#mysql to hdfs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
蜘蛛池优化需要哪些数据库?TG@yuantou2048
在进行蜘蛛池优化时,选择合适的数据库是非常关键的一步。蜘蛛池优化主要涉及到对网站爬虫行为的管理和优化,以提高搜索引擎对网站内容的抓取效率和频率。为了实现这一目标,我们需要依赖于一些特定类型的数据库来存储和管理相关信息。以下是几种常用的数据库类型及其在蜘蛛池优化中的应用:
1. 关系型数据库(如MySQL、PostgreSQL):这类数据库主要用于存储结构化的数据,比如网站的URL列表、爬取状态等信息。它们能够提供强大的查询功能,便于我们对爬虫任务进行监控和管理。
2. NoSQL数据库(如MongoDB、Redis):NoSQL数据库因其灵活的数据模型和高性能而被广泛应用于蜘蛛池系统中。例如,可以使用MongoDB来存储非结构化或半结构化数据,如网页链接、爬取日志等。Redis则常用于缓存和快速访问频繁变化的数据,比如待爬取的URL队列以及已爬取页面的状态信息等。
3. 图数据库(如Neo4j):对于复杂的关系网络分析场景下特别有用,可以帮助我们���好地理解和处理大规模链接之间的关系,从而优化爬虫的工作流程。
4. 分布式文件系统(如Hadoop HDFS):当面对海量数据时,分布式文件系统能够高效地处理大量数据的存储与检索需求。
5. 键值存储数据库(如Redis):这类数据库非常适合用来存储临时性数据或者作为高速缓存层,提高系统的响应速度。
6. 时间序列数据库(如InfluxDB):如果需要记录和分析大量的历史数据,时间序列数据库是一个不错的选择。它们能够有效地支持高并发读写操作,并且易于扩展以应对不断增长的数据量。
7. 搜索引擎专用数据库(如Elasticsearch):这类数据库擅长处理实时搜索请求,适用于需要快速检索特定关键词或模式匹配的应用场景中。通过使用这些工具,我们可以快速查找特定条件下的数据集,这对于跟踪每个URL的爬取进度及性能指标非常有帮助。
8. 内存数据库(如Memcached):这类数据库通常用于缓存经常访问的内容,减少对磁盘I/O操作的需求,提升整体性能表现。
9. 列式数据库(如Cassandra):当需要对大量历史数据进行高效查询时尤为有效。
10. 消息队列中间件(如RabbitMQ):利用消息队列技术构建高效的分布式爬虫架构,确保多个爬虫节点之间同步工作负载均衡器配置参数设置等功能模块的设计与实现过程中可能会用到此类技术方案。
总之,在构建一个高效的蜘蛛池系统时,合理选择并组合使用不同类型的数据存储解决方案将极大地提升整个项目的运行效率。
综上所述,根据具体应用场景选择合适类型的数据库至关重要。同时也要考虑到成本效益比等因素综合考量后做出最佳决策。
加飞机@yuantou2048

王腾SEO
ETPU Machine
0 notes
Text
Big Data and Data Engineering
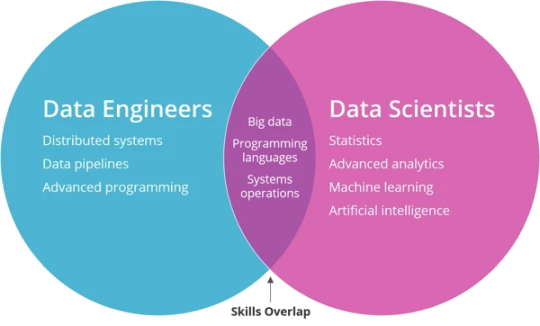
Big Data and Data Engineering are essential concepts in modern data science, analytics, and machine learning.
They focus on the processes and technologies used to manage and process large volumes of data.
Here’s an overview:
What is Big Data? Big Data refers to extremely large datasets that cannot be processed or analyzed using traditional data processing tools or methods.
It typically has the following characteristics:
Volume:
Huge amounts of data (petabytes or more).
Variety:
Data comes in different formats (structured, semi-structured, unstructured). Velocity: The speed at which data is generated and processed.
Veracity: The quality and accuracy of data.
Value: Extracting meaningful insights from data.
Big Data is often associated with technologies and tools that allow organizations to store, process, and analyze data at scale.
2. Data Engineering:
Overview Data Engineering is the process of designing, building, and managing the systems and infrastructure required to collect, store, process, and analyze data.
The goal is to make data easily accessible for analytics and decision-making.
Key areas of Data Engineering:
Data Collection:
Gathering data from various sources (e.g., IoT devices, logs, APIs). Data Storage: Storing data in data lakes, databases, or distributed storage systems. Data Processing: Cleaning, transforming, and aggregating raw data into usable formats.
Data Integration:
Combining data from multiple sources to create a unified dataset for analysis.
3. Big Data Technologies and Tools
The following tools and technologies are commonly used in Big Data and Data Engineering to manage and process large datasets:
Data Storage:
Data Lakes: Large storage systems that can handle structured, semi-structured, and unstructured data. Examples include Amazon S3, Azure Data Lake, and Google Cloud Storage.
Distributed File Systems:
Systems that allow data to be stored across multiple machines. Examples include Hadoop HDFS and Apache Cassandra.
Databases:
Relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra, HBase).
Data Processing:
Batch Processing: Handling large volumes of data in scheduled, discrete chunks.
Common tools:
Apache Hadoop (MapReduce framework). Apache Spark (offers both batch and stream processing).
