypto exchanges are prime targets for cyber attacks.
rules: Depending on your target sector, you will need to comply with various financial and crypto regulations (e.g., AML/KYC regulations).
scalability: The platform must be able to handle millions of transactions, especially during market surges.
real time data: Handling real-time market data and ensuring low latency is crucial for a trading platform.
conclusion
Creating a Binance clone is a complex but rewarding project that requires advanced technical skills in blockchain integration, secure payment processing, and real-time data management. By focusing on key features, choosing the right tech stack, and implementing strong security measures, you can build a secure and feature-rich cryptocurrency exchange.
If you are involved in web development with WordPress and want to add a crypto payment system to your site, or if you want to integrate cryptocurrency features, feel free to get in touch! I will be happy to guide you in this.
0 notes
Text
Principais Ferramentas para Construir Pipeline de Dados - Real Time Analytics
Leonardo Santos da Mata
Engenheiro de Dados, DBA | SQL, Python para Analise de Dados, Pentaho Data Integration, Cloud AWS, Cloud Azure, Mongodb, Mongodb Compass, Docker e Portainer.io
19 de outubro de 2024
A construção de pipelines de dados para Real Time Analytics envolve a escolha de ferramentas que permitam processar, analisar e visualizar dados em tempo real. Abaixo, listamos algumas das principais ferramentas, com seus prós, contras e os tipos de projetos em que cada uma se destaca.
1. Tableau
Prós:
Interface amigável e intuitiva
Grande capacidade de criação de visualizações interativas
Suporte para integração com diversas fontes de dados
Contras:
Custo elevado para grandes equipes
Limitações no processamento de grandes volumes de dados em tempo real
Aplicação: Projetos que demandam visualização interativa de dados para decisões de negócios, como relatórios e dashboards executivos.
2. Amazon Kinesis
Prós:
Excelente para processar e analisar grandes volumes de dados em tempo real
Integrado com o ecossistema AWS
Altamente escalável e flexível
Contras:
Curva de aprendizado acentuada para iniciantes
Custo pode aumentar conforme o volume de dados processado
Aplicação: Ideal para projetos de IoT, análise de logs de aplicações e monitoramento de eventos em tempo real.
3. Metabase
Prós:
Open-source e de fácil uso
Suporte a várias bases de dados
Boa opção para equipes menores que buscam relatórios simples
Contras:
Funcionalidades limitadas para grandes volumes de dados
Menos opções de personalização de visualizações
Aplicação: Pequenas e médias empresas que precisam de relatórios básicos e acessíveis com rápida implementação.
4. Looker Studio
Prós:
Integração com diversas fontes de dados, incluindo Google Analytics
Interface de fácil uso para criação de relatórios e dashboards interativos
Bom para análises colaborativas em tempo real
Contras:
Funcionalidades limitadas para manipulação avançada de dados
Pode ser mais simples do que necessário para grandes volumes de dados
Aplicação: Ideal para empresas que já estão no ecossistema Google e precisam de dashboards fáceis de usar.
5. Apache Flink
Prós:
Processamento de dados em tempo real com baixa latência
Suporte a análise de grandes volumes de dados distribuídos
Flexível para integração com diferentes pipelines de dados
Contras:
Requer uma curva de aprendizado significativa
Configuração complexa para iniciantes
Aplicação: Processamento de dados em tempo real para casos de uso como análise de fraudes, monitoramento de IoT e sistemas de recomendação.
6. Apache Druid
Prós:
Alta performance no processamento e análise de dados em tempo real
Otimizado para grandes volumes de dados com baixas latências de consulta
Suporte a OLAP (Online Analytical Processing)
Contras:
Configuração e gerenciamento podem ser desafiadores
Requer conhecimento técnico avançado para configuração otimizada
Aplicação: Projetos que exigem ingestão de grandes volumes de dados em tempo real, como análise de streaming de eventos e relatórios analíticos.
7. Apache Superset
Prós:
Open-source e gratuito
Suporte a uma ampla gama de fontes de dados
Flexível para criação de dashboards e visualizações
Contras:
Requer conhecimento técnico para instalação e configuração
Limitado para análise em tempo real em comparação com outras soluções
Aplicação: Empresas que precisam de uma solução open-source para visualização de dados sem custo de licenciamento.
8. Azure Synapse Analytics
Prós:
Totalmente integrado ao ecossistema Azure
Suporta análise em tempo real de grandes volumes de dados
Possui recursos de SQL e big data integrados
Contras:
Curva de aprendizado para quem não está familiarizado com Azure
Pode ter um custo elevado dependendo do uso
Aplicação: Projetos de grande escala que exigem processamento de dados em tempo real com integração total no Azure.