Stream Processing:
Handling real-time data flows. Common tools: Apache Kafka (message broker). Apache Flink (streaming data processing). Apache Storm (real-time computation).
ETL (Extract, Transform, Load):
Tools like Apache Nifi, Airflow, and AWS Glue are used to automate data extraction, transformation, and loading processes.
Data Orchestration & Workflow Management:
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. Kubernetes and Docker are used to deploy and scale applications in data pipelines.
Data Warehousing & Analytics:
Amazon Redshift, Google BigQuery, Snowflake, and Azure Synapse Analytics are popular cloud data warehouses for large-scale data analytics.
Apache Hive is a data warehouse built on top of Hadoop to provide SQL-like querying capabilities.
Data Quality and Governance:
Tools like Great Expectations, Deequ, and AWS Glue DataBrew help ensure data quality by validating, cleaning, and transforming data before it’s analyzed.
4. Data Engineering Lifecycle
The typical lifecycle in Data Engineering involves the following stages: Data Ingestion: Collecting and importing data from various sources into a central storage system.
This could include real-time ingestion using tools like Apache Kafka or batch-based ingestion using Apache Sqoop.
Data Transformation (ETL/ELT): After ingestion, raw data is cleaned and transformed.
This may include:
Data normalization and standardization. Removing duplicates and handling missing data.
Aggregating or merging datasets. Using tools like Apache Spark, AWS Glue, and Talend.
Data Storage:
After transformation, the data is stored in a format that can be easily queried.
This could be in a data warehouse (e.g., Snowflake, Google BigQuery) or a data lake (e.g., Amazon S3).
Data Analytics & Visualization:
After the data is stored, it is ready for analysis. Data scientists and analysts use tools like SQL, Jupyter Notebooks, Tableau, and Power BI to create insights and visualize the data.
Data Deployment & Serving:
In some use cases, data is deployed to serve real-time queries using tools like Apache Druid or Elasticsearch.
5. Challenges in Big Data and Data Engineering
Data Security & Privacy:
Ensuring that data is secure, encrypted, and complies with privacy regulations (e.g., GDPR, CCPA).
Scalability:
As data grows, the infrastructure needs to scale to handle it efficiently.
Data Quality:
Ensuring that the data collected is accurate, complete, and relevant. Data
Integration:
Combining data from multiple systems with differing formats and structures can be complex.
Real-Time Processing:
Managing data that flows continuously and needs to be processed in real-time.
6. Best Practices in Data Engineering Modular Pipelines:
Design data pipelines as modular components that can be reused and updated independently.
Data Versioning: Keep track of versions of datasets and data models to maintain consistency.
Data Lineage: Track how data moves and is transformed across systems.
Automation: Automate repetitive tasks like data collection, transformation, and processing using tools like Apache Airflow or Luigi.
Monitoring: Set up monitoring and alerting to track the health of data pipelines and ensure data accuracy and timeliness.
7. Cloud and Managed Services for Big Data
Many companies are now leveraging cloud-based services to handle Big Data:
AWS:
Offers tools like AWS Glue (ETL), Redshift (data warehousing), S3 (storage), and Kinesis (real-time streaming).
Azure:
Provides Azure Data Lake, Azure Synapse Analytics, and Azure Databricks for Big Data processing.
Google Cloud:
Offers BigQuery, Cloud Storage, and Dataflow for Big Data workloads.
Data Engineering plays a critical role in enabling efficient data processing, analysis, and decision-making in a data-driven world.

0 notes
Text
Data engineering
The Backbone of Modern Analytics: Data Engineering in Practice
In an increasingly data-driven world, organizations are constantly leveraging the power of analytics to gain competitive advantages, enhance decision-making, and uncover valuable insights. However, the value of data is only realized when it is structured, clean, and accessible — this is where data engineering comes into play. As the foundational discipline underpinning data science, machine learning, and business intelligence, data engineering is the unsung hero of modern analytics.
In this comprehensive blog, we’ll explore the landscape of data engineering: its definition, components, tools, challenges, and best practices, as well as its pivotal role in today’s digital economy.
What is Data Engineering?
Data engineering refers to the process of designing, building, and maintaining systems and architectures that allow large-scale data to be collected, stored, and analyzed. Data engineers focus on transforming raw, unstructured, or semi-structured data into structured formats that are usable for analysis and business.
Think of data engineering as constructing the "plumbing" of data systems: building pipelines to extract data from various sources, ensuring data quality, transforming it into a usable state, and loading it into systems where analysts and data scientists can access it easily.
The Core Components of Data Engineering
1. Data Collection and Ingestion
Data engineers start by collecting data from various sources like databases, APIs, files, IoT devices, and other third-party systems. Data ingestion is the term given for this process. The incorporation of different systems forms the basis of data ingestion with consistent and efficient importation into centralized repositories.
2. Data Storage
Once consumed, data has to be stored in systems that are scalable and accessible. Data engineers will decide whether to use conventional relational databases, distributed systems such as Hadoop, or cloud-based storage solutions, such as Amazon S3 or Google Cloud Storage. Depending on the volume, velocity, and variety of the data, the choice is made Raw data is rarely usable in its raw form. Data transformation involves cleaning, enriching, and reformatting the data to make it analysis-ready. This process is encapsulated in the ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipelines.
4. Data Pipelines
At the heart of data engineering are data pipelines that automate the movement of data between systems. These can be designed to handle either real-time (streaming) or batch data, based on the use case.
5. Data Quality and Governance
To obtain reliable analytics, the data must be correct and consistent. Data engineers put in validation and deduplication processes and ensure standardization with proper adherence to data governance standards such as GDPR or CCPA.
6. Data Security
Data is a very important business resource, and safeguarding it must be a data engineer's core responsibility. They therefore use encryption, access controls, and other security measures over sensitive information.
Common Tools in Data Engineering
Data engineering has seen lots of change in recent history, with numerous tools having emerged to tackle various themes in the discipline. Following are some of the leading tools:
1. Data Ingestion Tools
Apache Kafka: A distributed event streaming platform ideal for real-time ingestion.
Apache Nifi: Simplifies the movement of data between systems.
Fivetran and Stitch: Cloud-based tools for ETL pipelines.
2. Data Storage Solutions
Relational Databases: MySQL, PostgreSQL, and Microsoft SQL Server.
Distributed Systems: Apache HDFS, Amazon S3, and Google BigQuery.
NoSQL Databases: MongoDB, Cassandra, and DynamoDB.
3. Data Processing Frameworks
Apache Spark: A unified analytics engine for large-scale data processing.
Apache Flink: Focused on stream processing.
Google Dataflow: A cloud-based service for batch and streaming data processing.
4. Orchestration Tools
Apache Airflow: Widely used for scheduling and managing workflows.
Prefect: A more recent alternative to Airflow, with a focus on flexibility.
Dagster: A platform for orchestrating complex data pipelines.
5. Cloud Ecosystems
AWS: Redshift, Glue, and EMR
Google Cloud: BigQuery, Dataflow, and Pub/Sub
Microsoft Azure: Synapse Analytics and Data Factory
The Role of Data Engineers in the Data Ecosystem
Data engineers play a very important role in the larger data ecosystem by working with other data professionals, including data scientists, analysts, and software engineers. Responsibilities include:
Enablement of Data Scientists: Ensuring that high-quality, well-organized data is available for modeling and machine learning tasks.
Enablement of Business Intelligence: Creating data models and warehouses that power dashboards and reports.
Scalability and Performance: Optimize systems for growing datasets with efficient delivery of real-time insights.
Building Resilient Architectures: Ensuring fault tolerance, disaster recovery, and scalability in data systems.
Challenges in Data Engineering
Data engineering is a challenge in its own right While data engineering is quite important, it's by no means without its problems:
1. Managing Data Volume, Velocity, and Variety
The exponential growth of data creates challenges in storage, processing, and integration. Engineers must design systems that scale seamlessly.
2. Data Quality Issues
Handling incomplete, inconsistent, or redundant data requires meticulous validation and cleansing processes.
3. Real-Time Processing
Real-time analytics demands low-latency systems, which can be difficult to design and maintain.
**4. Keeping Up with Technology
The pace of innovation in data engineering tools and frameworks requires continuous learning and adaptation.
5. Security and Compliance
Data security breaches and ever-changing regulations add complexity to building compliant and secure pipelines.
Best Practices in Data Engineering
To address these challenges, data engineers adhere to best practices that ensure reliable and efficient data pipelines:
Scalability Design: Use distributed systems and cloud-native solutions to manage large datasets.
Automation of Repetitive Tasks: Use tools like Airflow and Prefect for workflow automation.
Data Quality: Implement validation checks and error-handling mechanisms.
DevOps Principles: Use CI/CD pipelines for deploying and testing data infrastructure.
Document Everything: Maintain comprehensive documentation for pipelines, transformations, and schemas.
Collaborate Across Teams: Work with analysts and data scientists to get what they need and make it actionable.
The Future of Data Engineering
As the amount of data continues to explode, data engineering will only grow in importance. Some of the key trends that will shape the future are:
1. The Rise of DataOps
DataOps applies DevOps-like principles toward automation, collaboration, and process improvement in data workflows.
2. Serverless Data Engineering
Cloud providers increasingly offer serverless solutions, and engineers can focus on data rather than infrastructure.
3. Real-Time Data Pipelines
As IoT, edge computing, and event-driven architectures become more prominent, real-time processing is no longer the exception but the rule.
4. AI in Data Engineering
Machine learning is being incorporated into data engineering workflows to automate tasks like anomaly detection and schema mapping.
5. Unified Platforms Databricks and Snowflake, among others, are becoming unified platforms to simplify data engineering and analytics.
Why Data Engineering Matters
Companies that put strong data engineering into their practice reap big advantages:
Faster Time-to-Insights: Clean, accessible data facilitates quicker and more reliable decisions.
Stronger Data-Driven Culture: Well-structured data systems enable each member of the team to leverage data.
Cost Savings: Efficient pipelines reduce storage and processing costs.
Innovation Enablement: High-quality data fuels cutting-edge innovations in AI and machine learning.
Conclusion
Data engineering is the backbone of the modern data-driven world. It enables the organization to unlock the full potential of data by building the infrastructure that transforms raw data into actionable insights. The field certainly poses significant challenges, but strong data engineering practices bring great rewards, from enhanced analytics to transformative business outcomes.
As data continues to grow in scale and complexity, the role of data engineers will become even more crucial. Whether you’re an aspiring professional, a business leader, or a tech enthusiast, understanding the principles and practices of data engineering is key to thriving in today’s digital economy.
for more information visit our website
https:// researchpro.online/upcoming
0 notes
Text
Exploring Free Data Engineering Courses- A Path to Mastery
Data engineering is a vital and rapidly evolving field in the realm of data science. It involves designing, building, and maintaining systems and architectures that collect, process, and store vast amounts of data. As businesses continue to rely on data-driven decision-making, the demand for skilled data engineers is on the rise. If you're looking to break into this exciting field without incurring significant costs, there are numerous free data engineering courses available online. This article explores some of the best free resources to help you get started on your data engineering journey.