9. Redash
Prós:
Open-source e fácil de usar
Suporte a várias bases de dados
Ótima ferramenta para equipes que precisam de consultas rápidas
Contras:
Funcionalidades limitadas para grandes empresas
Não é ideal para processamento de dados complexos em tempo real
Aplicação: Empresas pequenas a médias que precisam de uma ferramenta simples e acessível para relatórios e dashboards.
10. MicroStrategy
Prós:
Ampla gama de funcionalidades de business intelligence
Suporte a dados em tempo real com alto nível de personalização
Ótimo para projetos corporativos de grande escala
Contras:
Custo elevado
Curva de aprendizado acentuada
Aplicação: Grandes corporações que precisam de uma solução robusta para business intelligence e análise em tempo real.
11. Dataedo
Prós:
Excelente para documentação e governança de dados
Interface simples e fácil de usar
Ajuda na visualização e organização dos metadados
Contras:
Não é projetado para análise de dados em tempo real
Funcionalidades limitadas para grandes volumes de dados
Aplicação: Projetos que exigem documentação e governança de dados clara, como ambientes de big data corporativos.
12. Power BI
Prós:
Fácil de usar e integrado ao ecossistema Microsoft
Boa solução para visualização de dados em tempo real
Grande variedade de conectores e integração com várias fontes de dados
Contras:
Limitações na manipulação de grandes volumes de dados
Custo de licenciamento pode ser alto para grandes equipes
Aplicação: Projetos de relatórios executivos e visualizações interativas para pequenas e médias empresas.
13. Presto
Prós:
Alta performance para consultas distribuídas em grandes volumes de dados
Suporte a SQL, ideal para grandes análises
Integração com vários sistemas de armazenamento de dados
Contras:
Configuração complexa
Requer conhecimento técnico avançado para otimização
Aplicação: Análises distribuídas em ambientes de big data, como consultas em clusters Hadoop.
Essas ferramentas são fundamentais para construir pipelines de dados eficientes para análises em tempo real, cada uma com seu conjunto de vantagens e limitações. A escolha da ferramenta depende do tipo de projeto, dos volumes de dados a serem processados e do nível de personalização e complexidade exigido.
0 notes
Text
Hướng dẫn triển khai Docker Graylog theo các bước chi tiết

Tài liệu để build Graylog được tôi sử dụng và tham khảo ở đây. Điều tôi làm chỉ là tận dụng cấu hình của họ và sửa lại để cho phù hợp với mục đích của mình. Lưu ý cấu hình mình đang sử dụng là 8 Cpus và 12 Gb Ram. Trong bài viết này, chúng tôi sẽ hướng dẫn bạn cách triển khai Graylog thông qua Docker để bắt đầu thu thập logs ngay lập tức.
1. Mô hình sử dụng
Ở mô hình này tôi sử dụng 3 container Graylog, opensearch, mongodb chúng liên lạc với nhau qua network : Graylog_net
Riêng container Graylog sử dụng expose port 9000:9000 để dùng truy cập trang web qua IP của host và các port khác dùng để nhận log các dịch vụ khác
"5044:5044" # Cổng cho nhận log từ Filebeat
"5140:5140" # Cổng cho nhận log từ syslog
"12201:12201" # Cổng cho nhận log từ GELF UDP
"13301:13301" # Cổng tùy chỉnh (thay thế cho dịch vụ khác)
"13302:13302" # Cổng tùy chỉnh khác
2. Cài đặt Docker Graylog
Đầu tiên sẽ tải xuống repo Docker github của mình
cd /opt/
git clone https://github.com/thanhquang99/Docker
Tiếp theo ta cần chạy file Docker compose
cd /opt/Docker/Graylog/
Docker compose up
Ta có thể tùy chỉnh biến trong file Docker compose để thay đổi user và password của Graylog hay opensearch. Nếu không thay đổi thì password mặc định của Graylog: minhtenlaquang
Bạn cũng cần sử lại cấu hình Graylog và opensearch sử dụng ram và cpu để phù hợp với máy của bạn. Thông thường opensearch sẽ chiếm 50% RAM và Graylog chiếm 25% RAM
Đợi 1 thời gian cho đến khi Docker compose chạy xong ta sẽ vào trang http://<ip-Docker-host>:9000. Với user: admin, password: minhtenlaquang
3. Tùy chỉnh tài nguyên sử dụng mà Graylog sử dụng
Các biến Graylog mà bạn cần lưu ý để có thể chỉnh sửa cho phù hợp với tài nguyên Graylog của mình:
processbuffer_processors: Số lượng bộ xử lý cho buffer xử lý.
outputbuffer_processors: Số lượng bộ xử lý cho buffer đầu ra (Elasticsearch).
processor_wait_strategy: Chiến lược chờ của bộ xử lý khi không có công việc để làm (yielding, sleeping, blocking, busy_spinning).