1. Introduction to Data Engineering
Before diving into the specifics of courses, it's important to understand what data engineering entails. Data engineering focuses on the infrastructure and processes necessary to collect, store, and analyze data. It involves working with databases, large-scale processing systems, and data pipelines. A solid foundation in programming, particularly in languages like Python and SQL, is essential for aspiring data engineers.
2. Key Areas of Data Engineering
Database Management
Understanding database management is crucial for data engineers. This includes learning about relational databases like MySQL, PostgreSQL, and non-relational databases such as MongoDB. Free courses like Stanford University's "Introduction to Databases" on Coursera provide a comprehensive overview of database concepts.
Data Warehousing
Data warehousing involves storing large volumes of data in a manner that supports efficient querying and analysis. The "Data Warehousing for Business Intelligence" course, offered by the University of Colorado on Coursera, covers the fundamentals of data warehousing and how to use tools like SQL for data manipulation.
ETL (Extract, Transform, Load) Processes
ETL processes are at the heart of data engineering. These involve extracting data from various sources, transforming it into a suitable format, and loading it into a destination system. Platforms like Udemy offer free courses such as "Data Engineering Essentials Hands-on - ETL with Python & MySQL" which provide practical knowledge on implementing ETL pipelines.
Big Data Technologies
Big data technologies such as Hadoop, Spark, and Kafka are essential for handling and processing large data sets. "Big Data Essentials: HDFS, MapReduce and Spark RDD" by Yandex on Coursera is a free course that introduces these technologies and their applications.
Conclusion
Embarking on a career in free data engineering course is both challenging and rewarding. By leveraging the wealth of free courses and resources available online, you can build a strong foundation in data engineering without incurring significant costs. Whether you're interested in database management, ETL processes, or big data technologies, there is a free course out there to help you achieve your goals. Start exploring these resources today and take the first step towards becoming a proficient data engineer.
0 notes
Text
Comprehensive Breakdown of a Data Science Curriculum: What to Expect from Start to Finish
Comprehensive Breakdown of a Data Science Curriculum: What to Expect from Start to Finish
A Data Science course typically covers a broad range of topics, combining elements from statistics, computer science, and domain-specific knowledge. Here’s a breakdown of what you can expect from a comprehensive Data Science curriculum:
1. Introduction to Data Science
Overview of Data Science: Understanding what Data Science is and its significance.
Applications of Data Science: Real-world examples and case studies.
2. Mathematics and Statistics
Linear Algebra: Vectors, matrices, eigenvalues, and eigenvectors.
Calculus: Derivatives and integrals, partial derivatives, gradient descent.
Probability and Statistics: Probability distributions, hypothesis testing, statistical inference, sampling, and data distributions.
3. Programming for Data Science
Python/R: Basics and advanced concepts of programming using Python or R.
Libraries and Tools: NumPy, pandas, Matplotlib, seaborn for Python; dplyr, ggplot2 for R.
Data Manipulation and Cleaning: Techniques for preprocessing, cleaning, and transforming data.
4. Data Visualization
Principles of Data Visualization: Best practices, visualization types.
Tools and Libraries: Tableau, Power BI, and libraries like Matplotlib, seaborn, Plotly.
5. Data Wrangling
Data Collection: Web scraping, APIs.
Data Cleaning: Handling missing data, data types, normalization.
6. Exploratory Data Analysis (EDA)
Descriptive Statistics: Mean, median, mode, standard deviation.
Data Exploration: Identifying patterns, anomalies, and visual exploration.
7. Machine Learning
Supervised Learning: Linear regression, logistic regression, decision trees, random forests, support vector machines.
Unsupervised Learning: K-means clustering, hierarchical clustering, PCA (Principal Component Analysis).
Model Evaluation: Cross-validation, bias-variance tradeoff, ROC/AUC.
8. Deep Learning
Neural Networks: Basics of neural networks, activation functions.
Deep Learning Frameworks: TensorFlow, Keras, PyTorch.
Applications: Image recognition, natural language processing.
9. Big Data Technologies
Introduction to Big Data: Concepts and tools.
Hadoop and Spark: Ecosystem, HDFS, MapReduce, PySpark.
10. Data Engineering
ETL Processes: Extract, Transform, Load.
Data Pipelines: Building and maintaining data pipelines.
11. Database Management
SQL and NoSQL: Database design, querying, and management.
Relational Databases: MySQL, PostgreSQL.
NoSQL Databases: MongoDB, Cassandra.
12. Capstone Project
Project Work: Applying the concepts learned to real-world data sets.
Presentation: Communicating findings effectively.
13. Ethics and Governance
Data Privacy: GDPR, data anonymization.
Ethical Considerations: Bias in data, ethical AI practices.
14. Soft Skills and Career Preparation
Communication Skills: Presenting data findings.
Team Collaboration: Working in data science teams.
Job Preparation: Resume building, interview preparation.
Optional Specializations
Natural Language Processing (NLP)
Computer Vision
Reinforcement Learning
Time Series Analysis
Tools and Software Commonly Used:
Programming Languages: Python, R
Data Visualization Tools: Tableau, Power BI
Big Data Tools: Hadoop, Spark
Databases: MySQL, PostgreSQL, MongoDB, Cassandra
Machine Learning Libraries: Scikit-learn, TensorFlow, Keras, PyTorch
Data Analysis Libraries: NumPy, pandas, Matplotlib, seaborn
Conclusion
A Data Science course aims to equip students with the skills needed to collect, analyze, and interpret large volumes of data, and to communicate insights effectively. The curriculum is designed to be comprehensive, covering both theoretical concepts and practical applications, often culminating in a capstone project that showcases a student’s ability to apply what they've learned.