ring_size: Kích thước của ring buffer.
message_journal_enabled: Kích hoạt hoặc vô hiệu hóa message journal.
message_journal_max_size: Kích thước tối đa của message journal.
inputbuffer_processors: Số lượng bộ xử lý cho input buffer.
inputbuffer_ring_size: Kích thước của ring buffer cho input buffer.
retention_strategy: Chiến lược giữ lại dữ liệu (ví dụ: delete, archive).
rotation_strategy: Chiến lược xoay vòng chỉ mục (ví dụ: count, time).
retention_max_index_count: Số lượng chỉ mục tối đa được giữ lại.
rotation_max_index_size: Kích thước tối đa của chỉ mục trước khi xoay vòng.
rotation_max_index_age: Tuổi thọ tối đa của chỉ mục trước khi xoay vòng.
tcp_recv_buffer_size: Kích thước bộ đệm nhận TCP.
tcp_send_buffer_size: Kích thước bộ đệm gửi TCP.
discarders: Cấu hình số lượng và loại discarder để xử lý tin nhắn vượt quá giới hạn.
threadpool_size: Số lượng luồng trong pool của Graylog.
Tôi sẽ hướng dẫn bạn tùy chỉnh biến message_journal_max_size để test thử.
Ta cần xem lại thông tin các volume của Graylog
Docker inspect graylog
Ta sẽ sửa file
vi /var/lib/docker/volumes/graylog_graylog_data/_data/graylog.conf
Restart lại Graylog
docker restart graylog
Kiểm tra kết quả:
Kết Luận
Hy vọng bài viết này đã giúp bạn triển khai Graylog sử dụng Docker và áp dụng vào hệ thống của mình. Docker Graylog là cách triển khai Graylog, một nền tảng quản lý và phân tích log bằng Docker. Điều này giúp dễ dàng thiết lập, cấu hình và quản lý Graylog trong các container, đảm bảo tính linh hoạt, khả năng mở rộng và đơn giản hóa quy trình cài đặt. Docker Graylog thường đi kèm với các container bổ sung như MongoDB (lưu trữ dữ liệu cấu hình) và Elasticsearch (xử lý và lưu trữ log).
Nguồn: https://suncloud.vn/huong-dan-trien-khai-docker-graylog-theo-cac-buoc-chi-tiet
0 notes
Text
What is data science?
Data science is an interdisciplinary field that involves using scientific methods, algorithms, processes, and systems to extract knowledge and insights from structured and unstructured data. It combines elements of statistics, computer science, domain expertise, and data engineering to analyze large volumes of data and derive actionable insights.
Key Components of Data Science:
Data Collection
Definition: Gathering data from various sources, which can include databases, APIs, web scraping, sensors, and more.
Types of Data:
Structured Data: Organized in tables (e.g., databases).
Unstructured Data: Includes text, images, videos, etc.
Data Cleaning and Preparation
Definition: Processing and transforming raw data into a clean format suitable for analysis. This step involves handling missing values, removing duplicates, and correcting errors.
Importance: Clean data is crucial for accurate analysis and model building.
Exploratory Data Analysis (EDA)
Definition: Analyzing the data to discover patterns, trends, and relationships. This involves statistical analysis, data visualization, and summary statistics.
Tools: Common tools for EDA include Python (with libraries like Pandas and Matplotlib), R, and Tableau.
Data Modeling
Definition: Building mathematical models to represent the underlying patterns in the data. This includes statistical models, machine learning models, and algorithms.
Types of Models:
Supervised Learning: Models that are trained on labeled data (e.g., classification, regression).
Unsupervised Learning: Models that find patterns in unlabeled data (e.g., clustering, dimensionality reduction).
Reinforcement Learning: Models that learn by interacting with an environment to maximize some notion of cumulative reward.
Model Evaluation and Tuning
Definition: Assessing the performance of models using metrics such as accuracy, precision, recall, F1 score, etc. Model tuning involves optimizing the model parameters to improve performance.
Cross-Validation: A technique used to assess how the results of a model will generalize to an independent dataset.
Data Visualization
Definition: Creating visual representations of data and model outputs to communicate insights clearly and effectively.
Tools: Matplotlib, Seaborn, D3.js, Power BI, and Tableau are commonly used for visualization.
Deployment and Monitoring
Definition: Implementing the model in a production environment where it can be used to make real-time decisions. Monitoring involves tracking the model's performance over time to ensure it remains accurate.
Tools: Cloud services like AWS, Azure, and tools like Docker and Kubernetes are used for deployment.
Ethics and Privacy
Consideration: Ensuring that data is used responsibly, respecting privacy, and avoiding biases in models. Data scientists must be aware of ethical considerations in data collection, analysis, and model deployment.
Applications of Data Science:
Business Intelligence: Optimizing operations, customer segmentation, and personalized marketing.