Acquire Skills and Secure a Job with best package in a reputed company in Ahmedabad with the Best Data Science Course Available
Or contact US at 1802122121 all Us 18002122121
Call Us 18002122121
Call Us 18002122121
Call Us 18002122121
Call Us 18002122121
0 notes
Text
Data Engineering Empowerment
In the fast-paced world of data engineering, having the right set of tools is crucial for efficiently managing and extracting insights from vast amounts of data. Data engineers play a pivotal role in building robust data pipelines and ensuring data quality, and they rely on a variety of tools to accomplish these tasks. In this article, we explore the essential data engineering tools that empower professionals to streamline data workflows, optimize performance, and drive successful data-driven initiatives.
1. Extract, Transform, Load (ETL) Tools:
ETL tools are fundamental to data engineering, enabling data engineers to extract data from various sources, transform it into a usable format, and load it into a target system. Popular ETL tools like Apache NiFi, Talend, or Informatica provide visual interfaces and drag-and-drop functionality, making it easier to design and manage complex data integration workflows. These tools often support various data formats and offer features like data validation, cleansing, and enrichment, ensuring data accuracy and consistency throughout the ETL process. Taking a data engineer course can help individuals gain the necessary skills to effectively utilize these ETL tools and excel in the field of data engineering.
2. Big Data Processing Frameworks:
With the rise of big data, data engineers need frameworks that can handle the volume, variety, and velocity of data. Apache Hadoop and Apache Spark are two widely adopted big data processing frameworks. Hadoop offers a distributed file system (HDFS) and a MapReduce framework for scalable storage and processing of large datasets. Spark, on the other hand, provides in-memory data processing capabilities, making it faster and more suitable for real-time analytics and machine learning tasks. Acquiring data engineer training can help individuals master these frameworks and enhance their ability to work with big data effectively.
3. Database Systems:
Database systems are at the core of data storage and retrieval in data engineering. Relational databases like MySQL, PostgreSQL, or Oracle are commonly used for structured data, offering ACID compliance and powerful query capabilities. NoSQL databases like MongoDB, Cassandra, or Redis are suitable for handling unstructured and semi-structured data, providing high scalability and flexibility. Data engineers need to be proficient in working with both types of databases, as each has its own strengths and use cases in data engineering projects. Obtaining a data engineer certification can validate and enhance the skills of professionals in working with diverse database systems and further their career prospects in the field.
4. Workflow Management Tools:
Data engineering projects often involve complex workflows that need to be orchestrated and scheduled efficiently. Workflow management tools like Apache Airflow or Luigi help data engineers define, schedule, and monitor data workflows with ease. These tools provide a visual interface to design workflows, manage dependencies between tasks, and execute them according to predefined schedules. They also offer monitoring and error handling capabilities, allowing data engineers to track the progress of workflows and troubleshoot any issues that arise. Data engineer institutes often include training on workflow management tools, empowering professionals to effectively utilize these tools in their data engineering projects.
5. Data Quality and Governance Tools:
Ensuring data quality and adhering to data governance practices are critical for reliable and trustworthy data analysis. Data quality and governance tools like Apache Atlas or Collibra help data engineers establish data quality rules, enforce data governance policies, and maintain metadata about data assets. These tools enable data lineage tracking, data cataloging, and data profiling, ensuring that data is accurate, compliant, and accessible to relevant stakeholders. Data engineers can leverage these tools to implement data validation, cleansing, and anomaly detection processes to maintain data integrity. Taking a data engineer training course can enhance proficiency in using these data quality and governance tools effectively, enabling professionals to excel in maintaining high-quality data and implementing robust governance practices.
6. Cloud Platforms:
Cloud computing has revolutionized the data engineering landscape, offering scalable and cost-effective solutions for storing and processing data. Cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure provide a range of managed services and storage options tailored for data engineering needs. Data engineers can leverage cloud-based storage solutions like Amazon S3 or GCP Storage for scalable and durable data storage. They can also use cloud-based data processing services like AWS Glue or GCP Dataflow for distributed data processing without the need to manage infrastructure.
Refer this article: How much is the Data Engineer Course Fee in India?
Final Say:
Data engineering tools are the backbone of efficient and impactful data engineering practices. With the right set of tools, data engineers can streamline data workflows, optimize performance, ensure data quality, and drive successful data-driven initiatives. ETL tools, big data processing frameworks, database systems, workflow management tools, data quality and governance tools, and cloud platforms empower data engineers to overcome the challenges of managing and analyzing vast amounts of data. By staying abreast of the latest tools and technologies, data engineers can enhance their skills and play a crucial role in the success of data-driven organizations.
Certified Data Engineer Course
youtube
Certified Data Analyst Course
youtube
0 notes
Text

Essential Python Tools Every Developer Needs
Today, we'll look at some of the most popular Python tools developers, coders & data scientists use worldwide. If you know how to use these Python tools correctly, they can be useful for various tasks.
Pandas: Used for Data Analysis Scipy: Algorithms to use with numpy PyMySQL: MYSQL connector HDFS: C/C++ wrapper for Hadoop connector Airflow: Data Engineering tool PyBrain: Algorithms for ML Matplotlib: Data visualization tool Python: Powerful shell Redis: Redis'access libraries Dask: Data Enginnering tool Jupyter: Research collabaration tool SQLAIchemy: Python SQL Toolkit Seaborn: Data Visuailzation tool Elasticsearch: Data Search Engine Numpy: Multidimensional arrays Pymongo: MongoDB driver Bookeh: Data Visualization tool Luigi: Data engineering tool Pattern: Natural language Keras: Hingh-lavel neural network API SymPy: Symbolic math
Visit our website for more information: https://www.marsdevs.com/python
0 notes
Text
Post 3 | HDPCD | Sqoop Import
Post 3 | HDPCD | Sqoop Import

Hi everyone, hope you are finding the tutorials useful. From this tutorial onwards, we are going to perform objectives for HDPCD certification.