Healthcare: Predicting disease outbreaks, personalized medicine, and drug discovery.
Finance: Fraud detection, risk management, and algorithmic trading.
E-commerce: Recommendation systems, inventory management, and price optimization.
Social Media: Sentiment analysis, trend detection, and user behavior analysis.
Tools and Technologies in Data Science:
Programming Languages: Python, R, SQL.
Machine Learning Libraries: Scikit-learn, TensorFlow, PyTorch.
Big Data Tools: Hadoop, Spark.
Data Visualization: Matplotlib, Seaborn, Tableau, Power BI.
Databases: SQL, NoSQL (MongoDB), and cloud databases like Google BigQuery.
Conclusion
Data science is a powerful field that is transforming industries by enabling data-driven decision-making. With the explosion of data in today's world, the demand for skilled data scientists continues to grow, making it an exciting and impactful career path.
data science course in chennai
data science institute in chennai
data analytics in chennai
data analytics institute in chennai
0 notes
Text
Ansible and Docker: Automating Container Management
In today's fast-paced tech environment, containerization and automation are key to maintaining efficient, scalable, and reliable infrastructure. Two powerful tools that have become essential in this space are Ansible and Docker. While Docker enables you to create, deploy, and run applications in containers, Ansible provides a simple yet powerful automation engine to manage and orchestrate these containers. In this blog post, we'll explore how to use Ansible to automate Docker container management, including deployment and orchestration.
Why Combine Ansible and Docker?
Combining Ansible and Docker offers several benefits:
Consistency and Reliability: Automating Docker container management with Ansible ensures consistent and reliable deployments across different environments.
Simplified Management: Ansible’s easy-to-read YAML playbooks make it straightforward to manage Docker containers, even at scale.
Infrastructure as Code (IaC): By treating your infrastructure as code, you can version control, review, and track changes over time.
Scalability: Automation allows you to easily scale your containerized applications by managing multiple containers across multiple hosts seamlessly.
Getting Started with Ansible and Docker
To get started, ensure you have Ansible and Docker installed on your system. You can install Ansible using pip: pip install ansible
And Docker by following the official Docker installation guide for your operating system.
Next, you'll need to set up an Ansible playbook to manage Docker. Here’s a simple example:
Example Playbook: Deploying a Docker Container
Create a file named deploy_docker.yml:
---
- name: Deploy a Docker container
hosts: localhost
tasks:
- name: Ensure Docker is installed
apt:
name: docker.io
state: present
become: yes
- name: Start Docker service
service:
name: docker
state: started
enabled: yes
become: yes
- name: Pull the latest nginx image
docker_image:
name: nginx
tag: latest
source: pull
- name: Run a Docker container
docker_container:
name: nginx
image: nginx
state: started
ports:
- "80:80"
In this playbook:
We ensure Docker is installed and running.
We pull the latest nginx Docker image.
We start a Docker container with the nginx image, mapping port 80 on the host to port 80 on the container.
Automating Docker Orchestration
For more complex scenarios, such as orchestrating multiple containers, you can extend your playbook. Here’s an example of orchestrating a simple web application stack with Nginx, a Node.js application, and a MongoDB database:
---
- name: Orchestrate web application stack
hosts: localhost
tasks:
- name: Ensure Docker is installed
apt:
name: docker.io
state: present
become: yes
- name: Start Docker service
service:
name: docker
state: started
enabled: yes
become: yes
- name: Pull necessary Docker images
docker_image:
name: "{{ item }}"
tag: latest
source: pull
loop:
- nginx
- node
- mongo
- name: Run MongoDB container
docker_container:
name: mongo
image: mongo
state: started
ports:
- "27017:27017"
- name: Run Node.js application container
docker_container:
name: node_app
image: node
state: started
volumes:
- ./app:/usr/src/app
working_dir: /usr/src/app
command: "node app.js"
links:
- mongo
- name: Run Nginx container
docker_container:
name: nginx
image: nginx
state: started
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
links:
- node_app
Conclusion
By integrating Ansible with Docker, you can streamline and automate your container management processes, making your infrastructure more consistent, scalable, and reliable. This combination allows you to focus more on developing and less on managing infrastructure. Whether you're managing a single container or orchestrating a complex multi-container environment, Ansible and Docker together provide a powerful toolkit for modern DevOps practices.
Give it a try and see how much time and effort you can save by automating your Docker container management with Ansible!
For more details click www.qcsdclabs.com
#redhatcourses#information technology#containerorchestration#container#linux#docker#kubernetes#containersecurity#dockerswarm#aws
0 notes
Text
Essential Tools for High-Quality Web Development Services

For web development services, having the right set of tools is crucial to streamline the development process, enhance productivity, and ensure top-quality outputs. Here are some recommended tools across different aspects of website development services:
1. Code Editors and IDEs
Visual Studio Code (VS Code): A lightweight yet powerful code editor with built-in Git support and a wide range of extensions.
Sublime Text: A fast, feature-rich code editor with extensive customization options.
JetBrains WebStorm: A robust IDE specifically designed for JavaScript development, offering powerful features for modern frameworks.
2. Version Control
Git: A distributed version control system essential for tracking changes and collaborating on code.
GitHub: A platform for hosting Git repositories, code collaboration, and project management.
GitLab: A comprehensive DevOps platform offering Git repository management, CI/CD, and more.
3. Front-end Development
React: A popular JavaScript library for building user interfaces.
Angular: A powerful framework for building dynamic web applications.
Vue.js: A progressive JavaScript framework for building user interfaces.
Bootstrap: A front-end framework for developing responsive and mobile-first websites, crucial for any website development service.
4. Back-end Development
Node.js: A JavaScript runtime for building scalable server-side applications.
Django: A high-level Python web framework that encourages rapid development and clean, pragmatic design.
Laravel: A PHP framework known for its elegant syntax and extensive feature set.
5. Database Management
MySQL: A widely-used relational database management system.
PostgreSQL: An advanced open-source relational database system with a strong reputation for reliability and feature robustness.
MongoDB: A popular NoSQL database for storing and retrieving large volumes of data, often used in web development services.
6. API Development
Postman: A collaboration platform for API development, testing, and documentation.
Swagger: Tools for designing, building, documenting, and consuming RESTful web services.
7. Containerization and Orchestration
Docker: A platform for developing, shipping, and running applications in containers.
Kubernetes: An open-source system for automating deployment, scaling, and management of containerized applications.
8. CI/CD Tools
Jenkins: An open-source automation server for continuous integration and delivery.
CircleCI: A CI/CD service that supports rapid software development and publishing.
Travis CI: A CI/CD service used to build and test software projects hosted on GitHub.
9. Project Management and Collaboration
Jira: A project management tool for planning, tracking, and managing agile software development projects.
Trello: A visual collaboration tool that creates a shared perspective on any project.
Slack: A messaging app for teams that supports collaboration through channels, direct messages, and integrations with other tools.
10. Design and Prototyping
Adobe XD: A vector-based tool for designing and prototyping user experiences for web and mobile apps.
Figma: A collaborative interface design tool that allows multiple designers to work simultaneously.
Sketch: A digital design toolkit for macOS focused on UI/UX design.
11. Performance and Testing
Selenium: A suite of tools for automating web browsers for testing purposes.
Lighthouse: An open-source tool for auditing web performance, accessibility, SEO, and more.
Jest: A JavaScript testing framework designed to ensure the correctness of any JavaScript codebase, important for website development services.
12. Security
OWASP ZAP: An open-source web application security scanner to find security vulnerabilities in web applications.
Burp Suite: A suite of tools for testing web security, including a proxy, scanner, and intruder.
13. Monitoring and Analytics
Google Analytics: A powerful tool for tracking and analyzing website traffic and user behavior.
New Relic: A suite of performance monitoring tools to observe application performance, infrastructure, and user experience.
Datadog: A monitoring and security platform for cloud applications, essential for maintaining professional web development services.
These tools can help streamline your web development services, improve productivity, ensure high-quality outputs, and maintain secure and efficient applications. Depending on your specific project requirements and team preferences, you can choose the tools that best fit your web development service workflow. For those looking to enhance their website development services, these tools are indispensable in creating robust, high-performing websites that meet client needs and industry standards.
0 notes
Text
The Best Full Stack Developer Course in Pune with Placement
In today's fast-paced digital world, full stack development has become a highly sought-after skill. Whether you're a novice eager to break into the tech industry or an experienced professional looking to upgrade your skills, choosing the right course is crucial. Pune, a burgeoning tech hub in India, offers numerous opportunities for aspiring developers. Among these, the Full Stack Developer course in pune by SyntaxLevelUp stands out as a premier choice, especially for those seeking comprehensive training and assured placements.

Why Choose Full Stack Development?
Full stack developers are versatile professionals who can handle both front-end and back-end development. This comprehensive skill set makes them indispensable in any software development team. Here are a few reasons why pursuing a career in full stack development is a smart move:
1. High Demand: With companies increasingly looking for versatile developers who can handle multiple aspects of a project, full stack developers training in pune are in high demand.
2. Competitive Salary: Full stack developers training in pune are among the highest-paid professionals in the tech industry due to their extensive skill set.
3. Versatility: The ability to work on both client-side and server-side gives developers a unique edge in the job market.
4. Opportunities for Growth: Full stack developer courses in pune opens doors to various roles, including project management, system architecture, and even entrepreneurship.