In this tutorial, we are going to see the first objective in Data Ingestion category. If you go to Hortonworks’ objective page here, you will find it to be worded as “Import data from a table in a relational database into HDFS.”, shown in below screenshot.
View On WordPress
#Big Data#big data certification#certification#certified#course objective#exam objective#hadoop#hadoop certification#HDPCD#hdpcd big data#hdpcd certification#Hortonworks#hortonworks big data#hortonworks certification#hortonworks data platform certified developer#hortonworks sandbox#import from mysql into hdfs#mysql to hdfs#Sqoop#sqoop import
0 notes
Text
蜘蛛池搭建需要哪些数据库?
在构建蜘蛛池(Spider Pool)时,选择合适的数据库是至关重要的一步。蜘蛛池主要用于自动化抓取和处理网络数据,���此,一个高效且稳定的数据库系统能够极大地提升整体的性能和可靠性。那么,在搭建蜘蛛池时,我们通常会用到哪些类型的数据库呢?本文将为您详细介绍。
1. 关系型数据库
关系型数据库是最常见的数据库类型之一,它通过表格的形式来存储数据,并使用SQL语言进行查询和操作。在蜘蛛池中,关系型数据库常用于存储结构化数据,如网站信息、链接列表等。常用的数据库包括:
MySQL:开源且广泛使用的数据库,适合处理大量数据。
PostgreSQL:功能强大且灵活,支持复杂的数据类型和查询。
2. NoSQL数据库
NoSQL数据库因其非关系型的特性,非常适合处理大规模的非结构化或半结构化数据。在蜘蛛池中,这类数据库可以用来存储网页内容、用户行为数据等。常用的NoSQL数据库包括:
MongoDB:文档型数据库,易于扩展,适合存储复杂的数据结构。
Redis:内存数据库,速度快,适用于缓存和实时数据分析。
3. 图数据库
图数据库特别适合处理具有复杂关联关系的数据。在蜘蛛池中,图数据库可以用来分析和存储网页之间的链接关系,从而帮助理解网络结构。常用的图数据库有:
Neo4j:功能强大的图数据库,支持复杂的图形查询。
4. 分布式文件系统
对于需要存储大量文本或二进制文件的情况,分布式文件系统是一个不错的选择。它们可以提供高可用性和可扩展性,适合处理海量数据。例如:
Hadoop HDFS:基于Hadoop的分布式文件系统,适合大数据环境。
结尾讨论点
在实际应用中,选择哪种数据库取决于具体的需求和场景。您在搭建蜘蛛池时,会选择哪种数据库呢?或者您是否遇到过其他类型的数据库需求?欢迎在评论区分享您的经验和见解!
加飞机@yuantou2048

SEO优化
Google外链代发
0 notes
Text
Big Data and Data Science with Java
Java has become an increasingly popular programming language for Big Data and Data Science applications, thanks to its performance, scalability, and rich set of libraries and frameworks. Here are some key points to keep in mind when developing Big Data and Data Science applications with Java:
Hadoop is the most popular Big Data framework and is written in Java. Hadoop provides a distributed file system (HDFS) and a distributed processing system (MapReduce) for large-scale data processing.
Spark is a popular distributed computing engine that can be used for Big Data processing. Spark is also written in Java and provides APIs for Java, Scala, Python, and R.
Apache Storm is another popular real-time distributed computing framework for Big Data processing. It is written in Java and provides APIs for Java and other languages.
Java has several powerful libraries for Data Science, including Weka, Apache Mahout, and Deeplearning4j. These libraries provide tools for machine learning, data mining, and deep learning.
Java has a strong presence in the database management space, and many popular databases, such as MySQL, PostgreSQL, and Oracle, are written in Java.
Java offers several powerful data visualization libraries, including JFreeChart, JavaFX, and Apache ECharts.
Java has several libraries for data processing and manipulation, including Apache Commons CSV, Apache Commons Math, and Apache Commons Text.
Java offers several powerful tools for working with big data in the cloud, including Apache Hadoop, Apache Spark, and Apache Cassandra.
In summary, Java offers a powerful platform for Big Data and Data Science applications, thanks to its performance, scalability, and rich set of libraries and frameworks. Developers working with Big Data and Data Science should be proficient in Java programming language, distributed computing frameworks, database management systems, data visualization libraries, and cloud computing. They should also have a good understanding of modern data processing practices and principles to build scalable, secure, and maintainable applications.
0 notes
Text
What are the exact Introduction to the Hadoop Services in Toronto Canada Ecosystem for Big Data?

Bilytica # 1 Hadoop Services in Toronto Canada is an open-source structure dependent on Google's record framework that can manage large information in a circulated climate. This dispersed climate is developed by a bunch of machines that work intently together to give an impression of a solitary working machine.
Bilytica # 1 Hadoop Services in Toronto Canada

Here are a portion of the significant properties of Hadoop you should know:
Hadoop is profoundly versatile on the grounds that it handles information in a circulated way
Contrasted with vertical scaling in RDBMS, Hadoop offers flat scaling
It makes and saves reproductions of information making it shortcoming lenient
It is efficient as every one of the hubs in the bunch are item equipment which is only modest machines
Hadoop Services in Toronto Canada uses the information region idea to deal with the information on the hubs on which they are put away rather than moving the information over the organization accordingly diminishing traffic
It can deal with information: organized, semi-organized, and unstructured. This is critical in the present time in light of the fact that the vast majority of our information (messages, Instagram, Twitter, IoT gadgets, and so on) has no characterized design
HDFS (Hadoop Distributed File System)
It is the capacity part of Hadoop Services in Toronto Canada that stores information as records.