Why SyntaxLevelUp is the Best Choice
Comprehensive Curriculum
SyntaxLevelUp offers a meticulously crafted curriculum that covers the latest technologies and frameworks in both front-end and back-end development. Students will learn:
Front-End Development: HTML, CSS, JavaScript, React.js, and Angular.js.
Back-End Development: Node.js, Express.js, Python, Django, and Ruby on Rails.
Database Management: SQL, NoSQL, MongoDB, and PostgreSQL.
DevOps: Introduction to AWS, Docker, and CI/CD pipelines.
Version Control: Git and GitHub.
Experienced Instructors
The course is taught by industry experts with years of experience in full stack development. These instructors bring real-world insights into the classroom, ensuring that students are not only learning theoretical concepts but also understanding their practical applications.
Hands-On Projects
SyntaxLevelUp believes in learning by doing. The course includes numerous hands-on projects that simulate real-world scenarios. By working on these projects, students can build a robust portfolio that showcases their skills to potential employers.
Placement Assistance
One of the standout features of the SyntaxLevelUp Full Stack Developer course in pune is its placement assistance program. The institute has tie-ups with numerous tech companies in Pune and beyond, ensuring that students have ample job opportunities upon course completion. The placement cell offers:
Resume Building Workshops: Learn how to craft a compelling resume that highlights your full stack development skills.
Mock Interviews: Practice with mock interviews conducted by industry professionals to build confidence and improve your interview skills.
Job Fairs and Networking Events: Participate in exclusive job fairs and networking events where you can meet potential employers.
Flexible Learning Options
Understanding the diverse needs of students, SyntaxLevelUp offers flexible learning options, including:
Full-Time Course: Ideal for those who can dedicate their full time to learning.
Part-Time Course: Perfect for working professionals who want to upgrade their skills without disrupting their job.
Online Course: For those who prefer learning from the comfort of their homes.
Success Stories
The success stories of SyntaxLevelUp alumni speak volumes about the quality of the course. Many graduates have secured lucrative positions in top tech companies, both in India and globally. Their testimonials highlight the effectiveness of the curriculum and the support provided by the placement cell.
Conclusion
In a city like Pune, where the tech industry is booming, equipping yourself with full stack development skills can be your ticket to a successful career. SyntaxLevelUp’s Full Stack Developer course in pune offers the perfect blend of theoretical knowledge, practical experience, and placement support. Whether you're starting from scratch or looking to enhance your existing skills, this course will help you level up your career in the competitive tech landscape.
Looking for the best full stack training in Pune? SyntaxLevelUp offers a comprehensive full stack developer course in Pune, designed for aspiring developers. Our full stack developer course in Pune with placement guarantees job assistance upon completion. Specializing in a full stack Java developer course in Pune, we provide top-notch full stack developer classes in Pune. Join the full stack course in Pune for hands-on learning. Enroll now in our full stack classes in Pune and become a skilled full stack web developer.
#fullstack training in pune#full stack developer course in pune#full stack developer course in pune with placement#full stack java developer course in pune#full stack developer classes in pune#full stack course in pune#best full stack developer course in pune#full stack classes in pune#full stack web development course in pune
0 notes
Text
The Role of a Senior Data Engineer: Key Responsibilities and Skills

Data Engineers play a crucial role in today's data-driven world. They collect, process, and store data, enabling data scientists and analysts to utilize it effectively. As the data landscape evolves, the demand for Senior Data Engineers continues to rise. In this article, we will explore the evolving role of a Senior Data Engineer, essential skills required to excel in this role and how a course at Datavalley can help you acquire and hone these skills.
The Evolving Role of a Data Engineer
Senior data engineers are accountable for building and upkeeping data collection systems, pipelines, and management tools. They oversee the activities of junior data engineers and the architectures themselves. While this role has always been essential, it has evolved significantly in recent years due to the proliferation of big data and cloud technologies. Here are some key aspects of a Senior Data Engineer's responsibilities:
1. Data Ingestion:
One of the primary tasks of a Data Engineer is to design systems that can efficiently ingest data from various sources, such as databases, APIs, and streaming platforms. This requires expertise in tools like Apache Kafka, Apache Nifi, or cloud-based solutions like AWS Kinesis.
2. Data Modeling and Transformation:
Data engineers play a critical role in creating data models that enhance data accessibility and comprehension for non-technical stakeholders, including analysts and data scientists.
Data Engineers need to create and manage data pipelines that transform raw data into a format suitable for analysis. Proficiency in SQL is crucial for data modeling, and ETL (Extract, Transform, Load) tools like Apache Spark or Talend are commonly used for data transformation.
3. Collaborative Engagement
Daily meetings are a fundamental aspect of a data engineer's routine. These meetings often include the daily scrum, where team members discuss recent achievements, ongoing tasks, and potential obstacles.