Each record is separated into squares of 128MB (configurable) and stores them on various machines in the group.
It has an expert slave engineering with two fundamental parts: Name Node and Data Node.
Name hub is the expert hub and there is only one for every group. Its undertaking is to realize where each square having a place with a record is lying in the group
Information hub is the slave hub that stores the squares of information and there are more than one for every bunch. Its undertaking is to recover the information as and when required. It keeps in consistent touch with the Name hub through pulses
YARN
YARN or Yet Another Resource Negotiator overseas assets in the bunch and deals with the applications over Hadoop. It permits information put away in Hadoop Services in Toronto Canada to be handled and run by different information handling motors, for example, cluster handling, stream handling, intuitive handling, chart handling, and some more. This builds productivity with the utilization of YARN.
HBase
HBase is a Column-based NoSQL information base. It runs on top of HDFS and can deal with information. It takes into account ongoing handling and irregular read/compose tasks to be acted on in the information.
Pig
Pig was produced for investigating huge datasets and conquers the trouble to compose plans and diminish capacities. It comprises two parts: Pig Latin and Pig Engine.
Pig Latin is the Scripting Language that is like SQL. Pig Engine is the execution motor on which Pig Latin runs. Inside, the code written in Pig is changed over to MapReduce capacities and makes it exceptionally simple for software engineers who aren't capable in Java.
Hive
Hive is a circulated information distribution center framework created by Facebook. It takes into consideration simple perusing, composing, and overseeing records on HDFS. It has its own questioning language for the reason known as Hive Querying Language (HQL) which is basically the same as SQL. This makes it extremely simple for developers to compose MapReduce capacities utilizing straightforward HQL questions.
Sqoop
A ton of uses actually store information in social data sets, hence making them a vital wellspring of information. In this manner, Sqoop has a significant impact in bringing information from Relational Databases into HDFS.
The orders written in Sqoop inside changes over into MapReduce assignments that are executed over HDFS. It works with practically all social data sets like MySQL, Postgres, SQLite, and so forth. It can likewise be utilized to trade information from HDFS to RDBMS.
Flume
Flume is an open-source, dependable, and accessible tool used to productively gather, total, and move a lot of information from different information sources into HDFS. It can gather information progressively just as in cluster mode. It has an adaptable design and is shortcoming open minded with numerous recuperation components.
Kafka
There are a ton of uses creating information and an equivalent number of uses burning-through that information. Be that as it may, interfacing them separately is an extreme assignment. That is the place where Kafka comes in. It sits between the applications creating information (Producers) and the applications devouring information (Consumers).
Hadoop Services in Toronto Canada Kafka is circulated and has in-constructed dividing, replication, and adaptation to internal failure. It can deal with streaming information and furthermore permits organizations to dissect information continuously.
Oozie
Oozie is a work process scheduler framework that permits clients to connect occupations composed on different stages like MapReduce, Hive, Pig, and so on Utilizing Oozie you can plan a task ahead of time and can make a pipeline of individual responsibilities to be executed consecutively or in corresponding to accomplish a greater errand. For instance, you can utilize Oozie to perform ETL procedure on information and afterward save the result in HDFS.
Animal specialist
apache animal specialist
In a Hadoop Services in Toronto Canada bunch, organizing and synchronizing hubs can be a difficult errand. Hence, Zookeeper is the ideal apparatus for the issue.
It is an open-source, circulated, and incorporated assistance for keeping up with design data, naming, giving disseminated synchronization, and giving gathering administrations across the group.
MS Power BI services in Pakistan is the key factor to provide scorecards and insights for different departments of the organization which consider power bi services in Lahore Karachi Islamabad Pakistan as a key factor to restore its functionality with the help of insights developed by Power BI developer in Pakistan.
Businesses in Pakistan are always looking best Power BI services in Pakistan through official partners of Microsoft which are known as Power BI Partners in Lahore Karachi Islamabad Pakistan to ensure that the best support is provided to companies in Pakistan for their projects under a certified Power BI Partner in Pakistan.
Microsoft is a leading company globally that provides the best business intelligence solutions using Power BI services in Pakistan.
Companies are dependent upon the best Power BI consultants in Pakistan to build their data warehouse and data integrations layer for data modelling using Power BI solutions in Pakistan which is also known as Power BI partner in Pakistan.