Additionally, data engineers actively participate in cross-functional meetings, collaborating with data scientists, data analysts, product managers, and application developers.
4. Data Storage and Data Query Optimization:
Selecting the right data storage solution is critical for performance and scalability. Data Engineers should be well-versed in traditional databases (e.g., PostgreSQL, MySQL) as well as NoSQL databases (e.g., MongoDB, Cassandra) and cloud-based storage options (e.g., Amazon S3, Azure Data Lake Storage).
As data volumes continue to grow, data engineers are tasked with optimizing data queries to ensure efficient data retrieval. This optimization process may involve the creation of indexes, data restructuring, or data aggregation to facilitate quicker queries.
5. Data Quality and Governance:
Ensuring data accuracy and compliance with regulations is vital. Data Engineers must implement data quality checks, data lineage tracking, and access controls to maintain data integrity.
6. Cloud Computing:
The cloud has revolutionized data engineering. Familiarity with cloud platforms like AWS, Azure, or Google Cloud is essential, as many organizations are migrating their data infrastructure to the cloud.
7. DevOps and Automation:
Data Engineers often collaborate closely with DevOps teams to automate deployment, scaling, and monitoring of data pipelines. Proficiency in tools like Docker and Kubernetes is increasingly valuable.
Data engineers are instrumental in managing the data infrastructure that underpins data processing and storage. This aspect of their role often encompasses a combination of development and operational tasks, particularly in larger teams.
8. Facilitating Data Flow
In essence, data engineers serve as intermediaries between data sources, storage systems, and end-users. Their role is to ensure the smooth flow of data within an organization, making certain that data is readily available and accessible to those who require it.
By bridging the gap between technology and business, data engineers empower analysts and data scientists to focus on deriving insights rather than grappling with data retrieval and manipulation.
9. Data Security:
Protecting sensitive data is a top priority. Knowledge of encryption techniques, IAM (Identity and Access Management), and security best practices is crucial.
Essential Skills for a Senior Data Engineer
Now that we've outlined the evolving role of a Senior Data Engineer, let's delve into the essential skills needed to excel in this field.
1. Strong Programming Skills:
A Senior Data Engineer should be proficient in at least one programming language commonly used in data engineering, such as Python, Java, or Scala. These languages are essential for building data pipelines and working with big data frameworks.
2. Proficiency in SQL:
SQL is the backbone of data manipulation and querying. A Senior Data Engineer should have a deep understanding of SQL to design efficient database schemas and perform complex data transformations.
3. Data Modeling:
Creating effective data models is crucial for organizing data and ensuring its accessibility and usability. Skills in data modeling techniques like entity-relationship diagrams and star schemas are invaluable. Getting advanced data engineering certifications with Snowflake’s cloud-based platform would be beneficial.
4. Big Data Technologies:
Familiarity with big data technologies such as Apache Hadoop, Spark, and Flink is essential. These tools are used for processing and analyzing massive datasets efficiently.
5. Cloud Platforms:
As mentioned earlier, cloud platforms like AWS, Azure Cloud Services, and Google Cloud Platform are increasingly central to data engineering. Knowledge of these platforms, including services like AWS Lambda and Azure Data Factory, is a must.
6. ETL Tools:
Data Engineers need expertise in ETL tools like Apache NiFi, Talend, or cloud-based alternatives to streamline data integration and transformation processes.
7. Database Management:
A deep understanding of both SQL and NoSQL databases is essential. Data Engineers should be able to design, optimize, and manage databases effectively.
8. Data Pipeline Orchestration:
Tools like Apache Airflow or cloud-native solutions like AWS Step Functions are essential for orchestrating complex data pipelines.
9. Version Control:
Proficiency with version control systems like Git is essential for collaboration and code management in data engineering projects.
10. Interpersonal Skills:
Communication, problem-solving, and teamwork are equally important for a Senior Data Engineer. They often collaborate with data scientists, analysts, and business stakeholders, so effective communication is vital.
Why Datavalley for Data Engineer?
To acquire and master these essential skills for a Senior Data Engineer, consider enrolling in a course at Datavalley. Datavalley offers a comprehensive Data Engineer program designed to provide hands-on experience and in-depth knowledge in all the areas mentioned above. Here's why Datavalley is the right choice:
Comprehensive Curriculum: Our courses cover Python, SQL fundamentals, Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, DevOps, Data lake, AWS data analytics.
1. Expert Instructors: Datavalley's courses are led by experienced data engineers who have worked in the industry for years. Experts teach modules to broaden your understanding and provide industrial insights.
2. Hands-on Projects: The best way to learn is by doing. Datavalley's curriculum includes hands-on projects that allow you to apply your skills in real-world scenarios.
3. Cutting-edge Tools and Technologies: Datavalley stays up-to-date with the latest tools and technologies used in the field of data engineering. You'll learn the most relevant and in-demand skills.