Services We Offer:
Strategy
Competitive Intelligence
Marketing Analytics
Sales Analytics
Data Monetization
Predictive Analytics
Planning
Assessments
Roadmaps
Data Governance
Strategy & Architecture
Organization Planning
Proof of Value
Analytics
Data Visualization
Big Data Analytics
Machine Learning
BI Reporting Dashboards
Advanced Analytics & Data Science
CRM / Salesforce Analytics
Data
Big Data Architecture
Lean Analytics
Enterprise Data Warehousing
Master Data Management
System Optimization
Outsourcing
Software Development
Managed Services
On-Shore / Off-Shore
Cloud Analytics
Recruiting & Staffing
Click to Start Whatsapp Chatbot with Sales

Mobile: +447745139693
Email: [email protected]
#Power BI Services in Toronto Canada#BI Consultant in Toronto Canada#BI Company in Toronto Canada#Tableau Consulting services in Toronto Canada#Cognos Consulting Services in Toronto Canada#Microstrategy Consulting services inToronto Canada#Qlikview Consulting services in Toronto Canada#bi consulting services in Toronto Canada#business intelligence services inToronto Canada#business intelligence solutions in Toronto Canada#data warehouse solutions inToronto Canada#data warehousing services in Toronto Canada#Manufacturing Analytics Solutions in Toronto Canada#Insurance Analytics Solutions inToronto Canada#Oil & Gas Analytics Solutions in Toronto Canada#Retail Analytics Solutions inPower BI Services in Toronto Canada#Pharma Analytics Solutions inToronto Canada#Banking Analytics Solutions in Power BI Services in Toronto Canada#healthcare business intelligence inPower BI Services in Toronto Canada#Supply Chain analytics Solutions inPower BI Services in Toronto Canada#healthcare analytics solutions in Power BI Services in Toronto Canada
0 notes
Link
0 notes
Text
Post 4 | HDPCD | Free-form Query Import
Post 4 | HDPCD | Free-form Query Import
Hello everyone, in this tutorial, we are going to see the 2nd objective in data ingestion category.
The objective is listed on Hortonworks website under data ingestion and looks like this.
Objective 2
In the previousobjective, we imported entire records from a MySQL table, whereas in this post, we are going to import data based on the result of a query. This query can be any SQL query, which…
View On WordPress
#Big Data#big data certification#certification#certified#course objective#exam objective#free form query import#hadoop#hadoop beginning#hadoop certification#HDPCD#hdpcd big data#hdpcd certification#Hortonworks#hortonworks big data#hortonworks certification#hortonworks data platform certified developer#mysql to hdfs#Sqoop#sqoop import#sqoop import with custom query#sqoop with custom query
0 notes
Text
蜘蛛池搭建需要哪些接口?
在互联网技术领域,蜘蛛池(Spider Pool)是一个非常重要的概念,它主要用于提升网站的SEO优化效果。通过模拟大量用户访问,蜘蛛池可以帮助网站更好地被搜索引擎抓取和索引。那么,在搭建一个高效的蜘蛛池时,我们需要关注哪些关键接口呢?本文将为您详细介绍。
1. 用户认证接口
首先,任何系统都需要一个安全的用户认证机制。对于蜘蛛池来说,这通常涉及到API密钥或令牌验证。确保只有授权用户能够使用蜘蛛池服务是至关重要的。
2. 任务管理接口
任务管理接口是蜘蛛池的核心部分之一。它允许用户提交新的爬虫任务、查询任务状态以及取消正在进行的任务。一个好的任务管理接口应该具备高可用性和可扩展性,以支持大量的并发请求。
3. 数据存储接口
爬取到的数据需要被有效地存储起来以便后续分析。因此,数据存储接口的设计至关重要。常见的选择包括关系型数据库(如MySQL)、NoSQL数据库(如MongoDB)以及分布式文件系统(如Hadoop HDFS)。选择合适的存储方案可以极大地提高系统的性能和可靠性。
4. 日志记录接口
日志记录接口用于跟踪系统运行情况并帮助诊断问题。它应该能够记录所有重要事件,包括但不限于任务执行结果、错误信息等。此外,为了便于维护人员快速定位问题所在,日志条目应清晰明了且易于理解。
5. 监控报警接口
监控报警接口负责实时监控系统健康状况,并在出现异常时及时通知相关人员。这可以通过设置阈值来实现——当某些指标超过预设范围时触发警报。例如,如果服务器负载过高,则可能需要增加资源或者调整策略来缓解压力。
6. 反馈与讨论
您认为还有哪些其他重要的接口应该被纳入蜘蛛池的构建中呢?欢迎在评论区分享您的观点!
加飞机@yuantou2048

ETPU Machine
EPS Machine
0 notes
Text
Migrating Messenger storage to optimize performance

Facebook decided to migrate messenger from HBase to MyRocks, "Facebook’s open source database project that integrates RocksDB as a MySQL storage engine." And they wrote an article on how they handled the migration, all along maintaining the whole thing live.
“More than a billion people now use Facebook Messenger to instantly share text, photos, video, and more. As we have evolved the product and added new functionality, the underlying technologies that power Messenger have changed substantially.
When Messenger was originally designed, it was primarily intended to be a direct messaging product similar to email, with messages waiting in your inbox the next time you visited the site. Today, Messenger is a mobile-first, real-time communications system used by businesses as well as individuals. To enable that shift, we have made many changes through the years to update the backend system. The original monolithic service was separated into a read-through caching service for queries; Iris to queue writes to subscribers (such as the storage service and devices); and a storage service to retain message history. This design optimized Messenger for a mobile-first world and helped fuel its success.
To help improve Messenger even more, we now have overhauled and modernized the storage service to make it faster, more efficient, more reliable, and easier to upgrade with new features. This evolution involved several major changes:
We redesigned and simplified the data schema, created a new source-of-truth index from existing data, and made consistent invariants to ensure that all data is formatted correctly.
We moved from HBase, an open source distributed key-value store based on HDFS, to MyRocks, Facebook’s open source database project that integrates RocksDB as a MySQL storage engine.
We moved from storing the database on spinning disks to flash on our new Lightning Server SKU.
The result has been a better experience for Messenger users themselves, who can now enjoy a more responsive product with enhanced functionality, such as mobile content search. We also have improved system resiliency, reduced latency, and decreased storage consumption by 90 percent. This was achieved in a seamless way that did not cause any disruption or downtime, but it required us to plan for and execute two different migration flows to account for every single Messenger user.”
Check out the article by Facebook Code
1 note
·
View note