4. Industry Networking: We provide opportunities to connect with industry professionals, helping you build a network that can be invaluable in your career.
5. Career Support: Datavalley goes beyond teaching technical skills. They offer career support services, including resume reviews and interview coaching, to help you land your dream job.
6. Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
7. On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with 3 months of on-call project assistance.
Conclusion
Becoming a Senior Data Engineer requires a diverse set of technical skills and a deep understanding of data infrastructure. As data continues to grow in importance, so does the demand for skilled data engineers.
Datavalley's Big Data Engineer Masters Program can provide you with the knowledge and practical experience you need to excel in this role. Whether you're looking to advance your career or enter the field of data engineering, Datavalley is the right choice to help you achieve your goals. Invest in your future as a Senior Data Engineer and unlock the potential of data on your journey.
#datavalley#dataexperts#data engineering#data enginner#data visualizations#data engineering training#data engineering course
0 notes
Text
Back-end developer (PHP 7, Symfony 4, PostgreSQL) - Remote

Company:Text Magic TextMagic AS is a Nasdaq listed SaaS technology company. Our flagship product is the A2P SMS messaging platform used by over 25,000+ business customers worldwide. In 2021, the total number of SMS messages sent on the TextMagic platform reached 250 million. In 2023 we will launch a new customer engagement software called Touchpoint. At the end of 2021, our company held a successful IPO - an initial public offering on the Nasdaq First North Tallinn market, in which 15,410 investors subscribed to TextMagic shares for a total of 49.5 million euros. Hi, we are TextMagic’s development team. TextMagic is an international SaaS technology company. Our flagship product is an SMS messaging platform used worldwide (including the USA, UK, Canada, and Australia). Our platform enables customers to send notifications, reminders, confirmations, and marketing campaigns via SMS and we already have more than 50 000 active business users. Last year almost 250 million messages were sent through our platform and our aim is to grow that volume to 1 billion messages per year. Our team We are constantly growing and there are already more than 90 of us in Estonia, Romania, Ukraine, Russia and Montenegro. As a developer at TextMagic, you can work in a comfortable office or remotely. Main technologies we use: - PHP 7, Symfony 4, Codeception, PHPUnit, OpenAPI - PostgreSQL 10, Memcached, MongoDB - Beanstalk - jQuery, Vue.js - socket.io - Node.js for the parallel processing - SIP/Asterisk - Docker What you will do - Develop new features and improve platform architecture. - Design and build REST API. - Integrate with third-party services using API. - Refactoring and code optimization. - Scale the project for increasing loads. - Participate in the team’s product logic development. - Undertake code reviews of other team members’ work. - Optimize database queries. What we expect from you: - Excellent knowledge of and experience with the technologies listed above. - A clear understanding of the architecture of a web application and its separate components. - An understanding of how the HTTP request lifecycle works. - Experience in building REST API. - An understanding of the principles of SOLID and OOP. - Experience in working with high-load systems. - An understanding of how to build efficient, scalable database architecture. Experience with PostgreSQL or MySQL (writing complex queries; understanding EXPLAIN; optimizing slow queries without changing the database structure; changing schemas of large tables without downtime, etc.) - Excellent knowledge of English or Russian is a must. Project documentation - in English. What we offer: - Flexible hours for an optimal work-life balance. - Any equipment you need for productive work. - The opportunity to bring your vision to the project. - Cozy office in the city center, or remote working. - Daily lunches at TextMagic’s expense (when working at the office). - A professional and friendly team, ready to help you. - Paid vacation (28 calendar days a year). Why you’ll love it here - We offer employees company share options to enjoy the fruits of their labor. - Your friendly and responsive teammates are always there to help you with anything you need. - We always provide room and opportunities to grow - on your own and with your teammates. - We provide equipment and resources to support your growth, productivity, and wellbeing. - You will always have the time to recharge and the flexibility to get your best work done. APPLY ON THE COMPANY WEBSITE To get free remote job alerts, please join our telegram channel “Global Job Alerts” or follow us on Twitter for latest job updates. Disclaimer: - This job opening is available on the respective company website as of 21st Jun 2023. The job openings may get expired by the time you check the post. - Candidates are requested to study and verify all the job details before applying and contact the respective company representative in case they have any queries. - The owner of this site has provided all the available information regarding the location of the job i.e. work from anywhere, work from home, fully remote, remote, etc. However, if you would like to have any clarification regarding the location of the job or have any further queries or doubts; please contact the respective company representative. Viewers are advised to do full requisite enquiries regarding job location before applying for each job. - Authentic companies never ask for payments for any job-related processes. Please carry out financial transactions (if any) at your own risk. - All the information and logos are taken from the respective company website. Read the full article
0 notes